Few-Shot Personalized Saliency Prediction Based on Adaptive Image Selection Considering Object and Visual Attention †


Abstract
1. Introduction
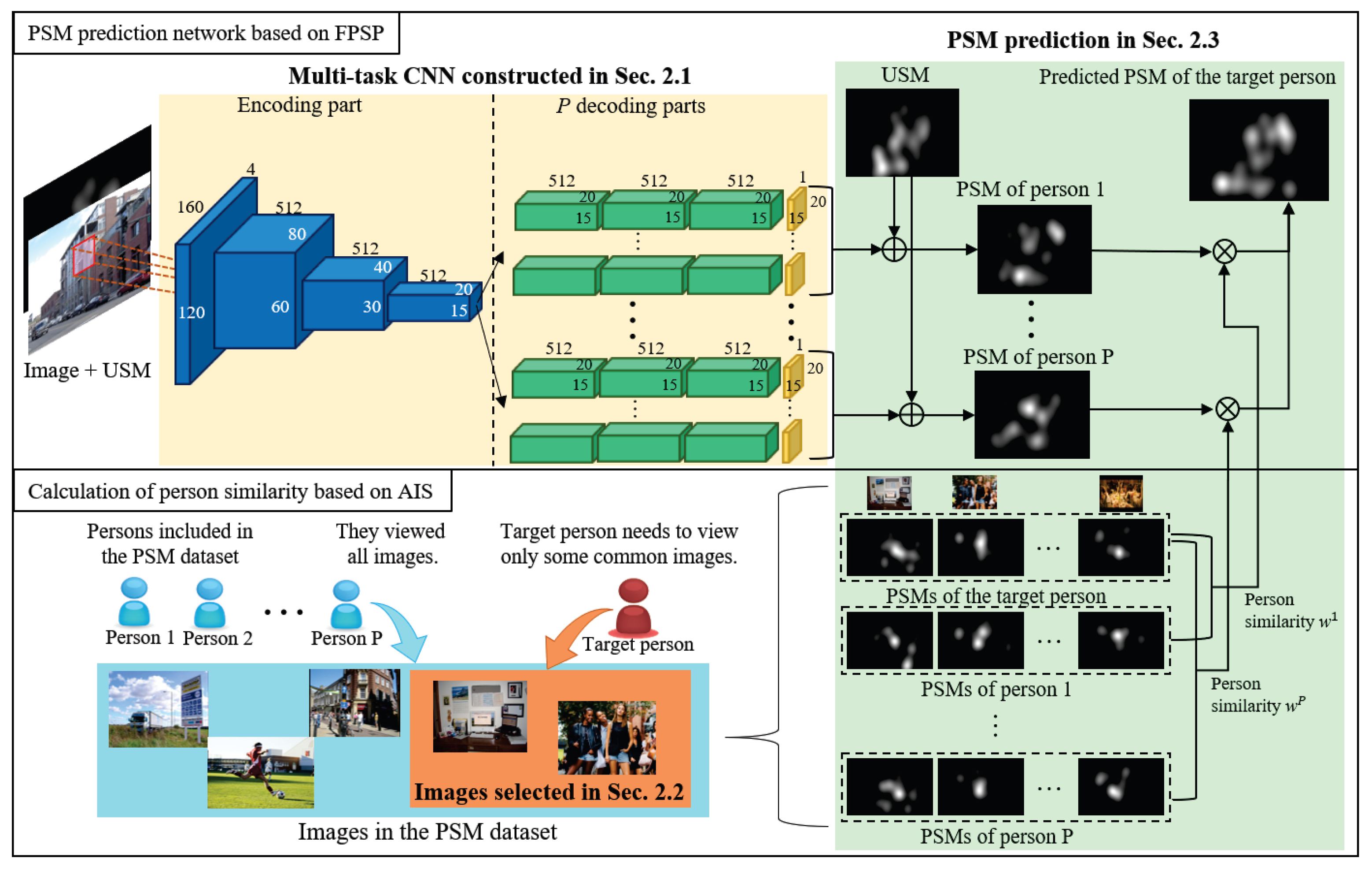
2. Few-shot PSM Prediction Based on Adaptive Image Selection
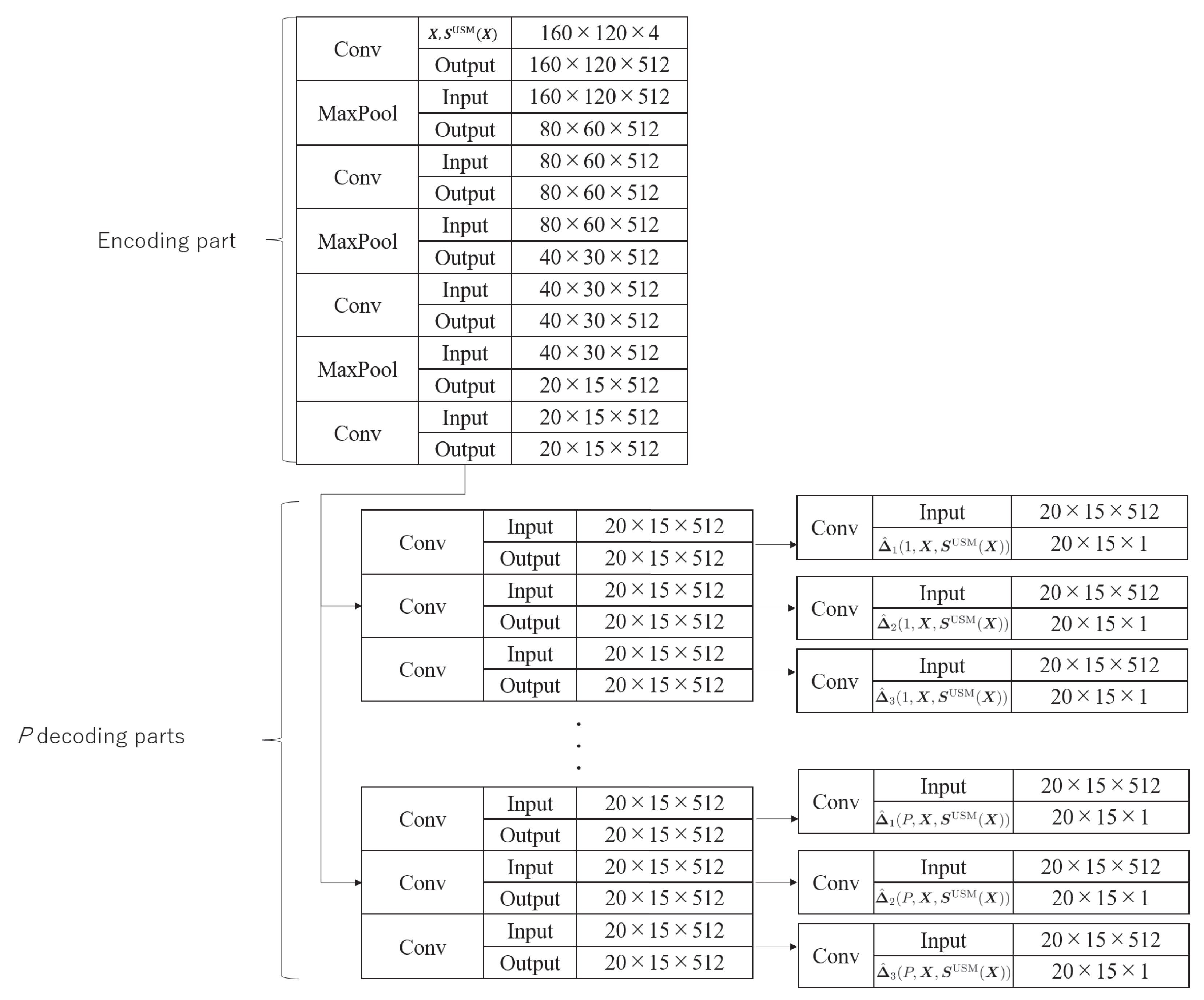
2.1. Construction of a Multi-Task CNN for PSM Prediction
2.2. Adaptive Image Selection for Reduction of Viewed Images
2.3. FPSP Based on Person Similarity
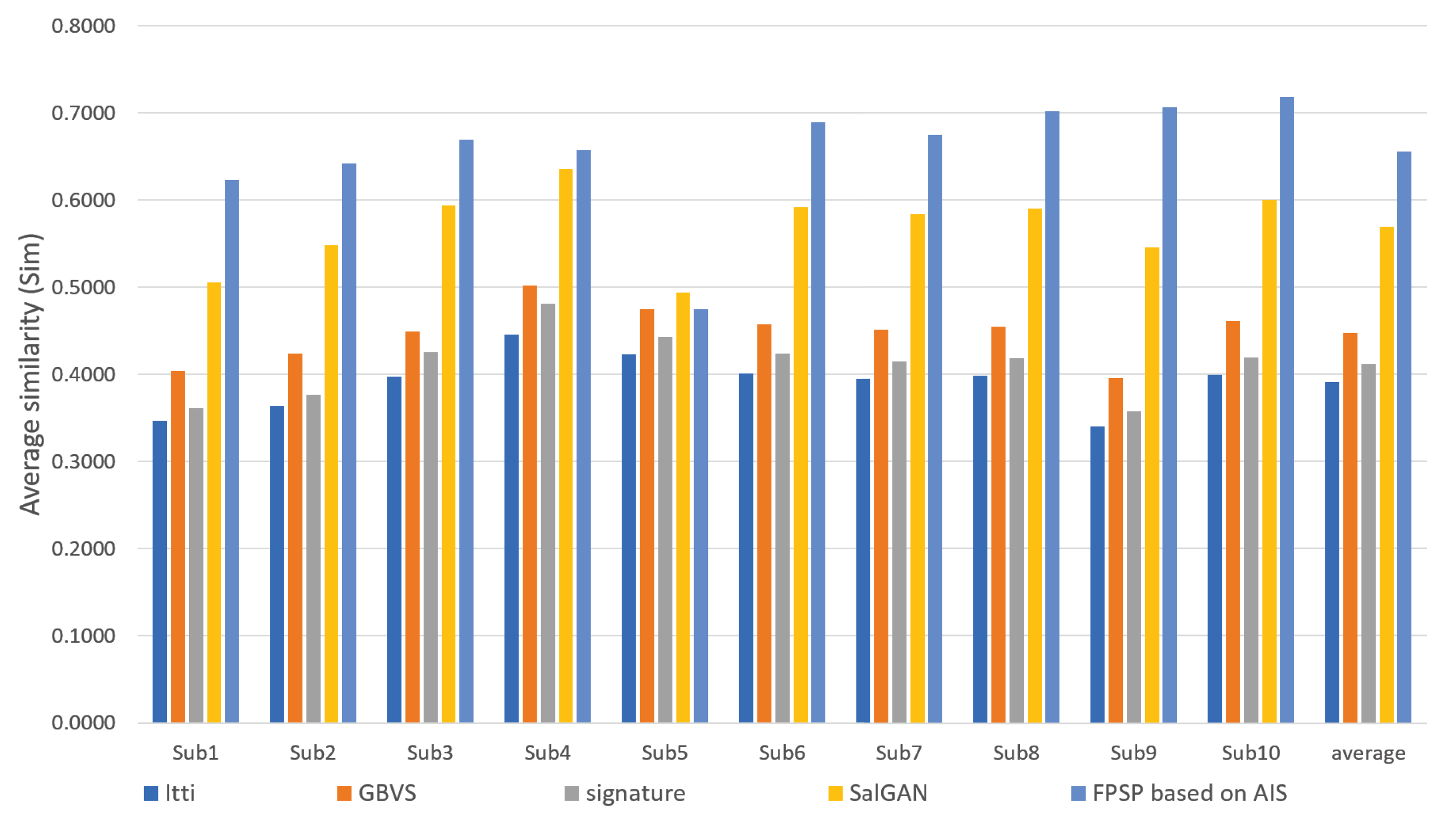
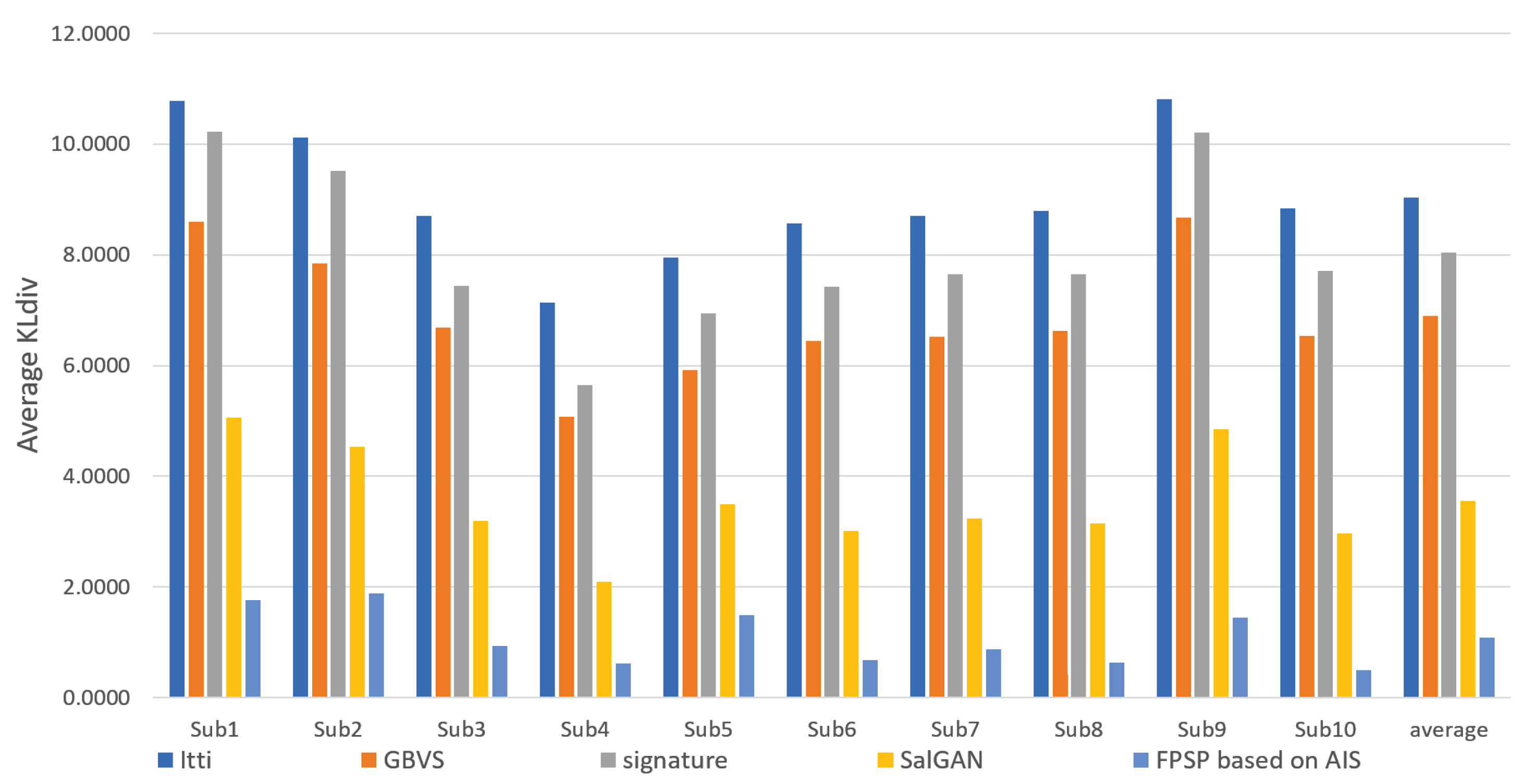
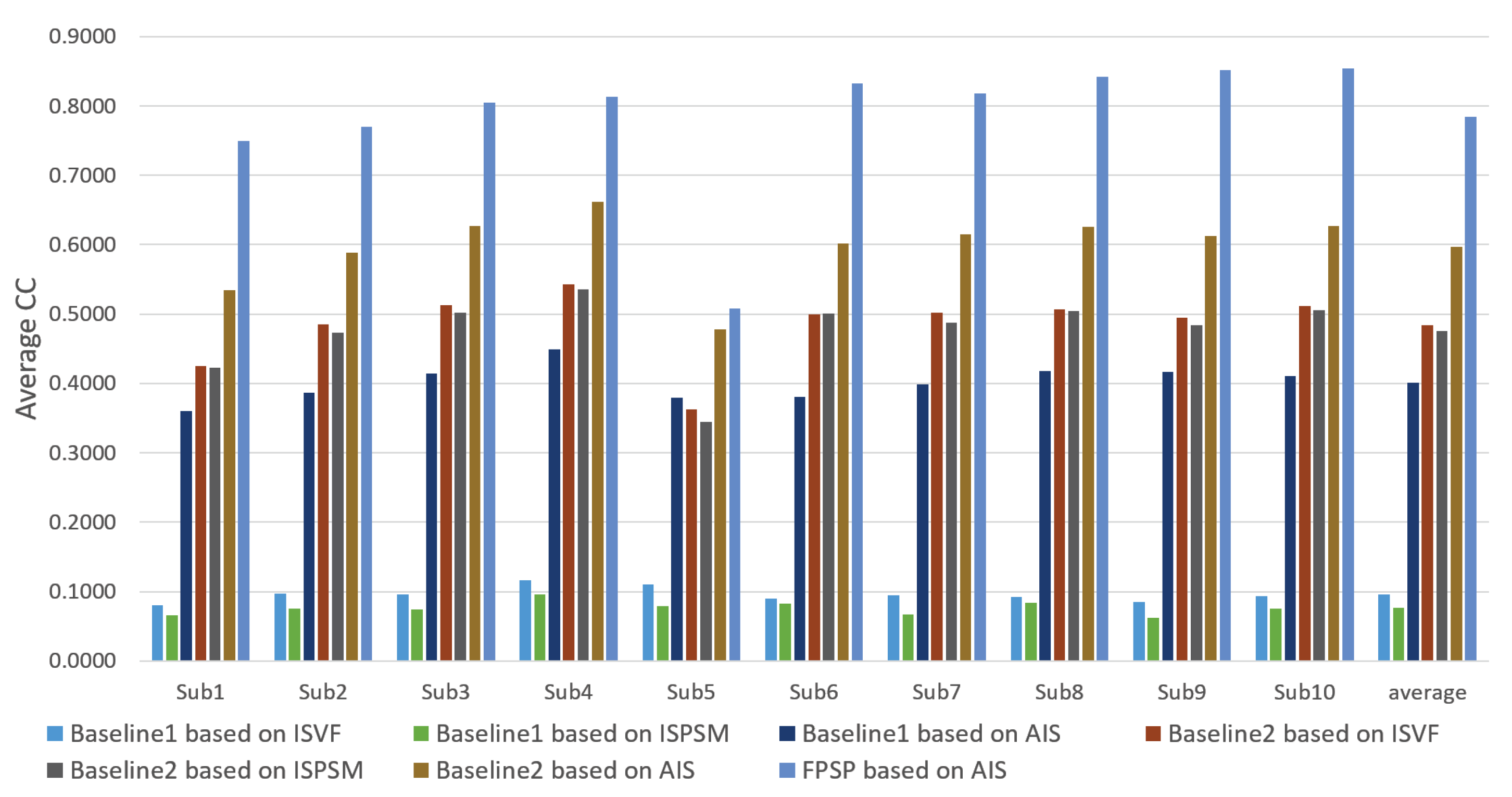
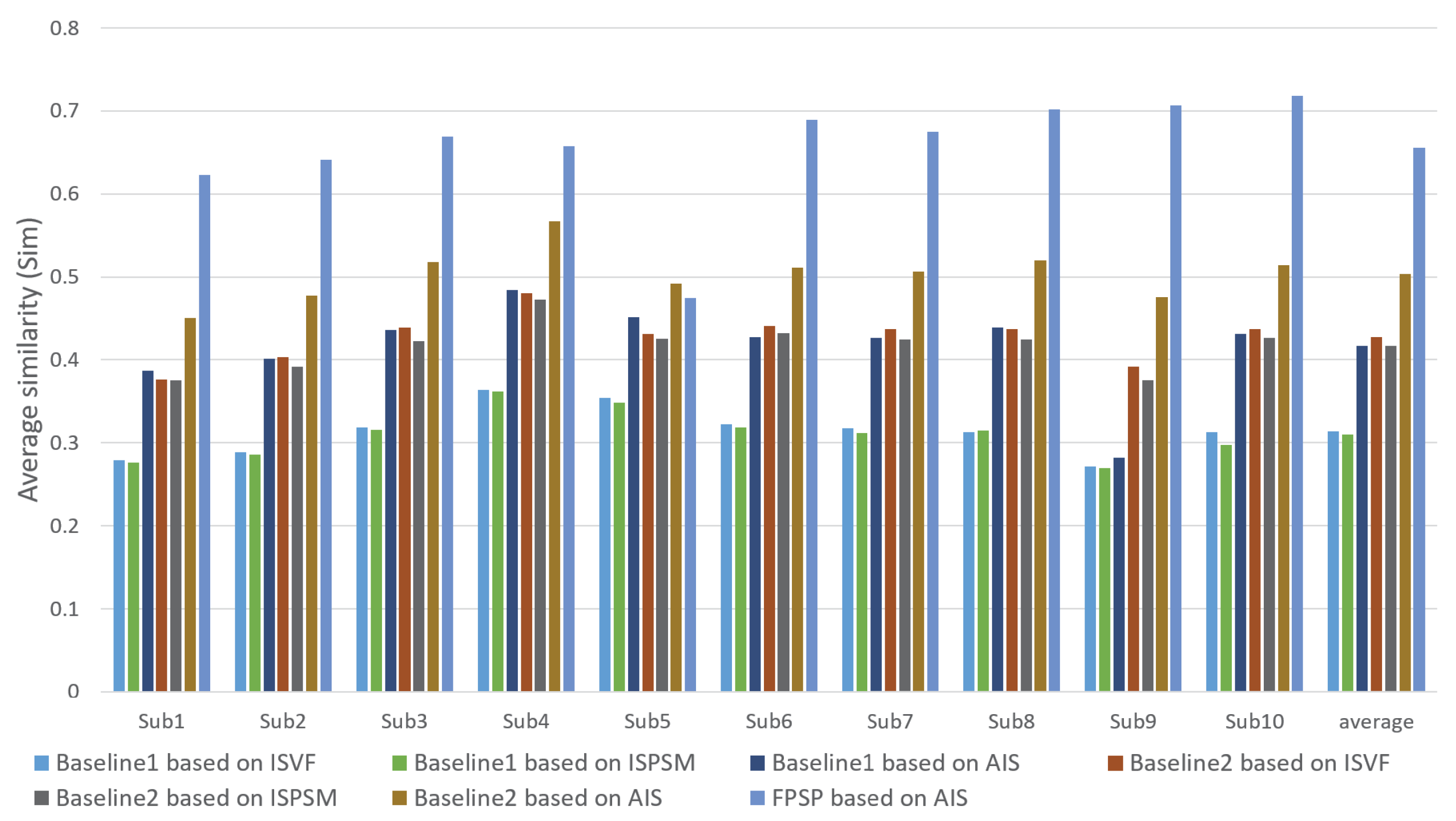
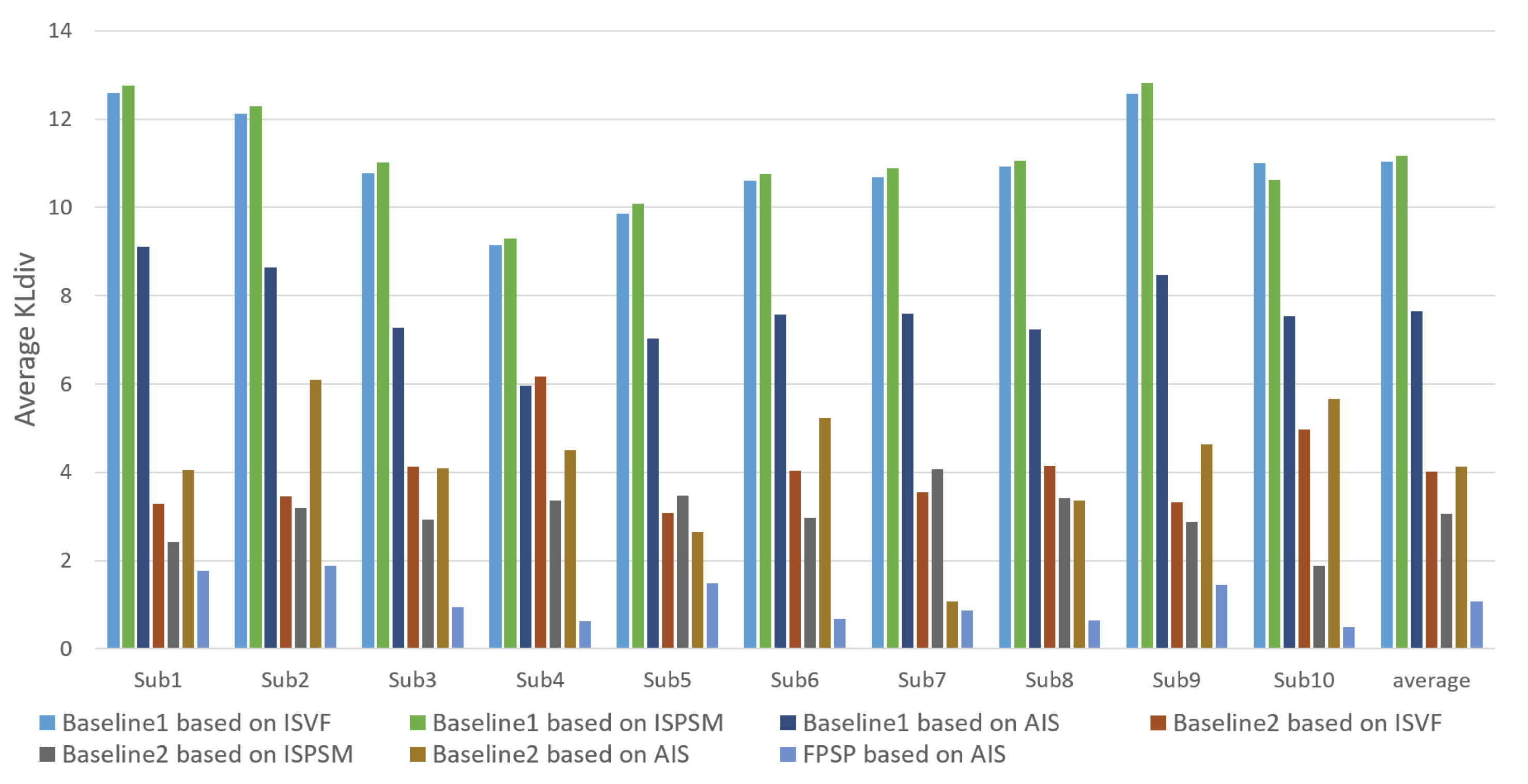
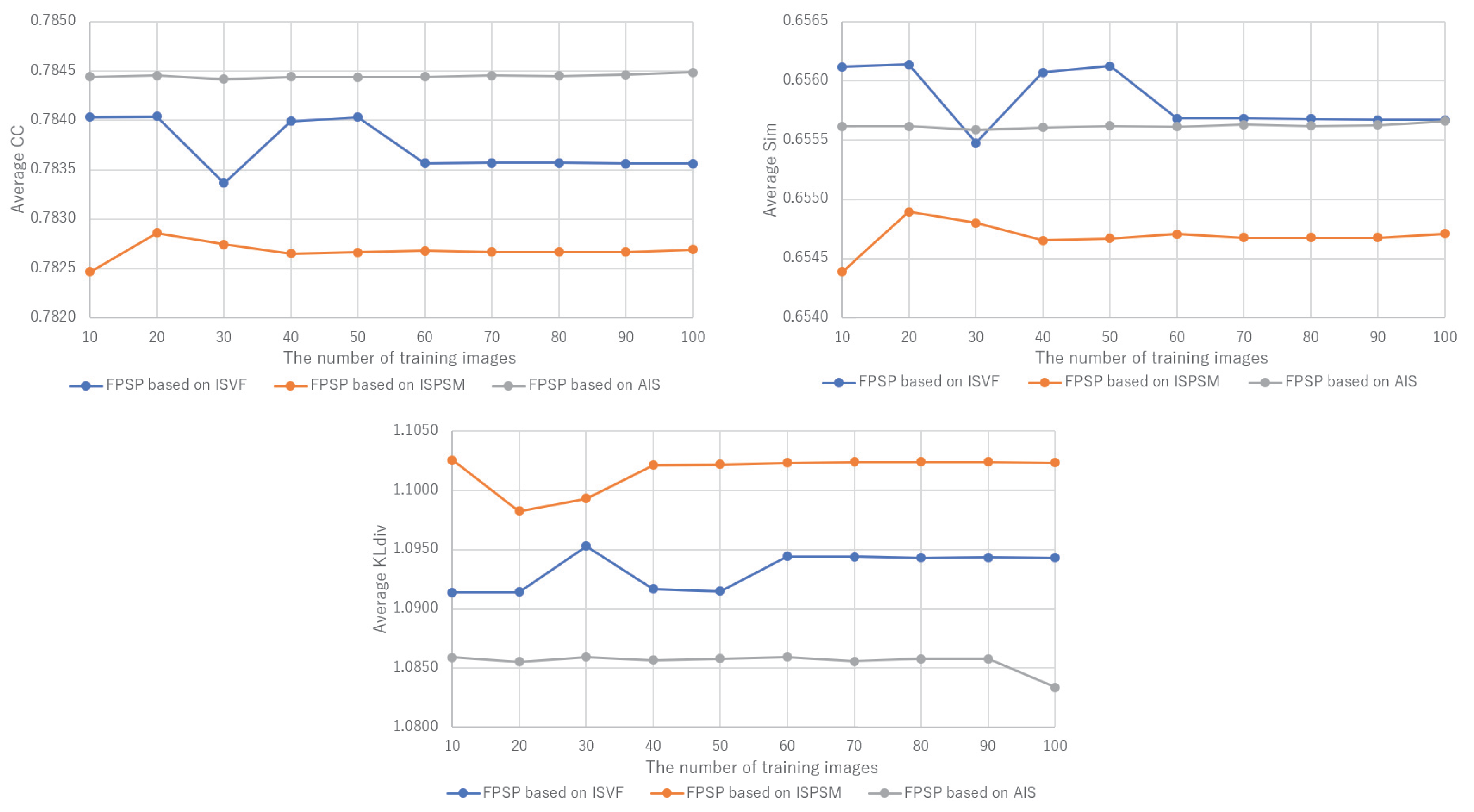
3. Experiment
3.1. Experimental Settings
- Image selection based on visual features (ISVF)Images having with a low similarity to those of visual features to other images were selected. We adopted the outputs of the final convolution layer of pre-trained DenseNet201 [31] as visual features.
- Image selection focusing on variance of PSMs (ISPSM)Images having a high variance of PSMs included in the PSM dataset were selected.
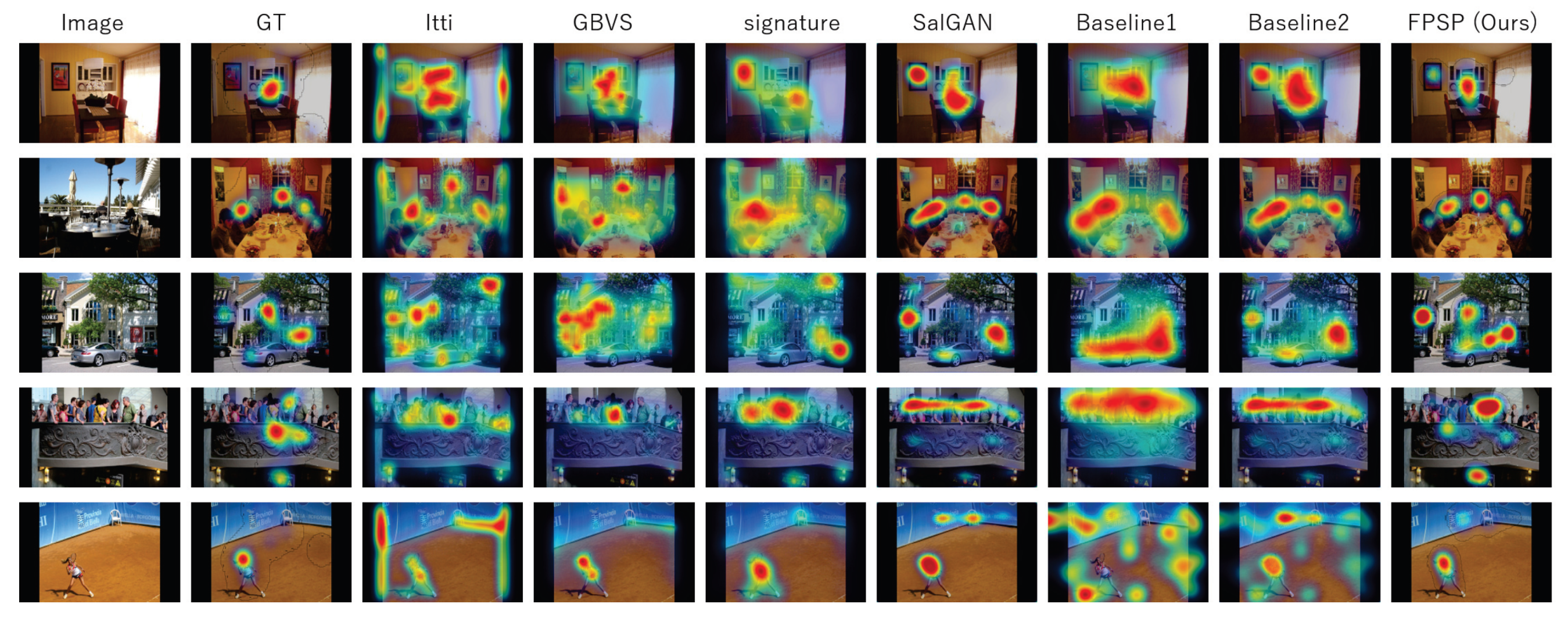
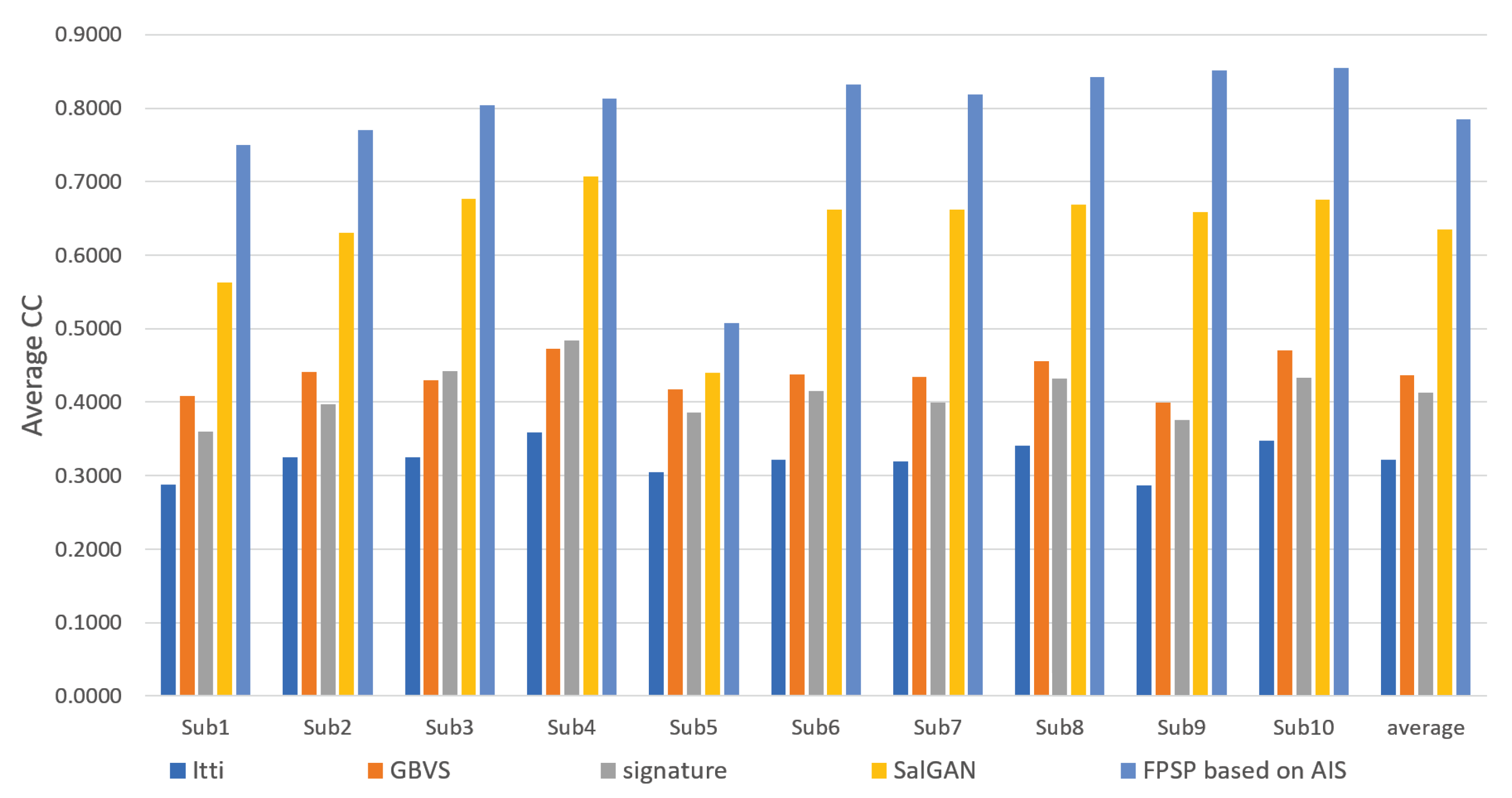
3.2. Performance Evaluation and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Proceedings of the Advances in Neural Information Processing Systems 20: 21st Annual Conference on Neural Information Processing Systems 2007, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Hou, X.; Harel, J.; Koch, C. Image signature: Highlighting sparse salient regions. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 194–201. [Google Scholar]
- Pan, J.; Ferrer, C.; McGuinness, K.; O’Connor, N.; Torres, J.; Sayrol, E.; Giro, X. Salgan: Visual saliency prediction with generative adversarial networks. arXiv 2017, arXiv:1701.01081. [Google Scholar]
- Setlur, V.; Takagi, S.; Raskar, R.; Gleicher, M.; Gooch, B. Automatic image retargeting. In Proceedings of the 4th International Conference on Mobile and Ubiquitous Multimedia, Christchurch, New Zealand, 8–10 December 2005. [Google Scholar]
- Fang, Y.; Zhang, C.; Li, J.; Lei, J.; Da Silva, M.P.; Le Callet, P. Visual attention modeling for stereoscopic video: A benchmark and computational model. IEEE Trans. Image Process. 2017, 26, 4684–4696. [Google Scholar] [CrossRef] [PubMed]
- Itti, L. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Trans. Image Process. 2004, 13, 1304–1318. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Xu, M.; Ren, Y.; Wang, Z. Closed-form optimization on saliency-guided image compression for HEVC-MSP. Trans. Multimedia 2017, 20, 155–170. [Google Scholar] [CrossRef]
- Gasparini, F.; Corchs, S.; Schettini, R. Low-quality image enhancement using visual attention. Opt. Eng. 2007, 46. [Google Scholar] [CrossRef]
- Fan, F.; Ma, Y.; Huang, J.; Liu, Z. Infrared image enhancement based on saliency weight with adaptive threshold. In Proceedings of the 3rd International Conference on Signal and Image Processing (ICSIP 2018), Shenzhen, China, 13–15 July 2018. [Google Scholar]
- Alwall, N.; Johansson, D.; Hansen, S. The gender difference in gaze-cueing: Associations with empathizing and systemizing. Pers. Indiv. Differ. 2010, 49, 729–732. [Google Scholar] [CrossRef]
- Fan, S.; Shen, Z.; Jiang, M.; Koenig, B.; Xu, J.; Kankanhalli, M.; Zhao, Q. Emotional attention: A study of image sentiment and visual attention. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Imafuku, M.; Kawai, M.; Niwa, F.; Shinya, Y.; Inagawa, M.; Myowa-Yamakoshi, M. Preference for dynamic human images and gaze-following abilities in preterm infants at 6 and 12 months of age: An Eye-Tracking Study. Infancy 2017, 22, 223–239. [Google Scholar] [CrossRef]
- Xu, Y.; Gao, S.; Wu, J.; Li, N.; Yu, J. Personalized saliency and its prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 2975–2989. [Google Scholar] [CrossRef] [PubMed]
- Gygli, M.; Grabner, H.; Riemenschneider, H.; Nater, F.; Van Gool, L. The interestingness of images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2013), Sydney, Australia, 1–8 December 2013; pp. 1633–1640. [Google Scholar]
- Li, Y.; Xu, P.; Lagun, D.; Navalpakkam, V. Towards measuring and inferring user interest from gaze. In Proceedings of the International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Bazrafkan, S.; Kar, A.; Costache, C. Eye gaze for consumer electronics: Controlling and commanding intelligent systems. IEEE Consum. Electron. Mag. 2015, 4, 65–71. [Google Scholar] [CrossRef]
- Zhao, Q.; Chang, S.; Harper, M.; Konstan, J. Gaze prediction for recommender systems. In Proceedings of the ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016. [Google Scholar]
- Xu, Y.; Li, N.; Wu, J.; Yu, J.; Gao, S. Beyond universal saliency: Personalized saliency prediction with multi-task CNN. In Proceedings of the International Joint Conferences on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Yin, X.; Liu, X. Multi-task convolutional neural network for pose-invariant face recognition. Trans. Image Process. 2017, 27, 964–975. [Google Scholar] [CrossRef] [PubMed]
- Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Estimation of user-specific visual attention based on gaze information of similar users. In Proceedings of the IEEE 8th Global Conference on Consumer Electronics (GCCE 2019), Las Vegas, NV, USA, 15–18 October 2019. [Google Scholar]
- Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. User-specific visual attention estimation based on visual similarity and spatial information in images. In Proceedings of the IEEE International Conference on Consumer Electronics—Taiwan (IEEE 2019 ICCE-TW), Ilan, Taiwan, 20–22 May 2019. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the IEEE 12th International Conference on Computer Vision (ICCV 2009), Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th international symposium on computational statistics, Paris, France, 22–27 August 2010. [Google Scholar]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to Predict Human Fixations; Technical Report; MITCSAIL-TR-2012-001; Massachusetts Institute of Technology Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 740–757. [Google Scholar] [CrossRef] [PubMed]
- Bylinskii, Z.; Judd, T.; Borji, A.; Itti, L.; Durand, F.; Oliva, A.; Torralba, A. Mit Saliency Benchmark. 2015. Available online: http://saliency.mit.edu/ (accessed on 11 April 2020).
- Jiang, M.; Huang, S.; Duan, J.; Zhao, Q. Salicon: Saliency in context. In Proceedings of the 28th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. User-centric visual attention estimation based on relationship between image and eye gaze data. In Proceedings of the 2018 IEEE 7th Global Conference on Consumer Electronics (GCCE 2018), Nara, Japan, 9–12 October 2018. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, K. Densely connected convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section 2.1 | |
|---|---|
| nth image in the training data | |
| Target image | |
| Universal Saliency Map (USM) of image | |
| PSM of image for person p | |
| PSM predicrted by multi-task Convolutional Neural Network (CNN) for image and person p | |
| P | Number of person |
| N | Number of images |
| Difference map between USM and PSM | |
| Difference map calculated for image and person p | |
| n | Index of images |
| p | Index of persons |
| l | Index of decoding layers |
| Height of image | |
| Width of image | |
| Number of color channels | |
| Section 2.2 | |
| mth object including nth image | |
| PSM of object | |
| Average PSM of object | |
| Width of mth object included in nth image | |
| Height of mth object included in nth image | |
| Variance of mth object including nth image | |
| Average of | |
| M | Kinds of objects in all images included in PSM dataset |
| C | Number of selected images |
| m | Index of objects |
| j | Index of width of pixel location |
| k | Index of height of pixel location |
| c | Index of selected images |
| Section 2.3 | |
| Similarity score between a target person and person p | |
| Target person | |
| Threshold value for person similarity | |
| Selection coefficient for person similarity | |
| Person similarity between a target person and person p | |
| PSM predicted by Few-shot Personalized Saliency Prediction (FPSP) | |
| Methods | CC↑ | Sim↑ | KLdiv↓ |
|---|---|---|---|
| Itti | 0.3218 | 0.3911 | 9.0397 |
| Gignature | 0.4126 | 0.4122 | 8.0410 |
| SalGAN | 0.6345 | 0.5689 | 3.5597 |
| Baseline1 based on ISVF | 0.0953 | 0.3140 | 11.029 |
| Baseline1 based on ISPSM | 0.0762 | 0.3100 | 11.161 |
| Baseline1 based on AIS | 0.4013 | 0.4165 | 7.641 |
| Baseline2 based on ISVF | 0.4842 | 0.4274 | 4.014 |
| Baseline2 based on ISPSM | 0.4761 | 0.4170 | 3.057 |
| Baseline2 based on AIS | 0.5972 | 0.5032 | 4.133 |
| FPSP based on AIS (Ours) | 0.7845 | 0.6557 | 1.083 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Few-Shot Personalized Saliency Prediction Based on Adaptive Image Selection Considering Object and Visual Attention. Sensors 2020, 20, 2170. https://doi.org/10.3390/s20082170
Moroto Y, Maeda K, Ogawa T, Haseyama M. Few-Shot Personalized Saliency Prediction Based on Adaptive Image Selection Considering Object and Visual Attention. Sensors. 2020; 20(8):2170. https://doi.org/10.3390/s20082170
Chicago/Turabian StyleMoroto, Yuya, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2020. "Few-Shot Personalized Saliency Prediction Based on Adaptive Image Selection Considering Object and Visual Attention" Sensors 20, no. 8: 2170. https://doi.org/10.3390/s20082170
APA StyleMoroto, Y., Maeda, K., Ogawa, T., & Haseyama, M. (2020). Few-Shot Personalized Saliency Prediction Based on Adaptive Image Selection Considering Object and Visual Attention. Sensors, 20(8), 2170. https://doi.org/10.3390/s20082170