Author Contributions
This research was carried out in collaborations with all authors. Please note the following details below. Conceptualization, Y.S. and Y.-G.C.; methodology, Y.S., S.H. and Y.-G.C.; software, Y.S.; validation, Y.S.; formal analysis, Y.S.; investigation, Y.S. and S.H.; resources, Y.S.; data curation, Y.S.; writing—original draft preparation, Y.S. and S.H.; writing—review and editing, S.H. and Y.-G.C.; visualization, Y.S.; supervision, S.H. and Y.-G.C.; project administration, Y.-G.C.; funding acquisition, Y.-G.C. All authors have read and agreed to the published version of the manuscript.
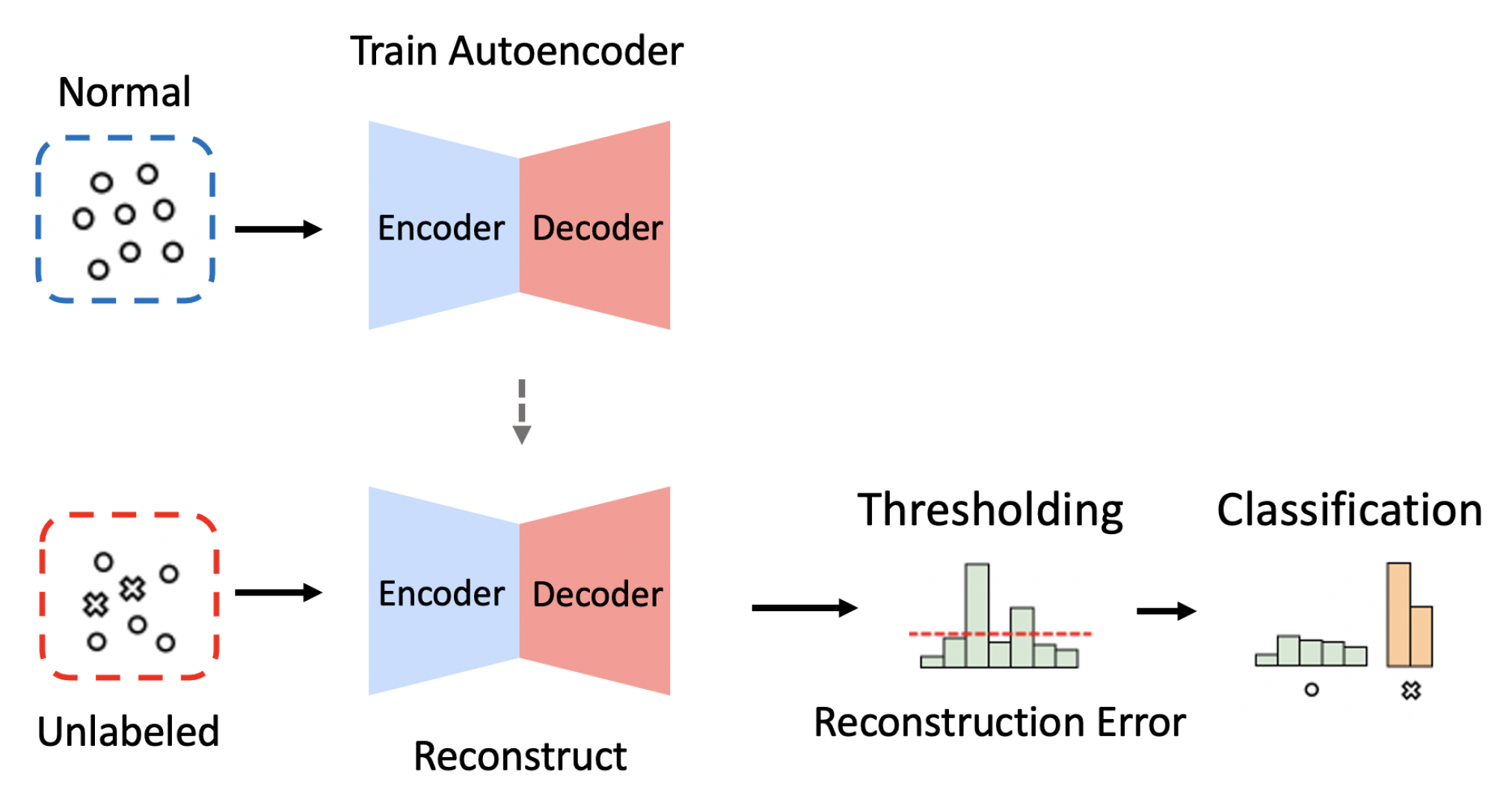
Figure 1.
The overall process of intrusion detection when using the dimension reduction (i.e., Encoder) and reconstruction (i.e., Decoder) methods of autoencoders.
Figure 1.
The overall process of intrusion detection when using the dimension reduction (i.e., Encoder) and reconstruction (i.e., Decoder) methods of autoencoders.
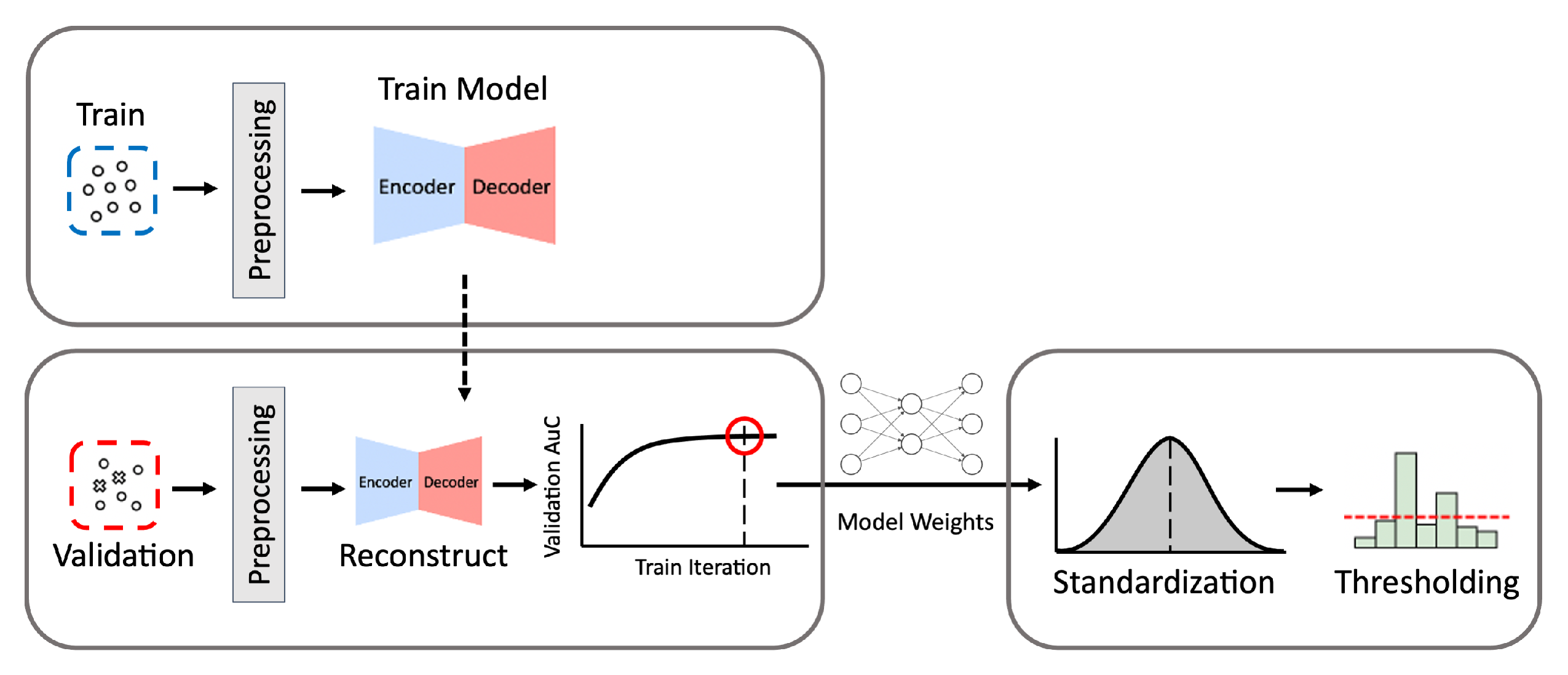
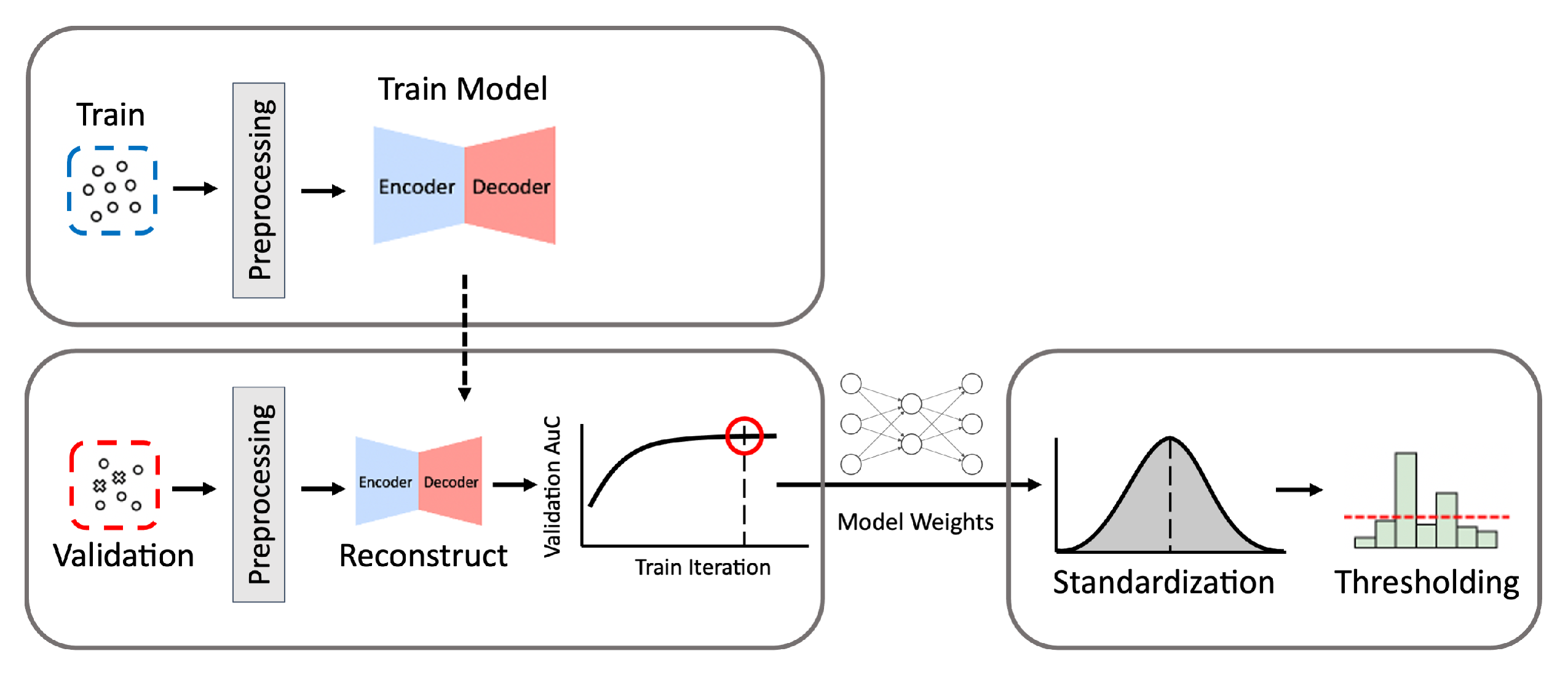
Figure 2.
The process of building autoencoder models. Train denotes the data for training, and Validation denotes the data for validation. The process consists of three phases: training, model selection, and validation.
Figure 2.
The process of building autoencoder models. Train denotes the data for training, and Validation denotes the data for validation. The process consists of three phases: training, model selection, and validation.
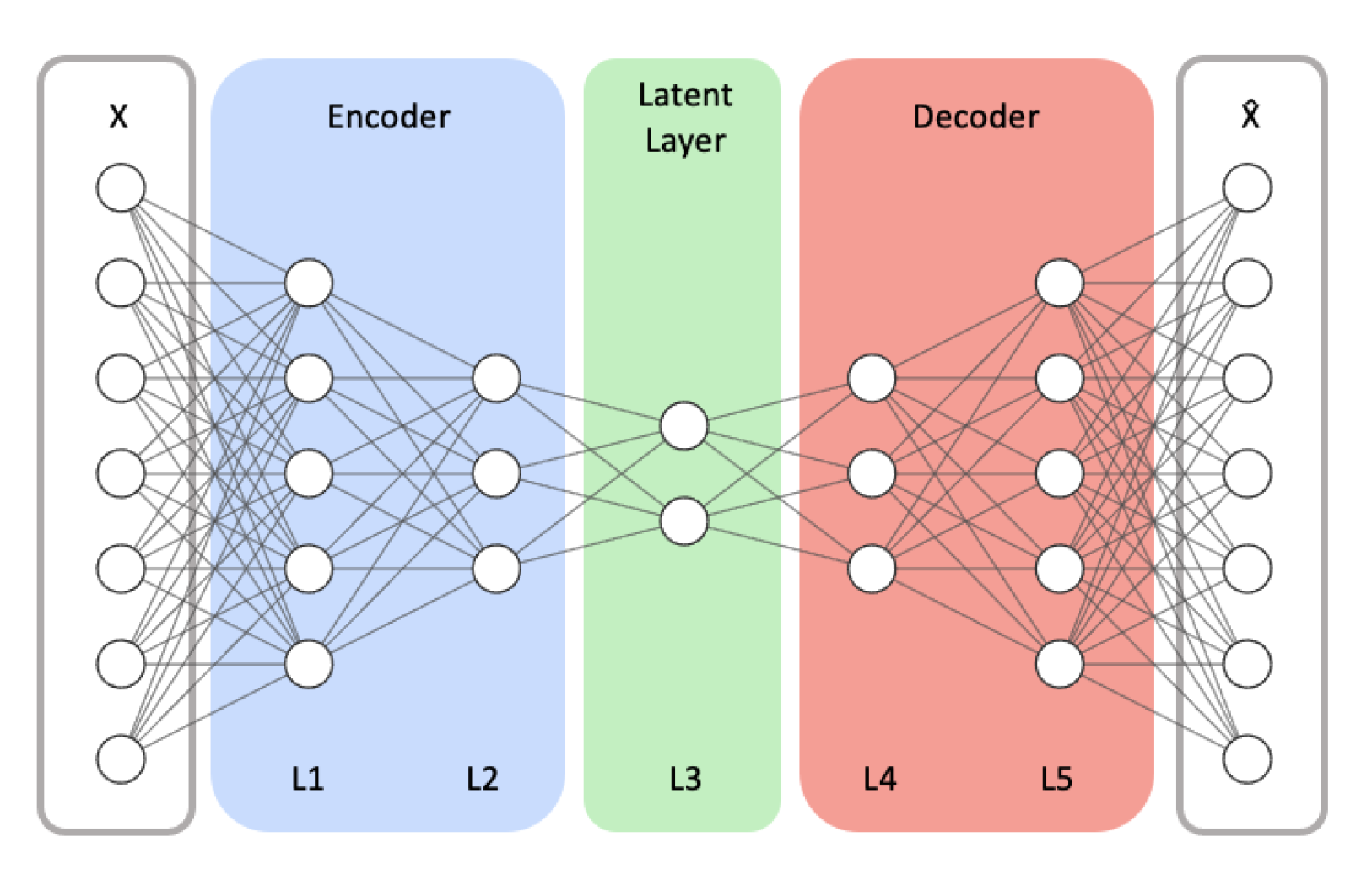
Figure 3.
An example autoencoder model architecture with symmetrical encoder and decoder networks. X and respectively represent the model’s input and its reconstructed output.
Figure 3.
An example autoencoder model architecture with symmetrical encoder and decoder networks. X and respectively represent the model’s input and its reconstructed output.
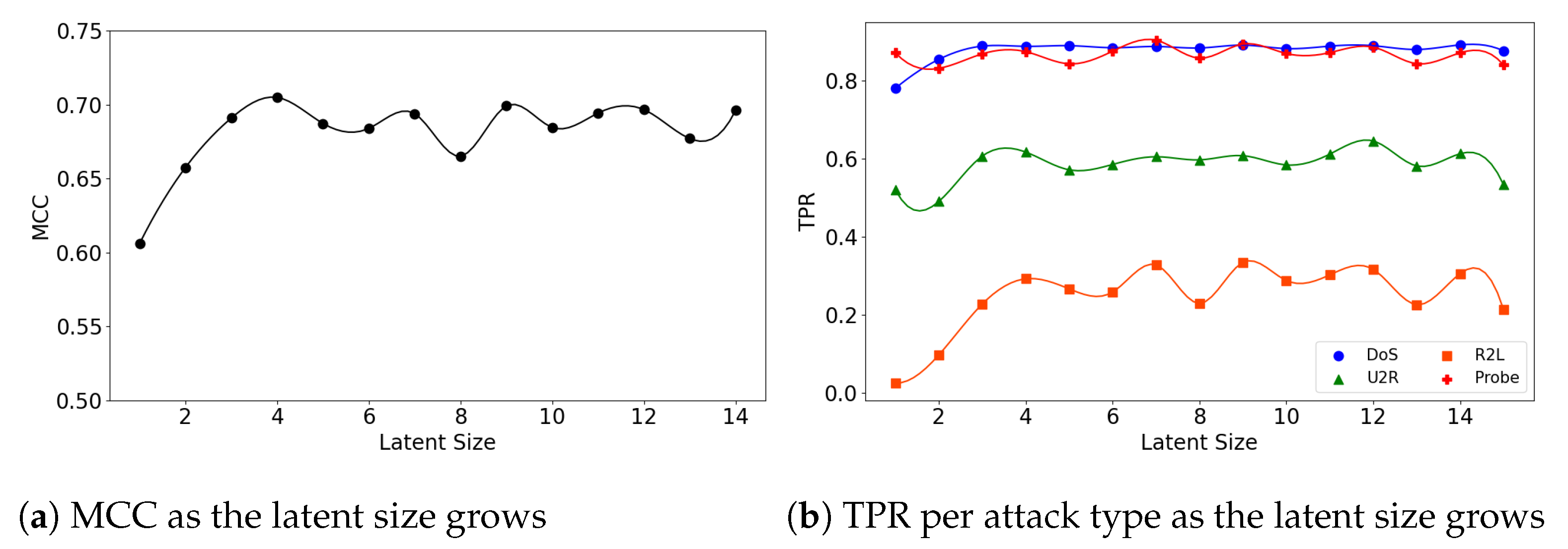
Figure 4.
The results of evaluation using the NSL-KDD dataset when the (5,32) model is employed.
Figure 4.
The results of evaluation using the NSL-KDD dataset when the (5,32) model is employed.
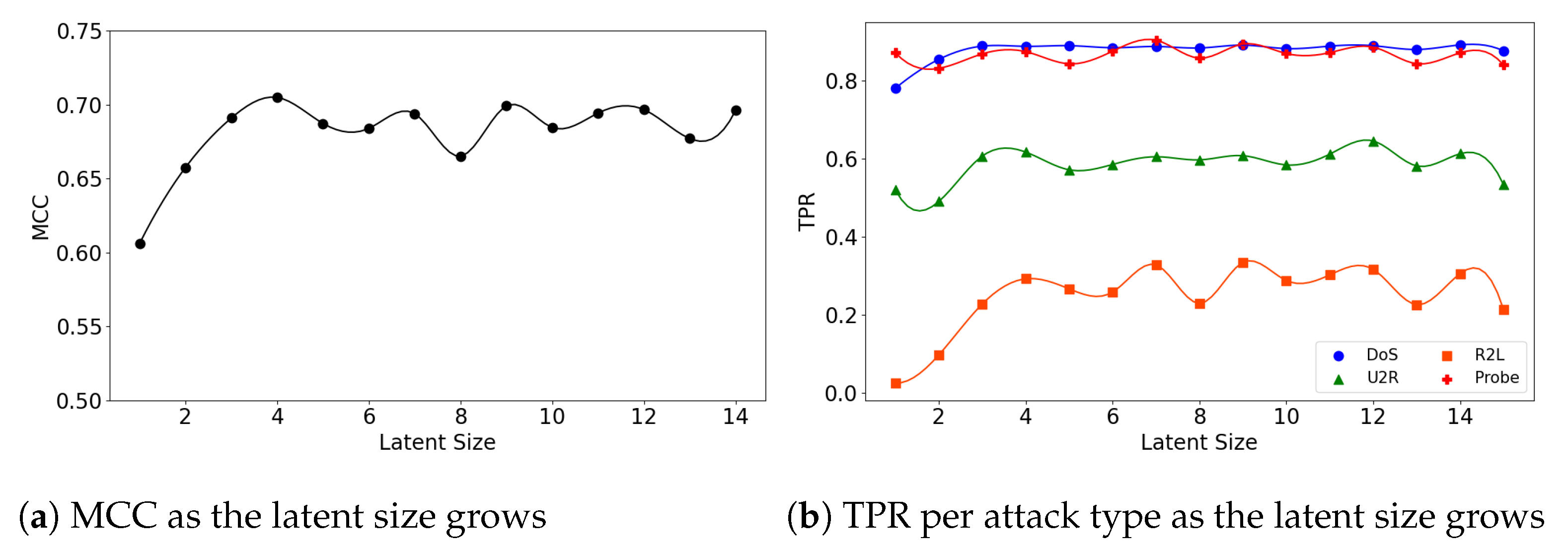
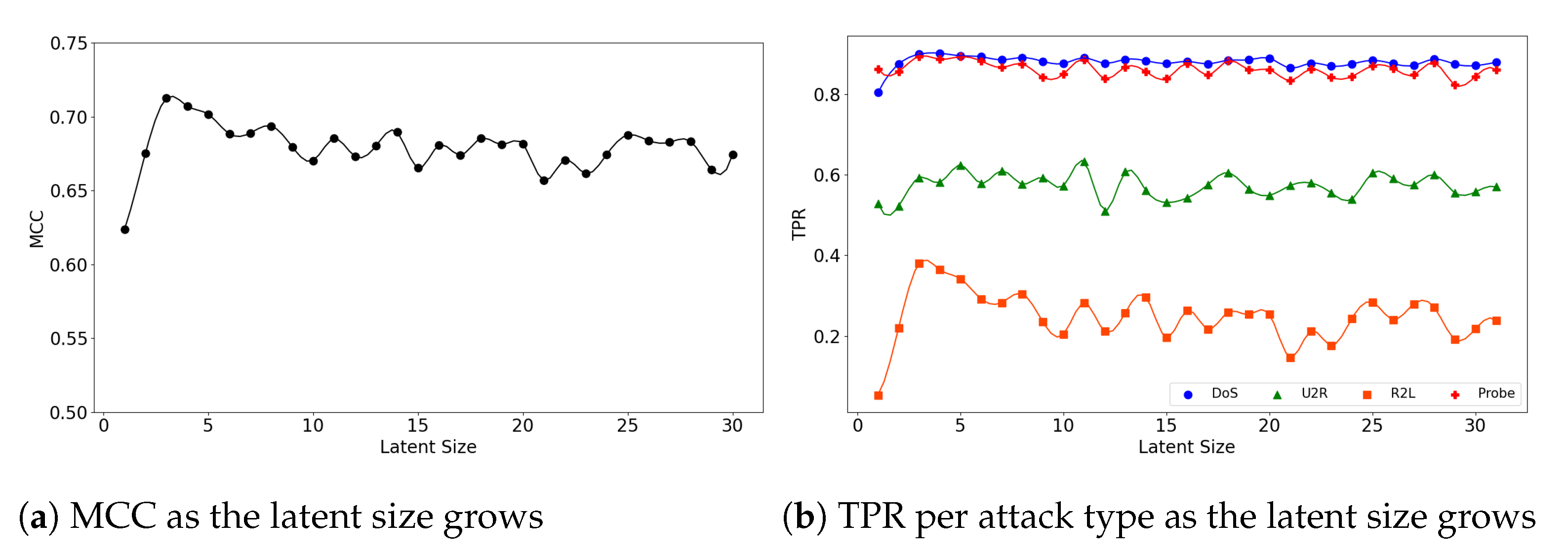
Figure 5.
The results of evaluation using the NSL-KDD dataset when the (5,64) model is employed.
Figure 5.
The results of evaluation using the NSL-KDD dataset when the (5,64) model is employed.
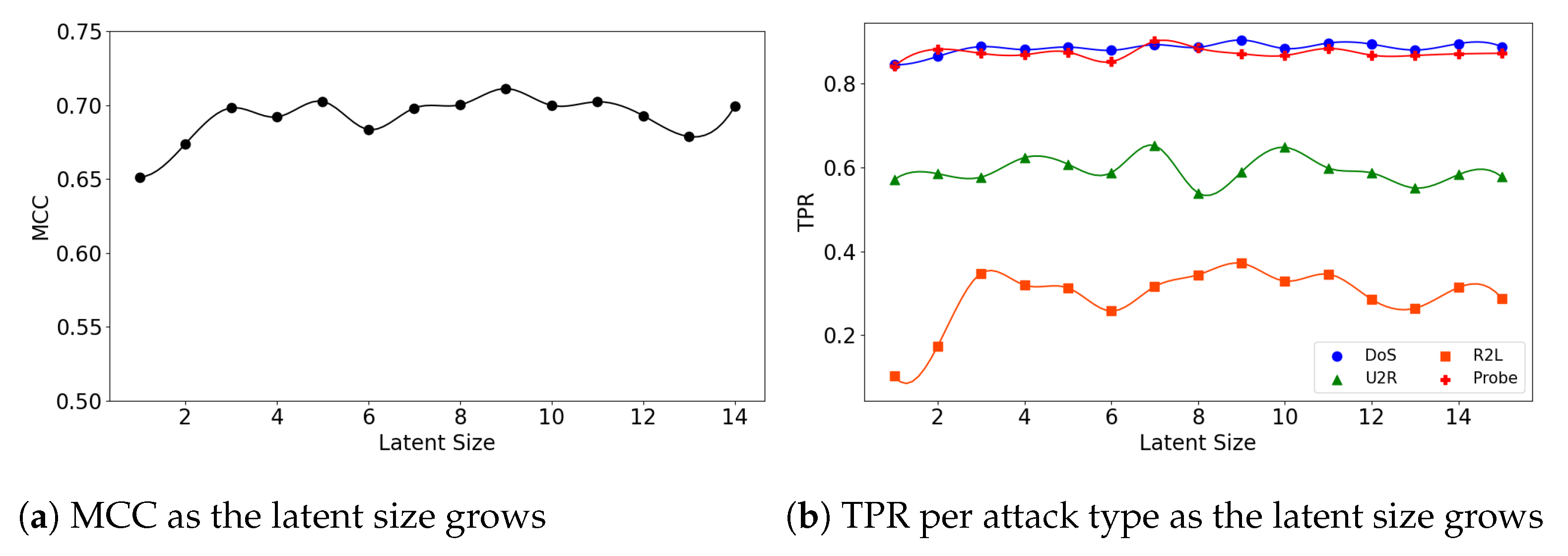
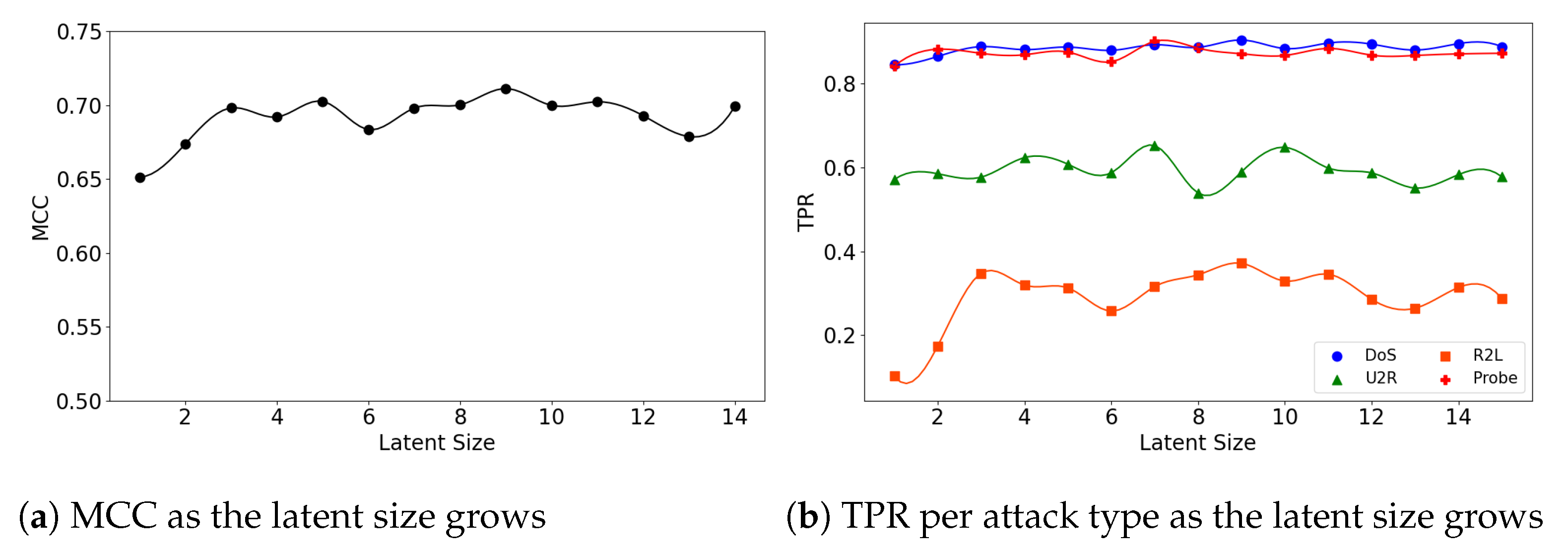
Figure 6.
The results of evaluation using the NSL-KDD dataset when the (7,64) model is employed.
Figure 6.
The results of evaluation using the NSL-KDD dataset when the (7,64) model is employed.
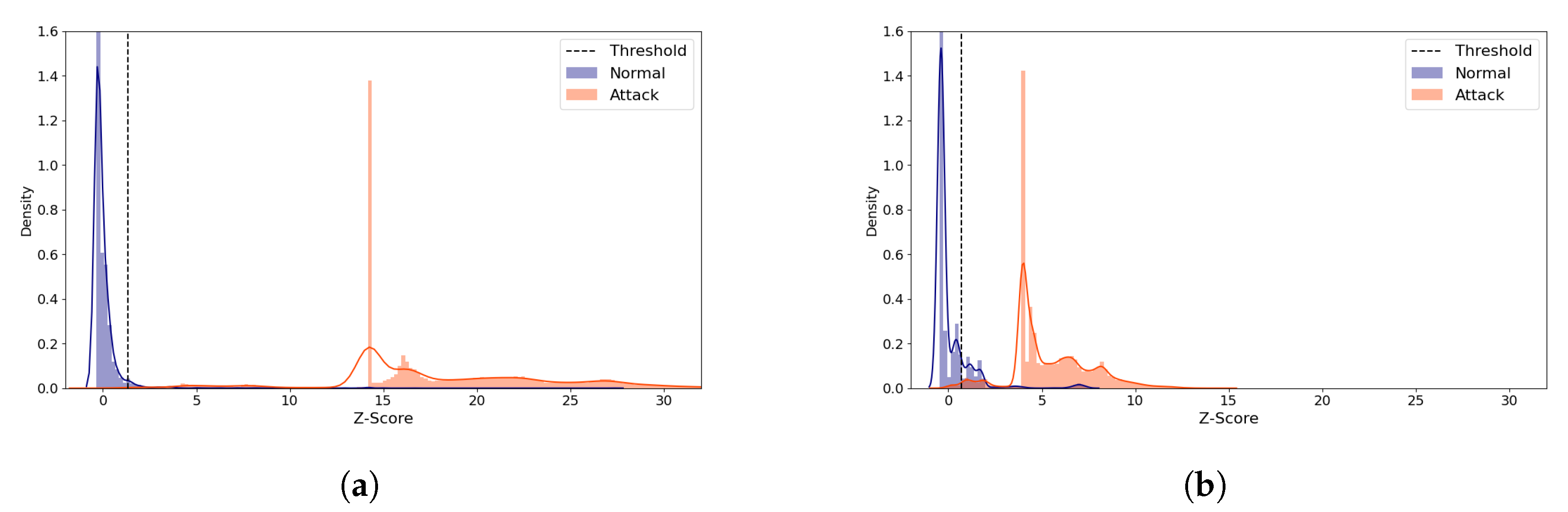
Figure 7.
NSL-KDD Reconstruction Distance Density Plot (Normal and R2L attack data) comparing the best and the worst performance cases with the (5,64) model. Blue denotes normal data and orange denotes R2L attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 2 for better visibility. (a) The best case (Latent size = 3, MCC = 0.712, Threshold = 2.488). (b) The worst case (Latent size = 1, MCC = 0.624, Threshold = 2.294).
Figure 7.
NSL-KDD Reconstruction Distance Density Plot (Normal and R2L attack data) comparing the best and the worst performance cases with the (5,64) model. Blue denotes normal data and orange denotes R2L attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 2 for better visibility. (a) The best case (Latent size = 3, MCC = 0.712, Threshold = 2.488). (b) The worst case (Latent size = 1, MCC = 0.624, Threshold = 2.294).
Figure 8.
The results of evaluation using the IoTID20 dataset when the (5,32) model is employed.
Figure 8.
The results of evaluation using the IoTID20 dataset when the (5,32) model is employed.
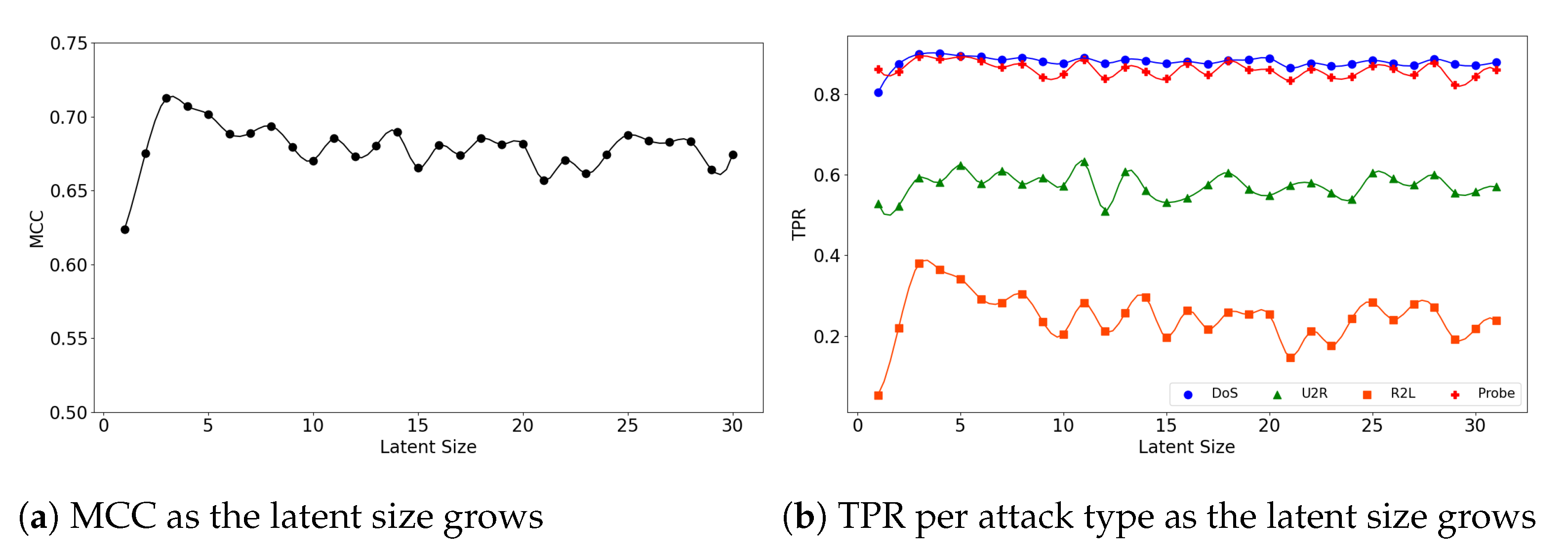
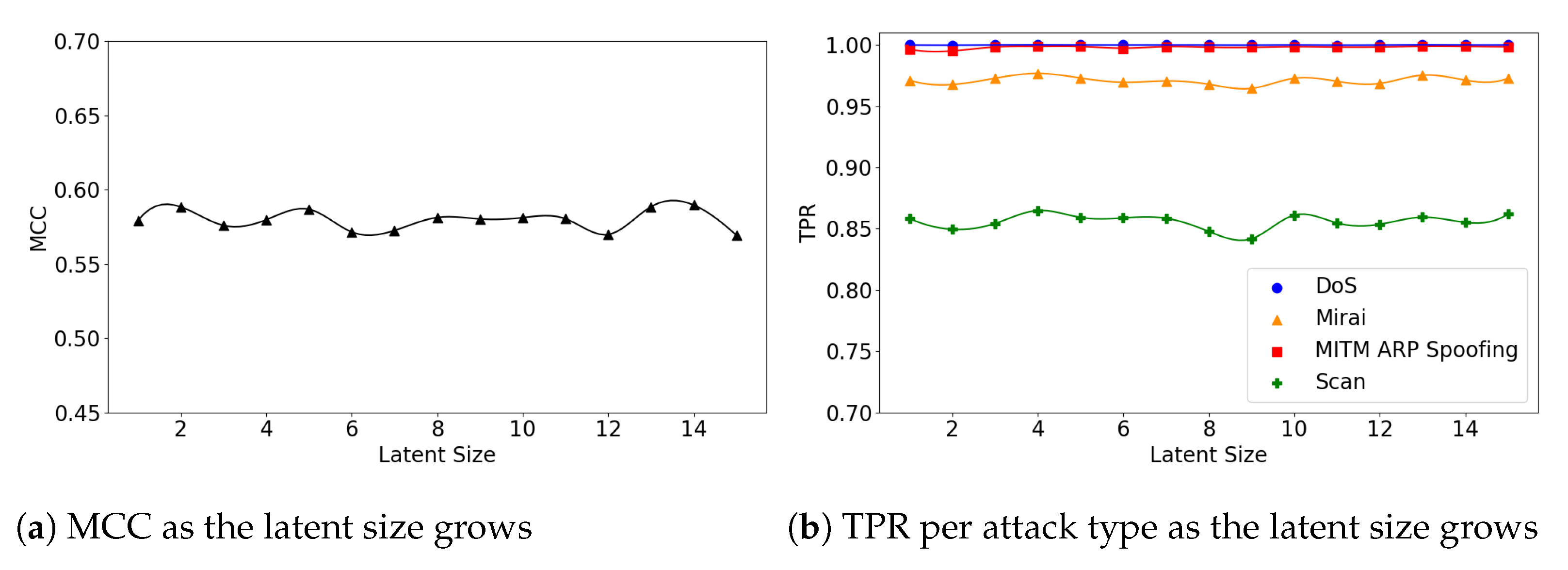
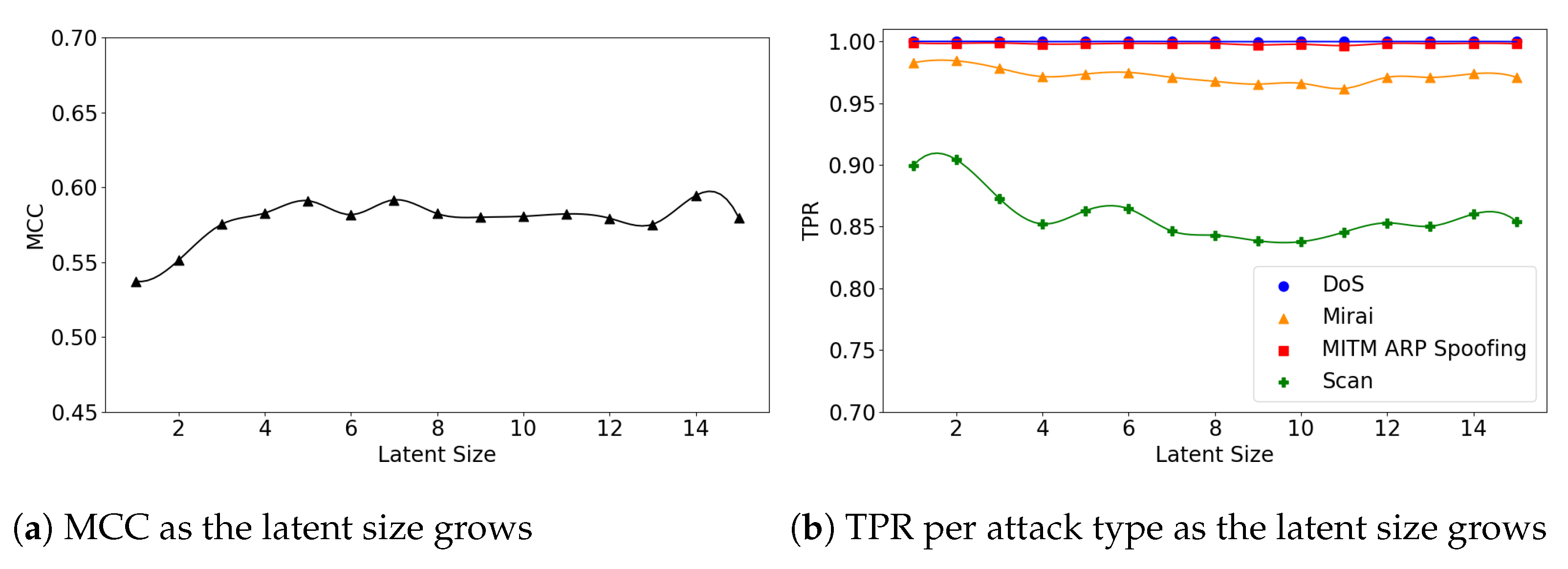
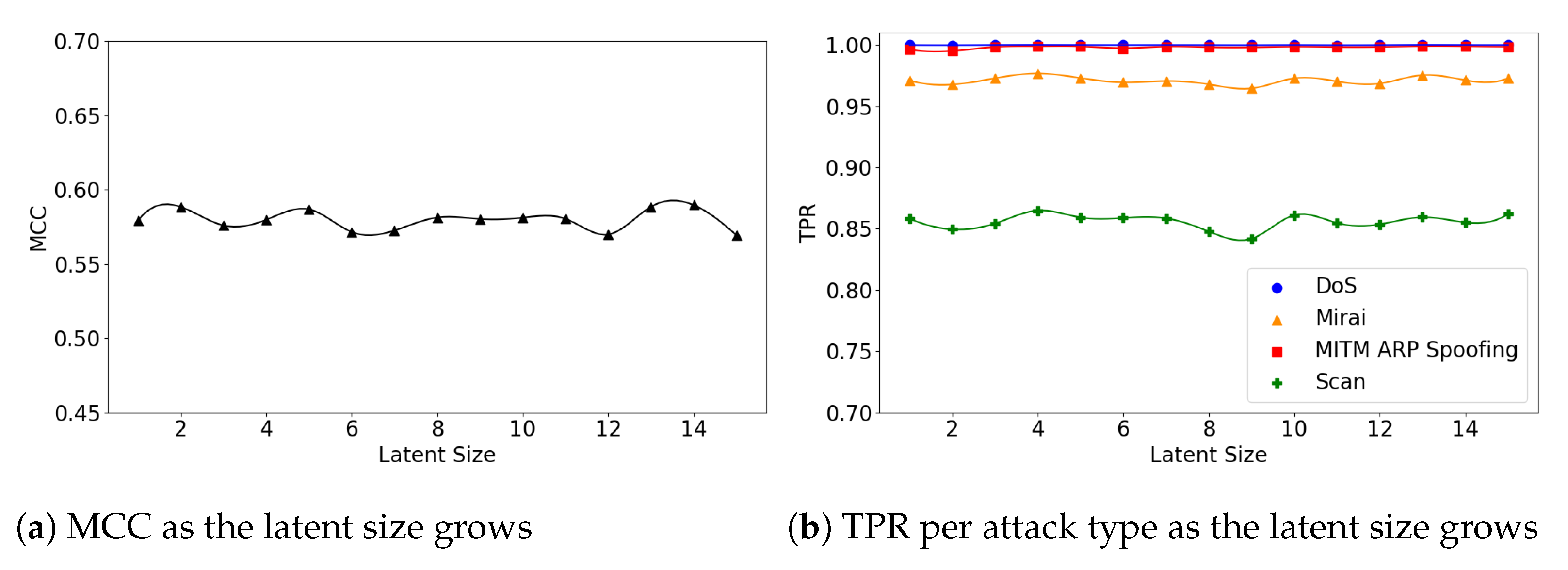
Figure 9.
The results of evaluation using the IoTID20 dataset when the (5,64) model is employed.
Figure 9.
The results of evaluation using the IoTID20 dataset when the (5,64) model is employed.
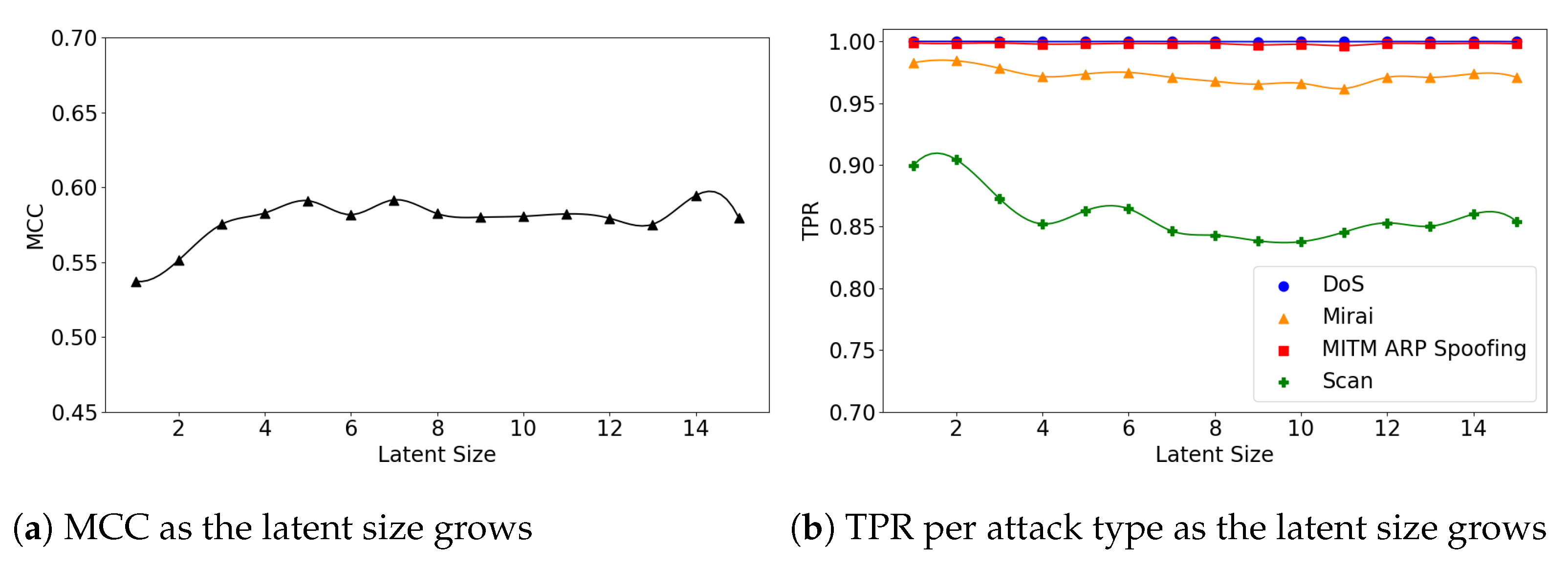
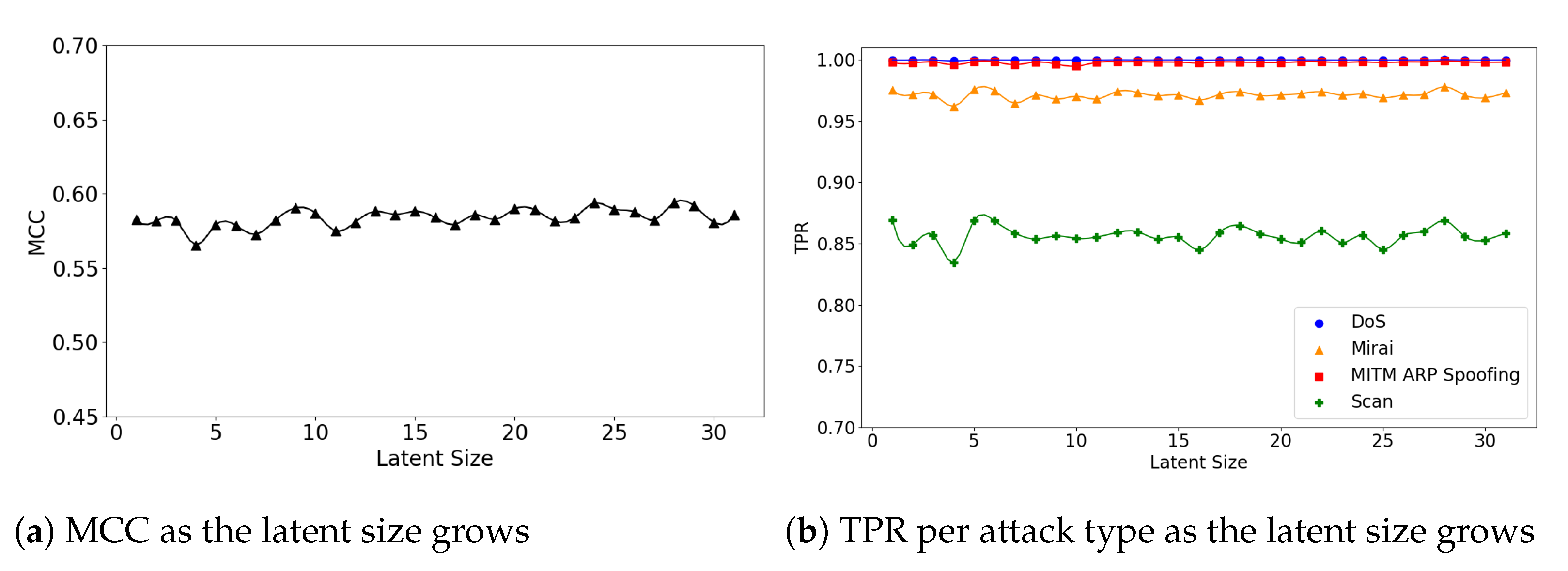
Figure 10.
The results of evaluation using the IoTID20 dataset when the (7,64) model is employed.
Figure 10.
The results of evaluation using the IoTID20 dataset when the (7,64) model is employed.
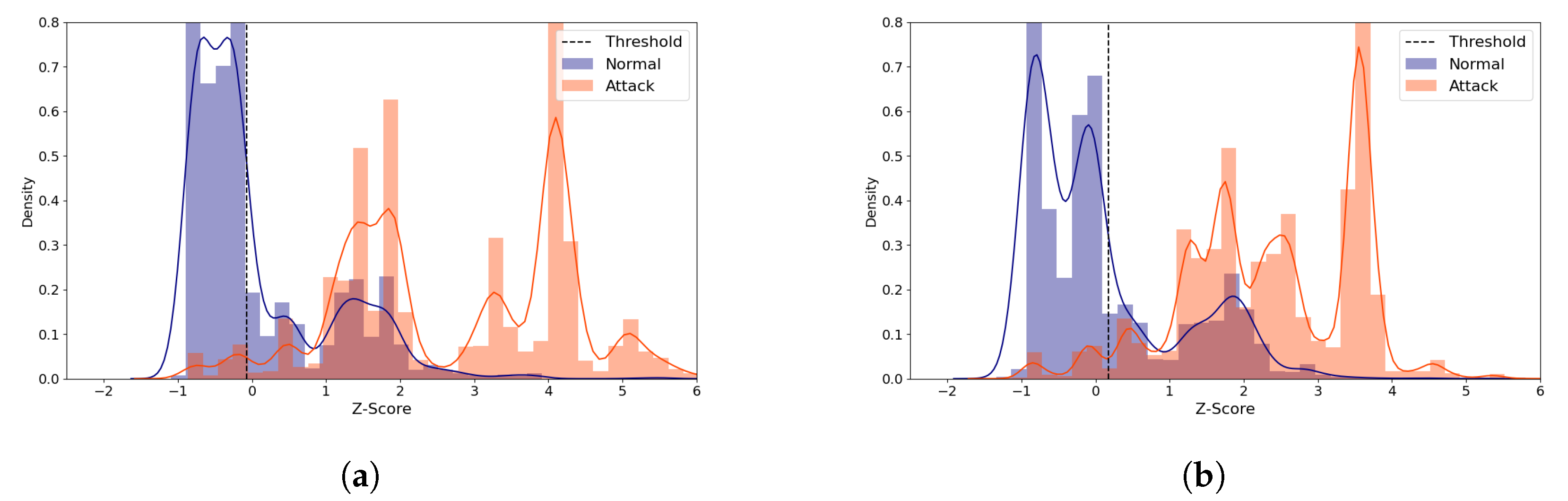
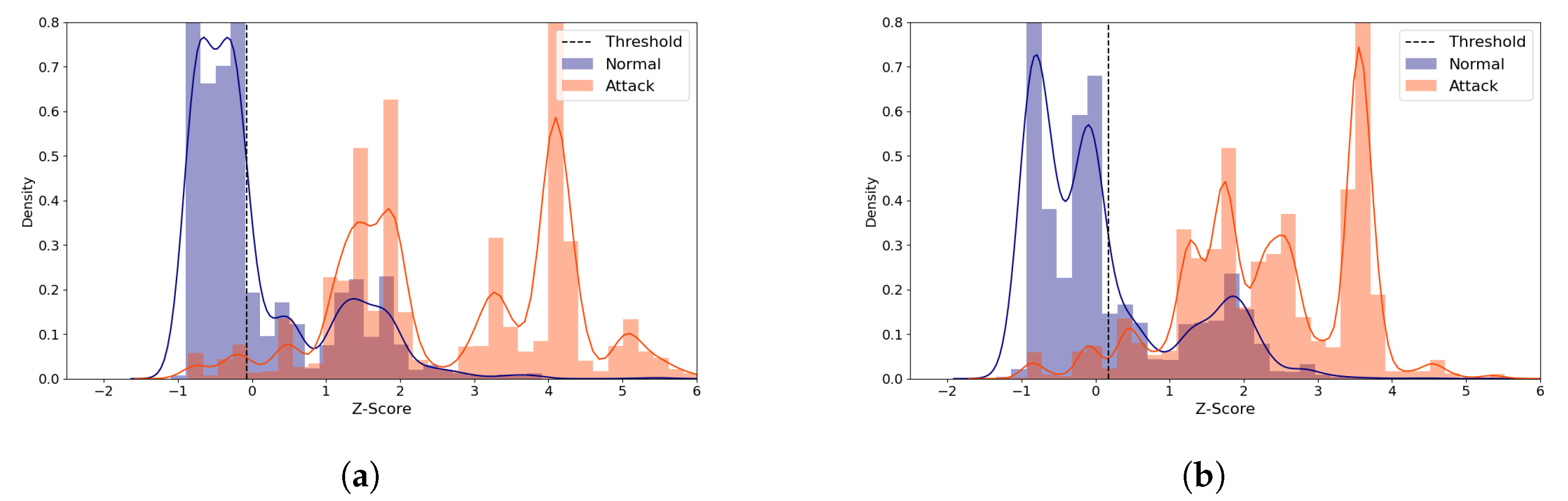
Figure 11.
IoTID20 Reconstruction Distance Distribution Density Plot (Normal and attack data) comparing two similarly performing cases with the (5,64) model. Blue denotes the normal data and orange denotes the attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 0.8 for better visibility. (a) The best case (Latent size = 28, MCC = 0.593, Threshold = 0.132). (b) A near-best case (Latent size = 9, MCC=0.59, Threshold = 0.132).
Figure 11.
IoTID20 Reconstruction Distance Distribution Density Plot (Normal and attack data) comparing two similarly performing cases with the (5,64) model. Blue denotes the normal data and orange denotes the attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 0.8 for better visibility. (a) The best case (Latent size = 28, MCC = 0.593, Threshold = 0.132). (b) A near-best case (Latent size = 9, MCC=0.59, Threshold = 0.132).
Figure 12.
MCC per device for the N-BaIoT dataset when the (5,32) model is employed.
Figure 12.
MCC per device for the N-BaIoT dataset when the (5,32) model is employed.
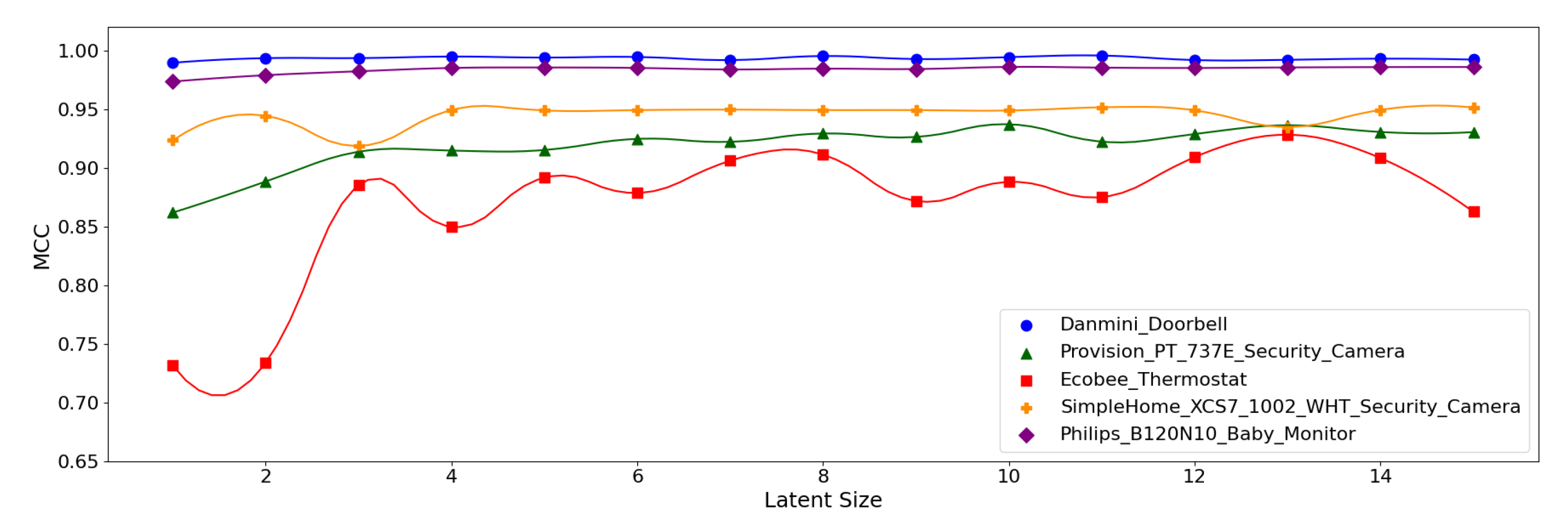
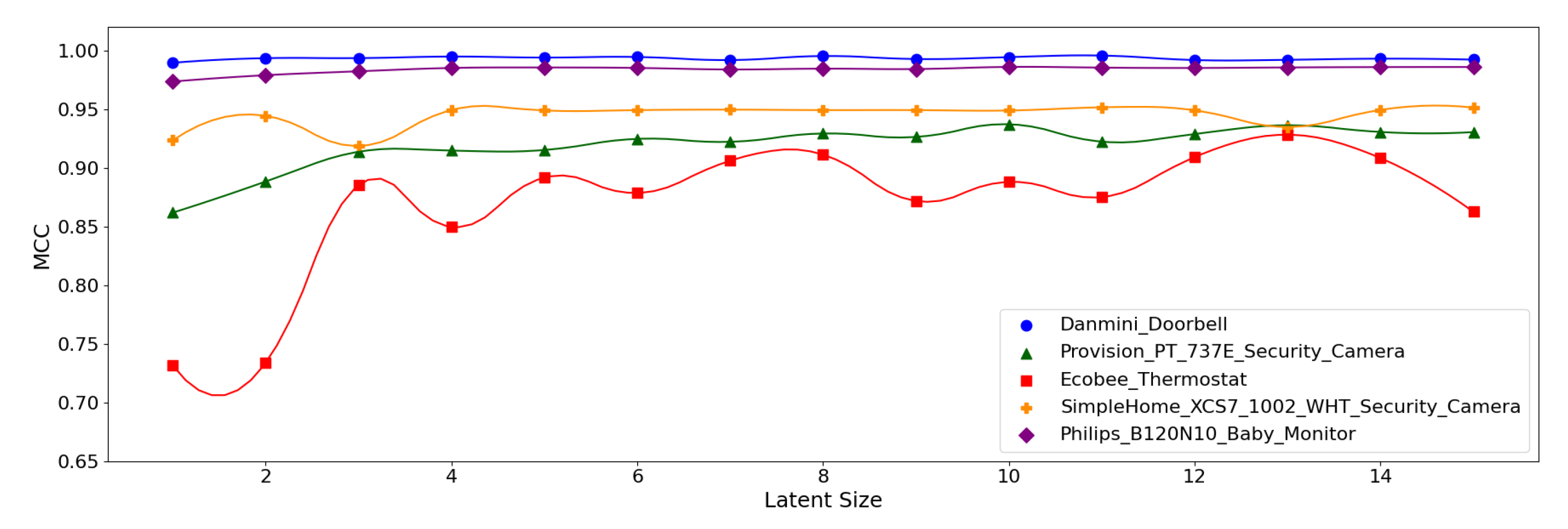
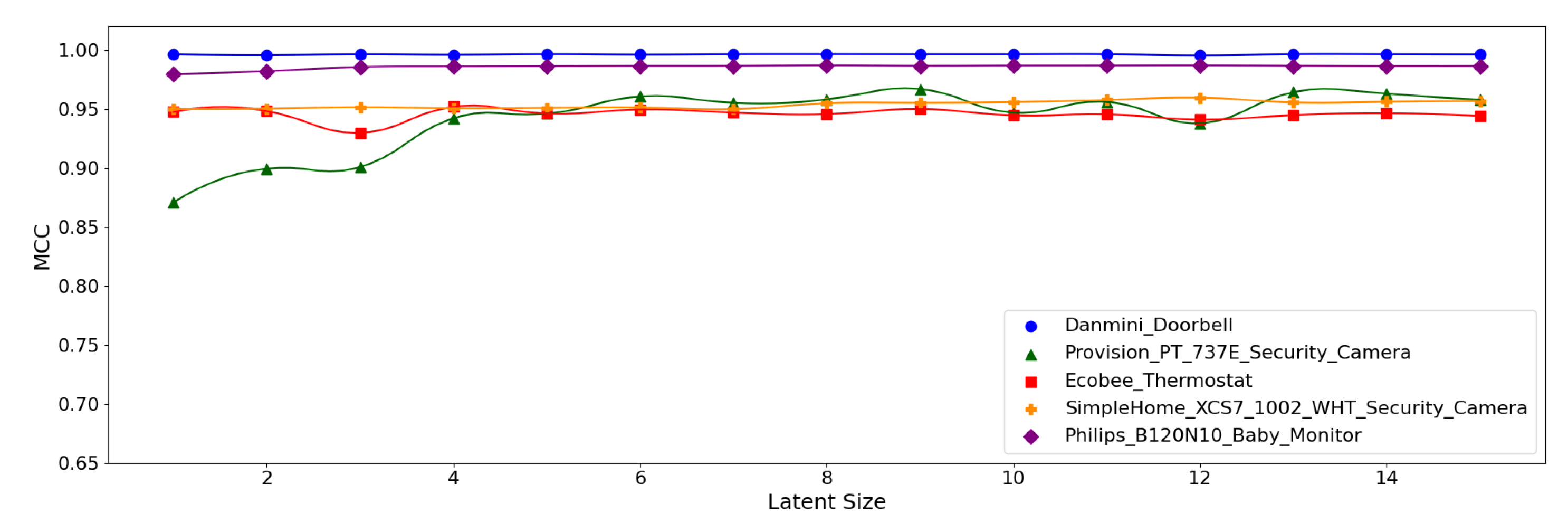
Figure 13.
MCC per device for the N-BaIoT dataset when the (5,64) model is employed.
Figure 13.
MCC per device for the N-BaIoT dataset when the (5,64) model is employed.
Figure 14.
MCC per device for the N-BaIoT dataset when the (7,64) model is employed.
Figure 14.
MCC per device for the N-BaIoT dataset when the (7,64) model is employed.
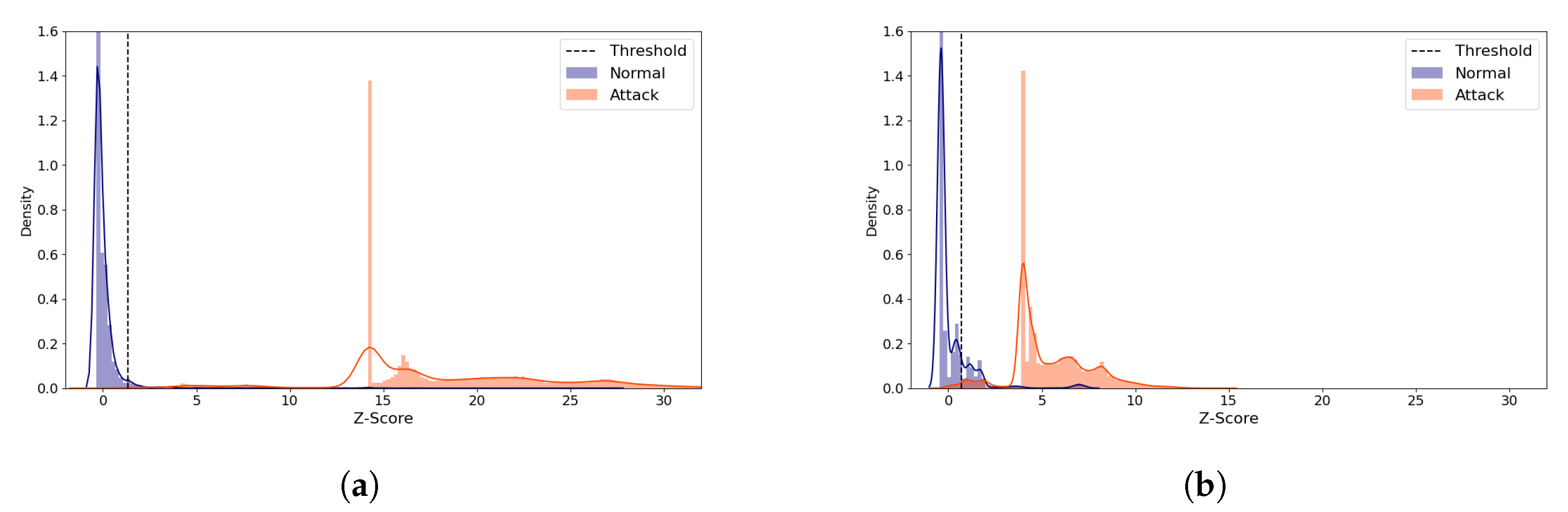
Figure 15.
N-BaIoT Provision PT-737E Reconstruction Distance Distribution Density Plot (Normal and attack data) comparing the best and the worst performing cases when the (5,64) model was used. Blue denotes the normal data and orange denotes the attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 1.6 for better visibility. (a) The best case (Latent Size = 29, MCC = 0.976, Threshold = 1.338). (b) The worst case (Latent Size = 1, MCC = 0.860, Threshold = 0.678).
Figure 15.
N-BaIoT Provision PT-737E Reconstruction Distance Distribution Density Plot (Normal and attack data) comparing the best and the worst performing cases when the (5,64) model was used. Blue denotes the normal data and orange denotes the attack data. A line depicts the kernel density estimated plot, and bar plot depicts the histogram. The dotted line indicates the threshold value, which divides the normal and the attack classes. The X-axis denotes Z-score. The Y-axis is density and limited to 1.6 for better visibility. (a) The best case (Latent Size = 29, MCC = 0.976, Threshold = 1.338). (b) The worst case (Latent Size = 1, MCC = 0.860, Threshold = 0.678).
Table 1.
Count Statistics of the NSL-KDD dataset.
Table 1.
Count Statistics of the NSL-KDD dataset.
| | Category | Training | Validation | Test |
|---|
| Benign | - | 60,642 | 6701 | 9711 |
| Attack | DoS | 41,325 | 4602 | 7458 |
| U2R | 50 | 2 | 200 |
| R2L | 908 | 87 | 2754 |
| Probe | 10,451 | 1205 | 2421 |
Table 2.
Count Statistics of the IoTID20 dataset.
Table 2.
Count Statistics of the IoTID20 dataset.
| | Category | Train | Validation | Test |
|---|
| Benign | - | 32,056 | 4001 | 4016 |
| Attack | Mirai | 332,569 | 41,744 | 41,364 |
| Scan | 60,249 | 7409 | 7607 |
| DoS | 47,519 | 5865 | 6007 |
| MITM | 28,233 | 3560 | 3584 |
Table 3.
Count Statistics for each device type of the N-BaIoT dataset.
Table 3.
Count Statistics for each device type of the N-BaIoT dataset.
| Device | Label | Train | Validation | Test |
|---|
| Danmini Doorbell | Benign | 39,675 | 4895 | 4978 |
| Attack | 774,963 | 96,935 | 96,852 |
| Ecobee Thermostat | Benign | 10,528 | 1303 | 1282 |
| Attack | 658,173 | 82,284 | 82,306 |
| Provision PT-737E | Benign | 49,753 | 6212 | 6189 |
| Attack | 612,85 | 76,614 | 76,637 |
| Philips B120N/10 Baby Monitor | Benign | 140,069 | 17,574 | 17,579 |
| Attack | 738,873 | 92,293 | 92,271 |
| SimpleHome XCS7-1002-WHT | Benign | 37,302 | 4620 | 4663 |
| Attack | 655,143 | 81,685 | 81,643 |
Table 4.
Model Structure Configurations.
Table 4.
Model Structure Configurations.
| Model Structure (Depth, Size) | Number of Neurons for Each Layer |
|---|
| (5,32) | input – 32 – 16 – latent layer – 16 – 32 – output |
| (5,64) | input – 64 – 32 – latent layer – 32 – 64 – output |
| (7,64) | input – 64 – 32 – 16 – latent layer – 16 – 32 – 64 – output |
Table 5.
Evaluation results with NSL-KDD. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 20 runs. The best MCC score is marked in bold.
Table 5.
Evaluation results with NSL-KDD. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 20 runs. The best MCC score is marked in bold.
| Model Structure | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
|---|
| (5,32) | 4 | 2.846 | 0.840 | 0.757 | 0.051 | 0.705 | 0.842 | 0.960 |
| (5,64) | 3 | 2.488 | 0.848 | 0.782 | 0.065 | 0.712 | 0.853 | 0.960 |
| (7,64) | 9 | 2.840 | 0.847 | 0.777 | 0.061 | 0.711 | 0.852 | 0.959 |
Table 6.
The best performance for each model configuration. The best F1-score is in bold.
Table 6.
The best performance for each model configuration. The best F1-score is in bold.
| Model Structure | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
|---|
| (5,32) | 4 | 2.120 | 0.887 | 0.851 | 0.066 | 0.778 | 0.895 | 0.961 |
| (5,64) | 3 | 2.090 | 0.885 | 0.859 | 0.081 | 0.771 | 0.894 | 0.961 |
| (7,64) | 9 | 2.340 | 0.882 | 0.826 | 0.045 | 0.774 | 0.888 | 0.971 |
Table 7.
The confusion matrix of the best performing model for each configuration. Positive label indicates attack sample.
Table 7.
The confusion matrix of the best performing model for each configuration. Positive label indicates attack sample.
| Model Structure | TP | FP | FN | TN |
|---|
| (5,32) | 10,920 | 636 | 1913 | 9075 |
| (5,64) | 11,019 | 768 | 1814 | 8925 |
| (7,64) | 10,604 | 428 | 2229 | 9283 |
Table 8.
Evaluation results with IoTID20 dataset. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 10 runs. The best MCC score is marked in bold.
Table 8.
Evaluation results with IoTID20 dataset. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 10 runs. The best MCC score is marked in bold.
| Model Structure | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
|---|
| (5,32) | 14 | 0.041 | 0.945 | 0.963 | 0.313 | 0.595 | 0.971 | 0.912 |
| (5,64) | 28 | −0.013 | 0.947 | 0.966 | 0.333 | 0.594 | 0.972 | 0.913 |
| (7,64) | 14 | 0.060 | 0.944 | 0.961 | 0.307 | 0.590 | 0.970 | 0.911 |
Table 9.
The best performance for each model configuration. The best F1-score is in bold.
Table 9.
The best performance for each model configuration. The best F1-score is in bold.
| Model Structure | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
|---|
| (5,32) | 14 | −0.350 | 0.951 | 0.971 | 0.329 | 0.614 | 0.974 | 0.909 |
| (5,64) | 28 | −0.150 | 0.952 | 0.971 | 0.324 | 0.617 | 0.974 | 0.915 |
| (7,64) | 14 | 0.060 | 0.952 | 0.970 | 0.321 | 0.618 | 0.974 | 0.918 |
Table 10.
The confusion matrix of the best performing model for each configuration. Positive label indicates attack sample.
Table 10.
The confusion matrix of the best performing model for each configuration. Positive label indicates attack sample.
| Model Structure | TP | FP | FN | TN |
|---|
| (5,32) | 55,683 | 1060 | 2841 | 2956 |
| (5,64) | 55,553 | 1017 | 2971 | 2999 |
| (7,64) | 52,480 | 815 | 6044 | 3201 |
Table 11.
Evaluation results per device type with N-BaIoT Data. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 5 runs. The best MCC score of each device type is marked in bold.
Table 11.
Evaluation results per device type with N-BaIoT Data. The best configuration from each model structure was chosen based on the MCC score. The reported metrics are averaged over 5 runs. The best MCC score of each device type is marked in bold.
| (a) Danmini Doorbell |
|---|
| Model | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
| (5,32) | 11 | 0.988 | 1.000 | 1.000 | 0.006 | 0.996 | 1.000 | 0.999 |
| (5,64) | 19 | 1.108 | 1.000 | 1.000 | 0.006 | 0.996 | 1.000 | 0.999 |
| (7,64) | 8 | 1.028 | 1.000 | 1.000 | 0.006 | 0.996 | 1.000 | 0.999 |
| (b) Philips B120N / 10 Baby Monitor |
| Model | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
| (5,32) | 10 | 3.130 | 0.996 | 0.998 | 0.013 | 0.986 | 0.998 | 0.999 |
| (5,64) | 25 | 3.270 | 0.997 | 0.999 | 0.011 | 0.989 | 0.998 | 0.999 |
| (7,64) | 8 | 3.344 | 0.996 | 0.998 | 0.012 | 0.987 | 0.998 | 0.999 |
| (c) SimpleHome XCS7-1002-WHT Security Camera |
| Model | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
| (5,32) | 11 | 0.438 | 0.995 | 0.999 | 0.074 | 0.952 | 0.997 | 0.990 |
| (5,64) | 20 | 1.050 | 0.996 | 0.999 | 0.051 | 0.963 | 0.998 | 0.998 |
| (7,64) | 12 | 0.846 | 0.996 | 0.999 | 0.058 | 0.959 | 0.998 | 0.996 |
| (d) Provision PT-737E |
| Model | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
| (5,32) | 10 | 0.854 | 0.991 | 0.994 | 0.050 | 0.937 | 0.995 | 0.992 |
| (5,64) | 29 | 1.338 | 0.997 | 0.999 | 0.027 | 0.976 | 0.998 | 0.999 |
| (7,64) | 9 | 1.102 | 0.995 | 0.998 | 0.040 | 0.967 | 0.998 | 0.999 |
| (e) Ecobee Thermostat |
| Model | Latent Size | Threshold | Accuracy | TPR | FPR | MCC | F1 | AUC |
| (5,32) | 13 | 0.802 | 0.998 | 0.999 | 0.067 | 0.928 | 0.999 | 0.997 |
| (5,64) | 4 | 0.408 | 0.999 | 1.000 | 0.064 | 0.959 | 0.999 | 0.999 |
| (7,64) | 4 | 0.366 | 0.999 | 1.000 | 0.079 | 0.952 | 0.999 | 0.999 |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}