
Agent-Based Semantic Role Mining for Intelligent Access Control in Multi-Domain Collaborative Applications of Smart Cities

 ,
,  , ,
, ,  ,
,
Abstract
:1. Introduction
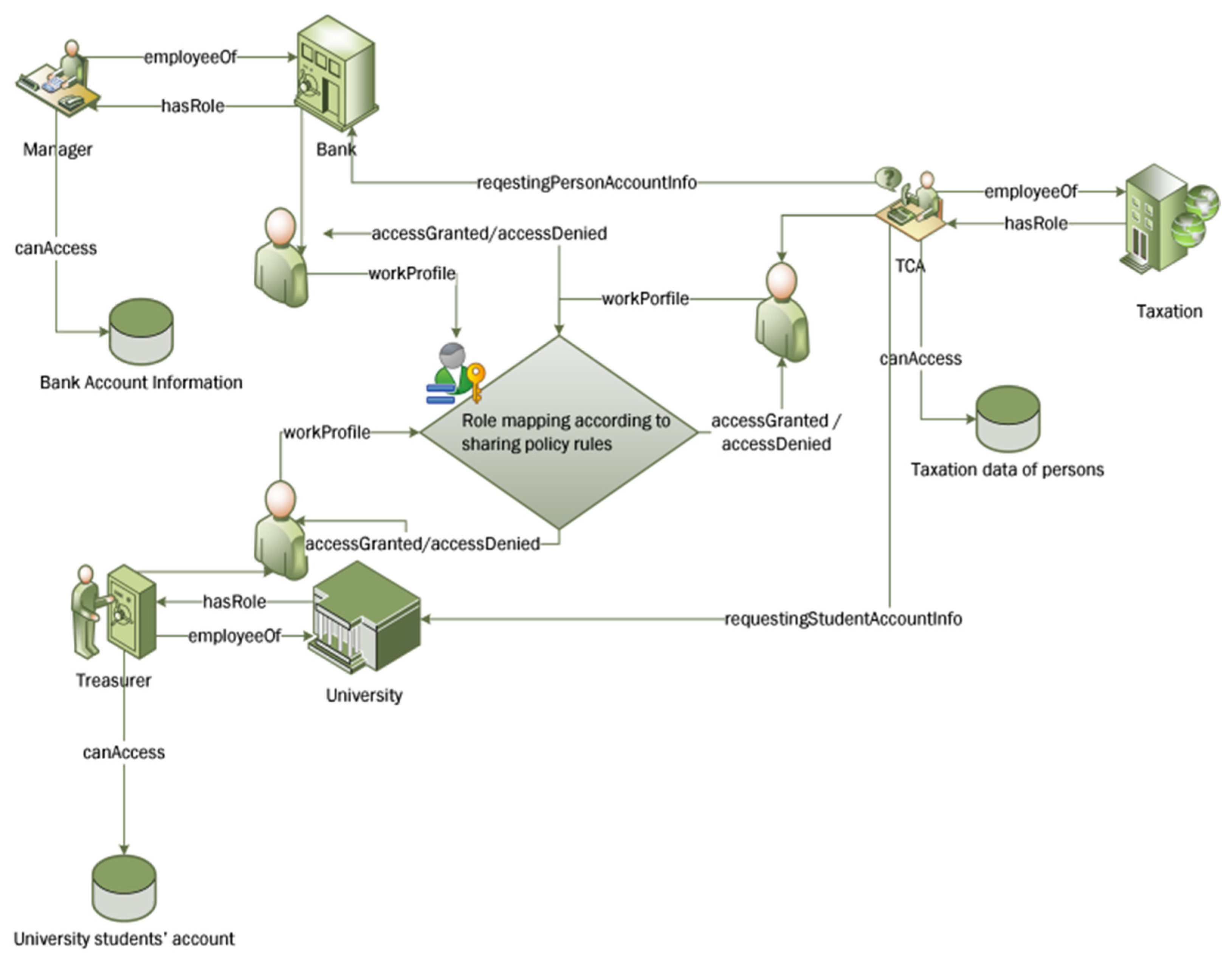
2. Intelligent Role-Based Access Control (I-RBAC)
3. Related Work
3.1. Existing RBAC Extended Models for Multidomain Collaborations
3.2. Semantic Role Mining in Domain-Specific RBAC
3.3. Automated Ontology Derivation from Text
3.4. Ontology Matching and Alignment
3.5. Agents Used in RBAC
4. Proposed Methodology of Semantic Role Mining
- Automated population of organizational ontology from policy text;
- Matching organizational ontology with core I-RBAC ontology;
- Ontology-based semantic role mining through intelligent agents.
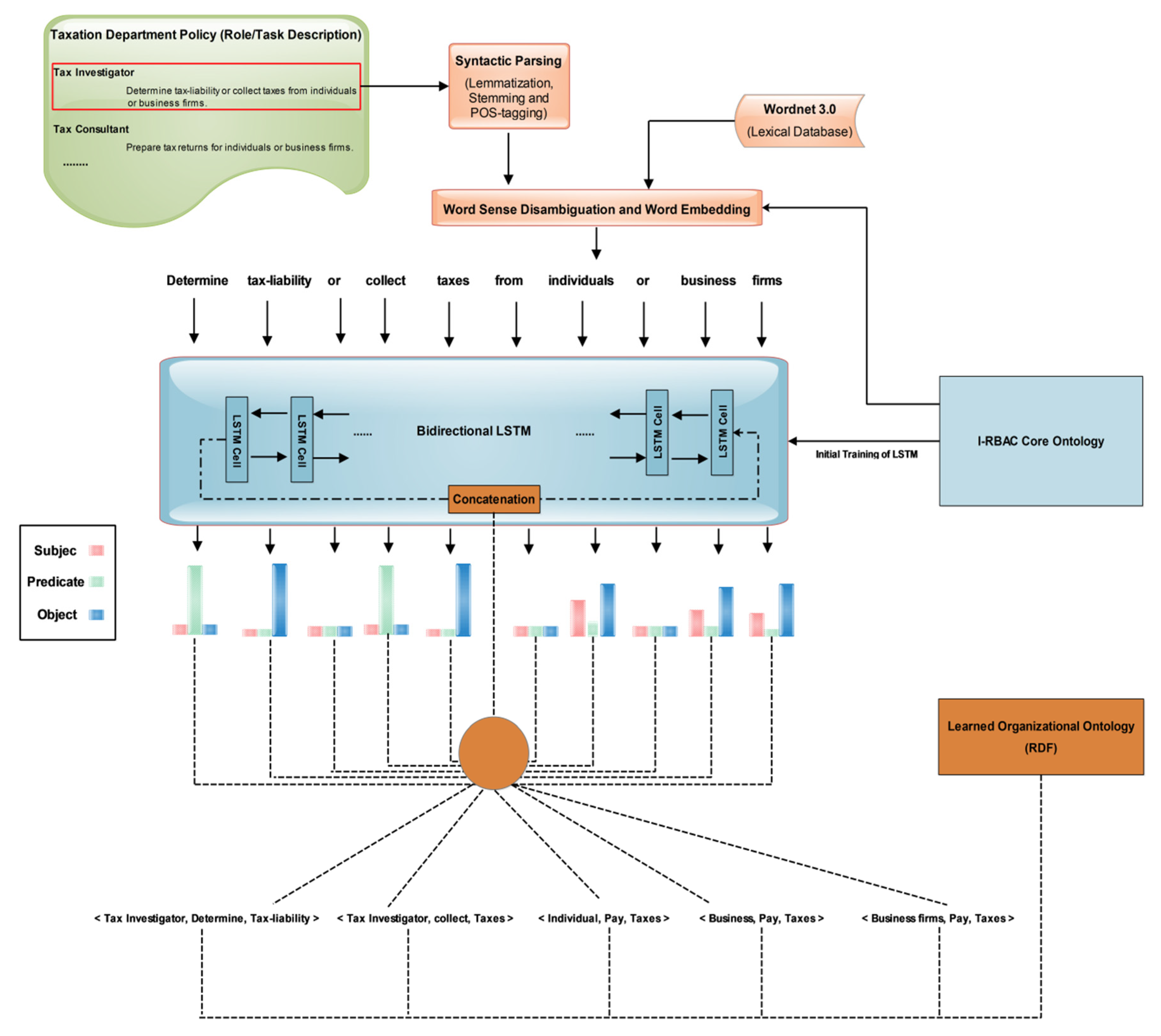
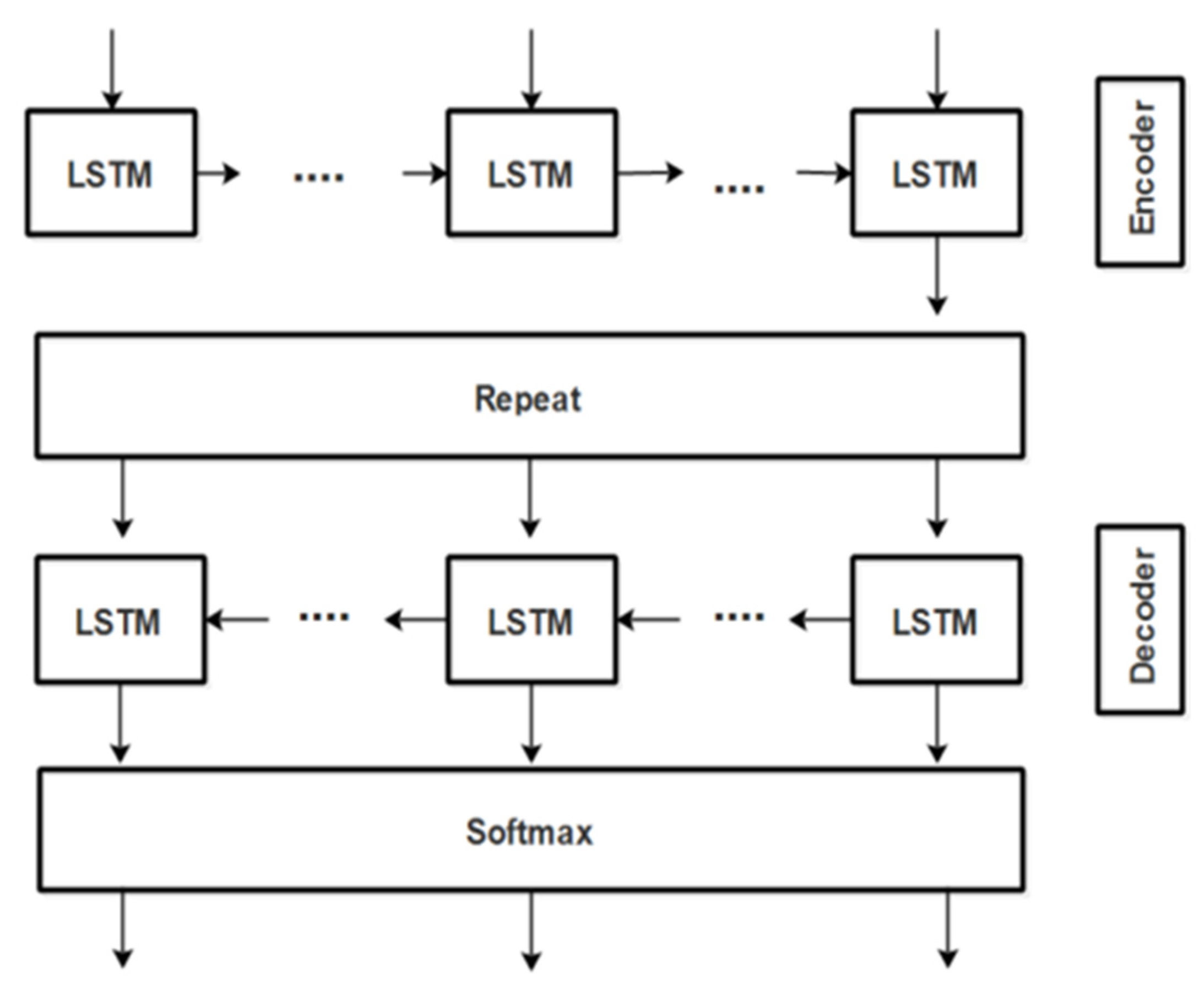
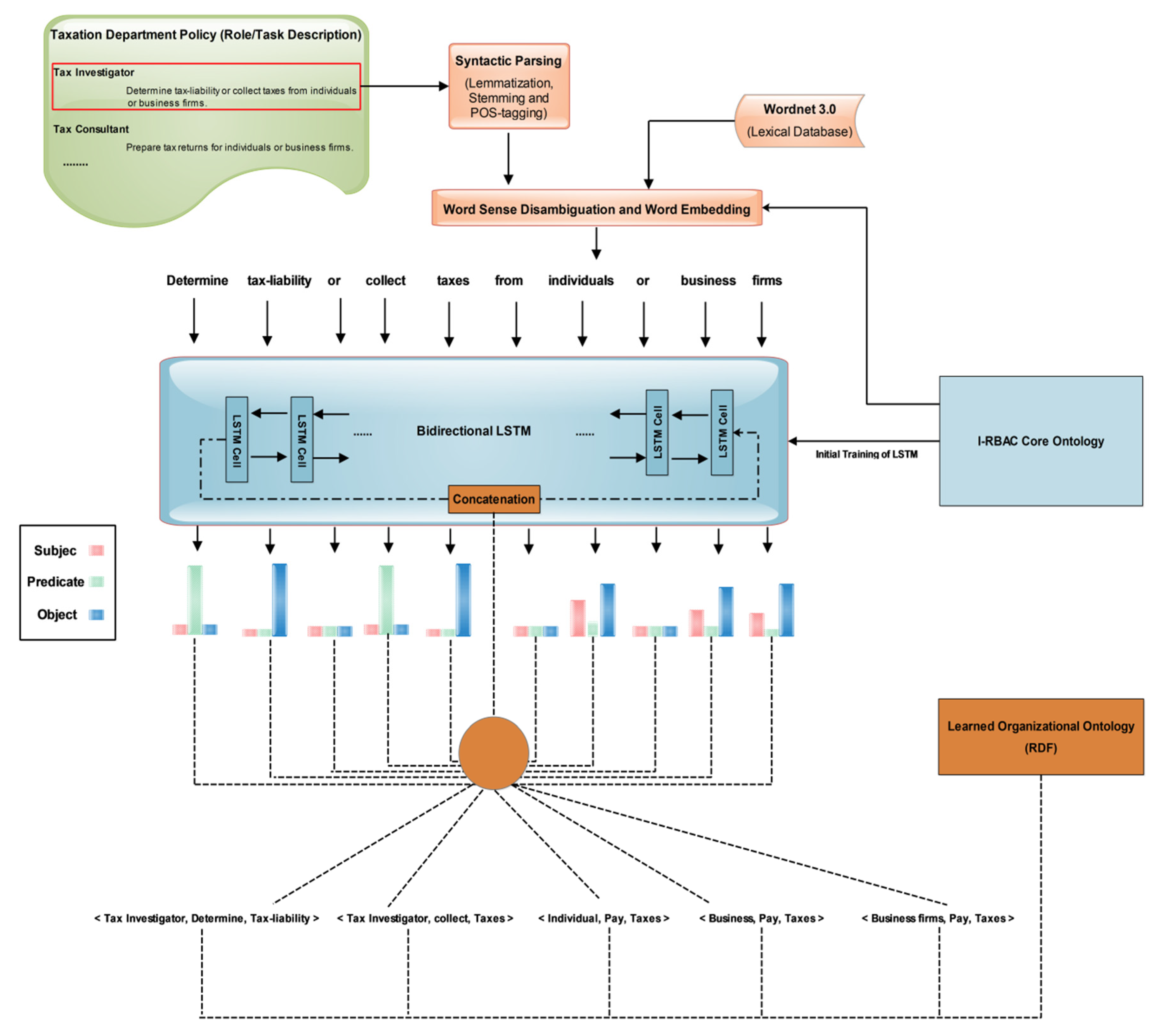
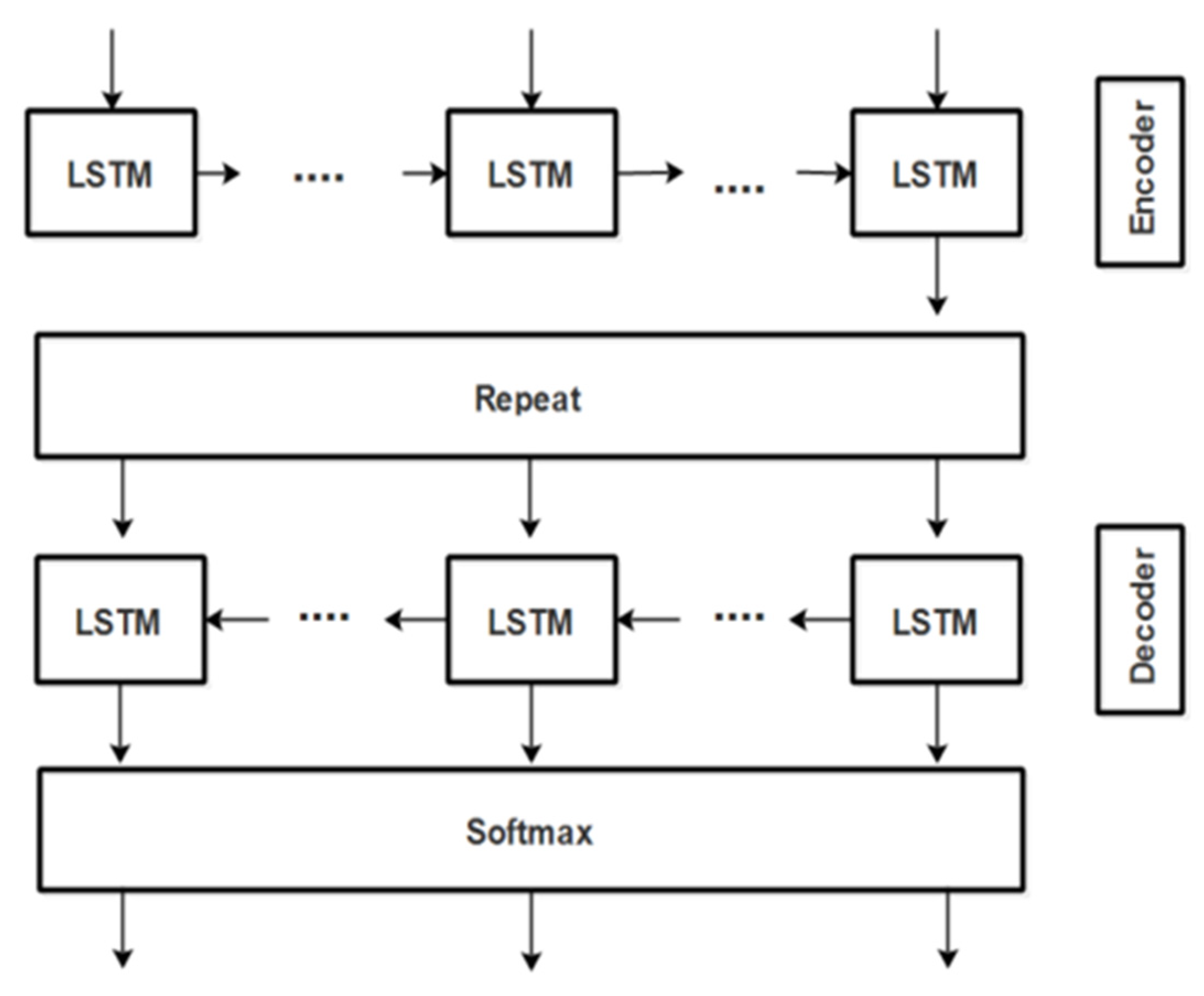
4.1. Policy Text to Ontology Derivation
| Algorithm 1: Triple Extraction. |
| 1: Input: policy text corpus (CPT) 2: Output: RDF 3: begin 4: load (text, onto) 5: cleantxt = preprocess(txt) 6: cleanOnto = preprocess(onto) 7: textDictionary = Word2Vec(cleantxt) 8: ontoDictionary = Word2Vec(cleanOnto) 9: encoder LSTM (sequenceClassifier) 10: decoder LSTM (sequenceClassifer) 11: new_rules{ } = infer(data); 12: end |
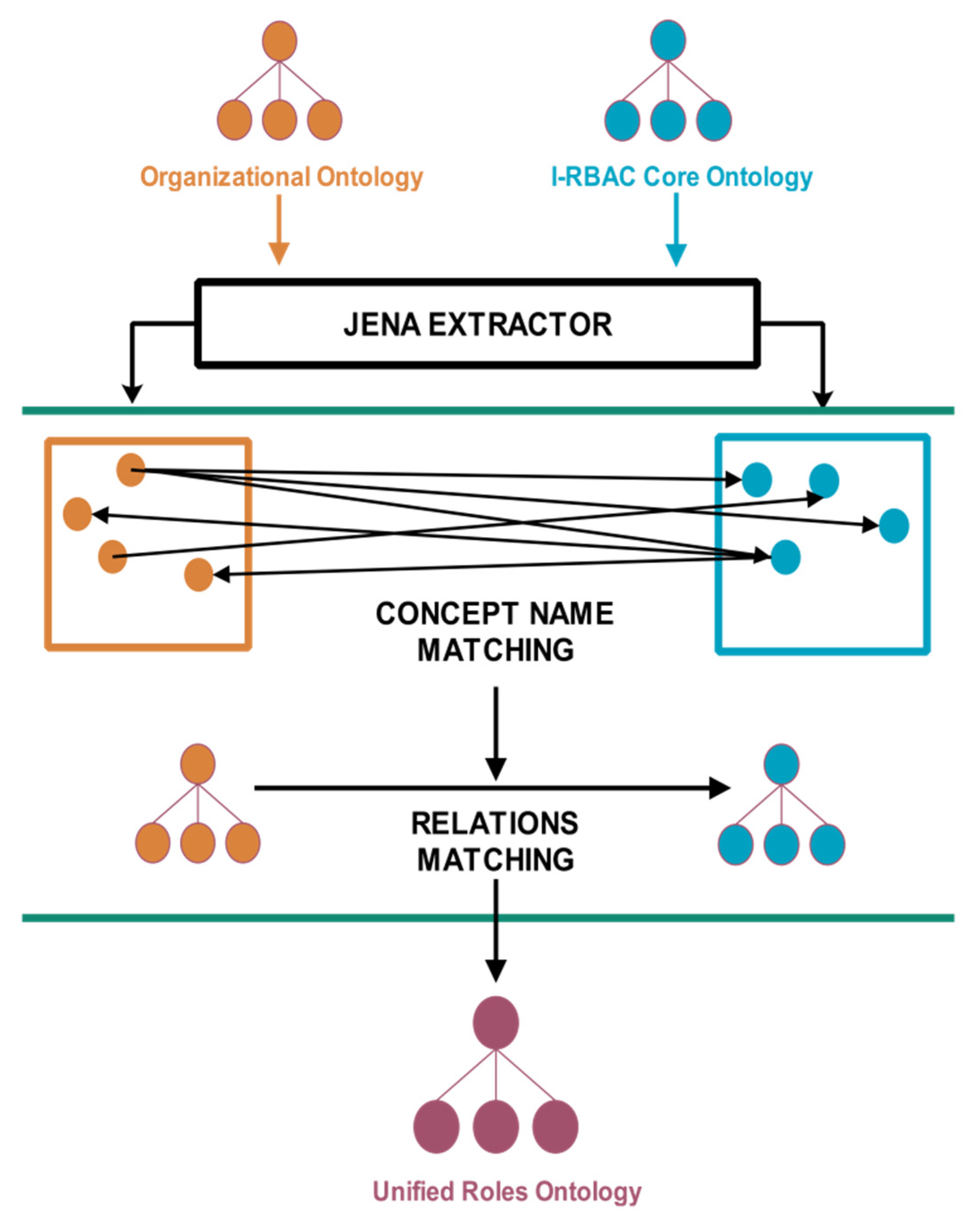
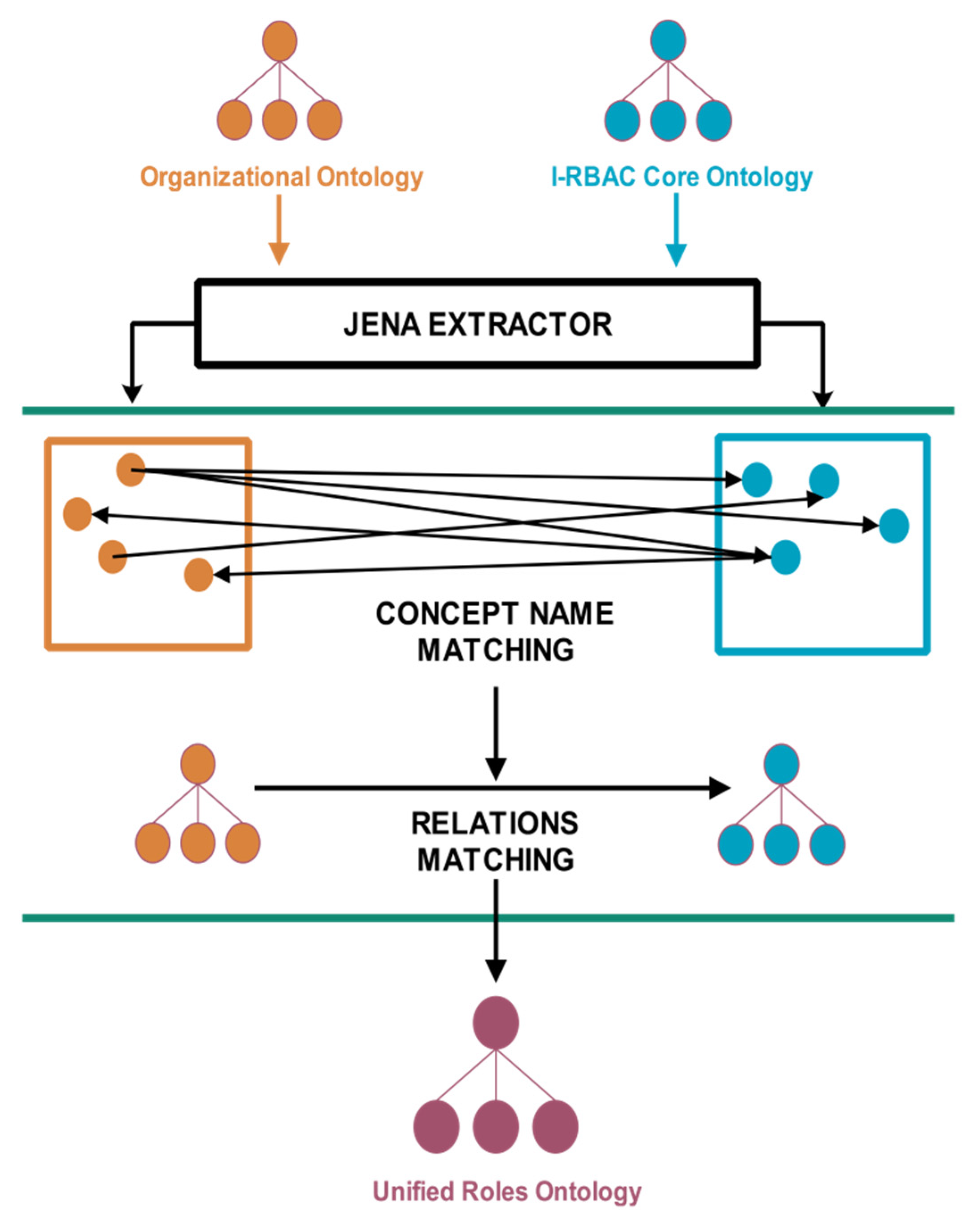
4.2. Ontology Matching
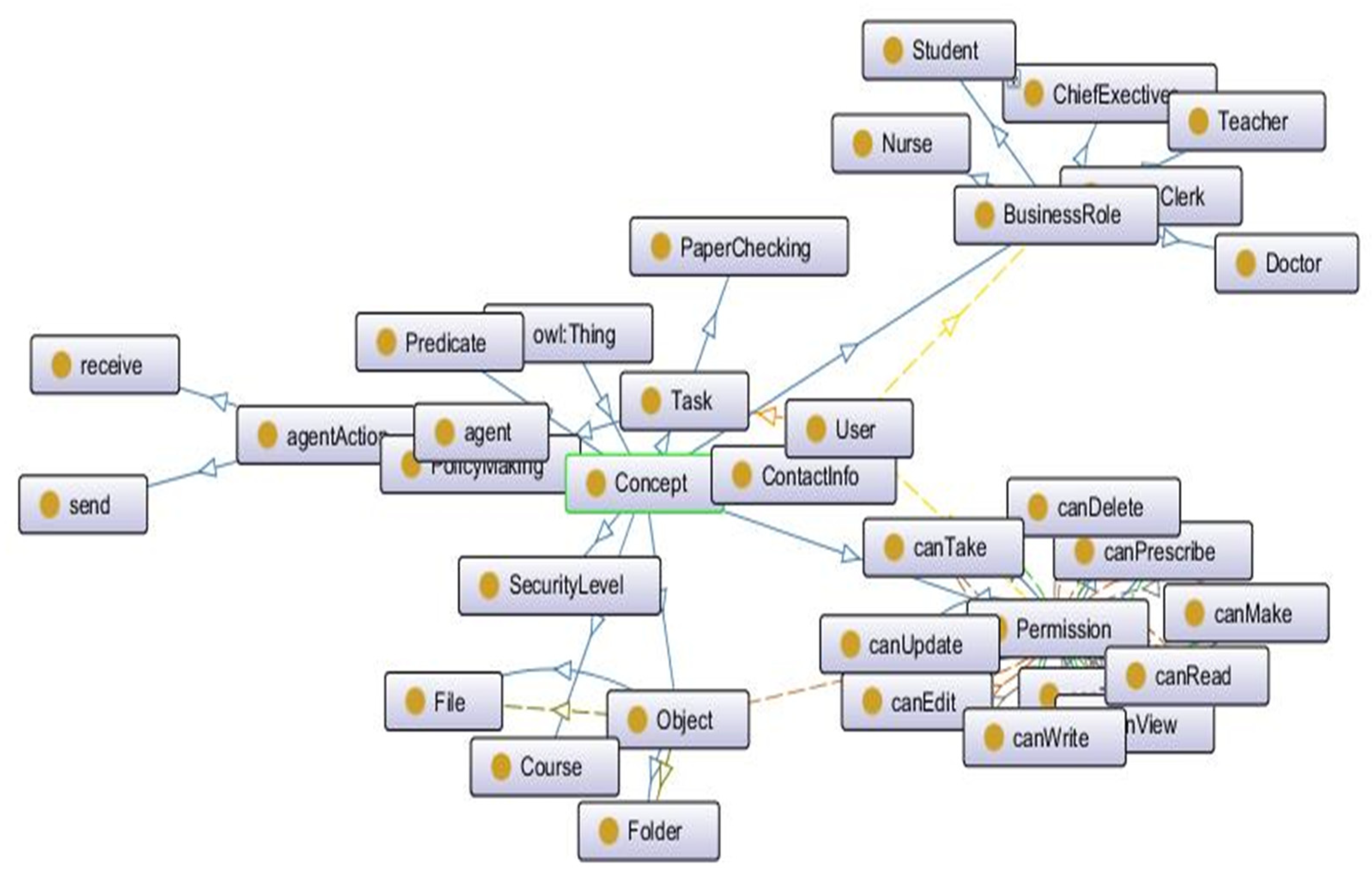
4.3. Semantic Role Mining
| Algorithm 2: Semantic Role Mining. |
| 1: Input: rdf_graph, pre_rules{ }, environment E 2: Output: R={t{ }p{ }, rdf_graph 3: begin 4: model M=loadOnto (rdf_graph) 5: while (!EOM) do 6: concepts{ } = M.retrieveClass( ) resources{ } = M.retrieveDataProperty( ) relations{ } = M.retreivePredicate( ) 7: end while 8: data{{},{},{}} = combine (concept, resources, relations) 9: new_rules{ } = infer (data) 10: agent_onto = learn (pre_rules{ }+ new_rules{ }) 11: updated_rule = infer (agent-onto) 12: rdf-graph = construct (updated_rule, concepts{ }, resources{ }, relations{ }) 13: role = getRole (agent-onto) 14: user = setRole (t{ }, p{ }) 15: return rdf-graph 16: end |
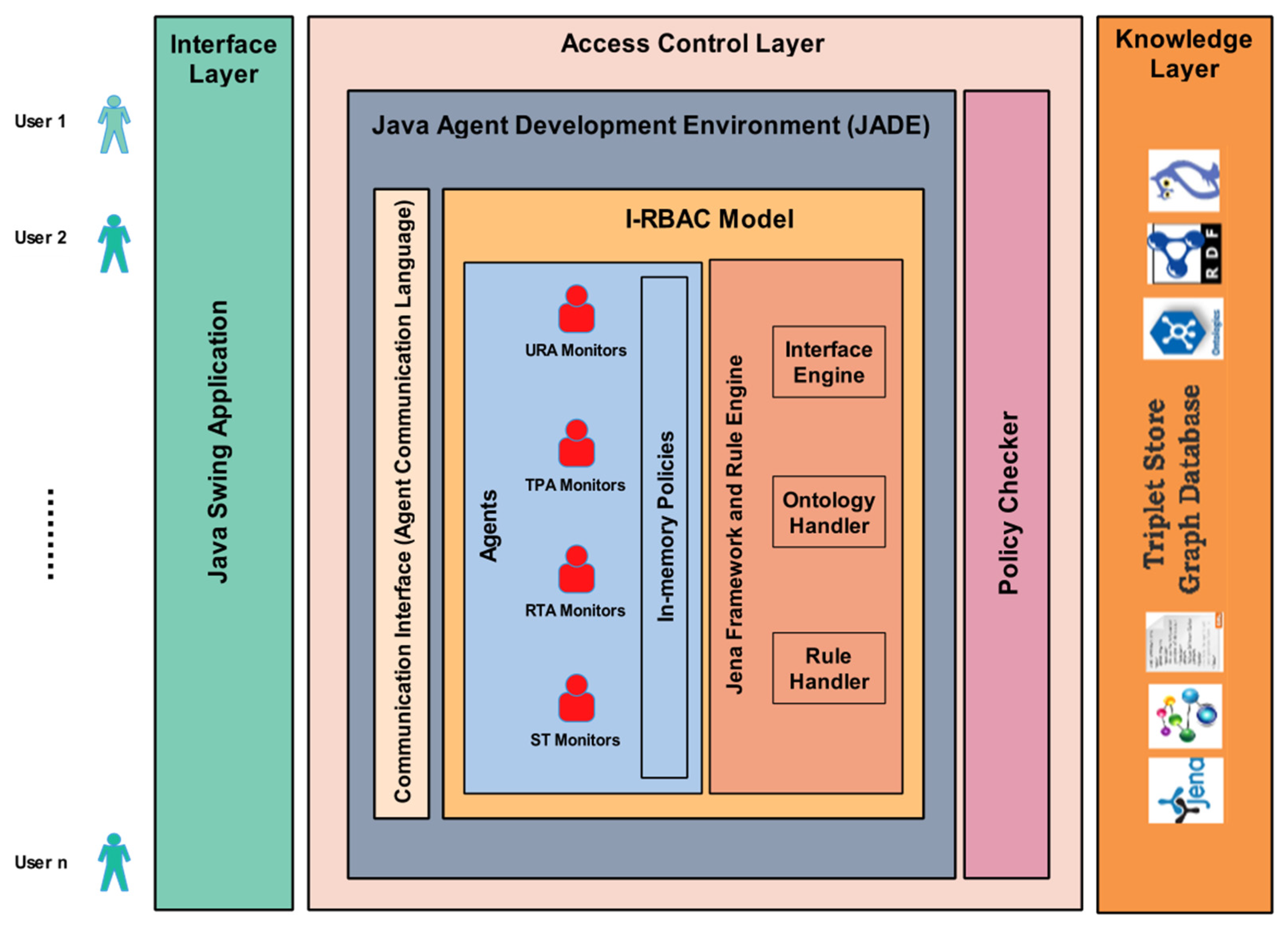
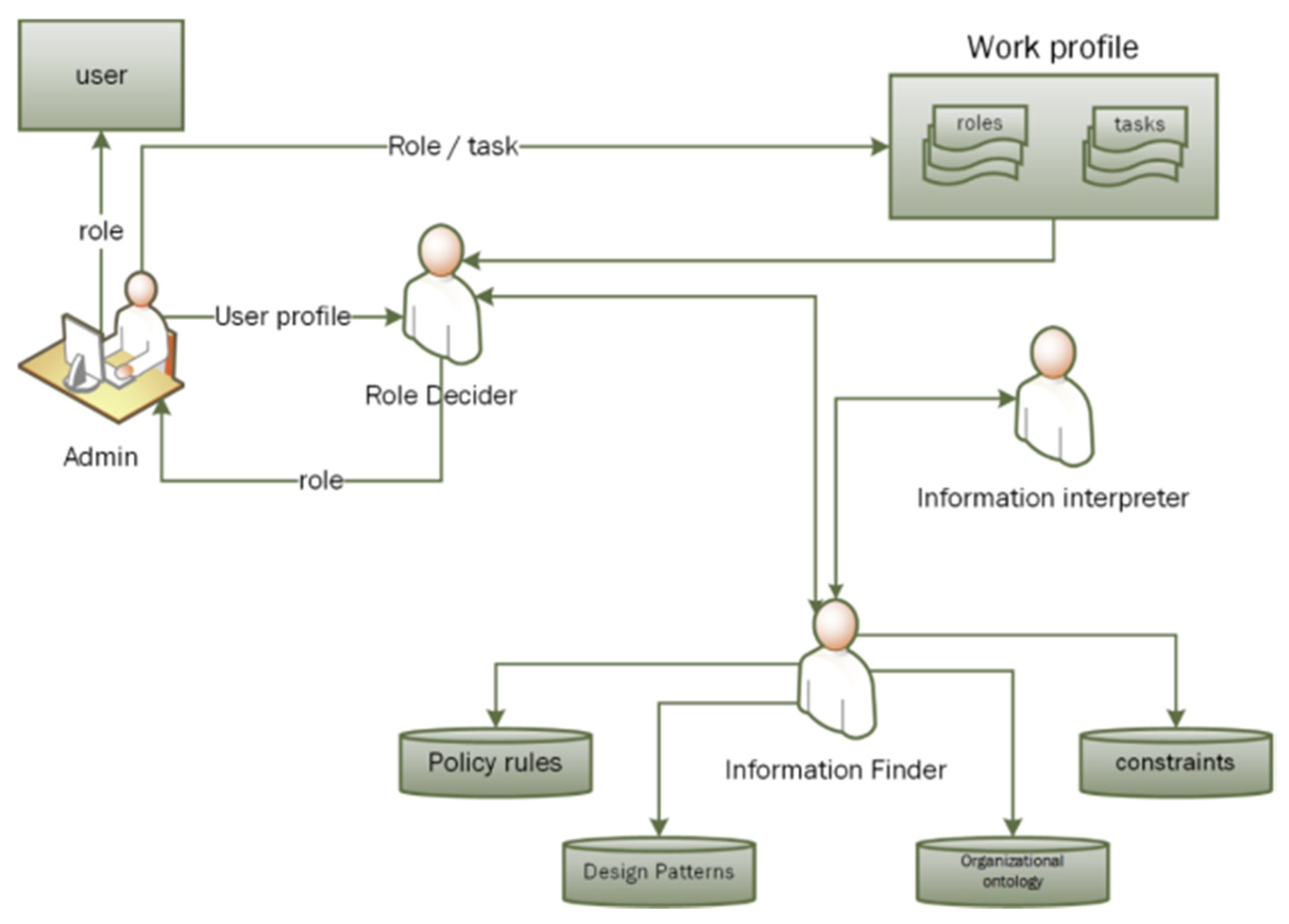
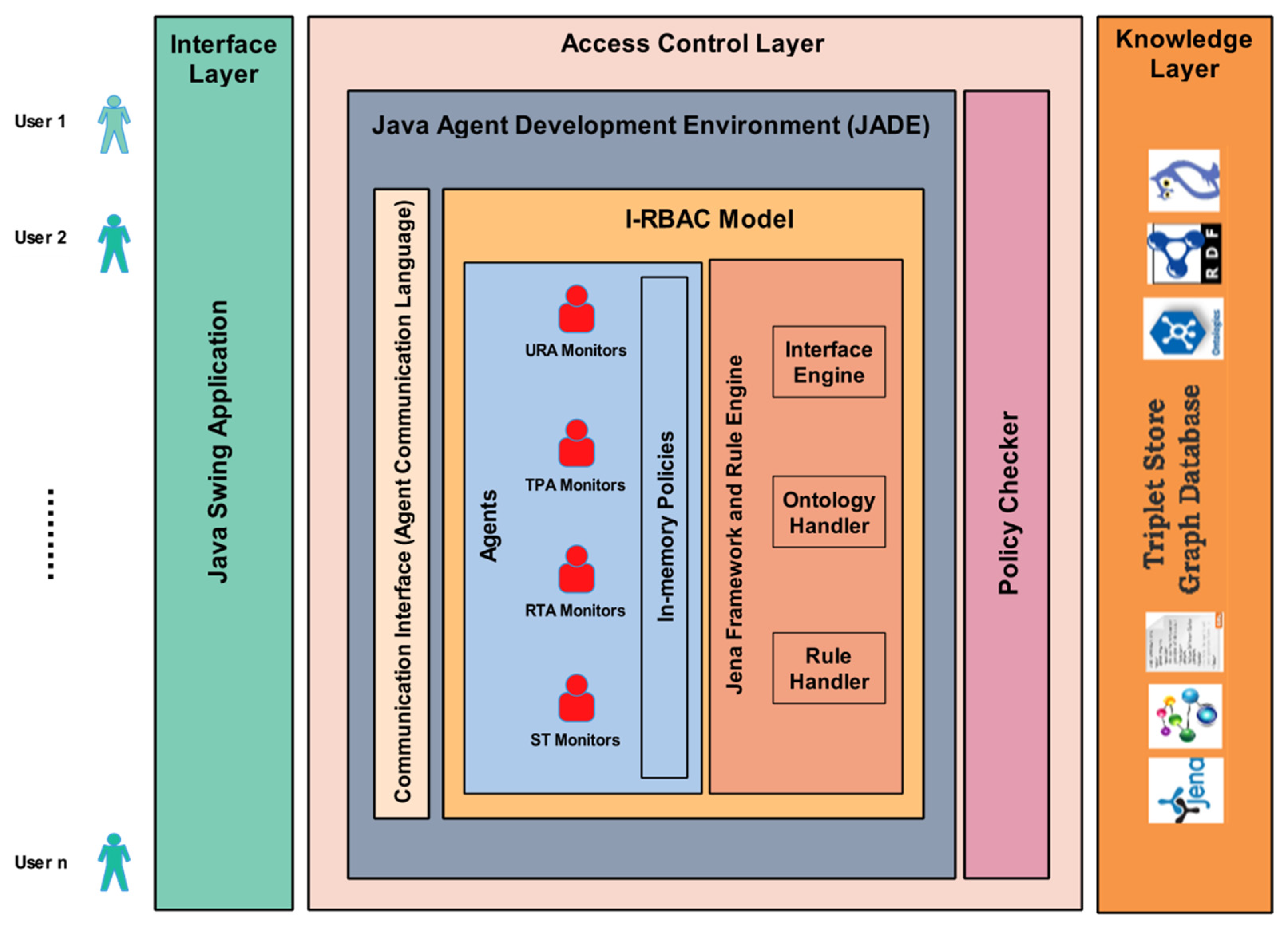
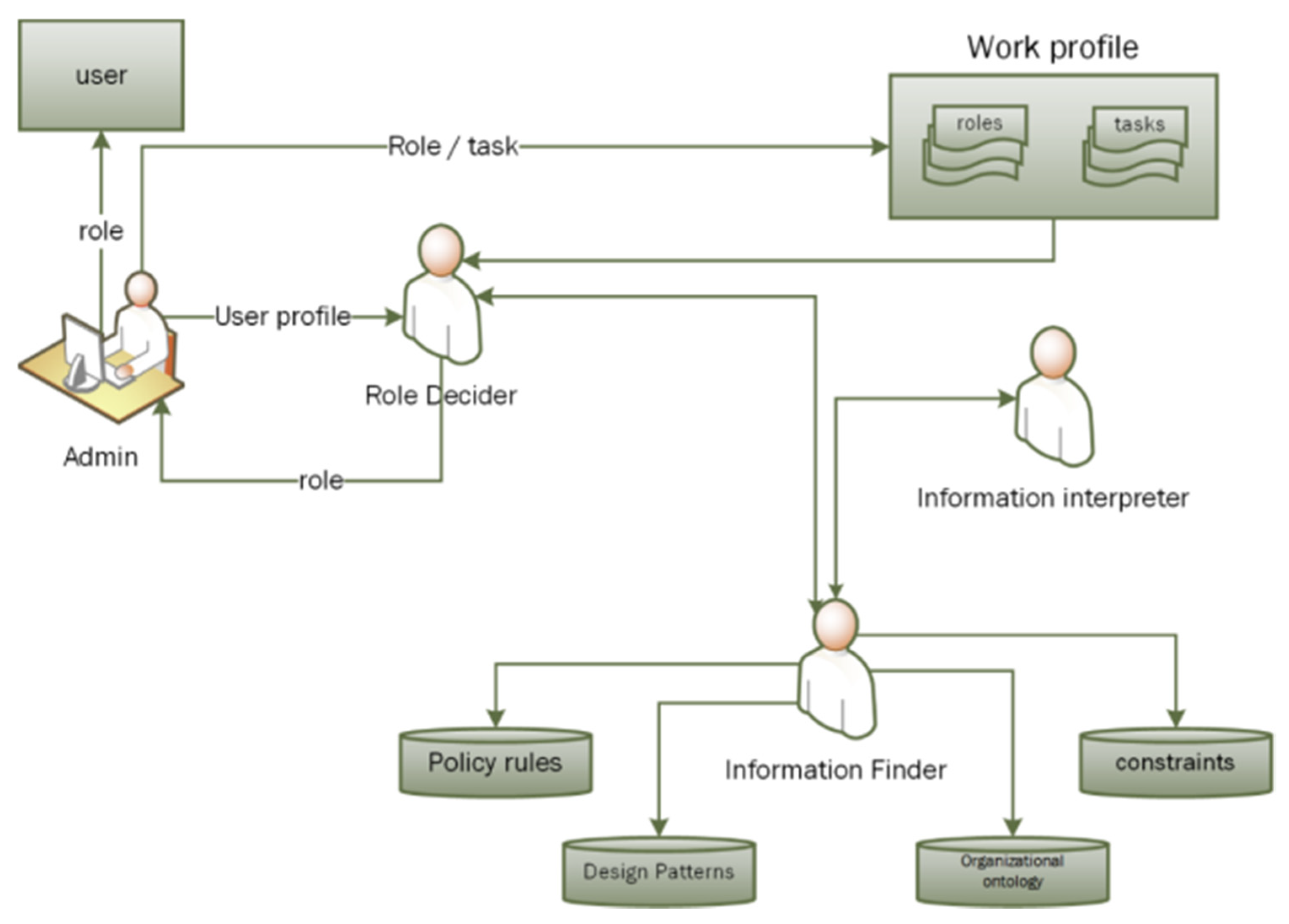
5. Agent-Based Implementation
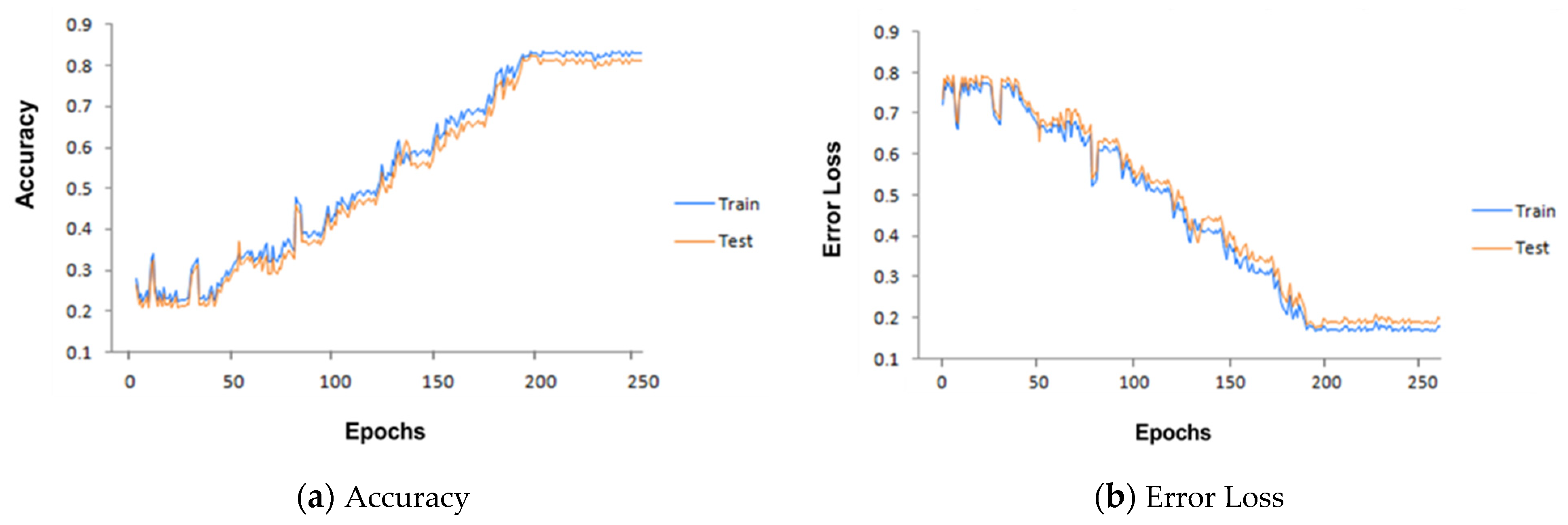
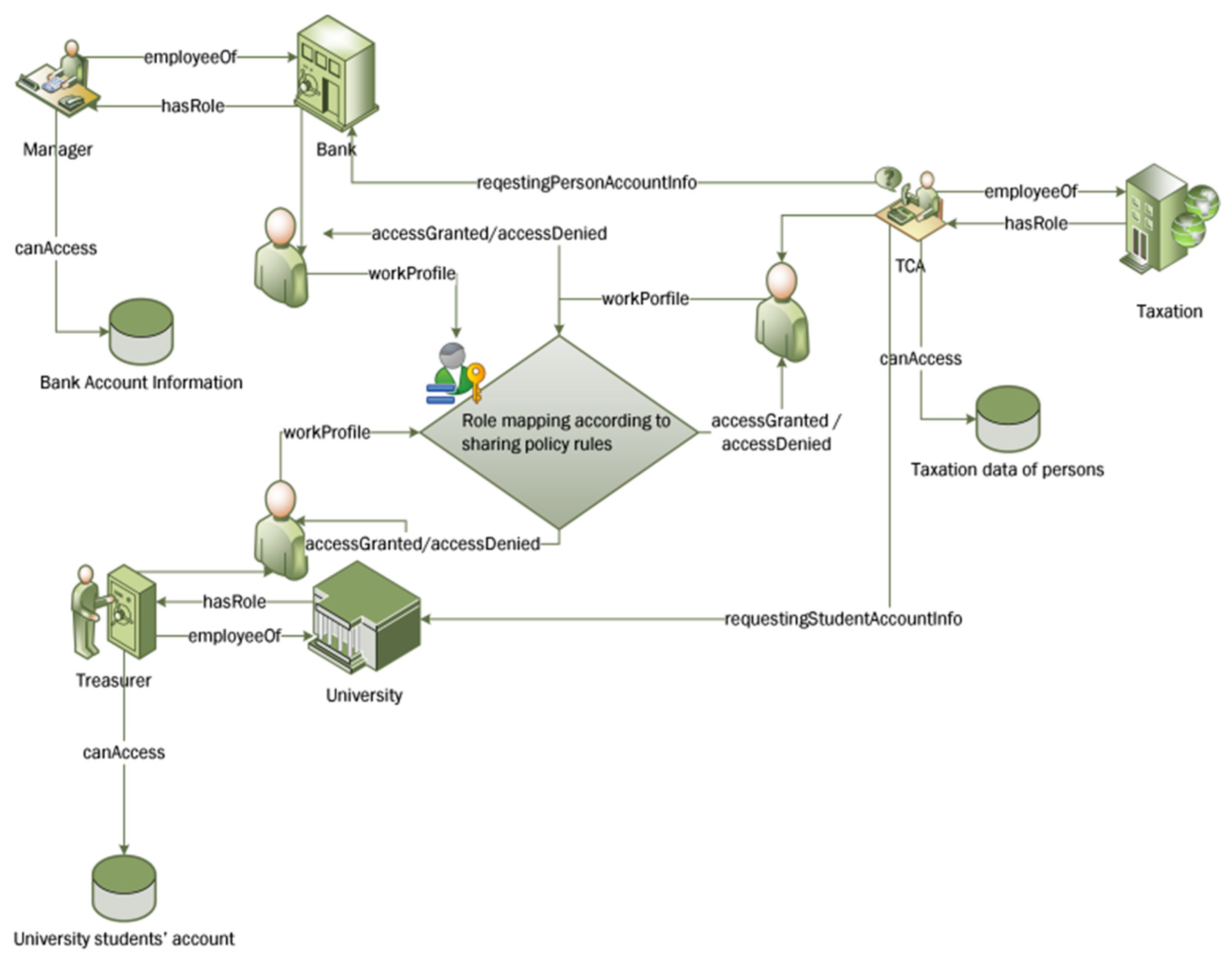
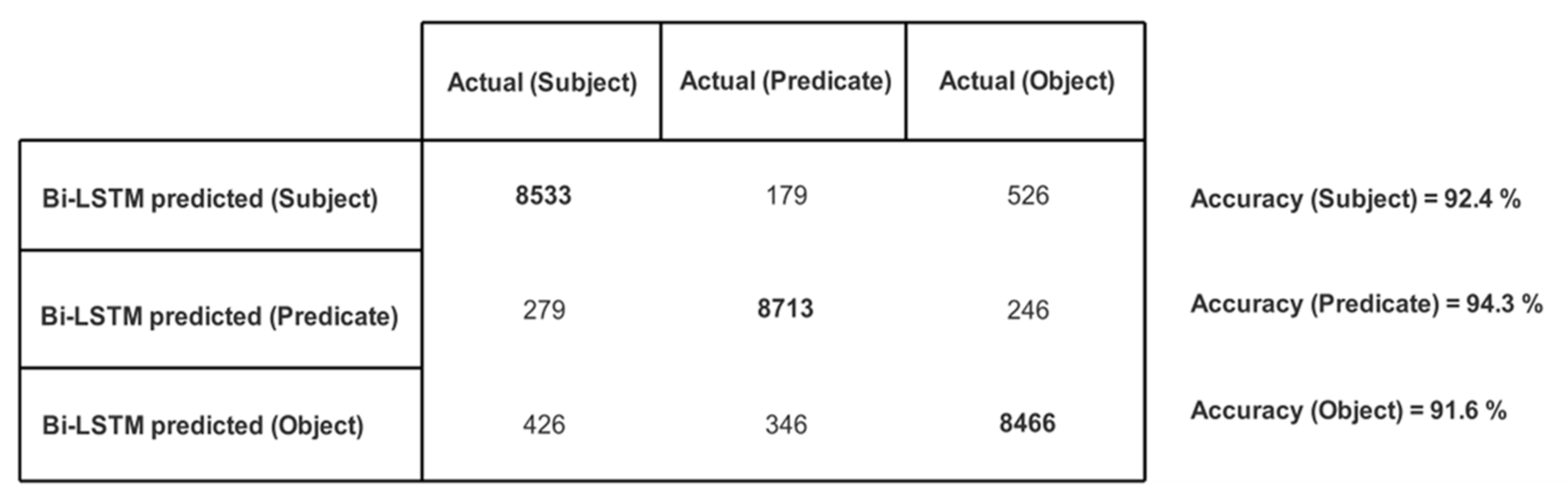
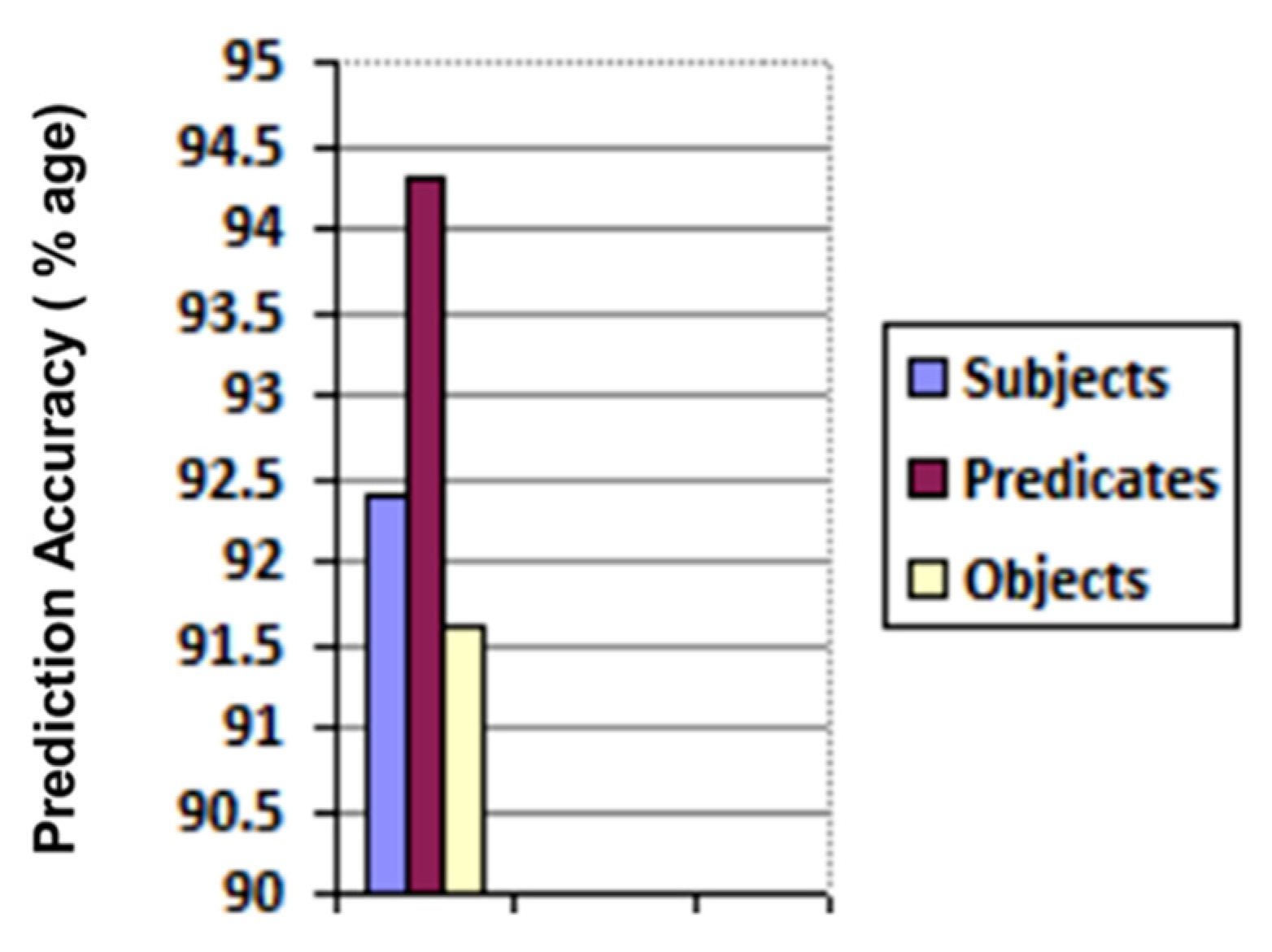
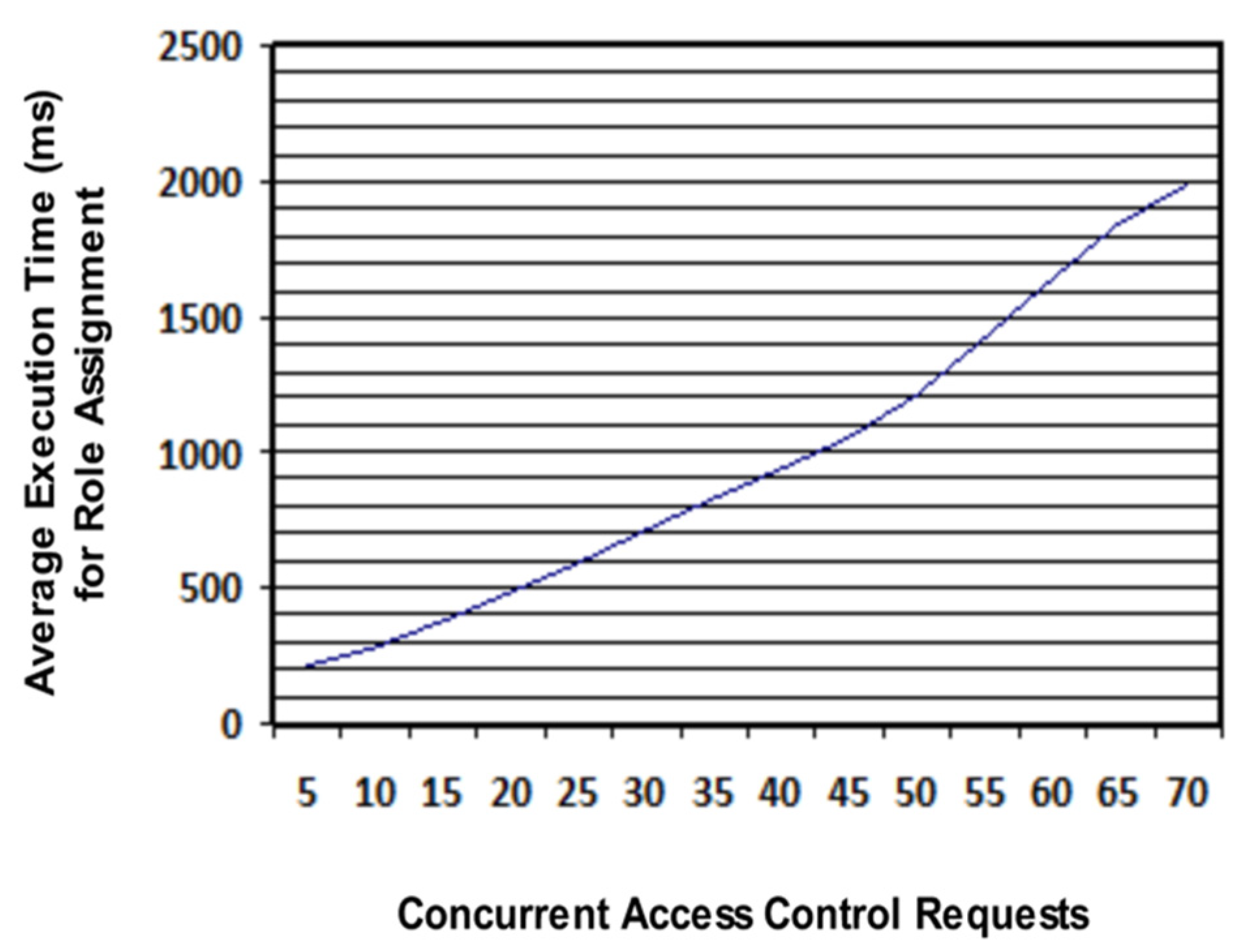
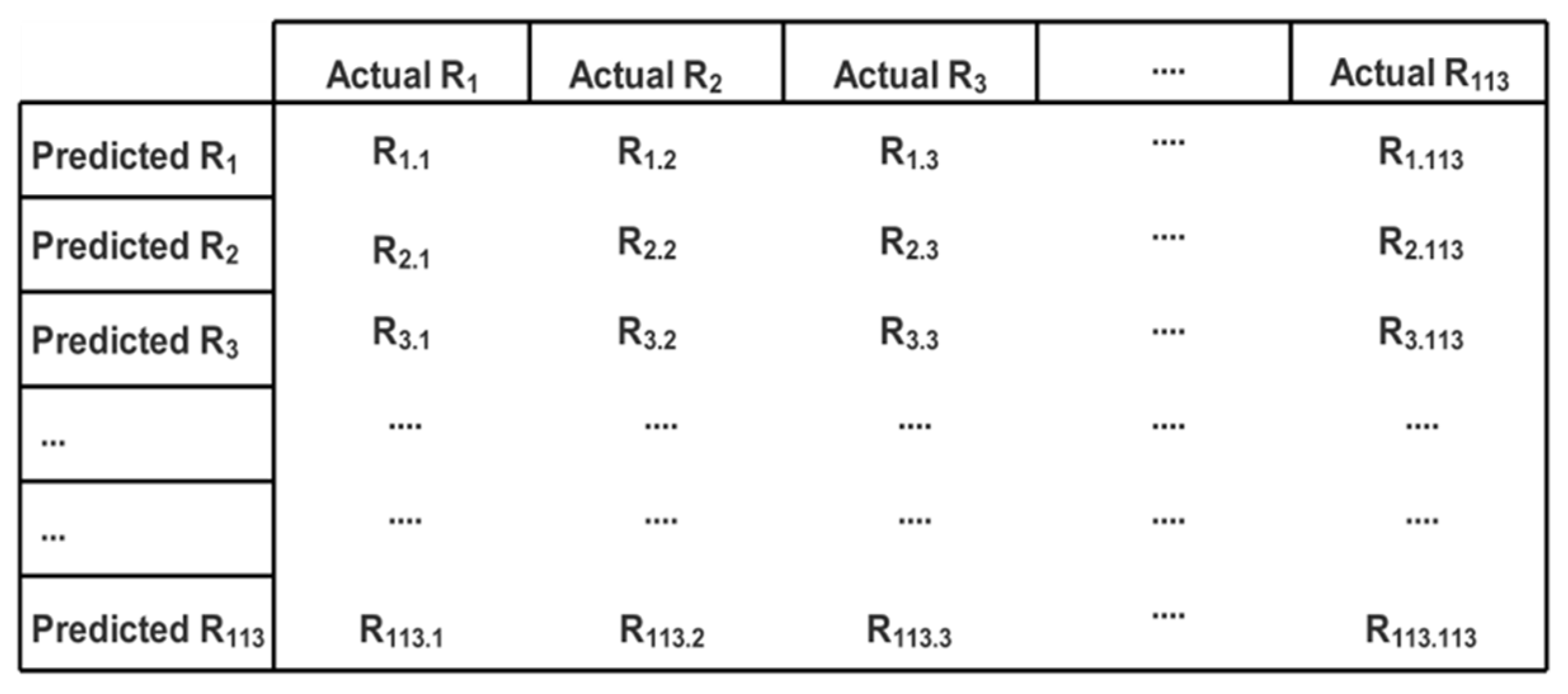
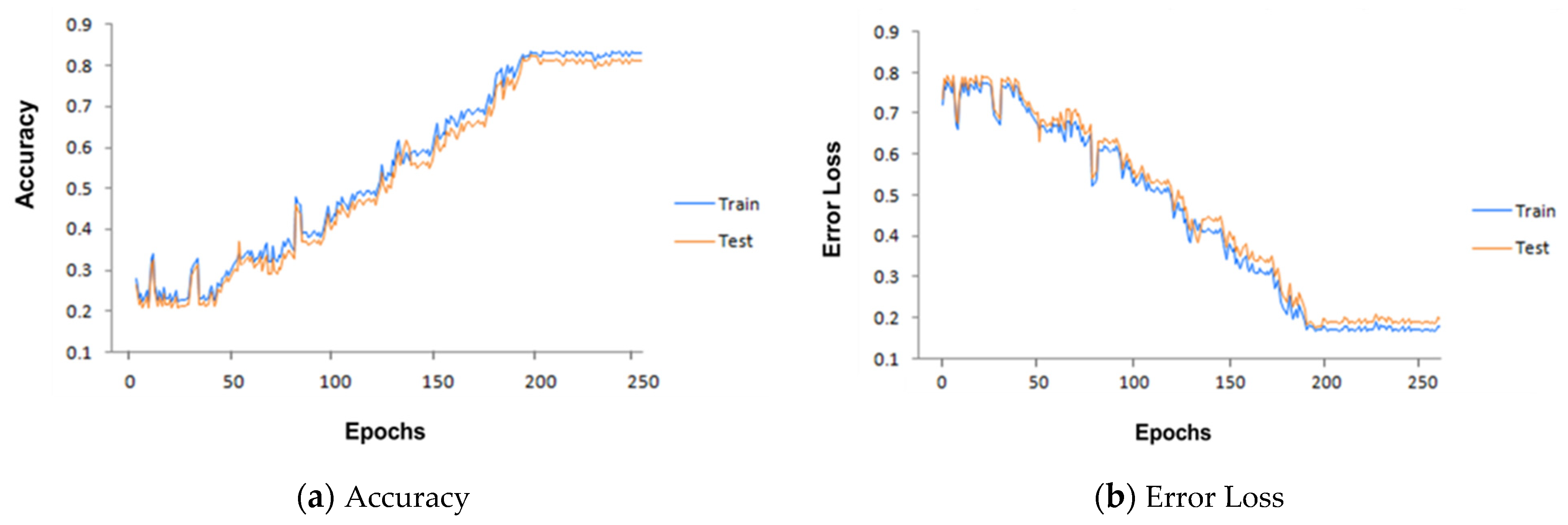
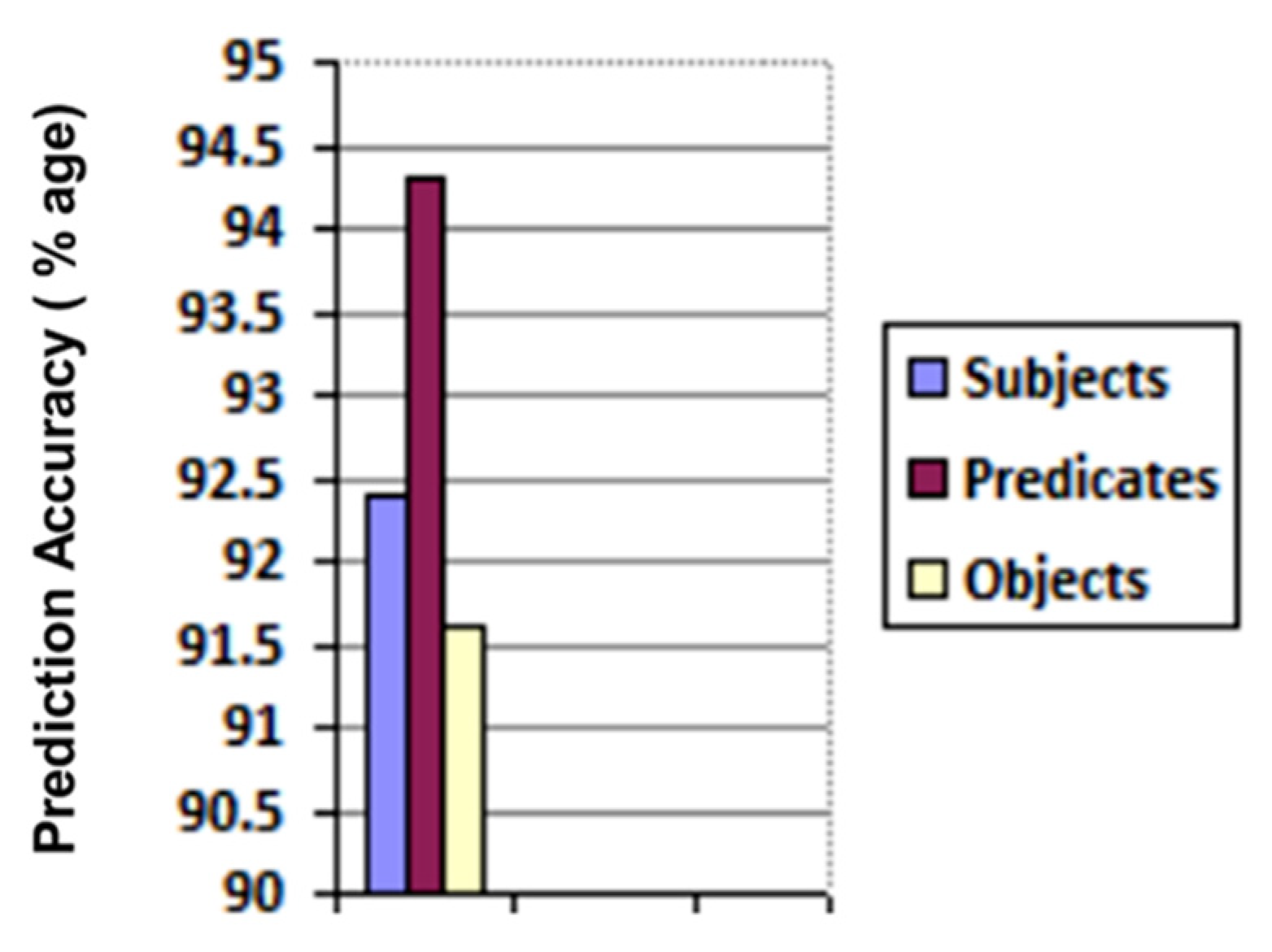
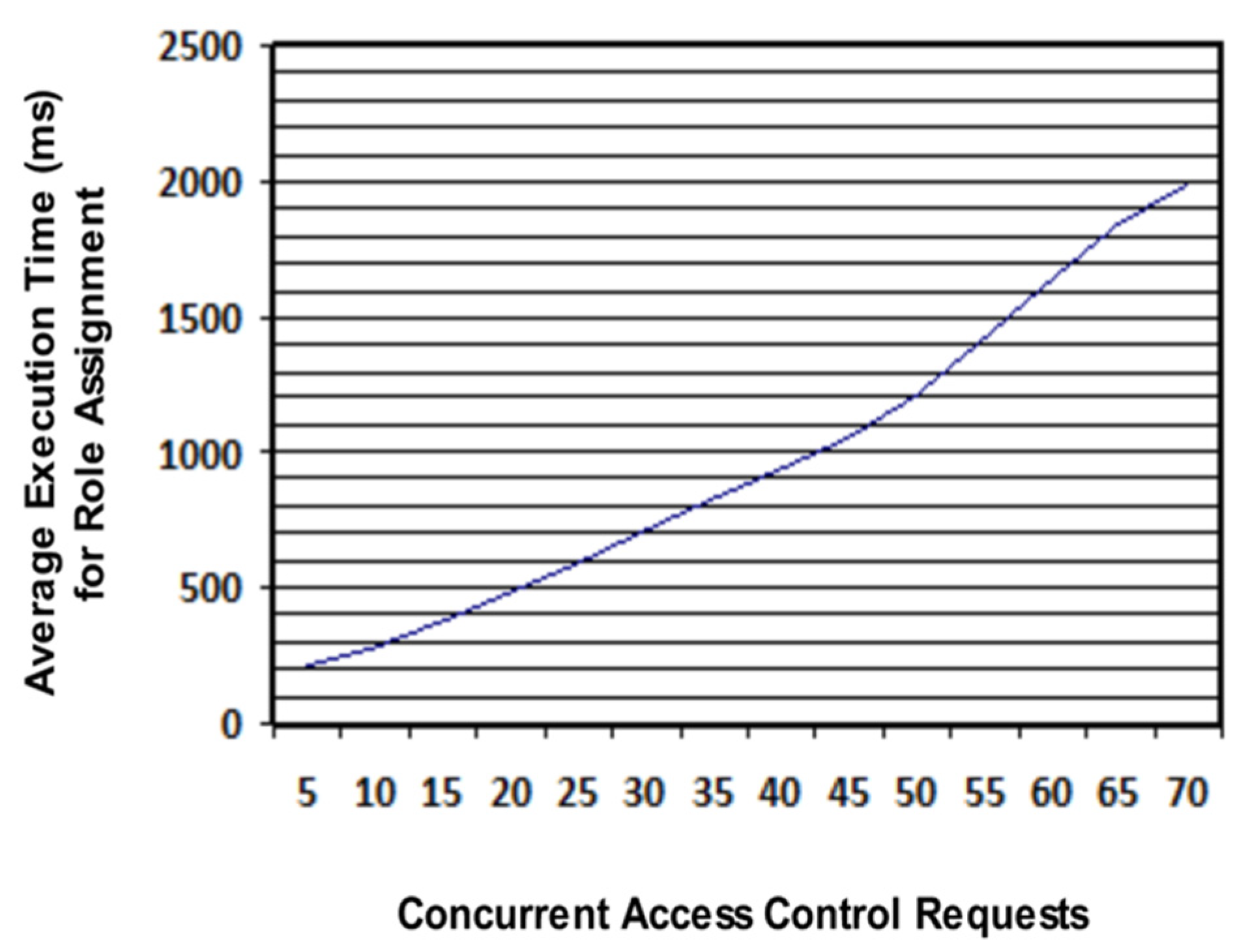
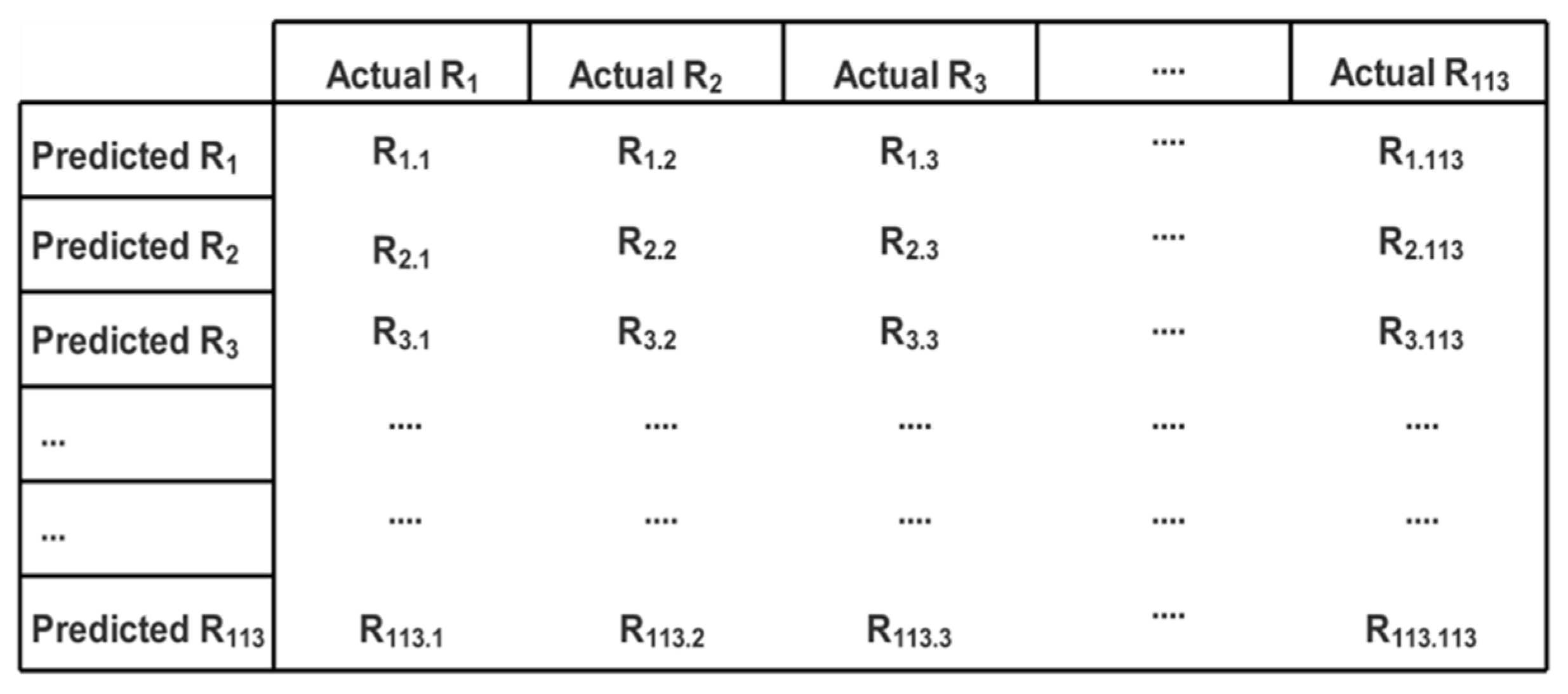
6. Results and Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Snow, C.C.; Håkonsson, D.D.; Obel, B. A smart city is a collaborative community: Lessons from smart Aarhus. Calif. Manage. Rev. 2016, 59, 92–108. [Google Scholar] [CrossRef]
- Malik, A.K.; Emmanuel, N.; Zafar, S.; Khattak, H.A.; Raza, B.; Khan, S.; Al-Bayatti, A.H.; Alassafi, M.O.; Alfakeeh, A.S.; Alqarni, M.A. From Conventional to State-of-the-Art IoT Access Control Models. Electronics 2020, 9, 1693. [Google Scholar] [CrossRef]
- Ferraiolo, D.F.; Sandhu, R.; Gavrila, S.; Kuhn, D.R.; Chandramouli, R. Proposed NIST standard for role-based access control. ACM Trans. Inf. Syst. Secur. TISSEC 2001, 4, 224–274. [Google Scholar] [CrossRef]
- Mitra, B.; Sural, S.; Vaidya, J.; Atluri, V. A Survey of Role Mining. ACM ComputSurv 2016, 48, 50:1–50:37. [Google Scholar] [CrossRef]
- Ghazal, R.; Malik, A.K.; Qadeer, N.; Raza, B.; Shahid, A.R.; Alquhayz, H. Intelligent Role-Based Access Control Model and Framework Using Semantic Business Roles in Multi-Domain Environments. IEEE Access 2020, 8, 12253–12267. [Google Scholar] [CrossRef]
- Ghazal, R.; Qadeer, N.; Malik, A.K.; Raza, B.; Ahmed, M. Intelligent Agent-Based RBAC Model to Support Cyber Security Alliance among Multiple Organizations in Global IT Systems. In 17th International Conference on Information Technology–New Generations (ITNG 2020); Springer: Berlin, Germany, 2020; pp. 87–93. [Google Scholar]
- Ghazal, R.; Malik, A.K.; Qadeer, N.; Ahmed, M. Intelligent Multi-Domain RBAC Model. In Innovative Solutions for Access Control Management; IGI Global: Hershey, PA, USA, 2016; pp. 66–95. [Google Scholar]
- 2018 Standard Occupational Classification System. Available online: https://www.bls.gov/soc/2018/major_groups.htm (accessed on 13 March 2018).
- Colantonio, A.; Di Pietro, R.; Ocello, A.; Verde, N. Mining business-relevant RBAC states through decomposition. In IFIP International Information Security Conference; Springer: Berlin, Heidelberg, 2010; pp. 19–30. [Google Scholar]
- Molloy, I.; Chen, H.; Li, T.; Wang, Q.; Li, N.; Bertino, E.; Calo, S.; Lobo, J. Mining Roles with Semantic Meanings. In Proceedings of the 13th ACM Symposium on Access Control Models and Technologies, New York, NY, USA, 11 June 2008; pp. 21–30. [Google Scholar]
- Colantonio, A.; Di Pietro, R.; Verde, N.V. A business-driven decomposition methodology for role mining. Comput. Secur. 2012, 31, 844–855. [Google Scholar] [CrossRef]
- Shafiq, B.; Joshi, J.B.; Bertino, E.; Ghafoor, A. Secure interoperation in a multidomain environment employing RBAC policies. IEEE Trans. Knowl. Data Eng. 2005, 17, 1557–1577. [Google Scholar] [CrossRef]
- Nazerian, F.; Motameni, H.; Nematzadeh, H. Secure access control in multidomain environments and formal analysis of model specifications. Turk. J. Electr. Eng. Comput. Sci. 2018, 26, 2525–2540. [Google Scholar] [CrossRef]
- Sun, Y.; Pan, P.; Leung, H.; Shi, B. Ontology based hybrid access control for automatic interoperation. Auton. Trust. Comput. 2007, 323–332. [Google Scholar]
- Abreu, V.; Santin, A.O.; Viegas, E.K.; Stihler, M. A Multi-Domain Role Activation Model. Provid. IdP 2017, 2, 24. [Google Scholar]
- Imran-Daud, M. Ontology-based Access Control in Open Scenarios: Applications to Social Networks and the Cloud. ArXiv 2016, arXiv:1612.09527. [Google Scholar]
- Mitra, P.; Pan, C.-C.; Liu, P.; Atluri, V. Privacy-preserving Semantic Interoperation and Access Control of Heterogeneous Databases. In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, Taipei, Taiwan, 21–24 March 2006; ACM: New York, NY, USA, 2006; pp. 66–77. [Google Scholar]
- Attia, H.B.; Kahloul, L.; Benharzallah, S. FRABAC: A new hybrid access control model for the heterogeneous multi-domain systems. Int. J. Manag. Decis. Mak. 2018, 17, 245–278. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, J.; Yang, L.; Yang, R.; Kou, B.; Chen, J.; Yang, S. The RBAC model and implementation architecture in multi-domain environment. Electron. Commer. Res. 2013, 13, 273–289. [Google Scholar] [CrossRef]
- Lu, J.; Li, R.; Varadharajan, V.; Lu, Z.; Ma, X. Secure Interoperation in Multidomain Environments Employing UCON Policies. In International Conference on Information Security; Springer: Berlin/Heidelberg, Germany, 2009; pp. 395–402. [Google Scholar]
- Ma, X.; Li, R.; Lu, Z. Role Mining Based on Weights. In Proceedings of the 15th ACM Symposium on Access Control Models and Technologies, Vienna, Austria, 1–3 June 2010; ACM: New York, NY, USA, 2010; pp. 65–74. [Google Scholar]
- Xu, Z.; Stoller, S.D. Algorithms for Mining Meaningful Roles. In Proceedings of the 17th ACM Symposium on Access Control Models and Technologies; ACM: New York, NY, USA, 2012; pp. 57–66. [Google Scholar]
- Molloy, I.; Park, Y.; Chari, S. Generative models for access control policies: Applications to role mining over logs with attribution. In Proceedings of the 17th ACM symposium on Access Control Models and Technologies, Newark, NJ, USA, 20–22 June 2012; pp. 45–56. [Google Scholar]
- Chari, S.N.; Molloy, I.M.; Park, Y. Role Mining with User Attribution Using Generative Models. U.S. Patent 8,983,877, 17 March 2015. [Google Scholar]
- Colantonio, A.; Di Pietro, R.; Ocello, A.; Verde, N.V. A new role mining framework to elicit business roles and to mitigate enterprise risk. Decis. Support Syst. 2011, 50, 715–731. [Google Scholar] [CrossRef]
- Kuhlmann, M.; Shohat, D.; Schimpf, G. Role Mining—Revealing Business Roles for Security Administration Using Data Mining Technology. In Proceedings of the Eighth ACM Symposium on Access Control Models and Technologies, Como, Italy, 1–3 June 2003; ACM: New York, NY, USA, 2003; pp. 179–186. [Google Scholar]
- Faruqui, R.U. Modelling and Verifying Dynamic Access Control Policies in Workflow-Based Healthcare Systems. J. Kejuruter. 2020, 32, 1–7. [Google Scholar]
- Saenko, I.; Kotenko, I. Genetic algorithms for role mining problem. In Proceedings of the 2011 19th International Euromicro Conference on Parallel, Distributed and Network-Based Processing, Ayia Napa, Cyprus, 9–11 February 2011; pp. 646–650. [Google Scholar]
- Liu, Y.; Zhang, T.; Liang, Z.; Ji, H.; McGuinness, D.L. Seq2RDF: An end-to-end application for deriving Triples from Natural Language Text. ArXiv 2018, arXiv:1807.01763. [Google Scholar]
- Chen, J.; Gu, J. ADOL: A novel framework for automatic domain ontology learning. J. Supercomput. 2020, 77, 152–169. [Google Scholar] [CrossRef]
- Makarenkov, V.; Rokach, L.; Shapira, B. Choosing the right word: Using bidirectional LSTM tagger for writing support systems. Eng. Appl. Artif. Intell. 2019, 84, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Borovkova, S.; Tsiamas, I. An ensemble of LSTM neural networks for high-frequency stock market classification. J. Forecast. 2019, 38, 600–619. [Google Scholar] [CrossRef] [Green Version]
- Belhadi, H.; Akli-Astouati, K.; Djenouri, Y.; Lin, J.C.-W. Data mining-based approach for ontology matching problem. Appl. Intell. 2020, 50, 1204–1221. [Google Scholar] [CrossRef]
- Cerón-Figueroa, S.; López-Yáñez, I.; Alhalabi, W.; Camacho-Nieto, O.; Villuendas-Rey, Y.; Aldape-Pérez, M.; Yáñez-Márquez, C. Instance-based ontology matching for e-learning material using an associative pattern classifier. Comput. Hum. Behav. 2017, 69, 218–225. [Google Scholar] [CrossRef]
- Iwata, T.; Kanagawa, M.; Hirao, T.; Fukumizu, K. Unsupervised group matching with application to cross-lingual topic matching without alignment information. Data Min. Knowl. Discov. 2017, 31, 350–370. [Google Scholar] [CrossRef]
- Smith, B.; Ashburner, M.; Rosse, C.; Bard, J.; Bug, W.; Ceusters, W.; Goldberg, L.J.; Eilbeck, K.; Ireland, A.; Mungall, C.J.; et al. The OBO Foundry: Coordinated evolution of ontologies to support biomedical data integration. Nat. Biotechnol. 2007, 25, 1251–1255. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Wang, Z.; Zhang, X.; Tang, J. Large scale instance matching via multiple indexes and candidate selection. Knowl.-Based Syst. 2013, 50, 112–120. [Google Scholar] [CrossRef]
- Xue, X.; Chen, J.; Chen, J.; Chen, D. Using compact coevolutionary algorithm for matching biomedical ontologies. Comput. Intell. Neurosci. 2018, 2018, 2309587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xue, X.; Liu, J. A compact hybrid evolutionary algorithm for large scale instance matching in linked open data cloud. Int. J. Artif. Intell. Tools 2017, 26, 1750013. [Google Scholar] [CrossRef]
- Navarro, G.; Borrell, J.; Ortega-Ruiz, J.A.; Robles, S. Access control with safe role assignment for mobile agents. In Proceedings of the Proceedings of the Fourth International Joint Conference on Autonomous agents and Multiagent Systems, Utrecht, The Netherlands,, 25–29 July 2005; pp. 1235–1236. [Google Scholar]
- Isern, D.; Moreno, A. Distributed guideline-based health care system. In Proceedings of the 4th International Conference on Intelligent Systems Design and Applications, ISDA, Budapest, Hungary, 26–28 August 2004; pp. 145–150. [Google Scholar]
- Santos-Pereira, C.; Augusto, A.B.; Cruz-Correia, R.; Correia, M.E. A secure RBAC mobile agent access control model for healthcare institutions. In Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems, Porto, Portugal, 20–22 June 2013; pp. 349–354. [Google Scholar]
- Schmidt, D.; Bordini, R.H.; Meneguzzi, F.; Vieira, R. An Ontology for Collaborative Tasks in Multi-agent Systems. In Proceedings of the ONTOBRAS, Sao Paulo, Brazil, 8–11 September 2015. [Google Scholar]
- Viroli, M.; Omicini, A.; Ricci, A. Infrastructure for RBAC-MAS: An approach based on agent coordination contexts. Appl. Artif. Intell. 2007, 21, 443–467. [Google Scholar] [CrossRef]
- Marikkannu, P.; Jovin, J.A.; Purusothaman, T. Fault-tolerant adaptive mobile agent system using dynamic role based access control. Int. J. Comput. Appl. 2011, 20, 1–6. [Google Scholar]
- Wang, T.; Chen, P.; Amaral, K.; Qiang, J. An experimental study of LSTM encoder-decoder model for text simplification. ArXiv 2016, arXiv:1609.03663. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. ArXiv 2015, arXiv:1508.01991. [Google Scholar]
- Guarino, N.; Welty, C. Evaluating ontological decisions with OntoClean. Commun. ACM 2002, 45, 61–65. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Role Hierarchy | Attributes | Semantic Techniques and Technology | Machine Learning Techniques | Business Roles | Intelligent Agents |
|---|---|---|---|---|---|---|
| [12] | ☑ | |||||
| [13] | ☑ | ☑ | ||||
| [14] | ☑ | ☑ | ||||
| [15] | ☑ | ☑ | ||||
| [16] | ☑ | |||||
| [17] | ☑ | |||||
| [18] | ☑ | ☑ | ||||
| [19] | ☑ | |||||
| [20] | ☑ | ☑ | ||||
| Our Model | ☑ | ☑ | ☑ | ☑ | ☑ | ☑ |
| Parameter | Value |
|---|---|
| No. of layers | 128 |
| No. of neurons in LSTM layer | 100 |
| Dropout rate | 0.2 |
| Batch size | 64 |
| No. of epochs (for minimum loss error) | 200 |
| Initial learning rate | 0.005 |
| Optimization Method | ADAM |
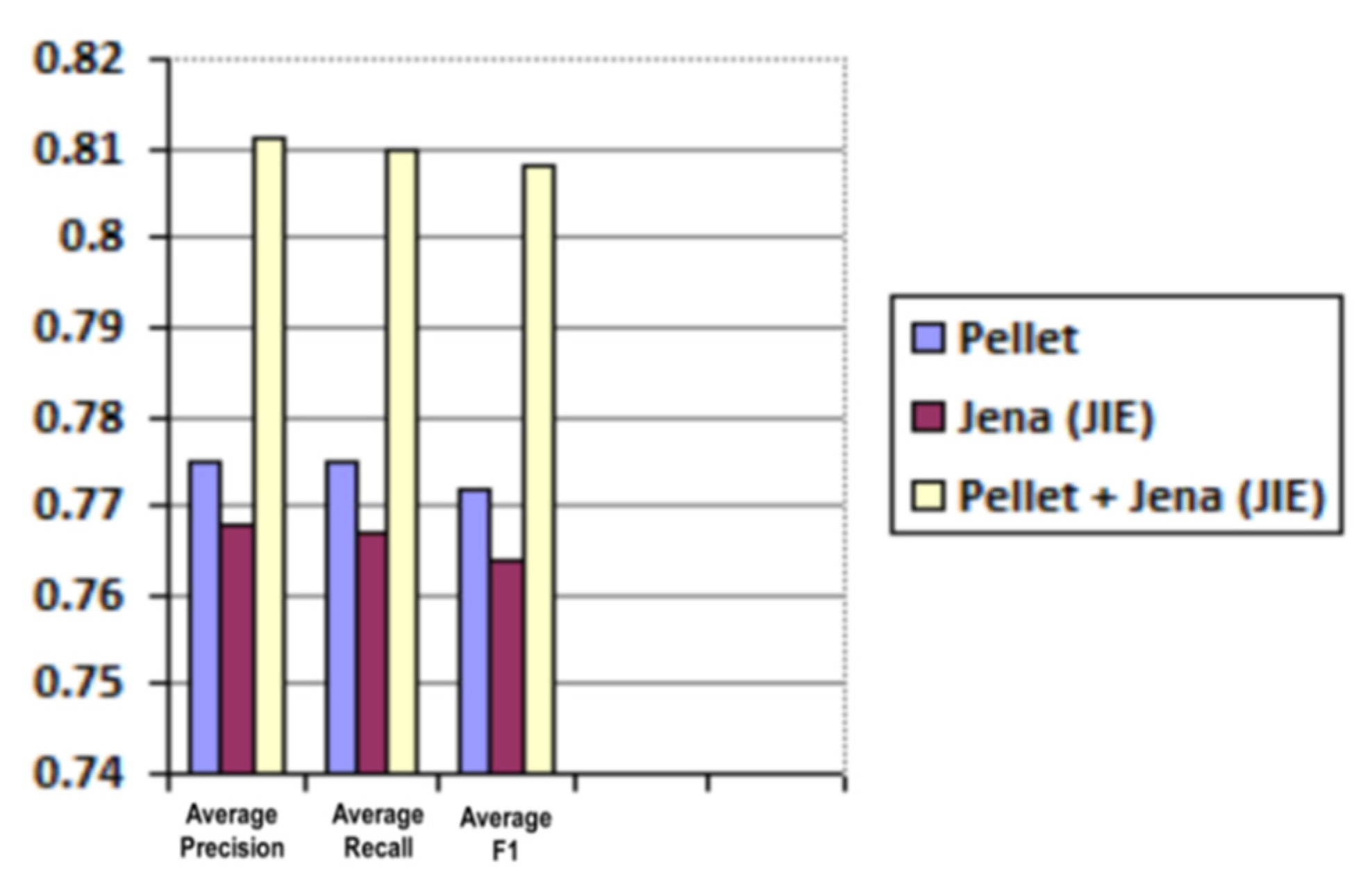
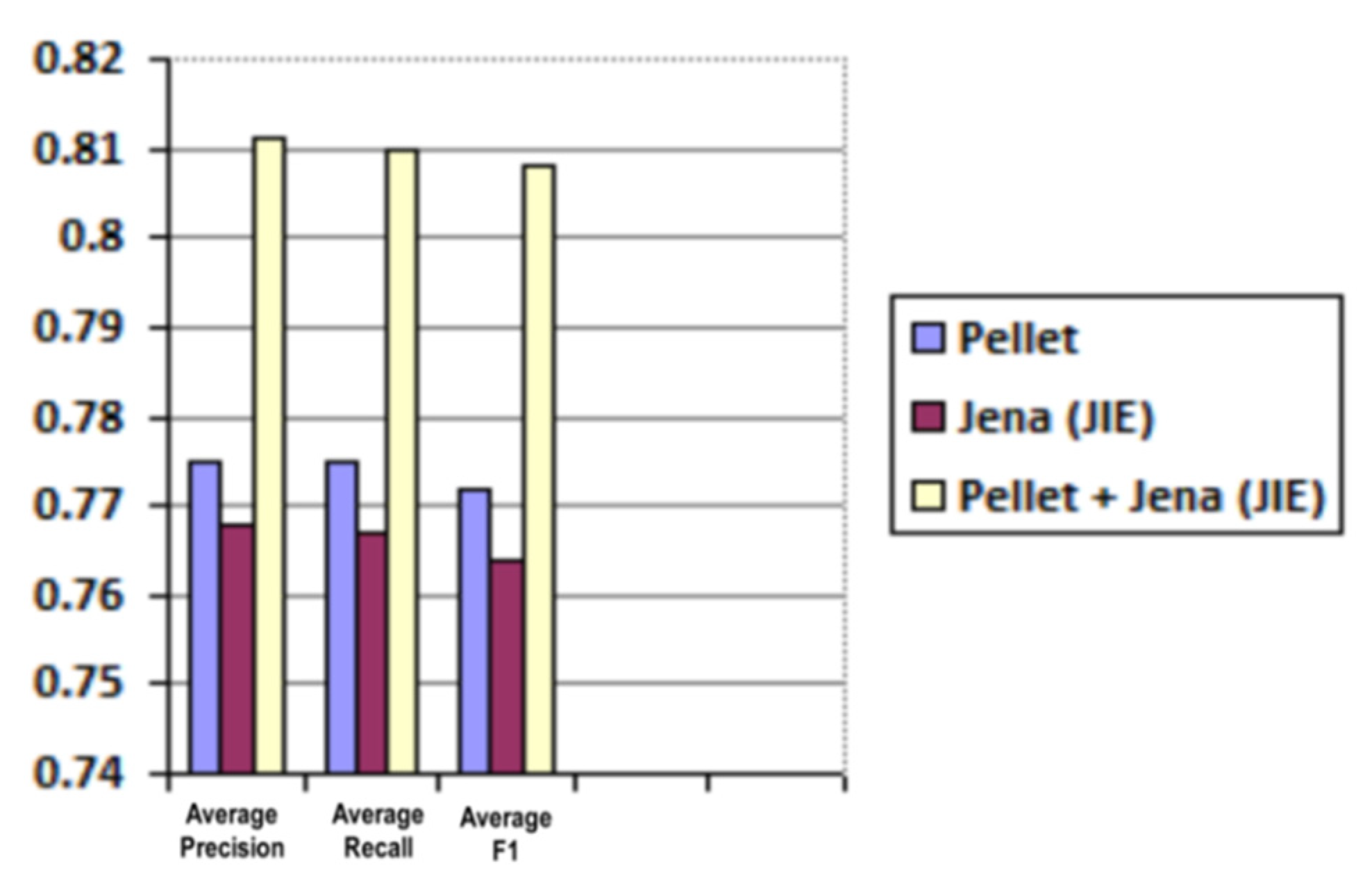
| Reasoner | Average Precision | Average Recall | Average F1 |
|---|---|---|---|
| Pellet | 0.775 | 0.775 | 0.772 |
| Jena (JIE) | 0.768 | 0.767 | 0.764 |
| Pellet + Jena (JIE) | 0.811 | 0.81 | 0.808 |
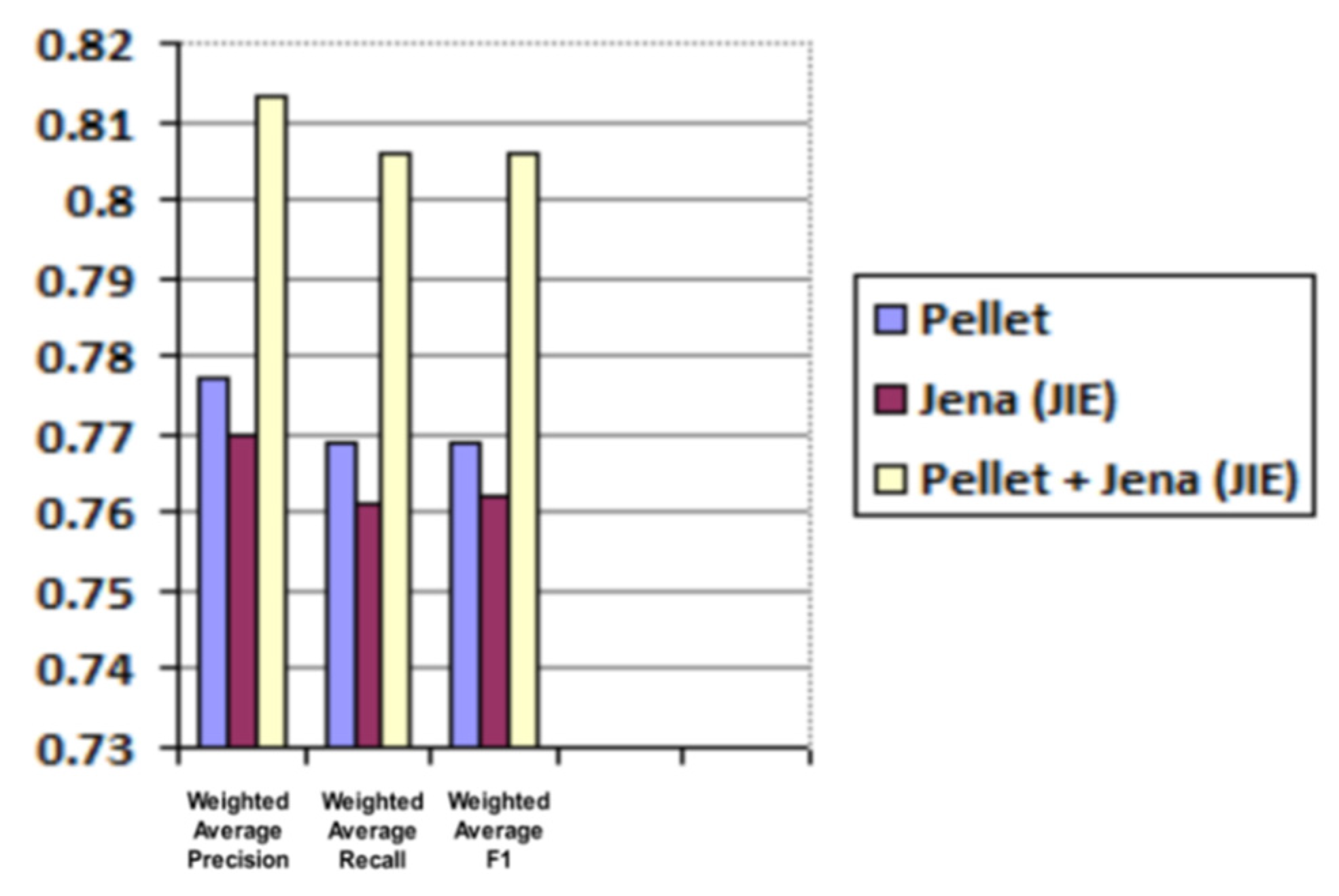
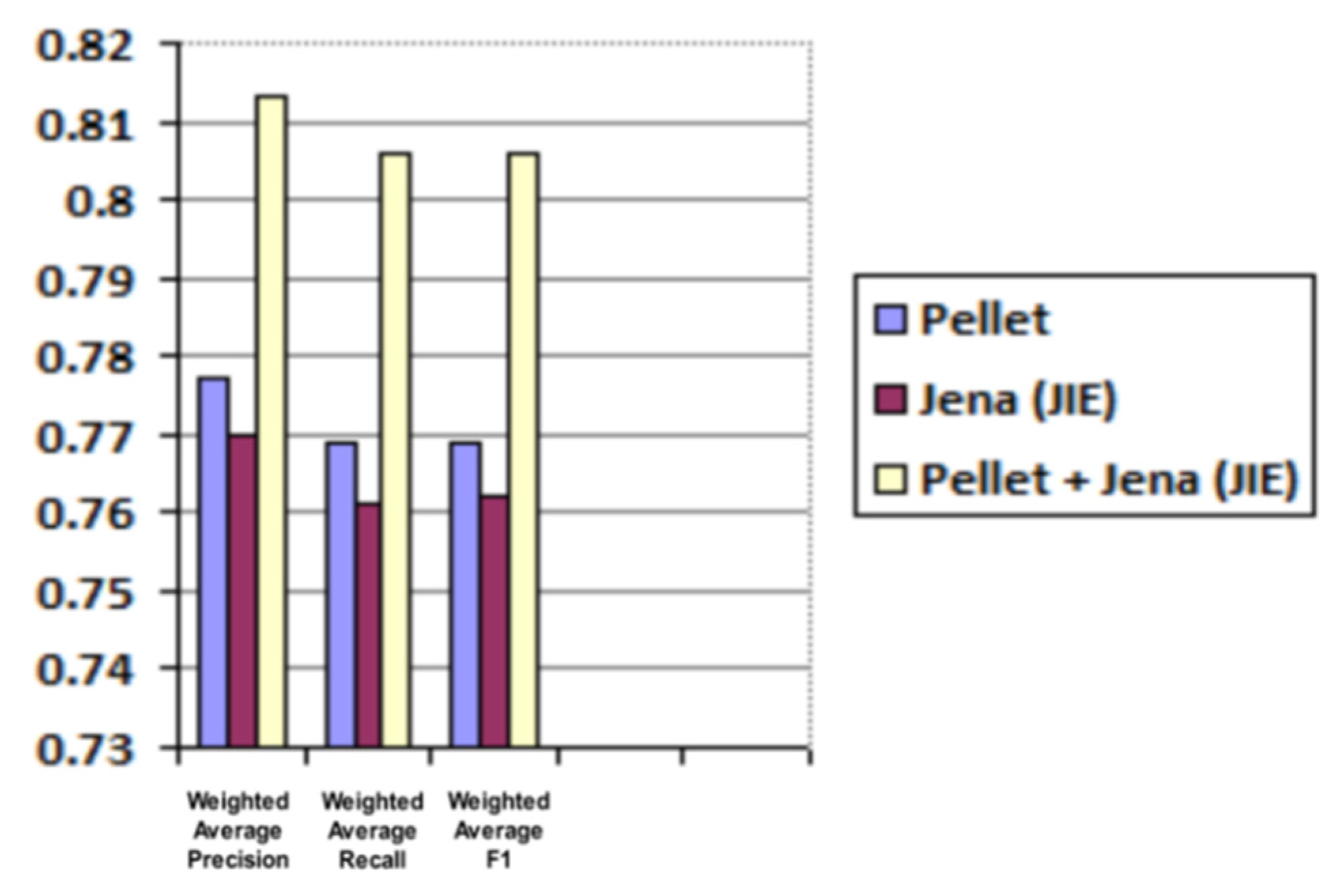
| Reasoner | Weighted Average Precision | Weighted Average Recall | Weighted Average F1 |
|---|---|---|---|
| Pellet | 0.777 | 0.769 | 0.769 |
| Jena (JIE) | 0.77 | 0.761 | 0.762 |
| Pellet + Jena (JIE) | 0.813 | 0.806 | 0.806 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghazal, R.; Malik, A.K.; Raza, B.; Qadeer, N.; Qamar, N.; Bhatia, S. Agent-Based Semantic Role Mining for Intelligent Access Control in Multi-Domain Collaborative Applications of Smart Cities. Sensors 2021, 21, 4253. https://doi.org/10.3390/s21134253
Ghazal R, Malik AK, Raza B, Qadeer N, Qamar N, Bhatia S. Agent-Based Semantic Role Mining for Intelligent Access Control in Multi-Domain Collaborative Applications of Smart Cities. Sensors. 2021; 21(13):4253. https://doi.org/10.3390/s21134253
Chicago/Turabian StyleGhazal, Rubina, Ahmad Kamran Malik, Basit Raza, Nauman Qadeer, Nafees Qamar, and Sajal Bhatia. 2021. "Agent-Based Semantic Role Mining for Intelligent Access Control in Multi-Domain Collaborative Applications of Smart Cities" Sensors 21, no. 13: 4253. https://doi.org/10.3390/s21134253
APA StyleGhazal, R., Malik, A. K., Raza, B., Qadeer, N., Qamar, N., & Bhatia, S. (2021). Agent-Based Semantic Role Mining for Intelligent Access Control in Multi-Domain Collaborative Applications of Smart Cities. Sensors, 21(13), 4253. https://doi.org/10.3390/s21134253