ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features


Abstract
1. Introduction
- (1)
- We proposed a novel feature map generation method using multi-scale voxel and multi-view projection. This algorithm can quickly and accurately extract the features and reduce the effect of ground object size on classification results.
- (2)
- We proposed a novel point cloud classification method by integrating an improved fully convolutional neural network into the transfer learning. This method uses the pre-trained DensNet201 model to derive deep features, which can characterize the object effectively. Then, the full CNN is improved by using max-pooling operation to extract the global features and average-pooling operation to derive the final feature of each object. Finally, the improved fully CNN is used for the classification of the ALS point cloud.
- (3)
- Our method achieves the highest accuracy in the ISPRS reference dataset [5]. When only 16,000 points of the original data are used as training samples, our overall accuracy is 89.84% and the average F1 score is 83.62%.
2. Methodology
2.1. Overview
- (1)
- Feature map generation includes the shallow feature extraction and the generation of feature maps by multi-scale voxel and multi-view projection.
- (2)
- Point cloud classification based on transfer learning, which includes deep feature extraction based on a pre-trained DenseNet201 model and a classification procedure using a fully convolutional neural network with convolutional and pooling layers.
- (3)
- Post processing, in which a graph-cuts algorithm considering context information is used to refine the classification result.
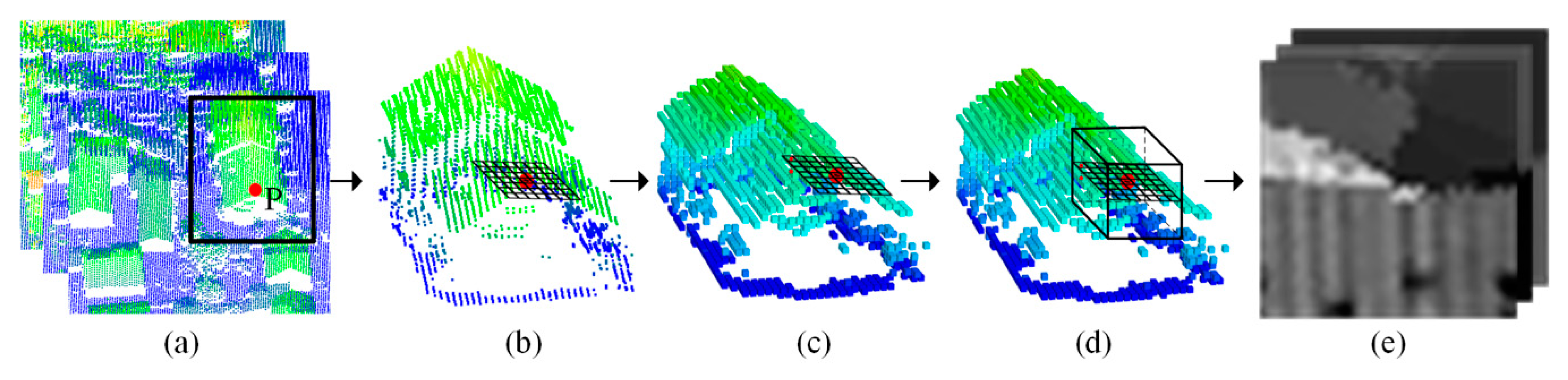
2.2. Feature Map Generation by Multi-Scale Voxel and Multi-View Projection
2.2.1. Shallow Feature Extraction
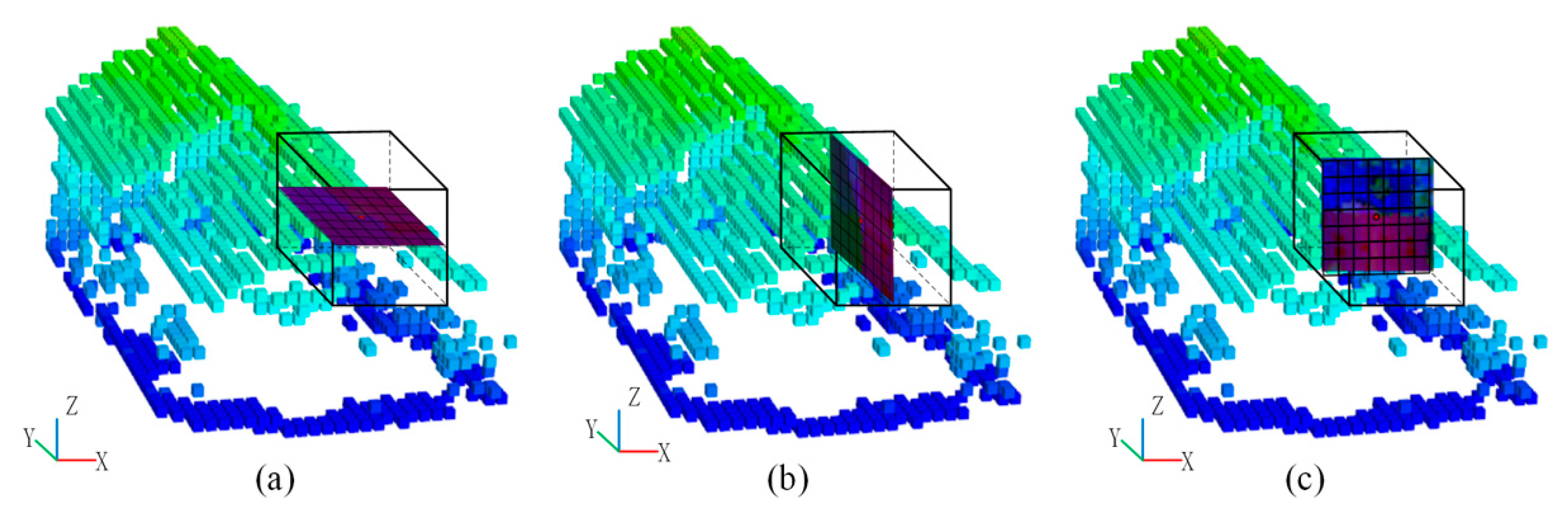
2.2.2. Projecting Shallow Feature into Feature Map
2.2.3. Multi-Scale and Multi-View Feature Maps Generation
2.3. Point Cloud Classification Based on Transfer Learning
2.3.1. Deep Feature Extraction
2.3.2. Classification by Using an Improved Fully Convolutional Neural Network
2.4. Post Processing with Graph-Cuts Optimization
3. Experimental Results
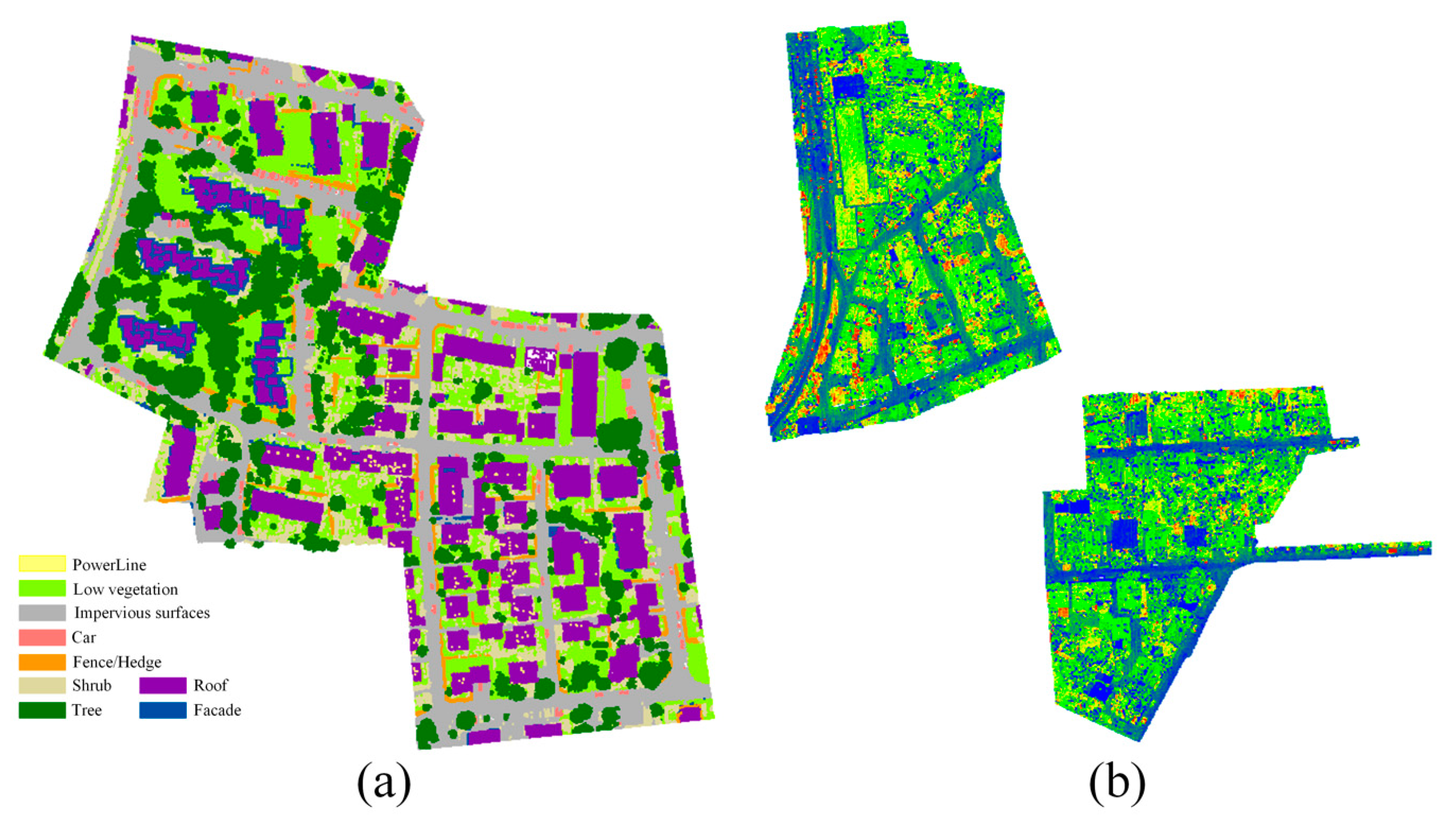
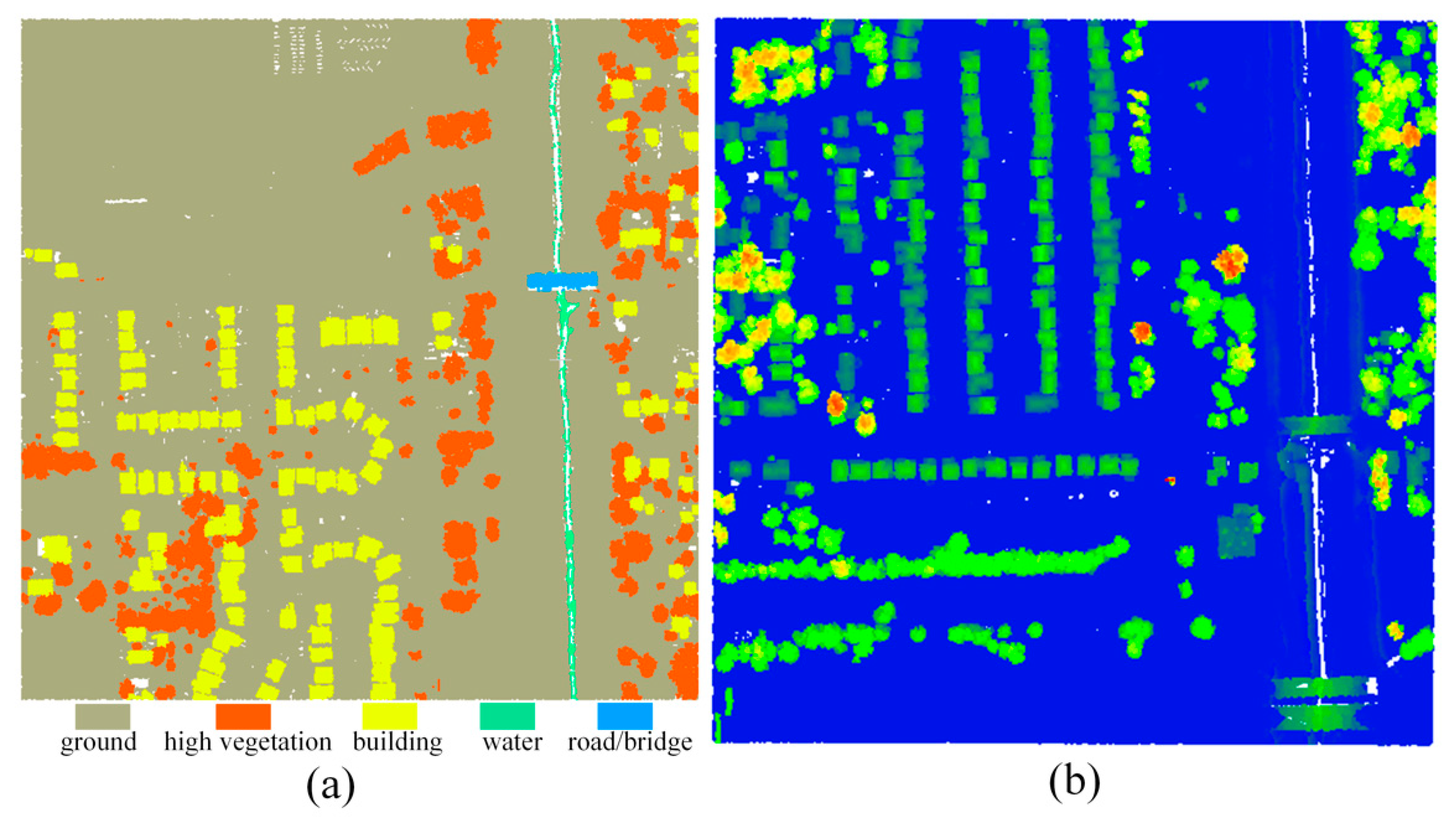
3.1. Dataset
3.2. Experiment Settings
3.3. Classification Result
4. Discussion
4.1. Impact of Multi-View and Multi-Scale Features
4.2. Performance of the Improved Fully Convolutional Neural Network
4.3. Effectiveness of Graph-Cuts Optimization
4.4. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kada, M. 3D building generalization based on half-space modeling. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2006, 36, 58–64. [Google Scholar]
- Axelsson, P. Dem generation from laser scanner data using adaptive tin models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Mauya, E.W.; Zahabu, E. Large-scale estimation of change in aboveground biomass in miombo woodlands using airborne laser scanning and national forest inventory data. Remote Sens. Environ. 2017, 188, 106–117. [Google Scholar] [CrossRef]
- Shi, T.; Ma, X.; Han, G.; Xu, H.; Gong, W. Measurement of CO2 rectifier effect during summer and winter using ground-based differential absorption lidar. Atmos. Environ. 2019, 220, 117097. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of LiDAR data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Xu, S.; Vosselman, G.; Oude Elberink, S. Detection and classification of changes in buildings from airborne laser scanning data. Remote Sens. 2015, 7, 17051–17076. [Google Scholar] [CrossRef]
- Vosselman, G. Point cloud segmentation for urban scene classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, 1, 257–262. [Google Scholar] [CrossRef]
- Maltezos, E.; Ioannidis, C. Automatic detection of building points from LiDAR and dense image matching point clouds. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 3, 33–40. [Google Scholar] [CrossRef]
- Lin, X.; Zhang, J. Segmentation-based filtering of airborne LiDAR point clouds by progressive densification of terrain segments. Remote Sens. 2014, 6, 1294–1326. [Google Scholar] [CrossRef]
- Zhang, J.Y.; Zhao, X.L.; Chen, Z. A review of Semantic Segmentation of Point Cloud Based on Deep Learning. Las. Optoelect. Prog. 2020, 57, 28–46. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Gevaert, C.M.; Persello, C.; Sliuzas, R.; Vosselman, G. Classification of informal settlements through the integration of 2D and 3D features extracted from UAV data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 317–324. [Google Scholar] [CrossRef]
- Guo, L.; Chehata, N.; Mallet, C.; Boukir, S. Relevance of airborne LiDAR and multispectral image data for urban scene classification using Random Forests. ISPRS J. Photogramm. Remote Sens. 2011, 66, 56–66. [Google Scholar] [CrossRef]
- Hackel, T.; Wegner, J.D.; Schindler, K. Fast semantic segmentation of 3D point clouds with strongly varying density. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 177–184. [Google Scholar] [CrossRef]
- Ni, H.; Lin, X.; Zhang, J. Classification of ALS point cloud with improved point cloud segmentation and random forests. Remote Sens. 2017, 9, 288. [Google Scholar] [CrossRef]
- Wen, C.; Yang, L.; Li, X.; Peng, L.; Chi, T. Directionally constrained fully convolutional neural network for airborne LiDAR point cloud classification. ISPRS J. Photogramm. 2020, 162, 50–62. [Google Scholar] [CrossRef]
- Wolf, D.; Prankl, J.; Vincze, M. Fast semantic segmentation of 3D point clouds using a dense CRF with learned parameters. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 4867–4873. [Google Scholar]
- Lu, Y.; Rasmussen, C. Simplified Markov random fields for efficient semantic labeling of 3D point clouds. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 2690–2697. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Feng, F.; Wang, S.; Wang, C.; Zhang, J. Learning Deep Hierarchical Spatial-Spectral Features for Hyperspectral Image Classification Based on Residual 3D-2D CNN. Sensors 2019, 19, 5276. [Google Scholar] [CrossRef]
- Das, N.; Hussain, E.; Mahanta, L.B. Automated classification of cells into multiple classes in epithelial tissue of oral squamous cell carcinoma using transfer learning and convolutional neural network. Neural Netw. 2020, 128, 47–60. [Google Scholar] [CrossRef]
- Hu, X.; Yuan, Y. Deep-learning-based classification for DTM extraction from ALS point cloud. Remote Sens. 2016, 8, 730. [Google Scholar] [CrossRef]
- Li, Y.; Tong, G.; Li, X.; Zhang, L.; Peng, H. MVF-CNN: Fusion of Multilevel Features for Large-Scale Point Cloud Classification. IEEE Access 2019, 7, 46522–46537. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Vancouve, BC, Canada, 12–14 December 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 2017 Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Yizhak, B.; Michael, L.; Anath, F. 3DmFV: Three-dimensional point cloud classification in real-time using convolutional neural networks. IEEE Robot. Autom. Lett. 2018, 25, 3145–3152. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN Convolution on X-transformed points. In Proceedings of the Annual Conference on Neural Information Processing Systems (NeurIPS), Montreal, QU, Canada, 2–8 December 2018. [Google Scholar]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv flexible and deformable convolution for point clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6410–6419. [Google Scholar]
- Arief, H.A.A.; Indahl, U.G.; Strand, G.; Tveite, H. Addressing overfitting on point cloud classification using Atrous XCRF. ISPRS J. Photogramm. 2019, 155, 90–101. [Google Scholar] [CrossRef]
- Zhao, C.; Guo, H.T.; Lu, J.; Yu, D.H.; Li, D.J.; Chen, X.W. ALS Point Cloud Classification with Small Training Dataset Based on Transfer Learning. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1406–1410. [Google Scholar] [CrossRef]
- Zhang, W.M.; Qi, J.B.; Wang, P.; Wang, H.T.; Xie, D.H.; Wang, X.Y.; Yan, G.J. An Easy-to-Use Airborne LiDAR Data Filtering Method Based on Cloth Simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NE, USA, 26 June–1 July 2016. [Google Scholar] [CrossRef]
- Kornblith, S.; Shlens, J.; Le, Q.V. Do Better imagenet models transfer better? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Los Angeles, CA, USA, 16–20 June 2019; pp. 2661–2671. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. In Proceedings of the IEEE International Conference on Learning Representations (ICLR), Scottsdale, AR, USA, 2–4 May 2013. [Google Scholar]
- Boykov, Y.; Kolmogorov, V. An experimental comparison of min-cut/max-flow algorithms for energy minimization in vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the IEEE International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Yang, Z.S.; Jiang, W.S.; Xu, B.; Zhu, Q.S.; Jiang, S.; Huang, W. A Convolutional Neural Network-Based 3D Semantic Labeling Method for ALS Point Clouds. Remote Sens. 2017, 9, 936. [Google Scholar] [CrossRef]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U.; Heipke, C. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. Remote Sense. 2016, 41, 655–662. [Google Scholar] [CrossRef]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32, 1–20. [Google Scholar] [CrossRef]
- Yang, Z.; Tan, B.; Pei, H.; Jiang, W.S. Segmentation and Multi-Scale Convolutional Neural Network-Based Classification of Airborne Laser Scanner Data. Sensors 2018, 18, 3347. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Hu, X.; Dai, H. A Graph-Voxel Joint Convolution Neural Network for ALS Point Cloud Segmentation. IEEE Access 2020, 8, 139781–139791. [Google Scholar] [CrossRef]
- Qin, N.; Hu, X.; Wang, P.; Shan, J.; Li, Y. Semantic Labeling of ALS Point Cloud via Learning Voxel and Pixel Representations. IEEE Geosci. Remote Sens. Lett. 2020, 17, 859–863. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifer | F1 Score | OA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Low_veg | Imp_sur | Car | Fe/He | Roof | Facade | Shrub | Tree | ||
| FC | 83.78 | 92.15 | 66.45 | 69.46 | 92.13 | 55.07 | 63.75 | 85.51 | 85.09 |
| FCN | 84.11 | 93.1 | 71.49 | 65.33 | 93.67 | 60.63 | 64.95 | 87.53 | 86.3 |
| CN-P | 86.36 | 93.69 | 73.44 | 71.14 | 94.3 | 61.55 | 70.18 | 89.01 | 87.96 |
| Method | F1 Score | OA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Low_veg | Imp_sur | Car | Fe/He | Roof | Facade | Shrub | Tree | ||
| N-GC | 86.36 | 93.69 | 73.44 | 71.14 | 94.3 | 61.55 | 70.18 | 89.01 | 87.96 |
| GC | 87.33 | 94.02 | 84.46 | 76.17 | 95.76 | 67.07 | 73.44 | 90.75 | 89.84 |
| Method | F1 Score | OA | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pow | Low_veg | Imp_sur | Car | Fe/He | Roof | Facade | Shrub | Tree | ||
| WhuY3 | 37.1 | 81.4 | 90.1 | 63.4 | 23.9 | 93.4 | 47.5 | 39.9 | 78.0 | 82.3 |
| RIT_1 | 37.5 | 77.9 | 91.5 | 73.4 | 18.0 | 94.0 | 49.3 | 45.9 | 82.5 | 81.6 |
| LUH | 59.6 | 77.5 | 91.1 | 73.1 | 34.0 | 94.2 | 56.3 | 46.6 | 83.1 | 81.6 |
| WhuY4 | 42.5 | 82.7 | 91.4 | 74.7 | 53.7 | 94.3 | 53.1 | 47.9 | 82.8 | 84.9 |
| NANJ2 | 62.0 | 88.8 | 91.2 | 66.7 | 40.7 | 93.6 | 42.6 | 55.9 | 82.6 | 85.2 |
| D-FCN | 70.4 | 80.2 | 91.4 | 78.1 | 37.0 | 93.0 | 60.5 | 46.0 | 79.4 | 82.2 |
| A-XCRF | 63.0 | 82.6 | 91.9 | 74.9 | 39.9 | 94.5 | 59.3 | 50.8 | 82.7 | 85.0 |
| JGVNet | 66.9 | 82.6 | 91.6 | 78.6 | 37.9 | 95.8 | 60.6 | 42.6 | 83.7 | 85.0 |
| VPNet | 74.5 | 82.1 | 91.6 | 83.4 | 45.9 | 93.3 | 60.6 | 51.1 | 82.3 | 84.0 |
| DRN | - | 83.3 | 92.5 | 52.4 | 62.5 | 95.2 | 62.8 | 64.9 | 88.7 | 86.8 |
| Ours | - | 87.3 | 94.0 | 84.5 | 76.2 | 95.8 | 67.1 | 73.4 | 90.8 | 89.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, X.; Wang, H.; Wang, C.; Zhao, Z.; Miao, J.; Tian, P. ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features. Sensors 2020, 20, 6969. https://doi.org/10.3390/s20236969
Lei X, Wang H, Wang C, Zhao Z, Miao J, Tian P. ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features. Sensors. 2020; 20(23):6969. https://doi.org/10.3390/s20236969
Chicago/Turabian StyleLei, Xiangda, Hongtao Wang, Cheng Wang, Zongze Zhao, Jianqi Miao, and Puguang Tian. 2020. "ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features" Sensors 20, no. 23: 6969. https://doi.org/10.3390/s20236969
APA StyleLei, X., Wang, H., Wang, C., Zhao, Z., Miao, J., & Tian, P. (2020). ALS Point Cloud Classification by Integrating an Improved Fully Convolutional Network into Transfer Learning with Multi-Scale and Multi-View Deep Features. Sensors, 20(23), 6969. https://doi.org/10.3390/s20236969