Data-Driven Method for Predicting Remaining Useful Life of Bearing Based on Bayesian Theory




Abstract
1. Introduction
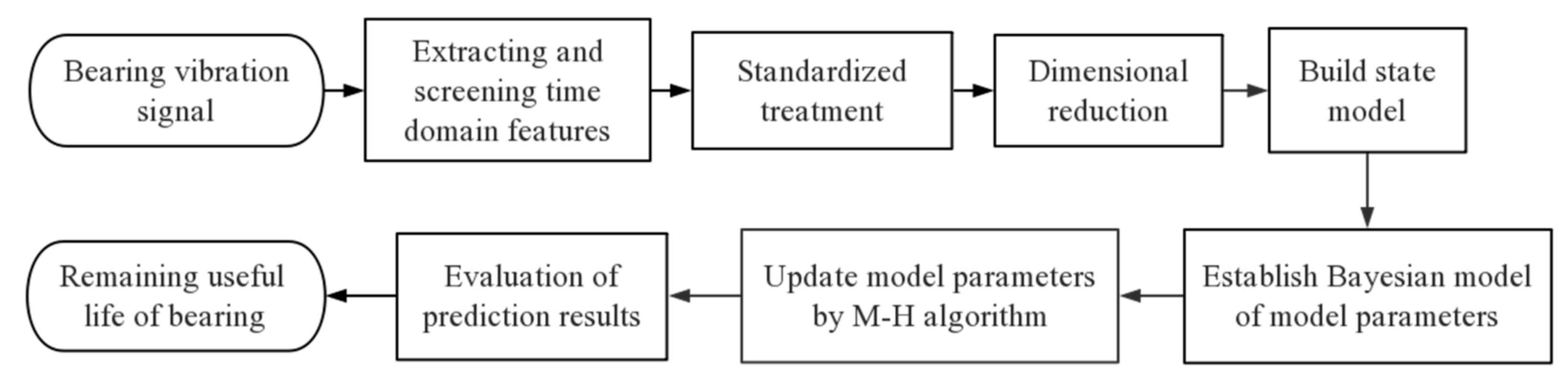
2. Data-Driven State Model
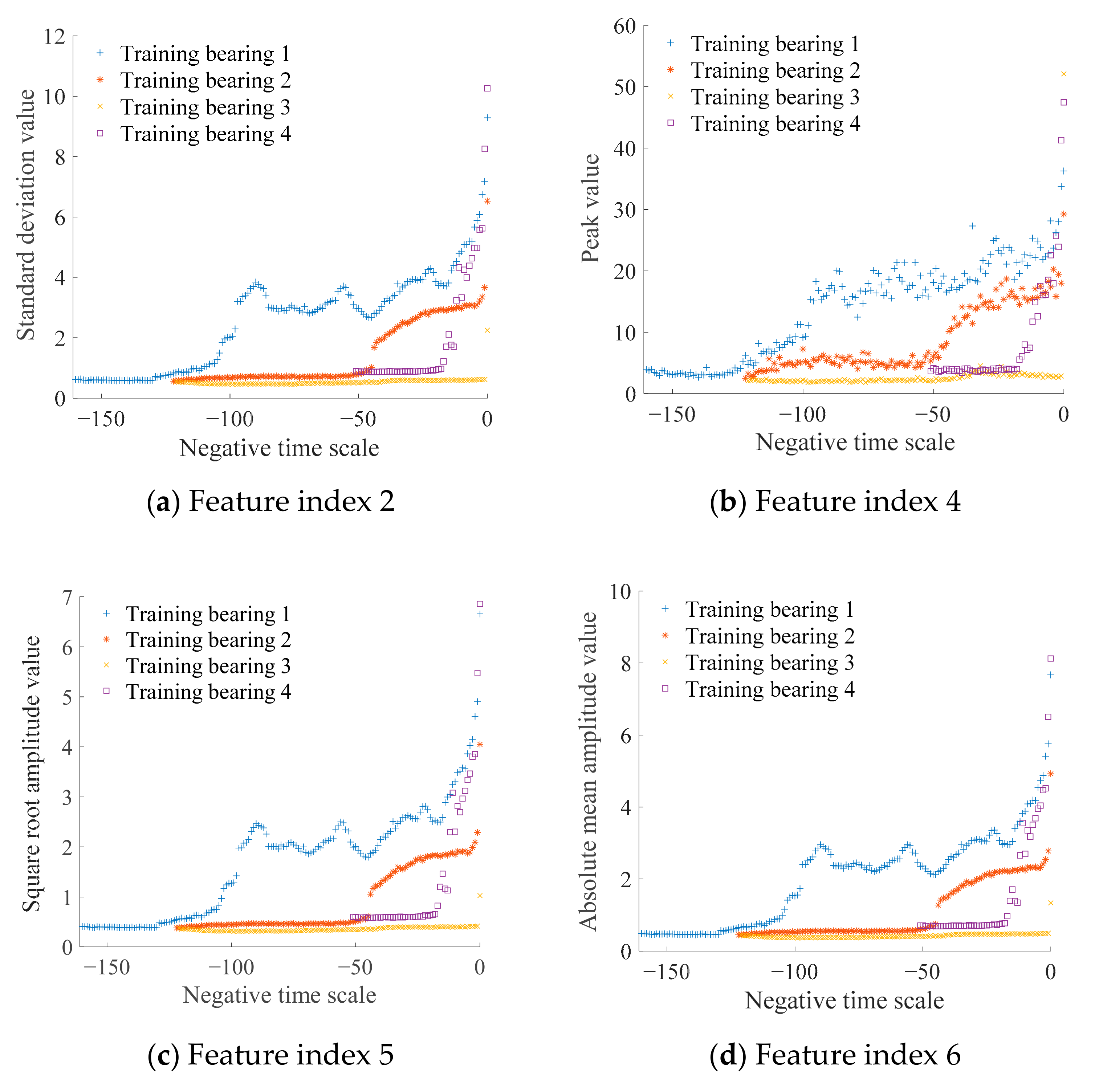
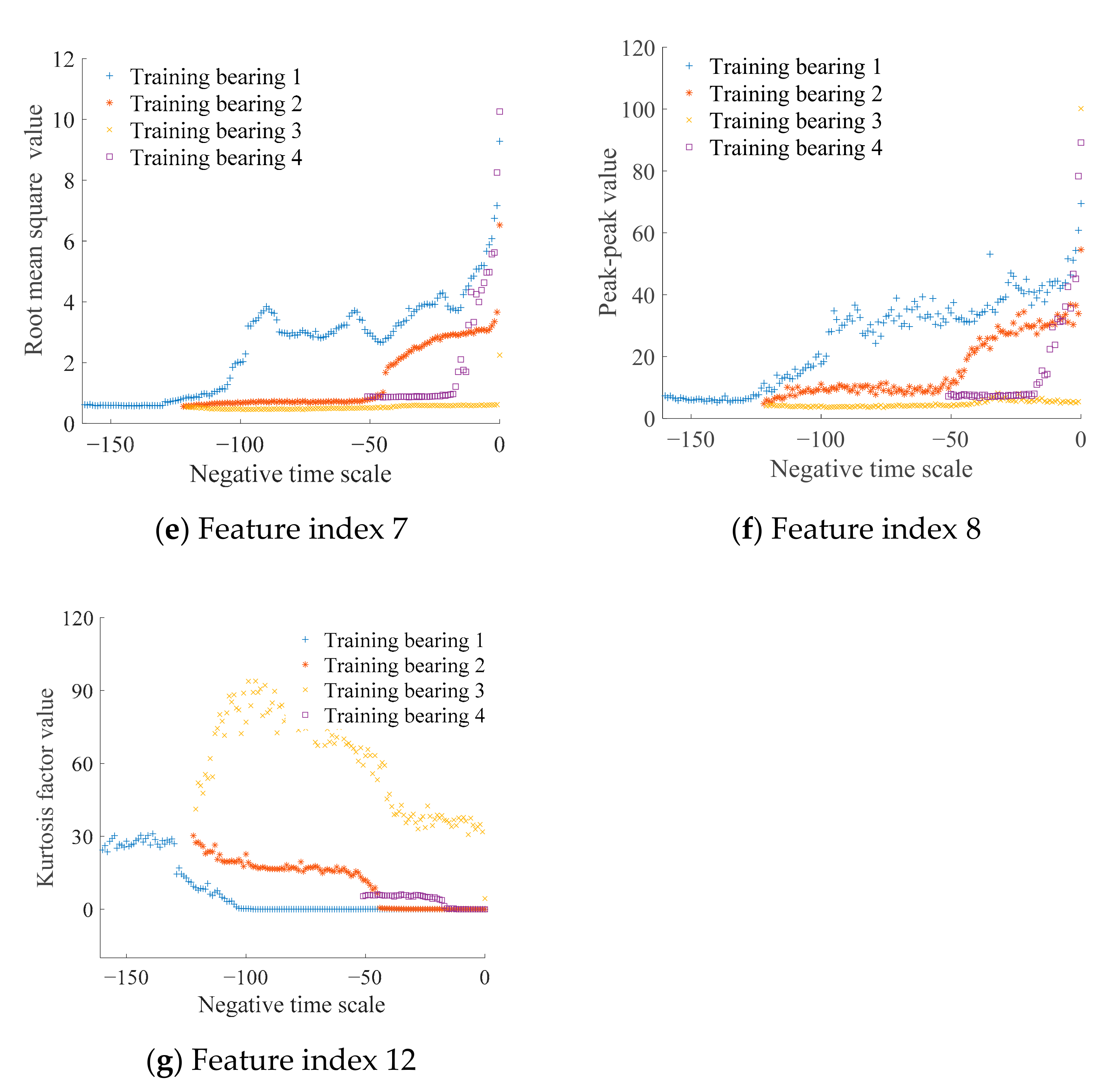
2.1. Feature Index Selection
2.2. Data Fusion
- Calculate the correlation coefficient matrix of standardized data . Then use the correlation coefficient to determine similarity among index variables.
- Calculate the eigenvalues and eigenvectors of the correlation coefficient matrix. Eigenvalue is the variance of the ith principal component . The eigenvector corresponding to each eigenvalue is a linear coefficient of variation, and the principal component can be defined aswhere is the ith principal component data (i.e., output data), is the jth dimensional original time series data (i.e., input data) after standardization, and is the linear transformation coefficient corresponding to the ith principal component and jth dimensional original time series data.
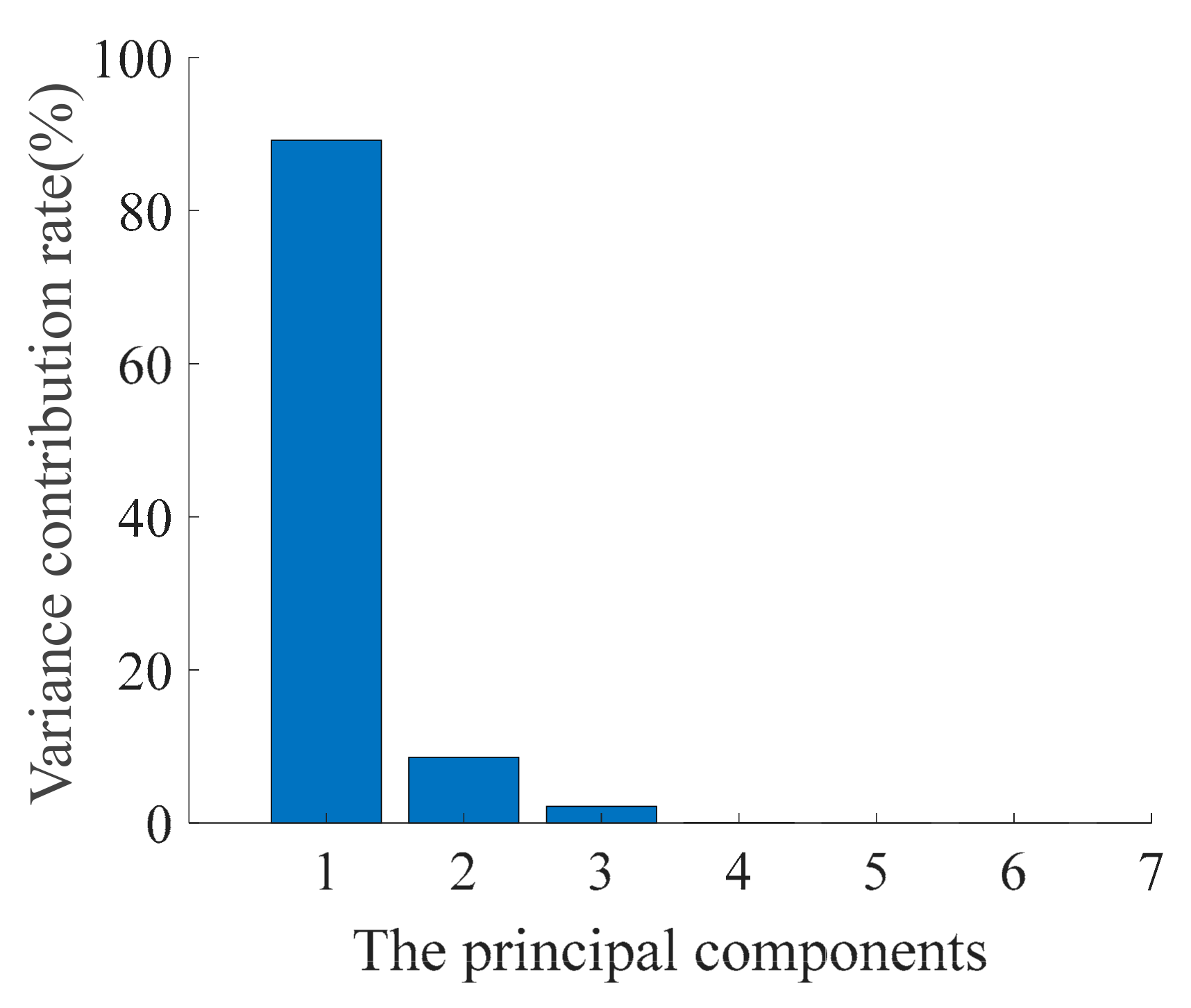
- Calculate the variance contribution rate and cumulative contribution rate. The variance contribution rate reflects the role of index variables in the evaluation; the larger the value, the more effective the principal components are at retaining information. Generally, a principal component with an 85% cumulative contribution rate will meet calculation requirements.
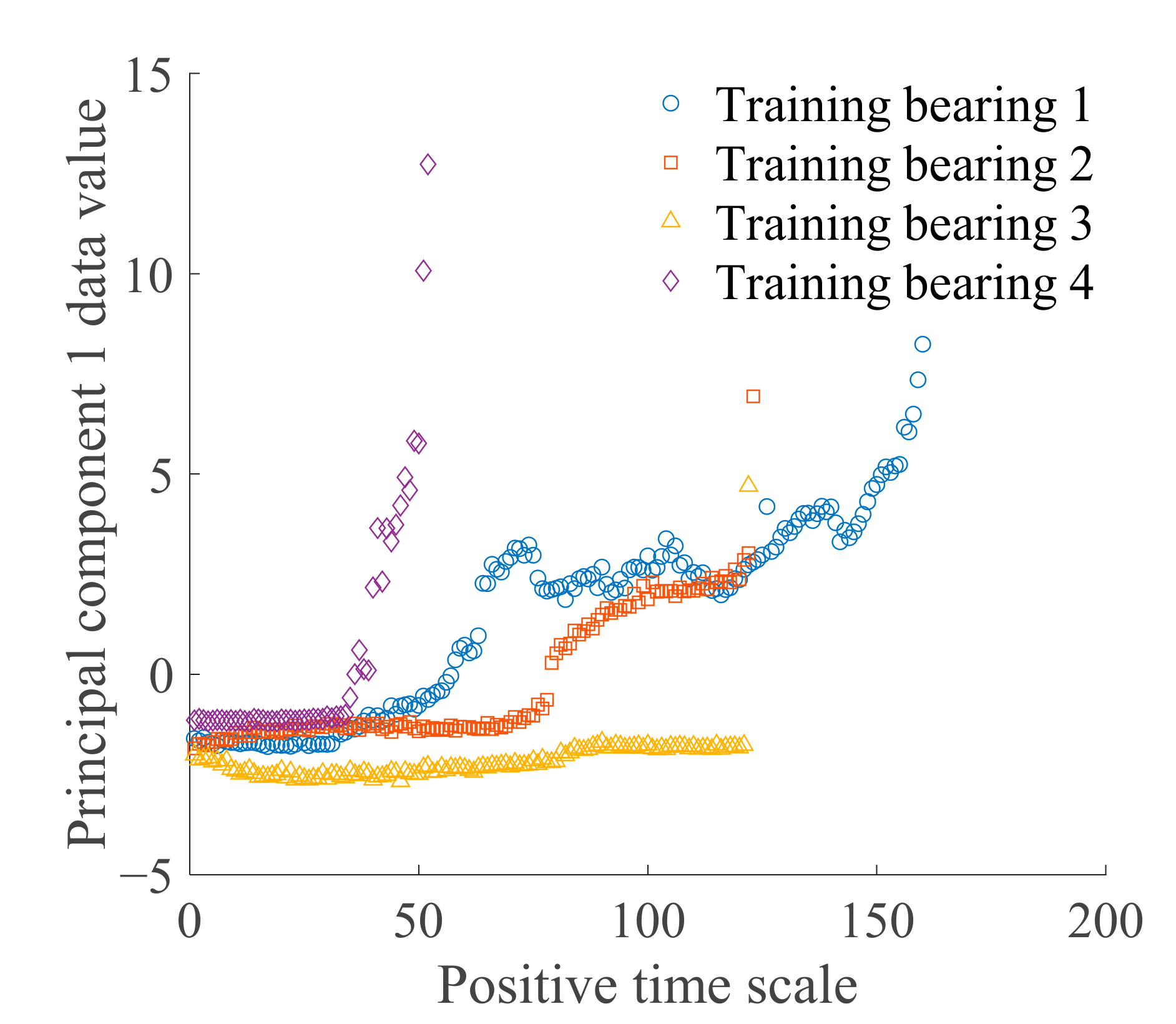
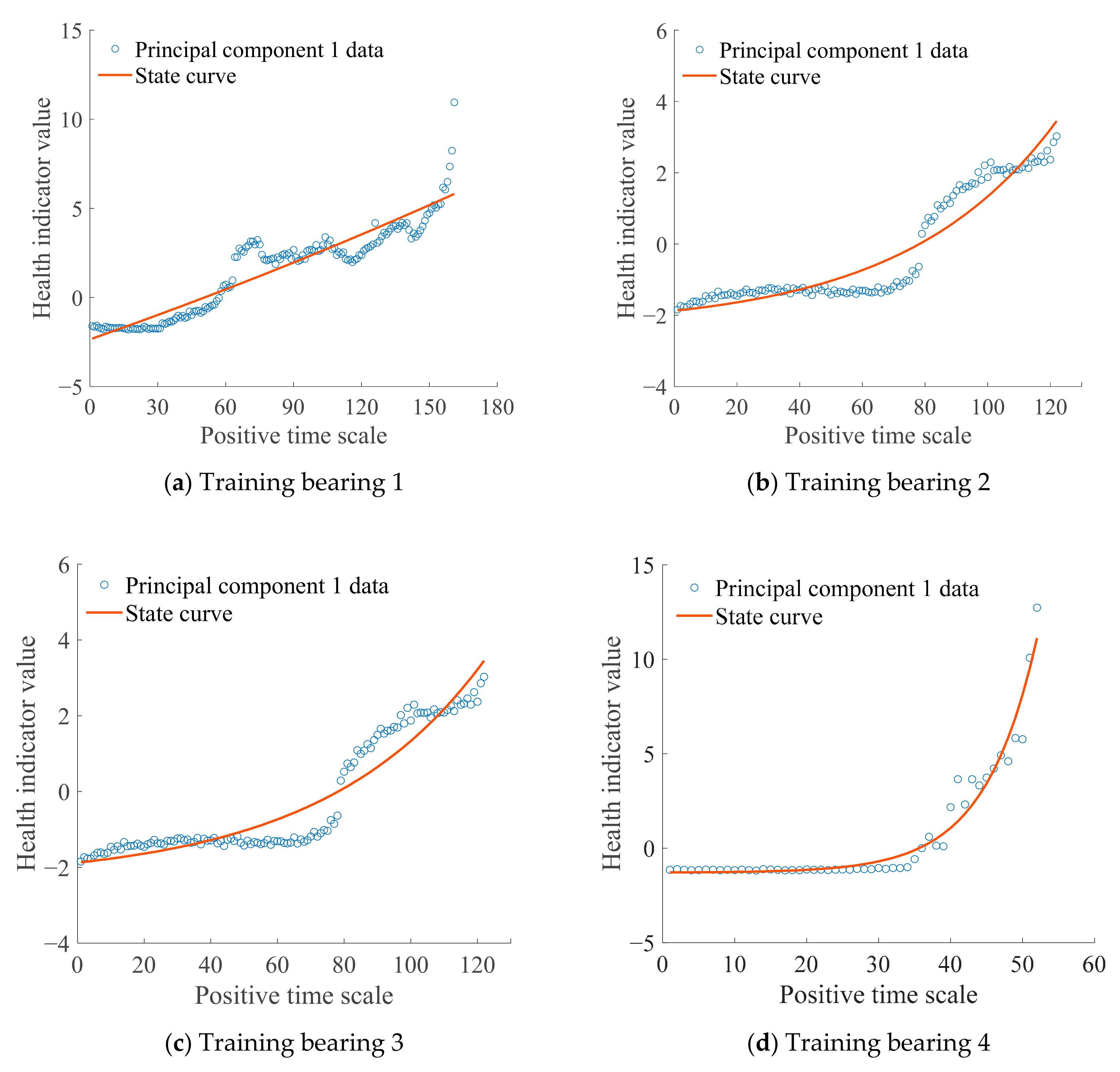
2.3. Establishment of HI and State Model
3. Remaining Useful Life Prediction Model Based on Bayesian Theory
3.1. Bayesian Model
3.2. Remaining Useful Life Prediction
- Initialize starting point .
- For N − 1 iterations, complete the following four steps:
- Draw a sample, x*, from the proposal distribution; the pdf value is where i denotes the current iteration and the distribution mean is xi with a selected standard deviation.
- Sample u from a uniform distribution with a lower limit of zero and an upper limit of 1, U(0,1).
- Compute the acceptance ratio, , where is the pdf value of the proposal distribution at for the selected standard deviation, is the pdf value of the target distribution at x*, and is the pdf value of the target distribution at xi.
- If u < A, set the new value of x, i.e., . Otherwise, x remains unchanged, .
4. Application of Proposed Method
4.1. Bearing Data
4.2. Data Processing
4.3. Establishment of HI and State Model
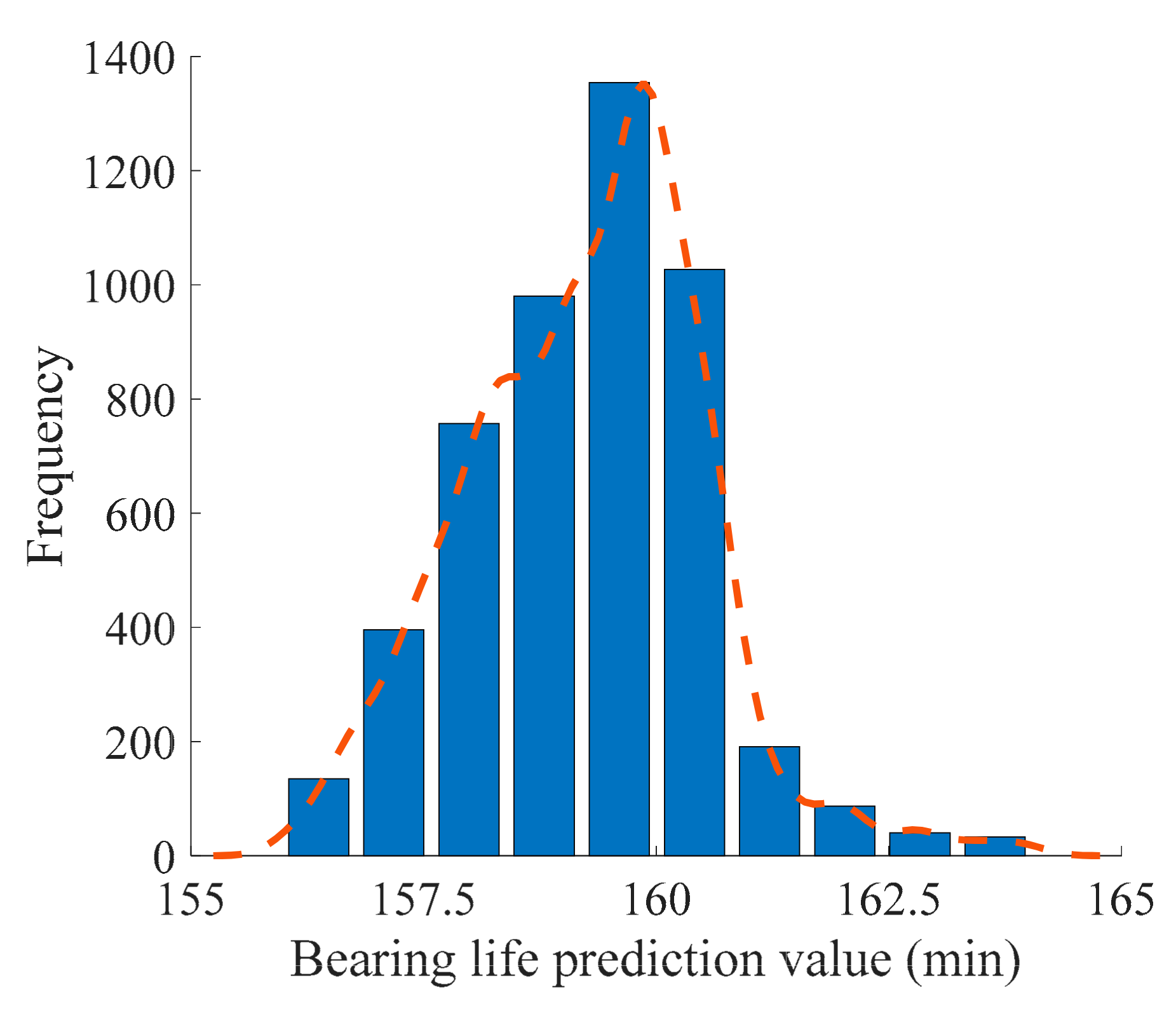
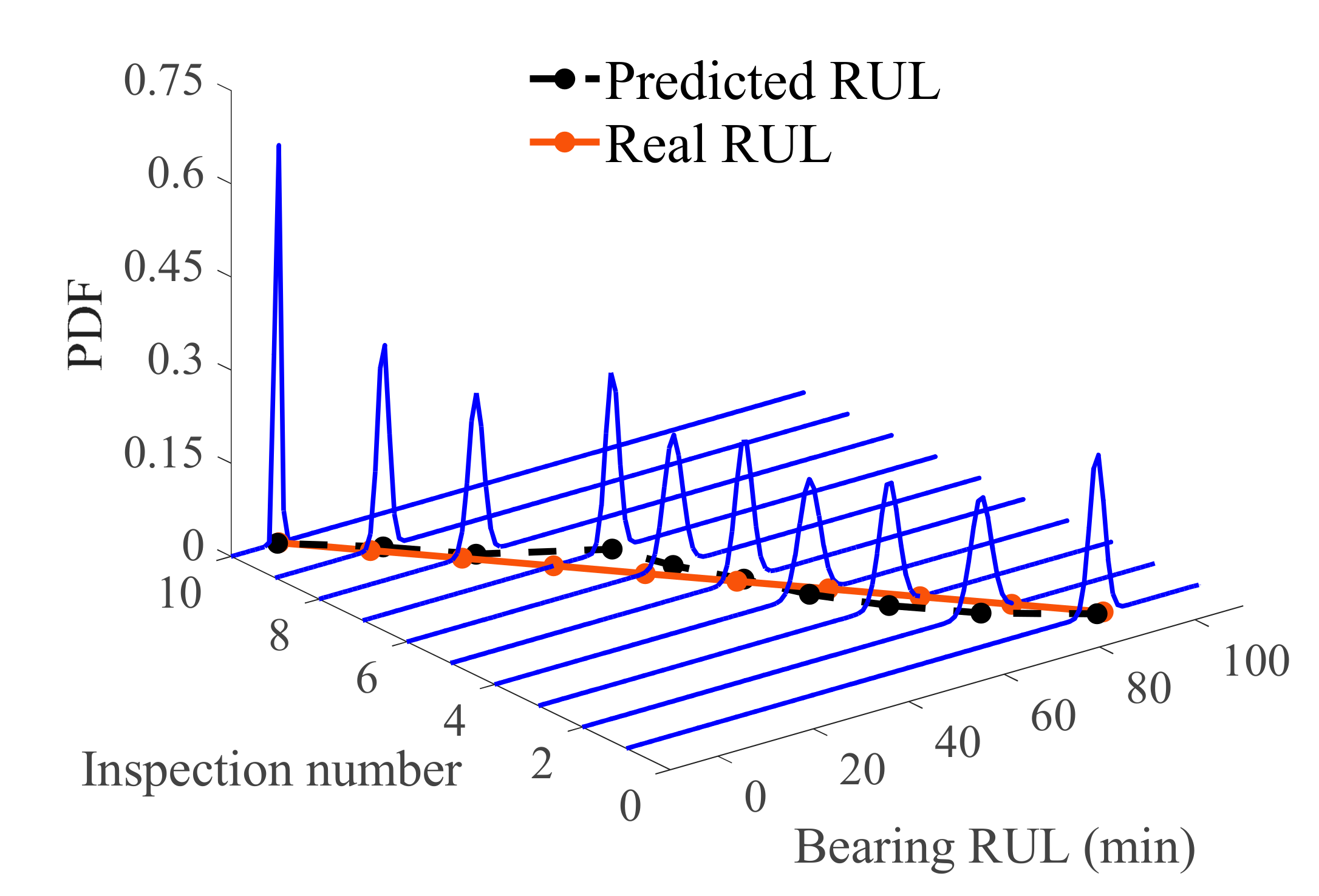
4.4. Bayesian Model and RUL Prediction
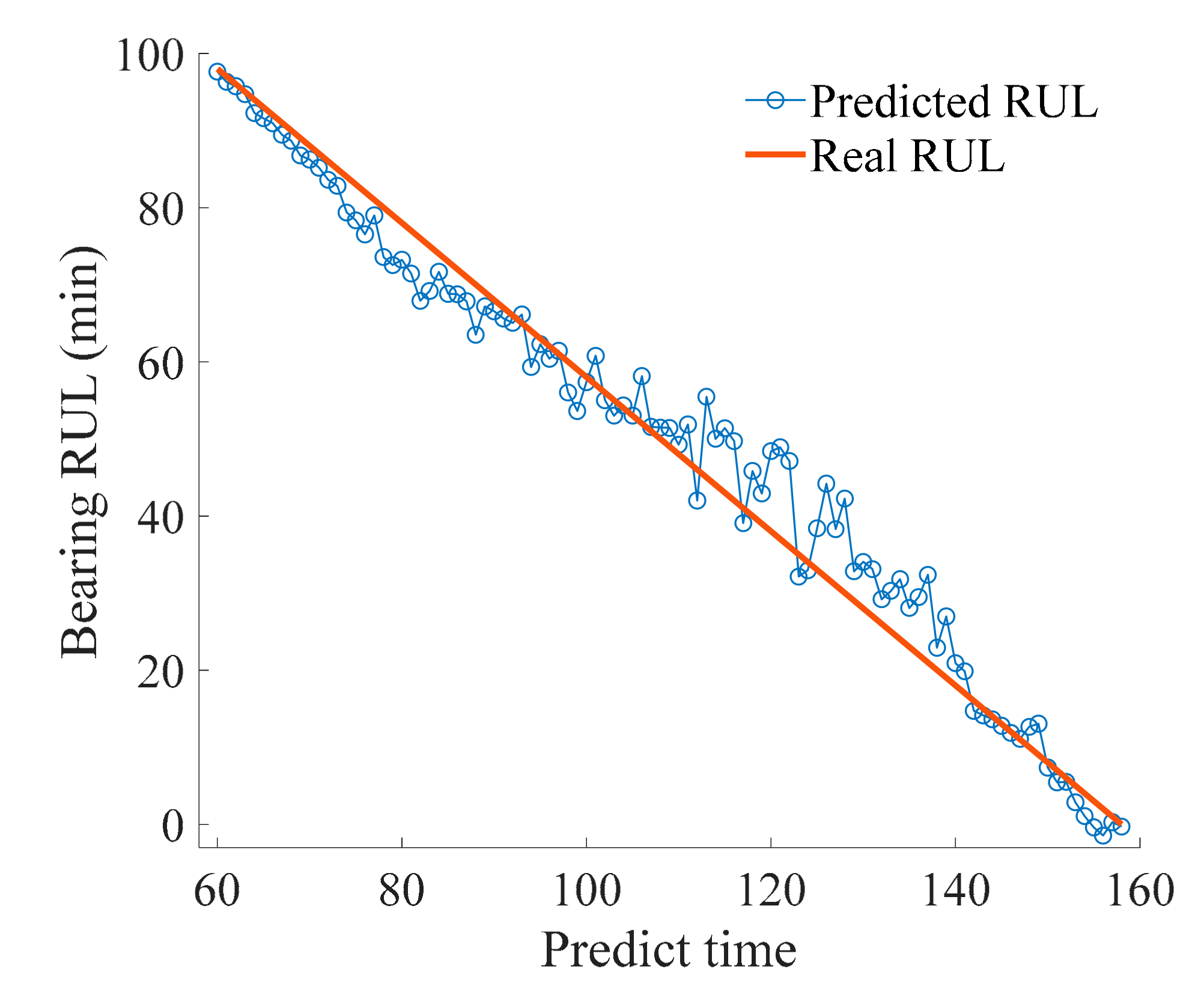
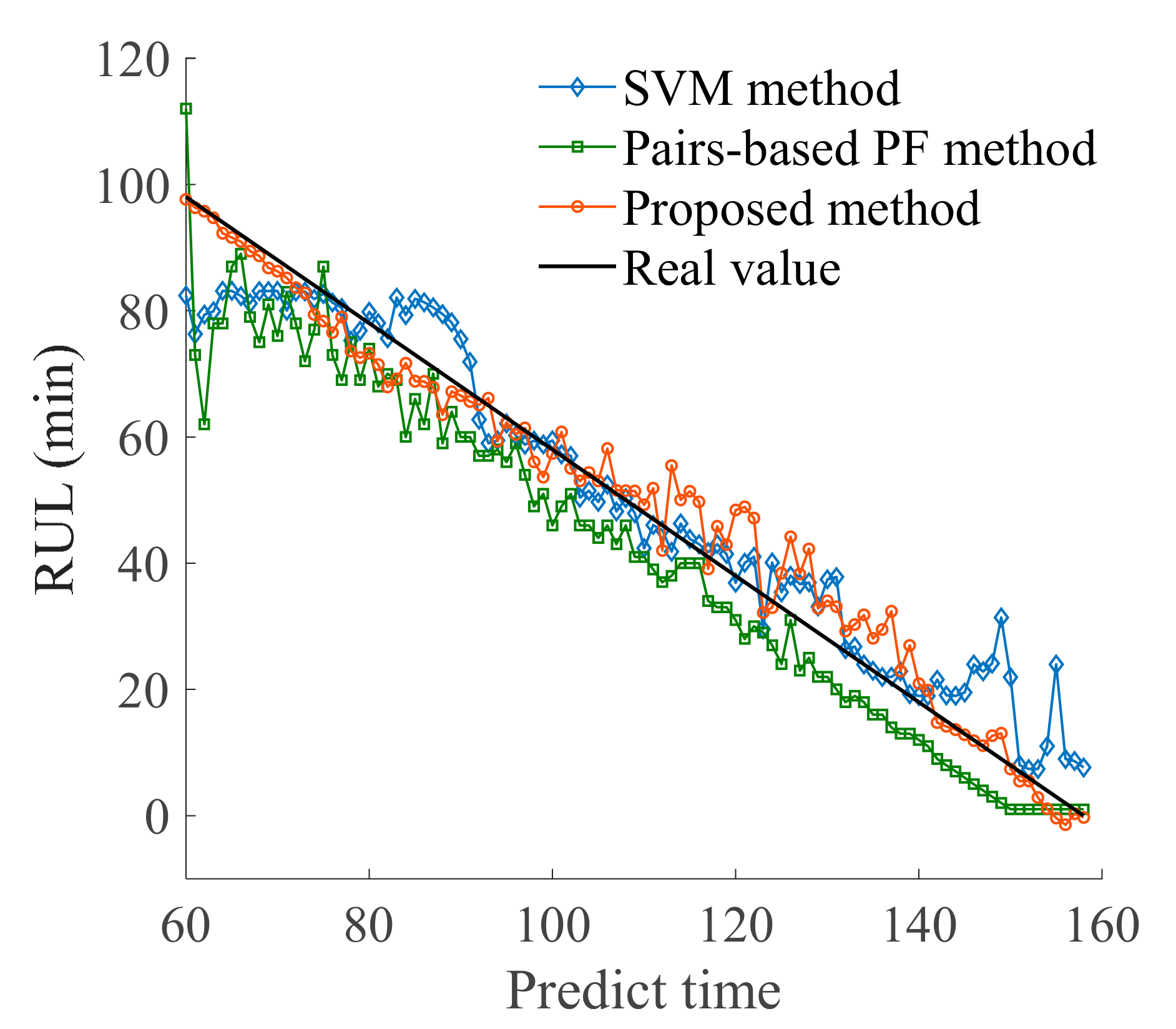
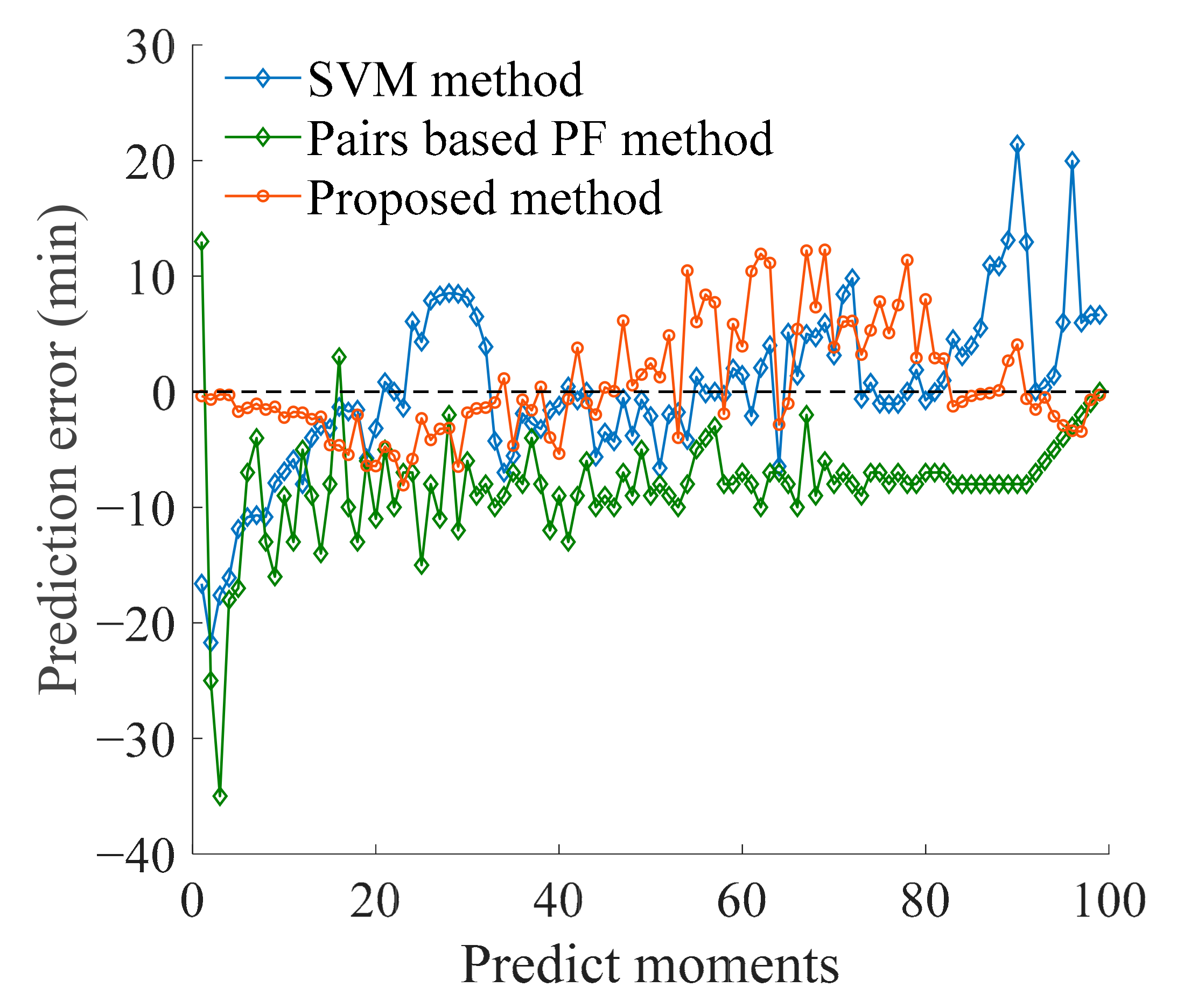
4.5. Evaluation of Prediction Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, F.; Su, S. Fault Diagnosis and Life Prediction of Rolling Bearings; Science Press: Beijing, China, 2018; pp. 21–25. [Google Scholar]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Robust performance degradation assessment methods for enhanced rolling element bearing prognostics. Adv. Eng. Inform. 2003, 17, 127–140. [Google Scholar] [CrossRef]
- Huang, X.Z.; Li, Y.X.; Zhang, Y.M.; Zhang, X.F. A new direct second-order reliability analysis method. Appl. Math. Model. 2018, 55, 68–80. [Google Scholar] [CrossRef]
- Li, Q.; Zuo, M.J.; Liang, S.Y. Prognosis of Bearing Degeneration Using Adaptive Quaternion Least Mean Biquadrate Under Framework of Hypercomplex Data. IEEE Sens. J. 2020, 20, 2659–2670. [Google Scholar] [CrossRef]
- Lei, Y.; Li, G.; Jia, N.P.; Lin, F.; Xing, J.S.B. A Nonlinear Degradation Model Based Method for Remaining Useful Life Prediction of Rolling Element Bearings. In Proceedings of the 2015 Prognostics System Health Management Conference, Beijing, China, 21–23 October 2015; Zhao, T., Pecht, M.G., Zhang, S., Eds.; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Liu, X.L.; Liu, L.S.; Liu, D.T.; Wang, L.L.; Guo, Q.; Peng, X.Y. A Hybrid Method of Remaining Useful Life Prediction for Aircraft Auxiliary Power Unit. IEEE Sens. J. 2020, 20, 7848–7858. [Google Scholar] [CrossRef]
- Jiang, Y.Y.; Zeng, W.W.; Shen, J.J.; Chu, J. Prediction of remaining useful life of lithium-ion battery based on convex optimization life parameter degradation mechanism model. Proc. CSU EPSA 2019, 31, 23–28. [Google Scholar]
- Liu, O.K.; Li, Q.; Wang, X.; Ding, R. Life prediction method for EMU axle box bearings based on actual measured loadings. J. Mech. Eng. 2016, 52, 45–54. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Zou, J.H.; Ma, J. Rolling bearing residual life prediction based on Grey prediction model with multiple degenerate variables. J. Detect. Control 2019, 41, 112–120. [Google Scholar]
- Wu, Y.T.; Yuan, M.; Dong, S.P.; Lin, L.; Liu, Y.Q. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.Q.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Xia, M.; Li, T.; Shu, T.X.; Wan, J.F.; de Silva, C.W.; Wang, Z.R. A Two-Stage Approach for the Remaining Useful Life Prediction of Bearings Using Deep Neural Networks. IEEE Trans. Ind. Inform. 2019, 1, 3703–3711. [Google Scholar] [CrossRef]
- Li, X.Q.; Jiang, H.K.; Xiong, X.; Shao, H.D. Rolling bearing health prognosis using a modified health index based hierarchical gated recurrent unit network. Mech. Mach. Theory 2019, 133, 229–249. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.G.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Process. 2016, 72, 303–315. [Google Scholar] [CrossRef]
- Lei, Y.G.; Jia, F.; Lin, J.; Xing, S.B.; Ding, S.X. An Intelligent Fault Diagnosis Method Using Unsupervised Feature Learning Towards Mechanical Big Data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Thirukovalluru, R.; Dixit, S.; Sevakula, R.K.; Verma, N.K.; Salour, A. Generating Feature Sets for Fault Diagnosis Using Denoising Stacked Auto-Encoder. In Proceedings of the 2016 IEEE International Conference on Prognostics and Health Management, Ottawa, ON, Canada, 20–22 June 2016. [Google Scholar]
- Ding, X.X.; He, Q.B. Energy-Fluctuated Multiscale Feature Learning with Deep ConvNet for Intelligent Spindle Bearing Fault Diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 1926–1935. [Google Scholar] [CrossRef]
- Mosallam, A.; Medjaher, K.; Zerhouni, N. Bayesian Approach for Remaining Useful Life Prediction. In Proceedings of the 2013 Prognostics and Health Management Conference, New Orleans, LA, USA, 14–17 October 2013; Zio, E., Baraldi, P., Pierucci, S., Klemes, J.J., Eds.; Chemical Engineering Transactions: Milano, Italy, 2013; Volume 33, pp. 139–144. [Google Scholar]
- Cheng, Y.J.; Lu, C.; Li, T.Y.; Tao, L.F. Residual lifetime prediction for lithium-ion battery based on functional principal component analysis and Bayesian approach. Energy 2015, 90, 1983–1993. [Google Scholar] [CrossRef]
- Liu, Y.H.; Shuai, Q.; Zhou, S.Y.; Tang, J. Prognosis of Structural Damage Growth via Integration of Physical Model Prediction and Bayesian Estimation. IEEE Trans. Reliab. 2017, 66, 700–711. [Google Scholar] [CrossRef]
- Tang, X.P.; Zou, C.F.; Yao, K.; Lu, J.Y.; Xia, Y.X.; Gao, F.R. Aging trajectory prediction for lithium-ion batteries via model migration and Bayesian Monte Carlo method. Appl. Energy 2019, 254, 113591. [Google Scholar] [CrossRef]
- Li, T.M.; Pei, H.; Pang, Z.N.; Si, X.S.; Zheng, J.F. A Sequential Bayesian Updated Wiener Process Model for Remaining Useful Life Prediction. IEEE Access 2020, 8, 5471–5480. [Google Scholar] [CrossRef]
- Zaidan, M.A.; Mills, A.R.; Harrison, R.F.; Fleming, P.J. Gas turbine engine prognostics using Bayesian hierarchical models: A variational approach. Mech. Syst. Signal Process. 2016, 70, 120–140. [Google Scholar] [CrossRef]
- Jin, W.J.; Chen, Y.; Lee, J. Methodology for Ball Screw Component Health Assessment and Failure Analysis. In Proceedings of the ASME 8th International Manufacturing Science and Engineering Conference, Madison, WI, USA, 10–14 June 2013; Volume 2. [Google Scholar]
- Foster, P. Exploring multivariate data using directions of high density. Stat. Comput. 1998, 8, 347–355. [Google Scholar] [CrossRef]
- Mosallam, A.; Medjaher, K.; Zerhouni, N. Data-driven prognostic method based on Bayesian approaches for direct remaining useful life prediction. J. Intell. Manuf. 2016, 27, 1037–1048. [Google Scholar] [CrossRef]
- Moghaddass, R.; Zuo, M.J. An integrated framework for online diagnostic and prognostic health monitoring using a multistate deterioration process. Reliab. Eng. Syst. Saf. 2014, 124, 92–104. [Google Scholar] [CrossRef]
- Hamada, M.S.; Wilson, A.; Reese, C.S.; Martz, H. Bayesian Reliability; Springer Science & Business Media: Berlin, Germany, 2008. [Google Scholar]
- Andrieu, C.; de Freitas, N.; Doucet, A.; Jordan, M.I. An introduction to MCMC for machine learning. Mach. Learn. 2003, 50, 5–43. [Google Scholar] [CrossRef]
- Wang, Z.L. Markov chain Monte Carlo sampling using a reservoir method. Comput. Stat. Data Anal. 2019, 139, 64–74. [Google Scholar] [CrossRef]
- Qi, H.S.; Hu, X.B. Bayesian inference of channelized section spillover via Markov Chain Monte Carlo sampling. Transp. Res. Part C Emerg. Technnol. 2018, 97, 478–498. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.G.; Li, N.P.; Li, N.B. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2020, 69, 401–412. [Google Scholar] [CrossRef]
- Son, K.L.; Fouladirad, M.; Barros, A.; Levrat, E.; Lung, B. Remaining useful life estimation based on stochastic deterioration models: A comparative study. Reliab. Eng. Syst. Saf. 2013, 112, 165–175. [Google Scholar] [CrossRef]
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage Propagation Modeling for Aircraft Engine Run-to-Failure Simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar]
- Dong, S.J.; Sheng, J.L.; Liu, Z.; Zhong, L.; Wei, H.B. Bearing remain life prediction based on weighted complex SVM models. J. Vibroeng. 2016, 18, 3636–3653. [Google Scholar]
- An, D.; Choi, J.H.; Kim, N.H. Prognostics 101: A tutorial for particle filter-based prognostics algorithm using Matlab. Reliab. Eng. Syst. Saf. 2013, 115, 161–169. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence Number | Feature Index | Expression | Sequence Number | Feature Index | Expression |
|---|---|---|---|---|---|
| 1 | Mean value | 2 | Standard deviation | ||
| 3 | Variation coefficient | 4 | Peak value | ||
| 5 | Square root amplitude | 6 | Absolute mean amplitude | ||
| 7 | Root mean square | 8 | Peak-to -peak | ||
| 9 | Skewness | 10 | Kurtosis | ||
| 11 | Skewness factor | 12 | Kurtosis factor | ||
| 13 | Crest factor | 14 | Impulse factor | ||
| 15 | Waveform factor | 16 | Margin factor |
| Operating Condition | Bearing Dataset | Number of Files | Bearing Lifetime | Fault Element |
|---|---|---|---|---|
| Condition1 (35 Hz/12 kN) | Bearing 1_1 (Test bearing) | 158 | 2 h 38 min | Outer race |
| Bearing 1_2 (Training bearing 1) | 161 | 2 h 41 min | Outer race | |
| Bearing 1_3 (Training bearing 2) | 123 | 2 h 3 min | Outer race | |
| Bearing 1_4 (Training bearing 3) | 122 | 2 h 2 min | Cage | |
| Bearing 1_5 (Training bearing 4) | 52 | 52 min | Inner and outer race |
| Selected Feature Index | |||||||
|---|---|---|---|---|---|---|---|
| Coefficient value | 0.3960 | 0.3940 | 0.3947 | 0.3959 | 0.3959 | 0.3859 | −0.2692 |
| Prediction Method | SVM Method | Pairs Based PF Method | Proposed Method |
|---|---|---|---|
| RMSE | 7.1005 | 8.7427 | 4.8843 |
| MARE | 3.2405 | 4.7628 | 2.3079 |
| S value | 80.7027 | 94.8183 | 46.5061 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, T.; Li, Y.; Huang, X.; Wang, C. Data-Driven Method for Predicting Remaining Useful Life of Bearing Based on Bayesian Theory. Sensors 2021, 21, 182. https://doi.org/10.3390/s21010182
Gao T, Li Y, Huang X, Wang C. Data-Driven Method for Predicting Remaining Useful Life of Bearing Based on Bayesian Theory. Sensors. 2021; 21(1):182. https://doi.org/10.3390/s21010182
Chicago/Turabian StyleGao, Tianhong, Yuxiong Li, Xianzhen Huang, and Changli Wang. 2021. "Data-Driven Method for Predicting Remaining Useful Life of Bearing Based on Bayesian Theory" Sensors 21, no. 1: 182. https://doi.org/10.3390/s21010182
APA StyleGao, T., Li, Y., Huang, X., & Wang, C. (2021). Data-Driven Method for Predicting Remaining Useful Life of Bearing Based on Bayesian Theory. Sensors, 21(1), 182. https://doi.org/10.3390/s21010182