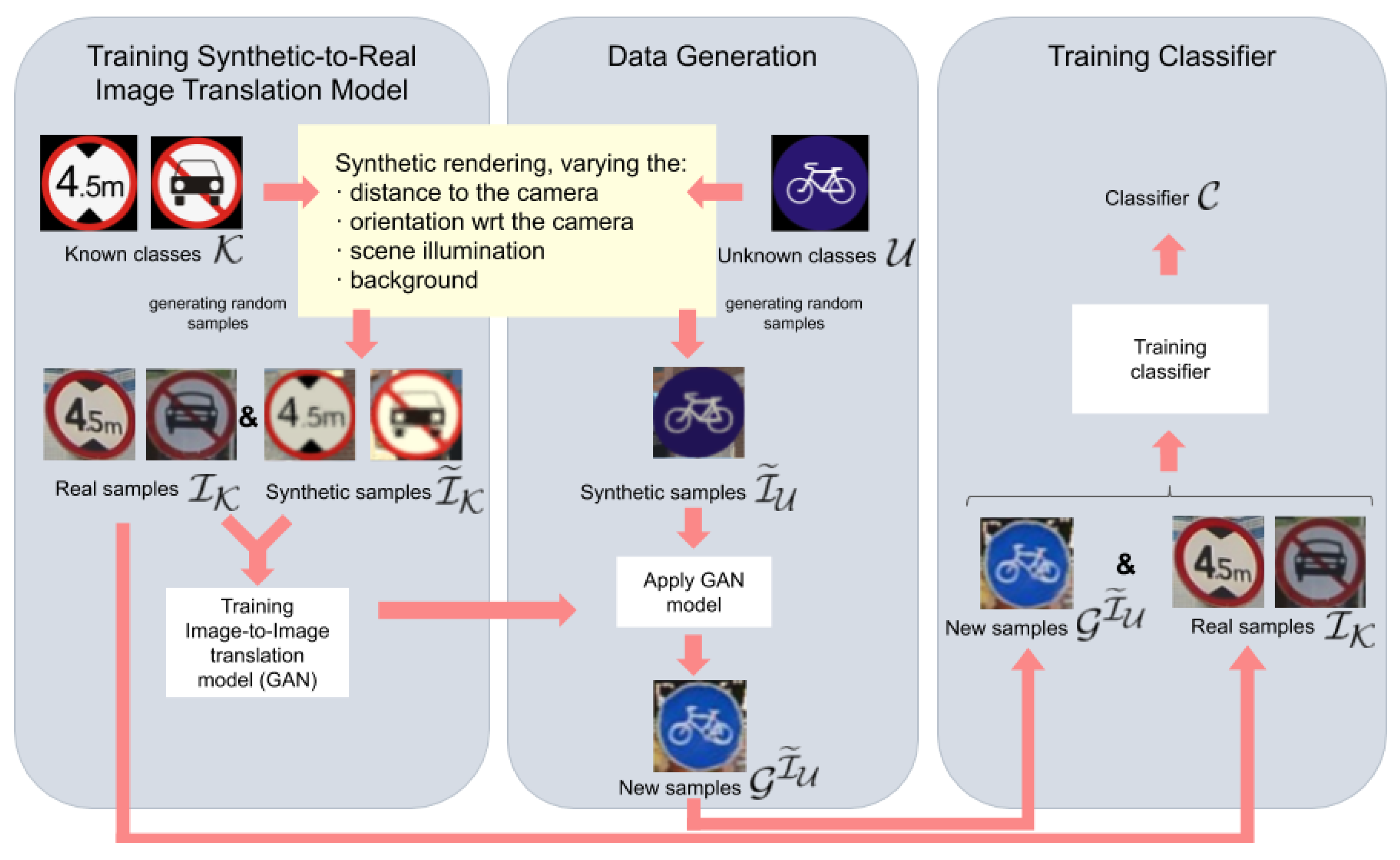
The experiments were designed to address two questions. Since we use synthetically generated instances of unknown classes to retrain the current classifier, we will have a domain shift problem. (Q1) Can we reduce this domain shift by applying an image-to-image translation GAN to the samples of the unknown classes, provided that such a GAN was trained only with samples of the known classes? and (Q2) What are the overall classification results when training the classifier using the real-world data of the known classes with the data generated for the new classes following this GAN-based proposal?
4.2. Experiments: Design, Results, and Discussion
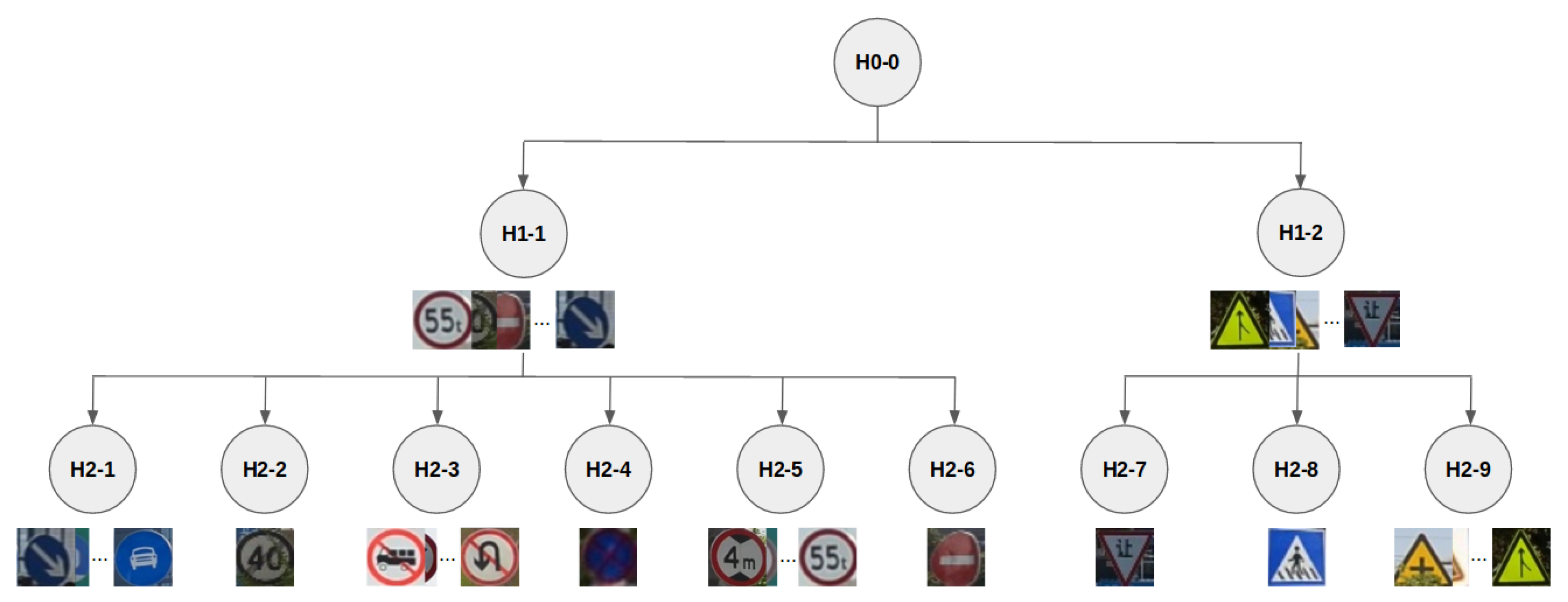
We have not only considered the Tsinghua and SYNTHIA-TS datasets as a whole, i.e., H0-0 in terms of the hierarchy shown in
Figure 3; instead, in order to perform a finer-grained analysis regarding questions
Q1 and
Q2, we also conducted experiments based on different nodes of this hierarchy, which we call
splits. Accordingly, our setup assumes that we have an existing split
of real-world annotated images for training, and that we also want to learn a new split
, for which we have no access to a proper amount of corresponding real-world images and, therefore, we have to synthesize them. It is understood that
and
have no intersection between classes. On the other hand, for the purpose of performing comparative evaluations in our experimental setting, we do in fact have access to the real-world annotated images of split
.
Since we will be referring to splits coming from synthetic and real-world data, the former sometimes transformed by a GAN, and the latter sometimes used as training or testing data, we have defined the compact notation of
Table 1, which will allow us to be precise and concise when describing the multiple experiments we report in this section. Using this notation and given two splits
and
, an example of an experiment for
Q2 would consist of using
and
to train a traffic sign classifier for the known classes in split
together with the new classes in split
, which we would like to be accurate when testing in
, i.e., accurate for all classes. Alternatively, if we use a GAN to transform the synthetic images, then the training of the classifier would be done with
and
. In fact, we transformed all of the synthetic images at once, which took less than 1.5 h using a desktop PC based on an INTEL Core i7 CPU and one NVIDIA GeForce TITAN X Pascal GPU.
As we can see in
Figure 3, we have three hierarchical levels: (1) The whole data, (2) two splits based on external shape, and (3) given a shape, different data based on content. Each considered split is defined in
Table 2, which specifies their features. We do not consider splits with only one class (i.e., H2-2, H2-4, H2-6, H2-7, and H2-8) since they would not allow the addressing of
Q1 (for which at least two classes are needed). However, note that although these splits are not considered in isolation, their data is considered when working with a split corresponding to their parent nodes in the hierarchy.
Now, we start the experiments by establishing the upper and lower bounds of different traffic sign classifiers. In these experiments, we use the full Tsinghua and SYNTHIA-TS datasets. Therefore, in this case, we use the split H0-0 (
Figure 3) for Tsinghua, i.e., we use
and
for training and testing, respectively. Both sets have samples of all of the traffic signs that we consider. More specifically, for each class,
of the samples are used for training tasks (CycleGAN and traffic sign classifiers) and the remaining
for testing traffic sign classifiers. The per-class training/testing sampling is performed randomly and once. Training on
and testing on
acts as the lower bound, since we are using only synthetic images (as they come from the virtual environment); therefore, we must expect a domain shift. Training on
acts as the upper bound, since we are using real-world images from the same distribution (camera and world area) as in the testing set.
Table 3 shows these upper and lower bound results for the different architectures that we have considered, namely VGG16 and ResNet101. Moreover, since during the training of CNNs, there is certain amount of randomness (e.g., when sampling the datasets during a mini-batch), we repeat each training five times and report testing accuracy in terms of the mean and standard deviation of the F1 classification score (i.e., F1 = (2TP)/(2TP + FN + FP)) computed on the respective classification results. These results show that: (1) We can achieve a high classification accuracy with the appropriate real-world data; (2) using the synthetic data for training produces a reasonable accuracy (far from random), but there is a dramatic domain shift, with results dropping from 97.59% to 36.05% for VGG16, and from 98.76% to 58.74% for ResNet101.
Table 4 and
Table 5 report results to answer
Q1. We consider paired splits—one is used as the set of known classes (
), and the other as the set of unknown classes (
). These splits do not intersect, but their union does not necessarily correspond to the full traffic sign hierarchy, because only splits from
Table 2 are considered. The pairs were designed to force different global appearances between known and unknown classes. The
columns report the lower bound of classification accuracy for each experiment, i.e., training a classifier for classes in
with samples in
but testing on the real-world data
. Columns
act as the upper bound, since training is done on real-world samples of
as if they were actually known. Columns
report the classification accuracies when training is done with the samples of
, i.e., the samples of
transformed by a CycleGAN trained to perform image-to-image translation from
to
. Therefore, the CycleGAN has not seen samples from classes in
at training time. Finally, we also include the case
, where the CycleGAN has been trained using samples from the unknown set of classes. Obviously, this is not realistic in our application setting; however, it can be taken as an upper bound of the accuracy, which would be possible to achieve by using CycleGAN to transform the synthetic images.
Figure 4 shows examples of the images involved in our experiments: Synthetic, real, and transformed by different CycleGANs.
These results based on splits confirm the observations made for H0-0 according to
Table 3; i.e., training and testing (for the unknown classes) with real-world data shows high classification accuracies, while training with the pure synthetic data and testing in the real-world data shows a significant drop of accuracy. Again, ResNet101 is more robust to domain shifts than VGG16. We can see how the gap gets larger as the number of classes based on synthetic data (unknown ones) increases. For instance, the gap for H1-1 is larger than for H1-2, both for VGG16 and ResNet101. Note that H1-1 contains 35 classes and H1-2 only seven (see
Table 2). If we analyze the splits of the next hierarchical level (H2-X), the same observations hold; note that H2-3 and H2-5 (10 and 16 classes, respectively) show a larger gap than H2-1 and H2-9 (six and five classes, respectively), both for VGG16 and ResNet101.
On the other hand, CycleGAN indeed helps to significantly reduce the domain shift. When using the H1-1 split as known classes to train the CycleGAN, and applying this GAN to the synthetic images of the unknown classes—i.e., those in H1-2 split—we see
points of accuracy gain when testing in real-world images of the H1-2 split (9.21 for VGG16 and 9.60 for ResNet101). Changing the roles of these splits, the gain is
for VGG16 and
for ResNet101. However, in the two situations (H1-1/H1-2 as known/unknown and vice versa), ResNet101 reports significantly higher accuracies (more than 10 points) after the GAN-based domain adaptation of the synthetic images. In addition, for VGG16 and ResNet101, H1-2 as the split of unknown classes shows significantly higher accuracies (more than 20 points) than when it is H1-1, which is just a consequence of starting with similar accuracy differences before domain adaptation. Looking to the H2-X splits, we can see that the GAN-based domain adaptation reports significantly higher accuracy in most of the experiments. In fact, it is more interesting to analyze when it is not the case. For instance, when split H2-1 is used to train the CycleGAN, we obtain either very low accuracy gains (e.g., for VGG16, 1.43 when the unknown classes are in H2-5 and 2.19 for H2-9) or even negative adaptation (e.g., –2.93 for H2-3 with VGG16, and for H2-3/5/9 with ResNet101). We think that, when using H2-1 to train the CycleGAN, the learned image-to-image transform is too biased towards a blue background, which is a color not present in the rest of the considered H2-X splits (in the role of unknown classes). When exchanging the roles between H2-1 and the rest of the considered H2-X splits, the conclusion is the same for VGG16. However, ResNet101 is still able to extract the most from the domain-adapted images, showing significant accuracy gains with respect to using the synthetic images as they come directly from the virtual environment.
Figure 5 presents some visual hints. For instance, when split H2-1 is used to train the CycleGAN, this adds a bluish color to the transformed images; when the CycleGAN is trained with the H2-9 split, the added color is yellowish. The former is more marked than the latter, which may be the reason behind some of the previously mentioned cases of poor domain adaptation. We can see other effects, like blue background images going to black backgrounds. According to the reviewed results, ResNet101 seems more robust to this effect than VGG16 (see the case of
in
Table 4 and
Table 5).
Table 4 and
Table 5 help to analyze results in scenarios where there are significant visual differences among the known/unknown classes. We are also interested in analyzing different balances between known and unknown classes. Analogously to
Table 1, we will define splits denoted by a percentage of classes; e.g.,
would be H0-0. Each of these splits also has a complementary one with the remaining classes. When forming the new splits, in order to be sure that we do not degenerate in the previous hierarchy-based experiments, the classes are not sampled from H0-0, but they are proportionally and randomly sampled from all of the H2-X splits. For example,
would consider half of the H2-1, H2-3, H2-5, and H2-9 classes, added to H2-2, H2-6, and H2-8, which only have one class.
Table 6 and
Table 7 present the corresponding results. We can see how previous observations are confirmed, namely: (1) Domain gap increases with the number of synthetic classes (the unknown ones) to be covered by the traffic sign classifier, but still, the obtained accuracies are reasonable; (2) CycleGAN is able to dramatically reduce the domain shift for the unknown classes, recovering from
to even
points of accuracy; (3) ResNet101 is able to produce the best results before and after domain adaptation.
Overall, to already answer Q1, we see that using known classes to train a GAN-based transformation from synthetic to real-world domains indeed helps to dramatically reduce the classification accuracy gap due to the domain shift for synthetically generated new classes. However, there are scenarios more favorable than others, and there is still room for improvement.
First, the CNN used matters. Here, Resnet101 shows significantly better classification accuracies than those of VGG16; i.e., ResNet101 is more robust to this kind of known/unknown class setting. We can see this by looking at
Table 4 and
Table 5. Note how, for H2-X splits, when the split of classes used to train CycleGAN is the same split as that used to train the traffic sign classifier (
columns), then the classification accuracies of VGG16 and ResNet101 are similar, and VGG16 even outperforms ResNet101 several times. A similar effect can be appreciated in
Table 6 and
Table 7. Hence, ResNet101 seems to be more robust to image imperfections introduced by CycleGAN. In this favorable but unrealistic setting, the domain-adapted images show fewer artifacts (see
Figure 4 and
Figure 5).
Second, the most adverse scenario is indeed when known and unknown classes show very different appearances combined with a low known/unknown class ratio. In a reasonable case, as for
splits of randomly selected known/unknown classes, using ResNet101, we can see how we obtain a classification accuracy of
on average (
Table 7) where training with real-world data reaches
. In the most imbalanced case,
, ResNet101 reaches a classification accuracy of
, still far from the
when training with real-world images. Note that in this scenario, there is room to improve GAN-based image-to-image translation, since even using the classification classes to train the CycleGAN, the obtained accuracy is
, still far from
.
Although in this paper, these are just intermediate results on our way to address Q2, this analysis is already useful if our goal is to perform transfer learning for the traffic sign classifier; i.e., if we want to train a classifier that only needs to operate in a new set of traffic signs for which we do not have enough samples, and we want to leverage knowledge from the known classes even if these are not going to be used for classification anymore—for instance, in particular environments with specialized traffic signs, like in some closed infrastructures or industrial facilities. In fact, the vision system does not need to be onboard a vehicle; it can even be on a humanoid or any other robotic platform. However, a probable requisite in this case would be to use the same camera sensor model to classify new classes as that used for collecting the real-world images involved in the training of the GAN-based domain adapter.
Finally, in order to address
Q2, we performed the experiments shown in
Table 8 and
Table 9. In these tables, columns
refer to training jointly with synthetic and real-world data.
is the full SYNTHIA-TS set, i.e., covering known (
k) and unknown (
u) classes. Therefore, we use all of the synthetic data available for the classes we want to classify. On the other hand,
refers to the training set of all known real-world classes; in these experiments,
are the 42 considered classes of split H0-0. Therefore,
equals the full Tsinghua training set (
). Columns
are analogous to previous ones, but in this case, rather than using the synthetic data as gathered from the virtual environment, we use it transformed by a CycleGAN. These GANs are trained only using the known classes in each experiment, i.e., in this case,
and
. Accordingly,
is composed by
, used as pure data augmentation, as well as
, which is really needed, since we assume that we do not have real-world training samples for the split
.
We see that the observations done in the context of Q1 apply here too: (1) The domain gap increases with the number of synthetic classes (the unknown ones); (2) CycleGAN is able to significantly reduce the domain shift; (3) ResNet101 performs better than VGG16 before and after domain adaptation; even when using the full Tsinghua training set, they report similar upper bounds ( for VGG16, for ResNet101). In the case of ResNet101, the best cases almost reach the upper bound: (1) When the known classes are those in split H1-1 ( of classes) and the unknown in split H1-2 ( of classes), we obtain , which is very close to ; (2) when classes are directly selected randomly on the H2-X hierarchy level, the case of of unknown classes reaches , which is also a very high accuracy; even the case still reports . Moreover, in all of these cases, the accuracy of the known classes keeps over 95 and over 84 for the unknown ones ( for H1-2, for the , for the ). Overall, we can conclude that with ResNet101, the proposed method works well when the ratio of unknown/known classes is of . In order to reach the upper bound, we can investigate if we can still improve CycleGAN, but in this regime, the last mile can probably be covered by adding a small number of real-world collected and annotated samples from the unknown classes. As the vision system keeps performing in the real-world, the samples falling in the new classes can be kept; then, we can replace the synthesized and transformed samples by these self-annotated ones in a future retraining of the classifier. In fact, these self-annotation cycles can be also a good approach for more challenging ratios of unknown/known classes; note that for the of unknown classes, the results are over 70, and over 50 for the .










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}