Bandwidth Detection of Graph Signals with a Small Sample Size


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Problem Formulation
3. Bandwidth Detection
3.1. High Dimensional Challenge
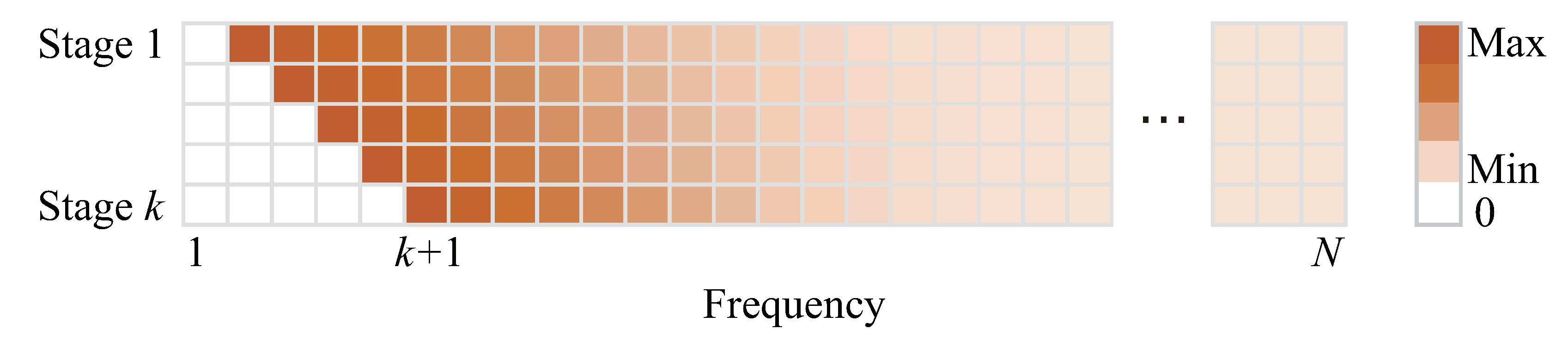
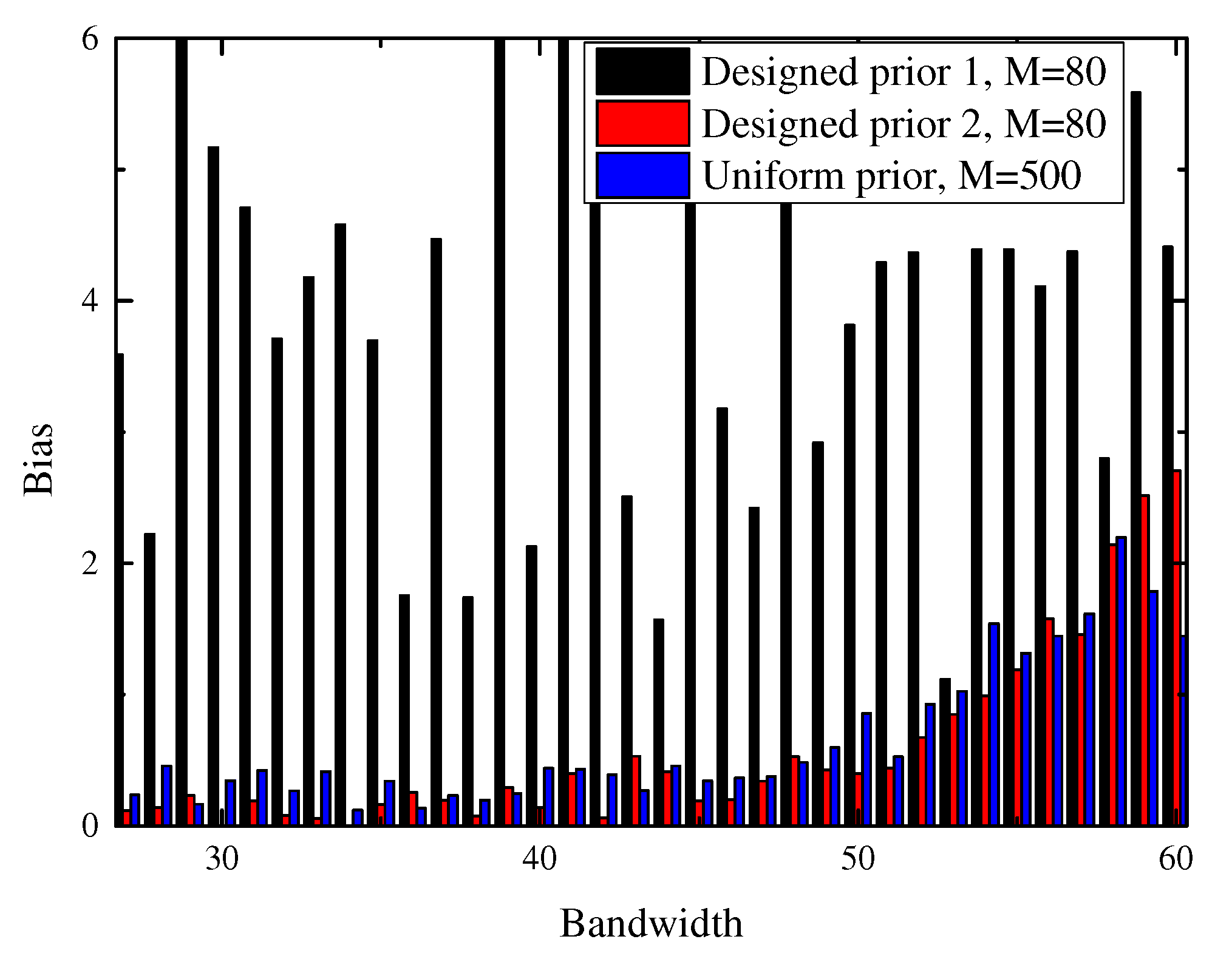
3.2. Design of the Prior
3.3. Method
- Interpretation of the test statistic: indicates the part of out of the range of . The numerator of (13) can be rewritten as with . Larger indicates a larger energy of lying in the range of , which links to a larger amplitude of the ith element in . equals Q, which is a weighted sum of , normalized by the energy of . When the weight decreases with i, will be larger if is larger for smaller i. Therefore, the test is more powerful against that has non-zero frequency coefficients in low frequency than that has non-zero frequency coefficients in high frequency. This is in accordance with the purpose of our design that the test should be more distinguishable from the model with bandwidth close to k.
| Algorithm 1: Multi-stage Bandwidth Detection. |
| Input Samples and significance level ; |
| Output Detected bandwidth K or None; |
| 1: for do |
| 2: Calculate test statistic according to (13); |
| 3: Calculate the p-value of the test according to (15); |
| 4: if then |
| 5: Let bandwidth and stop; |
| 6: else |
| 7: ; |
| 8: end if |
| 9: end for |
3.4. Power Analysis
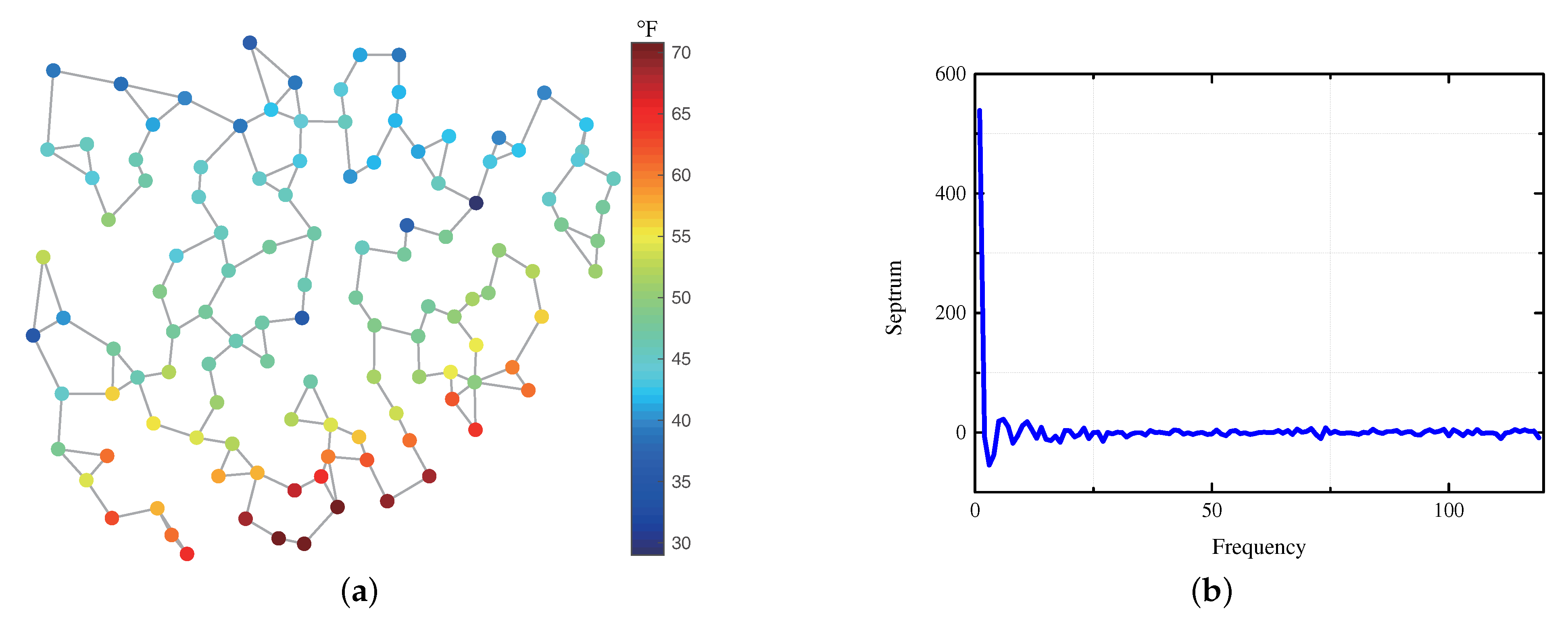
4. Numerical Analysis
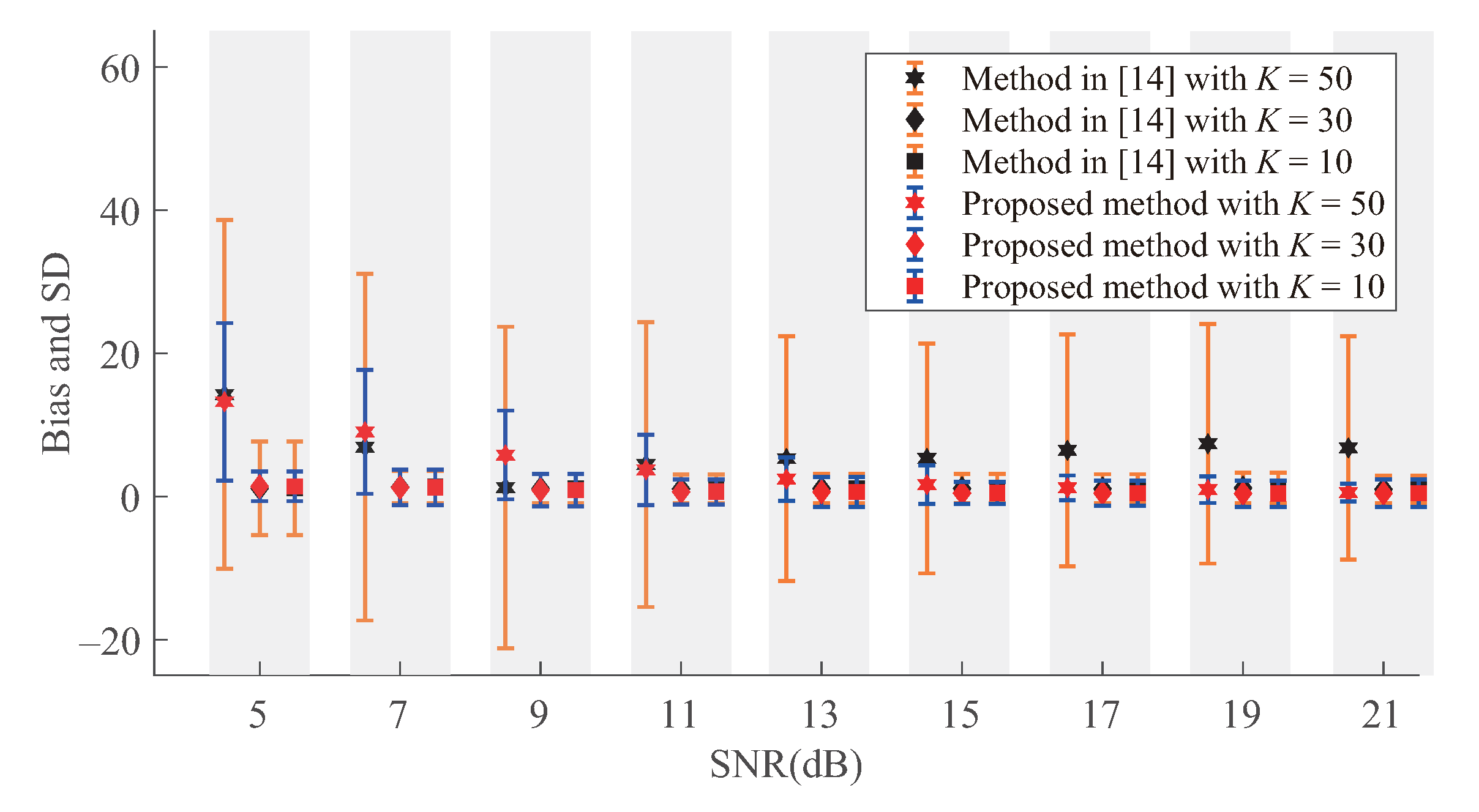
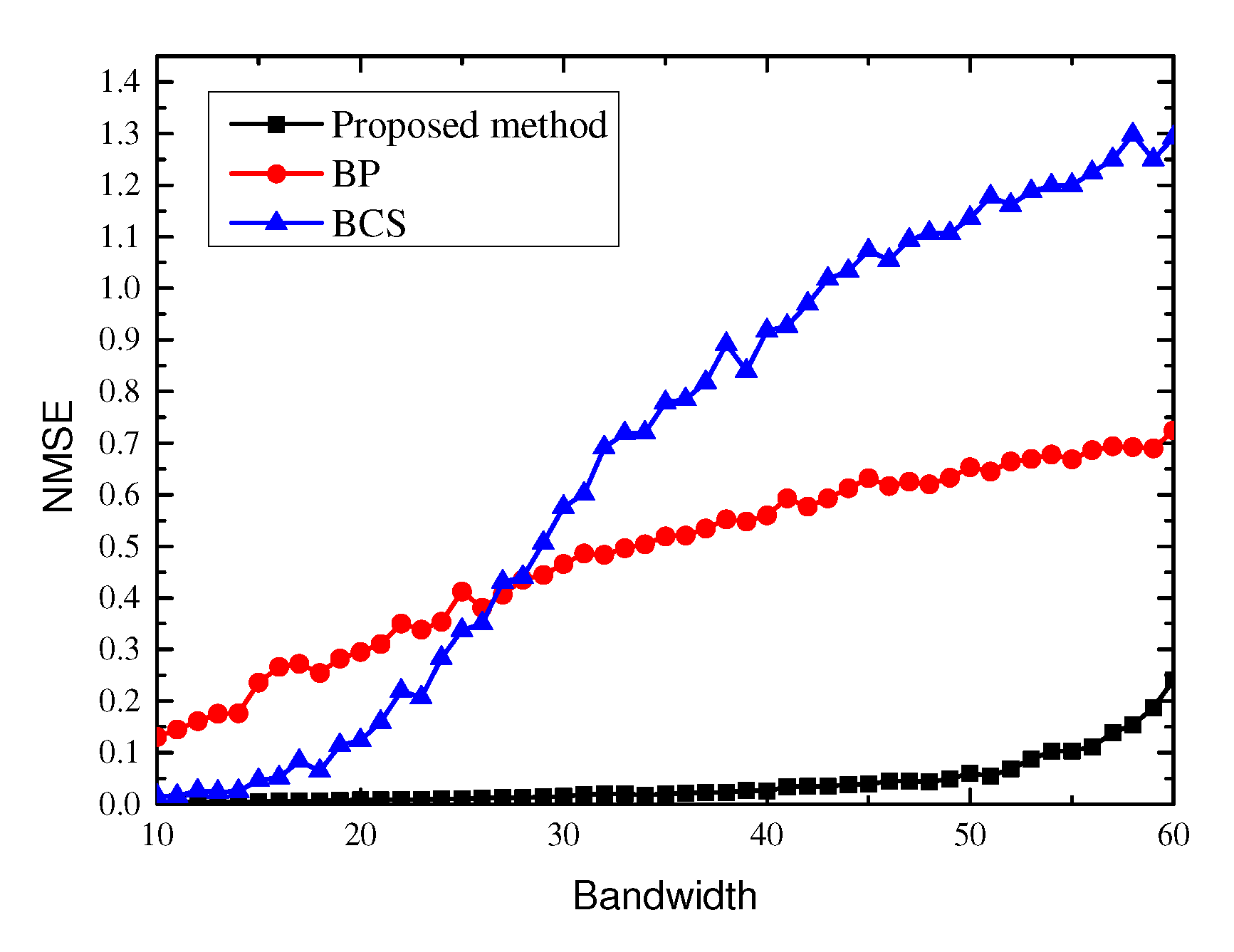
4.1. Bandwidth Detection
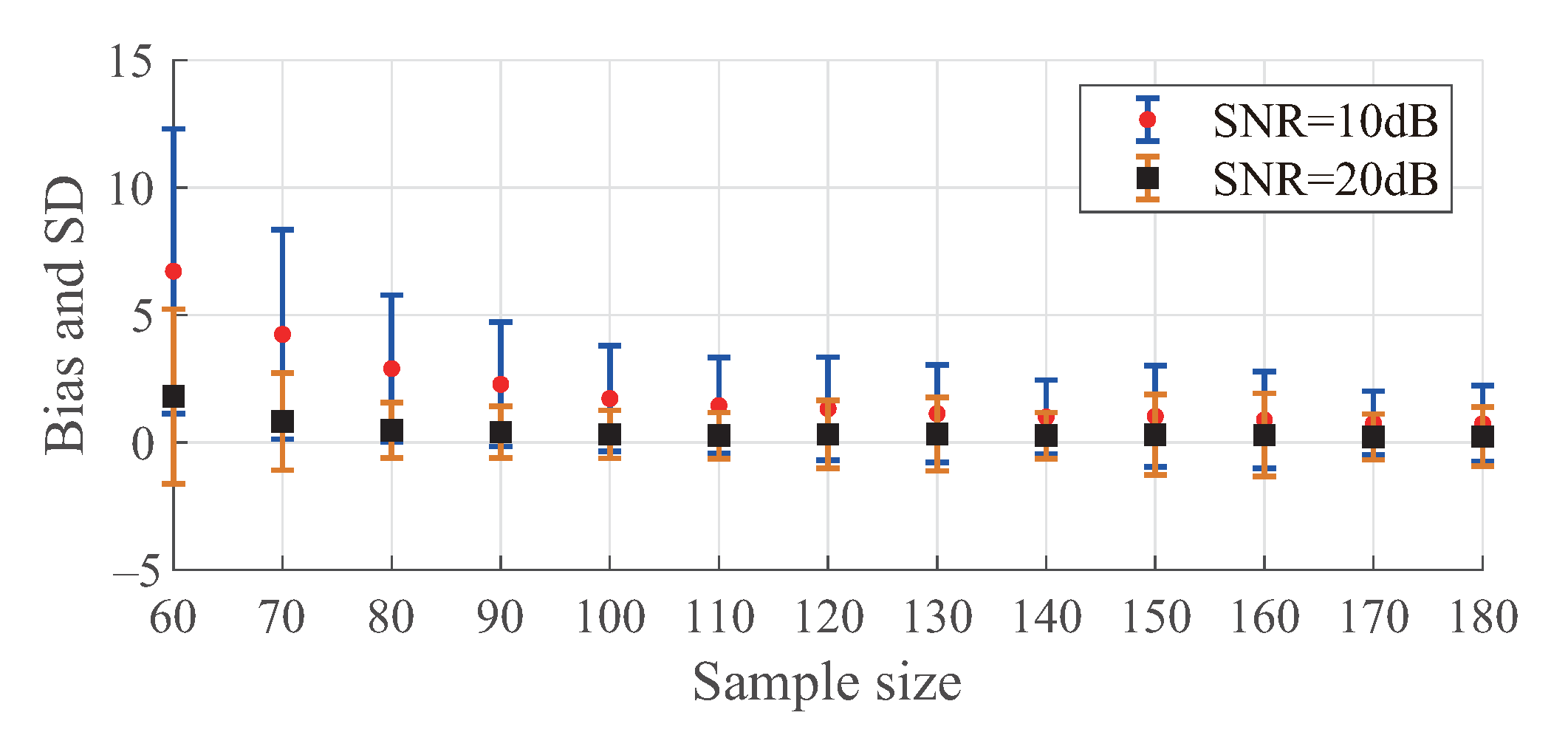
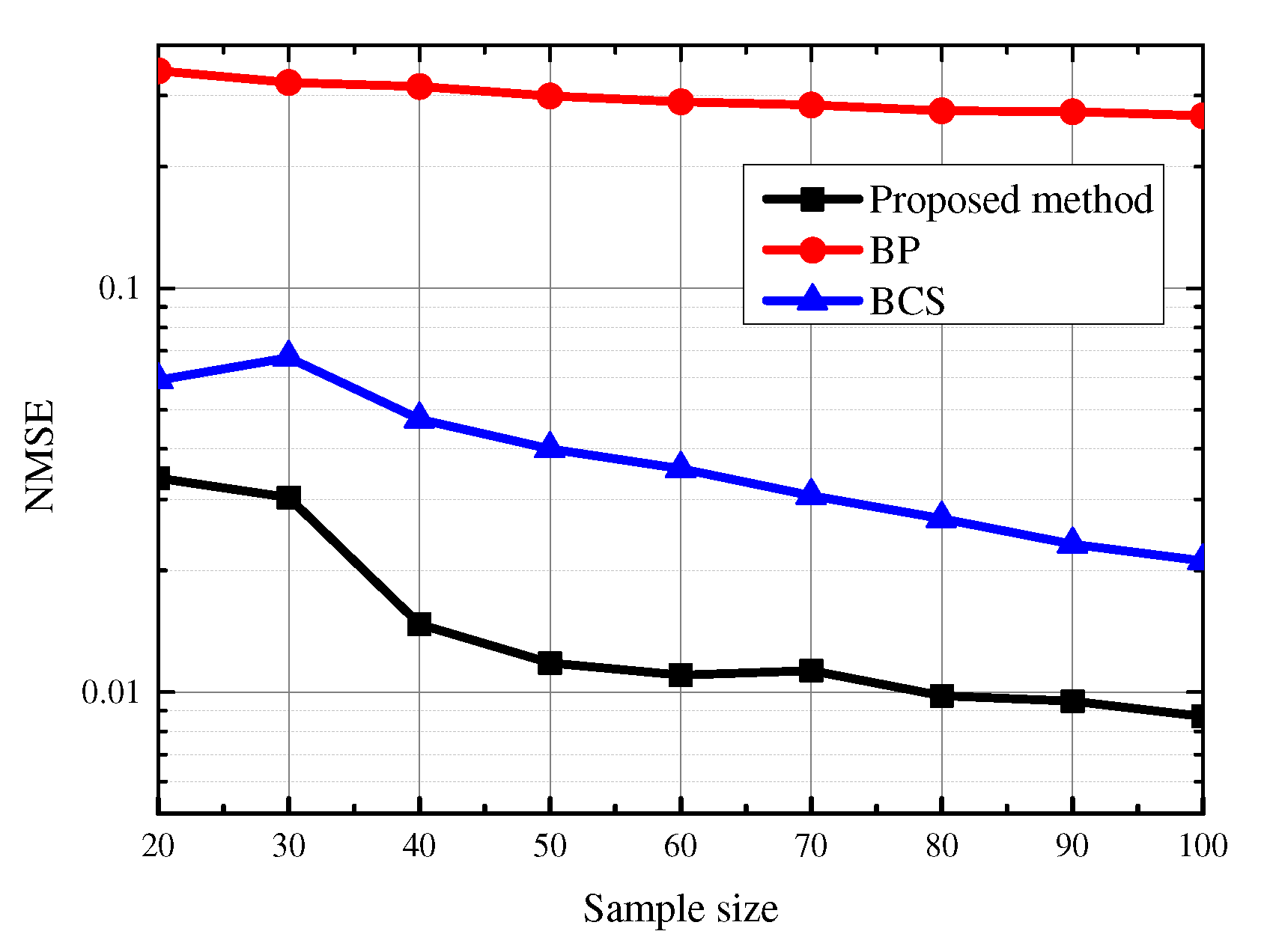
4.2. Signal Estimation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Egilmez, H.E.; Ortega, A. Spectral anomaly detection using graph-based filtering for wireless sensor networks. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1085–1089. [Google Scholar]
- Sakiyama, A.; Tanaka, Y.; Tanaka, T.; Ortega, A. Efficient sensor position selection using graph signal sampling theory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 6225–6229. [Google Scholar]
- Goldsberry, L.; Huang, W.; Wymbs, N.F.; Grafton, S.T.; Bassett, D.S.; Ribeiro, A. Brain signal analytics from graph signal processing perspective. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 851–855. [Google Scholar]
- Hu, C.; Cheng, L.; Sepulcre, J.; Johnson, K.A.; Fakhri, G.E.; Lu, Y.M.; Li, Q. A spectral graph regression model for learning brain connectivity of Alzheimer’s disease. PLoS ONE 2015, 10, e0128136. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Cheung, G.; Ortega, A.; Au, O.C. Multiresolution graph fourier transform for compression of piecewise smooth images. IEEE Trans. Image Process. 2014, 24, 419–433. [Google Scholar] [CrossRef] [PubMed]
- Thanou, D.; Chou, P.A.; Frossard, P. Graph-based compression of dynamic 3D point cloud sequences. IEEE Trans. Image Process. 2016, 25, 1765–1778. [Google Scholar] [CrossRef] [PubMed]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Ortega, A.; Frossard, P.; Kovačević, J.; Moura, J.M.F.; Vandergheynst, P. Graph Signal Processing: Overview, Challenges, and Applications. Proc. IEEE 2018, 106, 808–828. [Google Scholar] [CrossRef]
- Anis, A.; Gadde, A.; Ortega, A. Efficient sampling set selection for bandlimited graph signals using graph spectral proxies. IEEE Trans. Signal Process. 2016, 64, 3775–3789. [Google Scholar] [CrossRef]
- Chen, S.; Varma, R.; Sandryhaila, A.; Kovačević, J. Discrete Signal Processing on Graphs: Sampling Theory. IEEE Trans. Signal Process. 2015, 63, 6510–6523. [Google Scholar] [CrossRef]
- Wei, Z.; Li, B.; Guo, W. Optimal sampling for dynamic complex networks with graph-bandlimited initialization. IEEE Access 2019, 7, 150294–150305. [Google Scholar] [CrossRef]
- Onuki, M.; Ono, S.; Yamagishi, M.; Tanaka, Y. Graph signal denoising via trilateral filter on graph spectral domain. IEEE Trans. Signal Inf. Process. Over Netw. 2016, 2, 137–148. [Google Scholar] [CrossRef]
- Wang, X.; Chen, J.; Gu, Y. Local measurement and reconstruction for noisy bandlimited graph signals. Signal Process. 2016, 129, 119–129. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, Q.; Huang, J.; Yang, L. Reconstruction of bandlimited graph signals from measurements. Digit. Signal Process. 2020, 101, 102728. [Google Scholar] [CrossRef]
- Romero, D.; Ma, M.; Giannakis, G.B. Kernel-based reconstruction of graph signals. IEEE Trans. Signal Process. 2016, 65, 764–778. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 821. [Google Scholar]
- Lan, W.; Wang, H.; Tsai, C.L. Testing covariates in high-dimensional regression. Ann. Inst. Stat. Math. 2013, 66, 279–301. [Google Scholar] [CrossRef]
- Zhong, P.S.; Chen, S.X. Tests for High-Dimensional Regression Coefficients With Factorial Designs. J. Am. Stat. Assoc. 2011, 106, 260–274. [Google Scholar] [CrossRef]
- Goeman, J.J.; Van De Geer, S.A.; Van Houwelingen, H.C. Testing against a high dimensional alternative. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2006, 68, 477–493. [Google Scholar] [CrossRef]
- Tropp, J.; Gilbert, A.C. Signal recovery from partial information via orthogonal matching pursuit. IEEE Trans. Inform. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Steyerberg, E. Stepwise Selection in Small Data Sets A Simulation Study of Bias in Logistic Regression Analysis. J. Clin. Epidemiol. 1999, 52, 935–942. [Google Scholar] [CrossRef]
- Davidson, R.; MacKinnon, J.G. Econom. Theory Methods; Oxford University Press: New York, NY, USA, 2004; Volume 5. [Google Scholar]
- Imhof, J.P. Computing the distribution of quadratic forms in normal variables. Biometrika 1961, 48, 419–426. [Google Scholar] [CrossRef]
- Omelka, M. The behavior of locally most powerful tests. Kybernetika 2005, 41, 699–712. [Google Scholar]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Federal Climate Complex Global Surface Summary of Day Data. Available online: http://www.ncdc.noaa.gov/cgi-bin/res40.pl?page=gsod.html (accessed on 29 August 2019).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, X.; Feng, H.; Hu, B. Bandwidth Detection of Graph Signals with a Small Sample Size. Sensors 2021, 21, 146. https://doi.org/10.3390/s21010146
Xie X, Feng H, Hu B. Bandwidth Detection of Graph Signals with a Small Sample Size. Sensors. 2021; 21(1):146. https://doi.org/10.3390/s21010146
Chicago/Turabian StyleXie, Xuan, Hui Feng, and Bo Hu. 2021. "Bandwidth Detection of Graph Signals with a Small Sample Size" Sensors 21, no. 1: 146. https://doi.org/10.3390/s21010146
APA StyleXie, X., Feng, H., & Hu, B. (2021). Bandwidth Detection of Graph Signals with a Small Sample Size. Sensors, 21(1), 146. https://doi.org/10.3390/s21010146