1. Introduction
Human activity recognition (HAR) systems have become an increasingly popular application area for machine learning across a range of domains, including the medical (e.g., monitoring ambulatory patients [
1]), industrial (e.g., monitoring workers for movements with increased risk of repetitive strain injury [
2]), home care and assisted living (e.g., monitoring the elderly for dangerous falls [
3]) domains. A particularly popular approach which has proven successful in numerous HAR applications is to extract a set of features from inertial data along a sliding window, and use the resulting matrix—whose rows and columns correspond to windows and features, respectively—as inputs to the machine learning algorithm [
4,
5]. More often than not the HAR task for which a learning algorithm is trained goes beyond separating two activities, requiring the algorithm to distinguish among many different activities such as lying, sitting, standing, walking, nordic walking, running, rowing, and cycling [
6]. To apply machine learning classification algorithms that are designed to deal with two target classes, such a multi-class problem must first be decomposed into a set of binary problems. Then, a separate instance of the machine learning algorithm is trained for each of these binary problems. When a new sample is presented to the system, it is passed to each of the trained classifiers and their outputs, which may be probabilities, are combined [
7]. Besides making the multi-class problem amenable to binary classification algorithms, there are other benefits to decomposing a multi-class problem into a set of dichotomous problems. Perhaps the most important benefit is that a binary classification algorithm can be subjected to any of a number of well-known analyses, such as Receiver Operator Characteristic (ROC) or Sensitivity/Specificity analysis, which can yield insights that serve to tune the classifier with respect to the relative cost of false positives and false negatives.
There are several methods for transforming a multi-class classification problem into a set of binary classification problems [
7,
8]. The most popular of these are undoubtedly one-vs-all and, to a lesser extent, one-vs-one. Another approach is based on error-correcting output codes, which may be learned from labelled or unlabelled data. Finally, there are hierarchical methods in which the classes are arranged in a tree or (in rare cases) in a directed acyclic graph, which may be constructed randomly, learned from the data, or constructed from common sense or domain knowledge. Such a hierarchical approach, which is often referred to as a
top-down approach, is particularly appealing in application areas where the concepts (or classes) of interest are naturally arranged in a hierarchy. There are examples of more or less formal class hierarchies in many application domains—such as gene and protein function ontologies, music (and other artistic) genres, and library classification systems—and this has inspired many authors to develop hierarchical classifiers that excel at text categorisation, protein function prediction, music genre classification, and emotional speech and phoneme classification.
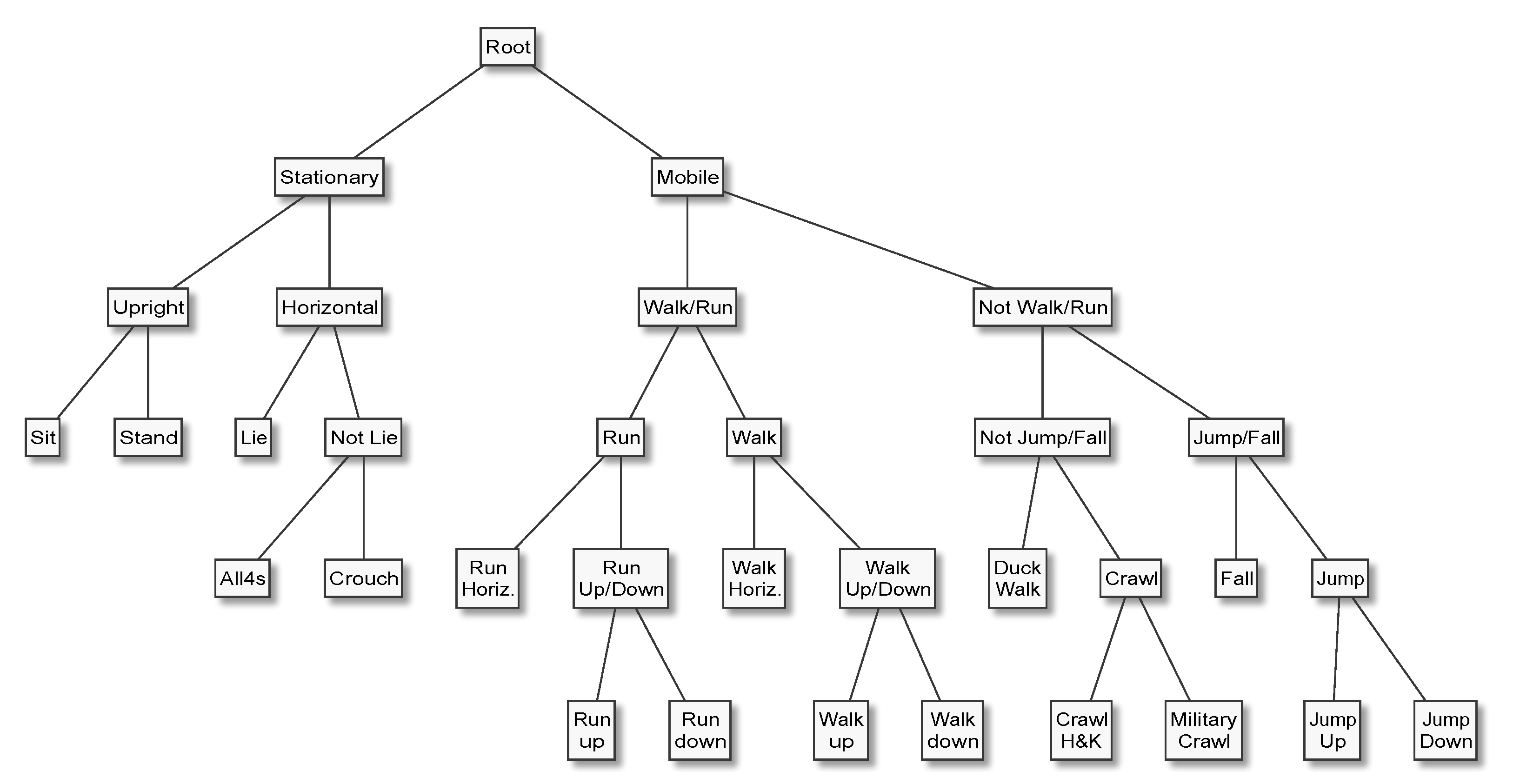
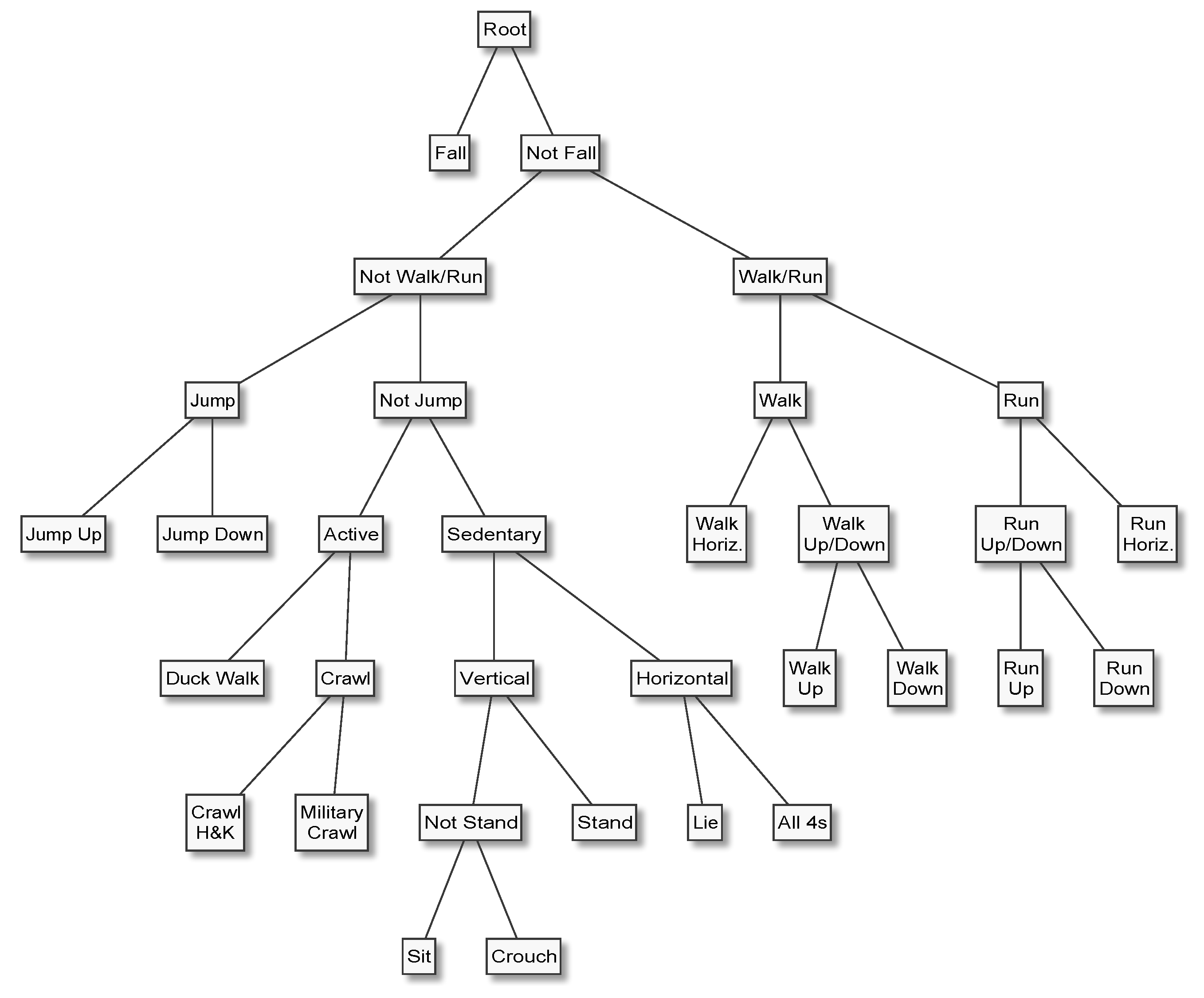
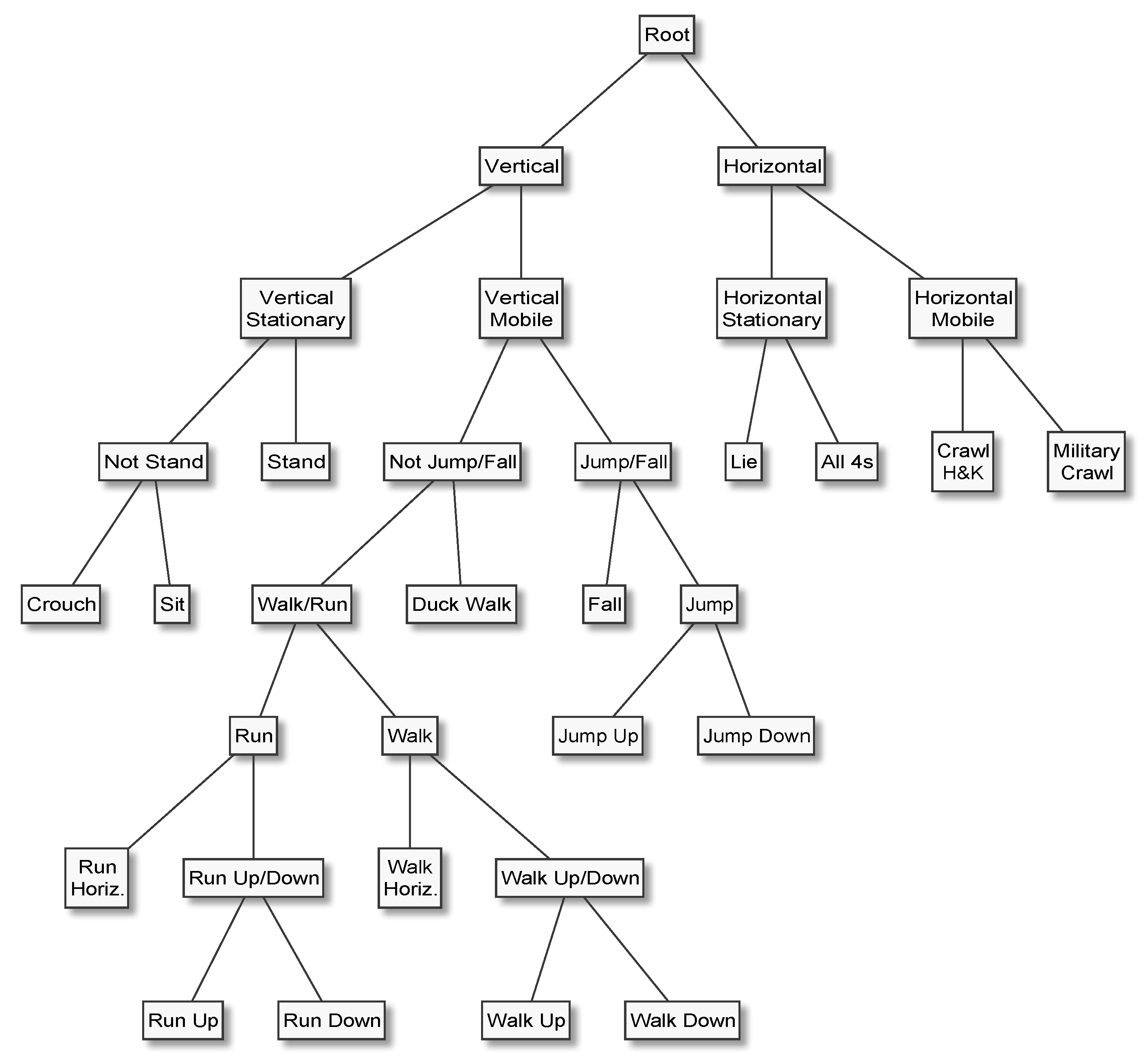
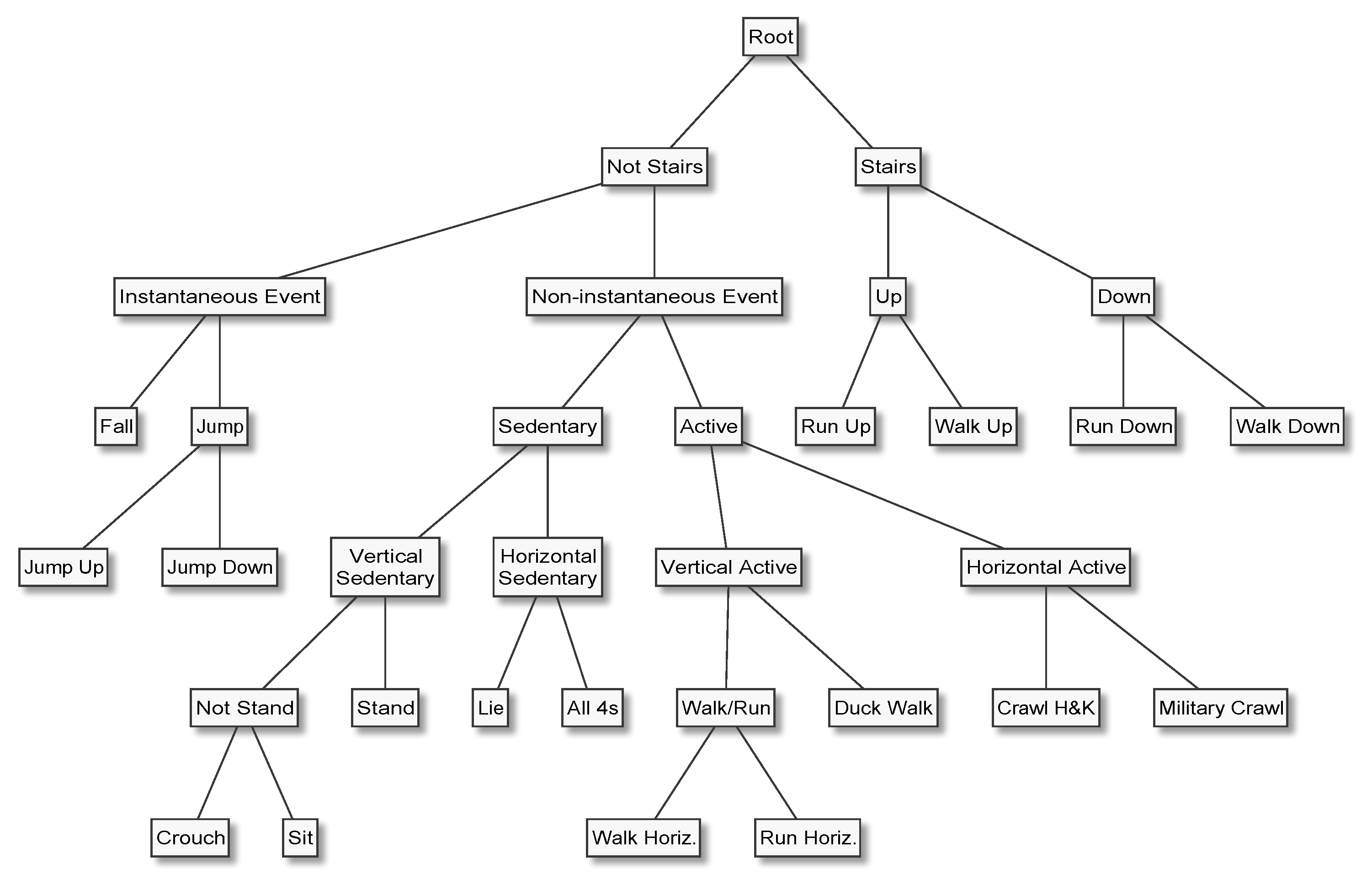
In HAR applications, it is almost always natural and easy to arrange the activities of interest in a hierarchy, for example by placing the most general categories (e.g., “mobile” and “stationary”) at the top or root of the tree, proceeding to increasingly specific categories (“walk” and “run”), and terminating with the most specific categories (“walk upstairs” and “walk downstairs”) at the leaves. Furthermore, it is not uncommon that a HAR system’s end users find it difficult to precisely specify which activities need to be recognised, not to mention class priors and misclassification costs, which are needed to properly design data acquisition protocols and tune classifiers. In such situations, nested dichotomies can be useful because they make it possible to develop increasingly fine-grained HAR capabilities iteratively. Having a classifier that can accurately distinguish between, for example, stationary and mobile behaviours at an early stage of the development life cycle not only enables early systems-level testing and end user feedback, but can speed up the annotation process—a task which is error-prone and often requires a disproportionate amount of human effort—for more specific activities. These advantages have inspired several applications of the principle [
1,
9,
10,
11]. Unfortunately, there has been little research into how hierarchical approaches to HAR inference compare to other multi-class decomposition methods, such as one-vs-one and one-vs-all. This is particularly striking because HAR problems tend to be multi-class problems, and because the performance of classification algorithms can be significantly affected by whether and how the multi-class problem is decomposed into a set of binary classification problems. Thus, it is unclear whether or not the benefits of a hierarchical approach for HAR come at the cost of worse predictive performance, and if so, just how high that cost might be. The main questions addressed in this work are:
Does the effect of the multi-class decomposition method choice on a HAR problem reflect what has been reported by other comparative studies of multi-class decomposition methods, namely that one-vs-one tends to perform slightly better than one-vs-all in most, but not all, cases?
How does the performance of expert hierarchies compare to that of one-vs-all, which is the de-facto standard in practice? How much does a multi-class classifier stand to gain or lose from the domain knowledge encoded in an expert hierarchy?
How does the performance of an ensemble of expert hierarchies compare to that of an equally sized ensemble of random nested dichotomies (i.e., an Ensemble of Nested Dichotomies), and to that achieved by individual expert hierarchies? The former comparison indicates whether the domain knowledge encoded in the expert hierarchies is useful information or detrimental bias for a classifier, and the latter whether, given some set of candidate expert hierarchies for a multi-class problem, we should look for and use a single expert hierarchy, or combine them into an ensemble of expert hierarchies.
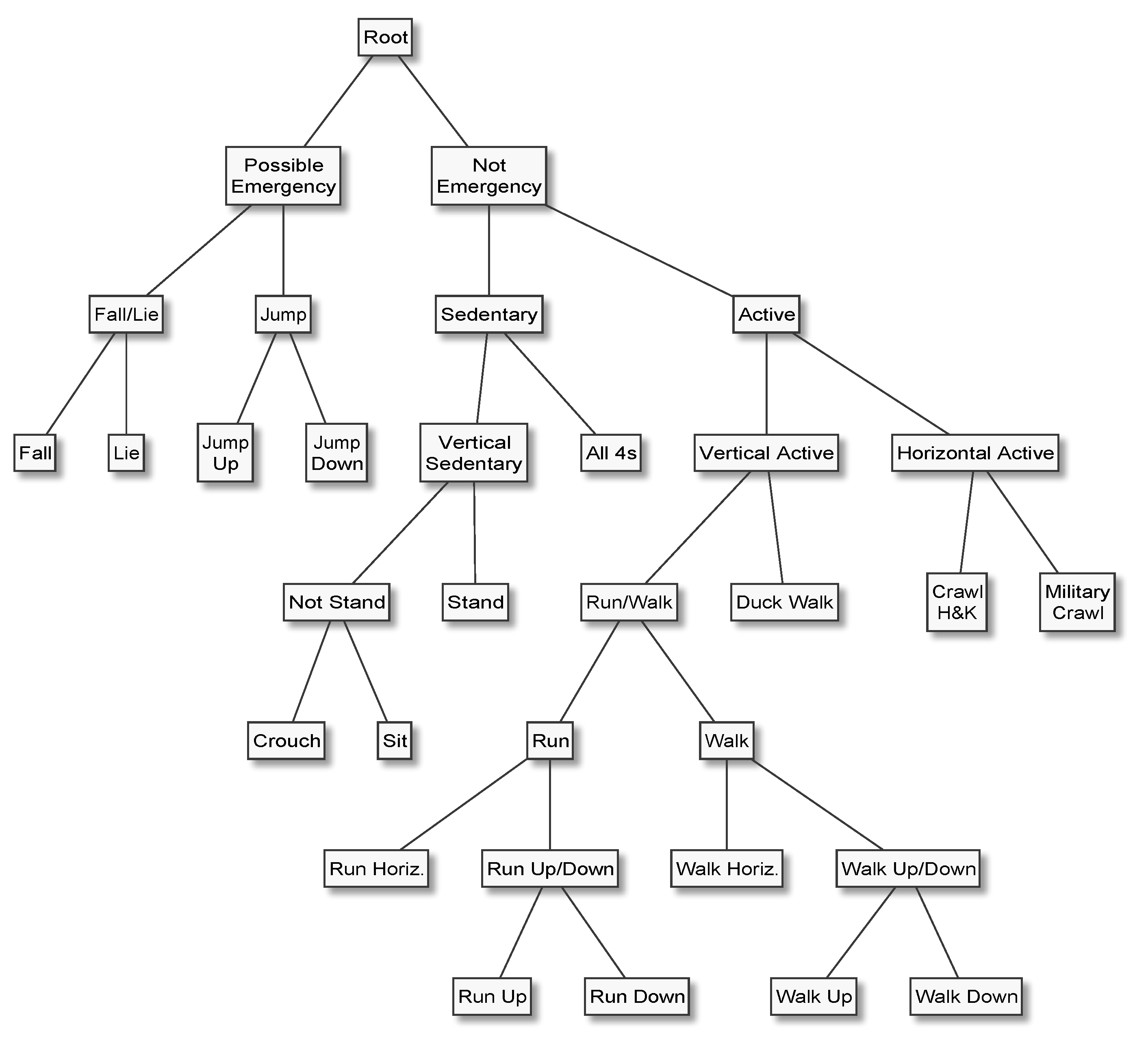
How do these methods perform when evaluated at an expert hierarchy’s topmost dichotomy, for example to separate “Mobile” from “Stationary”, or “Emergency” from “Not Emergency” activities?
In answering these questions, we make four main contributions: (1) the first empirical evaluation of the effect that the choice of multi-class decomposition method has on the performance of various binary learning algorithms on a multi-class HAR problem; (2) the first direct comparison of hierarchical classification that is guided by domain knowledge with standard domain-agnostic multi-class decomposition methods on a multi-class HAR problem; (3) we formulate a threshold that indicates when a nested dichotomy’s branch cannot possibly be on the path to the predicted class, and therefore does not need to be explored; and (4) we show that domain knowledge can be used to construct a multi-class classifier that has lower computational complexity and is easier to interpret than, but performs comparable to one-vs-all.
The remainder of this paper is organised as follows. The following section describes the most popular multi-class decomposition methods, and the one after that (
Section 3) briefly reviews the literature investigating multi-class decomposition methods in a HAR context. Then,
Section 4 describes the data and computational experiments, whose results show that expert hierarchies are able to compete with one-vs-all, and indeed many of the other multi-class decomposition methods discussed in
Section 2, regardless of whether we look at the results for the original multi-class problem or those for the binary classification problem induced by an expert hierarchy’s topmost dichotomy. The results, presented in
Section 5, also show that Ensembles of Expert Hierarchies perform comparably to an equally sized Ensemble of Nested Dichotomies on the multi-class problem, but with significantly lower variance among both the cross-validation folds and the learning algorithms than the ensemble of nested dichotomies.
Section 6 concludes our presentation of the results by summarising and discussing the main findings. Finally,
Section 7 concludes the paper.
3. Related Works
Given the recent breakthroughs achieved by deep learning in many machine learning application areas—most notably computer vision and natural language processing—and the fact that deep learning models are inherently multi-class, we begin our survey of the literature with a brief summary of deep learning for human activity recognition. We then turn our attention to the literature on multi-class decomposition methods and the impact they have on the performance of classification algorithms.
In 2011, Wang et al. [
27] they surveyed 56 papers that use deep learning models—deep neural, convolutional, and recurrent neural networks, autoencoders, and restricted Boltzmann machines—to perform sensor-based human activity recognition. They concluded that there is no single “model that outperforms all others in all situations,” and recommend to choose a model based on the application scenario. They identify four papers [
28,
29,
30,
31] as the state of the art in deep learning for HAR, based on a comparison of three HAR benchmark data-sets, viz. the Opportunity [
32], Skoda [
33], and the UCI (University of California, Irvine) smartphone [
34] data-sets, all of which consist of data acquired from subjects wearing multiple inertial measurement units (IMUs). What follows is a summary of these results.
Jiang and Yin [
28] proposed DCNN+, a deep convolutional neural network (DCNN) model to recognise human activities from signal and activity images constructed by applying 2D Wavelets or the Discrete Fourier Transform to signals from a single IMU. To improve DCNN performance, they use binary support vector machine (SVM) classifiers to discriminate between pairs of classes whose predicted probabilities are similarly large. Their DCNN+ (DCNN + disambiguating SVMs) achieves the same, or only marginally (0.55 to 1.19 percentage points) higher, accuracy than an SVM operating on the same 561 features used for training the binary SVMs that are used to disambiguate between potentially confused predictions in the DCNN+. On the FUSION data-set [
35], the DCNN and DCNN+ approach both achieved the same performance (99.3% accuracy) as the SVM. Zhang et al. [
29] proposed a DNN that recognises human activities from the raw signals acquired by a single IMU, and the signal magnitude of the accelerometer’s combined three axes. They compare their method with traditional machine learning algorithms operating on five features (mean, standard deviation, energy, spectral entropy, and pairwise correlations between the accelerometer axes) without tuning any of the algorithms’ hyper-parameters. DNN achieved an error rate of 17.7% (SVM: 19.3%) on the Opportunity data-set, 8.3% (SVM: 22.2%) on USC-HAD [
36], and 9.4% (kNN: 22.7%) on the Daily and Sports Activities data-set [
37].
Ordóñez and Roggen [
30] proposed a Deep Convolutional Long Short-Term Memory cell (LSTM) model. Their proposed method outperformed a baseline Convolutional Neural Network (CNN)—which in turn achieved better performance than the best traditional learning algorithms—by 1.8 percentage points (F-score: 93% vs. 91.2%) on the Opportunity data-set. On the Skoda data-set—which also consists of data from multiple IMUs per subject—their deep convolutional LSTM outperformed the state of the art by 6.5 percentage points (95.8% vs. 89.3%). Hammerla et al. [
31] explored the application of DNNs, CNNs, and three different flavours of LSTMs on three benchmark HAR data-sets (Opportunity, PAMAP2 [
38], and Daphnet [
39]), all of which consist of data from subjects instrumented with multiple IMUs. They explored the impact of various hyper-parameters, which determine the architecture, learning, and regularisation of the various deep models by running hundreds or thousands of experiments with randomly sampled parameter configurations. They, too, found that no model dominates the others across all three data-sets. A bi-directional LSTM achieved the best F-score (92.7%) on the Opportunity data (4% better than the deep convolutional LSTM by Ordóñez and Roggen [
30]), a CNN the best score (93.7%) on PAMAP2, and a forward LSTM the best score (76%) on the Daphnet data-set. They further show that tuning the hyper-parameters is critical to achieve good performance, as the best model’s median score was 17.2 percentage points lower than its best score on the Opportunity data, and 7.1 percentage points lower than its best on the PAMAP2 data. The latter quantity represents the smallest discrepancy they found across all models and data-sets. The largest discrepancy was a 29.7 percentage points difference on the Daphnet data.
We recently applied the classification algorithms and features used in this paper to a single IMU for various benchmark data-sets [
40]. The results give an idea of how the deep learning results discussed above compare to our approach. Although we presented our results in terms of Cohen’s
, we have calculated the F-scores, accuracy, and error rate corresponding to the published results. The ensemble of gradient boosted trees also used in this paper achieved an F-score of 88.5% (± 1.6) and an error rate of 10.9% (± 1.5) on the Opportunity data, an accuracy of 98.4% (± 0.3) on the FUSION data, and an F-score of 89.7% (± 0.5%) on the PAMAP2 data-set. These results show that deep learning outperforms traditional machine learning with handpicked features on data from multiple IMUs by a margin of >6%. However, we cannot draw the same conclusion when it comes to HAR with a single IMU—which is more convenient for end users who have to remember to wear and charge the IMUs. Here, deep learning performs comparable, or only marginally better, than traditional machine learning with handpicked features. Furthermore, many papers that demonstrate deep learning methods that outperform traditional machine learning by a large margin compare a deep architecture that was carefully tailored to the data-set and whose hyper-parameters were finely tuned, against machine learning algorithms with default hyper-parameters operating on a handful of basic features. It is, therefore, too early to altogether abandon research into machine learning with handpicked features for HAR.
We now turn to the literature about how multi-class decomposition methods affect the performance of classification algorithms. This discussion is presented in two parts. In the first, we focus on the more popular flat multi-class decomposition methods, such as one-vs-all and one-vs-one, and on multi-class decomposition methods based on error-correcting output codes. The second discusses hierarchical multi-class decomposition methods, such as nested dichotomies and ensembles of nested dichotomies.
Joseph et al. [
41], who combined one-vs-one and one-vs-all with a latent variable model, and compared the performance on two DNA micro-array data tumour classification problems [
42,
43], found that while one-vs-one performed quite clearly better than one-vs-all on one problem (by over 10 percentage points on average), one-vs-all tended to perform better than one-vs-one on the other, albeit only marginally. In 2011, Galar et al. [
7], they presented an empirical comparison of one-vs-one and one-vs-all, in which they combined one-vs-one and one-vs-all with SVM, decision trees,
k-Nearest Neighbours (kNN), Ripper [
44], and a positive definite fuzzy classifier [
45], and evaluated their performance on 19 publicly available multi-class data-sets. They found that one-vs-one outperformed one-vs-all in almost all cases, although rarely by more than one standard error. Raziff et al. [
46] compared one-vs-one, one-vs-all, and error-correcting output codes (with random code matrices of varying size) in combination with decision trees to identify (
) people from accelerometer data acquired via a handheld mobile phone, and found that one-vs-one, which achieved an accuracy of 88%, performed better than either one-vs-all or error-correcting output codes, which achieved 70% and 86%, respectively. They also found that when the width of the error-correcting output codes code matrix was increased from
k to
, the accuracy increased by 11%. However, when the width was increased beyond that—to
,
, and finally
—the rate of improvement slowed down to 2% to 3%. These studies show that while one-vs-one is likely to perform better than one-vs-all in most cases, it is not guaranteed to do so for any particular problem.
Hierarchical models in the form of nested dichotomies (a binary hierarchy or tree of binary classifiers) have long been a popular statistical tool for analysing polychotomous response variables [
22], where they are usually combined with the binomial logistic regression model to draw inferences about the relationships between predictors and the response. The link between the statistical theory of nested dichotomies (namely that the constituent nested dichotomies are independent) and hierarchical classification in a machine learning context was established when Frank and Kramer [
24] introduced the ensemble of nested dichotomies in 2004, and compared its performance to one-vs-one, error-correcting output codes, and one-vs-all on 21 publicly available data-sets. Besides confirming that one-vs-one tends to perform better than one-vs-all, they also found that ensembles of nested dichotomies were comparable to error-correcting output codes and more accurate than one-vs-one when combined with decision trees, and comparable to one-vs-one and more accurate than error-correcting output codes when combined with Logistic Regression, Zimek et al. [
47] compared the performance of expert hierarchies with that of ensembles of nested dichotomies—some of which were constrained by an expert hierarchy built from a machine-readable ontology—and a non-binary expert hierarchy with an ensemble of nested dichotomies at internal nodes (HEND). They found that while expert hierarchies improved the performance on simulated data, the HEND performed better on the data-set of real protein expressions. This shows that hierarchical multi-class decomposition methods that are based on domain knowledge can achieve better performance than ensembles of random nested dichotomies on real-world data. Due to the ease of constructing an intuitive hierarchy of increasingly detailed human activities, hierarchical classification has been exploited for HAR by Mathie et al. [
9] and Karantonis et al. [
1]. Both papers develop a hierarchical classifier for a multi-class HAR problem that is similar to a nested dichotomy. Their hierarchical classifier predicts a discrete activity at internal nodes via hard thresholding, arriving at a single predicted activity label. A nested dichotomy, on the other hand, multiplies the probabilities of the internal nodes on the path to each leaf to predict a probability for each activity, rather than a single activity label.
This non-probabilistic approach—trace the path of discrete “yes” or “no” predictions down the tree until hitting at a leaf, and return its class as the predicted class label—appears to be the norm in the hierarchical classification literature. None of the 74 papers—38 on text categorisation, 25 on protein function prediction, six on music genre classification, three on image classification, and one each on phoneme and emotional speech classification—reviewed by Silla and Freitas [
48] in their 2011 survey of hierarchical classification used probabilistic hierarchies, opting instead for non-probabilistic hierarchies that discard their constituent classifiers’ confidence in their predictions. Nevertheless, Silla and Freitas [
48] found that hierarchical classification is a better approach to hierarchical classification problems than flat approaches, including not only one-vs-one and one-vs-all, but also inherent multi-class algorithms. More recently, in 2018, Silva-Palacios et al. [
49], experimenting with learned, rather than pre-defined, hierarchies across 15 multi-class benchmark data-sets (none of them HAR data) from the UCI machine learning repository [
50], reported that probabilistic nested dichotomies clearly tend to outperform, albeit only by a small margin, their non-probabilistic counterparts.
Unfortunately neither of these, nor any of the other comparative studies of multi-class decomposition methods in the literature included a HAR problem in their evaluation, and, because there appears to be no multi-class decomposition method that is dominant across all multi-class classification problems, we cannot assume that one-vs-one, which tends to perform best in most domains, is going to do so in the HAR domain. Furthermore, it can be argued that the activities (concepts), which HAR algorithms are trained to recognise, have a much stronger hierarchical structure than the concepts targeted by most multi-class classification benchmarks, which may affect multi-class decomposition method performance. Moreover, none of the papers that do address the multi-class decomposition problem in a HAR context compares the performance of the proposed method to that of other multi-class decomposition methods such as one-vs-all or one-vs-one. Given the intuitiveness and popularity of hierarchical multi-class decomposition methods for HAR, and their inherent modularity and flexibility, it is important to study whether or not there is a trade-off between using a hierarchical multi-class decomposition method such as an expert hierarchy and using domain-agnostic multi-class decomposition methods such as one-vs-one and one-vs-all, and, if this is the case, estimate how much we stand to gain (or lose) from using a hierarchical multi-class decomposition method that encodes HAR domain knowledge.
5. Results
This section presents and analyses the results of the experiments described in
Section 4. We use Cohen’s Kappa (
) statistic as our metric of predictive performance because of its inherent ability to quantify a classifier’s performance on a multi-class classification problem, and because it is adjusted for the prior class distributions of both the ground truth and the predicted class labels.
For a detailed analysis of the differences between the various combinations of machine learning algorithms and multi-class decomposition methods we employ (binomial) logistic regression of the
statistic on the two factors of interest, viz. the learning algorithm and multi-class decomposition method. The
statistic, calculated once for each cross-validation test fold, corresponds to the proportion of successful Bernoulli trials—the proportion of test instances classified correctly, adjusted for the probability of chance agreement—and the number of instances in a test fold to the number of trials. Together, these two numbers determine the binomial distribution, allowing us to apply a (binomial) logistic regression model to estimate the log-odds of the
statistic,
, which relate to the
statistic via the logistic function
Because one-vs-all is by far the most popular multi-class decomposition method in practice, and the gradient-boosted ensemble of decision trees (GBT) the algorithm most likely to outperform the others, we use that combination (one-vs-all with GBT) as the baseline (i.e., the regression equation’s intercept) against which the other combinations of multi-class decomposition methods and algorithms are compared. The models were fitted using the R Language and Environment for Statistical Computing ([
62], version 3.6.1). In our analysis we limit ourselves to those regression coefficients that are significant at the
= 0.1 significance level.
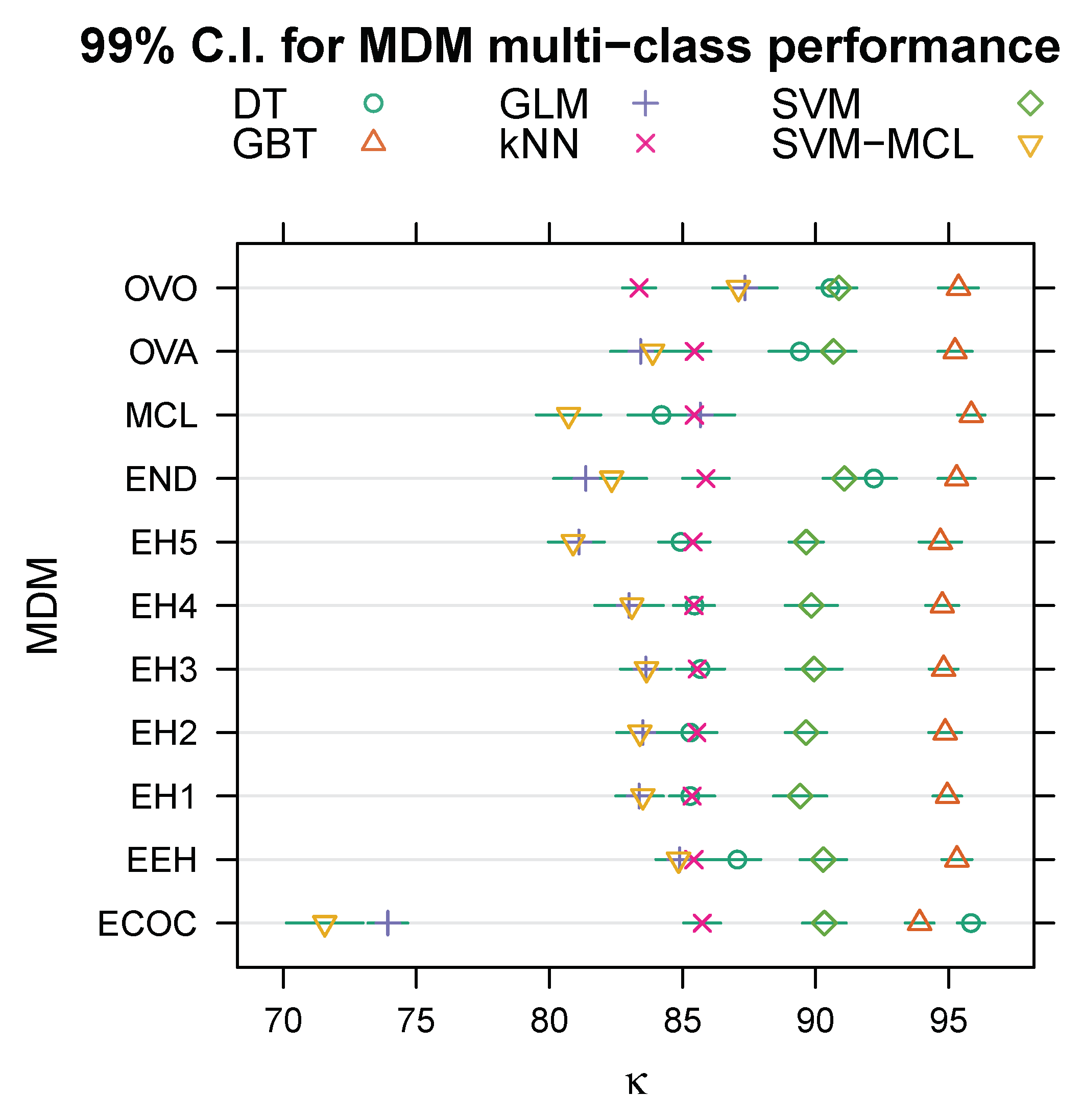
Table 2 shows the mean
(in percent, ± its standard error) across the ten cross-validation folds for each multi-class decomposition method. The column labelled “Avg.” lists the mean and standard error (SE) for each multi-class decomposition method, computed across the five machine learning algorithms, and the two rows labelled “Avg.” the mean and standard error over the preceding five rows.
Figure 1 illustrates normal (Gaussian) 99% confidence intervals (C.I.) calculated from the means and standard errors given in
Table 2. Clearly, the variance between expert hierarchies is negligible compared to that between the other multi-class decomposition methods, and there is no a priori reason to prefer any particular expert hierarchy over the others. Therefore, we pooled the five expert hierarchies (EH1, EH2, …, EH5) into a single category labelled “EH”, and then fitted the regression model to the data summarised in
Table 2 to estimate coefficients for seven, rather than eleven, multi-class decomposition methods—one-vs-all (OVA, the baseline/intercept), one-vs-one (OVO), ensembles of nested dichotomies (END), error-correcting output codes (ECOC), multi-class (MCL), expert hierarchies (EH, with no distinction between individual hierarchies), and ensembles of expert hierarchies (EEH)—and five machine learning algorithms, namely ensembles of gradient boosted trees (the baseline/intercept), (binary) SVM, multi-class SVM (SVM-MCL), decision trees (DT), kNN, and logistic regression (GLM).
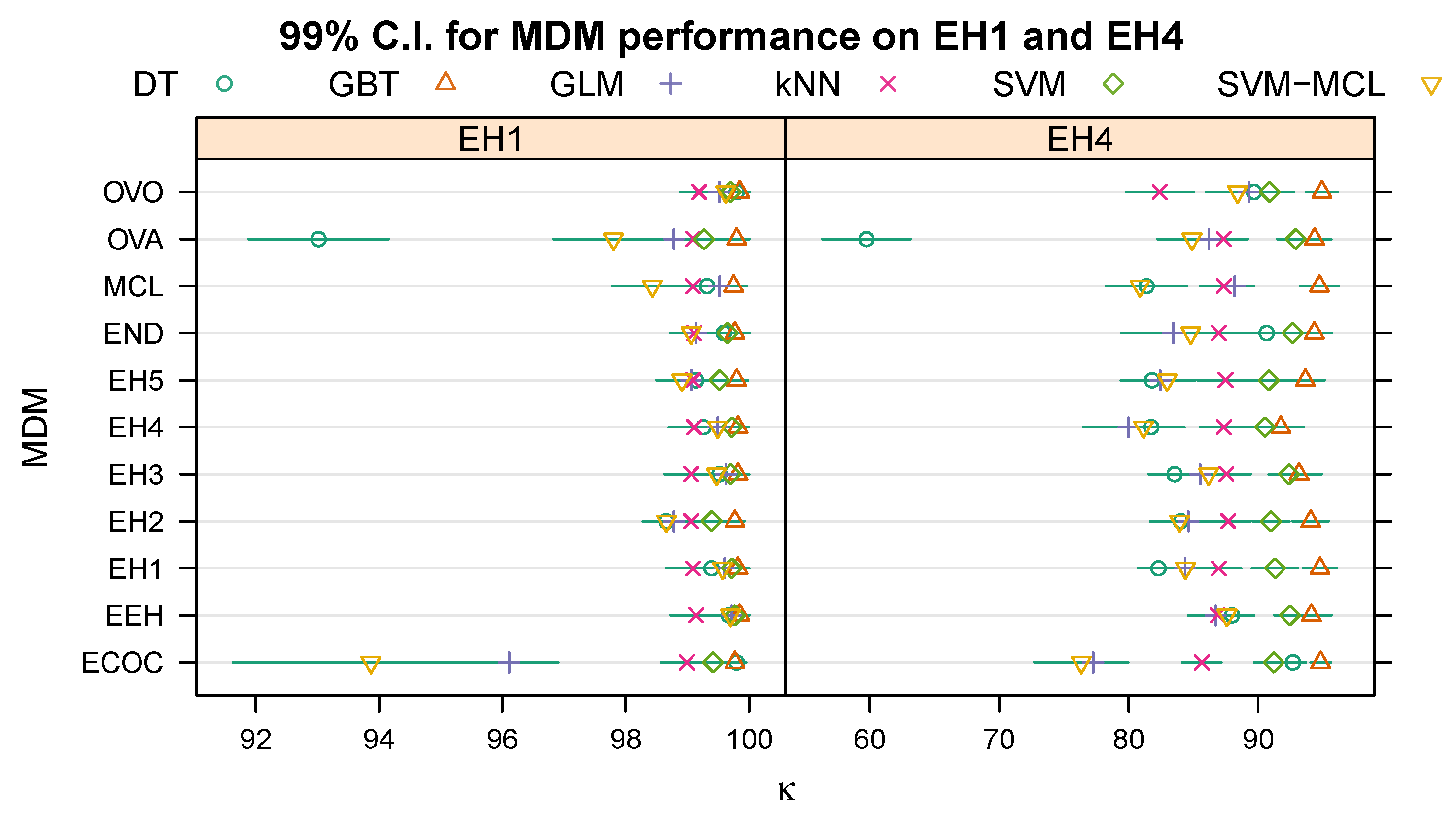
Table 3 and
Table 4 show the mean
(± standard error), in percent, when evaluating each multi-class decomposition method/machine learning algorithm combination on the topmost (root) dichotomy of EH1 (“Stationary” vs. “Mobile”) and EH4 (“Possible Emergency” vs. “Not Emergency”), respectively. The column labelled “Avg.” lists the mean
(± standard error), again in percent, across the five machine learning algorithms for each multi-class decomposition method, and the rows labelled “Avg.” the mean and its standard error across the preceding five rows.
Figure 2 illustrates the 99% C.I.s for each combination of multi-class decomposition method and learning algorithm based on the means and standard errors in
Table 3 and
Table 4.
The results of our analysis of the data from the multi-class problem summarised in
Table 2 are given in
Table 5, and those for the dichotomous problems induced by EH1 and EH4 (
Table 3 and
Table 4) are given in
Table 6 and
Table 7, respectively. The tables list the estimate (
) along with its 99% C.I. and
p-value for those coefficients that are significant at the
= 0.1 level, that is, those with
p < 0.1. The row labelled “(Intercept)” corresponds to the baseline method’s (OVA ∧ GBT) estimated log odds. For example, the log odds for OVA ∧ GBT on the multi-class problem are estimated as
. Therefore, the odds ratio is
and hence
. The other coefficients’ estimates and C.I.s indicate the marginal change in log-odds associated with the corresponding multi-class decomposition method (MDM), learning algorithm, or combination of multi-class decomposition method and learning algorithm. Note that because a positive coefficient signifies an increase in the odds and a negative coefficient a decrease in the odds, a coefficient with a C.I. that spans zero is not significant at the
= 0.01 significance level. Coefficients labelled with a multi-class decomposition method, rather than a combination of multi-class decomposition method and algorithm, estimate the marginal effect that the multi-class decomposition method has on algorithm performance and therefore apply when the multi-class decomposition method is combined with any of the algorithms. Conversely, coefficients labelled with an algorithm, rather than a combination of algorithm and multi-class decomposition method, estimate the marginal effect that the algorithm has on multi-class decomposition method performance, and thus apply when the algorithm is combined with any of the multi-class decomposition methods. Finally, these independent multi-class decomposition method and algorithm coefficients may be amplified or attenuated by a coefficient labelled with a combination of multi-class decomposition method and algorithm (“MDM ∧ algorithm”). These interaction coefficients apply in addition to the independent multi-class decomposition method and algorithm coefficients.
The following examples serve to illustrate these concepts. Consider the logistic regression (GLM) estimates for the multi-class problem from
Table 5. The “(Intercept)” (GBT ∧ OVA) is estimated at 2.99, corresponding to odds of
, and hence to a mean
of
. An estimate of −1.38 means that the GLM odds are
times the baseline odds, that is,
which is equivalent to a mean
of
. This estimate does not significantly change when GLM is combined with an expert hierarchy or an ensemble of expert hierarchies, as is attested by the absence of the corresponding coefficients from
Table 5. However, when GLM is combined with an ensemble of nested dichotomies (END), the estimated odds change by a factor of
, corresponding to a change of
and a mean
of
. Note that decision tree (DT) is the only other algorithm whose END performance is significantly different (by a factor of
) from its baseline (one-vs-all) performance. When GLM is applied in its multi-class formulation its odds are subject to the multi-class effect (MCL) that applies to all algorithms, estimated as a
change, which corresponds to a mean
of
for logistic regression. Note that an estimate of −0.15 for the “MCL ∧ kNN” coefficient means that the 16.2% improvement does not hold for kNN, and that an estimate of −0.61 for the “MCL ∧ DT” coefficient, which equates to a
change in the odds, means that decision trees perform better with one-vs-all than in its multi-class formulation. Finally, let us consider the “ECOC ∧ GLM” combination. When combined with one-vs-all, the log-odds for GLM are
. This baseline estimate is subject to the −0.26 change associated with error-correcting output codes overall, and an additional −0.31 change specific to the “ECOC ∧ GLM” interaction, accumulating in odds that are only
, equivalent to a mean
of
, of logistic regression’s baseline odds.
6. Discussion
Our analysis shows that the ensemble of gradient boosted trees significantly and consistently outperforms the other algorithms, both on the original 17-class problem and on the two dichotomous problems induced by the topmost dichotomy of EH1 and EH4. On all three problems, the next best learning algorithm tends to be SVM, followed by decision trees, kNN, and finally logistic regression and the multi-class SVM. While there is no such clear ranking for the multi-class decomposition methods, there are some discernible patterns. Logistic regression, decision trees, and the multi-class SVM are more sensitive to the choice of multi-class decomposition method than the other learning algorithms. Decision trees consistently achieve their best performance when combined with error-correcting output codes. In fact, combining decision trees with error-correcting output codes achieves a on the 17-class problem that is only 0.01 percentage points lower than the 95.82% achieved by a multi-class ensemble of gradient boosted trees, our best result on this problem. With any other algorithm, error-correcting output codes perform comparably or worse than one-vs-all, making it one of the worse multi-class decomposition methods for this problem. This is particularly true for logistic regression, which achieves its worst result on all three problems with error-correcting output codes. One-vs-one, which many studies found to perform slightly better than one-vs-all, does not consistently outperform one-vs-all in our evaluation, nor does it achieve the top result for any of our three classification problems. One-vs-one performs significantly (at the = 0.01 significance level) better than one-vs-all on the 17-class problem when combined with logistic regression or the multi-class SVM, the EH1 dichotomy when combined with decision trees or the multi-class SVM, and on the EH4 dichotomy when combined with decision trees. Furthermore, one-vs-one achieves significantly worse performance on the EH4 problem when combined with SVM, where it achieves 31.6% lower odds than one-vs-all, or kNN, where it achieves 39.3% lower odds than one-vs-all. Applying an algorithm’s multi-class formulation performs significantly (at the = 0.01 significance level) better than one-vs-all on the topmost EH1 dichotomy when combined with decision trees or logistic regression, and on the topmost EH4 dichotomy when combined with decision trees. Otherwise, an algorithm’s multi-class formulation performs comparably to one-vs-all.
Performance varies much less among expert hierarchies than among the other multi-class decomposition methods, which indicates that any reasonable expert hierarchy is a reasonable choice, and searching for better hierarchies is unlikely to yield significant improvements. Expert hierarchies perform comparably or better than one-vs-all with most algorithms on all three problems. One exception is decision trees, which achieve 24.4% lower odds on the 17-class problem with expert hierarchies than with one-vs-all. The other exceptions are SVM (both in its binary and multi-class formulation), the ensemble of gradient boosted trees, and logistic regression, all of which achieve 13.9% lower odds on the topmost dichotomy of EH4 with expert hierarchies than with one-vs-all. Ensembles of nested dichotomies perform comparably or better than one-vs-all with all but one algorithm. That exception is logistic regression on both the 17-class problem, where it achieves 13.9% lower odds with an ensemble of nested dichotomies than with one-vs-all, and the binary problem induced by the topmost dichotomy of EH4, where it achieves 18.9% lower odds than with one-vs-all. Ensembles of expert hierarchies, on the other hand, perform comparably or better than one-vs-all with all algorithms on all three problems. This makes an ensemble of expert hierarchies a better multi-class decomposition method for this problem than an arbitrary ensemble of (random) nested dichotomies, which may be more difficult to justify to a domain expert.
These results show that expert hierarchies can compete with other multi-class decomposition methods and inherent multi-class classifiers. As mentioned in the introduction, expert hierarchies have two main advantages over both multi-class classifiers and domain agnostic multi-class decomposition methods. The first advantage is iterative and modular development, and the second is targeted tuning and optimisation. Iterative and modular development can speed up and facilitate many of the tasks involved in designing, developing, and maintaining and improving a HAR system. Data annotation is often the most (human) time consuming part of HAR development. With an inherent multi-class classification algorithm, predictive modelling must wait until a data-set has been annotated with all the activities of interest, and be repeated if a new class is introduced. A new class can be introduced if a requirement emerges to distinguish between different types of some higher-level activity. For example, it might be decided upon further consultation with professionals that a HAR system developed for monitoring firefighters’ during operations really ought to distinguish between crawling on one’s hands and knees, and military style on one’s stomach. The distinction is an important one, because smoke tends to rise which makes it important to keep as close to the ground as possible. With one-vs-all it is possible, at least in principle, to begin modelling as soon as the annotations for one class (say, standing) are complete. However, the class imbalance inherent to a one-vs-all decomposition (e.g., “standing” vs. “not standing”) means that any insights gleaned from the modelling will be heavily biased and may not apply to the other dichotomisers. Furthermore, it is probably less efficient and possibly more error-prone to go through a data-set (e.g., fast-forward through hours of video footage) and annotate every time the subject is, or ceases to be, standing, than to annotate when subjects transition between, for example, stationary and mobile behaviour. With expert hierarchies, annotators can generate high-level annotations (e.g., stationary versus mobile) and hand them over to the data science team. The data scientists can then develop and tune the top-level discriminator, knowing that the degree to which they succeed in developing an accurate discriminator for the given labels is directly linked to the system’s overall accuracy. Furthermore, the independence of the dichotomisers that constitute an expert hierarchy makes it possible to replace any of them with a pre-trained model. This means that it is in principle possible to integrate models that have been developed by a third party and fitted to data private or confidential to them, be it to improve the expert hierarchy by replacing an existing dichotomiser or to extend the expert hierarchy with the capacity to make a finer-grained distinction by replacing a leaf in the expert hierarchy with a dichotomiser.
Targeted tuning and optimisation of HAR inference capabilities makes it possible to not only identify problematic activities (e.g., activities with high misclassification costs that tend to be confused with each other), but to effectively improve the performance on the problematic activities without negatively affecting performance on the other activities. Each dichotomiser in an expert hierarchy is an independent binary classifier whose performance can not only be analysed and tuned, but which can can be swapped out for a different algorithm. If the resulting dichotomiser is more accurate than the one it is replacing, then it is bound to improve the multi-class performance. While it is easy to aggregate the probabilities predicted by a true multi-class classifier or some multi-class decomposition method according to an expert hierarchy, we cannot map performance at some internal node of the hierarchy to a single classifier. The independence between an expert hierarchy’s constituent dichotomies makes it easier to explain a prediction to someone without a background in machine learning. Instead of having to simultaneously examine and balance the predicted probabilities of multiple classifiers, none of which says much about the probability distribution over all classes, we can easily identify and examine the output of the binary classifier corresponding to the level at which the prediction first went wrong. Because that classifier is independent of its ancestors and because its own performance has no effect on its descendants’, we can focus our efforts on improving a single binary classifier without having to worry about negatively affecting the performance on other classes.
7. Conclusions
We presented the first empirical comparison of the merits of different multi-class decomposition methods for human activity recognition, which covers not only the most popular methods from the literature, namely one-vs-all, one-vs-one, error-correcting output codes, and ensembles of nested dichotomies, but also nested dichotomies that are constructed from domain knowledge, which we call expert hierarchies, and ensembles of expert hierarchies. An expert hierarchy has the advantage that it requires one less binary classifier than one-vs-all, which requires k classifiers to represent a k-class problem, and that it results in a multi-class decomposition that is easier to interpret than that resulting from one-vs-all. In particular, an expert hierarchy can be designed such that it separates the two most important general concepts—for example “Potential Emergency” and “Not An Emergency”—first, that is, at the topmost level of the hierarchy. With an expert hierarchy it is possible to obtain an estimate for the topmost dichotomy using only a single model (the one corresponding to the topmost dichotomy), which is impossible with any other multi-class decomposition method. We demonstrated this scenario by comparing the predictive performance on the binary classification problem induced by the topmost dichotomy of two example expert hierarchies. Finally, we formulated a threshold that can be used to further reduce the computational complexity of predicting the most likely class label with expert hierarchies—or any nested dichotomy, since an expert hierarchy is just a special case of a nested dichotomy.
The results show that expert hierarchies perform comparably to one-vs-all, both on the original multi-class problem, and on a more general binary classification problem such as that induced by an expert hierarchy’s topmost dichotomy. Our results further show that individual expert hierarchies tend to perform similarly, particularly when compared to the much larger variance among other multi-class decomposition methods or learning algorithms. When multiple expert hierarchies are combined into an ensemble, they perform comparably to one-vs-one and better than one-vs-all on the full multi-class problem, and outperform all multi-class decomposition methods on the two dichotomous problems. Because an expert hierarchy’s constituent dichotomisers are independent of each other it is possible to analyse and optimise each dichotomiser in isolation. This enables modular and iterative development of increasingly complex HAR capabilities, which is a pre-requisite for agile development techniques, and targeted tuning and optimisation of the resulting HAR system.
These results were obtained with a single data-set, and we cannot therefore assume that they will hold up for other HAR problems. They do, however, show that expert hierarchies can have merits in some applications, and justify further research of expert hierarchies. In future work, we therefore plan to evaluate their merits on benchmark HAR data-sets, and investigate whether their potential for integrating data-sets with different activities and transfer HAR models from one set of data and activities to another.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}