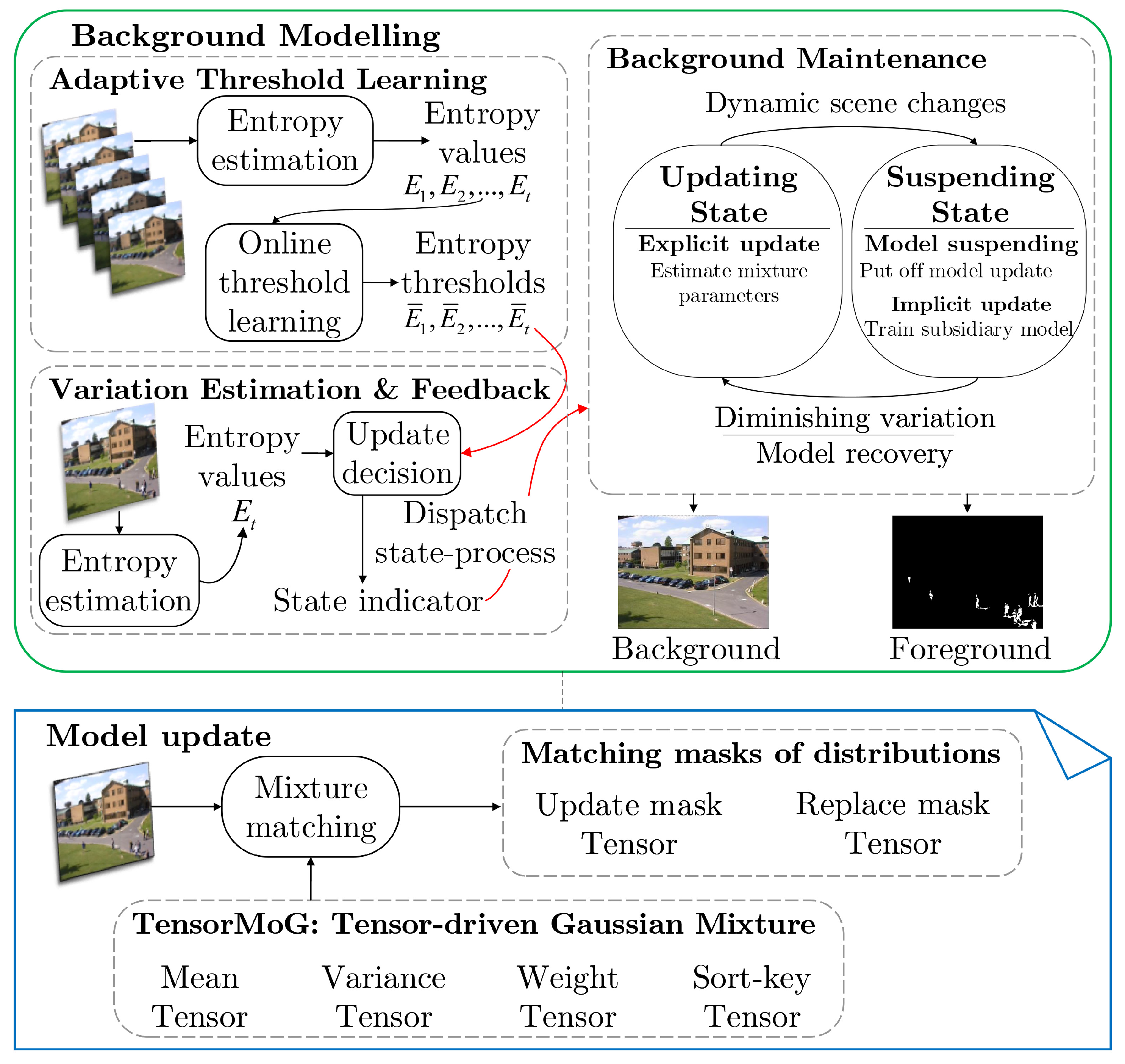
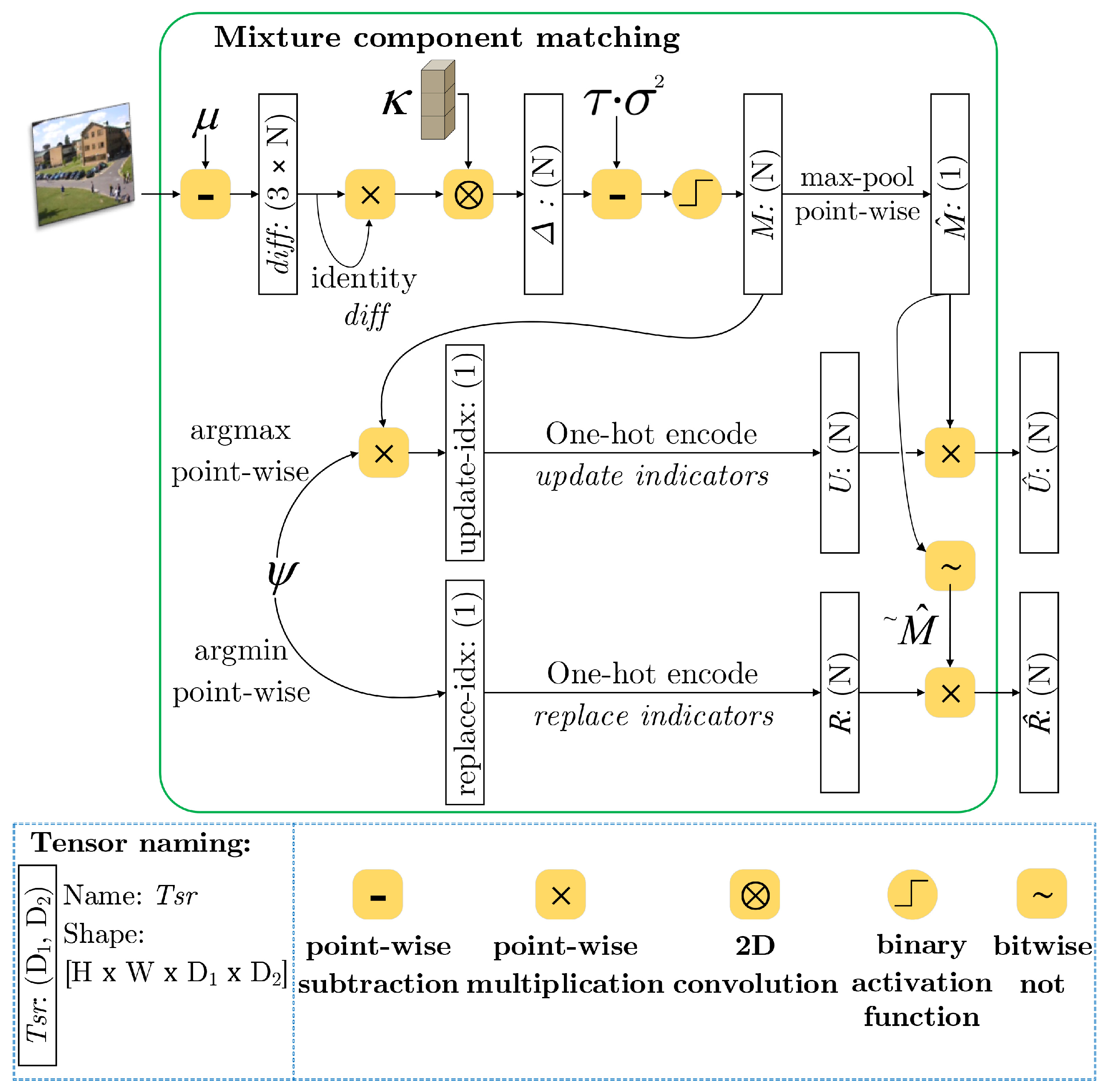
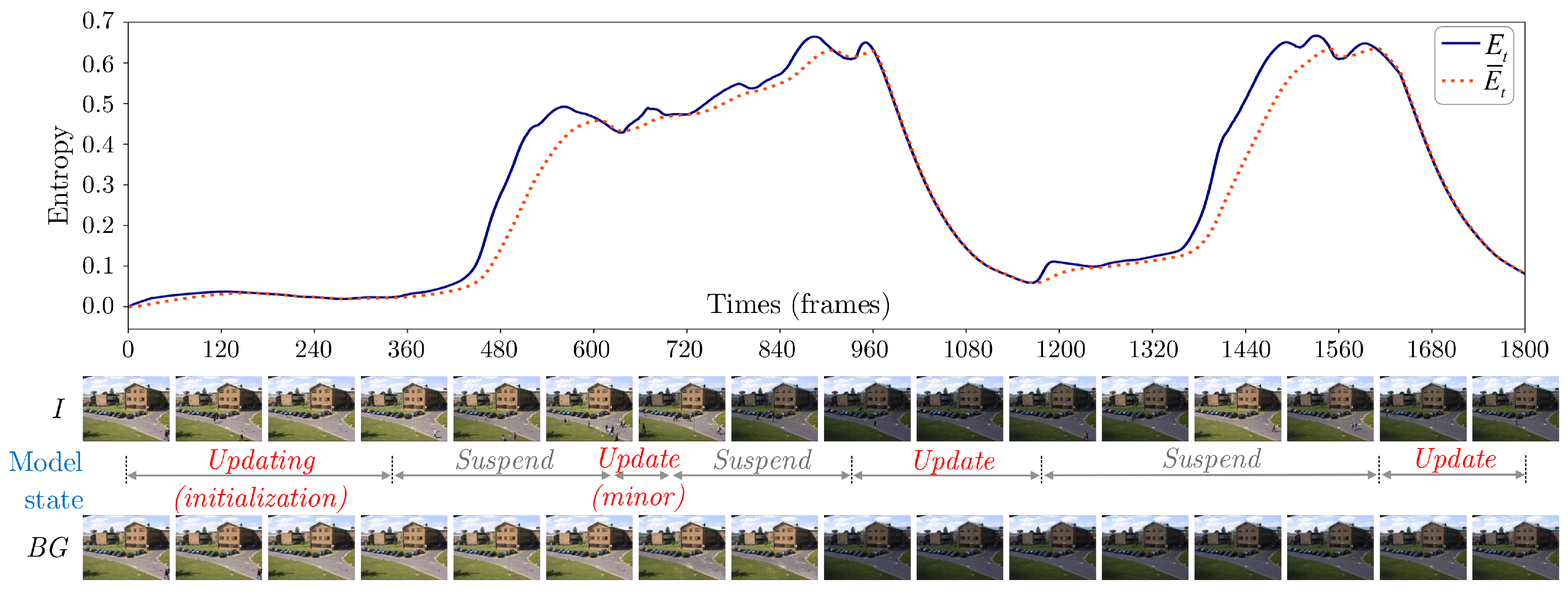
4.1. Experimental Setup and Dataset Selection
In this section, we demonstrate that our proposed TensorMoG is effective and can compete with existing state-of-the-art methods in terms of accuracy and processing time. TensorMoG was compared with state-of-the-art of methods that adopted an unsupervised learning approach: GMM—Stauffer & Grimson [
19], GMM—Zivkovic [
37], LOBSTER [
39], SuBSENSE [
40], SJN-Multiclue [
41], IBMS [
42], PAWCS [
15], SWCD [
43], PBAS [
44], FTSG [
26], and BMOG [
23]. In addition, regarding the strategy of supervised learning, we make a comparison with some of recent deep-learning-based methods that are related to the problem of change detection and background modelling: DeepPBM [
45]. DeepBS [
11], Cascade CNN [
12], STAM [
34], FgSegNet [
9], and FgSegNet_v2 [
35].
In our experiment,
N is empirically and heuristically determined by the TensorMoG’s capability of modeling constantly evolving contexts (e.g., moving body of water) under the effects of potentially corruptive noises, such that the framework utilizes reasonable space and time complexity, where
N is a scaling factor. Because
N is greater, there are many GMM components that are either unused or they simply capture the various noises presenting within the imaging sequences, especially contextual dynamics. This is because the background component would only revolve around the most frequently occuring color subspaces to draw predictions; so, the extra components would serve as either placeholders for abrupt changes in backgrounds, be empty, or capture intermittent noises of various degrees. In addition, using a greater value of
N would increase the probability that the observed intensiy values match with the Gaussian mixture. Nevertheless, the extent to small non-matching probability mathematically depends on the minimum variance that is configured. In practice, noise Gaussian components in GMMs are pulse-like, as they would appear for short durations, and are low-weighted because they are not as often matched as background components. Hence, when
N is great enough, the cumulative combination of non-background Gaussian components in the mixture would greatly reduce the non-matching probability if certain minimum variances are introduced. Otherwise, the pulse-like distributions would have negligible effects and the probability of finding no matches could still be high on assumption of completely random color vector input. In our work, we have emperically chosen
, so that TensorMOG can capture the high-frequency GMM components that are representative of backgrounds; it can also address certain degrees of noises with its non-background components whilst refraining from introducing too many computational overheads.
Table 1 illustrates a set of TensorMoG’s parameters.
Retrieving relevant information from recently comprehensive account of public video datasets for background subtraction and foreground detection [
46], our evaluations are conducted while using four publicly available benchmarking datasets:
- –
CDnet 2014 [
47]: the large-scale database of videos for motion detection across various scenarios.
- –
CAMO-UOW [
48]: a dataset specifically designed for evaluating the segmentation of camouflaged motion changes where foreground objects are of similar color as that of the background. This is less frequently used for benchmarking algorithms.
- –
SBMnet [
49]: the Scene Background modelling.NET dataset contains realistic videos to investigate modelling background scenes.
- –
SBI [
50]: the Scene Background Initialization (SBI) dataset is a set of image sequences where background images are occluded by foreground objects, which are designed to evaluate the formulation of background under a variety of challenging conditions.
In measuring the quality of our method along with others in terms of changes and motions, we adopt the common evaluation metrics that require computations of a confusion matrix: Precision, Recall, F-Measure, Specificity, False-Negative Rate (FNR), False-Positive Rate (FPR), and Percentage of Wrong Classification (PWC) [
51]. The overall results are similarly extracted from combining all sequence-based confusion matrices. Benchmarks using CDnet and CAMO-UOW employ these metrics for foreground predictions against provided ground-truths. Similarly for modelling background scenes, common and specific evaluation metrics are used, including the Average Gray-level Error (AGE), percentage of Error Pixels (pEPS), and percentage of Clustered Error Pixels (pCEPS), where, for all three, lower is better; and, the Multi-Scale Structural Similarity Index (MS-SSIM), Peak-Signal-to-Noise-Ratio (PSNR), and Color-image Quality Measure (CQM), where higher scores mean better. Among the metrics, because AGE, pEPS, and pCEPS are sensitive to even small variations and require exactness, they are practically less informative to demonstrate similarity measures against ground-truths than MS-SSIM. Evaluations with SBI and SBMnet datasets employ these metrics for comparing background modelling results against the true backgrounds. We used the available implementation of these metrics that were provided by SBI and SBMnet challenges [
49], but evaluated for all background predictions against their ground-truths and not just the cleanest prediction. The final result for a sequence is the average of all calculations for all frames against the sequence’s provided ground-truths. Lastly, we analyze all of the methods in terms of processing speed with the image resolution of
.
4.2. Results on CDnet 2014 Benchmark
With the large-scale CDnet2014 dataset, we demonstrate the effectiveness of our method by performing evaluations for all scenarios of differing multimodality and conditions of noises.
Table 2 illustrates our F-measure comparison and
Table 3 provides further details with regard to the recorded average of foreground metrics. Furthermore,
Figure 4 provides a visual close-up of the compared methods’ motion extraction results. It can be seen that the proposed method takes the first place overall across the different scenarios and even several of the scenarios (i.e.,
BDW,
TBL,
BSL,
DBG,
SHD), whilst still in top-3 with
NVD,
LFR, and
THM among the compared unsupervised methods. However, it is not without its weaknesses, as seen in the results of
Table 3 for F-measure scores of
PTZ,
NVD,
CJT, and
IOM.
Firstly, TensorMoG is highly effective in foreground segmentation on common cases (the BDW, BSL, TBL, DBG, SHD and THM scenarios) whose dynamic contexts contain both constant ambient motions innate to the background, and object motions of interest. Holding top place in overall F-score with the scenarios (and top-3 on THM) regarding unsupervised approaches, TensorMoG demonstrates remarkable improvements over its GMM counterparts and, at times, even over the more computationally expensive approaches SuBSENSE, PAWCS, and SWCD by noticeable margins. For instance, whilst BSL sequences are effectively tackled by TensorMoG with clean backgrounds that are only slightly better than the SuBSENSE’s score at 0.9503, on the DBG scenario, our proposed approach is able to distinguish object motions from the background much better at 0.9325 than SuBSENSE at 0.8177. This suggests that the proposed model could capture locally varying degrees of dynamics in order to construct the overall backgrounds for selecting out raw irrelevant information predicted as foregrounds. TensorMoG’s accuracy is reduced when scene dynamics vary globally with spatial translations, like in TBL. This scenario also presents a great challenge for the compared approaches, because, while objects’ displacements can be captured, scene contextual variations may also be considered to be object motions due to the unpredictably translating background objects that are caused by turbulence from the camera perspectives. THM sequences present much better camouflaging effects than have been recently addressed by TensorMoG at 0.8380; these effects can be discussed along the next subsection with other experiments.
Apparently, TensorMoG is fairly erroneous at
LFR, which is the scenario of great portions of motions for extraction due to its intermittent capturing of imaging signals. The similar situation is also seen at
CJT, which perpetuates spatially locally translating imaging inputs due to the video recorder’s motions and, at
IOM, where objects of interest exert intermittent motions throughout the observational views. TensorMoG’s motion predictions on the
LFR scenario contain “holes” in the foreground map and they impose significant cumulative errors to the overall results, as shown in
Figure 4. This is clarified by TensorMoG’s actual score of only 0.6852, whereas SWCD’s detailed analysis can produce the overall score of 0.7374. Because
CJT presents similar situations to
TBL, but more enhanced in translated motions of background objects, our overall score is only 0.6594, being weighed down by a significant number of False Positives, and it is toppled by SuBSENSE’s 0.8152 with its locally adaptive sensitivity. For
IOM, TensorMoG’s reduced accuracy of 0.6493 is expected, as the method’s adaptiveness considers stopped objects as part of the background after they have stayed within the observational area for a very long amount of time. Being designed to tackle stopped objects, the Flux-Tensor method produces better results, at 0.7891 overall, in the F-measure for the same scenario.
However, the results of TensorMoG also suggest poor performance on
NVD scenes, where night-lightings and moving objects intertwine on the motion maps, and its worst scores are on the
PTZ scenario, with abrupt camera motions. Other methods, even some supervised ones, are not able to perform at more than 0.8 in F-measure with
NVD. Like other unsupervised, TensorMoG is riddled with many False Negatives in this scenario, because night-lightings present very high degrees of motion noises. However, TensorMoG was able to stay in top-2 at 0.5604, and only slightly lower than SWCD’s 0.5807 among the unsupervised approaches. Among all scenarios,
PTZ presents the greatest challenge for TensorMoG, as its F-score is only at 0.2626.
PTZ also emerges as a challenge for all of the compared unsupervised methods, where the greatest score is only 0.4615 by PAWCS, along with the supervised DeepBS at only 0.3133. This is because the changes in camera perspectives can turn historically recorded information quickly obsolete. Thus, TensorMoG and methods utilizing durational information (e.g., DeepBS with background learning on pre-generated labels) are faulted by the lack of relevant information for correct predictions.
Figure 4 also showcases this.
Nevertheless, the overall result on all scenarios of TensorMoG, which is top-1 among the unsupervised approaches and it is within top-3 for eight out of 11 CDnet2014 scenarios in the F-measure. In addition, we draw, from
Table 3, more detailed evaluation of the proposed method in terms of Recall, Specificity, FPR, FNR, PWC, and Precision. Apparently, TensorMoG is the most precise among the compared unsupervised methods, at 0.8215, with an overall Recall score that is third best, at 0.7772. Furthermore, error rates, such as FPR at 0.0107, FNR at 0.2228, and PWC at 2.3315, do not deviate too far from the top scores at FPR-0.0051 of PAWCS, FNR-0.1876 of SuBSENSE, and PWC-1.1992 of PAWCS. All of which illustrate the proposed method’s general utility in practice without requiring intensive pretraining.
For supervised methods, we include, for comparative discussion in both
Table 2 and
Figure 4, the experimental results of methods utilizing DNNs. Specifically, we include a group of scene-specific DNNs that can detect motion changes by training with 200 frames per video sequence FgSegNet, FgSegNet_v2, and Cascade CNN, and another group consisting of multi-scene-single-model methods, DeepBS and STAM, which were trained with 5% of data from CDnet2014. From the results of
Table 2 and
Table 3, these DNN methods are capable of producing highly accurate results for motion segmentation across varying degrees of scenarios, aside from DeepBS, whose results are dependent on its background process, their accuracy results significantly surpass those of TensorMoG. They do this by learning the mapping function from series of imaging inputs to the expected motion maps, where their heavy architectural structures of parameters are found at extrema in the target-prediction function of difference. Thus, they are very capable of capturing useful, high-level motion patterns of their domain for extracting predictions. This is demonstrated best with scene-specific methods FgSegNet and FgSegNet_v2’s almost perfect overall results, at 0.9770 and 0.9847 in F-measure, and that of Cascade CNN at 0.9209, along with their respective self-explanatory results for other metrics (e.g., Specificity, FPR, FNR, PWC, etc.). Whereas, the scene-specific approach’s goal is to slightly overfit to the video of interest without the requirement of generalizing to any other contexts, thereby conceiving multiple models for multiple video scenarios of a dataset, the multi-scene-single-model approach adopted by DeepBS and STAM learns to generalize by sampling on the dataset for training. Specifically, DeepBS and STAM each only needed a single model for 53 sequences in CDnet2014 via training on 5% of the given data in order to capture patterns in the domain. DeepBS’s accuracy performance in terms of F-measure is weighed down by reduced scores in
LFR at 0.6002,
NVD at 0.5835,
IOM at 0.6098, and
PTZ at only 0.3133, thereby resulting in an overall lowest score of 0.7458 among the supervised approaches. DeepBS’s accuracy performance in terms of F-measure is weighed down by reduced scores in
LFR at 0.6002,
NVD at 0.5835,
IOM at 0.6098, and
PTZ at only 0.3133, thereby resulting in an overall lowest score of 0.7458 among supervised approaches. As this overall result is even lower than that of TensorMoG, it suggests that the DeepBS is still under-trained with only 5% of data, especially on
LFR with a large number of intermittent objects,
NVD with high degrees of lighting noises,
IOM where there may be assimilation of stopped objects into DeepBS background model, and
PTZ where the perspectives vary so much. In a similar way, on the
LFR and
NVD scenarios, STAM achieved F-measure scores of 0.6683 and 0.7102, respectively. Despite being less trained on
PTZ than other scene-specific approaches, STAM’s high grading of 0.8648 in F-measure far surpasses those of unsupervised methods, which suggests the great mapping correctness reaped from heavy computations.
The numerical outcomes from other metrics (Recall, Specificity, etc.) further clarifies the advantage that DNN models hold. Aside from DeepBS, which relies on the performance of its background model, others demonstrated top input-output learned mapping capability at roughly 0.9 in Precision, Specificity, and Recall or above, and very low error rates. Nevertheless, like Cascade CNN and FgSegNets, which overfit to a video sequence and benefit from its results, the generalization that is obtained with the single-model approach is dataset-specific, as demonstrated in [
34] with reduced accuracy when switching datasets. Therefore, in practice, if the contextual perspectives significantly deviate from what have been trained (i.e., switching perspectives, outdoor weather changed, camera repositions, etc.), these multi-scene-single-models would still require hardware-intensive, data-driven fine-tuning on the new views in order to incorporate their patterns into the architectural parameters. Consequently, the DNN technologies are still challenged by the trade-offs between accurate generalization and computational expenses, given the availability of data.
4.3. Results on CAMO-UOW Benchmark
In the same way, we analyze the performances of all methods with the Camouflaged Object dataset. Our goal for testing with this dataset is to demonstrate the effectiveness of the proposed method for extracting objects of interest under camouflaging effects, notable conditions that often hinder performance. We filtered out several sequences to only leave three sequences of grayscale and three of RGB color spaces. The reason for this is to provide meaningful discussion of the overall results, as not only the overall values will vary little when compared to those extracted with separate sequences, but it also allows for more thorough inspection of cases with the experimented methods. For this dataset, because SWCD was only tuned for CDnet via its own set of hyperparameters, we could not objectively provide its predictions for this dataset. On account of the fact that this dataset consists of imaging resolutions that vary from to pixels, the computational expenses incurred for retraining supervised methods on video sequences are very prohibitive. Consequently, objective measurements for DeepBS, FgSegnet, FgSegnet_v2, and STAM could not be provided by us on the dataset. In addition, we have to replace FTSG and BMOG with LOBSTER, PBAS, SJN-Multiclue, and IMBS, which are also unsupervised state-of-the-arts due to encountered objective implementational issues for this dataset. Because our experiments with camouflaging effects only serve to emphasize our proposed model’s generalization capability to the problematic case, the comparative evaluation with the selected methods can still provide objective analysis without any lack of rigour.
For this dataset, overall, our proposed method is third best in terms of F-measure, as illustrated in
Table 4. TensorMoG is comparable to both LOBSTER (best) and SuBSENSE (second best) in these cases. Particularly, it can be seen that TensorMoG performs very well on
Video 03,
Video 09, and
Video 10 at around 0.8 and, especially,
Video 07 at 0.9131. These sequences are similar, as each has moving people that are partially dressed in similar color as the background. Although it is surpassed by the top methods (LOBSTER and SuBSENSE) and PAWCS in
Video 07,
Video 09, and
Video 10, where there exists small but still humanly distinguishable color differences in the camouflaging areas, TensorMoG is still competitive against them, because it can better address the outdoor camouflaging effects, with the addition of lighting noises and a stopped object, in
Video 03 at 0.8090. Cases of marginal color deviations are also demonstrated among the methods in
Video 01 and
Video 05, where people are completely dressed in indistinguishable colors from the backgrounds. All of the compared methods are still challenged in tackling these scenarios, as even the best result of
Video 05 from GMM—Stauffer & Grimson is only 0.6666. Like related methods, TensorMoG is also challenged, where its results are 0.7311 on
Video 01, despite being third-best, and only 0.6066 on
Video 05. This suggests a weakness of the proposed method in the presence of high degrees of overlaps. Nevertheless, the overall score of 0.7944 still suggests TensorMoG’s reasonable utility in practical contexts.
An explanation for TensorMoG performance is that since mixtures’ top distributions are trained to initialize the background, their variances become smaller as their weights approach one, thereby making TensorMoG more sensitive to variations. However, difficult cases that are common to Video 05 are like what happened at the 160th frame of Video 01, where all of the methods struggle to figure out foreground components that are indistinguishable from the canvas behind. This suggests a weakness of the proposed method. Because all of the variances of TensorMoG’s mixtures have a lower-bound in order to always allow certain degrees of color variations, then, if an object’s color compared to background is too similar, it will be assimilated as a background value.
At closer inspection, apparently, TensorMoG’s prediction results of colored images average higher than those of grayscale images. This is objectively attributed to the fact that distance measures between input and mixture distributions are in Euclidean space, where intensities and information completeness of colored images are better emphasized. Regardless of color spaces, it can be said that TensorMoG’s handling of foreground generation illustrates good improvements over other GMM models in many cases. Firstly, as demonstrated with
Video 05 and
Video 09 from
Figure 5, it provides considerable removal of shadow effects whilst maintaining a high degree of granularity in terms of color changes. This is unlike the GMM version of Stauffer & Grimson, where, despite its capability of distinguishing granular color variations with the same video, object shadows are also captured from the sensitivity. Secondly, another advantage of TensorMoG is the provision of clean foregrounds, where not only foreground predictions are well-connected, but small noises are also removed (as compared to the GMM of Zivkovic), as shown in
Video 03 of
Figure 5 with sunlight variations through the leaves, and objectively drawn from the corresponding F-measure. Thirdly, also with
Video 03, due to TensorMoG’s mechanism of selective updates, it was able to capture the placed object on the table by resorting to the last stable background as entropy increases, unlike how the GMM of Stauffer & Grimson considers the plate part of the background so quickly.
The overall results are shown in
Table 5 for elaborations with all other metrics. The proposed method at its worst is in fifth place against the more computationally expensive SWCD, PAWCS, LOBSTER, and SuBSENSE. Upon close inspection, it can be seen that TensorMoG’s overall results on performed metrics is very balanced, and they do not deviate too far from those at the top with tolerable error magnitudes. On the other hand, TensorMOG has slightly lower recall and higher FNR when compared to those of GMM—Stauffer & Grimson, which may be attributed to the fixed lower-bound mentioned that leads to missing minuscule differences between an object and its background. Nevertheless, as a GMM-based architecture for background modeling, TensorMoG scores illustrate good improvements over both its GMM counterparts at precision, specificity, FPR, and PWC, which suggests cleaner foregrounds with filtered noises and light shadows. It can be concluded that, although TensorMoG may not be the best at addressing camouflaging effects, its utility is evidently still within the practical domain.
4.4. Results on SBI and SBMnet Benchmark
The scene background modelling datasets SBI and SBMnet are used, as we compare the performances of different algorithms while using the discussed metrics for background construction. By default, there are several methods that inherently do not model background scenes (SJN-Multiclue, PBAS and SWCD) and thus are left out. We experimented on all of 13 video sequences in SBI and 10 video sequences in SBMnet with labelled grouthtruth of background images. The results on SBI and SBMnet datasets are summarized in
Table 6 and
Table 7, respectively.
The generation of backgrounds using TensorMoG is generally in the range from second to fourth best with its simple calculations. The scores of all GMM-based models (TensorMoG and GMM counterparts) are competitive with one another. However, they fall slightly short of IMBS and, at times, SuBSENSE with these durationally short sequences, due to initialization properties. Specifically, if the first frame, which biasedly provides the first mixture distributions, greatly deviates from the true background, then the GMM-based models require enough time to recover, otherwise the predictions will be riddled with faults. However, the GMM model that was devised by Zivkovic and, especially, that of Stauffer & Grimson, can still be considered to be the top performing approaches. This is based on the fact that, in terms of MS-SSIM (the structural similarity measure to evaluate perceived visual distortions), PSNR (the ratio between the maximum possible power of a signal and the power of corrupting noise), and CQM (the metric based on a reversible transformation of the YUV color space and on the PSNR computed in the single YUV bands), which are the especially designed imaging quality metrics for background evaluation, they are hardly surpassed with their mathematical rigour on pixel-wise evaluations.
Unlike SuBSENSE, whose performance evaluation scores greatly differ between the two datasets, it can be seen that TensorMoG is capable of maintaining balanced measurements for all metrics, such as Average Gray Error at 13.5404 for SBI versus that at 13.8699 for SBMnet across the separate corresponding sequences. With AGE, pEPs, and pCEPS measuring, the strictly precise similarity between background prediction and groundtruth in the grayscale color space, TensorMoG’s performance errors at constructing backgrounds for image understanding at around second–fourth place are tolerable, given that the input resolutions for SBI vary from 144 × 144 to 800 × 600 pixels, and those of SBMnet vary from 200 × 164 to 720 × 576 pixels. On the other hand, whilst IMBS produces the lowest errors in terms of these precise metrics, its perceived background predictions are still afflicted with motion features. This is best indicated by measurements that are made with the structural similarity metric MS-SSIM.
DeepPBM, which engages a variational autoencoder (VAE) framework of DNNs in learning compressed representations of visual features in video sequence, is taken into consideration in this matter. We perform a training this architect from scratch with a batch size of 200, the dimension of the latent variables
. The background outputs that are constructed by DeepPBM are approximately satisfied with respect to the labelled groundtruth regarding video sequences with few variations like the sequence
Candela_m1.10,
CAVIAR1 in SBI and the sequences
511,
BusStopMorning. However, the adaptation of this unsupervised probabilistic model estimation with VAE is not really sufficient in situations with drastic scene dynamics and high variation in a short period of time within short sequence, like the sequences
Board,
Foliage,
HumanBody2 in SBI and the sequences
CameraParameter,
badminton, and
boulevard in SBMnet. The absence of a large-scale video sequence makes statistical regularities in this model weak to acquire the true background of scenes. When considering the MS-SSIM metric for both the SBI and SBMnet dataset, DeepPBM achieves a groundtruth similarity of 77.66% and 78.00%, respectively. Meanwhile, with an online statistical learning, our proposed TensorMoG takes the first and second place in MS-SSIM measurement, respectively, for these two dataset. Moreover, we maintain the third-lowest signal-noise ratio PSNR for both of the datasets, which is analyzed with provided background groundtruth.
Figure 6 and
Figure 7, respectively, illustrate the visual comparison for background modelling on the datasets SBI and SBMnet.
4.6. Experimental Summary
Our experimental results indicated that the framework is robust against various situations for producing satisfactory foreground segments and background views. Its adaptiveness from the light-weighted architecture evidently suggests the capability for generalizations across scenes in the unsupervised manner without requiring prior data for pretraining. Specifically, whilst the proposed model presents marked improvements over the GMM-counterparts BMOG, GMM–Stauffer & Grimson, GMM–Zivkovic across the diverse array of scenarios (i.e., dynamic backgrounds, weather conditions, low framerate, etc.), it is also capable of surpassing the more sophisticated approaches SuBSENSE, SWCD, PAWCS, and FTSG, overall, on the CDnet2014 dataset. TensorMoG has also illustrated its utility in addressing the camouflaging effects for motion analysis with CAMO-UOW, being, overall, third-best and slightly numerically worse than LOBSTER and SuBSENSE. Furthermore, in terms of background construction, the results obtained by TensorMoG are only structurally second to GMM–Stauffer & Grimson or even the best among compared methods, as indicated by the MS-SSIM metric. Coupled with its very impressive speed, TensorMoG can be practically deployed across multiple outdoor and indoor real-time video scenes. Regarding this technological aspect, whereas the unsupervised models when compared with TensorMoG in CDnet2014, CAMO-UOW, SBI, and SBM follow the sequentially iterative paradigm of computations (even Flux-Tensor, despite its tensor-driven framework), TensorMoG is designed in order to utilize modern parallel computing technologies. On the speed test, TensorMoG is at 302.5261 frames-per-second, and is only surpassed by the performance of the less accurate GMM–Zivkovic. Nevertheless, aside from the great balance between accuracy and speed across scenes, the method is also shown to be challenged under certain ruinous effects (e.g., camera jitters in CJT, motion noises in NVD, changing perspectives in PTZ of CDnet2014, etc.) that would require further study.
In comparison with supervised approaches, it has been showcased that TensorMoG’s unsupervised statistical learning cannot outperform the data-driven, learned mapping of Cascade CNN, STAM, FgSegNet, and FgSegNet_v2, which are capable of finding detailed, high-leveled patterns across multiple scenarios, in terms of accuracy. Because DeepBS may be hindered by corrupted background models in certain scenarios, its performance being outperformed cannot be objectively viewed as an advantage of TensorMoG. Whereas, Cascade CNN and FgSegNets overfit to a video sequence and benefit from its results, the generalization that is obtained with the single-model approach with DeepBS and STAM is dataset-specific, which suggest further intensive training with more labeled data if contextual perspectives are significantly changed in practice (e.g., camera reposition) in order to incorporate new information. Thus, TensorMoG’s actual advantages over the supervised methods are its compromise in accuracy for low computational burdens, not requiring hardware-intensive pre-training on manually sampled data whilst being highly generalizable. This advantage can be emphasized in real-time, constantly evolving scenes, where deploying the light-weight TensorMoG would provide an edge in factoring out motions adaptively.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}