Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts †



Abstract
1. Introduction
2. Related Work
3. Methodology
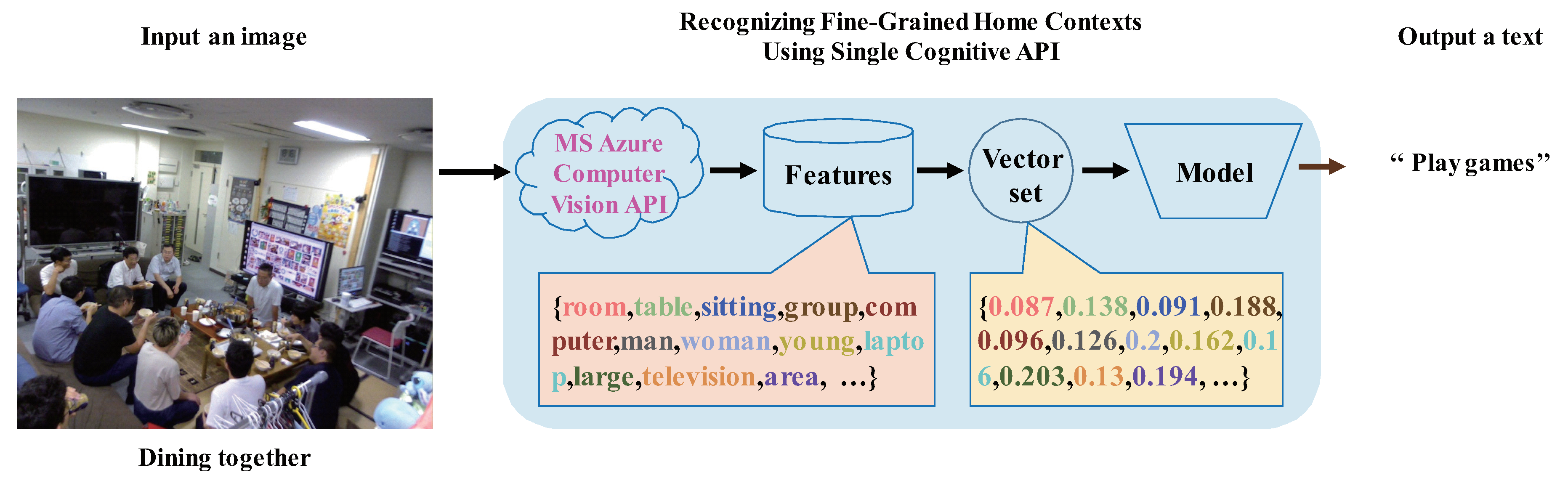
3.1. Preliminary Study
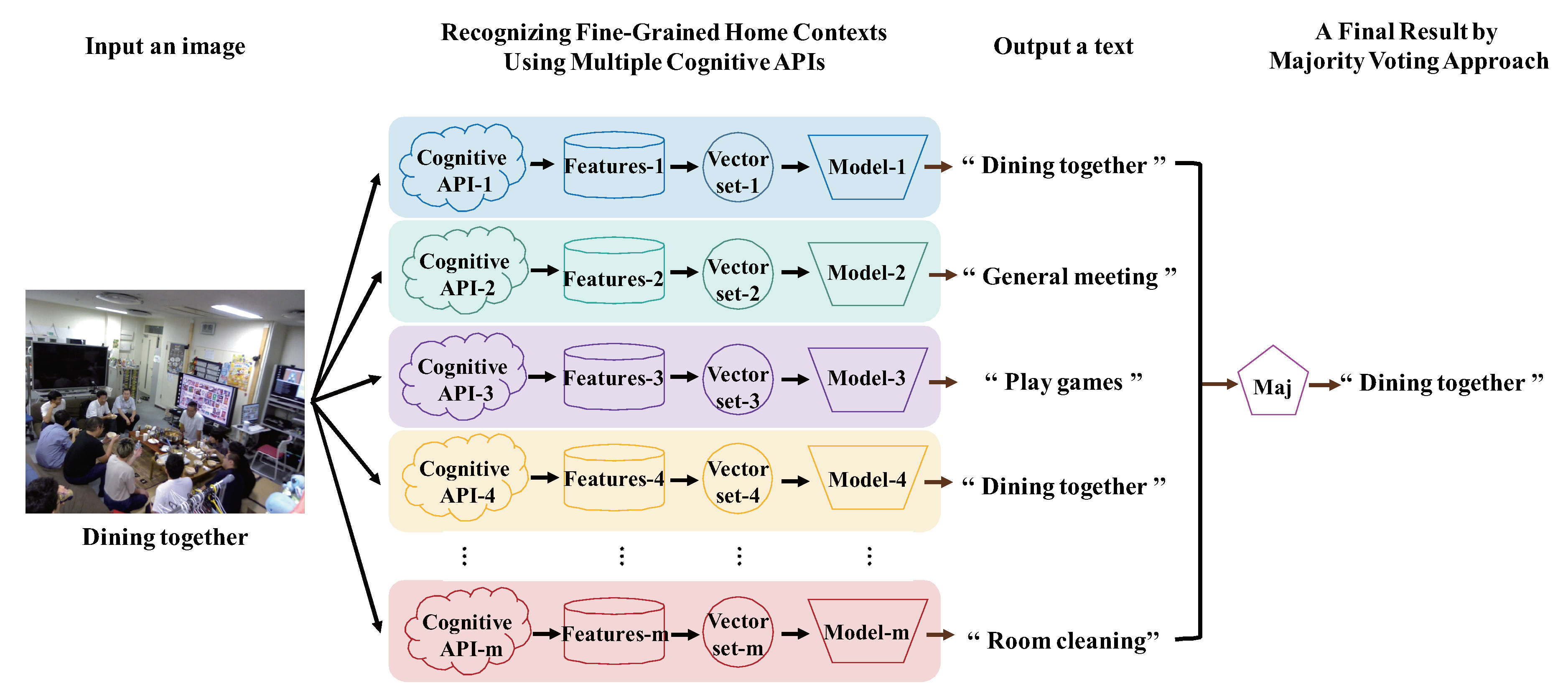
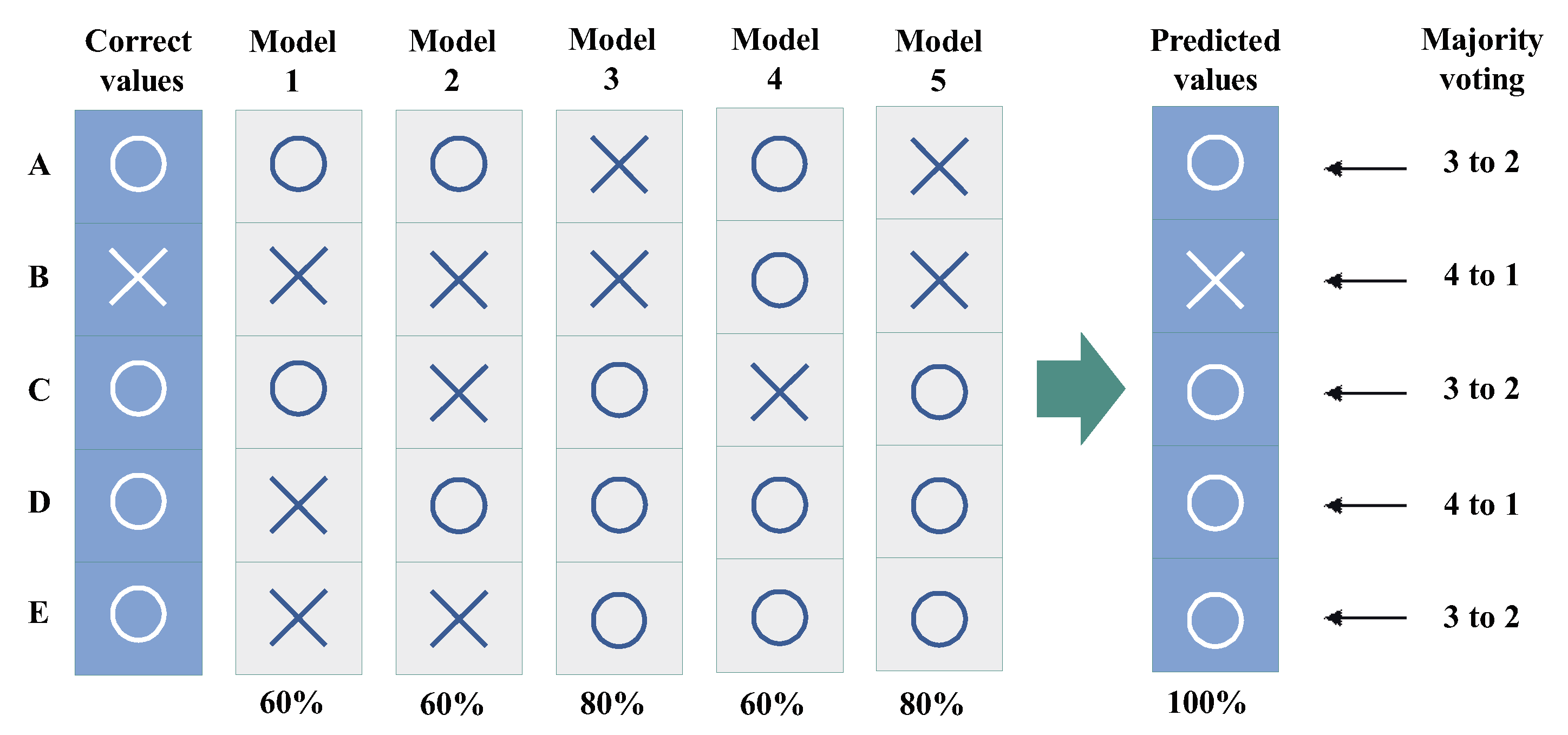
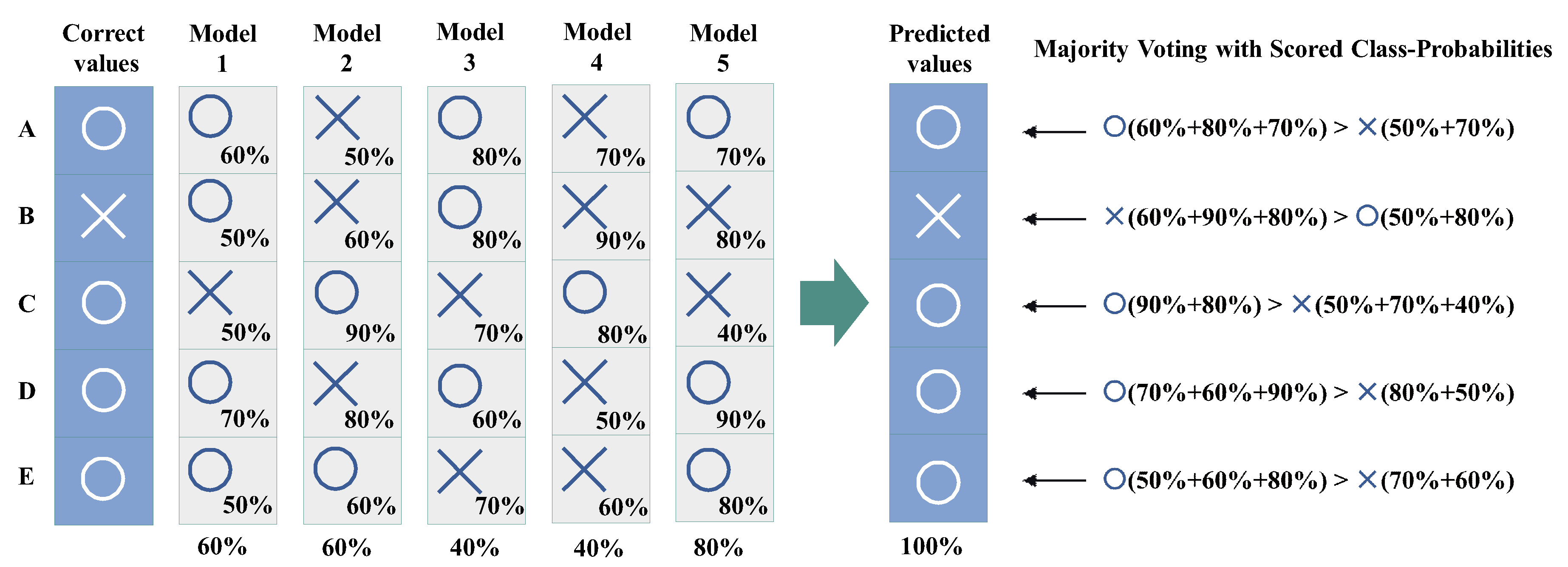
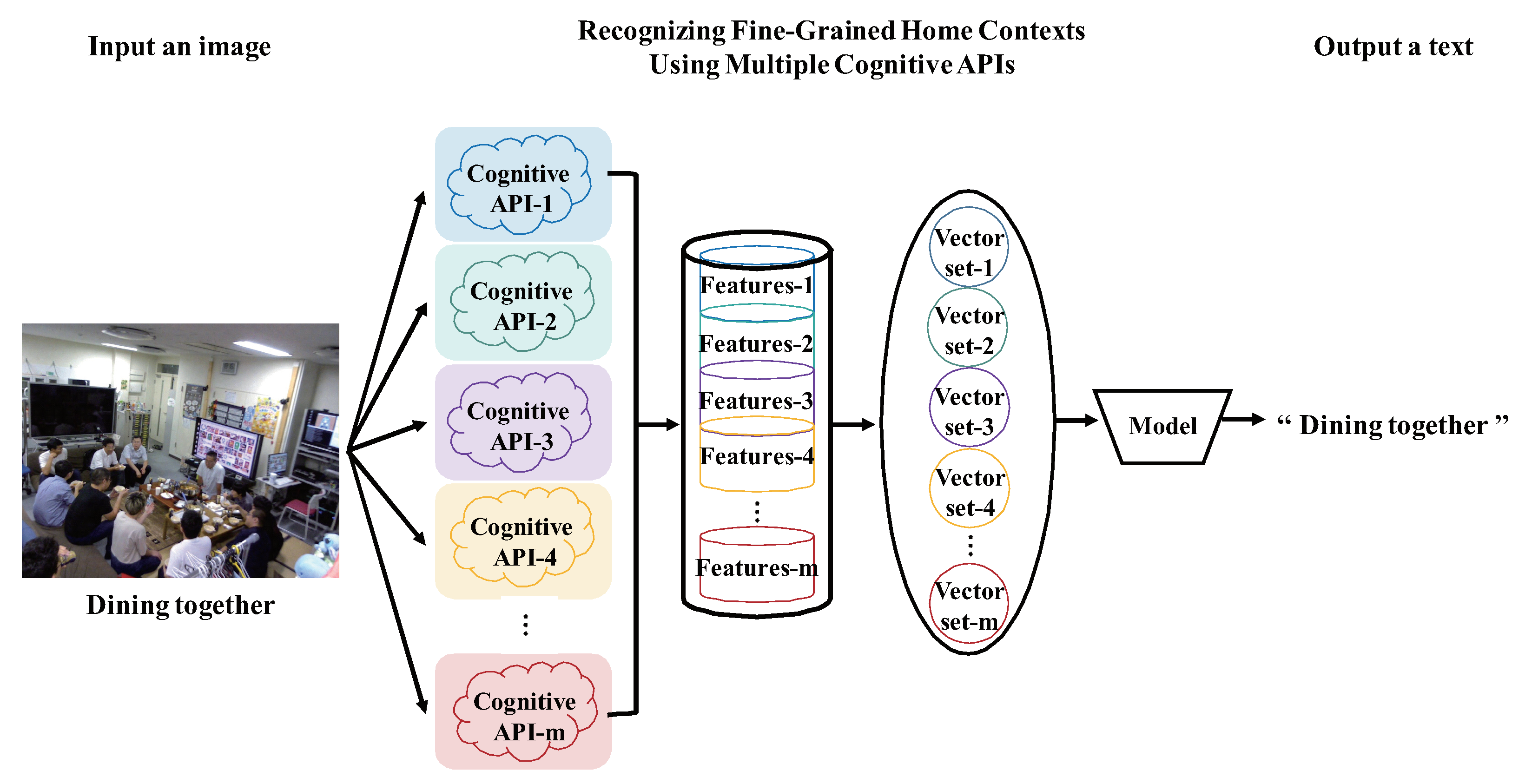
3.2. Proposed Method
3.3. Discussion
4. Experimental Evaluation
4.1. Experimental Setup
4.2. Building and Combining API-Based Models
4.3. Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vuegen, L.; Van Den Broeck, B.; Karsmakers, P.; Van hamme, H.; Vanrumste, B. Automatic Monitoring of Activities of Daily Living based on Real-life Acoustic Sensor Data: A preliminary study. In Proceedings of the Fourth Workshop on Speech and Language Processing for Assistive Technologies, Association for Computational Linguistics, Grenoble, France, 21–22 August 2013; pp. 113–118. [Google Scholar]
- Debes, C.; Merentitis, A.; Sukhanov, S.; Niessen, M.; Frangiadakis, N.; Bauer, A. Monitoring Activities of Daily Living in Smart Homes: Understanding human behavior. IEEE Signal Process. Mag. 2016, 33, 81–94. [Google Scholar] [CrossRef]
- Marjan, A.; Jennifer, R.; Uwe, K.; Annica, K.; Eva, K.L.B.; Nicolas, T.; Thiemo, V.; Amy, L. An Ontology-based Context-aware System for Smart Homes: E-care@home. Sensors 2017, 17, 1586. [Google Scholar] [CrossRef]
- Ashibani, Y.; Kauling, D.; Mahmoud, Q.H. A context-aware authentication framework for smart homes. In Proceedings of the 2017 IEEE 30th Canadian Conference on Electrical and Computer Engineering (CCECE), Windsor, ON, Canada, 30 April–3 May 2017. [Google Scholar] [CrossRef]
- Deeba, K.; Saravanaguru, R.K. Context-Aware Healthcare System Based on IoT—Smart Home Caregivers System (SHCS). In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems, Madurai, India, 14–15 June 2018. [Google Scholar] [CrossRef]
- Joo, S.C.; Jeong, C.W.; Park, S.J. Context Based Dynamic Security Service for Healthcare Adaptive Application in Home Environments. In Proceedings of the 2009 Software Technologies for Future Dependable Distributed Systems, Tokyo, Japan, 17 March 2009. [Google Scholar] [CrossRef]
- Sharpe, V.M. Issues and Challenges in Ubiquitous Computing. Tech. Commun. 2004, 51, 332–333. [Google Scholar]
- Greenfield, A. Everyware: The Dawning Age of Ubiquitous Computing; Peachpit Press: Berkeley, CA, USA, 2006. [Google Scholar]
- Chen, Y.H.; Tsai, M.J.; Fu, L.C.; Chen, C.H.; Wu, C.L.; Zeng, Y.C. Monitoring elder’s living activity using ambient and body sensor network in smart home. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; pp. 2962–2967. [Google Scholar]
- Sprint, G.; Cook, D.; Fritz, R.; Schmitter-Edgecombe, M. Detecting health and behavior change by analyzing smart home sensor data. In Proceedings of the 2016 IEEE International Conference on Smart Computing (SMARTCOMP), St. Louis, MO, USA, 18–20 May 2016; pp. 1–3. [Google Scholar]
- Cook, D.J.; Schmitter-Edgecombe, M.; Dawadi, P. Analyzing activity behavior and movement in a naturalistic environment using smart home techniques. IEEE J. Biomed. Health Inform. 2015, 19, 1882–1892. [Google Scholar] [CrossRef] [PubMed]
- Bergeron, F.; Bouchard, K.; Gaboury, S.; Giroux, S.; Bouchard, B. Indoor positioning system for smart homes based on decision trees and passive RFID. In Proceedings of the 20th Pacific-Asia Conference on Knowledge Discovery and Data Mining, Auckland, New Zealand, 19–22 April 2016; pp. 42–53. [Google Scholar]
- Yadav, U.; Verma, S.; Xaxa, D.K.; Mahobiya, C. A deep learning based character recognition system from multimedia document. In Proceedings of the 2017 Innovations in Power and Advanced Computing Technologies (i-PACT), Vellore, India, 21–22 April 2017; pp. 1–7. [Google Scholar]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Audio-visual speech recognition using deep learning. Appl. Intell. 2015, 42, 722–737. [Google Scholar] [CrossRef]
- Saito, S.; Wei, L.; Hu, L.; Nagano, K.; Li, H. Photorealistic facial texture inference using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5144–5153. [Google Scholar]
- Li, R.; Si, D.; Zeng, T.; Ji, S.; He, J. Deep convolutional neural networks for detecting secondary structures in protein density maps from cryo-electron microscopy. In Proceedings of the 2016 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Shenzhen, China, 15–18 December 2016; pp. 41–46. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep Learning for Sensor-based Activity Recognition: A Survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Brenon, A.; Portet, F.; Vacher, M. Context Feature Learning through Deep Learning for Adaptive Context-Aware Decision Making in the Home. In Proceedings of the 14th International Conference on Intelligent Environments, Rome, Italy, 25–28 June 2018. [Google Scholar] [CrossRef]
- Microsoft Azure. Object Detection—Computer Vision—Azure Cognitive Services | Microsoft Docs. Available online: https://docs.microsoft.com/en-us/azure/cognitive-services/computer-vision/concept-object-detection (accessed on 9 January 2020).
- IBM Cloud. Speech to Text—IBM Cloud API Docs. Available online: https://cloud.ibm.com/apidocs/speech-to-text/speech-to-text (accessed on 9 January 2020).
- Google Cloud. Cloud Natural Language API documentation. Available online: https://cloud.google.com/natural-language/docs/ (accessed on 9 January 2020).
- Tadejko, P. Cloud Cognitive Services Based on Machine Learning Methods in Architecture of Modern Knowledge Management Solutions. In Data-Centric Business and Applications; Springer: Cham, Switzerland, 2020; pp. 169–190. [Google Scholar]
- Shirsat, S.; Naik, A.; Tamse, D.; Yadav, J.; Shetgaonkar, P.; Aswale, S. Proposed System for Criminal Detection and Recognition on CCTV Data Using Cloud and Machine Learning. In Proceedings of the 2019 International Conference on Vision Towards Emerging Trends in Communication and Networking (ViTECoN), Vellore, India, 30–31 March 2019; pp. 1–6. [Google Scholar]
- Mumbaikar, S.; Padiya, P. Web services based on soap and rest principles. Inter. J. Sci. Res. Publ. 2013, 3, 1–4. [Google Scholar]
- Crockford, D. Introducing JSON. Available online: https://www.json.org/json-en.html (accessed on 9 January 2020).
- Fu, J.; Mei, T. Image Tagging with Deep Learning: Fine-Grained Visual Analysis. In Big Data Analytics for Large-Scale Multimedia Search; Wiley: Hoboken, NJ, USA, 2019; p. 269. [Google Scholar]
- Jocic, M.; Obradovic, D.; Malbasa, V.; Konjo, Z. Image tagging with an ensemble of deep convolutional neural networks. In Proceedings of the 2017 International Conference on Information Society and Technology, ICIST Workshops, Beijing, China, 17–20 September 2017; pp. 13–17. [Google Scholar]
- Nguyen, H.T.; Wistuba, M.; Grabocka, J.; Drumond, L.R.; Schmidt-Thieme, L. Personalized deep learning for tag recommendation. In Proceedings of the 21st Pacific-Asia Conference (PAKDD 2017), Jeju, South Korea, 23–26 May 2017; pp. 186–197. [Google Scholar]
- Chen, S.; Saiki, S.; Nakamura, M. Towards Affordable and Practical Home Context Recognition: –Framework and Implementation with Image-based Cognitive API–. Int. J. Netw. Distrib. Comput. (IJNDC) 2019, 8, 16–24. [Google Scholar] [CrossRef]
- Kalech, M.; Kraus, S.; Kaminka, G.A.; Goldman, C.V. Practical voting rules with partial information. Auton. Agents Multi-Agent Syst. 2011, 22, 151–182. [Google Scholar] [CrossRef]
- Umamaheswararao, B.; Seetharamaiah, P.; Phanikumar, S. An Incorporated Voting Strategy on Majority and Score-based Fuzzy Voting Algorithms for Safety-Critical Systems. Int. J. Comput. Appl. 2014, 98. [Google Scholar] [CrossRef]
- Filos-Ratsikas, A.; Miltersen, P.B. Truthful approximations to range voting. In International Conference on Web and Internet Economics; Springer: Cham, Switzerland, 2014; pp. 175–188. [Google Scholar]
- Cao, L.; Chua, K.S.; Chong, W.; Lee, H.; Gu, Q. A comparison of PCA, KPCA and ICA for dimensionality reduction in support vector machine. Neurocomputing 2003, 55, 321–336. [Google Scholar] [CrossRef]
- Mousas, C.; Anagnostopoulos, C.N. Learning Motion Features for Example-Based Finger Motion Estimation for Virtual Characters. 3D Res. 2017, 8, 25. [Google Scholar] [CrossRef]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Penn, G. Applying convolutional neural networks concepts to hybrid NN-HMM model for speech recognition. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 May 2012; pp. 4277–4280. [Google Scholar]
- Bilmes, J.A.; Bartels, C. Graphical model architectures for speech recognition. IEEE Signal Process. Mag. 2005, 22, 89–100. [Google Scholar] [CrossRef]
- Mousas, C.; Newbury, P.; Anagnostopoulos, C.N. Evaluating the covariance matrix constraints for data-driven statistical human motion reconstruction. In Proceedings of the 30th Spring Conference on Computer Graphics, Smolenice, Slovakia, 28–30 May 2014; pp. 99–106. [Google Scholar]
- Chéron, G.; Laptev, I.; Schmid, C. P-CNN: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3218–3226. [Google Scholar]
- Li, Z.; Zhou, Y.; Xiao, S.; He, C.; Li, H. Auto-conditioned lstm network for extended complex human motion synthesis. arXiv 2017, arXiv:1707.05363. [Google Scholar]
- Rekabdar, B.; Mousas, C. Dilated Convolutional Neural Network for Predicting Driver’s Activity. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3245–3250. [Google Scholar]
- Nakamura, S.; Hiromori, A.; Yamaguchi, H.; Higashino, T.; Yamaguchi, Y.; Shimoda, Y. Activity Sensing, Analysis and Recommendation in Smarthouse. In Proceedings of the Multimedia, Distributed Collaboration and Mobile Symposium 2014 Proceedings, Niigata, Japan, 7–9 July 2014; pp. 1557–1566. [Google Scholar]
- Ueda, K.; Tamai, M.; Yasumoto, K. A System for Daily Living Activities Recognition Based on Multiple Sensing Data in a Smart Home. In Proceedings of the Multimedia, Distributed Collaboration and Mobile Symposium 2014 Proceedings, Niigata, Japan, 7–9 July 2014; pp. 1884–1891. [Google Scholar]
- Sevrin, L.; Noury, N.; Abouchi, N.; Jumel, F.; Massot, B.; Saraydaryan, J. Characterization of a multi-user indoor positioning system based on low cost depth vision (Kinect) for monitoring human activity in a smart home. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 5003–5007. [Google Scholar]
- Dobhal, T.; Shitole, V.; Thomas, G.; Navada, G. Human activity recognition using binary motion image and deep learning. Procedia Comput. Sci. 2015, 58, 178–185. [Google Scholar] [CrossRef]
- Asadi-Aghbolaghi, M.; Clapes, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. A survey on deep learning based approaches for action and gesture recognition in image sequences. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 476–483. [Google Scholar]
- Pham, M.; Mengistu, Y.; Do, H.; Sheng, W. Delivering home healthcare through a cloud-based smart home environment (CoSHE). Future Gener. Comput. Syst. 2018, 81, 129–140. [Google Scholar] [CrossRef]
- Menicatti, R.; Sgorbissa, A. A Cloud-Based Scene Recognition Framework for In-Home Assistive Robots. In Proceedings of the 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Lisbon, Portugal, 28 August–1 September 2017. [Google Scholar] [CrossRef]
- Menicatti, R.; Bruno, B.; Sgorbissa, A. Modelling the Influence of Cultural Information on Vision-Based Human Home Activity Recognition. CoRR 2018. [Google Scholar] [CrossRef]
- Qin, Z.; Weng, J.; Cui, Y.; Ren, K. Privacy-preserving image processing in the cloud. IEEE Cloud Comput. 2018, 5, 48–57. [Google Scholar] [CrossRef]
- Dorri, A.; Kanhere, S.S.; Jurdak, R.; Gauravaram, P. Blockchain for IoT security and privacy: The case study of a smart home. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Big Island, HI, USA, 13–17 March 2017; pp. 618–623. [Google Scholar]
- Geneiatakis, D.; Kounelis, I.; Neisse, R.; Nai-Fovino, I.; Steri, G.; Baldini, G. Security and privacy issues for an IoT based smart home. In Proceedings of the 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017; pp. 1292–1297. [Google Scholar]
- Chen, S.; Saiki, S.; Nakamura, M. Evaluating Feasibility of Image-Based Cognitive APIs for Home Context Sensing. In Proceedings of the 2018 International Conference on Signal Processing and Information Security (ICSPIS), Dubai, UAE, 7–8 November 2018; pp. 5–8. [Google Scholar] [CrossRef]
- Maklin, C. TF IDF | TFIDF Python Example—Towards Data Science. Available online: https://towardsdatascience.com/natural-language-processing-feature-engineering-using-tf-idf-e8b9d00e7e76 (accessed on 27 November 2019).
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning, Beijing, China, June 21–26 June 2014; pp. II-1188–II-1196. [Google Scholar]
- Polito, M.; Perona, P. Grouping and dimensionality reduction by locally linear embedding. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 9–14 December 2002; pp. 1255–1262. [Google Scholar]
- Dumais, S.T. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; De Silva, V.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps for dimensionality reduction and data representation. Neural Comput. 2003, 15, 1373–1396. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Nam, J.; Herrera, J.; Slaney, M.; Smith, J.O. Learning Sparse Feature Representations for Music Annotation and Retrieval. In Proceedings of the ISMIR 2012, Porto, Portugal, 8–12 October 2012; pp. 565–570. [Google Scholar]
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing human action in time-sequential images using hidden markov model. In Proceedings of the 1992 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992; pp. 379–385. [Google Scholar]
- Chun, H.; Lee, M.H.; Fleet, J.C.; Oh, J.H. Graphical models via joint quantile regression with component selection. J. Multivar. Anal. 2016, 152, 162–171. [Google Scholar] [CrossRef]
- Microsoft. Computer Vision | Microsoft Azure. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/computer-vision/ (accessed on 27 November 2019).
- IBM. Watson Visual Recognition. Available online: https://www.ibm.com/watson/services/visual-recognition/ (accessed on 27 November 2019).
- Clarifai. TRANSFORMING ENTERPRISES WITH COMPUTER VISION AI. Available online: https://clarifai.com/ (accessed on 15 April 2019).
- Imagga. Imagga API. Available online: https://docs.imagga.com/ (accessed on 15 April 2019).
- ParallelDots. Image Recognition. Available online: https://www.paralleldots.com/object-recognizer (accessed on 15 April 2019).
- Microsoft. Azure Machine Learning | Microsoft Azure. Available online: https://azure.microsoft.com/en-us/services/machine-learning/ (accessed on 27 November 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Context Labels | The Contents of What the Images of Each Context Represent |
|---|---|
| Dining together | We often cook by ourselves to dining together in our laboratory |
| General meeting | We are sitting together in a general meeting every Monday |
| Nobody | There is also the nobody situation during the weekend or holidays |
| One-to-one meeting | We often have a one-to-one meeting for the study discussion |
| Personal study | Sometimes the public computer is used for personal study |
| Play games | We often gather around and play games to relax in our spare time |
| Room cleaning | The staff twice a week come for room cleaning in our laboratory |


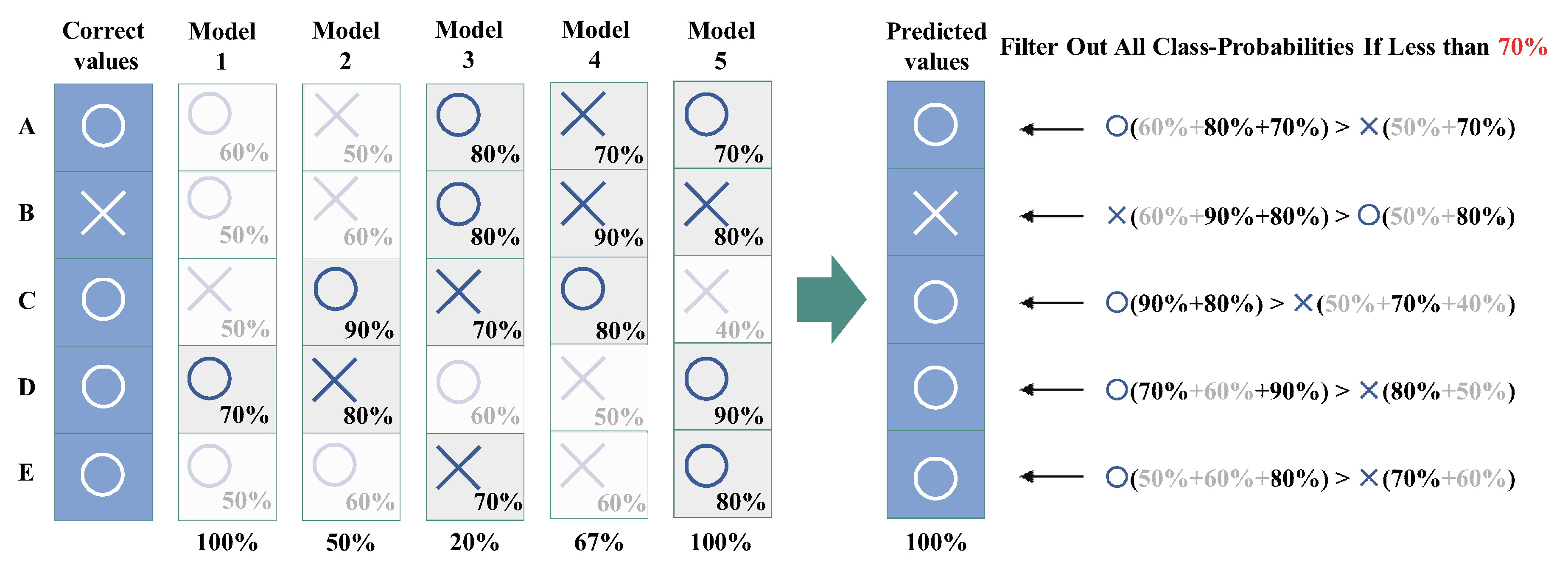
| Model or Voting Names | Overall Accuracy | Dining Together | General Meeting | Nobody | One-to-One Meeting | Personal Study | Play Games | Room Cleaning |
|---|---|---|---|---|---|---|---|---|
| Azure API – model | 0.8543 | 0.9550 | 0.8910 | 1.0000 | 0.6610 | 0.9170 | 0.8430 | 0.7650 |
| Watson API – model | 0.8000 | 0.8860 | 0.6730 | 0.8230 | 0.8040 | 0.9380 | 0.8040 | 0.7060 |
| Clarifai API – model | 0.9143 | 0.9090 | 0.9820 | 0.9110 | 0.8390 | 0.9170 | 0.9220 | 0.9220 |
| Imagga API – model | 0.9429 | 0.9550 | 0.9270 | 1.0000 | 0.8930 | 0.9580 | 0.9220 | 0.9610 |
| ParalleDots API – model | 0.7718 | 0.7950 | 0.8910 | 0.9330 | 0.4460 | 0.8750 | 0.6670 | 0.8040 |
| Majority voting | 0.9753 | 0.9565 | 1.0000 | 1.0000 | 1.0000 | 0.9561 | 1.0000 | 0.9572 |
| Score voting | 0.9776 | 1.0000 | 0.9685 | 1.0000 | 1.0000 | 0.9751 | 1.0000 | 0.9720 |
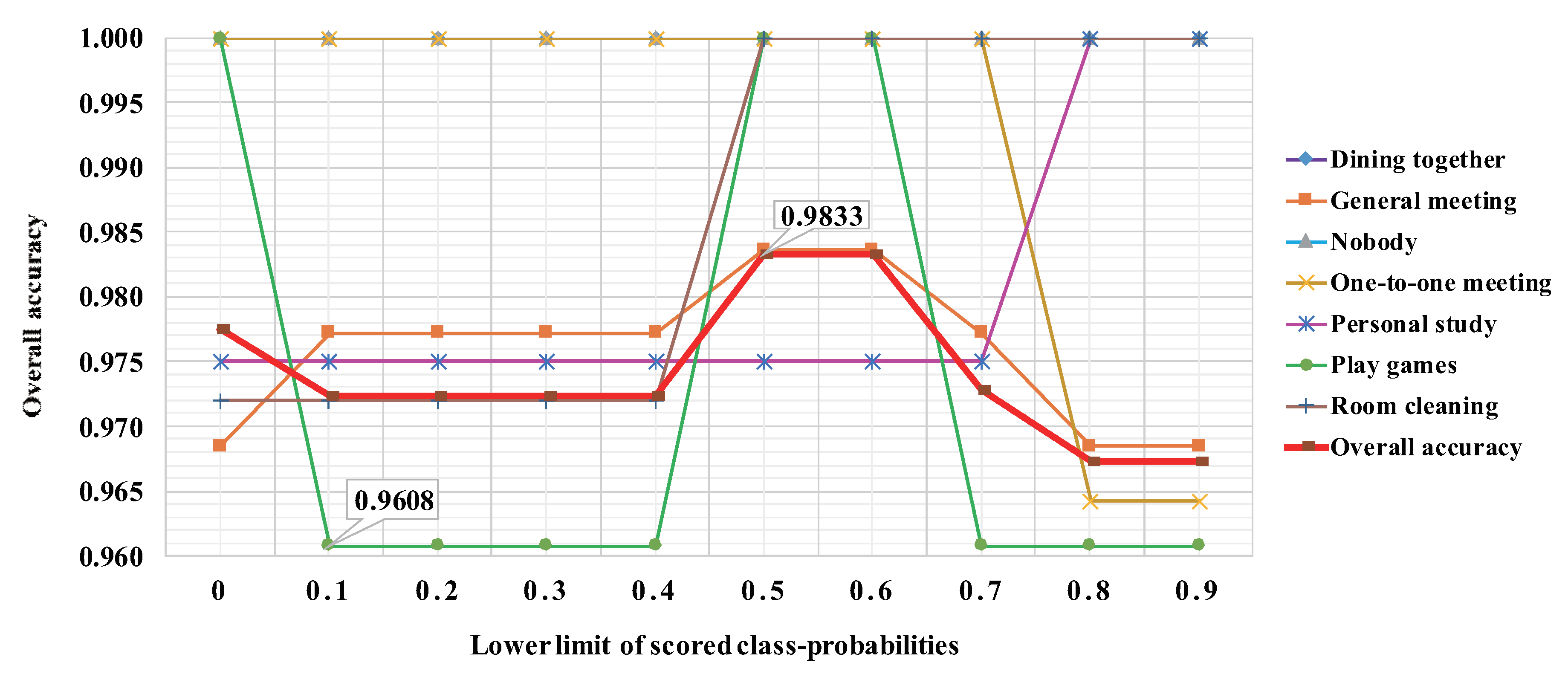
| Range voting (0.5 to 0.6) | 0.9833 | 1.0000 | 0.9836 | 1.0000 | 1.0000 | 0.9800 | 1.0000 | 1.0000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Saiki, S.; Nakamura, M. Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts. Sensors 2020, 20, 666. https://doi.org/10.3390/s20030666
Chen S, Saiki S, Nakamura M. Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts. Sensors. 2020; 20(3):666. https://doi.org/10.3390/s20030666
Chicago/Turabian StyleChen, Sinan, Sachio Saiki, and Masahide Nakamura. 2020. "Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts" Sensors 20, no. 3: 666. https://doi.org/10.3390/s20030666
APA StyleChen, S., Saiki, S., & Nakamura, M. (2020). Integrating Multiple Models Using Image-as-Documents Approach for Recognizing Fine-Grained Home Contexts. Sensors, 20(3), 666. https://doi.org/10.3390/s20030666