1. Introduction
In WSNs, the wireless sensors are spatially distributed autonomous devices responsible for sensing the change in the required physical phenomena of their surrounding environment using a small microprocessor, a few transducers, a radio transceiver and a low-power battery [
1,
2]. These wireless sensor devices collaborate with each other for data sensing, data collection and aggregation purposes [
2,
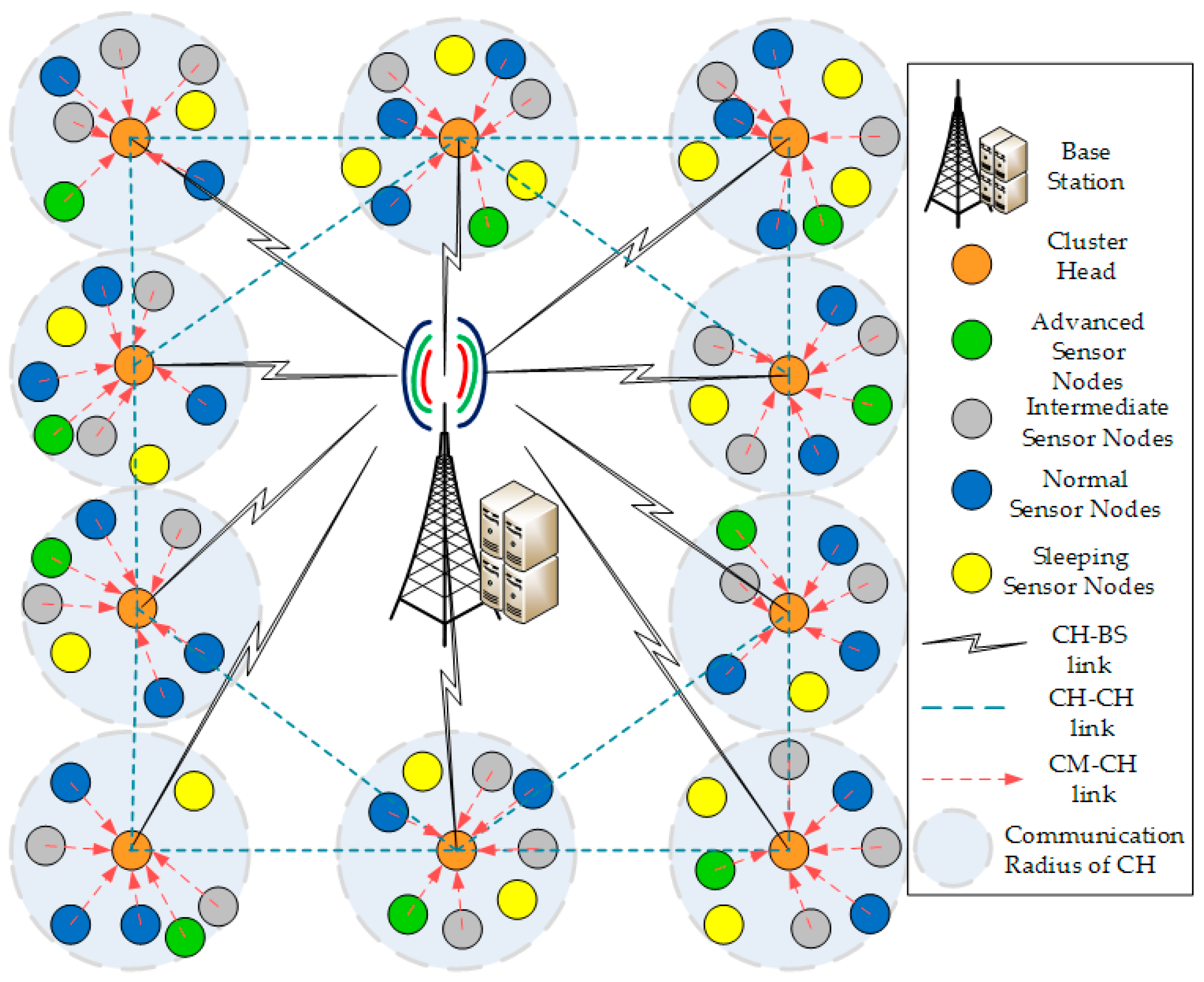
3]. In order to reduce the communication overhead and to allocate resources to sensor nodes effectively, we need a topology architecture in which sensor nodes are organized in clusters. Each cluster includes one Cluster Head (CH) and several Cluster Members (CM) [
4]. The multi-hop routing used in clustering topology to forward the sensed data from source to destination results in the overall decrease in energy consumption and also reduces the interference among sensor nodes due to specific allocation of timeslots for communication purposes [
4,
5]. The clustering topology in WSN can effectively optimize the data redundancy by significantly reducing the size of the collected data using data aggregation and data fusion techniques at CH level. The aggregated or fused data can then be forwarded to the Base Station (BS) for further processing and accurate decision making of interested events [
4,
5,
6].
The recent literature shows that researchers have proposed a working–sleeping cycle strategy in WSN to save battery power in case the sensor nodes are idle and not performing any of the designated tasks. Alfayez et al. [
7] discussed that the sensor nodes go to sleep to save their battery power and wake up before performing their routine operations. These node scheduling techniques can be categorized as synchronous and asynchronous working–sleeping scheduling. These node scheduling techniques are designed in accordance with the scenario to prolong the network lifetime and improve energy utilization by creating an opportunistic node connection between sensor nodes. According to [
8,
9,
10,
11,
12], Opportunistic Routing (OR) is a paradigm for wireless networks that benefits from broadcast characteristics of a wireless medium by selecting multiple sensor nodes as candidate forwarders. In [
10,
11,
12], a set of nodes were selected as potential forwarders that transmitted the data packet according to some special criteria after receiving data packet from their neighbors. This set of sensor nodes is called a Candidate Set (CS). The performance of OR significantly depends on several key factors, such as the OR metric, the candidate selection algorithm, and the candidate coordination method. The idea of OR can also be exploited in clustering topology of WSN to extend network lifetime, improve energy utilization, increase the packet delivery ratio (PDR) by adapting asynchronous working-sleeping cycle strategy.
Entropy in information theory is employed in various fields involving data analysis. Entropy uses the Probability Distribution Function (PDF) to statistically measure the degree of uncertainty in information sources [
13]. The entropy
of a random variable
having probability distribution as
can be given as
for
[
14,
15,
16]. As we want to utilize the functionality of information entropy in clustering WSN, it should be kept in focus that CH or BS should not be hesitant or irresolute about any of their decisions regarding cluster formation and data fusion. Keeping in view the opportunistic connection between sensor nodes in heterogeneous clustering, we selected multiple parameters including an asynchronous working–sleeping cycle, status transition frequencies, residual energy, link quality factor in terms of signal-to-noise ratio, distance between sensor node and BS, and number of supported sensor nodes by a potential CH as our attributes of hesitant fuzzy set. Furthermore, we need Multi-Attribute Decision Modeling (MADM) to efficiently utilize our hesitant fuzzy set to generate hesitant fuzzy entropy matrix and determine our entropy weight coefficients [
14,
15,
17,
18].
In this paper, we propose a hesitant fuzzy entropy based opportunistic clustering and data fusion scheme in which a hesitant fuzzy set is created by acquiring the multi-attribute values of sensor nodes. Moreover, the hesitant entropy matrix is generated after finding entropy values of each attribute in the hesitant fuzzy set using data standardization process. Subsequently, the entropy weight model [
14,
15,
17] is employed to determine the entropy weight coefficients for each sensor node and, finally, the threshold attribute values are determined and then compared with the original attribute values for making a decision about new CH. This entire process is part of the CH election procedure which is initiated by the BS and continued by every CH for all communication rounds. The BS creates a CH election set and adds sensor nodes in this set which have original attribute values greater than threshold attribute values. After that, the BS invokes these added sensor nodes by sending them a CH election set message. Furthermore, the hesitant fuzzy entropy technique is also used for reliable data fusion performed by CHs in such a way that CMs integrate and forward their sensed data to the assigned CH by removing the redundant information from the sensed data. CHs perform data aggregation on integrated data packets by concatenating them into a single larger data packet of a specified length. Later on, CHs exploit hesitant fuzzy entropy and entropy weight coefficients to detect the change in sensed data periodically and then send the aggregated data to the BS upon detecting that change in sensed data [
19,
20].
The rest of the paper is organized as follows:
Section 2 describes the related research work conducted for heterogeneous clustering in WSNs, entropy-based clustering schemes, hesitant fuzzy entropy, and OR. System modeling is presented in
Section 3. Our proposed scheme, HFECS, is presented in
Section 4.
Section 5 describes the case study of HFECS in neighborhood area networks. The performance evaluation and simulation results are described in
Section 6. Finally,
Section 7 and
Section 8 discuss and conclude the paper, respectively, and provide some future research directions.
2. Related Research Work
Various researchers have focused on proposing different routing protocols for WSNs based on different parameters, such as end–end delay, successful packets delivered to sink, network lifetime, overall energy consumption, control packet overhead, and sink node mobility, etc. Ogundile et al. [
21] presented a detailed survey for energy efficient and energy balanced routing protocols for WSNs. The authors argued that energy efficiency, packet delivery ratio and average end–end delay are the most critical and significant parameters for delay-tolerant and delay-sensitive applications involving WSNs. Furthermore, in this survey, the taxonomy of cluster-based routing protocols for WSNs was also discussed in terms of the energy efficiency and energy balancing aspects. Routing protocols in WSNs can be segmented into two main categories, i.e., hierarchical and non-hierarchical routing protocols. Non-hierarchical routing protocols are proposed on the basis of overhearing, flooding, and information related to the advertisement of the sink’s position through agent node selection, whereas hierarchical routing protocols are proposed on the basis of (i) grid-based, tree-based, cluster-based and area-based routing. Different hierarchical routing protocols have their own merits and demerits, but as far as cluster-based hierarchical routing protocols are concerned, researchers have been challenged with a task of achieving an optimal balance between end–end delay and energy consumption [
4,
5,
6,
21].
Yang et al. [
22] introduced an emerging concept—the ‘utilization of working–sleeping cycle’ of sensor nodes to prolong the network lifetime. The working–sleeping cycle can be segmented into two categories—synchronous and asynchronous working–sleeping cycle. Recent studies have revealed that a synchronous working–sleeping cycle in sensor nodes could lead to an improvement in energy consumption, but significant contribution is required for efficient synchronization of sensor nodes. Ng et al. [
23] presented an energy-efficient synchronization algorithm for sensor nodes in which counter-based and exponential smoothing algorithms could improve the energy consumption using adaptive adjustment of traffic and wakeup period. Moreover, the asynchronous working–sleeping cycle strategy was explored in recent studies as well. Asynchronous working-sleeping schedules depend on network connectivity requirements in terms of traffic coverage area [
8,
9]. Mukherjee et al. [
24] proposed an asynchronous working-sleeping schedule technique in which required network coverage was achieved with a minimum number of awake sensor nodes. Due to the independent working-sleeping cycle of each sensor node in asynchronous working-sleeping strategy, opportunistic node connection can be established between sensor node and its neighbors, thus we need an Opportunistic Connection Random Graph (OCRG) theory to form a spanning tree formation of sensor nodes having opportunistic node connections between each other. In [
25], Norman et al. proposed a novel random graph modeling for heterogeneous sensor networks based on different transmission ranges and a new routing metric supporting opportunistic node connections. Anees et al. [
26] proposed an energy-efficient multi-disjoint path opportunistic node connection routing protocol for smart grids (SGs) neighborhood area networks (NAN) inspired by opportunistic connection random graph theory in WSNs with sink mobility. This routing protocol reduces the overall energy consumption, increases the PDR, increases the network lifetime and decreases the end–end network delay against existing benchmark schemes.
Many recent studies have addressed the problem of WSN clustering. Low Energy Adaptive Clustering Hierarchy (LEACH) variants were proposed by Liang et al. [
27], Handy et al. [
28] and Khediri et al. [
29] in which each round of communication is segmented into two phases, i.e., (i) the setup phase, in which limited number of sensor nodes are selected as CH depending upon their probability values and CMs of that CH, (ii) each CH assigns a particular timeslot to every CM in order to avoid collision. Each CM forwards the sensed data only in that timeslot. Various researchers have also proposed many variants of LEACH in [
28,
29,
30,
31,
32,
33]. Smaragdakis et al. [
31] proposed the heterogeneous aware Stable Election Protocol (SEP), which is based on weighted election probabilities of sensor nodes for selection of CH depending upon their residual energies. In SEP, the energy heterogeneity problem is characterized using node classification, in which nodes are either labeled as normal or advanced. This protocol ensures that, during CH election procedure, CH is selected randomly based on the fraction of energy of each sensor node, thus assuring a uniform energy usage of all sensor nodes. Foregoing this view, Femi et al. [
34] presented an extension of SEP which is known as SEP-Enhanced or SEP-E. In SEP-E, the energy heterogeneity problem is characterized using a three-node classification, in which nodes are labeled as normal, intermediate and advanced sensor nodes. According to [
34], the main goal of SEP-E is to achieve a robust self-configured heterogeneous WSN with a longer network lifetime of sensor nodes and better energy utilization. Sharma et al. [
33] proposed a Heterogeneity-aware Energy efficient Clustering (HEC) protocol, which is based on three different phases and CH is selected in every phase in a different manner, i.e., (i) in the first phase, sensor nodes labeled as advanced are allowed to participate in CH selection, (ii) all sensor nodes, irrespective of their residual energies, are allowed to participate in CH selection procedure with equal probabilities, (iii) for the last phase, direct transmission to BS is preferred instead of clustering, due to low residual energy of sensor nodes.
Qing et al. [
35] suggested a novel heterogeneous WSN supporting a Distributed Energy-Efficient Clustering (DEEC) scheme in which energy heterogeneity is characterized using normal and advanced sensor nodes. Additionally, Saini et al. [
36] proposed an extension of the DEEC protocol which is known as the Enhanced Distributed Energy-Efficient Clustering (E-DEEC) scheme, in which the energy heterogeneity problem is addressed using three-node classification, i.e., normal, intermediate and advanced. In E-DEEC, the CH selection probabilities are not adapted as per the energy levels of sensor nodes. Javaid et al. [
37] proposed a heterogeneous network model based on Enhanced Developed DEEC (ED-DEEC or DEEC-E) which is established on two-node power classification and three energy levels of sensor nodes for dynamically modifying the CH election probability. Manjeshwar et al. [
38] introduced a novel energy-efficient protocol known as Threshold sensitive Energy-Efficient Sensor Network (TEEN) protocol for reactive networks. In TEEN, each CM in a cluster takes turns to become the CH for a time interval, called the cluster period. After every cluster period, the CH broadcasts a soft and hard threshold to its CMs along with other attributes. CMs only send the sensed data to its CH by changing the status from working to sleeping, only if the data values are in the range of interest, keeping in view the hard threshold. In addition to this, CMs send the data to CH by changing their status from sleeping to working only if their data values change by at least the soft threshold. Although there are no collisions between data transmissions due to TDMA scheduling, TEEN introduces an extra delay during the reporting of time-critical data.
It has been revealed through a detailed literature review that most of the clustering schemes consider attributes such as residual energy, distance to the BS, etc. as parameters of criteria. Meanwhile, the Entropy-Based Clustering Scheme (EBCS) also considers cluster load in terms of supported sensor nodes as a key parameter of criteria for the CH election procedure. [
39]. The cluster load can be defined as the number of CMs that can be efficiently handled and supported by the current CH. EBCS includes remaining energy, distance to the BS, and the sum of distances to neighboring sensor nodes as other parameters of criteria besides cluster load. In EBCS, a new method is introduced to predict the residual energy at the start of the next round of communication based on consumed energy. This new method is used to select the CH for next round of communication. Energy heterogeneity is characterized using sensor nodes labeled as normal, intermediate and advanced in EBCS. In previous studies, several researchers have adopted entropy weight coefficient method for making decision in clustering environment [
14,
15,
16,
18]. Entropy weight-based multi-criteria decision routing is a routing technique in which the next hop decision is based on Multi-Criteria Decision Analysis (MCDA) and Multi-Attribute Decision Modeling (MADM) using entropy weight coefficients [
14,
15,
17,
18]. Qiang et al. [
16] presented an optimization of objective and subjective weights based on fuzzy MADM routing for selection of next best hop in a heterogeneous WSN. Authors in [
16] utilized the entropy weight coefficient method to avoid excessive deviation from the objective weights. Wang et al. [
14] developed an index system for capacity assessment using entropy weight coefficient method.
Xia et al. [
40] discussed hesitant fuzzy information aggregation in decision making problems. Xia et al. [
41] discussed the hesitant fuzzy entropy, cross entropy, and their usage in MADM applications. Su et al. [
42] merged the fuzzy logic method with clustering in order to propose a new data fusion method based on a fault tolerant WSN for improving the availability of communication bandwidth. In order to reduce the data processing load on BS and efficiently distinguish the authenticity of archived data, Izadi et al. [
43] proposed a wireless sensor data fusion method based on fuzzy theory to improve the service quality in WSNs. Chaurasia et al. [
44] presented an adaptive fuzzy logic algorithm to address the inaccuracies in data fusion. Zhai et al. [
45] developed Hesitant Language Preference Relationships (HLPR) to improve the credibility of WSNs by fusing uncertain information and putting forward exact opinion about different WSN schemes. Wang et al. [
19] proposed a novel data fusion algorithm inspired by hesitant fuzzy entropy to reduce the redundant sensory data transfer in WSN clustering. In this paper, we have utilized some ideas from state-of-the-art research and provided a detailed solution for optimally handling problems like energy consumption and network lifetime using a novel hesitant fuzzy entropy-based opportunistic clustering and data fusion scheme in WSN.
4. The Proposed Scheme HFECS
Information entropy is the statistical measure of the degree of uncertainty of an information source and it has always played a significant role in uncertainty decision analysis [
13]. Likewise, hesitant fuzzy entropy is defined as the statistical measure of degree of hesitant fuzzy uncertainty, which depends on MADM to make a decision about certain events. In heterogeneous clustering schemes of WSNs, the role of CH within a cluster needs to be substituted using some decision criteria in order to avoid the hotspot problem. Using a single parameter such as the energy level of the sensor nodes is not sufficient enough to make an accurate decision about CH selection after every round of communication. In order to ensure that the best possible working sensor node is chosen as CH in every round of communication, we have to incorporate MADM in our clustering scheme. The hesitant fuzzy set including multi attributes and alternatives could help us out in implementing MADM for opportunistic clustering in WSNs [
40,
41].
Our main objective is to design a hesitant fuzzy entropy-based self-organizing opportunistic clustering scheme which can prolong the network lifetime and bring an improvement in overall energy consumption of sensor nodes. In our proposed scheme, we determined the entropy weight coefficients using hesitant fuzzy entropy to select the best possible CH through election procedure and perform reliable data fusion at CH level to reduce the information flow. Since we are dealing with MADM problem, we considered several parameters like time frequency parameter (depends on and status transition frequency ), residual energy , link quality factor LQR in terms of signal-to-noise ratio, distance to BS , and number of supported sensor nodes as our different attributes of hesitant fuzzy set to compute the hesitant fuzzy entropy.
We have three different types of nodes in our network which can lead to energy heterogeneity and might result in three different types of CH, i.e.,
,
, and
, with the initial energy
,
, and
, respectively, but in order to avoid frequent change in the CH role, we used only two different types of CH, i.e.,
and
, for calculating
. However, the percentage of energy consumption for
(
) is more than that of
(
) due to the reason that
>
. As the consumed energy in relation to available energy is uneven for CHs, it leads us to determine the optimum number of sensor nodes which can be supported by each type of CH. Therefore, we used the remaining energy and average of
and
to find the optimum number of sensor nodes supported by both
and
in Equation (7) as:
4.1. CH Election Procedure
Based on the sensory data being generated by sensor nodes, we make a decision about CH role in the cluster using ,, LQR, and . But before that, we have to construct the hesitant fuzzy entropy matrix and determine the corresponding weight coefficents of each attribute. Subsequently, the attribute values are synthesized to determine the threshold attribute values. The threshold attribute values are then compared with original attribute values of each sensor node. Based on their comparison, the BS selects the sensor nodes with original attribute values greater than threshold attribute values and add those sensor nodes in CH election set.
The entropy measures for hesitant fuzzy set were already discussed by Xu et al. in [
40] and Xia et al. in [
41]. Due to the fact that hesitancy is a common problem in decision making problems, we need to develop some entropy or cross entropy measures for hesitant fuzzy sets. Wang et al. in [
19] discussed that if X is a fixed set and the hesitant fuzzy set
when applied on X returns a subset in [0,1]. Let
be the number of values in
where
be the
th smallest value in
in which
. In order to find the cross entropy of two hesitant fuzzy sets, i.e.,
and
, we assume that both of them have same length, or, if there is only one value in
, we extend it by repeating that value until it reaches the length of
. Moreover, if there is only one hesitant fuzzy set, then we use
and
(complement of
) in the cross-entropy and calculate the hesitant fuzzy entropy in Equations (8) and (9) as
where
where
. Then, we calculate the entropy weight coefficients for all sensor nodes using Equation (10) after generating entropy matrix using Equation (9).
where
,
and
. In the next step, we find the average data value of attributes in measured value matrix, i.e.,
and then synthesize the value of each attribute to find the threshold attribute value using Equation (11) as:
The decision about placing sensor nodes in CH election set depends on the comparison between the original attribute values of sensor nodes in a cluster with that of threshold attribute values. A sensor node can be placed in the CH election set only if the maximum of its original attribute values is greater than the threshold attribute values generated from Equation (11). The pseudocode for this procedure is given in Algorithm 1.
| Algorithm 1. CH Election Procedure in HFECS |
| Input: Multi-Attribute values of each sensor node |
| Output: Sensor nodes in CH election set |
| Begin: |
| 1. | r: number of attributes |
| 2. | s: number of sensor nodes |
| 3. | : attribute value |
| 4. | for i = 1 to r, do |
| 5. | for j = 1 to s, do |
| 6. | Measure the attribute values for all the sensors |
| 7. | Formation of measured value matrix |
| 8. | Standardize the attribute values of all sensors |
| 9. | end for |
| 10. | Generate the hesitant entropy decision matrix after standardization of each attribute value |
| 11. | Calculate the hesitant fuzzy entropy using |
| 12. | Refer to Equations (8) and (9) for calculation of cross entropy |
| 13. | Generate the entropy matrix based on calculated hesitant fuzzy entropy for all attributes |
| 14. | end for |
| 15. | Find the entropy value of each attribute using |
| 16. | for i = 1 to r, do |
| 17. | Determine the weight value for all sensor nodes using Equation (10) |
| 18. | end for |
| 19. | Find the average data value in measured value matrix, i.e., |
| 20. | for i = 1 to r, do |
| 21. | Synthesize the value of each attribute to find the threshold value using Equation (11) |
| 22. | if (sensor node with > ), then |
| 23. | Add sensor nodes with highest > in CH Election Set |
| 24. | end if |
| 25. | end for |
4.2. Cluster Formation
In HFECS, the BS executes the election procedure and creates a CH election set. Initially, when
, the BS adds
sensor nodes with highest values of
in the CH election set after executing the election procedure given in Algorithm 1 and then invokes those
sensor nodes by sending them a CH_Election_set message. After receiving the CH_Election_Set message from the BS, the potential CH starts preparing its CH_announce message and then send this message to all working neighbors in that cluster to advertise its role as a potential CH. The pseudocode for this procedure is given in Algorithm 2.
| Algorithm 2. HFECS (BS Side) |
| Input: CH election procedure |
| Output: Potential CH advertising its role and making local decision for data fusion |
| Begin: |
| 1. | if ( = 1), then |
| 2. | BS executes the CH election procedure |
| 3. | BS creates a CH election set |
| 4. | BS adds sensor nodes in CH election set with highest > |
| 5. | BS invokes working sensors with highest attribute values in CH election set by sending |
| 6. | CH_Election_Set message |
| 7. | end if |
| 8. | Wait for collected data from CHs |
| 9. | if (final prediction result received from CH), then |
| 10. | Evaluate the collected data to determine the possibility of event happening |
| 11. | if (event happened) |
| 12. | Perform standard operation procedure |
| 13. | end if |
| 14. | end if |
If the CH_announce message is sent by multiple potential CHs, then CMs send Connection Request ‘Con_Req’ message to the CH with highest attribute values > . For example, if a neighboring sensor node receives CH_announce from multiple potential CHs, then the sensor node becomes a cluster member of that CH which offers better link quality with that neighboring sensor node in comparison to other CHs. However, if the CH_announce message is sent by a single potential CH, then CMs send a Con_Req message to that CH without any delay. Meanwhile, the new CH creates a CM_set and adds all the working CMs in CM_set after receiving the Con_Req messages from CMs. Subsequently, the new CH transmits the TDMA schedule to all CMs in that cluster, keeping in view the asynchronous working–sleeping cycle of CMs. This TDMA schedule for every CM should be selected vigilantly from a CH as the timeslot for forwarding the sensory data to the CH should be within working time of that CM. Each CM extracts its own CM timeslot from the TDMA schedule sent by the CH, stores the CM timeslot in its local buffer and waits until the CM timeslot becomes current timeslot. The pseudocode for CM task execution is given in Algorithm 3.
The construction of OCRG is very important to understand the asynchronous working–sleeping cycle of sensor nodes. Therefore, we need to construct an OCRG to analyze the opportunistic connections between CM-CH and CM-CM in a heterogeneous WSNs. When the CM timeslot becomes the current timeslot,
calculates its link connectivity with
in terms of time-frequency parameter, residual energy, LQR, distance from the BS and Nsupport as per Equation (12),
where
,
is the time-frequency parameter between
and
,
is the residual energy of node
and
,
is the link quality factor between
and
,
is the distance to the BS from
and
is the number of sensor nodes supported by
in case
becomes
. α, β, γ, σ and δ are the appropriate weights assigned to time-frequency parameter, residual energy, link quality factor, distance to the BS and number of supported sensor nodes, respectively. The time-frequency parameter depends on working-sleeping cycle
and status transition frequency
. We can calculate the time-frequency parameter
using Equation (13) as
where
and
are the total working time of the adjacent nodes
and
,
is the data collection period,
and
are the status transition frequencies of the adjacent nodes
and
, and
is the max status transition frequency value obtained during
. Then,
acquires the sensory data, integrates it while removing the redundant information, and forwards the integrated data along with the link connectivity information to the current CH.
| Algorithm 3. HFECS (CM Side) |
| Input: CH election procedure executed |
| Output: Executing all tasks relevant to CM after CH election procedure |
| Begin: |
| 1. | if (CH_Announce message received from multiple potential CH), then |
| 2. | Send the Con_Req to potential CH with highest attribute value > |
| 3. | else if (CH_Announce message received from single potential CH), then |
| 4. | Send the Con_Req to that potential CH |
| 5. | else Wait till the CH_Announce message is received from any potential CH |
| 6. | end if |
| 7. | Wait till the TDMA schedule is received from new CH |
| 8. | if (TDMA based schedule received from new CH), then |
| 9. | Store the schedule (especially CM timeslot) in local buffer |
| 10. | if (timeslot = CM timeslot), then |
| 11. | Calculate Link connectivity of with using Equation (12) |
| 12. | Integrate data and remove the redundant and identical info. for every time period T |
| 13. | while , do // detecting the change in integrated data |
| 14. | Transmit the integrated data to CH along with |
| 15. | end while |
| 16. | else if (timeslot ≠ CM timeslot), then |
| 17. | Wait until timeslot = CM timeslot |
| 18. | end if |
| 19. | end if |
Besides the benefits of hesitant fuzzy entropy in the CH election procedure of heterogeneous clustering scheme, it can also help in predicting an event in the heterogeneous clustering scheme and in reducing the number of transmissions in the network by applying reliable data fusion. Let us assume that CH requires time period to transmit aggregated data packet to BS, and CM requires time period to transmit the integrated data to CH where . Moreover, we considered context-based data forwarding, which means that when the CH receives the integrated data from , it performs lossless aggregation by concatenating multiple data packets into single packet of specified length. In addition, CH also standardizes the received integrated data, calculates the hesitant fuzzy entropy and assign corresponding weight coefficients to integrated data of all sensor nodes. Then, CH synthesizes the attribute values of each sensor node to determine the threshold attribute values. After that, the threshold attribute values are compared with original attribute values to make a decision about data forwarding to the BS. If the original attribute values (current integrated data) are greater than threshold attribute values, it means that integrated data is changed after time period T, only then the CH transmits the result to the BS so that the BS can initiate the Standard Operating Procedure (SOP) accordingly against the event occurred in the cluster, but if the original attribute values are less than threshold attribute values, it means that the integrated data are not changed after time period T and CHs do not need to forward the integrated data to the BS. In this case, CHs should wait for time period so that more sensory data are available.
After forwarding the aggregated data packets to BS, CH calculates the link connectivity with all of its CM as given in Equation (14),
where
is the time-frequency parameter between
and
,
is the residual energy of
and
,
is the link quality factor between
and
,
is the distance to the BS from
and
is the number of sensor nodes supported by
. In this paper, the decision about the next CH is based on the link connectivity information of current CH and CMs. For each
in CM_set, we compare the link connectivity
with that of
. If
, we add
in CH_Election_Procedure set
but if
, then we add
to CH_Election_Procedure set
.
If the current
is the only sensor node in CH_Election_Procedure set
, then current
will be the new
for next round
but if there is only one sensor node in the CH_Election_Procedure set
and
, then the sensor node
present in
will be the new
for the next round
. However, if sensor nodes present in
are more than 1, then the current CH executes the CH election procedure using hesitant fuzzy entropy and selects the
based on highest
criteria. Subsequently, the current CH sends the CH_Election_Set message to the new CH. Upon receiving the CH_Election_Set message, the new CH needs to multicast the CH_announce message to its CMs in order to advertise its role as a potential CH. The pseudocode for CH task execution is given in Algorithm 4.
| Algorithm 4. HFECS (CH Side) |
| Input: CH election procedure executed by BS |
| Output: CH decision and local data fusion decision using HFECS |
| Begin: |
| 1. | if (CH_Election_Set message received), then |
| 2. | Start preparing CH_Announce message in order to advertise your role as potential CH |
| 3. | Send CH_Announce message to neighboring sensor nodes which are in working mode |
| 4. | end if |
| 5. | Wait till the Con_Req message is received from neighboring |
| 6. | if (Con_Req message is received from neighboring ), then |
| 7. | CH creates a cluster member set, i.e., CM_set |
| 8. | Add the neighboring in CM_set |
| 9. | end if |
| 10. | if (all working in a cluster are part of CM_set of their new CH), then |
| 11. | Each new CH transmits the TDMA schedule to all CMs keeping in view the |
| 12. | working-sleeping cycle of CMs |
| 13. | end if |
| 14. | if (integrated data received from | CM_set), then |
| 15. | CH performs aggregation on multiple data packets received from by concatenating |
| 16. | into a single file of specified length |
| 17. | CH standardizes the data received from , calculates the hesitant fuzzy entropy and weights |
| 18. | CH synthesize the attribute values of sensor nodes to determine threshold attribute values |
| 19. | CH compares the original attribute value with that of threshold attribute values |
| 20. | if (original attribute values are greater than threshold attribute values after T), then |
| 21. | CH periodically transmits the aggregated data to BS |
| 22. | else if (original attribute values are less than threshold attribute values after T), then |
| 23. | CH will not transmit the aggregated data to BS |
| 24. | end if |
| 25. | end if |
| 26. | Calculate Link connectivity of CH with its cluster members using Equation (14) |
| 27. | for each cluster member in CM_set, do |
| 28. | if ( ≥ ), then |
| 29. | Add to CH_Election_Procedure set |
| 30. | else if ( < ), then |
| 31. | Add to CH_Election_Procedure set |
| 32. | end if |
| 33. | end for |
| 34. | if ( = 1) and , then |
| 35. | will be new for next round |
| 36. | else if ( = 1) and |
| 37. | will be new for next round |
| 38. | else if ( > 1) |
| 39. | executes the CH election procedure and selects new CH with highest |
| 40. | sends CH_Election_Set message to new CH |
| 41. | end if |
4.3. Packet Overhead Calculation
In our proposed scheme, each CH acquires the integrated sensed data from its CMs and then forwards the aggregated data to BS after detecting the change in integrated data for every time period T. In our paper, the hesitant fuzzy entropy balances the network load during CH rotation in successive rounds of communication when applied on MADM. Let us assume that we have exchanged packets as an overhead in which is the number of working sensor nodes in the network. If we assume that is the number of CHs per round, then we can calculate the overhead packets as:
packets used for broadcasting CH_Announce by all CHs.
packets in terms of Con_Req by working CMs.
packets used for broadcasting TDMA schedule to working CMs in CM_set by all CHs.
packets used for sending data to CHs by working CMs.
packets used for forwarding data to the BS by all CHs in case if final prediction result is changed after time period T.
packets received by all CHs from their CMs for link connectivity calculation.
packets received by all CMs from their neighboring CMs and current CH for link connectivity calculation comparison.
k packets used for the CHs rotation in case if all CHs select one of its CMs as the next CH.
Therefore, the overhead of HFECS will be as .
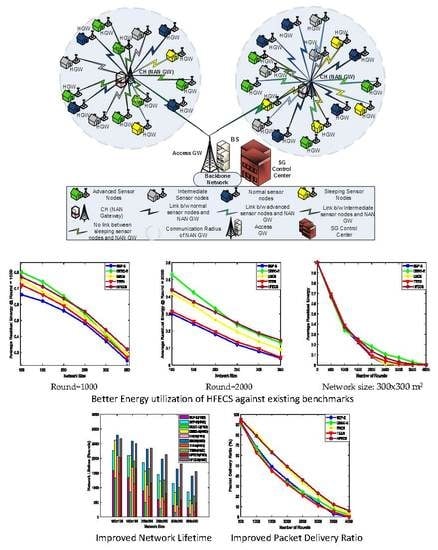
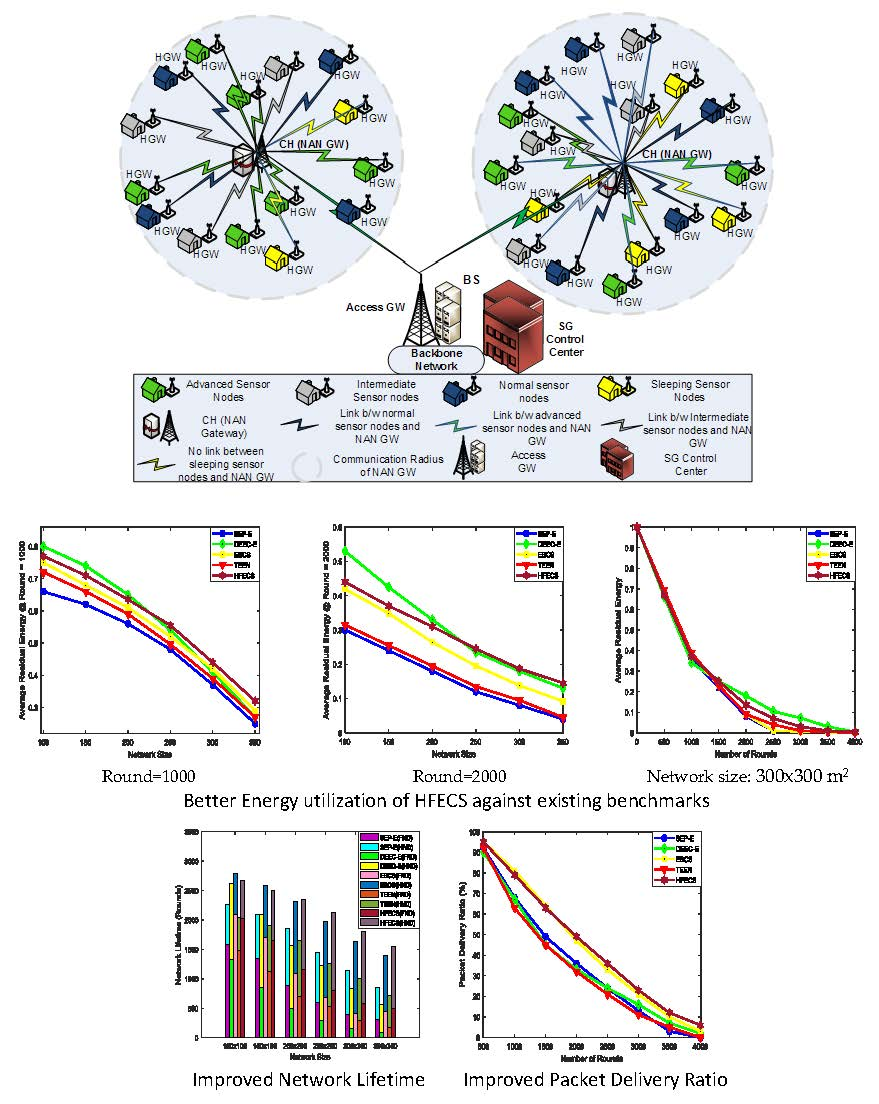
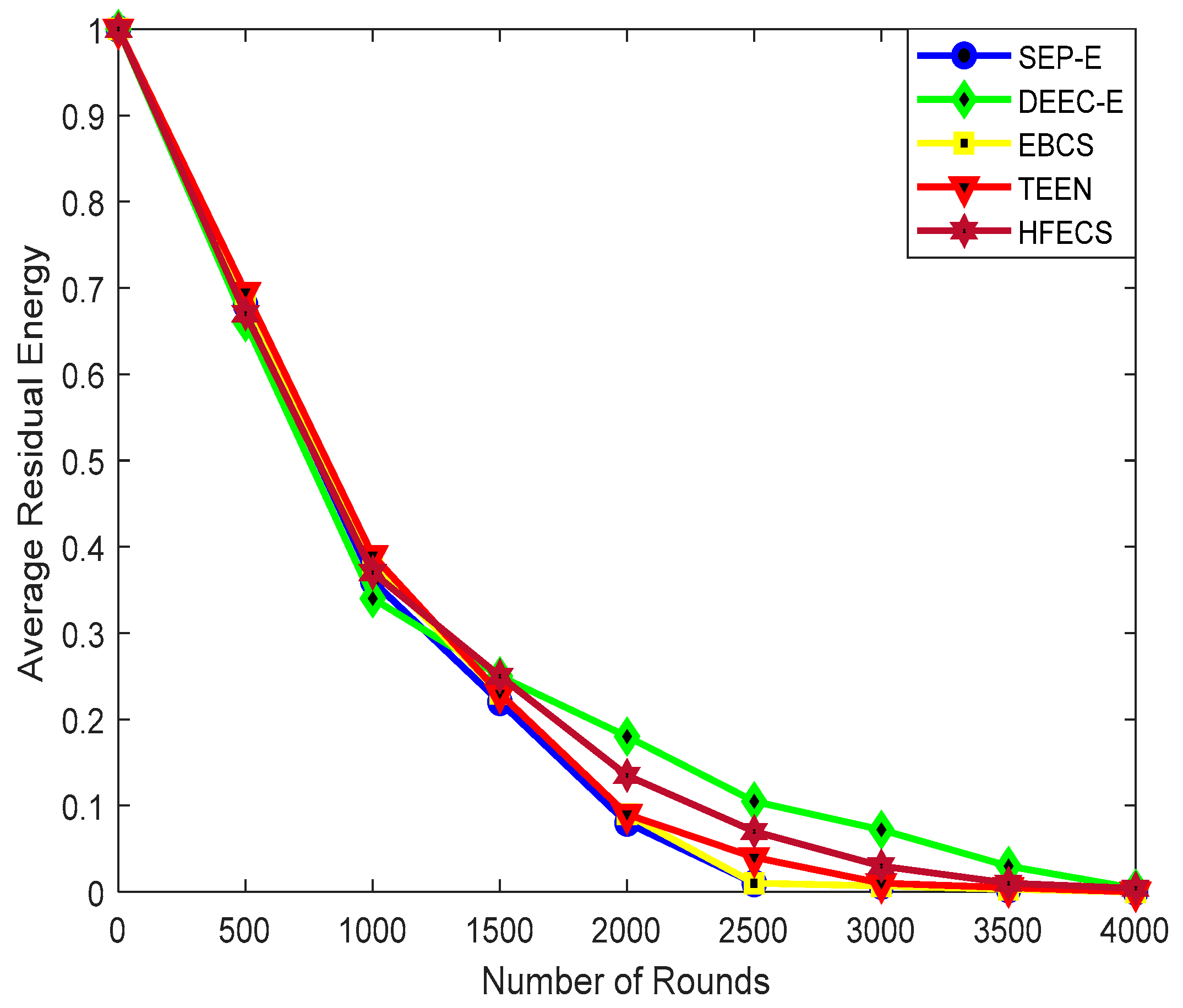
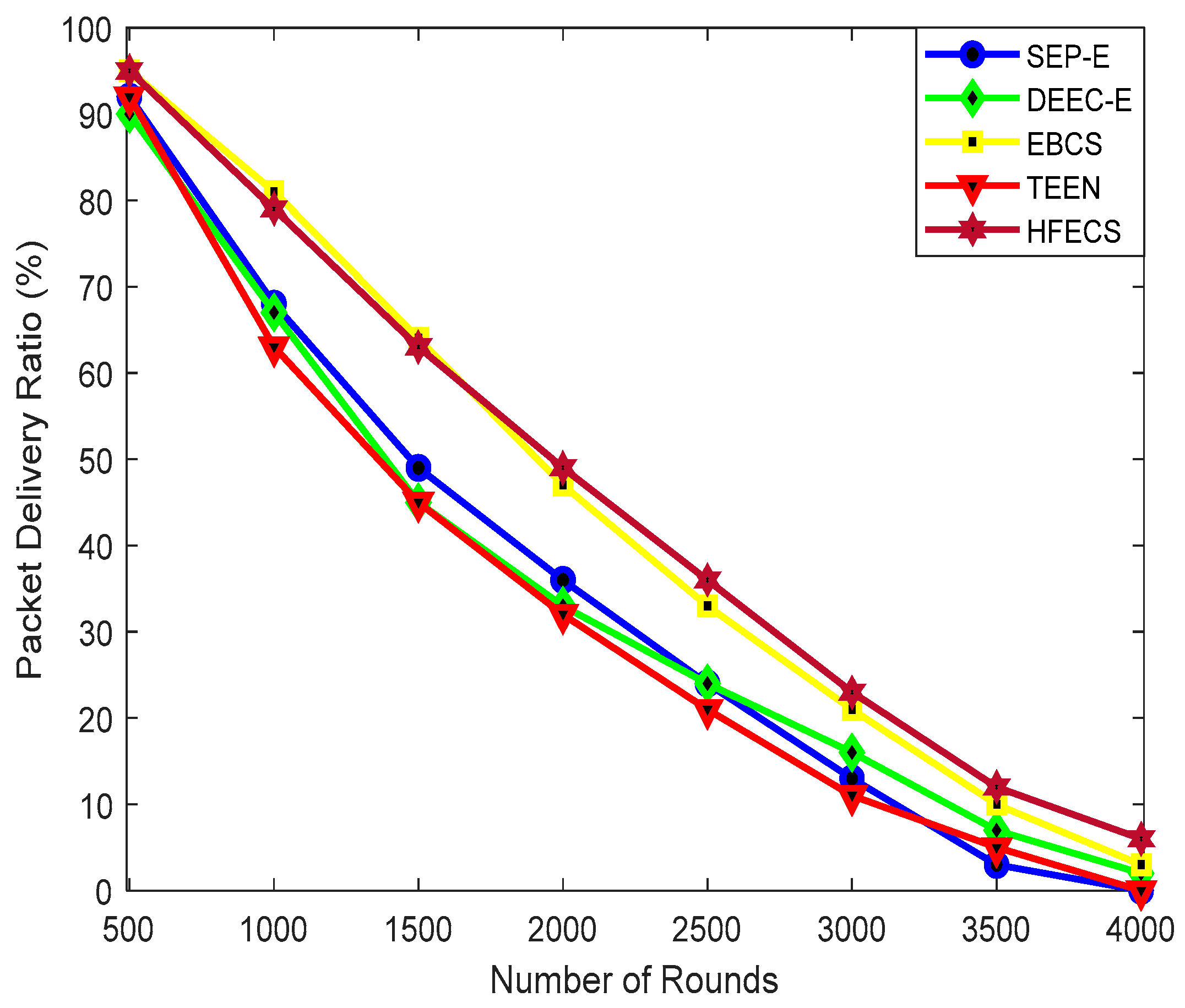
5. Case Study: HFECS in Neighborhood Area Networks
In this paper, we have described the opportunistic clustering mechanism based on hesitant fuzzy entropy using several parameters, such as the time-frequency parameter, residual energy, LQR, distance from the BS and Nsupport. Anees et al. in [
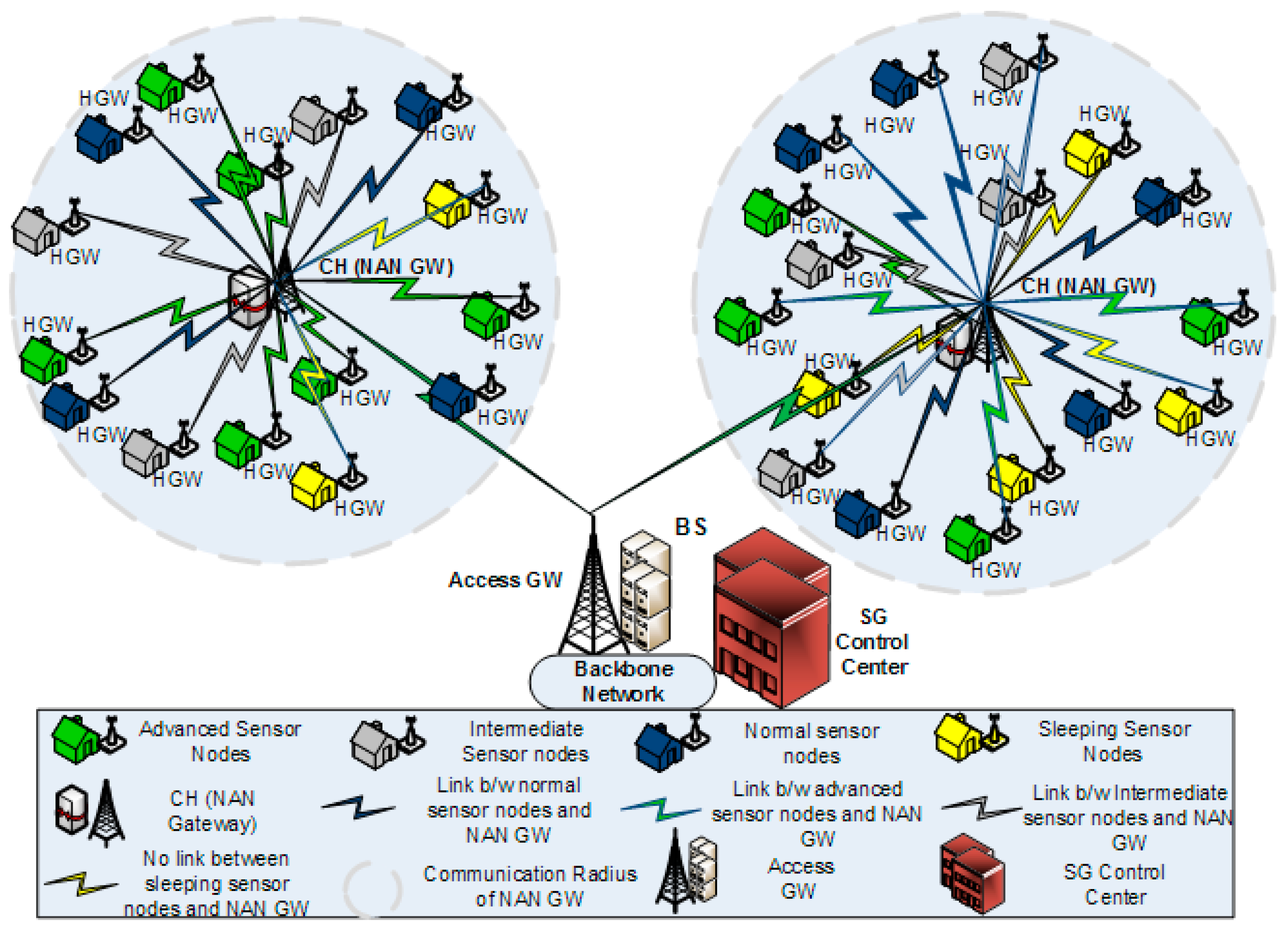
26] proposed an energy-efficient multi-disjoint path opportunistic node connection routing protocol for smart grids in which the OCRG was utilized to calculate the link and path connectivity between sensor nodes for data forwarding purposes. Likewise, we have considered the neighborhood area networks (NANs) of smart grids in our case study to prove the significance of hesitant fuzzy entropy in heterogeneous clustering of WSNs. If we make an analogy between heterogeneous clustering and NANs of SGs, we can consider the NAN gateway as the CH and the several Home Area Network (HAN) gateways connected to the NAN gateway as CMs connected to their CH, as shown in
Figure 2. Furthermore, the Access gateway in NANs can be considered as the BS, which receives the aggregated data from multiple NAN gateways and forwards it to the control center [
46]. In this case study, we can see how the efficient use of hesitant fuzzy entropy can help us in making the CH election decision and also perform reliable data fusion.
We have selected the measured values of six attributes from five sensor nodes placed randomly in a cluster. It is important to mention here that for this case study we considered the network area as centralized NAN for SGs communication. As each of the attributes have different [min max] values, so we needed to perform the data standardization in order to bring all the attributes on the same scale and to convert our measured data values into hesitant fuzzy set. So, we divided the attribute values into 10 parts according to their [min max] values and then assign values corresponding to 0–1.0.
Table 2 represents the interval for each attribute used for data standardization whereas
Table 3 represents the measured value of attributes for all sensor nodes. Different monitoring values for each attribute indicate that data acquisition cycle for each sensor node is different due to the asynchronous working-sleeping cycle strategy. For example, for the attribute time-frequency parameter in
Table 3, its measured values are normalized to
{([0,10] → [0,0.1]), ([10,20] → [0.1,0.2]), …([60,70] → [0.6,0.7]), …([90,100] → [0.9,1])}. Similarly, for residual energy, the standardized attribute values will be {([0,0.25] → [0,0.1]), ([0.25,0.5] → [0.1,0.2]), …([1.5,1.75] → [0.6,0.7]), …([2.25,2.5] → [0.9,1])}. The procedure of data standardization is the same for all other attributes mentioned in
Table 3, along with their intervals, but for attribute ‘Distance to BS’, the standardized values are {([150,136] → [0,0.1]), ([136,122] → [0.1,0.2]), ……([66,52] → [0.6,0.5])…([24,10] → [0.9,1.0])} because if ‘Distance to BS’ is minimum, then we can have better connectivity with BS.
Table 4 shows the corresponding hesitant fuzzy sets after the data standardization process. We utilized the hesitant fuzzy sets to compute hesitant fuzzy entropy using Equation (12) to acquire the statistical measure of uncertainty in our decision analysis for the CH election procedure and data fusion by CH.
Table 5 represents the hesitant fuzzy entropy of each attribute used in our case study. After generating the hesitant fuzzy entropy matrix, we determined the entropy weight coefficients using Equation (13).
Table 6 represents the entropy weight coefficients of all sensor nodes, i.e.,
Moreover, the average values of all attributes in
Table 2 and entropy weight coefficients in
Table 6 were used to compute the threshold attribute values using Equation (14). As we have six attributes in total, so the six threshold attribute values in our case study are
. Consequently, we compare the measured attribute value of each sensor with that of theshold attribute value in
Table 7. Here, we considered the attributes with the three highest entropy coefficient weights, i.e.,
,
and
.
According to
Table 7, only three sensors fulfill our criteria after comparing the measured attribute values with threshold attribute values. The BS puts the sensor nodes with highest
>
in CH election set and then invokes those sensor nodes in the CH election set. Hence, in this case study, only S5 will be selected as the CH, but in reality, the whole process is much more complex than the one mentioned in this case study due to interference, overhead and energy constraints.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
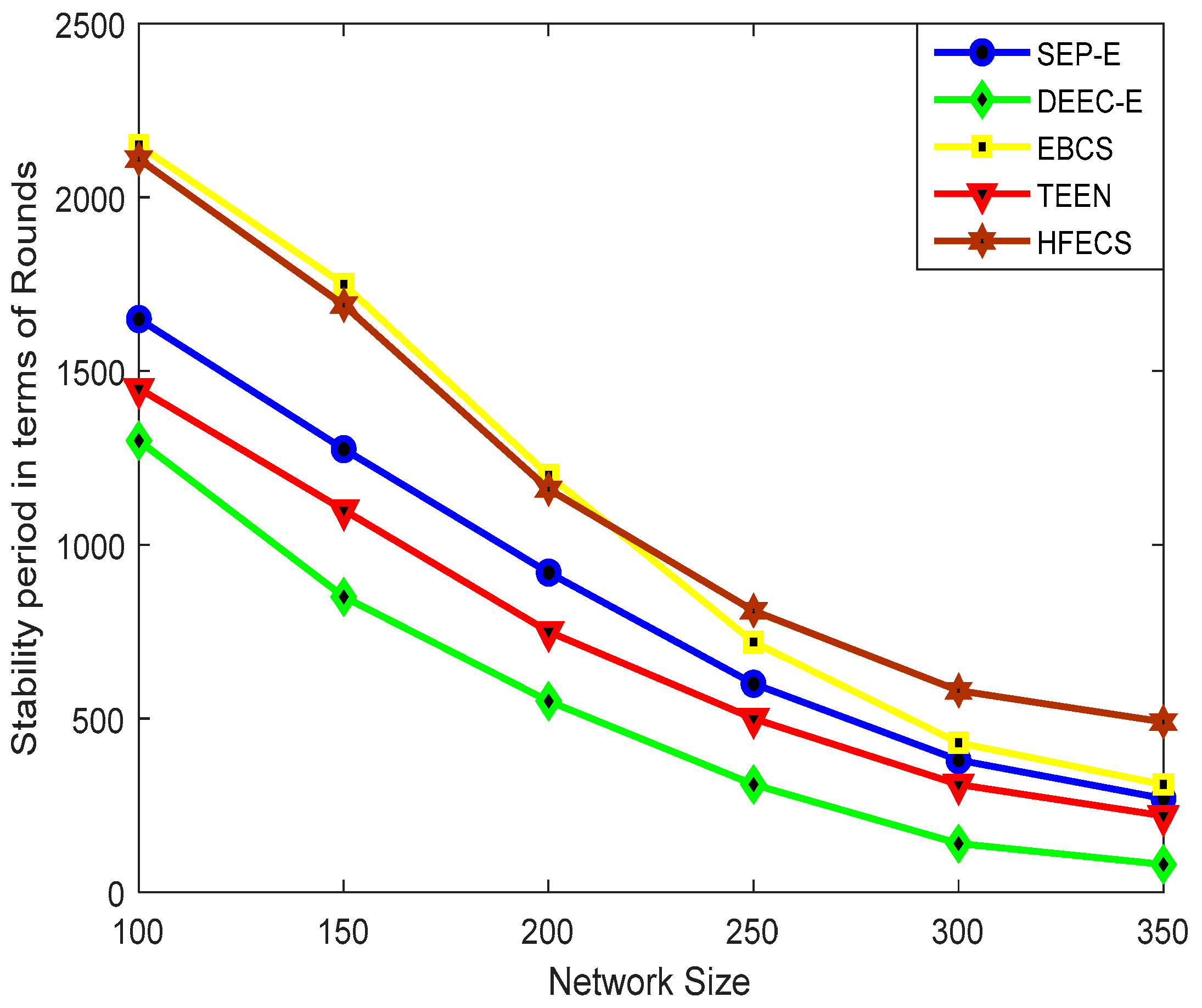{kind=link}
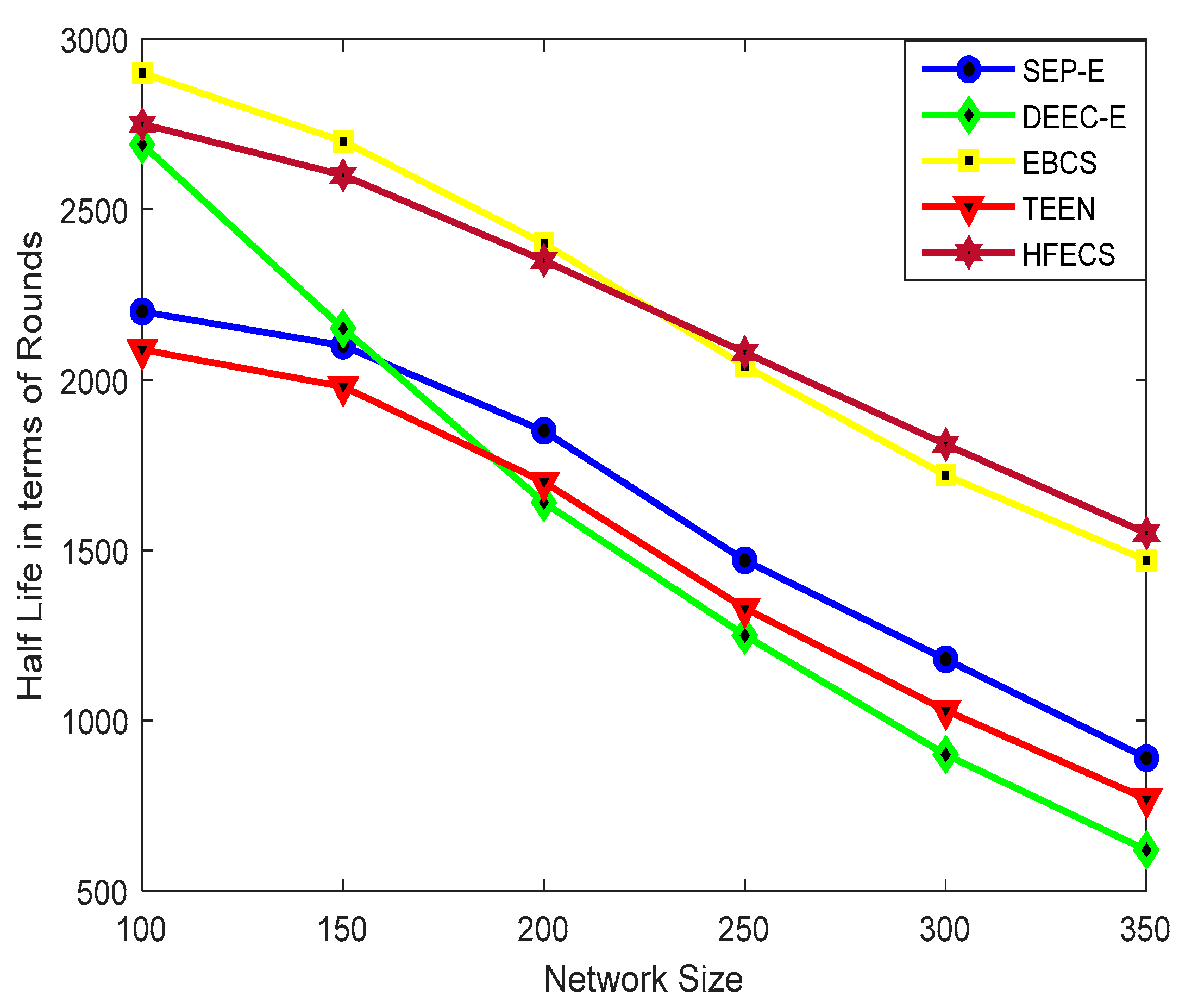{kind=link}
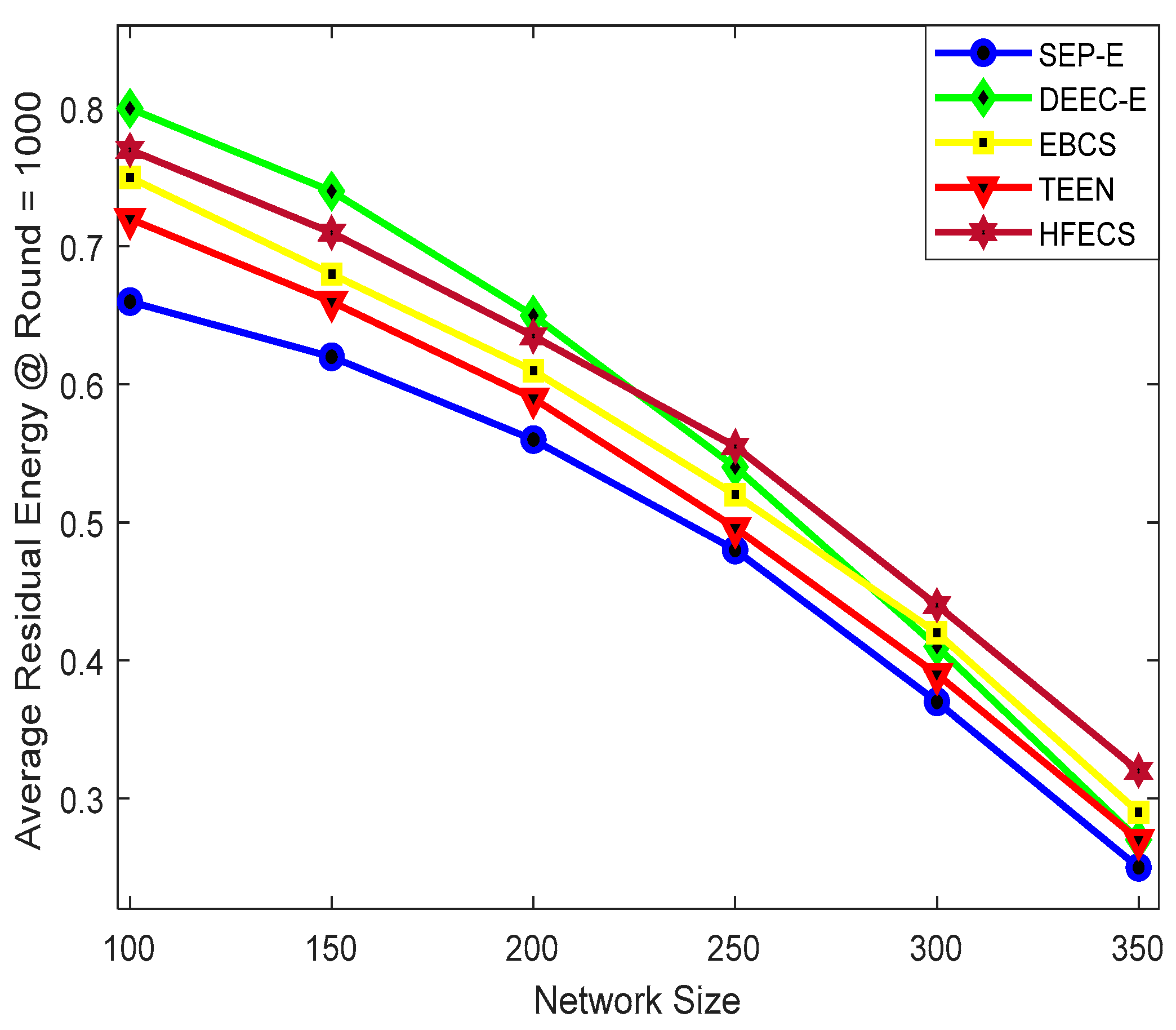{kind=link}
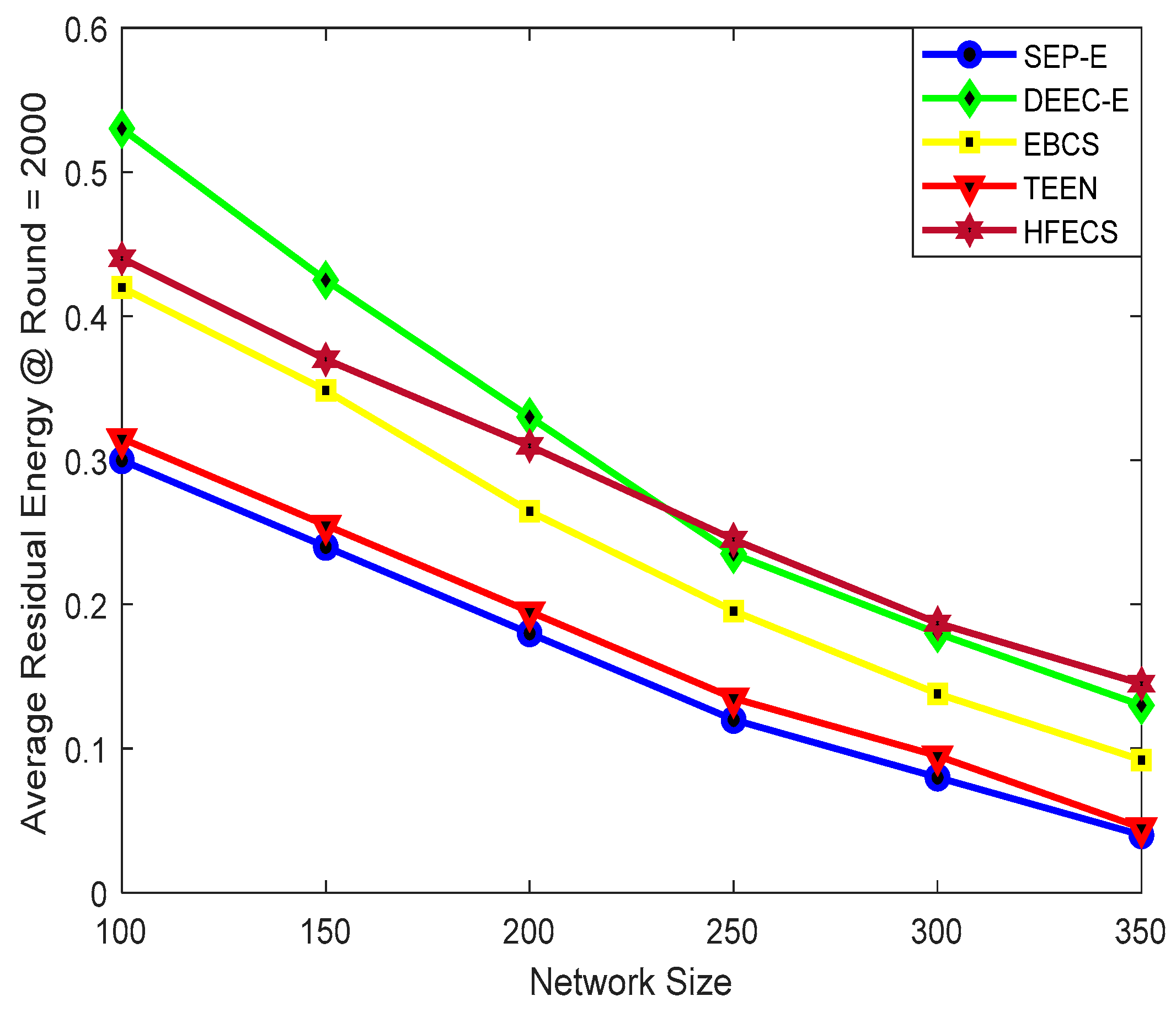{kind=link}
{kind=link}
{kind=link}
{kind=link}