Tensor-Based Emotional Category Classification via Visual Attention-Based Heterogeneous CNN Feature Fusion


Abstract
1. Introduction
2. Related Works
3. Tensor-Based Emotional Category Classification
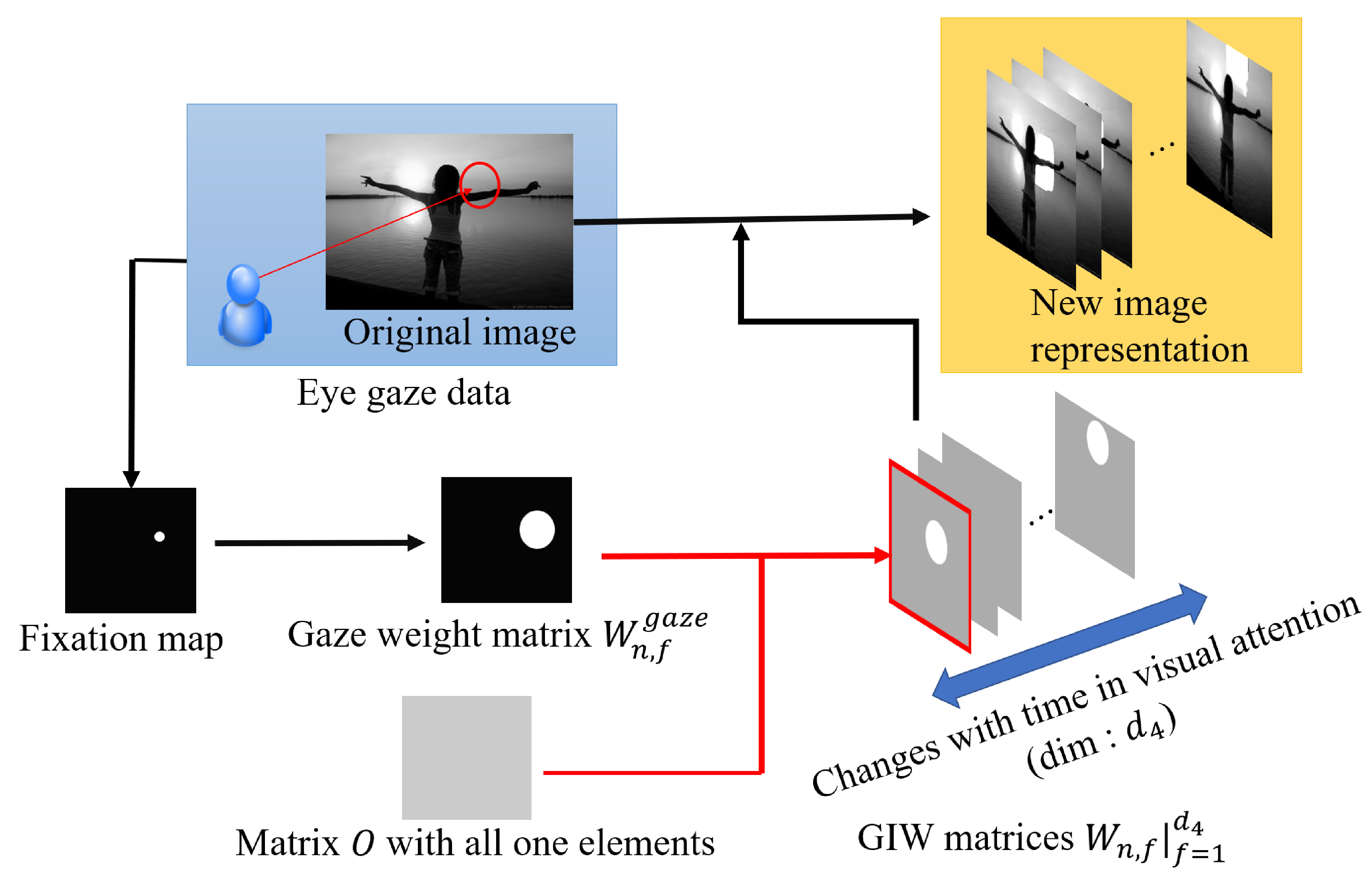
3.1. Construction of Gaze-Based Image Representation
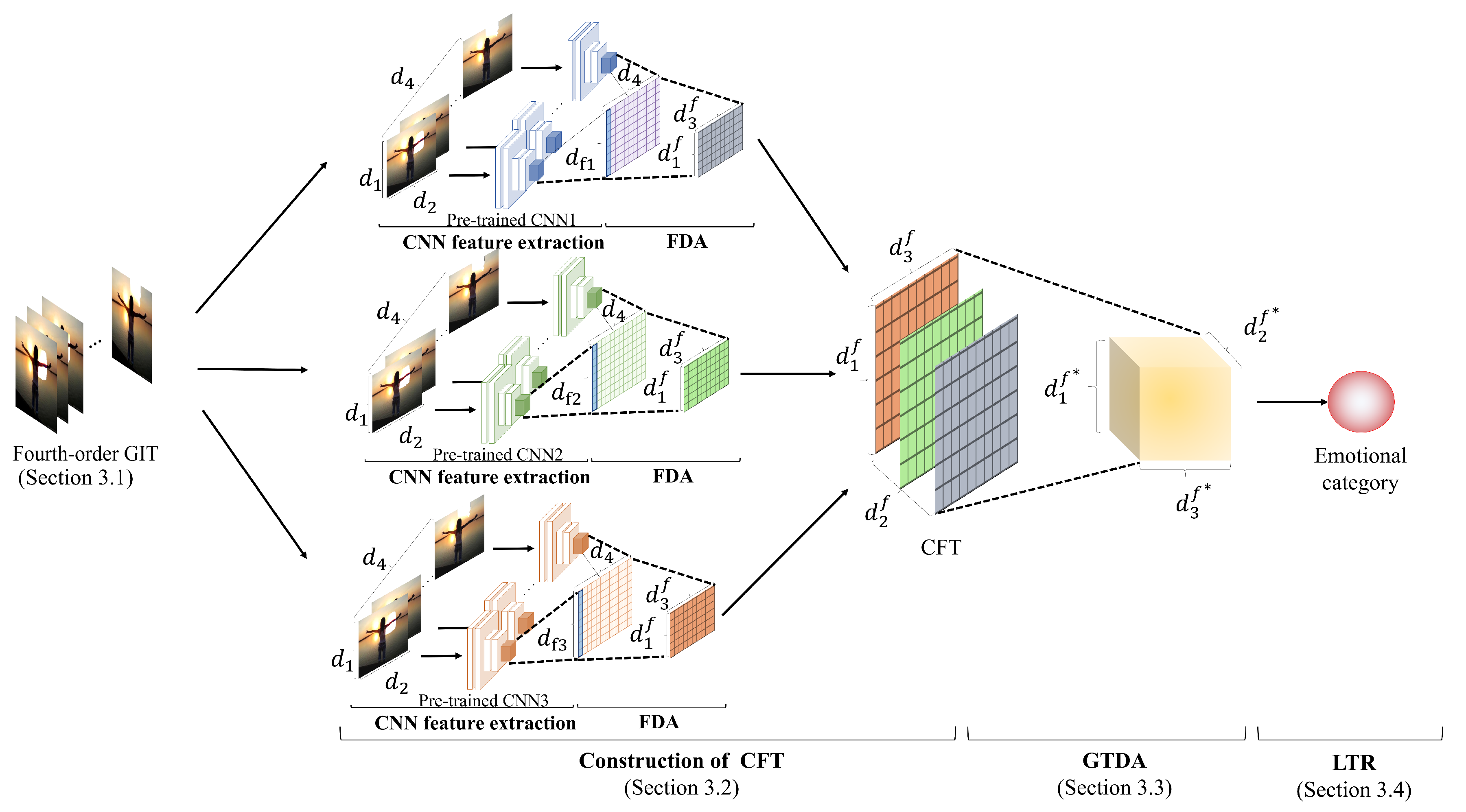
3.2. Extraction of CNN Features and Construction of CFT
3.3. Feature Transformation Based on GTDA
3.4. Emotional Category Classification Based on LTR
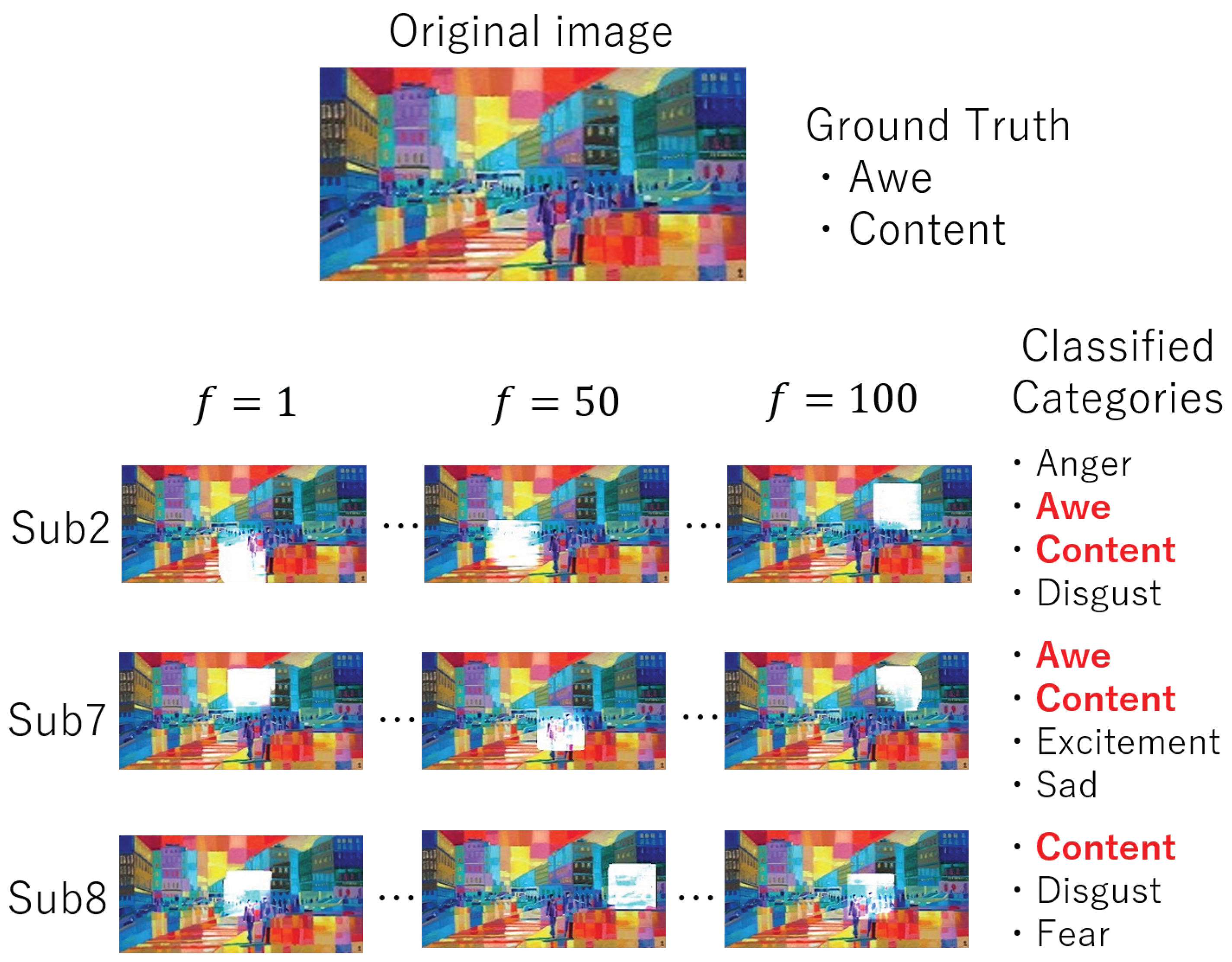
4. Experimental Results
4.1. Experimental Conditions
4.2. Performance Evaluation
5. Discussion and Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Mathematical Notations
References
- Rothe, R. A Deep Understanding from a Single Image. Ph.D. Thesis, ETH Zurich, Zurich, Switzerland, 2016. Available online: https://www.research-collection.ethz.ch/bitstream/handle/20.500.11850/125752/eth-50318-02.pdf (accessed on 9 April 2020).
- Xia, Z.; Wang, X.; Zhang, L.; Qin, Z.; Sun, X.; Ren, K. A privacy-preserving and copy-deterrence content-based image retrieval scheme in cloud computing. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2594–2608. [Google Scholar] [CrossRef]
- Yan, C.; Li, L.; Zhang, C.; Liu, B.; Zhang, Y.; Dai, Q. Cross-modality bridging and knowledge transferring for image understanding. IEEE Trans. Multimed. (TMM) 2019, 21, 2675–2685. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 1520–1528. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the IEEE/RSJ International Conference Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. Available online: https://arxiv.org/pdf/1804.02767.pdf (accessed on 9 April 2020).
- Zhao, S.; Ding, G.; Gao, Y.; Han, J. Approximating discrete probability distribution of image emotions by multi-modal features fusion. Transfer 2017, 1000, 4669–4675. [Google Scholar]
- Sasaka, Y.; Ogawa, T.; Haseyama, M. Multimodal interest level estimation via variational bayesian mixture of robust CCA. In Proceedings of the 24th ACM International Conference Multimed (ACMMM), Amsterdam, The Netherlands, 15–19 October 2016; pp. 387–391. [Google Scholar]
- Koehler, T.; Bontus, C. Reconstruction of a Region-of-Interest Image. U.S. Patent No. 9,466,135, 11 October 2016. [Google Scholar]
- Chaabouni, S.; Precioso, F. Impact of saliency and gaze features on visual control: Gaze-saliency interest estimator. In Proceedings of the 24th ACM International Conference Multimed. (ACMMM), Nice, France, 21–25 October 2019; pp. 1367–1374. [Google Scholar]
- Ma, J.; Tang, H.; Zheng, W.L.; Lu, B.L. Emotion recognition using multimodal residual LSTM network. In Proceedings of the 24th ACM International Conference Multimed (ACMMM), Nice, France, 21–25 October 2019; pp. 176–183. [Google Scholar]
- Smeulders, A.W.; Worring, M.; Santini, S.; Gupta, A.; Jain, R. Content-based image retrieval at the end of the early years. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1349–1380. [Google Scholar] [CrossRef]
- Wang, W.; He, Q. A survey on emotional semantic image retrieval. In Proceedings of the IEEE International Conference Image Processing (ICIP), San Diego, CA, USA, 12–15 October 2008; pp. 117–120. [Google Scholar]
- Sugata, K.; Ogawa, T.; Haseyama, M. Selection of significant brain regions based on MvGTDA and TS-DLF for emotion estimation. IEEE Access 2018, 6, 32481–32492. [Google Scholar] [CrossRef]
- Yoon, H.; Chung, S. EEG-based emotion estimation using bayesian weighted-log-posterior function and perceptron convergence algorithm. Comput. Biol. Med. 2013, 43, 2230–2237. [Google Scholar] [CrossRef] [PubMed]
- Tai, K.; Chau, T. Single-trial classification of NIRS signals during emotional induction tasks: Towards a corporeal machine interface. J. Neuroeng. Rehabil. 2009, 6, 39. [Google Scholar] [CrossRef] [PubMed]
- Soleymani, M.; Pantic, M.; Pun, T. Multimodal emotion recognition in response to videos. IEEE Trans. Affect. Comput. 2011, 3, 211–223. [Google Scholar] [CrossRef]
- Vuilleumier, P. How brains beware: Neural mechanisms of emotional attention. Trends. Cogn. Sci. 2005, 9, 585–594. [Google Scholar] [CrossRef] [PubMed]
- Compton, R. The interface between emotion and attention: A review of evidence from psychology and neuroscience. Behav. Cogn. Neurosci. Rev. 2003, 2, 115–129. [Google Scholar] [CrossRef] [PubMed]
- Fan, S.; Shen, Z.; Jiang, M.; Koenig, B.; Xu, J.; Kankanhalli, M.; Zhao, Q. Emotional attention: A study of image sentiment and visual attention. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7521–7531. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Estimation of emotion labels via tensor-based spatiotemporal visual attention analysis. In Proceedings of the IEEE International Conference Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4105–4109. [Google Scholar]
- Tao, D.; Li, X.; Wu, X.; Maybank, S. General tensor discriminant analysis and gabor features for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. (TPAMI) 2007, 29, 1700–1715. [Google Scholar] [CrossRef] [PubMed]
- Tan, X.; Zhang, Y.; Tang, S.; Shao, J.; Wu, F.; Zhuang, Y. Logistic tensor regression for classification. In International Conference Intelligent Science and Intelligent Data Engineering; Springer: Heidelberg/Berlin, Germany, 2012; pp. 573–581. [Google Scholar]
- Pasupa, K.; Chatkamjuncharoen, P.; Wuttilertdeshar, C.; Sugimoto, M. Using image features and eye tracking device to predict human emotions towards abstract images. In Image and Video Technology; Springer: Cham, Switzerland, 2015; pp. 419–430. [Google Scholar]
- Machajdik, J.; Hanbury, A. Affective image classification using features inspired by psychology and art theory. In Proceedings of the 18th ACM International Conference Multimed (ACMMM), Firenze, Italy, 25–29 October 2010; pp. 83–92. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Rao, T.; Li, X.; Xu, M. Learning multi-level deep representations for image emotion classification. arXiv 2016, arXiv:1611.07145v2. Available online: https://arxiv.org/abs/1611.07145.pdf (accessed on 9 April 2020).
- Chen, M.; Zhang, L.; Allebach, J.P. Learning deep features for image emotion classification. In Proceedings of the IEEE International Conference Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 4491–4495. [Google Scholar]
- You, Q.; Luo, J.; Jin, H.; Yang, J. Building a large scale dataset for image emotion recognition: The fine print and the benchmark. In Proceedings of the 30th AAAI Conference Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhao, S.; Ding, G.; Gao, Y.; Zhao, X.; Tang, Y.; Han, J.; Yao, H.; Huang, Q. Discrete probability distribution prediction of image emotions with shared sparse learning. IEEE Trans. Affect. Comput. 2018. [Google Scholar] [CrossRef]
- Sugata, K.; Ogawa, T.; Haseyama, M. Emotion estimation via tensor-based supervised decision-level fusion from multiple brodmann areas. In Proceedings of the IEEE International Conference Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 999–1003. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the 30th AAAI Conference Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 4278–4284. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Fisher, R. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Mikels, J.A.; Fredrickson, B.L.; Larkin, G.R.; Lindberg, C.M.; Maglio, S.J.; Reuter-Lorenz, P.A. Emotional category data on images from the international affective picture system. Behav. Res. Methods 2005, 37, 626–630. [Google Scholar] [CrossRef] [PubMed]
- Welch, B.L. The significance of the difference between two means when the population variances are unequal. Biometrika 1938, 29, 350–362. [Google Scholar] [CrossRef]
- Karessli, N.; Akata, Z.; Schiele, B.; Bulling, A. Gaze embeddings for zero-shot image classification. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4525–4534. [Google Scholar]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- Qiu, J.; Liu, W.; Lu, B. Multi-view emotion recognition using deep canonical correlation analysis. In International Conference Neural Information Processing; Springer: Cham, Switzerland, 2018; pp. 221–231. [Google Scholar]
- Andrew, G.; Arora, R.; Bilmes, J.; Livescu, K. Deep Canonical Correlation Analysis. Available online: http://proceedings.mlr.press/v28/andrew13.pdf (accessed on 9 April 2020).
- Hotelling, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar] [CrossRef]
- Vapnik, V. Pattern recognition using generalized portrait method. Autom. Remote Control. 1963, 1963 24, 774–780. [Google Scholar]
- Schuller, B.; Zhang, Z.; Weninger, F.; Rigoll, G. Using Multiple Databases for Training in Emotion Recognition: To Unite or to Vote? Available online: https://www.isca-speech.org/archive/archive_papers/interspeech_2011/i11_1553.pdf (accessed on 9 April 2020).
- Gunes, H.; Piccardi, M. Affect recognition from face and body: Early fusion vs. late fusion. In Proceedings of the IEEE International Conference Systems, man and cybernetics, Waikoloa, HI, USA, 12 October 2005. [Google Scholar]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Time Change | Gaze Feature | Fusion | |
|---|---|---|---|
| PM | √ | GIT | CFT |
| CM1 | X | GIT | CFT |
| CM2 | X | Novel gaze feature [42] | Only gaze feature |
| CM3 | X | Hand-crafted feature [28] | Concatenation |
| CM4 | X | Novel gaze feature [42] | DeepCCA [45] |
| CM5 | X | Novel gaze feature [42] | CCA [46] |
| CM6 | √ | GIT | Concatenation |
| CM7 | X | GIT | Concatenation |
| CM8 | √ | GIT | Softmax |
| PM | PM | PM | CM1 | CM1 | CM1 | CM2 [42] | CM3 [28] | CM4 [44] | CM5 [46] | CM6 | CM6 | CM7 | CM7 | CM8 | CM8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN Feature | D-I-X | D-X-I | X-D-I | D | I | X | - | - | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X |
| Classifier | ELM | ELM | ELM | ELM | ELM | ELM | ELM | SVM | SVM | SVM | SVM | ELM | SVM | ELM | SVM | ELM |
| Sub1 | 0.616 | 0.613 | 0.631 | 0.426 | 0.468 | 0.452 | 0.567 | 0.546 | 0.512 | 0.529 | 0.533 | 0.543 | 0.578 | 0.544 | 0.531 | 0.560 |
| Sub2 | 0.616 | 0.591 | 0.635 | 0.514 | 0.429 | 0.486 | 0.402 | 0.371 | 0.311 | 0.455 | 0.508 | 0.519 | 0.413 | 0.414 | 0.506 | 0.570 |
| Sub3 | 0.592 | 0.552 | 0.538 | 0.469 | 0.415 | 0.362 | 0.490 | 0.379 | 0.567 | 0.538 | 0.531 | 0.567 | 0.442 | 0.501 | 0.494 | 0.498 |
| Sub4 | 0.567 | 0.558 | 0.583 | 0.401 | 0.417 | 0.423 | 0.402 | 0.520 | 0.532 | 0.540 | 0.502 | 0.563 | 0.503 | 0.571 | 0.468 | 0.527 |
| Sub5 | 0.606 | 0.603 | 0.551 | 0.507 | 0.446 | 0.441 | 0.512 | 0.488 | 0.564 | 0.502 | 0.489 | 0.560 | 0.504 | 0.525 | 0.473 | 0.528 |
| Sub6 | 0.603 | 0.542 | 0.589 | 0.486 | 0.453 | 0.440 | 0.505 | 0.397 | 0.478 | 0.512 | 0.495 | 0.526 | 0.504 | 0.498 | 0.446 | 0.528 |
| Sub7 | 0.565 | 0.643 | 0.593 | 0.393 | 0.498 | 0.341 | 0.521 | 0.396 | 0.440 | 0.489 | 0.487 | 0.592 | 0.513 | 0.507 | 0.469 | 0.546 |
| Sub8 | 0.567 | 0.597 | 0.598 | 0.378 | 0.424 | 0.533 | 0.468 | 0.473 | 0.567 | 0.537 | 0.510 | 0.511 | 0.565 | 0.588 | 0.400 | 0.515 |
| Sub9 | 0.598 | 0.558 | 0.597 | 0.471 | 0.436 | 0.414 | 0.505 | 0.463 | 0.565 | 0.479 | 0.503 | 0.475 | 0.498 | 0.433 | 0.484 | 0.539 |
| Sub10 | 0.560 | 0.526 | 0.603 | 0.463 | 0.395 | 0.400 | 0.425 | 0.471 | 0.522 | 0.563 | 0.487 | 0.483 | 0.447 | 0.474 | 0.451 | 0.555 |
| Sub11 | 0.628 | 0.564 | 0.568 | 0.465 | 0.431 | 0.433 | 0.423 | 0.468 | 0.468 | 0.494 | 0.548 | 0.521 | 0.497 | 0.492 | 0.408 | 0.599 |
| Sub12 | 0.597 | 0.597 | 0.588 | 0.333 | 0.442 | 0.408 | 0.414 | 0.406 | 0.497 | 0.466 | 0.509 | 0.515 | 0.562 | 0.529 | 0.489 | 0.625 |
| Sub13 | 0.570 | 0.579 | 0.598 | 0.503 | 0.487 | 0.381 | 0.667 | 0.537 | 0.409 | 0.495 | 0.550 | 0.537 | 0.436 | 0.440 | 0.506 | 0.584 |
| Average | 0.591 | 0.579 | 0.590 | 0.447 | 0.442 | 0.424 | 0.485 | 0.453 | 0.487 | 0.502 | 0.512 | 0.532 | 0.497 | 0.503 | 0.471 | 0.552 |
| p-value | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.01) |
| PM | PM | PM | CM1 | CM1 | CM1 | CM2 [42] | CM3 [28] | CM4 [44] | CM5 [46] | CM6 | CM6 | CM7 | CM7 | CM8 | CM8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CNN Feature | D-I-X | D-X-I | X-D-I | D | I | X | - | - | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X | D,I,X |
| Classifier | ELM | ELM | ELM | ELM | ELM | ELM | ELM | SVM | SVM | SVM | SVM | ELM | SVM | ELM | SVM | ELM |
| Amusement | 0.667 | 0.667 | 0.667 | 0.409 | 0.473 | 0.564 | 0.527 | 0.418 | 0.531 | 0.501 | 0.486 | 0.648 | 0.488 | 0.489 | 0.462 | 0.622 |
| Anger | 0.667 | 0.667 | 0.667 | 0.605 | 0.506 | 0.446 | 0.527 | 0.449 | 0.493 | 0.517 | 0.502 | 0.493 | 0.505 | 0.545 | 0.483 | 0.490 |
| Awe | 0.667 | 0.667 | 0.667 | 0.360 | 0.354 | 0.410 | 0.529 | 0.453 | 0.469 | 0.536 | 0.387 | 0.500 | 0.648 | 0.457 | 0.540 | 0.526 |
| Content | 0.424 | 0.414 | 0.394 | 0.426 | 0.443 | 0.355 | 0.411 | 0.498 | 0.497 | 0.503 | 0.553 | 0.501 | 0.502 | 0.514 | 0.389 | 0.519 |
| Disgust | 0.667 | 0.667 | 0.667 | 0.452 | 0.481 | 0.475 | 0.521 | 0.435 | 0.505 | 0.476 | 0.420 | 0.488 | 0.460 | 0.450 | 0.524 | 0.481 |
| Excitement | 0.550 | 0.599 | 0.630 | 0.431 | 0.450 | 0.419 | 0.434 | 0.494 | 0.475 | 0.500 | 0.527 | 0.533 | 0.480 | 0.482 | 0.544 | 0.622 |
| Fear | 0.612 | 0.523 | 0.563 | 0.452 | 0.388 | 0.366 | 0.531 | 0.441 | 0.456 | 0.495 | 0.660 | 0.547 | 0.530 | 0.551 | 0.406 | 0.551 |
| Sad | 0.474 | 0.426 | 0.468 | 0.438 | 0.439 | 0.358 | 0.402 | 0.435 | 0.473 | 0.487 | 0.558 | 0.544 | 0.543 | 0.533 | 0.421 | 0.602 |
| Average | 0.591 | 0.579 | 0.590 | 0.447 | 0.442 | 0.424 | 0.485 | 0.453 | 0.487 | 0.502 | 0.512 | 0.532 | 0.497 | 0.503 | 0.471 | 0.552 |
| p-value | (p < 0.01) | (p < 0.01) | (p < 0.01) | (p < 0.05) | (p < 0.01) | (p < 0.05) | (p < 0.05) | (p < 0.06) | (p < 0.08) | (p < 0.02) | (p < 0.05) | (p < 0.01) | (p < 0.2) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moroto, Y.; Maeda, K.; Ogawa, T.; Haseyama, M. Tensor-Based Emotional Category Classification via Visual Attention-Based Heterogeneous CNN Feature Fusion. Sensors 2020, 20, 2146. https://doi.org/10.3390/s20072146
Moroto Y, Maeda K, Ogawa T, Haseyama M. Tensor-Based Emotional Category Classification via Visual Attention-Based Heterogeneous CNN Feature Fusion. Sensors. 2020; 20(7):2146. https://doi.org/10.3390/s20072146
Chicago/Turabian StyleMoroto, Yuya, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2020. "Tensor-Based Emotional Category Classification via Visual Attention-Based Heterogeneous CNN Feature Fusion" Sensors 20, no. 7: 2146. https://doi.org/10.3390/s20072146
APA StyleMoroto, Y., Maeda, K., Ogawa, T., & Haseyama, M. (2020). Tensor-Based Emotional Category Classification via Visual Attention-Based Heterogeneous CNN Feature Fusion. Sensors, 20(7), 2146. https://doi.org/10.3390/s20072146