
Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network

 , , ,
, , ,
Abstract
1. Introduction
1.1. Background
1.2. Objective and Scope
2. Related Work
2.1. Fatigue Crack Detection from Motion
2.2. Fatigue Crack Detection from Still Images
2.2.1. Patch-Level Fatigue Crack Detection
2.2.2. Pixel-Level Fatigue Crack Detection
3. Methodology
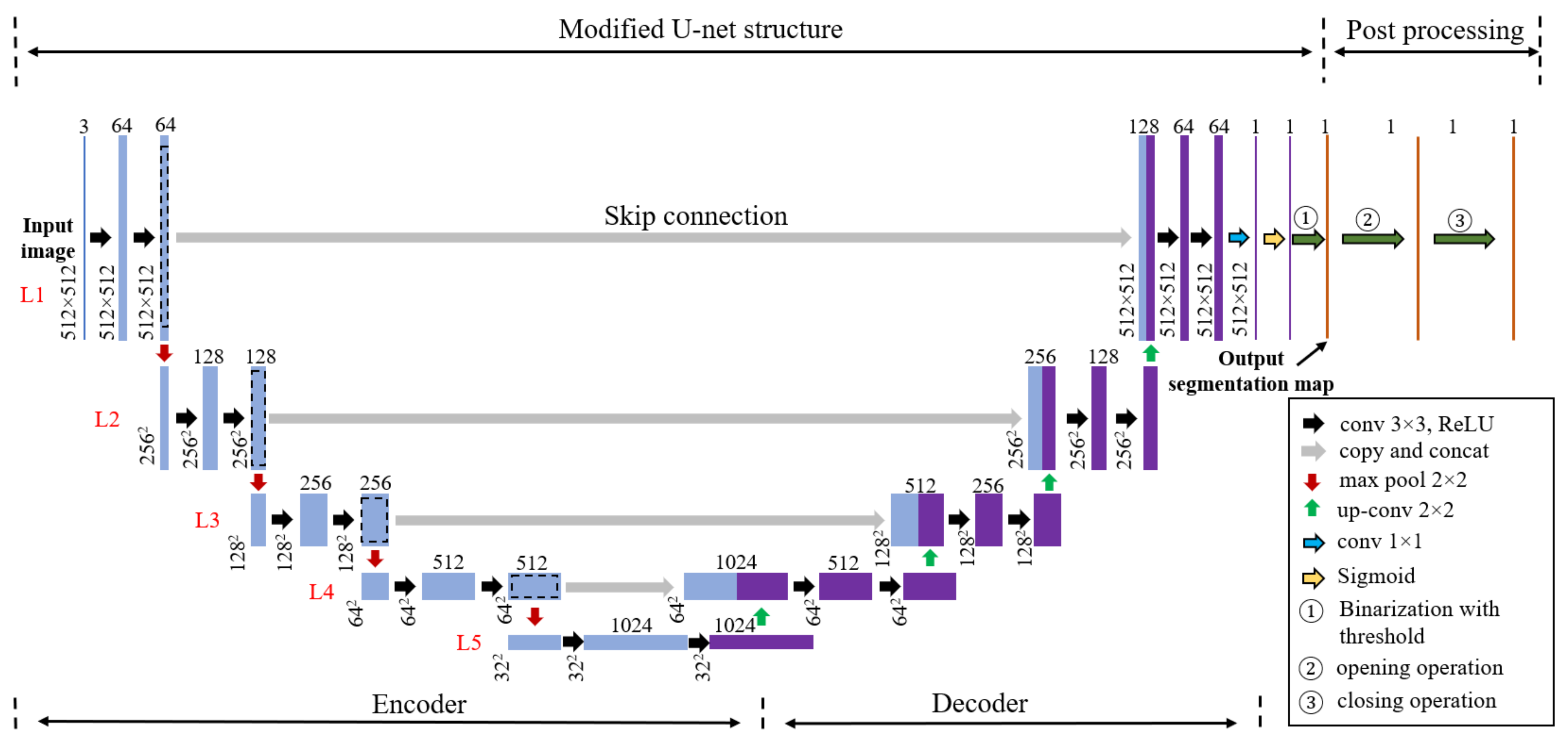
3.1. The Modified U-Net Structure
3.2. Post Processing
4. Dataset Generation
5. Training Details
5.1. Training Setup
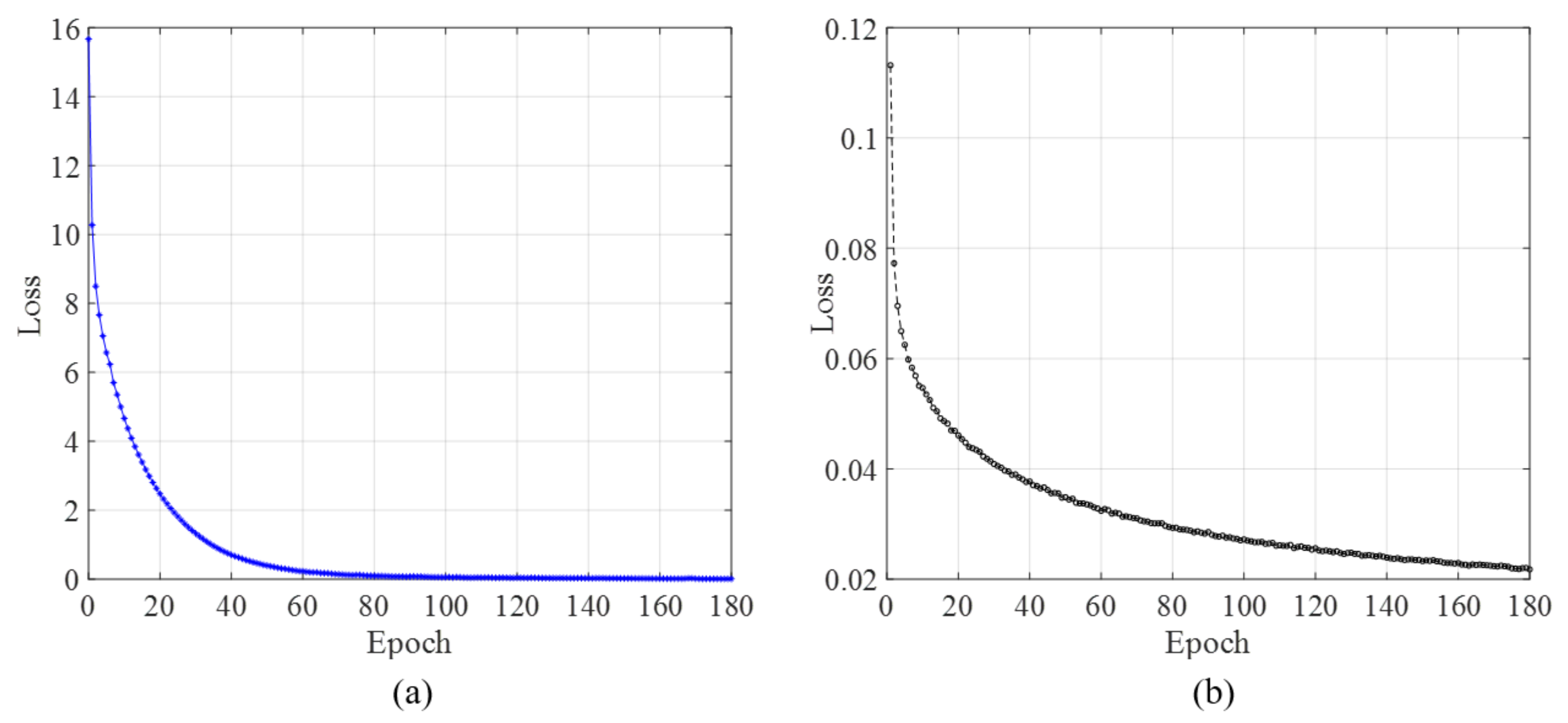
5.2. Loss Function and Parameters Selection
6. Results Analysis and Discussion
6.1. Evaluation Indicators
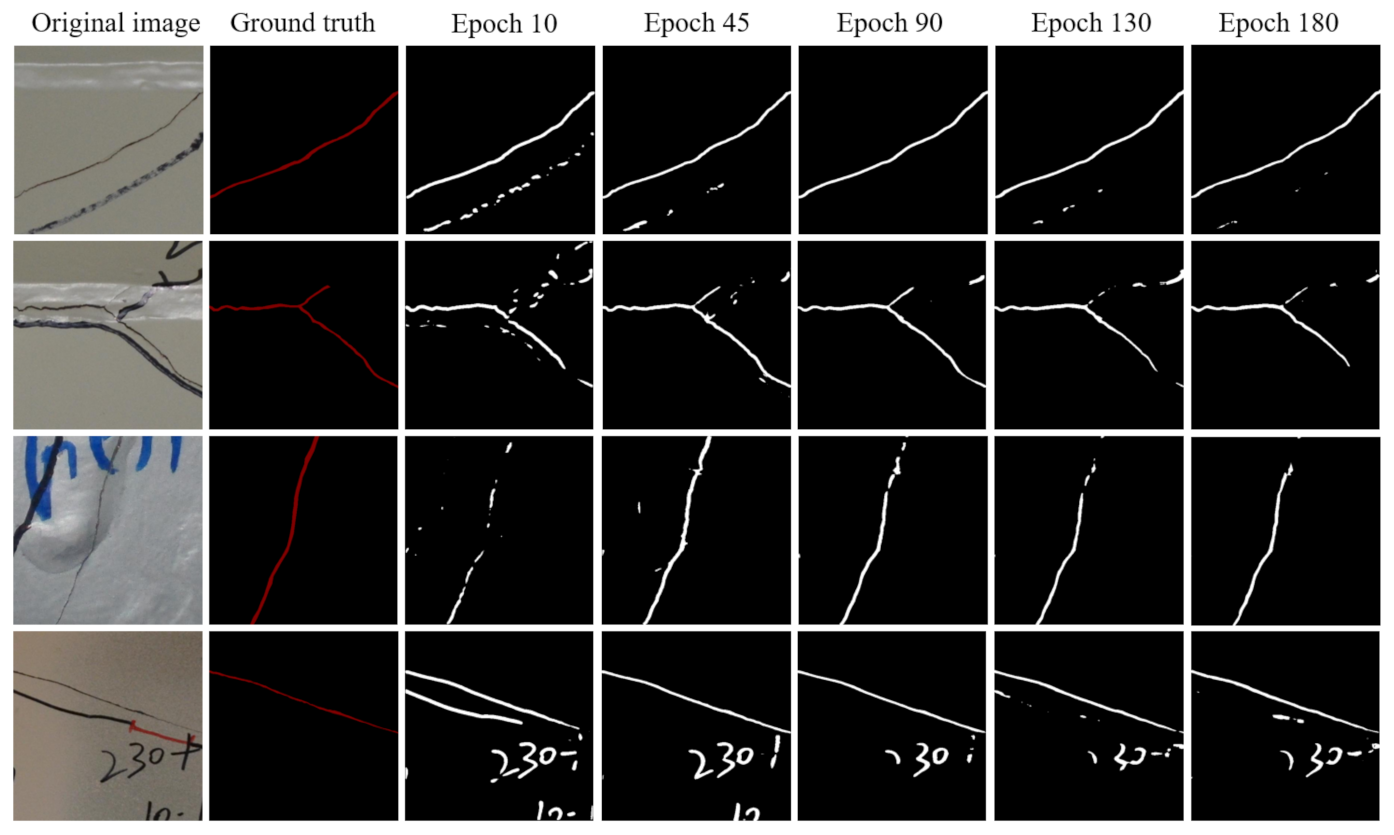
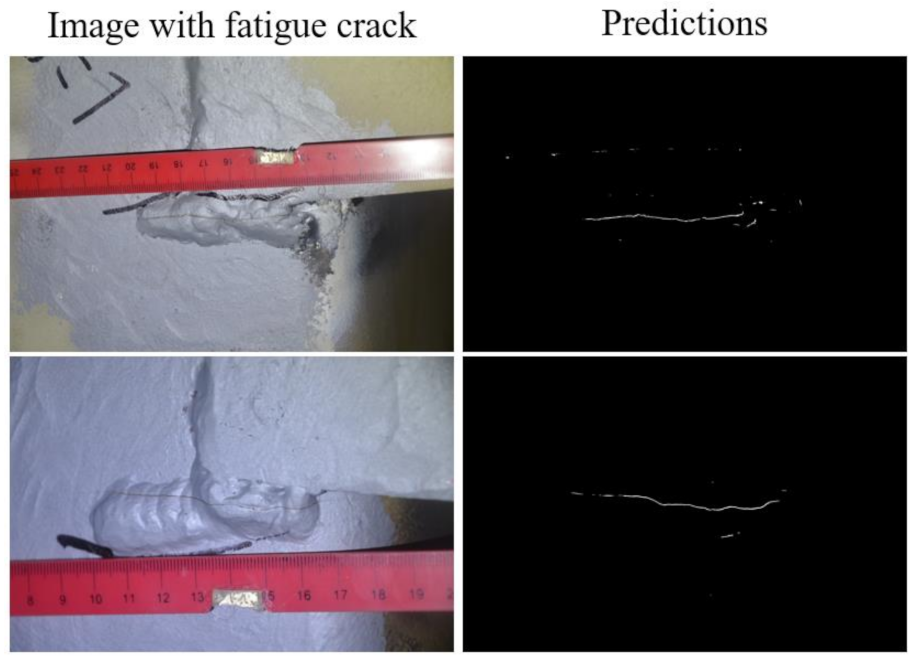
6.2. Result Analysis
6.3. Discussions of the Considerations and Recommendations for Engineering Practices
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barker, R.M.; Puckett, J.A. Design of Highway Bridges An LRFD Approach, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 9780471697589. [Google Scholar]
- Chen, Y.; Zhang, B.; Zhang, N.; Zheng, M. A condensation method for the dynamic analysis of vertical vehicle–track interaction considering vehicle flexibility. J. Vib. Acoust. 2015, 137, 041010. [Google Scholar] [CrossRef]
- Zhu, Z.; Luo, S.; Feng, Q.; Chen, Y.; Wang, F.; Jiang, L. A hybrid DIC–EFG method for strain field characterization and stress intensity factor evaluation of a fatigue crack. Meas. J. Int. Meas. Confed. 2020, 154, 107498. [Google Scholar] [CrossRef]
- Russo, F.M.; Mertz, D.R.; Frank, K.H.; Wilson, K.E. Design and Evaluation of Steel Bridges for Fatigue and Fracture—Reference Manual; FHWA-NHI-16-016; National Highway Institute: Arlington, VA, USA, 2016; Volume FHWA-NHI-16-016. [Google Scholar]
- Dong, C.Z.; Bas, S.; Catbas, F.N. A portable monitoring approach using cameras and computer vision for bridge load rating in smart cities. J. Civ. Struct. Health Monit. 2020, 10, 1001–1021. [Google Scholar] [CrossRef]
- Campbell, L.E.; Connor, R.J.; Whitehead, J.M.; Washer, G.A. Benchmark for evaluating performance in visual inspection of fatigue cracking in steel bridges. J. Bridg. Eng. 2020, 25, 1–10. [Google Scholar] [CrossRef]
- Megid, W.A.; Chainey, M.A.; Lebrun, P.; Robert Hay, D. Monitoring fatigue cracks on eyebars of steel bridges using acoustic emission: A case study. Eng. Fract. Mech. 2019, 211, 198–208. [Google Scholar] [CrossRef]
- Yan, J.; Downey, A.; Cancelli, A.; Laflamme, S.; Chen, A.; Li, J.; Ubertini, F. Concrete crack detection and monitoring using a capacitive dense sensor array. Sensors 2019, 19, 1843. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Pan, H.; Wang, X.; Lin, Z. Machine learning-enriched lamb wave approaches for automated damage detection. Sensors 2020, 20, 1790. [Google Scholar] [CrossRef]
- Xu, Y.; Bao, Y.; Chen, J.; Zuo, W.; Li, H. Surface fatigue crack identification in steel box girder of bridges by a deep fusion convolutional neural network based on consumer-grade camera images. Struct. Health Monit. 2019, 18, 653–674. [Google Scholar] [CrossRef]
- Spencer, B.F.; Hoskere, V.; Narazaki, Y. Advances in computer vision-based civil infrastructure inspection and monitoring. Engineering 2019, 5, 199–222. [Google Scholar] [CrossRef]
- Dong, C.Z.; Catbas, F.N. A review of computer vision–based structural health monitoring at local and global levels. Struct. Health Monit. 2020, 1475921720935585. [Google Scholar] [CrossRef]
- Kong, X.; Li, J. Vision-based fatigue crack detection of steel structures using video feature tracking. Comput. Civ. Infrastruct. Eng. 2018, 33, 783–799. [Google Scholar] [CrossRef]
- Bao, Y.; Chen, Z.; Wei, S.; Xu, Y.; Tang, Z.; Li, H. The State of the Art of Data Science and Engineering in Structural Health Monitoring. Engineering 2019, 5, 234–242. [Google Scholar] [CrossRef]
- Bao, Y.; Li, H. Machine learning paradigm for structural health monitoring. Struct. Health Monit. 2020. [Google Scholar] [CrossRef]
- Dong, C.Z.; Celik, O.; Catbas, F.N.; OBrien, E.; Taylor, S. A robust vision-based method for displacement measurement under adverse environmental factors using Spatio-Temporal context learning and Taylor approximation. Sensors 2019, 19, 3197. [Google Scholar] [CrossRef]
- Hoskere, V.; Park, J.; Yoon, H.; Spencer , B.F., Jr. Vision-based modal survey of civil infrastructure using unmanned aerial vehicles. J. Struct. Eng. 2019, 145, 040190621. [Google Scholar] [CrossRef]
- Dong, C.Z.; Bas, S.; Catbas, F.N. A completely non-contact recognition system for bridge unit influence line using portable cameras and computer vision. Smart Struct. Syst. 2019, 24, 617–630. [Google Scholar]
- Dong, C.Z.; Celik, O.; Catbas, F.N. Marker free monitoring of the grandstand structures and modal identification using computer vision methods. Struct. Health Monit. 2019, 18, 1491–1509. [Google Scholar] [CrossRef]
- Dong, C.Z.; Celik, O.; Catbas, F.N.; O’Brien, E.J.; Taylor, S. Structural displacement monitoring using deep learning-based full field optical flow methods. Struct. Infrastruct. Eng. 2020, 16, 51–71. [Google Scholar] [CrossRef]
- Dong, C.Z.; Bas, S.; Catbas, F.N. Investigation of vibration serviceability of a footbridge using computer vision-based methods. Eng. Struct. 2020, 224, 111224. [Google Scholar] [CrossRef]
- Xu, Y.; Li, S.; Zhang, D.; Jin, Y.; Zhang, F.; Li, N.; Li, H. Identification framework for cracks on a steel structure surface by a restricted Boltzmann machines algorithm based on consumer-grade camera images. Struct. Control Health Monit. 2018, 25, 1–20. [Google Scholar] [CrossRef]
- Dellenbaugh, L.; Kong, X.; Al-Salih, H.; Collins, W.; Bennett, C.; Li, J.; Sutley, E.J. Development of a distortion-induced fatigue crack characterization methodology using digital image correlation. J. Bridg. Eng. 2020, 25, 1–13. [Google Scholar] [CrossRef]
- Chen, Y.; Avitabile, P.; Dodson, J. Data Consistency Assessment Function (DCAF). Mech. Syst. Signal Process. 2020, 141, 106688. [Google Scholar] [CrossRef]
- Chen, F.C.; Jahanshahi, M.R.; Wu, R.T.; Joffe, C. A texture-based video processing methodology using Bayesian data fusion for autonomous crack detection on metallic surfaces. Comput. Civ. Infrastruct. Eng. 2017, 32, 271–287. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Z.; Wang, L.; Zhang, Z.; Chen, X.; Meng, L. Machine learning based real-time visible fatigue crack growth detection. Digit. Commun. Netw. 2021. [Google Scholar] [CrossRef]
- Wang, D.; Dong, Y.; Pan, Y.; Ma, R. Machine vision-based monitoring methodology for the fatigue cracks in U-Rib-to-deck weld seams. IEEE Access 2020, 8, 94204–94219. [Google Scholar] [CrossRef]
- Karaaslan, E.; Bagci, U.; Catbas, F.N. Artificial Intelligence Assisted Infrastructure Assessment using Mixed Reality Systems. J. Transp. Res. Board 2019. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput. Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput. Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Shi, J.; Dang, J.; Cui, M.; Zuo, R.; Shimizu, K.; Tsunoda, A.; Suzuki, Y. Improvement of damage segmentation based on pixel-level data balance using vgg-unet. Appl. Sci. 2021, 11, 518. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, J.; Zhu, B. A research on an improved Unet-based concrete crack detection algorithm. Struct. Health Monit. 2020. [Google Scholar] [CrossRef]
- Cui, X.; Wang, Q.; Dai, J.; Xue, Y.; Duan, Y. Intelligent crack detection based on attention mechanism in convolution neural network. Adv. Struct. Eng. 2021. [Google Scholar] [CrossRef]
- Aslam, Y.; Santhi, N.; Ramasamy, N.; Ramar, K. Localization and segmentation of metal cracks using deep learning. J. Ambient Intell. Humaniz. Comput. 2020, 12, 4205–4213. [Google Scholar] [CrossRef]
- Mei, Q.; Gül, M. A cost effective solution for pavement crack inspection using cameras and deep neural networks. Constr. Build. Mater. 2020, 256, 119397. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Choi, W.; Cha, Y.J. SDDNet: Real-Time Crack Segmentation. IEEE Trans. Ind. Electron. 2020, 67, 8016–8025. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (Computer Vision—ECCV 2018), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; pp. 833–851. [Google Scholar]
- IPC-SHM The 1st International Project Competition for Structural Health Monitoring (IPC-SHM 2020). 2020. Available online: http://www.schm.org.cn/#/IPC-SHM (accessed on 30 August 2020).
- Bao, Y.; Li, J.; Nagayama, T.; Xu, Y.; Spencer, B.F.; Li, H. The 1st International Project Competition for Structural Health Monitoring (IPC-SHM, 2020): A summary and benchmark problem. Struct. Health Monit. 2021. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Epoch | 10 | 45 | 90 | 130 | 180 | |
|---|---|---|---|---|---|---|
| U-net | mP | 0.3365 | 0.3498 | 0.4423 | 0.4577 | 0.4457 |
| mR | 0.3712 | 0.5635 | 0.5209 | 0.5145 | 0.5313 | |
| mF1 | 0.2958 | 0.3744 | 0.4295 | 0.4172 | 0.4279 | |
| mIOU | 0.5960 | 0.6248 | 0.6506 | 0.6430 | 0.6479 | |
| FCN | mP | 0.1995 | 0.4163 | 0.5199 | 0.5194 | 0.5693 |
| mR | 0.0032 | 0.0578 | 0.1226 | 0.1686 | 0.1942 | |
| mF1 | 0.0032 | 0.1016 | 0.1985 | 0.2546 | 0.2896 | |
| mIOU | 0.4939 | 0.5190 | 0.5475 | 0.5654 | 0.5774 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, C.; Li, L.; Yan, J.; Zhang, Z.; Pan, H.; Catbas, F.N. Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network. Sensors 2021, 21, 4135. https://doi.org/10.3390/s21124135
Dong C, Li L, Yan J, Zhang Z, Pan H, Catbas FN. Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network. Sensors. 2021; 21(12):4135. https://doi.org/10.3390/s21124135
Chicago/Turabian StyleDong, Chuanzhi, Liangding Li, Jin Yan, Zhiming Zhang, Hong Pan, and Fikret Necati Catbas. 2021. "Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network" Sensors 21, no. 12: 4135. https://doi.org/10.3390/s21124135
APA StyleDong, C., Li, L., Yan, J., Zhang, Z., Pan, H., & Catbas, F. N. (2021). Pixel-Level Fatigue Crack Segmentation in Large-Scale Images of Steel Structures Using an Encoder–Decoder Network. Sensors, 21(12), 4135. https://doi.org/10.3390/s21124135