Probabilistic Modelling for Unsupervised Analysis of Human Behaviour in Smart Cities


Abstract
1. Introduction
- We develop an extension of the ubiquitous Hidden Markov model, which can robustly segment different behaviours in monitoring applications while accounting for present contextual factors.
- We have derived a principled framework for inference in the developed AI-HMM approach.
- We have shown the particularly suitability of the nonparametric switching autoregressive model for analysis of GPS and traffic count data.
2. Related Work
3. Dynamic Time Series Modelling
3.1. Vector Autoregressive Model (VAR)
3.2. Autoregressive Infinite Hidden Markov Model (AR-iHMM)
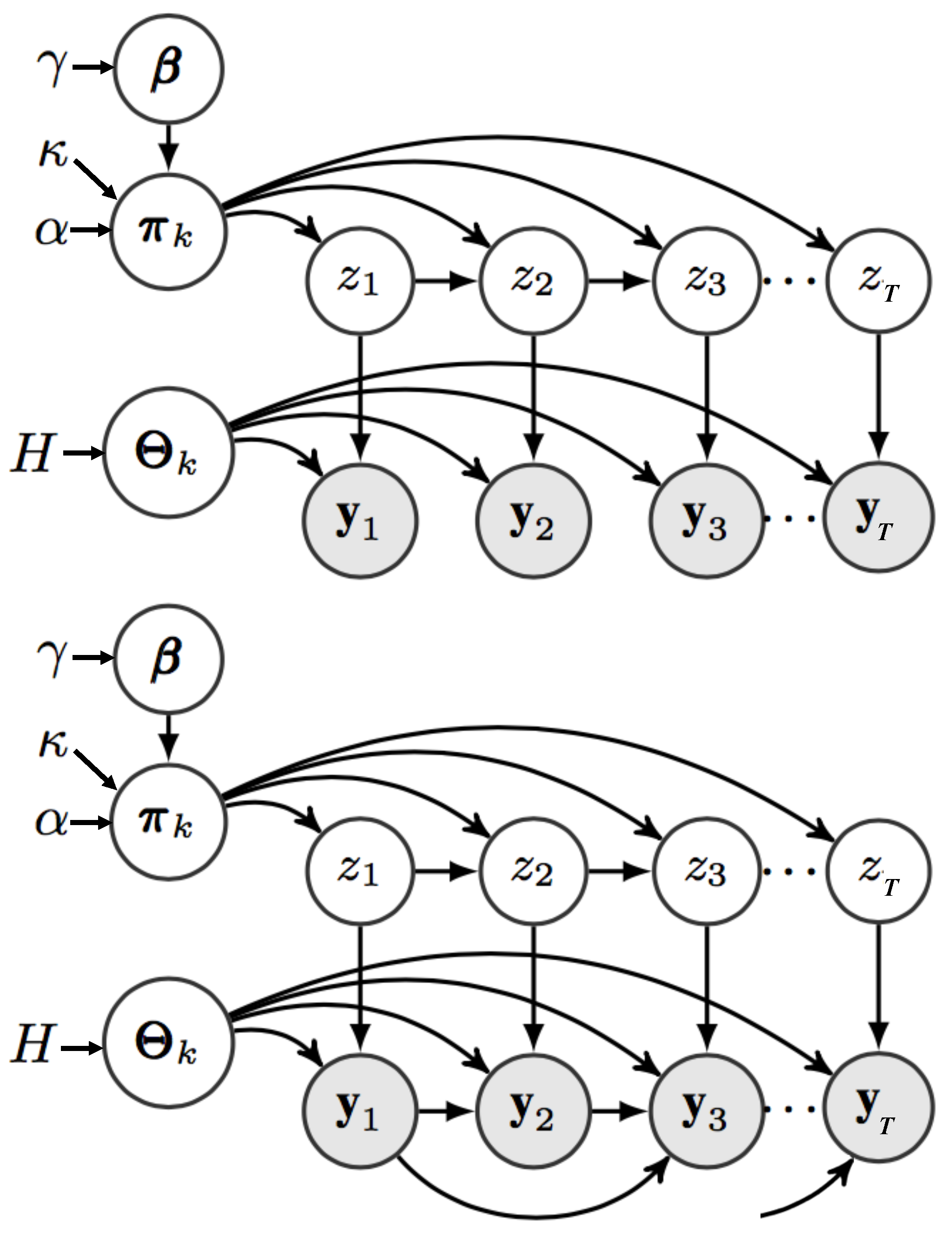
4. Adaptive Input Infinite Hidden Markov Model (AI-iHMM)
4.1. Model Specification
4.2. Inference
5. Modelling With Fixed Inputs
5.1. Dodgers Loop Sensor Dataset
5.2. T-Drive Dataset
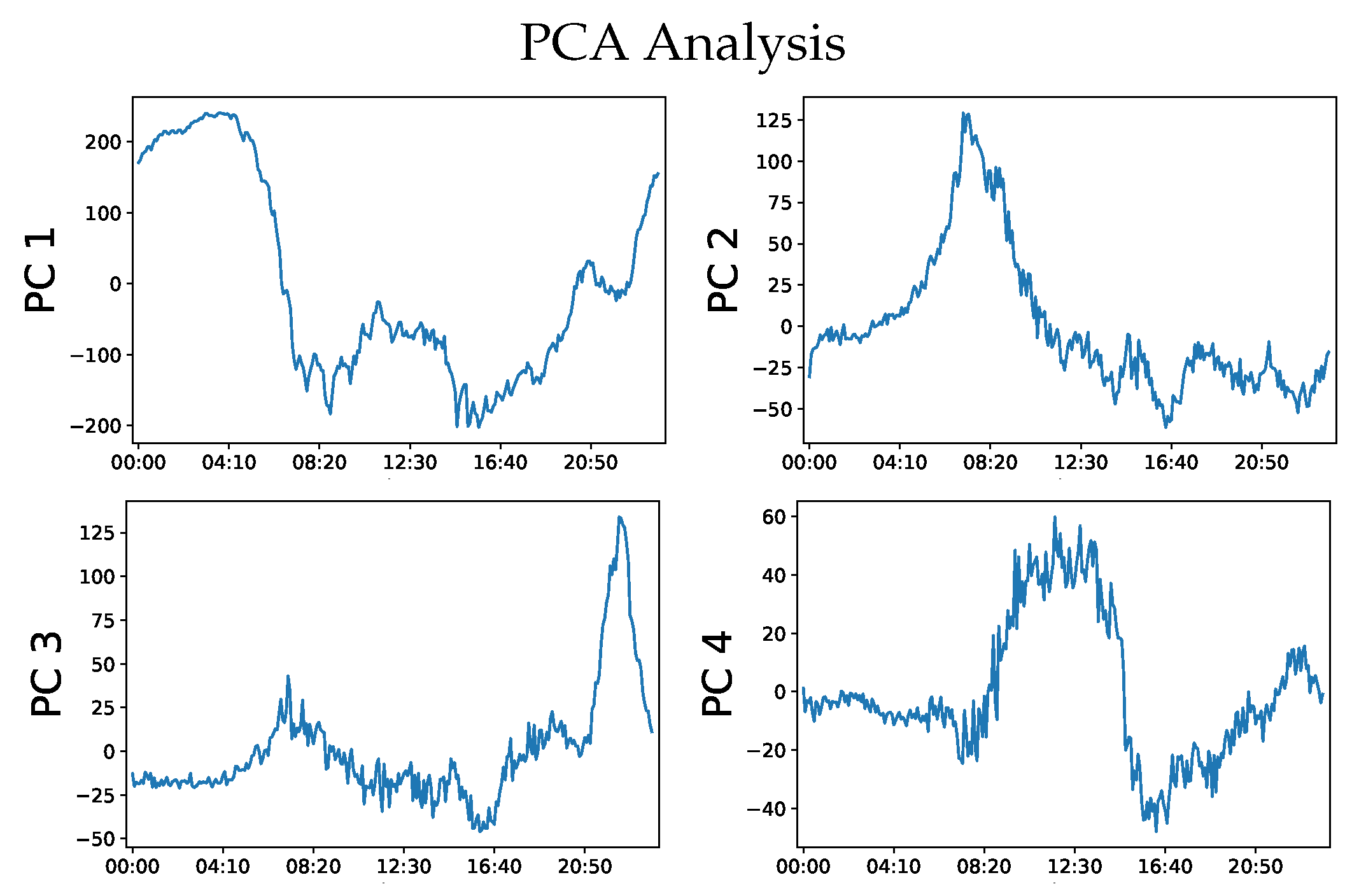
5.2.1. Data Preprocessing
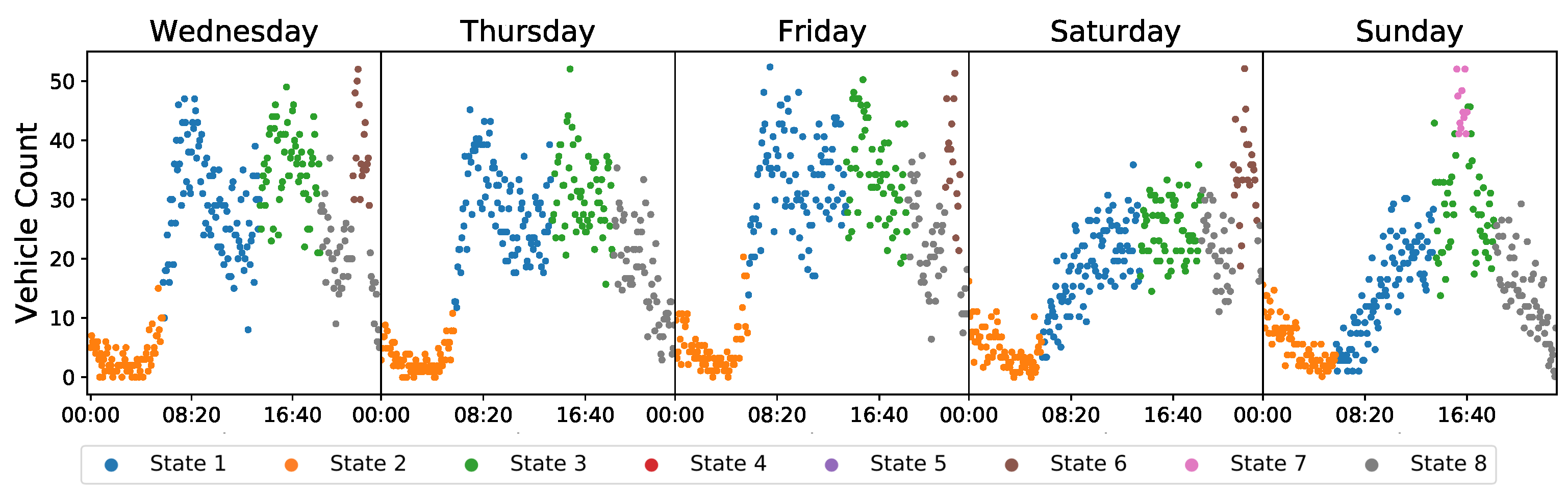
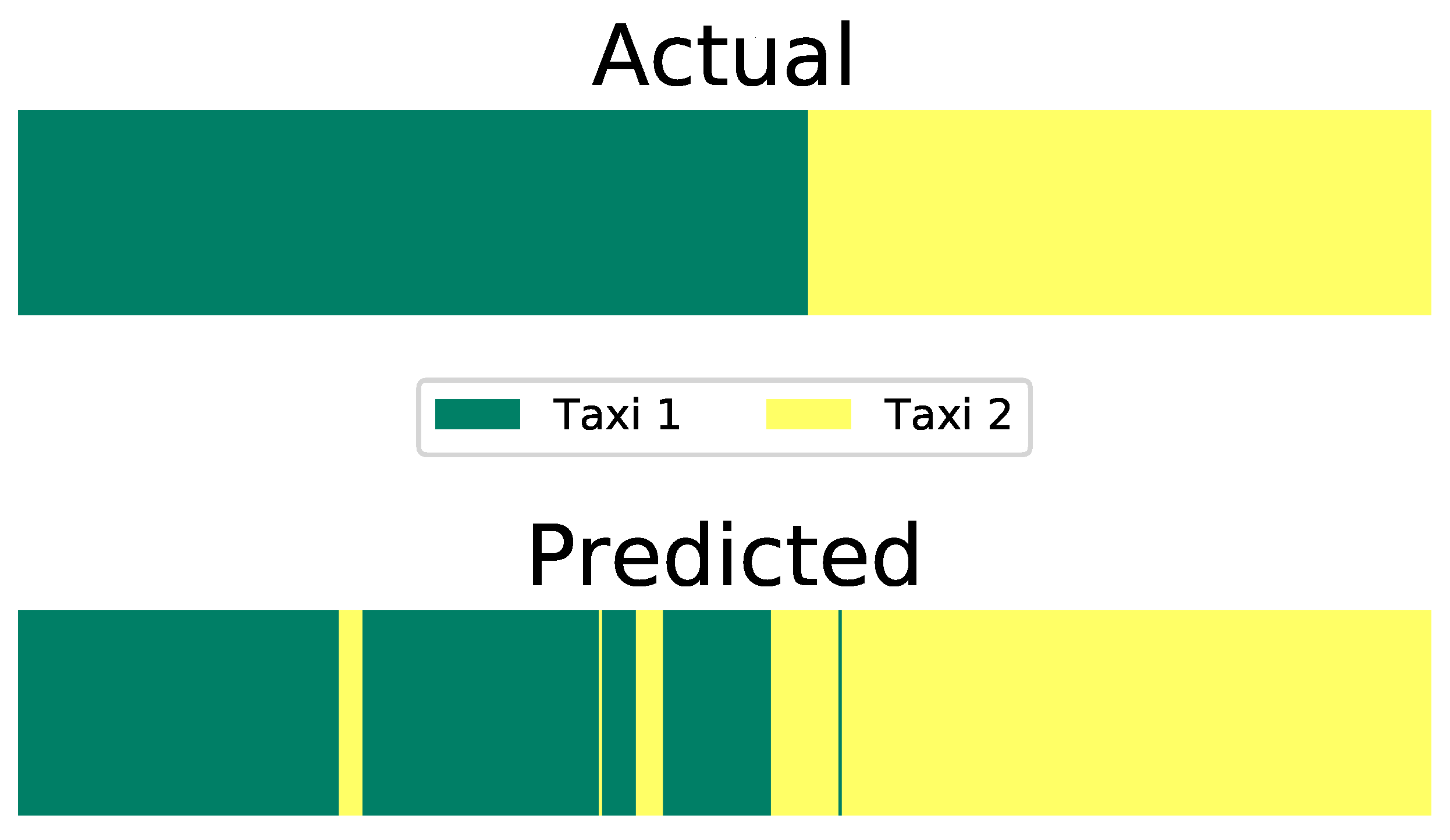
5.2.2. AI-HMM Modelling with Predefined Input
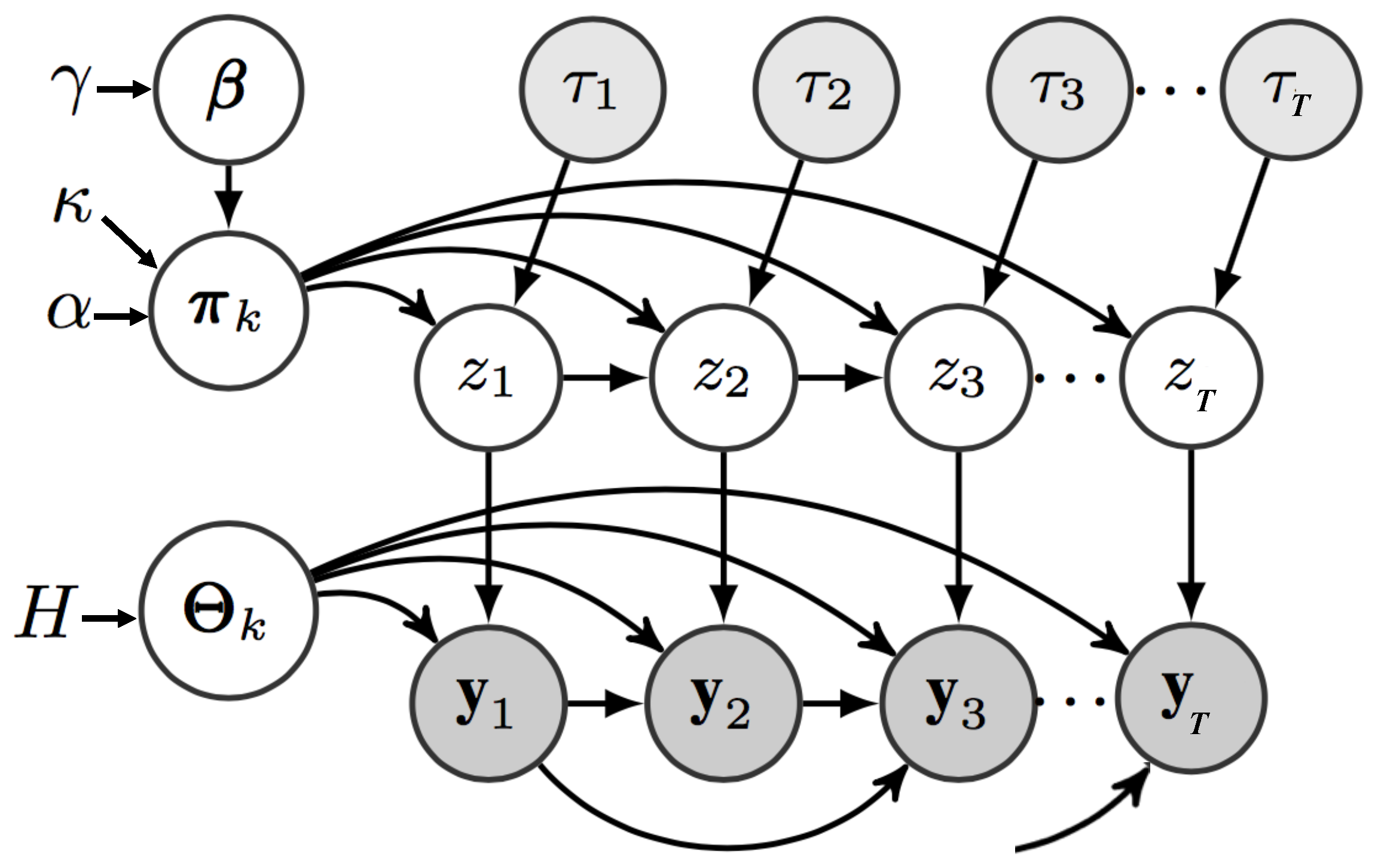
6. Adaptive Input
7. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| AR | Autoregressive |
| AI-HMM | Adaptive Input Hidden Markov Model |
| AR-iHMM | Autoregressive infinite Hidden Markov Model |
| CRHTI | Chicago Regional Household Travel Inventory |
| DP | Dirichlet Process |
| FF-BS | Forward Filtering Backward Sampling |
| GEM | Griffiths, Engen and McCloskey |
| GPS | Global Positioning System |
| GRU | Gated Recurrent Unit |
| HDP-HMM | Hierarchical Dirichlet Process Hidden Markov Model |
| HMM | Hidden Markov Model |
| iHMM | infinite Hidden Markov Model |
| IQR | interquartile Range |
| LSTM | Long-Short Term Memory |
| MCMC | Markov Chain Monte Carlo |
| MLP | Multi-Layer Perceptron |
| MNIW | Matrix-Normal Inverse-Wishart |
| PC | Principal Component |
| PCA | Principal Component Analysis |
| PGM | Probabilistic Graphical Model |
| tSNE | t-distributed Stochastic Neighbour Embedding |
| VAR | Vector Autoregressive |
| VAR-HMM | Vector Autoregressive Hidden Markov Model |
References
- Jang, S.; Jo, H.; Cho, S.; Mechitov, K.; Rice, J.A.; Sim, S.H.; Jung, H.J.; Yun, C.B.; Spencer, B.F., Jr.; Agha, G. Structural health monitoring of a cable-stayed bridge using smart sensor technology: Deployment and evaluation. Smart Struct. Syst. 2010, 6, 439–459. [Google Scholar] [CrossRef]
- Hong, I.; Park, S.; Lee, B.; Lee, J.; Jeong, D.; Park, S. IoT-based smart garbage system for efficient food waste management. Sci. World J. 2014, 2014, 646953. [Google Scholar] [CrossRef] [PubMed]
- Castro, M.; Jara, A.J.; Skarmeta, A.F. Smart lighting solutions for smart cities. In Proceedings of the 2013 27th International Conference on Advanced Information Networking and Applications Workshops, Barcelona, Spain, 25–28 March 2013; pp. 1374–1379. [Google Scholar]
- Masse, R.A.C.; Ochoa-Zezzatti, A.; García, V.; Mejía, J.; Gonzalez, S. Application of IoT with haptics interface in the smart manufacturing industry. Int. J. Comb. Optim. Probl. Inform. 2019, 10, 57–70. [Google Scholar]
- De Marsico, M.; Mecca, A.; Barra, S. Walking in a smart city: Investigating the gait stabilization effect for biometric recognition via wearable sensors. Comput. Electr. Eng. 2019, 80, 106501. [Google Scholar] [CrossRef]
- Paul, A.; Ahmad, A.; Rathore, M.M.; Jabbar, S. Smartbuddy: Defining human behaviors using big data analytics in social internet of things. IEEE Wirel. Commun. 2016, 23, 68–74. [Google Scholar] [CrossRef]
- Torre-Bastida, A.I.; Del Ser, J.; Laña, I.; Ilardia, M.; Bilbao, M.N.; Campos-Cordobés, S. Big Data for transportation and mobility: Recent advances, trends and challenges. IET Intell. Transp. Syst. 2018, 12, 742–755. [Google Scholar] [CrossRef]
- Bhatti, F.; Shah, M.A.; Maple, C.; Islam, S.U. A novel internet of things-enabled accident detection and reporting system for smart city environments. Sensors 2019, 19, 2071. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, A.; Paul, A.; Rathore, M.M.; Chang, H. Smart cyber society: Integration of capillary devices with high usability based on Cyber–Physical System. Future Gener. Comput. Syst. 2016, 56, 493–503. [Google Scholar] [CrossRef]
- Kanungo, A.; Sharma, A.; Singla, C. Smart traffic lights switching and traffic density calculation using video processing. In Proceedings of the 2014 Recent Advances in Engineering and Computational Sciences (RAECS), Chandigarh, India, 6–8 March 2014; pp. 1–6. [Google Scholar]
- Ozkurt, C.; Camci, F. Automatic traffic density estimation and vehicle classification for traffic surveillance systems using neural networks. Math. Comput. Appl. 2009, 14, 187–196. [Google Scholar] [CrossRef]
- Ma, X.; He, Y.; Luo, X.; Li, J.; Zhao, M.; An, B.; Guan, X. Camera placement based on vehicle traffic for better city security surveillance. IEEE Intell. Syst. 2018, 33, 49–61. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X.; Sun, G. Driving with knowledge from the physical world. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, San Diego, CA, USA, 21–24 August 2011; pp. 316–324. [Google Scholar]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Yao, D.; Zhang, C.; Zhu, Z.; Huang, J.; Bi, J. Trajectory clustering via deep representation learning. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3880–3887. [Google Scholar]
- Wang, Y.; Zhu, Y.; He, Z.; Yue, Y.; Li, Q. Challenges and Opportunities in Exploiting Large-Scale GPS Probe Data; Technical Report HPL-2011-109; HP Laboratories: Palo Alto, CA, USA, 21 July 2011. [Google Scholar]
- Ellam, L.; Girolami, M.; Pavliotis, G.; Wilson, A. Stochastic modelling of urban structure. Proc. R. Soc. A Math. Phys. Eng. Sci. 2018, 474, 20170700. [Google Scholar] [CrossRef] [PubMed]
- Witayangkurn, A.; Horanont, T.; Sekimoto, Y.; Shibasaki, R. Anomalous event detection on large-scale gps data from mobile phones using hidden markov model and cloud platform. In Proceedings of the 2013 ACM conference on Pervasive and ubiquitous computing adjunct publication, Zurich, Switzerland, 8–12 September 2013; pp. 1219–1228. [Google Scholar]
- Fox, E.; Sudderth, E.B.; Jordan, M.I.; Willsky, A.S. Nonparametric Bayesian learning of switching linear dynamical systems. In Proceedings of the Neural Information Processing Systems 2008, Vancouver, BC, Canada, 8–10 December 2008; pp. 457–464. [Google Scholar]
- Suzuki, N.; Hirasawa, K.; Tanaka, K.; Kobayashi, Y.; Sato, Y.; Fujino, Y. Learning motion patterns and anomaly detection by human trajectory analysis. In Proceedings of the 2007 IEEE International Conference on Systems, Man and Cybernetics, Montreal, QC, Canada, 7–10 October 2007; pp. 498–503. [Google Scholar]
- Jiang, S.; Ferreira, J.; González, M.C. Clustering daily patterns of human activities in the city. Data Min. Knowl. Discov. 2012, 25, 478–510. [Google Scholar] [CrossRef]
- Shih, D.H.; Shih, M.H.; Yen, D.C.; Hsu, J.H. Personal mobility pattern mining and anomaly detection in the GPS era. Cartogr. Geogr. Inf. Sci. 2016, 43, 55–67. [Google Scholar] [CrossRef]
- Mahadevan, V.; Li, W.; Bhalodia, V.; Vasconcelos, N. Anomaly detection in crowded scenes. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1975–1981. [Google Scholar]
- Rodriguez, M.; Sivic, J.; Laptev, I.; Audibert, J.Y. Data-driven crowd analysis in videos. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1235–1242. [Google Scholar]
- Fu, Z.; Hu, W.; Tan, T. Similarity based vehicle trajectory clustering and anomaly detection. In Proceedings of the IEEE International Conference on Image Processing 2005, Genova, Italy, 14 Septemer 2005. [Google Scholar]
- Piciarelli, C.; Micheloni, C.; Foresti, G.L. Trajectory-based anomalous event detection. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1544–1554. [Google Scholar] [CrossRef]
- Frank, P. Chicago Regional Household Travel Inventory. Available online: https://www.cmap.illinois.gov/documents/10180/77659/TravelTracker_ModeShareReport20100604.pdf/a67bf419-c05a-45c2-a127-a18d7984cd7d (accessed on 28 January 2020).
- Zheng, Y.; Xie, X.; Ma, W.Y. Geolife: A collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]
- Raykov, Y.P.; Ozer, E.; Dasika, G.; Boukouvalas, A.; Little, M.A. Predicting room occupancy with a single passive infrared (PIR) sensor through behavior extraction. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 1016–1027. [Google Scholar]
- Kunst, R.M. Vector Autoregressions. Available online: https://homepage.univie.ac.at/robert.kunst/var.pdf (accessed on 28 January 2020).
- Beal, M.J.; Ghahramani, Z.; Rasmussen, C.E. The infinite hidden Markov model. In Proceedings of the Advances in Neural Information Processing Systems 2002, Vancouver, BC, Canada, 9–14 December 2002; pp. 577–584. [Google Scholar]
- Teh, Y.W.; Jordan, M.I.; Beal, M.J.; Blei, D.M. Hierarchical Dirichlet Processes. J. Am. Stat. Assoc. 2006, 101, 1566–1581. [Google Scholar] [CrossRef]
- Fox, E.B. Bayesian Nonparametric Learning of Complex Dynamical Phenomena. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2009. [Google Scholar]
- Pitman, J. Poisson–Dirichlet and GEM invariant distributions for split-and-merge transformations of an interval partition. Comb. Probab. Comput. 2002, 11, 501–514. [Google Scholar] [CrossRef]
- Ihler, A.; Hutchins, J.; Smyth, P. Adaptive event detection with time-varying poisson processes. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 207–216. [Google Scholar]
- Yuan, J.; Zheng, Y.; Zhang, C.; Xie, W.; Xie, X.; Sun, G.; Huang, Y. T-drive: Driving directions based on taxi trajectories. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 99–108. [Google Scholar]
- Van Brummelen, G. Heavenly Mathematics: The Forgotten Art of Spherical Trigonometry; Princeton University Press: Princeton, NJ, USA, 2012; pp. 160–162. [Google Scholar]
- Zhang, H.H. Beijing Still Struggling Deal Traffic Congestion. Available online: https://www.scmp.com/news/china/article/1298559/beijing-still-struggling-deal-traffic-congestion (accessed on 7 March 2019).
- Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Singleton, A.D.; Spielman, S.; Folch, D. Urban Analytics; Sage Publishing: Thousand Oaks, CA, USA, 2017. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| State | AI-HMM | GRU | ||||
|---|---|---|---|---|---|---|
| 1 | 26 | 35 | 00:00–23:00 | 18 | 24 | 12:00–18:00 |
| 2 | 18 | 19 | 17:00–23:00 | 18 | 34 | 00:00–06:00 |
| 3 | 0 | 0 | 00:00–23:00 | 2147 | 7697 | 00:00–23:00 |
| 4 | 23 | 27 | 00:00–06:00 | 16 | 29 | 06:00–13:00 |
| 5 | 19 | 19 | 10:00–18:00 | 16 | 22 | 18:00–23:00 |
| 6 | 497 | 1336 | 00:00–23:00 | 186 | 176 | 00:00–23:00 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qarout, Y.; Raykov, Y.P.; Little, M.A. Probabilistic Modelling for Unsupervised Analysis of Human Behaviour in Smart Cities. Sensors 2020, 20, 784. https://doi.org/10.3390/s20030784
Qarout Y, Raykov YP, Little MA. Probabilistic Modelling for Unsupervised Analysis of Human Behaviour in Smart Cities. Sensors. 2020; 20(3):784. https://doi.org/10.3390/s20030784
Chicago/Turabian StyleQarout, Yazan, Yordan P. Raykov, and Max A. Little. 2020. "Probabilistic Modelling for Unsupervised Analysis of Human Behaviour in Smart Cities" Sensors 20, no. 3: 784. https://doi.org/10.3390/s20030784
APA StyleQarout, Y., Raykov, Y. P., & Little, M. A. (2020). Probabilistic Modelling for Unsupervised Analysis of Human Behaviour in Smart Cities. Sensors, 20(3), 784. https://doi.org/10.3390/s20030784