1. Introduction
Research in the field of intelligent transport systems (ITSs) [
1] is very active. Numerous advances have been made to increase user safety and comfort. Vehicular ad hoc networks (VANETs) are part of ITS, and developing them to obtain completely autonomous vehicles is a necessity. One of the most important characteristics of VANETs is their dynamic topology [
2], which is a consequence of the network being made up of mobile nodes: nodes can change their position quite frequently. This means that there is a need for routing protocols that are capable of quickly adapting to changes in network topology. The geographical location of nodes (i.e., node co-ordinates) has been suggested as a means to address this issue. Location-based (geographic) routing protocols base their routing decisions on location information using the location of the destination node to forward packets to this node [
3,
4,
5]. Establishing the destination’s location is the first step towards communicating with the destination. Different means are available for a node to identify its own position, and the GPS is certainly the best-known and most used [
6,
7]. Determining its own position is usually locally done by the node, even though other solutions exist. However, identifying the location of the destination node when sending a message cannot be done locally without the use of external data or services. In geographic routing protocols, this is achieved by means of a location service. This service is used by the sender of a packet to determine the location of the destination. As a result, the performance of a geographic routing protocol mainly depends on the performance of the location service.
A location service provides the location information for a specific node in a VANET by implementing a mechanism that tracks the location of nodes in the network.
Figure 1 shows the general structure of a location-service management protocol. The scheme essentially consists of three different entities (a location service, a source node, and a destination node), and two main operations (a location query and a location update). Every node updates the location service responsible for handling the location information. When a node needs to send a packet, it queries the location service and retrieves the destination’s location. The location service of a node may be situated on the source node itself or on another node. When the location service is present on the source node, the query is locally resolved by the source node, as is the case for location-information dissemination methods.
A location-service protocol has to exhibit the following properties:
Efficiency: induced overhead by control packets (e.g., location updates and location queries) should be kept to a minimum.
Robustness: the location service should not be disrupted by node mobility or failure (especially for location servers if they are separate nodes), or disconnection from the network.
Load balancing: the protocol should apply traffic-balancing schemes to avoid bottleneck problems.
Scalability: the protocol should maintain all of the above properties when the network scales to a large number of nodes.
Locality awareness: the distance of the location server from the querying source should not be greater than the distance between the source and the destination nodes. In other words, location queries for nearby nodes should not travel unnecessarily over the network. However, the benefits of this feature rely on the presence of local data-traffic patterns.
This article provides the following contributions:
A new location-service protocol that limits the amount of control information exchanged between nodes while maintaining accurate location information. Two versions of the protocol are proposed, a deterministic and a probabilistic version.
An analytical model to evaluate the number of messages sent by the protocol is provided. Models were developed for 1D, 2D, and 3D networks.
Simulations to confirm the validity of the analytical model are presented.
Comparisons with the simple flooding technique and the optimized-link-state-routing (OLSR) multipoint-relay (MPR) [
8] flooding technique are provided, which show the scaling properties of our algorithm.
The algorithm presented in this paper (semiflooding location service, SFLS) was previously published in the Mobile and Wireless Networking Symposium of the IEEE ICC 2016 Conference [
9]. However, the present paper introduces new material: a probabilistic version of the algorithm, a better analytical model with both the probabilistic algorithm and the 3D network case, simulation results, and scaling analysis that compares our algorithm with simple flooding and with an improved flooding scheme, i.e., the MPR flooding of OLSR.
2. Related Work
Location services for VANETs can be divided into two categories. In the first, protocols use information from the network of vehicles and from the urban infrastructure, such as cellular-network base stations or road-side units (RSUs) [
10]. This infrastructure is usually present on the roads. This allows reliable positions to be obtained by reducing the number of signaling messages exchanged between nodes. However, these algorithms are dependent on urban-structure providers and do not allow a spontaneous VANET to emerge. The second category of algorithms does not rely on any urban infrastructure, and thus allows the creation of independent spontaneous networks. Our proposal falls within the second kind of location services.
The state of the art shows that all proposals for this second kind are based on the choice of the number of vehicles that are used as location servers (usually called rendezvous vehicles) [
11]. These elected nodes store and distribute location information. The performance of such algorithms also primarily depends on the choices made to elect those servers. In VANETs, another way to set up a location service consists of sharing location information between all nodes in the network using broadcast messages. The main advantage of this technique is that it eliminates the phase of choosing the servers, this phase often being quite complex. Its main drawback is that flooding may overload the network, which can lead to the rapid degradation of overall performance.
In this article, we propose a flooding-based mechanism for VANETs where a partial broadcast of location-information packets is performed. The following are the most notable location algorithms found in the literature.
2.1. Region-Based Location-Service Management Protocol (RLSMP)
The RLSMP [
12] is a rendezvous-based location service that divides the network into regions (called segments) that are further divided into cells. Each cell has a cluster leader (CL) that manages the location of all nodes in the cell, and sends its location information to the cell responsible for the cluster, called the location-service cell (LSC). A vehicle querying for destination co-ordinates sends its location query to its LSC. If the requested information is not found in this LSC, the query is forwarded to neighboring LSCs, following a spiral shape until the co-ordinates of the destination are found. The RLSMP generates a significant signaling load, as the same query may visit several LSCs before reaching the one holding the requested information. This approach provides reliable location information. However, a lot of traffic must be generated to keep the cluster leaders up to date.
2.2. Vehicle-Location Service (VLS)
The VLS [
13] is a rendezvous-based location service that uses information from digital maps to partition the network and avoid the creation of empty zones (i.e., zones with no active nodes). Each zone contains a location server. The location server of a vehicle is obtained using the vehicle identifier and a hash function. Hence, a vehicle can send its location-update message using the co-ordinates of the nearest location server. Location updates are sent to the nearest location server, and location queries are sent to the nearest location server of the queried vehicle. When leaving its zone, each server has to transfer its location information to a new server. In high-mobility configurations, the VLS protocol induces a high overhead.
2.3. Density-Aware-Map-Based Location Service (DMBLS)
The DMBLS [
14] is a location service protocol where the network zone is divided into a hierarchy of regions. A region is a network zone with high traffic density, and all the location servers are chosen in this region. In this protocol, queries from vehicles are forwarded to the higher levels until the required information is found and sent back to the client. The performance of this protocol is highly dependent on the choice of region, especially when considering the changing characteristics of traffic during different periods of the day.
2.4. Zoom-Out Geographic-Location Service (ZGLS)
The ZGLS [
15] is a quorum-based location service. A quorum is a subset of nodes in the network [
16]. In the scope of the ZGLS, each node is associated with two quora, the update quorum that is used to update the location information, and the query quorum that is used to look for the location of another node. For a single node, these two quora can be different. However, they are designed so that the intersection of the query quorum of each node with the update quorum of any of the other nodes is not empty. This ensures that the update quorum always satisfies the query. The specificity of ZGLS, according to the authors, is that location updates and answers are done through single-hop communications. In order to provide quora for each node, a one-hop location server called the parent is found. All parents are included in a chain of parents. This leads to a very good response time for location queries at the expense of a very high cost for setting up the infrastructure, especially regarding the identification of all quora.
2.5. Vehicle-Aided Location Service (VALS)
The VALS [
17] is a location service in urban environments. It is based on the use of a hierarchy of location servers. VALS forms clusters of vehicles. Each cluster chooses a cluster head, whose role is to supply the location servers with the current position of its members. In VALS, an urban area is divided into two levels of hierarchies. The first level consists of road-side units (RSUs) located at each intersection of the area. The cluster head regularly sends its location to the nearest RSU. At Level 2 of the hierarchy, regional location servers (RLS) are used to regularly collect the location tables of the nearest RLS. This service can only operate in urban areas.
2.6. Mobile-Group-Based Location Service (MoGLS)
The MoGLS [
10] uses a hierarchical structure of location servers. The lower level is made up of dynamic groups of vehicles with similar trajectories. Each group has a cluster head that acts as the location server for its group. The upper level is made up of fixed servers. Cluster heads regularly send their location base to fixed servers. MoGLS offers the data aggregation and dynamic management of vehicle groups. This location service can only operate with a fixed infrastructure, and the management of the group of vehicles can quickly generate significant traffic overhead, particularly in the event of high density and mobility.
3. Semiflooding Location Service
The semiflooding location service (SFLS) was developed to take advantage of both flooding- and rendezvous-based location services for VANETs while avoiding their drawbacks. The advantage of flooding-based solutions is that each node in the network is aware of the position of all the other nodes, while the advantage of rendezvous-based solutions is the low number of messages exchanged to keep the positions of the nodes up to date. The drawback of flooding solutions is the high number of messages exchanged between nodes (location messages are forwarded without any change to the boundary of the network), while the drawback of rendezvous solutions is their difficulty to handle node disappearance and communication problems. The SFLS allows all nodes in the network to have accurate-enough location information about all other nodes in the network, while not overwhelming the network with location packets. Moreover, SFLS is resilient to node disappearances and network problems.
3.1. Principle
The main idea of the semiflooding location service is as follows. All nodes in the network periodically broadcast a packet containing their location information with the time when the location was issued. Nodes do not need to be synchronized for this operation, i.e., all nodes’ internal times do not need to be aligned to a single time reference, and location packets can even be broadcast at different updating rates if needed. When a node receives a location packet, it first compares the timestamp in the location packet with the one stored in the node’s location table. If the incoming information is older than or equal to the locally stored one, the incoming packet is discarded. Otherwise, the new location information is saved, replacing the former information, and 1 in q, the packet is forwarded to the neighbors. The way parameter is used is twofold. On the one hand, can be seen as a probability, in which case a random generator can be used to determine whether the packet has to be forwarded. If the value returned by the (pseudo)random generator is smaller than , the packet is forwarded; otherwise, it is not. On the other hand, can be understood as a threshold for deterministic forwarding. For example, if , only one packet in three is forwarded, i.e., the first two are not forwarded, while the last one is. The value for q is not necessarily an integer and could be any real number greater than 1. The closer to 1, the higher the frequency of packet forwarding.
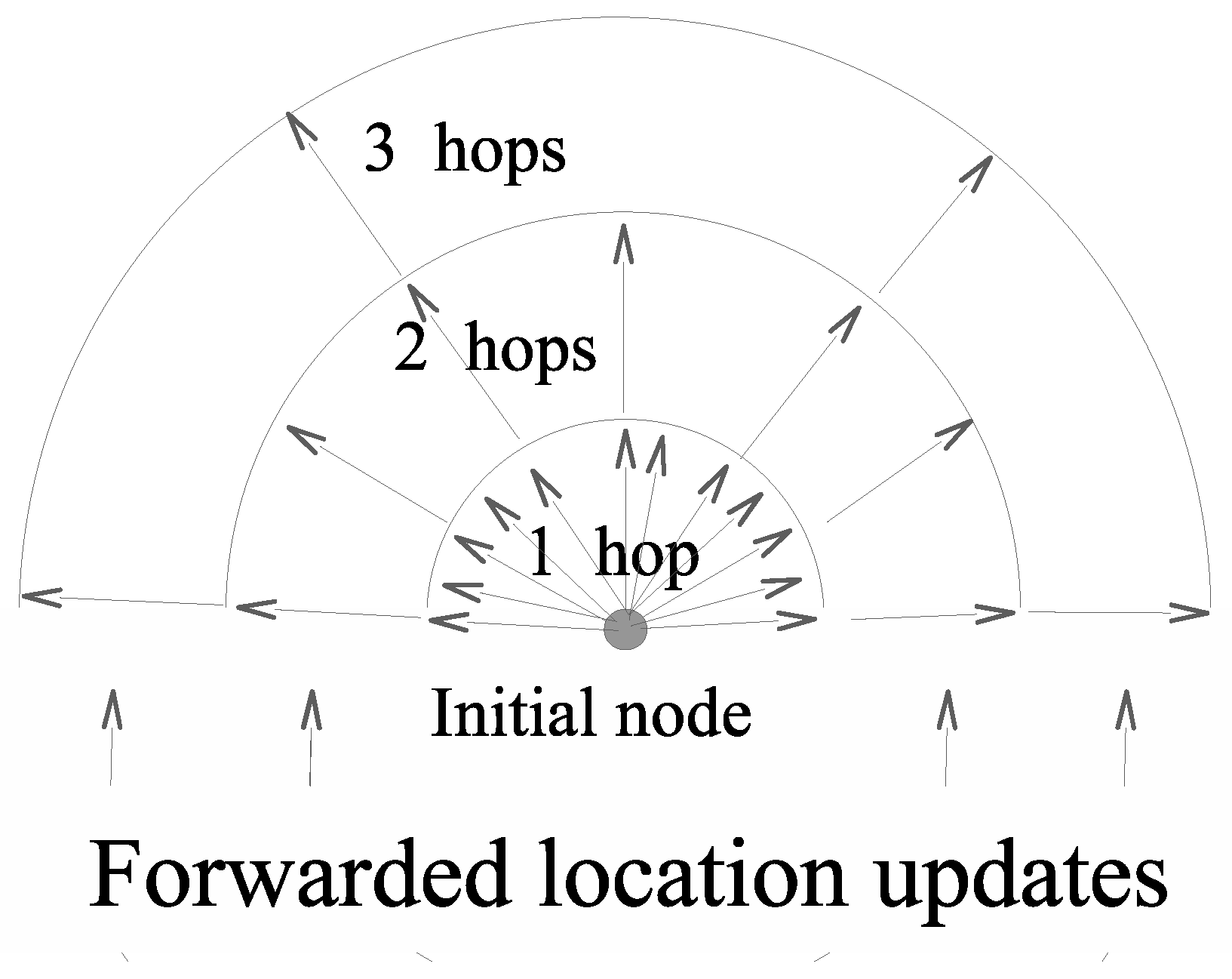
Figure 2 shows how far location packets are propagated at each location update when
q is equal to 2, and a deterministic algorithm is used. In this example, the longest path from the node emitting the location packets to any other nodes is 3. The first location packet (the first arrow clockwise in
Figure 2) reaches all nodes in the network, i.e., those that are at a distance of up to three hops from the emitting node. The second location packet (the second arrow in the same direction) only reaches one-hop nodes. The third location packet (and the same goes for packet numbers 7, 11, 15, etc.) reaches nodes at one and two hop(s). The fourth location packet (and any other odd-ranked location packet) only reaches nodes at one hop. Location packet 5 reaches all nodes up to three hops away.
Figure 2 also highlights the fact that the greater the distance from the node emitting the location update is, the longer the period of time between two location updates. However, for most applications (including routing), the greater the distance between two nodes is, the less accurate the knowledge of the other node’s position is. Most of the time, an approximate position is more than enough, the accurate location of the destination node becoming increasingly important as a data packet gets closer to the destination node. As a result, only significant changes in node locations should be reported, and this is exactly what the semiflooding location service does.
3.2. Algorithms
The semiflooding location service can be formalized using two algorithms running asynchronously on all nodes in the network. The first algorithm (see
Figure 3a) aims at periodically broadcasting local location information. The second (see
Figure 3b) aims at updating the local location information of other nodes when an update packet that is received and forwarding it 1 in
q.
Each node in the network stores an array (node) to save information about the other nodes. This array is indexed by the node ID. Information for each node includes:
position, the most recent position issued by the node and received locally.
timestamp, the time the position was issued. This timestamp is the one given by the issuer node and not by the receiver. Synchronization is not an issue since only timestamps related to the same node are compared.
done, a Boolean value that can be used to make sure that, the first time a location position is issued for a node, this message is forwarded up to the boundary of the network. This property is only available for the probabilistic version of the algorithm.
counter, a value used to determine when a location update has to be forwarded. It is incremented every time a packet is received. When its value becomes larger than q, the packet is forwarded, and q is subtracted from the counter. This property is only available for the deterministic version of the algorithm.
For the description of the algorithms, functions broadcast and receive have the following meaning:
broadcast (id, position, time) sends the node ID, the position, and the timestamp associated with the position to all nodes at one hop.
receive (& id, & position, & time) waits for the next broadcast message to be received, and returns the node ID, the position, and the timestamp from the content of the packet.
4. Performance Analysis
The aim of this section is to demonstrate the low complexity and scalability of our algorithm. In order to do so, we developed an analytical mathematical model and used it to determine the mean number of messages generated by each location update. We also show that the locally generated updates in the location tables by each location update were only related to the mean number of generated messages. Thus, we only focus on the mean number of messages generated per location update. The section is organized as follows. First, the cost of SFLS in terms of messages sent is estimated and this shows the scalability of the solution. Secondly, SFLS is compared with an optimized flooding algorithm used in the OLSR protocol.
4.1. Mathematical Model
Table 1 summarizes the notations used in this section. However, these notations are introduced in the text when they are needed in the description.
Let N be the number of nodes in the network, and be the length of the longest path from node i to any other node in the network. By definition, .
Let be the number of nodes at h hops from node i. When there is no node at h hops, which is always possible with a nonzero probability, we set ), and by convention .
Let
be the mean number of messages broadcast to update the location information of node
i in the network. Node
i is continuously broadcasting. Nodes at one hop from node
i broadcast 1 in
q. Nodes at two hops from node
i broadcast 1 in
(they receive 1 location update in
q and forward them 1 in
q), etc. As a result,
can be written:
where
is the expected value of
N.
Let
be the mean number of location updates performed in the network every time node
i broadcasts its new location information. Node
i is continuously updating. Nodes at one hop are also continuously updating. Nodes at two hops update 1 in
q (they receive only one update in
q from nodes at one hop). Nodes at three hops update 1 in
, etc. As a result,
can be written as
Consequently, and vary identically. In the following, we only focus on .
4.2. Node-Location Patterns
Equations (
1) and (
2) show that the mean number of both the sent messages and the updates for every new location update broadcast over the network depend on the number of nodes at each hop from node
i.
In the following, the nodes were assumed to be uniformly distributed over the network according to a homogeneous Poisson point process of rate . The radio-transmission range of the nodes was assumed to be R.
Three different cases were considered: (1) cars located on a highway where all vehicles are on the same axis, moving in the same direction or (2) in the exact opposite direction, or (3) cars located in a city, and the movement of the other vehicles could be considered as a pseudorandom movement on a plane. To provide the complete picture, we also considered a 3D scenario. The most plausible scenario for this last case was not a VANET, but a set of drones flying together.
4.2.1. One-Dimensional Scenario
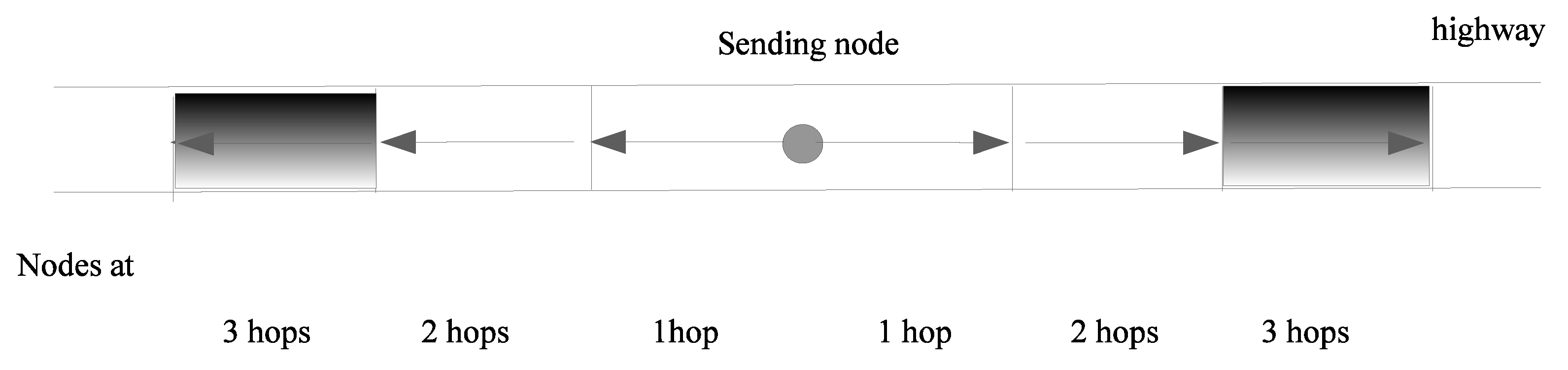
For the highway scenario, nodes were assumed to be located on a rectangle of which the width was the width of the road, and the length was infinite. The width of the road was small compared to the broadcast range, and it was acceptable to consider that the nodes were on a line. In this case, our model was a line with node density , expressed in vehicles per meter. Since all nodes at distance j were in a segment, starting from the position of the farthest node at distance from i, nodes at distance j were in a segment of length R. Thus, the mean number of nodes at distance j is the mean number of nodes in a segment of length (one segment to the right of i and one segment to the left of i).
Figure 4 shows the location of nodes at
n hops according to the hypotheses above. For example, the grey rectangles, i.e., those at a distance between
and
from the center (i.e., node
i), show the location of nodes at three hops.
The mean number of nodes at various distances from
i is
4.2.2. Two-Dimensional Scenario
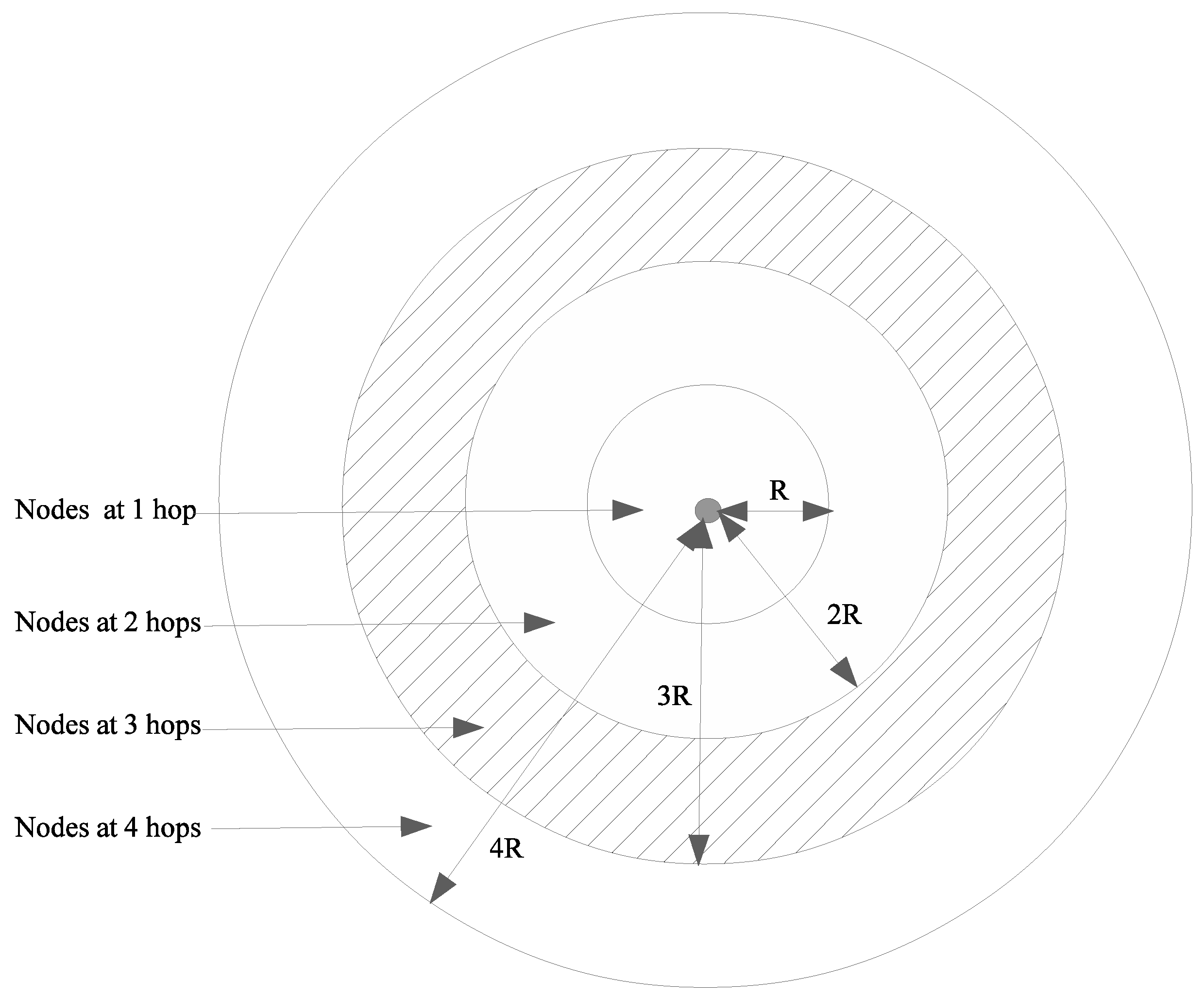
In this case, our model was a plane with node density
, expressed in vehicles per square meter. The exact model would have to compute number of nodes
at
j hops from node
i, and compute the mean value of
averaged on the whole spatial configuration. Although this computation did not seem possible with state-of-the-art of stochastic geometry, we proposed to compute an upper bound. We assumed that the largest area in which
nodes could be found was between the circle of radius
and the circle of radius
(see
Figure 5). This occurred when density of nodes
was very high. In this case, one could find nodes at
hops exactly at distance
from node
i. However, this property has still not been rigorously demonstrated, but it was verified in the following simulations. The mean number of nodes at
j hops from
i was thus
4.2.3. Three-Dimensional Scenario
We developed the 3D case for the sake of completeness. However, these networks seem more suitable for a fleet of drones than for VANETs. The model is a 3D space of random nodes with density of nodes expressed in nodes per cubic meter. The exact model would require computing number of nodes at j hops from node i, and evaluating the mean value of averaged on many spatial configurations. As for the 2D case, the largest area in which the nodes could be located was assumed to be between the sphere of radius and the sphere of radius . This was obviously true when there was very high density of nodes , and this property was also assumed to hold with smaller densities. This was also verified by simulations.
The mean number of nodes at
j hops from node
i was
4.3. Algorithm Scalability
From the uniform distributions presented above, it was possible to determine the mean number of broadcast messages to update the location information of node i in a network.
We first considered a 1D network. The number of nodes at distance
j from node
i was computed above. Each of these nodes retransmitted 1 over
times. Thus, the mean number of messages generated per location update is:
Since
, Equation (
4) can be rewritten as
For the probabilistic approach with the retransmission of a packet with probability
r, we have
We now consider a 2D network. The number of nodes at distance
j from node
i was upper-bounded above. Each of these nodes retransmitted 1 over
times. The mean number of messages generated per location update could be upper-bounded as follows:
Equation (
7) can be rewritten as
For the probabilistic approach, Equation (
7) becomes
We now consider a 3D network. The number of nodes at distance
j from node
i was upper-bounded above. Each of these nodes retransmitted 1 over
times. The mean number of messages generated per location update could be upper-bounded as follows:
Equation (
10) can be rewritten as
For the probabilistic approach, Equation (
10) becomes
From Equations (
5), (
8), and (
12), it is straightforward to demonstrate that
and
These limits are of the
form, where
M is the mean number of neighbors of node
i, and
a only depends on
q. One can easily derive the mean number of transmissions for node
i with a simple flooding:
The comparison between and N clearly shows the advantage and scaling properties of our proposed algorithm.
4.4. Numerical Results
In our numerical examples, densities of the nodes were chosen so that the mean number of neighbors of a node was 20; transmission range was .
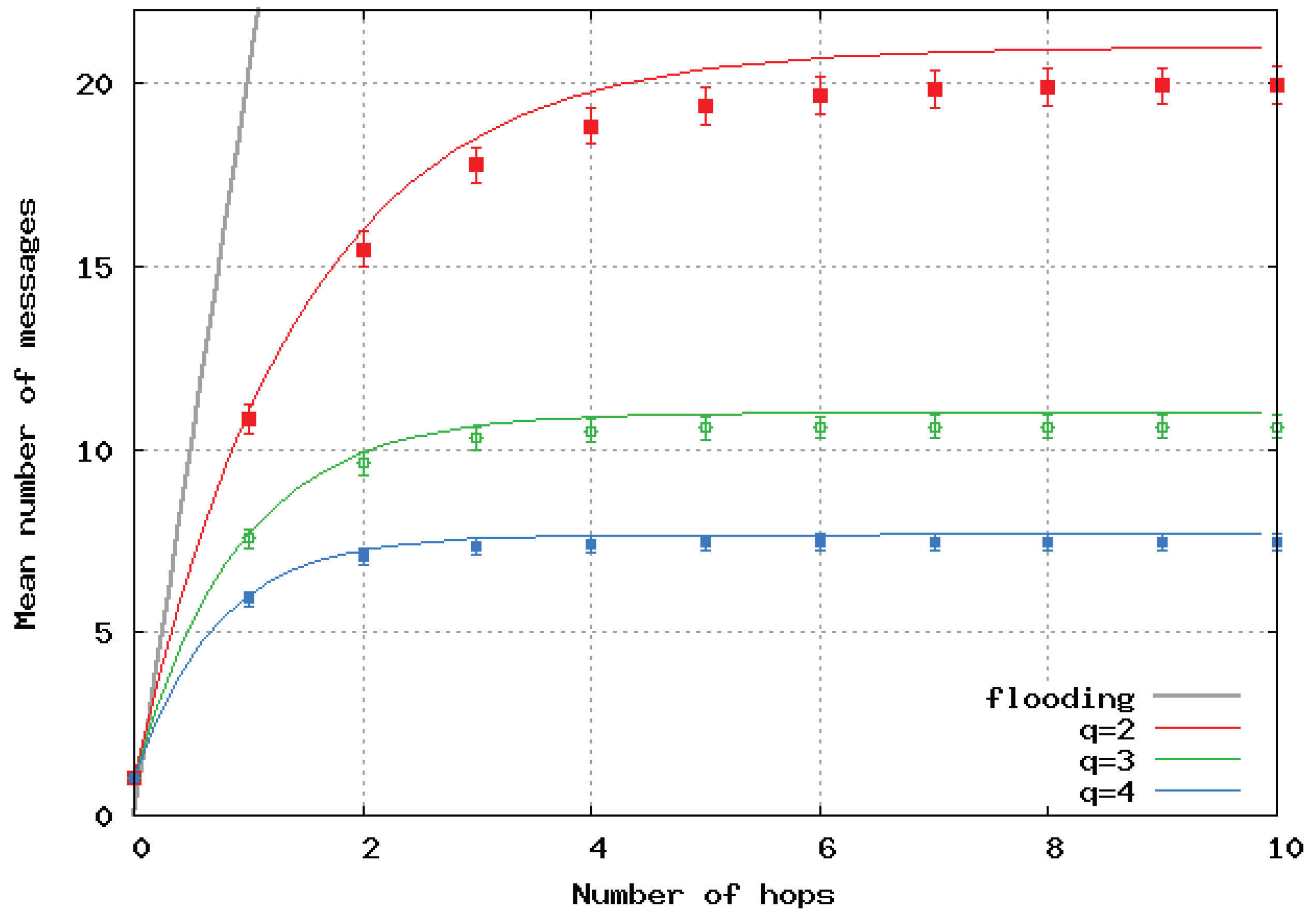
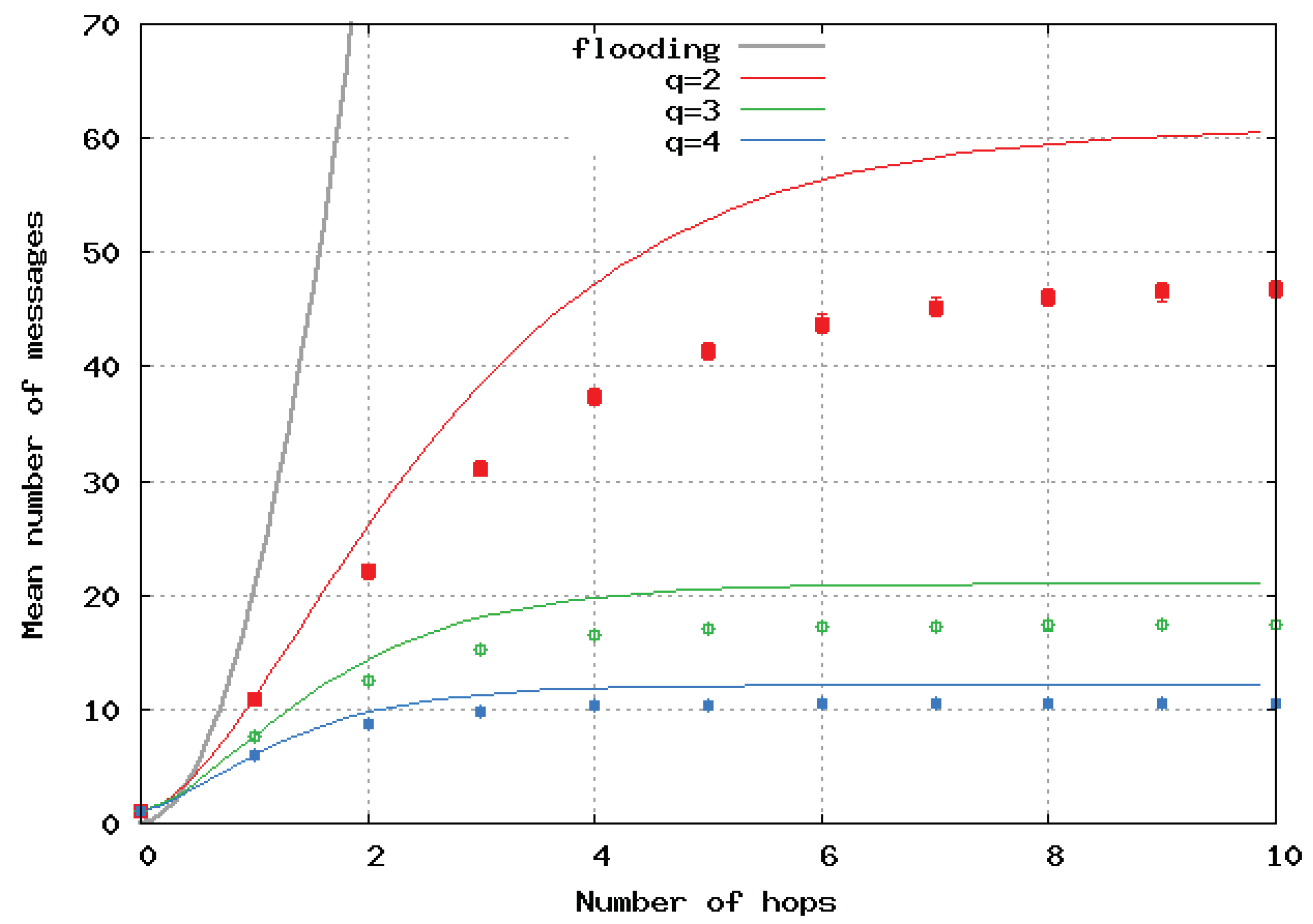
Figure 6 presents the mean number of broadcast messages per location update versus the maximal path lengths computed by the analytical model and simulations in the case of a homogeneous linear (1D) network. Analytical results are represented by a continuous line, and simulation results by dots and error bars. The same color is used for the same value of
q for the simulations and the analytical model. We observed very good matching of the two approaches. The black curve shows the number of messages with the pure flooding algorithm, and it clearly shows the great benefit of SFLS.
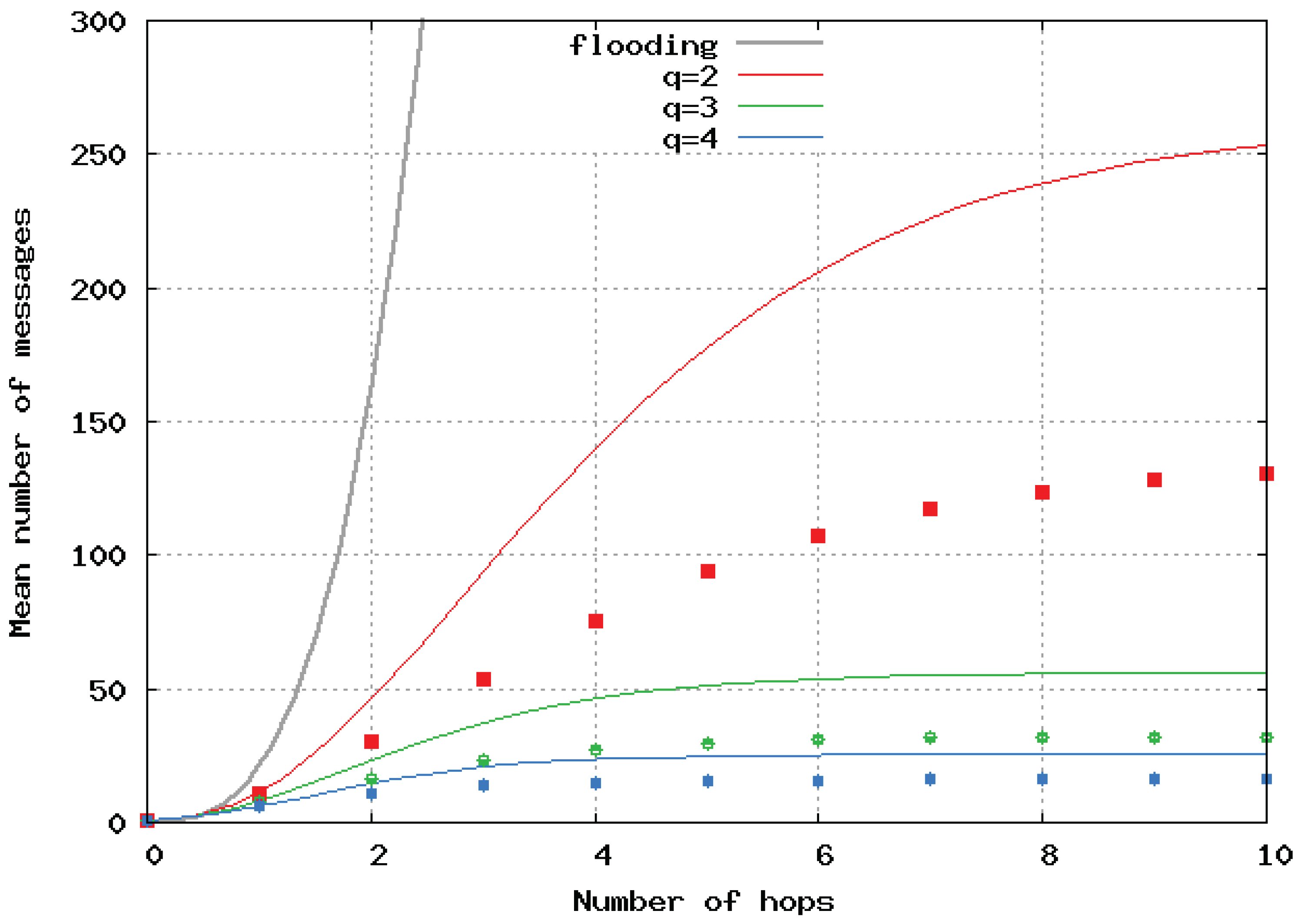
Figure 7 and
Figure 8 show the mean number of messages per location update versus the path length computed by the simulation and its upper-bound, analytically computed for homogeneous 2D and 3D networks, respectively. The analytical results are represented by a continuous line, and the simulation results by dots and error bars. Simulations presented in
Figure 6,
Figure 7 and
Figure 8 show error bars corresponding to a confidence level of 95%. The upper bounds largely overestimated the number of broadcast messages in 2D and 3D networks. This is because these bounds were only tight when the density of nodes was very high. When the number of hops
increased, it can be seen that increasing
q strongly decreased the mean number of generated messages. The benefit of having a large
q is greater for 2D and even greater for 3D networks. Here, again, we observe the great benefit of the algorithm we propose over pure flooding.
4.5. Comparison with Other Flooding Techniques
The section above shows that SFLS scaled well with the total number of nodes in the network since the mean number of retransmissions was of form
, where
M is the mean number of neighbors of a node (M is constant since the network is homogeneous.). However, if a proactive routing protocol is already implemented in the network, one may consider using information that is already present to help the flooding of location information. The MPR flooding of the optimized-link-state -routing (OLSR) protocol, which exploits the information included in the Hello packets, was shown to be very efficient and, in particular, more efficient than the dominating set flooding (see [
8]). We propose to disseminate location information with the multipoint relays (MPRs) of OLSR. The main idea is to ensure the dissemination of a packet using special nodes called multipoint relays (MPRs). The multipoint-relay set of a node is a minimal set of its neighbors that can reach all of its two-hop neighbors (The two-hop neighbors of a node are the neighbors of the neighbors that are not one-hop neighbors. Using MPRs recursively is enough to broadcast a packet to all network nodes. The MPR set is minimal in terms of number of nodes.).
We now consider a 2D homogeneous network. Using MPR flooding, an upper bound on the total number of retransmissions required to complete full flooding is
, where
M denotes the mean number of neighbors of a node. Thus, the upper bound of the total number of retransmissions for MPR flooding is
For SFLS, where flooding is based on the retransmission of 1 in
q messages, the upper bound on the total number of retransmissions per update is
which can be written as
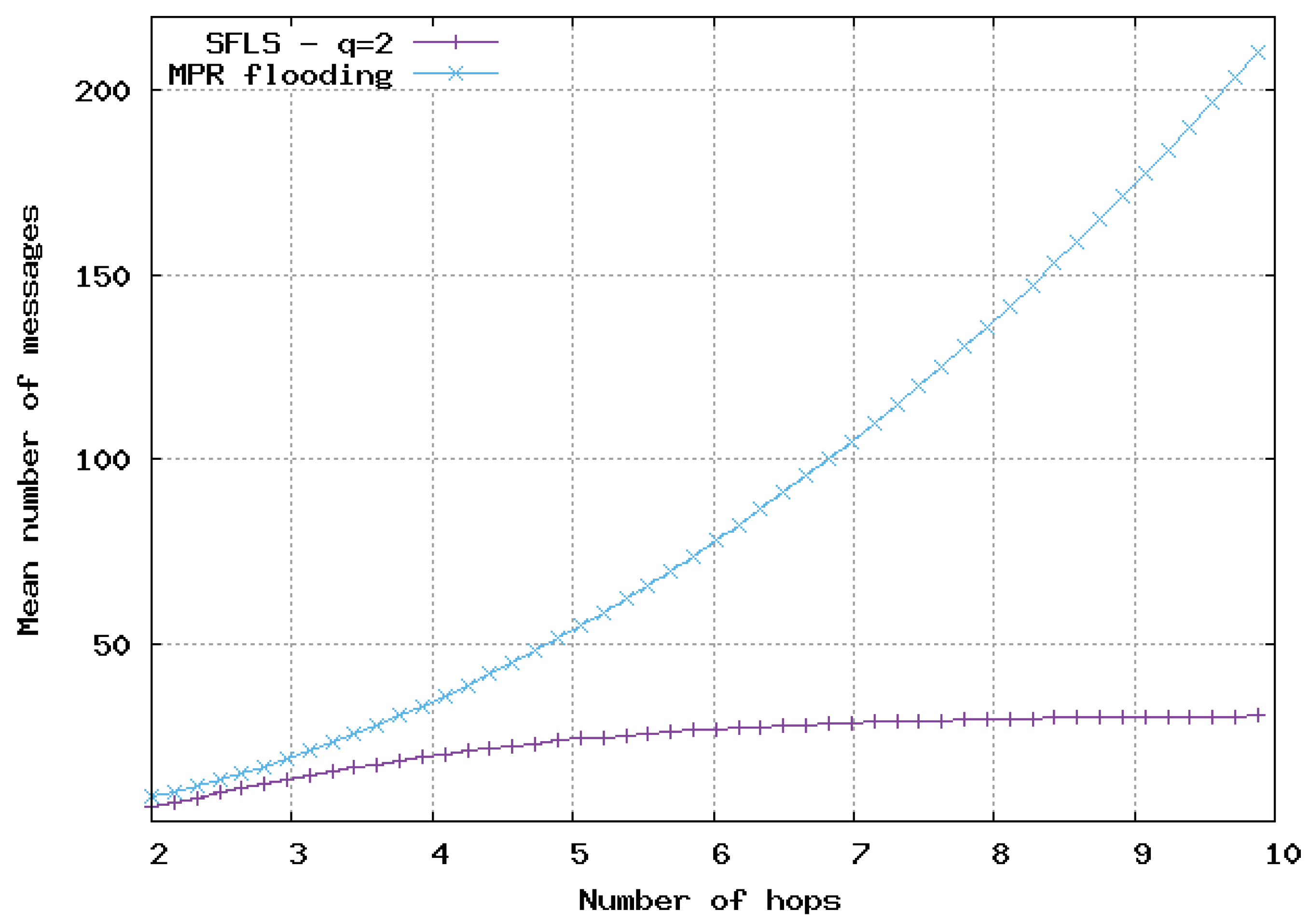
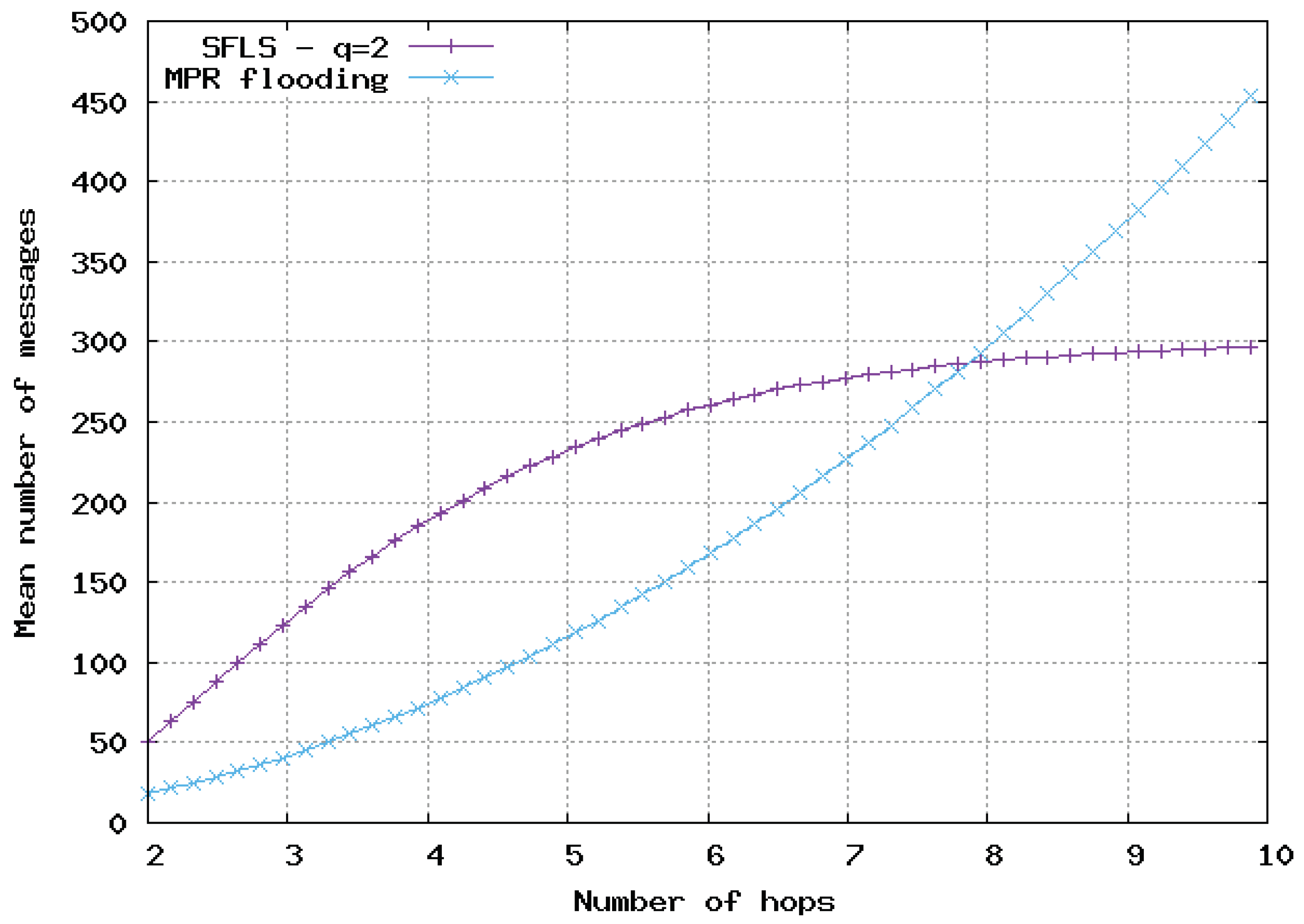
In
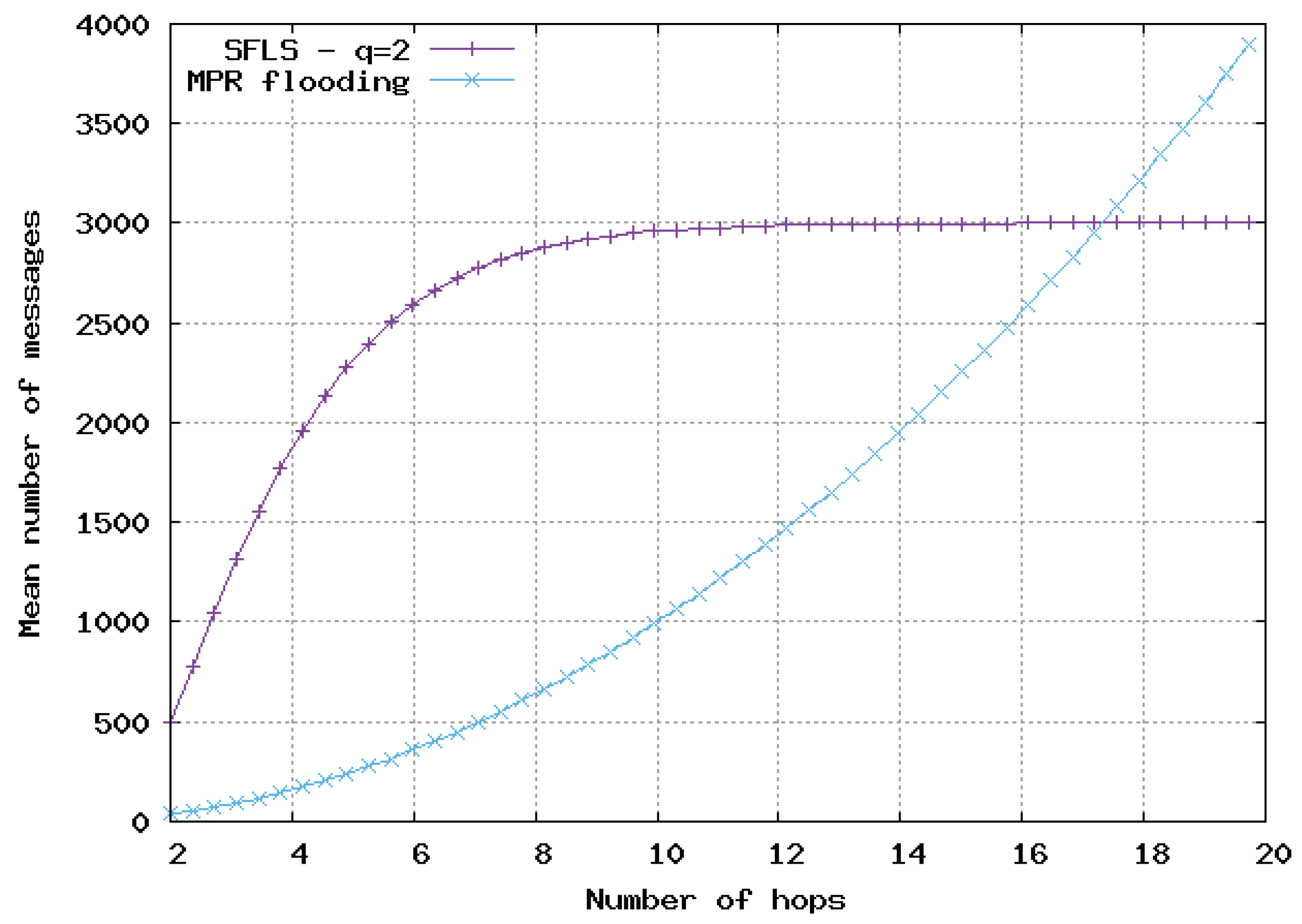
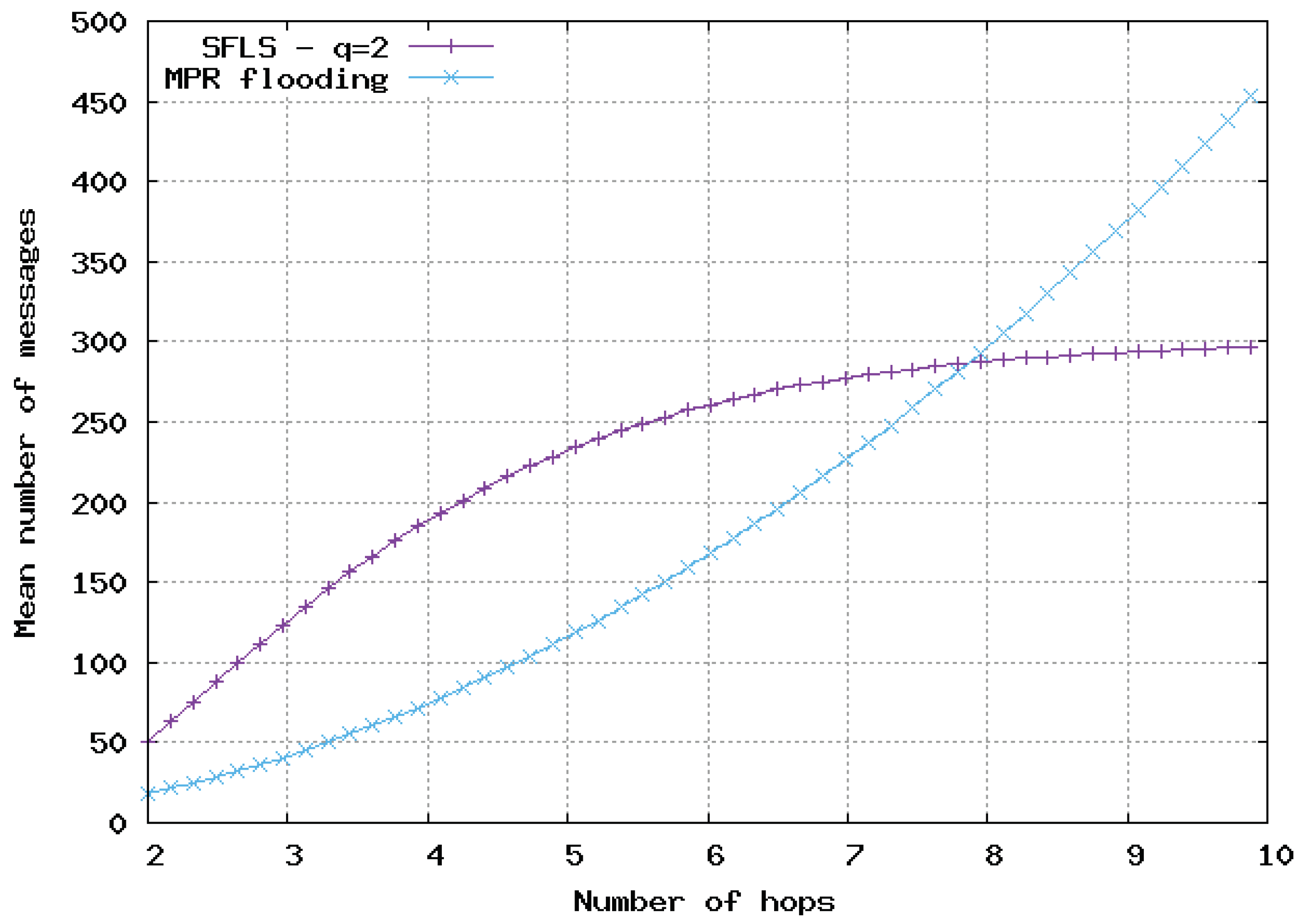
Figure 9,
Figure 10 and
Figure 11, the flooding overhead of SFLS is compared with the overhead of OLSR in homogeneous 2D networks. We varied density
or equivalently
M, i.e., the mean number of neighbors for a random node. In
Figure 9,
Figure 10 and
Figure 11,
M is equal to 10, 100 and 1000, respectively.
For SFLS, the developed upper bound in the analytical model was used. Our protocol always outperformed OLSR when the number of hops was large. However, OLSR outperformed our scheme for a small number of hops or when the network was very dense.
As a result, unlike other flooding-based location services, the semiflooding location service is scalable in terms of the number of messages that must be sent to keep all the nodes updated, the number of updates that are performed in the network, and the time required to answer a location request.
5. Conclusions and Future Work
SFLS, the semiflooding location service, an efficient and yet simple solution for the dissemination of location information in VANETs, was described in this paper. We analyzed the performance of this protocol with a uniform Poisson point process of nodes in 1D, 2D, and 3D networks. Even though the basis of this protocol is a broadcast scheme, we showed that the number of messages per update remains very low. For different cases, we built an analytical model to upper bound the number of messages per update, and carried out simulations to verify our computations. The matching of the analytical model and the simulations was very good. We also compared SFLS with the broadcast optimization scheme of OLSR: the multipoint-relay technique. We presented two case studies where SFLS and the multipoint-relay technique performed differently. In dense or very dense networks, the MPR scheme was better, but SLFS outperformed the MPR flooding of OSLR in sparse or moderately dense networks, and in any case, when the number of hops was large.
It would be interesting to combine SFLS with a location-prediction technique based on node kinematics to refine their positions between the reception of two consecutive SFLS updates. This idea could be the starting point for further studies.
Author Contributions
S.B. and É.R. proposed the SFLS protocol at the ICC 2016 conference. P.M. has extended this conference paper with a more advanced analytical model and has proposed the comparison of SFLS with pure flooding and the MPR flooding of OLSR. In this extended version, S.B. has also proposed a more complete Related Work section and Eric Renault has produced the simulation results with the help of P.M. P.M. has managed the overall revision of the paper with the help of S.B. and É.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
We acknowledge the finance support of Inria.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zheng, K.; Zheng, Q.; Chatzimisios, P.; Xiang, W.; Zhou, Y. Heterogeneous vehicular networking: A survey on architecture, challenges, and solutions. IEEE Commun. Surveys Tuts. 2015, 17, 2377–2396. [Google Scholar] [CrossRef]
- Ullah, A.; Yao, X.; Shaheen, S.; Ning, H. Advances in Position Based Routing Towards ITS Enabled FoG-Oriented VANET–A Survey. IEEE Trans. Intell. Transp. Syst. 2020, 21, 828–840. [Google Scholar] [CrossRef]
- Karp, B.; Kung, H.T. GPSR: Greedy perimeter stateless routing for wireless networks. In Proceedings of the ACM/IEEE International Conference on Mobile Computing and Networking (MobiCom), Boston, MA, USA, 6–11 August 2000. [Google Scholar]
- Liu, C.; Qiu, L.; Yang, T.; Gong, K. ASGR: An Artificial Spider-Web-Based Geographic Routing in Heterogeneous Vehicular Networks. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1604–1620. [Google Scholar]
- Nebboua, T.; Lehsainia, M.; Fouchal, H. Partial backwards routing protocol for VANETs. Veh Commun. 2019, 18, 100162. [Google Scholar]
- Han, G.; Jiang, J.; Zhang, C.; Duong, T.Q.; Guizani, M.; Karagiannidis, G.K. A survey on mobile anchor node assisted localization in wireless sensor networks. IEEE Commun. Surv. Tutor. 2016, 18, 2220–2243. [Google Scholar] [CrossRef]
- Iliev, N.; Paprotny, I. Review and comparison of spatial localization methods for low-power wireless sensor networks. IEEE Sens. J. 2015, 15, 5971–5987. [Google Scholar] [CrossRef]
- Jacquet, P.; Laouiti, A.; Minet, P.; Viennot, L. Performance Analysis of OLSR Multipoint Relay Flooding in Two Ad Hoc Wireless Network Models RR-4260, INRIA. 2001. Available online: https://hal.inria.fr/inria-00072327 (accessed on 1 March 2020).
- Boumerdassi, S.; Renault, É. A flooding-based solution to improve location services in VANETs. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016. [Google Scholar]
- Woo, H.; Lee, M. A Hierarchical Location Service Architecture for VANET with Aggregated Location Update. Comput. Commun. 2018, 125, 38–55. [Google Scholar] [CrossRef]
- Yim, Y.; Choa, H.; Kim, S.; Lee, E.; Gerla, M. Vehicle location service scheme based on road map in Vehicular Sensor Networks. Comput. Networks 2017, 127, 138–150. [Google Scholar] [CrossRef]
- Saleet, H.; Basir, O.; Langar, R.; Boutaba, R. Region-based location service- management protocol for vanetsin. IEEE Trans. Veh. Technol. 2010, 29, 917–931. [Google Scholar] [CrossRef]
- Bai, X.Y.; Ye, X.M.; Li, J.; Jiang, H. VLS: A Map-Based Vehicle Location Service for City Environments. In Proceedings of the IEEE International Conference on Communications ICC 2009, Dresden, Germany, 14–18 June 2009. [Google Scholar]
- Brahmi, N.; Boussedjra, M.; Mouzna, J.; Cornelio, A.K.V.; Manohar, M.M. An improved map-based location service for vehicular ad hoc networks. In Proceedings of the IEEE 6th international conference on wireless and mobile computing, networking and communications (WiMob), Niagara Falls, NY, USA, 11–13 October 2010; pp. 21–26. [Google Scholar]
- Rehan, M.; Hasbullah, H.; Faye, I.; Rehan, W.; Chughtai, O.; Rehmani, M.H. ZGLS: a novel flat quorum-based and reliable location management protocol for VANETs. Wirel. Networks 2018, 24, 1885–1903. [Google Scholar] [CrossRef]
- Lee, E.; Choe, H.; Thirumurthi, P.; Gerla, M.; Kim, S. Quorum-based location service in Vehicular Sensor Networks. In Proceedings of the 2013 9th International Wireless Communications and Mobile Computing Conference (IWCMC), Sardinia, Italy, 1–5 July 2013; pp. 1744–1749. [Google Scholar]
- Aissaoui, R.; Dhraief, A.; Belghith, A.; Menouar, H.; Filali, F.; Mathkour, H. VALS: Vehicle-aided location service in urban environment. In Proceedings of the IEEE Wireless Communications and Networking Conference, Doha, Qatar, 3–6 April 2016; pp. 1–6. [Google Scholar]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}