1. Introduction
With the continuous development of economic globalization and social integration, more and more people are eager to learn a second language. The computer-assisted language learning (CALL) system, which can provide flexible self-paced learning anytime and anywhere, and cheaper and more immersive learning with real-time feedback and personalized guidance, is becoming more and more popular. CALL systems that focus on speech and pronunciation are usually called computer-assisted pronunciation training (CAPT) systems. CAPT systems can efficiently process and analyze the speech uttered by language learners and then provide the quantitative or qualitative assessment of pronunciation quality or ability to them as feedback. This process is also known as the automatic pronunciation (quality/proficiency) assessment (evaluation/scoring). More to the point, CAPT systems should be able to accurately detect pronunciation errors in the utterances produced by language learners, diagnose the types and locations of pronunciation errors, and then provide corrective feedback and operational guidance for improvement. Thus, it can be deduced that automatic pronunciation error detection (APED) is the core of CAPT systems. APED is also referred to as mispronunciation detection and diagnose (MD or MDD) in some literature [
1,
2,
3].
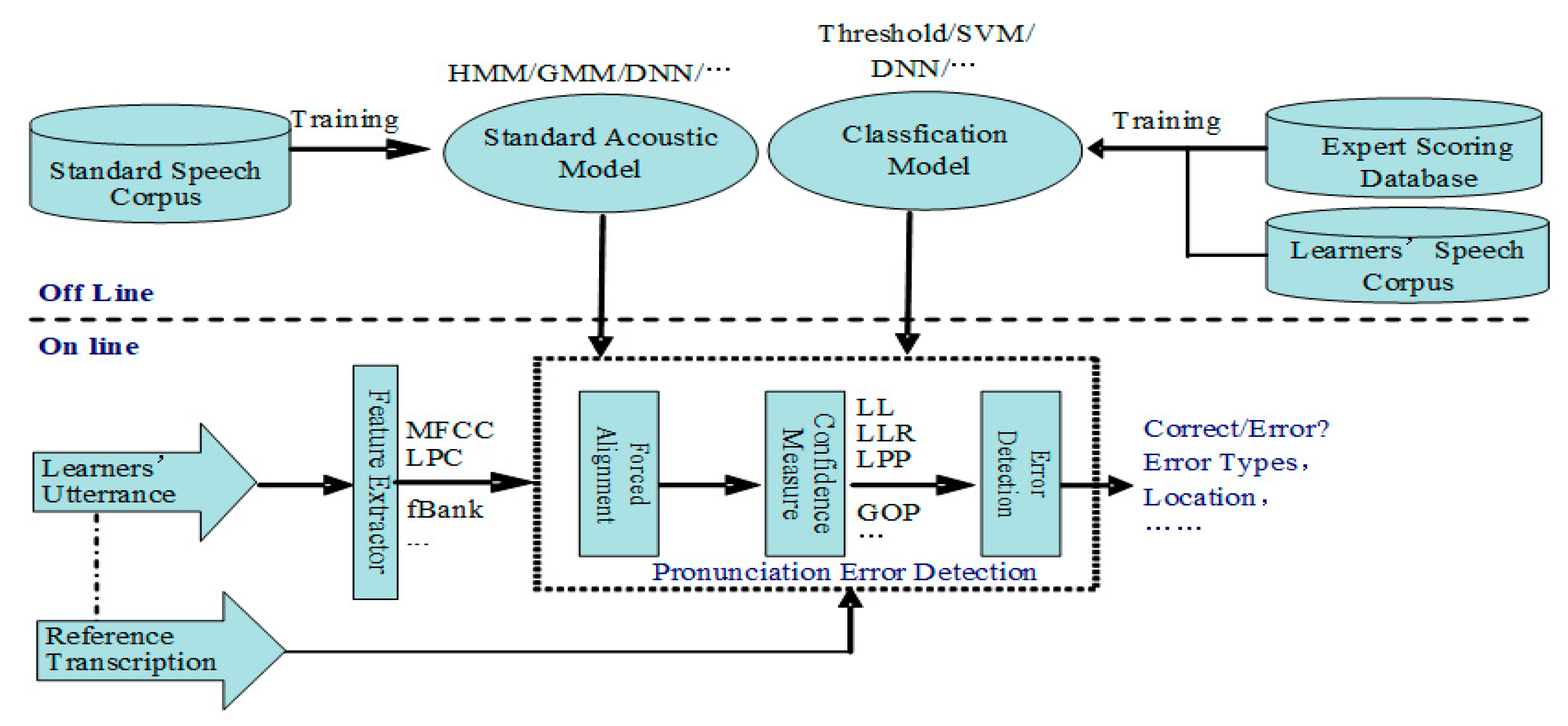
Presently, the advanced APED is mainly based on the state-of-the-art automatic speech recognition (ASR) technique and has made steady progress with the development of the ASR. As shown in
Figure 1, the framework of a typical APED system is as follows: first, force alignment is applied, in which the sequence of acoustic frames of language learners’ utterances is fixed by the sequence of phone models derived from the reference (prompt) transcription of the utterance, with a standard speech recognizer trained in advance through the standard speech corpus; then the likelihood or probabilities of the force alignment segments are calculated as confidence measures, which indicate how similar the pronunciation is to the canonical pronunciation; finally, a classifier is also constructed through language learners’ speech corpora and the corresponding expert scoring database, which uses confidence measures and other speech features (e.g., phone duration, also obtained by force alignment) to judge whether the pronunciation is correct or not [
4]. The effective confidence measures usually include logarithm likelihood (LL), logarithm likelihood ratio (LLR), logarithm posterior probability (LPP), normalization logarithm likelihood ratio (NLLR), goodness of pronunciation (GOP), and more [
5].
The construction of an APED system is very complex. The first step is to construct a sophisticated ASR system, and then a classifier or model for the identification of pronunciation errors, which is trained by using the speech corpora containing pronunciation errors and the expert scoring database, annotating the errors.
An ASR system can be implemented by several different technologies, including the earliest dynamic time warping (DTW) and vector quantization (VQ), the classical gaussian mixture model–hidden Markov model (GMM–HMM), and the now-most popular deep neural network-hidden Markov model (DNN–HMM), DNN–DNN, and various neural network (NN) models within a deep learning framework [
6,
7,
8]. Classifiers for an APED task can also be built by some models, for example, the early decision tree (DT), the classical support vector machine (SVM) and ensemble learning (EM), and the most popular NN. When the classifier cannot be trained without the expert annotated data, APED can also be achieved by setting thresholds directly in accordance to confidence measures [
4]. With the continuous development of ASR technology, the accuracy of ASR is so high that some studies directly detect pronunciation errors based on results of the ASR and achieve good performance in the APED task [
9].
Observing the framework of the APED system, we can see that there are many factors affecting the performance. As such, the related works focus on the following aspects: (1) improving the calculation method of the confidence measure; (2) discriminative training to improve the accuracy of the acoustic model; (3) using a more refined DNN-based acoustic model; (4) selecting more distinctive features; (5) building better classifiers. We will introduce them in detail in
Section 2.
However, there are some problems in the above work. First, a basic GMM–HMM acoustic model must be trained, and then it is used to make force alignment and segmentation of speech based on the reference transcription. If segmentations are wrong at the beginning, confidence measures, extracted features, trained classifiers, and so on become inaccurate, or even completely wrong. Moreover, due to the diversity and complexity of many aspects, such as application environment, recording devices, speakers’ voices (especially the non-native pronunciation of second language learners), it is usually challenging to achieve accurate segmentation. Force alignment segmentation, which not only depends heavily on the accuracy of speech recognition model but also above factors, has become an inevitable bottleneck in the APED system.
With the development of deep learning technology, end-to-end ASR technology has gradually matured and achieved positive practical results, which provides us with a new opportunity to update the APED algorithm. Traditional ASR consists of many modules, including the acoustic model, lexicon model, language model, and more. It also requires linguistic resources, such as a handcrafted pronunciation dictionary to map word to phone sequences, tokenization for some languages without the explicit word boundary, and phonetic context dependence trees. It is especially challenging to build an ASR system for a new language. Moreover, each module in an ASR system needs to be optimized independently, and their optimization objective functions are inconsistent with the overall goal of the task. In addition, because there are many modules, the error in the previous module has a significant impact on the subsequent module. End-to-end ASR can simplify many modules in traditional ASR into a single-network architecture within a deep learning framework and solve the above problems well. It is a unified model which is simple and direct, and the whole training process does not require forced alignment and segmentation.
At present, there are two major architectures for end-to-end ASR, one is the connectionist temporal classification (CTC) model [
10,
11], and the other is the attention-based Seq2seq model [
12,
13]. Among them, the CTC model uses the Markov hypothesis to solve sequential problems effectively through dynamic programming, and the attention-based model adopts attention mechanism to perform alignment between acoustic frames and recognizable symbols. The most significant advantage of end-to-end ASR is that it abandons a series of assumptions of traditional HMM-based ASR, and no longer requires forced alignment and segmentation, and has a maximum likelihood of training speech segments. It does not even require language models, and simplifies the ASR system by using a single network architecture to represent complex modules in traditional ASR. It greatly reduces the difficulty of building an ASR system.
These two kinds of end-to-end ASR methods have their own advantages and disadvantages. The CTC method is more geared to time series modeling and the attention-based method does not need to satisfy the independence assumption. However, the attention-based method is too flexible to guarantee the order of output sequences, which is defective for the ASR task. To utilize the advantages of both methods, a hybrid CTC/attention architecture for end-to-end ASR was proposed [
14,
15]. In the training process, the multi-objective learning (MOL) framework was used to improve robustness and achieve fast convergence. In the decoding process, two objective functions were interpolated linearly by a hyper-parameter and then a joint decoding using an optimized objective function was employed in a one-pass beam search algorithm to further eliminate irregular alignments. However, this hyper-parameter needed to be set manually before decoding and kept constant throughout the decoding process. In
Section 3, an adaptive parameter is proposed instead of the hyper-parameter. The value of the adaptive parameter can be adjusted continuously according to the current values of two loss functions in the whole decoding process, and therefore alignment processing will be better.
In this paper, an end-to-end APED system based on improved hybrid CTC/attention architecture was constructed, and then the performance of the system was further evaluated. This APED system based on hybrid CTC/attention architecture is very innovative and promising, as it does not require force alignment segmentation and language models.
The contributions of this paper are as follows:
From the perspective of the technical development of ASR, we carefully review the classical models and technical methods of APED technology over the past 20 years, and then observe the monumental APED systems at different periods as baseline systems to analyze their advantages and disadvantages and to evaluate their performance.
To solve the problem of the empirical parameter of the traditional end-to-end ASR based on hybrid CTC/attention architecture needing to be set manually before the training and remaining unchanged throughout the training process, we introduce an adaptive parameter based on the Sigmoid function that does not need to be set in advance and can be adjusted continuously during training. It can make full use of the advantages and disadvantages of the CTC model and the attention-based model, and helps estimate the alignment process better. In the ASR task of Mandarin, the improved system with an adaptive parameter achieved better recognition results, which is superior to all the traditional systems with different manual parameters.
We use the improved ASR system in the APED task of Mandarin and obtain a result. To the best of our knowledge, there are no previously published results for the end-to-end APED system. The end-to-end APED based on improved hybrid CTC/attention architecture does not require segmentation by force alignment and multiple complex models. It is convenient and straightforward, and will be a suitable general solution for L1-independent CAPT.
The rest of this paper is organized as follows: The related works for the APED task are introduced in detail from the perspective of ASR technology in
Section 2; In
Section 3, a new and promising APED system based on improved hybrid CTC/attention architecture is proposed; In
Section 4, we present the results obtained from the experiments and discuss them; Finally, the conclusion along with future work based on our research findings is shown in
Section 5.
2. Literature Review
There are two ways to build an APED system. One is based on ASR technology, and the other is based on acoustic phonetics. The ASR-based approach regards the problem of APED as the problem in the calculation confidence measures where phones (or other basic pronunciation units) can be correctly recognized by a standard ASR system, that is, the confidence measure of signal decoded into pattern . Based on this idea, the goal of an APED system is to find effective confidence measures and combined features, which can produce higher scores for standard pronunciation, but lower scores for non-standard pronunciation. If these scores are lower than certain thresholds, they can be detected as pronunciation error, or these scores are fed into the trained classifier to determine whether the pronunciation is correct. The approach based on acoustic phonetics usually regards the problem of APED as the problem of comparison or classification. Therefore, based on the statistical analysis of phonetics, it first extracts all kinds of features at the segment, including acoustic features, perceptual features, and structural features, and then finds discriminative features or combined features from them. Finally, using these features, an advanced classifier or comparator is built for a specific APED task on a specific set of phones.
2.1. APED Methods Based on ASR Technology
The APED method based on ASR technology focuses on the following three aspects: constructing and optimizing the calculation of confidence measures, improving the adaptability and evaluation performance of the acoustic model, and refining the acoustic model by deep learning technology.
2.1.1. Confidence Measure and Its Improvement
The basic confidence measure is derived from the probability that a GMM–HMM-based phone acoustic model is able to generate the phonetic segmentation according to intermediate results obtained in the decoding process of an ASR system.
In 1996, Neumeyer L of the Stanford Research Institute (SRI) first proposed the confidence measure in a pronunciation quality assessment, which was based on HMM logarithmic likelihood. However, the experimental results were not satisfactory, and the correlation with the expert scores is worse than the normalized length scores of phonetic segmentation [
16]. In 1997, Franco H of SRI proposed a new confidence algorithm, with the logarithmic posterior probability based on HMM. The experimental results in the speaker levels and sentence levels show that the new algorithm was clearly better than other confidence measures [
17]. Kim Y extended the above research to the phone level. The correlation between logarithmic posterior probability based on HMM and the expert scores was the best, but there is still a big gap between this correlation and the correlation at speaker level and sentence level, which indicates that the confidence measure is not reliable enough at the phone level alone [
18].
Over the same period, Witt S M of the University of Cambridge (CU) conducted a phone-level mispronunciation diagnosis study. Goodness of pronunciation (GOP) was proposed as a confidence measure, and a predefined threshold was used to determine whether the pronunciation was correct [
4,
19]. The literature [
20] outlined a detailed analysis of the performance of GOP algorithm under various application conditions. The experimental results showed that the GOP algorithm is excellent in adaptability and stability, and it has low requirements for speaker and threshold. Nowadays, the GOP algorithm and its improved algorithm are widely used in most APED systems.
Aiming at the shortcomings of classical GOP algorithm in the method of computation, Song presented a lattice-based GOP algorithm utilizing the information from the lattice of ASR, and generally found better results than in the classical GOP except for the APED of short sentences [
21]. Zhang expanded the standard pronunciation space to include pronunciation errors through an adaptive unsupervised clustering algorithm, and then refined more detailed acoustic models for APED within the extended pronunciation space (EPS). If the EPS is large enough and models all types of pronunciation errors of each phone, the APED within the EPS not only produces a better result, but also points out the locations and types of pronunciation errors [
22].
2.1.2. L1-Dependent Confidence Measure
In the L1-dependent L2 APED task, researchers utilized non-native corpora to construct learners’ typical pronunciation conversion rules (L1/L2 error patterns) to build a dictionary of pronunciation variation or a network of pronunciation variation. After this, each phone, and phones that are easily confused with those phones, are processed uniformly in a decoding process or in a multi-level system. Usually, these L1-dependent methods can improve the accuracy of detection.
Wang analyzed the differences between Cantonese and American English from the perspective of cross-linguistics, summed up the rules of pronunciation errors generated by Cantonese, and built a dictionary of pronunciation variations containing all possible errors. To remove the unreasonable pronunciation in the dictionary, an efficient pruning algorithm was used to modify the dictionary through the confusion network in the training set. Utilizing the dictionary learners’ pronunciation errors could be detected quickly and accurately [
23]. Meng established CUCHLOE (Chinese University Chinese Learners of English) corpora. Through the comparative analysis and error analysis of non-native speakers’ accents and standard native speakers’ pronunciation, the typical error patterns of Cantonese speakers in English were obtained. These error patterns were used to expand the recognition network and generate a pronunciation variation network, which could fix the positions of pronunciation errors and give some advice for correct pronunciation [
24,
25,
26].
The above methods of automatically generated pronunciation conversion rules (pronunciation variation dictionary or pronunciation variation network) often lead to the expansion of error coverage and an increase in complexity. Therefore, Kawahara T. proposed a decision tree-based method to directly generate a speech recognition grammar network, which achieved better results in the experiment of foreign students learning Japanese [
27]. Stanley directly applied machine translation technology to automatically construct L1 pronunciation error patterns, which significantly improved the precision and recall rate of pronunciation errors and had similar accuracy with the method based on pronunciation conversion rules [
28].
The L1-dependent confidence measures can make use of the typical pronunciation errors of language learners from different countries or regions to the greatest extent possible. It is targeted more in the pronunciation quality assessment and helps to improve the performance of the assessment method. However, this method cannot cover all possible errors. The corresponding pronunciation dictionary or pronunciation conversion rules need to be adjusted according to the application scenarios. It relies heavily on prior knowledge and has obvious shortcomings. It is more suitable for the application tasks that only need to detect typical pronunciation errors.
2.1.3. Improved Acoustic Model
In addition to confidence measures, the ways in which the adaptability and discriminability of the acoustic model for APED tasks could be improved has also been widely concerned.
Witt analyzed the similarities and differences in the frequency spectrum, time duration, and pronunciation style between native and non-native speakers. The speaker adaptive technology was introduced to adjust the mean of the model, which reduced the mismatch between the acoustic model and the speakers and improved the speech recognition of non-native speakers [
29]. Ohkawa used bilingual speakers’ utterances to adapt L1 and L2 acoustic models and trained multiple bilinguals’ models for the CALL system. Through these methods, the system performance was improved by 5% to 10%, respectively [
30]. Song Y et al. used three strategies to get a better standard acoustic model. One was to regulate the changes between speakers through speaker adaptive training, the other was to improve the distinction between confusing phones by minimizing phone error training, and the third was to compensate for the difference of accent between L1/L2 by maximum likelihood linear regression (MLLR). Finally, the correlation of man–machine scoring increased from 0.651 to 0.679 at sentence level and increased from 0.788 to 0.822 at speaker level [
31]. To avoid over-adaptation and improve the fault tolerance of MLLR, Luo D., a Japanese scholar, proposed a regularized MLLR transformation method that used a group of teachers’ data to regularize learners’ transformation matrices. This method assumed that the learners’ transformation matrices were the linear combinations of teachers’ matrices, which theoretically guaranteed that the acoustic model still maintained the golden standard after adaptive transformation. The experimental results also showed that the methods could utilize MLLR adaptation better and have good fault tolerance [
32]. Zhang J. et al. trained phone models with different pronunciation qualities by using speech sample data of different pronunciation qualities. By applying force alignment using conventional acoustic models, they decoded the boundary information of the phone and obtained the pronunciation quality grade of the phone directly. At the phone level and sentence level, the results are better than the GOP scores [
33].
2.1.4. Acoustic Model Based on Deep Neural Network
DNNs can learn the multi-level abstract representations of input data through their multiple processing layers and have recently made remarkable achievements in many pattern recognition tasks, such as image classification, speech recognition, object detection, and drug discovery [
34,
35]. In the field of ASR, many kinds of DNNs, including feedforward neural networks [
36], convolutional neural networks [
37,
38], and recurrent neural networks [
39,
40], are mainly used in acoustic models and used partly in lexicon models and language models [
12,
41]. They have widely improved the performance of advanced ASR systems.
Qian first modeled the phone-state posteriors in HMMs using the deep belief network (DBN) to replace GMMs in APED. The acoustic models based on the DBN–HMM framework that were trained in an unsupervised manner with additional unannotated L2 data displayed significant improvements but were computationally more expensive [
42]. Hu refined acoustic models based on DNN with discriminative training and defined three different GOP scores in the framework of DNN–HMM. The experimental results showed the best GOP, in which DNN was 22% higher than the standard GOP with non-DNN in the correlation of man–machine scoring [
43]. In the following research, multiple logistic regression classifiers were integrated into a neural network with shared hidden layers to replace a GOP-based classifier and SVM classifier, which achieved better performances in the APED task [
2]. Kun proposed an acoustic-graphemic-phonemic model (AGPM) for the mispronunciation detection, whose acoustic model and state transition model are multi-distribution DNNs. To implicitly model error patterns, acoustic features, graphemes, and phonemes are integrated as inputs of the AGPM. It worked similarly to freephone recognition, but achieved excellent results [
9].
2.2. APED Methods Based on Acoustic Phonetics
ASR-based methods are the mainstream methods used in the existing APED systems. Their advantages are simple calculations, which can use the intermediate results of speech recognition directly, and their calculation methods, which are the same for all phones. Their disadvantage is that their diagnostic information is not precise enough and lacks more instructive feedback. Acoustic–phonetic-based methods usually extract distinctive features (selection of pronunciation features) for the specified target to be evaluated, and then use DTW algorithms to calculate similarity after force alignment (comparison-based method); or select classifiers to distinguish the pronunciation levels (classification-based method).
2.2.1. Selection of Pronunciation Features
The APED methods based on acoustic phonetics usually aim at specific research tasks, and combine the existing research experience of acoustic phonetics to select a variety of distinctive pronunciation features. Therefore, the selected pronunciation features are often diverse, including time domain features, time–frequency features, auditory model features, short-term spectrum features [
44], trap structure [
45], speech structure feature [
46,
47], formant [
48], and pronunciation articulatory [
49,
50]. However, it is not yet clear which features can truly represent the speaker’s pronunciation quality.
2.2.2. Comparison-Based Methods
The earliest method of APED is based on comparison. This method generally uses DTW algorithms to align the speech to be evaluated with the standard speech, and then extracts the corresponding evaluation features, calculates the distance between these features, and finally maps them to the pronunciation quality score according to the distance.
Lee A. proposed a comparative method to detect pronunciation errors at the word level of non-native speech. Through DTW of non-native speech and native speech, word-level and phone-level features that can effectively describe mismatched degree information on matching paths and distance matrices were extracted [
51]. Subsequently, the author used the posterior probability of the deep neural network as an input feature, and the performance of the system was improved by at least 10.4%. When only 30% of the labeled data was used, the performance of the system remained stable [
52].
2.2.3. Classification-Based Methods
The APED task can essentially be regarded as a classification problem, using a set of scoring features as an input, optimizing some criteria or objective function, and finally classifying them into different pronunciation levels. Therefore, classification-based methods have become the most important methods in the APED task, and various types of classifiers have been widely used, such as DT, SVM, AdaBoost, and NN.
Truong K. carried out the APED task for three phones, /A/, /Y/, and /x/, that are frequently mispronounced by L2-learners of Dutch. By comparing the different acoustic–phonetic features of correct and incorrect pronunciation, some distinguishing features, such as time duration, rate of rise (ROR) maximum, and energy amplitude, were chosen to train and test classifiers. Linear discriminant analysis and decision trees were used to train the classification model respectively, and positive results were obtained in both native and non-native speech [
53,
54]. Patil V. selected appropriate acoustic–phonetic features, including frication duration, difference between the first and second harmonic, spectral tilt, signal-to-noise ratio, B1-band energy, and more in the APED task on aspirated consonants of Hindi, and showed that acoustic–phonetic features outperform traditional cepstral features [
55].
Acoustic–phonetic-based methods are usually aimed at specific APED tasks for some commonly confused phones on small-scale speech corpora, utilizing the abundant knowledge of linguistic phonetics. To find the most discriminative features, and to combine these features to train an efficient classifier for the APED, is the key.
In recent years, the acoustic–phonetic-based methods have been deeply integrated with the ASR-based methods and they have been shown to complement each other. With the help of state-of-the-art ASR technology, the accurate segmentation of multi-level segments on the large-scale corpus and the robust confidence measures are achieved. Discriminative features are constructed by using acoustic–phonetic knowledge and refined acoustic models. These multi-type complementary features feed in a well-structured classifier, thus improving the accuracy of APED in a well-rounded way.
3. Proposed Methodology
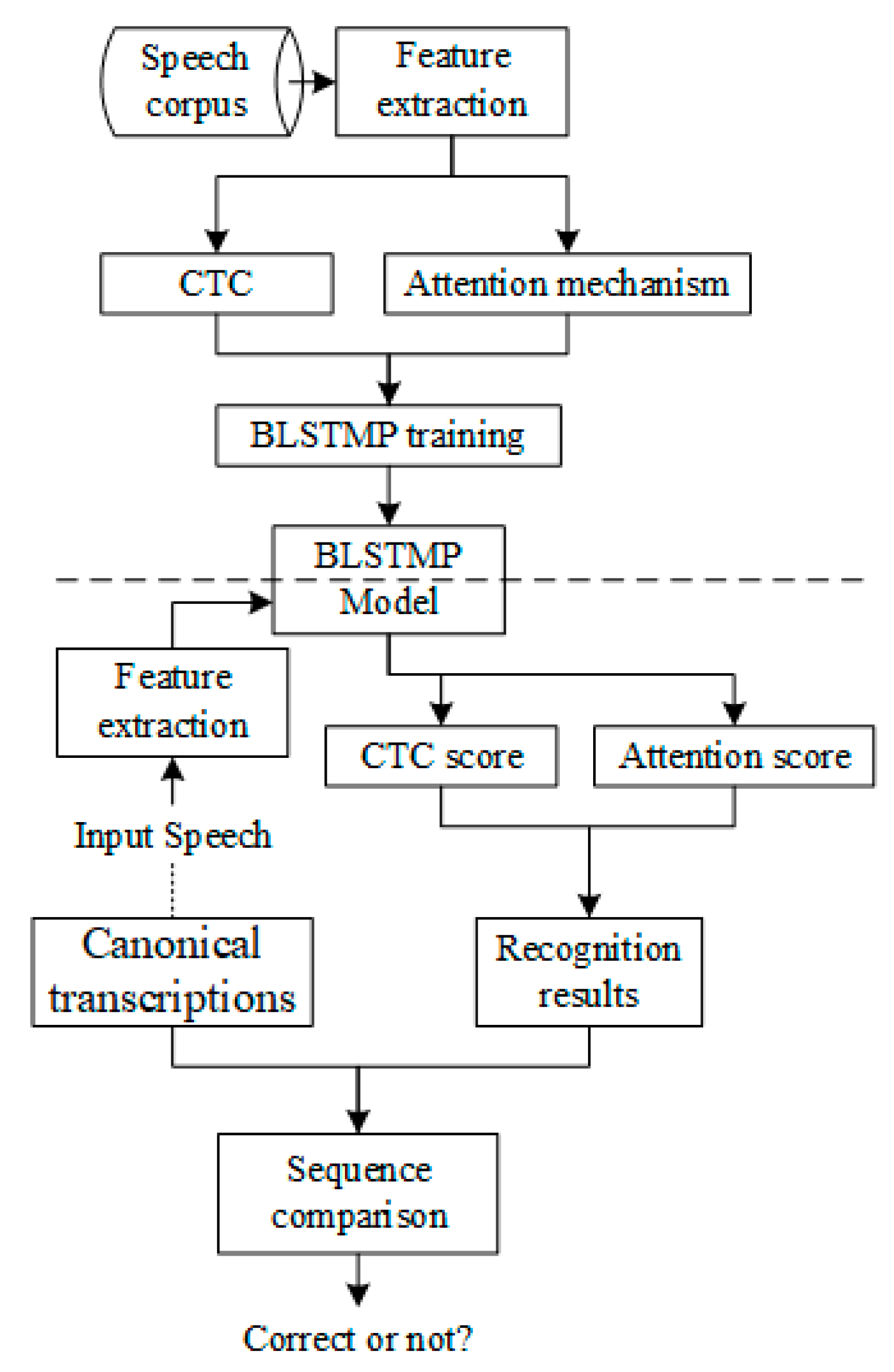
In this section, we propose a new end-to-end ASR system based on improved hybrid CTC/attention architecture to detect pronunciation errors. The main process of this method is five steps: (1) Data preparation. There is no need to prepare a pronunciation dictionary and a language model, and trained GMM–HMMs and force alignment are not necessary in the stage; (2) Acoustic feature extraction. To extract Mel scale filter bank coefficients and fundamental frequency features from speech waveforms; (3) Encoder and decoder network training using hybrid CTC/attention end-to-end architecture. To reduce the error rate and accelerate the training, bidirectional long short term memory projection (BLSTMP) is selected [
56,
57]. The encoder network is trained by CTC criterion and the attention mechanism, and the probability of CTC is considered to find more consistent inputs. The CTC probability enforces monotonic alignment in the decoding process and does not allow large jumps or the cycle of the same frame. At the same time, CTC and attention-based probability scores are calculated to obtain robust decoding results; (4) Speech recognition. Recognition results can be obtained by using the end-to-end network models from step 3; (5) Sequence comparison. To compare speech recognition results with canonical transcriptions, the Needleman–Wunsch algorithm [
58] can be used to calculate the insertion error, deletion error, and substitution error of the two sequences, and it then can produce the detection of pronunciation errors. The whole process is shown in
Figure 2.
Next, we introduce the CTC model, the attention-based model, and the hybrid CTC/attention model in detail.
3.1. CTC Model
ASR can be considered the sequence mapping an acoustic observation vector sequence of length
,
, to the corresponding word sequence of length
N,
. Where
is the observation vector of the frame
,
is the
word of
in the vocabulary,
. The aim of ASR is to evaluate all possible word sequences,
, to find the most likely word sequence,
.
Therefore, how to get the posterior probability, , of the word sequence, , given the observation vector sequence , is the most critical problem.
The CTC uses a character sequence of length
,
, to represent a possible word sequence. Here,
is a set of distinct characters. To deal with the repetition of character labels, the CTC defines an extra blank label,
, to explicitly represent the character boundary. The enhanced character sequence
with the label
is defined as:
The posterior probability,
, can be calculated by Equation (3):
where
is a character sequence with the label
, which has the same length with the corresponding observation vector sequence
.
CTC obtains Equation (3) by using a conditional independence assumption, which can simplify the dependence between the character model, , and the acoustic model, , in CTC. is the objective function of CTC, and will be used in a later equation.
3.2. Attention-Based Model
Unlike CTC, the attention-based model estimates the posterior probability without the assumption of the condition independence, such as Equation (4).
where
is an objective function based on the attention mechanism.
is calculated by Equations (5)–(8).
where Equations (5) and (8) are encoder and decoder networks, respectively. Here
is the output hidden vector of the encoder, and
is the output character of the decoder. Attention weight
in Equation (6) is used to denote the soft alignment of
. The hidden vector
in Equation (7) is the weighted sum of
.
and
in Equation (6) are content-based attention mechanisms with and without convolutional features, respectively [
59]. The decoder network in (8) is a recursive network which takes the previous output
, hidden vector
, and hidden vector
, as conditions.
3.3. Hybrid CTC/Attention Architecture
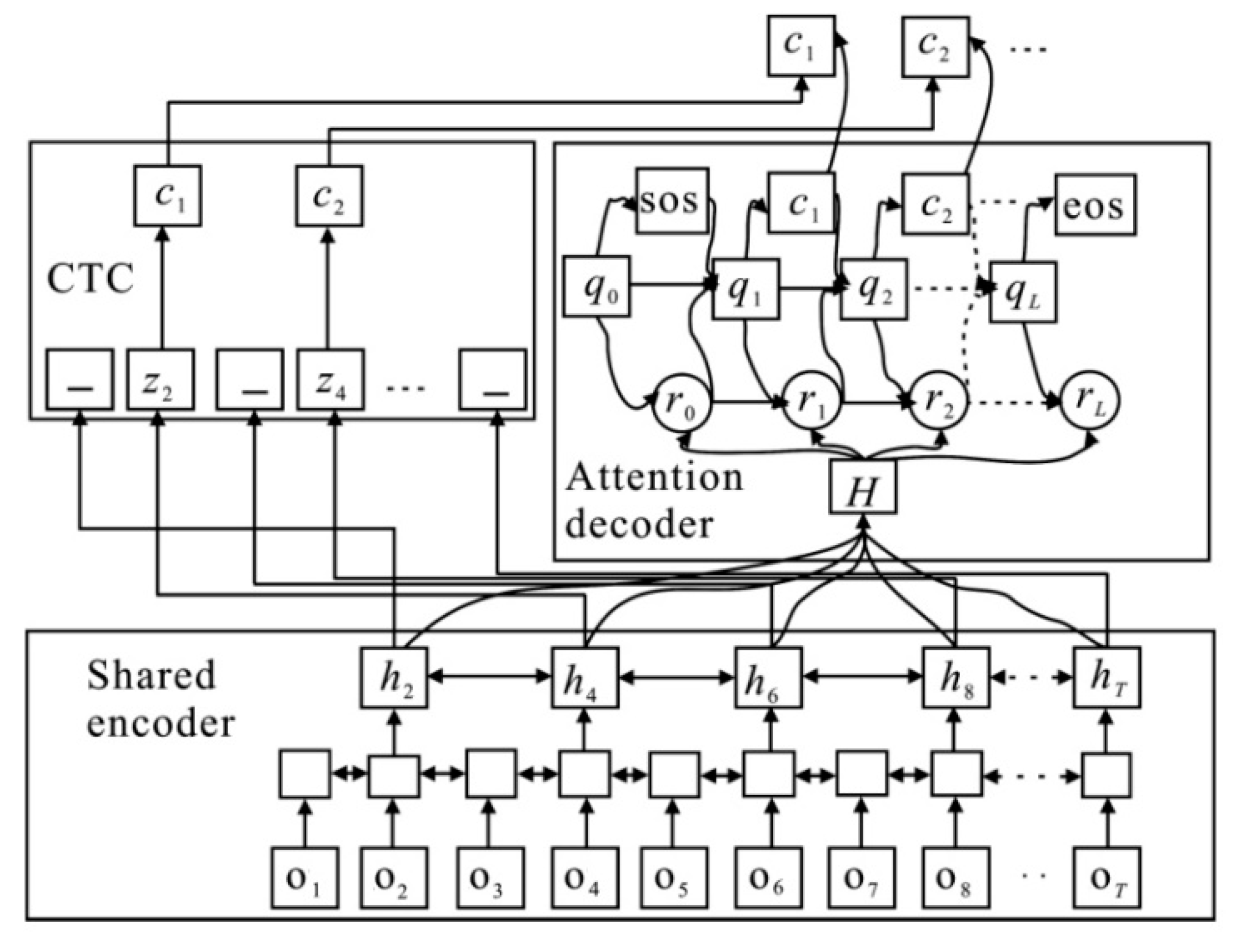
A hybrid CTC/attention architecture is adopted in the end-to-end ASR of Mandarin. The advantages of a CTC and attention mechanism are fully utilized in the process of encoding and decoding.
The shared encoder uses CTC criterion and attention mechanisms for joint training, and the observation vector sequence,
, is converted into the advanced feature sequence,
. Then a character sequence,
, is generated by the attention-based decoder. Label
and
are used to represent the beginning and end of the sequence, respectively. The overall framework of the end-to-end ASR based on hybrid CTC/attention architecture is illustrated in
Figure 3.
In [
14,
15], a multi objective learning (MOL) framework is adopted. Among them, the attention-based method is the main method, and the CTC method is the auxiliary method for robustness. The CTC ensures the accurate alignment between the observation vector sequence and the character sequences during training. Within the MOL framework, the new objective,
, is an interpolation of the CTC objective,
, and the attention objective,
. It should be noted that
and
are the logarithm of
in Equation (3) and
in Equation (4) respectively.
where
is a tunable parameter, which satisfies
. When
, the objective to be maximized is the attention objective, and when
, it is the CTC objective.
However, in [
14,
15], the parameter
, used for linear interpolation, needs to be set manually before the beginning of training and remains unchanged throughout the training process. Despite its shortcomings, a dynamic parameter adjustment method is introduced in this paper.
This parameter, , which does not need to be set manually before training, can be adjusted continuously during training and helps estimate the alignment process better. When is greater than , and is greater than 0.5, the contribution of in Equation (9) is strengthened, and the contribution of is inhibited. When is less than , and is less than 0.5, the contribution of in Equation (9) is strengthened, and the contribution of is inhibited.
In the decoding process, a one-pass beam search algorithm is used to combine attention-based and CTC probability logarithm scores and perform joint decoding to further eliminate irregular alignment.
Assuming
is the
output given the history outputs,
, and the output of the encoder,
, a linear combination of attention-based and CTC probability logarithm scores is performed during one-pass beam search.
Here,
in
,
and
are different, corresponding to the
output of the attention-based decoder, the CTC decoder, and the mixed decoder with the MOL framework respectively, as shown in
Figure 3.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}