Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition


Abstract
1. Introduction
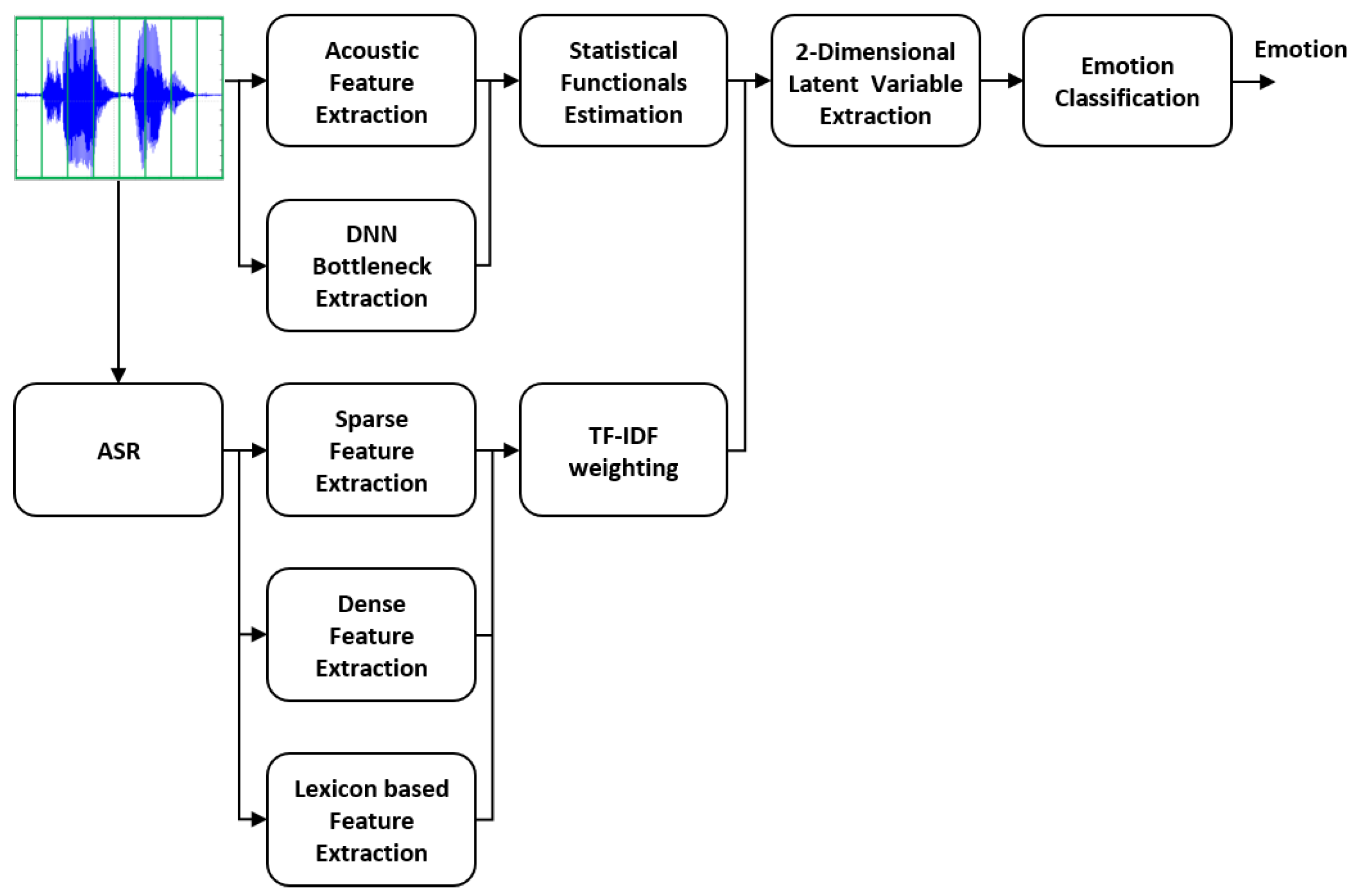
2. Adversarial Autoencoder-Based Emotion Recognition Using Acoustic and Lexical Features
2.1. Acoustic and Lexical Feature Set
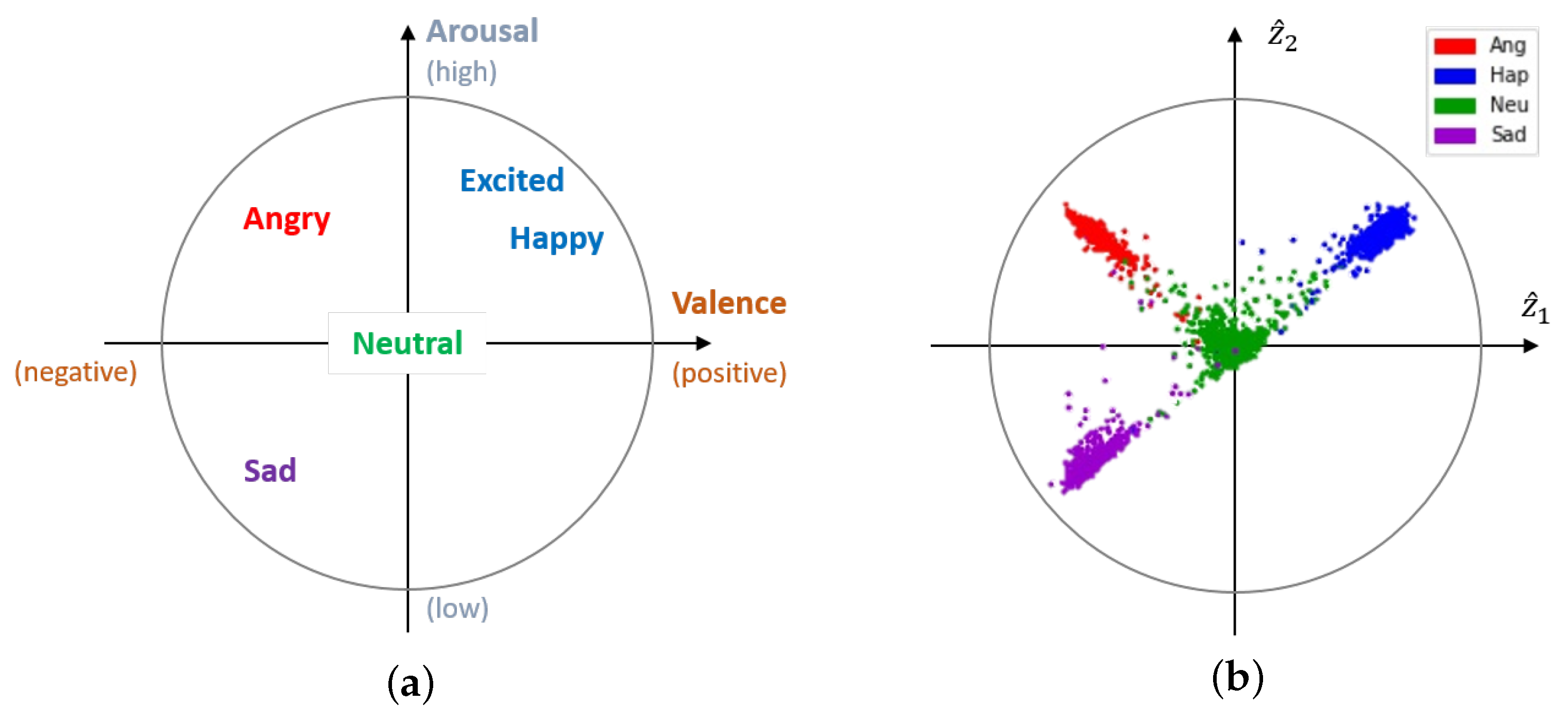
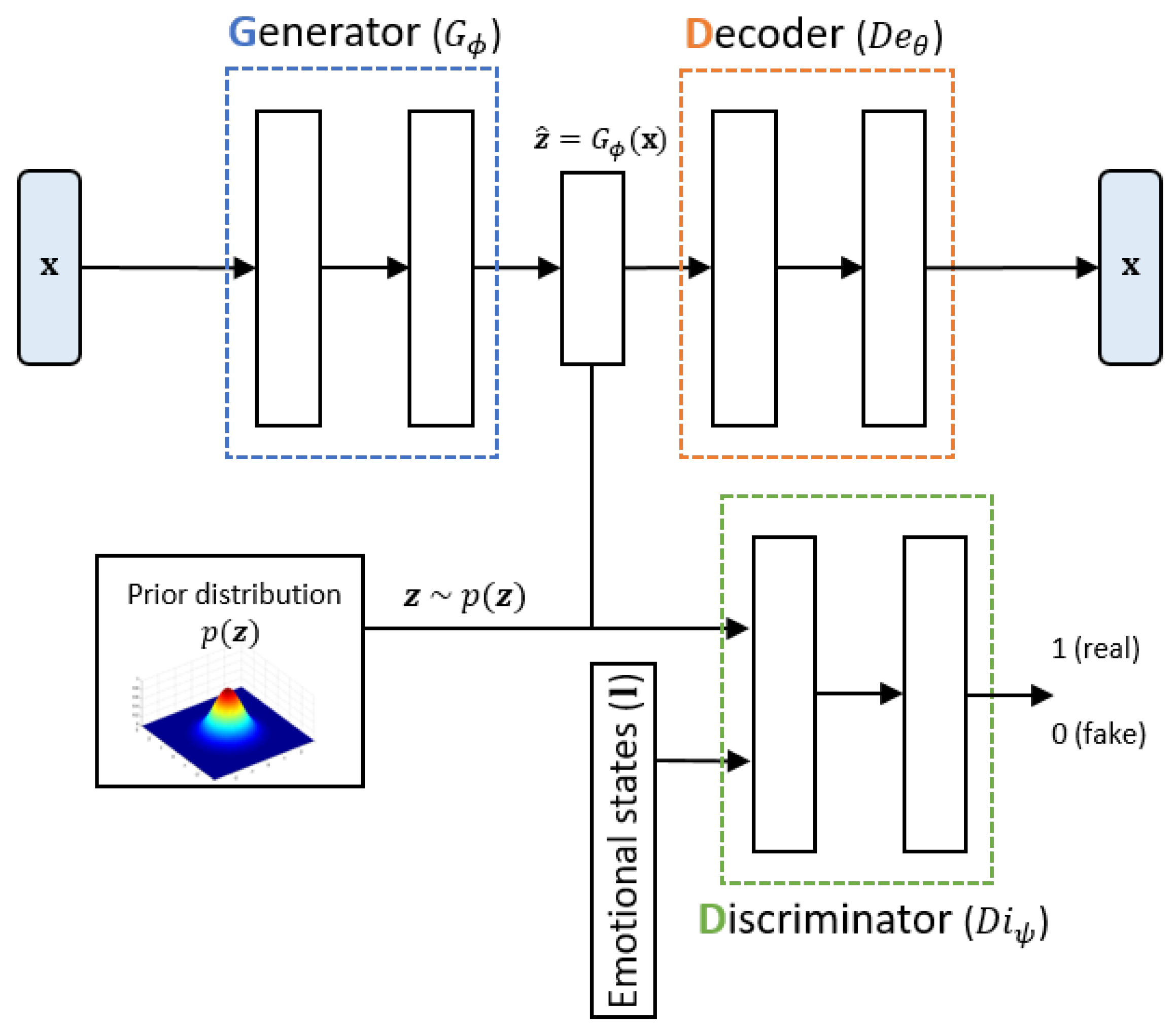
2.2. Extraction of Emotion-Relevant Latent Vectors Using a Conditional Adversarial Autoencoder
3. Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Howard, N.; Hsu, J.; Hussain, A. Sentic blending: Scalable multimodal fusion for the continuous interpretation of semantics and sentics. In Proceedings of the 2013 IEEE Symposium on Computational Intelligence for Human-Like Intelligence (CIHLI), Singapore, 16–19 April 2013; pp. 108–117. [Google Scholar]
- Tran, H.N.; Cambria, E. Ensemble application of ELM and GPU for real-time multimodal sentiment analysis. Memet. Comput. 2018, 10, 3–13. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Satapathy, R.; Cavallari, S.; Cambria, E. Fuzzy commonsense reasoning for multimodal sentiment analysis. Pattern Recognit. Lett. 2019, 125, 264–270. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the INTERSPEECH, Makuhari, Chiba, Japan, 26–30 September 2010. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Schuller, B.; Steidl, S.; Batliner, A.; Vinciarelli, A.; Scherer, K.; Ringeval, F.; Chetouani, M.; Weninger, F.; Eyben, F.; Marchi, E.; et al. The INTERSPEECH 2013 computational paralinguistics challenge: social signals, conflict, emotion, autism. In Proceedings of the INTERSPEECH, Lyon, France, 25–29 August 2013. [Google Scholar]
- Eyben, F.; Scherer, K.R.; Schuller, B.W.; Sundberg, J.; André, E.; Busso, C.; Devillers, L.Y.; Epps, J.; Laukka, P.; Narayanan, S.S.; et al. The geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE Trans. Affect. Comput. 2016, 7, 190–202. [Google Scholar] [CrossRef]
- Sahu, S.; Gupta, R.; Sivaraman, G.; AbdAlmageed, W.; Espy-Wilson, C. Adversarial auto-encoders for speech based emotion recognition. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Latif, S.; Rana, R.; Qadir, J.; Epps, J. Variational autoencoders for learning latent representations of speech emotion. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Eskimez, S.E.; Duan, Z.; Heinzelman, W. Unsupervised learning approach to feature analysis for automatic speech emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5099–5103. [Google Scholar]
- Sahu, S.; Gupta, R.; Espy-Wilson, C. On enhancing speech emotion recognition using generative adversarial networks. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Chen, X.; Han, W.; Ruan, H.; Liu, J.; Li, H.; Jiang, D. Sequence-to-sequence modelling for categorical speech emotion recognition using recurrent neural network. In Proceedings of the IEEE Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–6. [Google Scholar]
- Latif, S.; Rana, R.; Khalifa, S.; Jurdak, R.; Epps, J. Direct modelling of speech emotion from raw Speech. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Neumann, M.; Vu, N.T. Improving speech emotion recognition with unsupervised representation learning on unlabeled speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7390–7394. [Google Scholar]
- Meng, H.; Yan, T.; Yuan, F.; Wei, H. Speech emotion recognition from 3D log-mel spectrograms with deep learning network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Lakomkin, E.; Zamani, M.A.; Weber, C.; Magg, S.; Wermter, S. On the robustness of speech emotion recognition for human-robot interaction with deep neural networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 854–860. [Google Scholar]
- Ma, X.; Wu, Z.; Jia, J.; Xu, M.; Meng, H.; Cai, L. Speech Emotion Recognition with Emotion-Pair Based Framework Considering Emotion Distribution Information in Dimensional Emotion Space. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- Plaza-del Arco, F.M.; Molina-González, M.D.; Martín-Valdivia, M.T.; Lopez, L.A.U. SINAI at SemEval-2019 Task 3: Using affective features for emotion classification in textual conversations. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 307–311. [Google Scholar]
- Chatterjee, A.; Gupta, U.; Chinnakotla, M.K.; Srikanth, R.; Galley, M.; Agrawal, P. Understanding emotions in text using deep learning and big data. Comput. Hum. Behav. 2019, 93, 309–317. [Google Scholar] [CrossRef]
- Rozgić, V.; Ananthakrishnan, S.; Saleem, S.; Kumar, R.; Vembu, A.N.; Prasad, R. Emotion recognition using acoustic and lexical features. In Proceedings of the INTERSPEECH, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Jin, Q.; Li, C.; Chen, S.; Wu, H. Speech emotion recognition with acoustic and lexical features. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 4749–4753. [Google Scholar]
- Gamage, K.W.; Sethu, V.; Ambikairajah, E. Salience based lexical features for emotion recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5830–5834. [Google Scholar]
- Gu, Y.; Chen, S.; Marsic, I. Deep multimodal learning for emotion recognition in spoken language. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5079–5083. [Google Scholar]
- Gu, Y.; Yang, K.; Fu, S.; Chen, S.; Li, X.; Marsic, I. Multimodal affective analysis using hierarchical attention strategy with word-level alignment. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2018. pp. 2225–2235. [Google Scholar]
- Cho, J.; Pappagari, R.; Kulkarni, P.; Villalba, J.; Carmiel, Y.; Dehak, N. Deep neural networks for emotion recognition combining audio and transcripts. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Yenigalla, P.; Kumar, A.; Tripathi, S.; Singh, C.; Kar, S.; Vepa, J. Speech emotion recognition using spectrogram & phoneme embedding. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Kim, E.; Shin, J.W. DNN-based emotion recognition based on bottleneck acoustic features and lexical features. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6720–6724. [Google Scholar]
- Sahu, S.; Mitra, V.; Seneviratne, N.; Espy-Wilson, C. Multi-modal learning for Speech Emotion Recognition: An Analysis and comparison of ASR outputs with ground truth transcription. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Aguilar, G.; Rozgić, V.; Wang, W.; Wang, C. Multimodal and Multi-view Models for Emotion Recognition. arXiv 2019, arXiv:1906.10198. [Google Scholar]
- Heusser, V.; Freymuth, N.; Constantin, S.; Waibel, A. Bimodal Speech Emotion Recognition Using Pre-Trained Language Models. arXiv 2019, arXiv:1912.02610. [Google Scholar]
- Yoon, S.; Dey, S.; Lee, H.; Jung, K. Attentive Modality Hopping Mechanism for Speech Emotion Recognition. arXiv 2019, arXiv:1912.00846. [Google Scholar]
- Pandey, S.K.; Shekhawat, H.; Prasanna, S. Emotion recognition from raw speech using wavenet. In Proceedings of the IEEE Region 10 Conference (TENCON), Kochi, Kerala, India, 17–20 October 2019; pp. 1292–1297. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Gonzalez, S.; Brookes, M. PEFAC-a pitch estimation algorithm robust to high levels of noise. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 518–530. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Warriner, A.B.; Kuperman, V.; Brysbaert, M. Norms of valence, arousal, and dominance for 13,915 English lemmas. Behav. Res. Methods 2013, 45, 1191–1207. [Google Scholar] [CrossRef] [PubMed]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Set | WAR | UAR |
|---|---|---|
| IS10 [5] | 57.2 | 59.3 |
| IS13 [7] | 57.3 | 58.6 |
| eGeMAPS [8] | 54.7 | 55.3 |
| LLD + MMFCC [21] | 59.3 | 60.2 |
| [BOW] + Cepstrum + GSV [22] | 55.4 | - |
| BN [28] | 59.7 | 61.4 |
| CNN-LSTM-DNN [14] | - | 60.23 |
| CTC-LSTM [13] | 64.0 | 65.7 |
| LLD + BN | 64.93 | 67.43 |
| 63.82 | 66.19 |
| Feature Set | WAR | UAR |
|---|---|---|
| eVector + BOW [22] | 58.5 | - |
| mLRF [23] | 63.8 | 64 |
| v [21] | 63.52 | 64.55 |
| v + v [28] | 64.8 | 65.7 |
| 63.91 | 64.84 | |
| 64.05 | 64.48 |
| Feature Set | Classifier | WAR | UAR |
|---|---|---|---|
| [21] | SVM | 69.5 | 70.1 |
| [22] | SVM | 69.2 | - |
| [23] | SVM | 67.2 | 67.3 |
| Hierarchical Attention Fusion [25] | DNN | 72.7 | 72.7 |
| [28] | DNN | 72.34 | 74.31 |
| DNN | 72.92 | 75.44 | |
| (Proposed) | DNN | 74.37 | 76.91 |
| (Proposed) | linear | 74.08 | 76.72 |
| PREDICTION | |||||
| TRUE | ANG | HAP | NEU | SAD | |
| ANG | 85.35 | 6.82 | 5.65 | 2.17 | |
| HAP | 6.81 | 79.16 | 11.53 | 2.48 | |
| NEU | 7.22 | 17.13 | 63.63 | 12.02 | |
| SAD | 2.01 | 3.07 | 15.4 | 79.51 | |
| PREDICTION | |||||
| TRUE | ANG | HAP | NEU | SAD | |
| ANG | 84.94 | 6.55 | 6.08 | 2.4 | |
| HAP | 6.86 | 77.82 | 12.48 | 2.85 | |
| NEU | 8.02 | 16.22 | 63.78 | 11.98 | |
| SAD | 2.06 | 4.27 | 13.39 | 80.29 | |
| PREDICTION | |||||
| TRUE | ANG | HAP | NEU | SAD | |
| ANG | 71.84 | 15.3 | 10.63 | 2.22 | |
| HAP | 10.71 | 65.93 | 19.54 | 3.82 | |
| NEU | 5.55 | 24.66 | 57.58 | 12.2 | |
| SAD | 1.88 | 8.32 | 20.36 | 69.45 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, E.; Song, H.; Shin, J.W. Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition. Sensors 2020, 20, 2614. https://doi.org/10.3390/s20092614
Kim E, Song H, Shin JW. Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition. Sensors. 2020; 20(9):2614. https://doi.org/10.3390/s20092614
Chicago/Turabian StyleKim, Eesung, Hyungchan Song, and Jong Won Shin. 2020. "Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition" Sensors 20, no. 9: 2614. https://doi.org/10.3390/s20092614
APA StyleKim, E., Song, H., & Shin, J. W. (2020). Affective Latent Representation of Acoustic and Lexical Features for Emotion Recognition. Sensors, 20(9), 2614. https://doi.org/10.3390/s20092614