A Machining State-Based Approach to Tool Remaining Useful Life Adaptive Prediction


Abstract
1. Introduction
- (1)
- Traditional predictive models cannot achieve self-adaptiveness in different complex processes. A conservative protection strategy could cause excessive tool wear and lead to a rapid increase in cutting force, affecting the processing quality of the workpiece and reducing the yield of the qualified workpiece; excessive protection strategies could waste the RUL of the tool, increase unnecessary downtime and lead to a decrease in production efficiency and an increase in manufacturing costs. Finding RUL prediction methods related to the process will effectively improve the quality of workpiece, increase production efficiency and optimize workpiece costs.
- (2)
- Traditional data sources rely on a single type of data and are mostly single dimensions. Such a prediction model will lack the coupling nonlinear influence factors under a different process, resulting in the reduction in credibility in the prediction process, reduction in the confidence interval, the generalization ability of the model not being strong and the actual working conditions not being able to be accurately described. It is especially important to choose the right data dimensions and combinations.
- (3)
- When extracting small-time granularity features in the traditional way, the features extracted by the quadratic features are directly added to the previously extracted features, which causes the inconsistency of the sample sparsity, and reduces the generalization ability of the model, the over-fitting of the model, “curse of dimensionality” and other issues. It is necessary to find a preprocessing method to solve the dimensional explosion problem.
- (1)
- A multi-information fusion strategy that can effectively reduce the model error and improve the generalization ability of the model is proposed.
- (2)
- A preprocessing method for improving the time precision and time granularity of feature extraction while avoiding dimensional explosion is proposed.
- (3)
- An importance coefficient and a custom loss function related to process and machining state are proposed. The new prediction model can realize the adaptive prediction of RUL under different processes.
2. Units Proposed Method
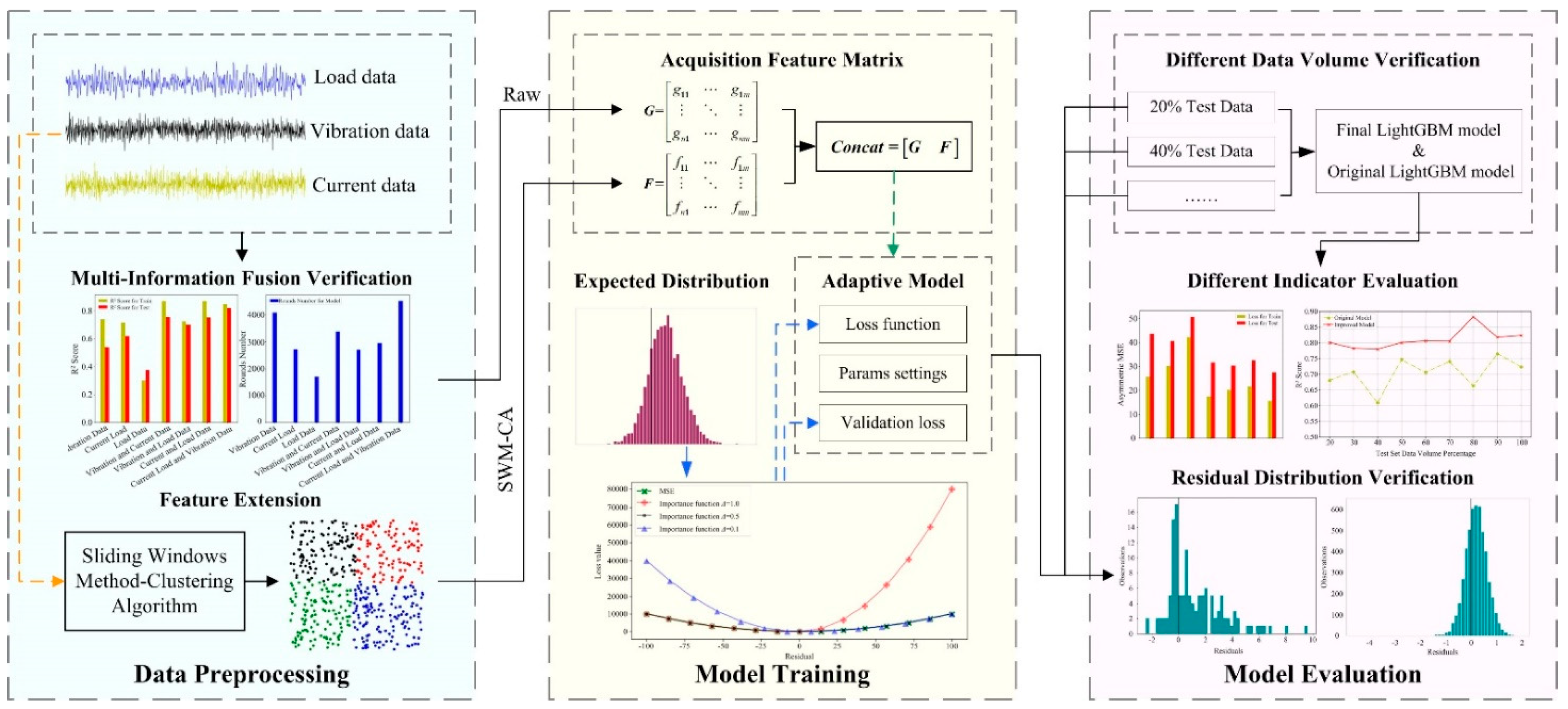
2.1. Architecture of the Proposed Method
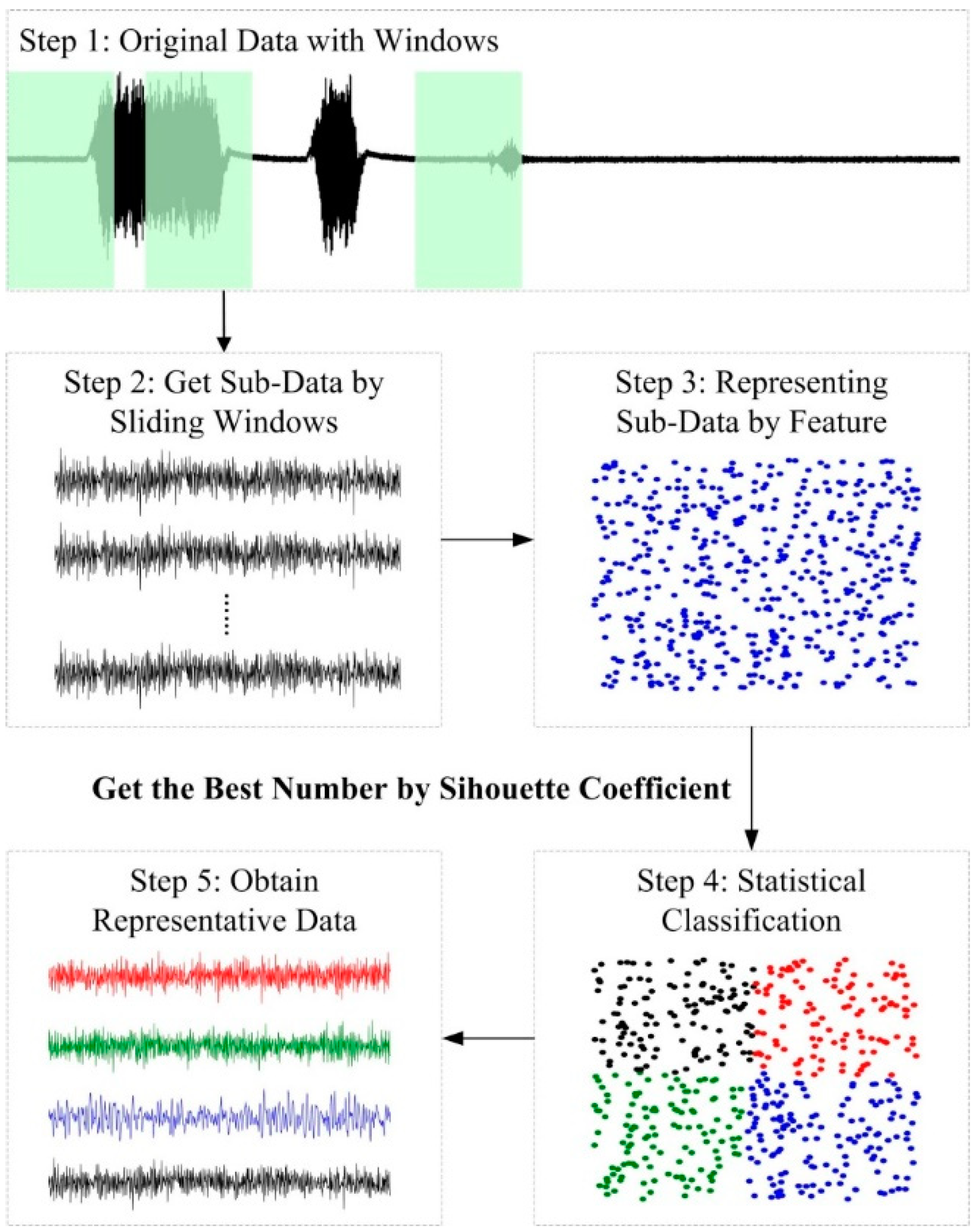
2.2. SWM-CA
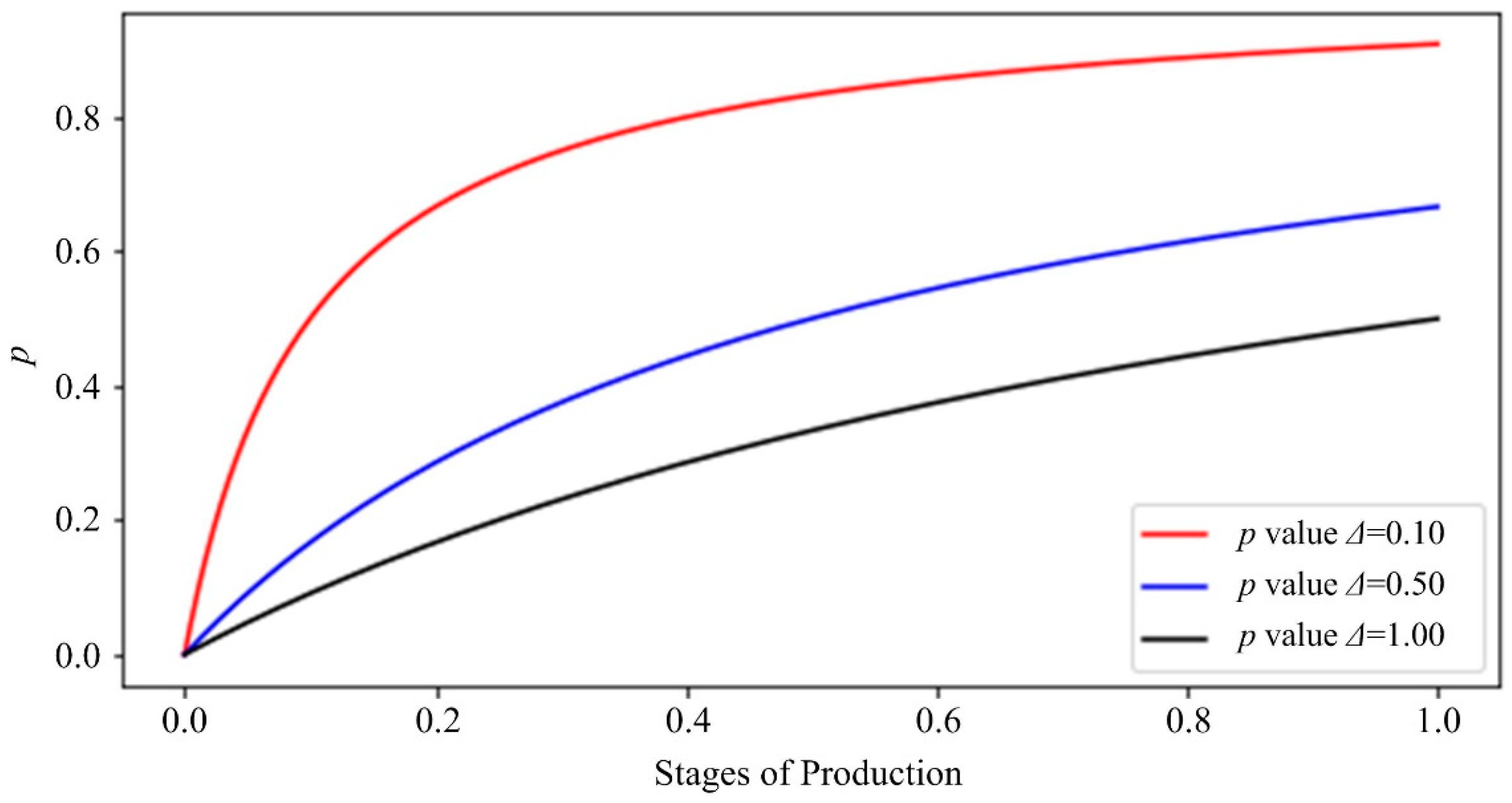
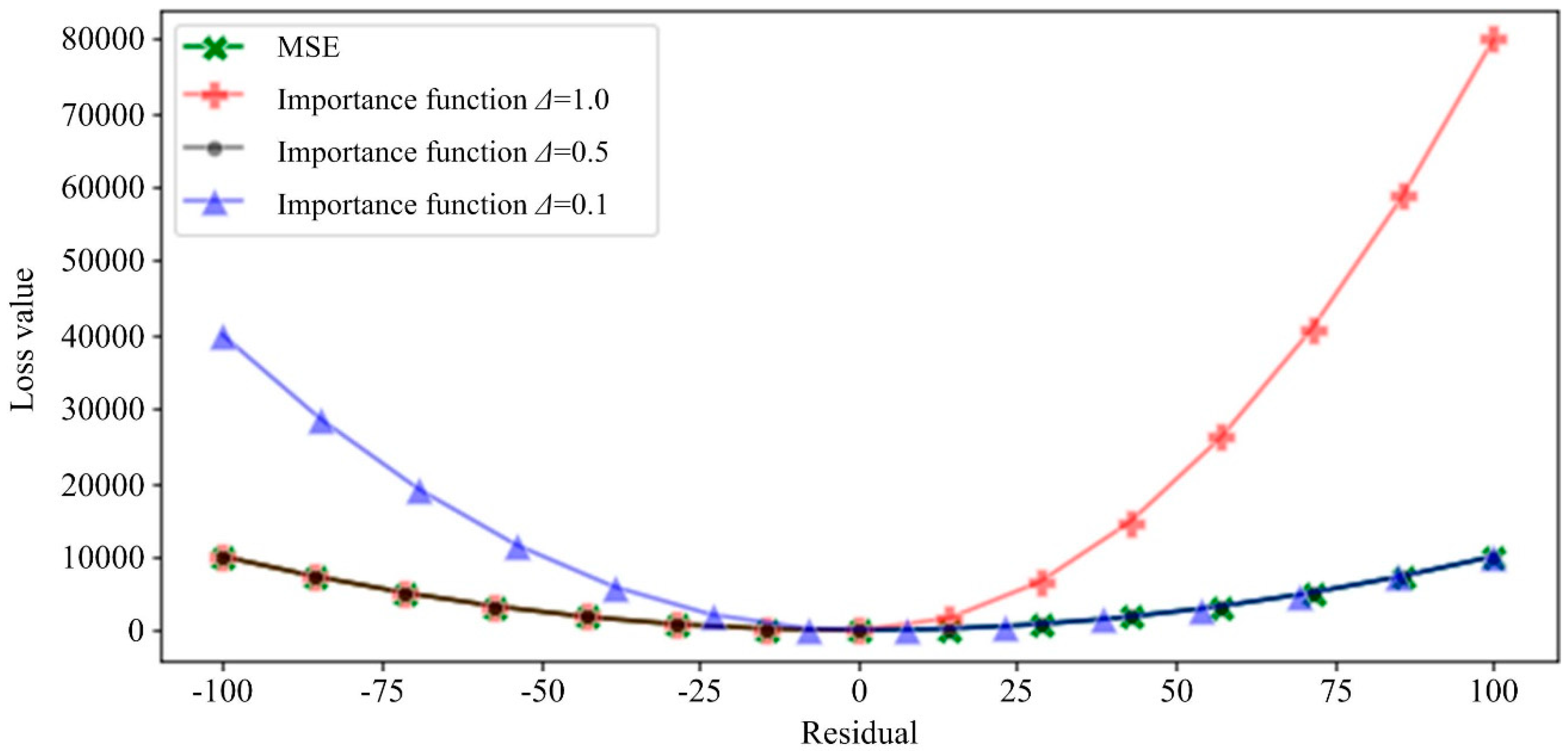
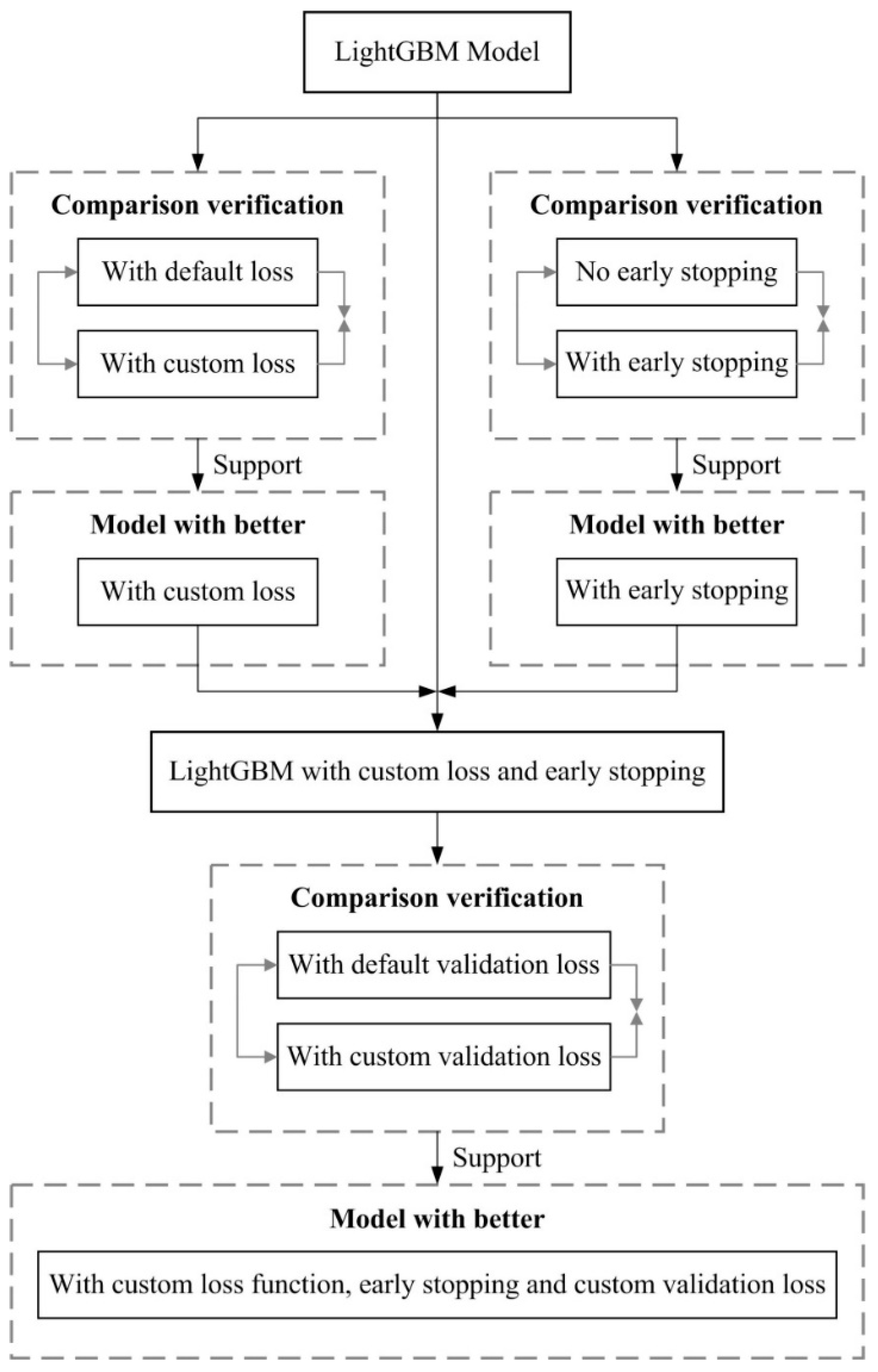
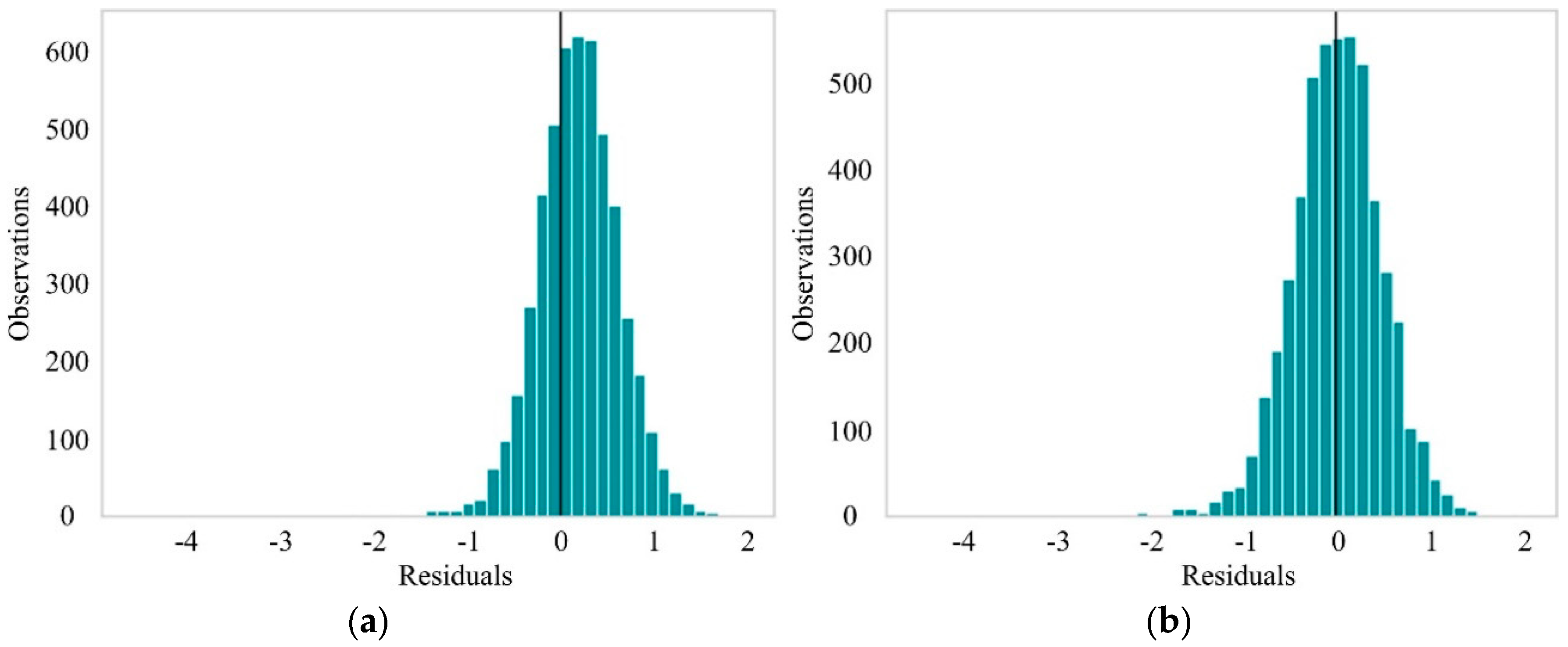
2.3. Loss Function of p-LightGBM
- (1)
- The importance coefficient
- (2)
- Custom loss function
- (3)
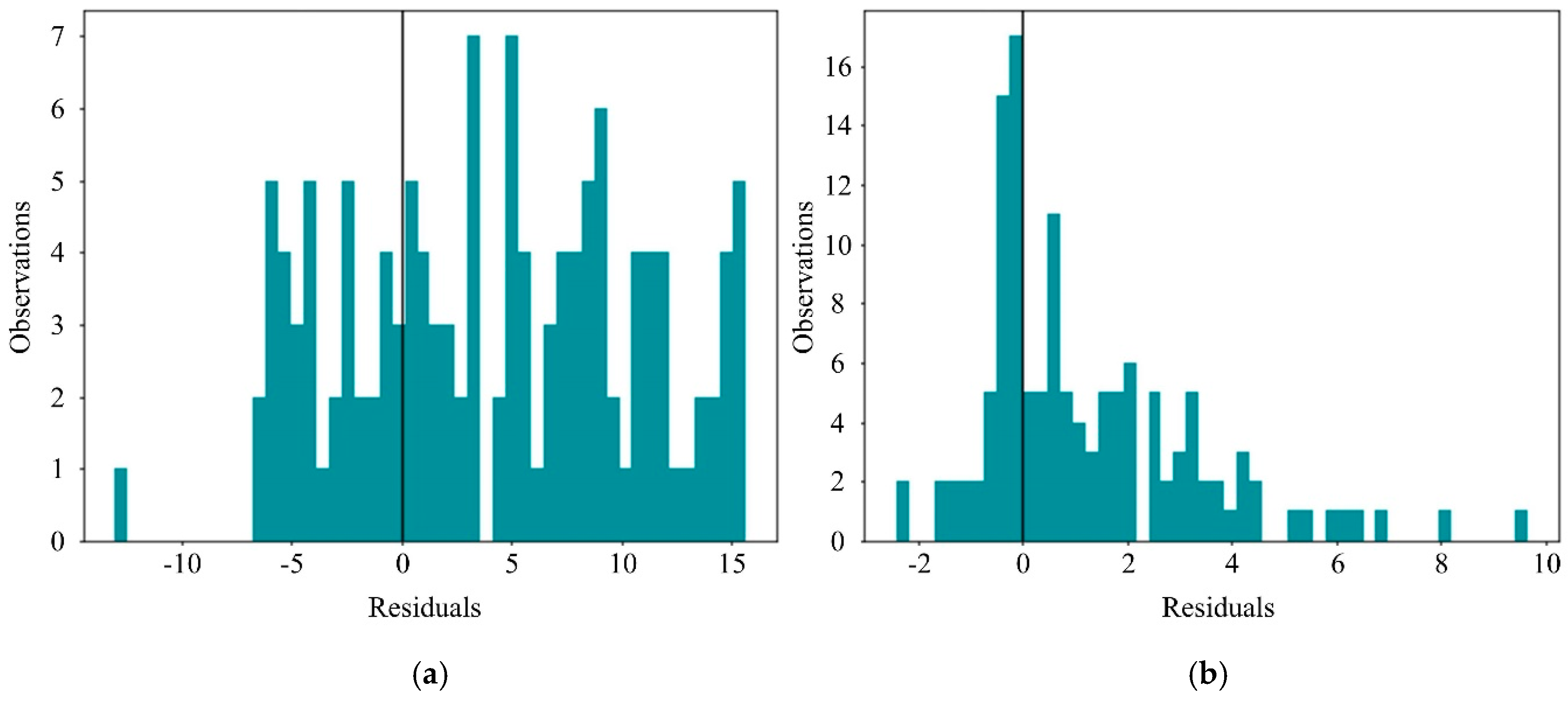
- Verify the engineering practice effect of CLF
3. Experiments and Discussion
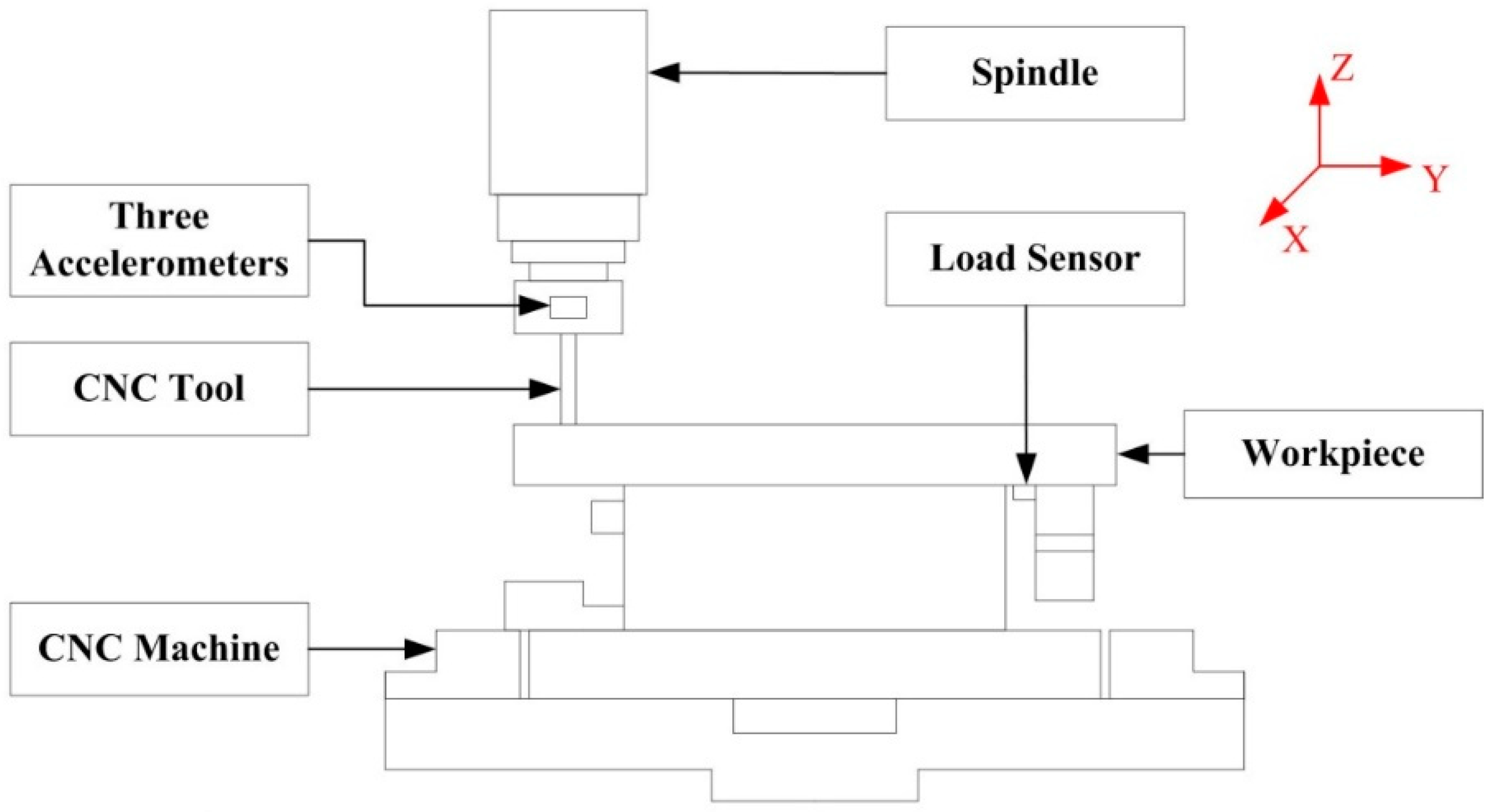
3.1. Process Description
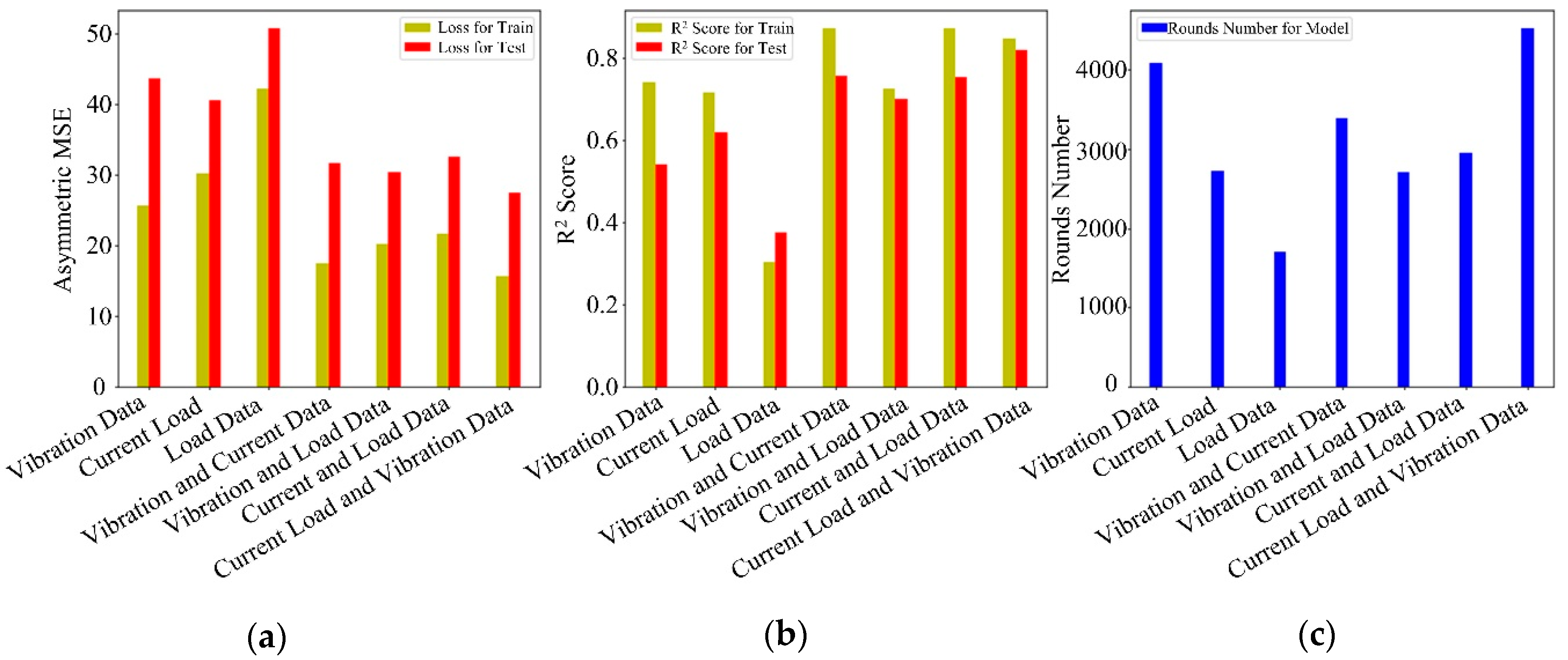
3.2. Verifying the Validity Muti-Information Fusion Strategy and Data Type Combination
3.3. The Effectiveness of SWM-CA
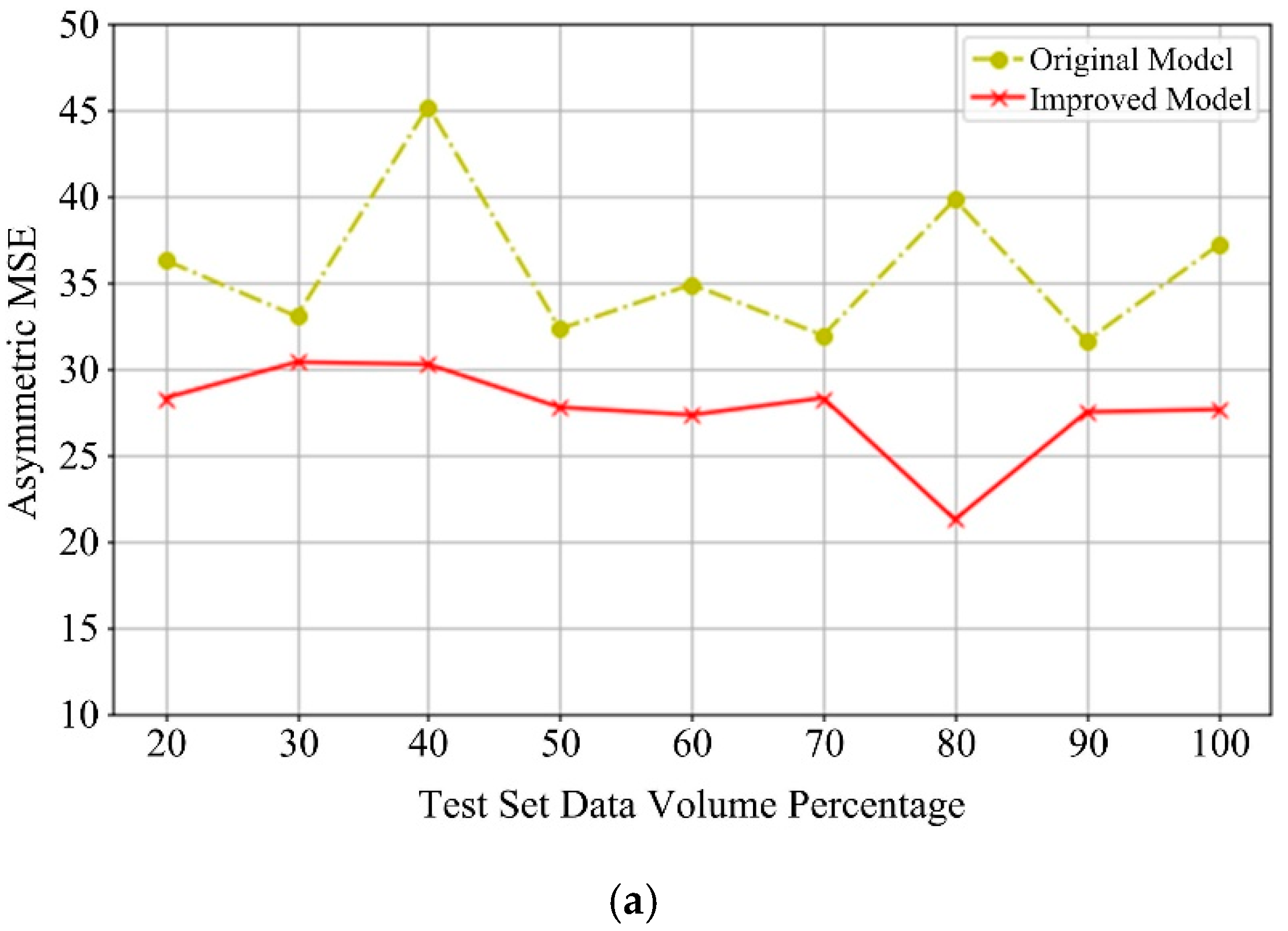
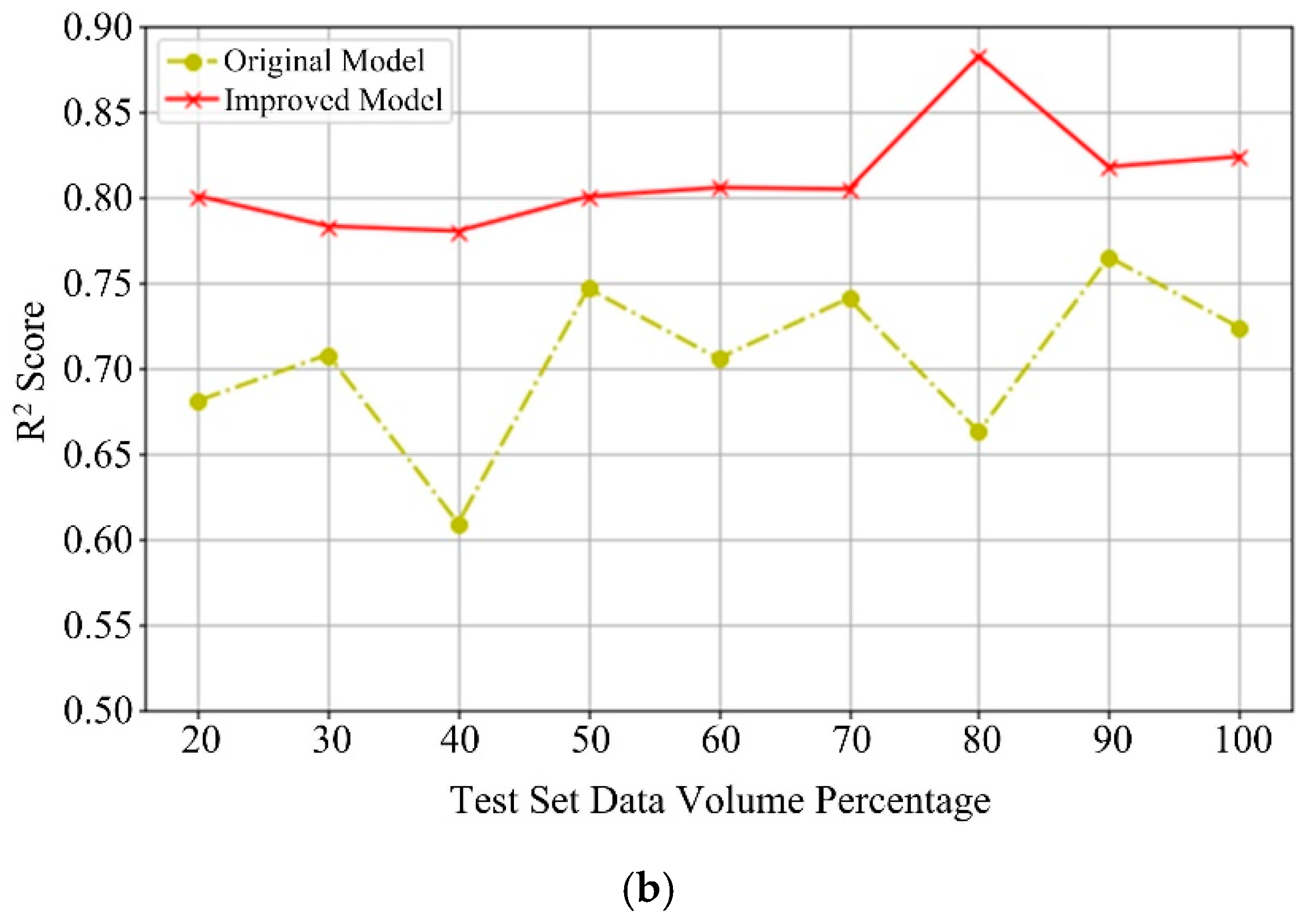
3.4. Comparative Experiments of the RUL Predictive Model
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Byrne, G.; Dornfeld, D.; Inasaki, I.; Ketteler, G.; König, W.; Teti, R. Tool Condition Monitoring (TCM)—The Status of Research and Industrial Application. CIRP Ann. 1995, 44, 541–567. [Google Scholar] [CrossRef]
- Teti, R.; Jemielniak, K.; O’Donnell, G.; Dornfeld, D. Advanced monitoring of machining operations. CIRP Ann.-Manuf. Technol. 2010, 59, 717–739. [Google Scholar] [CrossRef]
- Caggiano, A.; Rimpault, X.; Teti, R.; Balazinski, M.; Chatelain, J.F.; Nele, L. Machine learning approach based on fractal analysis for optimal tool life exploitation in CFRP composite drilling for aeronautical assembly. CIRP Ann.-Manuf. Technol. 2018, 67, 483–486. [Google Scholar] [CrossRef]
- Sikorska, J.; Hodkiewicz, M.; Ma, L. Prognostic modelling options for remaining useful life estimation by industry. Mech. Syst. Signal Process. 2011, 25, 1803–1836. [Google Scholar] [CrossRef]
- Silva, R.; Reuben, R.; Baker, K.; Wilcox, S. Tool wear monitoring of turning operations by neural network and expert system classification of a feature set generated from multiple sensors. Mech. Syst. Signal Process. 1998, 12, 319–332. [Google Scholar] [CrossRef]
- Li, Y.; Billington, S.; Zhang, C.; Kurfess, T.; Danyluk, S.; Liang, S. Adaptive prognostics for rolling element bearing condition. Mech. Syst. Signal Process. 1999, 13, 103–113. [Google Scholar] [CrossRef]
- Kacprzynski, G.J.; Sarlashkar, A.; Roemer, M.J.; Hess, A.; Hardman, B. Predicting remaining life by fusing the physics of failure modeling with diagnostics. JOM 2004, 56, 29–35. [Google Scholar] [CrossRef]
- Li, C.J.; Lee, H. Gear fatigue crack prognosis using embedded model, gear dynamic model and fracture mechanics. Mech. Syst. Signal Process. 2005, 19, 836–846. [Google Scholar] [CrossRef]
- Marksberry, P.; Jawahir, I. A comprehensive tool-wear/tool-life performance model in the evaluation of NDM (near dry machining) for sustainable manufacturing. Int. J. Mach. Tools Manuf. 2008, 48, 878–886. [Google Scholar] [CrossRef]
- Wang, P.; Gao, R.X. Adaptive resampling-based particle filtering for tool life prediction. J. Manuf. Syst. 2015, 37, 528–534. [Google Scholar] [CrossRef]
- Tian, Z. An Artificial Neural Network Approach for Remaining Useful Life Prediction of Equipments Subject to Condition Monitoring; IEEE: New York, NY, USA, 2009; pp. 143–148. [Google Scholar]
- Luo, R.C.; Chang, C.-C.; Lai, C.C. Multisensor Fusion and Integration: Theories, Applications, and its Perspectives. IEEE Sens. J. 2011, 11, 3122–3138. [Google Scholar] [CrossRef]
- Luo, R.C.; Chang, C.-C. Multisensor Fusion and Integration: A Review on Approaches and Its Applications in Mechatronics. IEEE Trans. Ind. Inform. 2011, 8, 49–60. [Google Scholar] [CrossRef]
- Tobon-Mejia, D.A.; Medjaher, K.; Zerhouni, N. CNC machine tool’s wear diagnostic and prognostic by using dynamic Bayesian networks. Mech. Syst. Signal Process. 2012, 28, 167–182. [Google Scholar] [CrossRef]
- Tran, V.T.; Pham, H.T.; Yang, B.-S.; Nguyen, T.T. Machine performance degradation assessment and remaining useful life prediction using proportional hazard model and support vector machine. Mech. Syst. Signal Process. 2012, 32, 320–330. [Google Scholar] [CrossRef]
- Loutas, T.H.; Roulias, D.; Georgoulas, G. Remaining Useful Life Estimation in Rolling Bearings Utilizing Data-Driven Probabilistic E-Support Vectors Regression. IEEE Trans. Reliab. 2013, 62, 821–832. [Google Scholar] [CrossRef]
- Soualhi, A.; Medjaher, K.; Zerhouni, N. Bearing Health Monitoring Based on Hilbert-Huang Transform, Support Vector Machine, and Regression. IEEE Trans. Instrum. Meas. 2015, 64, 52–62. [Google Scholar] [CrossRef]
- Wang, G.; Yang, Y.; Xie, Q.; Zhang, Y. Force based tool wear monitoring system for milling process based on relevance vector machine. Adv. Eng. Softw. 2014, 71, 46–51. [Google Scholar] [CrossRef]
- Zhang, K.-F.; Yuan, H.-Q.; Nie, P. A method for tool condition monitoring based on sensor fusion. J. Intell. Manuf. 2015, 26, 1011–1026. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, X.-F.; Zhang, J.; Jin, H. Tool Condition Monitoring and Remaining Useful Life Prognostic Based on a Wireless Sensor in Dry Milling Operations. Sensors 2016, 16, 795. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A Model-Based Method for Remaining Useful Life Prediction of Machinery. IEEE Trans. Reliab. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Wang, Y.; Yizhen, P.; Zi, Y.; Jin, X.; Tsui, K.-L. A Two-Stage Data-Driven-Based Prognostic Approach for Bearing Degradation Problem. IEEE Trans. Ind. Inform. 2016, 12, 924–932. [Google Scholar] [CrossRef]
- Pedregal, D.J.; Carnero, M.C. State space models for condition monitoring: A case study. Reliab. Eng. Syst. Saf. 2006, 91, 171–180. [Google Scholar] [CrossRef]
- Zhang, J.; Starly, B.; Cai, Y.; Cohen, P.H.; Lee, Y.-S. Particle learning in online tool wear diagnosis and prognosis. J. Manuf. Process. 2017, 28, 457–463. [Google Scholar] [CrossRef]
- Liu, X.; Song, P.; Yang, C.; Hao, C.; Peng, W. Prognostics and Health Management of Bearings Based on Logarithmic Linear Recursive Least-Squares and Recursive Maximum Likelihood Estimation. IEEE Trans. Ind. Electron. 2017, 65, 1549–1558. [Google Scholar] [CrossRef]
- Wu, J.; Su, Y.; Cheng, Y.; Shao, X.; Deng, C.; Liu, C. Multi-sensor information fusion for remaining useful life prediction of machining tools by adaptive network based fuzzy inference system. Appl. Soft Comput. 2018, 68, 13–23. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.-Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Zhang, C.; Yao, X.; Tan, W.; Zhang, Y.; Zhang, F. Proactive Scheduling for Job-Shop Based on Abnormal Event Monitoring of Workpieces and Remaining Useful Life Prediction of Tools in Wisdom Manufacturing Workshop. Sensors 2019, 19, 5254. [Google Scholar] [CrossRef]
- Yang, Y.; Guo, Y.; Huang, Z.; Chen, N.; Li, L.; Jiang, Y.; He, N. Research on the milling tool wear and life prediction by establishing an integrated predictive model. Measurement 2019, 145, 178–189. [Google Scholar] [CrossRef]
- Guo, L.; Lei, Y.; Xing, S.; Yan, T.; Li, N. Deep Convolutional Transfer Learning Network: A New Method for Intelligent Fault Diagnosis of Machines With Unlabeled Data. IEEE Trans. Ind. Electron. 2019, 66, 7316–7325. [Google Scholar] [CrossRef]
- Kumar, A.; Chinnam, R.B.; Tseng, F. An HMM and polynomial regression based approach for remaining useful life and health state estimation of cutting tools. Comput. Ind. Eng. 2019, 128, 1008–1014. [Google Scholar] [CrossRef]
- An, Q.; Tao, Z.; Xu, X.; El Mansori, M.; Chen, M. A data-driven model for milling tool remaining useful life prediction with convolutional and stacked LSTM network. Measurement 2020, 154, 107461. [Google Scholar] [CrossRef]
- Selim, S.Z.; Ismail, M.A. K-Means-Type Algorithms: A Generalized Convergence Theorem and Characterization of Local Optimality. IEEE Trans. Pattern Anal. Mach. Intell. 1984, 6, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Meng, X.; Zhang, Z.; Song, G. A Remaining Useful Life Prediction Method Considering the Dimension Optimization and the Iterative Speed. IEEE Access 2019, 7, 180383–180394. [Google Scholar] [CrossRef]
- Al-Sulaiman, F.A.; Baseer, M.A.; Sheikh, A.K. Use of electrical power for online monitoring of tool condition. J. Mater. Process. Technol. 2005, 166, 364–371. [Google Scholar] [CrossRef]
- Liu, H.; Lee, B.; Tarng, Y. Monitoring of drill fracture from the current measurement of a three-phase induction motor. Int. J. Mach. Tools Manuf. 1996, 36, 729–738. [Google Scholar] [CrossRef]
- Li, X.; Tso, S. Drill wear monitoring based on current signals. Wear 1999, 231, 172–178. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, Y. A generic tool wear model and its application to force modeling and wear monitoring in high speed milling. Mech. Syst. Signal Process. 2019, 115, 147–161. [Google Scholar] [CrossRef]
- Nouri, M.; Fussell, B.K.; Ziniti, B.L.; Linder, E. Real-time tool wear monitoring in milling using a cutting condition independent method. Int. J. Mach. Tools Manuf. 2015, 89, 1–13. [Google Scholar] [CrossRef]
- Chen, S.-L.; Jen, Y. Data fusion neural network for tool condition monitoring in CNC milling machining. Int. J. Mach. Tools Manuf. 2000, 40, 381–400. [Google Scholar] [CrossRef]
- Mahajan, A.; Wang, K.; Ray, P. Multisensor integration and fusion model that uses a fuzzy inference system. IEEE/ASME Trans. Mechatron. 2001, 6, 188–196. [Google Scholar] [CrossRef]
- Banerjee, T.P.; Das, S. Multi-sensor data fusion using support vector machine for motor fault detection. Inf. Sci. 2012, 217, 96–107. [Google Scholar] [CrossRef]
- Drouillet, C.; Karandikar, J.; Nath, C.; Journeaux, A.-C.; El Mansori, M.; Kurfess, T. Tool life predictions in milling using spindle power with the neural network technique. J. Manuf. Process. 2016, 22, 161–168. [Google Scholar] [CrossRef]
- Ghorbani, S.; Kopilov, V.V.; Polushin, N.I.; Rogov, V.A. Experimental and analytical research on relationship between tool life and vibration in cutting process. Arch. Civ. Mech. Eng. 2018, 18, 844–862. [Google Scholar] [CrossRef]
- Huang, M.; Liu, Z. Research on Mechanical Fault Prediction Method Based on Multifeature Fusion of Vibration Sensing Data. Sensors 2019, 20, 6. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Setting | Boosting Rounds | MSE (Train) | Asymmetric Loss (Train) | Asymmetric Loss (Test) |
|---|---|---|---|---|
| LightGBM default | 100 | 0.236246 | 0.628296 | 1.31852 |
| LightGBM with custom loss | 100 | 0.330155 | 0.27638 | 0.819872 |
| LightGBM with eraly stopping | 780 | 0.137639 | 0.0531724 | 0.783725 |
| LightGBM with early stopping and custom loss | 1848 | 0.162248 | 0.0136494 | 0.868132 |
| LightGBM with early stopping, custom loss and custom validation loss | 241 | 0.22839 | 0.13002 | 0.740384 |
| Features | Equations |
|---|---|
| Root mean square xrms | |
| Square root amplitude xsra | |
| Kurtosis value xkv | |
| Skewness value xsv | |
| Peak to peak value xppv | |
| Crest factor xcf | |
| Impusle factor xif | |
| Clearance factor xCF | |
| Center of gravity frequency | |
| Mean square frequency | |
| Root mean square frequency | |
| Variance of frequency |
| Model Setting | Boosting Rounds | Asymmetric Loss (Test) | Asymmetric Loss (Train) | R2 Score (Test) | R2 Score (Train) |
|---|---|---|---|---|---|
| LightGBM with Vibration Data | 4083 | 43.616 | 25.629 | 0.5407 | 0.7411 |
| LightGBM with Current Data | 2713 | 40.591 | 30.194 | 0.6184 | 0.7146 |
| LightGBM with Load Data | 1707 | 50.859 | 42.304 | 0.3748 | 0.3030 |
| LightGBM with Vibration and Current Data | 3384 | 31.744 | 17.579 | 0.7561 | 0.8718 |
| LightGBM with Vibration and Load Data | 2699 | 30.360 | 20.254 | 0.6987 | 0.7237 |
| LightGBM with Current and Load Data | 2940 | 32.607 | 21.716 | 0.7545 | 0.8732 |
| LightGBM with Current, Load and Vibration Data | 4522 | 27.472 | 15.615 | 0.8176 | 0.8465 |
| Model Setting | Boosting Rounds | Asymmetric Loss (Test) | Asymmetric Loss (Train) | R2 Score (Test) | R2 Score (Train) |
|---|---|---|---|---|---|
| LightGBM with Default Data Feature | 4522 | 27.472 | 15.615 | 0.81760 | 0.8465 |
| p-LightGBM with New Data Feature | 4227 | 24.383 | 16.542 | 0.8268 | 0.8357 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Meng, X.; Zhang, Z.; Song, G. A Machining State-Based Approach to Tool Remaining Useful Life Adaptive Prediction. Sensors 2020, 20, 6975. https://doi.org/10.3390/s20236975
Li Y, Meng X, Zhang Z, Song G. A Machining State-Based Approach to Tool Remaining Useful Life Adaptive Prediction. Sensors. 2020; 20(23):6975. https://doi.org/10.3390/s20236975
Chicago/Turabian StyleLi, Yiming, Xiangmin Meng, Zhongchao Zhang, and Guiqiu Song. 2020. "A Machining State-Based Approach to Tool Remaining Useful Life Adaptive Prediction" Sensors 20, no. 23: 6975. https://doi.org/10.3390/s20236975
APA StyleLi, Y., Meng, X., Zhang, Z., & Song, G. (2020). A Machining State-Based Approach to Tool Remaining Useful Life Adaptive Prediction. Sensors, 20(23), 6975. https://doi.org/10.3390/s20236975