Vehicle Make and Model Recognition using Bag of Expressions

 , ,
, , 
Abstract
1. Introduction
- An evaluation of different combinations of feature keypoint detectors and the HOG descriptor for feature extraction from vehicle images.
- A global dictionary building scheme to tackle the ambiguity and multiplicity problems for vehicle make and model recognition. The optimal size of the dictionary is investigated by a series of experiments.
- An evaluation of a previously unexplored approach, “bag of expressions,” for VMMR. On the basis of BoE, a multiclass linear SVM classifier was trained for classification. Contributions to VMMR work include learning visual words from a specific class with BoE features enhancement and an improvement in performance.
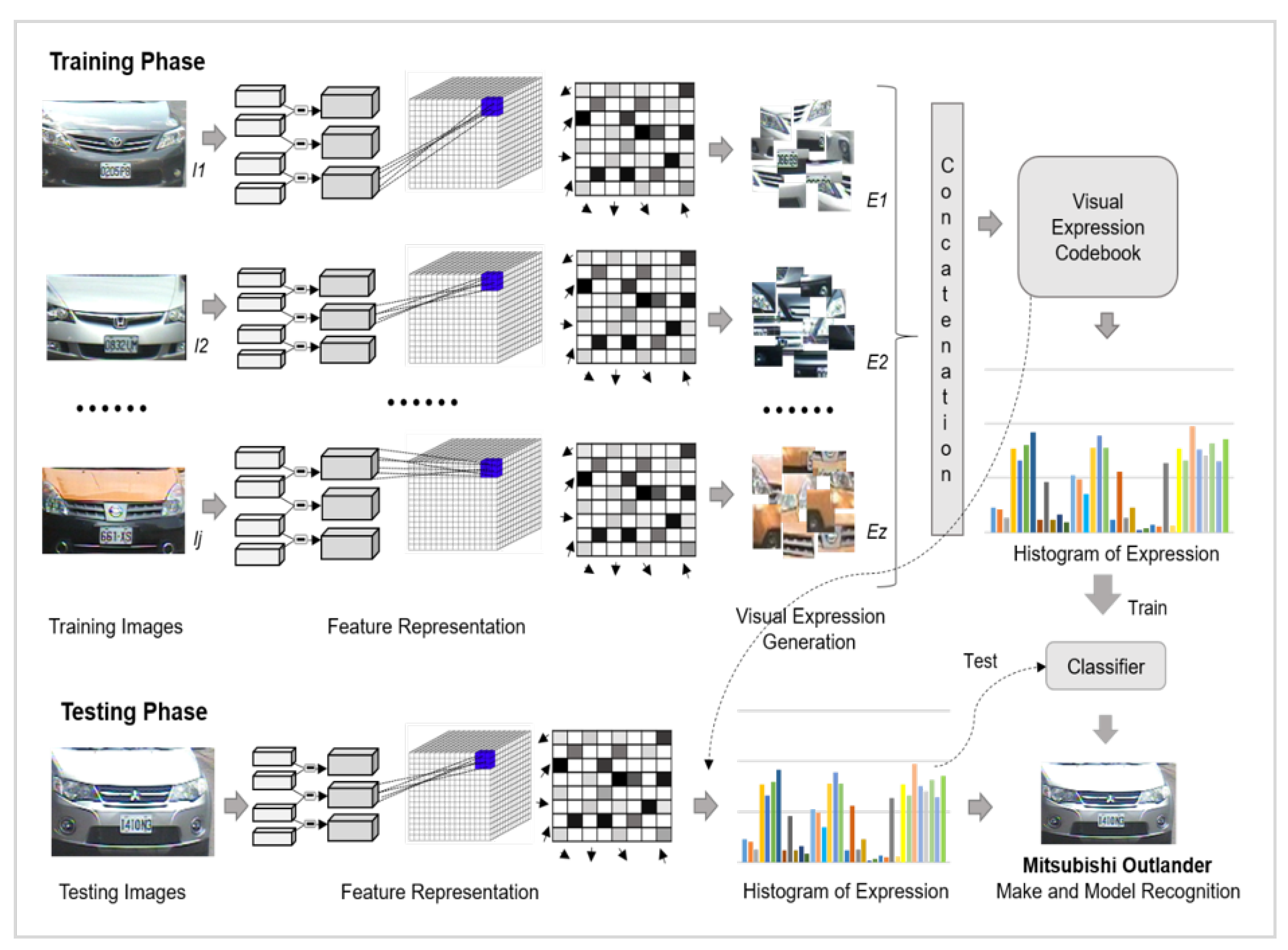
2. Proposed Methodology
2.1. Feature Points Detection
2.2. Description of Features
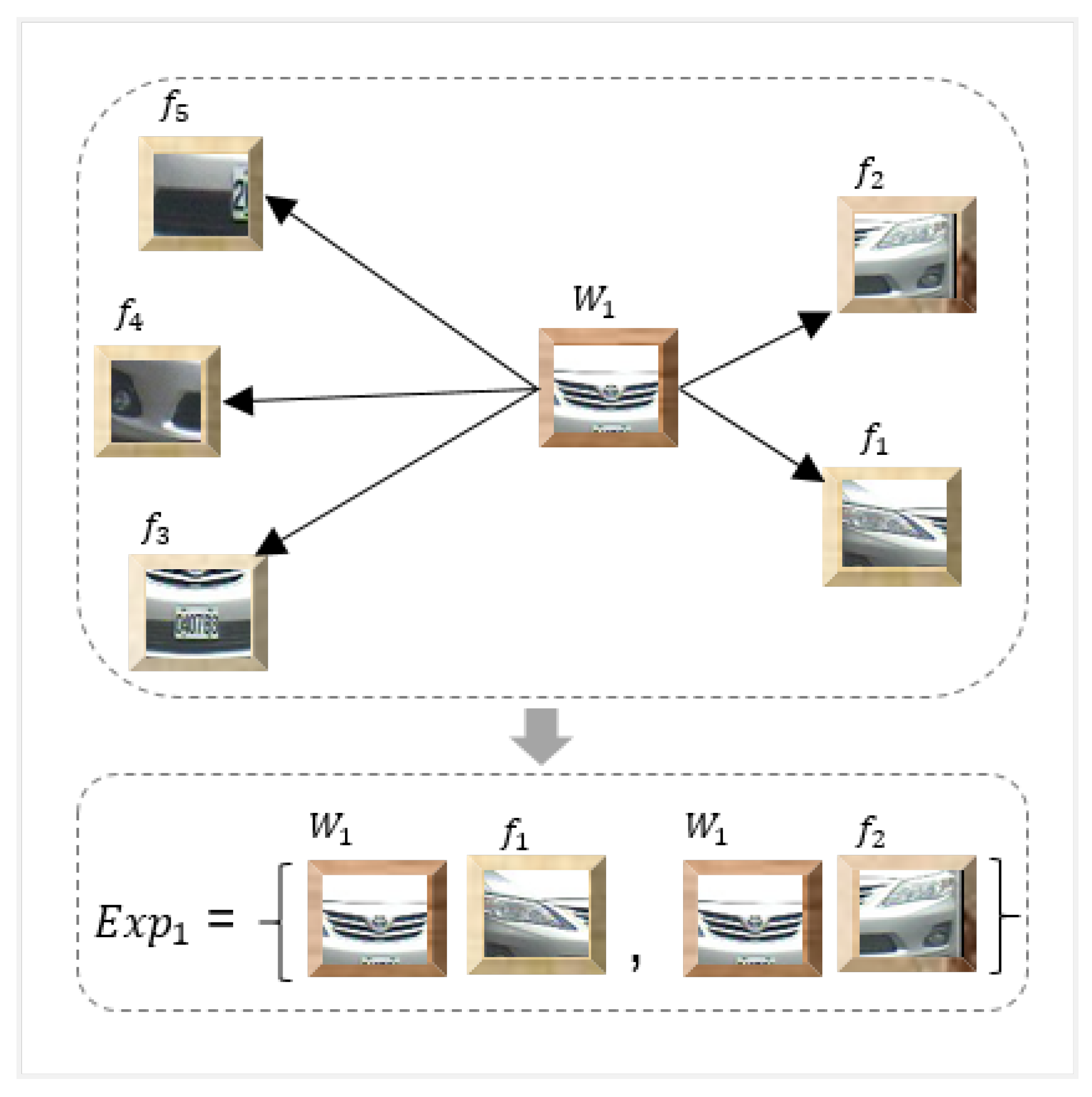
2.3. Generation of Visual Expressions
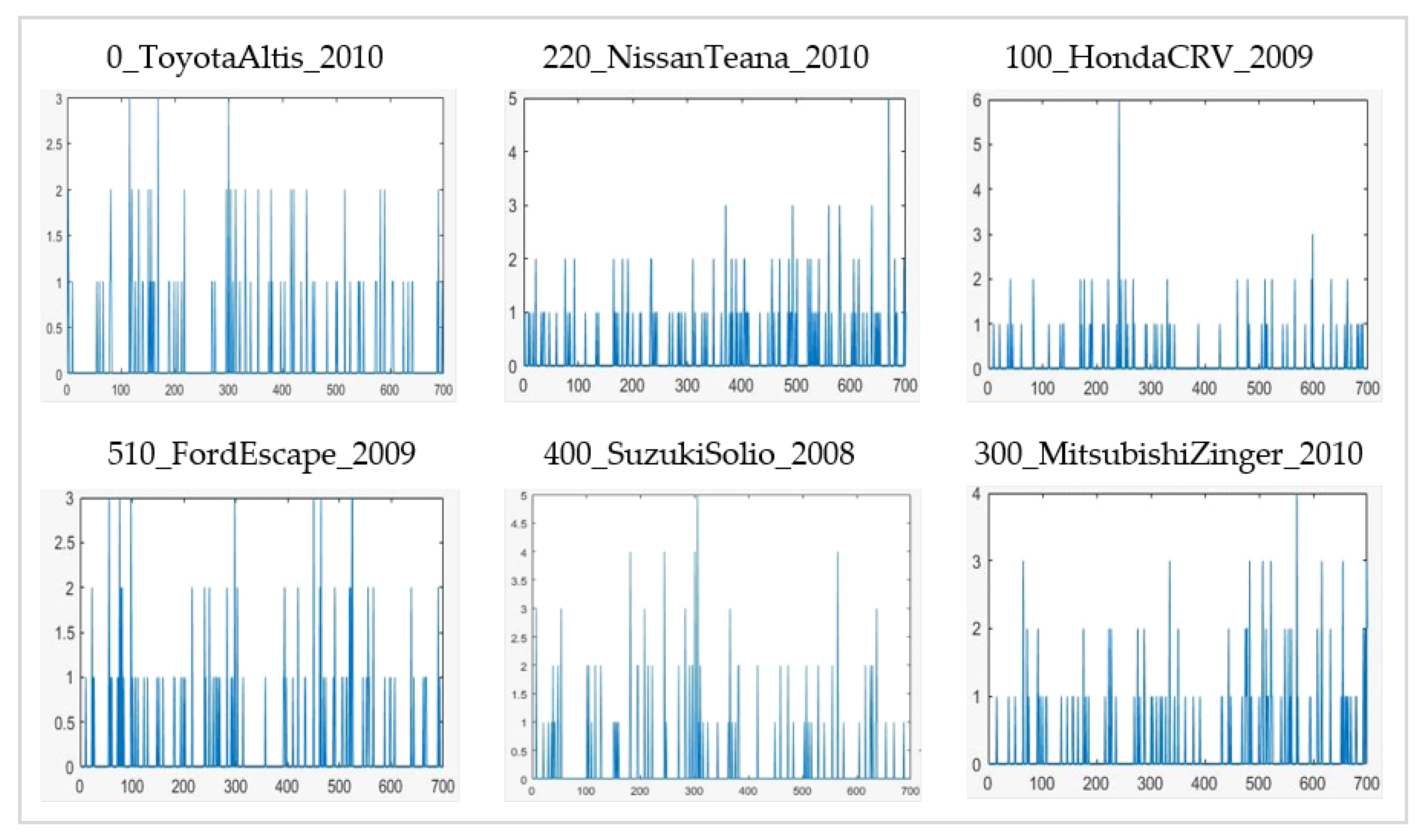
2.4. Histogram of Expressions
2.5. Classification
3. Experimental Results and Discussion
3.1. Selection of Optimal Parameters
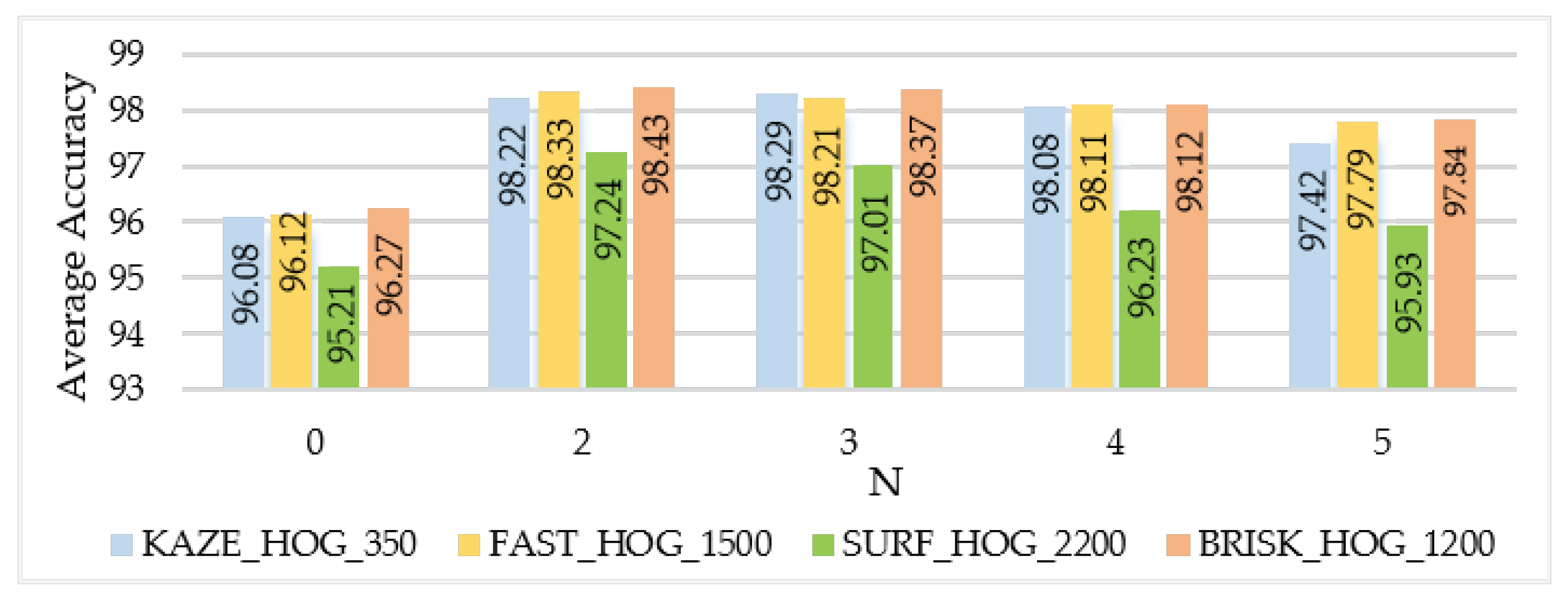
3.1.1. Dictionary Size
3.1.2. BoE Parameters
3.1.3. SVM Parameters
3.2. Performance Evaluation
3.3. Computational Cost
3.4. Comparison with State-Of-The-Art
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Pearce, G.; Pears, N. Automatic make and model recognition from frontal images of cars. In Proceedings of the 2011 8th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Klagenfurt, Austria, 30 August–2 September 2011; pp. 373–378. [Google Scholar]
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Hsieh, J.W.; Chen, L.C.; Chen, D.Y. Symmetrical SURF and its applications to vehicle detection and vehicle make and model recognition. Trans. Intell. Transp. Syst. 2014, 15, 6–20. [Google Scholar] [CrossRef]
- Tsai, L.W.; Hsieh, J.W.; Fan, K.C. Vehicle detection using normalized color and edge map. IEEE Trans. Image Process. 2007, 16, 850–864. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Cui, L.; Liu, D.; Huck, R.; Verma, P.; Sluss, J.J.; Cheng, S. Vehicle Identification Via Sparse Representation. IEEE Trans. Intell. Transp. Syst. 2012, 13, 955–962. [Google Scholar] [CrossRef]
- Kim, Z.; Malik, J. Fast vehicle detection with probabilistic feature grouping and its application to vehicle tracking. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003. [Google Scholar]
- Kumar, T.S.; Sivanandam, S. A modified approach for detecting car in video using feature extraction techniques. Eur. J. Sci. Res. 2012, 77, 134–144. [Google Scholar]
- Betke, M.; Haritaoglu, E.; Davis, L.S. Real-time multiple vehicle detection and tracking from a moving vehicle. Mach. Vis. Appl. 2000, 12, 69–83. [Google Scholar] [CrossRef]
- Gu, H.Z.; Lee, S.Y. Car model recognition by utilizing symmetric property to overcome severe pose variation. Mach. Vis. Appl. 2013, 24, 255–274. [Google Scholar] [CrossRef]
- Hoffman, C.; Dang, T.; Stiller, C. Vehicle detection fusing 2D visual features. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004. [Google Scholar]
- Leotta, M.J.; Mundy, J.L. Vehicle surveillance with a generic, adaptive, 3d vehicle model. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1457–1469. [Google Scholar] [CrossRef]
- Guo, Y.; Rao, C.; Samarasekera, S.; Kim, J.; Kumar, R.; Sawhney, H. Matching vehicles under large pose transformations using approximate 3d models and piecewise mrf model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Hou, T.; Wang, S.; Qin, H. Vehicle matching and recognition under large variations of pose and illumination. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Faro, A.; Giordano, D.; Spampinato, C. Adaptive background modeling integrated with luminosity sensors and occlusion processing for reliable vehicle detection. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1398–1412. [Google Scholar] [CrossRef]
- Jazayeri, A.; Cai, H.; Zheng, J.Y.; Tuceryan, M. Vehicle detection and tracking in car video based on motion model. IEEE Trans. Intell. Transp. Syst. 2011, 12, 583–595. [Google Scholar] [CrossRef]
- Rojas, J.C.; Crisman, J.D. Vehicle detection in color images. In Proceedings of the Conference on Intelligent Transportation Systems, Boston, MA, USA, 12 November 1997. [Google Scholar]
- Guo, D.; Fraichard, T.; Xie, M.; Laugier, C. Color modeling by spherical influence field in sensing driving environment. In Proceedings of the IEEE Intelligent Vehicles Symposium 2000 (Cat. No. 00TH8511), Dearborn, MI, USA, 5 October 2000. [Google Scholar]
- Chen, L.C.; Hsieh, J.W.; Yan, Y.; Chen, D.Y. Vehicle make and model recognition using sparse representation and symmetrical SURFs. Pattern Recognit. 2015, 48, 1979–1998. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Baran, R.; Glowacz, A.; Matiolanski, A. The efficient real-and non-real-time make and model recognition of cars. Multimedia Tools Appl. 2015, 74, 4269–4288. [Google Scholar] [CrossRef]
- Fraz, M.; Edirisinghe, E.A.; Sarfraz, M.S. Mid-level-representation based lexicon for vehicle make and model recognition. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Manzoor, M.A.; Morgan, Y. Vehicle make and model recognition using random forest classification for intelligent transportation systems. In Proceedings of the 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018. [Google Scholar]
- He, H.; Shao, Z.; Tan, J. Recognition of car makes and models from a single traffic-camera image. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3182–3192. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vision Image Understanding 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Siddiqui, A.J.; Mammeri, A.; Boukerche, A. Real-time vehicle make and model recognition based on a bag of SURF features. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3205–3219. [Google Scholar] [CrossRef]
- Nazir, S.; Yousaf, M.H.; Nebel, J.C.; Velastin, S.A. Dynamic Spatio-Temporal Bag of Expressions (D-STBoE) model for human action recognition. Sensors 2019, 19, 2790. [Google Scholar] [CrossRef]
- Nazir, S.; Yousaf, M.H.; Nebel, J.C.; Velastin, S.A. A Bag of Expression framework for improved human action recognition. Pattern Recognit. Lett. 2018, 103, 39–45. [Google Scholar] [CrossRef]
- Psyllos, A.; Anagnostopoulos, C.N.; Kayafas, E. Vehicle model recognition from frontal view image measurements. Comput. Stand. Interfaces 2011, 33, 142–151. [Google Scholar] [CrossRef]
- Varjas, V.; Tanács, A. Car recognition from frontal images in mobile environment. In Proceedings of the 8th International Symposium on Image and Signal Processing and Analysis (ISPA), Trieste, Italy, 4–6 September 2013. [Google Scholar]
- Tang, Y.; Zhang, C.; Gu, R.; Li, P.; Yang, B. Vehicle detection and recognition for intelligent traffic surveillance system. Multimed. Tools Appl. 2017, 76, 5817–5832. [Google Scholar] [CrossRef]
- Fang, J.; Zhou, Y.; Yu, Y.; Du, S. Fine-grained vehicle model recognition using a coarse-to-fine convolutional neural network architecture. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1782–1792. [Google Scholar] [CrossRef]
- Dehghan, A.; Masood, S.Z.; Shu, G.; Ortiz, E. View Independent Vehicle Make, Model and Color Recognition Using Convolutional Neural Network. Available online: https://arxiv.org/abs/1702.01721 (accessed on 10 February 2020).
- Manzoor, M.A.; Morgan, Y.; Bais, A. Real-Time Vehicle Make and Model Recognition System. Mach. Learn. Knowl. Extr. 2019, 1, 611–629. [Google Scholar] [CrossRef]
- Soon, F.C.; Khaw, H.Y.; Chuah, J.H.; Kanesan, J. PCANet-based convolutional neural network architecture for a vehicle model recognition system. IEEE Trans. Intell. Transp. Syst. 2018, 20, 749–759. [Google Scholar] [CrossRef]
- Alcantarilla, P.F.; Bartoli, A.; Davison, A.J. KAZE features. In Computer Vision—ECCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7577, pp. 214–227. [Google Scholar]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Computer Vision—ECCV 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3951, pp. 430–443. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the 2011 IEEE international conference on computer vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Nazemi, A.; Shafiee, M.J.; Azimifar, Z.; Wong, A. Unsupervised Feature Learning Toward a Real-time Vehicle Make and Model Recognition. Available online: https://arxiv.org/abs/1806.03028 (accessed on 10 February 2020).
- Lee, H.J.; Ullah, I.; Wan, W.; Gao, Y.; Fang, Z. Real-time vehicle make and model recognition with the residual SqueezeNet architecture. Sensors 2019, 19, 982. [Google Scholar] [CrossRef]
- Manzoor, M.A.; Morgan, Y. Vehicle Make and Model classification system using bag of SIFT features. In Proceedings of the 7th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 9–11 January 2017. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dictionary Size | 100 | 200 | 300 | 350 | 400 | 500 | 600 | 700 | 1000 |
|---|---|---|---|---|---|---|---|---|---|
| KAZE_HOG _ BoE | 93.03 | 96.36 | 97.93 | 98.22 | 98.39 | 98.58 | 98.74 | 98.88 | 99.01 |
| Dictionary Size | FAST_HOG_BoE | SURF_HOG_BoE | BRISK_HOG_BoE |
|---|---|---|---|
| 100 | 90.56% | 86.54% | 91.65% |
| 500 | 96.67% | 93.68% | 97.59% |
| 1000 | 97.56% | 95.93% | 98.21% |
| 1200 | 97.94% | 96.11% | 98.43% |
| 1500 | 98.33% | 96.26% | 98.76% |
| 2000 | 98.65% | 97.08% | 98.94% |
| 2200 | 98.73% | 97.24% | 99.06% |
| 2500 | 98.78% | 97.66% | 99.09% |
| 3000 | 98.86% | 97.71% | 99.14% |
| Feature Extraction | Average Accuracy % with Validation Scheme | |||
|---|---|---|---|---|
| Mahalanobis + sparse-random | Mahalanobis + sparse-random | Mahalanobis + sparse-random | ||
| 60–40 | 70–30 | 80–20 | ||
| KAZE _350 | HOG + BoE | 97.75% | 97.97% | 98.22% |
| FAST_ 1500 | 97.03% | 97.66% | 98.33% | |
| SURF _2200 | 96.84% | 97.09% | 97.24% | |
| BRISK _1200 | 97.60% | 98.08% | 98.43% | |
| Feature Extraction | Distance Measure | Average Accuracy % with Coding Design | |||
|---|---|---|---|---|---|
| One-vs.-all | All-pairs | Sparse-random | |||
| KAZE_350 | HOG + BoE | Mahalanobis | 98.27% | 98.00% | 98.22% |
| Euclidean | 98.19% | 97.83% | 98.18% | ||
| FAST_1500 | Mahalanobis | 98.22% | 97.09% | 98.33% | |
| Euclidean | 98.36% | 96.85% | 98.21% | ||
| SURF_2200 | Mahalanobis | 97.15% | 96.32% | 97.24% | |
| Euclidean | 97.32% | 96.41% | 97.19% | ||
| BRISK_1200 | Mahalanobis | 98.49% | 97.37% | 98.43% | |
| Euclidean | 98.35% | 97.66% | 98.25% | ||
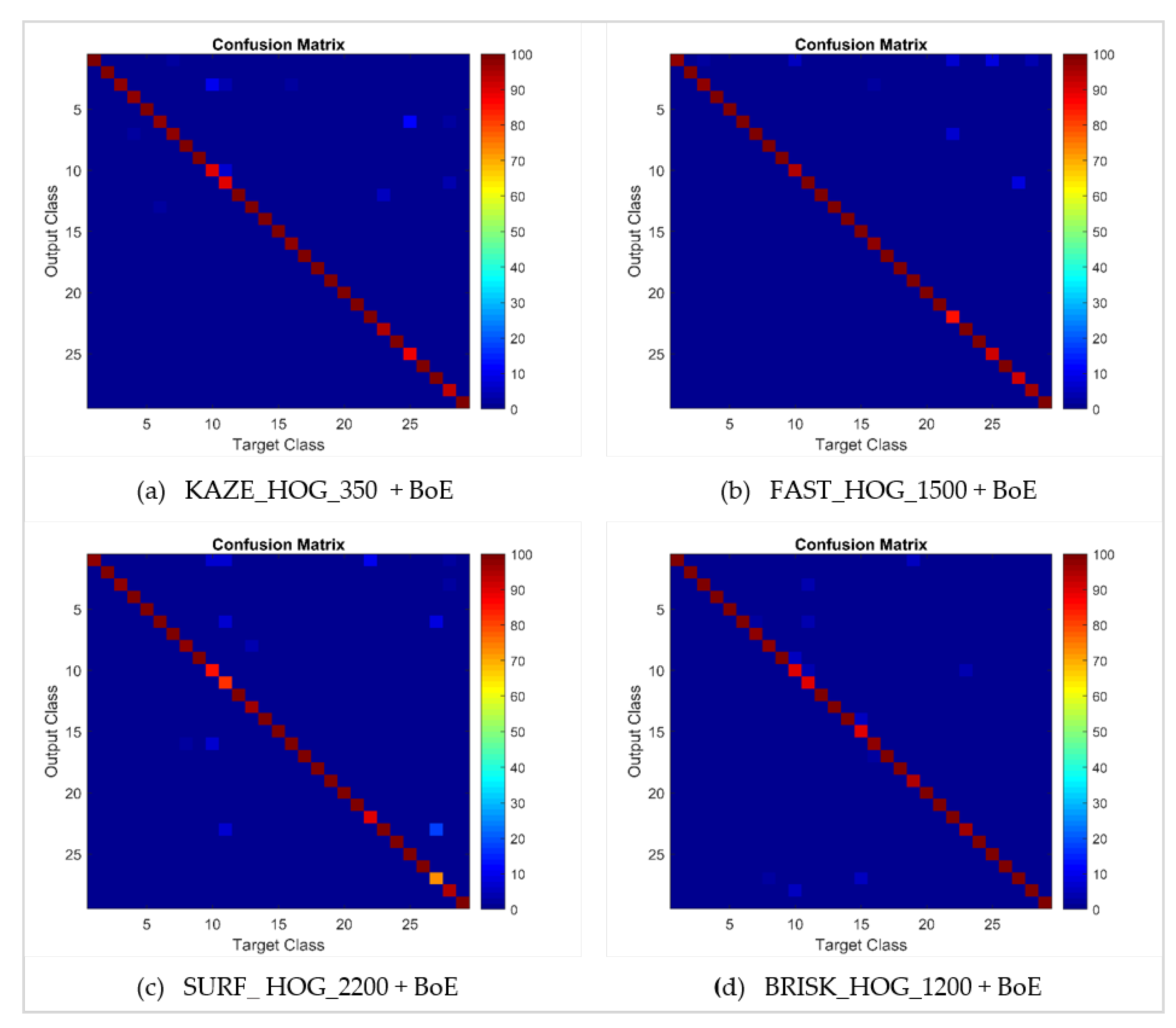
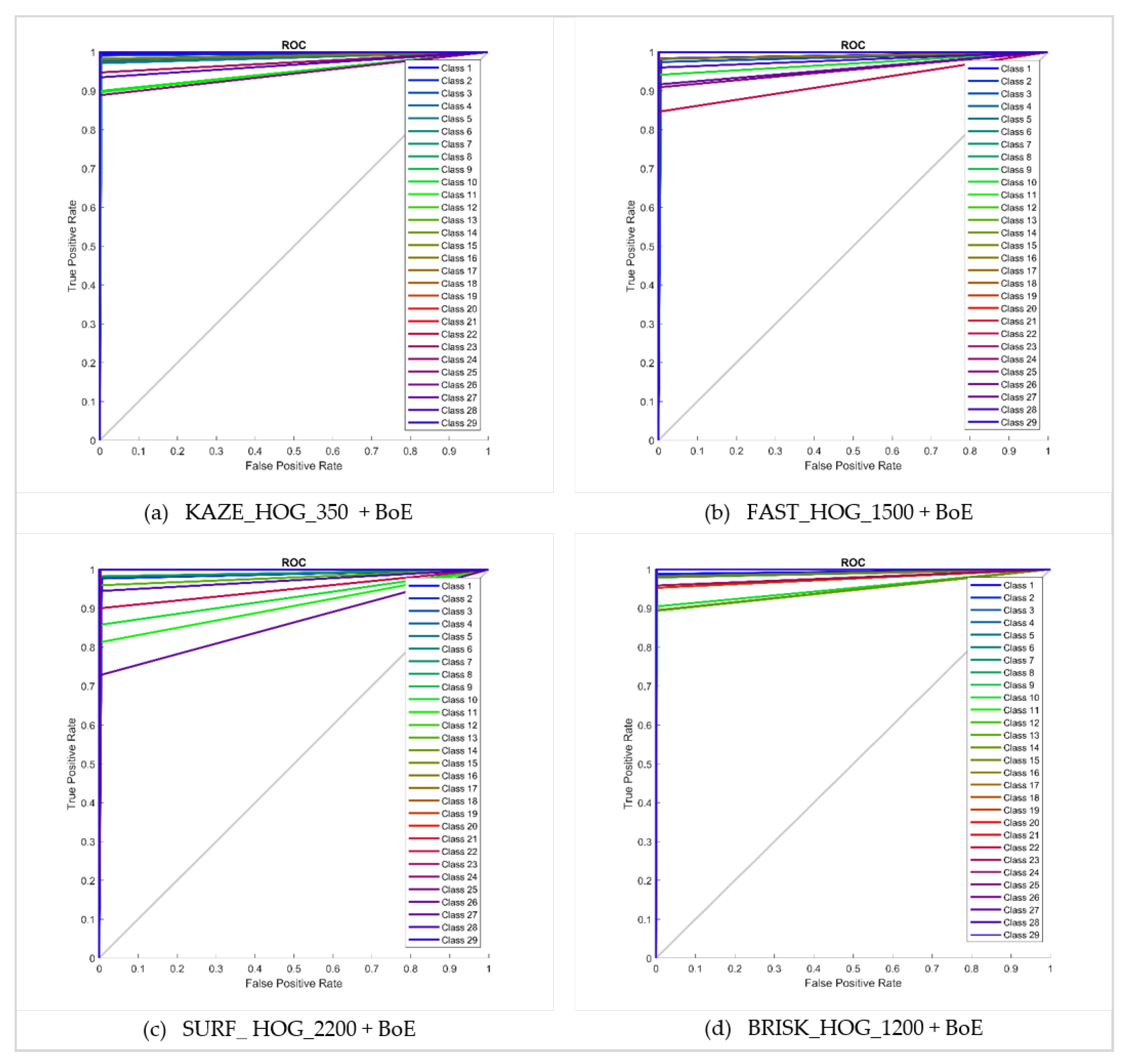
| Method | C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | C11 | |
| KAZE_350 | HOG + BoE | 99.6 | 99.4 | 98.4 | 99.1 | 100 | 97.9 | 99.3 | 99.7 | 100 | 90.8 | 90.4 |
| FAST_1500 | 99.4 | 100 | 97.8 | 100 | 99.8 | 100 | 100 | 99.5 | 100 | 94.6 | 99.6 | |
| SURF_2200 | 98.1 | 100 | 97.9 | 99.6 | 100 | 99.7 | 99.4 | 98.5 | 100 | 87.5 | 82.4 | |
| BRISK_1200 | 99.1 | 100 | 99.6 | 100 | 100 | 100 | 98.7 | 98.3 | 100 | 90.8 | 89.6 | |
| Method | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | C21 | C22 | |
| KAZE_350 | HOG + BoE | 100 | 100 | 99.7 | 99.4 | 98.5 | 99.3 | 99.8 | 100 | 99.5 | 99.2 | 99.7 |
| FAST_1500 | 100 | 100 | 100 | 99.6 | 98.4 | 99.4 | 99.7 | 99.5 | 100 | 99.7 | 86.7 | |
| SURF_2200 | 100 | 96.9 | 100 | 100 | 99.6 | 99.8 | 100 | 100 | 99.7 | 100 | 91.2 | |
| BRISK_1200 | 100 | 100 | 100 | 89.8 | 98.4 | 100 | 100 | 95.6 | 100 | 100 | 99.6 | |
| Method | C23 | C24 | C25 | C26 | C27 | C28 | C29 | Average per-class Accuracy | ||||
| KAZE_350 | HOG + BoE | 95.7 | 100 | 89.6 | 99.6 | 99.4 | 94.4 | 100 | 98.22% | |||
| FAST_1500 | 99.6 | 99.7 | 90.9 | 99.5 | 91.9 | 96.3 | 100 | 98.33% | ||||
| SURF_2200 | 100 | 100 | 99.3 | 100 | 73.9 | 95.6 | 100 | 97.24% | ||||
| BRISK_1200 | 96.1 | 100 | 99.7 | 100 | 99.7 | 99.5 | 100 | 98.43% | ||||
| Work/Hardware | Features | Classification | Dataset | Average Accuracy | Speed (fps) | |
|---|---|---|---|---|---|---|
| Baran et al. [20] (2015) CPU—Dual Core i5 650 CPU 3200 MHz 2GB RAM Win. Server 2008 R2 Enterprise (64-bit). | SURF, SIFT, Edge-Histogram | Multi-class SVM | 3859 vehicle images with 17 classes | 91.70% 97.20% | 30 0.5 | |
| He et al. [23] (2015) Hardware unknown | Multi-scale retinex | Artificial Neural Network | 1196 vehicle images and 30 classes | 92.47% | 1 | |
| Tang et al. [30] (2017) i7 3.4GHz, 4GB RAM Quadro 2000 GPU | Local Gabor Binary Pattern | Nearest Neighborhood | 223 vehicle images with 8 classes | 91.60% | 3.3 | |
| Nazemi et al. [40] (2018) 3.4 GHz Intel CPU 32 GB RAM | Dense-SIFT | A fine-grained classification | Iranian on-road vehicle dataset | 97.51% | 11.1 | |
| Jie Fang et al. [31] (2017) ı7-4790K CPU TITAN X GPU | Convolution Neural Network | 44,481 vehicle images with 281 classes | 98.29% | – | ||
| Afshin Dehghan et al. [32] (2017) TITAN XP GPUs | Convolution Neural Network | 44,481 vehicle images with 281 classes | 95.88% | – | ||
| Hyo Jong et al. [41] (2019) i7-4790 CPU 3.6GHz GTX 1080 GPU | Residual Squeeze Net | 291,602 vehicle images with 766 classes | 96.33% | 9.1 | ||
| Chen et al. [18] (2015) Hardware unknown | Symmetric SURF | Sparse representation and hamming distance | NTOU-MMR | 91.10% | 0.46 | |
| Manzoor et al. [42] [2017) i7 3.4GHz 16GB RAM | SIFT | SVM | NTOU-MMR | 89.00% | – | |
| Jabbar et al. [25] (2016) i5 CPU 2.94GHz 16GB RAM | SURF | Single and ensemble of multi-class SVM | NTOU-MMR | 94.84% | 7.4 | |
| Manzoor et al. [33] [2019) i7 3.4GHz 16GB RAM | HOG | Random Forest SVM | NTOU-MMR | 94.53% 97.89% | 35.7 13.9 | |
| Our Approach i7-4600M CPU 2.90GHz 8GB RAM | KAZE_350 | HOG + BoE | Linear SVM | NTOU-MMR | 98.22% | 24.7 |
| FAST_1500 | 98.33% | 15.4 | ||||
| SURF_2200 | 97.24% | 18.6 | ||||
| BRISK_1200 | 98.43% | 6.7 | ||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamil, A.A.; Hussain, F.; Yousaf, M.H.; Butt, A.M.; Velastin, S.A. Vehicle Make and Model Recognition using Bag of Expressions. Sensors 2020, 20, 1033. https://doi.org/10.3390/s20041033
Jamil AA, Hussain F, Yousaf MH, Butt AM, Velastin SA. Vehicle Make and Model Recognition using Bag of Expressions. Sensors. 2020; 20(4):1033. https://doi.org/10.3390/s20041033
Chicago/Turabian StyleJamil, Adeel Ahmad, Fawad Hussain, Muhammad Haroon Yousaf, Ammar Mohsin Butt, and Sergio A. Velastin. 2020. "Vehicle Make and Model Recognition using Bag of Expressions" Sensors 20, no. 4: 1033. https://doi.org/10.3390/s20041033
APA StyleJamil, A. A., Hussain, F., Yousaf, M. H., Butt, A. M., & Velastin, S. A. (2020). Vehicle Make and Model Recognition using Bag of Expressions. Sensors, 20(4), 1033. https://doi.org/10.3390/s20041033