Incentivizing for Truth Discovery in Edge-assisted Large-scale Mobile Crowdsensing


Abstract
1. Introduction
- Reduce the computational complexity: the edge computing based mobile crowdsensing architecture can parallelize the computing through offloading the computing from the cloud to multiple edge servers.
- Decrease the latency: There is less or no necessary communication between the cloud and the mobile users.
- Location-awareness: Most mobile crowdsensing tasks are location dependent [12,13,14]. The edge computing resources (such as base stations and access points) are usually with specific locations. Since the edge servers only collect the sensing data within their deployment area, it is easy to verify the location property of sensing data. For example, the crowdsensing of noise monitoring or traffic monitoring for specific locations. The sensing data largely depends on the accuracy of location information.
- Flexible data processing. Edge computing based mobile crowdsensing brings the flexibility of local data processing (such as aggregation, truth discovery and inference of temperature, noise level, transportation and air condition for specific areas) in edge servers. For example, the edge cloud can be used to estimate the local noise level or analyze local traffic video, which do not need to be executed in the deep cloud.
- Reduce privacy threats: The sensing data is distributed in multiple edge servers. The distributed storage of sensing data in multiple edge servers not only enhances security of data but also reduces privacy threats of users. For example, the crowdsensing data of personal living environment/photos are private information, and are more suitable to be processed in edge servers.
- How to estimate the true value (truth discovery) under edge computing based mobile crowdsensing architecture?
- Further, how to incentivize the strategic users to contribute more for truth discovery?
- To the best of our knowledge, we are the first to present an integrated solution, which stimulates the strategic users to contribute for truth discovery in the edge computing based mobile crowdsensing.
- We present an edge-assisted large-scale mobile crowdsensing architecture, which enables the platform in the deep cloud to offload the sensing tasks to the edge clouds deployed in different geographical areas.
- We formulate the quality function based on the importance of tasks and the weight of users in truth discovery. We model the Budget Feasible Quality Optimization (BFQO) problem to maximize the quality function under the budget constraint. We show that the BFQO problem is a budget feasible submodular maximization problem, and design a budget feasible reverse auction mechanism to solve the BFQO problem based on a random mechanism and the proportional share allocation rule [20], which is computationally efficient, individually rational, truthful, budget feasible and a constant approximate.
2. System Model
2.1. Edge-Assisted Mobile Large-scale Crowdsensing Model
2.2. Desirable Properties
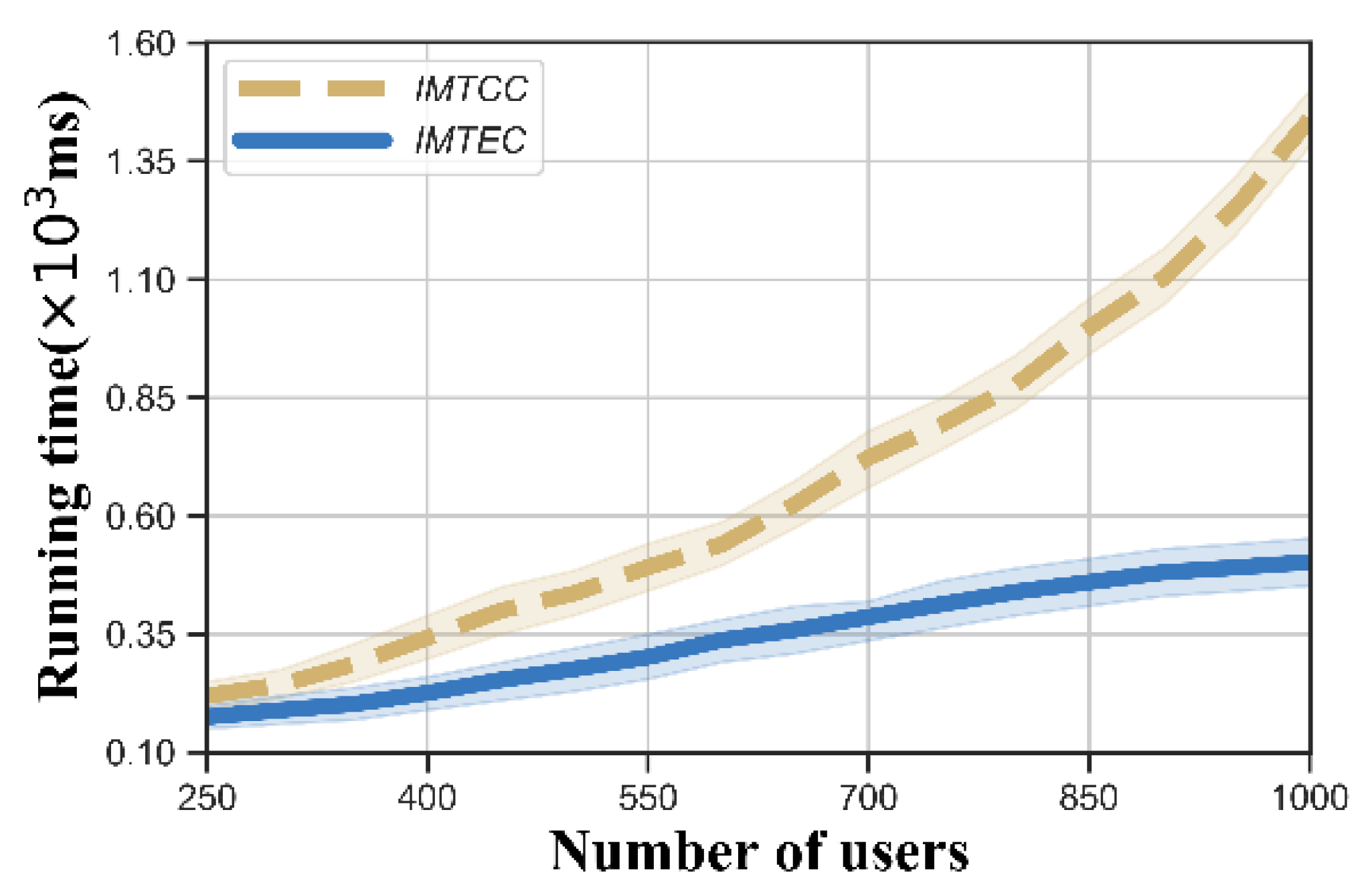
- Computational efficiency: An incentive mechanism is computationally efficient if the truth, the winner set and the payment profile can be computed in polynomial time.
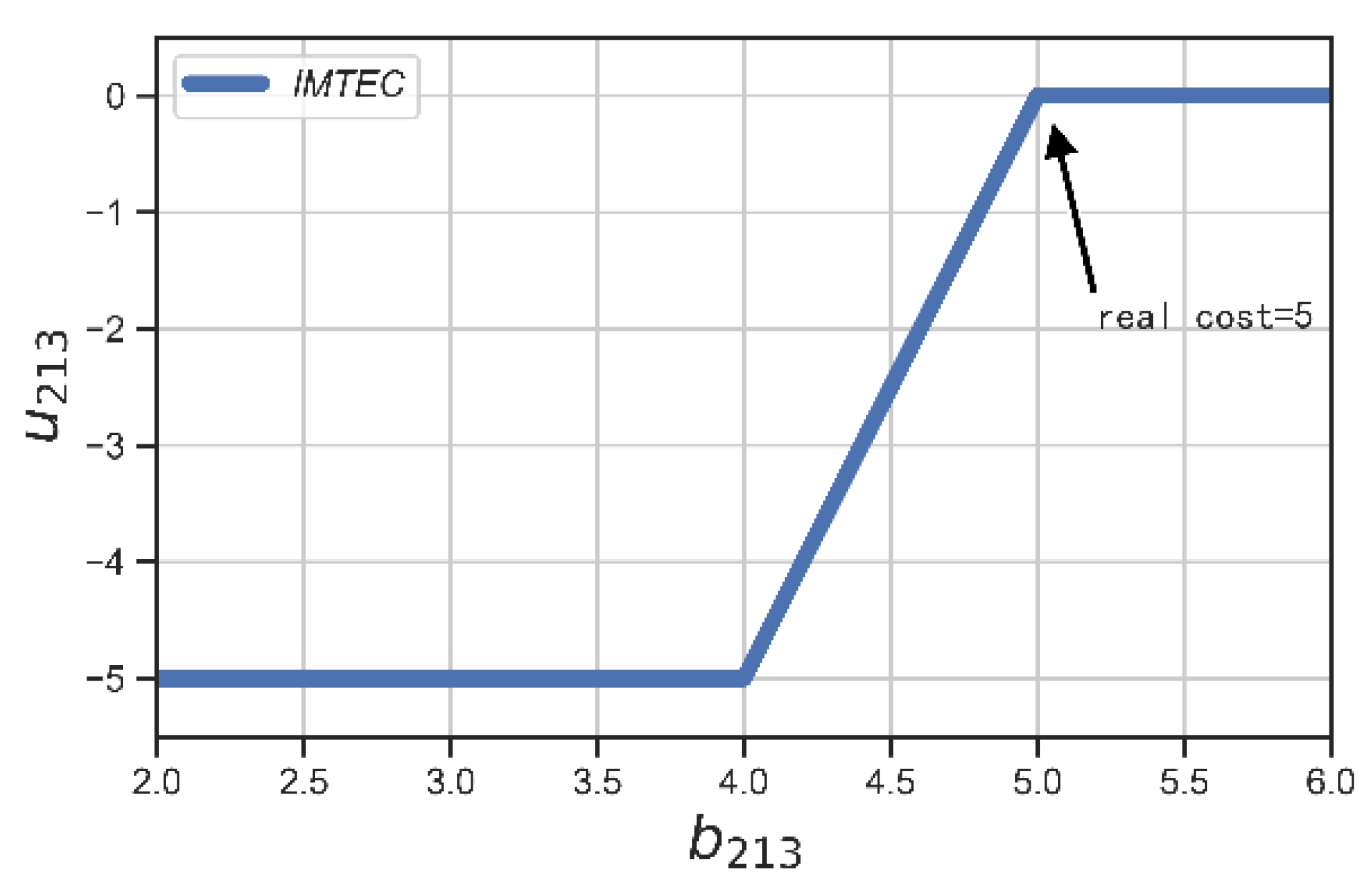
- Individual rationality: Each winner will have a non-negative utility while bidding its true cost, i.e.,
- Truthfulness: An incentive mechanism is truthful if reporting that the true cost is a weakly dominant strategy for all users. In other words, no user can improve its utility by submitting a false cost, no matter what others submit.
- Budget feasibility: In every edge cloud, the total payments to the winners are no more than the budget of the edge cloud, i.e., , for .
- Approximation: We attempted to find a solution with the highest possible value of quality function. For , we said the incentive mechanism was the -approximate if the mechanism selects a winner set such that .
3. Truth Discovery
3.1. Truth Discovery in Edge Clouds
| Algorithm 1: Truth Discovery |
 |
3.2. Truth Discovery in Deep Cloud
4. Budget Feasible Reverse Auction
| Algorithm 2: Budget Feasible Reverse Auction |
 |
5. Performance Evaluation
5.1. Simulation Setup
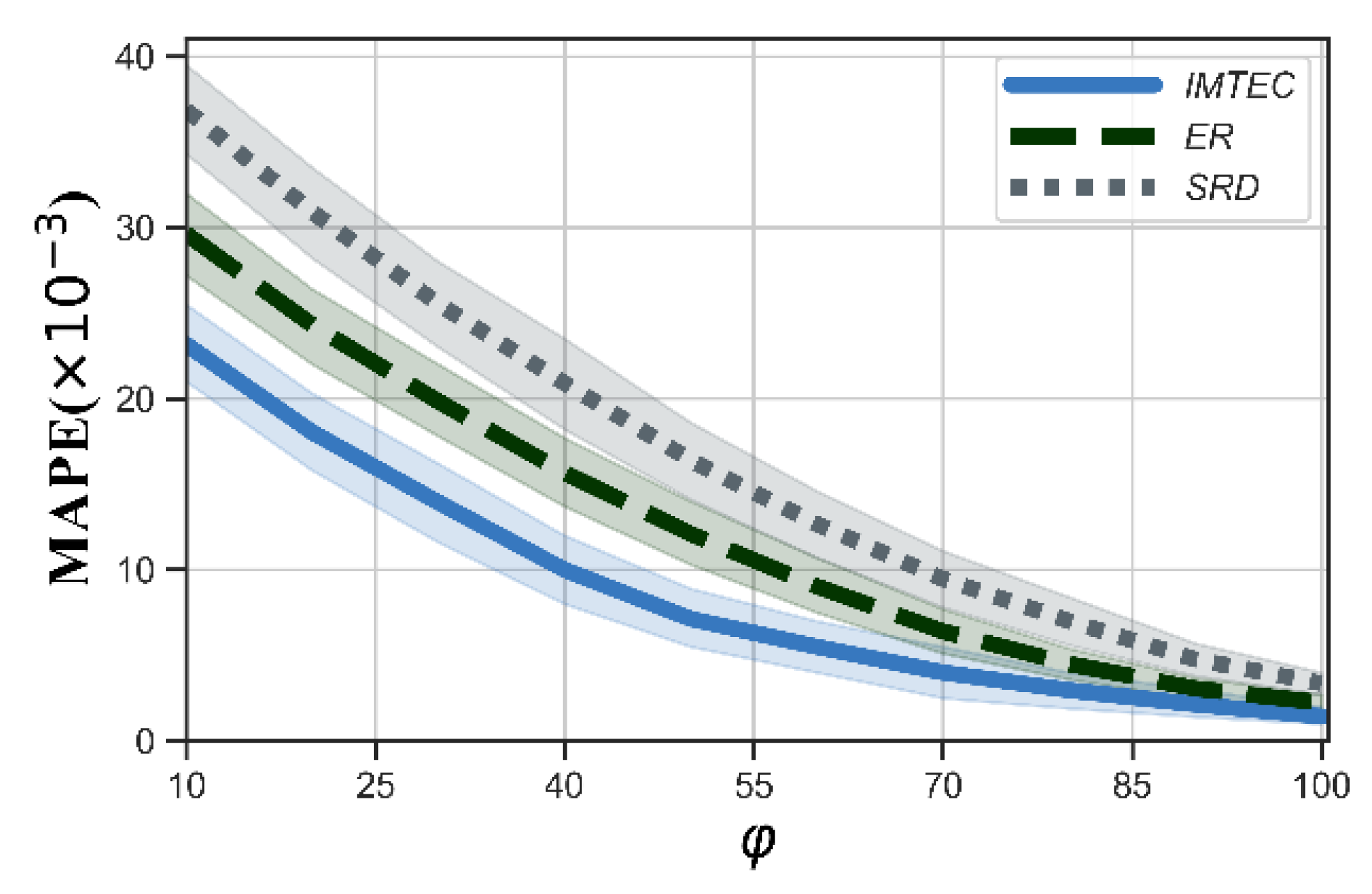
- Equal Reliability (ER): ER considers that each edge cloud is with the same reliability. This means that ER estimates the truth in the deep cloud through Formula (9) with .
- Square Root Distance (SRD): SRD uses the distance function instead of the normalized squared distance function given in Formula (7) to estimate the truth both in edge clouds and deep cloud.
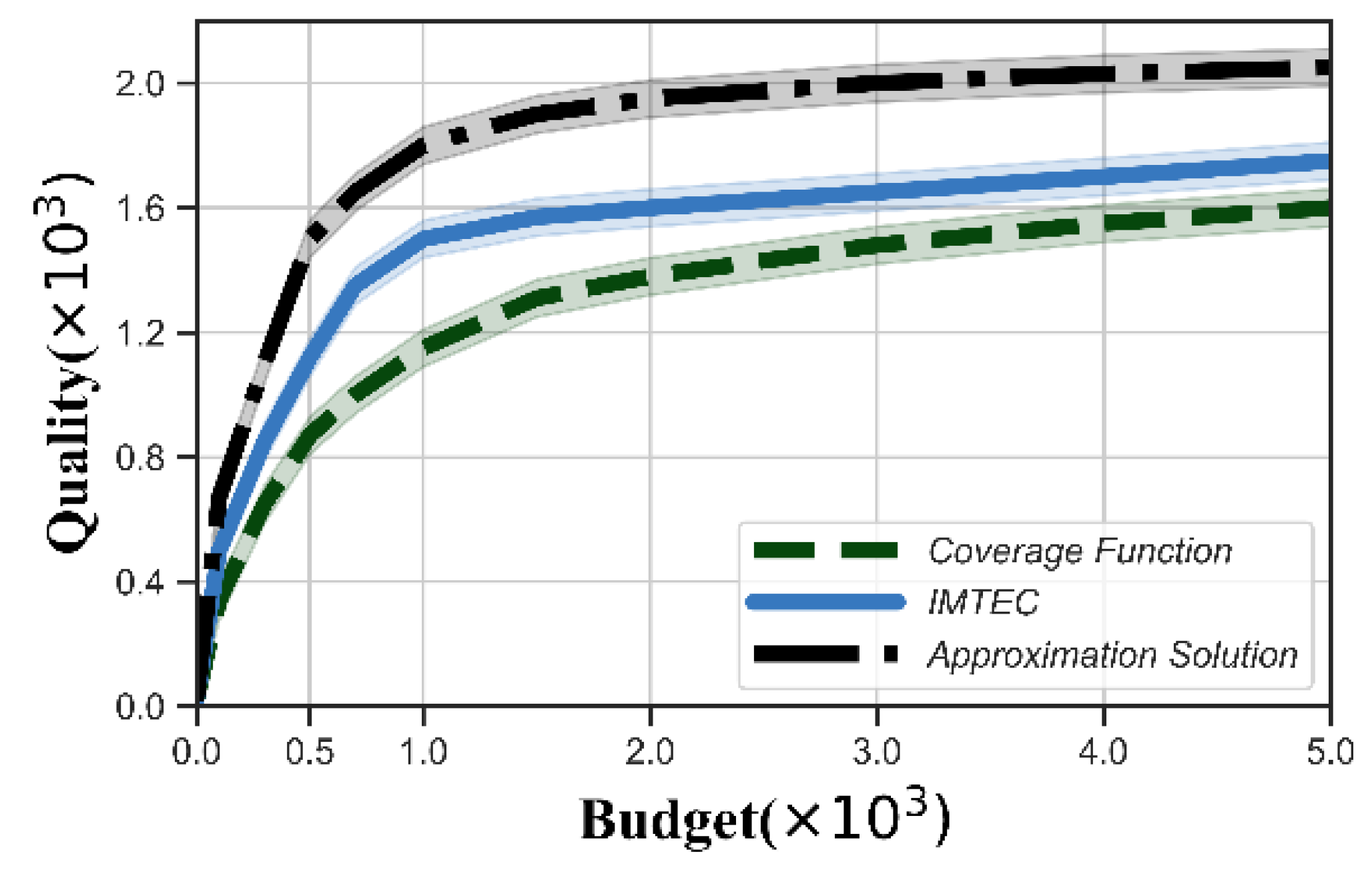
- Approximate optimal: For any edge cloud , approximate optimal mechanism selects the winners from to maximize the quality with budget . The problem is essentially a budgeted maximum coverage problem, which is a well-known NP-hard problem. It is known that the greedy algorithm provides approximation solution [27]. Note that the approximate optimal mechanism is untruthful.
- Coverage function: The objective is maximizing the value function, defined as , such that the total payment is no more than the budget. In other words, the coverage function is the reverse auction, which aims to maximize the coverage of tasks.
5.2. Evaluation of Truth Discovery
5.3. Evaluation of Reverse Auction
5.4. Summary
6. Related Work
6.1. Mobile Corwdsensing with the Edge Computing Paradigm
6.2. Quality-aware Incentive Mechanims in Crowdsensing
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhou, T.Q.; Xiao, B.; Cai, Z.; Xu, M.; Liu, X. From Uncertain Photos to Certain Coverage: A Novel Photo Selection Approach to Mobile Crowdsensing. In Proceedings of the IEEE International Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1979–1987. [Google Scholar]
- Zhang, J.H.; Lu, P.Q.; Li, Z.; Gan, J. Distributed Trip Selection Game for Public Bike System with Crowdsourcing. In Proceedings of the IEEE International Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 2717–2725. [Google Scholar]
- Li, T.; Chen, Y.M.; Zhang, R.; Zhang, Y.; Hedgpeth, T. Secure crowdsourced indoor positioning systems. In Proceedings of the IEEE International Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1034–1042. [Google Scholar]
- Xu, J.; Xiang, J.X.; Yang, D.J. Incentive mechanisms for time window dependent tasks in mobile crowdsensing. IEEE Trans. Wireless Commun. 2015, 14, 6353–6364. [Google Scholar] [CrossRef]
- Yang, D.J.; Xue, G.L.; Fang, X.; Tang, J. Crowdsourcing to smartphones: Incentive mechanism design for mobile phone sensing. In Proceedings of the 18th annual international conference on Mobile computing and networking, Istanbul, Turkey, 22–26 August 2012; pp. 173–184. [Google Scholar]
- Jiang, L.Y.; Niu, X.F.; Xu, J.; Yang, D.; Xu, L. Incentivizing the Workers for Truth Discovery in Crowdsourcing with Copiers. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 1286–1295. [Google Scholar]
- Zhou, Z.Y.; Liao, H.J.; Gu, B.; Huq, K.M.S.; Mumtaz, S.; Rodriguez, J. Robust Mobile Crowd Sensing: When Deep Learning Meets Edge Computing. IEEE Network 2018, 32, 54–60. [Google Scholar] [CrossRef]
- Wei, J.J.; Wang, X.J.; Li, N.; Yang, G.M.; Mu, Y. A Privacy-Preserving Fog Computing Framework for Vehicular Crowdsensing Networks. IEEE Access 2018, 6, 43776–43784. [Google Scholar] [CrossRef]
- Ma, L.C.; Liu, X.F.; Pei, Q.Q.; Xiang, Y. Privacy-Preserving Reputation Management for Edge Computing Enhanced Mobile Crowdsensing. IEEE Trans. Serv. Comput. 2019, 12, 786–799. [Google Scholar] [CrossRef]
- Pu, L.J.; Chen, X.; Mao, G.Q.; Xie, Q.Y.; Xu, J.D. Chimera: An Energy-efficient and Deadline-aware Hybrid Edge Computing Framework for Vehicular Crowdsensing Applications. IEEE Internet Things J. 2019, 6, 84–99. [Google Scholar] [CrossRef]
- Yang, S.J.; Bian, J.; Wang, L.C.; Zhu, H.j.; Fu, Y.J.; Xiong, H.Y. EdgeSense: Edge-Mediated Spatial- Temporal Crowdsensing. IEEE Access 2019, 7, 95122–95131. [Google Scholar] [CrossRef]
- Xu, J.; Guan, C.C.; Dai, H.P.; Yang, D.J.; Xu, L.J.; Kai, J.Y. Incentive Mechanisms for Spatio-temporal Tasks in Mobile Crowdsensing. In Proceedings of the IEEE MASS, Monterey, CA, USA, 4–7 November 2019. [Google Scholar]
- He, S.B.; Shin, D.H.; Zhang, J.S.; Chen, J.M. Toward optimal allocation of location dependent tasks in crowdsensing. In Proceedings of the IEEE International Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 745–753. [Google Scholar]
- He, S.B.; Shin, D.H.; Zhang, J.S.; Chen, J.M. Near-optimal allocation algorithms for location-dependent tasks in crowdsensing. IEEE Trans. Veh. Technol. 2017, 66, 3392–3405. [Google Scholar] [CrossRef]
- Wang, T.; Luo, H.; Zheng, X.; Xie, M.D. Crowdsourcing Mechanism for Trust Evaluation in CPCS based on Intelligent Mobile Edge Computing. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Wang, T.; Mei, Y.X.; Jia, W.J.; Zheng, X.; Wang, G.J.; Xie, M. Edge-based Differenital Privacy Computing for Sensor-Cloud Systems. J. Parallel Distrib. Comput. 2020, 136, 75–85. [Google Scholar] [CrossRef]
- Wang, T.; Bhuiyan, M.Z.A.; Wang, G.J.; Qi, L.Y.; Wu, J.; Hayajneh, T. Preserving Balance between Privacy and Data Integrity in Edge-Assisted Internet of Things. IEEE Int. Things J. 2019. [Google Scholar] [CrossRef]
- Li, Y.L.; Li, Q.; Gao, J.; Su, L.; Zhan, B.; Fan, W.; Han, J.W. Conflicts to harmony: A framework for resolving conflicts in heterogeneous data by truth discovery. IEEE Trans. Knowl. Data Eng. 2016, 28, 1986–1999. [Google Scholar] [CrossRef]
- Li, Q.; Li, Y.L.; Gao, J.; Zhao, B.; Fan, W.; Han, J.W. Resolving conflicts in heterogeneous data by truth discovery and source reliability estimation. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, New York, NY, USA; 2014; pp. 1187–1198. [Google Scholar]
- Singer, Y. Budget feasible mechanisms. In Proceedings of the 2010 IEEE 51st Annual Symposium on Foundations of Computer Science, Las Vegas, NV, USA, 23–26 October 2010; pp. 765–774. [Google Scholar]
- Xu, J.; Li, H.; Li, Y.X.; Yang, D.J.; Li, T. Incentivizing the Biased Requesters: Truthful Task Assignment Mechanisms in Crowdsourcing. In Proceedings of the 2017 14th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), San Diego, CA, USA, 12–14 June 2017; pp. 1–9. [Google Scholar]
- Xu, J.; Guan, C.C.; Wu, H.B.; Yang, D.J.; Xu, L.J.; Li, T. Online incentive mechanism for mobile crowdsourcing based on two-tiered social crowdsourcing architecture. In Proceedings of the 2018 15th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON), Hong Kong, China, 11–13 June 2018; pp. 1–9. [Google Scholar]
- Xu, J.; Rao, Z.Q.; Xu, L.J.; Yang, D.J.; Li, T. Incentive Mechanism for Multiple Cooperative Tasks with Compatible Users in Mobile Crowd Sensing via Online Communities. IEEE Trans. Mob. Comput. 2019. [Google Scholar] [CrossRef]
- Koutsopoulos, I. Optimal incentive-driven design of participatory sensing systems. In Proceedings of the IEEE International Conference on Computer Communications, Turin, Italy, 14–19 April 2013; pp. 1402–1410. [Google Scholar]
- Chen, N.; Gravin, N.; Lu, P.Y. On the approximability of budget feasible mechanisms. In Proceedings of the 22nd Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 23–25 January 2011; pp. 685–699. [Google Scholar]
- Khalilabadi, P.; Tardos, E. Simple and Efficient Budget Feasible Mechanisms for Monotone Submodular Valuations. In Proceedings of the International Conference on Web and Internet Economics, Cham, Germany, 15–17 December 2018; pp. 246–263. [Google Scholar]
- Khullera, S.; Mossb, A.; Naor, J. The budgeted maximum coverage problem. Inf. Process. Lett. 1999, 70, 39–45. [Google Scholar] [CrossRef]
- Available online: https://crawdad.org//queensu/crowd_temperature/20151120/ (accessed on 1 February 2020).
- Available online: http://www.modelingonlineauctions.com/datasets (accessed on 1 February 2020).
- Wang, Z.; Pang, X.; Hu, J.; Liu, W.; Wang, Q.; Li, Y.; Chen, H. When Mobile Crowdsensing Meets Privacy. IEEE Commun. Mag. 2019, 57, 72–78. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, J.; Lv, R.; Wei, J.; Wang, Q.; Yang, D.; Qi, H. Personalized Privacy-Preserving Task Allocation for Mobile Crowdsensing. IEEE Trans. Mob. Comput. 2019, 18, 1330–1341. [Google Scholar] [CrossRef]
- Jin, H.M.; Su, L.; Xiao, H.P.; Nahrstedt, K. INCEPTION: Incentivizing Privacy-Preserving Data Aggregation for Mobile Crowd Sensing Systems. In Proceedings of the 17th ACM International Symposium on Mobile Ad Hoc Networking and Computing, New York, NY, USA, 5–8 July 2016; pp. 341–350. [Google Scholar]
- Wang, H.W.; Guo, S.; Cao, J.N.; Guo, M.Y. MeLoDy: A long-term dynamic quality-aware incentive mechanism for crowdsourcing. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 901–914. [Google Scholar] [CrossRef]
- Wen, Y.T.; Shi, J.Y.; Zhang, Q.; Tian, X.H.; Huang, Z.Y.; Yu, H.; Cheng, Y.; Shen, X.M. Quality-driven auction based incentive mechanism for mobile crowd sensing. IEEE Trans. Veh. Technol. 2014, 64, 4203–4214. [Google Scholar] [CrossRef]
- Jin, H.M.; Su, L.; Chen, D.Y.; Nahrstedt, K.; Xu, J.H. Quality of information aware incentive mechanisms for mobile crowd sensing systems. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, New York, NY, USA, 22–25 June 2015; pp. 167–176. [Google Scholar]
- Xu, J.; Bao, W.W.; Gu, H.Y.; Xu, L.J.; Jiang, G.P. Improving Both Quantity and Quality: Incentive Mechanism for Social Mobile Crowdsensing Architecture. IEEE Access 2018, 6, 44992–45003. [Google Scholar] [CrossRef]
- Li, M.; Lin, J.; Yang, D.J.; Xue, G.L.; Tang, J. QUAC: Quality-Aware Contract-Based Incentive Mechanisms for Crowdsensing. In Proceedings of the 2017 IEEE 14th International Conference on Mobile Ad Hoc and Sensor Systems (MASS), Orlando, FL, USA, 22–25 October 2017; pp. 72–80. [Google Scholar]
- Jin, H.; Su, L.; Nahrstedt, K. Theseus: Incentivizing truth discovery in mobile crowd sensing systems. In Proceedings of the 18th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Chennai, India, 10–14 July 2017; pp. 1–10. [Google Scholar]
- Zhang, H.; Bagchi, S.; Wang, H. Integrity of Data in a Mobile Crowdsensing Campaign: A Case Study. In Proceedings of the First ACM Workshop on Mobile Crowdsensing Systems and Applications, Delft, The Netherlands, 5 November 2017; pp. 50–55. [Google Scholar]
- Nava Auza, J.M.; de Marca, B.; Roberto, J.; Lima Siqueira, G. Design of a Local Information Incentive Mechanism for Mobile Crowdsensing. Sensors 2019, 19, 2532. [Google Scholar] [CrossRef]
- Zupančič, E.; Žalik, B. Data Trustworthiness Evaluation in Mobile Crowdsensing Systems with Users’ Trust Dispositions’ Consideration. Sensors 2019, 19, 1326. [Google Scholar] [CrossRef]
- Yang, S.; Wu, F.; Tang, S.; Gao, X.; Yang, B.; Chen, G. On designing data quality-aware truth estimation and surplus sharing method for mobile crowdsensing. IEEE J. Sel. Areas Commun. 2017, 35, 832–847. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| , | edge cloud set, edge cloud k |
| task set, task j | |
| task set of user i, task set of edge cloud k | |
| type set of tasks, type of task j | |
| budget profile, budget of edge cloud k | |
| number of tasks, number of users, number of edge clouds | |
| user set, user set of edge cloud k | |
| winner set, winner set of edge cloud k | |
| bid profile of users in edge cloud k, bid of user i | |
| bid price of user i, cost of user i | |
| all sensing data, sensing data of edge cloud k | |
| sensing data of user i, sensing data of user i for task j, estimated truth of task j | |
| estimated truth of edge cloud k, estimated truth of all edge clouds, estimated truth of deep cloud | |
| weights of all users in , weight of user i, weight of edge cloud k | |
| payment profile of , payment profile of , payment to user i | |
| utility of user i | |
| quality function, marginal quality of user i | |
| distance function | |
| maximum number of iterations for truth discovery | |
| parameters of reliability and importance for truth discovery in deep cloud |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Yang, S.; Lu, W.; Xu, L.; Yang, D. Incentivizing for Truth Discovery in Edge-assisted Large-scale Mobile Crowdsensing. Sensors 2020, 20, 805. https://doi.org/10.3390/s20030805
Xu J, Yang S, Lu W, Xu L, Yang D. Incentivizing for Truth Discovery in Edge-assisted Large-scale Mobile Crowdsensing. Sensors. 2020; 20(3):805. https://doi.org/10.3390/s20030805
Chicago/Turabian StyleXu, Jia, Shangshu Yang, Weifeng Lu, Lijie Xu, and Dejun Yang. 2020. "Incentivizing for Truth Discovery in Edge-assisted Large-scale Mobile Crowdsensing" Sensors 20, no. 3: 805. https://doi.org/10.3390/s20030805
APA StyleXu, J., Yang, S., Lu, W., Xu, L., & Yang, D. (2020). Incentivizing for Truth Discovery in Edge-assisted Large-scale Mobile Crowdsensing. Sensors, 20(3), 805. https://doi.org/10.3390/s20030805