Using Complexity-Identical Human- and Machine-Directed Utterances to Investigate Addressee Detection for Spoken Dialogue Systems




Abstract
1. Introduction
2. Related Work
3. Methods
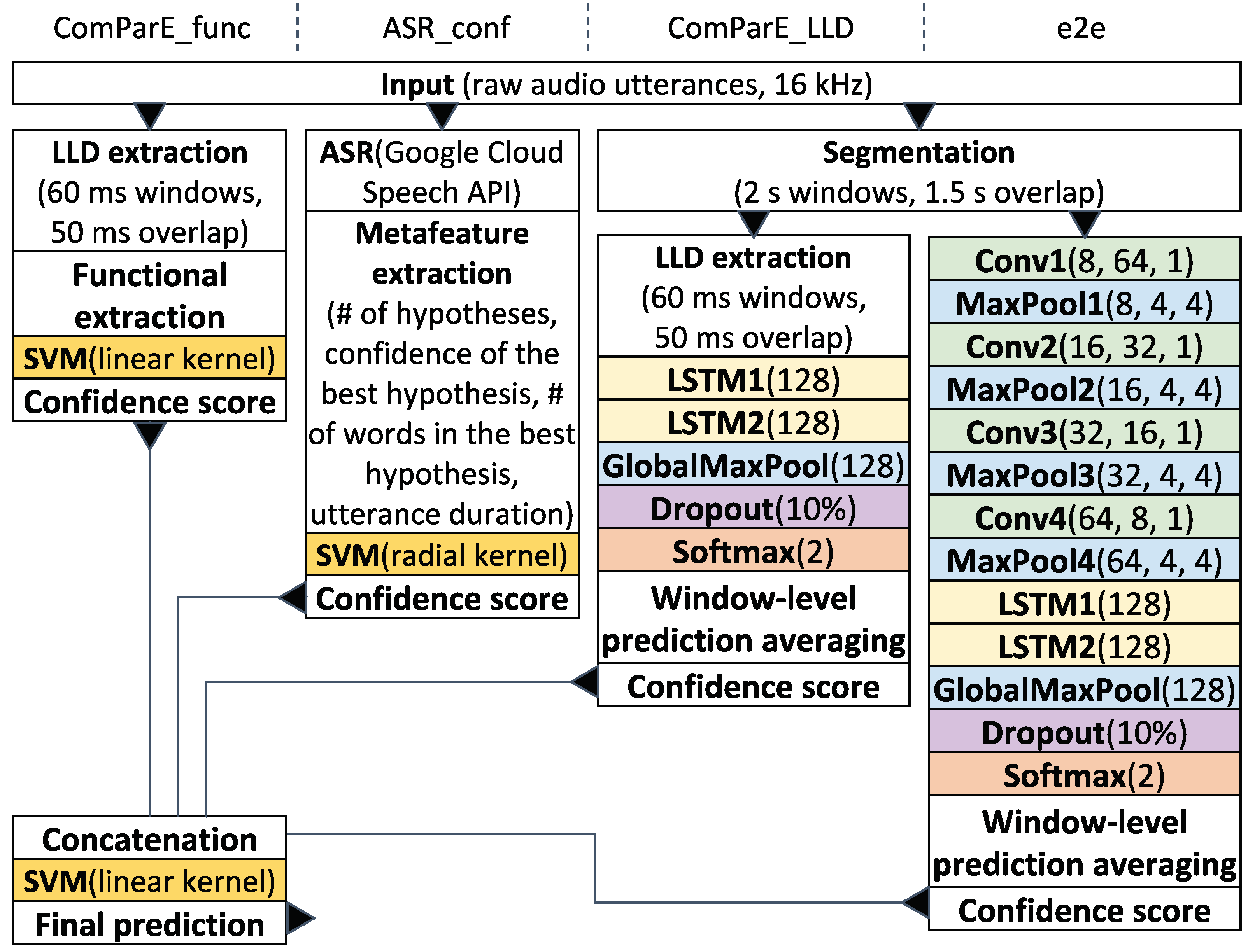
3.1. Classifier Architecture
3.2. Data Augmentation
| Algorithm 1: One training epoch of the proposed algorithm based on mixup. |
 |
4. Corpora
4.1. Voice Assistant Conversation Corpus
4.2. SmartWeb Video Corpus
4.3. Restaurant Booking Corpus
5. Results and Discussion
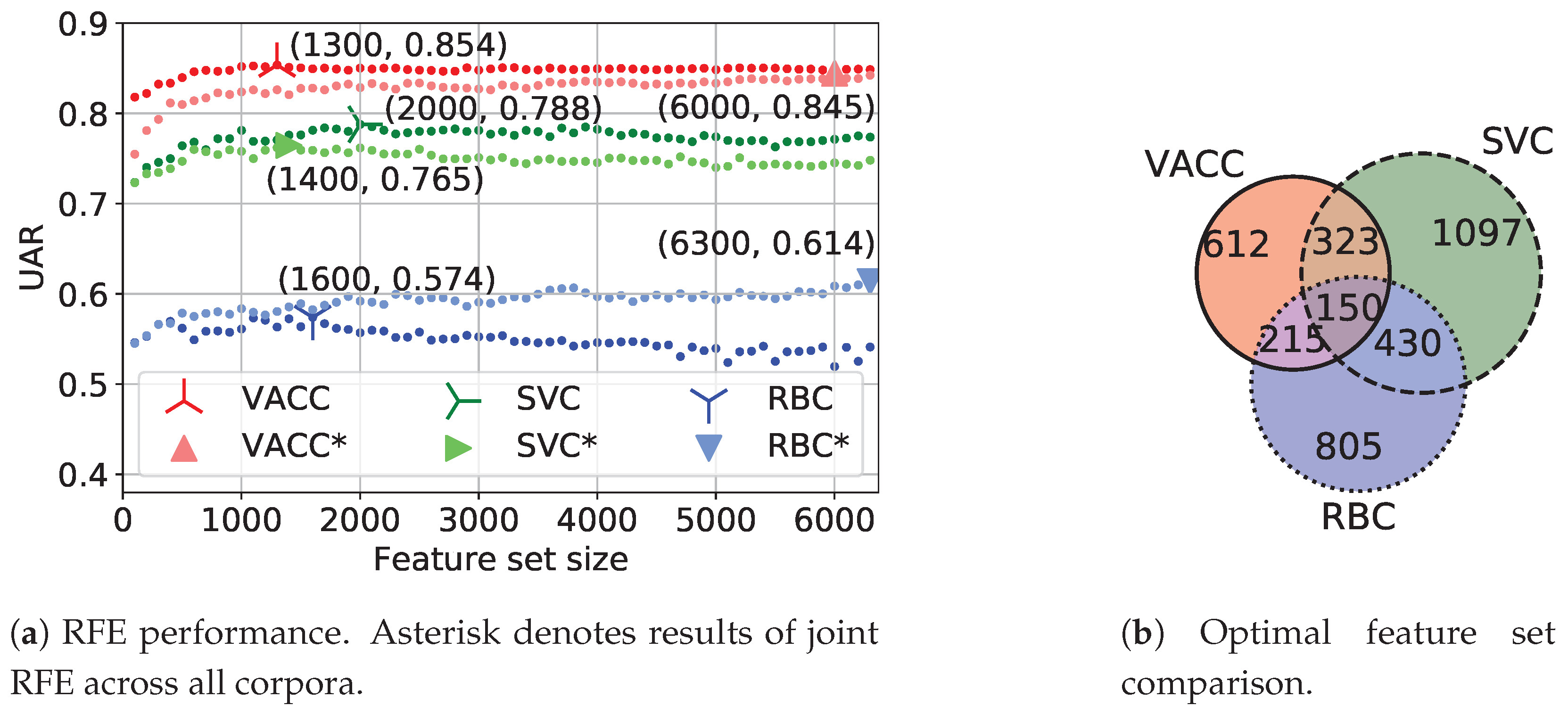
5.1. Feature Selection
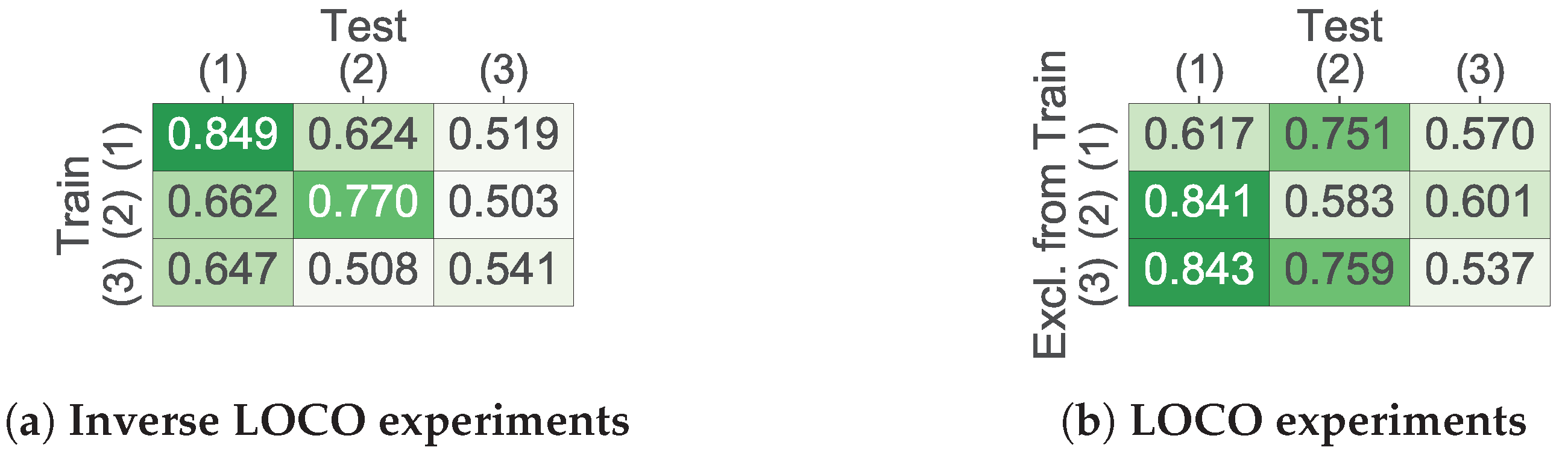
5.2. Leave-One-Corpus-Out Experiments
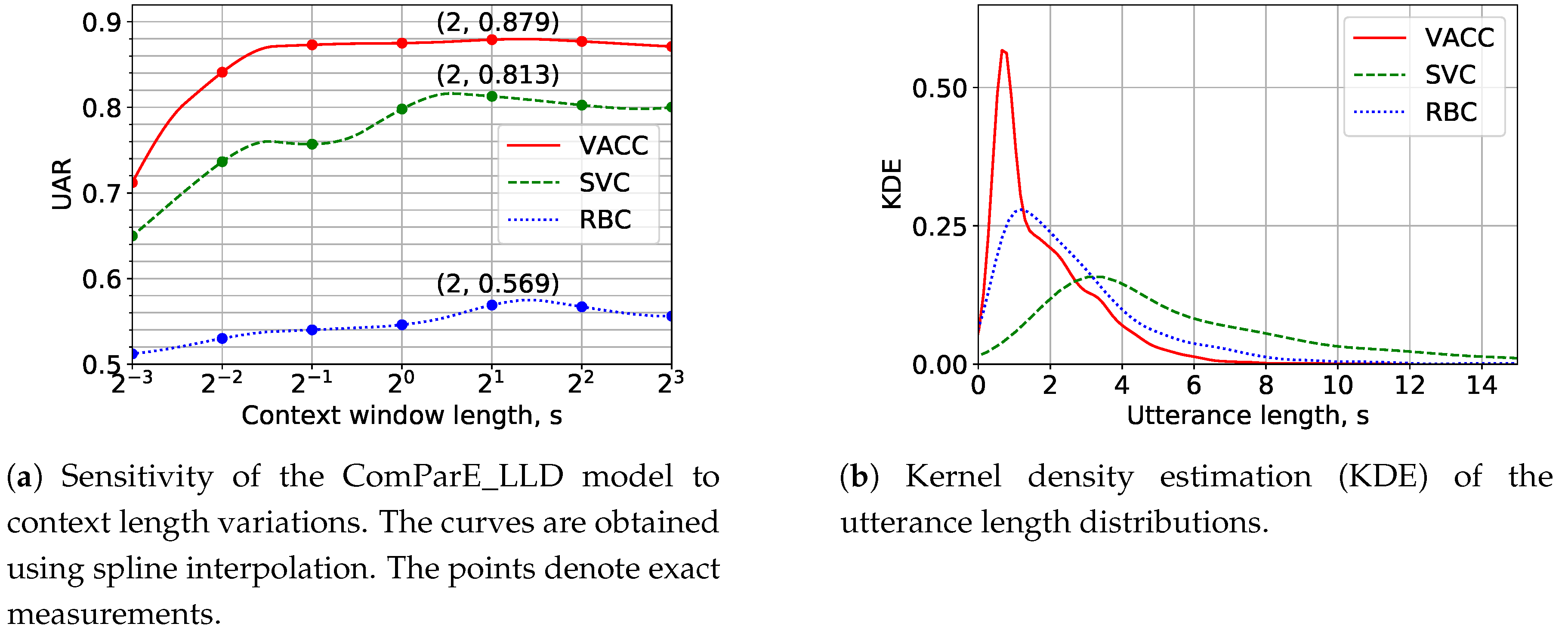
5.3. Experiments with Various Acoustic Context Lengths
5.4. RBC Data Augmentation
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kinsella, B. Voicebot.ai. Amazon Echo Device Sales Break New Records, Alexa Tops Free App Downloads for iOS and Android, and Alexa Down in Europe on Christmas Morning. Available online: https://voicebot.ai/2018/12/26/amazon-echo-device-sales-break-new-records-alexa-tops-free-app-downloads-for-ios-and-android-and-alexa-down-in-europe-on-christmas-morning/ (accessed on 30 April 2020).
- Billinghurst, M. Hands and Speech in Space: Multimodal Interaction with Augmented Reality Interfaces. In Proceedings of the 15th ACM on International Conference on Multimodal Interaction, Sydney, Australia, 9–13 December 2013; pp. 379–380. [Google Scholar] [CrossRef]
- Tse, E.; Shen, C.; Greenberg, S.; Forlines, C. Enabling Interaction with Single User Applications through Speech and Gestures on a Multi-User Tabletop. In Proceedings of the Working Conference on Advanced Visual Interfaces, Venezia, Italy, 23–26 May 2006; pp. 336–343. [Google Scholar] [CrossRef]
- Bubalo, N.; Honold, F.; Schüssel, F.; Weber, M.; Huckauf, A. User Expertise in Multimodal HCI. In Proceedings of the European Conference on Cognitive Ergonomics, Nottingham, UK, 5–8 September 2016. [Google Scholar] [CrossRef]
- Raveh, E.; Steiner, I.; Gessinger, I.; Möbius, B. Studying Mutual Phonetic Influence with a Web-Based Spoken Dialogue System. In Proceedings of the International Conference on Speech and Computer (SPECOM 2018), Leipzig, Germany, 18–22 September 2018; Springer: Cham, Switzerland, 2018; pp. 552–562. [Google Scholar]
- Busso, C.; Georgiou, P.G.; Narayanan, S.S. Real-Time Monitoring of Participants’ Interaction in a Meeting using Audio-Visual Sensors. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2007, Honolulu, HI, USA, 15–20 April 2007; pp. 685–688. [Google Scholar]
- Akker, R.O.D.; Traum, D. A Comparison of Addressee Detection Methods for Multiparty Conversations. In Proceedings of the Workshop on the Semantics and Pragmatics of Dialogue (SemDial), Sockholm, Sweden, 24–26 June 2009; pp. 99–106. [Google Scholar]
- Gilmartin, E.; Cowan, B.R.; Vogel, C.; Campbell, N. Explorations in multiparty casual social talk and its relevance for social human machine dialogue. J. Multimodal User Interfaces 2018, 12, 297–308. [Google Scholar] [CrossRef]
- Batliner, A.; Hacker, C.; Nöth, E. To talk or not to talk with a computer. J. Multimodal User Interfaces 2008, 2, 171–186. [Google Scholar] [CrossRef]
- Siegert, I. “Alexa in the Wild”—Collecting Unconstrained Conversations with a Modern Voice Assistant in a Public Environment. In Proceedings of the Twelfth International Conference on Language Resources and Evaluation (LREC 2020), Marseille, France, 11–16 May 2020; ELRA: Paris, France, 2020. in print. [Google Scholar]
- Liptak, A. The Verge. Amazon’s Alexa Started Ordering People Dollhouses after Hearing Its Name on TV. Available online: https://www.theverge.com/2017/1/7/14200210/amazon-alexa-tech-news-anchor-order-dollhouse (accessed on 30 April 2020).
- Horcher, G. Woman Says Her Amazon Device Recorded Private Conversation, Sent It out to Random Contact. Available online: https://www.cnbc.com/2018/05/24/amazon-echo-recorded-conversation-sent-to-random-person-report.html (accessed on 30 April 2020).
- Tilley, A. Forbes, Neighbor Unlocks Front Door Without Permission with the Help of Apple’s Siri. Available online: https://www.forbes.com/sites/aarontilley/2016/09/17/neighbor-unlocks-front-door-without-permission-with-the-help-of-apples-siri/#e825d8817c2c (accessed on 17 September 2017).
- Shriberg, E.; Stolcke, A.; Ravuri, S.V. Addressee Detection for Dialog Systems Using Temporal and Spectral Dimensions of Speaking Style. In Proceedings of the INTERSPEECH-2013, Lyon, France, 25–29 August 2013; pp. 2559–2563. [Google Scholar]
- Siegert, I.; Krüger, J. How Do We Speak with Alexa—Subjective and Objective Assessments of Changes in Speaking Style between HC and HH Conversations. Available online: https://duepublico2.uni-due.de/receive/duepublico_mods_00048596 (accessed on 30 April 2020).
- Sidorov, M.; Ultes, S.; Schmitt, A. Emotions are a Personal Thing: Towards Speaker-Adaptive Emotion Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2014, Florence, Italy, 4–9 May 2014; pp. 4803–4807. [Google Scholar]
- Gosztolya, G.; Tóth, L. A feature selection-based speaker clustering method for paralinguistic tasks. Pattern Anal. Appl. 2018, 21, 193–204. [Google Scholar] [CrossRef]
- Siegert, I.; Shuran, T.; Lotz, A.F. Acoustic Addressee Detection—Analysing the Impact of Age, Gender and Technical Knowledge. In Elektronische Sprachsignalverarbeitung 2018. Tagungsband der 29. Konferenz; TUD Press: Ulm, Germany, 2018; pp. 113–120. [Google Scholar]
- Tsai, T.; Stolcke, A.; Slaney, M. A study of multimodal addressee detection in human-human-computer interaction. IEEE Trans. Multimed. 2015, 17, 1550–1561. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Bergelson, E.; Krajewski, J.; Janott, C.; Amatuni, A.; Casillas, M.; Seidl, A.; Soderstrom, M.; et al. The INTERSPEECH 2017 Computational Paralinguistics Challenge: Addressee, Cold & Snoring. In Proceedings of the INTERSPEECH-2017, Stockholm, Sweden, 20–24 August 2017; pp. 3442–3446. [Google Scholar]
- Mallidi, S.H.; Maas, R.; Goehner, K.; Rastrow, A.; Matsoukas, S.; Hoffmeister, B. Device-directed Utterance Detection. In Proceedings of the INTERSPEECH-2018, Hyderabad, India, 2–6 September 2018; pp. 1225–1228. [Google Scholar]
- Norouzian, A.; Mazoure, B.; Connolly, D.; Willett, D. Exploring Attention Mechanism for Acoustic-Based Classification of Speech Utterances into System-Directed and non-System-Directed. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; pp. 7310–7314. [Google Scholar]
- Siegert, I.; Nietzold, J.; Heinemann, R.; Wendemuth, A. The Restaurant Booking Corpus—Content-Identical Comparative Human-Human and Human-Computer Simulated Telephone Conversations. In Elektronische Sprachsignalverarbeitung 2019. Tagungsband der 30. Konferenz; TUD Press: Dresden, Germany, 2019; pp. 126–133. [Google Scholar]
- Siegert, I.; Krüger, J.; Egorow, O.; Nietzold, J.; Heinemann, R.; Lotz, A. Voice Assistant Conversation Corpus (VACC): A Multi-Scenario Dataset for Addressee Detection in Human-Computer-Interaction Using Amazon ALEXA. In Proceedings of the LREC 2018 Workshop “LB-ILR2018 and MMC2018 Joint Workshop”, Miyazaki, Japan, 7–12 May 2018; ELRA: Paris, France, 2018; pp. 51–54. [Google Scholar]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Medennikov, I.; Khokhlov, Y.; Romanenko, A.; Popov, D.; Tomashenko, N.; Sorokin, I.; Zatvornitskiy, A. An Investigation of Mixup Training Strategies for Acoustic Models in ASR. In Proceedings of the INTERSPEECH-2018, Hyderabad, India, 2–6 September 2018; pp. 2903–2907. [Google Scholar]
- Akhtiamov, O.; Siegert, I.; Karpov, A.; Minker, W. Cross-Corpus Data Augmentation for Acoustic Addressee Detection. In Proceedings of the 20th Annual SIGdial Meeting on Discourse and Dialogue, Stockholm, Sweden, 11–13 September 2019; pp. 274–283. [Google Scholar]
- Akhtiamov, O.; Sidorov, M.; Karpov, A.; Minker, W. Speech and Text Analysis for Multimodal Addressee Detection in Human-Human-Computer Interaction. In Proceedings of the INTERSPEECH-2017, Stockholm, Sweden, 20–24 August 2017; pp. 2521–2525. [Google Scholar]
- Huang, C.W.; Maas, R.; Mallidi, S.H.; Hoffmeister, B. A Study for Improving Device-Directed Speech Detection toward Frictionless Human-Machine Interaction. In Proceedings of the INTERSPEECH-2019, Graz, Austria, 15–19 September 2019; pp. 3342–3346. [Google Scholar]
- Terken, J.; Joris, I.; De Valk, L. Multimodal cues for Addressee-hood in Triadic Communication with a Human Information Retrieval Agent. In Proceedings of the 9th International Conference on Multimodal Interfaces, ICMI 2007, Nagoya, Japan, 12–15 November 2007; pp. 94–101. [Google Scholar]
- Lunsford, R.; Oviatt, S. Human Perception of Intended Addressee during Computer-Assisted Meetings. In Proceedings of the 8th International Conference on Multimodal Interfaces, ICMI 2006, Banff, AB, Canada, 2–4 November 2006; pp. 20–27. [Google Scholar] [CrossRef]
- Branigan, H.P.; Pickering, M.J.; Pearson, J.; McLean, J.F. Linguistic alignment between people and computers. J. Pragmat. 2010, 42, 2355–2368. [Google Scholar] [CrossRef]
- Raveh, E.; Siegert, I.; Steiner, I.; Gessinger, I.; Möbius, B. Threes a Crowd? Effects of a Second Human on Vocal Accommodation with a Voice Assistant. In Proceedings of the INTERSPEECH-2019, Graz, Austria, 15–19 September 2019; pp. 4005–4009. [Google Scholar]
- Baba, N.; Huang, H.H.; Nakano, Y.I. Addressee Identification for Human-Human-Agent Multiparty Conversations in Different Proxemics. In Proceedings of the 4th Workshop on Eye Gaze in Intelligent Human Machine Interaction, Gaze-In’12, Santa Monica, CA, USA, 22–26 October 2012; pp. 1–6. [Google Scholar]
- Bohus, D.; Horvitz, E. Multiparty Turn Taking in Situated Dialog: Study, Lessons, and Directions. In Proceedings of the SIGDIAL 2011 Conference, Portland, OR, USA, 17–18 June 2011; pp. 98–109. [Google Scholar]
- Jovanovic, N.; op den Akker, R.; Nijholt, A. Addressee Identification in Face-to-Face Meetings. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 169–176. [Google Scholar]
- Lee, M.K.; Kiesler, S.; Forlizzi, J. Receptionist or Information Kiosk: How do People Talk with a Robot? In Proceedings of the 2010 ACM Conference on Computer Supported Cooperative Work, Savannah, GA, USA, 6–10 February 2010; pp. 31–40. [Google Scholar]
- Silber-Varod, V.; Lerner, A.; Jokisch, O. Prosodic Plot of Dialogues: A Conceptual Framework to Trace Speakers’ Role. In Proceedings of the International Conference on Speech and Computer (SPECOM 2018), Leipzig, Germany, 18–22 September 2018; Springer: Cham, Switzerland, 2018; pp. 636–645. [Google Scholar] [CrossRef]
- Eyben, F. Real-Time Speech and Music Classification by Large Audio Feature Space Extraction; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Eyben, F.; Weninger, F.; Gross, F.; Schuller, B. Recent Developments in Opensmile, the Munich Open-Source Multimedia Feature Extractor. In Proceedings of the MM 2013: 21st ACM International Conference on Multimedia, Barcelona, Spain, 21–25 October 2013; pp. 835–838. [Google Scholar]
- Google Cloud Speech-to-Text. Available online: https://cloud.google.com/speech-to-text/ (accessed on 30 April 2020).
- Lopes, J.; Eskenazi, M.; Trancoso, I. Incorporating ASR Information in Spoken Dialog System Confidence Score. In Proceedings of the 10th International Conference on Computational Processing of the Portuguese Language, Coimbra, Portugal, 17–20 April 2012; Springer: Cham, Switzerland, 2012; pp. 403–408. [Google Scholar]
- Aytar, Y.; Vondrick, C.; Torralba, A. SoundNet: Learning Sound Representations from Unlabeled Video. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, Barcelona, Spain, 9–10 December 2016; pp. 892–900. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu Features? End-to-End Speech Emotion Recognition Using a Deep Convolutional Recurrent Network. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Abadi, M. Tensorflow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Hofmann, M.; Klinkenberg, R. RapidMiner: Data Mining Use Cases and Business Analytics Applications; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Gillespie, K.; Konstantakopoulos, I.C.; Guo, X.; Vasudevan, V.T.; Sethy, A. Improving Directedness Classification of Utterances with Semantic Lexical Features. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP 2020, Barcelona, Spain, 4–8 May 2020; pp. 7859–7863. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | VACC | SVC | RBC | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Set | Train | Dev | Test | Train | Dev | Test | Train | Dev | Test |
| M | 1809 | 501 | 1493 | 546 | 90 | 442 | 752 | 142 | 558 |
| H | 862 | 218 | 756 | 557 | 135 | 423 | 368 | 86 | 328 |
| # of utterances (# of speakers) | 2671 (12) | 719 (3) | 2249 (10) | 1103 (48) | 225 (10) | 865 (41) | 1120 (16) | 228 (3) | 886 (11) |
| 5639 (25), 2:50:20 s | 2193 (99), 3:27:35 s | 2234 (30), 1:39:17 s | |||||||
| Data Augmentation Method | (1) | (2) | (3) | (4) | (5) | (6) | (7) | (8) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RBC | 0.539 | 0.550 | 0.533 | 0.541 | 0.548 | 0.556 | 0.552 | 0.570 | 0.628 | 0.539 | 0.544 | 0.596 |
| 0.643 | 0.659 | 0.565 | 0.589 | 0.559 | 0.572 | 0.558 | 0.578 | 0.632 | 0.540 | 0.544 | 0.591 | |
| mix(RBC) | 0.533 | 0.552 | 0.526 | 0.540 | 0.532 | 0.545 | 0.529 | 0.548 | - | - | - | - |
| 0.635 | 0.657 | 0.568 | 0.581 | 0.546 | 0.566 | 0.548 | 0.568 | - | - | - | - | |
| RBC + VACC | 0.577 | 0.590 | 0.579 | 0.601 | 0.584 | 0.598 | 0.591 | 0.609 | - | - | - | - |
| 0.617 | 0.630 | 0.619 | 0.638 | 0.599 | 0.611 | 0.606 | 0.622 | - | - | - | - | |
| mix(RBC + VACC) | 0.574 | 0.588 | 0.577 | 0.598 | 0.604 | 0.620 | 0.548 | 0.569 | - | - | - | - |
| 0.615 | 0.628 | 0.616 | 0.635 | 0.613 | 0.631 | 0.567 | 0.581 | - | - | - | - | |
| RBC + SVC | 0.546 | 0.567 | 0.549 | 0.570 | 0.547 | 0.567 | 0.563 | 0.587 | - | - | - | - |
| 0.585 | 0.598 | 0.580 | 0.599 | 0.556 | 0.577 | 0.575 | 0.598 | - | - | - | - | |
| mix(RBC + SVC) | 0.554 | 0.569 | 0.546 | 0.569 | 0.563 | 0.582 | 0.513 | 0.529 | - | - | - | - |
| 0.581 | 0.597 | 0.584 | 0.597 | 0.576 | 0.591 | 0.537 | 0.554 | - | - | - | - | |
| RBC + VACC + SVC | 0.500 | 0.502 | 0.574 | 0.600 | 0.539 | 0.552 | 0.545 | 0.554 | - | - | - | - |
| 0.578 | 0.590 | 0.619 | 0.632 | 0.541 | 0.560 | 0.547 | 0.568 | - | - | - | - | |
| mix(RBC + VACC + SVC) | 0.500 | 0.500 | 0.576 | 0.595 | 0.535 | 0.554 | 0.513 | 0.531 | - | - | - | - |
| 0.573 | 0.591 | 0.605 | 0.624 | 0.555 | 0.569 | 0.540 | 0.551 | - | - | - | - | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akhtiamov, O.; Siegert, I.; Karpov, A.; Minker, W. Using Complexity-Identical Human- and Machine-Directed Utterances to Investigate Addressee Detection for Spoken Dialogue Systems. Sensors 2020, 20, 2740. https://doi.org/10.3390/s20092740
Akhtiamov O, Siegert I, Karpov A, Minker W. Using Complexity-Identical Human- and Machine-Directed Utterances to Investigate Addressee Detection for Spoken Dialogue Systems. Sensors. 2020; 20(9):2740. https://doi.org/10.3390/s20092740
Chicago/Turabian StyleAkhtiamov, Oleg, Ingo Siegert, Alexey Karpov, and Wolfgang Minker. 2020. "Using Complexity-Identical Human- and Machine-Directed Utterances to Investigate Addressee Detection for Spoken Dialogue Systems" Sensors 20, no. 9: 2740. https://doi.org/10.3390/s20092740
APA StyleAkhtiamov, O., Siegert, I., Karpov, A., & Minker, W. (2020). Using Complexity-Identical Human- and Machine-Directed Utterances to Investigate Addressee Detection for Spoken Dialogue Systems. Sensors, 20(9), 2740. https://doi.org/10.3390/s20092740