Proactive Congestion Avoidance for Distributed Deep Learning


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Background and Motivation
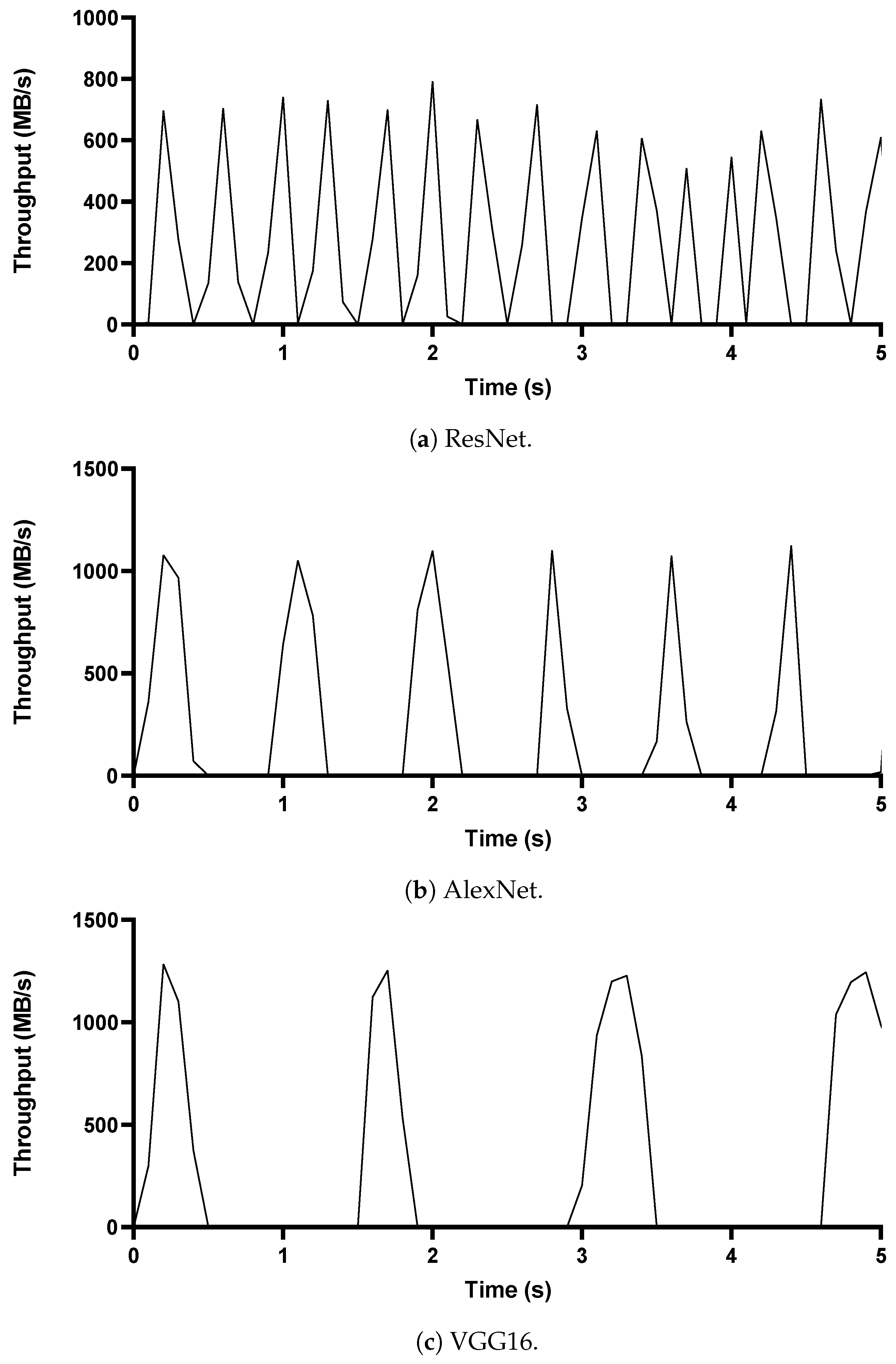
2.1. Distributed Deep Learning Traffic
2.2. Related Work
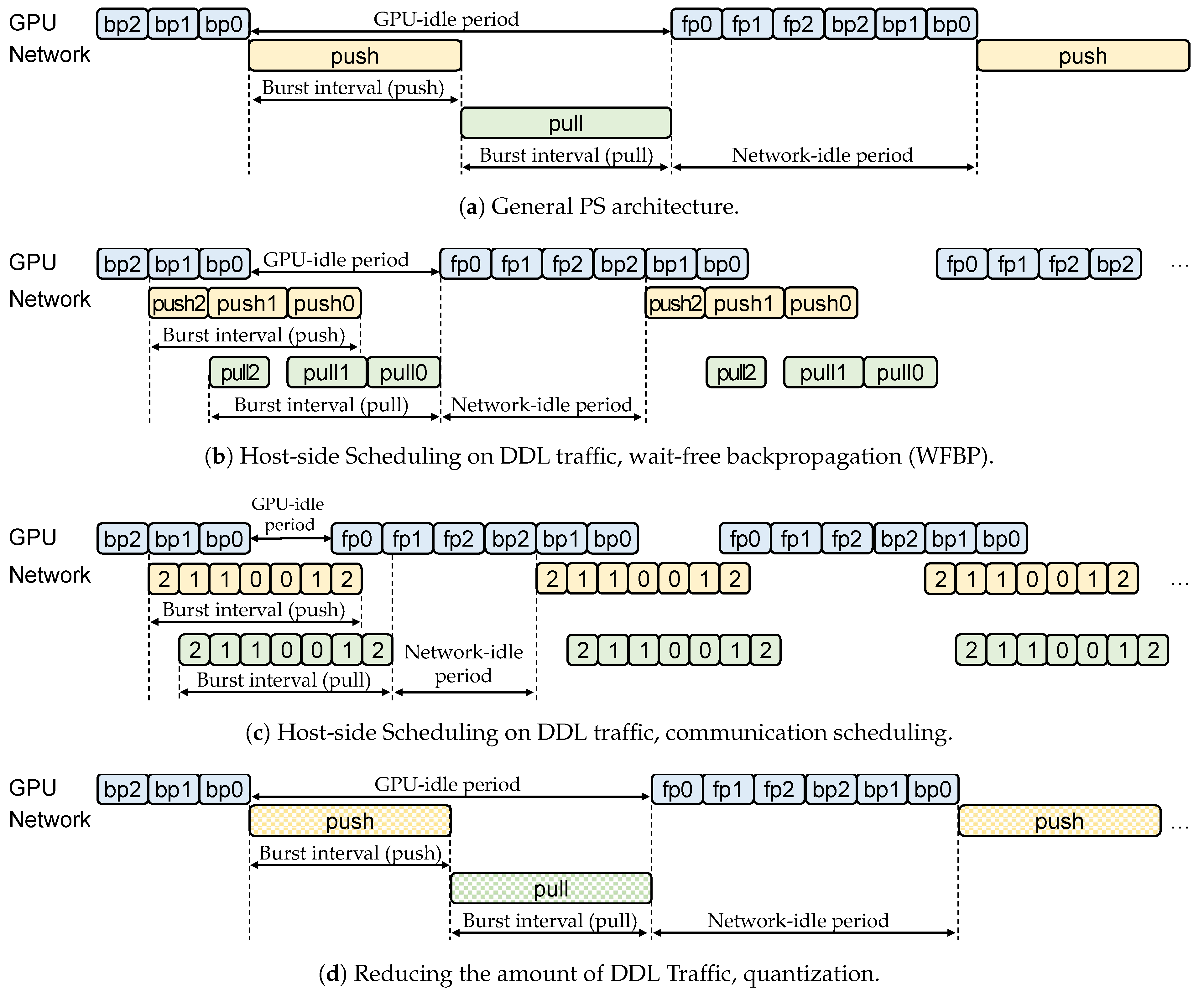
2.2.1. Host-Side Scheduling on DDL Traffic
2.2.2. Reducing the Amount of DDL Traffic
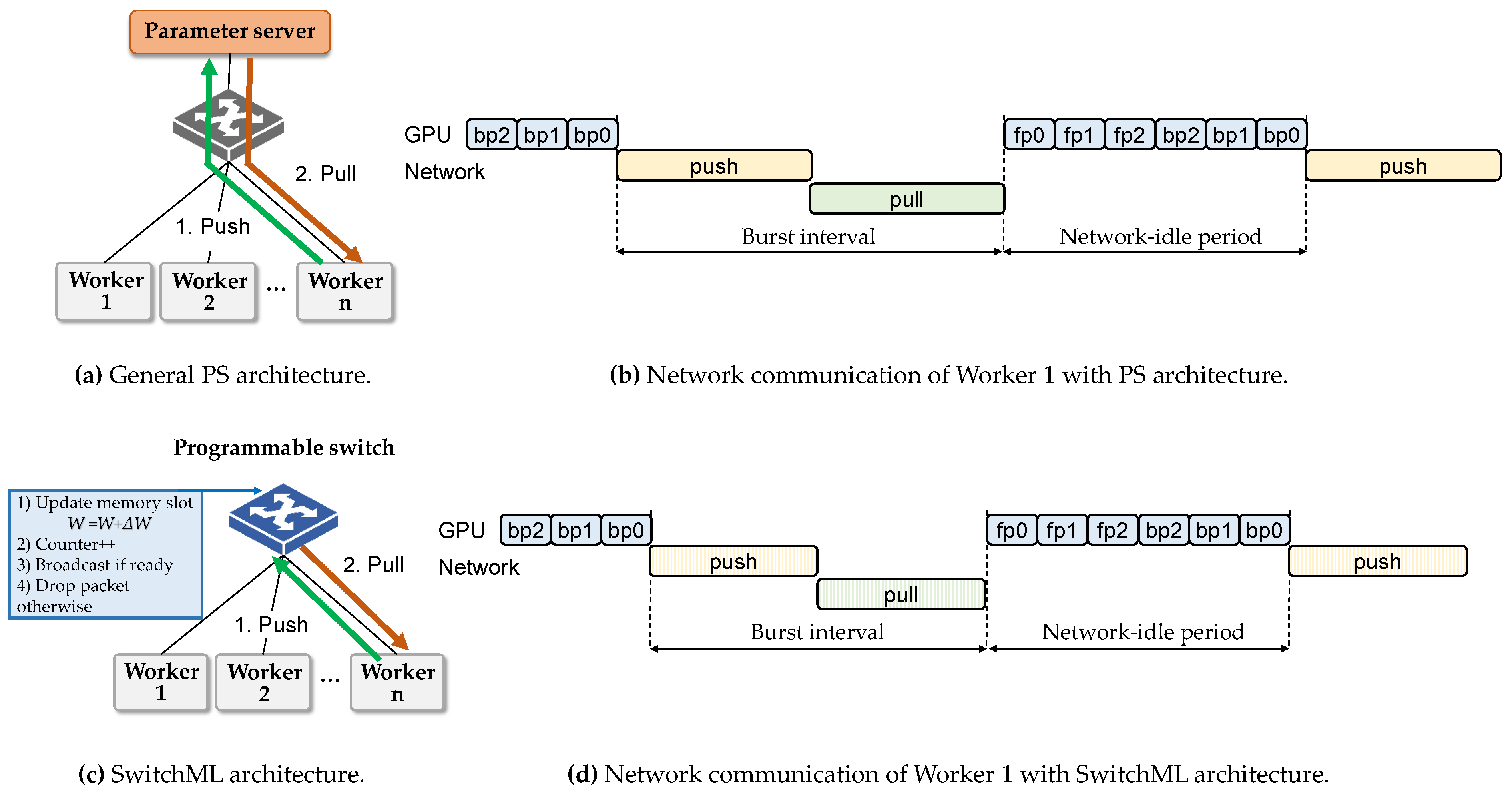
2.2.3. Improvement Using an In-Network Switch
2.2.4. ECN-Based Approach
2.2.5. Novelty of PCN
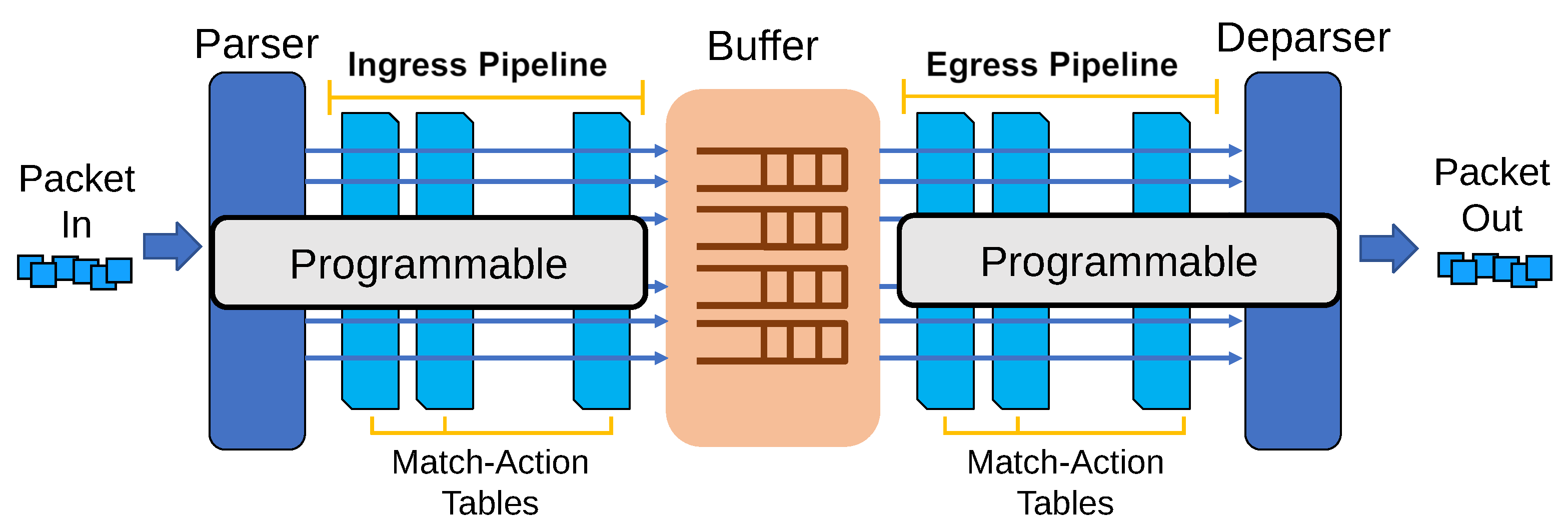
2.3. P4 and Switch Programmability
3. Design
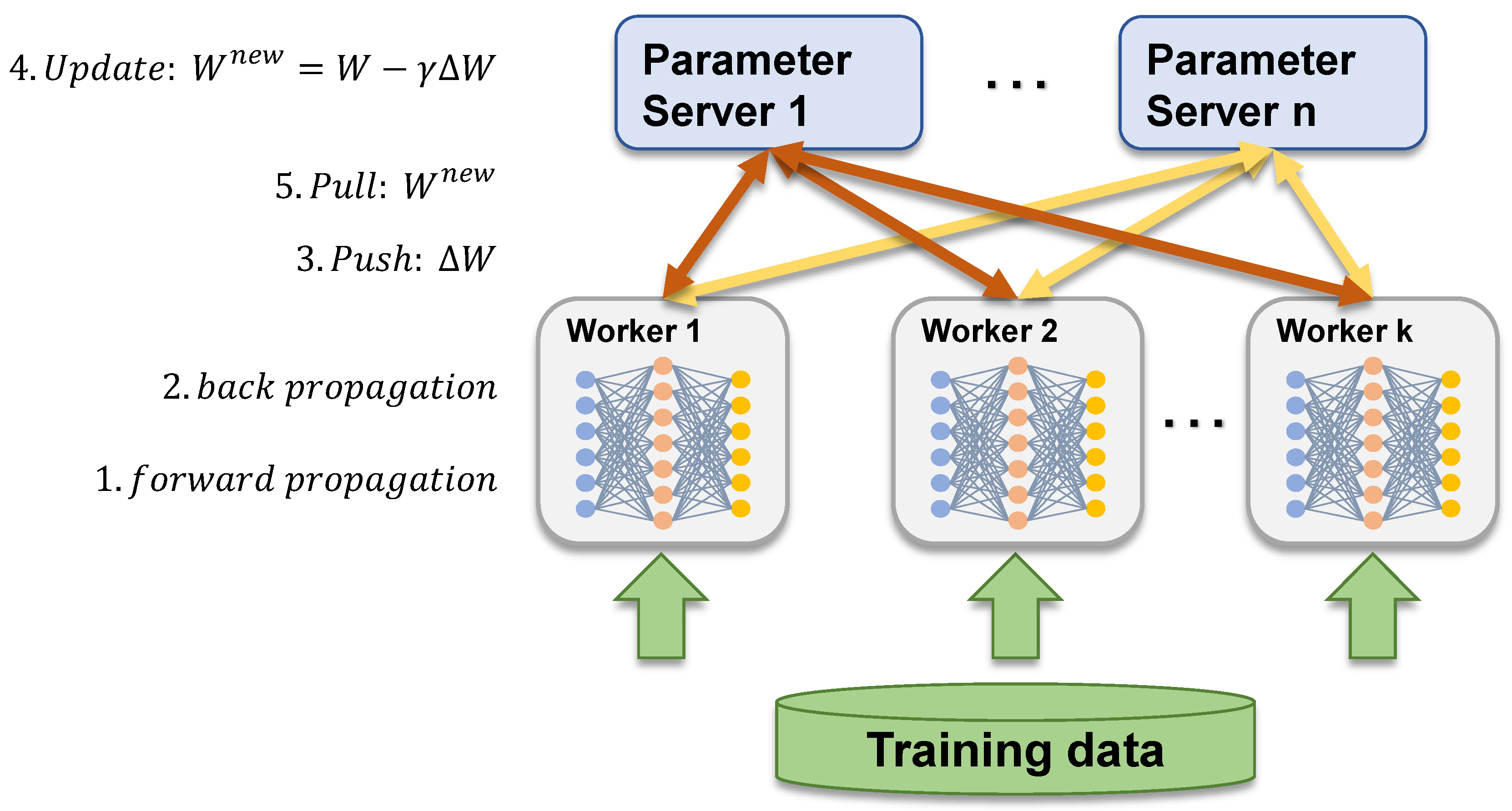
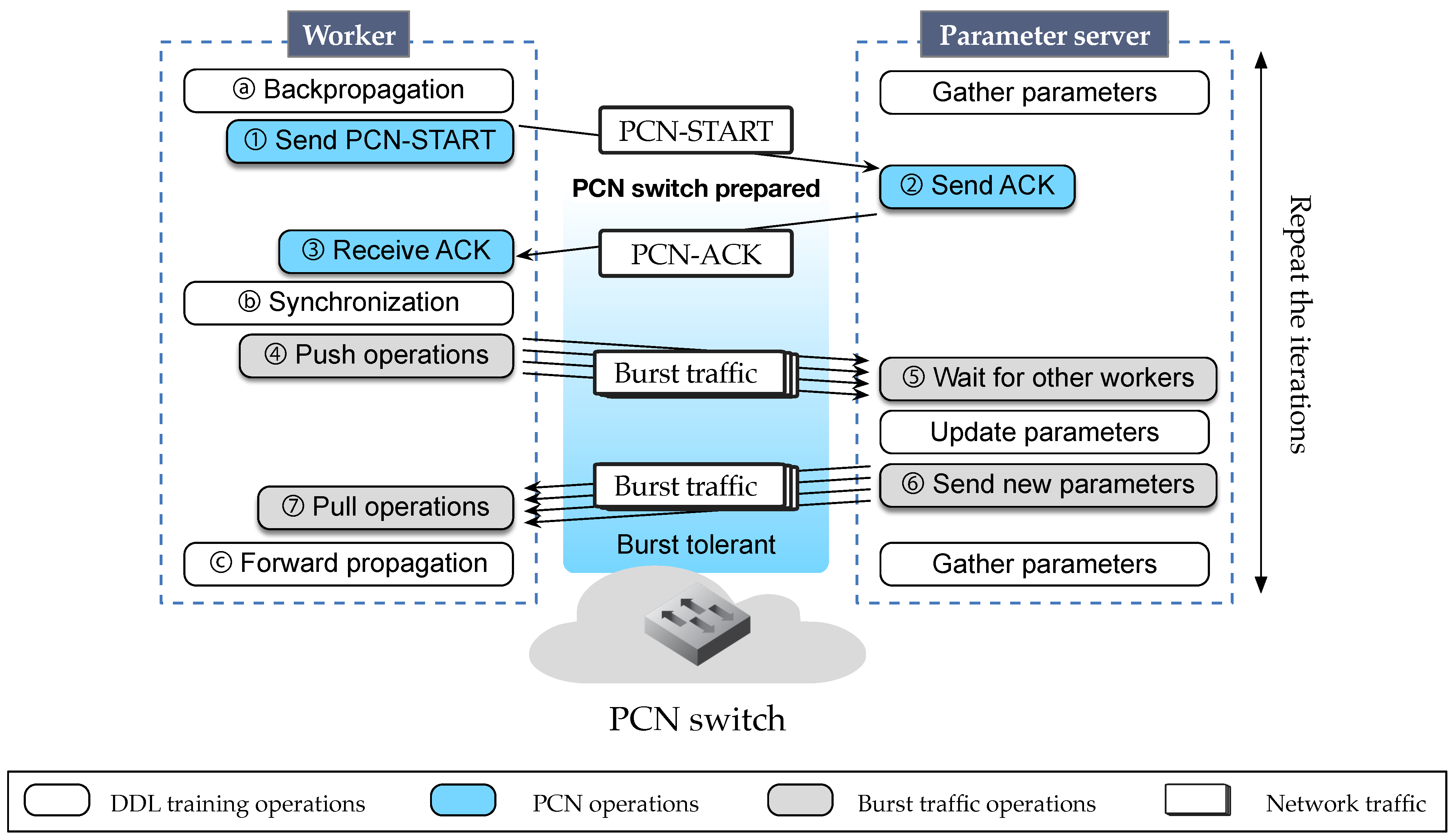
3.1. Communication Sequence between Worker and PS
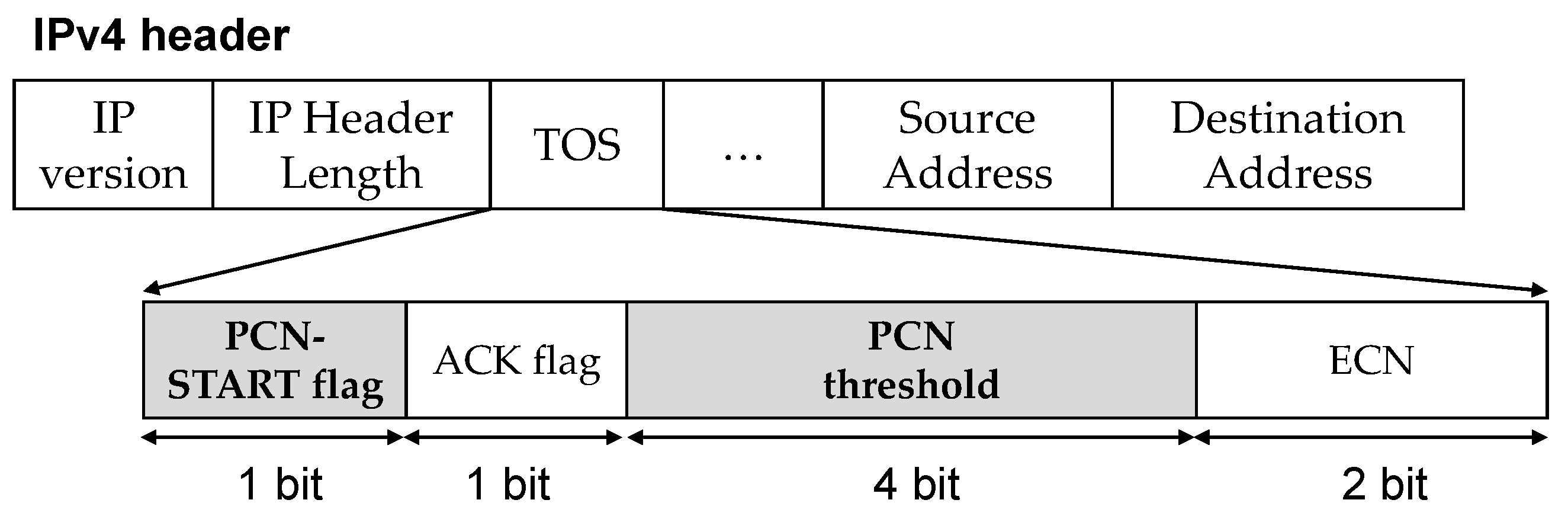
3.2. Switch Operation for PCN
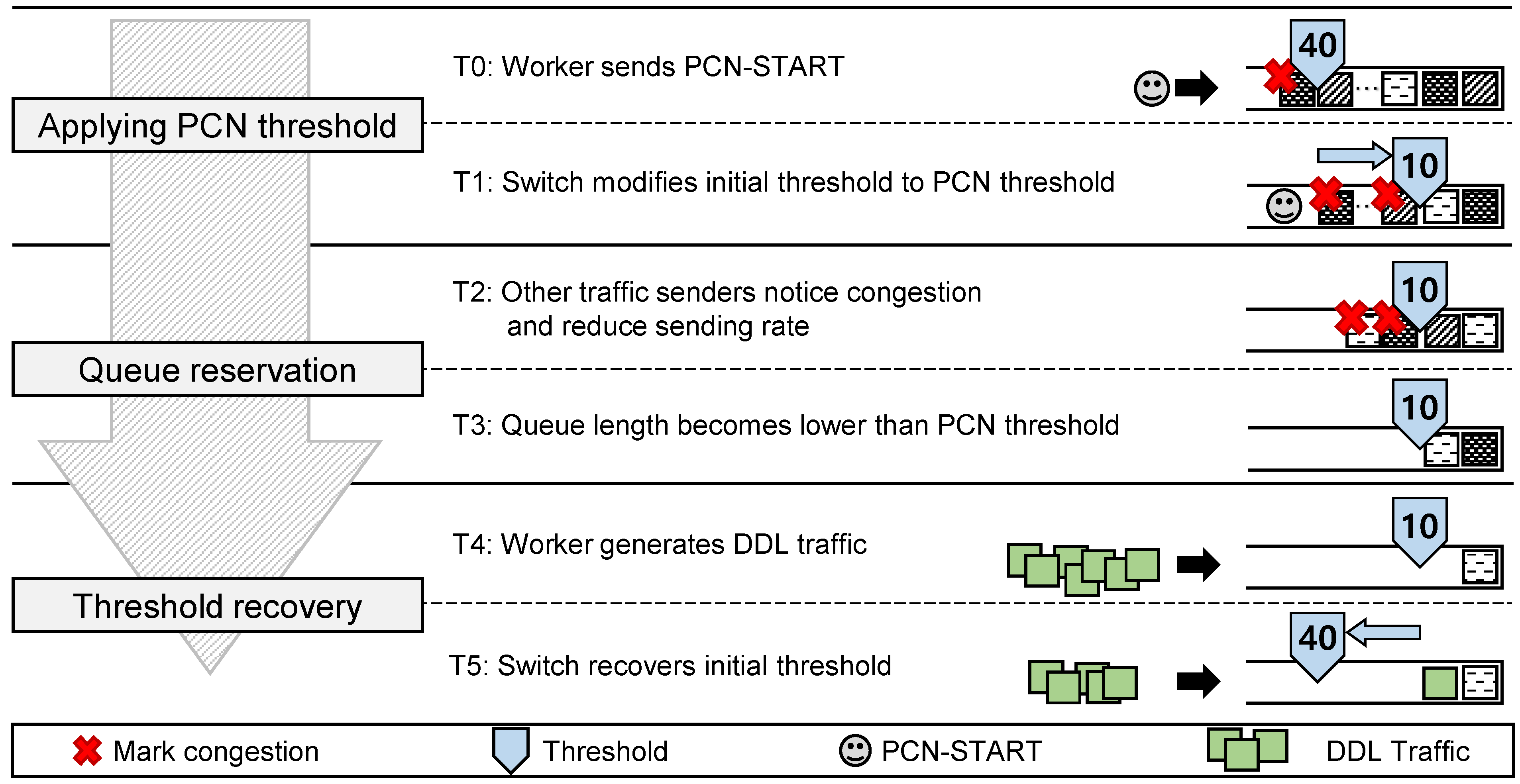
- Applying the PCN threshold: When a worker sends the PCN-START packet (T0 in Figure 8), the switch parses the PCN-START header and obtains the PCN threshold. Then, the switch saves the PCN threshold in the switch register and applies the PCN threshold for its queue (T1), instead of the current queue threshold (initial threshold). The PCN threshold should be smaller than the initial threshold in order to prepare for the burst DDL traffic (details in Section 3.3). In case when multiple workers send the PCN-START packets at the same time, the switch manages the counter, increases the counter every time the PCN-START packet arrives, and decreases the counter every time the burst DDL traffic arrives. The PCN threshold is applied when the counter is non-zero.
- Queue reservation: Queue length tends to fluctuate around the threshold value. For example, if the initial threshold is 40, the queue length usually fluctuates from 25 to 50 in our environment, showing a saw-tooth pattern because of host-side congestion control. In this situation, when the PCN threshold is applied (for example, 10), packets enqueued at the switch (from 10th to the last packets) are considered as the ones that cause network congestion. So, since the initial threshold is larger than the PCN threshold, a number of packets (higher than PCN threshold) occupy the switch’s queue when the PCN threshold is applied. Incoming packets are then marked as congested, and the packets’ senders get notified of congestion. So, the senders slow down their packet sending rates according to the TCP/IP protocol (T2). Thus, the switch’s queue length becomes lower than the PCN threshold (T3), which makes the switch more burst tolerable.
- Threshold recovery: The time between T0 and T3 takes about one RTT because the queue length gets changed to the PCN threshold when senders change their sending rates. So, in T4, workers need to start the burst DDL traffic after one RTT from sending the PCN-START packet so that the switch is ready for the burstiness. This scheme is achieved by workers that generate DDL traffic after receiving an ACK packet for the PCN-START packet from the PS. Then, the DDL traffic is processed in the switch. Once the DDL traffic arrives at the switch, in T5, PCN restores the threshold back to the initial threshold in order to recover the sending rates. While DDL traffic is being processed, the background traffic also recovers its sending rate. This may cause another congestion to the DDL traffic. However, because the DDL traffic is already being queued earlier than the background traffic, and the background traffic senders increase sending rates slowly (according to TCP additive increase), the chance for this congestion is low. If it happens, the switch can use the ECN approach to slow down the sender of background traffic. The rationale of T5 is to minimize the throughput reduction, and the throughput reduction will be measured in Section 4.4.
3.3. PCN Threshold Policy
4. Evaluation
4.1. Evaluation Metrics
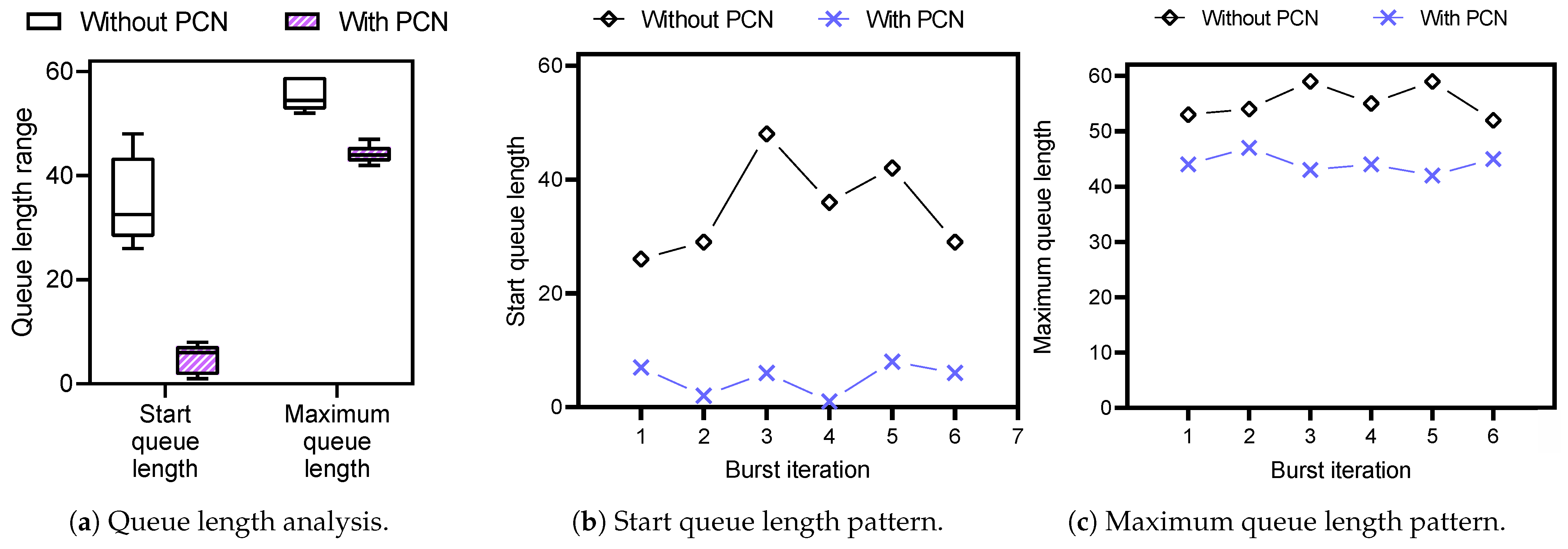
- Queue length change: We measure the queue length of a switch as the preparedness for the burst packets of PCN. Two measurements, start queue length and maximum queue length, are measured. Start queue length represents the queue length occupied by the background packets before the DDL packets arrive at the switch, which shows the switch queue status right before the burst packets of the iteration arrive. The maximum queue length is the highest switch queue length during each burst interval.
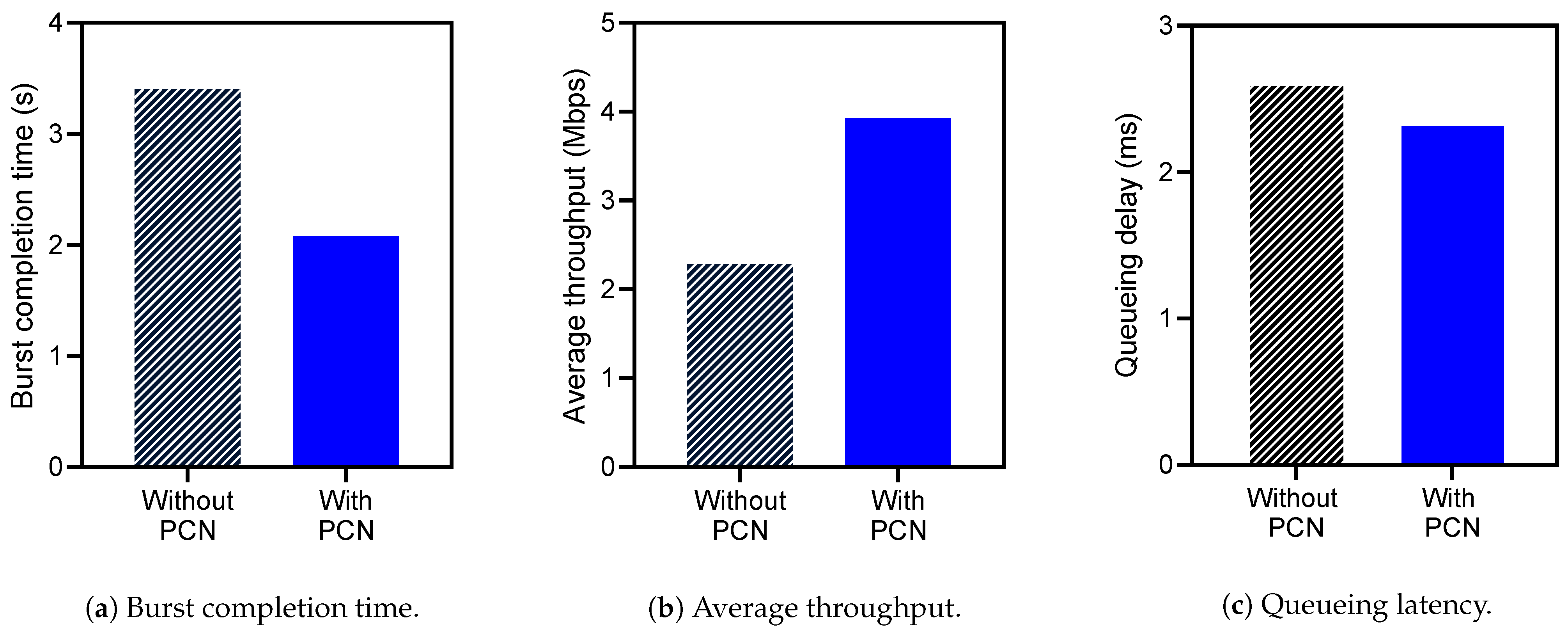
- Performance improvement: To evaluate the performance improvement by PCN, we use three metrics–average throughput, burst completion time, and queueing latency. The average throughput is the amount of transmitted network traffic, and the burst completion time refers to the time taken for network communication of burst packets to be completed. Also, queueing latency is per-packet latency in a network switch caused by the existing packets in the switch queue. These three metrics are measured and compared with and without running PCN. To measure the queueing latency, we implement in-band telemetry [40] that makes the packets contain custom network statistics, such as queueing latency per switch.
- Overheads: PCN makes the switch available for burst packets by reducing its queue threshold. Although this scheme is effective on DDL packets, it could reduce the throughput of other background traffic. So, we measure the decreased throughput of background traffic as an overhead of PCN.
4.2. Queue Length Change
4.3. Performance Improvement
4.4. Overheads
5. Discussion
5.1. Estimation of the Total DDL Training Time
5.2. The Impact of Environment Changes on PCN
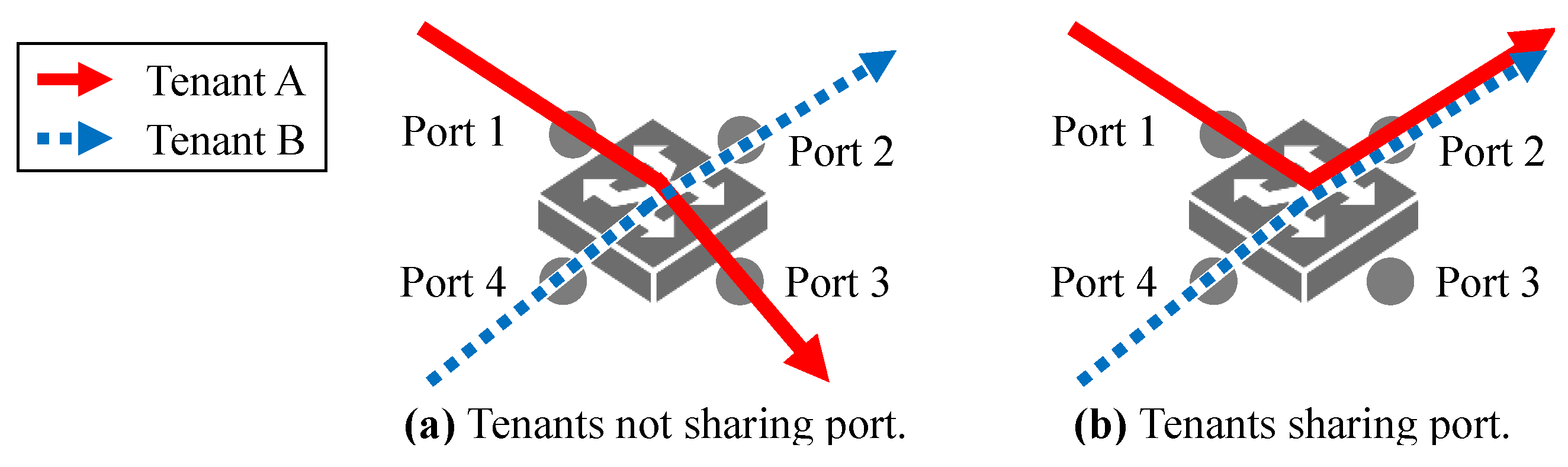
5.3. Multi-Tenancy
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Long, J.; Shekita, E.J.; Su, B.Y. Scaling distributed machine learning with the parameter server. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 583–598. [Google Scholar]
- Bao, Y.; Peng, Y.; Chen, Y.; Wu, C. Preemptive all-reduce scheduling for expediting distributed dnn training. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 626–635. [Google Scholar]
- Peng, Y.; Zhu, Y.; Chen, Y.; Bao, Y.; Yi, B.; Lan, C.; Wu, C.; Guo, C. A generic communication scheduler for distributed dnn training acceleration. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 27–30 October 2019; pp. 16–29. [Google Scholar]
- Chen, C.; Wang, W.; Li, B. Round-robin synchronization: Mitigating communication bottlenecks in parameter servers. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 532–540. [Google Scholar]
- Zhang, H.; Zheng, Z.; Xu, S.; Dai, W.; Ho, Q.; Liang, X.; Hu, Z.; Wei, J.; Xie, P.; Xing, E.P. Poseidon: An efficient communication architecture for distributed deep learning on GPU clusters. In Proceedings of the 2017 USENIX Annual Technical Conference (USENIX ATC 17), Santa Clara, CA, USA, 12–14 July 2017; pp. 181–193. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Rossetti, D.; Team, S. GPUDIRECT: Integrating the GPU with a Network Interface. In Proceedings of the GPU Technology Conference, San Jose, CA, USA, 17–20 March 2015. [Google Scholar]
- NVIDIA Collective Communication Library (NCCL) Documentation. Available online: https://docs.nvidia.com/deeplearning/sdk/nccl-developer-guide/docs/index.html (accessed on 28 October 2020).
- Alizadeh, M.; Greenberg, A.; Maltz, D.A.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center tcp (dctcp). In Proceedings of the ACM SIGCOMM 2010 Conference, New Delhi, India, 30 August–3 September 2010; pp. 63–74. [Google Scholar]
- Wu, H.; Ju, J.; Lu, G.; Guo, C.; Xiong, Y.; Zhang, Y. Tuning ECN for data center networks. In Proceedings of the 8th International Conference on Emerging Networking Experiments and Technologies, Nice, France, 10–13 December 2012; pp. 25–36. [Google Scholar]
- Hashemi, S.H.; Abdu Jyothi, S.; Campbell, R. Tictac: Accelerating distributed deep learning with communication scheduling. Proc. Mach. Learn. Syst. 2019, 1, 418–430. [Google Scholar]
- Jayarajan, A.; Wei, J.; Gibson, G.; Fedorova, A.; Pekhimenko, G. Priority-based parameter propagation for distributed DNN training. arXiv 2019, arXiv:1905.03960. [Google Scholar]
- Awan, A.A.; Hamidouche, K.; Hashmi, J.M.; Panda, D.K. S-caffe: Co-designing mpi runtimes and caffe for scalable deep learning on modern gpu clusters. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Austin, TX, USA, 4–8 February 2017; pp. 193–205. [Google Scholar]
- Floyd, S.; Ramakrishnan, D.K.K.; Black, D.L. The Addition of Explicit Congestion Notification (ECN) to IP. RFC 3168. 2001. Available online: https://tools.ietf.org/html/rfc3168 (accessed on 20 December 2020).
- Paxson, D.V.; Allman, M.; Stevens, W.R. RFC 2581–TCP Congestion Control. Available online: https://tools.ietf.org/html/rfc2581 (accessed on 20 December 2020).
- Bosshart, P.; Daly, D.; Gibb, G.; Izzard, M.; McKeown, N.; Rexford, J.; Schlesinger, C.; Talayco, D.; Vahdat, A.; Varghese, G.; et al. P4: Programming protocol-independent packet processors. ACM SIGCOMM Comput. Commun. Rev. 2014, 44, 87–95. [Google Scholar] [CrossRef]
- Wang, S.; Li, D.; Geng, J. Geryon: Accelerating distributed cnn training by network-level flow scheduling. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1678–1687. [Google Scholar]
- Sapio, A.; Canini, M.; Ho, C.Y.; Nelson, J.; Kalnis, P.; Kim, C.; Krishnamurthy, A.; Moshref, M.; Ports, D.R.; Richtárik, P. Scaling distributed machine learning with in-network aggregation. arXiv 2019, arXiv:1903.06701. [Google Scholar]
- Consortium, P.L. Behavioral Model (bmv2). Available online: https://github.com/p4lang/behavioral-model (accessed on 28 October 2020).
- gRPC, a High Performance, Open-Source Universal RPC Framework. Available online: https://grpc.io/ (accessed on 2 November 2020).
- Jia, D.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- NVIDIA V100. Available online: https://www.nvidia.com/en-us/data-center/v100/ (accessed on 9 September 2020).
- Boettiger, C. An introduction to Docker for reproducible research. ACM SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]
- Jacobson, V.; Leres, C.; McCanne, S. The Tcpdump Manual Page; Lawrence Berkeley Laboratory: Berkeley, CA, USA, 1989; Volume 143, p. 117.
- Kapoor, R.; Snoeren, A.C.; Voelker, G.M.; Porter, G. Bullet trains: A study of NIC burst behavior at microsecond timescales. In Proceedings of the Ninth ACM Conference on Emerging Networking Experiments and Technologies, Santa Barbara, CA, USA, 9–12 December 2013; pp. 133–138. [Google Scholar]
- Sergeev, A.; Del Balso, M. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Seide, F.; Fu, H.; Droppo, J.; Li, G.; Yu, D. 1-bit stochastic gradient descent and its application to data-parallel distributed training of speech dnns. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Alistarh, D.; Grubic, D.; Li, J.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. Adv. Neural Inf. Process. Syst. 2017, 30, 1709–1720. [Google Scholar]
- Hsieh, K.; Harlap, A.; Vijaykumar, N.; Konomis, D.; Ganger, G.R.; Gibbons, P.B.; Mutlu, O. Gaia: Geo-distributed machine learning approaching LAN speeds. In Proceedings of the 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17), Boston, MA, USA, 27–29 March 2017; pp. 629–647. [Google Scholar]
- TensorFlow Lite: ML for Mobile and Edge Devices. Available online: https://www.tensorflow.org/lite (accessed on 28 October 2020).
- Bosshart, P.; Gibb, G.; Kim, H.S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Turner, A.; Bing, M. Tcpreplay Tool. Available online: http://tcpreplay.sourceforge.net (accessed on 20 December 2020).
- Gueant, V. Iperf3. Available online: https://iperf.fr/ (accessed on 28 October 2020).
- Kim, C.; Sivaraman, A.; Katta, N.; Bas, A.; Dixit, A.; Wobker, L.J. In-band network telemetry via programmable dataplanes. In Proceedings of the ACM SIGCOMM, London, UK, 17–21 August 2015. [Google Scholar]
- Thangakrishnan, I.; Cavdar, D.; Karakus, C.; Ghai, P.; Selivonchyk, Y.; Pruce, C. Herring: Rethinking the parameter server at scale for the cloud. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 15 November 2020; pp. 1–13. [Google Scholar]
- Yang, G.; Yu, B.y.; Jin, H.; Yoo, C. Libera for Programmable Network Virtualization. IEEE Commun. Mag. 2020, 58, 38–44. [Google Scholar] [CrossRef]
- Yoo, Y.; Yang, G.; Kang, M.; Yoo, C. Adaptive Control Channel Traffic Shaping for Virtualized SDN in Clouds. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 19–23 October 2020; pp. 22–24. [Google Scholar]
- Kang, M.; Yang, G.; Yoo, Y.; Yoo, C. TensorExpress: In-Network Communication Scheduling for Distributed Deep Learning. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 19–23 October 2020; pp. 25–27. [Google Scholar]
- Yang, G.; Jin, H.; Kang, M.; Moon, G.J.; Yoo, C. Network Monitoring for SDN Virtual Networks. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1261–1270. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, M.; Yang, G.; Yoo, Y.; Yoo, C. Proactive Congestion Avoidance for Distributed Deep Learning. Sensors 2021, 21, 174. https://doi.org/10.3390/s21010174
Kang M, Yang G, Yoo Y, Yoo C. Proactive Congestion Avoidance for Distributed Deep Learning. Sensors. 2021; 21(1):174. https://doi.org/10.3390/s21010174
Chicago/Turabian StyleKang, Minkoo, Gyeongsik Yang, Yeonho Yoo, and Chuck Yoo. 2021. "Proactive Congestion Avoidance for Distributed Deep Learning" Sensors 21, no. 1: 174. https://doi.org/10.3390/s21010174
APA StyleKang, M., Yang, G., Yoo, Y., & Yoo, C. (2021). Proactive Congestion Avoidance for Distributed Deep Learning. Sensors, 21(1), 174. https://doi.org/10.3390/s21010174