Deep Learning-Based Secure MIMO Communications with Imperfect CSI for Heterogeneous Networks





Abstract

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
- We employ the deep learning-based technique for secure MIMO communications in heterogeneous networks, which can exploit the benefits of CNN learning model to produce more accurate CSI and meanwhile reduce the bit error rate (BER) of the receiver.
- We provide the detailed framework of deep learning-based detectors, where imperfect CSI as well as the original messages or ideal CSI are included in the training set, and can be used in different application scenarios.
- We present simulation results for deep learning-based detectors in heterogeneous networks. With the help of the CNN technique, the proposed detectors show obvious performance gain over the MLD with acceptable computational cost.
2. Related Work
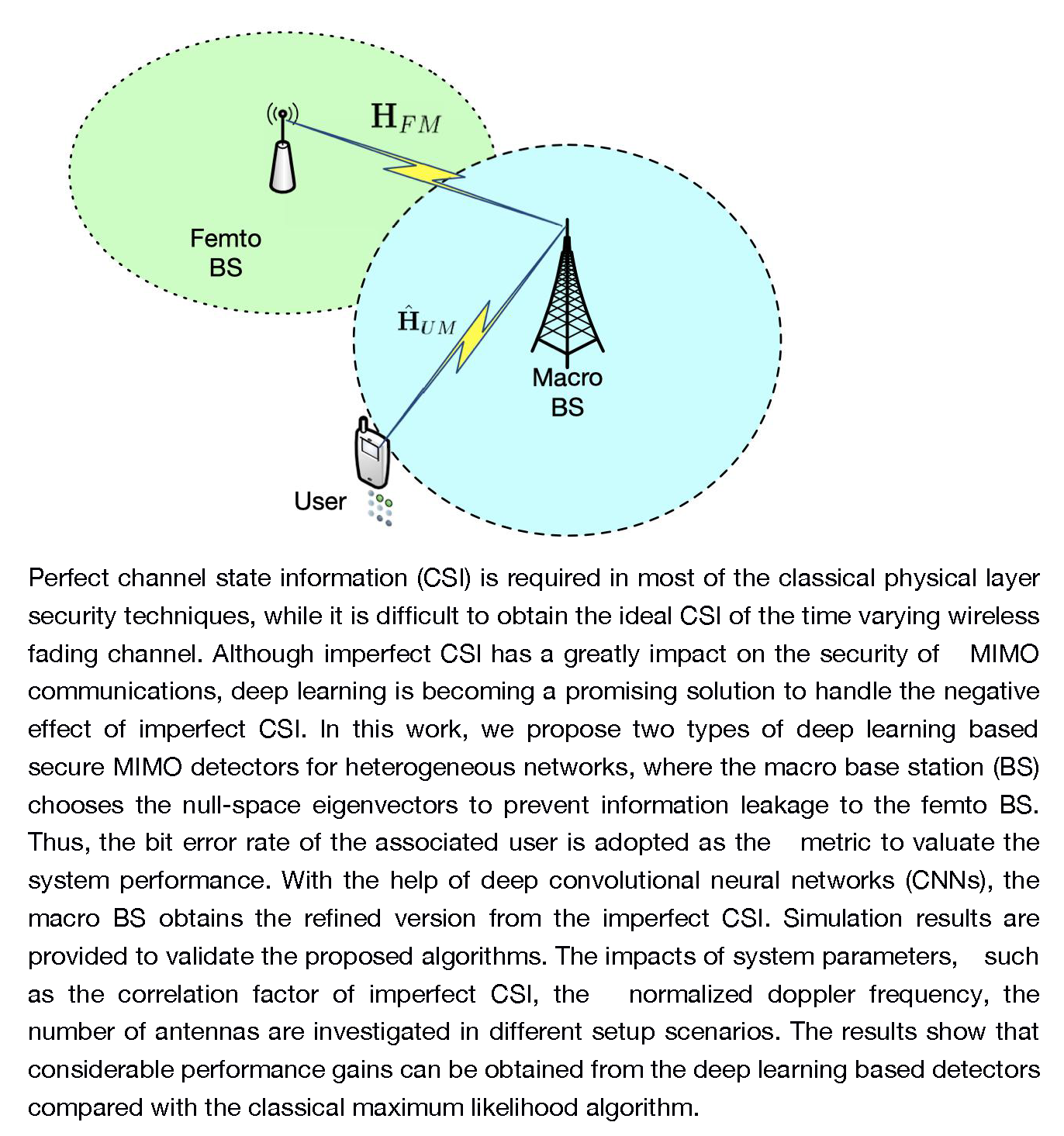
3. System Model
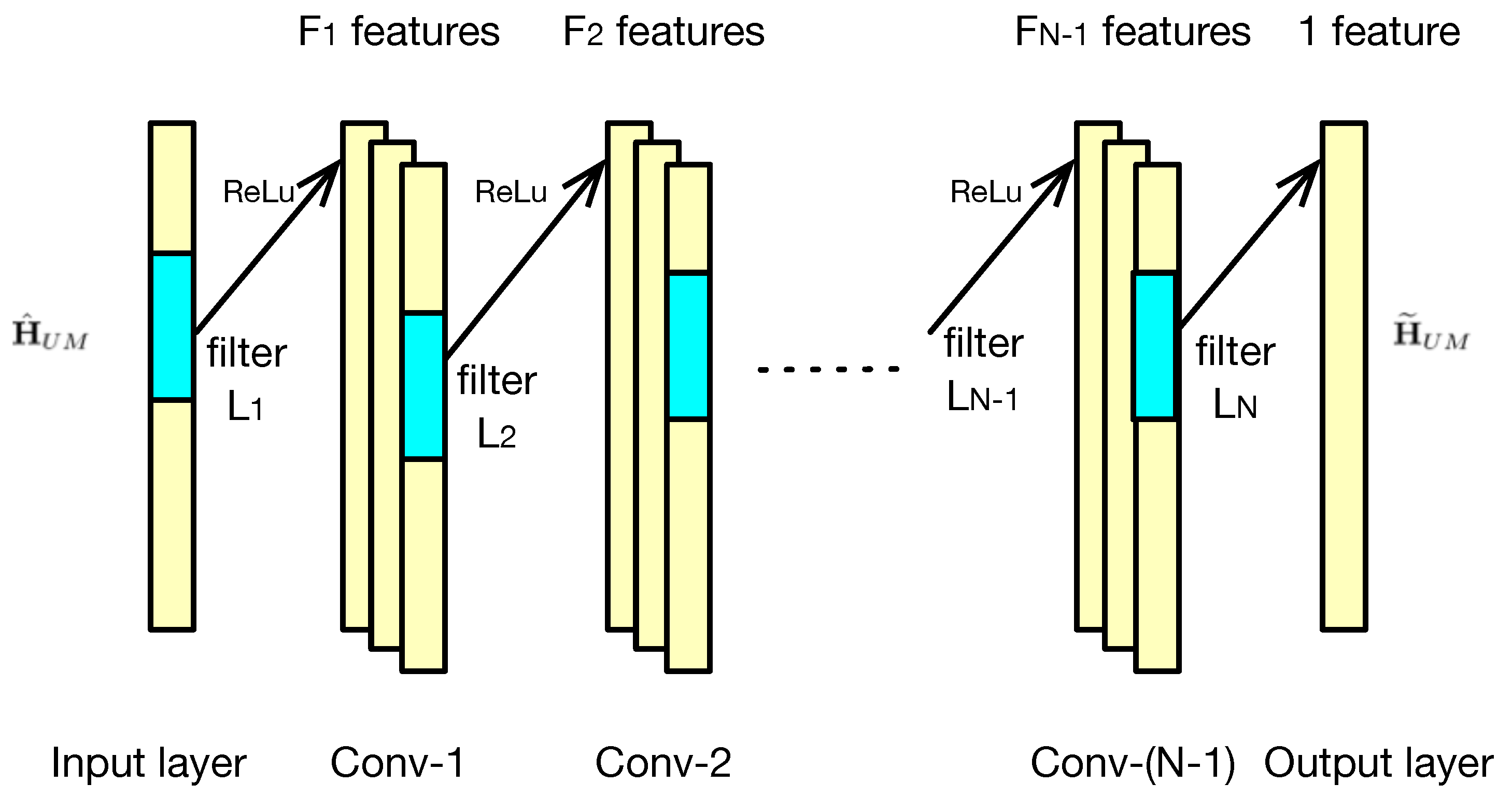
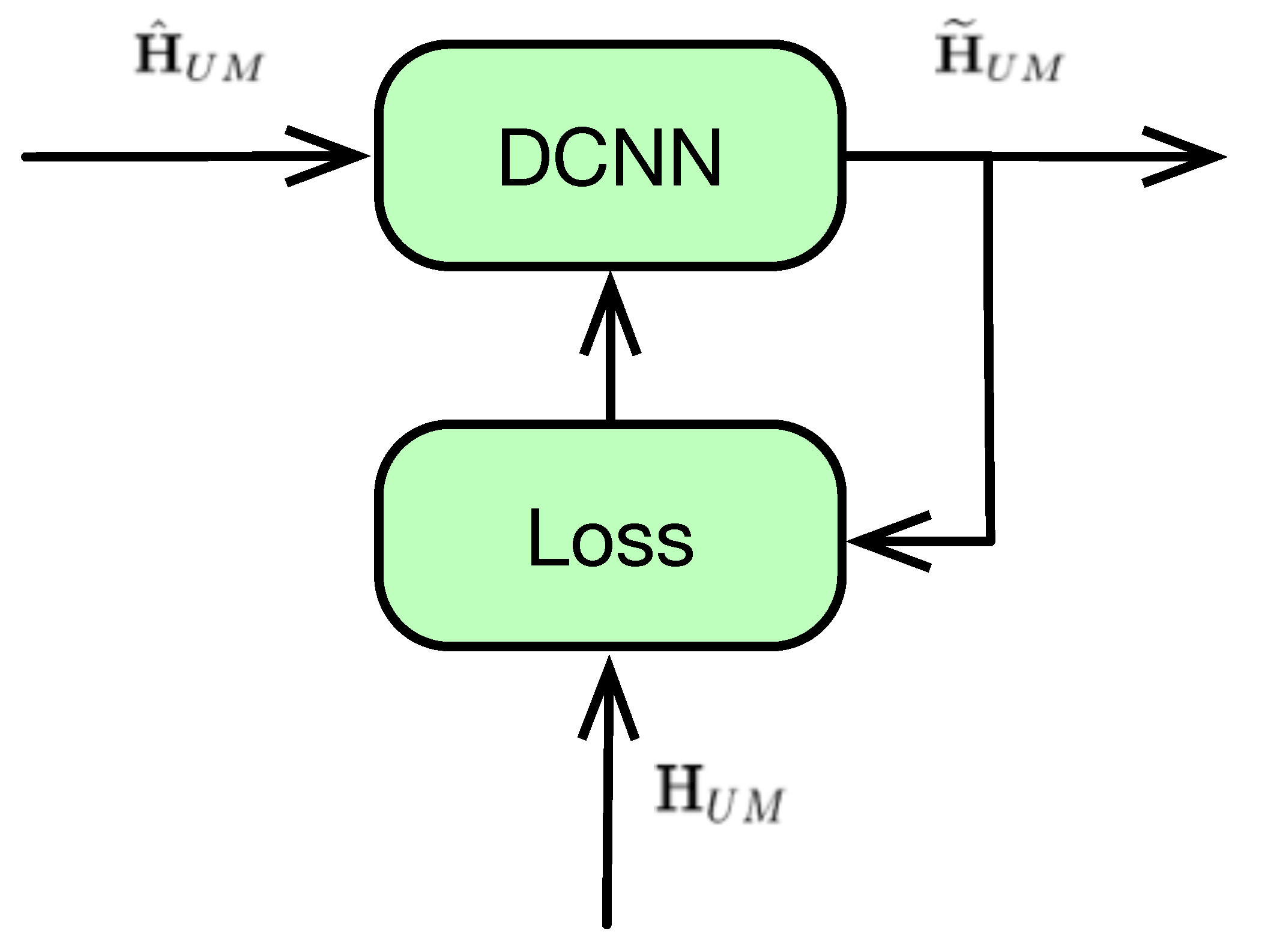
4. Deep CNN-Based Detector
4.1. DCNN Type-I: Training with Accurate CSI
4.2. DCNN Type-II: Training with Original Message
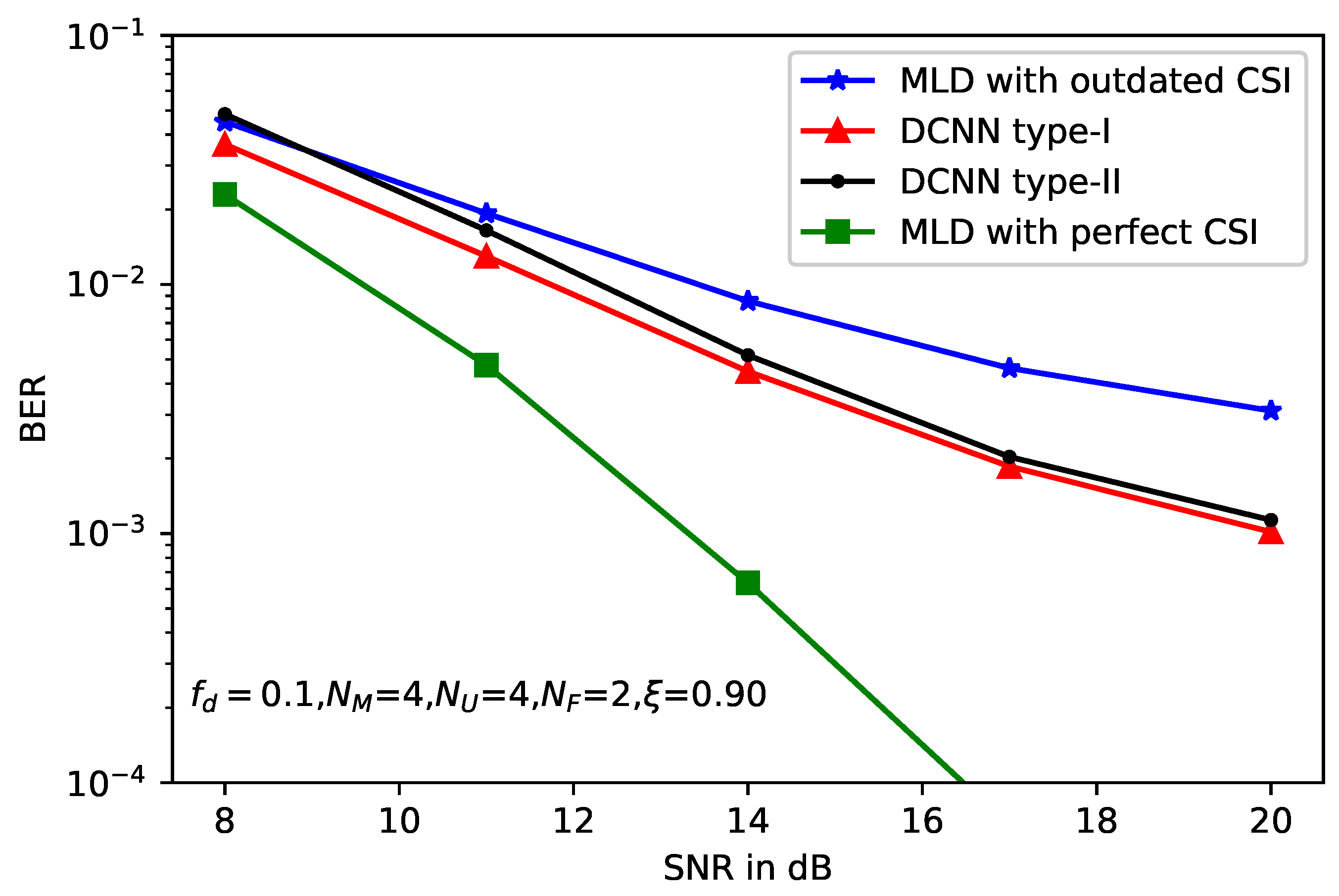
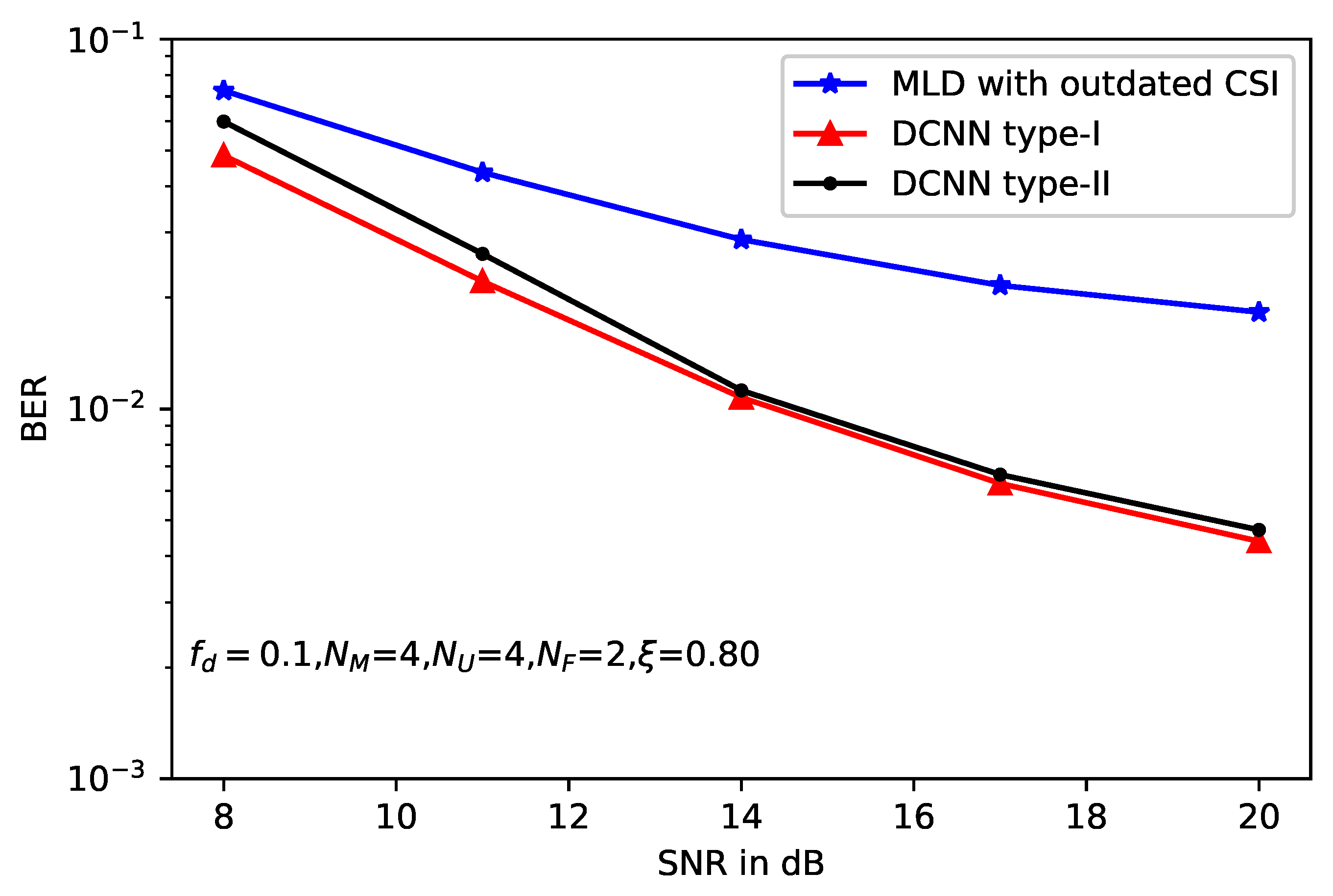
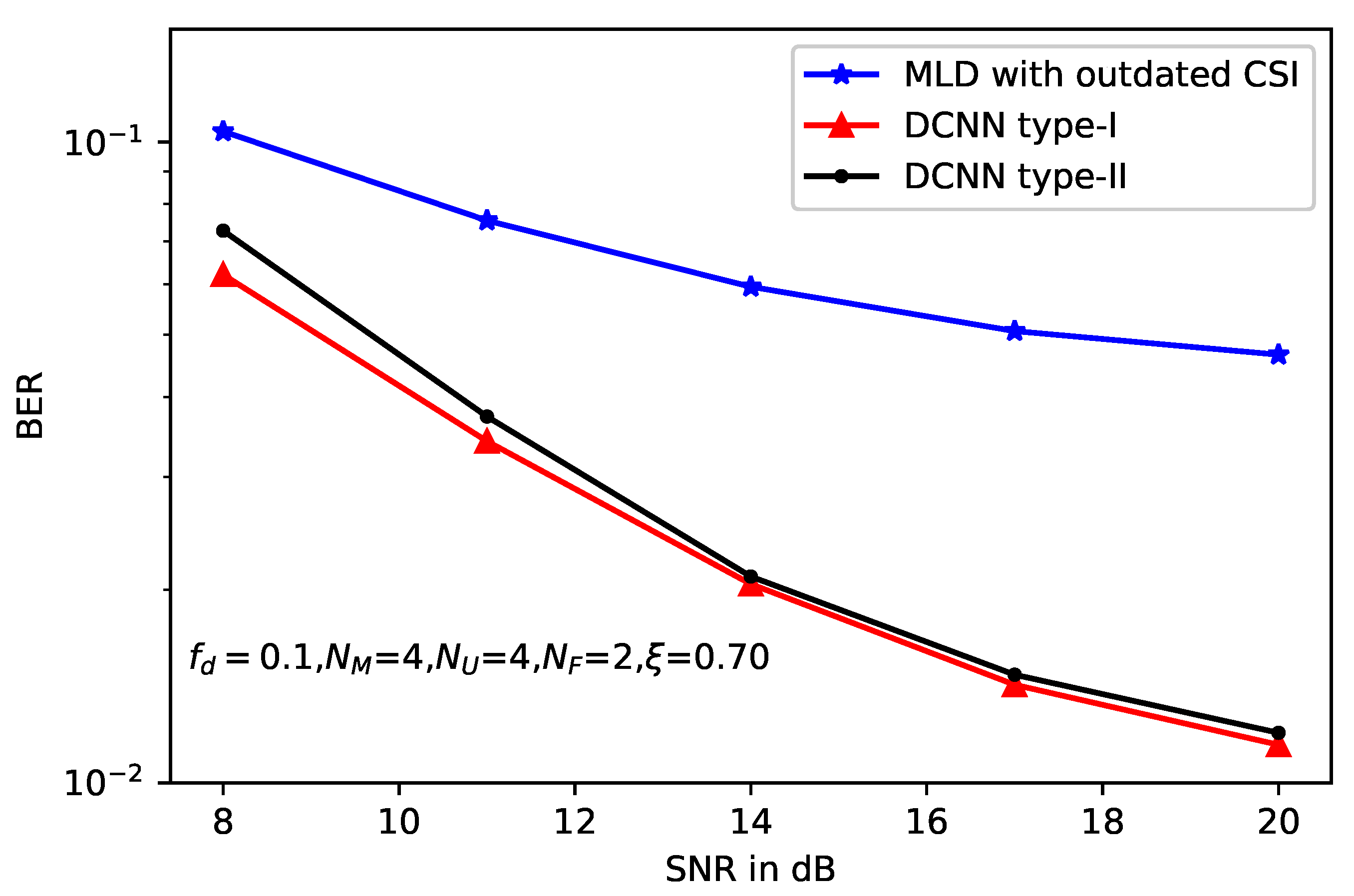
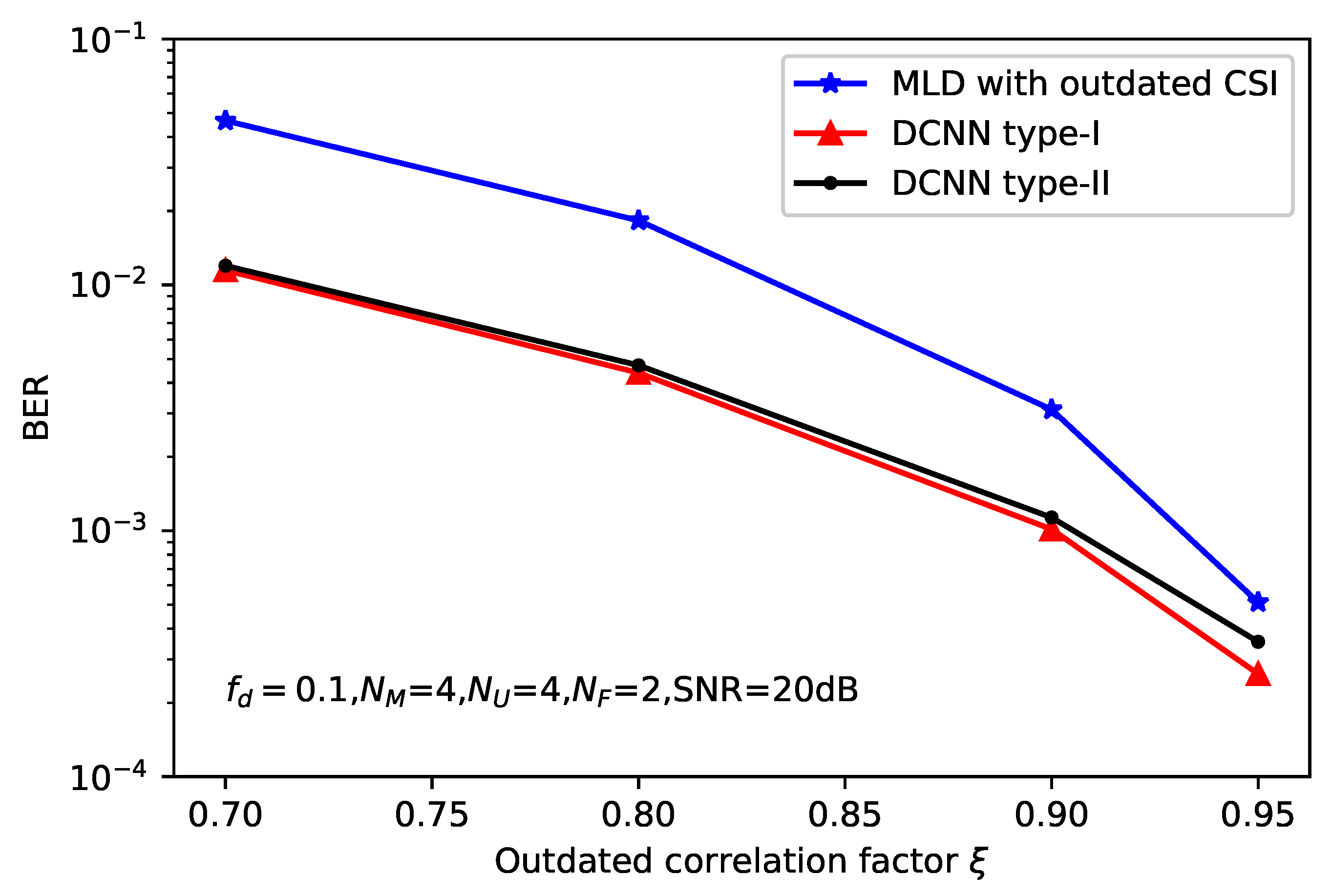
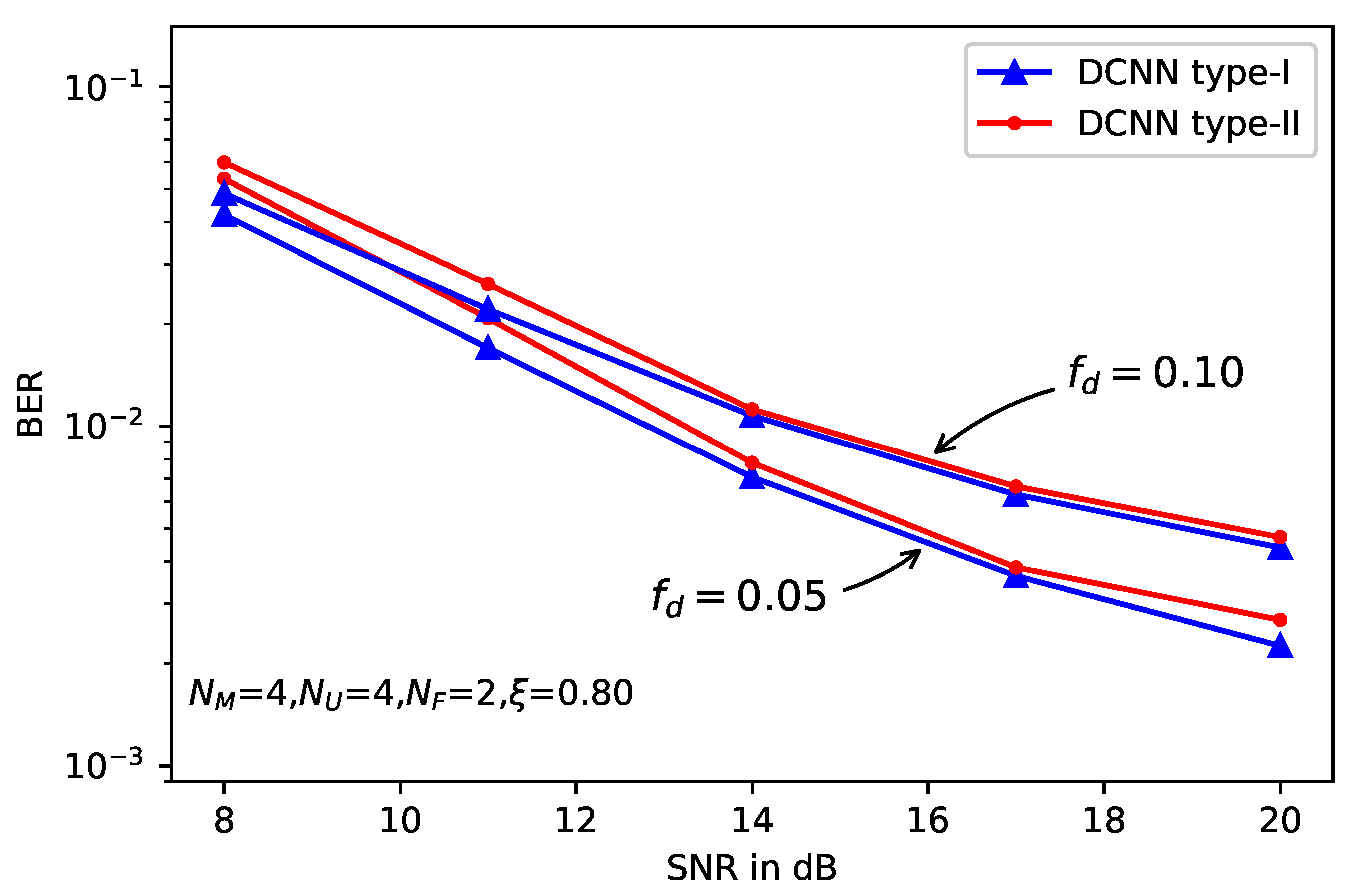
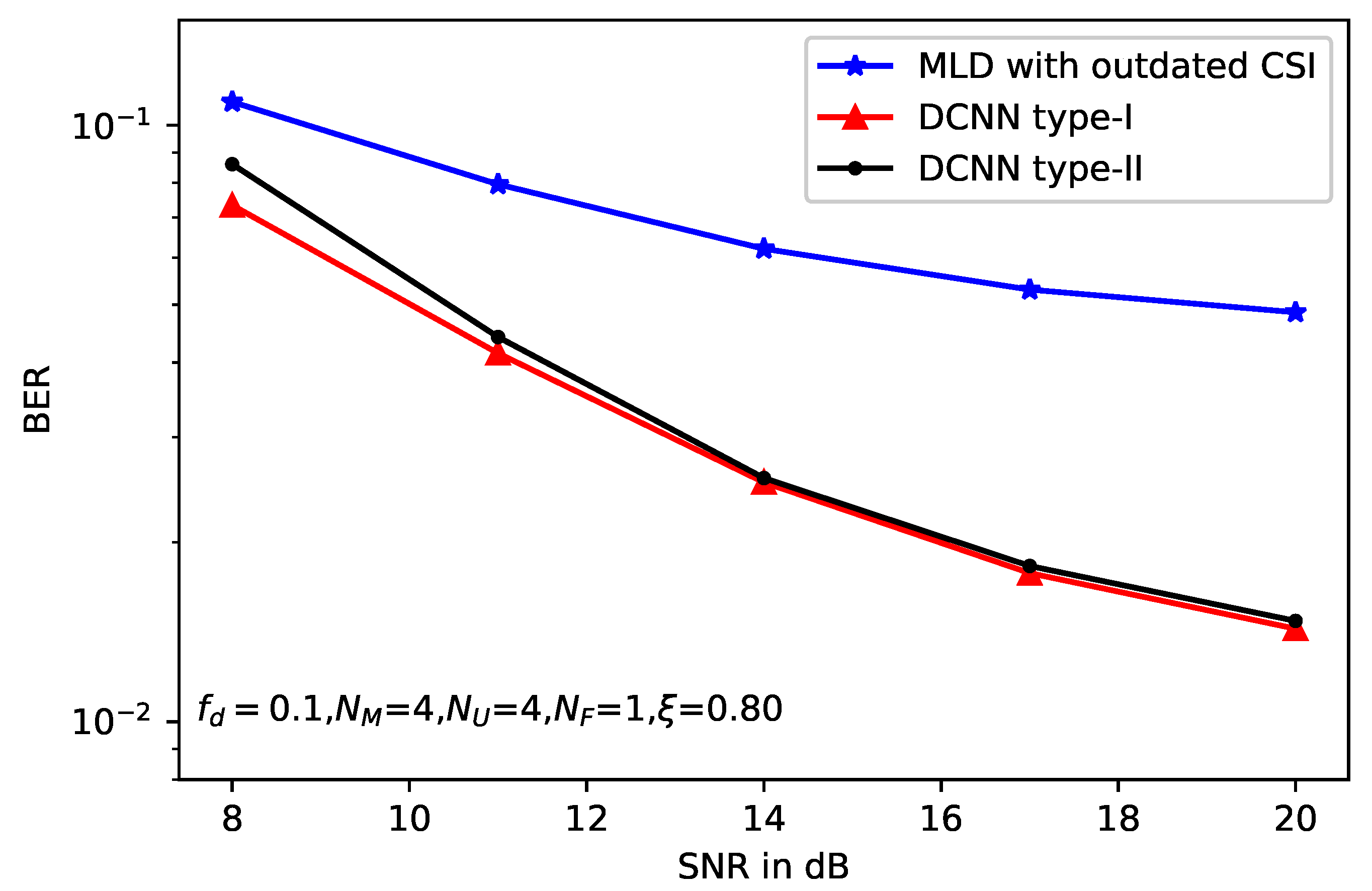
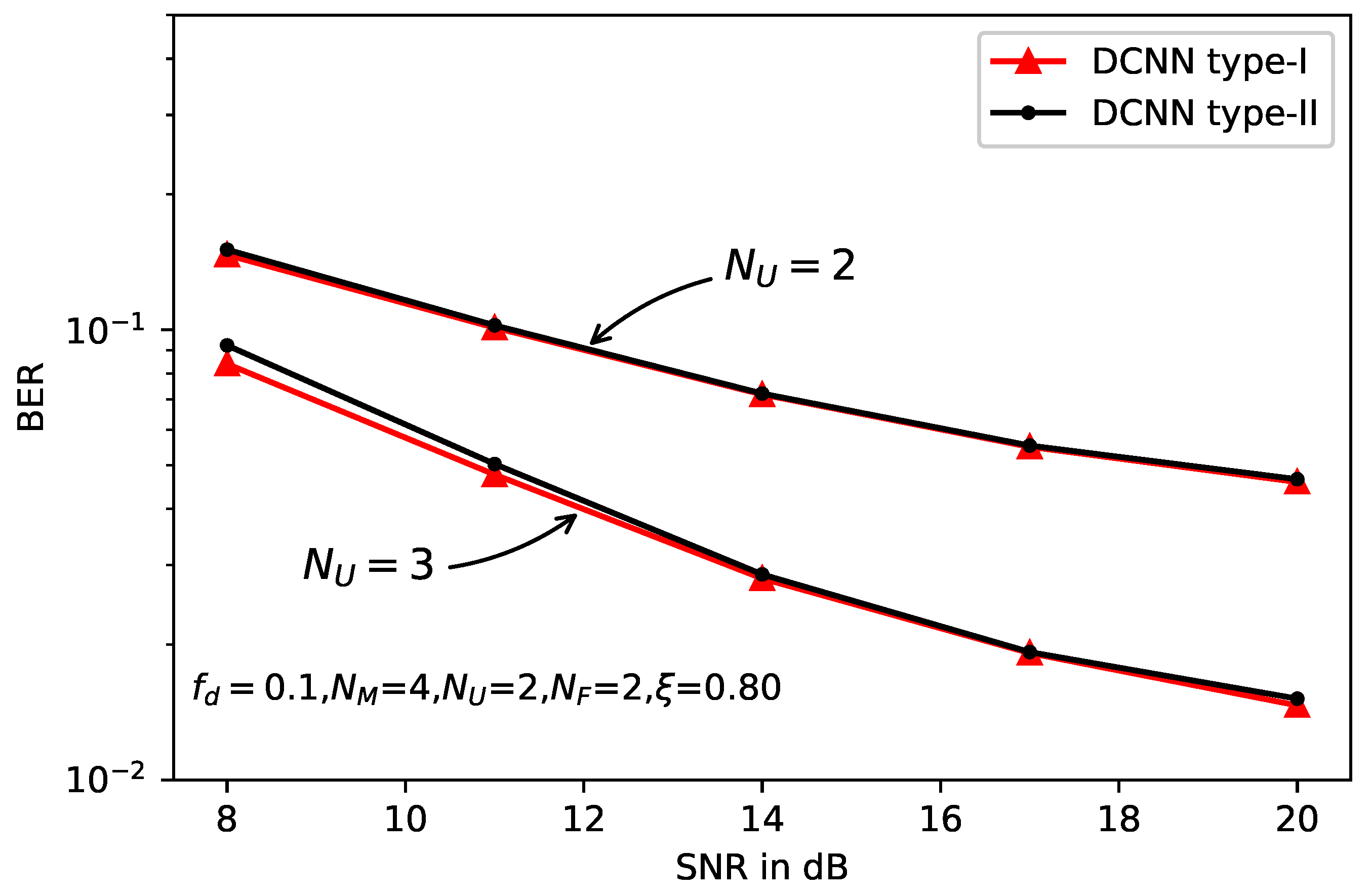
5. Simulation Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, D.; Bai, B.; Lei, K.; Zhao, W.; Yang, Y.; Han, Z. Enhancing Information Security via Physical Layer Approaches in Heterogeneous IoT With Multiple Access Mobile Edge Computing in Smart City. IEEE Access 2019, 7, 54508–54521. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Liu, Y.; Ding, Z.; Nallanathan, A. Residual Transceiver Hardware Impairments on Cooperative NOMA Networks. IEEE Trans. Inf. Forensics Secur. 2020, 19, 680–695. [Google Scholar] [CrossRef]
- Li, X.; Wang, Q.; Peng, H.; Zhang, H.; Do, D.-T.; Rabie, K.M.; Kharel, R.; Cavalcante, A. A Unified Framework for HS-UAV NOMA Networks: Performance Analysis and Location Optimization. IEEE Wirel. Commun. Lett. 2020, 8, 13329–13340. [Google Scholar] [CrossRef]
- Dai, P.; Liu, K.; Wu, X.; Liao, Y.; Lee, V.C.S.; Son, S.H. Bandwidth Efficiency and Service Adaptiveness Oriented Data Dissemination in Heterogeneous Vehicular Networks. IEEE Trans. Veh. Technol. 2018, 67, 6585–6598. [Google Scholar] [CrossRef]
- Zhou, Y.; Yu, F.R.; Chen, J.; Kuo, Y. Resource Allocation for Information-Centric Virtualized Heterogeneous Networks With In-Network Caching and Mobile Edge Computing. IEEE Trans. Veh. Technol. 2017, 66, 11339–11351. [Google Scholar] [CrossRef]
- Zhong, Z.; Peng, J.; Huang, K.; Zhong, Z. Analysis on Physical-Layer Security for Internet of Things in Ultra Dense Heterogeneous Networks. In Proceedings of the 2016 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Chengdu, China, 15–18 December 2016; pp. 39–43. [Google Scholar] [CrossRef]
- Wang, H.; Zheng, T.; Yuan, J.; Towsley, D.; Lee, M.H. Physical Layer Security in Heterogeneous Cellular Networks. IEEE Trans. Commun. 2016, 64, 1204–1219. [Google Scholar] [CrossRef]
- Wu, Y.; Khisti, A.; Xiao, C.; Caire, G.; Wong, K.; Gao, X. A Survey of Physical Layer Security Techniques for 5G Wireless Networks and Challenges Ahead. IEEE J. Sel. Areas Commun. 2018, 36, 679–695. [Google Scholar] [CrossRef]
- Tang, W.; Feng, S.; Ding, Y.; Liu, Y. Physical Layer Security in Heterogeneous Networks With Jammer Selection and Full-Duplex Users. IEEE Trans. Wireless Commun. 2017, 16, 7982–7995. [Google Scholar] [CrossRef]
- Ma, Z.; Lu, Y.; Shen, L.; Liu, Y.; Wang, N. Cooperative Jamming and Relay Beamforming Design for Physical Layer Secure Two-Way Relaying. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 333–3336. [Google Scholar] [CrossRef]
- Yang, N.; Yan, S.; Yuan, J.; Malaney, R.; Subramanian, R.; Land, I. Artificial Noise: Transmission Optimization in Multi-Input Single-Output Wiretap Channels. IEEE Trans. Commun. 2015, 63, 1771–1783. [Google Scholar] [CrossRef]
- Zheng, T.; Wang, H.; Yuan, J.; Towsley, D.; Lee, M.H. Multi-Antenna Transmission With Artificial Noise Against Randomly Distributed Eavesdroppers. IEEE Trans. Commun. 2015, 63, 4347–4362. [Google Scholar] [CrossRef]
- Wang, W.; Teh, K.C.; Luo, S.; Li, K.H. Physical Layer Security in Heterogeneous Networks With Pilot Attack: A Stochastic Geometry Approach. IEEE Trans. Commun. 2018, 66, 6437–6449. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, Z.; Li, K.; Liu, N.; Xia, B.; Luo, L. Caching-Aided Physical Layer Security in Wireless Cache-Enabled Heterogeneous Networks. IEEE Access 2018, 6, 68920–68931. [Google Scholar] [CrossRef]
- Zhu, J.; Gong, C.; Zhang, S.; Zhao, M.; Zhou, W. Foundation study on wireless big data: Concept, mining, learning and practices. Chin. Commun. 2018, 15, 1–15. [Google Scholar]
- Deng, D.; Fan, L.; Zhao, R.; Hu, R.Q. Secure communications in multiple amplify-and-forward relay networks with outdated channel state information. Trans. Emerging Telecommun. Technol. 2016, 27, 494–503. [Google Scholar] [CrossRef]
- Michalopoulos, D.S.; Suraweera, H.A.; Karagiannidis, G.K.; Schober, R. Amplify-and-Forward Relay Selection with Outdated Channel Estimates. IEEE Trans. Commun. 2012, 60, 1278–1290. [Google Scholar] [CrossRef]
- Fan, L.; Lei, X.; Fan, P.; Hu, R. Outage probability analysis and power allocation for two-way relay networks with user selection and outdated channel state information. IEEE Commun. Lett. 2012, 16, 638–641. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Li, L. Performance Analysis of Impaired SWIPT NOMA Relaying Networks Over Imperfect Weibull Channels. IEEE Syst. J. 2020, 99, 669–672. [Google Scholar] [CrossRef]
- Li, X.; Liu, M.; Deng, C. Full-Duplex Cooperative NOMA Relaying Systems With I/Q Imbalance and Imperfect SIC. IEEE Wirel. Commun. Lett. 2020, 9, 17–20. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Li, L.; Jin, J.; Zhang, J.; Zhang, D. Effective Rate of MISO Systems Over κ - μ Shadowed Fading Channels. IEEE Access 2017, 5, 10605–10611. [Google Scholar] [CrossRef]
- Wu, Y.; Louie, R.H.Y.; McKay, M.R. Analysis and Design of Wireless Ad Hoc Networks With Channel Estimation Errors. IEEE Trans. Signal Process. 2013, 61, 1447–1459. [Google Scholar] [CrossRef]
- Savazzi, S.; Spagnolini, U. Optimizing Training Lengths and Training Intervals in Time-Varying Fading Channels. IEEE Trans. Signal Process. 2009, 57, 1098–1112. [Google Scholar] [CrossRef]
- Han, S.; Tian, Y.; Yang, C. User-Specified Training Symbol Placement for Channel Prediction in TDD MIMO Systems. IEEE Trans. Veh. Technol. 2011, 60, 2837–2843. [Google Scholar] [CrossRef]
- Soltani, M.; Pourahmadi, V.; Mirzaei, A.; Sheikhzadeh, H. Deep Learning-Based Channel Estimation. IEEE Commun. Lett. 2019, 23, 652–655. [Google Scholar] [CrossRef]
- Balevi, E.; Andrews, J.G. One-Bit OFDM Receivers via Deep Learning. IEEE Trans. Commun. 2019, 67, 4326–4336. [Google Scholar] [CrossRef]
- Wu, Y.; Li, X.; Fang, J. A Deep Learning Approach for Modulation Recognition via Exploiting Temporal Correlations. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Yuan, J.; Ngo, H.Q.; Matthaiou, M. Machine Learning-Based Channel Prediction in Massive MIMO with Channel Aging. IEEE Trans. Wireless Commun. 2020, 1. [Google Scholar] [CrossRef]
- Amirabadi, M.A. Deep learning for channel estimation in FSO communication system. arXiv 2020, arXiv:1909.11003. [Google Scholar] [CrossRef]
- Amirabadi, M.A. A deep learning based solution for imperfect CSI problem in correlated FSO communication channel. arXiv 2020, arXiv:1909.11002. [Google Scholar]
- Yang, N.; Elkashlan, M.; Duong, T.Q.; Yuan, J.; Malaney, R. Optimal Transmission With Artificial Noise in MISOME Wiretap Channels. IEEE Trans. Veh. Technol. 2016, 65, 2170–2181. [Google Scholar] [CrossRef]
- Fritschek, R.; Schaefer, R.F.; Wunder, G. Deep Learning for the Gaussian Wiretap Channel. In Proceedings of the 2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xing, J.; Lv, T.; Zhang, X. Cooperative Relay Based on Machine Learning for Enhancing Physical Layer Security. In Proceedings of the 2019 IEEE 30th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Istanbul, Turkey, 8–11 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Xiao, L.; Sheng, G.; Liu, S.; Dai, H.; Peng, M.; Song, J. Deep Reinforcement Learning-Enabled Secure Visible Light Communication Against Eavesdropping. IEEE Trans. Commun. 2019, 67, 6994–7005. [Google Scholar] [CrossRef]
- He, D.; Liu, C.; Wang, H.; Quek, T.Q.S. Learning-Based Wireless Powered Secure Transmission. IEEE Wirel. Commun. Lett. 2019, 8, 600–603. [Google Scholar] [CrossRef]
- Xiao, L.; Li, Y.; Han, G.; Dai, H.; Poor, H.V. A Secure Mobile Crowdsensing Game With Deep Reinforcement Learning. IEEE Trans. Inf. Forensics Secur. 2018, 13, 35–47. [Google Scholar] [CrossRef]
- Simon, M.K.; Alouini, M.S. Digital Communication Over Fading, 2nd ed.; Wiley: Hoboken, NJ, USA, 2005. [Google Scholar]
- Ji, Y.; Fan, W.; Kyösti, P.; Li, J.; Pedersen, G.F. Antenna Correlation Under Geometry-Based Stochastic Channel Models. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 2567–2571. [Google Scholar] [CrossRef]
- Jiang, Z.; Chen, S.; Molisch, A.F.; Vannithamby, R.; Zhou, S.; Niu, Z. Exploiting Wireless Channel State Information Structures Beyond Linear Correlations: A Deep Learning Approach. IEEE Commun. Mag. 2019, 57, 28–34. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Engineering Applications of Neural Networks; Jayne, C., Iliadis, L., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 213–226. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Jian, S. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. Available online: http://download.tensorflow.org/paper/whitepaper2015.pdf (accessed on 20 March 2020).











© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, D.; Li, X.; Zhao, M.; Rabie, K.M.; Kharel, R. Deep Learning-Based Secure MIMO Communications with Imperfect CSI for Heterogeneous Networks. Sensors 2020, 20, 1730. https://doi.org/10.3390/s20061730
Deng D, Li X, Zhao M, Rabie KM, Kharel R. Deep Learning-Based Secure MIMO Communications with Imperfect CSI for Heterogeneous Networks. Sensors. 2020; 20(6):1730. https://doi.org/10.3390/s20061730
Chicago/Turabian StyleDeng, Dan, Xingwang Li, Ming Zhao, Khaled M. Rabie, and Rupak Kharel. 2020. "Deep Learning-Based Secure MIMO Communications with Imperfect CSI for Heterogeneous Networks" Sensors 20, no. 6: 1730. https://doi.org/10.3390/s20061730
APA StyleDeng, D., Li, X., Zhao, M., Rabie, K. M., & Kharel, R. (2020). Deep Learning-Based Secure MIMO Communications with Imperfect CSI for Heterogeneous Networks. Sensors, 20(6), 1730. https://doi.org/10.3390/s20061730