1. Introduction
Recognizing daily activities in smart environment requires various devices to collect data from sensors like cameras, video recordings, static images, and other activity recording/detection sensors. Activity recognition-based sensors (non-audio/visual sensors) have a series of specific advantages compared with other devices due to the characteristics of their sensor equipment such as low-cost, less-intrusive, privacy, and security preserving nature [
1,
2]. These advantages make these sensors more acceptable by users, and thus widely used in activity recognition concepts and related machine learning algorithms [
3,
4,
5,
6,
7,
8,
9]. However, traditional methods mostly use supervised machine learning to recognize human activity that require both training data and corresponding labels for each activity involved. Training data recording and activity-labeling are often time-consuming and costly to obtain, as it demands a huge effort from test subjects, annotators, and domain experts. Therefore, it has been reported that a fully supervised learning method, where labeled instances from different contexts are provided to the system, may not be possible for many applications [
10,
11].
Furthermore, the existing approaches to activity recognition cannot recognize a new activity which is not presented in its training set. According to the activity lexicon in the ATUS survey [
12], there are at least 1104 different activities that people perform in their everyday life. Considering the differences between individuals, cultures, and situations that were not covered by the study, the actual number of the activities is likely to be more. However, the primary drawback of the existing activity recognition-based sensors is that they prevent systems from recognizing any previously invisible activities. On the other hand, sensor data contain rich semantic relationships that can be appropriately investigated to the estimate and or detect novel (i.e., not previously seen in the training set) activities. Considering the lastly described existing limitations, there are key research questions we aim to answer in this paper:
Q1. How do we exploit the advantages of involving specific sensors types in the activity recognition process (e.g. low cost, less intrusive, and privacy preserving)? Q2. How do we embed sensor readings data to predict or recognize previously unseen new activities? Q3. How do we recognize high-level activity labels when there is no related data in the training model? Q4. Is it possible to apply zero-shot activity recognition using only a small data sample amount in the training set?
In this paper, we present a technique to recognize activity events when there is no related training data for a target activity by utilizing the previous knowledge on the existing activities. Herein, we have developed the current approach to tackle the above-mentioned research questions. We involve heterogeneous knowledge from sensor data and semantic word space, which is extracted from low-level sensor data and uses some external machine learning method.
In particular, we refer here to the zero-shot learning, where the classes covered by training and testing samples are disjoint [
13,
14].
Zero-shot learning has recently demonstrated promising performance results according to the latest computer vision literature [
15]. This type of learning enables the prediction (or detection) of newly observed activity type or calls by using semantic similarity between the activity and other embedded words in the semantic space. It uses the so-called “word2vec” tool [
16] for modeling latent semantic text by taking each activity-label as an input and then producing a corresponding high dimensional vector space [
17].
For example, assume that we have training data for two activities “CookingLunch” and “WashingDishes”. If we want to detect a new activity “EatingLunch” rather than hiring subjects to collect and annotate a new activity, our approach employs semantic similarity to predict a new activity by reusing the model that has already been trained on two known activities. Still, there are several challenges that must be overcome to apply zero-shot learning in activity recognition for the following reasons. (1) Most of the previous works on zero-shot learning focused on images and videos, which are totally different from other forms of sensor data; (2) sensor data are generally noisy, and the noise may change the relationship between the features and the desired output; (3) it is not clear which features within the sensor data are useful to recognize activities; and (4) to train a normal model, one generally needs a large amount of sensor data, but in our case, we consider situations where one has only a small amount of sensor data for training. To address the above formulated research questions Q1, Q2, and Q3, we have designed a representation for human activity recognition through correlating high-level activity-labels by embedding semantic similarity. The description of semantic similarities is based on low-level features captured from event occurrences in the sensor data. For research question Q4, to improve the recognition accuracy, we compared the output using various scenarios to reach the best recognition performance. We summarize our core contributions in this work as follows.
Designing a method to recognize human activity from non-visual sensor readings instead of traditional methods, which depends on images or video observations.
Combining both the semantic similarity and zero-shot algorithms for robustly recognizing previously unseen human activities.
Implementing our approach by using different training and testing samples to enhance and validate the good/high recognition accuracy of previously unseen activities.
Evaluating the system through the use of two well-known public activity recognition datasets.
Furthermore, the suggested system may also help the machine to gain a deeper understanding of activity patterns such as a person’s long-term habits. Additionally, it can be used to motivate a person to add new healthy activities into his/her normal routine to improve the quality of his life. Unlike recognition concepts using only pure low-level features of sensor data, semantic similarity makes the activity recognition task more reliable, especially when the same activity may look different due to the variety of activities performed. Additionally, this method may also be useful for those scenarios where the training model has been learned for recognizing activities in one smart house and then be used/utilized later in another house. The rest of this paper is structured as follows. In
Section 2, we discuss and compare the related works. In
Section 3, we give a detailed description of our novel method. In
Section 4, we present the datasets used in the various experiments. Then,
Section 5 presents the evaluation methodology used and then discusses the results obtained. Finally, in
Section 6, we present a comprehensive summary of the quintessence of the paper contribution and the core results obtained. The paper ends with a series of concluding remarks along with a comprehensive outlook w.r.t. future subsequent works in
Section 7.
2. Related Works
In this section, we briefly review the prior works or relevance and do group them into three main directions. To avoid the redundancy, we briefly reviewed the state-of-the-art, considering the diversity of underlined method, activity, input source, and the highest performance, as follows.
2.1. Activity Recognition-Based Supervised Learning
Regarding human activity recognition approaches, most of the related published studies address such a recognition using supervised learning [
18,
19,
20,
21,
22] or semisupervised learning [
23,
24]. Transfer learning has also been investigated, whereby the instances or models for activities in one domain can be transferred to improve the recognition accuracy in another domain for the purpose of reducing the need for training data [
25,
26,
27]. Although many promising results have been achieved, a widely acknowledged problem is that labeling all the activities is often very expensive, as it takes a lot of effort for the test subjects, human annotators, domain experts, and it does nevertheless remain error-prone [
28,
29]. However, providing accurate and opportune information is one of the most important tasks in identifying human activity. A lot of studies are based on supervised learning for recognizing human activity, some of which are summarized in
Table 1. In this table, one compares the classification techniques, the different activities, the input sources, the respective observed performance, and finally the best performance that has been achieved using a particular classifier.
Furthermore, activity recognition has been widely reported in many fields using sensor modalities, including ambient sensors [
35], wearable sensors [
36], smart phones [
34], and smart watches [
37]. Those sensors contribute to developing a wide range of application domains such as sport [
38], human–computer interaction [
39], surveillance [
40], video streaming [
41], healthcare system [
42], and computer vision area [
43]. Due to the properties of noninvasive sensors, some studies discussed how to monitor human activities using this type of sensors (i.e., non-visual sensors) because they are both easy to install and privacy preserving [
44,
45].
Regarding supervised learning, it should be mentioned that Deep Learning has been applied for human activity recognition.
Table 2 overviews previous works for recognizing activity using different sensors.
2.2. Activity Recognition-Based on Zero-Shot Learning
Zero-shot learning is an extended form of supervised learning to solve classification problems where there are not enough (i.e., only few) training instances are available for all classes. It depends on reusing the semantic knowledge between seen and unseen classes [
50]. The notion of zero-shot learning was firstly presented in the field of computer vision [
51,
52,
53]. The goal was to teach a classifier to predict novel classes that were omitted from the training set. After that, a lot of works have emerged [
54,
55,
56,
57]. To predict human activity, the major applications were related to visual attributes acquired from image or video sources.
Table 3 presents prior studies on zero-shot human activity-recognition that depict different accuracy levels. The prediction of the next activity was also investigated in the work [
58] to provide better assistance for elderly people. Unlike in the aforementioned studies, the focus in this last cited work was on predicating a next action based on the behavior history of a person.
Despite the fact that a significant progress has been made in zero-shot based activity recognition in the last years, it is unfair to compare their performance with that of supervised learning because the zero-shot concepts used to recognize activities have never been never seen before.
Today, there is a tendency towards using a noninvasive and non-visual activity sensing to collect information and infer activity without disturbing the person, as nobody wants to be constantly monitored and recorded by cameras. Additionally, they (i.e., non-visual sensors) are more flexible computing resources. It is indeed difficult to attach video recorders to a target subject to collect body information during daily activities. Besides, video or image processing methods are comparatively more expensive and time-consuming.
However, as we mentioned earlier, the limitations of the previous studies compared to our work is that the existing activity recognition-based supervised learning methods still cannot recognize a previously unseen new activity if there are no training samples of that activity in the dataset. Besides, the existing studies on activity recognition-based zero-shot learning focus mostly on images and videos as inputs, which is quite different from recognition involving non-visual sensor data. Due to the availability of huge samples sizes and rich features in the concepts that use images or videos, it is much easier for them to identify activities when compared to a noninvasive and non-visual sensor that relies thereby also only on very few samples.
3. Proposed Framework
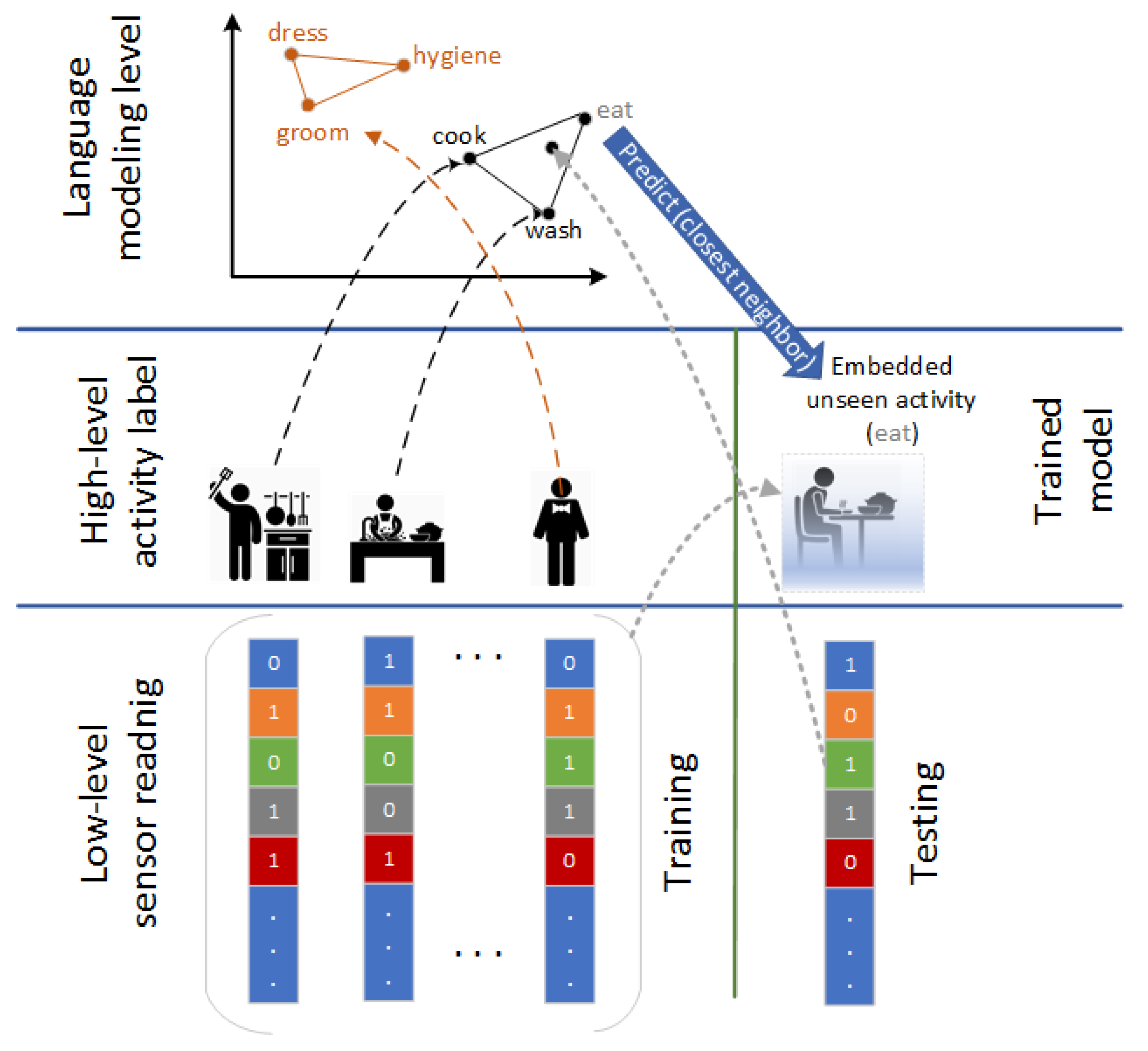
In our framework, the features of each activity are extracted from corresponding sensor readings using fixed-length trained dataset. Due to the dissimilarity between trained and tested activities, a mapping from a different space is required to infer high-level activity labels. Predicting a new label for hidden activities is supported by a language modeling level that presents the nearest embedded words matching the target activity in the shared semantic space (see
Figure 1). We have initialized the word embedding with a pre-trained embedding Google-News dataset. We specify word vectors of 300-dimensions for each trained activity [
62].
As we have described before, the training and testing instances in zero-shot learning have different lengths . Furthermore, the intersection between “already seen” and “previously unseen” activities is empty .
3.1. Problem Definition
Assume a labeled training set of N samples is given as , with an associated class label set , where ∈ is the tr-th training activities (sensor readings), ∈ is its corresponding L-dimensional semantic representation vector, and ∈ is the the training class label. We have , i.e., the training (seen) classes and test (unseen) classes are disjoint. Note that each class label is associated with a predefined semantic space representation and (e.g., attribute vector), referred to as semantic class prototypes. Given a new test activity and which is the corresponding L-dimensional semantic representation vector, the goal of zero-shot learning is to predict a class label .
3.2. Preprocessing Procedure
Sensor data are represented as a sequence of events, and every change in a sensor state (i.e., value) generates an event. All sensor readings/events (SE) produce binary values: ON/OFF motion sensors, OPEN/CLOSE door sensor, and/or numeric values for environmental sensors (e.g., temperature, humidity, light, etc.). These events are used to extract/infer complex activities. As a result, we have a matrix
, where
m is the number of activities and
n is the dimensionality of the data. The construction (or generation) of the data relies on the fact that when the sensor (s) turns “ON”, its value is set to 1, and then to 0 when its value is “OFF”. In this case, we count how many times ONs occurred in a specific activity. A preprocessing of raw data consists of multiple-steps as shown in Algorithm 1.
| Algorithm 1: Preprocessing procedure. |
 |
3.3. Approach
As we have already previously explained it, zero-shot learning is an extension of the supervised learning to overcome a well-known problem in machine learning when too few labeled examples are available for all classes.
We collect sensor readings for training classes and thereby, we can get them for all available activity samples. However, we do not have any sensor readings samples for zero-shot classes, and we do not even know how they look like. Additionally, as zero-shot activities are not involved in the training phase, a different and appropriate data representation for the zero-shot and training activity labels is required, which will function as a bridge between training and zero-shot classes. This data representation should be generated from all data samples by ignoring that they belong either to training classes or to zero-shot classes.
Concerning activity labels embedding, we use Google Word2Vec representation trained on Google News documents (
https://code.google.com/archive/p/word2vec/). We consider a Wor2Vec of 300 dimensions for each of the training classes we have specified. Therefore, the algorithm is structured as follows [
52] in the training phase (see
Figure 2).
Given some known training class category labels , the sensor readings of training activities and the corresponding L-dimensional semantic representation vectors of the training labels .
Learn activities using a shallow neural network model ,.
In the test phase, which means the recognition phase (see
Figure 3):
Given online sensor readings of a new unseen activity which has not been used in training
Map test data to category vector space
Apply nearest neighbor matching of vs
3.4. Classification Model
The aim of this model is to map inputs (sensor readings) to corresponding outputs (Word2Vecs). To perform the classification task, we use a shallow neural network neural model [
63,
64]. The shallow neural network model consists of four layers, input layer, two hidden layers, and an output layer. First, the sensor readings of training activities (input layer) are fed into the two hidden layers in the neural model which consist of 128 neurons and 300 neurons, respectively, supported by an Exponential Linear Units (SELU) activation function, then the final layer is the output layer which consists of a softmax activation function and its size is related to the number of training activity classes. Adam optimizer [
65] has been used which is an adaptive learning rate optimization algorithm that has been designed specifically for training deep neural networks. The parameters are selected by using grid search from scikit-learn library (see
Figure 4).
The proposed shallow neural network model has been trained on both datasets (see
Section 4). Additionally, we should mention that batch normalization is taken into consideration during training and the last layer has been customized.
The goal of the customized layer is that the weights should be initialized using Word2Vecs of the training activities and the layer should not be trainable. Namely, it should be a simple matrix multiplication placed at the end of the network.
3.5. Evaluation Metrics
To evaluate the overall performance of the classifiers, we consider several performance metrics. In particular, we use precision, recall, f-measure, and accuracy, as in [
66].
The Equations (2)–(4) show mathematical expressions of the metrics precision, recall, accuracy and f-measure respectively, where TP, TN, FP, and FN refer respectively to “True-Positives”, “True-Negatives”, “False-Positives”, and “False-Negatives”, respectively.
4. Datasets Description
We selected two datasets (HH101, HH125) obtained in the CASAS (
http://casas.wsu.edu) smarthomes that reflect daily activities in the real-world using sensor streams. In the HH101 dataset, there are 30 distinct activities belong to one subject and 76 sensor types. HH125 dataset includes 34 activities performed by single-resident apartment and 27 different sensors. However, both datasets contain sensor readings indicating the beginning and ending of an activity. In the evaluation, we chose some appropriate activities to demonstrate our concept.
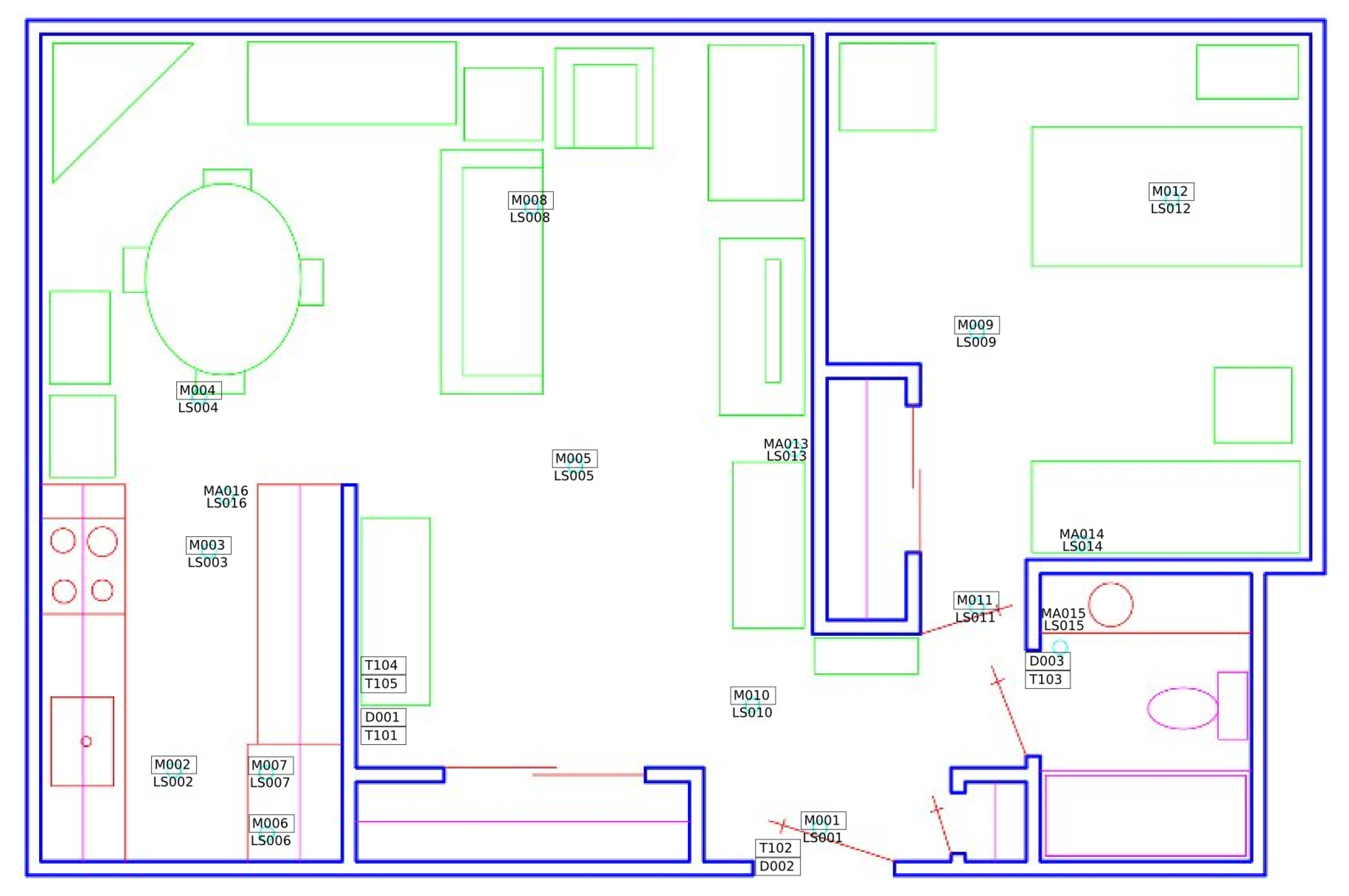
Table 4 compares the total number of each activity that is used in our experiment for both HH101 and HH125 smart-homes. Home layout and sensor placement of each dataset is different. Each house is equipped with a combination of different types of sensors deployed in different locations (e.g., battery levels, motion, temperature, door, and light sensors).
Figure 5 shows a sample layout and sensor placement for HH101 smarthome.
The raw data from various sensor readings are filtered and preprocessed to extract low-level features. This process is based on sensor status, either ON/OFF or a numeric value. The resulted low-level features transform into embedded vector to examine contextual word similarity. The nearest similar word is computed to classify activity label despite the fact that there is no training data for that activity. The size of vector space can be specified to a particular dimension, in our case, 300-dimensional vectors.
5. Results
We evaluate our method with datasets collected from households using simple data sensors. In this section, we investigate whether an activity that has never been seen in the training set is predicted correctly and how the system’s performance changes when various scenarios are observed. In order to evaluate the activity recognition approach, we selected two scenarios using two well-known benchmark datasets. Moreover, four performance measures are considered: Accuracy, Precision, Recall and F-Measure. They are calculated to give a full evaluation of the performance of our proposed system.
Table 5 shows two scenarios: the first scenario “scenario 1” uses activities such as “bathe, cook, wash dinner dishes, watch TV, and read” for training, and activities such as “sleep, toilet, and relax” for zero-shot. The table also shows the second scenario “scenario 2”, which uses activities such as “cook breakfast, wash dishes, phone, dress, and eat dinner” for training, and activities such as “ cook breakfast, personal hygiene, and eat lunch” for zero-shot, respectively.
In the previous scenarios, note that there are semantic relations between activities. For example, in scenario 1:
bathe may relate to sleep and dinner
toilet may relate to wash
relax may relate to read, watch, and bathe
5.1. Scenario 1
Table 6 shows the confusion matrix for scenario 1 using the HH101 and HH125 dataset. However, for the HH101 dataset, there are false positive cases between some toilet and sleep activities.
Table 7 shows the performance metrics for scenario 1 using the HH101 dataset and the HH125. It can be seen that the proposed approach achieved the best accuracy for relax activity and toilet for HH101 and HH125 datasets, respectively. Furthermore, for both datasets HH101 and HH125, some relax activities are recognized as sleep.
5.2. Scenario 2
Table 8 shows the confusion matrix for scenario 2 using the HH125 and HH101 datasets. However, there are some false-positive cases between personal hygiene activities and cook lunch, and between personal hygiene and eat lunch for HH101 and HH125, respectively.
Table 9 shows the performance metrics for scenario 2 using the HH101 and the HH125 datasets. It can be seen that the proposed approach achieved the best accuracy for eat lunch and cook lunch for HH101 and HH125 datasets, respectively.
Regarding the false-positives related misclassification, this is due mostly to (a) activities that share the same sensors (e.g., relax and sleep or toilet and sleep); (b) activities that have very close word vectors in the embedding space; and (c) sensors that are allocated close to each other although related to the zero-shot activities.
6. Discussion
We have used sensor-semantic embedding for zero-shot and addressed the problems associated with the framework that are specific for zero-shot learning. Based on the research question (Q1), our method has shown success in utilizing the characteristics of simple sensor readings, by embedding (Q2) the semantic information of the sensors and the activities. The classification model (Q3) is learned with a data set and used to recognize the activity that has never appeared in a testing set, which has different label and sensor readings. Experiments on real-world small data learning (Q4) show the effectiveness of the proposed zero-shot activity recognition.
Despite the success of the standard zero-shot learning, there are some challenges that limit its performance.
The majority of zero-shot models ignore that the semantic space is highly subjective, as they are created by a human or automatically extracted. It may not be complete or discriminatory enough to classify different classes because of the scarcity of similar seen classes which describe the unseen.
There is a semantic gap between existing semantic space and the ideal space, because the model trained on huge possible words, for example GoogleNews or Wikipedia, may contain unrelated texts. This may raise concerns about the validity of the results.
Zero-shot suffers from well-known: hubness [
67,
68,
69] and bias problems [
53,
70,
71]. Due to these problems, the models sometimes perform poorly towards unseen classes.
In a real-world setting, an appropriate sensor data segmentation concept that can define a robust windowing approach for human activities’ recognition is still a challenging issue. Hereby, when dealing with the inputs (which are the sensor data) in real-life (i.e., online), a possible solution proposed by the approach in [
72], which follows the so-called best-fitting sensors strategy. The proposed approach consists of two phases: (a) an offline phase where the best-fitting sensors are selected for each activity by using the related respective information gain, and (b) an online phase (or real-life phase), which defines a windowing algorithm that segments sensor readings to be given as input to the support vector machine classifier. Basically, a window is so selected that all best-fitting sensors are activated for any given activity.
However, in this paper, our objective is not to overcome the above-mentioned challenges. Instead, we exploit the benefits of this important algorithm in predicting unseen activities.
It is a complex task to observe model behavior on unseen activities by training the model on seen activities, as it is highly probable that it receives misclassification. In our empirical evaluations, we identify several pertinent issues that underpin zero-shot in recognition task. Moreover, we have computed the correlation between seen and unseen activities, which resulted in zero-shot recognition (see
Figure 6).
We observed that
The correlation between seen classes “that infer unseen” must be less than the correlation between unseen and seen ones (e.g., corr(CookBreakfast, EatDinner) < corr(CookLunch, CookBreakfast), and < corr(CookLunch, EatDinner)).
To obtain a better result, the correlation in the seen training set must be spaced. For example, when phone activity is discarded in training, it will lead to poorly unseen result, as the semantic space is small.
It is difficult to anticipate to which seen activity the unseen belongs if the distance between “seen” instances is very close. E.g., CookLunch+EatLunch to infer WashLunch.
Generally, in both training and testing sets, the semantic relationship between samples should be small. In other words, the distance between samples, must not be small.
Since the semantic space contains a huge number of similar words, the recognition task is more susceptible to predict an incorrect label (e.g., wrongly predicting a “WashHands” as “WashDishes”, where both are semantically similar, because they belong to washing activities).
Exploiting less labeled data in real life to recognize more activities involves several challenges. As a potential solution, a study [
73] proposes a practical way to predict data labels outside the laboratory.
We should mention that zero-shot activities should also be classified correctly when there is a large number of unseen categories to choose from. To evaluate such a setting with many possible but incorrect unseen classes, we may create a set of distractor words. We compare two scenarios: in the first, we add random nouns to the semantic space. In the second, a much harder setting, we add the k-nearest neighbors of a word vector. As a result, the accuracy should not change much when random distractor nouns are added. Such an experiment can show that the semantic space is spanned well and our zero-shot learning model is quite robust.
However, regarding the issue of comparing the proposed approach, which is based on non-visual sensors with other zero-shot approaches, which are based on visual data (such as videos and images as shown in
Table 3), we can state the following. (a) Our high/better performance is due to the fact that the input dimension of our sensors’ readings is much smaller than that of sensor visual data, and (b) the complexity of visual data is much higher than that of non-visual sensors data especially w.r.t., for example, noise, enhancement, and restoration. Generally, in [
74], several researchers have already addressed the accuracy of various zero-shot learning approaches using visual datasets, e.g., Animal with Attributes(AwA) [
75], aPascal and aYahoo (aPY) [
76], Caltech-UCSD Birds-200-2011 (CUB) [
77], and SUN [
78]. Those authors have mentioned that the Joint Latent Similarity Embedding (JLSE) approach showed a promising accuracy, e.g., 80.46%, 50.35%, 42.11%, and 83.83% for AwA, aPY, CUB, and SUN, respectively. However, another approach proposed in [
74], which is based on formulating a softmax-based compatibility function and an improved optimization technique showed better accuracy, e.g., 84.50%, 42.40%, 48.10%, and 85.50% for AwA, aPY, CUB, and SUN, respectively.
7. Conclusions
Due to the cost of obtaining human generated activity data and similarities between existing activities, it can be more efficient to reuse information from existing activity recognition models instead of collecting more data to train a new model from scratch. In this paper, we have presented a method for integrating low-level sensor data with semantic similarity of word vectors to infer unseen activities depending on seen ones. We applied zero-shot learning to estimate occurrences of unseen activities. Furthermore, we have presented several challenges that must be taken into account when selecting training and testing samples using the suggested zero-shot learning. Experimental results show that our approach has achieved a promising accuracy for unseen new activities’ recognition. As a future work, to confirm our hypothesis, we have to train our model with various combinations of activities. We also plan to integrate different machine learning algorithms to improve system performance. Moreover, we will extend our evaluation to train activity samples in one smarthome environment and predict unseen activity in a different environment.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}