
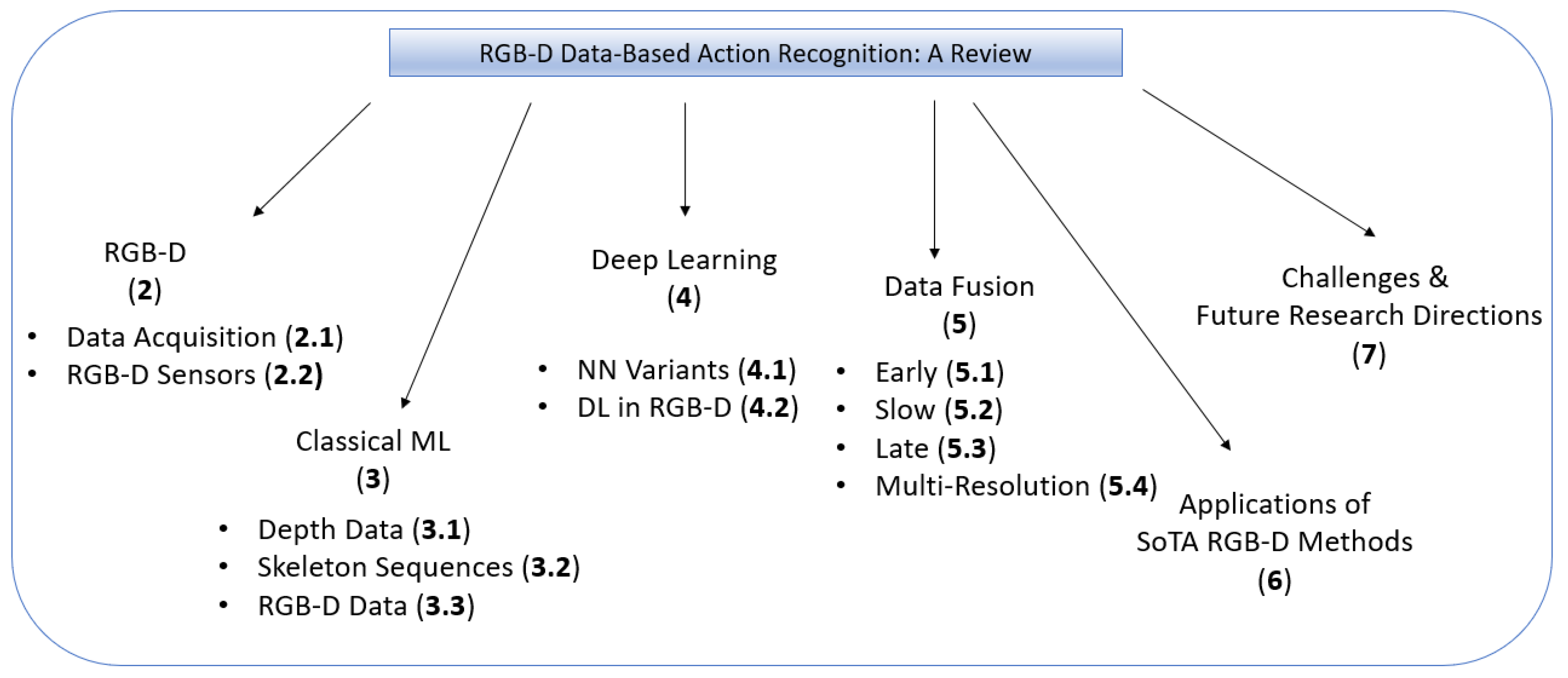
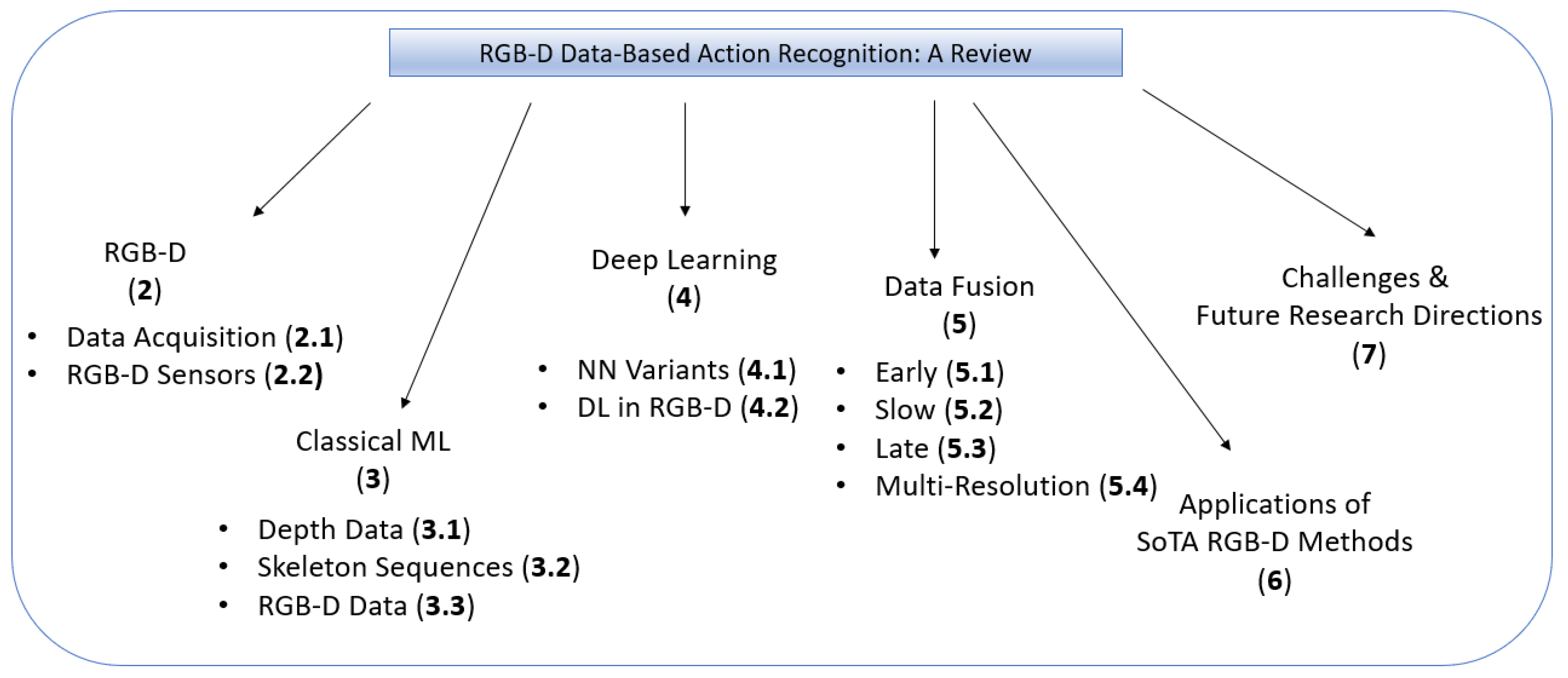
RGB-D Data-Based Action Recognition: A Review


Abstract
:1. Introduction
- Review of state-of-the-art action recognition techniques on common RGB-D datasets that will provide readers with an overview of recent developments in action recognition.
- Analysis of current methods from a perspective of multimodality and hybrid classification methods.
- Intuitive categorization and analysis of recent and advanced classical machine learning-based and deep learning-based techniques.
- Discussion of the challenges of data fusion and action recognition and potentials future research directions.
2. RGB-D
2.1. RGB-D Data Acquisition
2.2. RGB-D Sensors
2.2.1. Microsoft® Kinect™ Sensors
2.2.2. Intel® RealSense™ Depth Cameras
2.2.3. Orbbec® Depth Cameras
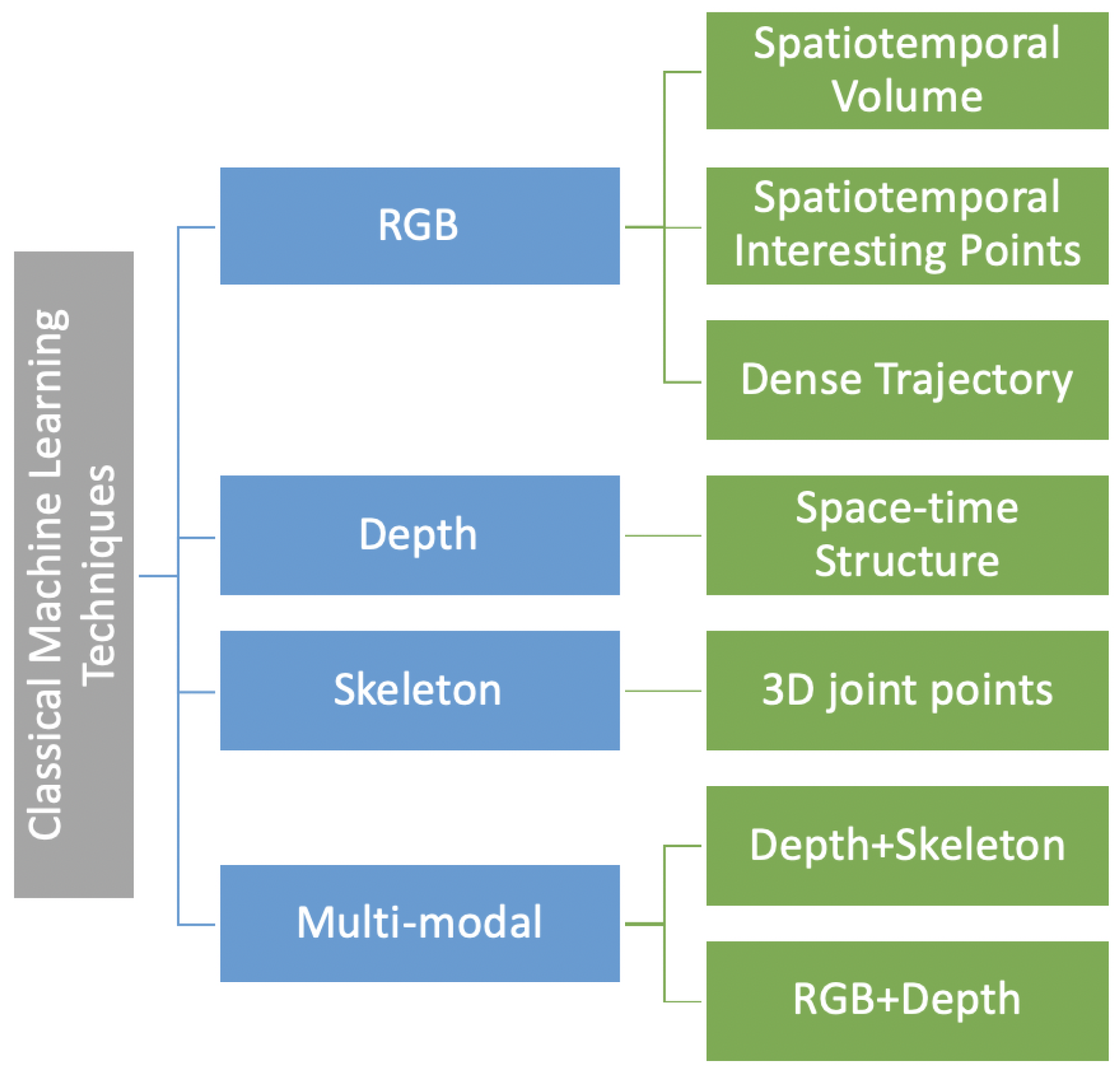
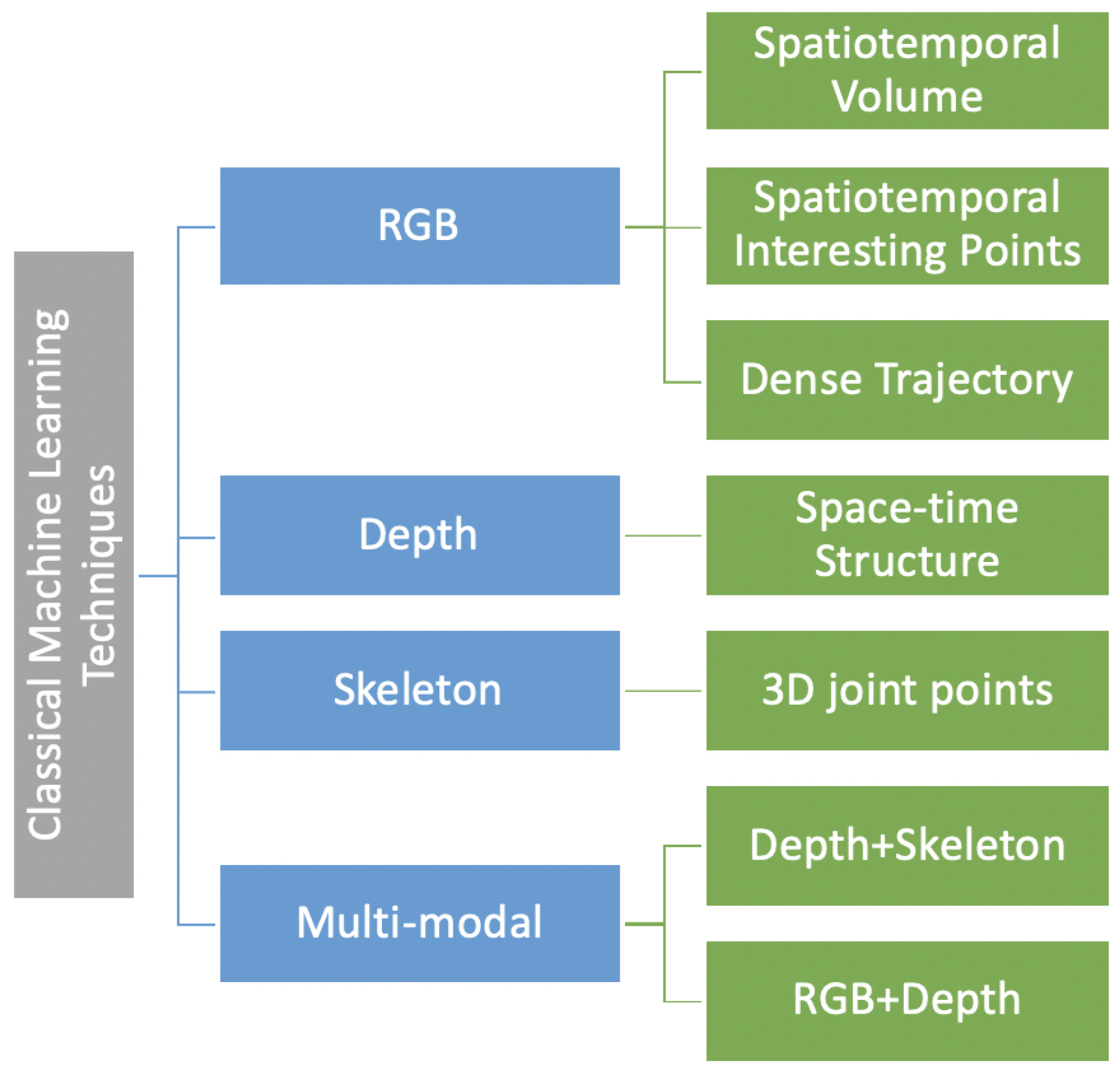
3. Classical Machine Learning-Based Techniques
3.1. Depth Data-Based Techniques
3.2. Skeleton Sequence-Based Techniques
3.3. RGB-D Data-Based Techniques
4. Deep Learning
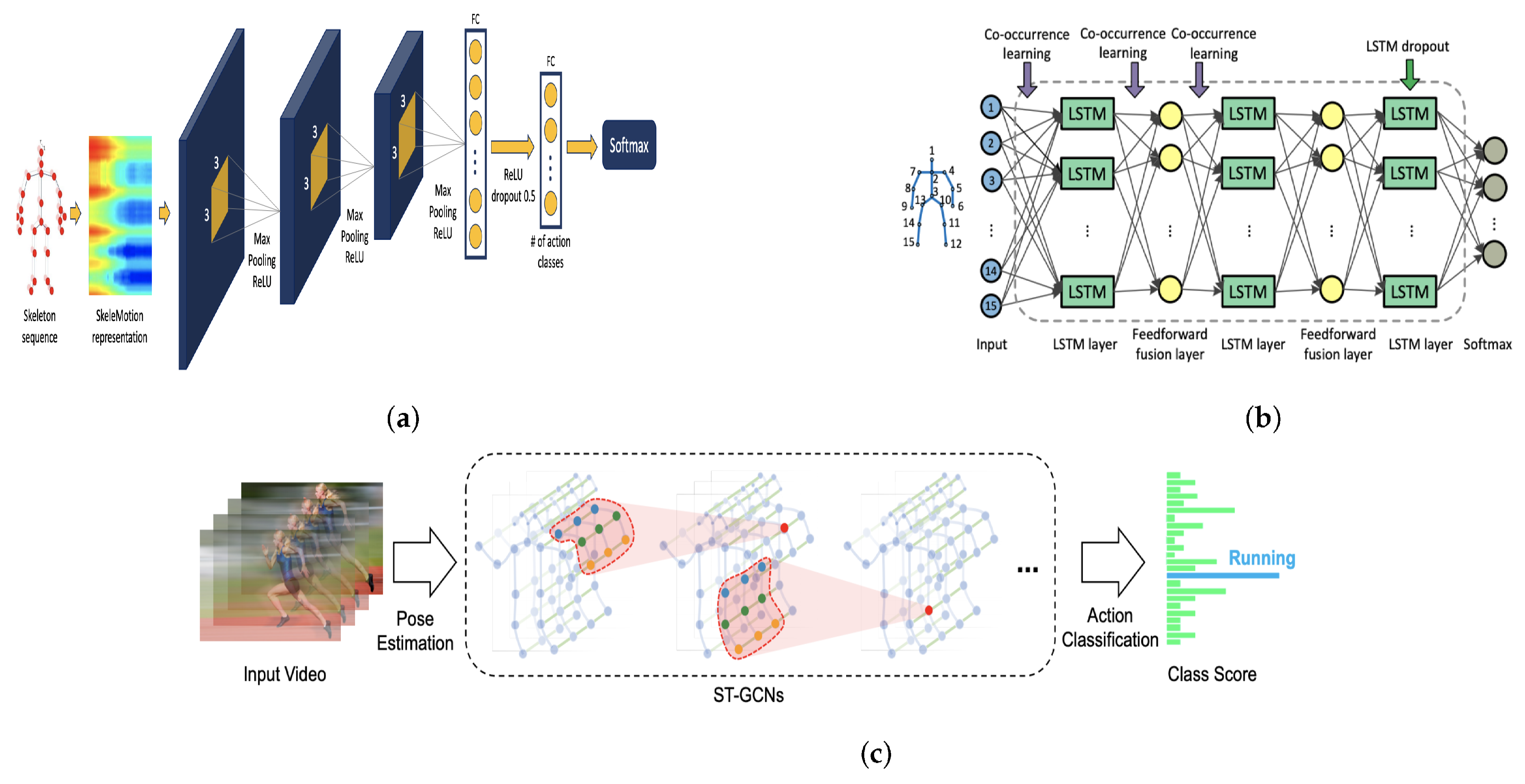
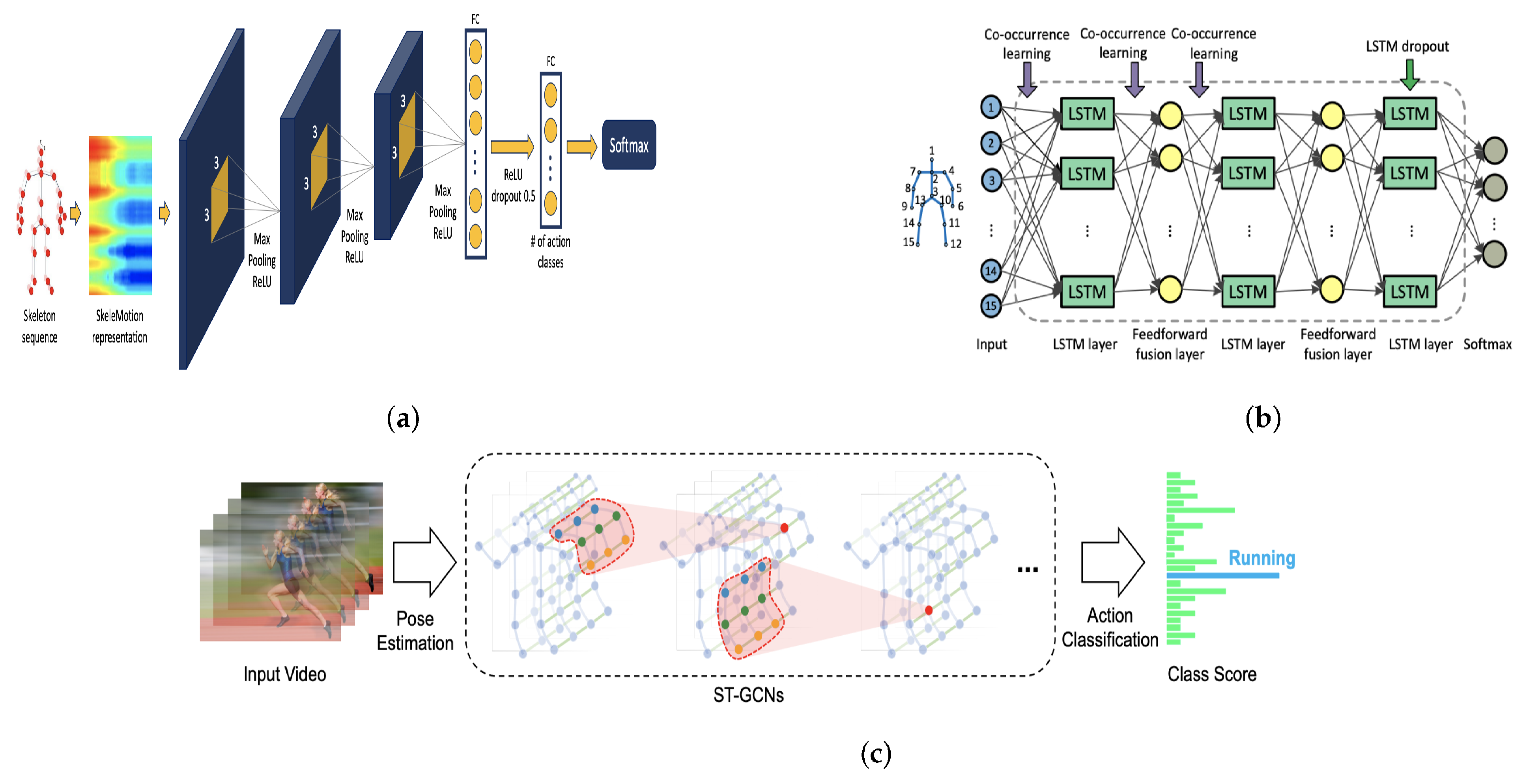
4.1. Neural Networks Variants
4.1.1. Convolutional Neural Networks (CNN)
4.1.2. Recurrent Neural Networks (RNN)
4.1.3. Graph Convolutional Networks (GCN)
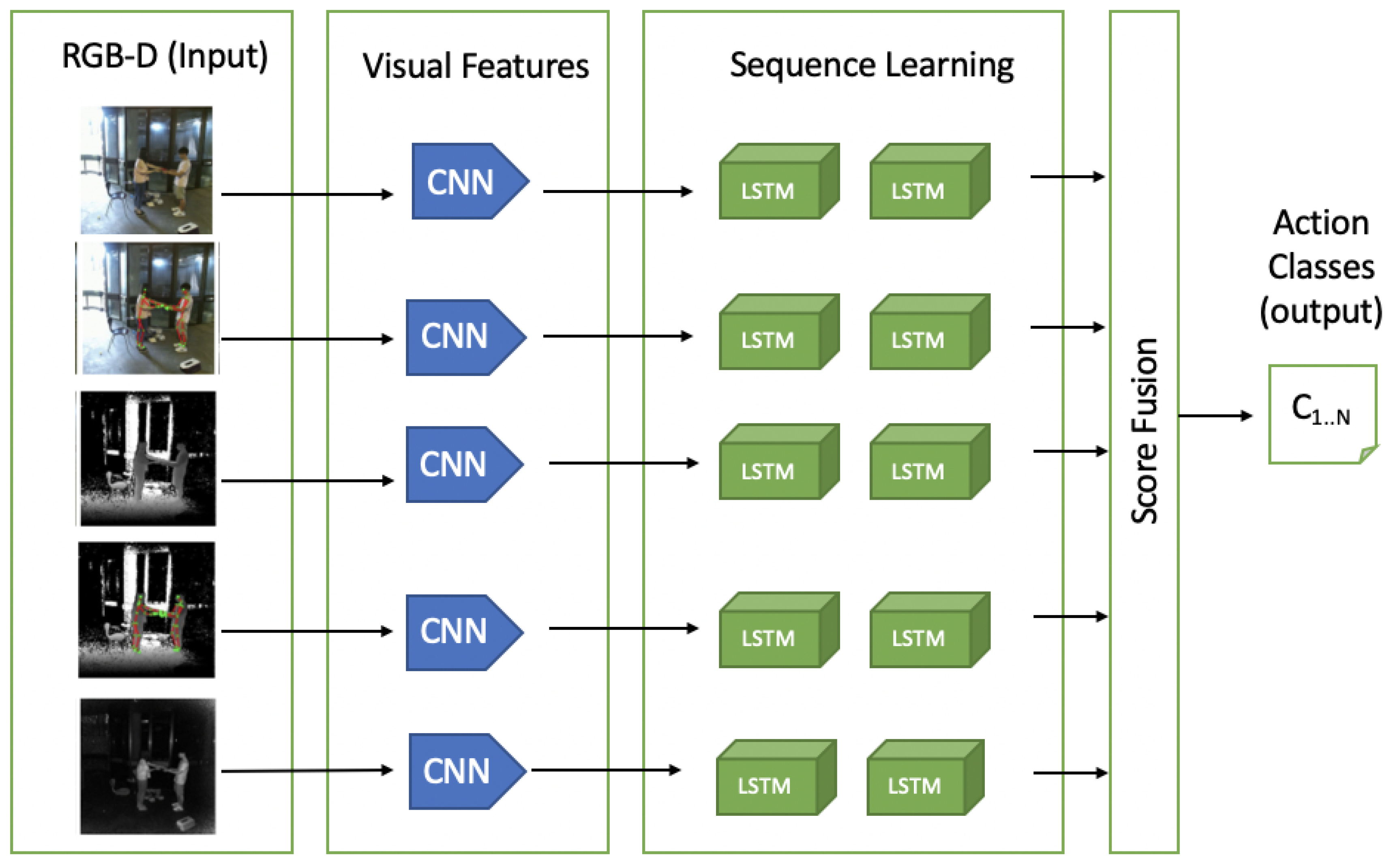
4.2. Deep Learning-Based Techniques Using RGB-D Data
4.2.1. Single Stream
4.2.2. Two Stream
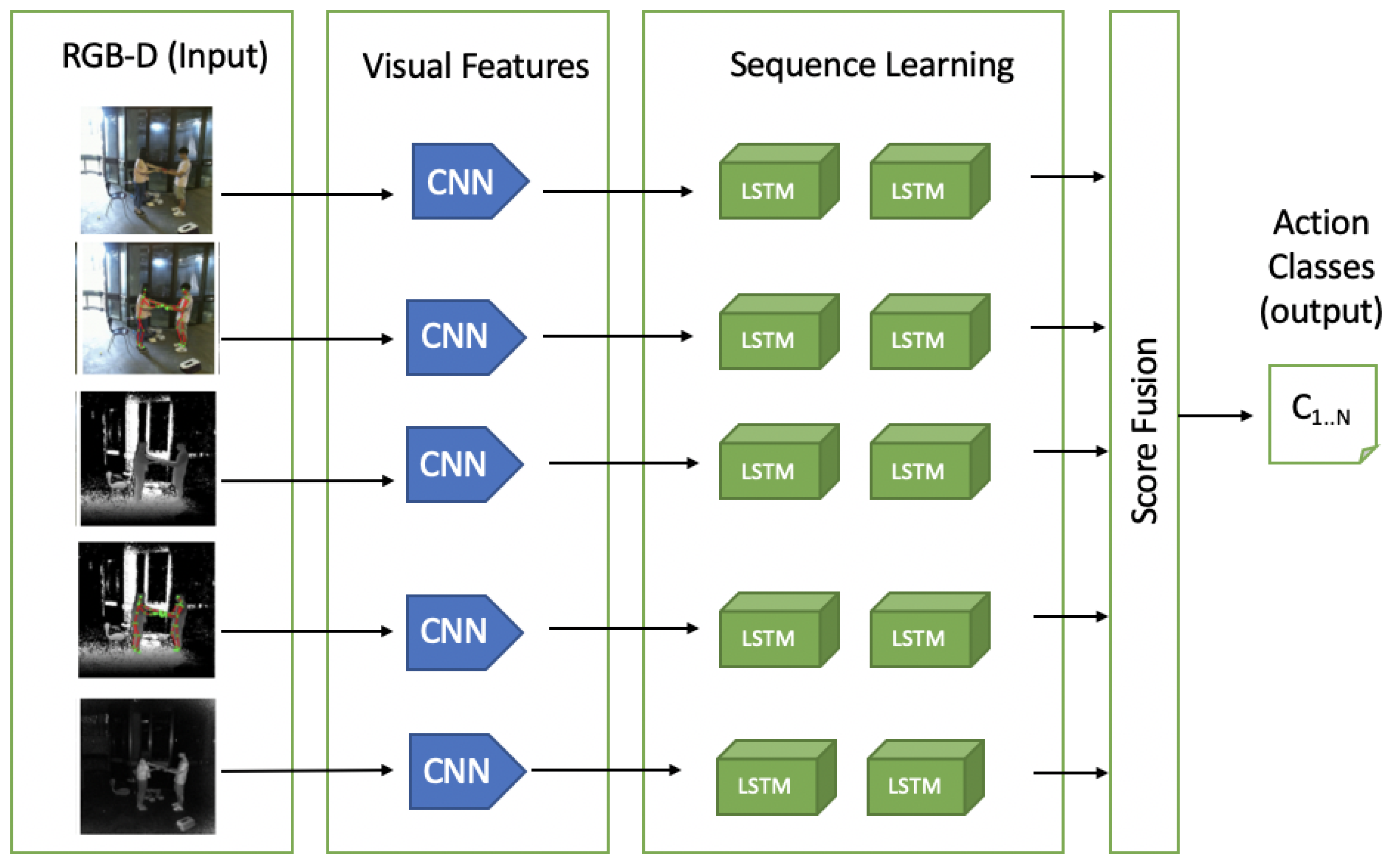
4.2.3. Long-Term Recurrent Convolutional Network (LRCN)
4.2.4. Hybrid Deep Learning-Based Techniques for HAR
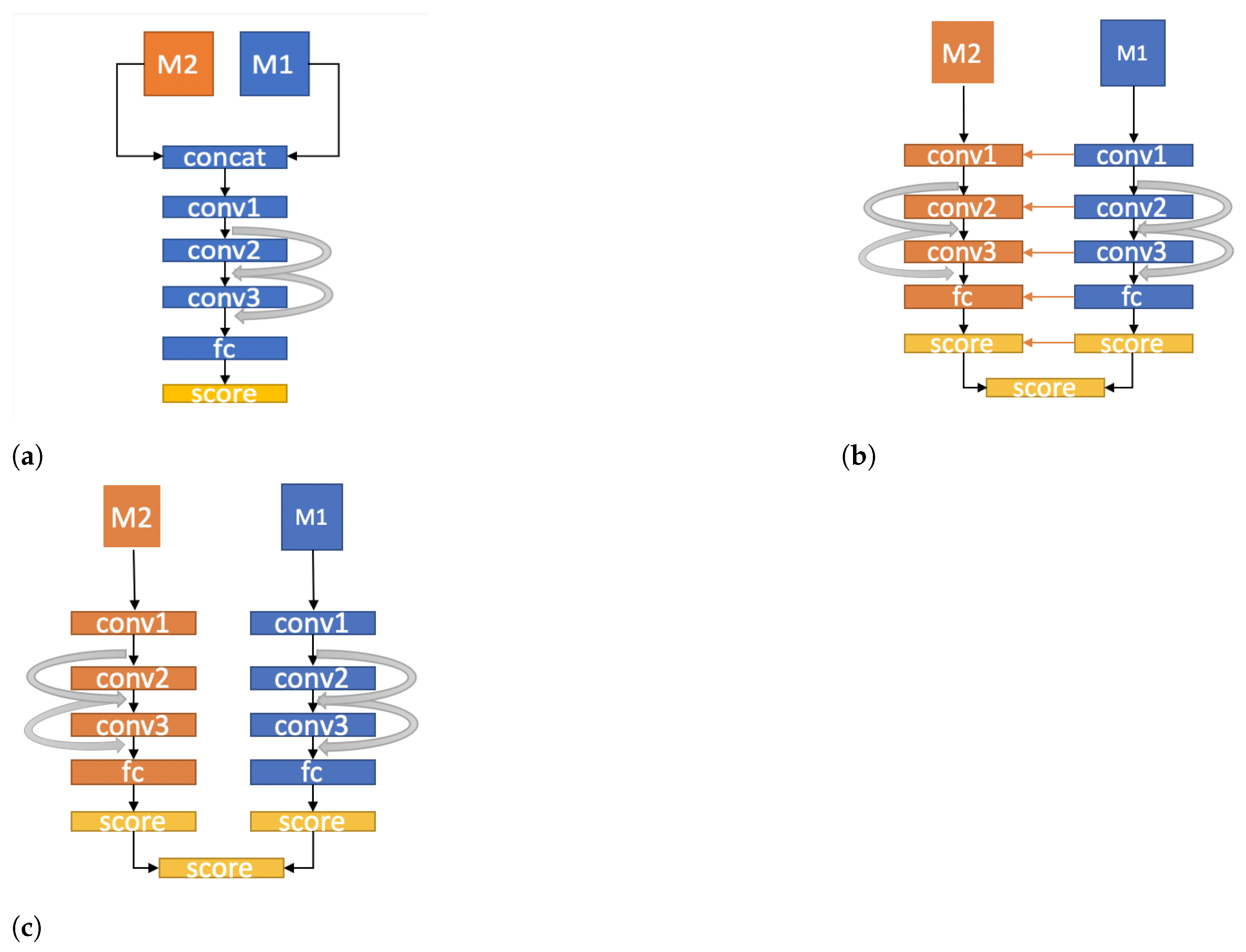
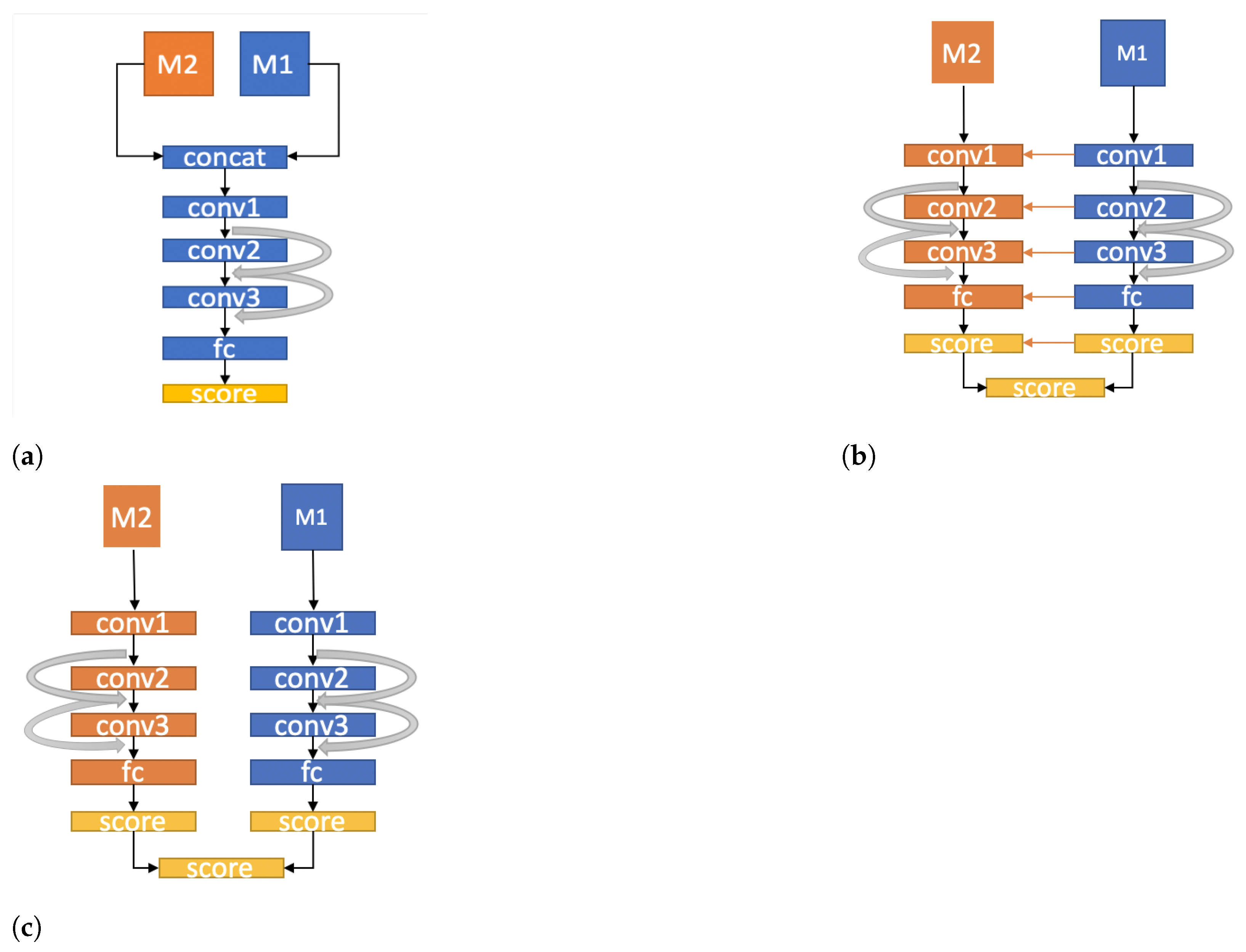
5. Data Fusion Techniques
5.1. Early Fusion
5.2. Slow Fusion
5.3. Late Fusion
5.4. Multi-Resolution
6. Applications of State-of-the-Art RGB-D Methods
6.1. Content-Based Video Summarization
6.2. Education and Learning
6.3. Healthcare Systems
6.4. Entertainment Systems
6.5. Safety and Surveillance Systems
6.6. Sports
7. Challenges and Future Research Directions
7.1. Challenges in RGB-D Data Fusion
- RGB-D datasets with different resolutions possesses an inherent challenge in data fusion because each modality has a very different temporal and spatial resolution.
- Practically, individual datasets contain incompatible numbers of data samples, which leads to data size incompatibility. Alignment of modalities to a standard coordinate system for maximizing mutual information sharing is an acute challenge in data fusion.
- Inherently, the information conveyed through each modality has different physical properties, which can be vital for better action learning. Identification of key characteristics from each modality that is contributing towards the overall recognition is an interesting problem.
- Negligible errors produced by RGB-D sensors are often abstracted as noise, which is unavoidable. Balancing noise with other modalities also causes problems in data fusion.
- Most data fusion techniques ignore the noise, but ignoring the noise from datasets collected through different sensors may lead to bias.
- Distinct data modalities confront contradictions, and data inconsistencies may occur. An open challenge is to infer a proper compromise; however, identifying these conflicts, contradictions, and inconsistencies is a fundamental challenge.
- RGB-D sensors may produce spurious data due to environmental or sensor failure issues, which may lead to false inferences based on biased estimations. Therefore, a challenge may arise in predicting and modeling spurious events.
- Other challenging factors include noise, spatial distortions, varying contrast, and arbitrary subject locations in image sequences.
7.2. Future Research Directions
7.2.1. Combination of Classical Machine Learning and Deep Learning-Based Methods
7.2.2. Assessment in Practical Scenarios
7.2.3. Self-Learning
7.2.4. Interpretation of Online Human Actions
7.2.5. Multimodal Fusion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AME | Accumulation of Motion Energy |
| AVA | Atomic Visual Actions |
| CSNN | Channel Separated Convolutional Networks |
| CNN | Convolutional Neural Network |
| DH-TCN | Dilated Hierarchical Temporal Convolutional Network |
| FAP | Frame Actionness Producer |
| GPU | Graphics Processing Unit |
| GVFE | Graph Vertex Feature Encoder |
| HoD | Histograms of Oriented Displacements |
| iDT | improved Dense Trajectories |
| IR | Infrared |
| HoG | Histogram of Gradients |
| LGD | Local and Global Diffusion |
| LRCN | Long-term Recurrent Convolutional Network |
| LSTM | Long-Short Term Memory |
| mAP | mean Average Precision |
| MGG | Multi-Granularity Generator |
| OHA-GCN | Object-Related Human Action recognition through Graph Convolution Networks |
| RGB | Red Green Blue |
| RGB-D | Red Green Blue-Depth |
| RNN | Recurrent Neural Network |
| SPP | Segment Proposal Producer |
| ST-GCN | Spatio-Temporal Graph Convolutional Networks |
| SVM | Scalar Vector Machines |
| TSM | Temporal Shift Module |
| VATN | Video Action Transformer Network |
References
- Yang, L.; Zhang, L.; Dong, H.; Alelaiwi, A.; Saddik, A.E. Evaluating and Improving the Depth Accuracy of Kinect for Windows v2. IEEE Sens. 2015, 15, 4275–4285. [Google Scholar] [CrossRef]
- Carfagni, M.; Furferi, R.; Governi, L.; Santarelli, C.; Servi, M.; Uccheddu, F.; Volpe, Y. Metrological and Critical Characterization of the Intel D415 Stereo Depth Camera. Sensors 2019, 19, 489. [Google Scholar] [CrossRef] [Green Version]
- Yeung, L.F.; Yang, Z.; Cheng, K.C.C.; Du, D.; Tong, R.K.Y. Effects of camera viewing angles on tracking kinematic gait patterns using Azure Kinect, Kinect v2 and Orbbec Astra Pro v2. Gait Posture 2021, 87, 19–26. [Google Scholar] [CrossRef]
- Herath, S.; Harandi, M.; Porikli, F. Going Deeper into Action Recognition: A Survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, J.; Cai, Q. Human Motion Analysis: A Review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Guo, G.; Lai, A. A Survey on Still-Image-based Human Action Recognition. Pattern Recognit. 2014, 47, 3343–3361. [Google Scholar] [CrossRef]
- Poppe, R. A Survey on Vision-based Human Action Recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Kläser, A.; Schmid, C.; Cheng-Lin, L. Action Recognition by Dense Trajectories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–20 June 2011; pp. 3169–3176. [Google Scholar]
- Zhu, G.; Zhang, L.; Mei, L.; Shao, J.; Song, J.; Shen, P. Large-scale Isolated Gesture Recognition using Pyramidal 3D Convolutional Networks. In Proceedings of the 23rd International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 19–24. [Google Scholar]
- Asadi-Aghbolaghi, M.; Clapés, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. A Survey on Deep Learning Based Approaches for Action and Gesture Recognition in Image Sequences. In Proceedings of the International Conference on Automatic Face Gesture Recognition, Washington, WA, USA, 30 May–3 June 2017; pp. 476–483. [Google Scholar]
- Prince, S. Computer Vision: Models, Learning, and Inference, 1st ed.; Cambridge University Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Szeliski, R. Computer Vision: Algorithms and Applications, 1st ed.; Springer: London, UK, 2010. [Google Scholar]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based Human Motion Recognition with Deep Learning: A Survey. Comput. Vis. Image Underst. 2018, 171, 118–139. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, J.; Xia, L. Human Activity Recognition from 3D Data: A Review. Pattern Recognit. Lett. 2014, 48, 70–80. [Google Scholar] [CrossRef]
- Chen, L.; Wei, H.; Ferryman, J. A Survey of Human Motion Analysis using Depth Imagery. Pattern Recognit. Lett. 2013, 34, 1995–2006. [Google Scholar] [CrossRef]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time Representation of People based on 3D Skeletal Data: A Review. J. Vis. Commun. Image Represent. 2017, 158, 85–105. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Li, W.; Ogunbona, P.O.; Wang, P.; Tang, C. RGB-D-based Action Recognition Datasets: A Survey. Pattern Recognit. 2016, 60, 86–105. [Google Scholar] [CrossRef] [Green Version]
- Ye, M.; Zhang, Q.; Wang, L.; Zhu, J.; Yang, R.; Gall, J. A Survey on Human Motion Analysis from Depth Data. In Time-of-Flight and Depth Imaging. Sensors, Algorithms, and Applications, Lecture Notes in Computer Science; Springer: Berlin, Germany, 2013; Volume 8200, pp. 149–187. [Google Scholar]
- Zhu, F.; Shao, L.; Xie, J.; Fang, Y. From Handcrafted to Learned Representations for Human Action Recognition: A Survey. Image Vis. Comput. 2016, 55, 42–52. [Google Scholar] [CrossRef]
- Zhang, H.B.; Zhang, Y.X.; Zhong, B.; Lei, Q.; Yang, L.; Du, J.X.; Chen, D.S. A Comprehensive Survey of Vision-Based Human Action Recognition Methods. Sensors 2019, 19, 1005. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A Survey of Depth and Inertial Sensor Fusion for Human Action Recognition. Multimed. Tools Appl. 2017, 76, 4405–4425. [Google Scholar] [CrossRef]
- Zhang, Z.; Ma, X.; Song, R.; Rong, X.; Tian, X.; Tian, G.; Li, Y. Deep Learning-based Human Action Recognition: A Survey. In Proceedings of the Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 3780–3785. [Google Scholar]
- Minh Dang, L.; Min, K.; Wang, H.; Jalil Piran, M.; Hee Lee, C.; Moon, H. Sensor-based and Vision-based Human Activity Recognition: A Comprehensive Survey. Pattern Recognit. 2020, 108, 107561. [Google Scholar] [CrossRef]
- Sun, Z.; Liu, J.; Ke, Q.; Rahmani, H.; Bennamoun, M.; Wang, G. Human Action Recognition from Various Data Modalities: A Review. arXiv 2020, arXiv:2012.11866. [Google Scholar]
- Liu, B.; Cai, H.; Ju, Z.; Liu, H. RGB-D sensing based human action and interaction analysis: A survey. Pattern Recognit. 2019, 94, 1–12. [Google Scholar] [CrossRef]
- Singh, R.; Sonawane, A.; Srivastava, R. Recent evolution of modern datasets for human activity recognition: A deep survey. Multimed. Syst. 2019, 26, 1–24. [Google Scholar] [CrossRef]
- Presti, L.L.; La Cascia, M. 3D skeleton-based human action classification: A survey. Pattern Recognit. 2016, 53, 130–147. [Google Scholar] [CrossRef]
- Sedmidubsky, J.; Elias, P.; Budikova, P.; Zezula, P. Content-based Management of Human Motion Data: Survey and Challenges. IEEE Access 2021, 9, 64241–64255. [Google Scholar] [CrossRef]
- Rosin, P.L.; Lai, Y.K.; Shao, L.; Liu, Y. RGB-D Image Analysis and Processing; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.Y.; Kot Chichung, A. NTU RGB + D 120: A Large-Scale Benchmark for 3D Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2019, 2684–2701. [Google Scholar] [CrossRef] [Green Version]
- Tölgyessy, M.; Dekan, M.; Chovanec, L.; Hubinskỳ, P. Evaluation of the Azure Kinect and Its Comparison to Kinect V1 and Kinect V2. Sensors 2021, 21, 413. [Google Scholar] [CrossRef]
- Microsoft. Buy the Azure Kinect Developer kit–Microsoft. 2019. Available online: https://www.microsoft.com/en-us/d/azure-kinect-dk/8pp5vxmd9nhq (accessed on 14 June 2021).
- EB Games. Kinect for Xbox One (Preowned)-Xbox One-EB Games Australia. 2015. Available online: https://www.ebgames.com.au/product/xbox-one/202155-kinect-for-xbox-one-preowned (accessed on 14 June 2021).
- EB Games. Kinect for Xbox 360 without AC Adapter (Preowned)-Xbox 360-EB Games Australia. 2013. Available online: https://www.ebgames.com.au/product/xbox360/151784-kinect-for-xbox-360-without-ac-adapter-preowned (accessed on 14 June 2021).
- Intel Corporation. LiDAR Camera L515 – Intel® RealSense™ Depth and Tracking Cameras. 2019. Available online: https://www.intelrealsense.com/lidar-camera-l515/ (accessed on 14 June 2021).
- Orbbec 3D. Astra Series-Orbbec. 2021. Available online: https://orbbec3d.com/product-astra-pro (accessed on 14 June 2021).
- Lee, I.J. Kinect-for-windows with augmented reality in an interactive roleplay system for children with an autism spectrum disorder. Interact. Learn. Environ. 2020, 1–17. [Google Scholar] [CrossRef]
- Yukselturk, E.; Altıok, S.; Başer, Z. Using game-based learning with kinect technology in foreign language education course. J. Educ. Technol. Soc. 2018, 21, 159–173. [Google Scholar]
- Pal, M.; Saha, S.; Konar, A. Distance matching based gesture recognition for healthcare using Microsoft’s Kinect sensor. In Proceedings of the International Conference on Microelectronics, Computing and Communications (MicroCom), Durga, India, 23–25 January 2016; pp. 1–6. [Google Scholar]
- Ketoma, V.K.; Schäfer, P.; Meixner, G. Development and evaluation of a virtual reality grocery shopping application using a multi-Kinect walking-in-place approach. In Proceedings of the International Conference on Intelligent Human Systems Integration, Dubai, UAE, 7–9 January 2018; pp. 368–374. [Google Scholar]
- Zhang, Y.; Chen, C.; Wu, Q.; Lu, Q.; Zhang, S.; Zhang, G.; Yang, Y. A Kinect-based approach for 3D pavement surface reconstruction and cracking recognition. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3935–3946. [Google Scholar] [CrossRef]
- Keselman, L.; Woodfill, J.I.; Grunnet-Jepsen, A.; Bhowmik, A. Intel(R) RealSense(TM) Stereoscopic Depth Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1267–1276. [Google Scholar]
- Drouin, M.A.; Seoud, L. Consumer-Grade RGB-D Cameras. In 3D Imaging, Analysis and Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 215–264. [Google Scholar]
- Grunnet-Jepsen, A.; Sweetser, J.N.; Woodfill, J. Best Known Methods for Tuning Intel® RealSense™ Depth Cameras D415. 2018. Available online: https://www.intel.com.au/content/www/au/en/support/articles/000027833/emerging-technologies/intel-realsense-technology.html (accessed on 28 January 2021).
- Zabatani, A.; Surazhsky, V.; Sperling, E.; Moshe, S.B.; Menashe, O.; Silver, D.H.; Karni, T.; Bronstein, A.M.; Bronstein, M.M.; Kimmel, R. Intel® RealSense™ SR300 Coded light depth Camera. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2019, 2333–2345. [Google Scholar] [CrossRef] [PubMed]
- Coroiu, A.D.C.A.; Coroiu, A. Interchangeability of Kinect and Orbbec Sensors for Gesture Recognition. In Proceedings of the 2018 IEEE 14th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 6–8 September 2018; pp. 309–315. [Google Scholar] [CrossRef]
- Villena-Martínez, V.; Fuster-Guilló, A.; Azorín-López, J.; Saval-Calvo, M.; Mora-Pascual, J.; Garcia-Rodriguez, J.; Garcia-Garcia, A. A Quantitative Comparison of Calibration Methods for RGB-D Sensors Using Different Technologies. Sensors 2017, 17, 243. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oreifej, O.; Liu, Z. HON4D: Histogram of Oriented 4D Normals for Activity Recognition from Depth Sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Chen, C.; Liu, K.; Kehtarnavaz, N. Real-time Human Action Recognition Based on Depth Motion Maps. J. Real Time Image Process. 2016, 12, 155–163. [Google Scholar] [CrossRef]
- Yang, X.; Tian, Y. Effective 3D Action Recognition using EigenJoints. J. Vis. Commun. Image Represent. 2014, 25, 2–11. [Google Scholar] [CrossRef]
- Li, M.; Leung, H.; Shum, H.P. Human Action Recognition via Skeletal and Depth based Feature Fusion. In Proceedings of the 9th International Conference on Motion in Games, Burlingame, CA, USA, 10–12 October 2016; pp. 123–132. [Google Scholar]
- Yang, X.; Tian, Y. Super Normal Vector for Activity Recognition using Depth Sequences. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OR, USA, 23–28 June 2014; pp. 804–811. [Google Scholar]
- Rahmani, H.; Mahmood, A.; Huynh, D.Q.; Mian, A. Real Time Action Recognition using Histograms of Depth Gradients and Random Decision Forests. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, (WCACV), SteamBoats Springs, CO, USA,, 24–26 March 2014; pp. 626–633. [Google Scholar]
- Yang, X.; Zhang, C.; Tian, Y. Recognizing Actions using Depth Motion Maps-based Histograms of Oriented Gradients. In Proceedings of the 20th ACM International Conference on Multimedia, Nara, Japan, 29 October–2 November 2012; pp. 1057–1060. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. Action Recognition from Depth Sequences using Depth Motion Maps-based Local Binary Patterns. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WCACV), Waikola, HI, USA, 5–9 January 2015; pp. 1092–1099. [Google Scholar]
- Chen, W.; Guo, G. TriViews: A General Framework to use 3D Depth Data Effectively for Action Recognition. J. Vis. Commun. Image Represent. 2015, 26, 182–191. [Google Scholar] [CrossRef]
- Miao, J.; Jia, X.; Mathew, R.; Xu, X.; Taubman, D.; Qing, C. Efficient Action Recognition from Compressed Depth Maps. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 16–20. [Google Scholar]
- Xia, L.; Chen, C.; Aggarwal, J. View Invariant Human Action Recognition using Histograms of 3D Joints. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Gowayyed, M.A.; Torki, M.; Hussein, M.E.; El-Saban, M. Histogram of Oriented Displacements (HOD): Describing Trajectories of Human Joints for Action Recognition. In Proceedings of the 23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Pazhoumand-Dar, H.; Lam, C.P.; Masek, M. Joint Movement Similarities for Robust 3D Action Recognition using Skeletal Data. J. Vis. Commun. Image Represent. 2015, 30, 10–21. [Google Scholar] [CrossRef]
- Papadopoulos, G.T.; Axenopoulos, A.; Daras, P. Real-time Skeleton-tracking-based Human Action Recognition using Kinect Data. In Proceedings of the International Conference on Multimedia Modeling, Dublin, Ireland, 6–10 January 2014; pp. 473–483. [Google Scholar]
- Chaaraoui, A.; Padilla-Lopez, J.; Flórez-Revuelta, F. Fusion of Skeletal and Silhouette-based Features for Human Action Recognition with RGB-D Devices. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 91–97. [Google Scholar]
- Althloothi, S.; Mahoor, M.H.; Zhang, X.; Voyles, R.M. Human Activity Recognition using Multi-features and Multiple Kernel Learning. Pattern Recognit. 2014, 47, 1800–1812. [Google Scholar] [CrossRef]
- Liu, L.; Shao, L. Learning Discriminative Representations from RGB-D Video Data. In Proceedings of the International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1493–1500. [Google Scholar]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust Human Activity Recognition from Depth Video using Spatiotemporal Multi-fused Features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Ni, B.; Pei, Y.; Moulin, P.; Yan, S. Multilevel Depth and Image Fusion for Human Activity Detection. IEEE Trans. Syst. Man Cybern. 2013, 43, 1383–1394. [Google Scholar]
- Kong, Y.; Fu, Y. Discriminative relational representation learning for RGB-D action recognition. IEEE Trans. Image Process. 2016, 25, 2856–2865. [Google Scholar] [CrossRef]
- Yu, M.; Liu, L.; Shao, L. Structure-preserving binary representations for RGB-D action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1651–1664. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Miikkulainen, R.; Liang, J.; Meyerson, E.; Rawal, A.; Fink, D.; Francon, O.; Raju, B.; Shahrzad, H.; Navruzyan, A.; Duffy, N.; et al. Chapter 15-Evolving Deep Neural Networks. In Artificial Intelligence in the Age of Neural Networks and Brain Computing; Academic Press: Cambridge, MA, USA, 2019; pp. 293–312. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Li, Y.; Shen, L.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep LSTM networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:cs.LG/1609.02907. [Google Scholar]
- Caetano, C.; Sena de Souza, J.; Santos, J.; Schwartz, W. SkeleMotion: A New Representation of Skeleton Joint Sequences Based on Motion Information for 3D Action Recognition. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar]
- Li, W.; Zhang, Z.; Liu, Z. Action recognition based on a bag of 3d points. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 13–18 June 2010; pp. 9–14. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 720–736. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:cs.CV/1212.0402. [Google Scholar]
- Das, S.; Dai, R.; Koperski, M.; Minciullo, L.; Garattoni, L.; Bremond, F.; Francesca, G. Toyota Smarthome: Real-World Activities of Daily Living. In Proceedings of the Internation Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Ni, B.; Wang, G.; Moulin, P. RGBD-HuDaAct: A color-depth video database for human daily activity recognition. In Proceedings of the Internation Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 1147–1153. [Google Scholar]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A Multimodal Dataset for Human Action Recognition Utilizing A Depth Camera and A Wearable Inertial Sensor. In Proceedings of the Int. Conf. on Image Processing, Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. In Proceedings of the European Conference Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 510–526. [Google Scholar]
- Korbar, B.; Tran, D.; Torresani, L. SCSampler: Sampling Salient Clips from Video for Efficient Action Recognition. In Proceedings of the International Conference on Compututer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6231–6241. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale Video Classification With Convolutional Neural Networks. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognit (CVPR), Columbus, OR, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Kim, S.; Yun, K.; Park, J.; Choi, J. Skeleton-Based Action Recognition of People Handling Objects. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WCACV), Waikoloa, HI, USA, 7–11 January 2019; pp. 61–70. [Google Scholar]
- Zhu, J.; Zou, W.; Xu, L.; Hu, Y.; Zhu, Z.; Chang, M.; Huang, J.; Huang, G.; Du, D. Action Machine: Rethinking Action Recognition in Trimmed Videos. arXiv 2018, arXiv:cs.CV/1812.05770. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A Large Video Database for Human Motion Recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB + D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Los Alamitos, CA, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view Action Modeling, Learning and Recognition. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Zhao, Y.; Liu, Z.; Yang, L.; Cheng, H. Combing RGB and Depth Map Features for human activity recognition. In Proceedings of the Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–4. [Google Scholar]
- Ye, J.; Li, K.; Qi, G.J.; Hua, K.A. Temporal order-preserving dynamic quantization for human action recognition from multimodal sensor streams. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 99–106. [Google Scholar]
- Shahroudy, A.; Ng, T.T.; Gong, Y.; Wang, G. Deep multimodal feature analysis for action recognition in RGB + D videos. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2017, 40, 1045–1058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ryoo, M.S.; Piergiovanni, A.; Tan, M.; Angelova, A. AssembleNet: Searching for Multi-Stream Neural Connectivity in Video Architectures. arXiv 2020, arXiv:cs.CV/1905.13209. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video Classification with Channel-separated Convolutional Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5552–5561. [Google Scholar]
- Wang, L.; Koniusz, P.; Huynh, D.Q. Hallucinating iDT Descriptors and i3D Optical Flow Features for Action Recognition with CNNs. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8698–8708. [Google Scholar]
- Kazakos, E.; Nagrani, A.; Zisserman, A.; Damen, D. EPIC-Fusion: Audio-Visual Temporal Binding for Egocentric Action Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Das, S.; Sharma, S.; Dai, R.; Brémond, F.; Thonnat, M. VPN: Learning Video-Pose Embedding for Activities of Daily Living. In ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 72–90. [Google Scholar]
- Islam, M.M.; Iqbal, T. HAMLET: A Hierarchical Multimodal Attention-based Human Activity Recognition Algorithm. arXiv 2020, arXiv:cs.RO/2008.01148. [Google Scholar]
- Davoodikakhki, M.; Yin, K. Hierarchical action classification with network pruning. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2020; pp. 291–305. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P. Deep Convolutional Neural Networks for Action Recognition Using Depth Map Sequences. arXiv 2015, arXiv:cs.CV/1501.04686. [Google Scholar]
- Wang, P.; Wang, S.; Gao, Z.; Hou, Y.; Li, W. Structured Images for RGB-D Action Recognition. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 1005–1014. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Spatio-Temporal Attention-Based LSTM Networks for 3D Action Recognition and Detection. IEEE Trans. Image Process. TIP 2018, 27, 3459–3471. [Google Scholar] [CrossRef]
- Ye, Y.; Tian, Y. Embedding Sequential Information into Spatiotemporal Features for Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1110–1118. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Lake Tahoe, CA, USA, 2012; pp. 1097–1105. [Google Scholar]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential Deep Learning for Human Action Recognition. In International Workshop on Human Behavior Understanding; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-Time Action Recognition With Deeply Transferred Motion Vector CNNs. IEEE Trans. Image Process. TIP 2018, 27, 2326–2339. [Google Scholar] [CrossRef] [PubMed]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Lan, Z.; Zhu, Y.; Hauptmann, A.G.; Newsam, S. Deep Local Video Feature for Action Recognition. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1219–1225. [Google Scholar]
- Zhou, B.; Andonian, A.; Torralba, A. Temporal Relational Reasoning in Videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11205, pp. 831–846. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? In A New Model and the Kinetics Dataset. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognit. (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Zhu, Y.; Lan, Z.; Newsam, S.; Hauptmann, A. Hidden Two-Stream Convolutional Networks for Action Recognition. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 363–378. [Google Scholar]
- Ng, J.Y.H.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond Short Snippets: Deep Networks for Video Classification. In Proceedings of the IIEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4694–4702. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Kot, A.C.; Wang, G. Skeleton-Based Action Recognition Using Spatio-Temporal LSTM Network with Trust Gates. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2018, 40, 3007–3021. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Donahue, J.; Hendricks, L.A.; Rohrbach, M.; Venugopalan, S.; Guadarrama, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2017, 39, 677–691. [Google Scholar] [CrossRef]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. YouTube-8M: A Large-Scale Video Classification Benchmark. arXiv 2016, arXiv:cs.CV/1609.08675. [Google Scholar]
- Caba Heilbron, F.; Victor Escorcia, B.G.; Niebles, J.C. ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Moon, J.; Jin, J.; Kwon, Y.; Kang, K.; Park, J.; Park, K. Extensible Hierarchical Method of Detecting Interactive Actions for Video Understanding. ETRI J. 2017, 39, 502–513. [Google Scholar] [CrossRef] [Green Version]
- Moon, J.; Kwon, Y.; Kang, K.; Park, J. ActionNet-VE Dataset: A Dataset for Describing Visual Events by Extending VIRAT Ground 2.0. In Proceedings of the 8th International Conference on Signal Processing, Image Processing and Pattern Recognition (SIP), Jeju, Korea, 25–28 November 2015; pp. 1–4. [Google Scholar]
- Liu, Y.; Ma, L.; Zhang, Y.; Liu, W.; Chang, S. Multi-Granularity Generator for Temporal Action Proposal. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3604–3613. [Google Scholar]
- Qiu, Z.; Yao, T.; Ngo, C.W.; Tian, X.; Mei, T. Learning Spatio-Temporal Representation With Local and Global Diffusion. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12056–12065. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Girdhar, R.; João Carreira, J.; Doersch, C.; Zisserman, A. Video Action Transformer Network. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 244–253. [Google Scholar]
- Hu, J.F.; Zheng, W.S.; Pan, J.; Lai, J.; Zhang, J. Deep Bilinear Learning for RGB-D Action Recognition. In Proceedings of the European Conference Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 346–362. [Google Scholar]
- Sudhakaran, S.; Escalera, S.; Lanz, O. Gate-Shift Networks for Video Action Recognition. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Los Alamitos, CA, USA, 26 June–1 July 2020; pp. 1099–1108. [Google Scholar]
- Liu, X.; Lee, J.; Jin, H. Learning Video Representations From Correspondence Proposals. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4273–4281. [Google Scholar]
- Materzynska, J.; Berger, G.; Bax, I.; Memisevic, R. The Jester Dataset: A Large-Scale Video Dataset of Human Gestures. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Martin, M.; Roitberg, A.; Haurilet, M.; Horne, M.; Reiß, S.; Voit, M.; Stiefelhagen, R. Drive & Act: A Multimodal Dataset for Fine-Grained Driver Behavior Recognition in Autonomous Vehicles. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2801–2810. [Google Scholar]
- Munro, J.; Damen, D. Multi-modal Domain Adaptation for Fine-grained Action Recognition. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Jiang, H.; Li, Y.; Song, S.; Liu, J. Rethinking Fusion Baselines for Multimodal Human Action Recognition. In Proceedings of the 19th Pacific-Rim Conference on Multimedia, Advances in Multimedia Information Processing, Hefei, China, 21–22 September 2018; pp. 178–187. [Google Scholar]
- Shereena, V.; David, J.M. Content based image retrieval: Classification using neural networks. Int. J. Multimed. Its Appl. 2014, 6, 31. [Google Scholar]
- Bhaumik, H.; Bhattacharyya, S.; Nath, M.D.; Chakraborty, S. Real-time storyboard generation in videos using a probability distribution based threshold. In Proceedings of the Fifth International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; pp. 425–431. [Google Scholar]
- Lim, J.H.; Teh, E.Y.; Geh, M.H.; Lim, C.H. Automated classroom monitoring with connected visioning system. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 386–393. [Google Scholar]
- Arifoglu, D.; Bouchachia, A. Activity recognition and abnormal behaviour detection with recurrent neural networks. Procedia Comput. Sci. 2017, 110, 86–93. [Google Scholar] [CrossRef]
- You, I.; Choo, K.K.R.; Ho, C.L. A smartphone-based wearable sensors for monitoring real-time physiological data. Comput. Electr. Eng. 2018, 65, 376–392. [Google Scholar]
- Laptev, I.; Marszalek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Wang, P.; Cao, Y.; Shen, C.; Liu, L.; Shen, H.T. Temporal pyramid pooling-based convolutional neural network for action recognition. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 2613–2622. [Google Scholar] [CrossRef]
- Kumar, K.; Kishore, P.; Kumar, D.A.; Kumar, E.K. Indian classical dance action identification using adaboost multiclass classifier on multifeature fusion. In Proceedings of the 2018 Conference on Signal Processing And Communication Engineering Systems (SPACES), Vijayawada, India, 4–5 January 2018; pp. 167–170. [Google Scholar]
- Castro, D.; Hickson, S.; Sangkloy, P.; Mittal, B.; Dai, S.; Hays, J.; Essa, I. Let’s Dance: Learning from Online Dance Videos. arXiv 2018, arXiv:1801.07388. [Google Scholar]
- Feng, Y.; Yuan, Y.; Lu, X. Learning deep event models for crowd anomaly detection. Neurocomputing 2017, 219, 548–556. [Google Scholar] [CrossRef]
- Li, T.; Liu, J.; Zhang, W.; Ni, Y.; Wang, W.; Li, Z. UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles. arXiv 2021, arXiv:2104.00946. [Google Scholar]
- Thomas, G.; Gade, R.; Moeslund, T.B.; Carr, P.; Hilton, A. Computer vision for sports: Current applications and research topics. Comput. Vis. Image Underst. 2017, 159, 3–18. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Haq, I.U.; Baik, S.W. Action recognition using optimized deep autoencoder and CNN for surveillance data streams of non-stationary environments. Future Gener. Comput. Syst. 2019, 96, 386–397. [Google Scholar] [CrossRef]
- Qi, M.; Wang, Y.; Qin, J.; Li, A.; Luo, J.; Van Gool, L. stagNet: An attentive semantic RNN for group activity and individual action recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 549–565. [Google Scholar] [CrossRef]
- Gao, F.; Wang, C.; Li, C. A Combined Object Detection Method With Application to Pedestrian Detection. IEEE Access 2020, 8, 194457–194465. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Definition |
|---|---|
| Gesture, Mime, Sign | Basic movement or positioning of the hand, arm, body, or head that communicates an idea, emotion, etc. |
| Action, Event | A type of motion performed by a single person during short time period and involves multiple body parts. |
| Activity | Composed of a sequence of actions. |
| Interaction | A type of motion performed by two actors; one actor is human while the other may be human or an object. |
| Unimodal, Single-mode | Having or involving one mode. |
| Multimodal, Multi-type, Multi-format | Different types of data acquired through sensors. |
| Fusion, Mixture, Combination | A process for combining different types of sensor data. |
| RGB-D | Per-pixel depth information aligned with corresponding image pixels. |
| Year | Ref. | Methods (Modality) | Action Datasets | MSR Daily Activity 3D [78] | UT-Kinect [59] | EPIC Kitchen-55 [79] | NW-UCLA [80] | Toyota-SH [81] | HuDaAct [82] | UTD-MHAD [83] | Charades [84] | NTU RGB-D 120 [31] | miniSports [85] | Sports-1M [86] | IRD [87,88] | HMDB-51 [89] | ICVL-4 [87,88] | NTU RGB-D 60 [90] | MSR-Action3D [91] |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2012 | [92] | 2D CNN (RGB-D) | 89 | ||||||||||||||||
| 2015 | [93] | DTQ-SVM (RGB-D) | 100 | 90 | |||||||||||||||
| 2017 | [94] | CNN (RGB-D) | 98 | 75 | |||||||||||||||
| 2018 | [88] | i3D CNN + 2D CNN (RGB-D) | 92 | 94 | |||||||||||||||
| 2019 | [95] | CNN (RGB + OF) | 56 | ||||||||||||||||
| 2019 | [85] | i3D CNN (RGB) | 74 | ||||||||||||||||
| 2019 | [96] | 3D CNN (RGB) | 75 | ||||||||||||||||
| 2019 | [87] | GCN (Skeleton) | 80 | 91 | |||||||||||||||
| 2019 | [97] | CNN (RGB) | 82 | ||||||||||||||||
| 2019 | [98] | TBN-Inception (RGB-Audio + OF) | 35 | ||||||||||||||||
| 2020 | [99] | 3D CNN + GCN (RGB-D) | 94 | 61 | 86 | ||||||||||||||
| 2020 | [100] | HAMLET (RGB-D) | 98 | 95 | |||||||||||||||
| 2020 | [101] | CNN (RGB-D) | 94 | 92 | 95 | 99 |
| Ref. | CA | ET | TL | Metric | Network/Classifier | Modality | Fusion | Novelty |
|---|---|---|---|---|---|---|---|---|
| [92] | N | N | N | Accuracy | SVM | RGB-D | M | Extracts interest points solely from RGB channels and combines RGB and depth map-based desciptors. |
| [93] | N | N | N | Accuracy | SVM | RGB-D | L | Modelling of temporal dynamics of human actions by temporal order preserving dynamic quantization method. |
| [94] | N | N | N | Accuracy | CNN + SVM | RGB-D | M | Deep hierarchical shared-specific defactorization of RGB-D features and a structured sparsity learning machine. |
| [96] | N | N | Y | Accuracy | 3D CNN | RGB | - | Separated spatio-temporal interactions. |
| [88] | Y | Y | Y | Accuracy | i3D CNN | RGB + Pose | L | Used person cropped frames as inputs. |
| [95] | N | Y | Y | mAP | CNN | RGB + OF | L | Reformulated neural architecture search for video representation. |
| [85] | N | - | Y | Accuracy | i3D CNN | IR + OF + RGB | M | Used salient clip sampling to improve efficiency. |
| [77] | Y | N | N | Accuracy | CNN | Skeleton | E | Employed graph vertex encoding along with few layers and parameters. |
| [87] | N | N | N | Accuracy | GCN | Skeleton | - | Used human-object related poses. |
| [97] | N | Y | N | Accuracy | CNN | iDT/FV/BoW | M | Combined classical handcrafted iDT features with CNN extracted features. |
| [98] | Y | N | Y | Accuracy | 3D-CNN + GCN | RGB-D + OF + Audio | M | Architecture for multimodal temporal binding. |
| [99] | Y | Y | Y | Accuracy | 3D-CNN + GCN | RGB-D | M | A spatial embedding with an attention network. |
| [100] | N | N | Y | Accuracy | CNN | RGB-D | M | Multimodal attention mechanism for disentangling and fusing the salient features. |
| [101] | N | N | Y | Accuracy | CNN | Skeleton | - | Inflated ResNet coupled with hierarchical classification and iterative pruning. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaikh, M.B.; Chai, D. RGB-D Data-Based Action Recognition: A Review. Sensors 2021, 21, 4246. https://doi.org/10.3390/s21124246
Shaikh MB, Chai D. RGB-D Data-Based Action Recognition: A Review. Sensors. 2021; 21(12):4246. https://doi.org/10.3390/s21124246
Chicago/Turabian StyleShaikh, Muhammad Bilal, and Douglas Chai. 2021. "RGB-D Data-Based Action Recognition: A Review" Sensors 21, no. 12: 4246. https://doi.org/10.3390/s21124246
APA StyleShaikh, M. B., & Chai, D. (2021). RGB-D Data-Based Action Recognition: A Review. Sensors, 21(12), 4246. https://doi.org/10.3390/s21124246