Identification of Building Damage from UAV-Based Photogrammetric Point Clouds Using Supervoxel Segmentation and Latent Dirichlet Allocation Model

Abstract
1. Introduction
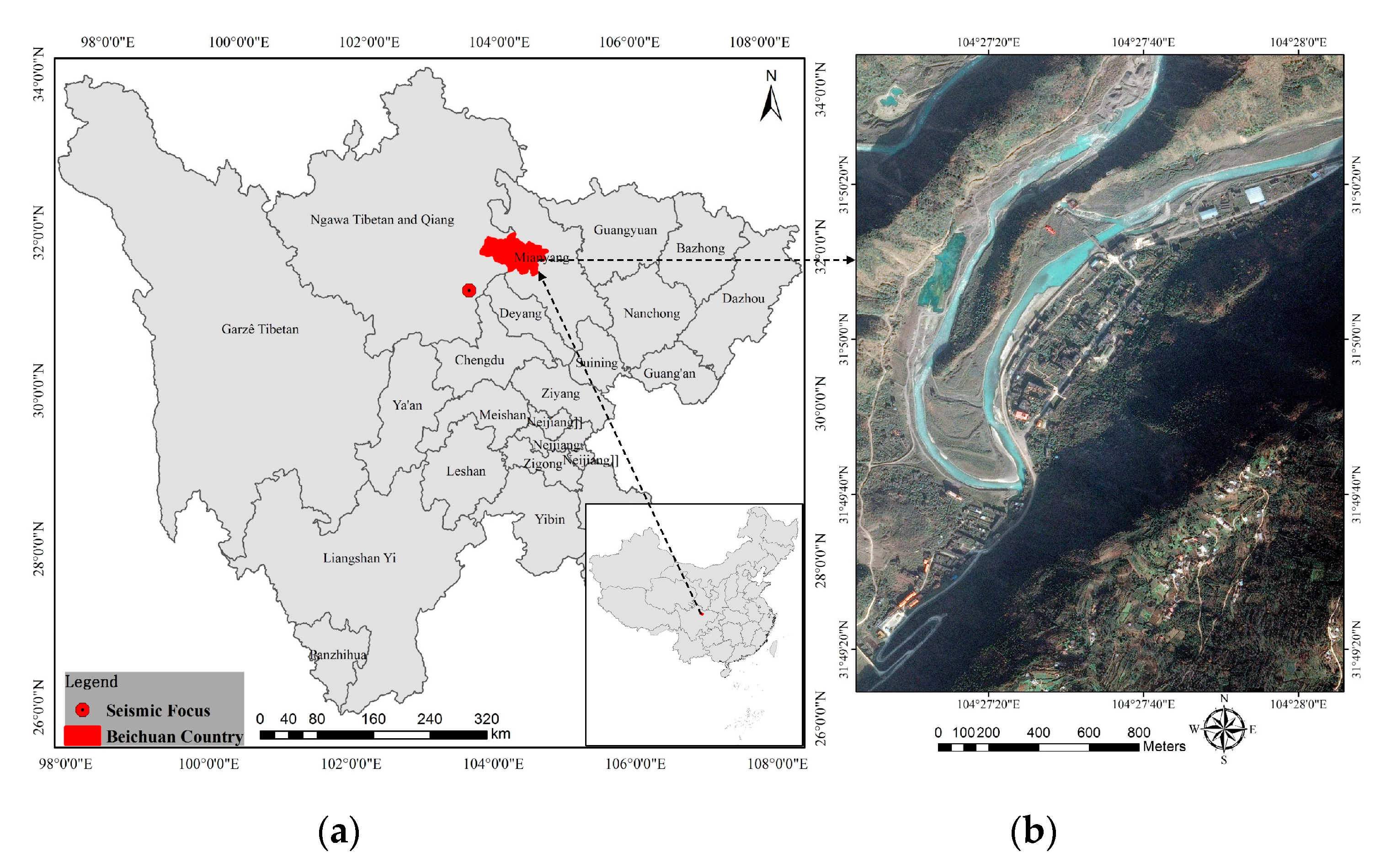
2. Study Area and Data Sources
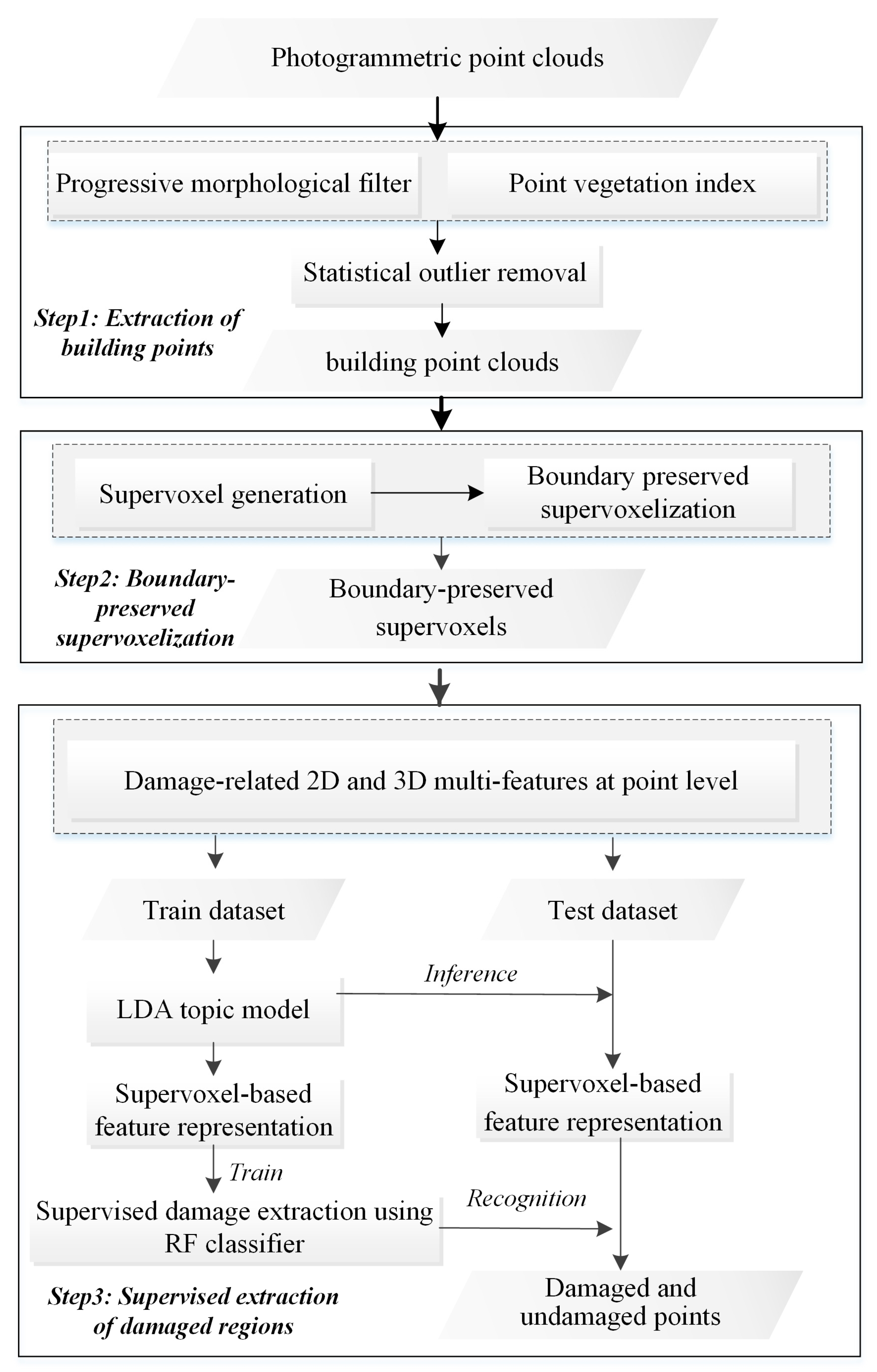
3. Methodology
3.1. Extraction of Building Points
3.1.1. Progressive Morphological Filter
3.1.2. Point Vegetation Index
3.1.3. Statistical Outlier Removal
3.2. Boundary Refined Supervoxel Segmentation
3.2.1. Supervoxel Generation
3.2.2. Boundary Refined Supervoxelization
3.3. Supervised Extraction of Damaged Building Regions
3.3.1. Damage-Related 2D and 3D Multi-Features at Point Level
- 2D features
- 2.
- 3D features
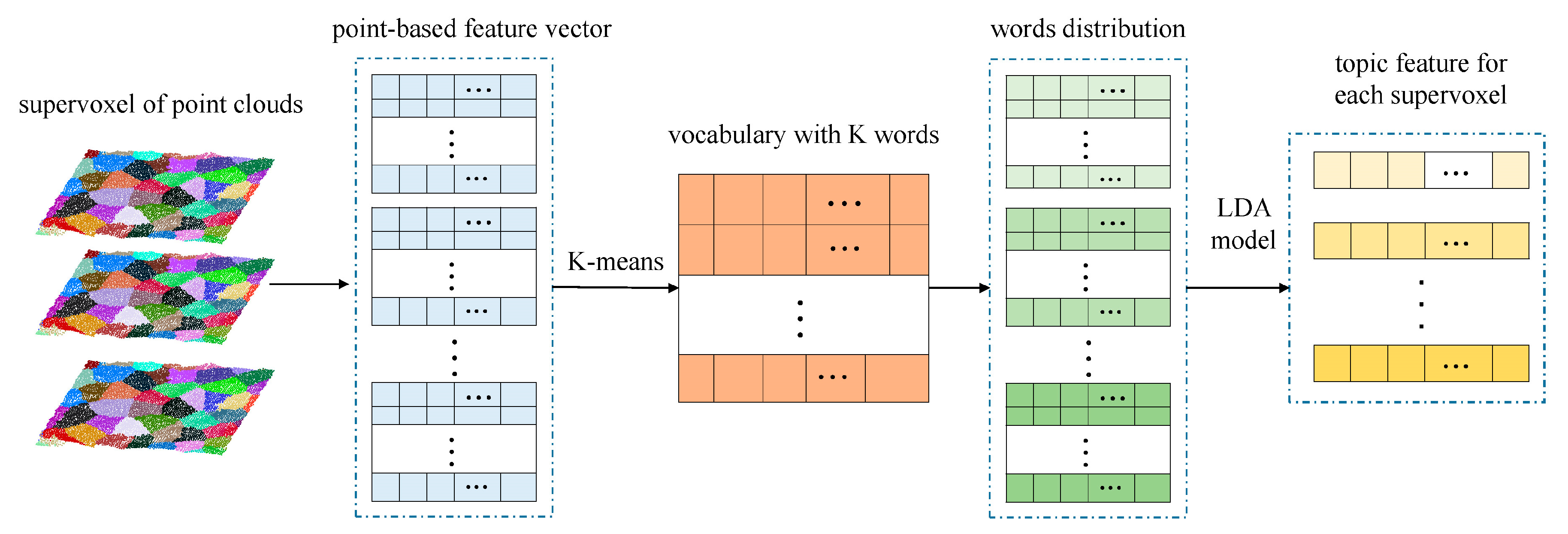
3.3.2. Supervoxel-Based Feature Representation Using the LDA Model
3.3.3. Damage Extraction Based on RF Classifier
4. Experiments
4.1. Experimental Dataset
4.2. Training Sample Collection
4.3. Evaluation Metric
5. Results and Discussion
5.1. Extraction of Building Points and Accuracy of Evaluation
5.2. Identification of Damaged Building Points and Accuracy of Evaluation
5.3. Comparative Analysis
5.3.1. Comparison of Different Methods for Building Point Extraction
5.3.2. Comparison of Different Methods for Building Damage Extraction
5.3.3. Comparison of Different Features for Building Damage Extraction
5.4. Parameter Sensitivity Analysis
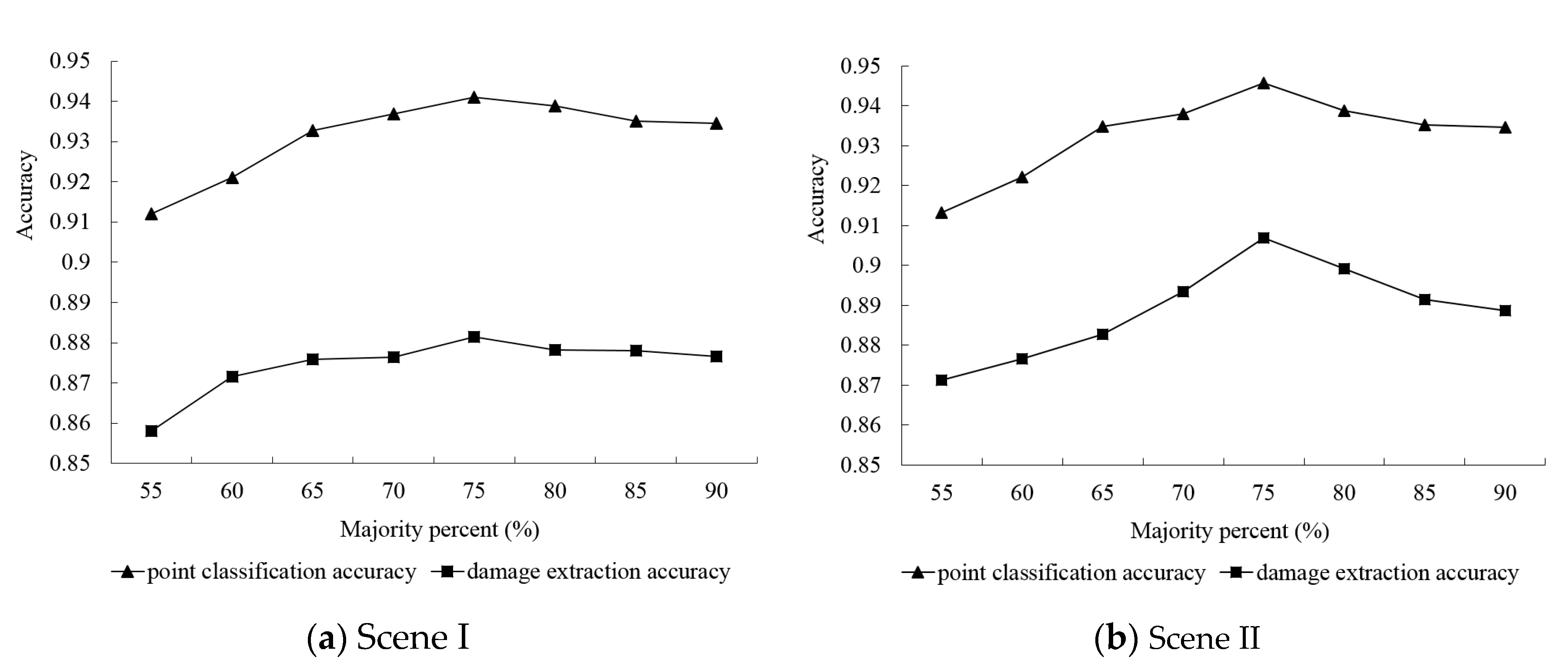
5.4.1. Majority Percent
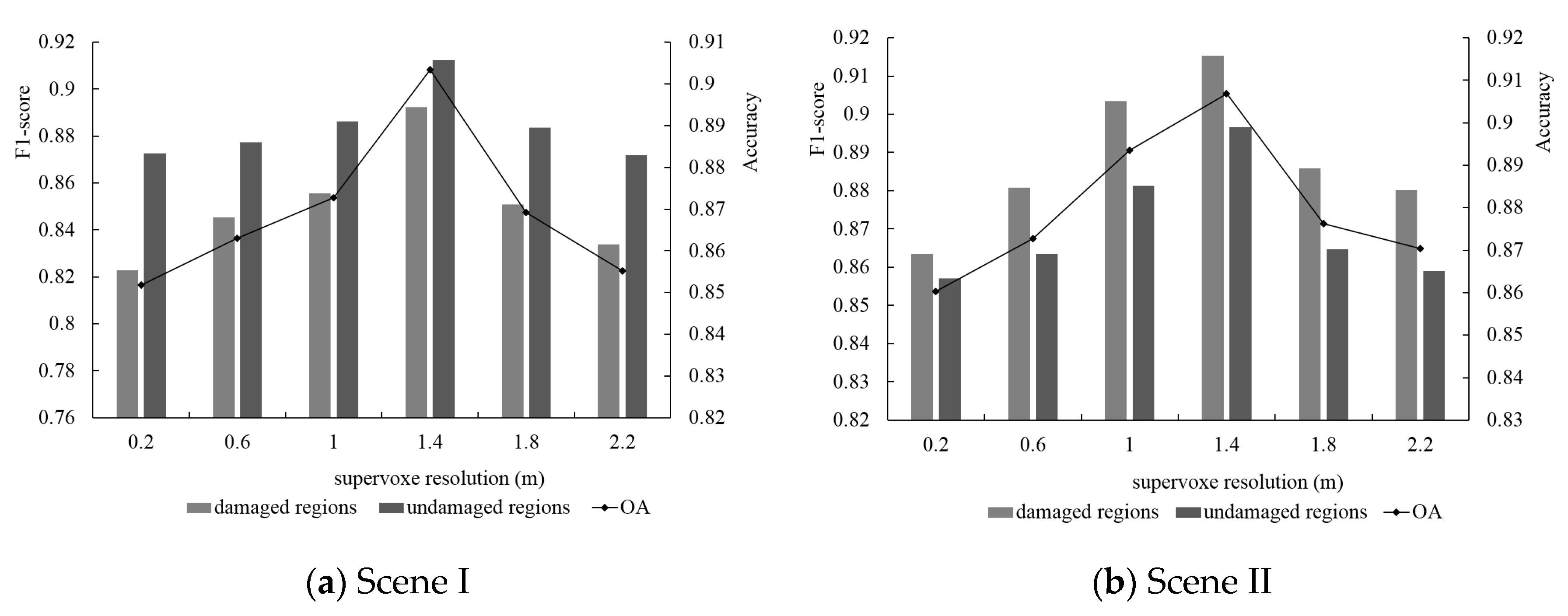
5.4.2. Supervoxel Resolution
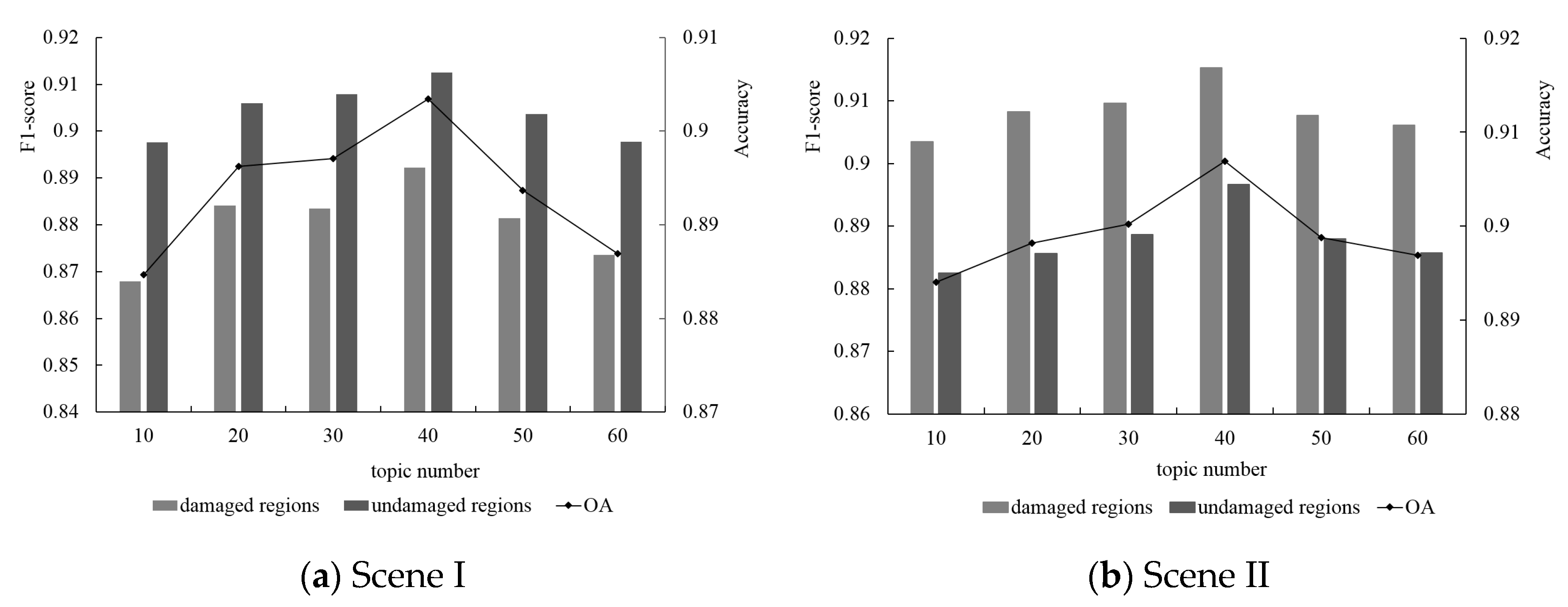
5.4.3. Latent Topic Number
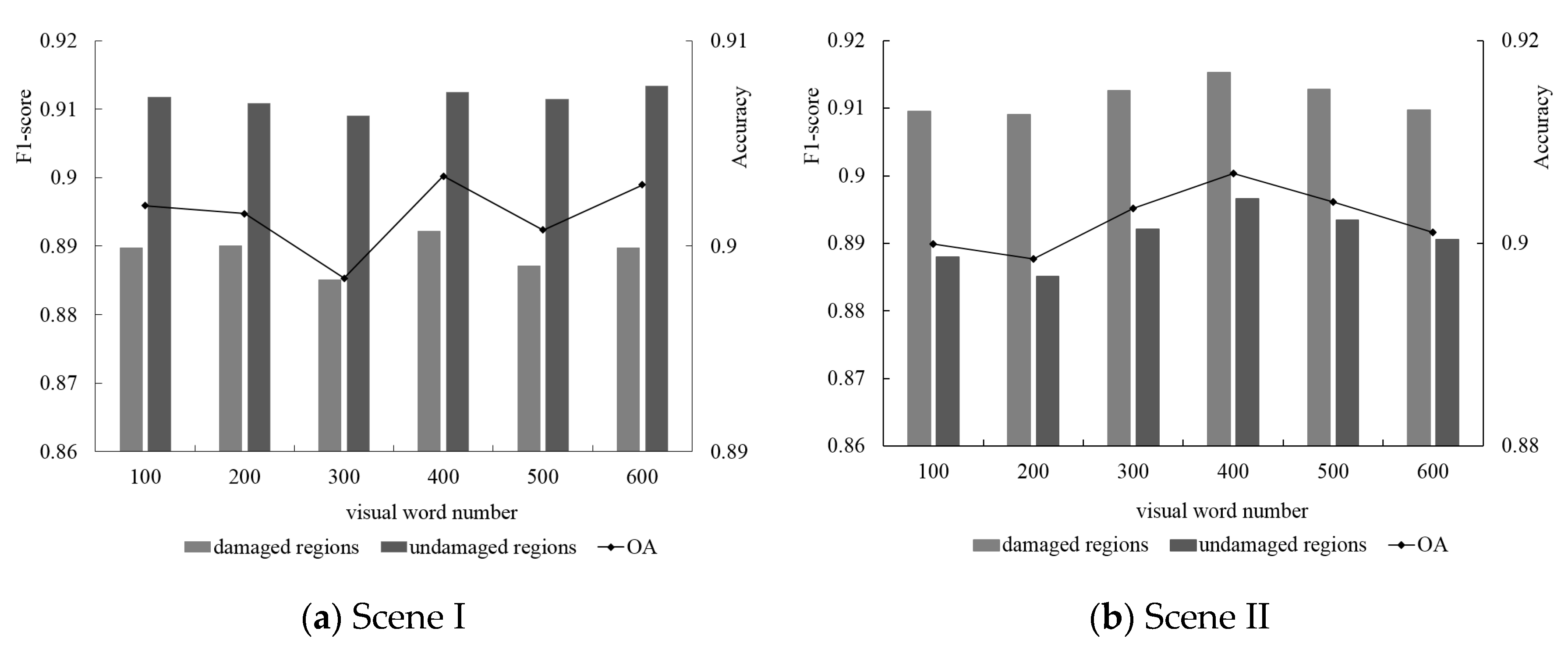
5.4.4. Visual Word Number
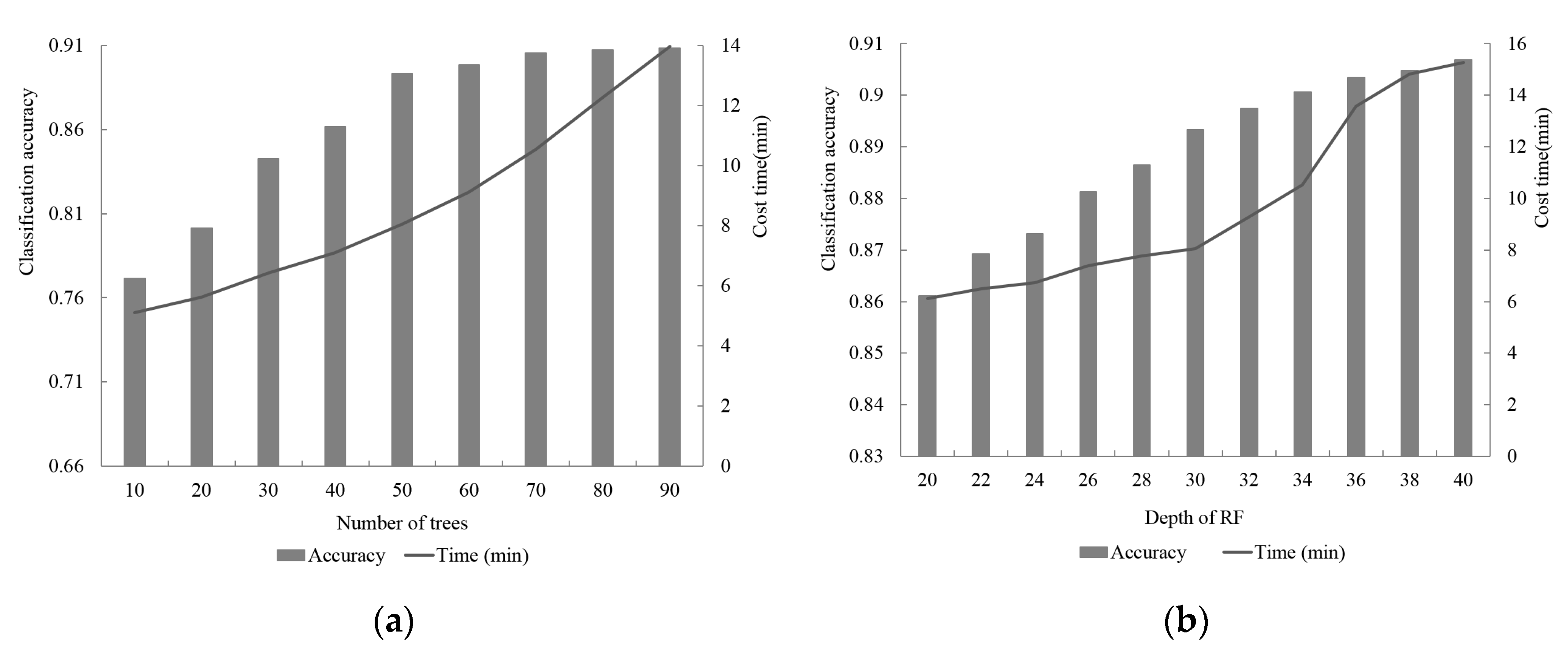
5.4.5. Number of Trees and Depth for RF Algorithm
5.5. Transferability Analysis of Other Areas
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dong, L.; Shan, J. A comprehensive review of earthquake-induced building damage detection with remote sensing techniques. ISPRS J. Photogramm. Remote Sens. 2013, 84, 85–99. [Google Scholar] [CrossRef]
- Ge, P.; Gokon, H.; Meguro, K. A review on synthetic aperture radar-based building damage assessment in disasters. Remote Sens. Environ. 2020, 240, 111693. [Google Scholar] [CrossRef]
- Foulser, R.; Spence, R.; Eguchi, R.; King, A. Using remote sensing for building damage assessment: GEOCAN study and validation for 2011 Christchurch earthquake. Earthq. Spectra 2016, 32, 611–631. [Google Scholar] [CrossRef]
- Adriano, B.; Xia, J.; Baier, G.; Yokaya, N.; Koshimura, S. Multi-source data fusion based on ensemble learning for rapid building damage mapping during the 2018 sulawesi earthquake and tsunami in Palu, Indonesia. Remote Sens. 2019, 11, 886. [Google Scholar] [CrossRef]
- Li, S.; Tang, H.; He, S.; Shu, Y. Unsupervised Detection of Earthquake-Triggered Roof-Holes From UAV Images Using Joint Color and Shape Features. IEEE Geosci. Remote Sens. Lett. 2015, 12, 823–1827. [Google Scholar]
- Park, S.; Jung, Y. Detection of Earthquake-Induced Building Damages Using Polarimetric SAR Data. Remote Sens. 2020, 12, 137. [Google Scholar] [CrossRef]
- Janalipour, M.; Mohammadzadeh, A. A novel and automatic framework for producing building damage map using post-event LiDAR data. Int. J. Disaster Risk Reduct. 2019, 39, 101238. [Google Scholar] [CrossRef]
- Matsuoka, M.; Yamazaki, F. Application of a methodology for detecting building-damage area to recent earthquakes using satellite sar intensity imageries and its validation. J. Struct. Constr. Eng. 2002, 67, 139–147. [Google Scholar] [CrossRef]
- Fernandez, G.; Kerle, N.; Gerke, M. UAV-based urban structural damage assessment using object-based image analysis and semantic reasoning. Nat. Hazards Earth Syst. Sci. 2015, 15, 1087–1101. [Google Scholar] [CrossRef]
- Choi, J.; Yeum, C.M.; Dyke, S.J.; Jahanshahi, M.R. Computer-aided approach for rapid post-event visual evaluation of a building façade. Sensors 2018, 18, 3017. [Google Scholar] [CrossRef]
- Kerle, N.; Nex, F.; Gerke, M.; Duarte, D.; Vetrivel, A. UAV-Based Structural Damage Mapping: A Review. ISPRS Int. Geo-Inf. 2020, 9, 14. [Google Scholar] [CrossRef]
- Zhu, M.; Du, X.; Zhang, X.; Luo, H.; Wang, G. Multi-UAV rapid-assessment task-assignment problem in a post-earthquake scenario. IEEE Access 2019, 7, 74542–74557. [Google Scholar] [CrossRef]
- Kang, C.L.; Cheng, Y.; Wang, F.; Zong, M.M.; Luo, J.; Lei, J.Y. The Application of UAV Oblique Photogrammetry in Smart Tourism: A Case Study of Longji Terraced Scenic SPOT in Guangxi Province. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 42, 575–580. [Google Scholar] [CrossRef]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Towards a more efficient detection of earthquake induced facade damages using oblique UAV imagery. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 93–100. [Google Scholar] [CrossRef]
- Duarte, D.; Nex, F.; Kerle, N.; Vosselman, G. Multi-resolution feature fusion for image classification of building damages with convolutional neural networks. Remote Sens. 2018, 10, 1636. [Google Scholar] [CrossRef]
- Vetrivel, A.; Gerke, M.; Kerle, N.; Nex, F.; Vosselman, G. Disaster damage detection through synergistic use of deep learning and 3D point cloud features derived from very high resolution oblique aerial images, and multiple-kernel-learning. ISPRS J. Photogramm. Remote Sens. 2018, 140, 45–59. [Google Scholar] [CrossRef]
- Mangalathu, S.; Burton, H.V. Deep learning-based classification of earthquake-impacted buildings using textual damage descriptions. Int. J. Disaster Risk Reduct. 2019, 36, 101111. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-supervised deep learning using pseudo labels for hyperspectral image classification. IEEE Trans. Image Process. 2017, 27, 1259–1270. [Google Scholar] [CrossRef]
- Huang, H.; Sun, G.; Zhang, X.; Hao, Y.; Zhang, A.; Ren, J.; Ma, H. Combined multiscale segmentation convolutional neural network for rapid damage mapping from post-earthquake very high-resolution images. J. Appl. Remote Sens. 2019, 13, 022007. [Google Scholar] [CrossRef]
- Zhou, Z.; Gong, J.; Guo, M. Image-based 3D reconstruction for posthurricane residential building damage assessment. J. Comput. Civ. Eng. 2016, 30, 04015015. [Google Scholar] [CrossRef]
- Luo, H.; Wang, C.; Wen, Y.; Guo, W. 3-D Object Classification in Heterogeneous Point Clouds via Bag-of-Words and Joint Distribution Adaption. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1909–1913. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C.; Wen, C. Bag of contextual-visual words for road scene object detection from mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3391–3406. [Google Scholar] [CrossRef]
- Zhang, K.; Chen, S.C.; Whitman, D.; Shyu, M.; Yan, J.; Zhang, C. A progressive morphological filter for removing nonground measurements from airborne LIDAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 872–882. [Google Scholar] [CrossRef]
- Serifoglu, C.; Gungor, O.; Yilmaz, V. Performance evaluation of different ground filtering algorithms for UAV-based point clouds. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 245–251. [Google Scholar] [CrossRef]
- Orsini, R.; Fiorentini, M.; Zenobi, S. Evaluation of Soil Management Effect on Crop Productivity and Vegetation Indices Accuracy in Mediterranean Cereal-Based Cropping Systems. Sensors 2020, 20, 3383. [Google Scholar] [CrossRef] [PubMed]
- Zeybek, M.; Şanlıoğlu, İ. Point cloud filtering on UAV based point cloud. Measurement 2019, 133, 99–111. [Google Scholar] [CrossRef]
- Axel, C.; van Aardt, J.A. Building damage assessment using airborne lidar. J. Appl. Remote Sens. 2017, 11, 046024. [Google Scholar] [CrossRef]
- Ban, Z.; Chen, Z.; Liu, J. Supervoxel segmentation with voxel-related gaussian mixture model. Sensors 2018, 18, 128. [Google Scholar]
- Guan, H.; Yu, Y.; Li, J.; Liu, P. Pole-like road object detection in mobile LiDAR data via supervoxel and bag-of-contextual-visual-words representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 520–524. [Google Scholar] [CrossRef]
- Lin, Y.; Wang, C.; Zhai, D.; Li, W.; Li, J. Toward better boundary preserved supervoxel segmentation for 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 39–47. [Google Scholar] [CrossRef]
- Xu, Y.; Ye, Z.; Yao, W.; Huang, R.; Tong, X. Classification of LiDAR Point Clouds Using Supervoxel-Based Detrended Feature and Perception-Weighted Graphical Model. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 13, 72–88. [Google Scholar] [CrossRef]
- Tu, J.; Sui, H.; Feng, W.; Sun, K.; Hua, L. Detection of damaged rooftop areas from high-resolution aerial images based on visual bag-of-words model. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1817–1821. [Google Scholar] [CrossRef]
- Merlin, G.S.; Jiji, G.W. Building Damage Detection of the 2004 Nagapattinam, India, Tsunami Using the Texture and Spectral Features from IKONOS Images. J. Indian Soc. Remote Sens. 2019, 47, 13–24. [Google Scholar] [CrossRef]
- Peng, S.; Ma, H.; Zhang, L. Automatic Registration of Optical Images with Airborne LiDAR Point Cloud in Urban Scenes Based on Line-Point Similarity Invariant and Extended Collinearity Equations. Sensors 2019, 19, 1086. [Google Scholar] [CrossRef] [PubMed]
- Wei, D.; Yang, W. Detecting damaged buildings using a texture feature contribution index from post-earthquake remote sensing images. Remote Sens. Lett. 2020, 11, 127–136. [Google Scholar] [CrossRef]
- Zhu, X.; Skidmore, A.K.; Darvishzadeh, R.; Liu, J.; Shi, Y. Foliar and woody materials discriminated using terrestrial LiDAR in a mixed natural forest. Int. J. Appl. Earth Obs. Geoinf. 2018, 64, 43–50. [Google Scholar] [CrossRef]
- Kang, Z.; Yang, J. A probabilistic graphical model for the classification of mobile LiDAR point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 108–123. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Wager, S.; Athey, S. Estimation and inference of heterogeneous treatment effects using random forests. J. Am. Stat. Assoc. 2018, 113, 1228–1242. [Google Scholar] [CrossRef]
- Graziani, L.; Del, M.S.; Tertulliani, A.; Arcoraci, L.; Maramai, A.; Rossi, A. Investigation on damage progression during the 2016–2017 seismic sequence in Central Italy using the European Macroseismic Scale (EMS-98). Bull. Earthq. Eng. 2019, 17, 5535–5558. [Google Scholar] [CrossRef]
- Sánchez, L.J.; Del, P.S.; Ramos, L.F.; Arce, A. Heritage site preservation with combined radiometric and geometric analysis of TLS data. Autom. Constr. 2018, 85, 24–39. [Google Scholar] [CrossRef]
- Shirow, Z.S.; Sepasgozar, S.M.E. Spatial analysis using temporal point clouds in advanced GIS: Methods for ground elevation extraction in slant areas and building classifications. ISPRS Int. Geo-Inf. 2019, 8, 120. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scene 1 | Scene 2 | |||
|---|---|---|---|---|
| Pre. | Rec. | Pre. | Rec. | |
| Building | 0.9416 | 0.9227 | 0.9525 | 0.9232 |
| Non-building | 0.9408 | 0.9555 | 0.9406 | 0.9635 |
| OA | 0.9411 | 0.9457 | ||
| TIME (min) | 10.11 | 10.25 | ||
| Scene 1 | Scene 2 | |||
|---|---|---|---|---|
| Pre. | Rec. | Pre. | Rec. | |
| Damage | 0.8622 | 0.8664 | 0.9026 | 0.9284 |
| Non-damage | 0.8964 | 0.8931 | 0.9125 | 0.8813 |
| OA | 0.8814 | 0.9069 | ||
| TIME (min) | 7.22 | 8.90 | ||
| Method I | Method II | Method III | Proposed Method | |||||
|---|---|---|---|---|---|---|---|---|
| Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | |
| Building | 0.8627 | 0.8044 | 0.8526 | 0.8391 | 0.9236 | 0.8905 | 0.9471 | 0.9229 |
| Non-building | 0.8348 | 0.8853 | 0.8713 | 0.8824 | 0.9148 | 0.9411 | 0.9407 | 0.9595 |
| OA | 0.8471 | 0.8631 | 0.9186 | 0.9434 | ||||
| TIME (min) | 16.85 | 6.26 | 9.30 | 10.18 | ||||
| Method I | Method II | Method III | Proposed Method | |||||
|---|---|---|---|---|---|---|---|---|
| Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | |
| Damage | 0.8758 | 0.8801 | 0.8158 | 0.7998 | 0.8561 | 0.8441 | 0.8835 | 0.8987 |
| Non-damage | 0.8837 | 0.8795 | 0.8009 | 0.8168 | 0.8427 | 0.8574 | 0.9029 | 0.8882 |
| OA | 0.8798 | 0.8082 | 0.8498 | 0.8933 | ||||
| TIME (min) | 8.37 | 22.31 | 8.93 | 8.06 | ||||
| Feature I | Feature II | Feature III | Combined Feature | |||||
|---|---|---|---|---|---|---|---|---|
| Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | Pre. | Rec. | |
| Damage | 0.7518 | 0.7264 | 0.7818 | 0.7861 | 0.8561 | 0.5829 | 0.5888 | 0.8987 |
| Non-damage | 0.7239 | 0.7494 | 0.7925 | 0.7883 | 0.6031 | 0.5972 | 0.9029 | 0.8882 |
| OA | 0.7377 | 0.7872 | 0.5931 | 0.8933 | ||||
| TIME (min) | 6.12 | 6.85 | 12.37 | 8.06 | ||||
| Building Point Extraction | Building Damage Extraction | |||
|---|---|---|---|---|
| Building | Non-Building | Damage | Non-Damage | |
| Pre. | 0.9103 | 0.9216 | 0.8974 | 0.8996 |
| Rec. | 0.9121 | 0.9199 | 0.8860 | 0.9098 |
| OA | 0.9163 | 0.8986 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Sui, H.; Huang, L. Identification of Building Damage from UAV-Based Photogrammetric Point Clouds Using Supervoxel Segmentation and Latent Dirichlet Allocation Model. Sensors 2020, 20, 6499. https://doi.org/10.3390/s20226499
Liu C, Sui H, Huang L. Identification of Building Damage from UAV-Based Photogrammetric Point Clouds Using Supervoxel Segmentation and Latent Dirichlet Allocation Model. Sensors. 2020; 20(22):6499. https://doi.org/10.3390/s20226499
Chicago/Turabian StyleLiu, Chaoxian, Haigang Sui, and Lihong Huang. 2020. "Identification of Building Damage from UAV-Based Photogrammetric Point Clouds Using Supervoxel Segmentation and Latent Dirichlet Allocation Model" Sensors 20, no. 22: 6499. https://doi.org/10.3390/s20226499
APA StyleLiu, C., Sui, H., & Huang, L. (2020). Identification of Building Damage from UAV-Based Photogrammetric Point Clouds Using Supervoxel Segmentation and Latent Dirichlet Allocation Model. Sensors, 20(22), 6499. https://doi.org/10.3390/s20226499