Movement Estimation Using Soft Sensors Based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture



Abstract
1. Introduction
2. Related Works
2.1. Bayesian-Based Movement Estimation
2.2. Deep Learning-Based Movement Estimation Approaches
2.3. Comparison of the Bayesian-Based and Deep Learning-Based Movement Estimation
2.4. Consideration of Deep Learning Frameworks
3. Movement Estimation Framework
3.1. Overview
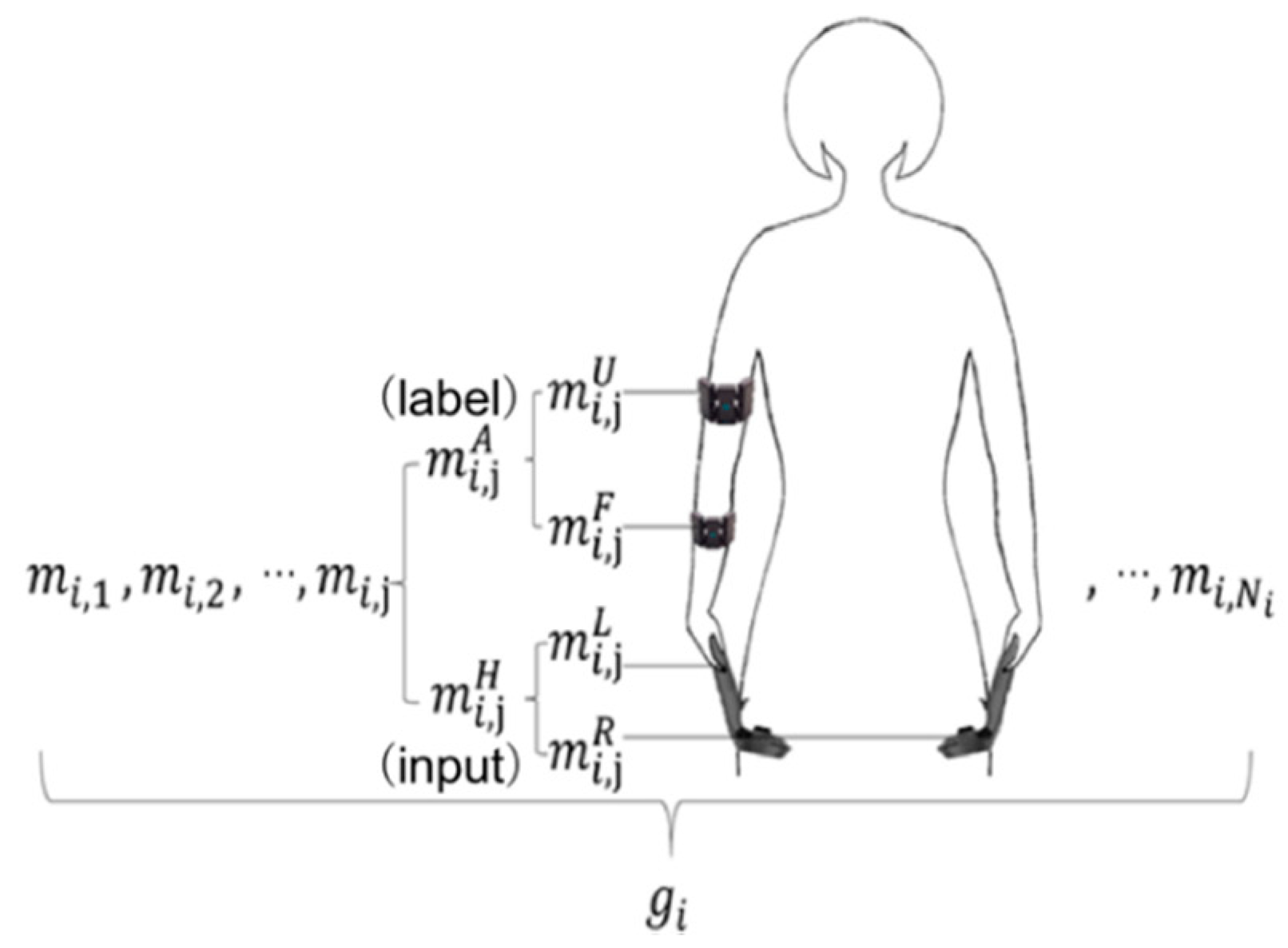
3.2. Pre-Processing Stage
3.3. Movement Estimation Stage
4. Experiments
4.1. Experimental Goals
4.2. Experimental Environments
4.3. Dataset Collection
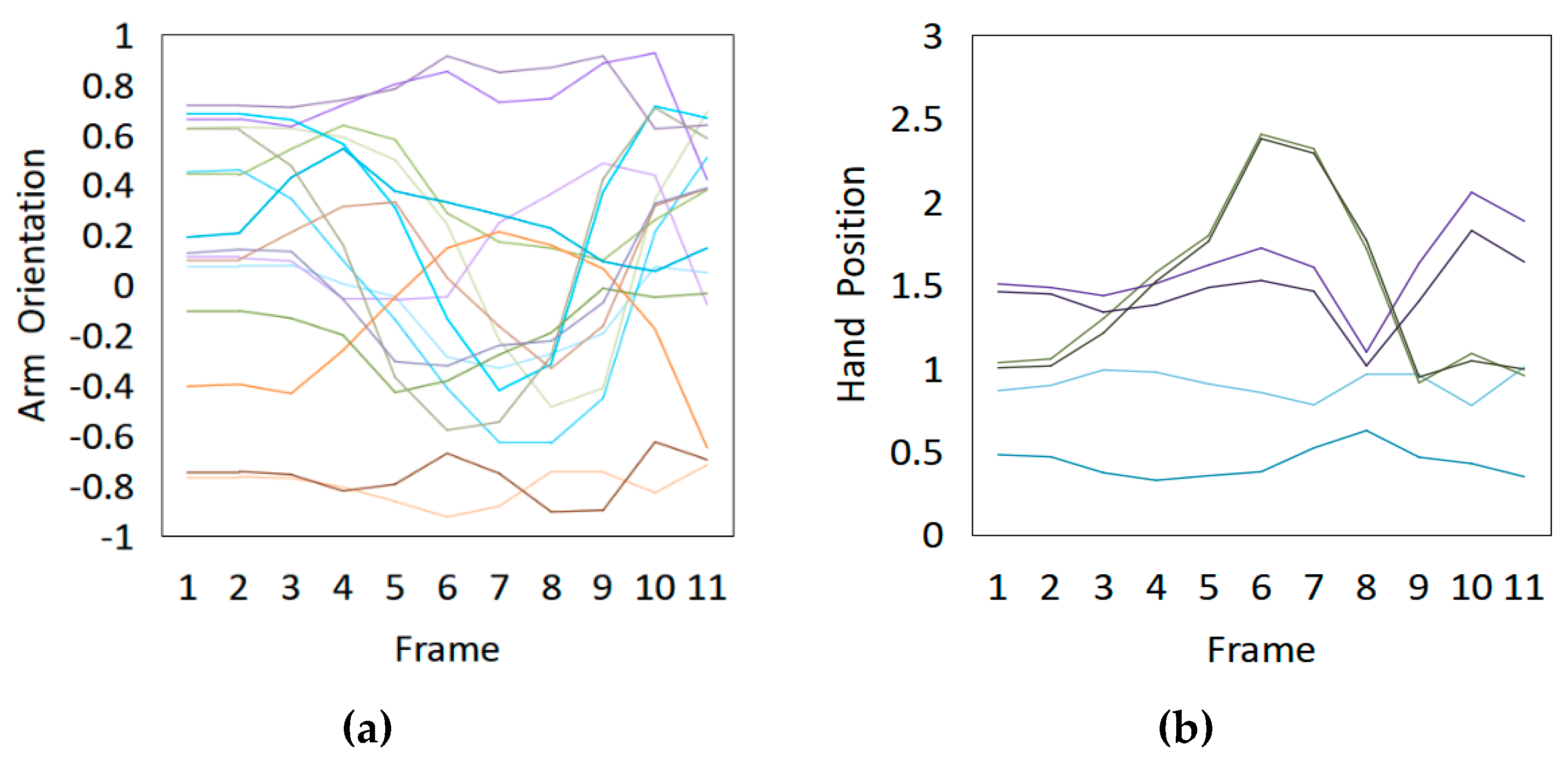
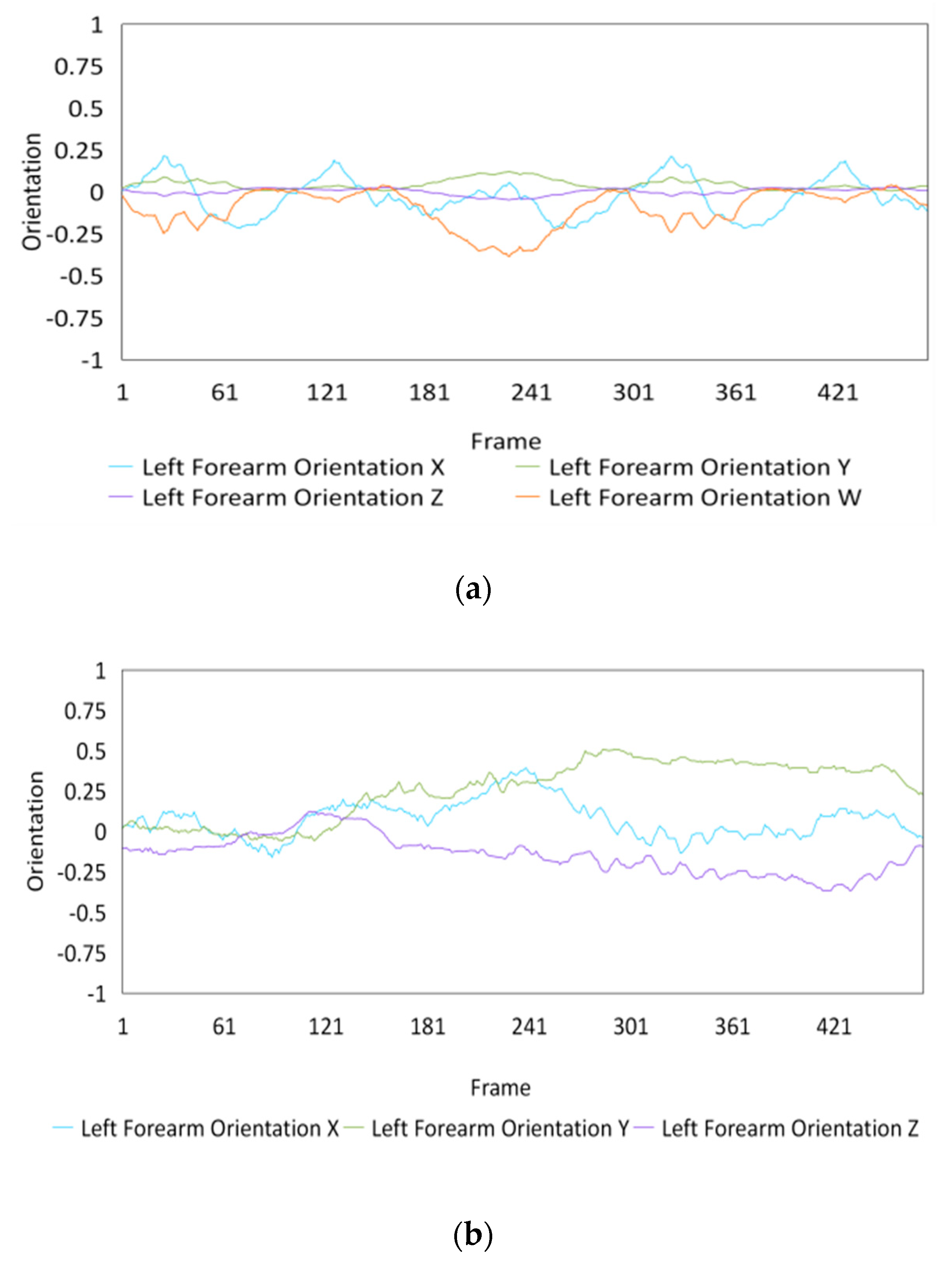
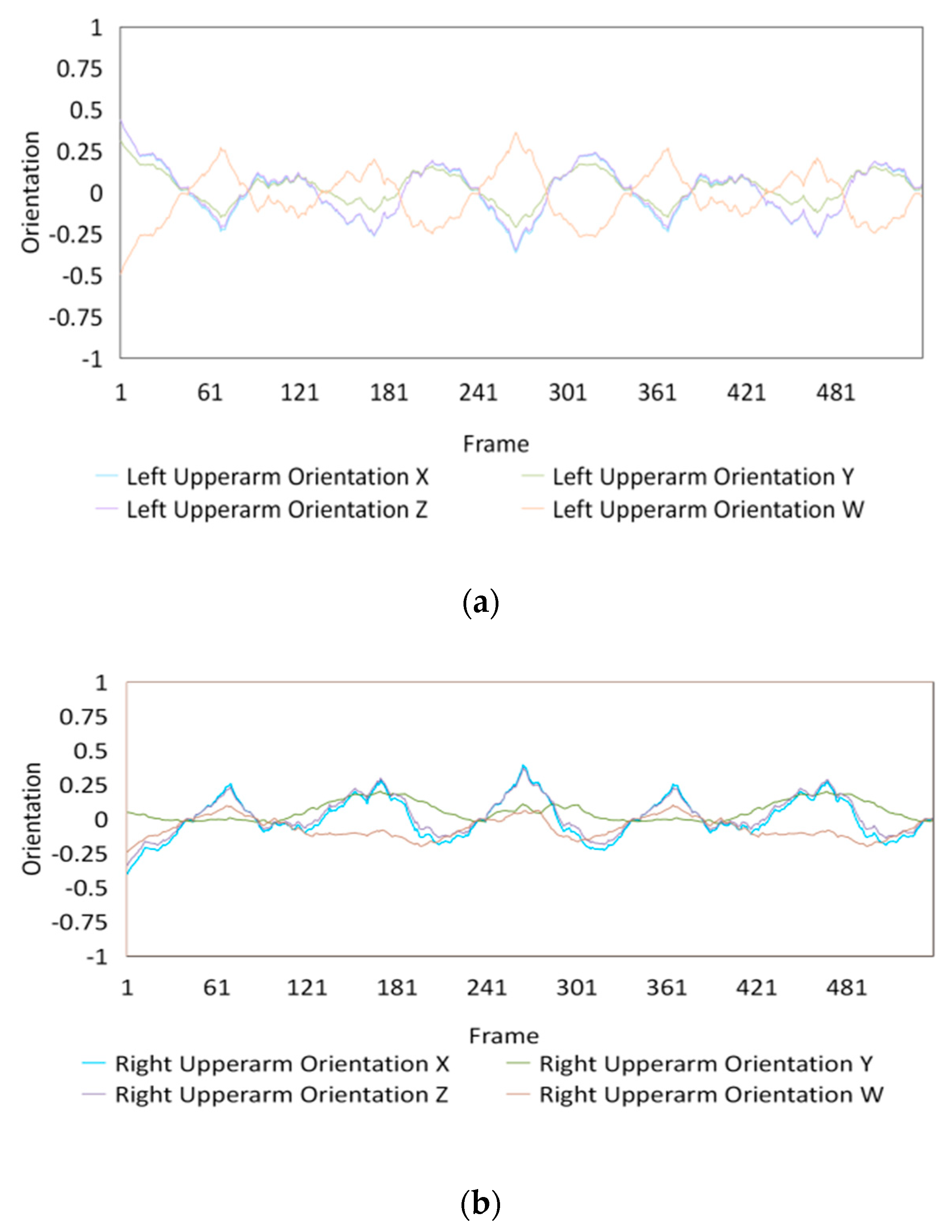
4.4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Maged, N.K.B.; Blanchard, J.B.; Cory, W.; Julio, M.; Aalap, T.; Ricardo, G.O. Web GIS in practice X: A microsoft kinect natural user interface for google earth navigation. Int. J. Health Geogr. 2011, 10, 45–55. [Google Scholar]
- Liu, W. Natural user interface-next mainstream product user interface. Comput. Aided Des. Concept. Des. 2010, 1, 203–205. [Google Scholar]
- Bruder, G.; Frank, S.; Klaus, H.H. Arch-Explore: A Natural User Interface for Immersive Architectural Walkthroughs. In Proceedings of the IEEE Symposium on 3D User Interfaces, Los Angeles, CA, USA, 14–15 March 2009. [Google Scholar]
- Lee, S.B.; Jung, H.I. A design and implementation of natural user interface system using kinect. J. Digit. Contents Soc. 2014, 15, 473–480. [Google Scholar] [CrossRef][Green Version]
- Chang, X.; Ma, Z.; Lin, M.; Yang, Y.; Hauptmann, A.G. Feature interaction augmented sparse learning for fast kinect motion detection. IEEE Trans. Image Process. 2017, 26, 3911–3920. [Google Scholar] [CrossRef] [PubMed]
- Asteriadis, S.; Chatzitofis, A.; Zarpalas, D.; Alexiadis, D.S.; Daras, P. Estimating Human Motion from Multiple Kinect Sensors. In Proceedings of the 6th International Conference on Computer Vision/Computer Graphics Collaboration Techniques and Applications, Berlin, Germany, 6–7 June 2013. [Google Scholar]
- Vive. Available online: https://www.vive.com/us/product/vive-virtual-reality-system (accessed on 12 March 2020).
- Egger, J.; Gall, M.; Wallner, J.; Boechat, P.; Hann, A.; Li, X.; Chen, X.; Schmalstieg, D. HTC Vive MeVisLab integration via OpenVR for medical applications. PLoS ONE 2017, 12, e0173972. [Google Scholar] [CrossRef] [PubMed]
- Diederick, C.N.; Li, L.; Markus, L. The Accuracy and precision of position and orientation tracking in the HTC vive virtual reality system for scientific research. Eng. Med. 2017, 8, 2041669517708205. [Google Scholar]
- Zhang, Z.; Waichoong, W.; Wu, J. Ubiquitous human upper-limb motion estimation using wearable sensors. IEEE Trans. Inf. Technol. Biomed. 2011, 15, 513–521. [Google Scholar] [CrossRef] [PubMed]
- Sung, Y.; Ryong, C.; Jeong, Y.S. Arm orientation estimation method with multiple devices for NUI/NUX. J. Inf. Process. Syst. 2018, 14, 980–988. [Google Scholar]
- Feichtenhofer, C.; Axel, P.; Andrew, Z. Convolutional Two-Stream Network Fusion for Video Action Recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Si, C.; Jing, Y.; Wang, W.; Wang, L.; Tan, T. Skeleton-Based Action Recognition with Spatial Reasoning and Temporal Stack Learning. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sung, Y.; Guo, H.; Lee, S.-G. Motion quaternion-based motion estimation method of MYO using K-means algorithm and bayesian probability. Soft Comput. 2018, 22, 6773–6783. [Google Scholar] [CrossRef]
- Kim, P.Y.; Sung, Y.; Park, J. Bayesian probability-based motion estimation method in ubiquitous computing environments. Lect. Notes Electr. Eng. 2015, 373, 593–600. [Google Scholar]
- Lee, S.G.; Yunsick, S.; Jong, H.P. Motion estimation framework and authoring tools based on MYOs and bayesian probability. In Intelligent Data Analysis and Applications; Springer: Basel, Switzerland, 2015. [Google Scholar]
- Zhang, R.; Li, C. Motion Sequence Recognition with Multi-sensors Using Deep Convolutional Neural Network. In Intelligent Data Analysis and Applications; Springer: Basel, Switzerland, 2015. [Google Scholar]
- Mehrizi, R.; Peng, X.; Metaxas, D.N.; Xu, X.; Li, K. Predicting 3-D lower back joint load in lifting: A deep pose estimation approach. IEEE Trans. Hum. Mach. Syst. 2019, 49, 85–94. [Google Scholar] [CrossRef]
- Arjun, J.; Jonathan, T.; Yann, L.; Christoph, B. Modeep: A Deep Learning Framework Using Motion Features for Human Pose Estimation. In Proceedings of the Asian Conference on Computer Vision, Singapore, Singapore, 1–5 November 2014. [Google Scholar]
- Aria, A.; Ioannis, P. Unsupervised Convolutional Neural Networks for Motion Estimation. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- FLIC Dataset. Available online: https://bensapp.github.io/flic-dataset.html (accessed on 12 March 2020).
- Khurram, S.; Amir, R.Z.; Mubarak, S. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Hu, B.; Dixon, P.C.; Jacobs, J.V.; Dennerlein, J.T.; Schiffman, J.M. Machine learning algorithms based on signals from a single wearable inertial sensor can detect surface-and age-related differences in walking. J. Biomech. 2018, 71, 37–42. [Google Scholar] [CrossRef] [PubMed]
- Miljanovic, M. Comparative analysis of recurrent and finite impulse response neural networks in time series prediction. Indian J. Comput. Sci. Eng. 2012, 3, 180–191. [Google Scholar]
- Sak, H.; Andrew, S.; Françoise, B. Long Short-Term Memory Recurrent Neural Network Architectures for Large Scale Acoustic Modeling. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14 September 2014. [Google Scholar]
- Bharat, S.; Tim, K.M.; Michael, J.; Oncel, T.; Ming, S. A Multi-stream Bi-directional Recurrent Neural Network for Fine-Grained Action Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 16–20 June 2016. [Google Scholar]
- Zhang, S.; Yang, Y.; Xiao, J.; Liu, X.; Yang, Y.; Xie, D.; Zhuang, Y. Fusing geometric features for skeleton-based action recognition using multilayer LSTM networks. IEEE Trans. Multimed. 2018, 20, 2330–2343. [Google Scholar] [CrossRef]
- Raheja, J.L.; Minhas, M.; Prashanth, D.; Shah, T. Chaudhary. Robust gesture recognition using Kinect: A comparison between DTW and HMM. Optik 2015, 126, 1098–1104. [Google Scholar] [CrossRef]
- Rise of the Tomb Raider. Available online: https://store.steampowered.com/app/391220/Rise_of_the_Tomb_Raider (accessed on 12 March 2020).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
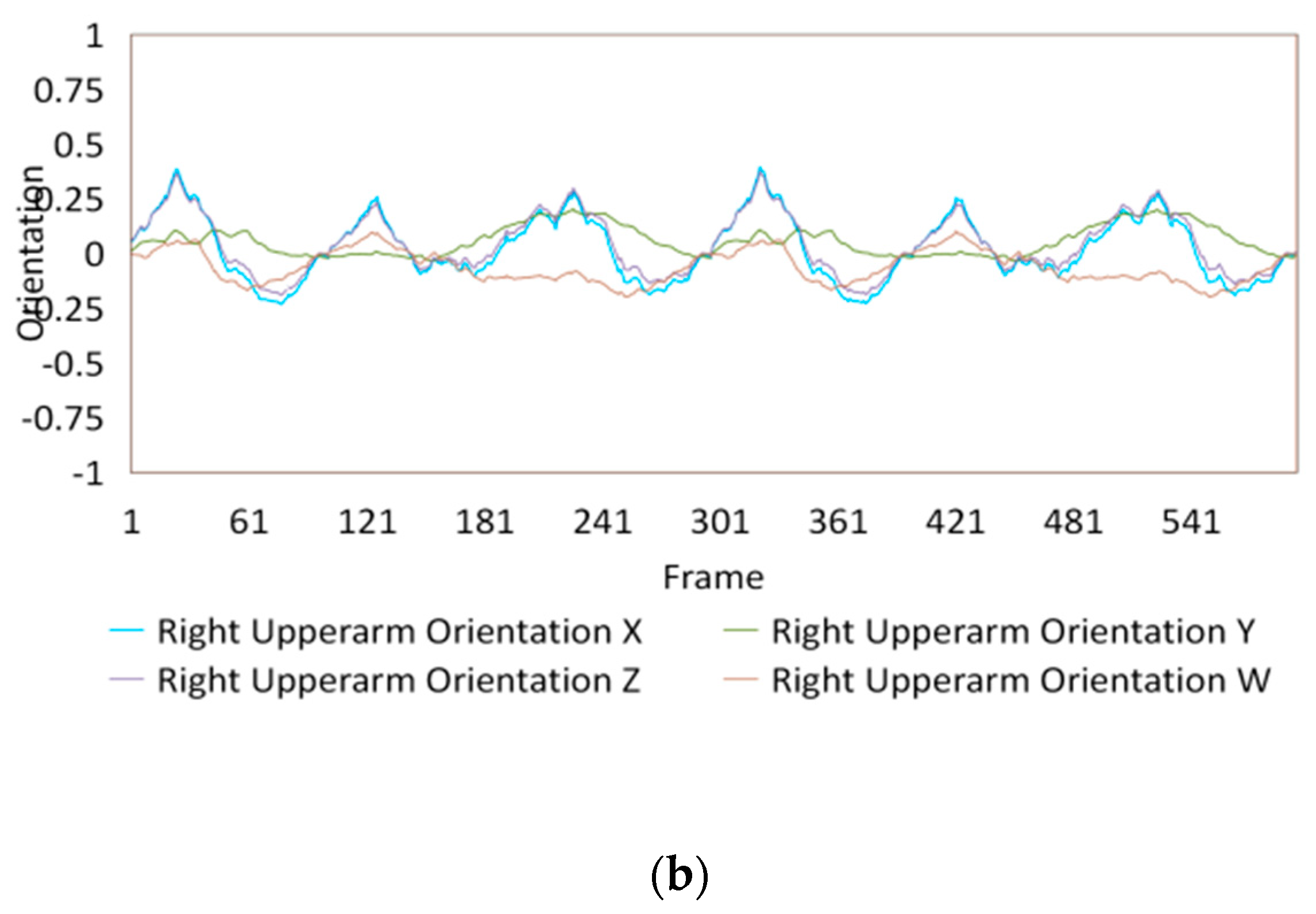{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Goal | Device | Input | Algorithm | Output | |
|---|---|---|---|---|---|
| Rahil [18] | Estimating accurate 3D pose of human | _ | Multi-view images | Deep neural network | Human 3D pose |
| Arjun [19] | Estimating the human gesture in videos with a CNN | _ | 3D tensor containing RGB images and their corresponding gesture features | Convolutional Neural Network | 3D tensor containing response-maps for estimated 2D locations of human joints |
| Hu [23] | Detecting the surface conditions of the road and age-group of the subjects | One IMU | Signals of a single IMU device | LSTM | Surface conditions and age-group status |
| Aria [20] | Estimating the human gesture in videos with an unsupervised CNN | _ | Pairs of images | Convolutional Neural Network | Dense gesture field |
| Kim [15] | Estimating one upper arm gesture depends on one forearm gesture | Two Myo armbands | Orientations of an upper arm and a forearm | Bayesian probability | Estimated upper arm gesture angles |
| Lee et al. [14] | Estimating one upper arm gesture depends on one forearm gesture | Myo armband | Orientations of an upper arm and a forearm | Bayesian probability | Estimated upper arm gesture angles |
| Choi [11] | Estimating one forearm depends on the positions of one hand | One Myo armband & one VIVE | Myo armbands: orientations of a forearm VIVE: positions of a hand | Bayesian probability | Estimated orientations of upper arm |
| The proposed framework | Estimating one upper arm and one forearm depends on the positions of two hands | Two Myo armbands & two VIVE | Myo armbands: orientations of forearms and upper arms of one arm VIVE: Positions of left and right hand | Bi-LSTM | Estimated orientations of forearms and upper arms of left and right arm |
| Index | Gesture | Consecutive Motions |
|---|---|---|
| 1 | Capturing equipment |  |
| 2 | Fighting with wolves |  |
| 3 | Searching for treasure |  |
| 4 | Going through the cave |  |
| 5 | Getting out of the reservoir |  |
| 6 | Exiting though the window |  |
| 7 | Exploring the cave |  |
| 8 | Running away |  |
| 9 | Through the waterfall |  |
| 10 | Through the tunnel |  |
| 11 | Robbing room |  |
| 12 | Forward to Mountain |  |
| 13 | Climbing |  |
| 14 | Attacking on the enemy |  |
| 15 | Fighting for survival |  |
| Subject #1 | Subject #2 | Subject #3 | |
|---|---|---|---|
| Gender | Female | Male | Female |
| Height (cm) | 160 | 173 | 164 |
| Weight (kg) | 52 | 61 | 55 |
| Length of Arms (cm) | 62 | 70 | 65 |
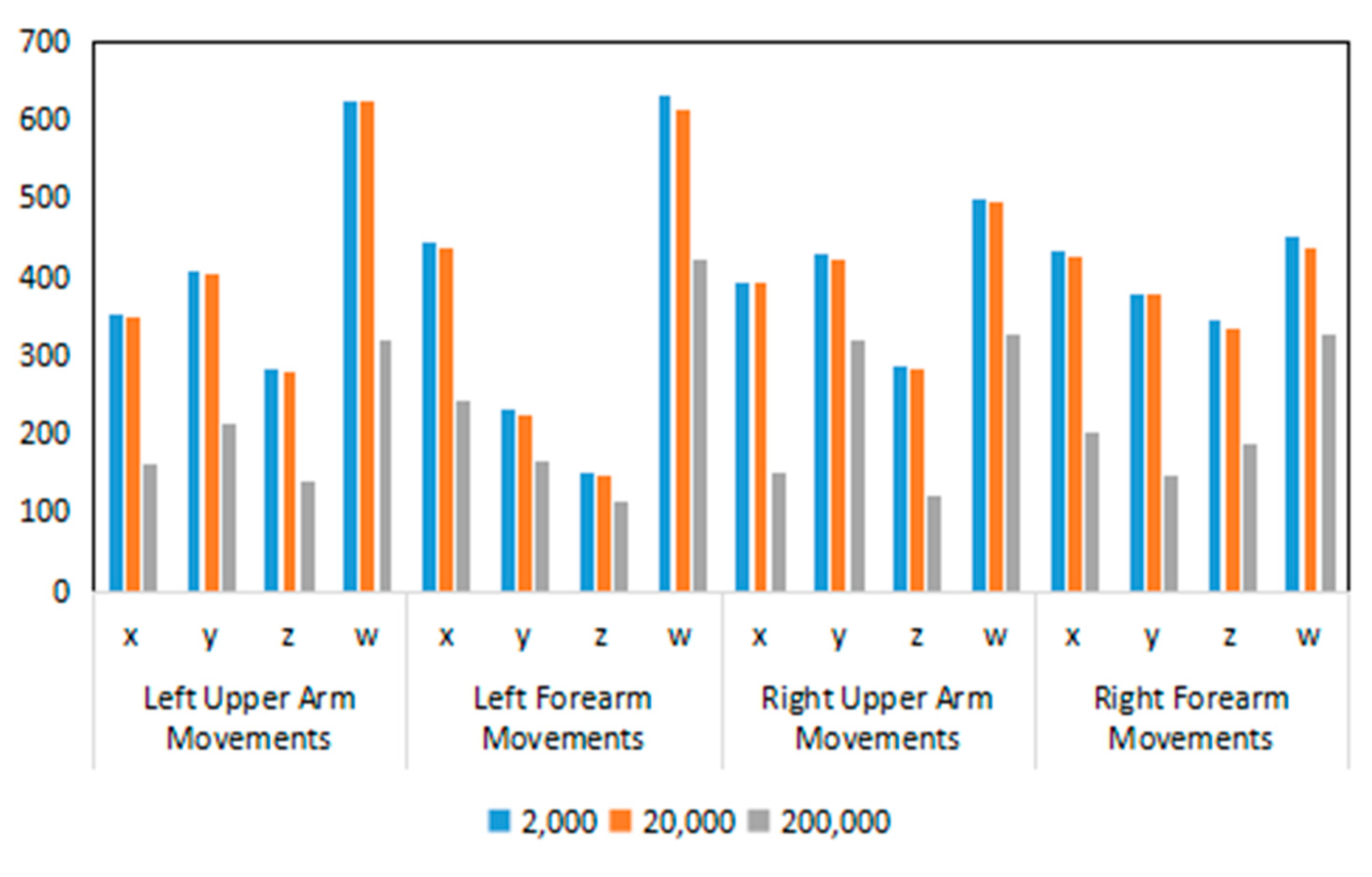
| Episodes | 2000 | 20,000 | 200,000 | |
|---|---|---|---|---|
| Estimated Movements | ||||
| Left Upper Arm Movements | x | 350.94 | 349.77 | 160.68 |
| y | 406.34 | 405.38 | 211.71 | |
| z | 284.34 | 280.96 | 140.71 | |
| w | 624.28 | 622.53 | 319.10 | |
| Left Forearm Movements | x | 443.70 | 437.74 | 241.90 |
| y | 230.44 | 223.56 | 166.38 | |
| z | 149.74 | 147.14 | 114.36 | |
| w | 631.33 | 612.90 | 421.90 | |
| Right Upper Arm Movements | x | 391.27 | 391.26 | 152.05 |
| y | 431.06 | 423.72 | 318.30 | |
| z | 286.06 | 282.60 | 122.65 | |
| w | 500.76 | 495.73 | 328.40 | |
| Right Forearm Movements | x | 434.38 | 426.66 | 201.85 |
| y | 379.77 | 377.07 | 146.45 | |
| z | 344.16 | 333.24 | 187.36 | |
| w | 451.01 | 438.51 | 326.53 | |
| Intervals | 50 | 100 | 1000 | |
|---|---|---|---|---|
| Estimated Gestures | ||||
| Left Forearm Movements | x | 750.55 | 780.85 | 680.01 |
| y | 681.49 | 708.28 | 751.25 | |
| z | 441.44 | 751.25 | 706.79 | |
| Right Forearm Movements | x | 846.90 | 677.68 | 854.68 |
| y | 815.04 | 882.20 | 823.23 | |
| z | 581.09 | 563.97 | 781.93 | |
| Estimated Movements | Reduction Rate of DTW Distance | |
|---|---|---|
| Left Forearm Orientations | x | 67.77% |
| y | 75.59% | |
| z | 74.09% | |
| Right Forearm Orientations | x | 76.17% |
| y | 82.03% | |
| z | 67.76% | |
| Average | 73.90% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, H.; Sung, Y. Movement Estimation Using Soft Sensors Based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture. Sensors 2020, 20, 1801. https://doi.org/10.3390/s20061801
Guo H, Sung Y. Movement Estimation Using Soft Sensors Based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture. Sensors. 2020; 20(6):1801. https://doi.org/10.3390/s20061801
Chicago/Turabian StyleGuo, Haitao, and Yunsick Sung. 2020. "Movement Estimation Using Soft Sensors Based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture" Sensors 20, no. 6: 1801. https://doi.org/10.3390/s20061801
APA StyleGuo, H., & Sung, Y. (2020). Movement Estimation Using Soft Sensors Based on Bi-LSTM and Two-Layer LSTM for Human Motion Capture. Sensors, 20(6), 1801. https://doi.org/10.3390/s20061801