Skeleton-Based Emotion Recognition Based on Two-Stream Self-Attention Enhanced Spatial-Temporal Graph Convolutional Network


Abstract
1. Introduction
2. Related Work
2.1. Emotion Recognition
2.2. Gesture-Based Emotion Recognition
2.3. Graph Neural Networks
3. Skeletal Data Extraction
3.1. Human Pose Estimation
3.2. Data Preprocessing
4. Proposed Networks
4.1. Graph Convolutional Network
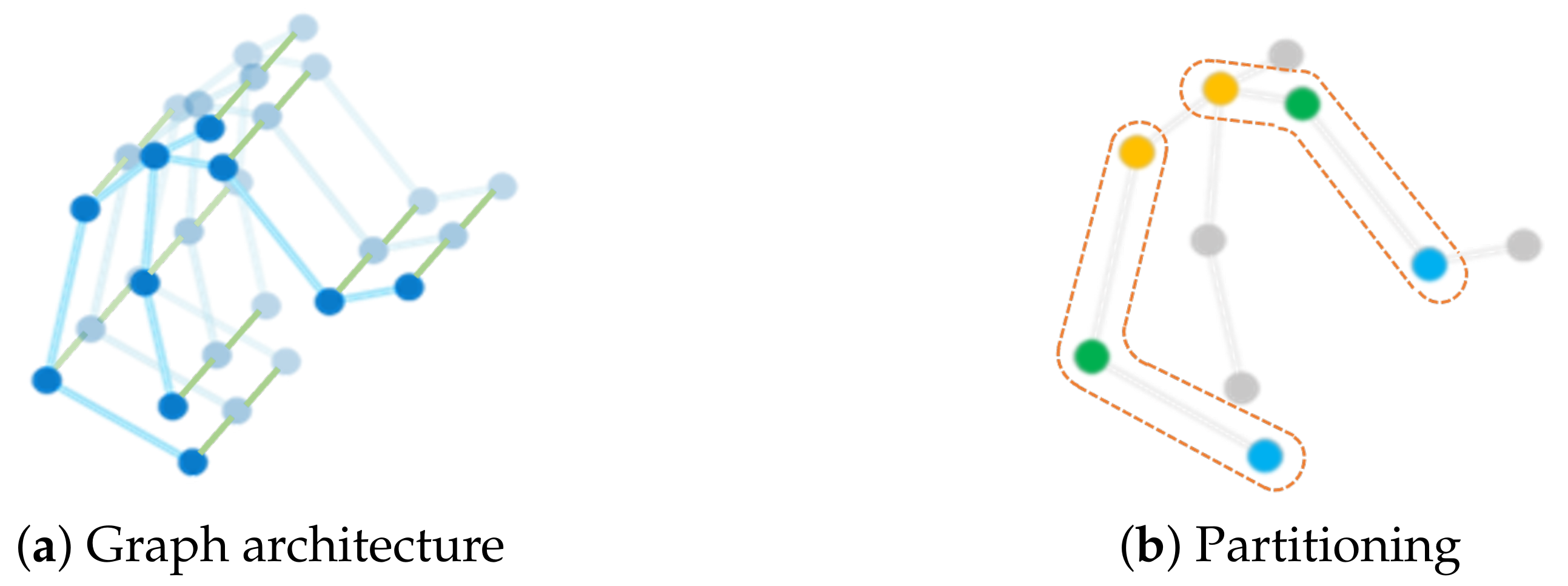
4.1.1. Skeleton Graph Construction
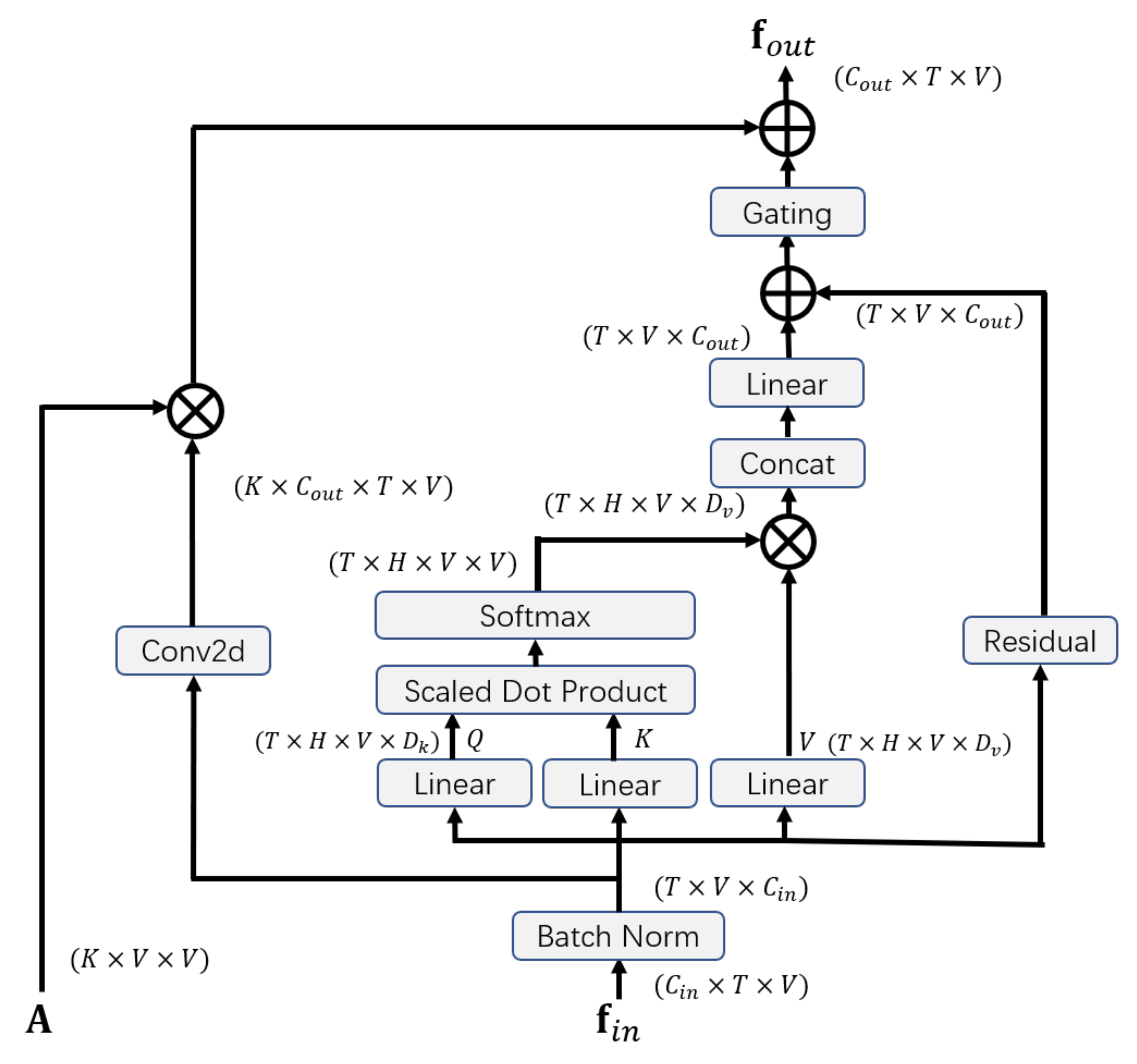
4.1.2. Self-Attention Enhanced Spatial Graph Convolutional Layer
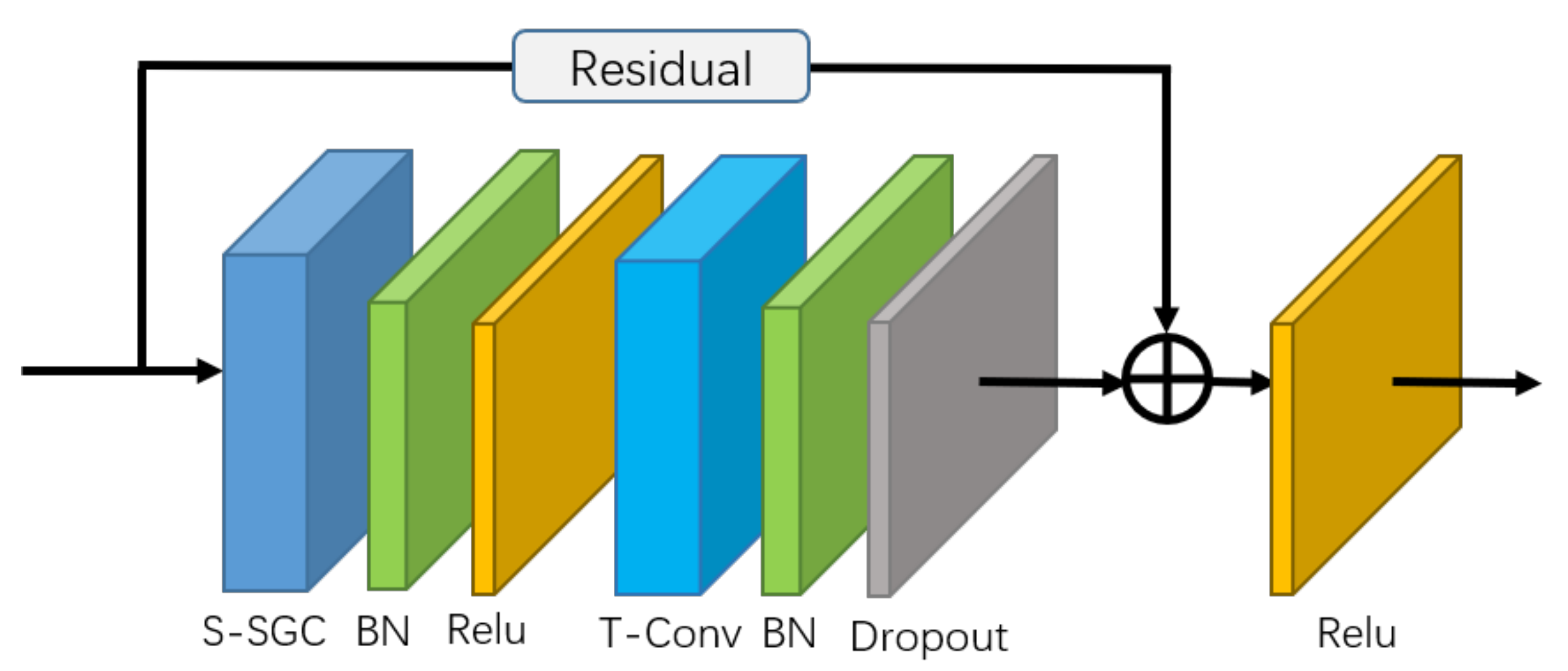
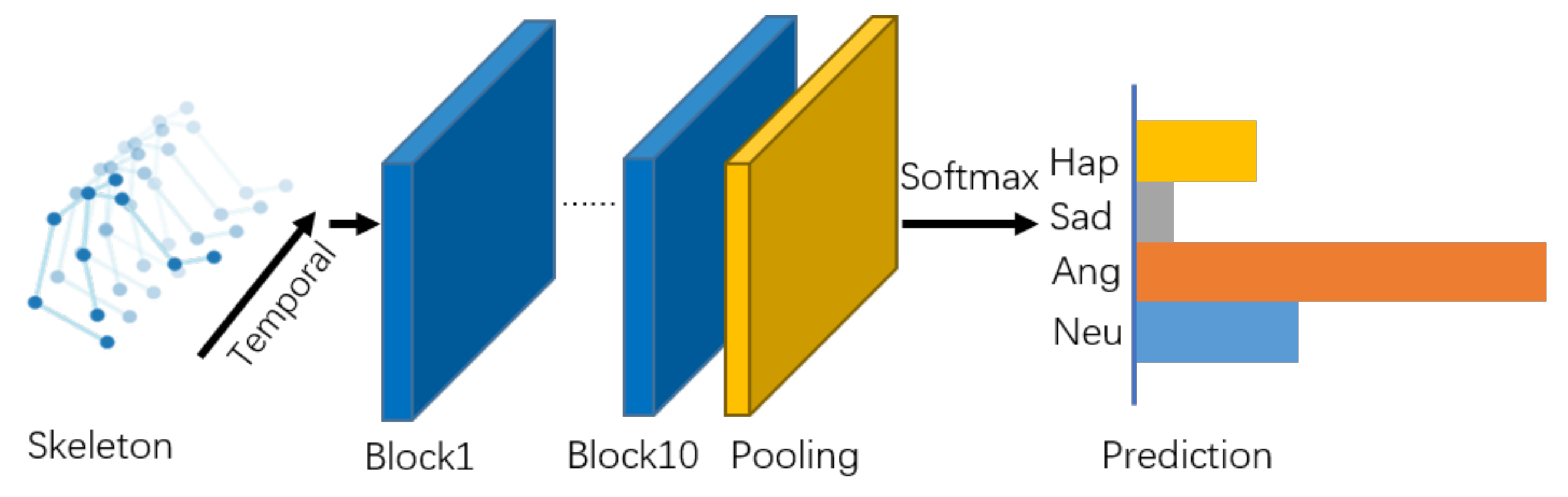
4.1.3. Self-Attention Enhanced Spatial Temporal Graph Convolutional Network
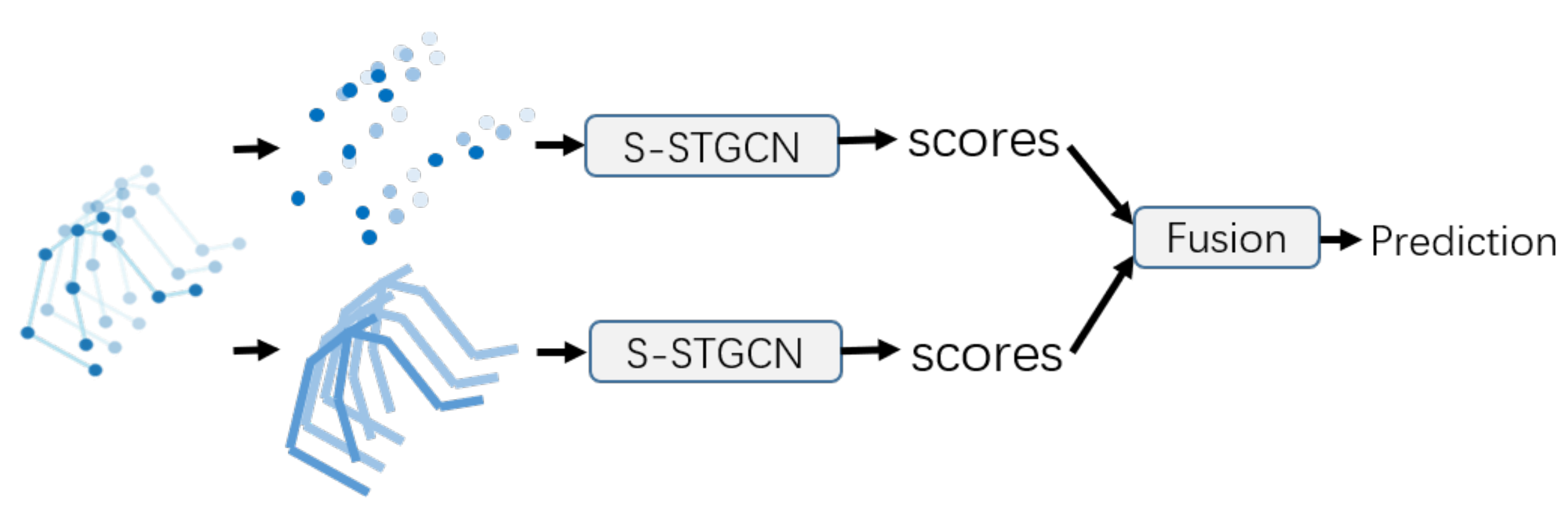
4.1.4. Two-Stream Architecture
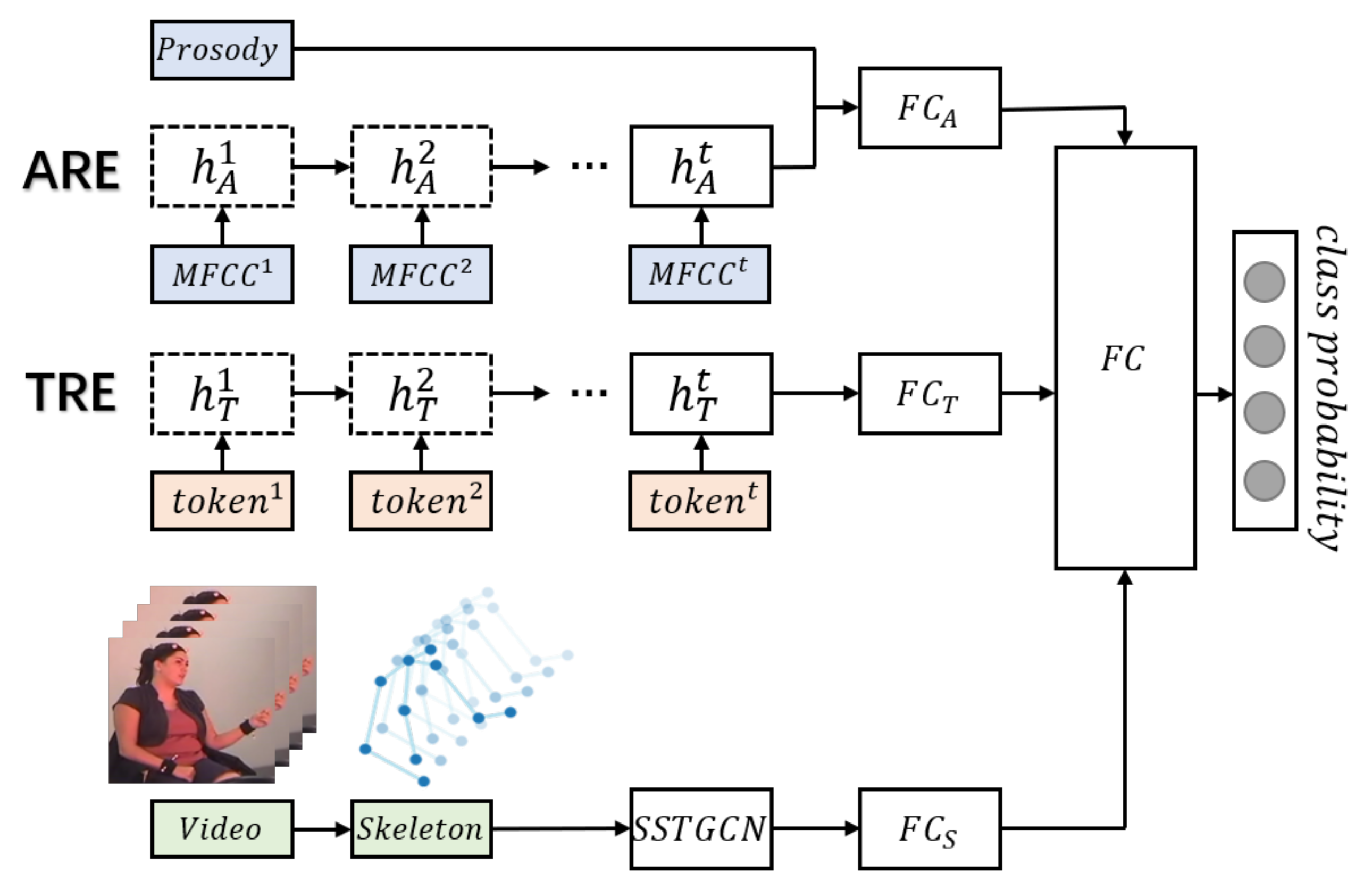
4.2. Multimodal Emotion Recognition Network
5. Experiment
5.1. Dataset
5.2. Feature Extraction and Experiment Setting
5.3. Results
6. Ablation Study and Discussion
6.1. Effect of the Preprocessing
6.2. Gating Mechanism
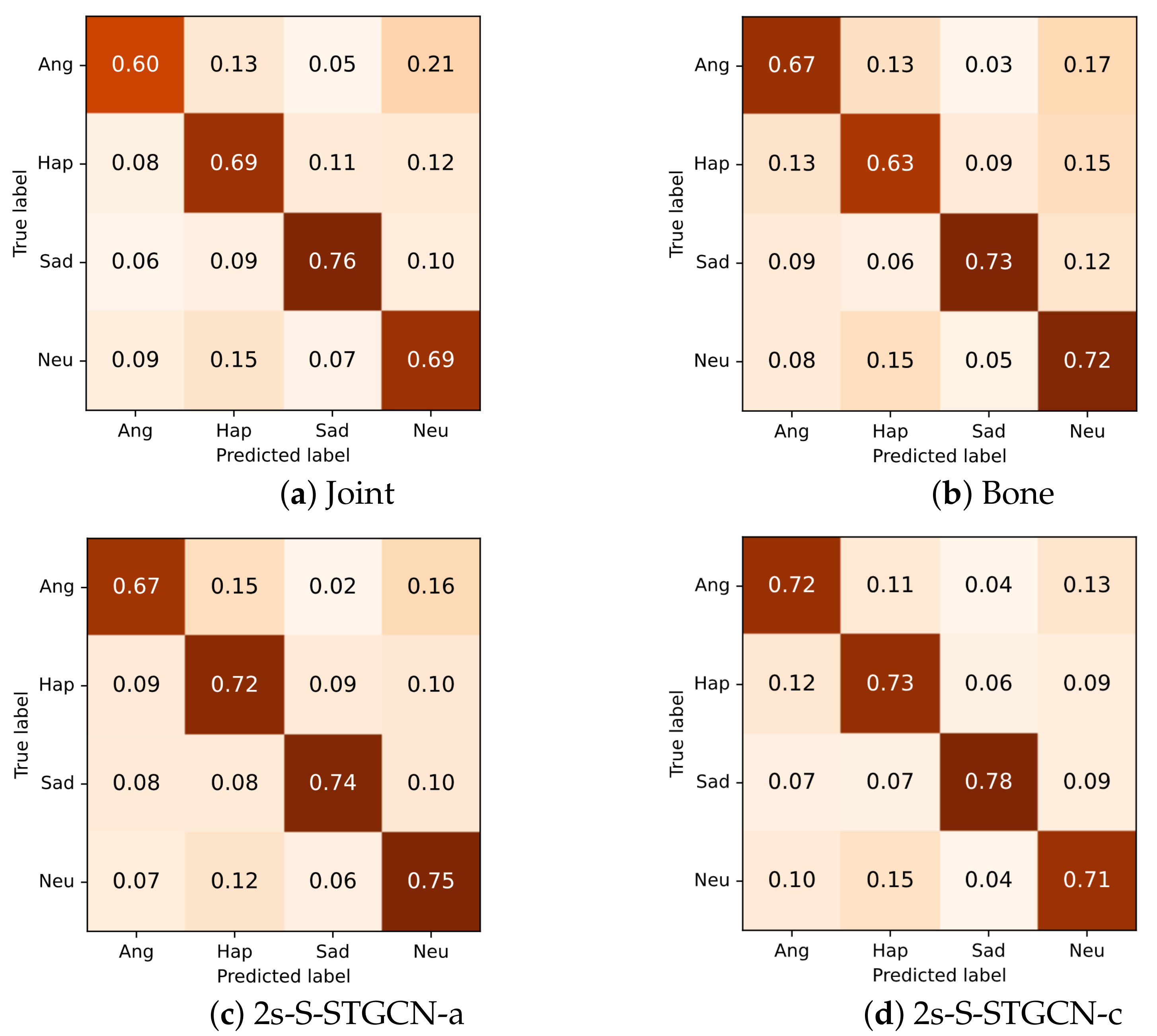
6.3. Effect of the Bone Information
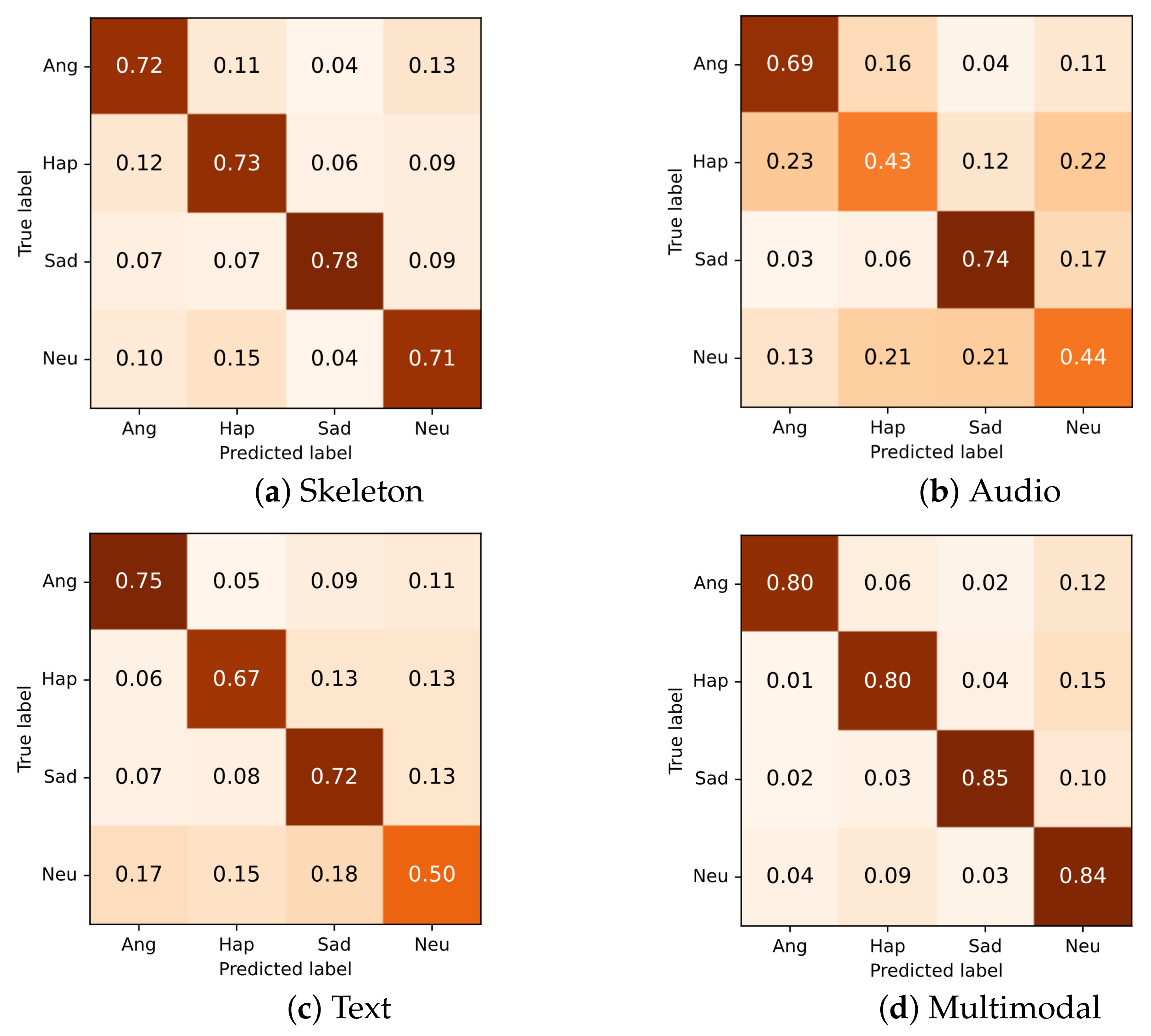
6.4. Multimodal Analysis
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Noroozi, F.; Kaminska, D.; Corneanu, C.; Sapinski, T.; Escalera, S.; Anbarjafari, G. Survey on emotional body gesture recognition. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Ahmed, F.; Bari, A.H.; Gavrilova, M.L. Emotion Recognition From Body Movement. IEEE Access 2019, 8, 11761–11781. [Google Scholar] [CrossRef]
- Wallbott, H.G. Bodily expression of emotion. Eur. J. Soc. Psychol. 1998, 28, 879–896. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal database of emotional speech, video and gestures. In Proceedings of the International Conference on Pattern Recognition, Beijing, China, 20–24 August 2018; pp. 153–163. [Google Scholar]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal emotion recognition using deep learning architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Anbarjafari, G. Emotion recognition from skeletal movements. Entropy 2019, 21, 646. [Google Scholar] [CrossRef] [PubMed]
- Filntisis, P.P.; Efthymiou, N.; Koutras, P.; Potamianos, G.; Maragos, P. Fusing Body Posture With Facial Expressions for Joint Recognition of Affect in Child–Robot Interaction. IEEE Rob. Autom Lett. 2019, 4, 4011–4018. [Google Scholar] [CrossRef]
- Ly, S.T.; Lee, G.S.; Kim, S.H.; Yang, H.J. Gesture-Based Emotion Recognition by 3D-CNN and LSTM with Keyframes Selection. Int. J. Contents 2019, 15, 59–64. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. arXiv 2018, arXiv:1801.07455. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12026–12035. [Google Scholar]
- Cai, Y.; Huang, L.; Wang, Y.; Cham, T.J.; Cai, J.; Yuan, J.; Liu, J.; Yang, X.; Zhu, Y.; Shen, X.; et al. Learning Progressive Joint Propagation for Human Motion Prediction. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 226–242. [Google Scholar]
- Dael, N.; Goudbeek, M.; Scherer, K.R. Perceived gesture dynamics in nonverbal expression of emotion. Perception 2013, 42, 642–657. [Google Scholar] [CrossRef]
- Schwarz, N. Emotion, cognition, and decision making. Cogn. Emot. 2000, 14, 433–440. [Google Scholar] [CrossRef]
- Kensinger, E.A. Negative emotion enhances memory accuracy: Behavioral and neuroimaging evidence. Curr. Directions Psychological Sci. 2007, 16, 213–218. [Google Scholar] [CrossRef]
- Jaimes, A.; Sebe, N. Multimodal human–computer interaction: A survey. Comput. Vis. Image Underst. 2007, 108, 116–134. [Google Scholar] [CrossRef]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wrobel, M.R. Emotion recognition and its applications. In Human-Computer Systems Interaction: Backgrounds and Applications 3; Springer: Cham, Switzerland, 2014; pp. 51–62. [Google Scholar]
- Franzoni, V.; Milani, A.; Nardi, D.; Vallverdú, J. Emotional machines: The next revolution. Web Intell. 2019, 17, 1–7. [Google Scholar] [CrossRef]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R.W. Driver Emotion Recognition for Intelligent Vehicles: A Survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Yoon, S.; Dey, S.; Lee, H.; Jung, K. Attentive modality hopping mechanism for speech emotion recognition. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3362–3366. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.W.; Zafeiriou, S. End-to-end multimodal emotion recognition using deep neural networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 1301–1309. [Google Scholar] [CrossRef]
- Heusser, V.; Freymuth, N.; Constantin, S.; Waibel, A. Bimodal Speech Emotion Recognition Using Pre-Trained Language Models. arXiv 2019, arXiv:1912.02610. [Google Scholar]
- Kaza, K.; Psaltis, A.; Stefanidis, K.; Apostolakis, K.C.; Thermos, S.; Dimitropoulos, K.; Daras, P. Body motion analysis for emotion recognition in serious games. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction, Toronto, ON, Canada, 17–22 July 2016; pp. 33–42. [Google Scholar]
- Ahmed, F.; Gavrilova, M.L. Two-layer feature selection algorithm for recognizing human emotions from 3d motion analysis. In Proceedings of the Computer Graphics International Conference, Calgary, AB, Canada, 17–20 June 2019; pp. 53–67. [Google Scholar]
- Karumuri, S.; Niewiadomski, R.; Volpe, G.; Camurri, A. From Motions to Emotions: Classification of Affect from Dance Movements using Deep Learning. In Proceedings of the the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Deng, J.J.; Leung, C.H.C.; Mengoni, P.; Li, Y. Emotion recognition from human behaviors using attention model. In Proceedings of the 2018 IEEE First International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 26–28 September 2018; pp. 249–253. [Google Scholar]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef]
- Bastings, J.; Titov, I.; Aziz, W.; Marcheggiani, D.; Sima’an, K. Graph convolutional encoders for syntax-aware neural machine translation. arXiv 2017, arXiv:1704.04675. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Hu, F.; Zhu, Y.; Wu, S.; Wang, L.; Tan, T. Hierarchical graph convolutional networks for semi-supervised node classification. arXiv 2019, arXiv:1902.06667. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3844–3852. [Google Scholar]
- Monti, F.; Boscaini, D.; Masci, J.; Rodola, E.; Svoboda, J.; Bronstein, M.M. Geometric deep learning on graphs and manifolds using mixture model cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5115–5124. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in neural information processing systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. RMPE: Regional Multi-person Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, J.; Wang, C.; Zhu, H.; Mao, Y.; Fang, H.S.; Lu, C. CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark. arXiv 2018, arXiv:1812.00324. [Google Scholar]
- Xiu, Y.; Li, J.; Wang, H.; Fang, Y.; Lu, C. Pose Flow: Efficient Online Pose Tracking. arXiv 2018, arXiv:1802.00977. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European conference on computer vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3d human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7753–7762. [Google Scholar]
- Coulson, M. Attributing emotion to static body postures: Recognition accuracy, confusions, and viewpoint dependence. J. Nonverbal Behav. 2004, 28, 117–139. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Multi-Stream Adaptive Graph Convolutional Networks. arXiv 2019, arXiv:1912.06971. [Google Scholar] [CrossRef]
- Yoon, S.; Byun, S.; Jung, K. Multimodal speech emotion recognition using audio and text. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 112–118. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: the munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
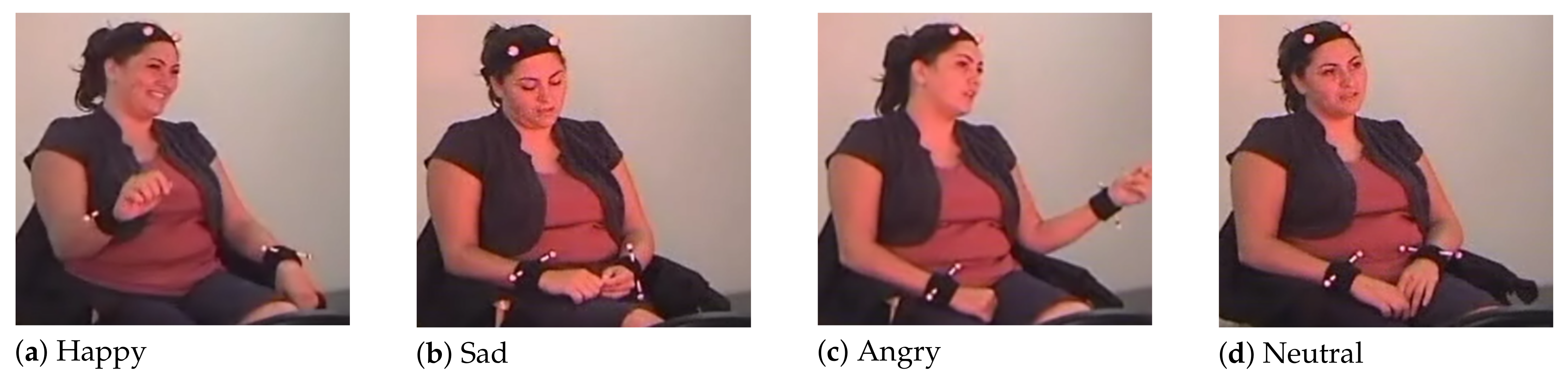{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Modality | UAR(%) | WAR(%) |
|---|---|---|---|
| ARE [44] | A | 59.7 | 57.1 |
| TRE [44] | T | 65.9 | 64.5 |
| ResNet18 [47] | S | 55.3 | 56.9 |
| ST-GCN [10] | S | 63.3 | 63.7 |
| S-STGCN | S | 68.4 | 68.4 |
| 2s-S-STGCN | S | 73.1 | 72.5 |
| MDRE [44] | A + T | 72.0 | 71.4 |
| SERN | A + T + S | 80.4 | 80.0 |
| SERN-2s | A + T + S | 82.2 | 82.3 |
| Data | UAR(%) | WAR(%) |
|---|---|---|
| Unpreprocessed | 66.5 | 66.4 |
| Preprocessed | 68.4 | 68.4 |
| Model | UAR(%) | WAR(%) |
|---|---|---|
| S-STGCN w/o G | 67.7 | 67.3 |
| S-STGCN | 68.4 | 68.4 |
| Model | Input | UAR(%) | WAR(%) |
|---|---|---|---|
| S-STGCN | J | 68.4 | 68.4 |
| S-STGCN | B | 68.8 | 68.9 |
| 2s-S-STGCN-a | J&B | 71.9 | 72.3 |
| 2s-S-STGCN-c | J&B | 73.1 | 72.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, J.; Liu, C.; Ishi, C.T.; Ishiguro, H. Skeleton-Based Emotion Recognition Based on Two-Stream Self-Attention Enhanced Spatial-Temporal Graph Convolutional Network. Sensors 2021, 21, 205. https://doi.org/10.3390/s21010205
Shi J, Liu C, Ishi CT, Ishiguro H. Skeleton-Based Emotion Recognition Based on Two-Stream Self-Attention Enhanced Spatial-Temporal Graph Convolutional Network. Sensors. 2021; 21(1):205. https://doi.org/10.3390/s21010205
Chicago/Turabian StyleShi, Jiaqi, Chaoran Liu, Carlos Toshinori Ishi, and Hiroshi Ishiguro. 2021. "Skeleton-Based Emotion Recognition Based on Two-Stream Self-Attention Enhanced Spatial-Temporal Graph Convolutional Network" Sensors 21, no. 1: 205. https://doi.org/10.3390/s21010205
APA StyleShi, J., Liu, C., Ishi, C. T., & Ishiguro, H. (2021). Skeleton-Based Emotion Recognition Based on Two-Stream Self-Attention Enhanced Spatial-Temporal Graph Convolutional Network. Sensors, 21(1), 205. https://doi.org/10.3390/s21010205