1. Introduction
With the development of information and communications technology (ICT) such as 5G and artificial intelligence and changes to the content creation environment, there is a growing demand for immersive media [
1,
2,
3,
4], which refers to a medium that conveys information of all types of senses in the scene to maximize immersion and presence for user satisfaction. Immersive media may include multisensory information such as high-quality visual information, multichannel audio information, and tactile information. In particular, as high-quality visual information, virtual reality (VR) media has attracted much attention because it can maximize immersion of users in 3D or ultra high definition (UHD) media. VR media are applied in many fields, such as broadcasting, education, and games, and they are being developed or planned by many companies as a core application service in the 5G era with augmented reality (AR) media [
5].
As VR media change from graphic to real images, various 360-degree image capturing equipment types and shooting techniques are being developed. A 360-degree image is synthesized using images taken using a plurality of cameras with wide-angle or fisheye lenses. Generally, 360-degree cameras are configured to shoot images from all directions by radially arranging the cameras of a narrow field of view (FoV) around the same point, and then stitching the captured images offline.
A stitching process is required to generate a 360-degree or panoramic photo-realistic image from images captured by a plurality of cameras [
6,
7,
8,
9]. Estimation of the correct alignment to relate various pairs of images, a choice of a final compositing surface to warp aligned images, and seamless cutting and blending of overlapped images are required for image stitching even in the presence of parallax, lens distortion, scene motion, and exposure difference. The stitching process is a critical step in determining the quality of panoramic images, and research is being actively conducted to improve stitching performance [
8,
9,
10,
11,
12,
13].
Three hundred and sixty-degree image stitching tools use the intrinsic and extrinsic parameters of the cameras used in the shooting to stitch images. Commercial 360-degree imaging equipment selects intrinsic parameters according to the camera model used and extrinsic parameters specific to the rig of a specific structure used to mount cameras. The structure of commercial 360-degree video recording equipment is generally set so that the optical axes of the cameras pass through the same point, and the cameras photograph radially using an omni-directional angle of view. Thus, only the rotational transform component is present in the extrinsic parameters of the cameras; the translational component is absent or small enough to be ignored. In such a setting, parallax distortion in a wide-angle panorama or a 360-degree stitched image rarely occurs.
However, when the optical axes of the cameras are not in a radial arrangement passing through a common point, and there is a translational component in the extrinsic parameters of the cameras, parallax may occur at the boundary portions of regions having different depths in the captured image. Parallax increases as the translational component between camera positions increases, and as the depth difference between regions in the image increases.
Due to inaccurate homography estimation, conventional tools for producing panoramic images have poor stitching performance for plain background images or noisy night images. The poor performance is because the number of extracted feature points is small, and these are not consistent in the temporal or spatial directions [
7,
10].
In real-world video applications such as sports and surveillance, multiple static cameras capture target scenes mainly composed of a ground, a far distant background, and foreground objects. In videos, foreground objects, especially dynamic objects, can draw more visual attention than the background. Typically, single or multiple homography-based stitching can be applied to such video sequences. If the estimated homographies are accurate, the stitched ground and background regions that make up most of the scenes and can be assumed to plane would not have parallax distortion. However, foreground objects at different distances from the cameras have depth differences from adjacent areas, leading to significant parallax distortion severely degrading the visual quality.
In this study, we focused on stitching video sequence pairs captured using static cameras in sports stadiums with running tracks enclosing a grass field. There are two challenges for stitching such video sequences. First, dynamic foreground objects in overlapped regions typically have parallax distortion. Second, the ground plane consisting of a grass field and a running track may not provide a sufficient number of feature points for homography estimation. This may cause misalignment distortion in the stitched ground region.
We propose a semantic segmentation-based video stitching method to reduce parallax and misalignment distortion in stitched video sequences. First, to reduce parallax distortion, video frames are divided into segments of different classes using a semantic segmentation module trained for sports stadium scenes. Stitching for matched segment pairs is performed assuming that these segments exist on the same plane. Second, to reduce the misalignment distortion for plain or noisy video frames, the homography is estimated by searching for consistent feature points in the temporal direction. Finally, the final video frames are stitched by stacking the stitched segments and foreground segments on the reference frame by descending order of area.
The contribution of the proposed method is three-fold. First, the proposed approach presents a reference framework for stitching videos, including foreground objects captured in specific scene environments such as sports stadiums. Although image or video stitching methods after foreground and background separation have been tried [
11,
14], parallax distortion still exists for static foreground regions [
14] and multiple foreground regions [
11]. A pre-trained semantic segmentation module can separate video frames into planar or multiple foreground segments of different classes and make per-segment stitching and stacking possible. For video stitching of other scene types, the semantic segmentation module should be re-trained with images from the scenes. Second, the proposed method can reduce the quality degradation of stitched videos by reducing the parallax distortion around foreground objects drawing great visual attention. Third, the proposed method can reduce the misalignment distortion in planar segments with simple texture or noise, such as the grass field in a typical sports stadium.
This paper is organized as follows: In
Section 2, existing studies related to the reduction of parallax distortion in image or video stitching are explained. In
Section 3, a semantic segmentation-based video stitching method is proposed for the reduction of parallax and misalignment distortion. In
Section 4, the performance and effectiveness of the proposed method are evaluated. Finally, in
Section 5, conclusions and future works are presented.
3. Semantic Segmentation-Based Static Video Stitching
In this section, a novel semantic segmentation-based static video stitching method is proposed to reduce parallax and misalignment distortion in stitched video frames. The proposed method, as shown in
Figure 1, consists of three steps. In the first step, semantic segmentation is applied to an incoming video sequence pair. In the second step, for each background segment, multi-frame-based homography estimation and stitching are performed to generate stitched segments. Finally, all of the stitched segments and foreground segments are stacked on the reference view plane to generate panoramic video frames.
3.1. Semantic Segmentation and Matching
Most image and video stitching algorithms yield unconvincing results if an input image or video frame pair violates the following assumptions: (1) two images or video frame planes differ purely by rotation, or (2) the captured scene is effectively planar. However, in general image or video shooting environments, these assumptions are often violated, yielding parallax distortion in the stitching results. This parallax distortion is more severe in sports stadium videos with dynamic foreground objects of different depth from the surrounding areas than in landscape videos without foreground objects. Since dynamic foreground objects receive more visual attention than their surrounding regions, parallax distortion around them can significantly degrade the quality of stitched videos.
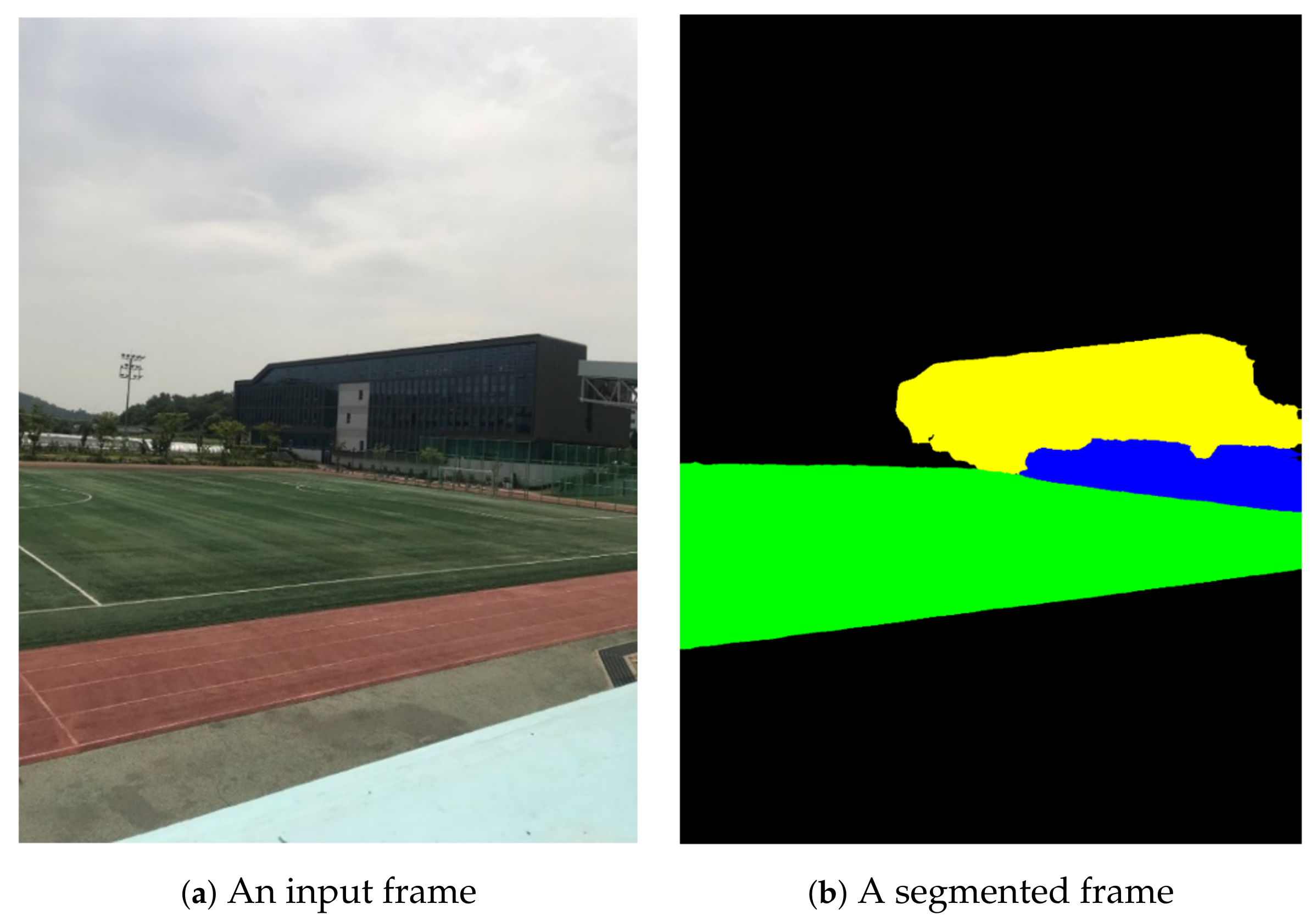
The purpose of the proposed algorithm is to reduce the parallax distortion around foreground objects and misalignment distortion in ground and background regions in stitching a video sequence pair captured using static cameras in sports stadiums. For semantic segmentation, the state-of-the-art algorithm DeepLab is employed [
25]. DeepLab is trained to segment five classes of regions using images taken inside stadiums, including
ground,
goalpost,
building,
human, and
other.
In the first step of the proposed algorithm, the reference and target frames are semantically segmented. Semantic labels are assigned to every pixel in the video frame by semantic segmentation. For scenes consisting of large planar segments, although pixels on the same segment may have different depths, they are assumed to be on the same plane. The pixels on small segments of foreground objects are also assumed to be on the same plane because the distance to the segment from the camera is a lot longer than the maximum difference of depth in the segment. The matched segment pairs, which have the same semantic class and are close to each other on the reference frame plane, are searched from the reference and target frames.
Let and denote the target and the reference video frames, respectively. After semantic segmentation, each video frame is divided into several disjoint segments. Each segment has its semantic class, such as ground (), building (), human (), goalpost (), and other (). A background segment is defined as a static segment such as ground, building, goalpost, and other. The category of the foreground segment is defined into small semantic segments surrounded by background segments, i.e., a human semantic segment in our study.
For the
i-th segment
in the target frame and the
j-th segment
in the reference frame, an indicator function comparing the semantic classes for two segments is defined as follows:
where
represents the semantic class of the argument.
After matching the feature points extracted from these frames, a global homography, , is estimated by random sample consensus (RANSAC), which relates a pixel in to a pixel in . Then, the segment in the target frame can be warped into the segment in the reference frame.
For each segment in the target frame, the matched segment in the reference frame is the one with a maximum overlapped area within a distance threshold. For the segment
, the index of the matched segment in the reference frame is found as follows:
where
,
, and
represent the distance between the centroids of
and
, the area of the argument, and the distance threshold, respectively.
3.2. Homography Estimation for Matched Segment Pairs
The correct alignment parameters need to be found between matched segment pairs while suppressing incorrect feature point extraction caused by time-varying noise. Primarily, segments of plain texture or small area may not provide a sufficient number of feature points for homography estimation by direct linear transformation [
26].
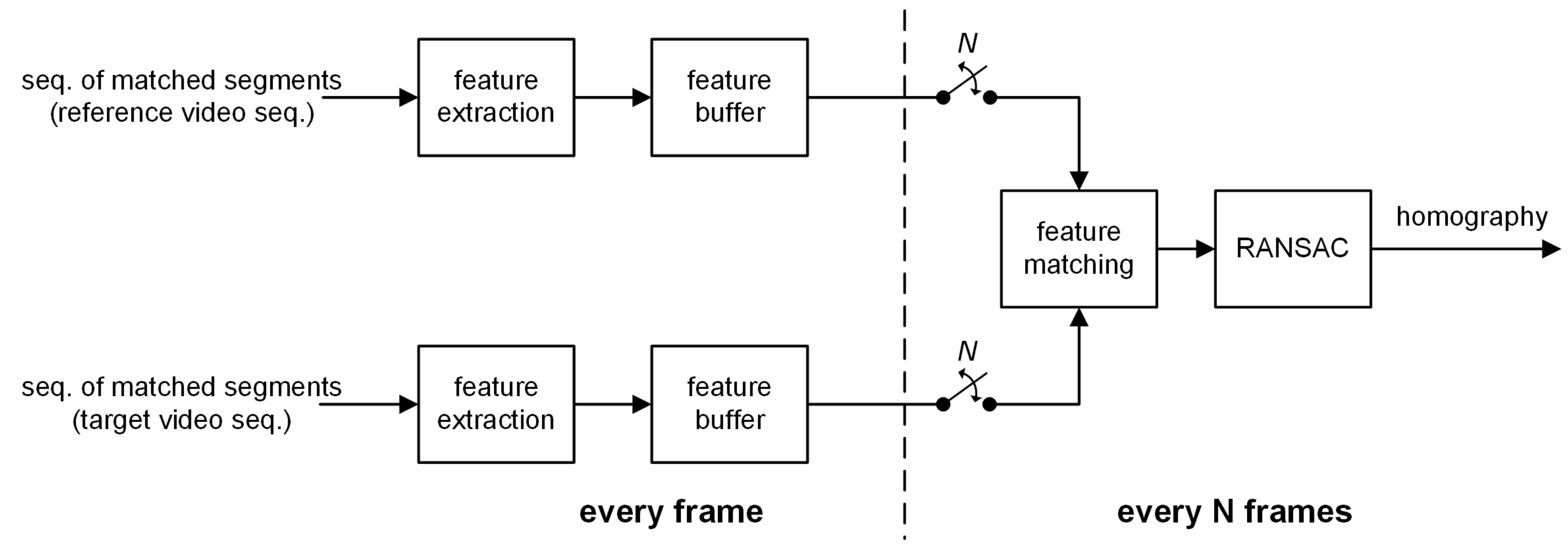
In this section, a homography estimation method on a multi-frame basis is proposed to stitch matched segment pairs in static video camera environments. The proposed method is performed on every matched segment pair. For each side of the video sequences, as shown in
Figure 2, feature points are extracted from the matched segment pair over an interval
N using the SURF algorithm [
27]. The extracted feature points are saved in the feature buffers until the end of the interval. Then, using the buffered feature points, a homography for the matched segment pair for the interval is estimated throughout feature matching and RANSAC [
28].
In video stitching, there may exist time-varying noise and different illumination conditions. The proposed homography estimation method uses feature points extracted for multiple frame intervals. Feature points extracted multiple times at the same location can be considered as consistent against noise in the spatio-temporal domain. Multiple occurrences of feature points at the same location may increase their chances of being sampled by RANSAC in proportion to their number of occurrences [
28]. Homography estimation is performed on background matched segment pairs, but not on foreground segments.
3.3. Panoramic Video Frame Synthesis Based on Segment-Based Stitching
In this section, a panoramic video frame synthesis method based on segment-based stitching is proposed. The left camera plane is selected as the reference view plane. After semantic segmentation and matching of segments, the segments can be grouped into three sets of segments. First, the sets and consist of matched pairs of background segments in the target and the reference frames, respectively. Second, the set consists of foreground segments or non-matched segments in the reference frame. Lastly, the set consists of non-matched segments in the target frame.
The target frame
can be defined as the union of its segments, as follows:
where
represents the number of segments.
Similarly, the reference frame
is defined as follows:
where
represents the number of segments.
The sets of matched background segments for the target and the reference frames are defined as follows:
The set of the foreground or non-matched segments in the reference frame is defined as follows:
The set of non-matched segments in the target frame is defined as follows:
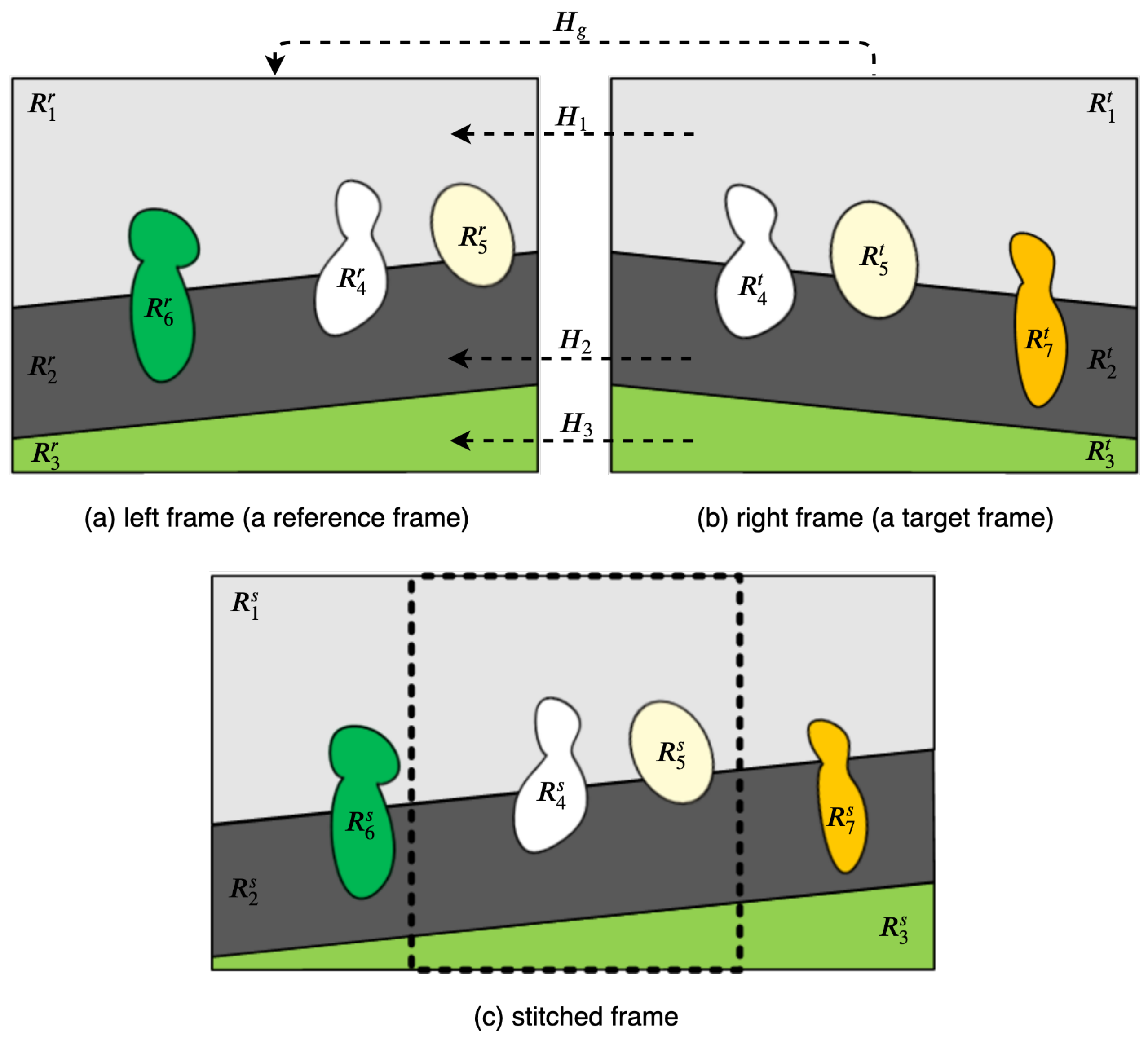
For the image pair shown in
Figure 3, these sets can be constructed as
,
,
, and
.
For the warping and stitching of segments, sets of different semantic classes are handled in different ways. For each pair of matched background segments in the sets
and
, a homography is estimated using the proposed multi-frame feature buffering during one interval. Then, the target background segment,
, is warped into the reference frame plane, aligned with its matched segment,
. The stitched matched segment can be defined as follows:
where
and ⊕ represent the warping of the segment
using the homography
and the stitching operation of two segments, respectively.
In this paper, to show unwanted parallax distortion or misalignment distortion from inaccurate homography in the overlapped segment, if they exist, the warped target background segments and their matched segments are average blended into background stitched segments without post-processing, such as the seam-line selection, gain compensation, or multi-band blending used in [
7,
16,
18].
Segments in the set
are kept intact, regardless of the existence of matched segments. The matched foreground segments in the target frame are discarded without their warping to the reference frame plane. In
Figure 3,
,
, and
are kept intact in the reference frame plane.
Each segment in the set
is warped to the reference frame plane using the homography estimated for the adjacent background segment having the highest number of edge pixels shared with the segment. In
Figure 3,
is warped to the reference frame plane using the homography
.
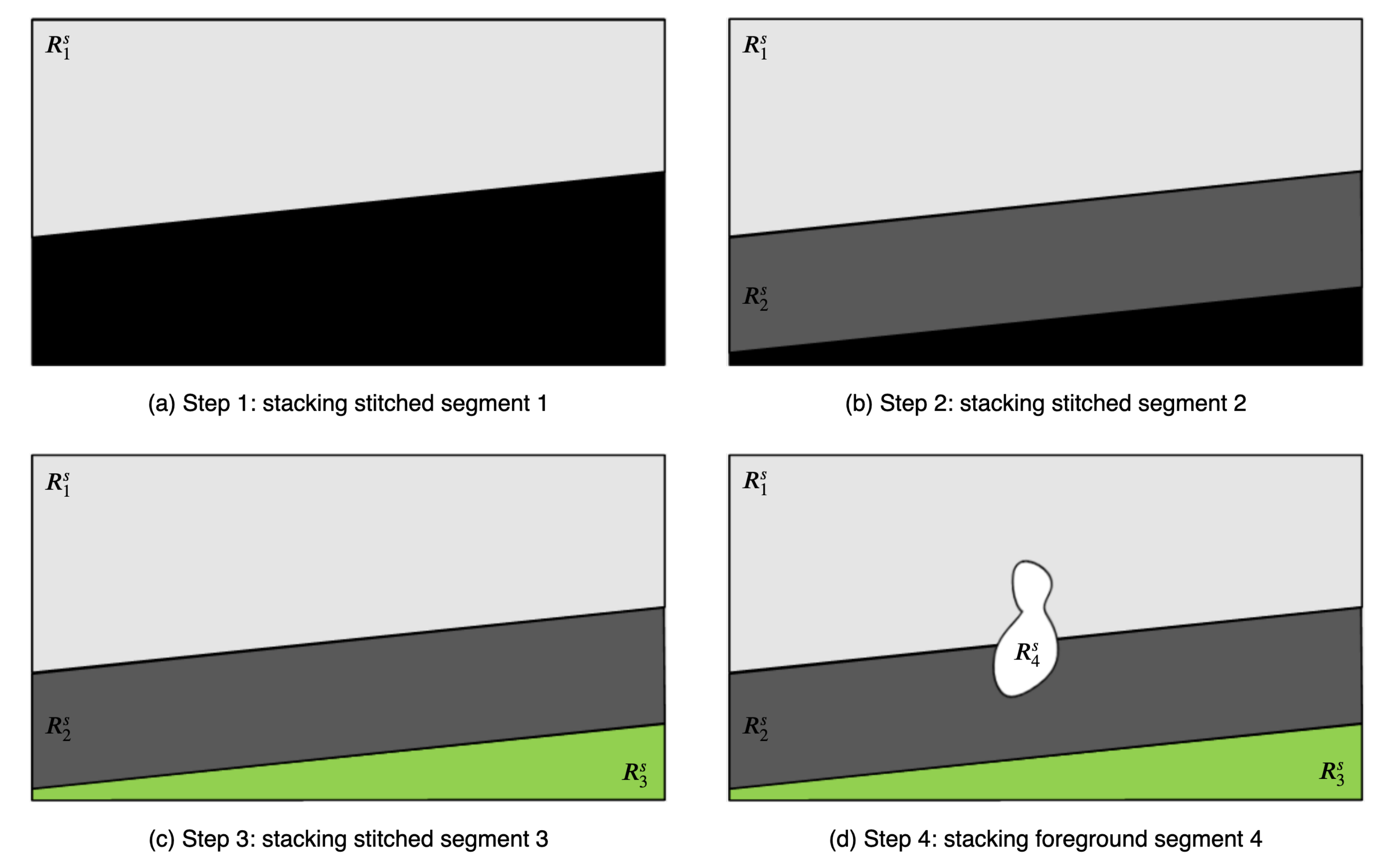
If all processes of segment-based stitching and warping are performed, there are background stitched segments, warped non-matched segments from the target frame, and foreground or non-matched segments from the reference frame. These segments are stacked on the reference frame plane. First, background stitched segments are stacked according to the area of the segments, in descending order. Thereafter, foreground and non-matched segments are stacked irrespective of the order. In
Figure 4, the stacking order of background stitched and foreground segments is shown. In this example, to synthesize the stitched video frame, the proposed algorithm stacks the segments in the order of
,
,
, and
. Then, the remaining unused segments are stacked as
,
, and
. The sequence of stacking foreground and non-matched segments is random.
5. Conclusions
In this paper, we proposed a semantic segmentation-based video stitching method to reduce parallax and misalignment distortion between cameras. To eliminate parallax distortion, video frames are segmented into different semantic classes of segments. Assuming that a matched segment pair of the same semantic class exists on the same plane, segment-based stitching and stacking of the stitched segments are performed. To reduce misalignment in video sequences with simple texture or noise, homography is estimated using consistent feature points in the temporal direction. The proposed method outperformed existing methods for parallax, misalignment, geometric, and pixel distortions, especially in the plain ground segment and the foreground human segments that have significant depth differences from surrounding segments.
The proposed method has two limitations. First, if the boundary between neighboring segments is not accurately extracted, afterimages of the segment boundary remain in the adjacent region. Second, misalignment distortion may occur in background other segments in some video sequences due to the significant depth difference.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}