CAPTCHA Image Generation: Two-Step Style-Transfer Learning in Deep Neural Networks †



Abstract
1. Introduction
- Existing CAPTCHA generation methods assume that only humans can correctly recognize text images after distorting the characters or letters by overlapping, rotating, font, acr, etc. Compared to existing methods, the proposed style-plugged-CAPTCHA method has a unique characteristic of synthesizing distortions generated from several CAPTCHAs. We systematically describe the framework of the proposed method, and show that CAPTCHA images of various styles can be generated by applying multiple image styles to the original image.
- We analyze the degree of distortion in the images generated by the proposed scheme using CAPTCHA image datasets that operate on actual websites. In addition, we report the performance of the proposed method as measured by dividing the results for the case of one style image by that for the case of two style images. A human recognition test was conducted using the proposed method to analyze the human recognition rate.
- We report the rates of recognition by the DeCAPTCHA system for the proposed CAPTCHA images compared with those of the original images to verify the performance of the proposed method. (The CAPTCHA images used in the experiment are considered realistic as they are used in actual websites.)
2. Related Work
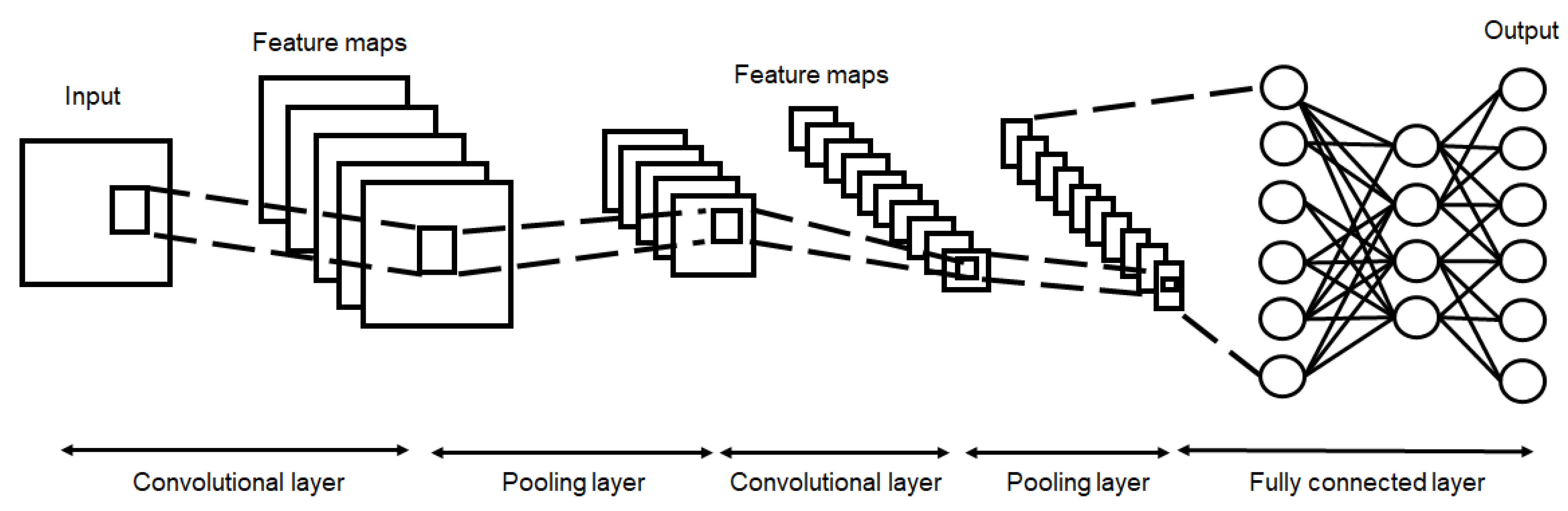
2.1. CNN Model
2.2. Image Style Transfer Method
2.3. Text-Based CAPTCHA
2.4. Other Methods for Generating CAPTCHAs
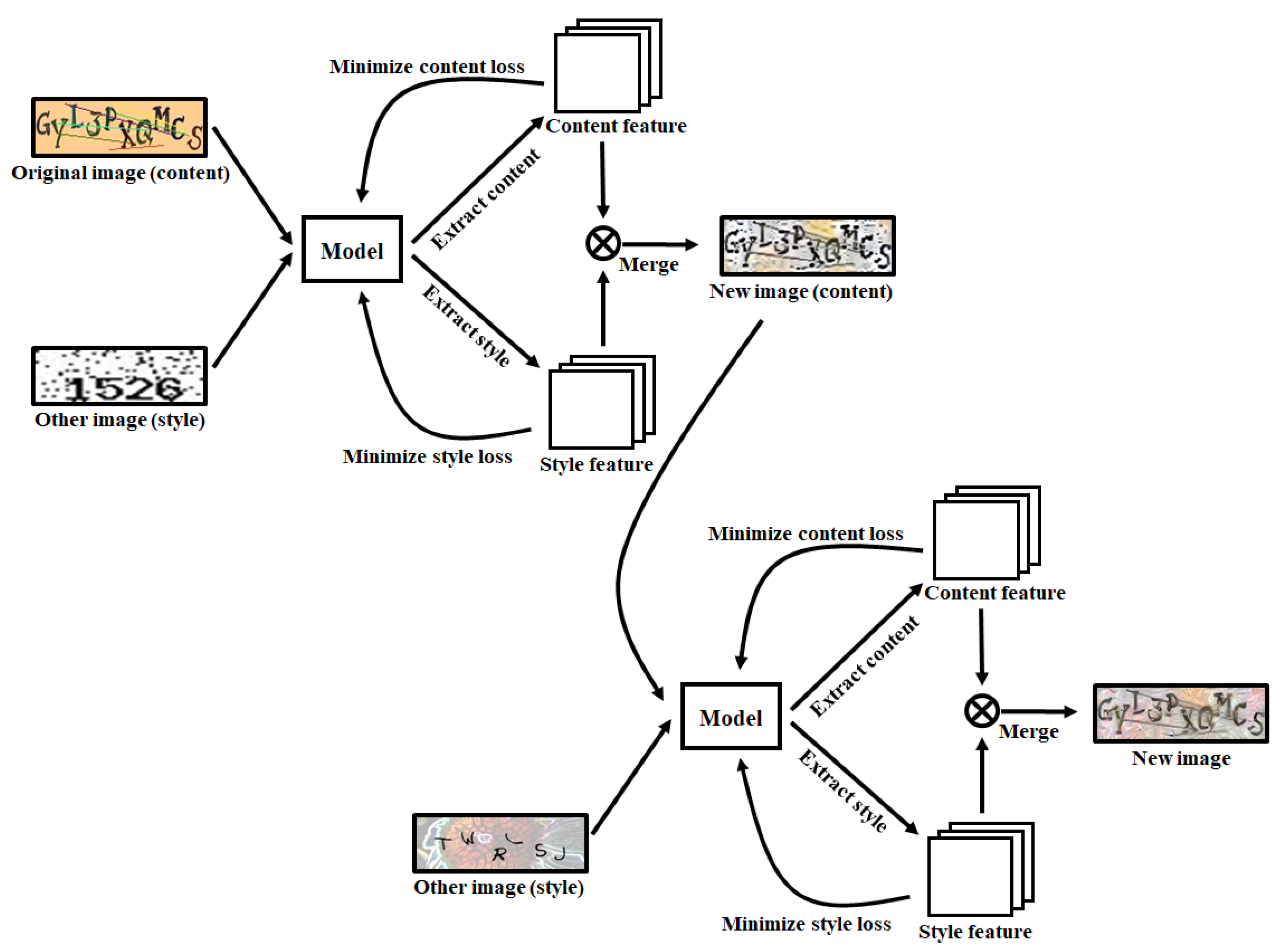
3. Proposed Scheme
3.1. Process for Transferring the Style Image to the Original Image
| Algorithm 1 Transferring the style image to the original image. |
|
3.2. CAPTCHA Creation Process with Two Style Images
4. Experiment and Evaluation
4.1. Experimental Methods
4.2. Experimental Results
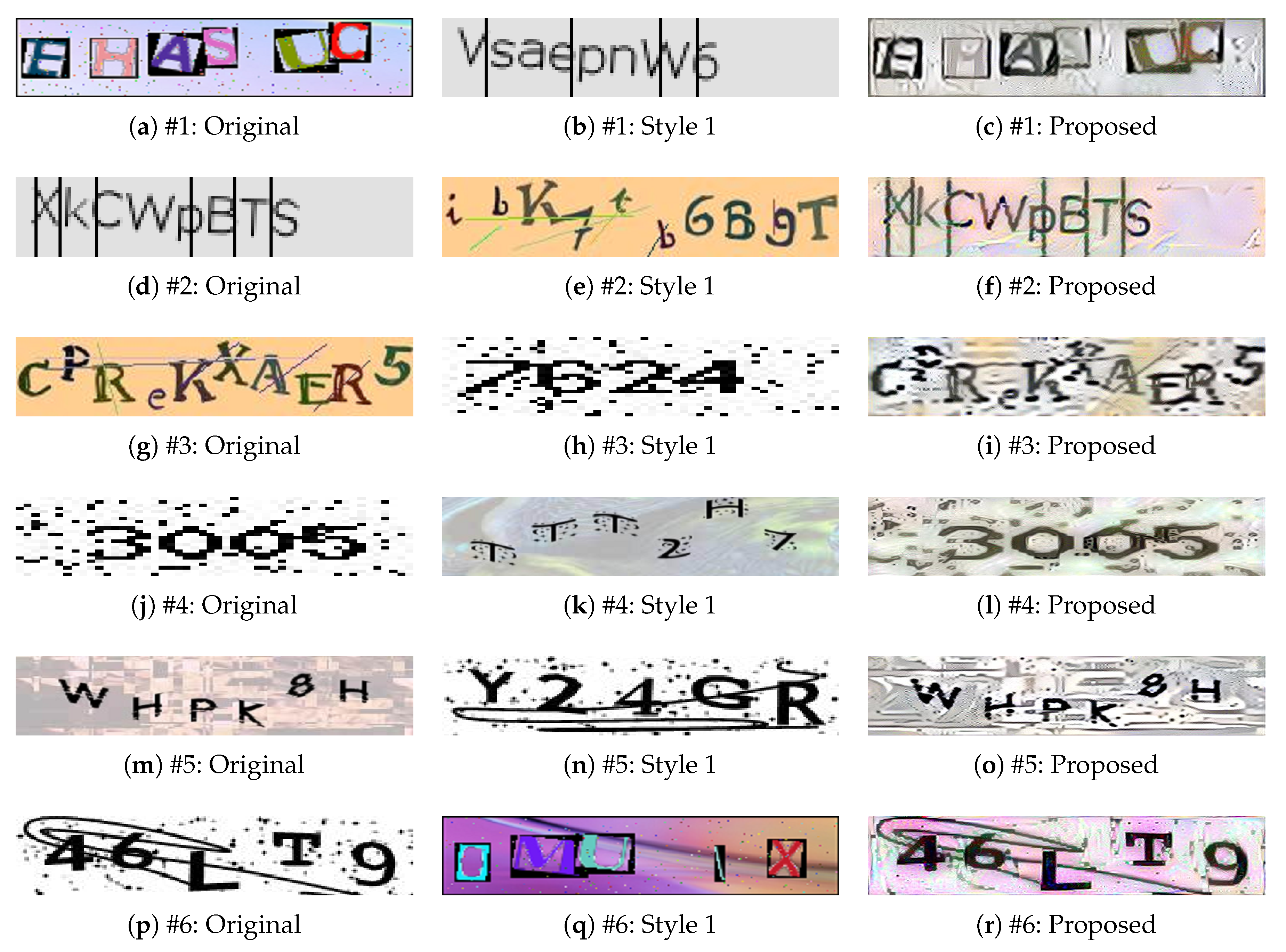
4.2.1. One Original Image and One Style Image
4.2.2. One Original Image and Two Style Images
4.2.3. Human Recognition
5. Discussion
5.1. Style Images
5.2. Attack Method Considerations
5.3. Human Recognition
5.4. Applications
5.5. Limitations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Demoulin, H.M.; Pedisich, I.; Phan, L.T.X.; Loo, B.T. Automated Detection and Mitigation of Application-level Asymmetric DoS Attacks. In Proceedings of the Afternoon Workshop on Self-Driving Networks, Budapest, Hungary, 24 August 2018; pp. 36–42. [Google Scholar]
- Alorini, D.; Rawat, D.B. Automatic Spam Detection on Gulf Dialectical Arabic Tweets. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 448–452. [Google Scholar]
- Bukac, V.; Stavova, V.; Nemec, L.; Riha, Z.; Matyas, V. Service in denial–clouds going with the winds. In Proceedings of the International Conference on Network and System Security, New York, NY, USA, 3–5 November 2015; pp. 130–143. [Google Scholar]
- Holz, T.; Marechal, S.; Raynal, F. New threats and attacks on the world wide web. IEEE Secur. Priv. 2006, 4, 72–75. [Google Scholar]
- Von Ahn, L.; Blum, M.; Hopper, N.J.; Langford, J. CAPTCHA: Using hard AI problems for security. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Warsaw, Poland, 4–8 May 2003; pp. 294–311. [Google Scholar]
- Bursztein, E.; Martin, M.; Mitchell, J. Text-based CAPTCHA strengths and weaknesses. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 125–138. [Google Scholar]
- Soupionis, Y.; Gritzalis, D. Audio CAPTCHA: Existing solutions assessment and a new implementation for VoIP telephony. Comput. Secur. 2010, 29, 603–618. [Google Scholar]
- Das, M.S.; Rao, K.R.M.; Balaji, P. Neural-Based Hit-Count Feature Extraction Method for Telugu Script Optical Character Recognition. In Innovations in Electronics and Communication Engineering; Springer: Singapore, 2019; pp. 479–486. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. Draw: A recurrent neural network for image generation. arXiv 2015, arXiv:1502.04623. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Li, C.; Wand, M. Combining markov random fields and convolutional neural networks for image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2479–2486. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Kwon, H.; Yoon, H.; Park, K. CAPTCHA Image Generation Using Style Transfer Learning in Deep Neural Network. In Proceedings of the 20th World Conference on Information Security Applications (WISA 2019), Jeju Island, Korea, 21–24 August 2019; pp. 234–246. [Google Scholar] [CrossRef]
- Hasan, W.K.A. A Survey of Current Research on Captcha. Int. J. Comput. Sci. Eng. Surv. (IJCSES) 2016, 7, 141–157. [Google Scholar]
- Su, H.; Qi, W.; Hu, Y.; Sandoval, J.; Zhang, L.; Schmirander, Y.; Chen, G.; Aliverti, A.; Knoll, A.; Ferrigno, G.; et al. Towards Model-Free Tool Dynamic Identification and Calibration Using Multi-Layer Neural Network. Sensors 2019, 19, 3636. [Google Scholar] [CrossRef] [PubMed]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A Fast and Robust Deep Convolutional Neural Networks for Complex Human Activity Recognition Using Smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef] [PubMed]
- Gao, H.; Wang, W.; Qi, J.; Wang, X.; Liu, X.; Yan, J. The robustness of hollow CAPTCHAs. In Proceedings of the 2013 ACM SIGSAC conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 1075–1086. [Google Scholar]
- Gao, H.; Wang, W.; Fan, Y.; Qi, J.; Liu, X. The Robustness of “Connecting Characters Together” CAPTCHAs. J. Inf. Sci. Eng. 2014, 30, 347–369. [Google Scholar]
- Gao, H.; Tang, M.; Liu, Y.; Zhang, P.; Liu, X. Research on the security of microsoft’s two-layer captcha. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1671–1685. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. CAPTCHA Image Generation Systems Using Generative Adversarial Networks. IEICE Trans. Inf. Syst. 2018, 101, 543–546. [Google Scholar] [CrossRef]
- Kwon, H.; Yoon, H.; Park, K.W. Robust CAPTCHA Image Generation Enhanced with Adversarial Example Methods. IEICE Trans. Inf. Syst. 2020, 103. [Google Scholar] [CrossRef]
- Cheng, Z.; Gao, H.; Liu, Z.; Wu, H.; Zi, Y.; Pei, G. Image-based CAPTCHAs based on neural style transfer. IET Inf. Secur. 2019, 13, 519–529. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 694–711. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- GSA Captcha Breaker. GSA—Softwareentwicklung und Analytik GmbH. Available online: https://captcha-breaker.gsa-online.de/ (accessed on 7 March 2020).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Moritz, P.; Nishihara, R.; Jordan, M. A linearly-convergent stochastic L-BFGS algorithm. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, AISTATS 2016, Cadiz, Spain, 9–11 May 2016; pp. 249–258. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Type | Shape |
|---|---|
| Con + R | [3, 3, 64] |
| Con + R | [3, 3, 64] |
| Max | [2, 2] |
| Con + R | [3, 3, 128] |
| Con + R | [3, 3, 128] |
| Max | [2, 2] |
| Con + R | [3, 3, 256] |
| Con + R | [3, 3, 256] |
| Con + R | [3, 3, 256] |
| Con + R | [3, 3, 256] |
| Max | [2, 2] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Max | [2, 2] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Con + R | [3, 3, 512] |
| Max | [2, 2] |
| Fully + R | [4096] |
| Fully + R | [4096] |
| Fully + R | [1000] |
| Softmax | [1000] |
| Contents | Value |
|---|---|
| Momentum | 0.9 |
| Learning rate | 0.01 |
| Decay rate | 0.0005 |
| Number of iterations | 370,000 |
| Number of epochs | 74 |
| Batch size | 256 |
| Dropout | 0.5 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwon, H.; Yoon, H.; Park, K.-W. CAPTCHA Image Generation: Two-Step Style-Transfer Learning in Deep Neural Networks. Sensors 2020, 20, 1495. https://doi.org/10.3390/s20051495
Kwon H, Yoon H, Park K-W. CAPTCHA Image Generation: Two-Step Style-Transfer Learning in Deep Neural Networks. Sensors. 2020; 20(5):1495. https://doi.org/10.3390/s20051495
Chicago/Turabian StyleKwon, Hyun, Hyunsoo Yoon, and Ki-Woong Park. 2020. "CAPTCHA Image Generation: Two-Step Style-Transfer Learning in Deep Neural Networks" Sensors 20, no. 5: 1495. https://doi.org/10.3390/s20051495
APA StyleKwon, H., Yoon, H., & Park, K.-W. (2020). CAPTCHA Image Generation: Two-Step Style-Transfer Learning in Deep Neural Networks. Sensors, 20(5), 1495. https://doi.org/10.3390/s20051495