
Brain–Computer Interface (BCI) Control of a Virtual Assistant in a Smartphone to Manage Messaging Applications

 ,
,  ,
,
Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | EEG Signal | Controlled Devices |
|---|---|---|
| [16] | P300 | 36 commands not specified |
| [17] | P300 | TV, DVD player, hi-fi system, multimedia hard drive, lights, heater, fan, and phone |
| [18] | Conceptual imagery | Kettle, shutters, TV, and light |
| [19] | P300 | lights, doors, fan, camera, media player, and predefined websites |
| [20] | Auditory ERP | TV, air conditioner, and emergency call |
| [21] | ASSR | Smart bulb and fan |
| [22] | P300 | Twitter and Telegram |
| [23] | SSVEP | Robotic vacuum, air cleaner, and humidifier |
| [24] | SMR | Medical call, service call, catering ordering, TV, and two air conditioners (wall-hanging and cabinet) |
| [25] | Visual ERP | TV, air conditioner, and emergency call |
| [26] | P300 | TV |
| [14] | SSVEP + temporalis muscle (EMG) | Wheelchair, nursing bed, TV, telephone, curtains, and lights |
| [15] | SMR + blinks (EOG) | Speller, web browser, e-mail client, and file explorer |
2. Materials and Methods
2.1. Participants
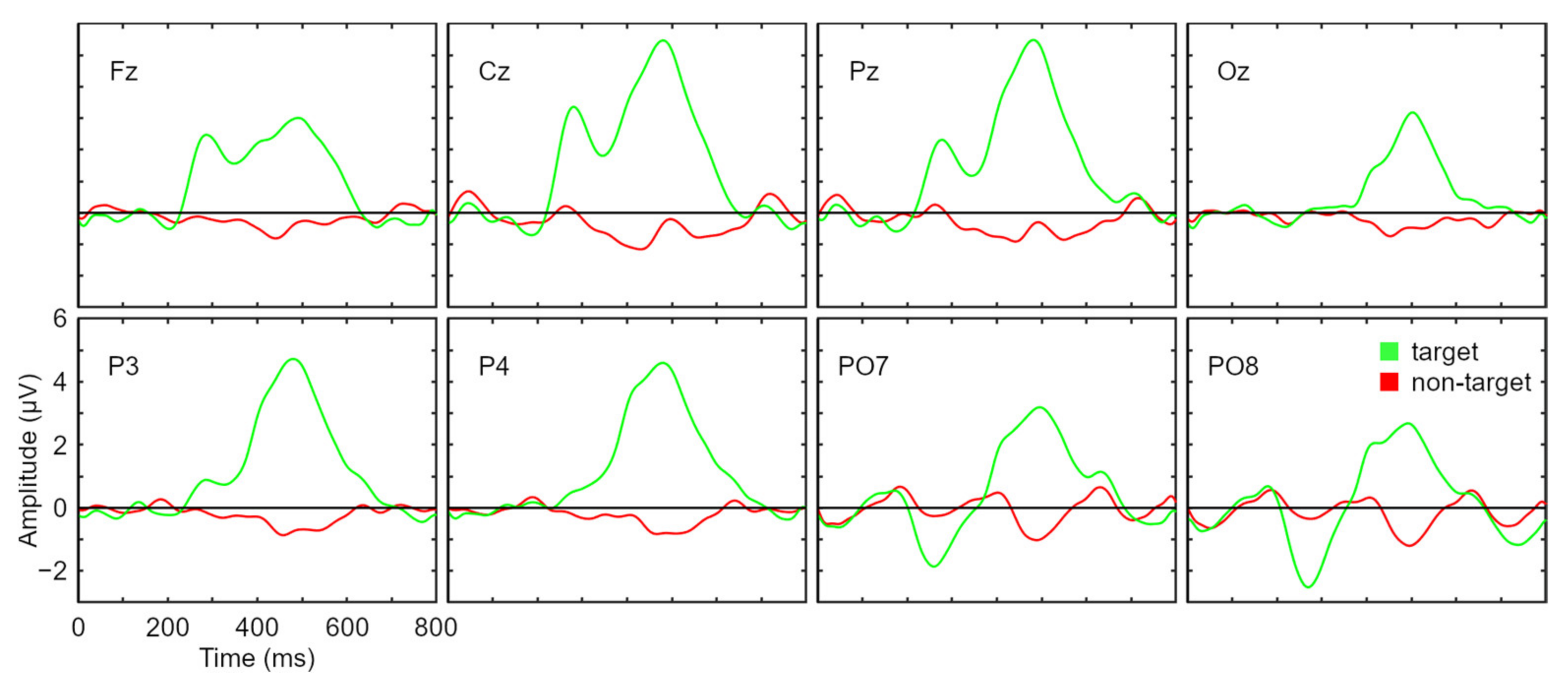
2.2. Data Acquisition and Signal Processing
2.3. System Implementation
2.4. Control Paradigm
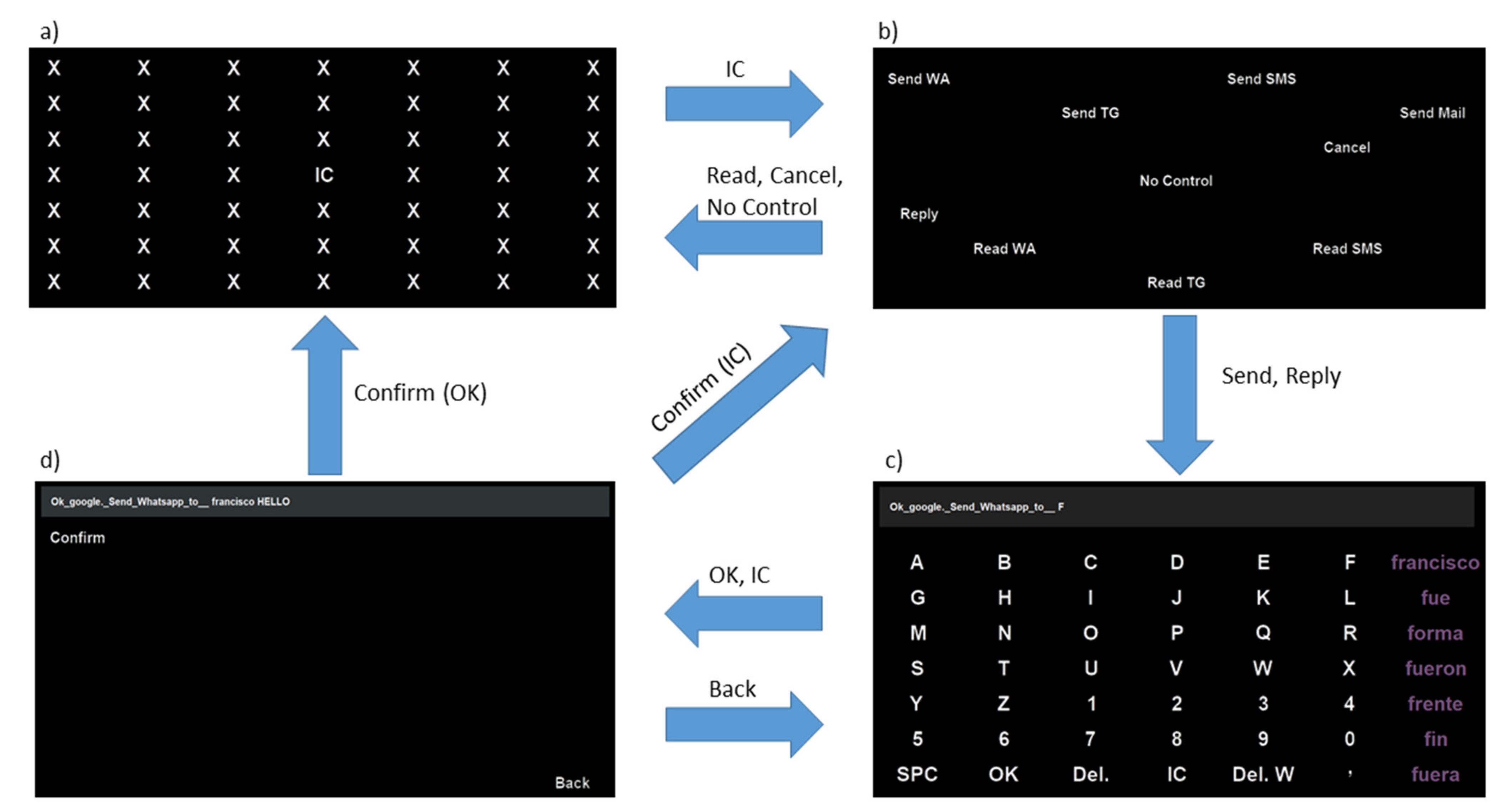
- (a)
- No Control (NC) menu (Figure 2a). This was a 7 × 7 matrix in which only one item was a valid command, and the other 48 items (“X”) were dummy commands. The objective of this menu was to allow subjects to remain in a state where they could rest without generating control commands; the term “no control” is generally used in asynchronous systems to refer to such a state. The only valid command was “IC” (in the center of the interface), whose selection changed the menu to an Intentional Control menu. The probability of unintentionally selecting this item and thus changing the menu was 1/49 ≅ 2%. No voice command was generated in this interface.
- (b)
- Intentional Control (IC) menu (Figure 2b). This was the main menu of the system, where subjects could choose what action they wanted to select. In a 7 × 7 matrix, ten valid options were available (the remaining 39 options were dummy non-visible items). These ten options can be grouped into three categories:
- Send messages. This group consisted of four commands: “Send WA”, “Send TG”, “Send SMS” and “Send Mail”, that enabled users to send a message using WhatsApp, Telegram, SMS, or e-mail, respectively. Once one of these commands was selected, the system wrote part of the sentence to be spoken, “Ok Google, send a WhatsApp to”, “Ok Google, send a Telegram to”, “Ok Google, send an SMS to” or “Ok Google, send an e-mail to” and then changed to a Spelling menu (Figure 2c) so that the user could next spell out the receiver of the message and the message itself. Please note that throughout the manuscript we use italics to indicate the spoken commands sent to the assistant, as well as the assistant’s responses.
- Read messages. Three commands formed this group: “Read WA”, “Read TG” and “Read SMS” used to read the messages received through WhatsApp, Telegram, and SMS, respectively. The selection of one of these commands made the system speak the corresponding sentence: “Ok Google, read my WhatsApp messages”, “Ok Google, read my Telegram messages” or “Ok Google, read my SMS messages”. After the sentence was spoken, the system deleted it and automatically switched to the NC menu so that subjects could listen to the received messages, if any. After the virtual assistant read each received message, it asked the users if they wanted to reply to it or not. To do this, subjects first had to change to the IC menu where two commands were available related to replying to messages. These commands will be explained in the third group. After canceling or replying to each message, the system continued to read the remaining messages, if any.
- Other commands. In this group, three commands were included: “Reply”, “Cancel”, and “NC”. The “Reply” command allowed users to reply to a WhatsApp, Telegram or SMS received message after the system read them. Once this command was selected, the system wrote the sentence “Ok Google, reply” and switched to the Spelling menu so that users could complete the sentence with the desired response (in a similar way to what was done with the “Send” commands); please note that in this case, it is not necessary to specify the receiver of the message to be sent. The “Cancel” command was used to indicate to the system that the user did not want to reply to a received message. Once it was selected, the system wrote and spoke the sentence “Ok Google, cancel” and then deleted it and switched to the NC menu. Finally, the “No Control” command was presented in order to allow subjects to voluntarily change to the NC menu, in case they wanted to take a rest.
- (c)
- Spelling menu (Figure 2c). When users selected one of the “Send” or “Reply” options from the IC menu, the system changed to the Spelling menu (after adding some predetermined text). Here, the users could spell out the receiver and the message to send (or just the message in the case of the option “Reply”). It is worth mentioning that the message had to be spelled right after the receiver, only separated by a space. This menu consisted of a 7 × 7 matrix with spelling and control commands. The first six columns and rows corresponded to specific characters to be added (English alphabet letters and numbers). The last column was used to provide subjects with seven predicted words (this column used a different text color, as shown in Figure 2c). The last row contained two characters (“SPC” (space) and “,”), two delete commands (“Del.” to delete a single character and “Del. W” to delete a complete word), and two control commands (“OK” and “IC”). The command “OK” was used to indicate to the system that the receiver (if needed) and the message to send were complete so that the written sentence could be spoken and interpreted by the virtual assistant. The “IC” command was used to return to the IC menu without generating any voice command (this was useful if a subject entered this menu unintentionally). The selection of “OK” or “IC” caused the currently written sentence to be deleted (after speaking it in the case of “OK”), so a confirmation menu was offered to subjects in order to avoid undesired selections of these two commands.
- (d)
- Confirmation menu (Figure 2d). Two valid commands were available (among 47 non-visible dummy options) in a 7 × 7 matrix, “Confirm” and “Back”. On the one hand, the “Confirm” command was used to corroborate the previous selection in the Spelling menu (that is, “OK” or “IC”). In the case of confirming an “OK” command, the system spoke (and deleted) the complete sentence so it could be interpreted by the virtual assistant, and it changed to the NC menu. In the case of confirming an “IC” command, the system deleted the written sentence and switched to the IC menu. On the other hand, the “Back” command was used to return to the Spelling menu in order to continue writing the sentence to be sent to the virtual assistant.
2.5. Procedure
- To send a WhatsApp message to a contact named “Francisco” with the content in the Spanish language “experimento en la universidad” (in English, “experiment at the university”). This task was the same for all subjects. The receiver’s name as well as the words “experimento” and “universidad” were proposed as predictions by the system when one, three, and two characters were selected, respectively. A minimum of 19 actions were needed to complete this task.
- To check the received SMS messages and reply to any message coming from a contact named “Ricardo”. This was the shortest task, as no SMS were received during the experiment. Only two actions were needed to complete this task.
- To check the received Telegram messages and reply to any message coming from a contact named “Álvaro”. In this case, there was only one received message and its sender was Álvaro (this message was sent just before each experiment), so all subjects had to reply to it. The incoming message was a question: “¿Cuál es tu comida favorita?” (in English, “what is your favorite food?”). This task did not have a minimum number of actions to perform, as the answer to the question was different for every subject (they did not know the question in advance so they improvised the answer).
- To send an e-mail to a contact that the subjects decided with the content that they also decided. The receiver contact was previously registered in the smartphone agenda and subjects were asked to write down the chosen message before the experiment (in order to facilitate the evaluation). They were instructed to choose a 20- to 30-character message.
2.6. Evaluation
2.6.1. Performance
2.6.2. Questionnaires
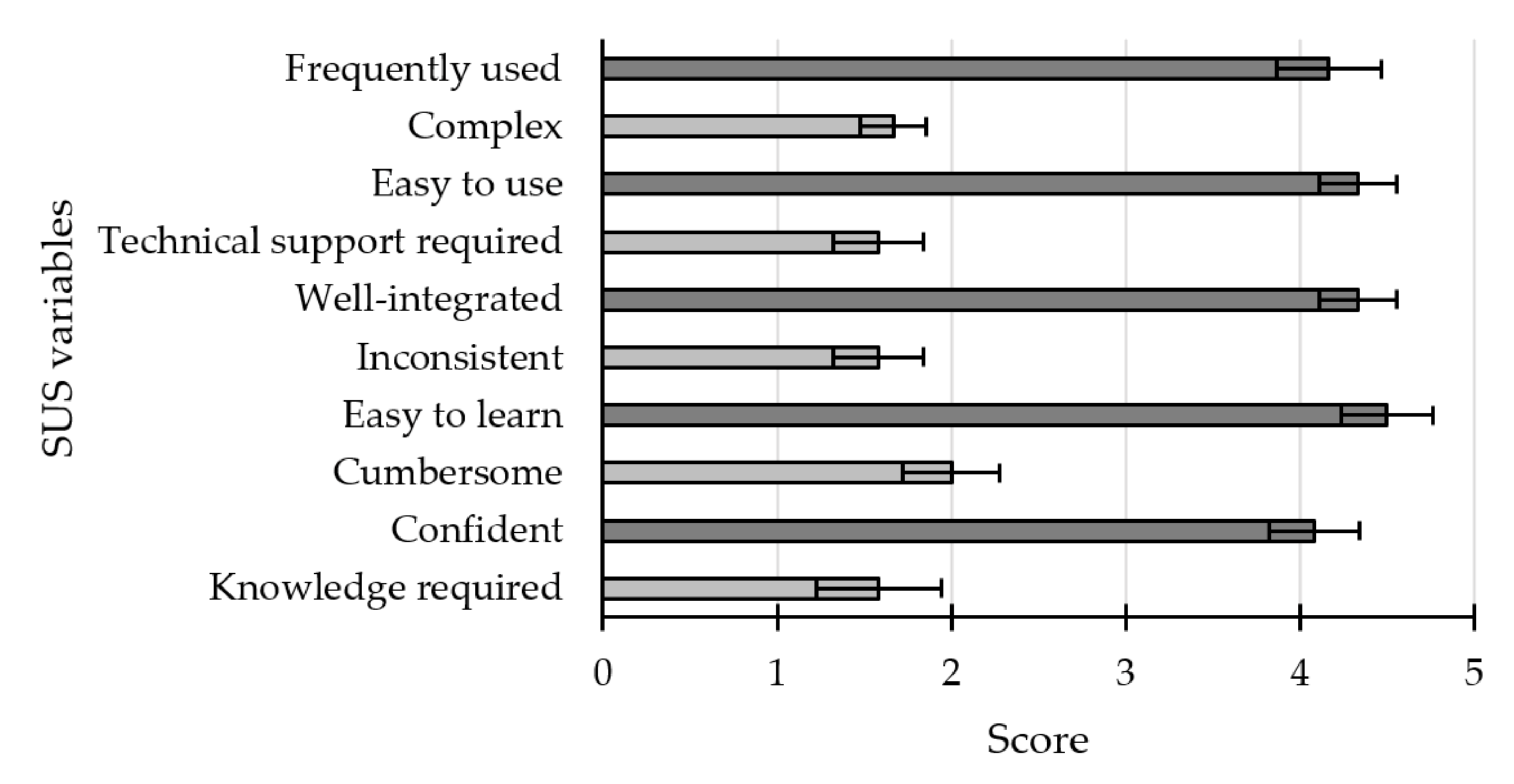
- I believe that patients and caregivers could use this application frequently (frequently used).
- I found this application unnecessarily complex (complex).
- I thought the app was easy to use (ease of use).
- I think I would need help from a tech-skilled person to use this application (technical support required).
- I found the various functions in this system were well integrated (well-integrated).
- I think the application is very inconsistent when executing the various actions (inconsistent).
- I would imagine that most people would learn to use this system very quickly (easy to learn).
- I found the application very cumbersome to use (cumbersome).
- I felt confident using this application (confident).
- I needed to learn many things before I was able to use this application (knowledge required).
- How mentally demanding was the task? (mental demand)
- How physically demanding was the task? (physical demand)
- How hurried or rushed was the pace of the task? (temporal demand)
- How successful were you in accomplishing what you were asked to do? (performance)
- How hard did you have to work to accomplish your level of performance? (effort)
- How insecure, discouraged, irritated, stressed, and annoyed were you? (frustration)
- List up to three negative features of the interface (negative features).
- List up to three positive features of the interface (positive features).
- Would you consider adding any other messaging application, and if so, which one? (other messaging application).
- Would you add any functionality to the system?If so, which one? (other functionality).
- Additional comments (additional comments).
3. Results
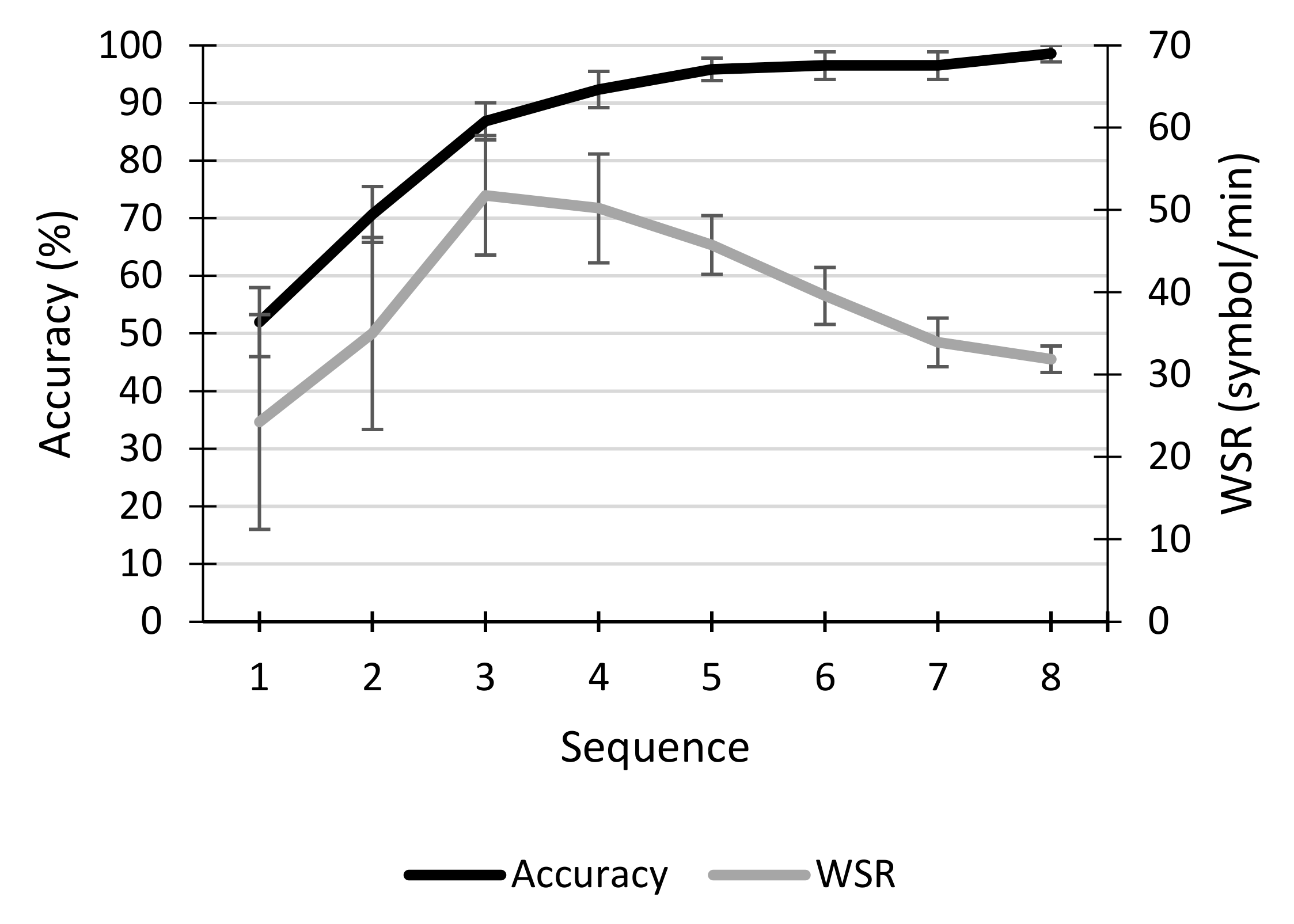
3.1. Performance
3.1.1. Calibration
3.1.2. Online Session
3.2. Questionnaires
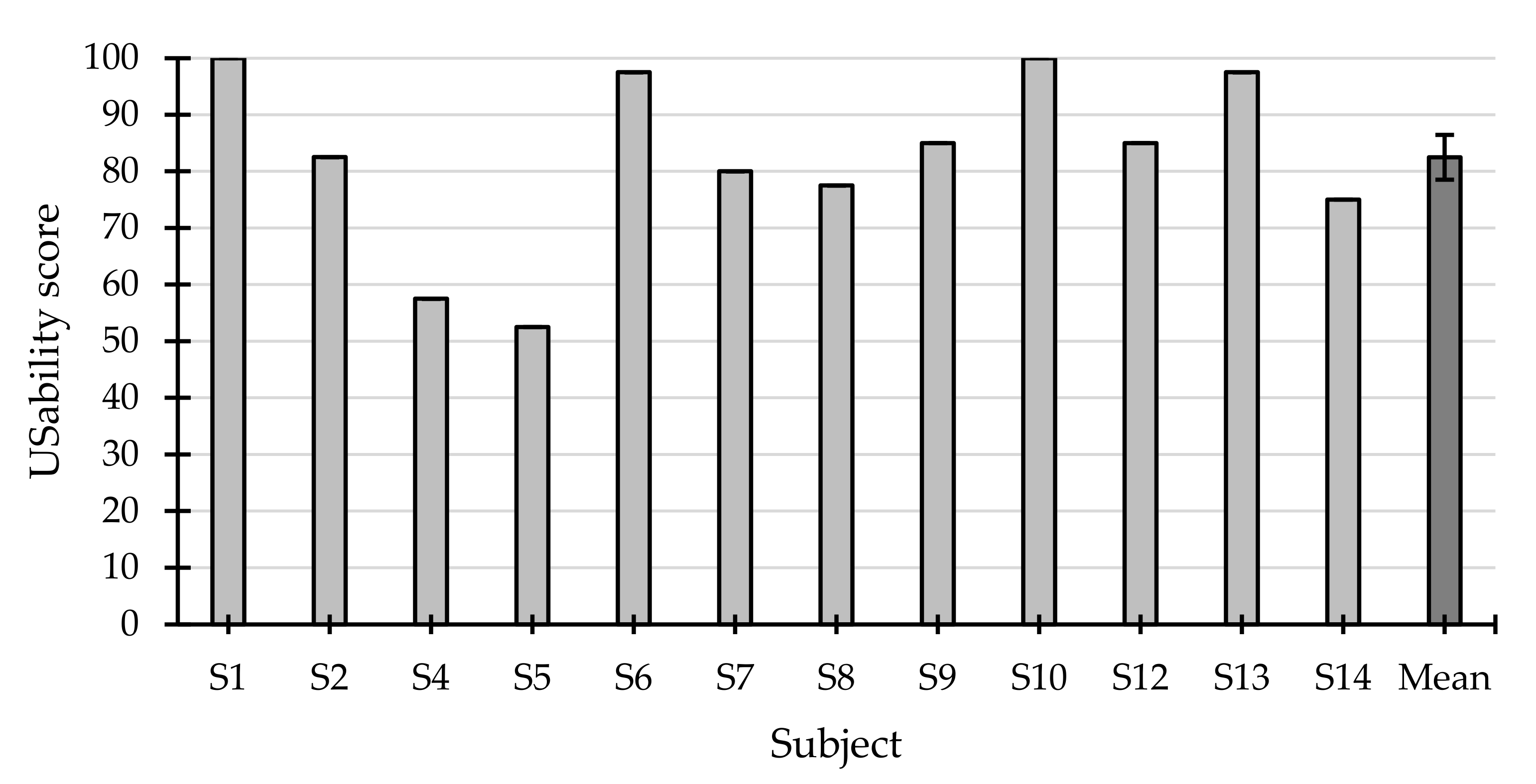
3.2.1. System Usability Scale
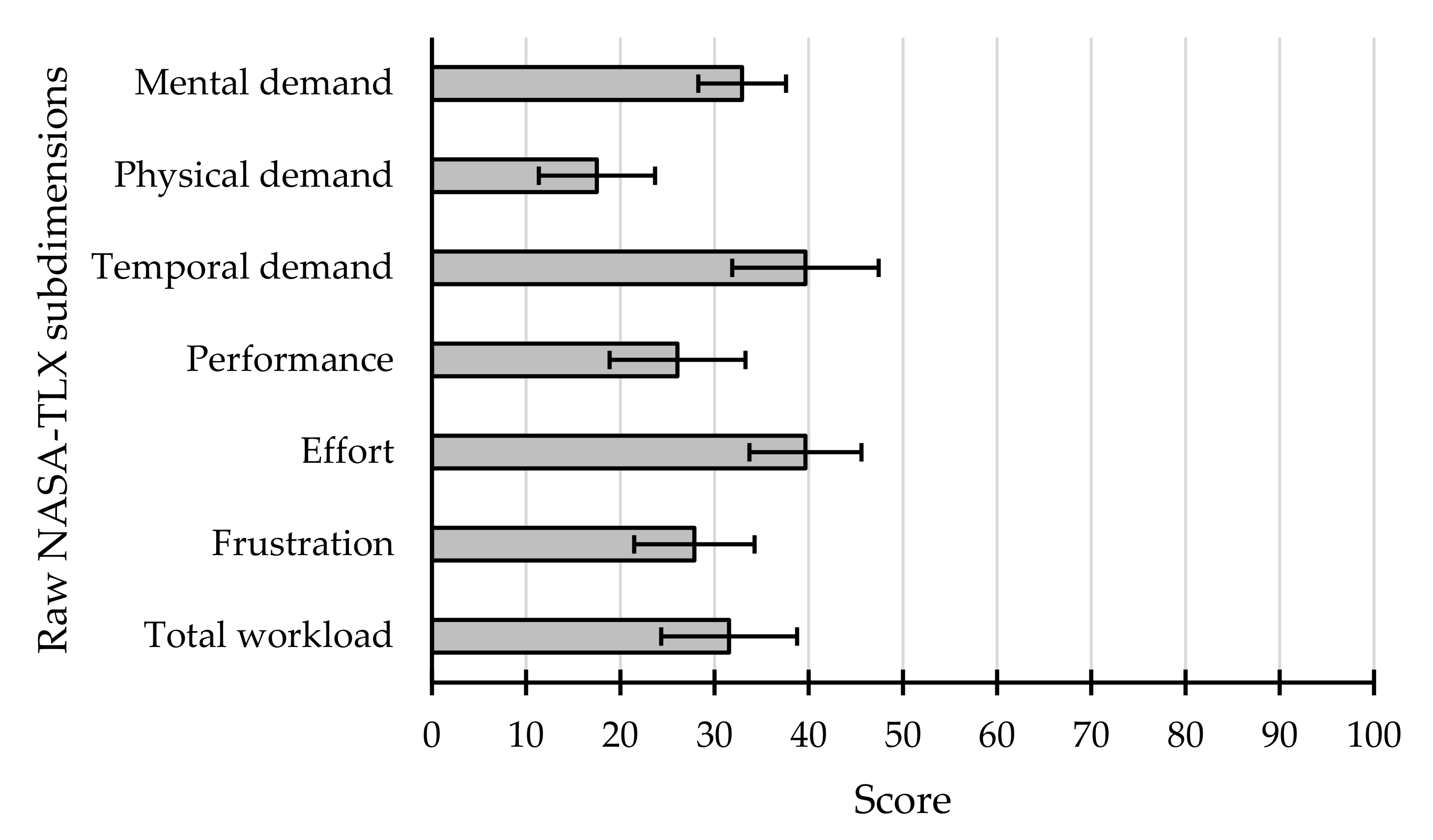
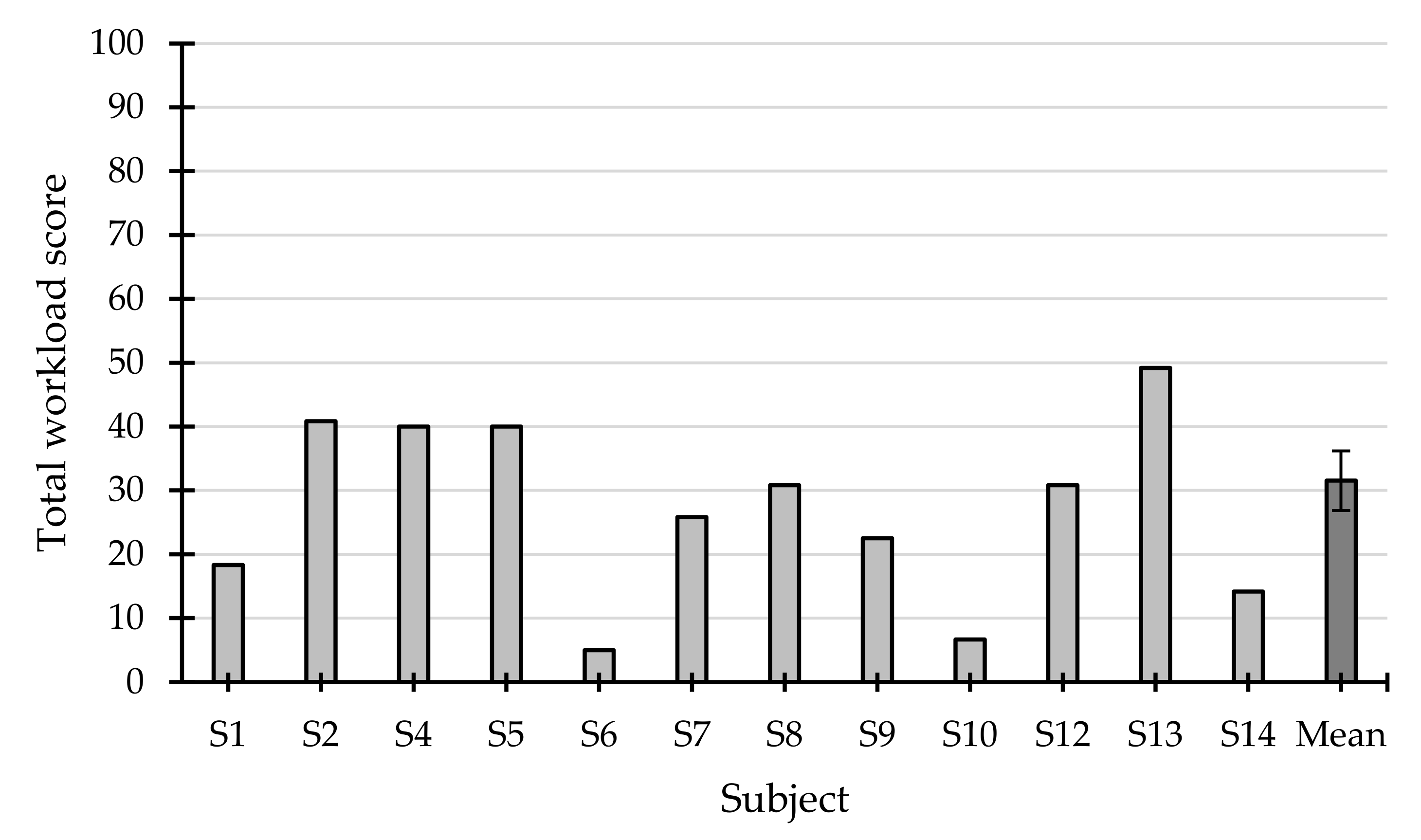
3.2.2. Raw NASA-TLX
3.2.3. Ad Hoc
- (A)
- Negative features
- (B)
- Positive features
- (C)
- Other messaging applications
- (D)
- Other functionality
- (E)
- Additional comments
3.3. Issues with the Virtual Assistant
- Type 1 error. Regarding Task 3, we found a timing problem during the preliminary tests. After the user read the Telegram message with the question “What is your favourite food?”, the assistant asked, “Do you want to reply?”. After this moment, the user had five minutes to send the command “Ok Google, reply [message]”. After five minutes, the assistant no longer recognized the context of the command (a previous message to be replied to), so the response was not sent. As five minutes was too short to form the response using the BCI system, we implemented a simple routine in the assistant. A routine consists of a series of actions that are grouped and executed when the user speaks a determined trigger command. In this case, the routine (named “Wait a while”) was triggered when the user selected the “Reply” command in the IC menu. When this command was selected, the system spoke the sentence “Ok Google, wait a while”, which was the trigger for the mentioned routine. The routine consisted of reducing the smartphone volume to an inaudible level, asking the assistant to (silently) count to 100, then counting again to 100, then to 80 (which lasted almost five minutes), and then asking the assistant “Can you repeat?”. To this question, the assistant replied by repeating the question to the user “Do you want to reply?”, which gave the user another five minutes to reply. After spelling their response, when the users confirmed the sending of the message, the volume level of the smartphone was restored with a new command. The aforementioned “Wait a while” routine caused a new problem. If the user selected the “Reply” command by mistake, thus entering the routine, he/she could cancel the actions of the routine by selecting the “Cancel” command from the IC menu. This selection, in turn, triggered a second routine (named “Routine Cancel”) that stopped the five-minute count and restored the volume level. This new routine was triggered with the voice command “Ok Google, routine cancel” (in Spanish “Ok Google, rutina cancelar”). However, while the assistant was involved in the counting of the first routine, it seemed to have trouble understanding the voice trigger and interpreted “routine ca-” (missing the last two syllables in Spanish), while it could correctly interpret the same voice trigger in an idle state (not counting). The adopted solution was to include a second trigger in the same routine, so this second routine could be triggered with “routine cancel” or with “routine ca”.In relation to this time limit, an error occurred with subject S13 in this same Task 3. Instead of answering with a short message, this subject spelled the whole sentence “la pasta es mi comida favorita” (in English, “pasta is my favorite food”), so he/she took too long to form the sentence “Ok Google, reply pasta is my favorite food” and thus the assistant did not interpret it as a response to a Telegram message, but as new information to be saved. In consequence, the assistant replied “Ok, I’ll remember that pasta is your favorite food” instead of sending the Telegram response.
- Type 2 error. Task 4 required that each user proposed an e-mail address to be registered in the smartphone list of contacts. We decided to use the same name for the contact and to change the e-mail address with each subject so that all users had to spell the same receiver. However, the virtual assistant remembered the e-mail address of the previous subject, even when it had been changed in the contact list of the smartphone because in the Gmail servers this contact did not have the address properly updated. This caused subject S2 to send his/her e-mail message to an undesired address (the one chosen by S1). This error was fixed using different contact names for each subject.
- Type 3 error. As a consequence of the previous error, we decided to use the user identifier as the new contact name for each e-mail address in Task 4. We started naming these contacts as “Subject Three”, “Subject Four” and so on. However, with subject S4 the virtual assistant misinterpreted this two-word contact and it considered the word “Subject” as the receiver and the second word (“Four”, the specific number identifying this subject) as part of the message. Since two names starting with “Subject” (“Subject three” and “Subject four”) were registered in the contact list, the virtual assistant asked the user to specify, “Which Subject do you want to send an e-mail to?”. As the user could not answer this unexpected question, this e-mail was not sent. From subject S5 on, we corrected this error using a single-word name for each contact, the user’s first name. Although the naming for each contact using a single-word could be a disadvantage in real world scenario (for example, to differentiate between two people with the same name), this was chosen to standardize the spelling task for the users and to facilitate the voice recognition task by the virtual assistant.
- Type 4 error. The fix to the previous error worked correctly for two subjects, but subject S7′s given name was already registered in the smartphone. For this subject we registered as the contact name the user’s given name, to which we added the first syllable of the user’s family name, thus resulting in an unrecognizable word that the assistant did not interpret correctly. For this reason, subject S7′s e-mail was not sent. This error was fixed using an easily recognizable single-word name for each contact, the users’ family name.
- Type 5 error. Regarding Task 3, the voice command used to read the received messages was, in Spanish “lee mis Telegram” (in English, “read my Telegrams”). It was used for the participants S1 to S7; however, with S8 the virtual assistant started to misunderstand the command, so it was interpreted as “lee mistela” (in English, “read mistela”, a meaningless phrase since “mistela” is a kind of fortified wine), which sounds somewhat similar to “lee mis telegrams”. The consequence was that the assistant did not read the Telegram messages. In order to fix this problem, this control command (as well as the other “read” commands) was modified to be more explicit: “lee mis mensajes de Telegram” (in English, “read my Telegram messages”).
- Type 6 error. In Task 4, the voice command that was used to send an e-mail was of the type “Ok Google, send an e-mail to [receiver], [message]”, without specifying any e-mail subject. In the case of user S8, however, the virtual assistant interpreted that the spelled message was the subject of the e-mail and that the body of the e-mail was the voice command “Ok Google, send it”, which was used to confirm the sending of the e-mail. As a consequence, the e-mail was not sent.
- Type 7 error. Subject S11′s intended response to Task 3 was “arroz” (“rice”, in English); however, this subject made a mistake and sent the word “arro”, missing the last character. As “arro” is not a word in Spanish, the assistant corrected the mistake and interpreted the answer as “arroz”. Although this automatic correction cannot be exactly considered an error, we included it in this category as it corresponds to a difference between what the user spelled and what the assistant interpreted.
- Type 8 error. Subject S14′s spelled e-mail in Task 4 was “hola Paula feliz Navidad” (in English, “hello Paula merry Christmas”) but the assistant missed the first word and sent the e-mail without it.
4. Discussion
4.1. Performance
4.2. Questionnaires
4.3. Issues with the Virtual Assistant
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kiernan, M.C.; Vucic, S.; Cheah, B.C.; Turner, M.; Eisen, A.; Hardiman, O.; Burrell, J.R.; Zoing, M.C. Amyotrophic lateral sclerosis. Lancet 2011, 377, 942–955. [Google Scholar] [CrossRef]
- Willison, H.J.; Jacobs, B.C.; van Doorn, P.A. Guillain-Barré syndrome. Lancet 2016, 388, 717–727. [Google Scholar] [CrossRef]
- Alper, S.; Raharinirina, S. Assistive Technology for Individuals with Disabilities: A Review and Synthesis of the Literature. J. Spéc. Educ. Technol. 2006, 21, 47–64. [Google Scholar] [CrossRef]
- Jamwal, R.; Jarman, H.K.; Roseingrave, E.; Douglas, J.; Winkler, D. Smart home and communication technology for people with disability: A scoping review. Disabil. Rehabil. Assist. Technol. 2020, 1–21. [Google Scholar] [CrossRef]
- Elsahar, Y.; Hu, S.; Bouazza-Marouf, K.; Kerr, D.; Mansor, A. Augmentative and Alternative Communication (AAC) Advances: A Review of Configurations for Individuals with a Speech Disability. Sensors 2019, 19, 1911. [Google Scholar] [CrossRef] [PubMed]
- Wolpaw, J.R.; Birbaumer, N.; McFarland, D.J.; Pfurtscheller, G.; Vaughan, T.M. Brain–computer interfaces for communication and control. Clin. Neurophysiol. 2002, 113, 767–791. [Google Scholar] [CrossRef]
- Millán, J.D.R.; Rupp, R.; Mueller-Putz, G.; Murray-Smith, R.; Giugliemma, C.; Tangermann, M.; Vidaurre, C.; Cincotti, F.; Kubler, A.; Leeb, R.; et al. Combining brain-computer interfaces and assistive technologies: State-of-the-art and challenges. Front. Neurosci. 2010, 1, 1–15. [Google Scholar] [CrossRef]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain Computer Interfaces, a Review. Sensors 2012, 12, 1211–1279. [Google Scholar] [CrossRef]
- Yadav, D.; Yadav, S.; Veer, K. A comprehensive assessment of Brain Computer Interfaces: Recent trends and challenges. J. Neurosci. Methods 2020, 346, 108918. [Google Scholar] [CrossRef]
- Rezeika, A.; Benda, M.; Stawicki, P.; Gembler, F.; Saboor, A.; Volosyak, I. Brain–Computer Interface Spellers: A Review. Brain Sci. 2018, 8, 57. [Google Scholar] [CrossRef]
- Monobe, K.; Matsubara, A.; Nishifuji, S. Impact of Characteristics of Noise Added to Auditory Stimulus on Auditory Steady-State Response. In Proceedings of the 2019 IEEE 8th Global Conference on Consumer Electronics (GCCE), Osaka, Japan, 15–18 October 2019; pp. 818–821. [Google Scholar] [CrossRef]
- Polich, J. Updating P300: An integrative theory of P3a and P3b. Clin. Neurophysiol. 2007, 118, 2128–2148. [Google Scholar] [CrossRef]
- Farwell, L.A.; Donchin, E. Talking off the top of your head: Toward a mental prothesis utilizing event-relatedpotencials. Electroencephalogr. Clin. Neurophysiol. 1988, 70, 510–523. [Google Scholar] [CrossRef]
- Chai, X.; Zhang, Z.; Guan, K.; Lu, Y.; Liu, G.; Zhang, T.; Niu, H. A hybrid BCI-controlled smart home system combining SSVEP and EMG for individuals with paralysis. Biomed. Signal Process. Control. 2020, 56, 101687. [Google Scholar] [CrossRef]
- He, S.; Zhou, Y.; Yu, T.; Zhang, R.; Huang, Q.; Chuai, L.; Mustafa, M.-U.; Gu, Z.; Yu, Z.L.; Tan, H.; et al. EEG- and EOG-Based Asynchronous Hybrid BCI: A System Integrating a Speller, a Web Browser, an E-Mail Client, and a File Explorer. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 519–530. [Google Scholar] [CrossRef] [PubMed]
- Carabalona, R.; Grossi, F.; Tessadri, A.; Castiglioni, P.; Caracciolo, A.; De Munari, I. Light on! Real world evaluation of a P300-based brain–computer interface (BCI) for environment control in a smart home. Ergonomics 2012, 55, 552–563. [Google Scholar] [CrossRef] [PubMed]
- Corralejo, R.; Nicolás-Alonso, L.F.; Álvarez, D.; Hornero, R. A P300-based brain–computer interface aimed at operating electronic devices at home for severely disabled people. Med. Biol. Eng. Comput. 2014, 52, 861–872. [Google Scholar] [CrossRef]
- Kosmyna, N.; Tarpin-Bernard, F.; Bonnefond, N.; Rivet, B. Feasibility of BCI Control in a Realistic Smart Home Environment. Front. Hum. Neurosci. 2016, 10, 416. [Google Scholar] [CrossRef] [PubMed]
- Aydın, E.A.; Bay, Ö.F.; Güler, I. Implementation of an Embedded Web Server Application for Wireless Control of Brain Computer Interface Based Home Environments. J. Med. Syst. 2015, 40, 27. [Google Scholar] [CrossRef]
- Hsieh, K.L.; Sun, K.T.; Yeh, J.K.; Pan, Y.U. Home care by auditory Brain Computer Interface for the blind with severe physical disabilities. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 527–530. [Google Scholar] [CrossRef]
- Shivappa, V.K.K.; Luu, B.; Solis, M.; George, K. Home automation system using brain computer interface paradigm based on auditory selection attention. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC): Discovering New Horizons in Instrumentation and Measurement, Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Martínez-Cagigal, V.; Santamaría-Vázquez, E.; Gomez-Pilar, J.; Hornero, R. Towards an accessible use of smartphone-based social networks through brain-computer interfaces. Expert Syst. Appl. 2019, 120, 155–166. [Google Scholar] [CrossRef]
- Park, S.; Cha, H.-S.; Im, C.-H. Development of an Online Home Appliance Control System Using Augmented Reality and an SSVEP-Based Brain–Computer Interface. IEEE Access 2019, 7, 163604–163614. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Tang, J.; Yin, E.; Hu, D.; Zhou, Z. A self-paced BCI prototype system based on the incorporation of an intelligent environment-understanding approach for rehabilitation hospital environmental control. Comput. Biol. Med. 2020, 118, 103618. [Google Scholar] [CrossRef]
- Sun, K.-T.; Hsieh, K.-L.; Syu, S.-R. Towards an Accessible Use of a Brain-Computer Interfaces-Based Home Care System through a Smartphone. Comput. Intell. Neurosci. 2020, 2020, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Heo, D.; Kim, M.; Kim, J.; Choi, Y.-J.; Kim, S.-P. Effect of Static Posture on Online Performance of P300-Based BCIs for TV Control. Sensors 2021, 21, 2278. [Google Scholar] [CrossRef] [PubMed]
- Schalk, G.; McFarland, D.J.; Hinterberger, T.; Birbaumer, N.; Wolpaw, J.R. BCI2000: A General-Purpose Brain-Computer Interface (BCI) System. IEEE Trans. Biomed. Eng. 2004, 51, 1034–1043. [Google Scholar] [CrossRef] [PubMed]
- Hoy, M.B. Alexa, Siri, Cortana, and More: An Introduction to Voice Assistants. Med. Ref. Serv. Q. 2018, 37, 81–88. [Google Scholar] [CrossRef]
- Lancioni, G.E.; Singh, N.N.; O’Reilly, M.F.; Sigafoos, J.; D’Amico, F.; Buonocunto, F.; Lanzilotti, C.; Alberti, G.; Navarro, J. Mainstream technology to support basic communication and leisure in people with neurological disorders, motor impairment and lack of speech. Brain Inj. 2020, 34, 921–927. [Google Scholar] [CrossRef]
- Simmons, Z.; Bremer, B.A.; Robbins, R.A.; Walsh, S.M.; Fischer, S. Quality of life in ALS depends on factors other than strength and physical function. Neurology 2000, 55, 388–392. [Google Scholar] [CrossRef]
- Felgoise, S.H.; Stewart, J.L.; Bremer, B.A.; Walsh, S.M.; Bromberg, M.B.; Simmons, Z. The SEIQoL-DW for assessing quality of life in ALS: Strengths and limitations. Amyotroph. Lateral Scler. 2009, 10, 456–462. [Google Scholar] [CrossRef]
- WhatsApp. Two Billion Users—Connecting the World Privately, WhatsApp Blog. 2020. Available online: https://blog.whatsapp.com/two-billion-users-connecting-the-world-privately (accessed on 10 February 2021).
- Telegram. 400 Million Users, Telegram Blog. 2020. Available online: https://telegram.org/blog/400-million (accessed on 10 February 2021).
- Statista. Number of E-Mail Users Worldwide, Statista. 2020. Available online: https://www.statista.com/statistics/255080/number-of-e-mail-users-worldwide/ (accessed on 10 February 2021).
- Statista. Number of Smartphone Users Worldwide. Statista. 2021. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 10 February 2021).
- Velasco-Álvarez, F.; Sancha-Ros, S.; García-Garaluz, E.; Fernández-Rodríguez, Á.; Medina-Juliá, M.T.; Ron-Angevin, R. UMA-BCI Speller: An easily configurable P300 speller tool for end users. Comput. Methods Programs Biomed. 2019, 172, 127–138. [Google Scholar] [CrossRef]
- Kübler, A.; Neumann, N.; Kaiser, J.; Kotchoubey, B.; Hinterberger, T.; Birbaumer, N. Brain-computer communication: Self-regulation of slow cortical potentials for verbal communication. Arch. Phys. Med. Rehabil. 2001, 82, 1533–1539. [Google Scholar] [CrossRef]
- Kaufmann, T.; Herweg, A.; Kübler, A. Toward brain-computer interface based wheelchair control utilizing tactually-evoked event-related potentials. J. Neuroeng. Rehabil. 2014, 11, 7. [Google Scholar] [CrossRef]
- User Reference:P300Classifier. 2011. Available online: https://www.bci2000.org/mediawiki/index.php/User_Reference:P300Classifier (accessed on 2 September 2020).
- Xu, L.; Xu, M.; Jung, T.-P.; Ming, D. Review of brain encoding and decoding mechanisms for EEG-based brain–computer interface. Cogn. Neurodyn. 2021, 1–16. [Google Scholar] [CrossRef]
- Frequency Dictionary. Word Frequency Data. 2018. Available online: https://www.wordfrequency.info/ (accessed on 13 March 2021).
- Furdea, A.; Halder, S.; Krusienski, D.; Bross, D.; Nijboer, F.; Birbaumer, N.; Kübler, A. An auditory oddball (P300) spelling system for brain-computer interfaces. Psychophysiology 2009, 46, 617–625. [Google Scholar] [CrossRef] [PubMed]
- Townsend, G.; LaPallo, B.; Boulay, C.; Krusienski, D.; Frye, G.; Hauser, C.; Schwartz, N.; Vaughan, T.; Wolpaw, J.; Sellers, E. A novel P300-based brain–computer interface stimulus presentation paradigm: Moving beyond rows and columns. Clin. Neurophysiol. 2010, 121, 1109–1120. [Google Scholar] [CrossRef]
- Wolpaw, J.; Ramoser, H.; McFarland, D.; Pfurtscheller, G. EEG-based communication: Improved accuracy by response verification. IEEE Trans. Rehabil. Eng. 1998, 6, 326–333. [Google Scholar] [CrossRef]
- Townsend, G.; Platsko, V. Pushing the P300-based brain–computer interface beyond 100 bpm: Extending performance guided constraints into the temporal domain. J. Neural Eng. 2016, 13, 026024. [Google Scholar] [CrossRef]
- Ma, Z.; Qiu, T. Performance improvement of ERP-based brain–computer interface via varied geometric patterns. Med. Biol. Eng. Comput. 2017, 55, 2245–2256. [Google Scholar] [CrossRef]
- Kellicut-Jones, M.R.; Sellers, E.W. P300 brain-computer interface: Comparing faces to size matched non-face stimuli. Brain Comp. Interfaces 2018, 5, 30–39. [Google Scholar] [CrossRef]
- Ryan, D.B.; Frye, G.E.; Townsend, G.; Berry, D.R.; Mesa-G, S.; Gates, N.A.; Sellers, E.W. Predictive Spelling with a P300-Based Brain–Computer Interface: Increasing the Rate of Communication. Int. J. Hum. Comput. Interact. 2010, 27, 69–84. [Google Scholar] [CrossRef] [PubMed]
- Brooke, J. SUS: A ‘Quick and Dirty’ Usability Scale. In Usability Evaluation in Industry; Taylore & Francis: London, UK, 1996. [Google Scholar]
- Hart, S.G. Nasa-Task Load Index (NASA-TLX); 20 Years Later. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2006, 50, 904–908. [Google Scholar] [CrossRef]
- Bangor, A.; Kortum, P.T.; Miller, J.T. An Empirical Evaluation of the System Usability Scale. Int. J. Hum. Comput. Interact. 2008, 24, 574–594. [Google Scholar] [CrossRef]
- Hart, S.G.; Staveland, L.E. Development of NASA-TLX (Task Load Index): Results of Empirical and Theoretical Research. Adv. Psychol. 1988, 52, 139–183. [Google Scholar] [CrossRef]
- Fernández-Rodríguez, Á.; Medina-Juliá, M.T.; Velasco-Álvarez, F.; Ron-Angevin, R. Different effects of using pictures as stimuli in a P300 brain-computer interface under rapid serial visual presentation or row-column paradigm. Med. Biol. Eng. Comput. 2021, 59, 869–881. [Google Scholar] [CrossRef]
- Geronimo, A.; Simmons, Z. TeleBCI: Remote user training, monitoring, and communication with an evoked-potential brain-computer interface. Brain Comput. Interfaces 2020, 7, 57–69. [Google Scholar] [CrossRef]
- Käthner, I.; Wriessnegger, S.C.; Müller-Putz, G.R.; Kübler, A.; Halder, S. Effects of mental workload and fatigue on the P300, alpha and theta band power during operation of an ERP (P300) brain–computer interface. Biol. Psychol. 2014, 102, 118–129. [Google Scholar] [CrossRef] [PubMed]
- Furnham, A. Response bias, social desirability and dissimulation. Personal. Individ. Differ. 1986, 7, 385–400. [Google Scholar] [CrossRef]
- Arora, S.; Athavale, V.A.; Maggu, H.; Agarwal, A. Artificial Intelligence and Virtual Assistant—Working Model. In Lecture Notes in Networks and Systems; Springer: Singapore, 2021; Volume 140, pp. 163–171. [Google Scholar]
- Piantadosi, G.; Marrone, S.; Sansone, C. On Reproducibility of Deep Convolutional Neural Networks Approaches. In Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics (LNCS); Springer International Publishing: Cham, Switzerland, 2019; Volume 11455, pp. 104–109. [Google Scholar]
- Michaely, A.H.; Zhang, X.; Simko, G.; Parada, C.; Aleksic, P. Keyword spotting for Google assistant using contextual speech recognition. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2017; pp. 272–278. [Google Scholar]
- Aleksic, P.; Ghodsi, M.; Michaely, A.; Allauzen, C.; Hall, K.; Roark, B.; Rybach, D.; Moreno, P. Bringing contextual information to google speech recognition. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 468–472. [Google Scholar]
- Nijboer, F.; Sellers, E.; Mellinger, J.; Jordan, M.; Matuz, T.; Furdea, A.; Halder, S.; Mochty, U.; Krusienski, D.; Vaughan, T.; et al. A P300-based brain–computer interface for people with amyotrophic lateral sclerosis. Clin. Neurophysiol. 2008, 119, 1909–1916. [Google Scholar] [CrossRef] [PubMed]
- McCane, L.M.; Sellers, E.W.; McFarland, D.J.; Mak, J.N.; Carmack, C.S.; Zeitlin, D.; Wolpaw, J.R.; Vaughan, T.M. Brain-computer interface (BCI) evaluation in people with amyotrophic lateral sclerosis. Amyotroph. Lateral Scler. Front. Degener. 2014, 15, 207–215. [Google Scholar] [CrossRef] [PubMed]
- Medina-Juliá, M.T.; Fernández-Rodríguez, Á.; Velasco-Álvarez, F.; Ron-Angevin, R. P300-Based Brain-Computer Interface Speller: Usability Evaluation of Three Speller Sizes by Severely Motor-Disabled Patients. Front. Hum. Neurosci. 2020, 14, 583358. [Google Scholar] [CrossRef] [PubMed]
- Cedarbaum, J.M.; Stambler, N.; Malta, E.; Fuller, C.; Hilt, D.; Thurmond, B.; Nakanishi, A. The ALSFRS-R: A revised ALS functional rating scale that incorporates assessments of respiratory function. J. Neurol. Sci. 1999, 169, 13–21. [Google Scholar] [CrossRef]








| Task 1 | Task 2 | Task 3 | Task 4 | ||||
|---|---|---|---|---|---|---|---|
| Menu | Actions | Menu | Actions | Menu | Actions | Menu | Actions |
| NC | (Wait 1 min) | NC | (Rest) | NC | (Rest) | NC | (Rest) |
| - IC | - IC | - IC | - IC | ||||
| IC | - Send WA | IC | - Read SMS | IC | - Read TG | IC | - Send Mail |
| Spelling | - Spell receiver | NC | - IC | Spelling | - Spell receiver | ||
| - Spell message | IC | - Reply | - Spell message | ||||
| - OK | Spelling | - Spell response | - OK | ||||
| Conf. | - Confirm | - OK | Conf. | - Confirm | |||
| Conf. | - Confirm | NC | (Wait 1 min) | ||||
| Minimum actions | |||||||
| 19 | 2 | 6 + free spelling response | 7 1 + free spelling message | ||||
| Subject | Seq. | Selected Commands | Time Required (s) | Acc | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Task 1 | Task 2 | Task 3 | Task 4 | Total | Task 1 | Task 2 | Task 3 | Task 4 | Total | |||
| S1 | 3 | 19 | 2 | 29 | 21 | 71/67 | 304 | 32 | 464 | 336 | 1136 | 98.59 |
| S2 | 4 | 31 | 3 | 28 | 31 | 93/57 | 591 | 57 | 534 | 591 | 1773 | 78.5 |
| S4 | 4 | 23 | 3 | 27 | 28 | 81/62 | 438 | 57 | 514 | 533 | 1542 | 86.42 |
| S5 | 5 | 20 | 3 | 23 | 24 | 70/55 | 444 | 67 | 510 | 533 | 1554 | 88.57 |
| S6 | 4 | 23 | 2 | 25 | 22 | 72/63 | 441 | 38 | 479 | 422 | 1380 | 93.06 |
| S7 | 8 | 25 | 3 | 24 | 39 | 91/59 | 789 | 95 | 757 | 1231 | 2872 | 80.22 |
| S8 | 3 | 30 | 3 | 28 | 52 | 113/65 | 475 | 48 | 444 | 824 | 1791 | 70.8 |
| S9 | 6 | 19 | 2 | 28 | 22 | 71/60 | 485 | 51 | 714 | 561 | 1811 | 92.96 |
| S10 | 4 | 19 | 3 | 23 | 39 | 84/57 | 362 | 57 | 439 | 744 | 1602 | 85.71 |
| S12 | 3 | 21 | 2 | 21 | 26 | 70/61 | 335 | 32 | 335 | 414 | 1116 | 94.29 |
| S13 | 3 | 23 | 2 | 50 | 37 | 112/73 | 365 | 48 | 794 | 588 | 1795 | 75 |
| S14 | 4 | 25 | 2 | 16 | 24 | 67/55 | 476 | 38 | 305 | 457 | 1276 | 89.55 |
| Mean | 4.25 | 23.17 | 2.5 | 26.83 | 30.42 | 82.92/61.17 | 458.8 | 51.67 | 524.08 | 602.8 | 1637.33 | 86.14 |
| Standard deviation | 1.49 | 4.06 | 0.52 | 8.19 | 9.51 | 16.27/5.3 | 130.1 | 17.51 | 155.69 | 240.5 | 463.06 | 8.46 |
| Subject | Task | Description 3 | Error Type |
|---|---|---|---|
| Preliminary tests, S13 | 3 | Time limit to reply to an incoming message | 1 |
| S2 | 4 | Use of the same name for different contacts | 2 |
| S4 | 4 | Use of a similar name for different contacts | 3 |
| S7 | 4 | Use of an unrecognisable word for a contact | 4 |
| S8 | 3 | Phonetic similarity | 5 |
| S8 | 4 | Confused subject/body of the message | 6 |
| S11 1 | 3 | Automatic correction of misspelled words | 7 |
| S14 | 4 | Words missing | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velasco-Álvarez, F.; Fernández-Rodríguez, Á.; Vizcaíno-Martín, F.-J.; Díaz-Estrella, A.; Ron-Angevin, R. Brain–Computer Interface (BCI) Control of a Virtual Assistant in a Smartphone to Manage Messaging Applications. Sensors 2021, 21, 3716. https://doi.org/10.3390/s21113716
Velasco-Álvarez F, Fernández-Rodríguez Á, Vizcaíno-Martín F-J, Díaz-Estrella A, Ron-Angevin R. Brain–Computer Interface (BCI) Control of a Virtual Assistant in a Smartphone to Manage Messaging Applications. Sensors. 2021; 21(11):3716. https://doi.org/10.3390/s21113716
Chicago/Turabian StyleVelasco-Álvarez, Francisco, Álvaro Fernández-Rodríguez, Francisco-Javier Vizcaíno-Martín, Antonio Díaz-Estrella, and Ricardo Ron-Angevin. 2021. "Brain–Computer Interface (BCI) Control of a Virtual Assistant in a Smartphone to Manage Messaging Applications" Sensors 21, no. 11: 3716. https://doi.org/10.3390/s21113716
APA StyleVelasco-Álvarez, F., Fernández-Rodríguez, Á., Vizcaíno-Martín, F.-J., Díaz-Estrella, A., & Ron-Angevin, R. (2021). Brain–Computer Interface (BCI) Control of a Virtual Assistant in a Smartphone to Manage Messaging Applications. Sensors, 21(11), 3716. https://doi.org/10.3390/s21113716