Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Framework and Methods
2.1. CNN Based Image Feature Extraction
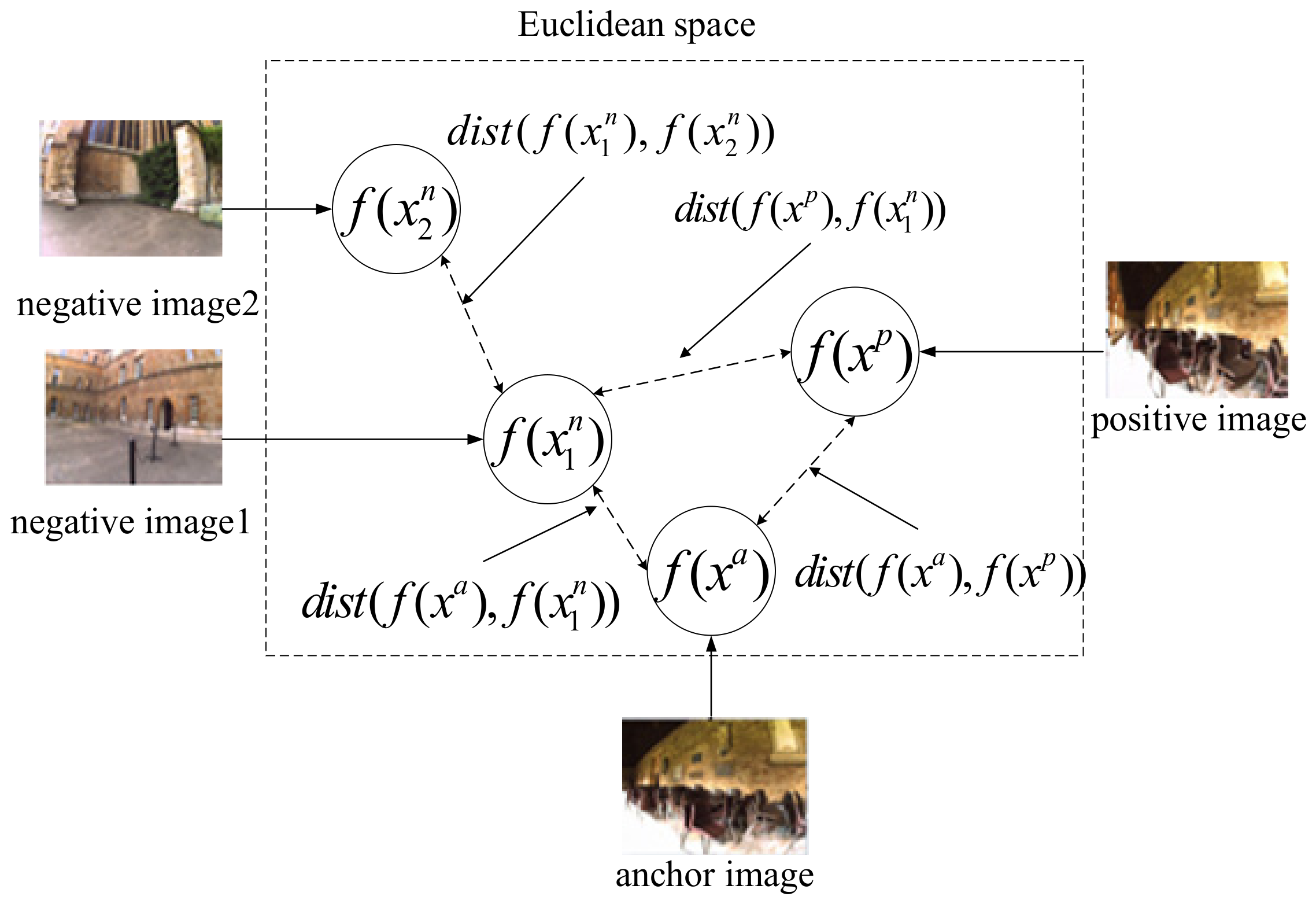
2.2. Triplet Loss
- Image i and image j are not the same image and from the same category.
- Image i and image k are from different categories.
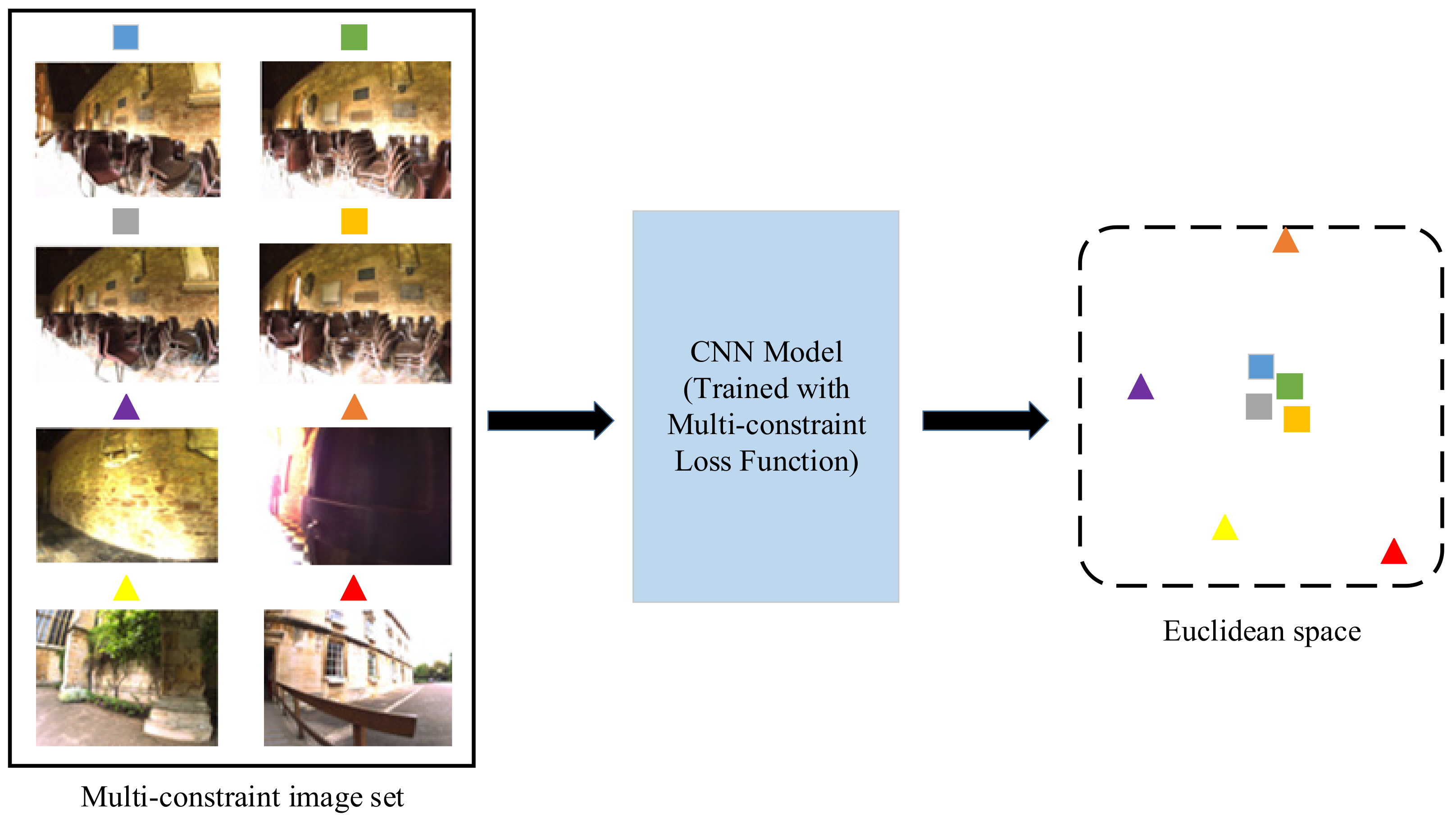
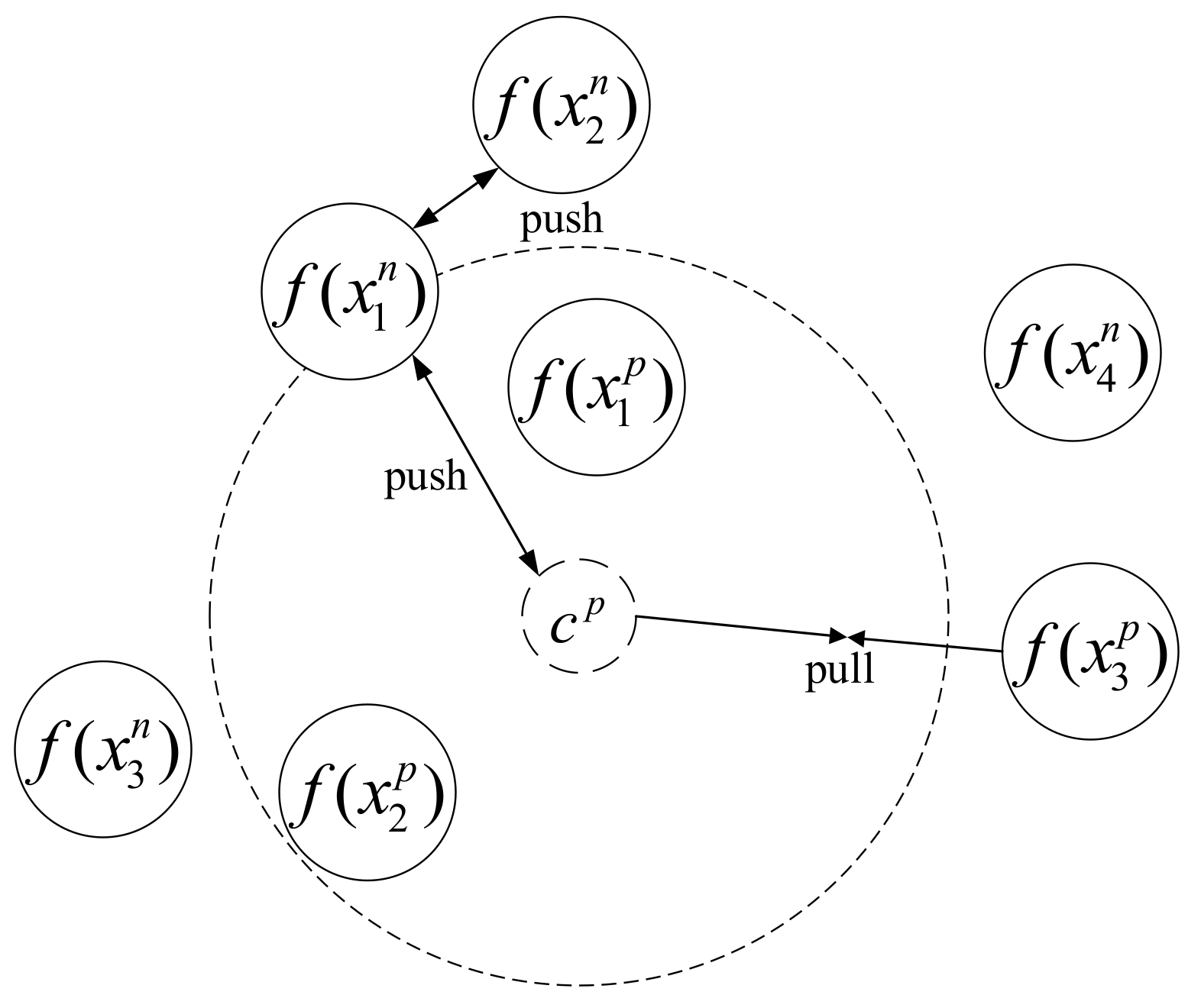
2.3. Multi-Constraint Loss
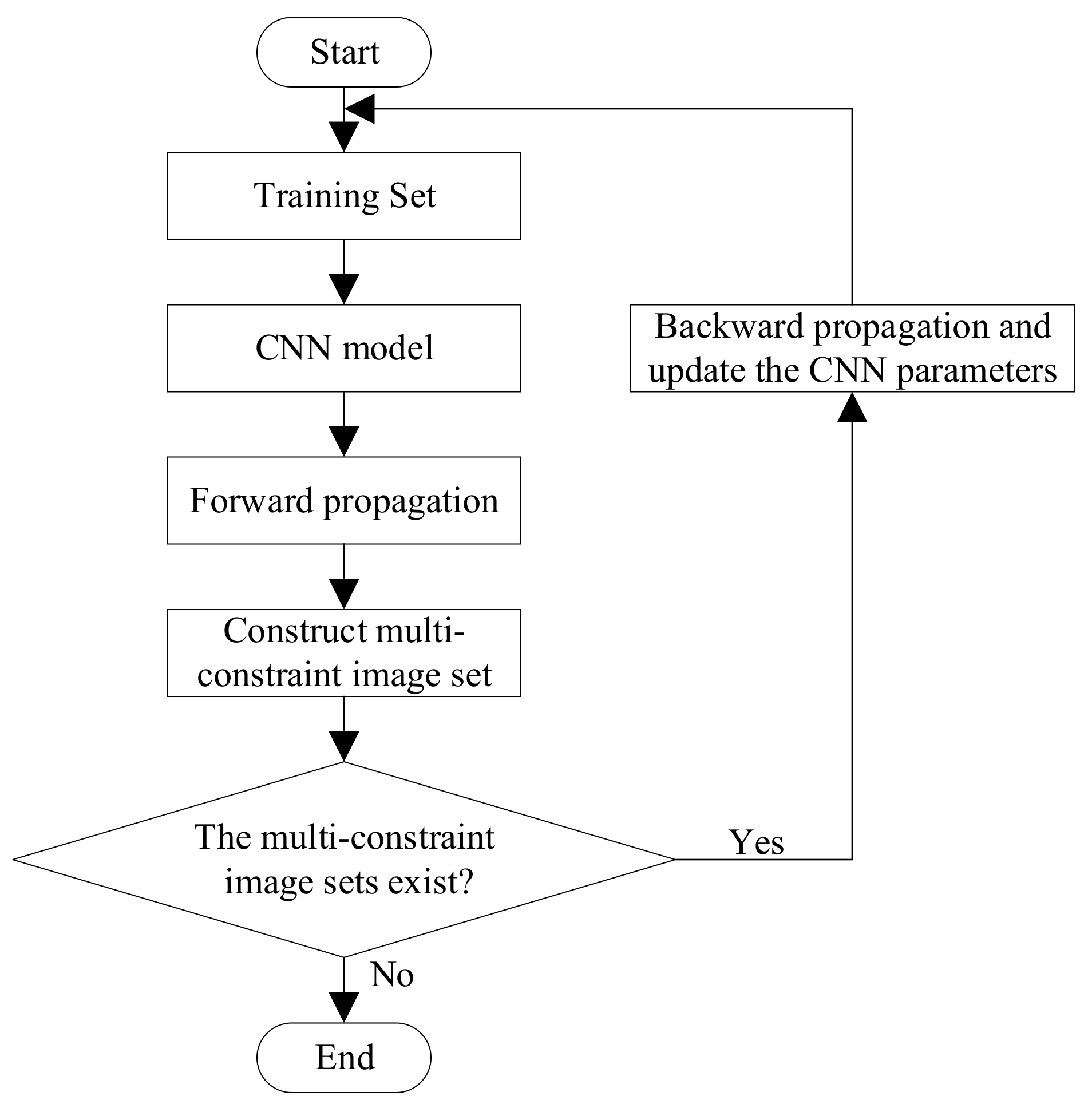
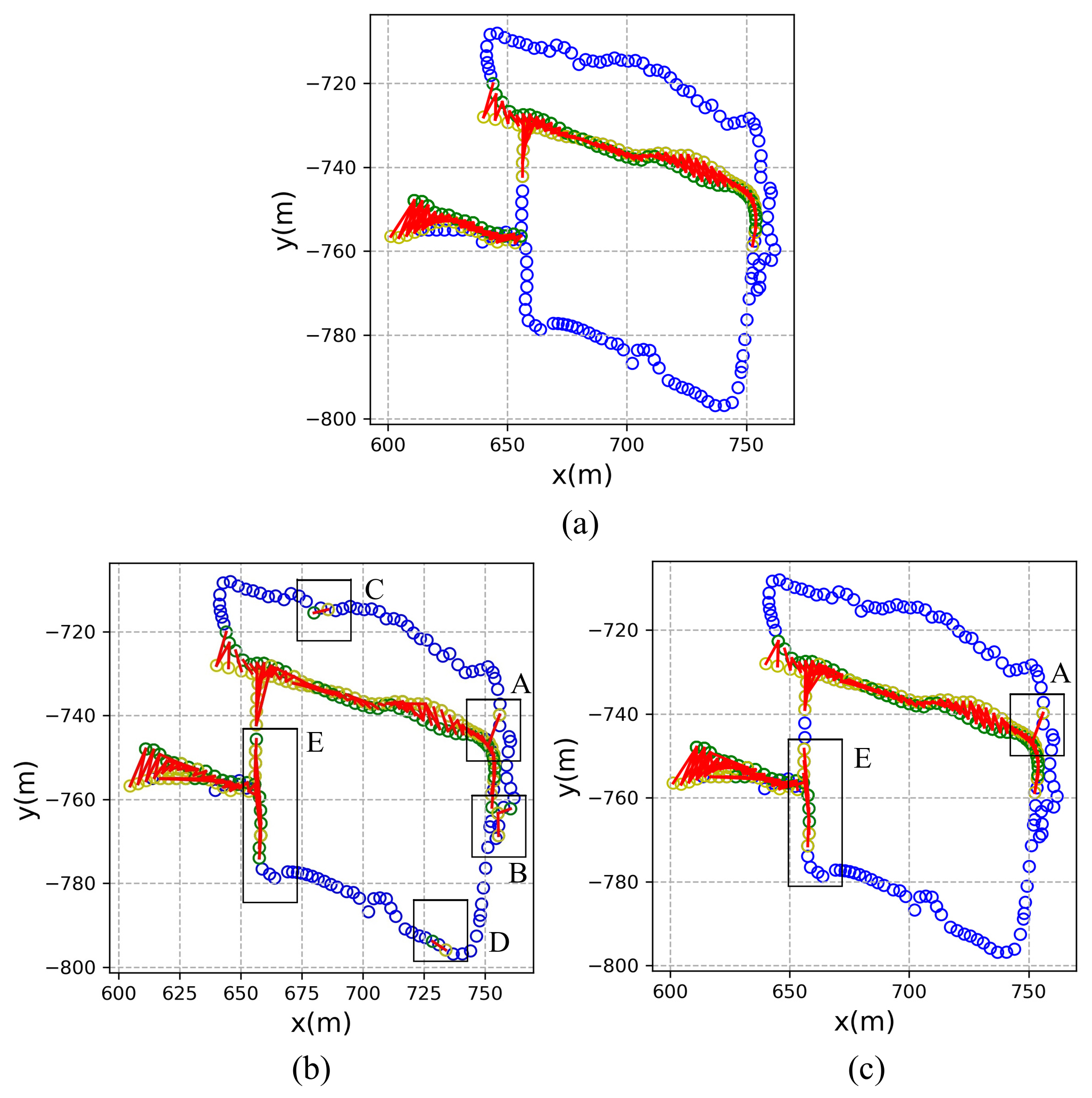
2.4. Construction of Multi-Constraint Image Set
| Algorithm 1. Method to construct multi-constraint image sets. |
| Input: Training set with place labels ; Output: Multi-constraint image sets X; 1: Extract the feature vector for each training image; 2: for each i in {1, 2, ……, n} do 3: Find u images from the same place with xi; 4: Calculate the center point cp; 5: for each j in {1, 2, ……, n} and j ≠ i do 6: Find images from the same place & satisfy the distance relationship . Add these images into positive image set ; 7: Find images from different places & satisfy the distance relationship . Add these images into negative image set ; 8: end for 9: if then 10: Randomly select B images from ; 11: end if 12: if or ( and ) then 13: Randomly select images from different places. 14: end if 15: if then 16: Randomly select A images from ; 17: end if 18: if or ( and ) then 19: Randomly copy images from the same place. 20: end if 21: if and exist then 22: Add into X; 23: end if 24: end for 25: return X |
2.5. Training Process
3. Results
3.1. Baselines
- (1)
- AMOSNet: Spatial-pyramidal pooling operation is implemented on the conv5 layer of AMOSNet to extract feature vectors. The model is open-sourced [20]. L1-difference is used to measure the distance.
- (2)
- HybridNet: HybridNet and AMOSNet have the same network structure. However, the weights of HybridNet are initialized from CaffeNet. The deployed model parameters of HybridNet are also available [20].
- (3)
- NetVLAD: We have employed the Python implementation of NetVLAD open-sourced in [44]. NetVLAD plug the VLAD layer into the CNN architecture. Given N D-dimensional local image feature vectors and K cluster centers (“visual words”) as input, the output feature vectors of the VLAD layer are dimensional. The concept of clustering is only used to obtain more global feature vectors in NetVLAD. In contrast to NetVLAD, the clustering method used in this paper is to directly optimize the distance constraint relationships in the Euclidean space. The model selected for evaluation is VGGNet which has been trained in an end-to-end manner on Pittsburgh 250 K dataset [45] with a dictionary size of 64 while performing whitening on the final descriptors.
- (4)
- R-MAC: We have employed the Python implementation for R-MAC [24]. We use conv5_2 of object-centric VGGNet for regions-based features and post-process it with L2 normalization and PCA-whitening [46]. The retrieved R-MACs are mutually matched, followed by aggregation of the mutual regions’ cross-matching scores.
- (5)
- Region-VLAD: We employed conv4 of AlexNet for evaluating the Region-VLAD visual place recognition approach [25]. The employed dictionary contains 256 visual words used for VLAD retrieval. Cosine similarity is subsequently used for descriptor comparison.
3.2. Evaluation Datasets
3.3. Results and Analysis
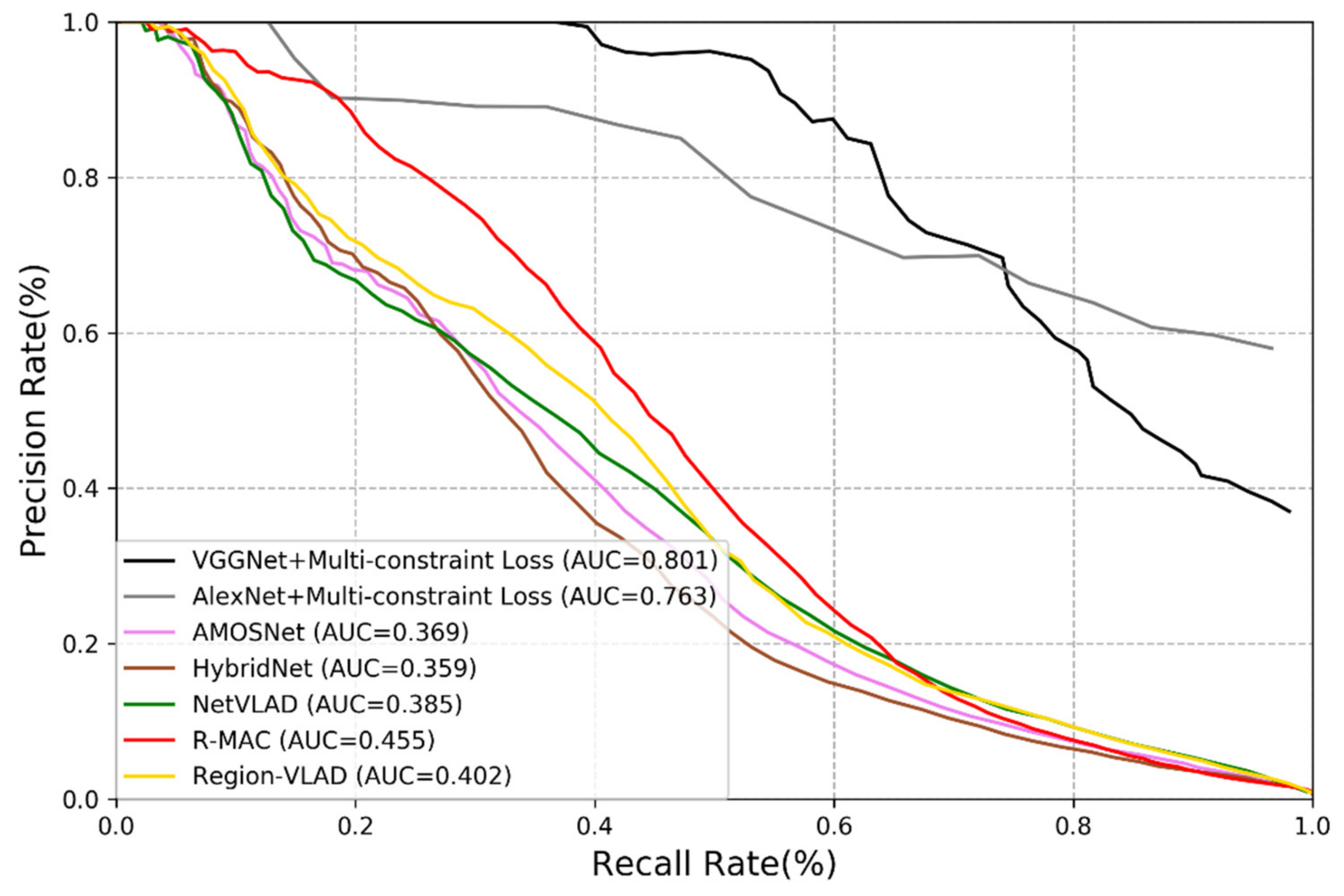
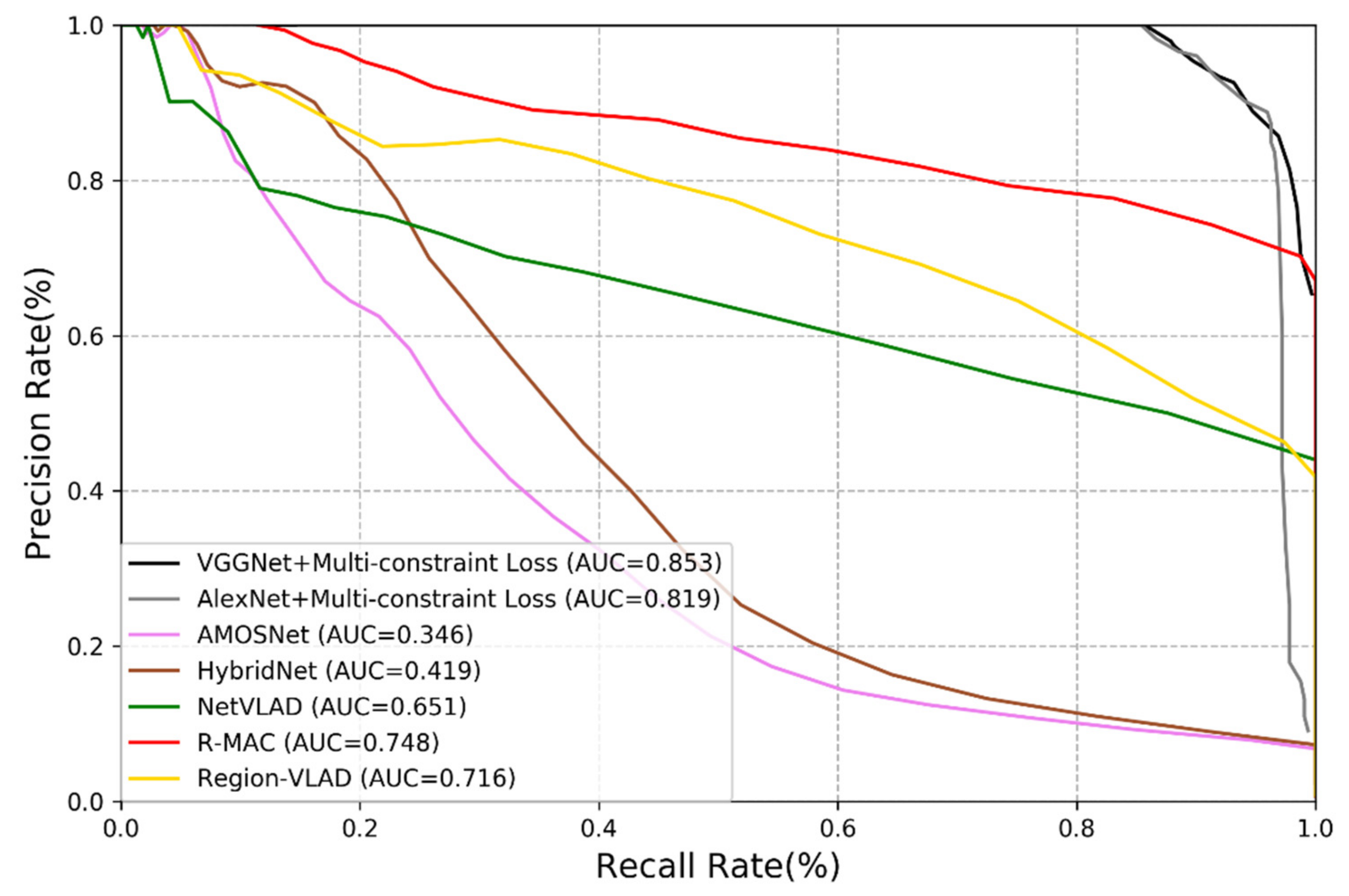
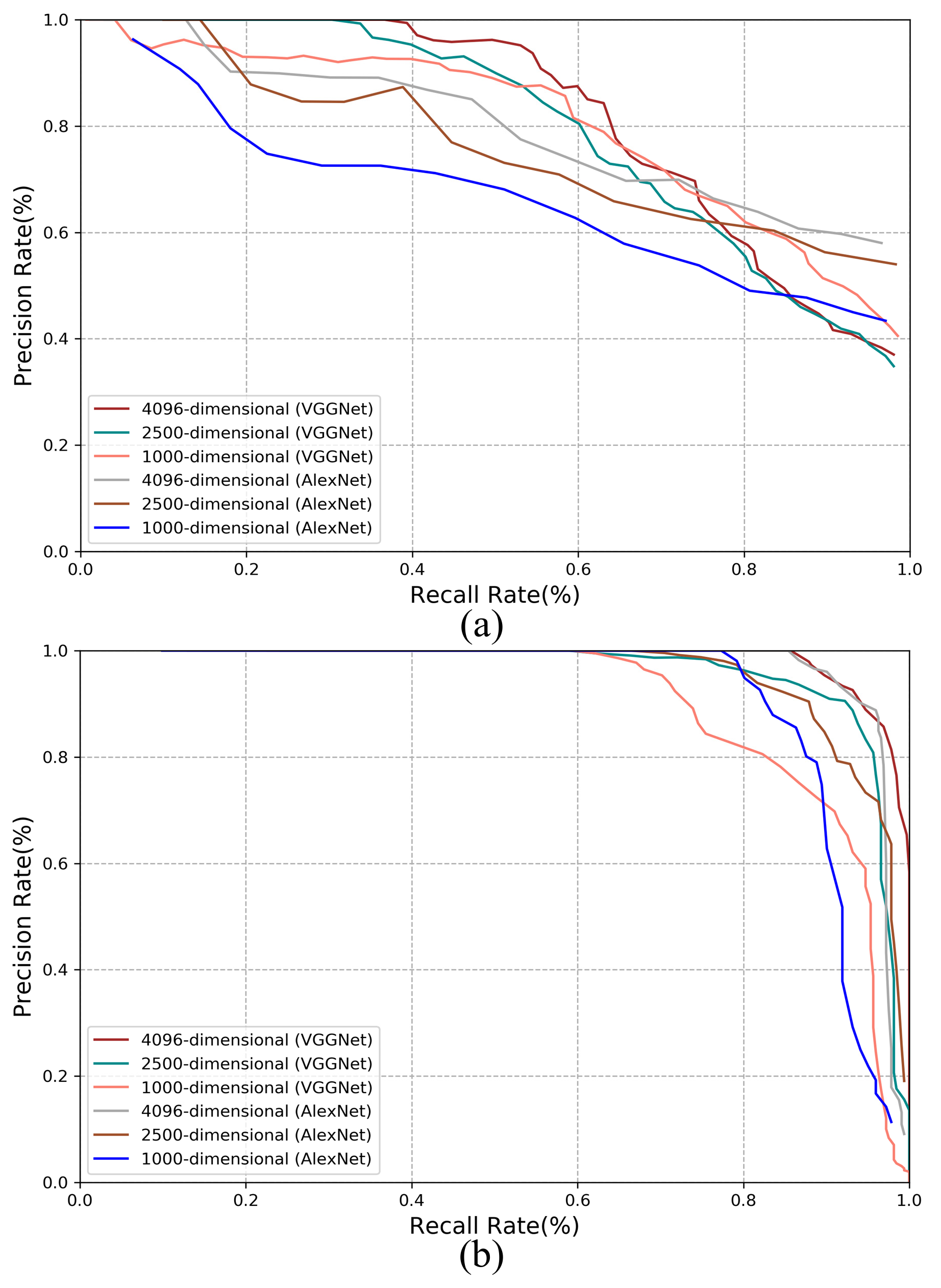
3.3.1. Comparison with Mainstream Methods
- (1)
- Among all deep learning-based methods, the performance of AMOSNet, HybridNet and NetVLAD is relatively poor.
- (2)
- Generally, the CNNs trained with multi-constraint loss function exhibit the best performance on both outdoor and indoor datasets. This proves that the multi-constraint loss based deep distance learning is suitable for the visual place recognition and the multi-constraint loss function has great advantages in discriminative feature extraction.
- (3)
- In Figure 5 and Figure 6, the proposed method performs better on the TUM dataset than the New College dataset. It is because images from the TUM dataset are more stable and static and the New College dataset contains more dynamic objects and illumination variations. We may conclude that the proposed method is more suitable for the static indoor environment. This is also valid for NetVLAD, R-MAC and Region-VLAD.
- (4)
- The versatility of the multi-constraint loss is verified in the experiment, i.e., it can support AlexNet, VGGNet and other user-defined networks. In other words, the AMOSNet and HybridNet model can also be combined with the multi-constraint loss for possible further improvement. The influence of the network structure on the performance is not as important as that of the loss function.
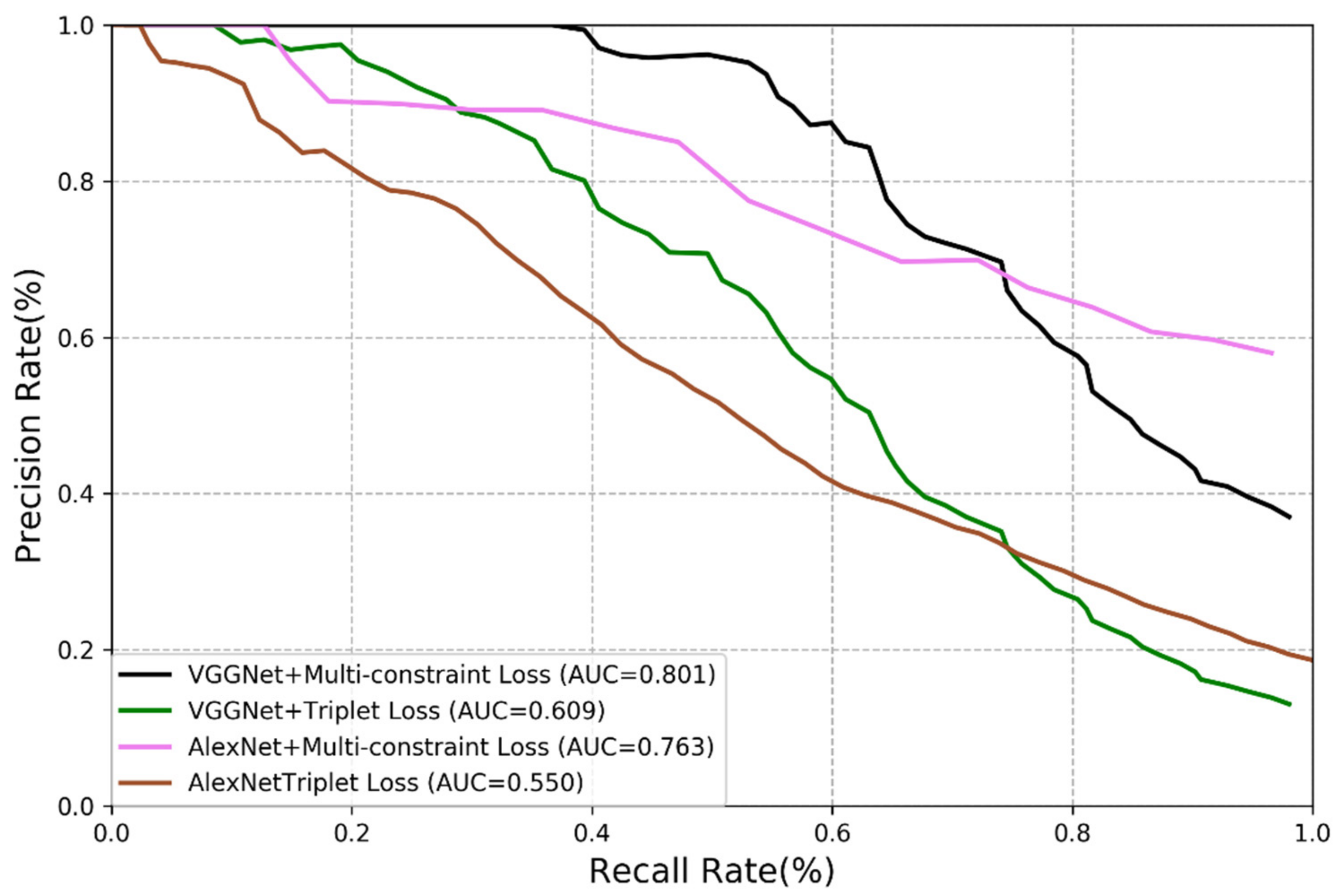
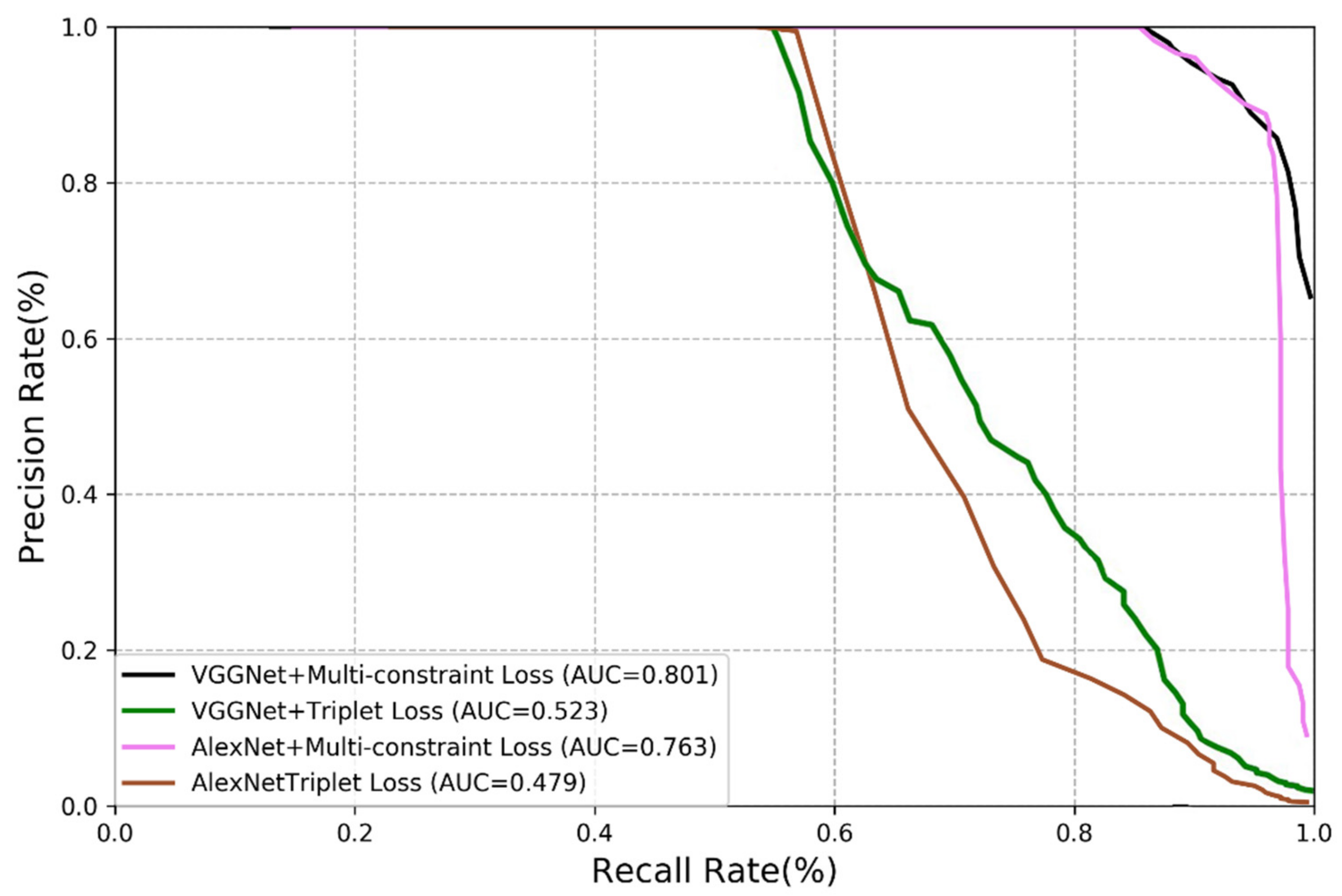
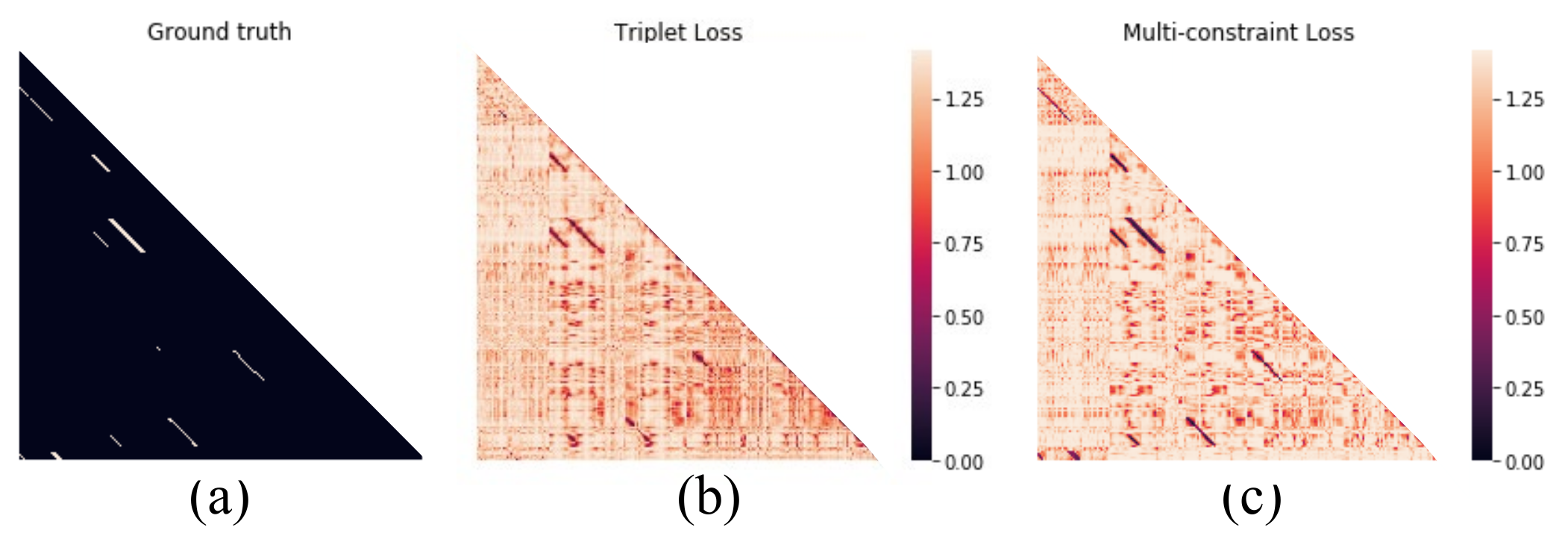
3.3.2. Comparison of Multi-Constraint Loss Function and Triplet Loss
3.3.3. Comparison of Multi-Constraint Loss Function and Triplet Loss
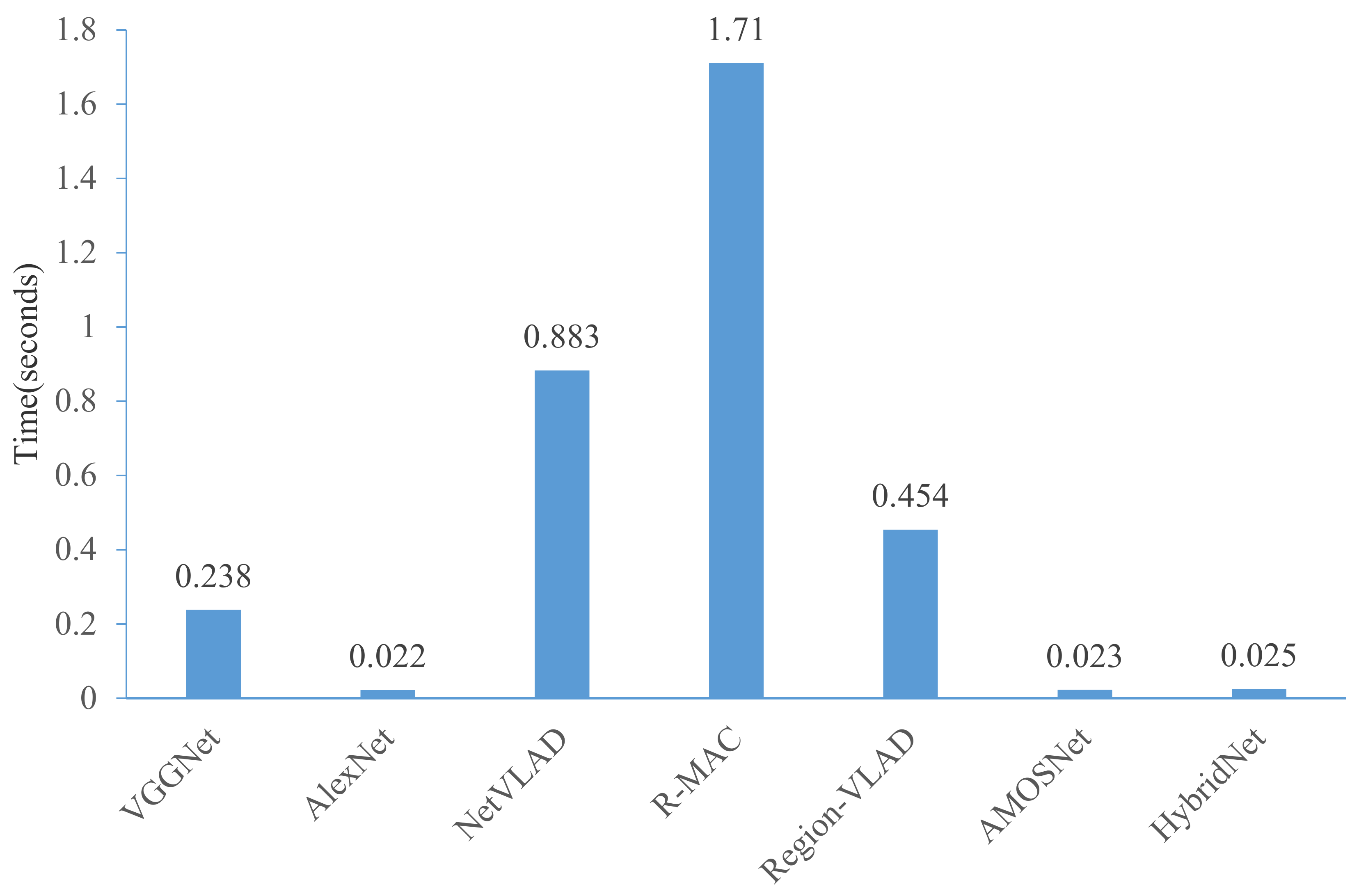
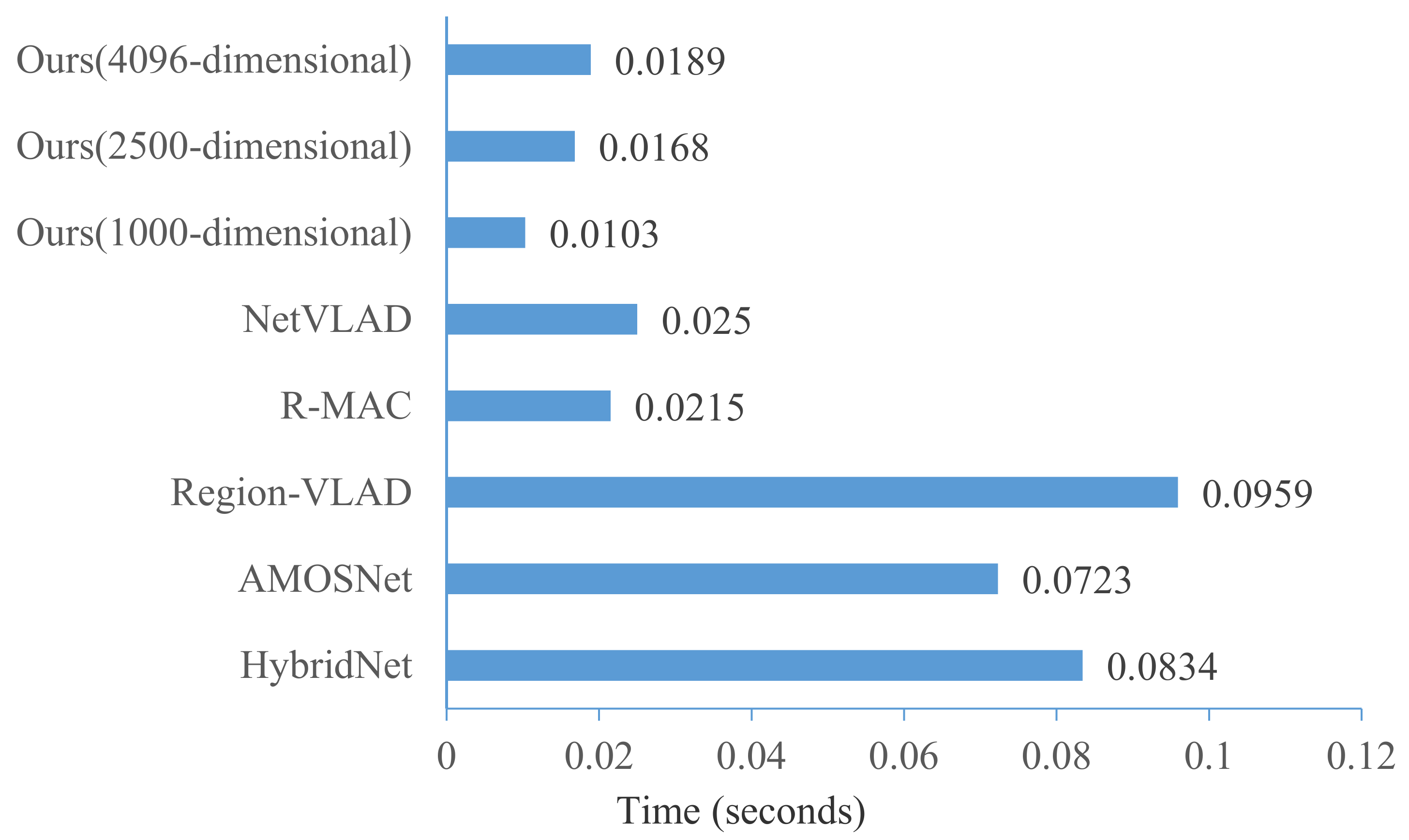
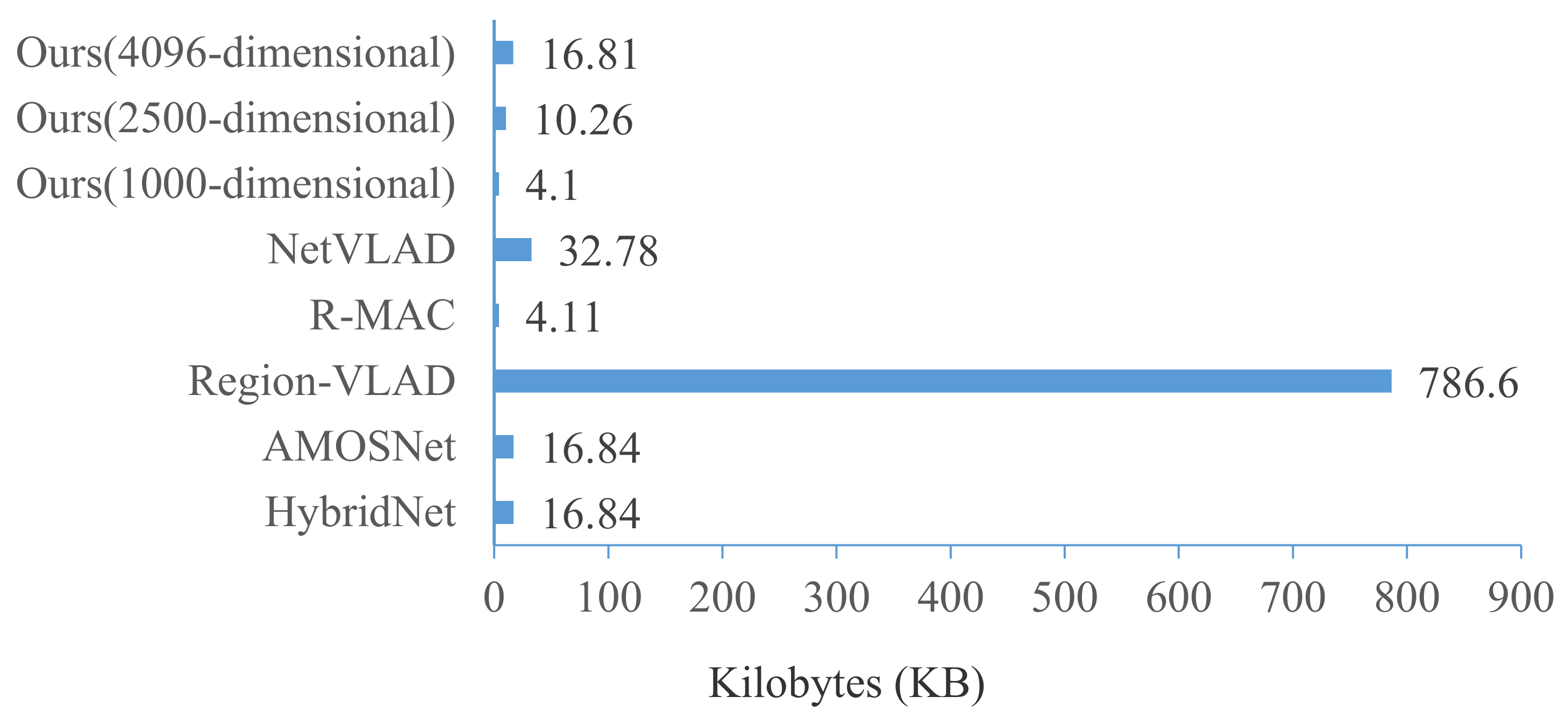
3.3.4. Time Performance Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lowry, S.; Sünderhauf, N.; Newman, P.; Leonard, J.; Cox, D.; Corke, P.; Milford, M. Visual place recognition: A survey. IEEE Trans. Rob. 2016, 32, 1–19. [Google Scholar] [CrossRef]
- Raúl, M.; Tardós, J. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J. Past, present, and future of simultaneous localization and mapping: Towards the robust-perception age. IEEE Trans. Rob. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Guclu, O.; Can, A. Fast and Effective Loop Closure Detection to Improve SLAM Performance. J. Intell Robot. Syst. 2019, 93, 495–517. [Google Scholar] [CrossRef]
- Zaffar, M. Visual Place Recognition for Autonomous Robots. Master’s Thesis, University of Essex, Essex, UK, September 2020. [Google Scholar]
- Lowe, D.R. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Goolab, L. Speeded-up robust features (SURF). Comput. Vision Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 13–16 October 2003. [Google Scholar]
- Gálvez-López, D.; Tardos, J. Bags of binary words for fast place recognition in image sequences. IEEE Trans. Rob. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Liu, H.; Wang, R.; Shan, S.; Chen, X. Deep Supervised Hashing for Fast Image Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2064–2072. [Google Scholar]
- Krizhevsky, A.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1–9. [Google Scholar]
- Babenko, A.; Slesarev, A.; Chigorin, A.; Lempitsky, V. Neural Codes for Image Retrieval. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the Devil in the Details: Delving Deep into Convolutional Nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Wan, J.; Wang, D.; Chu Hong Hoi, S.; Wu, P.; Zhu, J.; Zhang, Y.; Li, J. Deep Learning for Content-Based Image Retrieval: A Comprehensive Study. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 157–166. [Google Scholar]
- Sünderhauf, N.; Shirazi, S.; Dayoub, F.; Upcroft, B. On the performance of ConvNet features for place recognition. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 4297–4304. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xia, Y.; Li, J.; Qi, L.; Fan, H. Loop closure detection for visual SLAM using PCANet features. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 24–29 July 2016; pp. 2274–2281. [Google Scholar]
- Chen, Z.; Jacobson, A.; Sünderhauf, N.; Upcroft, B.; Liu, L.; Shen, C.; Reid, I.; Milford, M. Deep learning features at scale for visual place recognition. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; pp. 3223–3230. [Google Scholar]
- Sun, T.; Liu, M.; Ye, H.; Yeung, D.-Y. Point-cloud-based place recognition using CNN feature extraction. IEEE Sens. J. 2019, 19, 12175–12186. [Google Scholar] [CrossRef]
- Camara, L.G.; Gäbert, C.; Přeučil, L. Highly Robust Visual Place Recognition through Spatial Matching of CNN Features. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3748–3755. [Google Scholar]
- Karen, S.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tolias, G.; Sicre, R.; Jegou, H. Particular object retrieval with integral max-pooling of CNN activations. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–12. [Google Scholar]
- Khaliq, A.; Ehsan, S.; Milford, M.; McDonald-Maier, K. A holistic visual place recognition approach using lightweight cnns for significant viewpoint and appearance changes. IEEE Trans. Robot. 2019, 36, 561–569. [Google Scholar] [CrossRef]
- Jegou, H.; Douze, M.; Schmid, C.; Perez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Zitnick, C.; Dollar, P. Edge boxes: Locating object proposals from edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 391–405. [Google Scholar]
- Sunderhauf, N.; Shirazi, S.; Jacobson, A.; Dayoub, F.; Pepperell, E.; Upcroft, B.; Milford, M. Place recognition with ConvNet landmarks: Viewpoint-robust, condition-robust, training-free. In Proceedings of the Robotics: Science and Systems, Rome, Italy, 13–17 July 2015; pp. 1–10. [Google Scholar]
- Milford, M.J.; Wyeth, G.F. SeqSLAM: Visual route-based navigation for sunny summer days and stormy winter nights. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 1643–1649. [Google Scholar]
- Oishi, S.; Inoue, Y.; Miura, J.; Tanaka, S. SeqSLAM++: View-based robot localization and navigation. Robot. Auton. Syst. 2019, 112, 13–21. [Google Scholar] [CrossRef]
- Johns, E.; Yang, G.Z. Feature co-occurrence maps: Appearance-based localisation throughout the day. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 3212–3218. [Google Scholar]
- Ho, K.L.; Newman, P.M. Detecting loop closure with scene sequences. Int. J. Comput. Vision. 2007, 74, 261–286. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J. End-to-end comparative attention networks for person re-identification. IEEE Trans. Image Process. 2017, 26, 3492–3506. [Google Scholar] [CrossRef]
- Xie, S.; Pan, C.; Peng, Y.; Liu, K.; Ying, S. Large-Scale Place Recognition Based on Camera-LiDAR Fused Descriptor. Sensors 2020, 20, 2870. [Google Scholar] [CrossRef]
- Martini, D.; Gadd, M.; Newman, P. kRadar++: Coarse-to-Fine FMCW Scanning Radar Localisation. Sensors 2020, 20, 6002. [Google Scholar] [CrossRef]
- Săftescu, Ş.; Gadd, M.; Martini, D.; Barnes, D.; Newman, P. Kidnapped Radar: Topological Radar Localisation using Rotationally-Invariant Metric Learning. arXiv 2020, arXiv:2001.09438. [Google Scholar]
- Gadd, M.; Martini, D.D.; Newman, P. Look around You: Sequence-based Radar Place Recognition with Learned Rotational Invariance. In Proceedings of the IEEE/ION Position, Location and Navigation Symposium (PLANS), Portland, OR, USA, 20–23 April 2020; pp. 270–276. [Google Scholar]
- Zheng, L.; Yang, Y.; Tian, Q. SIFT meets CNN: A decade survey of instance retrieval. IEEE Trans. Pattern. Anal. Mach. Intell. 2018, 40, 1224–1244. [Google Scholar] [CrossRef]
- Azizpour, H.; Razavian, A.; Sullivan, J.; Maki, A. Factors of Transferability for a Generic ConvNet Representation. IEEE Trans. Pattern. Anal. Mach. Intell. 2016, 38, 1790–1802. [Google Scholar] [CrossRef]
- Zheng, L.; Zhao, Y.; Wang, S.; Wang, J.; Tian, Q. Good practice in CNN feature transfer. arXiv 2016, arXiv:1604.00133. [Google Scholar]
- Jin, S.; Gao, Y.; Chen, L. Improved Deep Distance Learning for Visual Loop Closure Detection in Smart City. Peer-to-Peer Netw. Appl. 2020. [Google Scholar] [CrossRef]
- Cieslewski, T.; Choudhary, S.; Scaramuzza, D. Data-efficient decentralized visual SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 2466–2473. [Google Scholar]
- Arandjelovi, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef] [PubMed]
- Jégou, H.; Chum, O. Negative Evidences and Co-occurences in Image Retrieval: The Benefit of PCA and Whitening. In Proceedings of the European Conference on Computer Vision, Firenze, Italy, 7–13 October 2012; pp. 774–787. [Google Scholar]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic localization and mapping in the space of appearance. Int. J. Rob. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, L.; Jin, S.; Xia, Z. Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning. Sensors 2021, 21, 310. https://doi.org/10.3390/s21010310
Chen L, Jin S, Xia Z. Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning. Sensors. 2021; 21(1):310. https://doi.org/10.3390/s21010310
Chicago/Turabian StyleChen, Liang, Sheng Jin, and Zhoujun Xia. 2021. "Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning" Sensors 21, no. 1: 310. https://doi.org/10.3390/s21010310
APA StyleChen, L., Jin, S., & Xia, Z. (2021). Towards a Robust Visual Place Recognition in Large-Scale vSLAM Scenarios Based on a Deep Distance Learning. Sensors, 21(1), 310. https://doi.org/10.3390/s21010310