1. Introduction
Heat loss quantification (HLQ) plays a crucial role in reducing the overall energy consumption for optimal operations in buildings, particularly since its usage has a considerable impact on the environment and a building’s life cycle [
1,
2]. A key objective of HLQ is retrofitting existing building envelopes. The first necessary step in the building envelope optimization process is assessing the actual thermal performance. Indicators, such as the energy performance or energy use intensity, are used to express this performance.
The building envelope in-situ measurement depends on factors that are classified into three main categories: site conditions, building conditions, and operating conditions [
3]. The site conditions category refers to the weather conditions under which the tests are performed. These weather conditions include, but are not limited to, wind velocity, rain, solar radiation, and humidity, all of which can significantly alter the building’s thermal performance quantification.
The building condition category refers to the age of the building materials and the laying of the structural elements used during construction. The operating conditions category refers to the building’s environmental management, such as heating or cooling, and air circulation from the opening or closing of windows, and building maintenance, regardless of whether or not these activities are currently affecting the building envelope. All of these factors must be monitored and considered carefully during the evaluation of building heat loss quantification.
Multiple research groups have recently investigated the use of infrared thermography to measure building envelope parameters in-situ with the thermal transmittance values, or the amount of heat-flow in one square meter when the temperature difference is one Kelvin (U-value). Most of these techniques present unique challenges [
4]. The in-situ-based measurement of the U-value, along with the heat flowmeter method (HFM), is not always possible [
5] or accurate [
6] due to the assumptions upon which the HFM methods are based, such as uni-directional heat flow; therefore, it is of crucial importance to develop practical techniques that quantify the heat loss.
One technique to obtain thermal imagery is by using drones, which creates opportunities in building assessment and inspections [
7,
8,
9]. Drones enables fast and safe building inspections, which are necessary to complete proactive maintenance to mitigate problems before they become costly. Reducing the costs associated with insurance inspections is another benefit to building owners and managers. The risks associated with using drones for roof inspection are low compared to traditional methods, where employees risk injury as they traverse the building to inspect the structure. Drones are increasingly used for data collection; however, thermal images captured by drones often contain objects, such as trees and ground surfaces, all of which can impact the calculation of the U-value calculation [
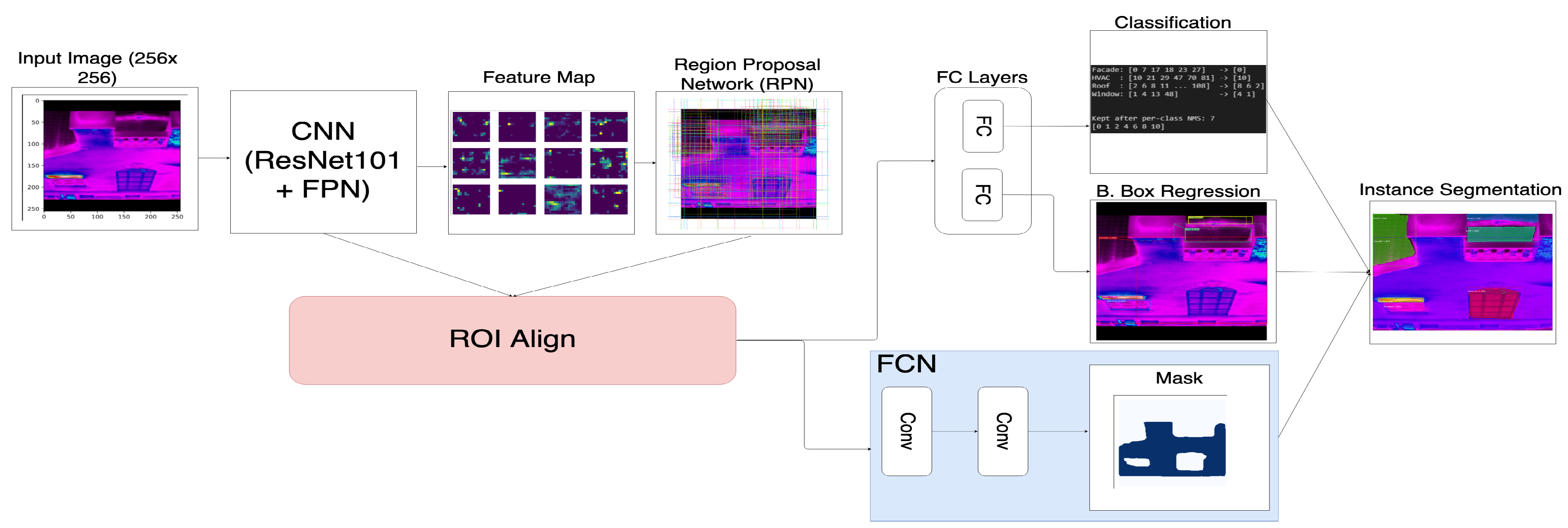
10]. Instance segmentation of the regions of interest, such as the facade of the building or roofs, is a necessary step after collecting data.
Over the past two decades, several instance segmentation and masking techniques have been considered using machine learning-based methods, which are the most successful at identifying objects [
11,
12]. Machine learning applies complex mathematical models to uncover hidden correlations between the different features in a given data set. There are two types of machine learning techniques: supervised and unsupervised. Supervised techniques require specific rules that an expert provides for the machine. These rules allow the machine to either classify or predict the outputs of the model given an input. Unsupervised techniques are applied when an expert cannot provide rules because of the large data sets. These techniques are applied to reveal any hidden correlations that the expert may not notice. Machine learning techniques require feature selection, which requires human expertise to determine appropriate features. A recent class of machine learning, called deep learning, does not require this step and is a new and powerful technique for computer vision tasks, which has not fully exploited by the heat loss research community [
13,
14].
In addition, the current research in heat loss quantification has relied largely on qualitative bench-top solutions or localized analysis in energy audit building evaluation. The existing quantitative models used to estimate surface temperature in buildings do not account for multi-variate uncertainties, such as energy requirement/consumption patterns, multiple sets of images per building object, time-of-day, seasons, and building material. There are also inconsistencies in the process of arriving at a reliable and quantifiable U-values for a building envelope.
For example, the thermal readings taken from a combination of thermocouple sensors and a thermal camera are only “raw values” that need to be pre-processed and subjected to multiple uncertainties (e.g., solar radiance, wind speed, time of the day, and black body radiation) and, thus, require the need for post-processing stages. In addition, the current literature does not provide guidance on how to arrive at an optimal and accurate way to detect building objects through which one can estimate surface temperatures from the region of interest (ROI) through heat loss metrics. Existing solutions are, therefore, not reliable for energy audit applications.
The specific research questions our work addresses include:
How do we acquire and process thermal images that account for building geometry uncertainties, such as orientation and angle, seasonal changes, and the influence of weather parameters on the building envelope?
How do we accurately detect various instances of objects, such as walls, roofs, and windows, using data-driven approaches?
How do we automatically tag or label images and report them?
Our work covers a comprehensive data-driven approach that examined approximately 100,000 thermal images, and performed object identification to classify objects accurately using instance segmentation to detect various building envelope structures, such roofs, walls, doors, windows, and facades. We also created a method for automated tagging, tracked pixel–pixel surface temperature values and reported the values in quantifiable and standard U-value estimation units.
There exists hundreds of variations of U-value formulae in the existing literature, and often they do not use large data but instead single point values. We investigated all available U-value equations and developed a cumulative U-value formula from three existing U-value equations. The U-value is a series of heat transfer equations that account for pixel temperature, outside temperature, wind speed, etc., to develop a quantitative measure of how that particular object is performing compared to how it should theoretically be performing. It can be thought of as an extension to the direct thermal readings, but we account for it from multiple low ceiling thermal images per building object acquired from small scale aerial systems.
We deployed two clustering methods (e.g., K-means and threshold-based clustering), which were then developed to estimate the accurate surface temperatures of multiple instances of an object. Then, using the estimated surface temperature for the region or envelope, we developed a cumulative U-value (U) formula that uses multiple existing U-value equations from the literature. We empirically verified our U as the most accurate formula when using a benchmark to meet the ASHRAE standard recommendations. U demonstrated relatively lower errors compared to the other U-value equations. The statistical difference of the U-value building envelope computations against ASHRAE varied between 0 to 30% depending on area size, building type, and material used. Since our AI model can detect multiple instances of any object with greater accuracy, including the roof, windows, doors, HVACs, and facades, the model is unique, it fills the research gap of inaccuracies and provides a quantifiable way to address uncertainties.
Our work adds to the body of knowledge by addressing the lack of automated solutions in energy audit applications and providing a comprehensive view of the building envelopes that will result in reliable, quantifiable, and scalable workflows to address heat loss quantification problems for next-generation building inspection problems. We determined that the thermal efficiency of a building depends on multiple factors, not only on the accurate acquisition of thermal images, but on factors such as the building geometry, season of the year, time of day, indoor heating or cooling conditions, past historical consumption, and power generation sources. These factors are all influential in determining the overall assessment of an energy audit evaluation.
In this paper, we demonstrated that thermal imagery to quantify heat loss combined with the recent advances in deep learning theory has many advantages, such as remote sensing, flexibility, and minimizing injury risks. To the best of our knowledge, the proposed approach is the first of its kind. U-values for different building blocks were analyzed and compared to the American Society of Heating, Refrigerating, and Air-conditioning Engineers (ASHRAE) building standards. This approach will allow stakeholders to overcome the challenges of traditional heat loss quantification methods. This work expounds upon previous publications [
4,
15] with the following new subject material,
A large thermal image data repository (∼100,000 images) of multiple university buildings was collected using a UAS and manually annotated to highlight objects of interest, such as facades, walls, trees, roofs, and windows.
Multiple models for object detection, such as Mask R-CNN, Fast R-CNN, and Faster R-CNN, were trained on several backbone types and validated with metrics, such as average precision (AP) and intersection-over-union (IoU), through a data-driven three-layered framework.
Two clustering schemes were tested to estimate surface temperature readings and identify hotspot regions reliably. Quantified surface temperature observations were used to compute the U-values of objects and validated with the ASHRAE standards.
The relationship between the indoors and HLQ is essential; however, this is out of the scope of this paper since our main focus is to provide a heat loss estimation using thermal imagery of the buildings from the outside and from which the heat loss is determined.
The rest of this paper is organized as follows:
Section 2 presents state-of-the-art techniques for object detection and instance segmentation. We devoted a specific section for this and did not integrate it as subsection of the introduction so as to not interrupt the flow of the paper as this section provides an in-depth review of the recent advances in deep learning and computer vision. This section provides also useful knowledge that can help in developing novel computer vision techniques.
Section 3 describes the methodology used in this paper to quantify the heat loss. We describe the training and testing methodology of several computer vision techniques as well as the analytical formulas used to calculate U-values through a three-layered framework.
Section 3 also describes the clustering techniques applied to detect hotspot regions within thermal images.
Section 4 presents the evaluation metrics and examples of the obtained results, which includes the results of instance segmentation, clustering analyses, heat loss quantification using U-values, and a qualitative and quantitative uncertainty analysis.
Section 5 summarizes the paper, presents our conclusions, and suggests future research work.
4. Results and Discussion
In this section, examples of results are presented and discussed. We start by presenting an evaluation of computer vision algorithms for detection and instance segmentation. Then, we present some examples of results related to clustering and their analysis as well as their discussion. In the last part, we present the U-value estimation as well as examples of the obtained results using different formulas.
4.1. Evaluation Metrics
In order to evaluate the performance of deep-learning-based thermal image instance segmentation, a confusion matrix can be used, and, from this, several other metrics can be derived.
Table 4 shows the confusion matrix and is defined to show the model’s ability to correctly and incorrectly identify objects.
One of the popular metrics used for measuring the accuracy of object detection is the average precision (AP). The average precision computes the AP value for a recall value of 0 to 1. The precision quantifies the percentage of correct predictions. Recall measures how well the positive values are detected. The mathematical definitions of precision and recall are as follows:
where
TP is true positive,
FP is false positive, and
FN is false negative.
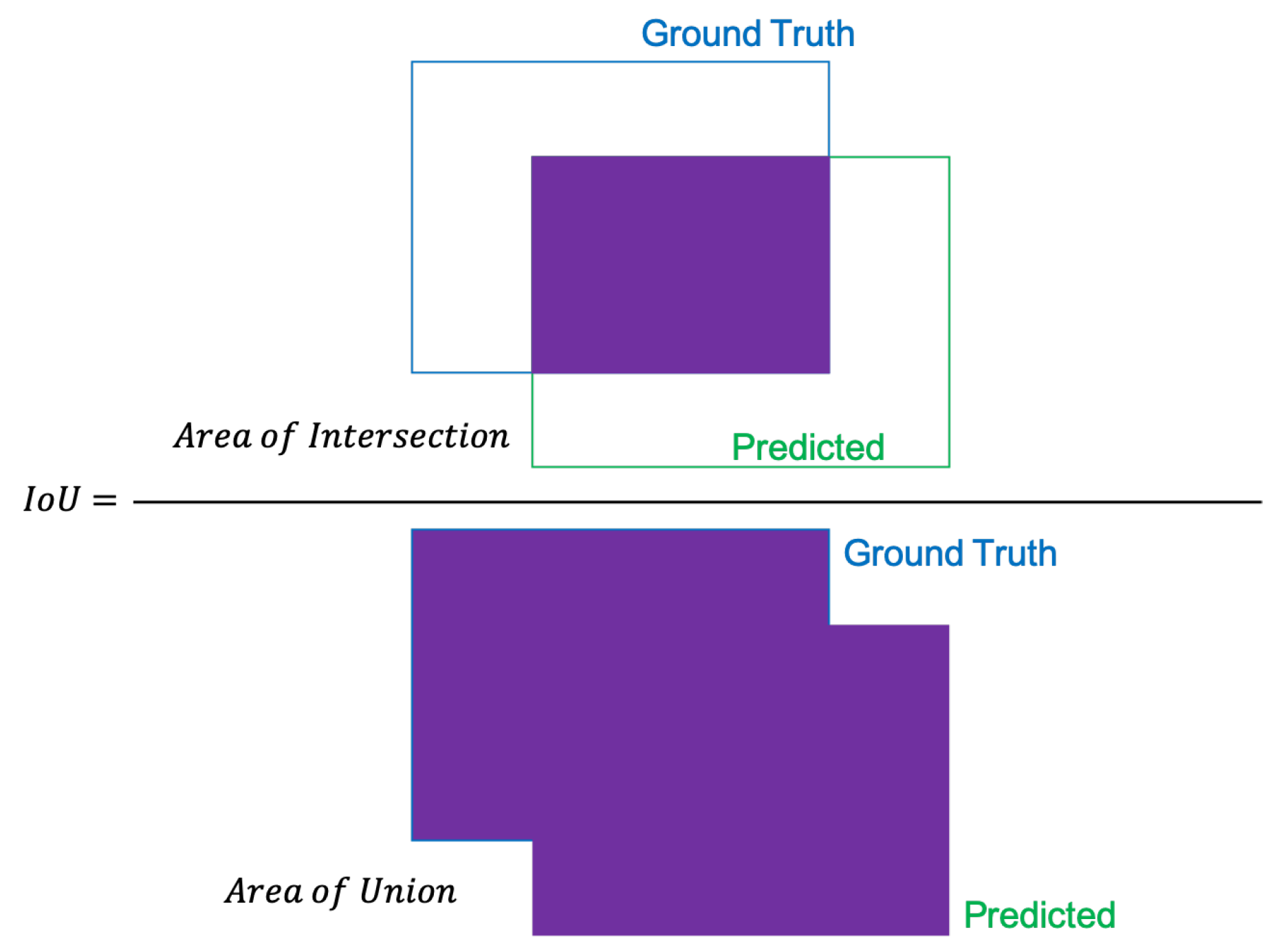
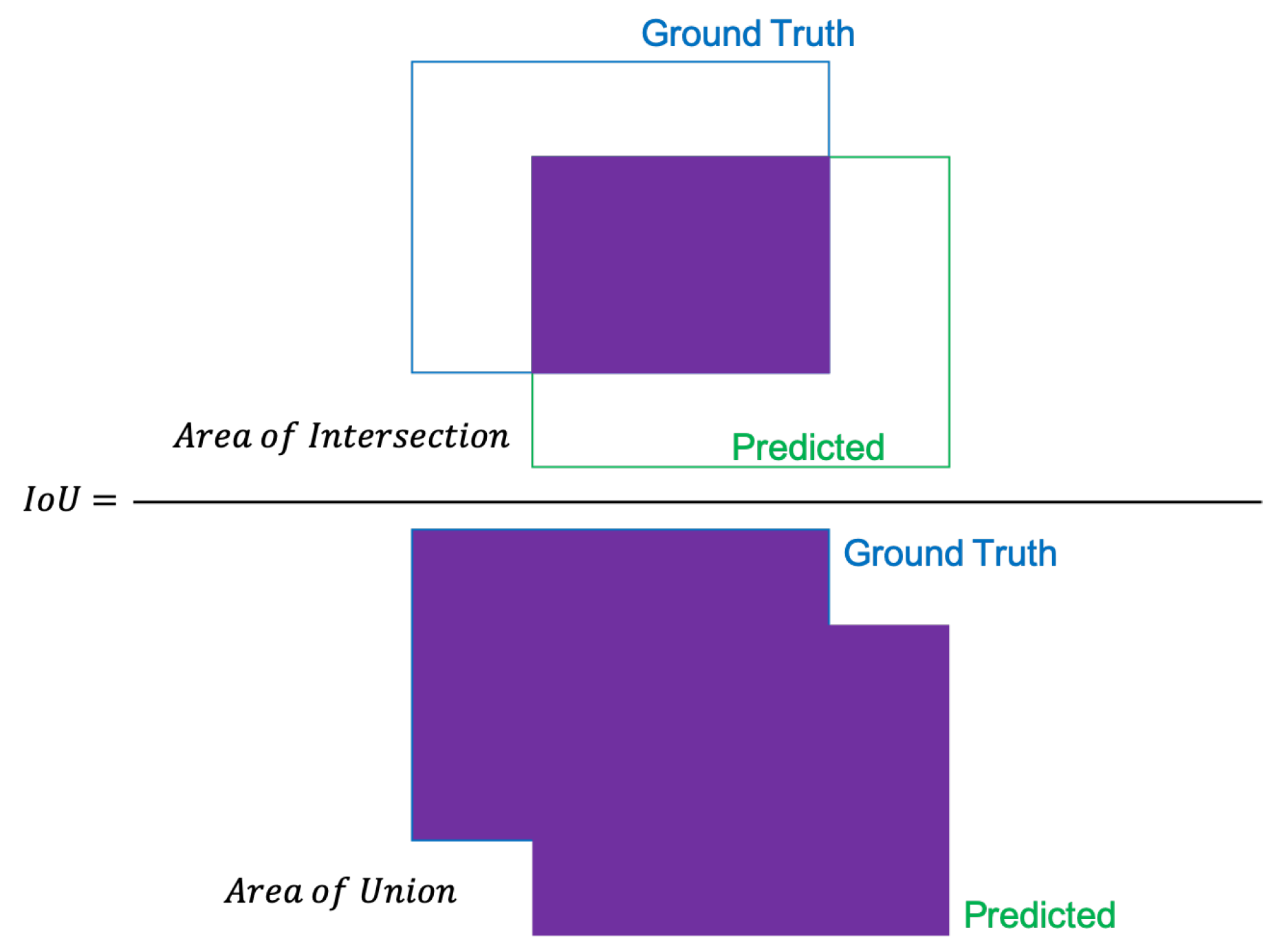
In order to determine true positives, the intersection over union is used (
Figure 5). The
IoU measures the area of overlap between the ground truth and prediction boundaries. Mathematically, the intersection over union is calculated as the ratio of the area of the overlap to the area of union.
where
and
are the areas of overlap and union respectively. If the
is greater than the threshold, the detection is considered correct, otherwise, it is a false detection.
The general definition of the average precision is finding the area under the precision–recall curve.
The interpolated AP is calculated by replacing
in Equation (
13) by
4.2. Results of Detection and Instance Segmentation Based on Deep Learning
The models were trained on a machine containing an Intel Core i9-9920X with four Nvidia GeForce RTX 2080 Ti GPU’s. Each card consists of 11 GB GDDR6 memory and 544 tensor cores. Each model was trained on one GPU with different configurations, and the model with the best metrics was chosen to be trained on by the next dataset. Adjusted configurations include the batch size, learning rate, and epochs.
Table 5 illustrates the learning rate, number of epochs, and training time for each dataset. For the first three datasets, we noticed that reducing the learning rate by a factor of ten at each subsequent training session helped to improve the model accuracy.
This improved model accuracy was due to the first three datasets containing data from UND campus buildings, which have similar architectures. Dataset four consisted of several different campuses, and thus a higher learning rate yielded better results. The training time for each dataset was proportional to the number of images found within them. Dataset four consisted of three different campuses, since training on each individual campus degraded the model performance.
The test dataset was generated with 10 images from each campus. These 70 images were subsequently deleted from their original datasets to eliminate them from the machine learning process. Similar augmentation techniques were applied to the test dataset to increase the size and test the models fitness. After the augmentation process, the size of the dataset increased to 213 images. The breakdown of dataset is provided in
Table 3, which breaks down each dataset by the number of instances in each class within it along with the cumulative values.
Table 6 shows the average precision and the mIoU of the three object detection models and one instance segmentation model. The models were trained on and validated using thermal images captured by the ICI Mirage 640 camera and the ratio to training verses testing was 90:10. A total of five classes were identified for the models to train on: Windows, Facades, Roofs, HVACs, and Doors. The models were evaluated after each training session; however, the results presented are after the final training session. The Average Precision at thresholds of 25%, 50%, and 75% were recorded, and the results show that Mask R-CNN outperformed the other three models for all thresholds. The other three models especially suffered at the 75% threshold, which indicates that the models are only able to identify a few objects with high confidence.
The feature maps generated were not adequately able to capture the patterns in this thermal dataset leading to low confidence in the models. The three object detection models suffered in estimating the size of objects as well. This is shown in the low mIoU scores achieved by the models. It is also beneficial to compare the pure object detection models against themselves. All three object detection models utilized Faster R-CNN with different backbone architectures.
These models were also evaluated to a similar AP score at all thresholds; however, the Inception ResNetV2 backbone performed slightly better. This is prevalent in the slightly higher AP at 0.75. The mIoU of both the Inception ResNetV2 and ResNet 50 were the same at 0.34; however, the Inception ResNetV2 backbone achieved higher results for windows, roofs, doors, and HVAC systems while the ResNet 50 model achieved a higher facade evaluation. Overall, Mask R-CNN achieved an average mIoU of 0.66 with Facade and Roofs having the highest overlap of 0.73 and 0.67, respectively.
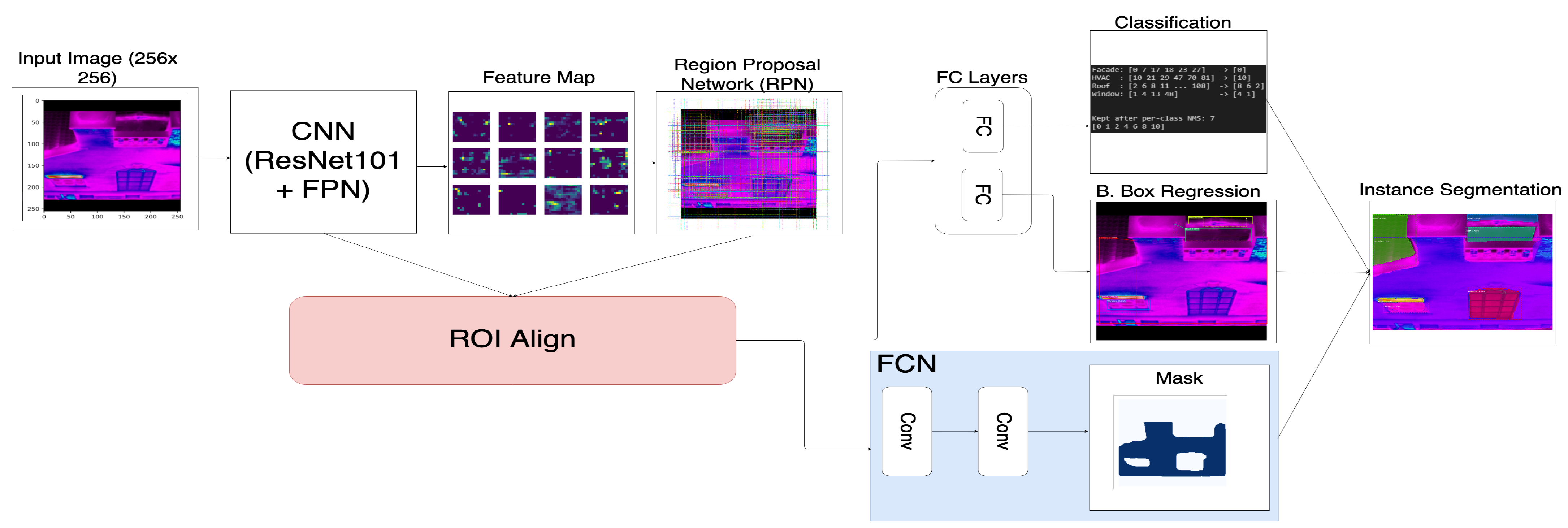
The Mask R-CNN model was selected for two main reasons. When quantifying heat loss on buildings, the U-value equations are extremely sensitive to small shifts in temperature and emissivity. This sensitivity required our detection to be precise, with traditional bounding box detection being insufficient for our purposes. Using bounding boxes allows for noise to be introduced since the object contour is not calculated. Instance Segmentation allows us to classify accurate results in greater detail to match ASHRAE standards. Emissivity plays a large role within each of the U-value equations and changes based on the material composition of the object in question. Based on the classification and composition, the emissivity value was looked up on multiple infrared emissivity tables.
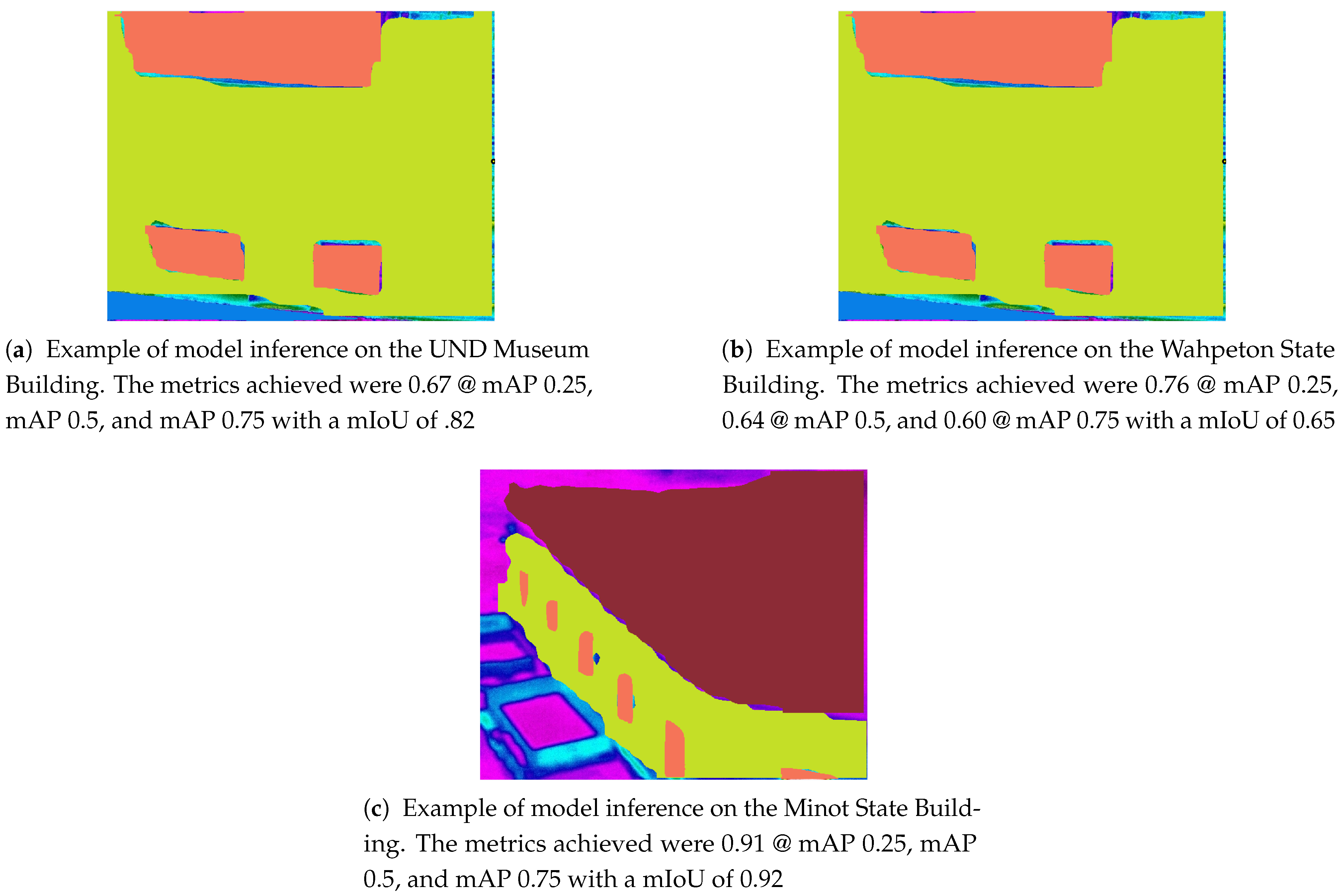
The Mask R-CNN model also yielded better results (please see
Figure 6) when compared to the Faster R-CNN models with different backbones. Both object detection and instance segmentation models were trained in a similar fashion with varying learning rate decay for the first three datasets, and higher decay for the fourth dataset. The number of epochs was held constant for all models. With the introduction of the mask branch, the Mask R-CNN model took longer to train with more favorable results. We, therefore, selected the Mask R-CNN model.
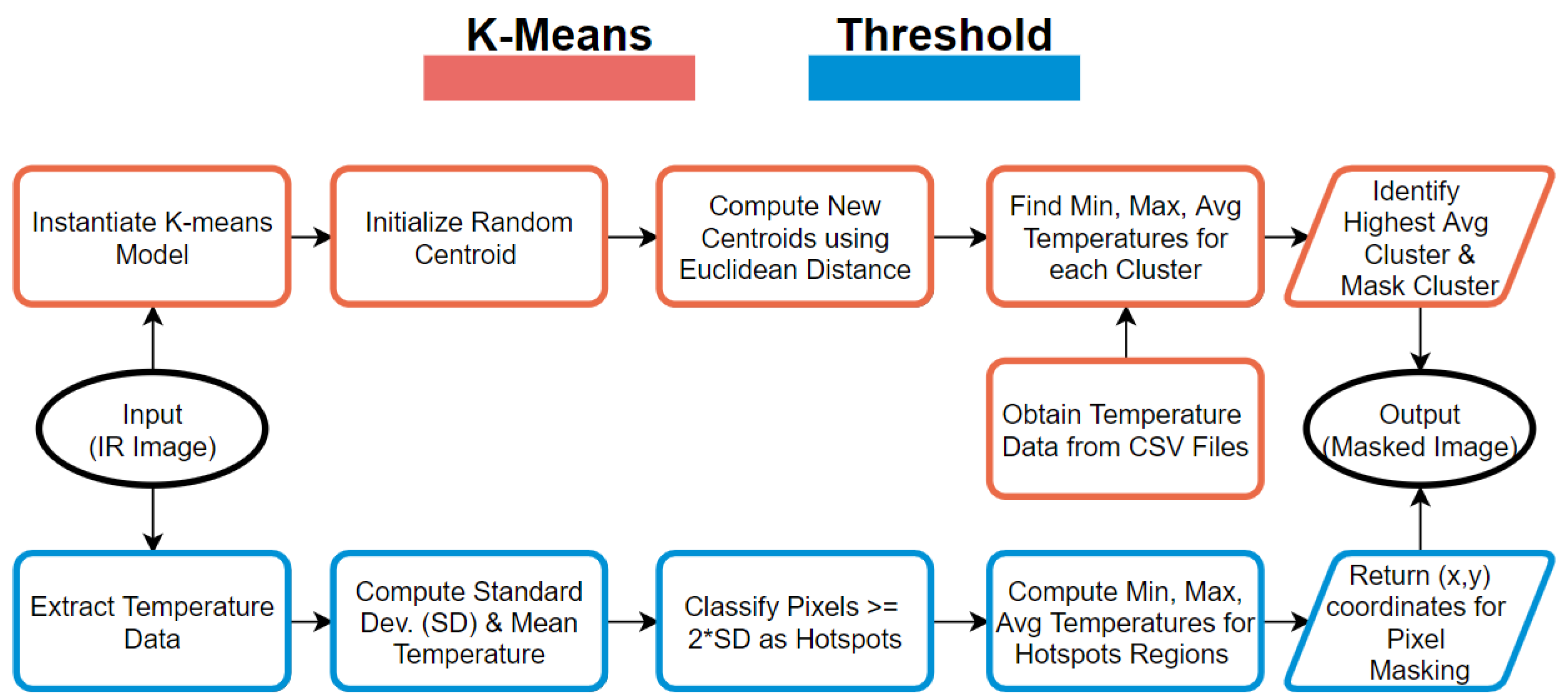
4.3. Clustering Performance
Metrics, such as the Silhouette Coefficient and Davis–Bouldin Index, were evaluated for K-means. As explained by [
58], the Silhouette Coefficient is a popular metric to find the quality of clustering. It is a measure of how a particular data point or pixel value in our use case is similar to its own cluster compared to other clusters. The coefficient ranges from −1 to 1, where a positive value signifies that the clustering was well performed. Davis et al. [
59] introduced the Davis–Bouldin Index. This metric is an average of the similarity for a cluster to its nearest cluster, which is a ratio of the intra-cluster distance to the inter-cluster distance. The minimum score is 0, with lower values indicating better clustering. The Silhouette Coefficient for the Museum of Art and Twamley buildings were 0.71 and 0.68, respectively. The Davis–Bouldin Index for the Museum of Art and Twamley buildings dataset were 0.81 and 0.75, respectively.
Figure 7 highlights the hotspot regions in discrete red and yellow sub-regions for a window (Window 1) at the UND Museum of Art and Twamley buildings using the TBC and K-means approaches, respectively.
Table 7 compares the two clustering methods and establishes a comparison metric (called the overlap) for windows and facades, respectively. The overlap metric is the ratio of overlapped hotspot pixels or similar pixels identified individually by the Threshold and K-means approaches to the total number of hotspot pixels identified by each of the clustering approaches. Keeping a maximum error of 10%, there were five instances when the two clustering methods can be considered to be in agreement. However, this is marginally short of a 50% split and cannot be used to definitively conclude a consensus. Two other metrics were considered for comparison and are discussed in the following two paragraphs.
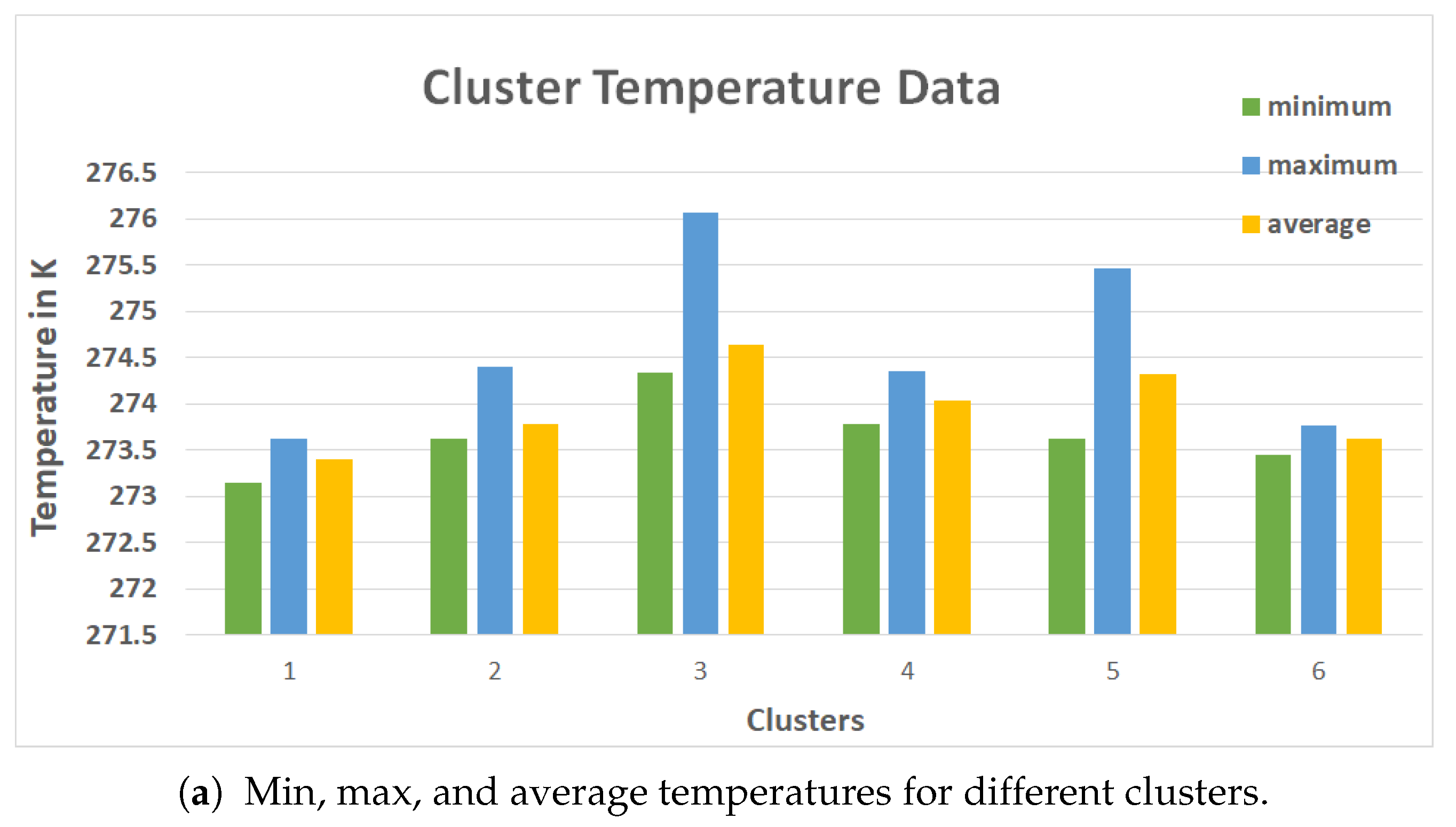
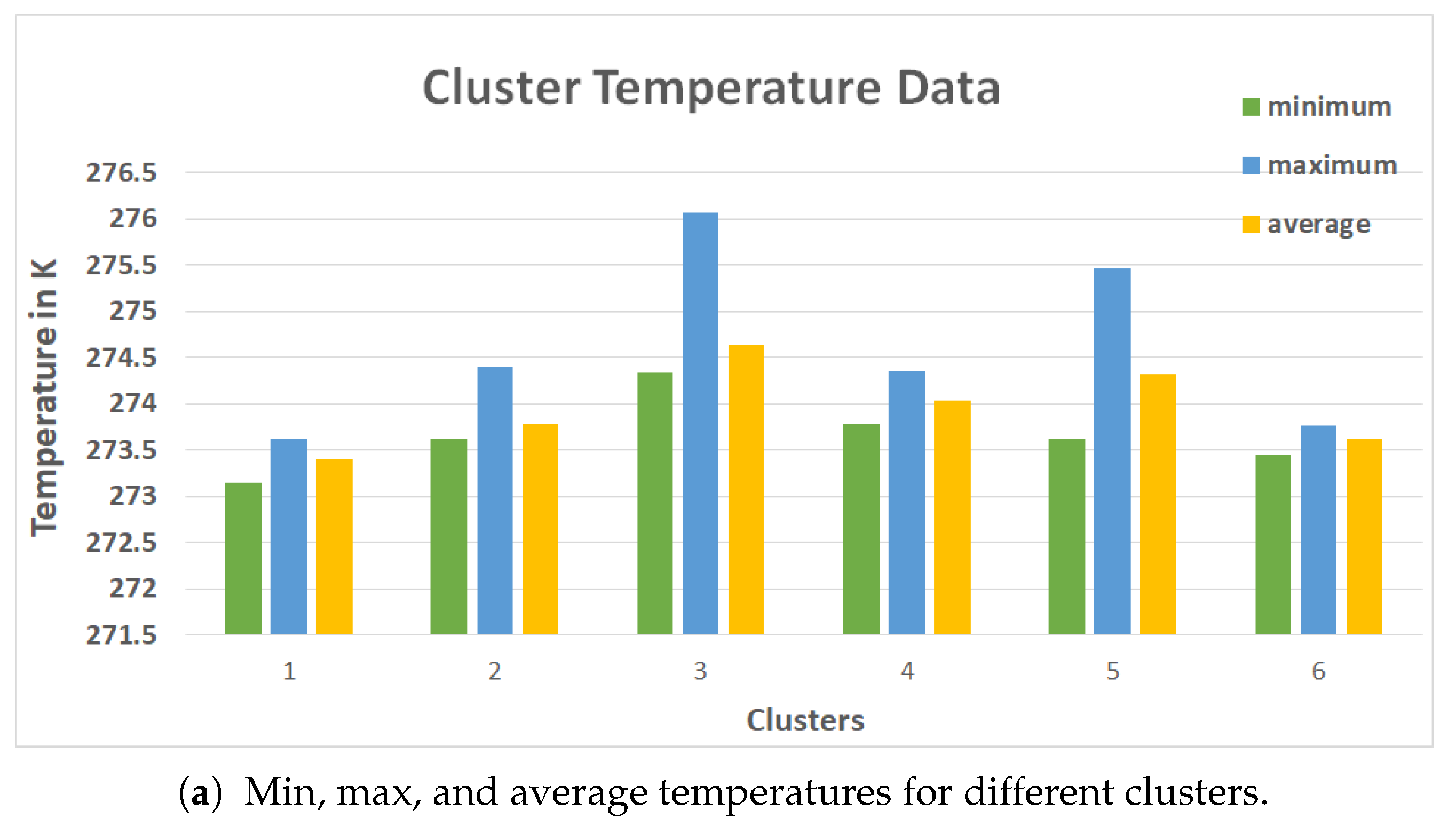
Figure 8b depicts the minimum, maximum, and average surface temperatures for six clusters created in the segmentation phase. The cluster with the highest average temperature (such as cluster 3
Figure 8b) was chosen as the hotspot.
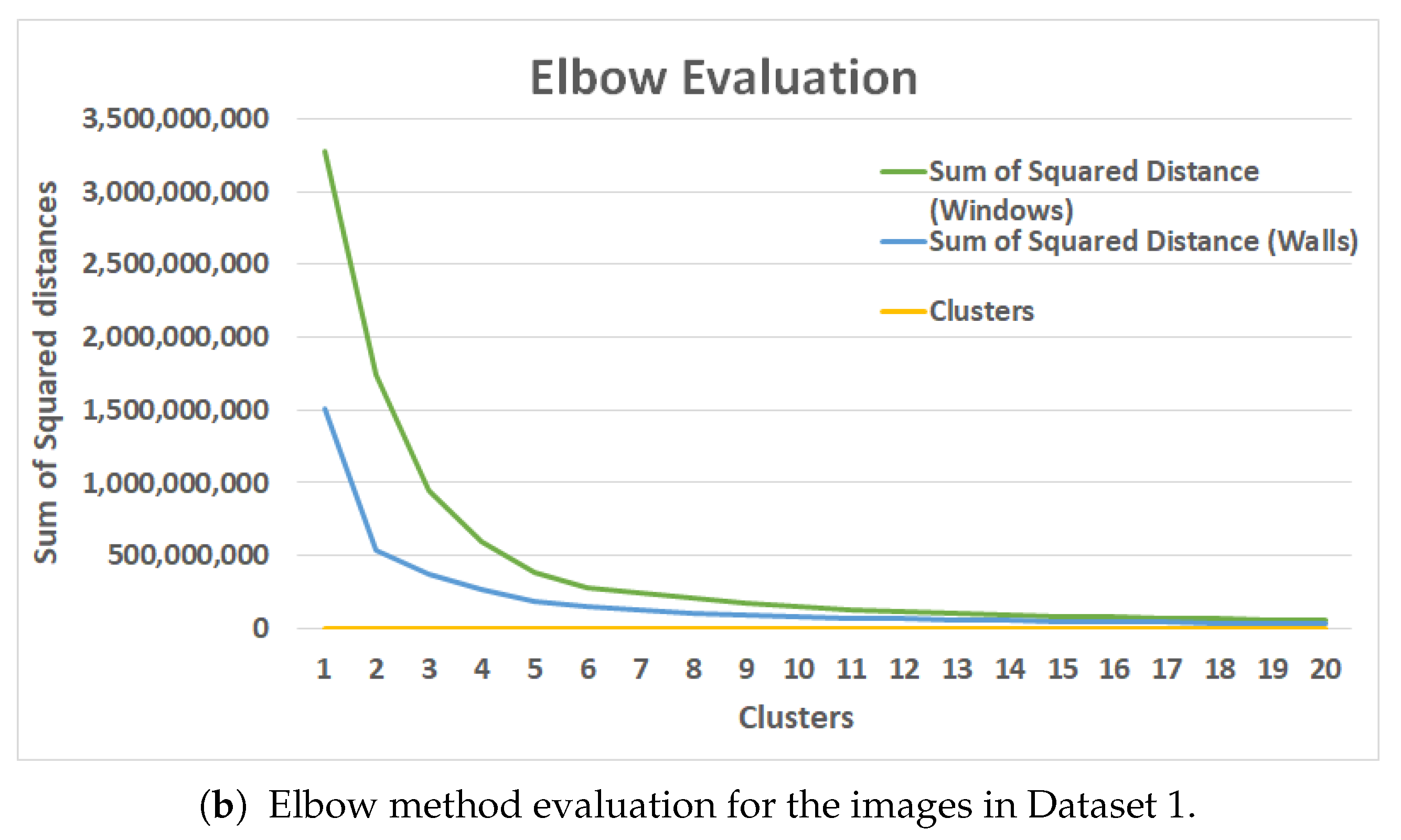
Figure 8b shows the Elbow evaluation for an image from the museum dataset. From the graph in
Figure 8, we can identify the
k value for the walls to be somewhere in the range between 3 to 6. After the seventh cluster, it was evident that there were no such changes in the squared distance. The K value of six was chosen using the temperature TBC as the ground truth because of the hotspot evaluation technique involving pixel temperatures. Computing the K-means to six clusters yielded results with few deviations with respect to Average Hotspot Temperature and Density of Hotspot from TBC. A value of K = 5 yielded results similar to the TBC for the windows. The performances of the clustering techniques across different parameters are listed in
Table 8.
Table 8 compares the results obtained by the clustering approaches based on a fixed set of five parameters across the morning, afternoon, and evening time periods. The “Density (Hotspot)” measure is a ratio of the number of hotspot pixels to the total number of pixels within the entire surface being measured, such as windows or facades. Similarly, the “Average Temperature (Hotspot)” measure is the average temperature of the hotspot regions identified by each of the clustering methods. The largest discrepancy can be seen when comparing the density metric between the two clustering approaches during the afternoon for Twamley. This discrepancy was caused by the incidence of solar radiation on Twamley’s surface.
For a fair comparison, the average hotspot temperatures across different time frames can be taken into account. The values obtained for these measures are consistent across the morning (both the buildings), afternoon (museum only), and evening (both the buildings) time periods with average hotspot temperature differences between 0.01 and 0.48 degrees Kelvin and can be considered negligible. The afternoon duration for Twamley is not considered because, as mentioned earlier, a skewing factor was introduced by solar irradiance. It should also be noted that the temperature values obtained by the sixth cluster from the K-means approach were the most accurate values for the Museum dataset. Accuracy here was assessed when the values of the K-means approach were closest to the values from the TBC as temperature values in the latter were extracted directly from each pixel and, thus, are taken to be the ground truth.
In order to obtain the U-value for UND’s buildings, the Stephen–Boltzmann constant
was replaced by 5.67 × 10
Wm
K
in Equation (
5) in addition to the spectrum emissivities mentioned earlier.
Table 9 and
Table 10 show the U-values and related parameters for UND’s Museum and Twamley buildings). Each of these tables contains the investigated building elements, number of images considered, min–max–average surface temperature captured from the thermal images, air temperature obtained from weather data,
,
,
, and
(first obtained in BTU/ft
h°F and then converted to W/m
K and where
) using the corresponding equations and ASHRAE standard data.
The thermocouple temperatures obtained from the building surface were through an Extech 3-channel data logger, which had conductive probes to measure surface temperatures. These probes were secured to the indoor and outdoor surfaces using electrical tape for average durations of 20–30 s to obtain a steady reading of the surface measured. Different points on the surface were used, and, if the temperature readings did not differ too greatly from one another within that time frame, average values were taken.
According to the results obtained from the thermal images, the single-pane window U-values (Twamley building) were always more than the double-pane window (Museum building) U-values due to the fact that the double-pane windows consist of an extra layer of air that acts as an insulation to the heat flow. It can also be observed that the wall 1’s (in
Table 9)
U values are more consistent with the ASHRAE standard while window 1’s
U and
U values in
Table 10 (highlighted in green) are more consistent with the ASHRAE standard than
U. As there are many factors that influence U-value estimation (please see the following subsection on uncertainty analysis), additional testing needs to be done through rigorous data collection (multiple time frames, precise indoor temperature readings, varied building types, etc.) to come to accurate conclusions.
4.4. Factors Contributing to Uncertainties in Thermal Data Capture and Processing
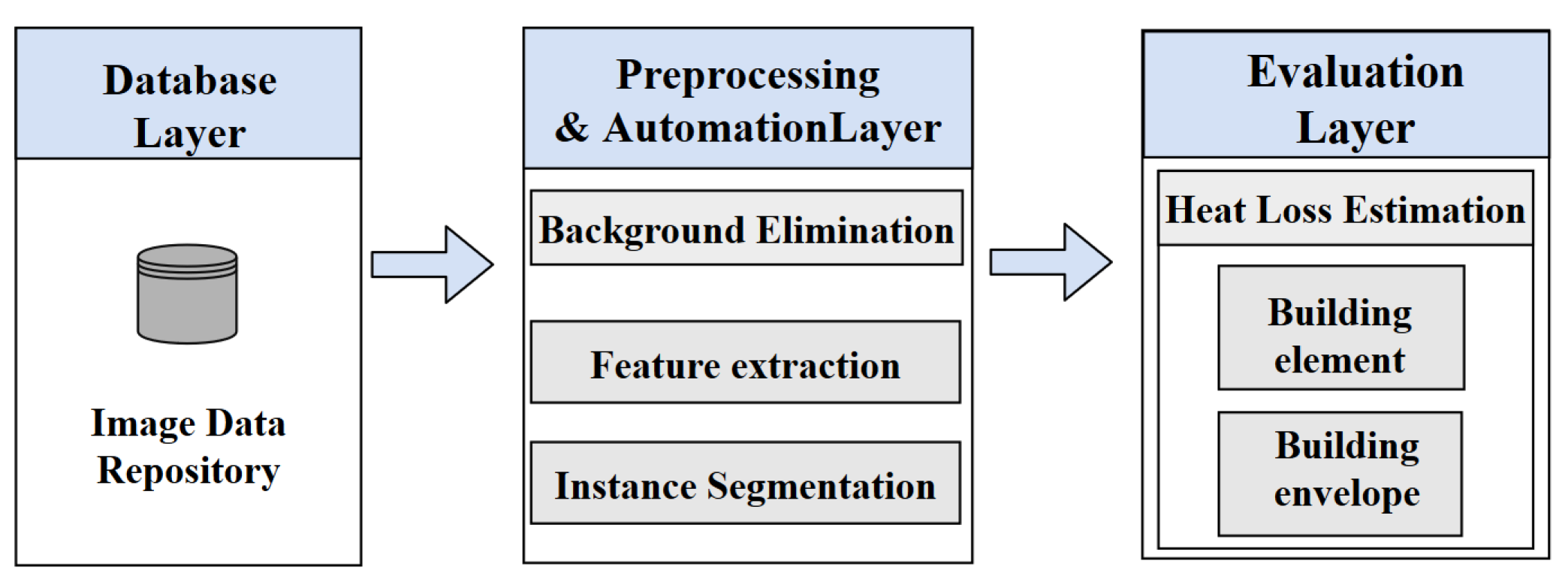
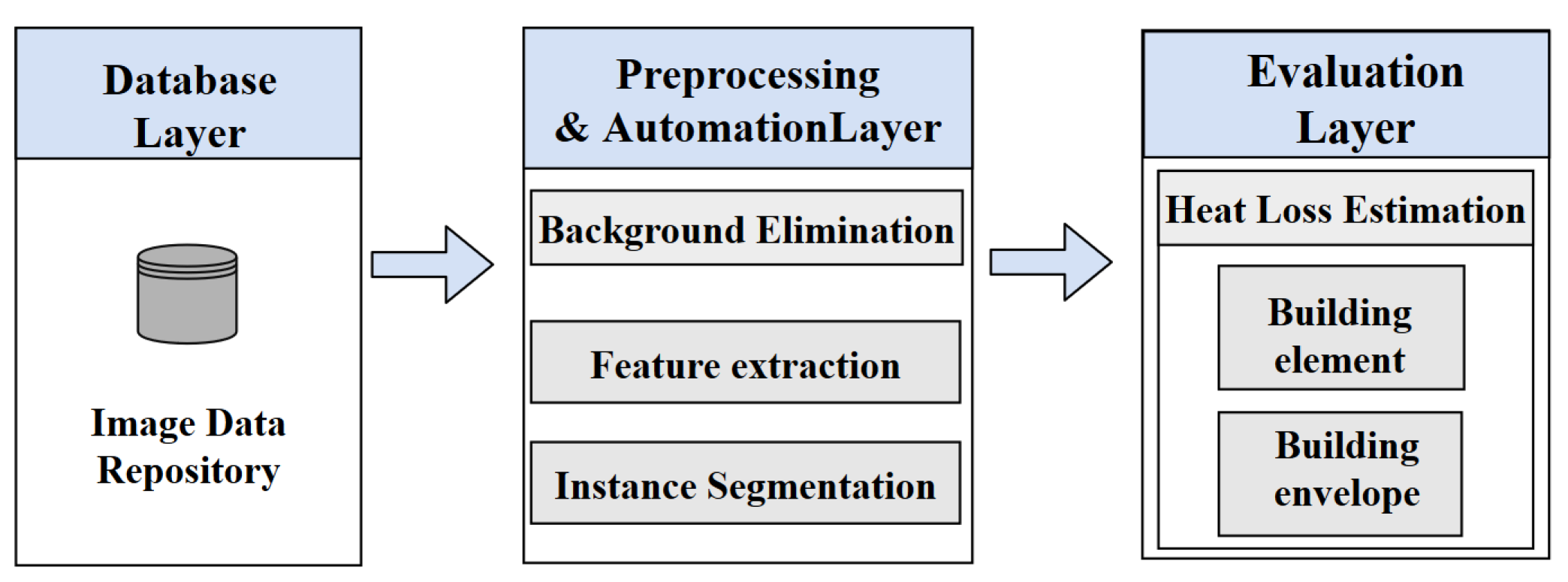
The proposed approach consists of three primary layers: (1) the collection of data and instance segmentation using deep learning; (2) clustering and hotspot detection; and (3) U-value estimation. These three layers contribute to the overall uncertainties of the proposed solution. In the following, we discuss each of these points:
Uncertainties associated with image capturing include the following:
Capturing images of surfaces during the daytime should be planned carefully since solar irradiance can skew readings from the imaging apparatus [
60]. Sunlight reflecting on external surfaces, such as brick, which is of high emissivity, will radiate more heat than if the surfaces were under shade. We used images obtained before sunrise and after sunset; however, the effects of incident sunlight will still affect the surface for hours after the surface is shaded.
Surrounding objects, such as metallic surfaces, may reflect high temperatures, leading to inaccurate surface measurements due to reflecting sunlight [
61]. We minimized this bias, recognizing that the buildings in these datasets are adjacent to parking lots, which had vehicles with reflective surfaces. These reflections will influence the thermal readings.
Heat and humidity are two atmospheric factors that will influence temperature readings [
62]. In regions where the temperatures and relative humidity fluctuate quite frequently, measurements must be systematically recorded when there is acceptable consistency in weather patterns for that day or time.
Uncertainties with object detection and instance segmentation: Uncertainty in deep learning can be classified mainly into two types: epistemic uncertainty and aleatory uncertainty. Epistemic uncertainty refers to the uncertainty associated with the objects that the model does not know because the training data was not appropriate. This type of uncertainty arises due to gaps in data and knowledge. We limited this type of uncertainty by generating sufficient data as this results in decreasing epistemic uncertainty. The aleatory uncertainty refers to the type of uncertainty rising from the stochasticity of the observations. This second type of uncertainty cannot be mitigated by providing more data to the models. Given the uncertainty in deep learning, the reading of the data associated with U-value calculation is subsequently uncertain, and there will be some variability the readings and the overall U-value estimation. These variabilities are added to other factors discussed in the previous paragraph.
Uncertainties with clustering and hotspot detection: The clustering and hotspot detection are directly related to object detection and instance segmentation and uncertainty associated with deep learning will propagate and create uncertainties associated with this part. Apart from these sources of uncertainty, additional sources exist, such as the observations, background knowledge, the induction principle, and the learning algorithm used for this unduction principle.
Uncertainties with U-value estimation: The formulas used for U-values are approximations and depend on many factors that are themselves subject to different types of uncertainties, which can result in different measurements.
Please see
Table 11 for quantitative reporting of the precision and average deviation when considering U-value estimation. Based on the results from our analysis and due to the high number of sample points for object-wise U-value estimation, unbiased rounding was used to retain one significant digit after the decimal for precision and error, and two significant digits after the decimal for the average deviation. For instance, the wall precision value for Twamley and the error in the wall readings for the Museum were rounded to 15.1% and 347.9% from 15.08% and 347.91%, respectively. For the purposes of our evaluation, we specify the definition of precision according to ISO 3534-1 [
63] to be “the closeness of agreement between independent test results obtained under stipulated conditions.”
The error was calculated by considering the % difference between the empirical observations and the true values (ASHRAE) [
64]. This can be considered to be a measure of accuracy. Following the standard definition for “true value”, the “true value” refers to values obtained by ASHRAE (which may have had systematic or random uncertainties) and not the absolute value for the measurand that is devoid of any contributing or biasing factors. The average deviation (
) is calculated using the following formula:
where
U represents the U-values 1, 2, and 3. The precision is calculated using Equation (
16)
As can be seen from
Table 11, the average deviation for windows was equal to or higher than those of walls for both the buildings. This means that the variation of U-values from their respective average value (
U) for a given object was lower in the case of walls than windows. We can infer from this table that the U-value measurements for walls were much more similar to one another relative to the windows’ U-values.
Similarly, in terms of accuracy, the U-values obtained for the windows are closer to the true ASHRAE values. These results also confirm an important result: U-values closer to one another may not necessarily indicate higher accuracies as can be seen when the accuracy for walls are considered. Using our methodology for U-value estimation and when considered relative to windows, it can be said that the measured values for walls are more precise (lower precision) but much less accurate (higher errors).
5. Conclusions
Building thermal performance information is crucial to reducing energy consumption and to achieving zero energy buildings. Researchers have proposed many methodologies over the past decades, including statistical approaches, engineering-based methods, and machine learning. These methods present many limitations; therefore, this study aimed to enhance the building thermal performance with a more precise heat loss quantification and to overcome the complexity of engineering methods.
We proposed a novel method using thermal imagery and deep-learning-based instance segmentation combined with analytical methods to compute U-values. We used thermal images captured by SkySkopes to train the machine learning models. The images were obtained during several flight rounds duringearly dawn to avoid any non-desirable reflections and accounted for several variables, such as the angle and distance to walls. The images obtained were annotated and archived using cloud storage. Several classes were defined, such as the facades of buildings, trees, and windows, after which Mask R-CNN was trained and tested.
The confusion matrix and AP were computed to evaluate the performance of the machine learning algorithms. The results indicated that the model trained on augmented datasets achieved total average precision values as high as 79% for facades, 69% for windows, and 67% for roofs. The heat loss calculation was also used to quantify the desired values. We proposed clustering and hotspot detection methods to identify the primary regions of heat loss in the facades and windows of the buildings.
Three measures were used to compare the clustering schemes. The overlap metric indicated a 50% agreement between the methods; however, we explored the average hotspot temperature metric to obtain a definitive conclusion. A maximum difference of 0.48 degrees was observed for the average hotspot temperature metric on surfaces not affected by sunlight and, thus, was effectively used to confirm our results. This information can be leveraged to make appropriate decisions related to building design and maintenance.
The analysis led to the following conclusions: (1) the proposed data driven approach provided an automatic and reliable process for energy audit applications; (2) our results are broadly consistent with the American Society of Heating, Refrigerating, and Air-conditioning Engineers building standards; (3) this research generated new information on the dependency of thermal efficiency, which relies on many factors, including the thermal images acquisition process, building geometry, and indoor heating or cooling conditions; and (4) the findings of this research and the quantitative and qualitative uncertainty analyses will provide a significant starting point for discussion and further research in the area of automated processes for energy audit applications.
Future work will include re-working Mask R-CNN to analyze more than thermal images and with datasets consisting of more balanced classes. Further studies should investigate the possible effects of the building typologies on the meteorological performances of the proposed method.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}