TAI-SARNET: Deep Transferred Atrous-Inception CNN for Small Samples SAR ATR


 ,
,
Abstract
1. Introduction
- (1)
- An improved lightweight CNN model based on the Atrous convolution and Inception module is proposed. This model can obtain a rich global receptive field, effectively preventing the network from overfitting, and obtain high recognition accuracy on the MSTAR dataset.
- (2)
- The Atrous-Inception module is designed to extract more detailed target feature information, and it has strong robustness on a small sample dataset of the constructed SAR targets images.
- (3)
- The transfer learning strategy is used to explore the performance of the prior knowledge based on optical, non-optical, hybrid optical and non-optical fields transferred to the SAR targets images recognition tasks, further improving the robustness as well as the generalization of the model on the SAR small sample datasets.
2. Related Work
2.1. CNN
2.2. Transfer Learning
3. Proposed Methods
3.1. Proposed Network
3.2. Atrous-Inception Module
3.3. RMSProp Optimization
3.4. Transfer Learning
4. Experimental Results and Analysis
4.1. Dataset
4.2. Experimental Environment and Configuration
4.3. Training/Validation Strategy
4.4. Analysis of the Proposed TAI-SARNET
4.4.1. Evaluation on Various Dilated Rate
4.4.2. Evaluation on Various Atrous-Inception Module
4.4.3. Evaluation on Various Merge Ways
4.4.4. Evaluation on BN
4.4.5. Confusion Matrix
4.5. Robustness Evaluation on Small Samples Dataset
4.6. Transfer Learning on Small Samples dataset
4.6.1. Transferring Prior Knowledge of Optical Images
4.6.2. Transferring Prior Knowledge of Non-Optical Images
4.6.3. Transferring Prior Knowledge of Mixed Optical and Non-Optical Images
4.7. Comparison Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tait, P. Introduction to Radar Target Recognition; The Institution of Engineering and Technology (IET): Stevenage, UK, 2005; Volume 18. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Bartlett, M.S.; Movellan, J.R.; Sejnowski, T.J. Face recognition by independent component analysis. IEEE Trans. Neural Netw. 2002, 13, 1450–1464. [Google Scholar] [CrossRef] [PubMed]
- Hall-Beyer, M. Practical guidelines for choosing GLCM textures to use in landscape classification tasks over a range of moderate spatial scales. Int. J. Remote Sens. 2017, 38, 1312–1338. [Google Scholar] [CrossRef]
- Kar, N.B.; Babu, K.S.; Jena, S.K. Face expression recognition using histograms of oriented gradients with reduced features. In Proceedings of the International Conference on Computer Vision and Image Processing, IIT Roorkee, India, 26–28 February 2016; Springer: Singapore, 2017; pp. 209–219. [Google Scholar] [CrossRef]
- Xu, G.; Wang, X.; Huang, Y.; Cai, L.; Jiang, Z. Joint Multi-Channel Sparse Method of Robust PCA for SAR Ground Moving Target Image Indication. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1709–1712. [Google Scholar] [CrossRef]
- Vasile, G. Independent Component Analysis Based Incoherent Target Decompositions for Polarimetric SAR Data-Practical Aspects. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 5859–5862. [Google Scholar] [CrossRef]
- Numbisi, F.N.; Van Coillie, F.; De Wulf, R. Delineation of Cocoa Agroforests Using Multiseason Sentinel-1 SAR Images: A Low Grey Level Range Reduces Uncertainties in GLCM Texture-Based Mapping. ISPRS Int. J. Geo-Inf. 2019, 8, 179. [Google Scholar] [CrossRef]
- Song, S.; Xu, B.; Yang, J. SAR target recognition via supervised discriminative dictionary learning and sparse representation of the SAR-HOG feature. Remote Sens. 2016, 8, 683. [Google Scholar] [CrossRef]
- Maulik, U.; Chakraborty, D. Remote Sensing Image Classification: A survey of support-vector-machine-based advanced techniques. IEEE Geosci. Remote Sens. Mag. 2017, 5, 33–52. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Biswas, N.; Chakraborty, S.; Mullick, S.S.; Das, S. A parameter independent fuzzy weighted k-nearest neighbor classifier. Pattern Recognit. Lett. 2018, 101, 80–87. [Google Scholar] [CrossRef]
- Sukawattanavijit, C.; Chen, J.; Zhang, H. GA-SVM algorithm for improving land-cover classification using SAR and optical remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 284–288. [Google Scholar] [CrossRef]
- Kim, S.; Song, W.J.; Kim, S.H. Robust ground target detection by SAR and IR sensor fusion using adaboost-based feature selection. Sensors 2016, 16, 1117. [Google Scholar] [CrossRef]
- Hou, B.; Kou, H.; Jiao, L. Classification of polarimetric SAR images using multilayer autoencoders and superpixels. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 3072–3081. [Google Scholar] [CrossRef]
- Eryildirim, A.; Cetin, A.E. Man-made object classification in SAR images using 2-D cepstrum. In Proceedings of the 2009 IEEE Radar Conference, Pasadena, CA, USA, 4–8 May 2009; pp. 1–4. [Google Scholar] [CrossRef]
- Clemente, C.; Pallotta, L.; Proudler, I.; De Maio, A.; Soraghan, J.J.; Farina, A. Pseudo-Zernike-based multi-pass automatic target recognition from multi-channel synthetic aperture radar. IET Radar Sonar Navig. 2015, 9, 457–466. [Google Scholar] [CrossRef]
- Sun, Y.; Du, L.; Wang, Y.; Wang, Y.; Hu, J. SAR automatic target recognition based on dictionary learning and joint dynamic sparse representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1777–1781. [Google Scholar] [CrossRef]
- Clemente, C.; Pallotta, L.; Gaglione, D.; De Maio, A.; Soraghan, J.J. Automatic Target Recognition of Military Vehicles with Krawtchouk Moments. IEEE Trans. Aerosp. Electron. Syst. 2017, 53, 493–500. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–13 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR image despeckling through convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar] [CrossRef]
- Pei, J.; Huang, Y.; Huo, W.; Zhang, Y.; Yang, J.; Yeo, T.S. SAR automatic target recognition based on multiview deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2196–2210. [Google Scholar] [CrossRef]
- Dong, H.; Xu, X.; Wang, L.; Pu, F. Gaofen-3 PolSAR image classification via XGBoost and polarimetric spatial information. Sensors 2018, 18, 611. [Google Scholar] [CrossRef]
- Wang, L.; Xu, X.; Dong, H.; Gui, R.; Pu, F. Multi-pixel simultaneous classification of PolSAR image using convolutional neural networks. Sensors 2018, 18, 769. [Google Scholar] [CrossRef]
- Shao, J.; Qu, C.; Li, J.; Peng, S. A lightweight convolutional neural network based on visual attention for sar image target classification. Sensors 2018, 18, 3039. [Google Scholar] [CrossRef]
- Zhang, Q.; Wei, X.; Xiang, D.; Sun, M. Supervised PolSAR Image Classification with Multiple Features and Locally Linear Embedding. Sensors 2018, 18, 3054. [Google Scholar] [CrossRef] [PubMed]
- He, C.; Xiong, D.; Zhang, Q.; Liao, M. Parallel Connected Generative Adversarial Network with Quadratic Operation for SAR Image Generation and Application for Classification. Sensors 2019, 19, 871. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. In Proceedings of the International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014; pp. 14–16. [Google Scholar]
- MSTAR, SAR. Data Set, Clutter and Targets, Collected by Sandia National Lab, Released by DARPA. MSTAR Data Collection. 1995. Available online: https://www.sdms.afrl.af.mil/index.php?collection=mstar (accessed on 19 March 2020).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–5 February 2017; pp. 4278–4284. [Google Scholar]
- Shao, J.; Qu, C.; Li, J. A performance analysis of convolutional neural network models in SAR target recognition. In Proceedings of the 2017 SAR in Big Data Era: Models, Methods and Applications (BIGSARDATA), Beijing, China, 13–14 November 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, S.Q.; Zhan, R.H.; Zhang, J. Robust single stage detector based on two-stage regression for SAR ship detection. In Proceedings of the 2nd International Conference on Innovation in Artificial Intelligence, Shanghai, China, 9–12 March 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Zhao, Z. Study on the Classification of Gaofen-3 Polarimetric SAR Images Using Deep Neural Network. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 2263–2266. [Google Scholar] [CrossRef]
- Wang, C.; Tandeo, P.; Mouche, A.; Stopa, J.E.; Gressani, V.; Longepe, N.; Vandemark, D.; Foster, R.C.; Chapron, B. Classification of the global Sentinel-1 SAR vignettes for ocean surface process studies. Remote Sens. Environ. 2019, 234, 111457–111468. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. J. Big Data 2016, 3, 9–49. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer learning with deep convolutional neural network for SAR target classification with limited labeled data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef]
- Malmgren-Hansen, D.; Kusk, A.; Dall, J.; Nielsen, A.A.; Engholm, R.; Skriver, H. Improving SAR automatic target recognition models with transfer learning from simulated data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1484–1488. [Google Scholar] [CrossRef]
- Zhong, C.; Mu, X.; He, X.; Wang, J.; Zhu, M. SAR Target Image Classification Based on Transfer Learning and Model Compression. IEEE Geosci. Remote Sens. Lett. 2018, 16, 412–416. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhan, R.H.; Tian, Z.Z.; Hu, J.M. SAR automatic target recognition based on deep convolutional neural network. In Proceedings of the 2016 International Conference on Artificial Intelligence: Techniques and Applications, Shanghai, China, 25–26 September 2016; pp. 170–178. [Google Scholar]
- Song, H.; Ji, K.; Zhang, Y.; Xing, X.; Zou, H. Sparse representation-based SAR image target classification on the 10-class MSTAR data set. Appl. Sci. 2016, 6, 26. [Google Scholar] [CrossRef]
- Tan, J.; Fan, X.; Wang, S.; Ren, Y. Target Recognition of SAR Images via Matching Attributed Scattering Centers with Binary Target Region. Sensors 2018, 18, 3019. [Google Scholar] [CrossRef] [PubMed]
- Jiang, T.; Cui, Z.; Zhou, Z.; Cao, Z. Data Augmentation with Gabor Filter in Deep Convolutional Neural Networks for Sar Target Recognition. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 689–692. [Google Scholar] [CrossRef]
- Miao, S.; Liu, X. Joint sparse representation of complementary components in SAR images for robust target recognition. J. Electromagn. Waves Appl. 2019, 33, 882–896. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
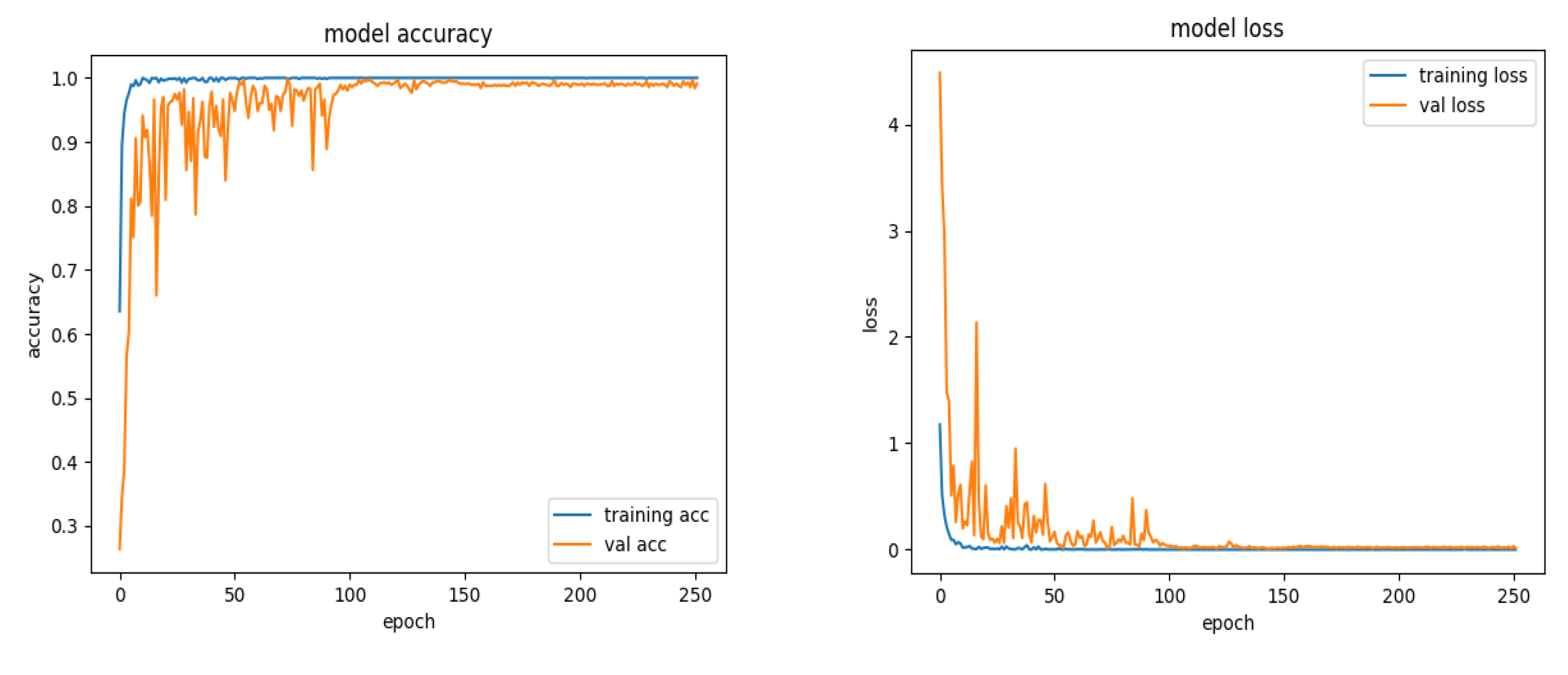{kind=link}
{kind=link}
| Description | Output Size | Filter Size/Stride | Parameters |
|---|---|---|---|
| Input | 64 × 64 × 1 | - | - |
| Conv1 | 31 × 31 × 32 | 3 × 3/2 | 288 |
| BN | 31 × 31 × 32 | - | 96 |
| Conv2 | 29 × 29 × 32 | 3 × 3/1 | 9216 |
| BN | 29 × 29 × 32 | - | 96 |
| Conv3 | 29 × 29 × 64 | 3 × 3/1 | 18,432 |
| BN | 29 × 29 × 64 | - | 192 |
| Maxpool | 14 × 14 × 64 | 3 × 3/2 | - |
| Conv4 | 14 × 14 × 80 | 1 × 1/1 | 5120 |
| BN | 14 × 14 × 80 | - | 240 |
| Atrous-Inception module | 14 × 14 × 96 | - | 395,616 |
| Atrous-Conv | 6 × 6 × 256 | 3 × 3/1 | 221,184 |
| BN | 6 × 6 × 256 | - | 768 |
| Global Averagepool | 256 | - | - |
| Softmax | 10 | - | 2570 |
| Total | 653,818 |
| Types | Tops | Train Set | Test Set | Image Size | ||||
|---|---|---|---|---|---|---|---|---|
| Serial | Depression Angle | Number | Serial | Depression Angle | Number | |||
| 2S1 | Artillery | B_01 | 17° | 299 | B_01 | 15° | 274 | 64 × 64 |
| ZSU234 | D_08 | 17° | 299 | D_08 | 15° | 274 | 64 × 64 | |
| BRDM2 | Truck | E_71 | 17° | 298 | E_71 | 15° | 274 | 64 × 64 |
| BTR60 | K10YT | 17° | 256 | K10YT | 15° | 195 | 64 × 64 | |
| BTR70 | C_71 | 17° | 233 | C_71 | 15° | 196 | 64 × 64 | |
| BMP2 | 9563 | 17° | 233 | 9563 | 15° | 587 | 64 × 64 | |
| 9566 | ||||||||
| C21 | ||||||||
| D7 | 92V | 17° | 299 | 92V | 15° | 274 | 64 × 64 | |
| ZIL131 | E_12 | 17° | 299 | E_12 | 15° | 274 | 64 × 64 | |
| T62 | Tank | A_51 | 17° | 299 | A_51 | 15° | 273 | 64 × 64 |
| T72 | 132 | 17° | 232 | 132 | 15° | 582 | 64 × 64 | |
| 812 | ||||||||
| S7 | ||||||||
| Total | 2747 | 3203 | ||||||
| Model | Rate | Accuracy (%) |
|---|---|---|
| TAI-SARNET | 1 | 91.72 |
| 2 | 95.56 | |
| 4 | 97.97 | |
| 6 | 88.63 | |
| 8 | - |
| Module | Number | Parameter | Accuracy (%) |
|---|---|---|---|
| Atrous-Inception module | 0 | 221,338 | 94.28 |
| 1 | 653,818 | 97.97 | |
| 2 | 1,077,082 | 96.31 | |
| 3 | 1,500,346 | 95.59 |
| Module | Type | Parameter | Accuracy (%) |
|---|---|---|---|
| Atrous-Inception module | Concatenate | 1,317,370 | 95.94 |
| Add | 653,818 | 96.32 | |
| Multiply | 653,818 | 93.35 | |
| Average | 653,818 | 95.32 | |
| Minimum | 653,818 | 93.41 | |
| Maximum | 653,818 | 97.97 |
| Model | BN | Accuracy (%) |
|---|---|---|
| TAI-SARNET | No | 89.60 |
| Yes | 97.97 |
| Types | Artillery | Truck | Tank | Acc (%) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2S1 | ZSU234 | BRDM2 | BTR60 | BTR70 | BMP2 | D7 | ZIL131 | T62 | T72 | ||
| 2S1 | 274 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| ZSU234 | 0 | 273 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 99.64 |
| BRDM2 | 2 | 0 | 271 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 98.91 |
| BTR60 | 4 | 0 | 3 | 176 | 11 | 0 | 0 | 1 | 0 | 0 | 90.26 |
| BTR70 | 1 | 0 | 0 | 0 | 195 | 0 | 0 | 0 | 0 | 0 | 99.49 |
| BMP2 | 5 | 0 | 2 | 1 | 7 | 558 | 0 | 0 | 0 | 14 | 95.06 |
| D7 | 0 | 1 | 0 | 0 | 0 | 0 | 273 | 0 | 0 | 0 | 99.64 |
| ZIL131 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 271 | 0 | 0 | 98.91 |
| T62 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 273 | 0 | 100 |
| T72 | 4 | 0 | 0 | 0 | 1 | 3 | 0 | 0 | 0 | 574 | 98.63 |
| Total | 97.97 | ||||||||||
| Method | Parameter | Model Size (Mb) | Accuracy (%) |
|---|---|---|---|
| LeNet | 1,134,806 | 9.1 | 87.96 |
| AlexNet | 21,598,922 | 172.8 | 93.40 |
| VGG16 | 39,928,522 | 319.5 | 90.15 |
| ResNet50 | 23,601,930 | 189.2 | 89.59 |
| MobileNet | 3,238,538 | 26.1 | 91.96 |
| TAI-SARNET | 653,818 | 5.4 | 97.97 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ying, Z.; Xuan, C.; Zhai, Y.; Sun, B.; Li, J.; Deng, W.; Mai, C.; Wang, F.; Labati, R.D.; Piuri, V.; et al. TAI-SARNET: Deep Transferred Atrous-Inception CNN for Small Samples SAR ATR. Sensors 2020, 20, 1724. https://doi.org/10.3390/s20061724
Ying Z, Xuan C, Zhai Y, Sun B, Li J, Deng W, Mai C, Wang F, Labati RD, Piuri V, et al. TAI-SARNET: Deep Transferred Atrous-Inception CNN for Small Samples SAR ATR. Sensors. 2020; 20(6):1724. https://doi.org/10.3390/s20061724
Chicago/Turabian StyleYing, Zilu, Chen Xuan, Yikui Zhai, Bing Sun, Jingwen Li, Wenbo Deng, Chaoyun Mai, Faguan Wang, Ruggero Donida Labati, Vincenzo Piuri, and et al. 2020. "TAI-SARNET: Deep Transferred Atrous-Inception CNN for Small Samples SAR ATR" Sensors 20, no. 6: 1724. https://doi.org/10.3390/s20061724
APA StyleYing, Z., Xuan, C., Zhai, Y., Sun, B., Li, J., Deng, W., Mai, C., Wang, F., Labati, R. D., Piuri, V., & Scotti, F. (2020). TAI-SARNET: Deep Transferred Atrous-Inception CNN for Small Samples SAR ATR. Sensors, 20(6), 1724. https://doi.org/10.3390/s20061724