
Steganographic Analysis of Blockchains †


Abstract
1. Introduction
- Free access with a degree of anonymity offered by, in particular, public blockchains. Besides, many blockchains are being in use today, thus increasing the available networks that steganography users could explore.
- Independence of third parties: in theory, no central authority can control the entirety of the blockchain due to its decentralized design.
- After the participants agreed to publish a block in the chain, no one can delete the data. Therefore, this feature can be attractive for political activists and protesters. They could communicate secretly with resistance against censorship of authoritarian regimes.
1.1. Summary of Previous Work
1.2. Contributions
- classification of the available techniques for data hiding in blockchains;
- a steganalysis approach which considers specific aspects of blockchains;
- a discussion about the limitations, performance constraints, and effectiveness of the proposed approach;
- a search for steganographic evidence in the Bitcoin and the Ethereum blockchains:
- -
- analyzing blocks and transactions sequentially, considering 625,941 bitcoin blocks (approximately GiB) and 6 million ethereum blocks (approximately 107 GiB of blocks and transactions data); and
- -
- analyzing up to 98 million bitcoin clusters.
1.3. Text Organization
2. Background
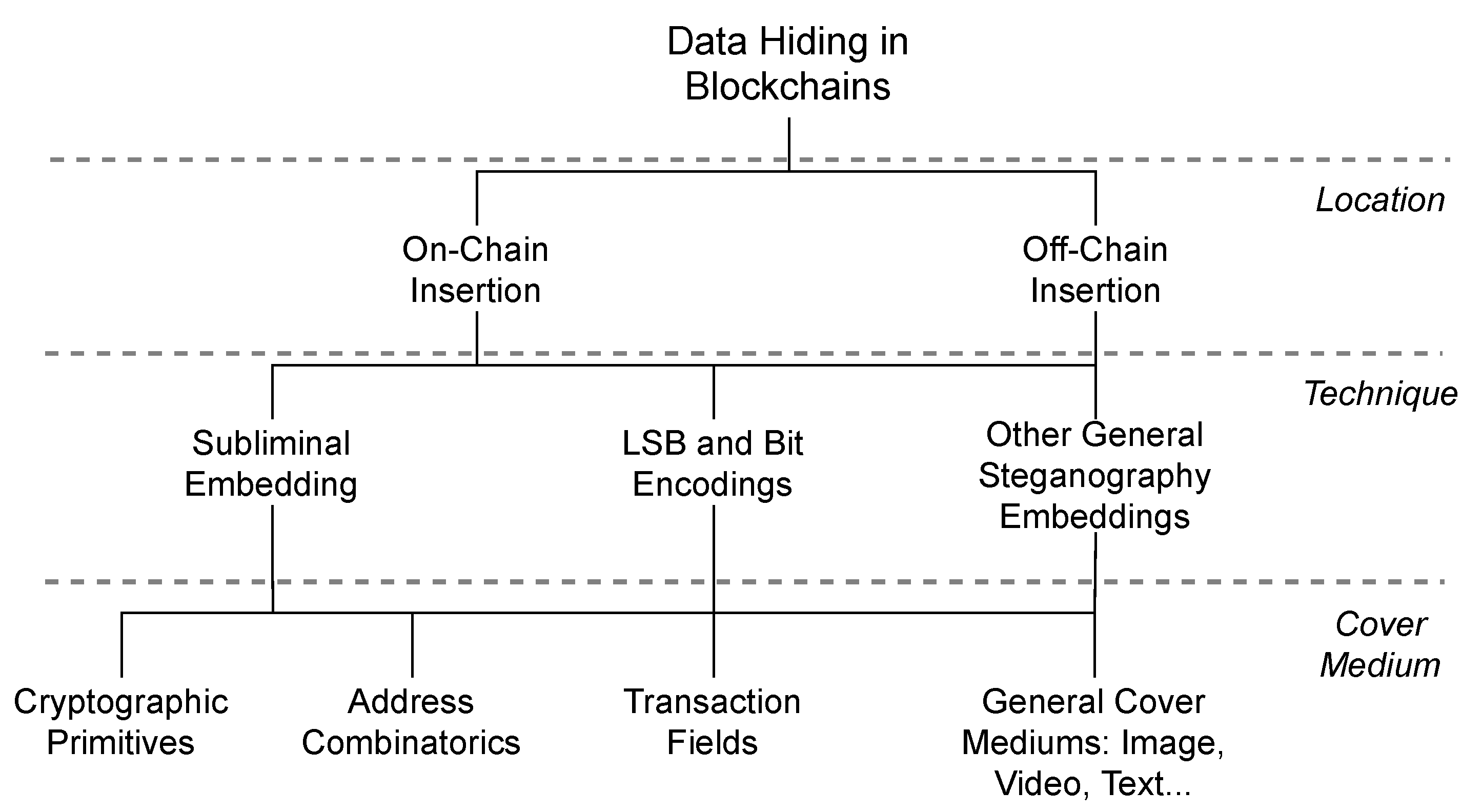
2.1. Data Insertion in Blockchains
2.1.1. On-Chain Data
- In Coinbase: the first transaction input of each block in Bitcoin. The Bitcoin miners control it [17]. Coinbase transactions allow the insertion of up to 100 bytes of arbitrary data.
- Using OP_RETURN: since 2014, OP_RETURN is an opcode of Bitcoin which invalidates the transaction. OP_RETURN is the Bitcoin standard of inserting arbitrary data (limited to 83 bytes) in the blockchain, but the outputs are unspendable.
- In Standard transactions: Bitcoin provides five “types” of transactions. They can be misused to insert data in the output scripts. The types are Pay-to-PubkeyHash (P2PKH), Pay-to-Script-Hash (P2SH), the obsolete Pay-to-Pubkey (P2PK), Multi-Signature, and, after 2014, OP_Return. We commonly find P2PK in coinbase transactions from the earlier blocks of the blockchain. The script hash can embed arbitrary data, and miners cannot verify it. An alternative nomenclature is the “Pay-to-Fake-Key”, “Pay-to-Fake-Key-Hash” and “Pay-to-Fake-Multisig” for this type of insertion [17]. Data insertion in standard transactions results in burning coins but allows KiB to KiB of arbitrary data.
- In Non-standard transactions: such transactions deviate from the standard rules of Bitcoin (e.g., minimum output value, maximum transaction size). It may not be the best way to store data because miners often ignore them, and, if ignored, they will not insert the data into the blockchain. On the other hand, if successful, this type can insert up to 100 KiB of arbitrary data. At the time of writing, this is the current size limit of transactions.
2.1.2. Off-Chain Data
2.2. Data Hiding in Blockchains
2.3. Related Work
- there already are publications of specific steganography approaches for blockchains, which one can use to embed and hide data (Table 2); and
- standard steganalysis techniques may not capture specific aspects of these data hiding approaches in blockchains.
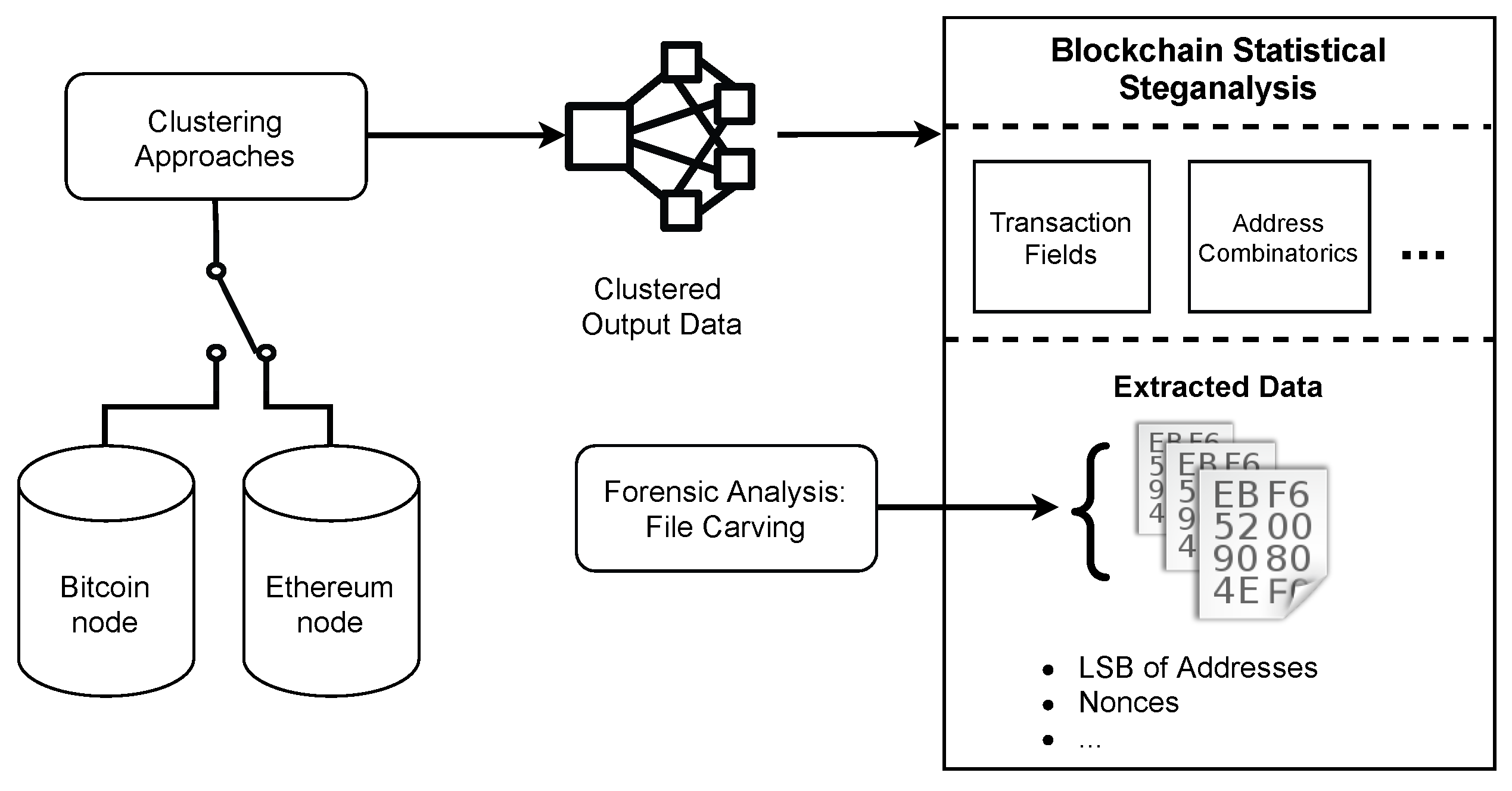
3. A Steganalysis Approach for Blockchains
3.1. Statistical Steganalysis
3.2. Clustering Approaches
- Multi-Input: Bitcoin clients’ behavior when a user selects a set of his possession addresses to perform a payment. Generally, we make this selection when the available currency of a user spreads among addresses. Then, he aggregates its inputs until it reaches the amount of currency that he wants to spend or transfer.
- Shadow: typically, Bitcoin clients generate a “shadow” (or change) address to send a payment/transfer change. For instance, an address that holds 2 BTC, if used by the user to send 1.5 BTC, the change (0.5 BTC) is sent to a newly generated address in possession of the user. Shadow addresses are further explored in two ways [56]:
- -
- Checking Address Format: if transactions that fit in the Shadow heuristics and have the same address format (e.g., P2PKH), it probably means that these transaction addresses belong to the same user.
- -
- Checking Change Value: a Bitcoin rule states that the sum of inputs of a transaction must be equal to or higher than the sum of outputs. The behavior of some Bitcoin clients is that the change value is the minimum value in the list of outputs of the transaction, as follows: if the sum of outputs minus the value of an output i is higher than the sum of inputs minus the minimum value in the inputs, then i is a change address.
- Deposit Address: regarding Ethereum, Friedhelm [57] argues that this is the most effective clustering technique. One can deposit to a deposit address. A financial exchange controls this address that forwards assets (or tokens) to another address, i.e., the recipient. The clustering technique builds on the assumption that the creation of deposit addresses is per customer (of the exchange). Under this assumption, multiple addresses related to the same deposit address belong to the same user or entity. Friedhelm argues that it is not easy to identify deposit addresses, and he demonstrates it using a specific token network built on ethereum (not for the cryptocurrency itself).
3.3. Forensic Analysis
- By time: useful for reconstructing the timeline related to the steganographic evidence. We divided Bitcoin blocks into 6-month wide chunks in previous work, each chunk being subject to steganalysis. This choice depends on the desired level of granularity of the analysis. The chunks may have variable sizes, depending on the blockchain under analysis.
- Clustering addresses: applying clustering approaches means that the steganographic evidence belongs to the cluster. Clustering addresses can relate the evidence with a user (of steganography, in this case) under the heuristics’ assumptions in the process. For example, they used clustering to discover and subsequent seizure of bitcoins of the Silk Road Case in 2013 [51]. Clustering is the focus of this approach, but they are not mutually exclusive options.
3.4. Methodology of this Study
| Algorithm 1 Steganographic_Analysis(Blocks B, Clusters C) |
|
- Sequential analysis (no clustering)
- Datasets:
- -
- Bitcoin (previous work): we obtained blockchain data from the official Bitcoin client. In numbers, approximately GiB in 625,941 blocks (synchronized at 14 April 2020).
- -
- Ethereum: obtained from Ethereum mainet. We analyzed 6 million blocks of data, which corresponds to of ethereum blocks (at 22 March 2021) and approximately 107 GiB (blocks and transactions).
- Scope: Statistical analysis of the LSB of addresses in transactions and Nonces of block headers. We considered only on-chain data. Scope includes the forensic analysis over the extracted data, aided by Scalpel.
- Clustering analysis:
- Cluster sets: Two bitcoin cluster sets, considering the first 3.3 GiB and 28 GiB, respectively, of blockchain data.
- Tools: Blocksci API [55] for parsing and clustering bitcoin data;and Scalpel tool [22] for file carving in the extracted data.
- Clustering methods (Section 3.2): we selected the multi-input heuristic of Blocksci.
- Scope: similar to the sequential analysis. The difference is that we clustered the addresses; therefore, only the LSB of addresses were investigated.
4. Results
4.1. Sequential Analysis
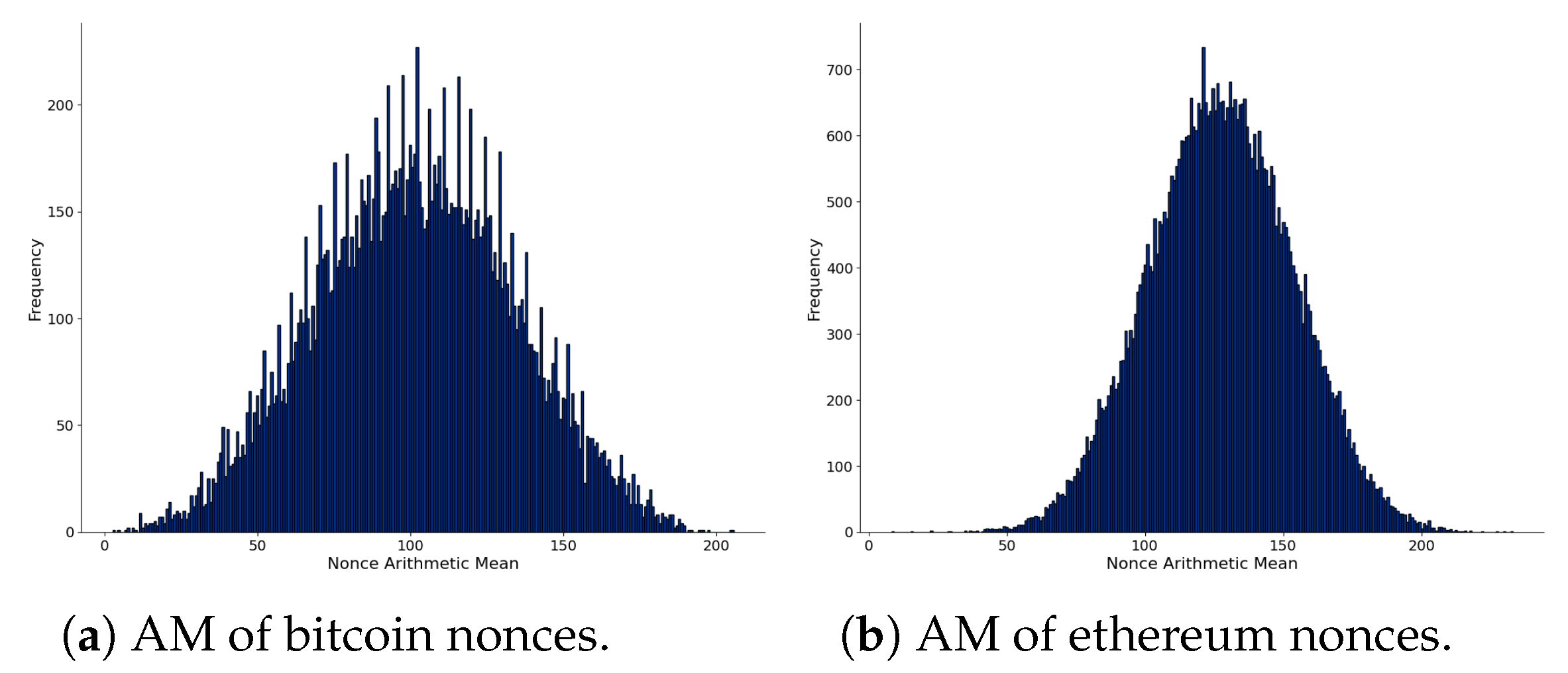
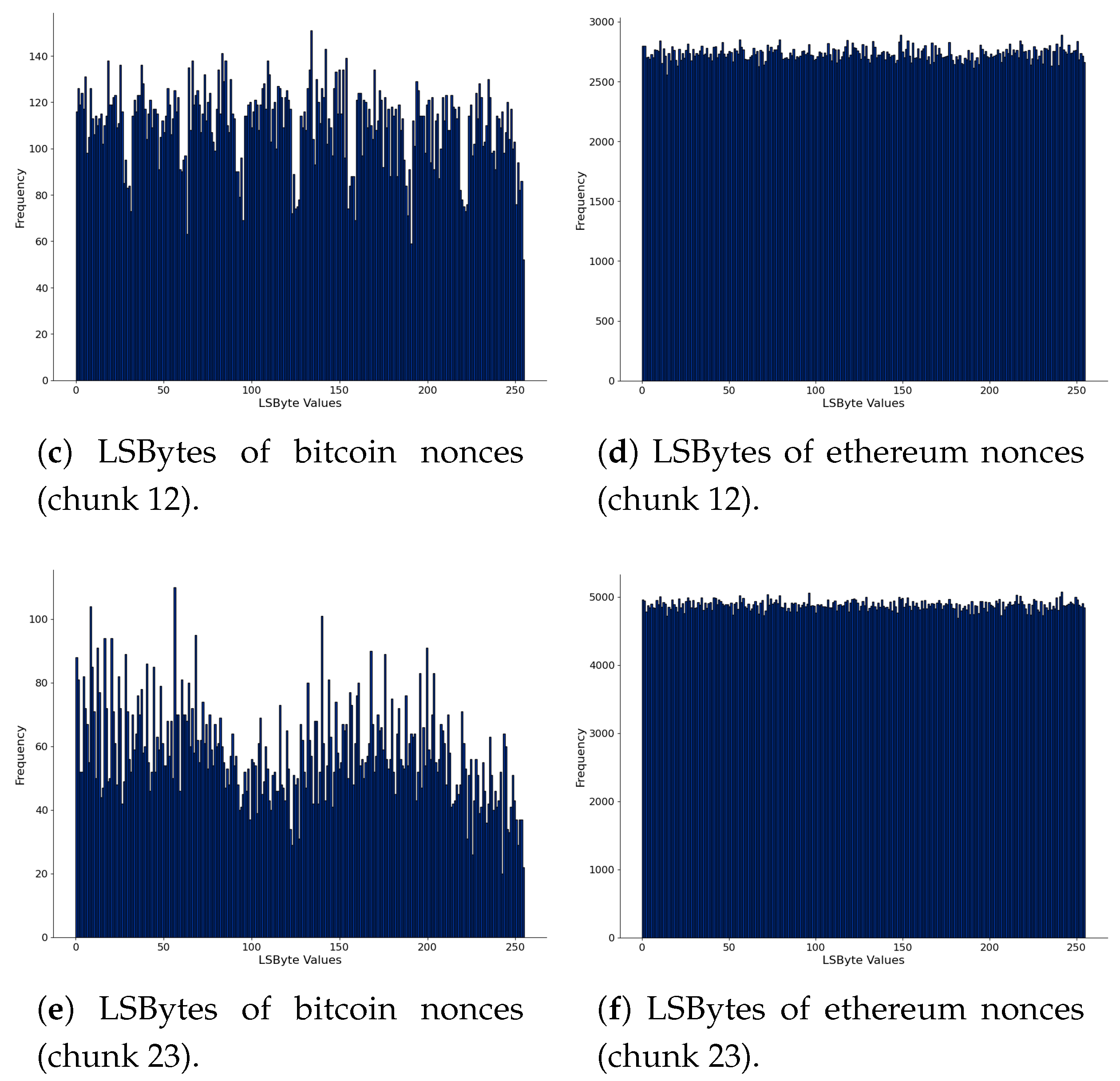
4.1.1. Block Nonces
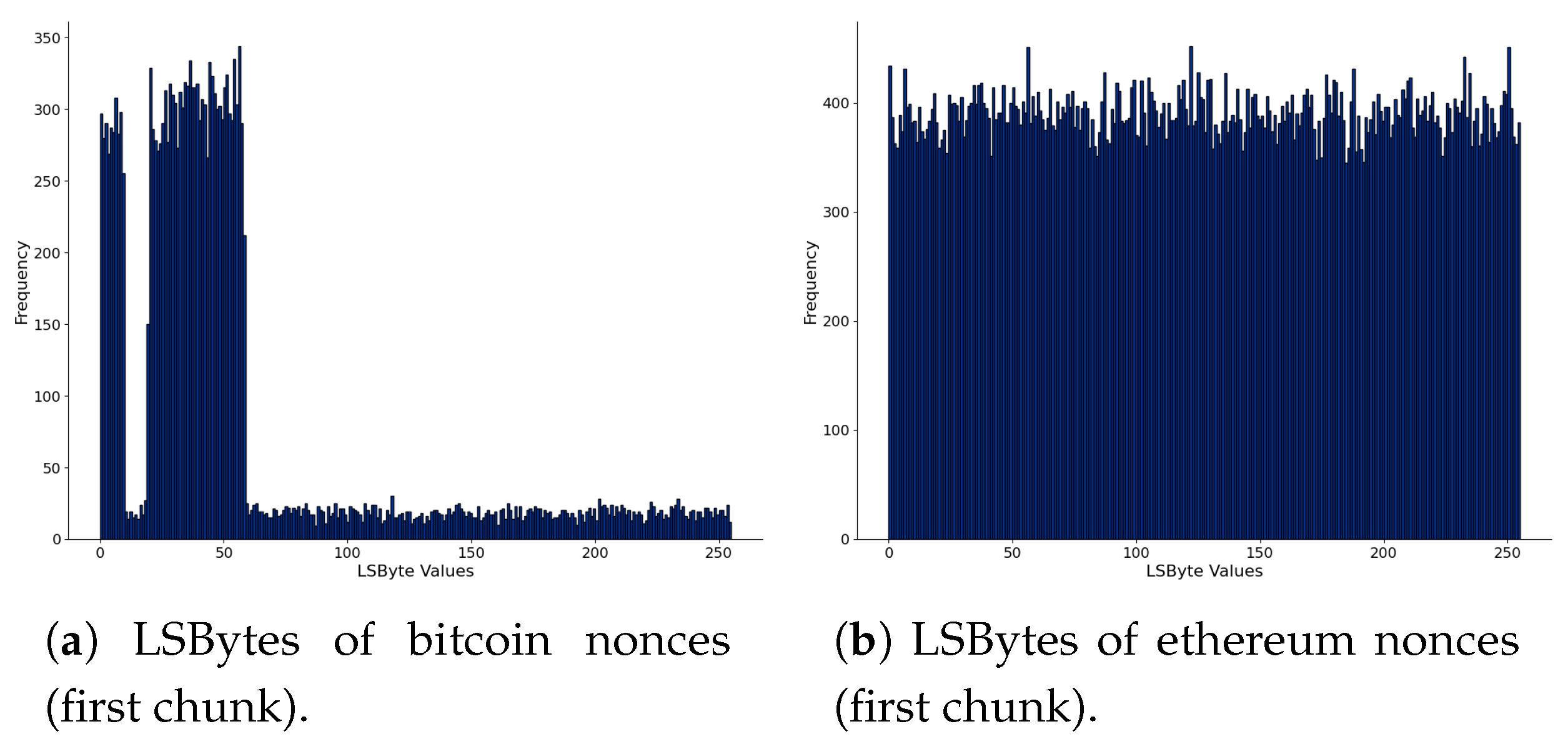
4.1.2. LSB of Addresses
4.2. Clustering Analysis
4.3. File Carving Results
5. Conclusions
- There are many blockchains available, with different characteristics, which can also be analyzed for steganography use.
- To the best of our knowledge, no work discussed the impacts of off-chain data hiding approaches in steganalysis. Although this topic mixes with standard forms of steganography (e.g., image-steganography), it may add difficulties in detection since the data can be sparse in different network locations. For instance, some blockchains provide private off-chain storage through the network, imposing a problem from a steganalysis perspective.
- The effectiveness of our clustering analysis is dependent on the success of the clustering methods. Not all methods were evaluated in our work. It is important to note that cluster size and clustering evasion (e.g., mixing approaches) directly impact the steganalysis’s effectiveness and time.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 20 May 2020).
- Andoni, M.; Robu, V.; Flynn, D.; Abram, S.; Geach, D.; Jenkins, D.; McCallum, P.; Peacock, A. Blockchain technology in the energy sector: A systematic review of challenges and opportunities. Renew. Sustain. Energy Rev. 2019, 100, 143–174. [Google Scholar] [CrossRef]
- Crosby, M.; Pattanayak, P.; Verma, S.; Kalyanaraman, V. Blockchain technology: Beyond bitcoin. Appl. Innov. 2016, 2, 71. [Google Scholar]
- Fernández-Caramés, T.M.; Fraga-Lamas, P. A Review on the Use of Blockchain for the Internet of Things. IEEE Access 2018, 6, 32979–33001. [Google Scholar] [CrossRef]
- Partala, J. Provably secure covert communication on blockchain. Cryptography 2018, 2, 18. [Google Scholar] [CrossRef]
- Puthal, D.; Malik, N.; Mohanty, S.P.; Kougianos, E.; Das, G. Everything you wanted to know about the blockchain: Its promise, components, processes, and problems. IEEE Consum. Electron. Mag. 2018, 7, 6–14. [Google Scholar] [CrossRef]
- Radanović, I.; Likić, R. Opportunities for use of blockchain technology in medicine. Appl. Health Econ. Health Policy 2018, 16, 583–590. [Google Scholar] [CrossRef]
- Scott, B.; Loonam, J.; Kumar, V. Exploring the rise of blockchain technology: Towards distributed collaborative organizations. Strateg. Chang. 2017, 26, 423–428. [Google Scholar] [CrossRef]
- Williams, S.P. Blockchain: The Next Everything; Scribner: New York, NY, USA, 2019. [Google Scholar]
- Kim, S.K.; Huh, J.H. Autochain platform: Expert automatic algorithm Blockchain technology for house rental dApp image application model. EURASIP J. Image Video Process. 2020, 2020, 47. [Google Scholar] [CrossRef]
- Henry, R.; Herzberg, A.; Kate, A. Blockchain Access Privacy: Challenges and Directions. IEEE Secur. Priv. 2018, 16, 38–45. [Google Scholar] [CrossRef]
- Conti, M.; Kumar, E.S.; Lal, C.; Ruj, S. A survey on security and privacy issues of bitcoin. arXiv 2017, arXiv:1706.00916. [Google Scholar] [CrossRef]
- Matzutt, R.; Hiller, J.; Henze, M.; Ziegeldorf, J.H.; Müllmann, D.; Hohlfeld, O.; Wehrle, K. A quantitative analysis of the impact of arbitrary blockchain content on bitcoin. In Proceedings of the 22nd International Conference on Financial Cryptography and Data Security (FC), Nieuwpoort, Curacao, 26 February 2018; pp. 420–438. [Google Scholar]
- Sato, T.; Imamura, M.; Omote, K. Threat Analysis of Poisoning Attack against Ethereum Blockchain. In Proceedings of the IFIP International Conference on Information Security Theory and Practice, Paris, France, 11–12 December 2020; pp. 139–154. [Google Scholar]
- Aitsam, M.; Chantaraskul, S. Blockchain Technology, Technical Challenges and Countermeasures for Illegal Data Insertion. Eng. J. 2020, 24, 65–72. [Google Scholar] [CrossRef]
- Alsalami, N.; Zhang, B. Uncontrolled Randomness in Blockchains: Covert Bulletin Board for Illicit Activity. Cryptology ePrint Archive, Report 2018/1184. 2018. Available online: https://eprint.iacr.org/2018/1184 (accessed on 20 May 2020).
- Sward, A.; Vecna, I.; Stonedahl, F. Data Insertion in Bitcoin’s Blockchain. Ledger 2018, 3. [Google Scholar] [CrossRef]
- Fionov, A. Exploring Covert Channels in Bitcoin Transactions. In Proceedings of the 2019 IEEE International Multi-Conference on Engineering, Computer and Information Sciences (SIBIRCON), Novosibirsk, Russia, 21–27 October 2019; pp. 0059–0064. [Google Scholar]
- Frkat, D.; Annessi, R.; Zseby, T. Chainchannels: Private botnet communication over public blockchains. In Proceedings of the 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Halifax, NS, Canada, 30 July–3 August 2018; pp. 1244–1252. [Google Scholar] [CrossRef]
- Steemit.com. Wikileaks Broadcasts Secret Message Hidden in Public Keys. Available online: https://steemit.com/news/@kharn/wikileaks-broadcasts-secret-message-hidden-in-public-keys-were-fine-8chan-post-fake (accessed on 20 March 2021).
- Böhme, R. Principles of Modern Steganography and Steganalysis. In Advanced Statistical Steganalysis; Springer: Berlin/Heidelberg, Germany, 2010; pp. 11–77. [Google Scholar] [CrossRef]
- Richard, G.G., III; Roussev, V. Scalpel: A Frugal, High Performance File Carver. In Proceedings of the DFRWS, New Orleans, LA, USA, 17–19 August 2005; pp. 1–10. [Google Scholar]
- Lerner, S.D. Bitslog.com. Available online: https://bitslog.com/2013/09/03/new-mystery-about-satoshi/ (accessed on 15 October 2019).
- Antonopoulos, A.M. Mastering Bitcoin: Unlocking Digital Cryptocurrencies; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2014. [Google Scholar]
- Kleinaki, A.S.; Mytis-Gkometh, P.; Drosatos, G.; Efraimidis, P.S.; Kaldoudi, E. A Blockchain-Based Notarization Service for Biomedical Knowledge Retrieval. Comput. Struct. Biotechnol. J. 2018, 16, 288–297. [Google Scholar] [CrossRef]
- Song, G.; Kim, S.; Hwang, H.; Lee, K. Blockchain-based Notarization for Social Media. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Matzutt, R.; Henze, M.; Ziegeldorf, J.H.; Hiller, J.; Wehrle, K. Thwarting unwanted blockchain content insertion. In Proceedings of the 2018 IEEE International Conference on Cloud Engineering (IC2E), Orlando, FL, USA, 17–20 April 2018; pp. 364–370. [Google Scholar]
- Paik, H.; Xu, X.; Bandara, H.M.N.D.; Lee, S.U.; Lo, S.K. Analysis of Data Management in Blockchain-Based Systems: From Architecture to Governance. IEEE Access 2019, 7, 186091–186107. [Google Scholar] [CrossRef]
- Zheng, P.; Zheng, Z.; Wu, J.; Dai, H.N. XBlock-ETH: Extracting and Exploring Blockchain Data From Ethereum. IEEE Open J. Comput. Soc. 2020, 1, 95–106. [Google Scholar] [CrossRef]
- HyperLedger Fabric 1.4 Documentation. Available online: https://hyperledger-fabric.readthedocs.io/en/release-1.4/private-data/private-data.html (accessed on 2 February 2021).
- NEO Smart Economy. Available online: https://neo.org/aboutl (accessed on 2 February 2021).
- Helium Blockchain Documentation. Available online: https://developer.helium.com/blockchain/blockchain-primitives (accessed on 2 February 2021).
- General Data Protection Regulation (GDPR) Official Text. Available online: https://gdpr-info.eu/ (accessed on 2 February 2021).
- Mazurczyk, W.; Caviglione, L. Information hiding as a challenge for malware detection. arXiv 2015, arXiv:1504.04867. [Google Scholar] [CrossRef]
- Berndt, S.; Liśkiewicz, M. Provable Secure Universal Steganography of Optimal Rate: Provably Secure Steganography does not Necessarily Imply One-Way Functions. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security, Vigo, Spain, 20–22 June 2016; pp. 81–92. [Google Scholar]
- Basuki, A.I.; Rosiyadi, D. Joint Transaction-Image Steganography for High Capacity Covert Communication. In Proceedings of the 2019 International Conference on Computer, Control, Informatics and Its Applications (IC3INA), Tangerang, Indonesia, 23–24 October 2019; pp. 41–46. [Google Scholar]
- Simmons, G.J. The prisoners’ problem and the subliminal channel. In Advances in Cryptology; Springer: Berlin/Heidelberg, Germany, 1984; pp. 51–67. [Google Scholar]
- Hartl, A.; Annessi, R.; Zseby, T. Subliminal Channels in High-Speed Signatures. J. Wirel. Mob. Networks Ubiquitous Comput. Dependable Appl. (JoWUA) 2018, 9, 30–53. [Google Scholar]
- Zhang, L.; Zhang, Z.; Wang, W.; Waqas, R.; Zhao, C.; Kim, S.; Chen, H. A Covert Communication Method Using Special Bitcoin Addresses Generated by Vanitygen. Comput. Mater. Contin. 2020, 65, 597–616. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. CCBRSN: A System with High Embedding Capacity for Covert Communication in Bitcoin. In Proceedings of the IFIP International Conference on ICT Systems Security and Privacy Protection, Maribor, Slovenia, 21–23 September 2020; pp. 324–337. [Google Scholar]
- Liu, S.; Fang, Z.; Gao, F.; Koussainov, B.; Zhang, Z.; Liu, J.; Zhu, L. Whispers on Ethereum: Blockchain-Based Covert Data Embedding Schemes. In Proceedings of the 2nd ACM International Symposium on Blockchain and Secure Critical Infrastructure, Taipei, Taiwan, 6 October 2020; pp. 171–179. [Google Scholar]
- Alsalami, N.; Zhang, B. Utilizing Public Blockchains for Censorship-Circumvention and IoT Communication. In Proceedings of the 2019 IEEE Conference on Dependable and Secure Computing (DSC), Hangzhou, China, 18–20 November 2019; pp. 1–7. [Google Scholar]
- Biryukov, A.; Feher, D.; Vitto, G. Privacy Aspects and Subliminal Channels in Zcash. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, United Kingdom, 6 November 2019; pp. 1813–1830. [Google Scholar]
- Xu, M.; Wu, H.; Feng, G.; Zhang, X.; Ding, F. Broadcasting Steganography in the Blockchain. In Proceedings of the Digital Forensics and Watermarking, Chengdu, China, 2–4 November 2020; pp. 256–267. [Google Scholar]
- Hopper, N.J.; Langford, J.; Von Ahn, L. Provably secure steganography. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2002; pp. 77–92. [Google Scholar]
- Wu, C.K. Hash channels. Comput. Secur. 2005, 24, 653–661. [Google Scholar] [CrossRef]
- Mayer, H. zk-SNARK Explained: Basic Principles. 2016. Available online: https://blog.coinfabrik.com/wp-content/uploads/2017/03/zkSNARK-explained_basic_principles.pdf (accessed on 2 February 2021).
- Frkat, D. Subliminal Channels in Blockchain Applications for Hidden Botnet Communication. Bachelor’s Thesis, TU Wien, Vienna, Austria, 2019. [Google Scholar]
- Nissar, A.; Mir, A. Classification of steganalysis techniques: A study. Digit. Signal Process. 2010, 20, 1758–1770. [Google Scholar] [CrossRef]
- Karampidis, K.; Kavallieratou, E.; Papadourakis, G. A review of image steganalysis techniques for digital forensics. J. Inf. Secur. Appl. 2018, 40, 217–235. [Google Scholar] [CrossRef]
- Spagnuolo, M.; Maggi, F.; Zanero, S. Bitiodine: Extracting intelligence from the bitcoin network. In Proceedings of the International Conference on Financial Cryptography and Data Security, Christ Church, Barbados, 3–7 March 2014; pp. 457–468. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Evans, D.L.; Bond, P.; Bement, A. FIPS Pub 140-2: Security Requirements for Cryptographic Modules; Federal Information Processing Standards Publication: Gaithersburg, MD, USA, 2002; Volume 12. [Google Scholar]
- Meiklejohn, S.; Pomarole, M.; Jordan, G.; Levchenko, K.; McCoy, D.; Voelker, G.M.; Savage, S. A fistful of bitcoins: Characterizing payments among men with no names. In Proceedings of the 2013 Conference on Internet Measurement, Barcelona, Spain, 23–25 October 2013; pp. 127–140. [Google Scholar]
- Kalodner, H.; Möser, M.; Lee, K.; Goldfeder, S.; Plattner, M.; Chator, A.; Narayanan, A. BlockSci: Design and applications of a blockchain analysis platform. In Proceedings of the 29th {USENIX} Security Symposium ({USENIX} Security 20), Boston, MA, USA, 12–14 August 2020; pp. 2721–2738. [Google Scholar]
- Petkanič, P. Bitcoin Blockchain Analysis [online]. Available online: https://theses.cz/id/oha703 (accessed on 20 February 2021).
- Victor, F. Address Clustering Heuristics for Ethereum. In Proceedings of the International Conference on Financial Cryptography and Data Security, Kota Kinabalu, Malaysia, 14 February 2020; pp. 617–633. [Google Scholar]
- Blockchain.com. Bitcoin Blockchain Size. Available online: https://blockchain.info/pt/charts/blocks-size (accessed on 1 March 2021).
- Ethereum. Ethereum Blockchain Size. Available online: https://etherscan.io/chartsync/chaindefault (accessed on 1 March 2021).
- Ye, Q.; Doermann, D. Text detection and recognition in imagery: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1480–1500. [Google Scholar] [CrossRef]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild: A survey. arXiv 2020, arXiv:2005.03492. [Google Scholar]
- Evgeny Medvedev and the D5 team. Ethereum ETL. Available online: https://github.com/blockchain-etl/ethereum-etl (accessed on 25 February 2021).
- Antoine Le Calvez. Bitcoin Blockchain Parser. Available online: https://github.com/alecalve/python-bitcoin-blockchain-parser (accessed on 3 August 2020).
- AAGiron. Steganalysis-tool-blockchain Github Repository. Available online: https://github.com/AAGiron/steganalysis-tool-blockchain (accessed on 30 March 2021).
- Ethash—Ethereum Wiki. Available online: https://eth.wiki/en/concepts/ethash/ethash (accessed on 12 January 2021).
- Mining—Bitcoin Developer Guide. Available online: https://developer.bitcoin.org/devguide/mining.html (accessed on 20 February 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Example | Type/Application | Public? | Data Insertion Methods |
|---|---|---|---|
| Bitcoin | Cryptocurrency | Yes | Coinbase, OP_Return, Standard and Non-Standard transactions |
| Ethereum | Cryptocurrency, Smart Contracts | Yes | Smart Contract state stored in a key-value like database (off-chain), and the hash is stored on-chain. |
| HyperLedger | Blockchain Platform | No | Private data collection: inserts arbitrary data off-chain |
| NEO | Cryptocurrency, Blockchain Platform | Yes | NeoFS stores data off-chain only smart contract code is stored on-chain |
| Helium | Cryptocurrency IoT & Wireless Networks | Yes | State-Channels for off-chain data (also allows transactions) |
| Transaction Fields | Cryptographic Primitives | Address Combinatorics | |
|---|---|---|---|
| Data Hiding Approach | Basuki and Rosiyadi, 2019 [36] Zhang et al., 2020 [39] Wang and Su, 2020 [40] Liu et al., 2020 [41] | Partala, 2018. [5] Frkat et al., 2018 [19] Alsalami and Zhang, 2018–2019 [16,42] Biryukov et al., 2019 [43] | Fionov, 2019 [18] Xu et al., 2019 [44] |
| Blockchain | Experiment Analysis | Dataset | Chunk/Cluster Size | Quantity of Chunks/Clusters |
|---|---|---|---|---|
| Bitcoin | Sequential | 253.38 GiB, 625,941 blocks | Variable | 23 chunks |
| Clustering | Blocksci: 3.33 GiB | Variable | 5763155 clusters | |
| Clustering | Blocksci: 28 GiB | Variable | 98266113 clusters | |
| Ethereum | Sequential | ~107 GiB, 6 million blocks | 0.5 M nonces, 1 M addresses | 119 chunks (nonces), 2720 (addresses) |
| Address Data | Dataset | Entropy | Arithmetic Mean (AM) | Monobit Failures |
|---|---|---|---|---|
| (Synthetic) SHA256 LSB | 1 Gbit | 7.999998 | 127.5034 | ~0.012% |
| coinbase LSB | 14.2 KiB | 7.966716 | 119.6772 | 100.00% |
| pubkey LSB | 10.2 KiB KiB | 1.392768 | 98.0966 | 100% |
| P2PKH LSB | 10.5 MiB | 7.982699 | 128.2420 | 27.87% |
| P2SH LSB | 625.8 KiB | 7.899532 | 137.4060 | 94.80% |
| (Synthetic) Keccak-256 LSB | 1 Gbit | 7.999999 | 127.5016 | ~0.068% |
| Ethereum EOA LSB | 12.5 KiB | 7.472802 | 107.0722 | 100% |
| Clusterer | Average Cluster LSB Data | Max. LSB Data in a Cluster | Statistics |
|---|---|---|---|
| Blocksci LSB (1) (3.33 GiB) | 721.56 bytes | 26 KiB (: ) | Entropy: 7.993215 AM: 127.3905 Monobit: 0% |
| Blocksci LSB (2) (28 GiB) | 584.92 bytes | 360 KiB (: ) | Entropy: 7.999426 AM: 127.4816 Monobit: 0% |
| Analysis Type | Total Extracted Size (Approx.) | Scalpel Output (Files) | False Positives? |
|---|---|---|---|
| Sequential (bitcoin) | 161.54 MiB | RPM, PGP | All |
| Sequential (ethereum) | 34.52 MiB | FWS, MPG, PGP | All |
| Clustering (blocksci—28 GiB) | 1.45 MiB | None | N/A |
| Clustering (blocksci—3.33 GiB) | 288.9 KiB | None | N/A |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giron, A.A.; Martina, J.E.; Custódio, R. Steganographic Analysis of Blockchains. Sensors 2021, 21, 4078. https://doi.org/10.3390/s21124078
Giron AA, Martina JE, Custódio R. Steganographic Analysis of Blockchains. Sensors. 2021; 21(12):4078. https://doi.org/10.3390/s21124078
Chicago/Turabian StyleGiron, Alexandre Augusto, Jean Everson Martina, and Ricardo Custódio. 2021. "Steganographic Analysis of Blockchains" Sensors 21, no. 12: 4078. https://doi.org/10.3390/s21124078
APA StyleGiron, A. A., Martina, J. E., & Custódio, R. (2021). Steganographic Analysis of Blockchains. Sensors, 21(12), 4078. https://doi.org/10.3390/s21124078