Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering


Abstract
1. Introduction
2. Materials and Methods
2.1. Related Work
2.1.1. Visual Question Answering
2.1.2. Co-Attention Models
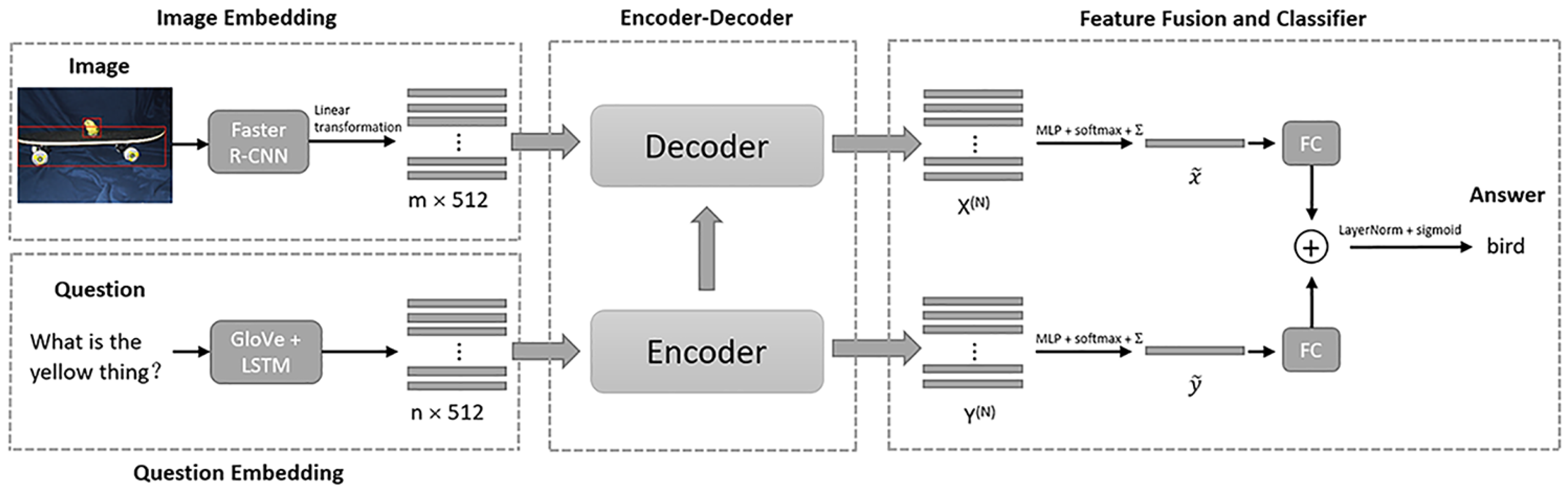
2.2. Multi-Modal Explicit Sparse Attention Networks
2.2.1. Image and Question Embeddings
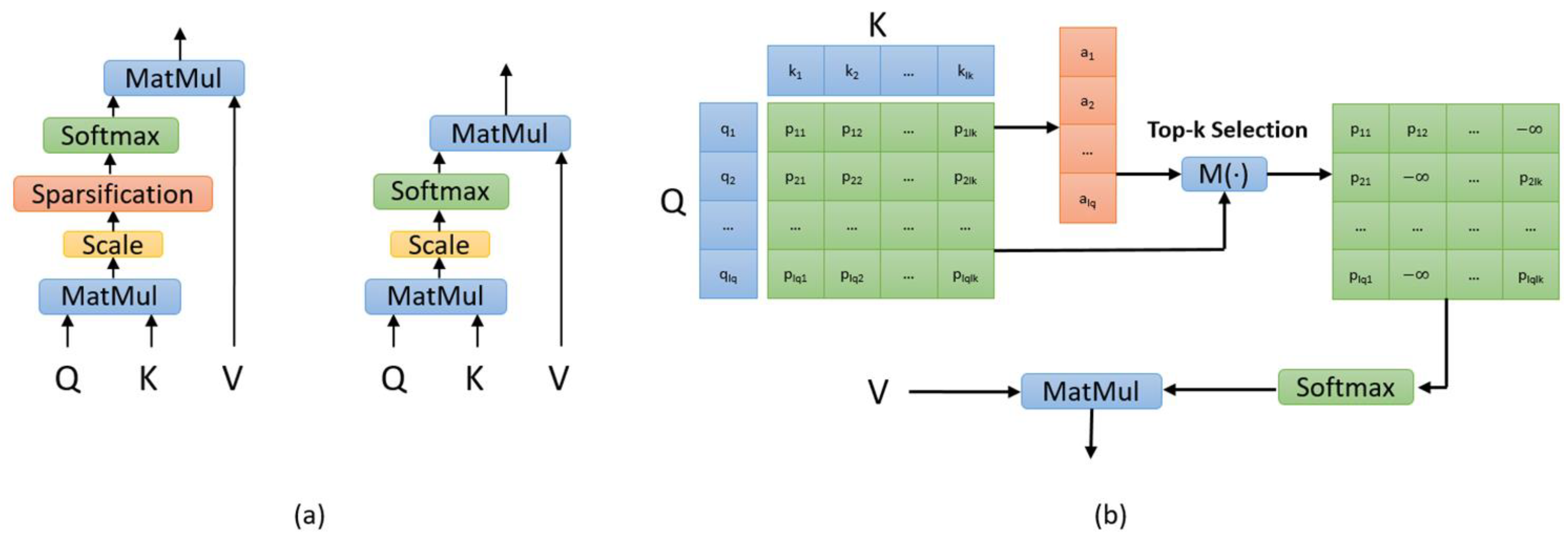
2.2.2. Explicit Sparse Attention
- Sparse Scaled Dot-Product Attention
- 2.
- Multi-Head Sparse Attention
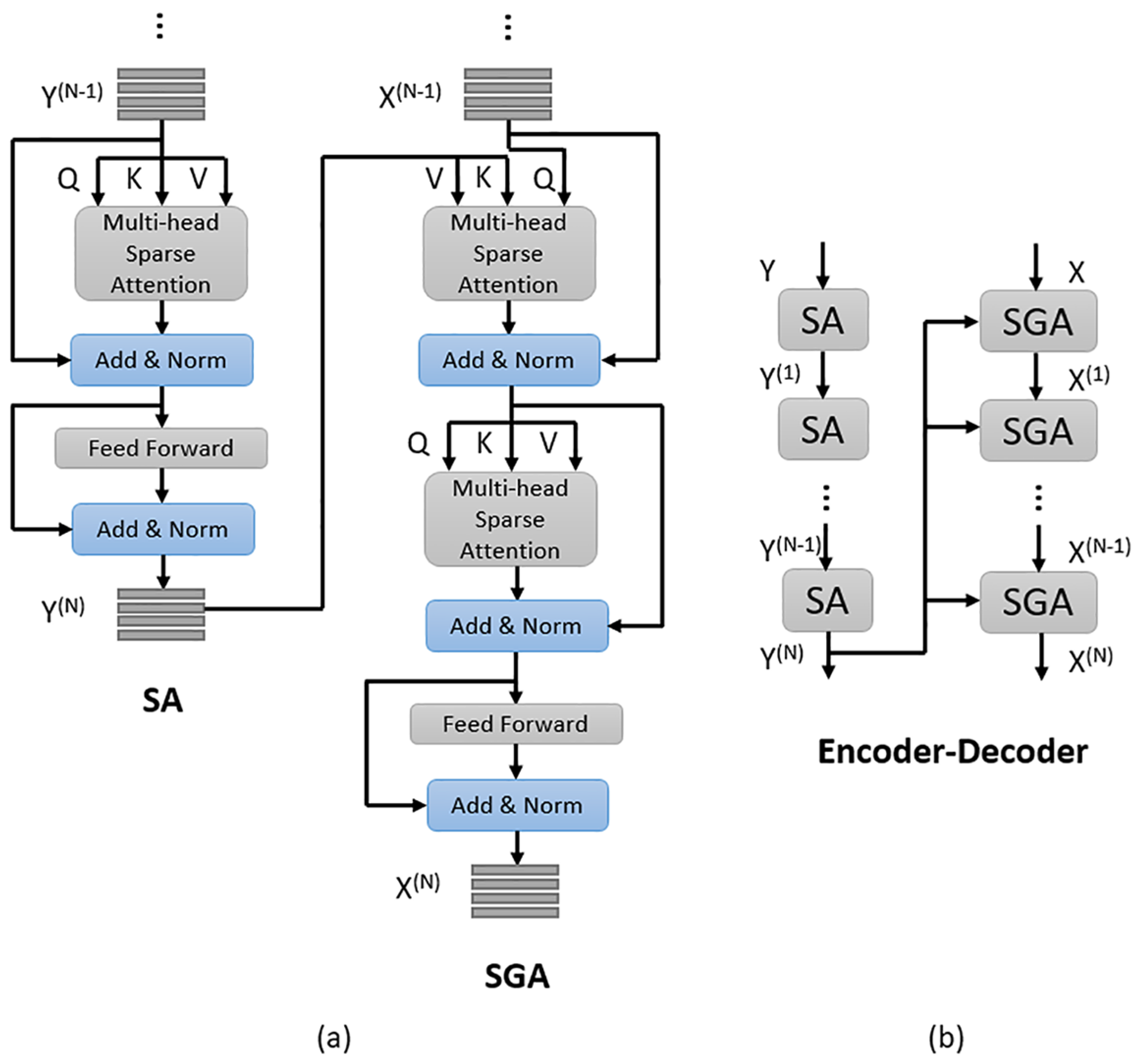
2.2.3. Encoder and Decoder
- Encoder: We use encoder to implement self-attention to learn fine-grained question features. The encoder consists of N stacked identical SA (self-attenion) units and each SA unit has two sub-layers. The first sub-layer is a multi-head sparse attention layer and the second is a pointwise fully connected feed-forward layer. The first SA unit takes question features as input, and its multi-head sparse attention layer learns the correlation between each word pair . The feed-forward layer of the first SA unit further transforms the output of its previous sub-layer through two fully connected layers with ReLu [38] and Dropout and outputs the attended question features. Every other SA unit takes the output of its previous SA unit as input and we mark the output of the encoder as .
- Decoder: The decoder consists of N stacked identical SGA (self&guided-attention) units, each of which has three sub-layers and outputs the attended image features. The first and the second sub-layers are both a multi-head sparse attention layer with sparse scaled dot-product attention as the core. The first sub-layer of the first SGA unit takes image features as input and every other SGA unit takes the output attended image features of its previous SGA unit as input to its first sub-layer. In practice, we use a linear transformation of X to make its dimension consistent with the question features. The second sub-layer takes the attended image features obtained from its previous sub-layer and the output of the encoder, i.e., the attended question features as input to learn question-guided attention for the input image features. The last sub-layer is a feed-forward layer, which is the same as that in the encoder and it also takes the output of its previous sub-layer as input. We mark the output of the decoder as .
2.2.4. Feature Fusion and Classifier
3. Results
3.1. The Dataset
3.2. Experimental Setup
3.3. Experimental Results and Ablation Studies
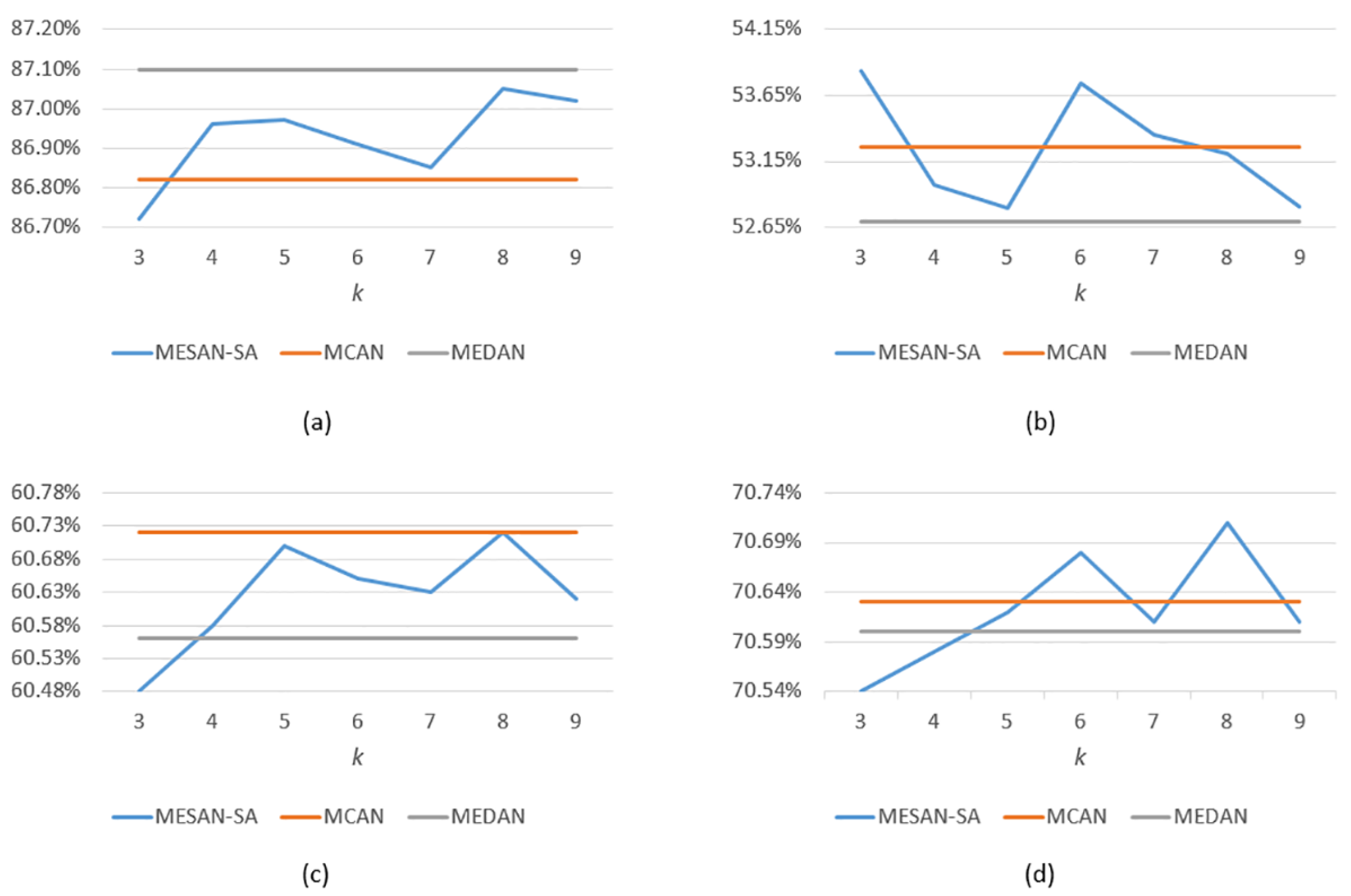
- MESAN-SA: MESAN-SA means that only the SA units for learning question self-attention in encoder adopt explicit sparse attention, while the SGA units in decoder adopt the ordinary scaled dot-product attention. The length of the input question words is 14, thus we need to select [1, 14] most relevant question key words for subsequent experiments. During ablation studies, we evaluate the performance of {3, 4, 5, 6, 7, 8, 9}. From Table 1 and Figure 4d, we can see that the accuracy of the model roughly increases first and then decreases with the increase of k. When k = 8, the model achieves the highest accuracy, 70.71%.
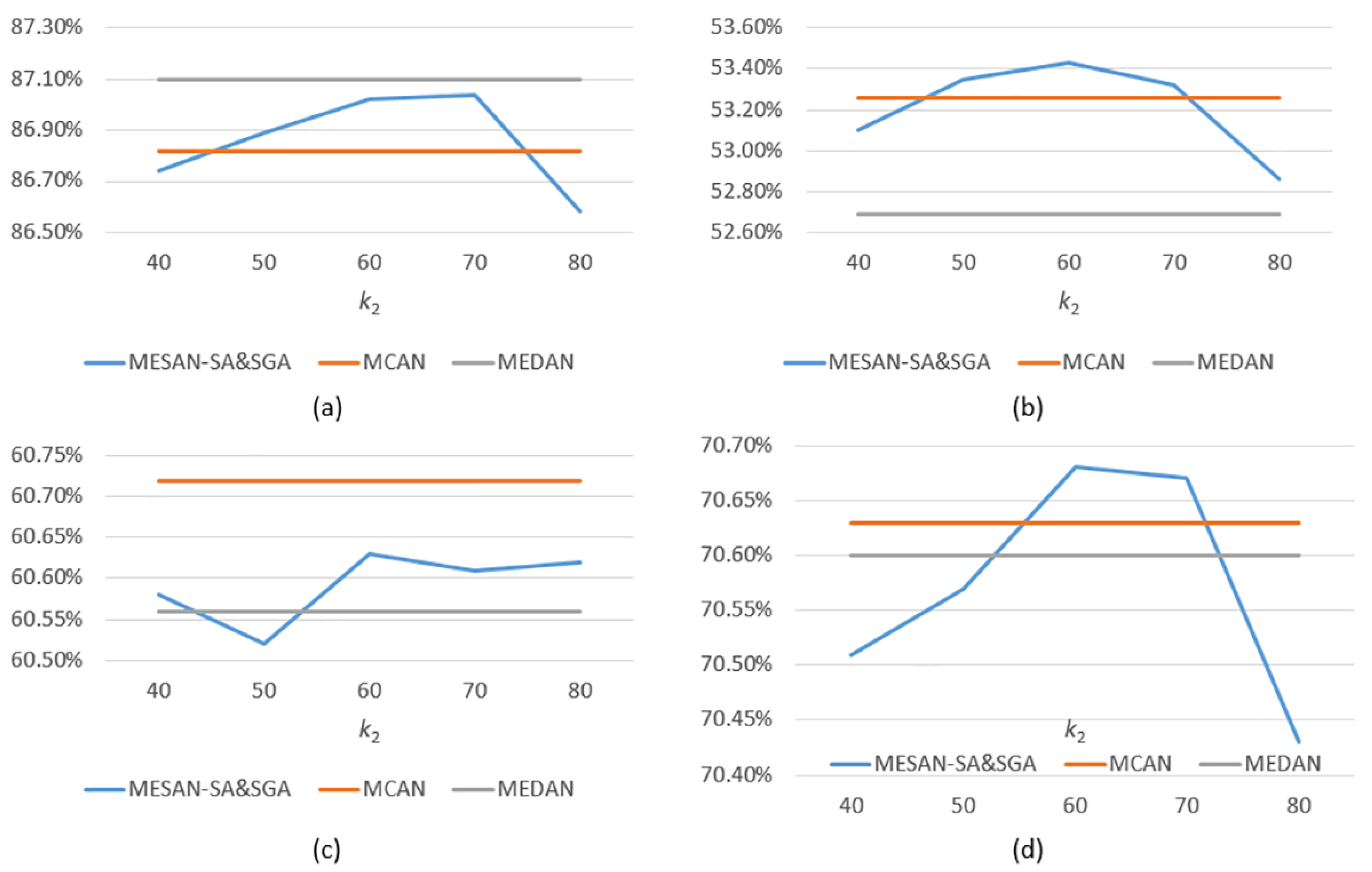
- MESAN-SA&SGA: MESAN-SA&SGA means that both the SA units in encoder and the first sub-layer for learning image self-attention in SGA in decoder adopt explicit sparse attention, while the second sub-layer for learning question-guided attention in SGA adopts the ordinary scaled dot-product attention. Considering that the input features of the second sub-layer in SGA are selected by top-k selection, we no longer use sparse attention in it. The number of regions of the input image is 100, thus we need to select [1, 100] most relevant image regions for subsequent experiments. During ablation studies, we set the parameter of top-k selection used in encoder to 6 and evaluate the performance of different {40, 50, 60, 70, 80} of top-k selection used in decoder. From Table 2 and Figure 5d, we can see that the performance of the model rises first and then falls as increases. When = 60, the model achieves the highest accuracy, 70.68%.
4. Discussion
4.1. Comparison with Advanced VQA Models
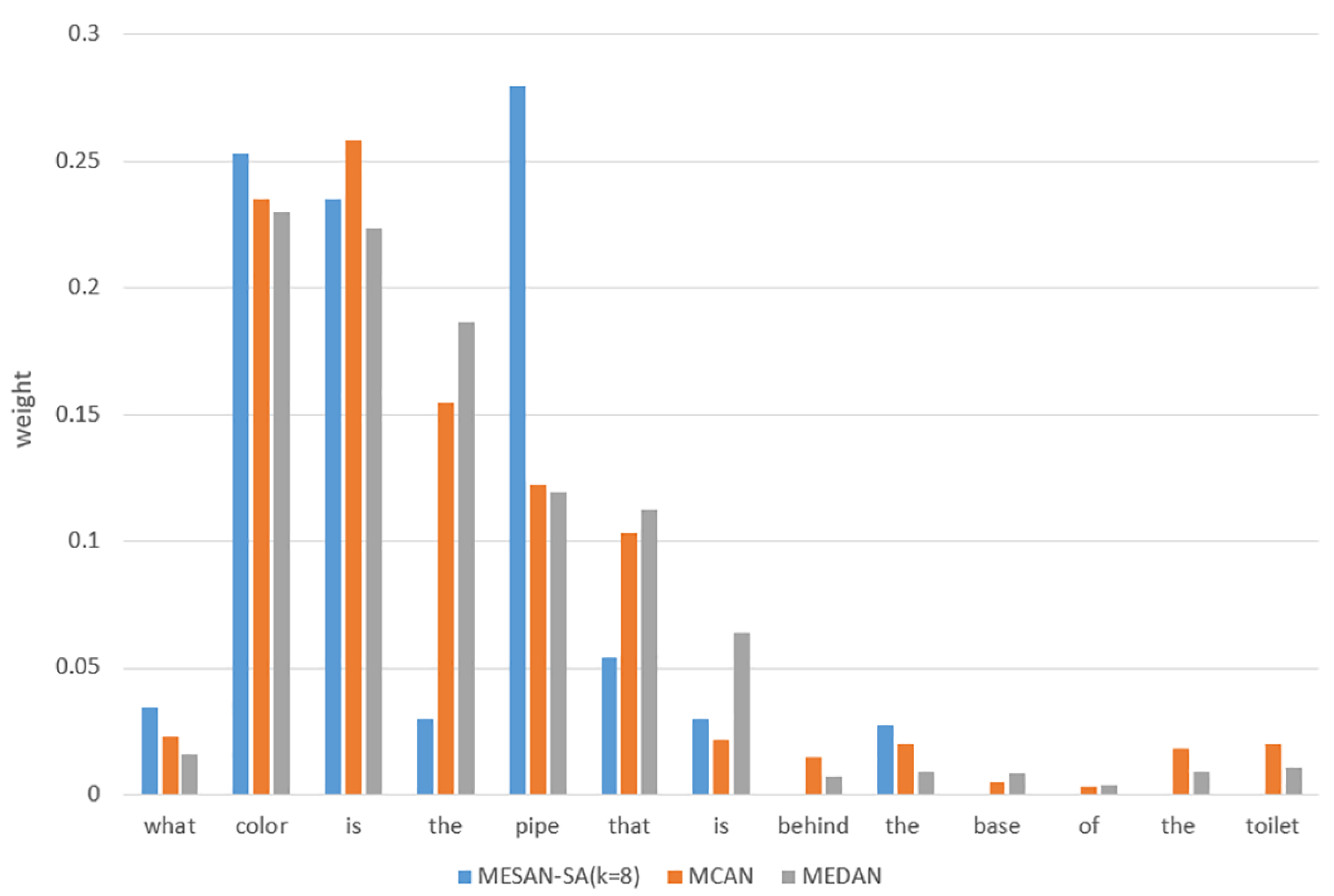
4.2. Attention Visualization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| VQA | visual question answering |
| NLP | natural language processing |
| CV | computer vision |
| AI | artificial intelligence |
| DCN | dense co-attention network |
| BAN | bilinear attention network |
| MCAN | modular co-attention network |
| MEDAN | multi-modal encoder-decoder attention networks |
| MESAN | Multi-modal Explicit Sparse Attention Networks |
| DAN | Dual Attention Network |
| HieCoAtt | Hierarchical Co-attention Model |
| LSTM | long short-term memory |
| SA | self-attention |
| SGA | self&guided-attention |
| AMT | Amazon Mechanical Turk |
| MFH | generalized multi-modal factorized high-order pooling approach |
| MFB | Multi-modal Factorized Bilinear Pooling |
| IoT | Internet of Things |
References
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning (ICML 2015), Lille, France, 6–11 July 2015; Volume 37, pp. 2048–2057. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.; Vedantam, R.; Gupta, S.; Dollar, P.C.; Zitnick, L. Microsoft COCO Captions: Data Collection and Evaluation Server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Gordo, A.; Almazan, J.; Revaud, J.; Larlus, D. Deep Image Retrieval: Learning global representations for image search. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 241–257. [Google Scholar]
- Nam, H.; Ha, J.; Kim, J. Dual Attention Networks for Multimodal Reasoning and Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; Volume 1, pp. 2156–2164. [Google Scholar]
- Kim, J.; Jun, J.; Zhang, B.T. Bilinear Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1571–1581. [Google Scholar]
- Agrawal, A.; Lu, J.; Antol, S.; Mitchell, M.; Zitnick, C.L.; Batra, D.; Parikh, D. VQA: Visual Question Answering. Int. J. Comput. Vis. 2017, 123, 4–31. [Google Scholar] [CrossRef]
- Gordo, A.; Larlus, D. Beyond Instance-Level Image Retrieval: Leveraging Captions to Learn a Global Visual Representation for Semantic Retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 6589–6598. [Google Scholar]
- Lasecki, W.S.; Zhong, Y.; Bigham, J.P. Increasing the bandwidth of crowdsourced visual question answering to better support blind users. In Proceedings of the 16th international ACM SIGACCESS Conference on Computers & Accessibility, Rochester, NY, USA, 20–22 October 2014; pp. 263–264. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 1, pp. 577–585. [Google Scholar]
- Shih, K.J.; Singh, S.; Hoiem, D. Where To Look: Focus Regions for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP 2016), Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Liang, W.; Zhang, D.; Lei, X.; Tang, M.; Li, K.; Zomaya, A. Circuit Copyright Blockchain: Blockchain-based Homomorphic Encryption for IP Circuit Protection. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.D.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. In Proceedings of the 2016 Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 289–297. [Google Scholar]
- Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D. Beyond Bilinear: Generalized Multimodal Factorized High-order Pooling for Visual Question Answering. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 5947–5959. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Pan, N.; Li, K. A Traceable and Revocable Ciphertext-policy Attribute-based Encryption Scheme Based on Privacy Protection. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Cui, M.; Han, D.; Wang, J.; Li, K.-C.; Chan, C.-C. ARFV: An Efficient Shared Data Auditing Scheme Supporting Revocation for Fog-Assisted Vehicular Ad-Hoc Networks. IEEE Trans. Veh. Technol. 2020, accepted. [Google Scholar] [CrossRef]
- Cui, M.; Han, D.; Wang, J. An Efficient and Safe Road Condition Monitoring Authentication Scheme Based on Fog Computing. IEEE Internet Things J. 2019, 6, 9076–9084. [Google Scholar] [CrossRef]
- He, S.; Han, D. An Effective Dense Co-Attention Networks for Visual Question Answering. Sensors 2020, 20, 4897. [Google Scholar] [CrossRef]
- Nguyen, D.-K.; Okatani, T. Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 2017 Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep Modular Co-Attention Networks for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Chen, C.; Han, D.; Wang, J. Multimodal Encoder-Decoder Attention Networks for Visual Question Answering. IEEE Access 2020, 8, 35662–35671. [Google Scholar] [CrossRef]
- Zhao, G.; Lin, J.; Zhang, Z.; Ren, X.; Su, Q.; Sun, X. Explicit Sparse Transformer: Concentrated Attention Through Explicit Selection. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Ma, L.; Lu, Z.; Li, H. Learning to Answer Questions From Image Using Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liang, W.; Long, J.; Li, K.; Xu, J.; Ma, N.; Lei, X. A Fast Defogging Image Recognition Algorithm based on Bilateral Hybrid Filtering. ACM Trans. Multimed. Comput. Commun. Appl. 2020. [Google Scholar] [CrossRef]
- Liu, X.; Obaidat, M.S.; Lin, C.; Wang, T.; Liu, A. Movement-Based Solutions to Energy Limitation in Wireless Sensor Networks: State of the Art and Future Trends. IEEE Netw. 2020. [Google Scholar] [CrossRef]
- Liu, X.; Lin, P.; Liu, T.; Wang, T.; Liu, A.; Xu, W. Objective-Variable Tour Planning for Mobile Data Collection in Partitioned Sensor Networks. IEEE Trans. Mob. Comput. 2020. [Google Scholar] [CrossRef]
- Wu, Y.; Huang, H.; Wu, Q.; Liu, A.; Wang, T. A Risk Defense Method Based on Microscopic State Prediction with Partial Information Observations in Social Networks. J. Parallel Distrib. Comput. 2019, 131, 189–199. [Google Scholar] [CrossRef]
- Li, H.; Han, D. A Novel Time-Aware Hybrid Recommendation Scheme Combining User Feedback and Collaborative Filtering. IEEE Syst. J. 2020. [Google Scholar] [CrossRef]
- Li, H.; Han, D.; Tang, M. A Privacy-Preserving Charging Scheme for Electric Vehicles Using Blockchain and Fog Computing. IEEE Syst. J. 2020. [Google Scholar] [CrossRef]
- Yang, Z.; He, X.; Gao, J.; Deng, L.; Smola, A. Stacked Attention Networks for Image Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer Normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Teney, D.; Anderson, P.; He, X.; van den, A.H. Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4223–4232. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–37. [Google Scholar] [CrossRef]
- Zhang, Y.; Hare, J.; Prügel-Bennett, A. Learning to Count Objects in Natural Images for Visual Question Answering. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Wang, T.; Luo, H.; Zeng, X.; Yu, Z.; Liu, A.; Sangaiah, A.K. Mobility Based Trust Evaluation for Heterogeneous Electric Vehicles Network in Smart Cities. IEEE Trans. Intell. Transp. Syst. 2020. [Google Scholar] [CrossRef]
- Liang, W.; Huang, W.; Long, J.; Zhang, K.; Li, K.; Zhang, D. Deep Reinforcement Learning for Resource Protection and Real-Time Detection in IoT Environment. IEEE Internet Things J. 2020, 7, 6392–6401. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | Yes/No | Number | Other | All |
|---|---|---|---|---|
| 3 | 86.72 | 53.83 | 60.48 | 70.54 |
| 4 | 86.96 | 52.97 | 60.58 | 70.58 |
| 5 | 86.97 | 52.79 | 60.70 | 60.62 |
| 6 | 86.91 | 53.74 | 60.65 | 70.68 |
| 7 | 86.85 | 53.35 | 60.63 | 70.61 |
| 8 | 87.05 | 53.21 | 60.72 | 70.71 |
| 9 | 87.02 | 52.81 | 60.62 | 70.61 |
| Yes/No | Number | Other | All | |
|---|---|---|---|---|
| 40 | 86.74 | 53.10 | 60.58 | 70.51 |
| 50 | 86.89 | 53.35 | 60.52 | 70.57 |
| 60 | 87.02 | 53.43 | 60.63 | 70.68 |
| 70 | 87.04 | 53.32 | 60.61 | 70.67 |
| 80 | 86.58 | 52.86 | 60.62 | 70.43 |
| Model | Test-dev | Test-std | |||
|---|---|---|---|---|---|
| Yes/No | Number | Other | All | All | |
| Bottom-up [42] | 81.82 | 44.21 | 56.05 | 65.32 | 65.67 |
| MFH [16] | - | - | - | 66.12 | - |
| BAN + GloVe [5] | 85.46 | 50.66 | 60.50 | 69.66 | - |
| BAN + Glove + counter [5] | 85.42 | 54.04 | 60.52 | 70.04 | 70.35 |
| MCAN [23] | 86.82 | 53.26 | 60.72 | 70.63 | 70.90 |
| MEDAN(Adam) [24] | 87.10 | 52.69 | 60.56 | 70.60 | 71.01 |
| MESAN-SA(k = 8) (ours) | 87.05 | 53.21 | 60.72 | 70.71 | 71.08 |
| MESAN-SA&SGA() (ours) | 87.02 | 53.43 | 60.63 | 70.68 | 70.94 |
| Model | Yes/No | Number | Other | All |
|---|---|---|---|---|
| MEDAN-Sparse(k = 4) | 86.89 | 52.50 | 60.54 | 70.48 |
| MEDAN-Sparse(k = 5) | 86.95 | 52.73 | 60.72 | 70.62 |
| MEDAN-Sparse(k = 6) | 86.76 | 52.72 | 60.55 | 70.46 |
| MEDAN(Adam) | 87.10 | 52.69 | 60.56 | 70.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Z.; Han, D. Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering. Sensors 2020, 20, 6758. https://doi.org/10.3390/s20236758
Guo Z, Han D. Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering. Sensors. 2020; 20(23):6758. https://doi.org/10.3390/s20236758
Chicago/Turabian StyleGuo, Zihan, and Dezhi Han. 2020. "Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering" Sensors 20, no. 23: 6758. https://doi.org/10.3390/s20236758
APA StyleGuo, Z., & Han, D. (2020). Multi-Modal Explicit Sparse Attention Networks for Visual Question Answering. Sensors, 20(23), 6758. https://doi.org/10.3390/s20236758