1. Introduction
With the rapid development of industrial technology, the complexity of engineering systems has increased significantly [
1,
2,
3,
4]. The increase in the failure cost of the system prompts people to pay more attention to the reliability and safety of the system [
5]. Therefore, prognostics and health management (PHM) technology are widely studied and applied in the industry [
3,
4,
6]. PHM is a method that allows for an assessment of the reliability of a system under actual application conditions. It uses the sensors to monitor the health status of a system for fault diagnosis, life prediction, and condition-based maintenance, which guides the decision making and reduces the usage and maintenance costs [
7,
8].
The sensor plays a significant role in PHM technology [
7,
9,
10,
11]. It is the basis of data for state evaluation and life prediction, and its selection result has a direct influence on the application effect of PHM [
12]. Therefore, it is vital to optimize sensor selection to reduce the scale of sensors and obtain the same or an even better monitoring effect. The existing sensor selection methods can be grouped into two categories: the model-based method [
10,
13,
14,
15,
16] and the optimization method considering testability constraints [
17,
18]. The former establishes a graph or mathematical model to describe the relationship between the sensors and failure modes, such as the dependency model, heuristic graph, and state diagram. Based on the models, the sensor selection results can be output through automatic traversal or matrix operation. The procedure of the later can be summarized in four steps: (1) determining an optimization goal (cost or time minimization); (2) defining testability indexes to describe testability requirement; (3) constructing the mathematical relationship between the goal and testability indexes; (4) using or designing an algorithm to solve the optimization problem under the constraints of the testability indexes. Usually, the testability indexes contain a fault detectable rate, a critical fault detectable failure rate, a fault isolation rate, and a fault prognostic rate [
18,
19,
20]. The heuristic algorithm is commonly used to solve the optimization problem, such as particle swarm and genetic algorithm [
20,
21].
However, a common weakness of the existing methods is that these methods do not have a standard to select sensors, which leads to a hard choice, facing the different selection results given by these methods. In the model-based way, it cannot give a proper selection for the equivalent sensors, which have the same testing response. In the optimization way, the parameter setting of the heuristic algorithm has a vital effect on the optimization, resulting in an unstable selection result [
22]. Meanwhile, the mathematical relationship is hard to be constructed because different types of parameters are difficult to be unified and processed. Therefore, it is necessary to form a principle to evaluate sensor selection of different methods, which helps to choose a better result by contrast and even adjust sensors based on the evaluation result to give a more convincing and reasonable result.
In this paper, we propose a comprehensive evaluation method of sensor selection for PHM based on grey clustering. This method is dedicated to evaluating the sensor selection according to its multiple relevant factors to give a more reasonable and convincing selection result. Sensor selection is a process full of uncertainty, and its result depends on expert advice, similar product experience, or measured data. For eliminating or reducing the uncertainty, the grey clustering is introduced and applied. Grey clustering is an important part of the grey theory, and it mainly studies the uncertainty of the system, which is suitable and active for evaluating sensor selection. Based on the method, the key factors are considered based on the previous studies, and they are quantized, manifested, and whitened, which can give a criterion for the evaluation of sensor selection. In the calculation process of grey clustering, the data in different types can be unified. The process also expands the range of evaluation indexes, which improves the comprehensiveness of evaluation result. Meanwhile, the weight in the grey clustering is extended to a combination weight considering subjective and objective factors, which is helpful to give a more valid result.
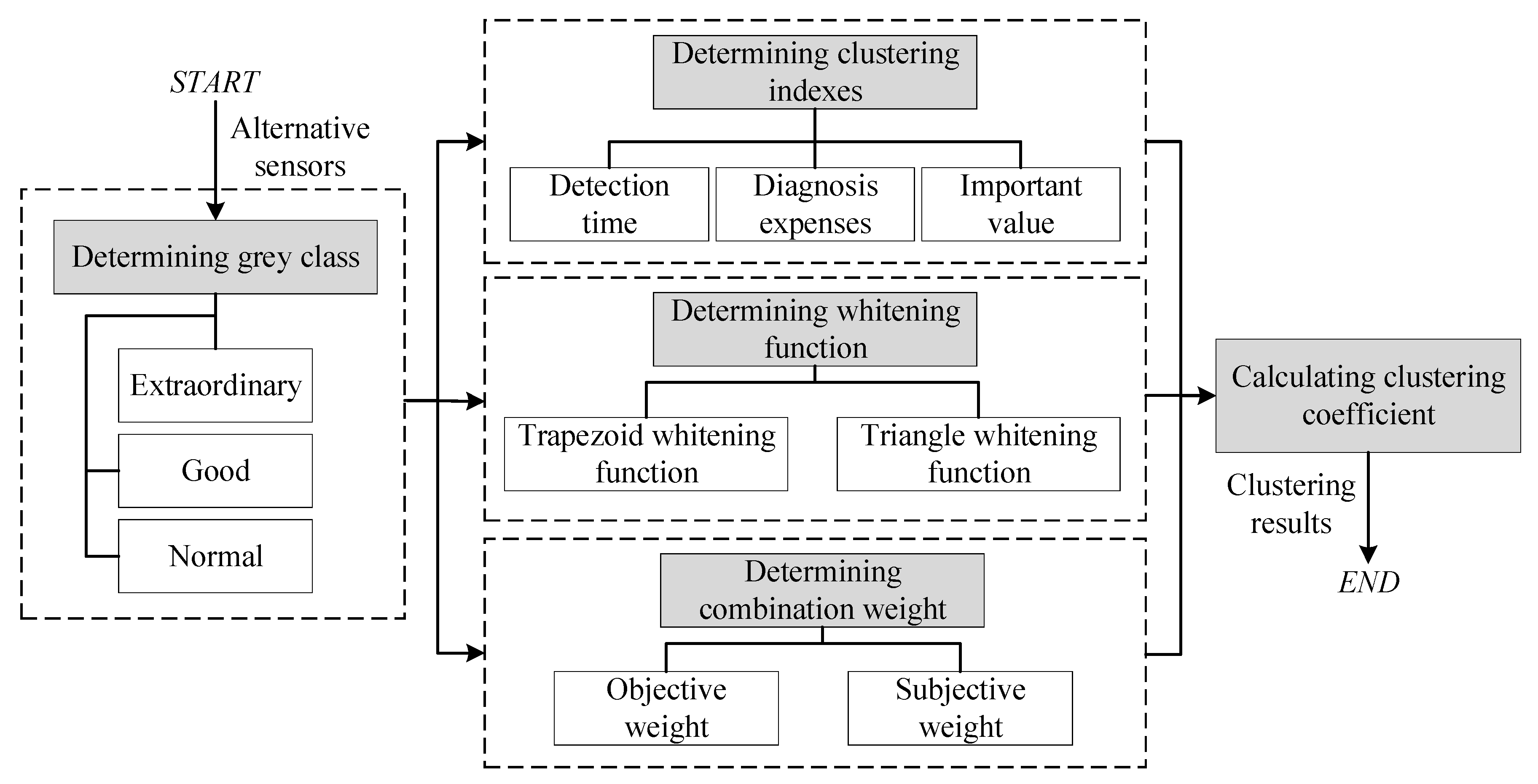
The workflow of the proposed method is shown in
Figure 1. Firstly, we divide the sensors (clustering object) into three grey classes: extraordinary, good, and normal, which learns from the state division of equipment [
23]. Based on the previous work on sensor selection, we determine three clustering indexes: the detection time, diagnosis expense, and importance value [
15,
18], which covers the factors related to sensor selection, and the indexes are quantified based on the dependency model. Then, we determine the whitening weight function to define the extent to which the clustering index belongs to a grey class, and propose a new and reasonable combination weight of the index to grey class considering the objective data and subjective factors. Finally, we obtain the sensor evaluation result by analyzing the clustering coefficients, which is calculated by the whitening weight function and the combination weight. To improve the selection result, we evaluate the selection result given by the dependency model and genetic algorithm (GA) because the two methods are commonly utilized in sensor selection. The evaluation principle is the proportion of good and extraordinary sensors. An electronic control system is taken as an example to illustrate the effectiveness of the proposed method.
The rest of this paper is organized as follows.
Section 2 gives the grey clustering model of sensors evaluation.
Section 3 describes an example in which the proposed method is applied. Finally, conclusions are drawn in
Section 4.
3. Case Study
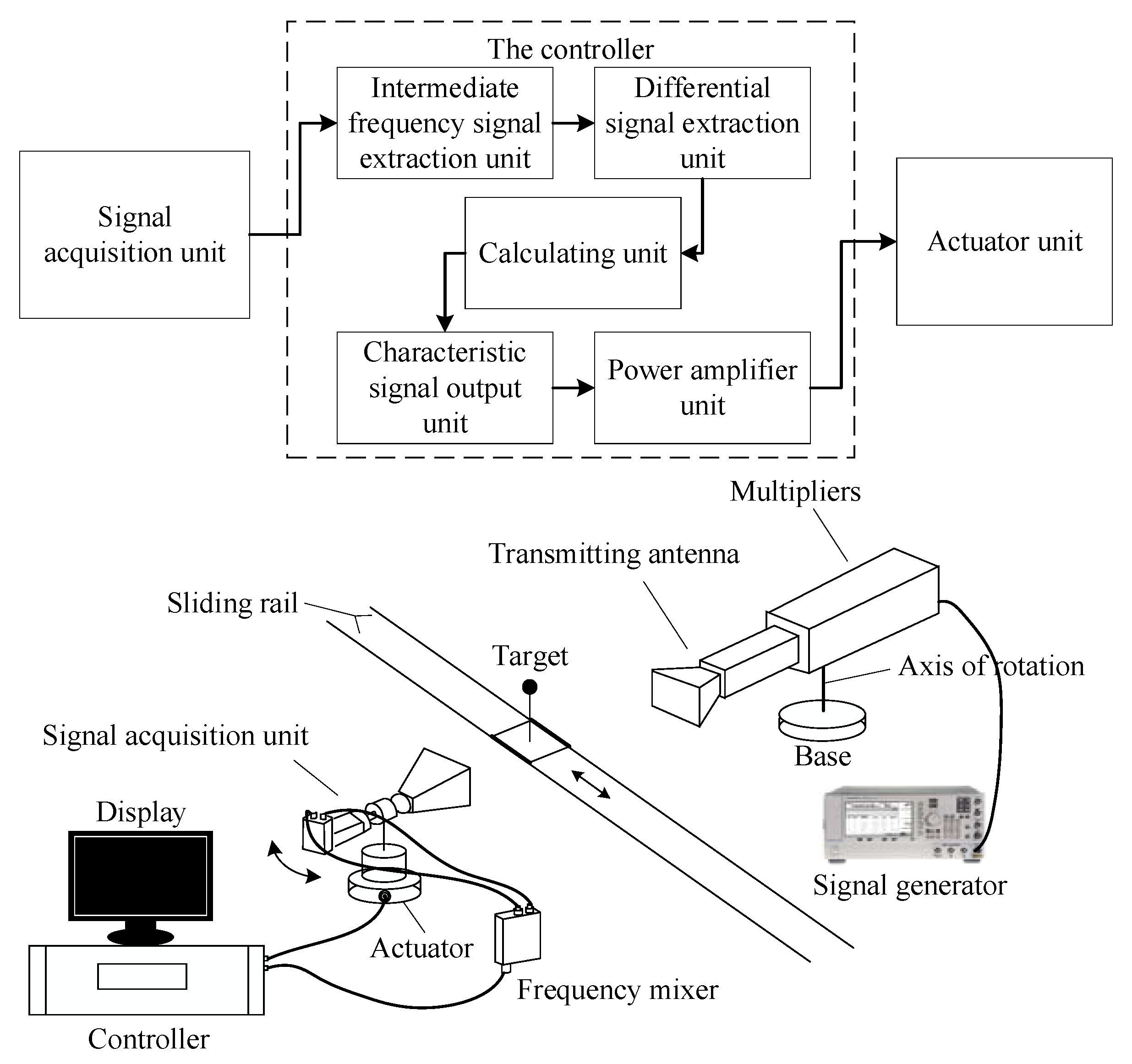
To illustrate the effectiveness of the proposed method, we take an electronic control system as an example. The system is the control part of a radar prototype, and it is designed to demonstrate the target tracking characteristics. The composition of the radar prototype is shown in
Figure 4.
The target can be moved automatically on the sliding rail, and the radar receives and processes the signal to control the trace motion. The controller of the radar is a piece of complicated electronic equipment, and it has a high requirement for PHM. The failure detection rate
is not less than 90%, the key failure mode
is 100%, and the failure isolation rate
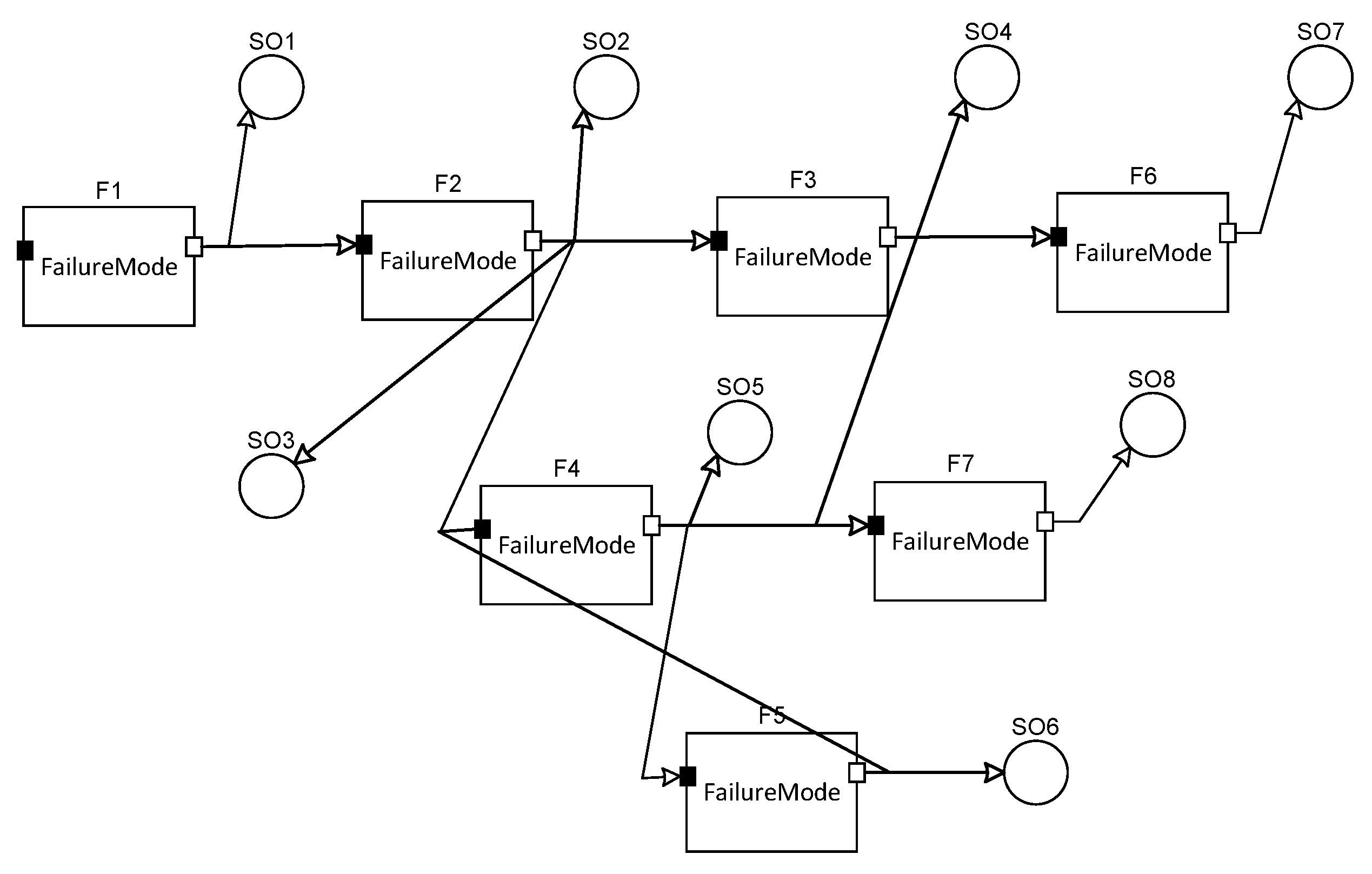
is not less than 90% (ambiguity is less than 2). Based on the composition of the radar, we can obtain the dependency graphic model of the controller by the dependency model theory, which is shown in
Figure 5. The dependency graphic model is used to illustrates the relationship between the failures and sensors. In the graphic model, the fault information flows with the arrows.
In
Figure 5,
F represents the failure mode, and
SO represents the alternative sensors (voltage sensor and signal sampler). The concrete information about the failure modes and sensors is shown in
Table 3.
Based on the graphic model, we obtain the dependency matrix, and it is shown in
Table 4.
We obtain the detection time by circuit simulation. From the price list of the bill of material (BOM), we obtain the diagnosis expense, which is the cost of the replacement of the faulty part detected by the sensor. From the reliability prediction results based on the standards (MIL-HDBK-217F in U.S.A or GJB299C in China), we obtain the failure rates. The information is shown in
Table 5,
Table 6, and
Table 7.
From the basic information above, we obtain the observation matrix
X of clustering object to the clustering index. For eliminating the effect of the index dimensions, the matrix is equalized and denoted as
X*.
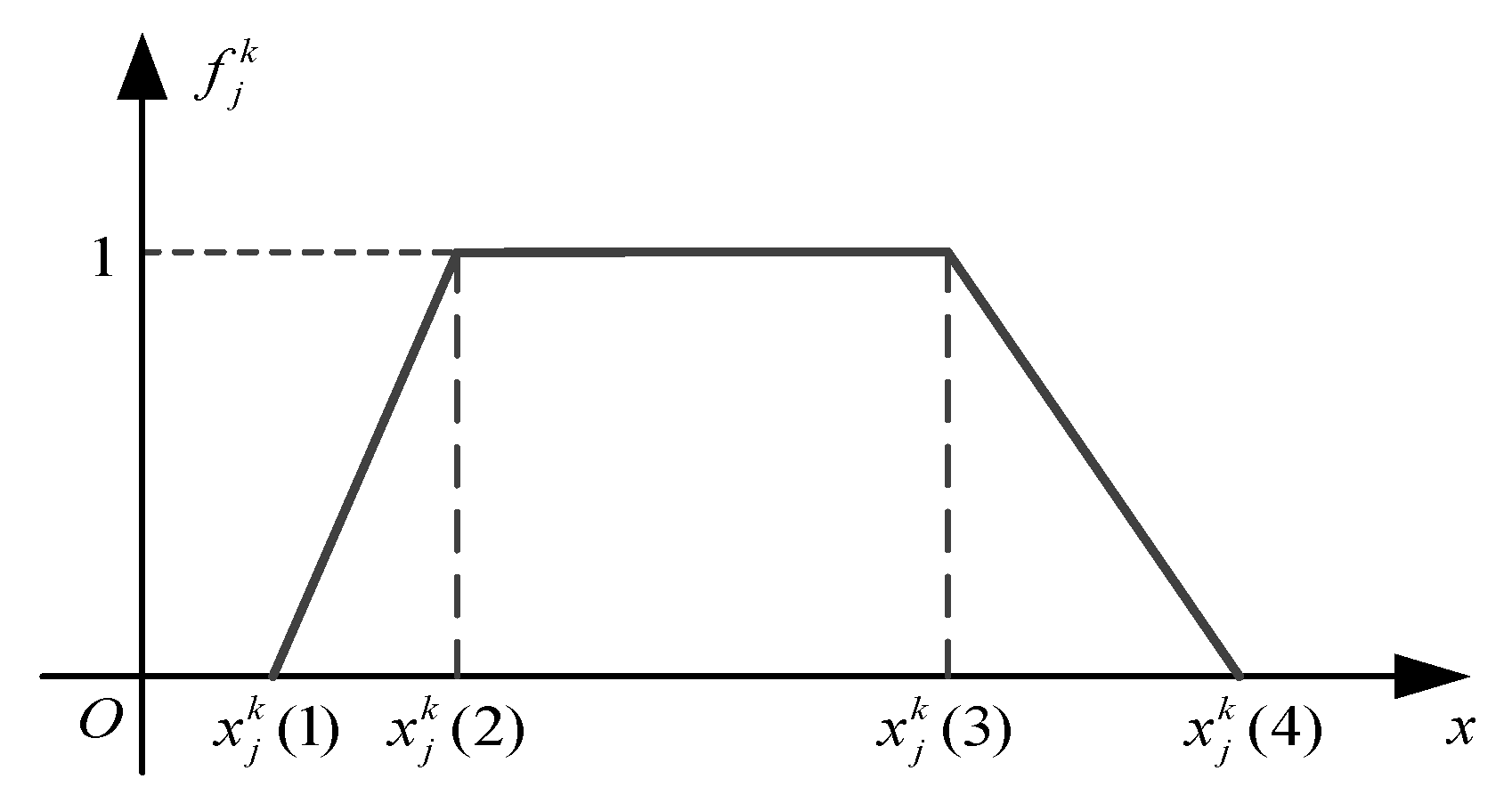
Then, we determine the whitening weight function, and we take the function
as an example to illustrate the process. The function
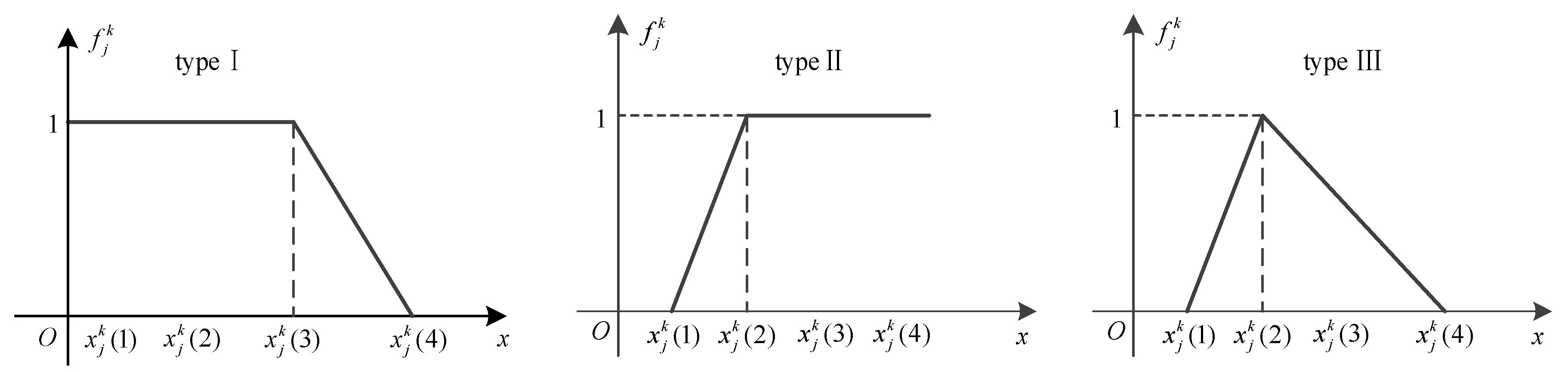
describes the relationship between detection time and the extraordinary class (E). Obviously, the sensors tend to the extraordinary class, as the value decreases. Therefore, we choose the type I function as the type of the detection time. The determination of the turning points mainly relies on historical data and subjective adjustments. In the historical records of testing and maintenance, there are many effect evaluations (very good, good, and normal) for every testing and maintenance activity of the operators. Based on the records, we count the range of the detection time on different evaluation levels, and then we slightly adjust the range by experience. The purpose of the adjustment is to make the different whitening functions of the index intersect because the attribution of the index is a continuous transition state, not a hard separation. The adjustment range is usually no more than 0.1 by experience. Thus, we finally obtain the turning points and the whitening weight function. Similarly, other function results are determined, as shown in
Table 8.
In the following equation, we obtain the subjective weight
by subjective assessment. The judgment matrix is as follows:
Based on the previous mathematical analysis, we obtain the objective weight
from Equations (8) and (9), and the subjective weight
from Equations (10) and (11). Thus, we obtain the combination weight
using subjective and objective weight from Equation (7). The weights are as follows:
Finally, we obtain the coefficient matrix from Equations (12) and (13), and the matrix is as follows:
From the coefficient matrix, we obtain the clustering result, and it is shown in
Table 9. It is seen that SO
7 and SO
8 are attributed to the extraordinary class, SO
4 and SO
6 are attributed to normal class, and the rests are attributed to the good class. Thus, we can evaluate not only the sensor selection based on the results, but also every single sensor.
To evaluate the different selection methods, we choose the dependency model and GA as the evaluated subject. We construct the dependency model of the controller by a software (Testability modeling and analysis system, TMAS), and the model is shown in
Figure 6.
By the software analyzing, we obtain the sensor selection result SO = {SO1, SO5(SO6), SO7, SO8}, and SO5 and SO6 are the equivalent sensors.
Then, we use the GA to achieve sensor selection, and the GA is commonly utilized and a typical one in the optimization method. Firstly, we construct the optimization problem, which is as follows:
where
ej is the expense of the
jth sensor, FDR is the required value of thefailure detection rate, and FIR is the required value of tfailure isolation rate.
is the failure mode rate that the chosen sensors can achieve, and it can be expressed as follows:
where
is the failure rate sum of the failure modes that can be detected by the chosen sensors, and
is the failure rate sum of all the failure modes. Therefore,
has the similar expression, and it can be expressed as follows:
where
is the failure rate sum of the failure modes, which can be isolated by the detection. Then, we use the GA to solve the optimization problem. The initial population size of the GA is determined as 30, the crossover probability is 0.8, the mutation probability is 0.02, and other parameters are set up by software (MATLAB) automatically. Finally, we obtain the selection result SO = {SO
1, SO
4, SO
5, SO
7}.
The valuation principle is the proportion of good and extraordinary sensors. If the proportions of the good and extraordinary sensors (P1) of different methods are the same, the proportions of extraordinary sensors (P2) are compared. If the two kinds of proportions are the same, the different selection methods are defined as equivalent. It is seen that the selection result of the dependency model is better than the GA synthetically because P1 and P2 of the dependency model are more than the GA, and then the dependency model method is recommended.
The contrast result can be explained in two ways. From the perspective of the algorithm itself, the selection result given by the GA is under an expense constraint, and the constraint reduces the influence of other factors on sensors, resulting in an expense-oriented result. From the perspective of physical meaning, the result difference between the dependency model and the GA is that the former selects SO
8 and the later selects SO
4. SO
8 samples the characteristic signal and SO
4 obtains the calculation validity test result. From
Figure 4, it is seen that the calculation result directly affects the characteristic signal output, which means the characteristic signal output is in the later position in the control chain. Thus, the characteristic signal output can reflect more information. Therefore, the proposed method is effective and can give a comprehensive evaluation result.
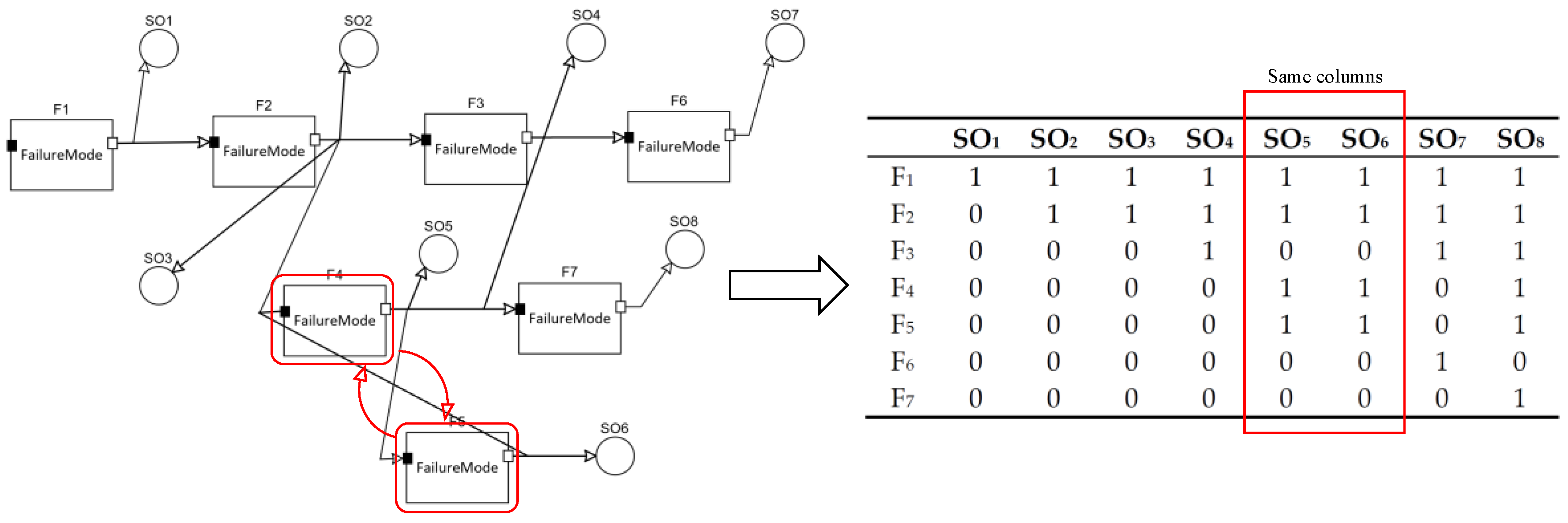
Moreover, it is noted that SO
5 and SO
6 are the equivalent sensors for their same testing response because F
4 and F
5 form a closed loop. It can be seen from the dependency model and the dependency matrix as shown in
Figure 7.
In the dependency model theory, SO
5 or SO
6 will be chosen equivalently. However, we will choose SO
5 instead of SO
6 for the evaluation of SO
5 (G class) as it is better than SO
6 (N class) (see
Table 9). From the perspective of physical meaning, it is reasonable because SO
5, the signal sampler, can obtain more useful information and is more sensitive than SO
6, which is the voltage sensor to monitor the actuator range. Then, the final selection result is SO = {SO
1, SO
5, SO
7, SO
8}. Therefore, we can improve the selection result to make a more precise choice by adjusting sensors based on the proposed method, which is more convincing and reasonable.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}