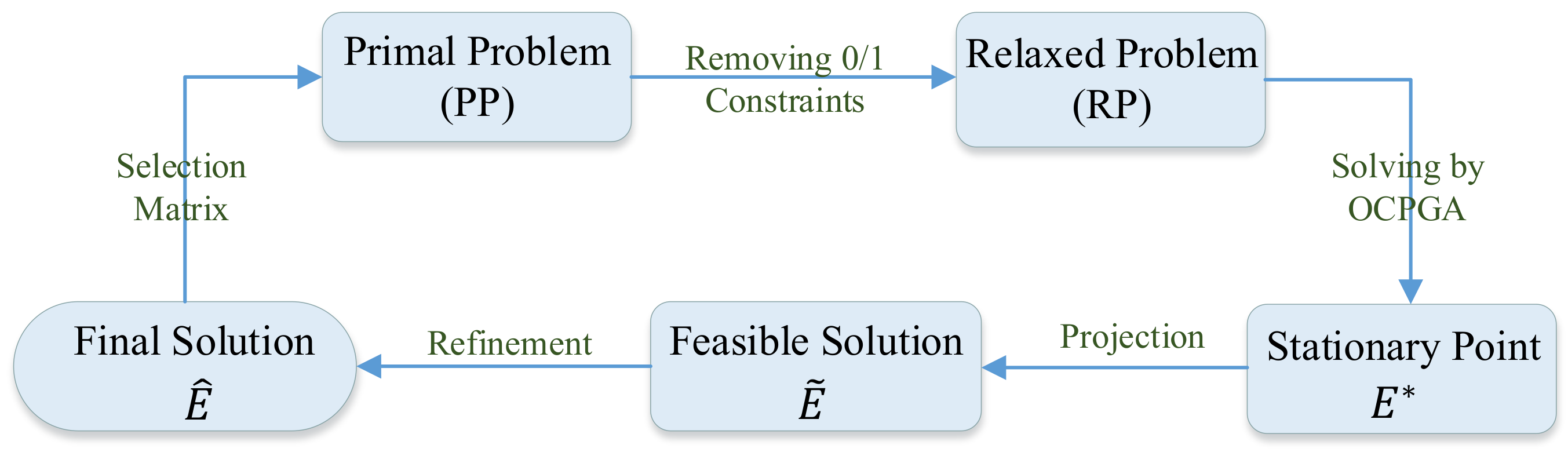
1. Introduction
Wireless sensor networks (WSNs) are extensively used to collect and transmit data in many applications, such as autonomous driving [
1], disaster detection [
2], target tracking [
3], etc. In the WSN, it is usually unaffordable to collect and process all sensor data due to the limitations of power and communication resources [
4,
5]. Therefore, it is of great significance to choose an optimal subset of sensors such that the best performance is attained only based on data collected by the selected sensors, which is the so-called sensor selection problem.
In the past dozen years, sensor selection has been widely studied in various fields, e.g., estimation [
6], target tracking [
7], condition monitoring [
8], to name a few. For parameter estimation in Kalman filtering dynamic system, [
6] chose the optimal subset of sensors in each iteration via minimizing the error covariance matrix of the next iteration. The sensor selection problem for target tracking in large sensor networks was addressed in [
7] based on generalized information gain. In [
8], it provided an entropy-based sensor selection method for condition monitoring and prognostics of aircraft engine, which can describe the information contained in the sensor data sets.
Meanwhile, the sensor selection problem in hypothesis testings has also attracted a lot of attention [
9,
10,
11]. For this type of hypothesis testings, only part of sensors in WSN are activated to transmit observation data, and then decisions are made based on the measurements of selected sensors to achieve the best detection performance. When the optimal sensor selection matrix is fixed, the corresponding hypothesis testing problem is reduced to a common one, which is easy to be dealt with. Hence, it is crucial to solve the involved sensor selection problem.
Work [
9] studied the sensor selection for the binary Gaussian distribution hypothesis testing in the Neyman–Pearson framework, where the true distribution under each hypothesis is exactly known. It approximately converted the minimization of the false alarm error probability to the maximization of the Kullback-Leibler (KL) divergence between the distributions of the selected measurements under null hypothesis and alternative hypothesis to be detected. Additionally, [
9] proposed a sensor selection framework of first relaxation and then projection for the first time, and provided the greedy algorithm to solve the relaxed problem by optimizing each column vector of the selection matrix.
In practical applications, the events to be detected (i.e., parameters of the hypothesis testing) are usually estimated from training data and affected by some uncertainty factors, such as poorly observation environment and system errors. Then, these parameters are not known precisely, but assumed to lie in some given uncertainty sets [
10,
11]. In these scenarios, the minimax robust sensor selection problem is formulated to cope with the parameter uncertainty. For the binary Gaussian distribution hypothesis testing under the Neyman–Pearson framework, following the framework in [
9], work [
10] investigated the involved sensor selection problem with distribution mean under each hypothesis falling in an ellipsoidal uncertainty set (the distribution covariance is known). Furthermore, [
11] considered the sensor selection problems involved in the Gaussian distribution robust hypothesis testings with both Neyman–Pearson and Bayesian optimal criteria, where the distribution mean under each hypothesis drifts in an ellipsoidal uncertainty set. For the Bayesian framework, minimizing the maximum overall error probability is approximately converted to maximizing the minimum Chernoff distance. Then the corresponding greedy algorithm together with projection and refinement is also proposed to solve the robust sensor selection problem in the above hypothesis testing.
It has been shown in [
11] that the robust sensor selection problem in the hypothesis testing is NP-hard under the Bayesian framework. Nevertheless, when the size of the sensor selection problem is small, its optimal solution can be obtained by the exhaustive method via traversing all possible choices. However, for a large-scale problem, the exhaustive method is not affordable due to its huge computation complexity. Although the aforementioned greedy algorithm-based method (i.e., greedy algorithm, projection and refinement) admits a lower computation complexity than the exhaustive method, it can not arrive at the globally optimal solution in many cases, and its computation complexity is still high for large-scale problems. Therefore, it is significant to seek a more efficient algorithm for solving the robust sensor selection problem in the hypothesis testing of WSN. To our surprise, even though other general sensor selection problems have been continuously investigated, for instance, sparse sensing [
12] and sensor selection in sequential hypothesis testing [
13], there is little progress for this type of sensor selection problems since [
11] was published in 2011, which motivates our research.
In this paper, we consider the same binary Gaussian distribution robust hypothesis testings under a Bayesian framework as in [
11], where the distribution mean under each hypothesis lies in an ellipsoidal uncertainty set. We attempt to select an optimal subset of sensors such that the maximum overall error probability is minimized. Following the similar idea in [
11], minimizing the maximum overall error probability is approximated by maximizing the minimum Chernoff distance between two distributions under null hypothesis and alternative hypothesis to be detected. Then, our main contributions can be summarized as follows.
First, we succeed in converting the maximinimization of the Chernoff distance to a maximization problem, and adopting the orthogonal constraint-preserving gradient algorithm (OCPGA) [
14] to obtain a stationary point of the relaxed maximization problem without 0/1 constraints.
Specifically, when implementing the OCPGA to the relaxed maximization problem, we utilize the Danskin’s theorem [
15] to acquire its gradient. Furthermore, the efficient bisection is applied to get the means of distributions under null hypothesis and alternative hypothesis to be detected corresponding to the minimum Chernoff distance.
The computational complexity of the OCPGA is shown to be lower than that of the greedy algorithm in [
11] from the theoretical point of view, while numerical simulations show that the OCPGA-based method (i.e., OCPGA, projection and refinement) can obtain better solutions than the greedy algorithm-based method (i.e., R-C algorithm in [
11]) with up to
shorter runtimes. Therefore, better solutions are available for our proposed OCPGA-based method in some scenarios.
The remainder of this paper is organized as follows.
Section 2 states the problem formulation. The proposed OCPGA, as well as projection and refinement phases, is characterized in
Section 3. In
Section 4, the existence and computation of gradient are provided.
Section 5 presents some numerical experiments to corroborate our theoretical results, while
Section 6 concludes the paper.
Notations: Denote and as the m-dimensional real vector space and dimensional real matrix space, respectively. Let and be the identity matrix and the zero matrix whose dimensions will be clear from the context; bold-face lower-case letters are used for vectors, while bold-face upper-case letters are for matrices. represents the Gaussian distribution with mean and covariance . For matrix , , , , and denote its trace, determinant, Frobenius norm, conjugate transpose and the -th entry, respectively. For square matrices and , represents that is semi-positive (positive) definite. For a semi-positive definite matrix , stands for its square-rooting matrix.
4. Existence and Computation of the Gradient in Problem (RP)
As can be easily seen from Algorithm 1, it is essential to compute the gradient
in problem (
RP). Invoking the definition of
in Equation (
9), we have
with
. To proceed, we first prove the strict concavity of
with respect to
s, which forms a key ingredient of our later arguments.
Proposition 1. Given and , defined by Equation (
6)
is a strictly concave function of s. Proof. It is easily seen that is continuously differentiable with respect to s for given and . Hence we turn to show the positiveness of the second derivative .
For notation brevity, define
and
. It is clear that both
and
are semi-positive definite. By taking derivative of
with respect to
s, we have
Then, taking derivative of
with respect to
s once again, we obtain
where
, equalities
and
both result from
and thus
, and equality
owing to the definition of
and the relationship
for matrices
and
.
If
, then we have
. Because of
, it holds
with
. Combined with
,
, and
, we conclude
from Equation (
13).
On the other hand, when
, then it follows from Equation (
3) that
. If
, Then we have
, that is
Then it immediately follows
, which leads to a contradiction. Therefore, when
, we deduce
, which means
by Equation (
13).
As a consequence, is a strictly concave function of s. □
Moreover, the following Proposition 2 shows that is continuously differentiable with respect to for given , which is also necessary for follow-up analysis.
Proposition 2. Given , defined by (
5)
is a continuously differentiable function of . Proof. For given
and
, denote
with
given by Equation (
6). Note that
and
under condition (
3). Hence,
, which, combined with the strict concavity of
in Proposition 1, implies that
is unique with satisfying
Recalling the expression of
in (
12), since all the involved terms
,
,
,
and
are continuously differentiable functions of
E, then
as a composite function of the above functions is also continuously differentiable with respect to
E. Similarly,
in (
13) is a composition of functions
,
and
, which are all continuous with respect to
s. Hence,
is continuous with respect to
s, that is,
is continuously differentiable with respect to
s. Due to
, it follows from the implicit function theorem [
23] that
is an implicit function of
. Hence, we rewrite
as
Furthermore, based on the implicit function theorem [
23],
is a continuously differentiable function of
, which means that
is continuous with respect to
.
Because of , we have immediately. In addition, is continuously differentiable with s and . Combined with the fact that is a continuously differentiable function of , thereby is differentiable with respect to .
Moreover, by leveraging on the chain rule [
24] to
, it holds
where
with
,
, and
. Since
,
and
are all continuous with respect to
, then
is also continuous. In conclusion,
is a continuously differentiable function of
. □
4.1. Compute the Gradient in Problem (RP) by Danskin’s Theorem
In the sequel, we will exploit Danskin’s theorem in
Appendix A to compute the gradient
, where
is defined by Equation (
9).
On basis of Proposition 2, the following results hold true for function and set :
is a compact set because it is a finite-dimensional bounded closed set. Meanwhile, , mapping is continuous at point due to the continuity of ;
For arbitrary given
and sufficiently small
, since
is differentiable, there exists a bounded directional derivative
Mapping is continuous at point , which is from the continuity of .
With identifications
,
,
,
,
, and
, all conditions of Danskin’s theorem in
Appendix A are satisfied. Subsequently, for a given selection matrix
, if the optimal solution
of problem (
10) is unique, then the gradient of
exists. Furthermore, on basis of the Danskin’s theorem, we have
Recall
from Equation (
5). For given
, we can again utilize the Danskin’s theorem in
Appendix A to obtain
. Obviously,
is continuously differentiable with respect to
. Therefore, it is easy to verify that conditions 1)−3) of Danskin’s theorem in Appendix
Appendix A are all satisfied with identifications
,
,
,
,
, and
. Combined with the uniqueness of
defined by Equation (
14), we can deduce
On the other hand, due to the equivalence of Problems (
7) and (
8), for a given matrix
, a solution
of Problem (
10) corresponds to a solution
of problem
satisfying
and
Combined with Equations (
16) and (
17), when the solution
is unique, we have
where
is given by Equation (
15) and
is the optimal solution of problem (
IP).
4.2. Compute the Optimal Solution of Problem (IP)
Owing to the Sion’s minimax theorem [
25] and Lemma 5 in [
11], for given
, we can exchange the orders of the minimization with respect to
and the maximization with respect to
s in problem (
IP). Correspondingly, problem (
IP) can be equivalently converted into
Therefore, we will solve Problem (
20) to attain the solution
of Problem (
IP).
First, for given matrix
and parameter
s, denote
Combining with the expression of
in Equation (
6) and removing items irrelevant to
, then we can get
by solving the following subproblem
with
. Clearly, Problem (
21) is convex, which can be directly solved by the CVX toolbox [
26] with computation complexity
[
27]. Thus, once
s is fixed, the corresponding
follows. Particularly,
.
Next, we will show how to determine the optimal
given by Equation (
18). Based on Proposition 1,
is concave with respect to
s. Combined with the fact that
is the minimum of a family of functions
over the uncertainty set
, we conclude that
is also a concave function of
s [
28]. Therefore,
is monotonically decreasing with respect to
s. Subsequently, we apply the efficient bisection method to search
such that
For given
, we can once again use the Danskin’s theorem in
Appendix A to derive
. Since
is continuously differentiable with respect to
s, all conditions of Danskin’s theorem in
Appendix A are met. Meanwhile, even if the optimal solution
of Problem (
21) is not unique,
in Equation (
12) is always the same no matter which
is substituted. Therefore,
is differentiable with respect to
s, and we have
where
is given by Equation (
12), and
is an arbitrary optimal solution of Problem (
21).
After we get the optimal
, the corresponding
, i.e.,
, is acquired by solving Problem (
21). That is, the optimal solution
of Problem (
IP) is obtained. We summarize the process of solving
as the following
Inner Procedure 1.
| Inner Procedure 1: Computing the Optimal Solution of Problem (IP) |
 |
Remark 3. If the true distribution under each hypothesis is exactly known, i.e., there is no uncertainty in the mean vector, then we omit the process of computing solution of problem (
21),
and directly regard the true mean vector as . Consequently, the robust sensor selection problem is reduced to one without uncertainty. Based on the previous discussion, if the optimal solution
of Problem (
IP) is unique, then the gradient
exists and can be computed by Equation (
19). Next we will discuss the existence of the gradient
detailedly.
4.3. Existence of the Gradient in Problem (RP)
It has been shown that the uniqueness of the optimal solution leads to the existence of the gradient . Therefore, in the following, we turn to show when is unique. First the following lemma demonstrates the uniqueness of .
Lemma 1. For given , let be the optimal solution of Problem (IP). Then is unique.
Proof. We will prove by contradiction. Assume that is also the optimal solution of problem (IP) with .
It is worth noting that, both
and
are the saddle points of problem (
IP). According to Proposition 1.4 in [
29], the set of saddle points admits the Cartesian product form. Hence,
is also a saddle point. That is, for given
, both
and
are the optimal solutions of problem
, which contradicts with the strict concavity of
with respect to
s. Consequently,
is unique. □
With the uniqueness of , we additionally make the following assumption to guarantee the existence of .
Assumption 1. For given matrix , the saddle point of Problem (IP) is unique.
Remark 4. Because Lemma 1 has proven that is unique, if the solution of Problem (
21)
is unique, then Assumption A1 is satisfied. Under some conditions (e.g., the distance of the two uncertainty sets and is large), of Problem (
21)
is naturally unique. Therefore, Assumption 1 is not very restrictive. Under Assumption 1,
is unique and achievable by
Inner Procedure 1. Hence,
exists and can be obtained by Equation (
19). Subsequently, Algorithm 1 can be executed. Furthermore, on basis of Theorem 1 in
Section 3.1, we conclude that
obtained by the OCPGA in Algorithm 1 is a stationary point of problem (
RP), which lays a foundation to attain a better solution of the original problem (
PP).
Remark 5. If Assumption 1 is not satisfied, we could use the Clark generalized gradient [30] to replace the gradient in Algorithm 1. Based on the Danskin’s theorem in Appendix A, the Clark generalized gradient can also be attained by Equation (
19),
where an arbitrary solution of Problem (
21)
is used. Then Algorithm 1 is still applicable and preserves the orthogonal constraint in each iteration. Although the resulting solution is not guaranteed to be a stationary point of Problem (RP), however, after projection and refinement phases, numerical simulations illustrate that the performance of the final result is also acceptable. 5. Numerical Simulations
In this section, numerical examples are carried out to show that the OCPGA-based method can obtain better solutions than the greedy algorithm-based method in [
11]. To this end, (1) for fixed-size sensor selection problems, i.e., the total number and selected number of sensors are fixed, with randomly generated 50 (or 20) cases with different uncertainty sets, we exhibit the proportions that the OCPGA-based method performs better than, the same as, and worse than the greedy algorithm-based method; (2) for small-scale sensor selection problems, we compare the OCPGA-based method with the greedy algorithm based method and the exhaustive method; (3) for larger-scale sensor selection problems, the OCPGA-based method is compared with the greedy algorithm based method; (4) for specific small-scale and larger-scale sensor selection problems, the corresponding receiver operating characteristic (ROC) curves are depicted. Notably, in cases of (1)–(3), the performance of the method is measured by the resulting Chernoff distance (i.e.,
in Problem (
PP)), that is, the method with larger Chernoff distance admits better performance. All the procedures are coded in MATLAB R2014b on an ASUS notebook with the Intel(R) Core(TM) i3-2310M CPU of 2.10GHz and memory of 6GB.
Assume that we need to choose p out of m sensors. In all simulations, for given , the ellipsoidal uncertainty sets in Problem (IP), , which contain the true distribution under each hypothesis, are generated as follows. Elements of the estimated mean vectors and are randomly generated from and , respectively. The covariance matrix is generated by , where is an orthogonal basis of -dimensional matrices whose elements are generally drawn from , and is a diagonal matrix with diagonal entries randomly generated in , . The robustness parameters .
When
and the ellipsoidal uncertainty sets
are given, we adopt
Inner Procedure 1 to compute
, use Equation (
19) to obtain the gradient
, and then apply the OCPGA in Algorithm 1 to get the stationary point
of Problem (RP). After the projection and refinement phases described in
Section 3.2, the final solution
of Problem (
PP) is achieved. Meanwhile, the greedy algorithm-based method is a deterministic approach, that is, for given
and ellipsoidal uncertainty set, its outputs are all the same no matter how many times it is recalled. On the contrary, since the initial point of the OCPGA in Algorithm 1 is randomly chosen, the outputs of the OCPGA-based method may vary with initial points of the OCPGA. If time permits, the OCPGA-based method can be recalled for several times to achieve better performance. Moreover, the OCPGA and the greedy algorithm based methods both execute one refinement only.
Fixed-Size Examples: For 8 fixed pairs of small
, we give the proportions that the OCPGA-based method performs better than, the same as, and worse than the greedy algorithm-based method. For each
, by implementing the two methods with randomly generated 50 different ellipsoidal uncertainty sets (only 20 different ellipsoidal uncertainty sets for
,
, and
due to their long runtimes), the corresponding results are listed in
Table 1. Here, with each ellipsoidal uncertainty set, the OCPGA-based method is recalled for two times and the better result is selected as the output. As shown in
Table 1, for each
, the OCPGA-based method performs as well as the greedy algorithm-based method in most cases, while the “better” proportion is more than twice as many as the “worse” proportion. Actually, simulations show that, for “worse” cases, if we recall the OCPGA-based method for more times, then it can perform as well as even better than the greedy algorithm-based method.
Small-Scale Examples: we consider small-scale sensor selection problems, whose globally optimal solutions can be attained by the exhaustive method. Hence, we compare the optimal Chernoff distance obtained by the OCPGA-based method with those of the greedy algorithm-based method and the exhaustive method. Suppose that
out of
sensors are chosen. The corresponding outputs of the three methods are given in
Table 2, and the corresponding runtimes of the three methods are listed in
Table 3. It can be easily seen from
Table 2 that, the Chernoff distances achieved by the OCPGA-based method are larger than those of the existing greedy algorithm-based method. For the case of
, the Chernoff distance achieved by the OCPGA-based method is even
larger than that of the greedy algorithm-based method. In particular, our proposed OCPGA-based method can attain the same performance as the exhaustive method. Meanwhile, it is shown in
Table 3 that, the OCPGA-based method is more efficient than the greedy algorithm-based method, and both of them possess much shorter runtimes than the exhaustive method, which is coincident with the theoretical computation complexity analyses. Via simple computations, we can see from
Table 3 that the runtime of the OCPGA-based method can be up to
shorter than that of greedy algorithm-based method (for the case of
). Therefore, our proposed OCPGA-based method admits better performance in terms of not only the objective value but also the runtime.
Larger-Scale Examples: Now we consider larger-scale problems, where
and
. Since
m and
p are large, which leads to the failure of the exhaustive method, we only compare the obtained Chernoff distances of our OCPGA-based method with those of the greedy algorithm-based method. The corresponding results are exhibited in
Table 4, while the corresponding runtimes of the two methods are displayed in
Table 5. As we can see from
Table 4, the OCPGA-based method can attain a better solution than the greedy algorithm-based method. In the case of
, the Chernoff distance obtained by the OCPGA-based method can be
larger than that of the greedy algorithm-based method. Moreover,
Table 5 illustrates that, the OCPGA-based method admits higher efficiency than the greedy algorithm -based method, and the runtime of the OCPGA-based method can reduce up to
in the case of
. Compared with small-scale cases in
Table 3, we can see from
Table 5 that the improvement in runtime is more obvious, which is due to the larger gap between
m and
p for larger-scale cases. Hence, for larger-scale cases, the OCPGA-based method also can achieve better solutions than the greedy algorithm-based method with shorter runtimes.
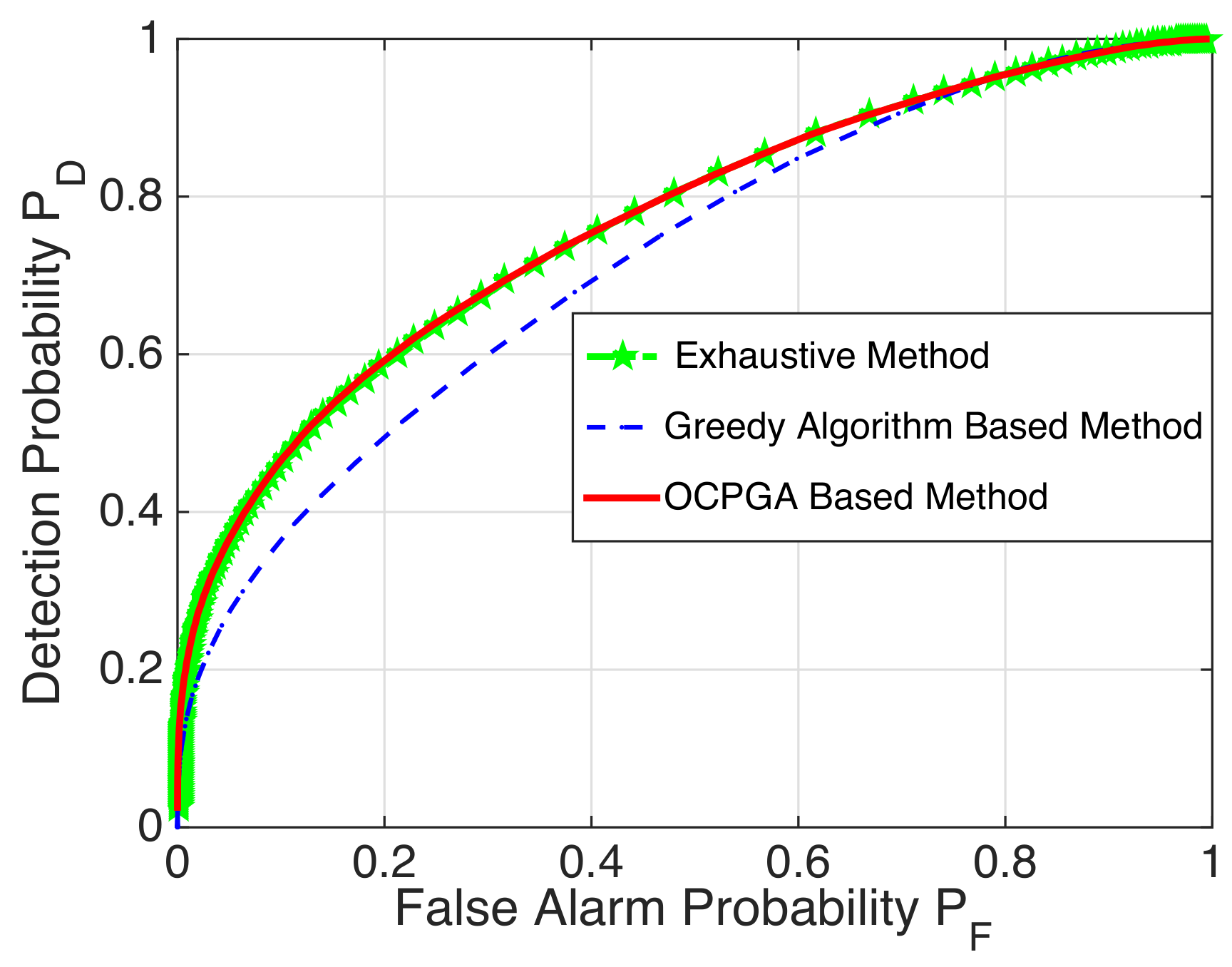
ROC Curves for Specific Examples: By Monte Carlo simulations with 200,000 instantiations of the LR tests and calculating
with
being the detection probability, we depict the ROC curves to show the validity of the OCPGA-based method. It is well known that the higher the ROC curve, the better the detection performance. For the case of
in
Table 2, we display the corresponding ROC curves of the exhaustive method, the greedy algorithm-based method and the OCPGA-based method. It can be seen from
Figure 2 that the OCPGA-based method is superior to the greedy algorithm-based method, while it can attain the same performance as that of the exhaustive method. Similarly, for the case of
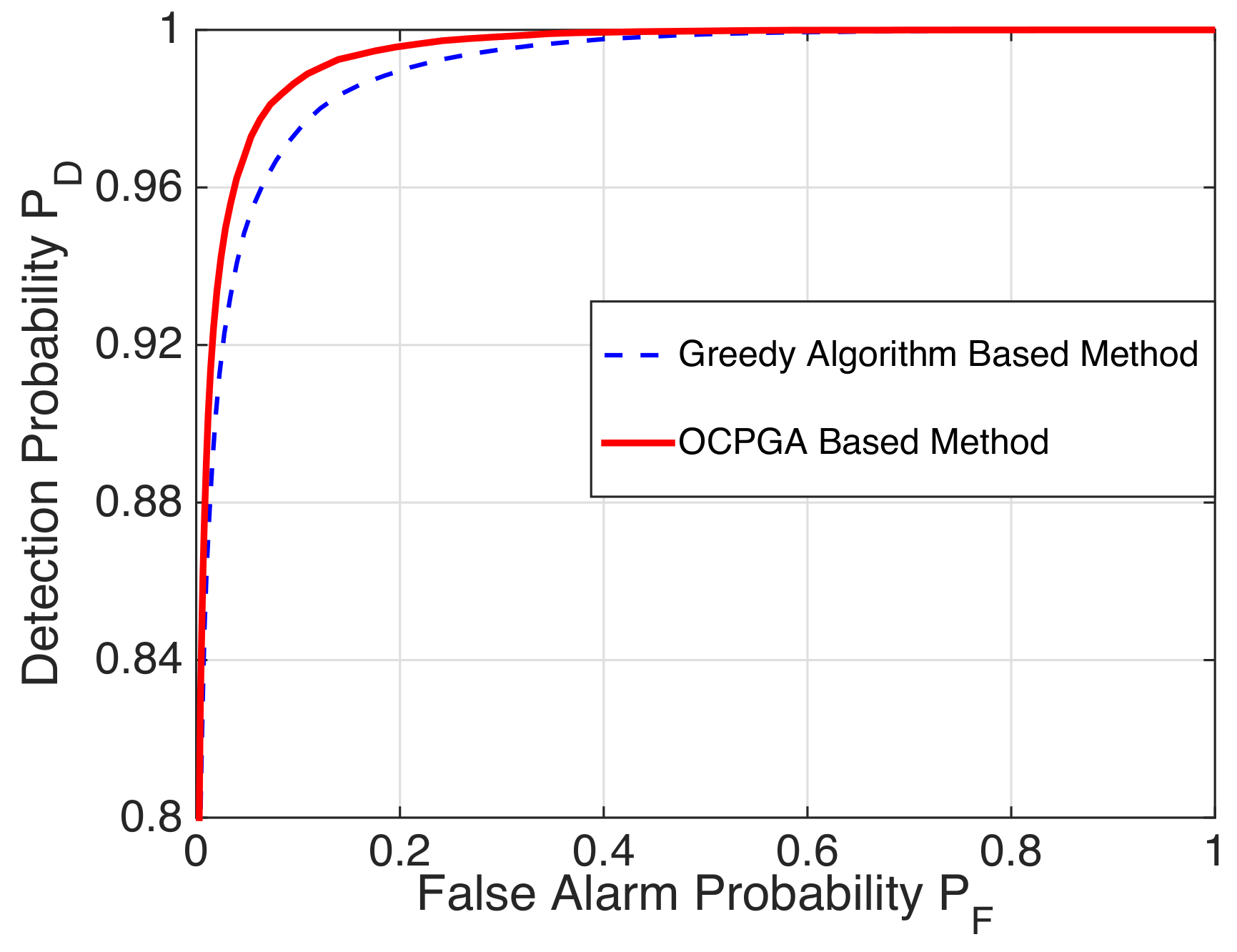
in
Table 4,
Figure 3 illustrates that our proposed approach performs better than the existing greedy algorithm-based method.
In summary, compared with the greedy algorithm-based method, the OCPGA-based method not only admits a lower theoretical computation complexity, but also can obtain better solutions with shorter runtimes in numerical simulations.







{kind=link}
{kind=link}
{kind=link}