An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification


Abstract
1. Introduction
- (1)
- The idea of a bilinear model in fine-grained visual recognition is introduced into remote sensing image classification, which enhances the ability of the CNN to identify different scene types. Compared with the state-of-the-art methods for remote sensing image scene classification, the proposed method can obtain superior performance.
- (2)
- By integrating the lightweight CNN MobileNetv2 and the feature fusion method of the bilinear model, the method in this study considers both the advantages of a lightweight structure and high accuracy. Compared with other state-of-the-art methods, the proposed architecture has fewer parameters and calculations. Therefore, image classification speed will be higher, rendering it more viable for production purposes and applications.
- (3)
- This study proposes that both the accuracy and complexity of the method should be considered simultaneously during classification. The method should be evaluated comprehensively in three aspects: accuracy, parameter, and calculation. In addition, we find that most methods use the UC Merced dataset with a training ratio of 80%, and the classification accuracy is close to saturation. We provide an accuracy benchmark when the training ratio is less than 30%.
2. Materials and Methods
2.1. Materials
2.2. Method
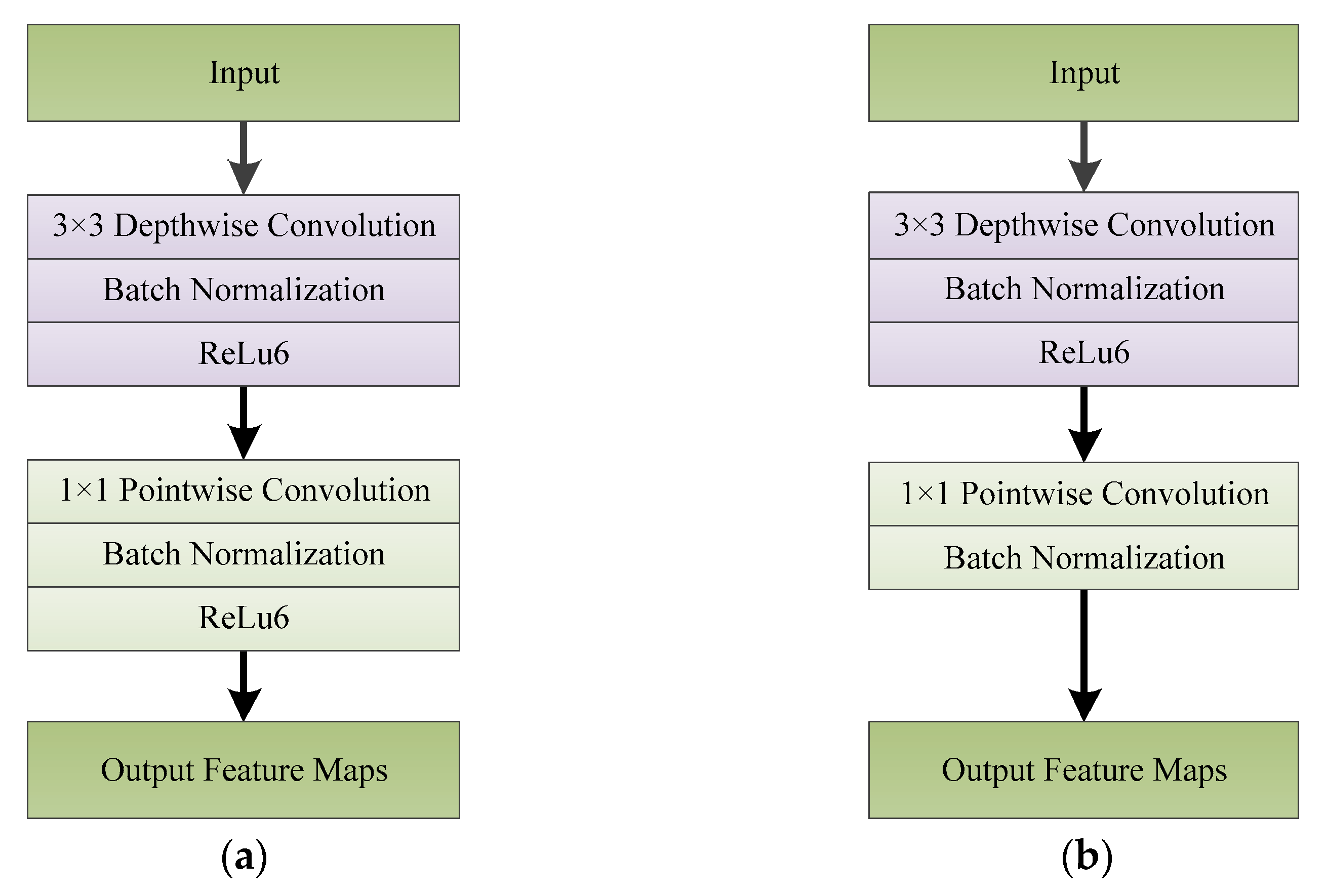
2.2.1. Depthwise Separable Convolution
2.2.2. Linear Bottleneck
2.2.3. Inverted Residual Block
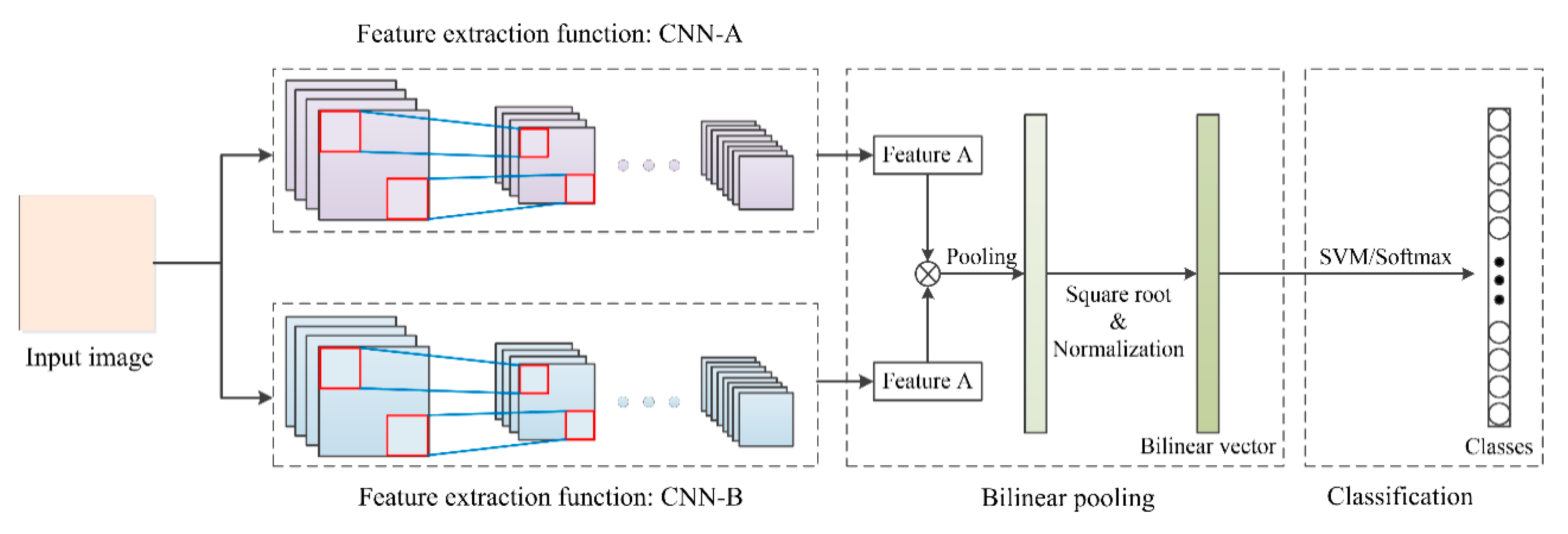
2.2.4. Bilinear Model
2.3. Proposed Architecture
2.4. Experimental Setup
2.4.1. Implementation Details
2.4.2. Evaluation Protocol
3. Results
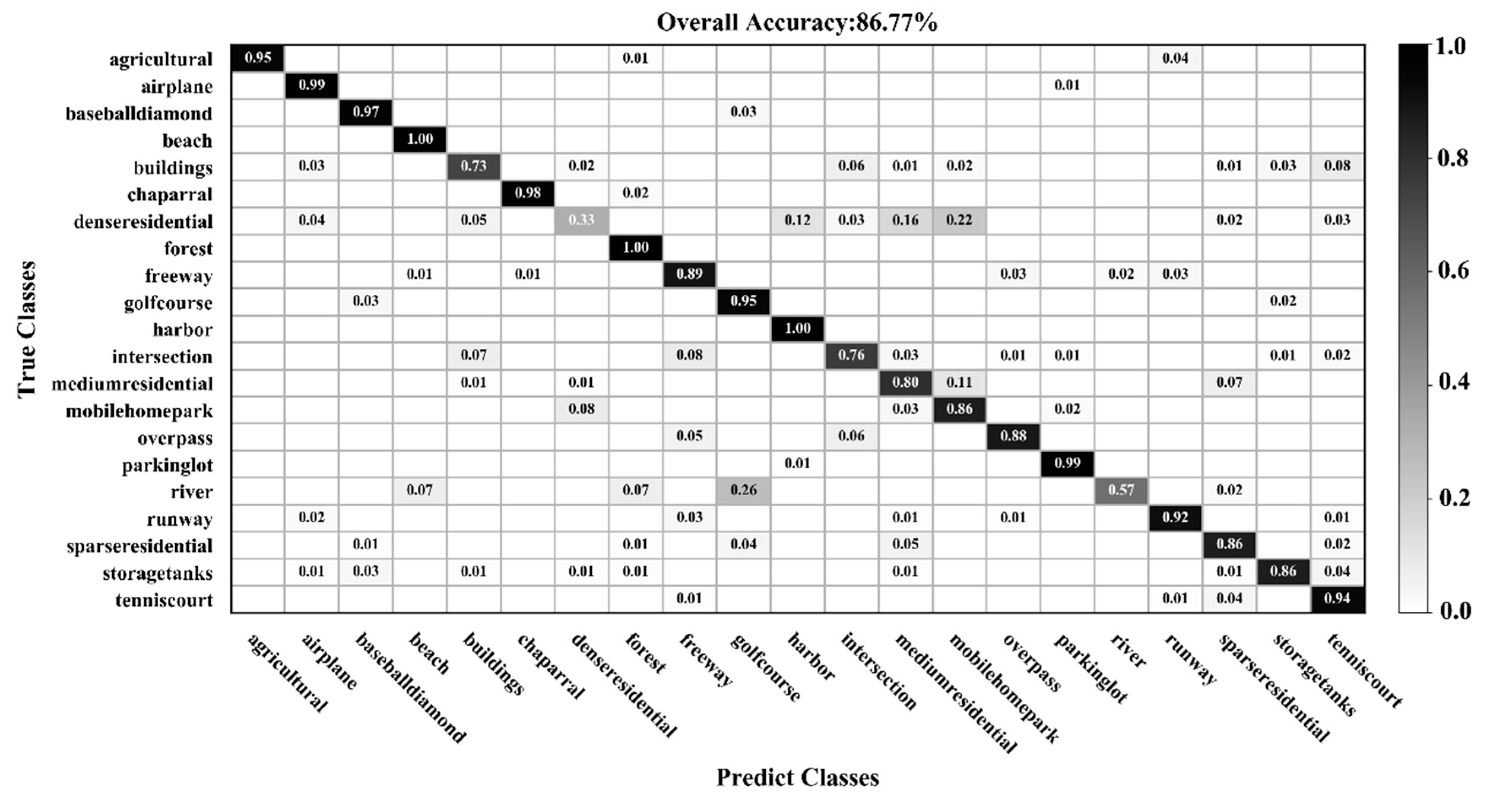
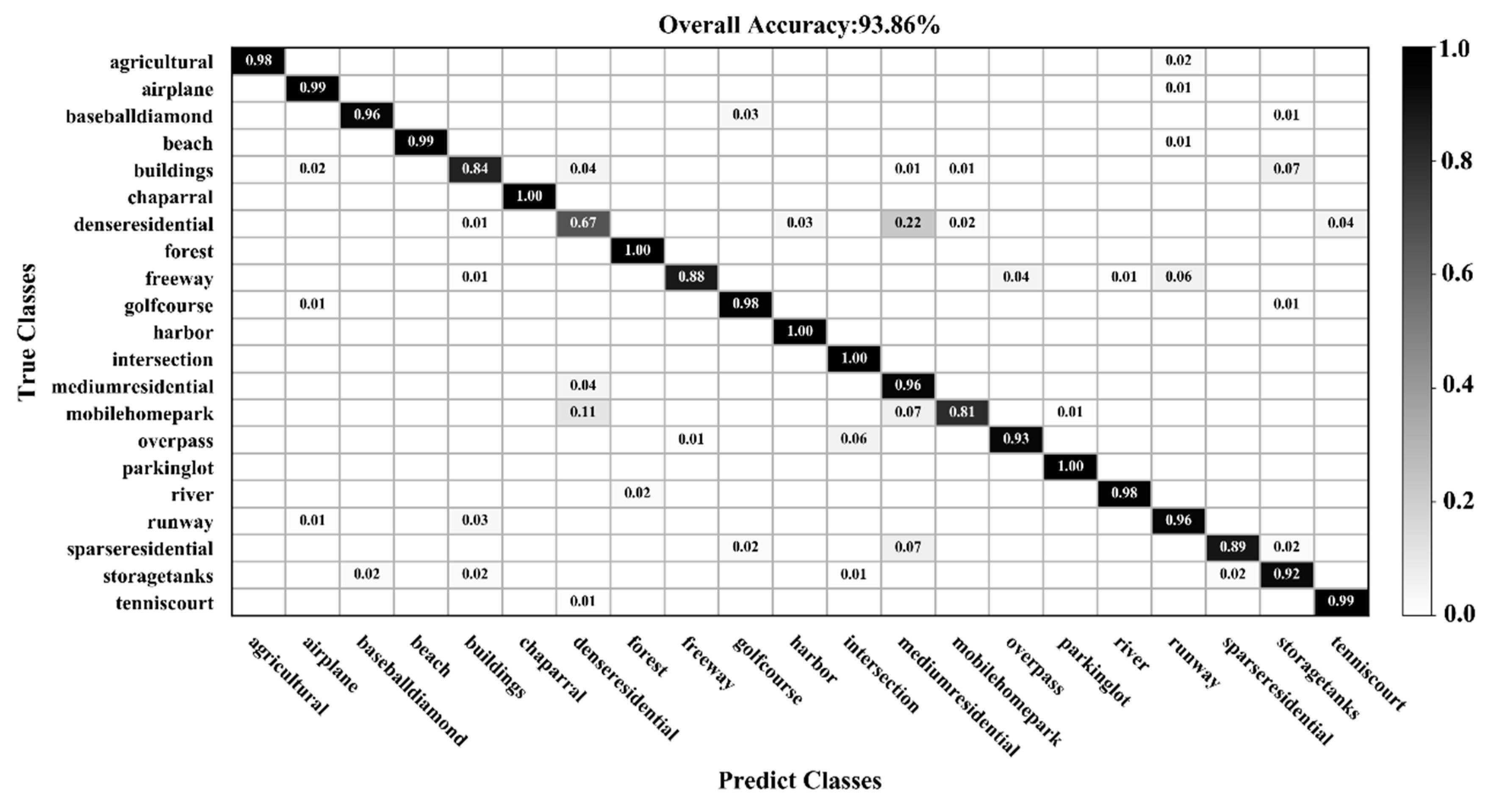
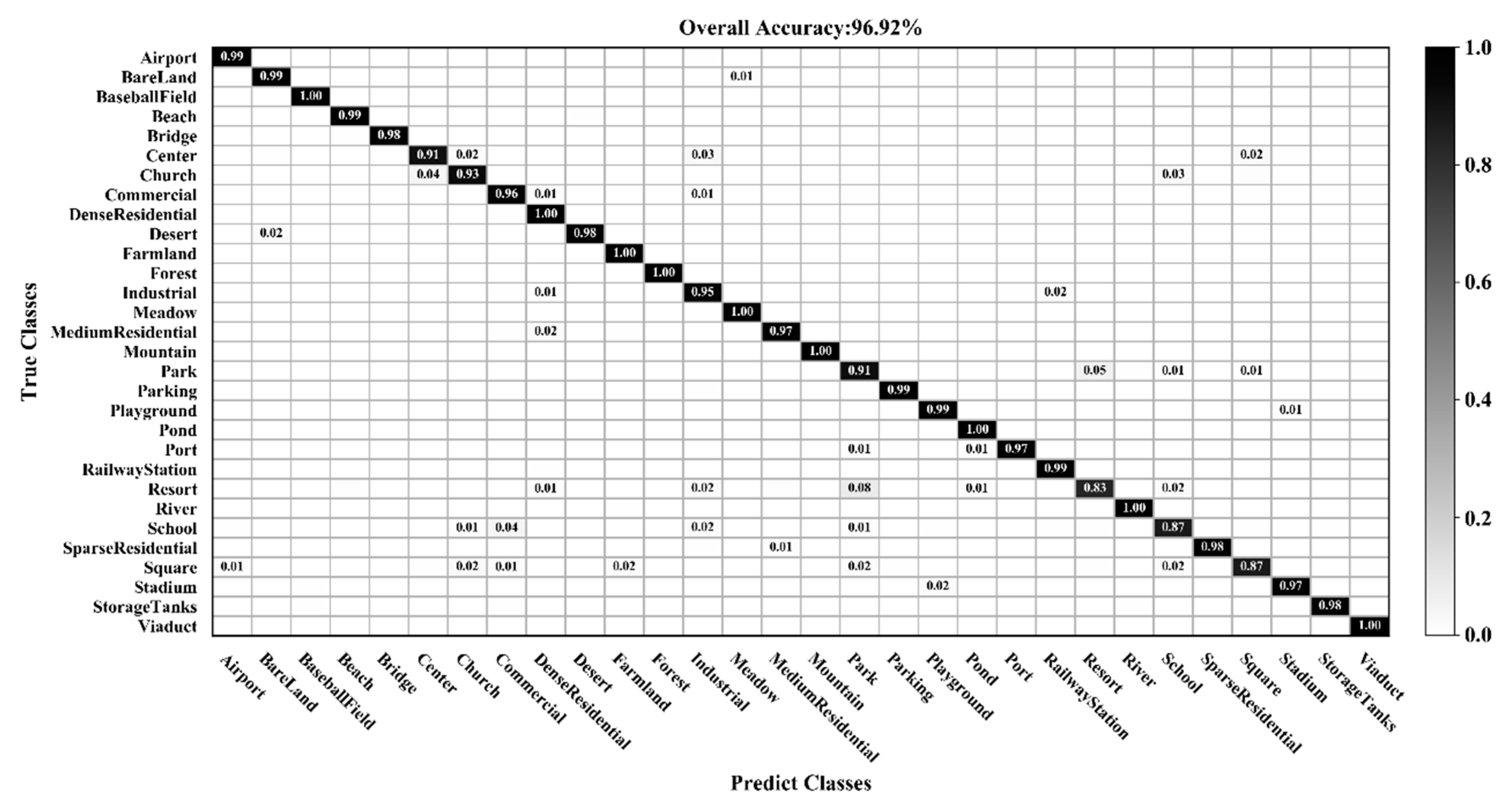
3.1. Classification of the UC Merced Dataset
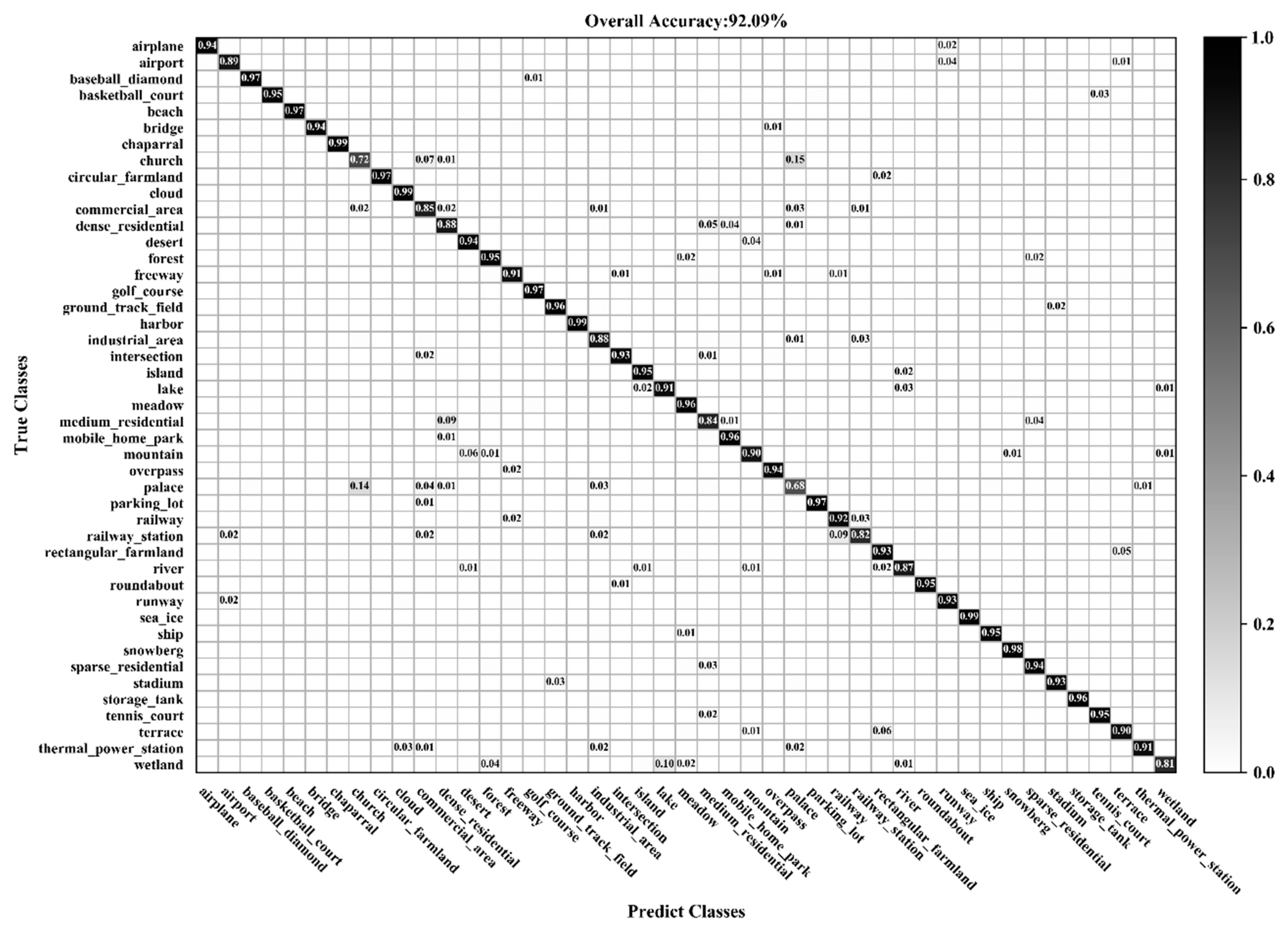
3.2. Classification of the AID Dataset
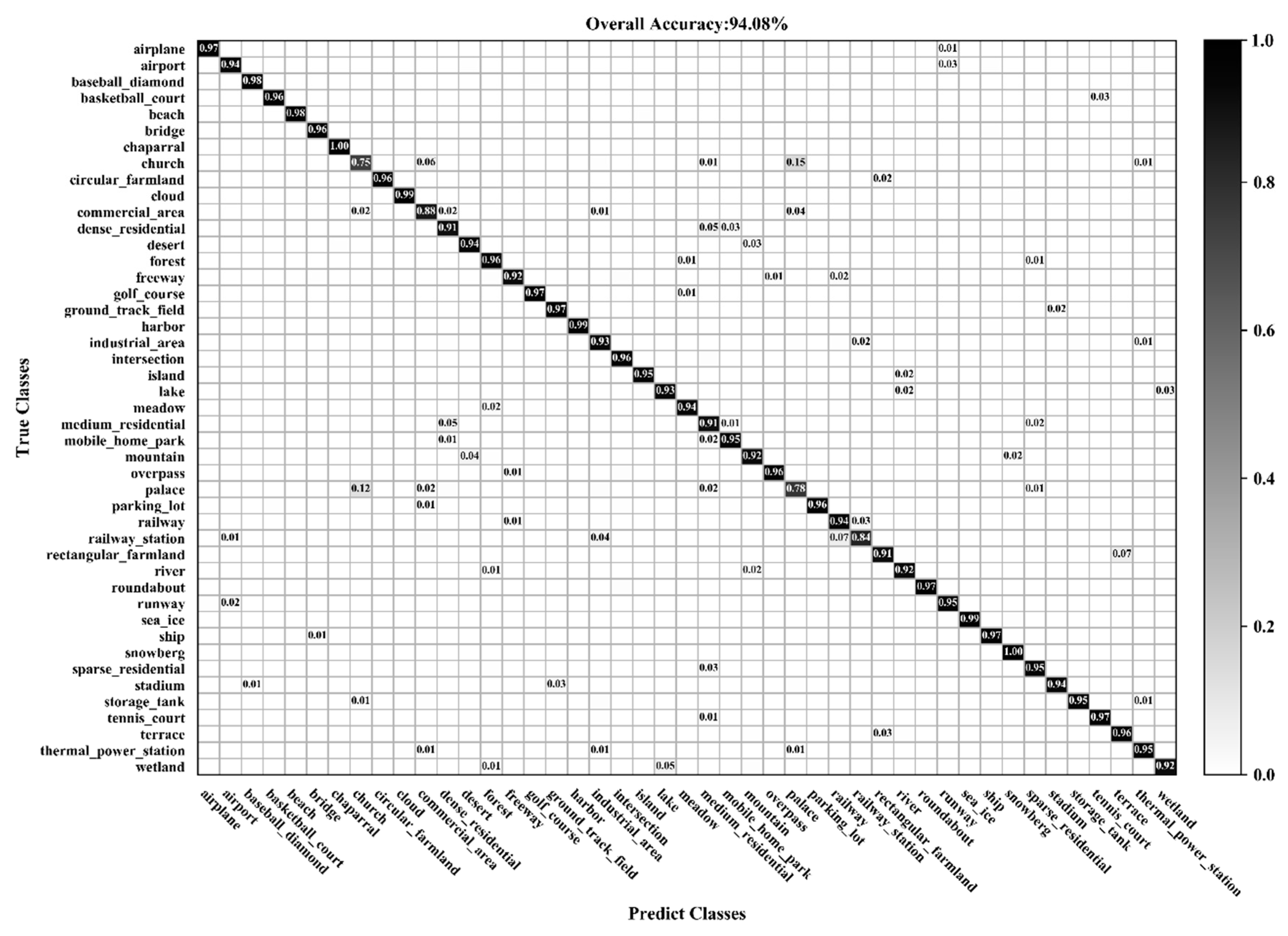
3.3. Classification of the NWPU-RESISC45 Dataset
4. Discussion
5. Conclusions
- 1
- The accuracy of BiMobileNet in remote sensing image scene classification surpasses most state-of-the-art methods, particularly with little training data.
- 2
- BiMobileNet requires fewer parameters and calculations making training and prediction faster and more efficient.
- 3
- The challenges of remote sensing image scene classification are intra-class inconsistency and inter-class indistinction. The method of using bilinear pooling overcomes some of the difficulties of scene classification providing a simple and efficient method for scene classification.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gómez-Chova, L.; Tuia, D.; Moser, G.; Camps-Valls, G. Multimodal classification of remote sensing images: A review and future directions. Proc. IEEE 2015, 103, 1560–1584. [Google Scholar] [CrossRef]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Gu, Y.; Wang, Y.; Li, Y. A survey on deep learning-driven remote sensing image scene understanding: Scene classification, scene retrieval and scene-guided object detection. Appl. Sci. 2019, 9, 2110. [Google Scholar] [CrossRef]
- He, X.; Zou, Z.; Tao, C.; Zhang, J. Combined Saliency with multi-convolutional neural network for high resolution remote sensing scene classification. Acta Geod. Cartogr. Sin. 2016, 45, 1073–1080. [Google Scholar]
- Liu, Y.; Huang, C. Scene classification via triplet networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 220–237. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. Dense connectivity based two-stream deep feature fusion framework for aerial scene classification. Remote Sens. 2018, 10, 1158. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving remote sensing scene classification by integrating global-context and local-object features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Swain, M.J.; Ballard, D.H. Color indexing. Int. J. Comput. Vis. 1991, 7, 11–32. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 6, 610–621. [Google Scholar] [CrossRef]
- Luo, B.; Jiang, S.; Zhang, L. Indexing of remote sensing images with different resolutions by multiple features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Bhagavathy, S.; Manjunath, B.S. Modeling and detection of geospatial objects using texture motifs. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3706–3715. [Google Scholar] [CrossRef]
- Dos Santos, J.A.; Penatti, O.A.B.; da Silva Torres, R. Evaluating the Potential of Texture and Color Descriptors for Remote Sensing Image Retrieval and Classification. In Proceedings of the 5th International Conference on Computer Vision Theory and Applications, Angers, France, 17–21 May 2010; pp. 203–208. [Google Scholar]
- Aptoula, E. Remote sensing image retrieval with global morphological texture descriptors. IEEE Trans. Geosci. Remote Sens. 2014, 52, 3023–3034. [Google Scholar] [CrossRef]
- Newsam, S.; Wang, L.; Bhagavathy, S.; Manjunath, B.S. Using texture to analyze and manage large collections of remote sensed image and video data. Appl. Opt. 2004, 43, 210–217. [Google Scholar] [CrossRef]
- Risojević, V.; Momić, S.; Babić, Z. Gabor descriptors for aerial image classification. In Proceedings of the International Conference on Adaptive and Natural Computing Algorithms, Ljubljana, Slovenia, 14–16 April 2011; pp. 51–60. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Comparing SIFT descriptors and Gabor texture features for classification of remote sensed imagery. In Proceedings of the 15th IEEE International Conference on Image Processing (ICIP 2008), San Diego, CA, USA, 12–15 October 2008; pp. 1852–1855. [Google Scholar]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; pp. 324–333. [Google Scholar]
- Yang, Y.; Newsam, S. Geographic image retrieval using local invariant features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 818–832. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Chen, S.; Tian, Y. Pyramid of spatial relatons for scene-level land use classification. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1947–1957. [Google Scholar] [CrossRef]
- Wu, H.; Liu, B.; Su, W.; Zhang, W.; Sun, J. Hierarchical coding vectors for scene level land-use classification. Remote Sens. 2016, 8, 436. [Google Scholar] [CrossRef]
- Zhou, L.; Zhou, Z.; Hu, D. Scene classification using a multi-resolution bag-of-features model. Pattern Recognit. 2013, 46, 424–433. [Google Scholar] [CrossRef]
- Zhao, L.J.; Tang, P.; Huo, L.Z. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4620–4631. [Google Scholar] [CrossRef]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472. [Google Scholar]
- Zhao, B.; Zhong, Y.; Zhang, L. Scene classification via latent Dirichlet allocation using a hybrid generative/discriminative strategy for high spatial resolution remote sensing imagery. Remote Sens. Lett. 2013, 4, 1204–1213. [Google Scholar] [CrossRef]
- Văduva, C.; Gavăt, I.; Datcu, M. Latent dirichlet allocation for spatial analysis of satellite images. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2770–2786. [Google Scholar] [CrossRef]
- Zhong, Y.; Cui, M.; Zhu, Q.; Zhang, L. Scene classification based on multi-feature probabilistic latent semantic analysis for high spatial resolution remote sensing images. J. Appl. Remote Sens. 2015, 9, 0950640. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L.; Huang, B. The Fisher kernel coding framework for high spatial resolution scene classification. Remote Sens. 2016, 8, 157. [Google Scholar] [CrossRef]
- Huang, L.; Chen, C.; Li, W.; Du, Q. Remote sensing image scene classification using multi-scale completed local binary patterns and fisher vectors. Remote Sens. 2016, 8, 483. [Google Scholar] [CrossRef]
- Jegou, H.; Perronnin, F.; Douze, M.; Sánchez, J.; Pérez, P.; Schmid, C. Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1704–1716. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote Sens. 2017, 9, 489. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Wang, J.; Liu, W.; Ma, L.; Chen, H.; Chen, L. IORN: An effective remote sensing image scene classification framework. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1695–1699. [Google Scholar] [CrossRef]
- Li, J.; Lin, D.; Wang, Y.; Xu, G.; Ding, C. Deep discriminative representation learning with attention map for scene classification. arXiv 2019, arXiv:1902.07967. [Google Scholar]
- Chen, Z.; Wang, S.; Hou, X.; Shao, L.; Dhabi, A. Recurrent transformer network for remote sensing scene categorization. In Proceedings of the 29th British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; p. 266. [Google Scholar]
- Boualleg, Y.; Farah, M.; Farah, I.R. Remote sensing scene classification using convolutional features and deep forest classifier. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1944–1948. [Google Scholar] [CrossRef]
- Xie, J.; He, N.; Fang, L.; Plaza, A. Scale-free convolutional neural network for remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6916–6928. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Guo, Y.; Ji, J.; Lu, X.; Huo, H.; Fang, T.; Li, D. Global-Local attention network for aerial scene classification. IEEE Access 2019, 7, 67200–67212. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Wei, T.; Wang, J.; Liu, W.; Chen, H.; Shi, H. Marginal center loss for deep remote sensing image scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Ye, L.; Wang, L.; Zhang, W.; Li, Y.; Wang, Z. Deep metric learning method for high resolution remote sensing image scene classification. Acta Geod. Cartogr. Sin. 2019, 48, 698–707. [Google Scholar]
- Goel, A.; Banerjee, B.; Pižurica, A. Hierarchical metric learning for optical remote sensing scene categorization. IEEE Geosci. Remote Sens. Lett. 2018, 16, 952–956. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. arXiv 2017, arXiv:1706.01171. [Google Scholar] [CrossRef]
- Huang, H.; Xu, K. Combing triple-part features of convolutional neural networks for scene classification in remote sensing. Remote Sens. 2019, 11, 1687. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Liu, Y.; Zhang, L.; Li, D. A deep-local-global feature fusion framework for high spatial resolution imagery scene classification. Remote Sens. 2018, 10, 568. [Google Scholar]
- Bian, X.; Chen, C.; Tian, L.; Du, Q. Fusing local and global features for high-resolution scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chaib, S.; Liu, H.; Gu, Y.; Yao, H. Deep feature fusion for VHR remote sensing scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4775–4784. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’15), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’16), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Zhang, B.; Zhang, Y.; Wang, S. A Lightweight and Discriminative Model for Remote Sensing Scene Classification with Multidilation Pooling Module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2636–2653. [Google Scholar] [CrossRef]
- Zhang, G.; Lei, T.; Cui, Y.; Jiang, P. A Dual-Path and Lightweight Convolutional Neural Network for High-Resolution Aerial Image Segmentation. ISPRS Int. J. Geo-Inf. 2019, 8, 582. [Google Scholar] [CrossRef]
- Teimouri, N.; Dyrmann, M.; Jørgensen, R. A Novel Spatio-Temporal FCN-LSTM Network for Recognizing Various Crop Types Using Multi-Temporal Radar Images. Remote Sens. 2019, 11, 990. [Google Scholar] [CrossRef]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Yu, C.; Zhao, X.; Zheng, Q.; Zhang, P.; You, X. Hierarchical bilinear pooling for fine-grained visual recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 574–589. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Negrel, R.; Picard, D.; Gosselin, P.H. Evaluation of second-order visual features for land-use classification. In Proceedings of the 12th International Workshop on Content-Based Multimedia Indexing (CBMI), Klagenfurt, Austria, 18–20 June 2014; pp. 1–5. [Google Scholar]
- Weng, Q.; Mao, Z.; Lin, J.; Guo, W. Land-use classification via extreme learning classifier based on deep convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 704–708. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A two-stream deep fusion framework for high-resolution aerial scene classification. Comput. Intell. Neurosci. 2018, 2018, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Lu, X.; Wan, L.; Huo, H.; Fang, T. Improving the separability of deep features with discriminative convolution filters for RSI classification. ISPRS Int. J. Geo-Inf. 2018, 7, 95. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B. Siamese convolutional neural networks for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Wang, C.; Lin, W.; Tang, P. Multiple resolution block feature for remote-sensing scene classification. Int. J. Remote Sens. 2019, 40, 6884–6904. [Google Scholar] [CrossRef]
- Liu, B.D.; Meng, J.; Xie, W.Y.; Shao, S.; Li, Y.; Wang, Y.J. Weighted spatial pyramid matching collaborative representation for remote-sensing-image scene classification. Remote Sens. 2019, 11, 518. [Google Scholar] [CrossRef]
- Zhang, W.; Tang, P.; Zhao, L. Remote sensing image scene classification using CNN-CapsNet. Remote Sens. 2019, 11, 494. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Number of Classes | Image Size | Resolution/m | Images per Class | Total Images |
|---|---|---|---|---|---|
| UC Merced | 21 | 256 × 256 | 2 | 100 | 2100 |
| AID | 30 | 600 × 600 | 0.5~8 | 200~400 | 10,000 |
| NWPU-RESISC45 | 45 | 256 × 256 | 0.2~30 | 700 | 31,500 |
| Layer Name | Operation | Input Size | Output Size |
|---|---|---|---|
| Conv2d | Conv2d, kernel size = (3 × 3), stride = 2 | 224 × 224 × 3 | 112 × 112 × 32 |
| Bottleneck-1 | Linear block, m = 1, stride = 1 | 112 × 112 × 32 | 112 × 112 × 16 |
| Bottleneck-2 | Linear block, m = 6, stride = 2 | 112 × 112 × 16 | 56 × 56 × 24 |
| Inverted residual block, m = 6, stride = 1 | 56 × 56 × 24 | 56 × 56 × 24 | |
| Bottleneck-3 | Linear block, m = 6, stride = 2 | 56 × 56 × 24 | 28 × 28 × 32 |
| Inverted residual block, m = 6, stride = 1 | 28 × 28 × 32 | 28 × 28 × 32 | |
| Inverted residual block, m = 6, stride = 1 | 28 × 28 × 32 | 28 × 28 × 32 | |
| Bottleneck-4 | Linear block, m = 6, stride = 1 | 28 × 28 × 32 | 28 × 28 × 64 |
| Inverted residual block, m = 6, stride = 1 | 28 × 28 × 64 | 28 × 28 × 64 | |
| Inverted residual block, m = 6, stride = 1 | 28 × 28 × 64 | 28 × 28 × 64 | |
| Inverted residual block, m = 6, stride = 1 | 28 × 28 × 64 | 28 × 28 × 64 | |
| Bottleneck-5 | Linear block, m = 6, stride = 2 | 28 × 28 × 64 | 14 × 14 × 96 |
| Inverted residual block, m = 6, stride = 1 | 14 × 14 × 96 | 14 × 14 × 96 | |
| Inverted residual block, m = 6, stride = 1 | 14 × 14 × 96 | 14 × 14 × 96 | |
| Bottleneck-6 | Linear block, m = 6, stride = 2 | 14 × 14 × 96 | 7 × 7 × 160 |
| Inverted residual block, m = 6, stride = 1 | 7 × 7 × 160 | 7 × 7 × 160 | |
| Inverted residual block, m = 6, stride = 1 | 7 × 7 × 160 | 7 × 7 × 160 | |
| Bottleneck-7 | Linear block, m = 6, stride = 1 | 7 × 7 × 160 | 7 × 7 × 320 |
| Bilinear Pooling | Conv2d-1, kernel size = (k × k), stride = 1 | 7 × 7 × 320 | 7 × 7 × 1024 |
| Conv2d-2, kernel size = (k × k), stride = 1 | 7 × 7 × 320 | 7 × 7 × 1024 | |
| AvgPooling kernel size = (7 × 7) | 7 × 7 × 1024 | 1 × 1 × 1024 | |
| Classification | Fully Connected | 1 × 1 × 1024 | class number |
| Method | Published Year | Training Ratio | ||
|---|---|---|---|---|
| 20% | 50% | 80% | ||
| BOVW [4] | 2010 | 76.81 | ||
| VLAT [67] | 2014 | 94.30 | ||
| MS-CLBP+FV [34] | 2016 | 88.76 ± 0.79 | 93.00 ± 1.20 | |
| TEX-NET-FL (ResNet) [51] | 2017 | 96.91 ± 0.36 | 97.72 ± 0.54 | |
| salM3LBP-CLM [54] | 2017 | 91.21 ± 0.75 | 95.75 ± 0.80 | |
| VGG-VD-16 [2] | 2017 | 94.14 ± 0.69 | 95.21 ± 1.20 | |
| CNN-ELM [68] | 2017 | 95.62 ± 0.32 | ||
| Two-Stream Fusion [69] | 2018 | 98.02 ± 1.03 | ||
| D-CNN (VGG16) [47] | 2018 | 98.93 ± 0.10 | ||
| RTN (VGG16) [42] | 2018 | 98.96 | ||
| DCF (VGG-VD16) [70] | 2018 | 95.42 ± 0.71 | 97.10 ± 0.85 | |
| GCFs+LOFs (VGG16) [9] | 2018 | 97.37 ± 0.44 | 99.00 ± 0.35 | |
| SAL-TS-Net (GoogLeNet) [8] | 2018 | 97.97 ± 0.56 | 98.90 ± 0.95 | |
| Siamese ResNet50 [71] | 2019 | 76.50 | 90.95 | 94.29 |
| SF-CNN (VGGNet) [44] | 2019 | 99.05 ± 0.27 | ||
| VGG16-DF [43] | 2019 | 5298.97 | ||
| MRBF [72] | 2019 | 94.19 ± 0.15 | ||
| DDRL-AM (ResNet18) [41] | 2019 | 99.05 ± 0.08 | ||
| WSPM-CRC (ResNet152) [73] | 2019 | 97.95 | ||
| CTFCNN [52] | 2019 | 98.44 ± 0.58 | ||
| CapsNet (Inception-v3) [74] | 2019 | 97.59 ± 0.16 | 99.05 ± 0.24 | |
| BiMobileNet (MobileNetv2) | 2020 | 96.41 ± 0.57 | 98.45 ± 0.27 | 99.03 ± 0.28 |
| Method | Training Ratio | ||||
|---|---|---|---|---|---|
| 5% | 10% | 15% | 20% | 25% | |
| Fine-tuning VGG16 | 39.53 ± 2.23 | 53.12 ± 1.15 | 59.83 ± 2.45 | 64.68 ± 2.70 | 69.51 ± 0.65 |
| Fine-tuning ResNet50 | 39.01 ± 1.62 | 51.35 ± 1.25 | 57.40 ± 0.96 | 64.82 ± 0.64 | 71.06 ± 0.72 |
| Fine-tuning MobileNetv2 | 38.64 ± 1.45 | 52.85 ± 0.85 | 60.90 ± 1.26 | 67.86 ± 1.12 | 72.48 ± 0.40 |
| BiMobileNet | 86.74 ± 1.63 | 93.78 ± 0.75 | 93.90 ± 0.25 | 96.41 ± 0.57 | 97.02 ± 0.55 |
| Method | Published Year | Training Ratio | ||
|---|---|---|---|---|
| 10% | 20% | 50% | ||
| TEX-Net-LF (ResNet) [51] | 2017 | 93.81 ± 0.12 | 95.73 ± 0.16 | |
| salM3LBP-CLM [54] | 2017 | 86.92 ± 0.35 | 89.76 ± 0.45 | |
| VGG-VD-16 [2] | 2017 | 86.59 ± 0.29 | 89.64 ± 0.36 | |
| DCA (VGGNet) [57] | 2017 | 91.86 ± 0.28 | ||
| RTN (VGG16) [42] | 2018 | 92.44 | ||
| D-CNN (VGG16) [47] | 2018 | 90.82 ± 0.16 | 96.89 ± 0.10 | |
| GCFs+LOFs (VGG16) [9] | 2018 | 92.48 ± 0.38 | 96.85 ± 0.23 | |
| SAL-TS-Net (GoogleNet) [8] | 2018 | 94.09 ± 0.34 | 95.99 ± 0.35 | |
| MRBF [72] | 2019 | 87.26 ± 0.42 | ||
| SF-CNN (VGGNet) [44] | 2019 | 93.60 ± 0.12 | 96.66 ± 0.11 | |
| CTFCNN [52] | 2019 | 94.91 ± 0.24 | ||
| WSPM-CRC (ResNet152) [73] | 2019 | 95.11 | ||
| BiMobileNet (MobileNetv2) | 2020 | 92.77 ± 0.49 | 94.83 ± 0.24 | 96.87 ± 0.23 |
| Method | Published Year | Training Ratio | |
|---|---|---|---|
| 10% | 20% | ||
| Fine-tune VGG16 [3] | 2017 | 87.15 ± 0.45 | 90.36 ± 0.18 |
| D-CNN (VGG16) [47] | 2018 | 89.22 ± 0.50 | 91.89 ± 0.22 |
| IOR4 (VGG16) [40] | 2018 | 87.83 ± 0.16 | 91.30 ± 0.17 |
| RTN (VGG16) [42] | 2018 | 89.90 | 92.71 |
| DCF (VGG-VD16) [70] | 2018 | 87.14 ± 0.19 | 89.56 ± 0.25 |
| DDRL-AM (ResNet18) [41] | 2018 | 92.17 ± 0.08 | 92.46 ± 0.09 |
| SAL-TS-Net (GoogLeNet) [8] | 2018 | 85.02 ± 0.20 | 87.01 ± 0.19 |
| Triplet Network [7] | 2018 | 92.33 ± 0.50 | |
| VGG16-DF [43] | 2019 | 89.66 | |
| Siamese ResNet50 [71] | 2019 | 92.28 | |
| SF-CNN (VGG16) [44] | 2019 | 89.89 ± 0.16 | 92.55 ± 0.14 |
| GLANet [46] | 2019 | 91.03 ± 0.18 | 93.45 ± 0.17 |
| CapsNet (Inception-v3) [74] | 2019 | 89.03 ± 0.21 | 92.60 ± 0.11 |
| DML (VGG16) [49] | 2019 | 91.73 ± 0.21 | 93.47 ± 0.30 |
| BiMobileNet (MobileNetv2) | 2020 | 92.06 ± 0.14 | 94.08 ± 0.11 |
| Methods | λ | Overall Accuracy | Parameters Numbers (Million) | GFLOPs1 | Model Size MB | |
|---|---|---|---|---|---|---|
| 10% | 20% | |||||
| Fine-tuning VGG16 [3] | / | 87.15 ± 0.45 | 90.36 ± 0.18 | ~134.44 | ~15.60 | ~512.87 |
| SF-CNN (VGG16) [44] | / | 89.89 ± 0.16 | 92.55 ± 0.14 | ~17.28 | ~15.49 | ~65.93 |
| DML (VGG16) [49] | / | 91.73 ± 0.21 | 93.47 ± 0.30 | ~134.44 | ~15.60 | ~512.87 |
| SAL-TS-Net (GoogLeNet) [8] | / | 85.02 ± 0.20 | 87.01 ± 0.19 | ~10.07 | ~1.51 | ~38.41 |
| BiMobileNet (k = 3) | 0.50 | 90.26 ± 0.23 | 92.77 ± 0.14 | 3.47 | 0.17 | 13.27 |
| 0.75 | 91.47 ± 0.16 | 93.64 ± 0.12 | 5.52 | 0.33 | 21.05 | |
| 1.00 | 92.06 ± 0.14 | 94.08 ± 0.11 | 7.76 | 0.45 | 29.59 | |
| BiMobileNet (k = 1) | 0.50 | 90.06 ± 0.11 | 92.74 ± 0.11 | 0.86 | 0.12 | 3.27 |
| 0.75 | 91.23 ± 0.09 | 93.67 ± 0.05 | 1.59 | 0.24 | 6.05 | |
| 1.00 | 91.89 ± 0.19 | 93.92 ± 0.11 | 2.52 | 0.34 | 9.59 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Xu, Q.; Guo, H.; Zhao, C.; Lin, Y.; Li, D. An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification. Sensors 2020, 20, 1999. https://doi.org/10.3390/s20071999
Yu D, Xu Q, Guo H, Zhao C, Lin Y, Li D. An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification. Sensors. 2020; 20(7):1999. https://doi.org/10.3390/s20071999
Chicago/Turabian StyleYu, Donghang, Qing Xu, Haitao Guo, Chuan Zhao, Yuzhun Lin, and Daoji Li. 2020. "An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification" Sensors 20, no. 7: 1999. https://doi.org/10.3390/s20071999
APA StyleYu, D., Xu, Q., Guo, H., Zhao, C., Lin, Y., & Li, D. (2020). An Efficient and Lightweight Convolutional Neural Network for Remote Sensing Image Scene Classification. Sensors, 20(7), 1999. https://doi.org/10.3390/s20071999