Training Convolutional Neural Networks with Multi-Size Images and Triplet Loss for Remote Sensing Scene Classification

 ,
,  ,
,  ,
, 
Abstract
1. Introduction
1.1. Background
1.2. Motivation
1.3. Main Contributions
- 1)
- We specially design a strategy to train the network, namely, training with multi-size images. An adaptive pooling is embedded for fixing the size of the feature maps, which makes the model process images with different sizes, enabling training on images with different sizes.
- 2)
- A branch dedicated to triplet loss is designed. The main purpose of this branch is to guide the model to learn a more discriminative feature vector of remote sensing scenes, thus improving the classification accuracy of the model.
- 3)
- The dropout technology is utilized between the feature extractor and classifier to avoid overfitting, therefore refining the generalization capability of the model.
- 4)
- Wintegrate the three modules mentioned above into the model to improve the classification accuracy without increasing parameters of model at the inference stage, and the end-to-end model that we constructed can classify the remote sensing scene well.
2. Materials and Methods
2.1. Materials
2.1.1. Dataset
2.1.2. Experimental Environment
2.2. Methods
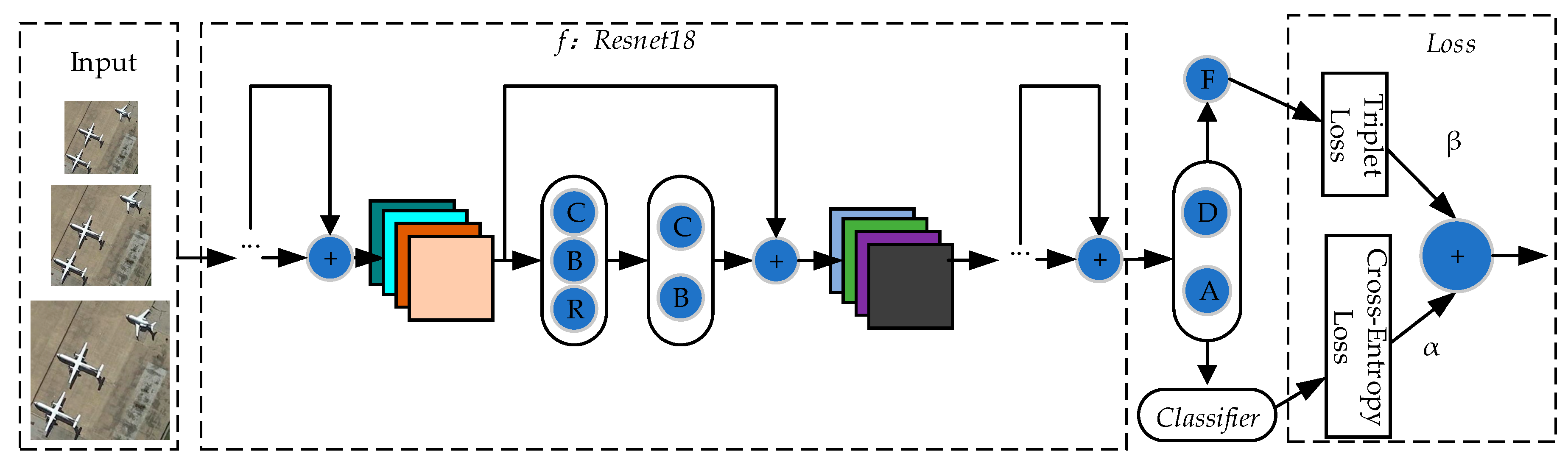
2.2.1. Overall Framework
2.2.2. Feature Extractor f
2.2.3. Classifier
2.2.4. Dropout
2.2.5. Triplet Loss
| Algorithm 1 Batch hard triplet loss |
| INPUT: labels, embeddings, margin |
| labels: the labels of images. labels, B represents the number of images of a training batch |
| embeddings: the feature vectors of images, embeddings, M represents the length of the feature vectors of the images. |
| OUTPUT: triplet_loss |
| 1. Calculate the European distance distances between every two embeddings in embeddings, distances |
| distances = calculate_pairwise_distances(embeddings) |
| 2. Calculate the mask of the same category, which is marked as mask_positive. mask_positive is a matrix of , which only contains 0 or 1. It is used to select distances of the same category. |
| mask_positive = calculate_valid_positive_mask(labels) |
| 3. Calculate the mask of the different category, which is marked as mask_negative, mask_negative is a matrix of , which only contains 0 or 1. It is used to select distances of the different category. |
| mask_positive = calculate_valid_negative_mask (labels) |
| 4. Calculate the distance of hard positive sample pairs, which is marked as hardest_positive_dist. hardest_positive_dist . |
| hardest_positive_dist = (distances * mask_positive.float()).max(dim=1)[0] |
| 5. Calculate the distance of hard negative sample pairs, which is marked as hardest_negative_dist. hardest_negative_dist . |
| max_dist = distances.max(dim=1, keepdim=True)[0] |
| distances = distances+ max_dist * (mask_negative.eq(0).byte()).float() |
| hardest_negative_dist = distances.min(dim=1)[0] |
| 6. Calculate triplet loss, which is marked as triplet_loss. triplet_loss . |
| triplet_loss=(hardest_positive_dist-hardest_negative_dist+margin).clamp(min=0) |
| triplet_loss = triplet_loss.mean() |
| return triplet_loss |
2.2.6. Training with Multi-Size Images
2.2.7. Loss
2.3. Evaluation Metrics
2.4. Hyper Parameters
3. Results and Discussion
3.1. Experimental Results on AID Dataset
- (1)
- Our model can classify most scenes in the AID dataset well. As shown in Figure 5, the classification accuracy of 23 scene categories exceeds 90%, and some categories can be exactly classified by the model, i.e., the accuracy reaches 100%. These categories include forest, meadow, and parking. In addition, the classification accuracies of some categories have reached 99%. As shown in Figure 6, the classification accuracies of 27 scene categories exceed 90%.
- (2)
- Our model does not perform well on some scene categories. As shown in Figure 5, resort has the lowest accuracy, which is easily identified as park. Besides, the classification accuracy of squares is also relatively low because it can be easily identified as park or school. It can be found that two similar categories are easily confused.
- (3)
- With the increasing number of training data, the classification accuracy of the model can be further improved. Compared to each category in Figure 5, the classification accuracy of each category in Figure 6 has improved, especially for category center. The classification accuracy of some categories in Figure 5 does not reach 100%, but its accuracy reaches 100% in Figure 6.
3.2. Experimental Results on NWPU-RESISC45 Dataset
- (1)
- The overall accuracy of the model on NWPU-RESISC45 is lower than that on AID. Compared to AID, NWPU-RESISC45 has more images and categories, which increases the difficulty of the dataset to some extent. In Figure 7 and Figure 8, most images are used for testing, and a small number of images are used for training. Therefore, the model performs relatively poor on this dataset.
- (2)
- For the NWPU-RESISC45 dataset, intra-class diversity and inter-class similarity are more obvious. From Figure 7, we can find that the classification accuracy of all categories has not reached 100% and the worst is the classification accuracy of palace, which is 52%. We can also find that the probability of palace being identified as church is 14% and being identified as commercial area is 10%. As we know, the three categories are extremely similar.
- (3)
- (3) With the increasing number of training data, the classification performance of the model improves. As can be seen from Figure 8, the classification accuracy of palace is 75%, which is 23% higher than that shown in Figure 7. It is worth mentioning that the probability of the palace being identified as a commercial area has dropped significantly, from 10% to 1%. In addition, the classification accuracy of the chaparral increases to 100%, which is the only category where the classification accuracy can reach 100%.
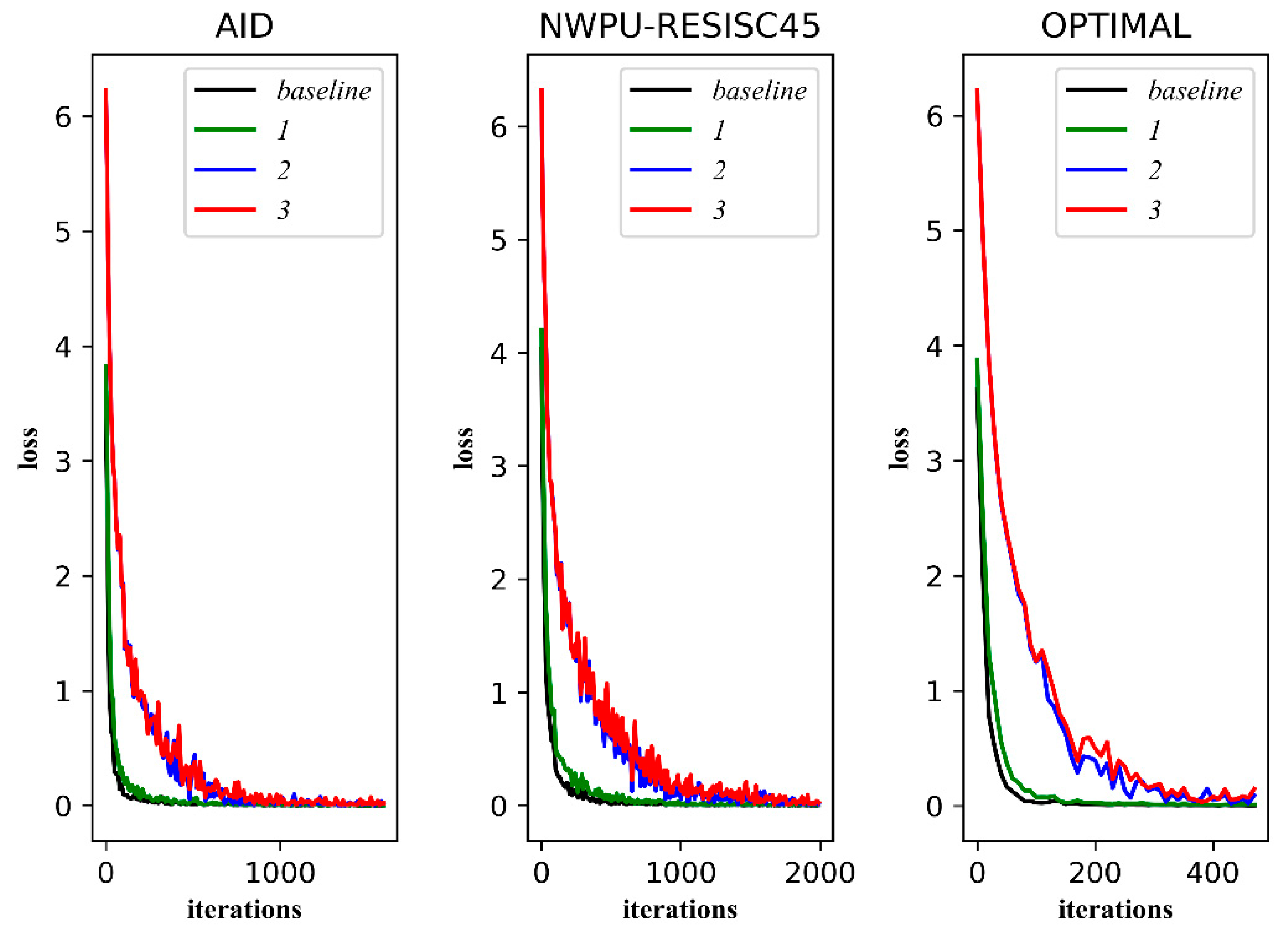
3.3. Ablation Experiment
3.3.1. Performances on the Training Sets and Validation Sets
3.3.2. Performances on the Validation Set and Test Set
3.3.3. Visualization of Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A Benchmark Data Set for Performance Evaluation of Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene Classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Wang, J.; Gu, X.; Liu, W.; Sangaiah, A.K.; Kim, H. An empower hamilton loop based data collection algorithm with mobile agent for WSNs. Hum. Cent. Comput. Inf. Sci. 2019, 9, 1–14. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Wang, K.; Sangaiah, A.K.; Lim, S.J. An affinity propagation-based self-adaptive clustering method for wireless sensor networks. Sensors 2019, 19, 2579. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gao, Y.; Yin, X.; Li, F.; Kim, H. An enhanced PEGASIS algorithm with mobile sink support for wireless sensor networks. Wireless Commun. Mob. Comput. 2018, 2018. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Zhou, C.; Sherratt, R.S.; Wang, L. Optimal Coverage Multi-Path Scheduling Scheme with Multiple Mobile Sinks for WSNs. Comput. Mater. Continua 2020, 62, 695–711. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Geographic Image Retrieval Using Local Invariant Features. IEEE Trans. Geosci. Remote Sens. 2013, 51, 818–832. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS-J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Luo, B.; Jiang, S.; Zhang, L. Indexing of remote sensing images with different resolutions by multiple features. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2013, 6, 1899–1912. [Google Scholar] [CrossRef]
- Avramovic, A.; Risojevic, V. Block-based semantic classification of high-resolution multispectral aerial images. Signal. Image Video Process. 2016, 10, 75–84. [Google Scholar] [CrossRef]
- Dos Santos, J.; Penatti, O.; Da Torres, R.S. Evaluating the potential of texture and color descriptors for remote sensing image retrieval and classification. In Proceedings of the International Conference on Computer Vision Theory and Applications, Angers, France, 17–21 May 2010; pp. 203–208. [Google Scholar]
- Chen, X.; Fang, T.; Huo, H.; Li, D. Measuring the Effectiveness of Various Features for Thematic Information Extraction From Very High Resolution Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4837–4851. [Google Scholar] [CrossRef]
- Zhu, R.; Yan, L.; Mo, N.; Liu, Y. Attention-Based Deep Feature Fusion for the Scene Classification of High-Resolution Remote Sensing Images. Remote Sens. 2019, 11, 1996. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Spatial pyramid co-occurrence for image classification. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1465–1472. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Xia, G.S.; Liu, G. A hierarchical scheme of multiple feature fusion for high-resolution satellite scene categorization. In Proceedings of the 9th International Conference on Computer Vision Systems, St. Petersburg, Russia, 16–18 July 2013; pp. 324–333. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar] [CrossRef]
- Chen, L.; Yang, W.; Xu, K.; Xu, T. Evaluation of local features for scene classification using VHR satellite images. In Proceedings of the 2011 Joint Urban Remote Sensing Event, Munich, Germany, 11–13 April 2011; pp. 385–388. [Google Scholar] [CrossRef]
- Chen, Y.; Xiong, J.; Xu, W.; Zuo, J. A novel online incremental and decremental learning algorithm based on variable support vector machine. Cluster Comput. 2019, 22, 7435–7445. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; Ma, Z.; Chen, J.; He, D.; Ackland, S. Remote sensing scene classification based on convolutional neural networks pre-trained using attention-guided sparse filters. Remote Sens. 2018, 10, 290. [Google Scholar] [CrossRef]
- Yuan, Y.; Fang, J.; Lu, X.; Feng, Y. Remote Sensing Image Scene Classification Using Rearranged Local Features. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1779–1792. [Google Scholar] [CrossRef]
- Zeng, D.; Chen, S.; Chen, B.; Li, S. Improving Remote Sensing Scene Classification by Integrating Global-Context and Local-Object Features. Remote Sens. 2018, 10, 734. [Google Scholar] [CrossRef]
- Bian, X.; Chen, C.; Chen, C.; Tian, L.; Du, Q. Fusing Local and Global Features for High-Resolution Scene Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 2889–2901. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.; Hu, J.; Zhang, L. Transferring Deep Convolutional Neural Networks for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, J.; Xia, R.; Zhang, Q.; Cao, Z.; Yang, K. The visual object tracking algorithm research based on adaptive combination kernel. J. Ambient Intell. Humanized Comput. 2019, 10, 4855–4867. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, Y.; Feng, W.; Wang, J. Spatially attentive visual tracking using multi-model adaptive response fusion. IEEE Access 2019, 7, 83873–83887. [Google Scholar] [CrossRef]
- Zhang, J.; Jin, X.; Sun, J.; Wang, J.; Li, K. Dual model learning combined with multiple feature selection for accurate visual tracking. IEEE Access 2019, 7, 43956–43969. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A Cascaded R-CNN with Multiscale Attention and Imbalanced Samples for Traffic Sign Detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, W.; Lu, C.; Wang, J.; Sangaiah, A. Lightweight deep network for traffic sign classification. Ann. Telecommun. 2019. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.; dos Santos, J. Towards Better Exploiting Convolutional Neural Networks for Remote Sensing Scene Classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef]
- Al Rahhal, M.M.; Bazi, Y.; Abdullah, T.; Mekhalfi, M.; AlHichri, H.; Zuair, M. Learning a multi-branch neural network from multiple sources for knowledge adaptation in remote sensing imagery. ISPRS Int. Geo-Inf. 2018, 10, 1890. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Li, W.; Xu, H.; Li, H.; Yang, Y.; Sharma, P.K.; Wang, J.; Singh, S. Complexity and algorithms for superposed data uploading problem in networks with smart devices. IEEE Internet Things J. 2019, 1-1. [Google Scholar] [CrossRef]
- He, S.; Li, Z.; Tang, Y.; Liao, Z.; Li, F.; Lim, S.J. Parameters Compressing in Deep Learning. Comput. Mater. Continua 2020, 62, 321–336. [Google Scholar] [CrossRef]
- Li, W.; Liu, H.; Wang, J.; Xiang, L.; Yang, Y. An improved linear kernel for complementary maximal strip recovery: Simpler and smaller. Theor. Comput. Sci. 2019, 786, 55–66. [Google Scholar] [CrossRef]
- Lu, L.; Guo, M.; Renals, S. Knowledge distillation for small-footprint highway networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech, and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 4820–4824. [Google Scholar] [CrossRef]
- Li, W.; Chen, C.; Zhang, M.; Li, H. Data Augmentation for Hyperspectral Image Classification with Deep CNN. IEEE Geosci. Remote Sens. Lett. 2019, 16, 593–597. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Li, X.; Kim, H.; Wang, J. A full convolutional network based on DenseNet for remote sensing scene classification. Math. Biosci. Eng. 2019, 16, 3345–3367. [Google Scholar] [CrossRef] [PubMed]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. J. Mach. Learn. Res. 2011, 15, 315–323. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Pontius, J.R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Liu, N.; Lu, X.K.; Wan, L.H.; Huo, H.; Fang, T. Improving the separability of deep features with discriminative convolution filters for RSI classification. ISPRS Int. Geo-Inf. 2018, 7, 95. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.P.; Yao, X.W.; Guo, L.; Wei, Z.L. Remote sensing image scene classification using bag of convolutional features. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1735–1739. [Google Scholar] [CrossRef]
- Yan, L.; Zhu, R.X.; Liu, Y.; Mo, N. Scene capture and selected codebook-based refined fuzzy classification of large high-resolution images. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4178–4192. [Google Scholar] [CrossRef]
- Anwer, R.M.; Khan, F.S.; van de Weijer, J.; Molinier, M.; Laaksonen, J. Binary patterns encoded convolutional neural networks for texture recognition and remote sensing scene classification. ISPRS-J. Photogramm. Remote Sens. 2018, 138, 74–85. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 2014 ACM Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Total Images | Scene Classes | Size | Url |
|---|---|---|---|---|
| AID | 10,000 | 30 | 600 × 600 | https://captain-whu.github.io/AID/ |
| NWPU-RESISC45 | 31,500 | 45 | 256 × 256 | http://www.escience.cn/people/JunweiHan/NWPU-RESISC45.html |
| OPTIMAL-31 | 1860 | 31 | 256 × 256 | https://1drv.ms/u/s!Ags4cxbCq3lUguxW3bq0D0wbm1zCDQ |
| Dataset | Training Set (%) | Validation Set (%) | Test Set (%) |
|---|---|---|---|
| AID | 10 | 10 | 80 |
| AID | 25 | 25 | 50 |
| NWPU-RESISC45 | 5 | 5 | 90 |
| NWPU-RESISC45 | 10 | 10 | 80 |
| OPTIMAL | 10 | 10 | 80 |
| Methods | 20% Training Ratio | 50% Training Ratio | Published Year |
|---|---|---|---|
| Ours | 92.65 ± 0.29 | 95.456 ± 0.24 | 2019 |
| ADFF | 93.68 ± 0.29 | 94.75 ± 0.24 | 2019 |
| VGG-VD16 with DCF | 91.57 ± 0.10 | 93.65 ± 0.18 | 2018 |
| CaffeNet with DCF | 91.35 ± 0.23 | 93.10 ± 0.27 | 2018 |
| Multi-Branch Neural Network | 89.38 ± 0.32 | 91.46 ± 0.44 | 2018 |
| BOCF | 85.24 ± 0.33 | 87.63 ± 0.41 | 2018 |
| Scene Capture | 87.25 ± 0.31 | 89.43 ± 0.33 | 2018 |
| TEX-Net-LF | 90.87 ± 0.11 | 92.96 ± 0.18 | 2017 |
| CaffeNet | 86.46 ± 0.47 | 89.53 ± 0.31 | 2017 |
| GoogleNet | 85.44 ± 0.40 | 88.39 ± 0.55 | 2017 |
| VGG-16 | 86.59 ± 0.29 | 89.64 ± 0.36 | 2017 |
| salM3LBP-CLM | 86.92 ± 0.35 | 89.76 ± 0.45 | 2017 |
| Methods | 10% Training Ratio | 20% Training Ratio | Published Year |
|---|---|---|---|
| Ours | 88.30 ± 0.24 | 91.62 ± 0.35 | 2019 |
| ADFF | 90.58 ± 0.19 | 91.91 ± 0.23 | 2019 |
| CaffeNet with DCF | 87.59 ± 0.22 | 89.20 ± 0.27 | 2018 |
| VGG-VD16 with DCF | 87.14 ± 0.19 | 89.56 ± 0.25 | 2018 |
| Multi-Branch Neural Network | 74.45 ± 0.26 | 76.38 ± 0.34 | 2018 |
| Scene Capture | 84.84 ± 0.26 | 86.24 ± 0.36 | 2018 |
| BOCF | 83.65 ± 0.31 | 85.32 ± 0.17 | 2018 |
| TEX-Net-LF | 86.05 ± 0.24 | 88.37 ± 0.32 | 2017 |
| CaffeNet | 77.69 ± 0.21 | 79.85 ± 0.13 | 2017 |
| GoogleNet | 77.19 ± 0.38 | 78.48 ± 0.26 | 2017 |
| VGG-16 | 77.47 ± 0.18 | 79.79 ± 0.15 | 2017 |
| salM3LBP-CLM | 85.32 ± 0.17 | 86.59 ± 0.28 | 2017 |
| Dropout | Triplet Loss | Training with Multi-Size Images | Time on Test Set (One Image) | The OA on Validation Set (%) | The OA on Test Set (%) |
|---|---|---|---|---|---|
| 0.006s | 92.12% | 91.08% | |||
| ✓ | 0.006s | 92.12% | 91.61% | ||
| ✓ | ✓ | 0.005s | 92.23% | 91.99% | |
| ✓ | ✓ | ✓ | 0.005s | 92.66% | 92.69% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Lu, C.; Wang, J.; Yue, X.-G.; Lim, S.-J.; Al-Makhadmeh, Z.; Tolba, A. Training Convolutional Neural Networks with Multi-Size Images and Triplet Loss for Remote Sensing Scene Classification. Sensors 2020, 20, 1188. https://doi.org/10.3390/s20041188
Zhang J, Lu C, Wang J, Yue X-G, Lim S-J, Al-Makhadmeh Z, Tolba A. Training Convolutional Neural Networks with Multi-Size Images and Triplet Loss for Remote Sensing Scene Classification. Sensors. 2020; 20(4):1188. https://doi.org/10.3390/s20041188
Chicago/Turabian StyleZhang, Jianming, Chaoquan Lu, Jin Wang, Xiao-Guang Yue, Se-Jung Lim, Zafer Al-Makhadmeh, and Amr Tolba. 2020. "Training Convolutional Neural Networks with Multi-Size Images and Triplet Loss for Remote Sensing Scene Classification" Sensors 20, no. 4: 1188. https://doi.org/10.3390/s20041188
APA StyleZhang, J., Lu, C., Wang, J., Yue, X.-G., Lim, S.-J., Al-Makhadmeh, Z., & Tolba, A. (2020). Training Convolutional Neural Networks with Multi-Size Images and Triplet Loss for Remote Sensing Scene Classification. Sensors, 20(4), 1188. https://doi.org/10.3390/s20041188