Analysis of Copernicus’ ERA5 Climate Reanalysis Data as a Replacement for Weather Station Temperature Measurements in Machine Learning Models for Olive Phenology Phase Prediction †

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Phenology Prediction Model
2.1.1. Model Inputs
2.1.2. Target Variable
2.2. Baseline Model
2.3. Data Used
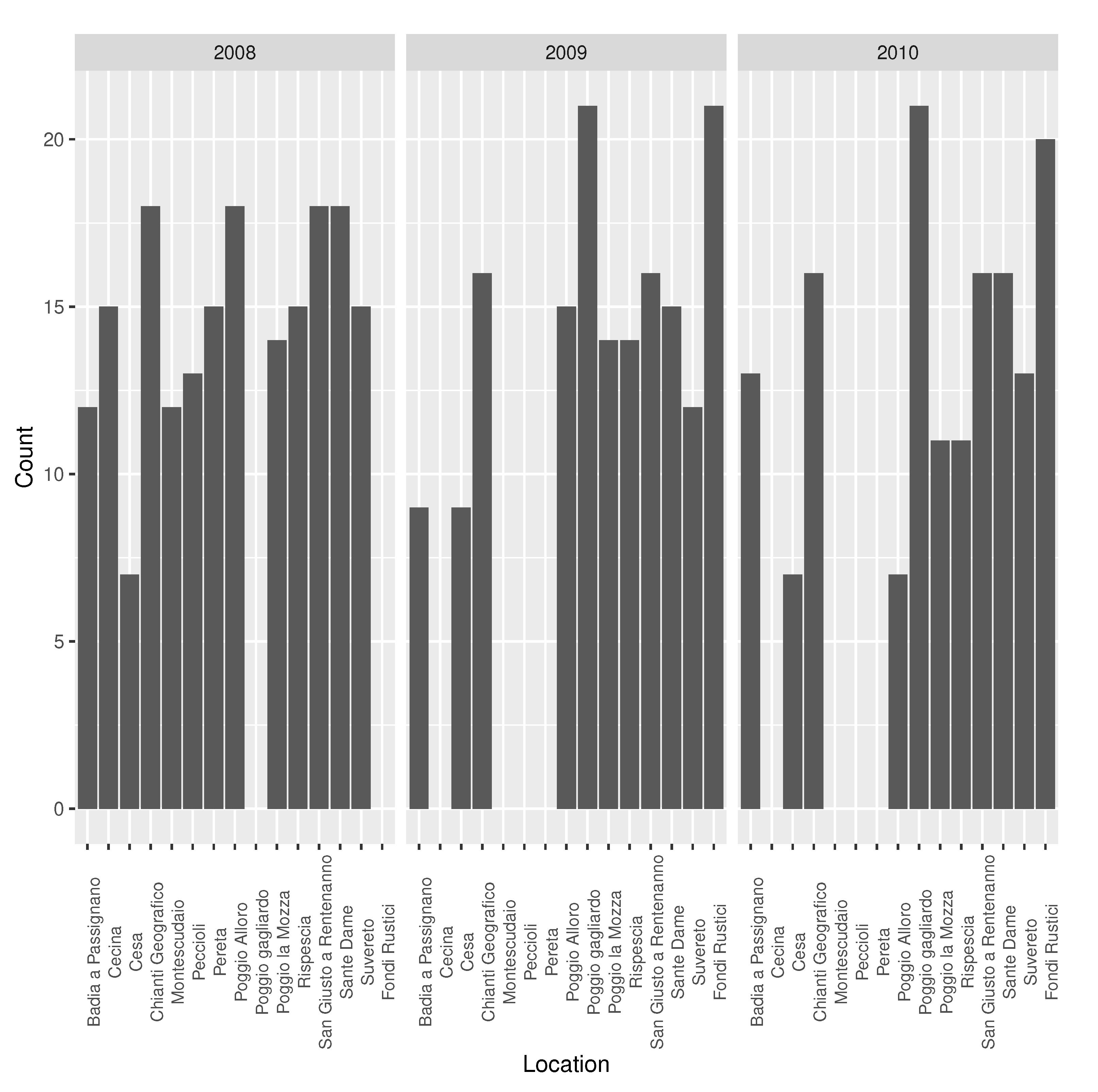
2.3.1. Phenology and Weather Station Data
2.3.2. Copernicus’ Era5 Climate Reanalysis Data
2.4. Ml Model Evaluation and Selection
2.5. Base Temperature Optimisation
3. Results
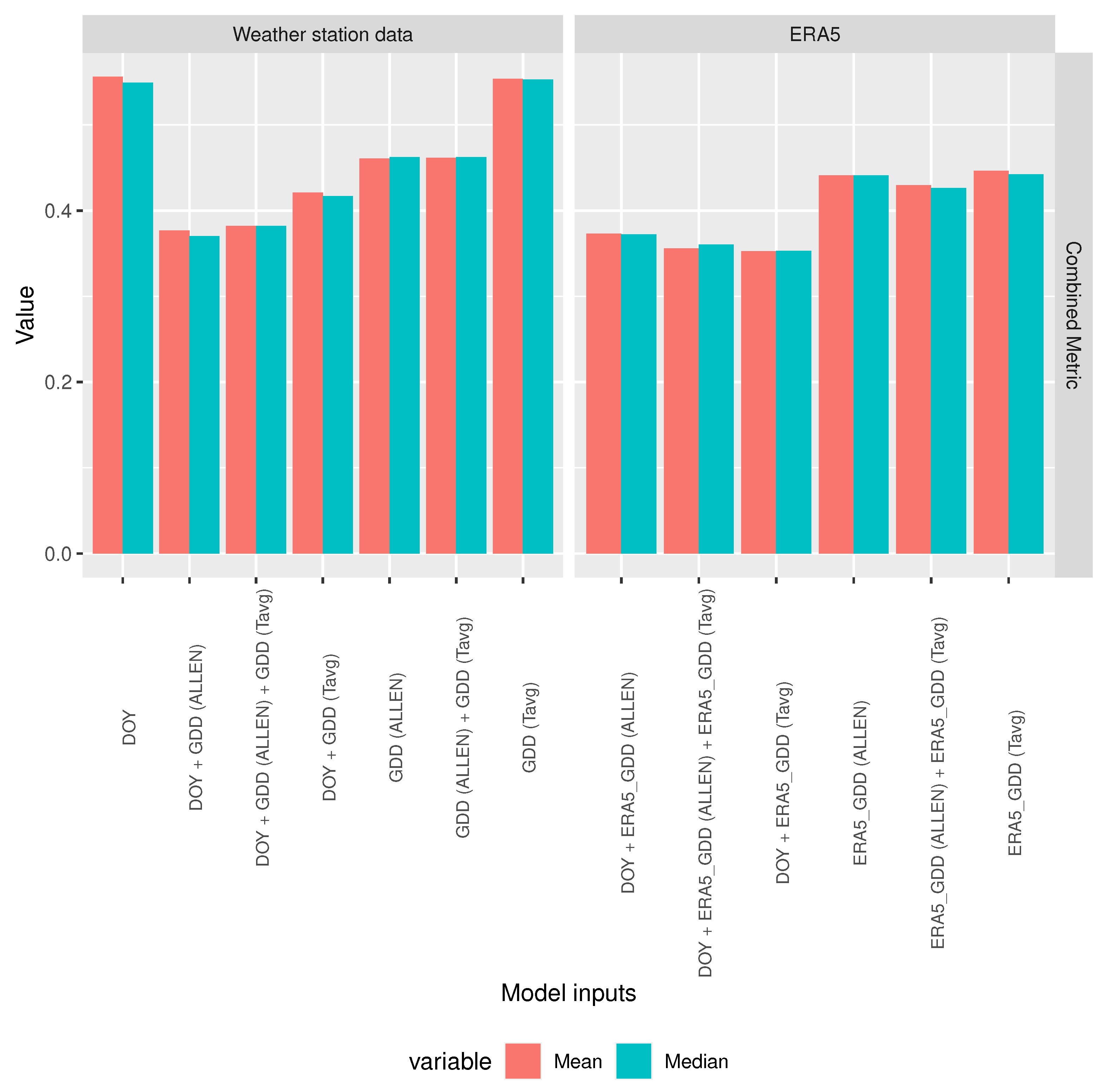
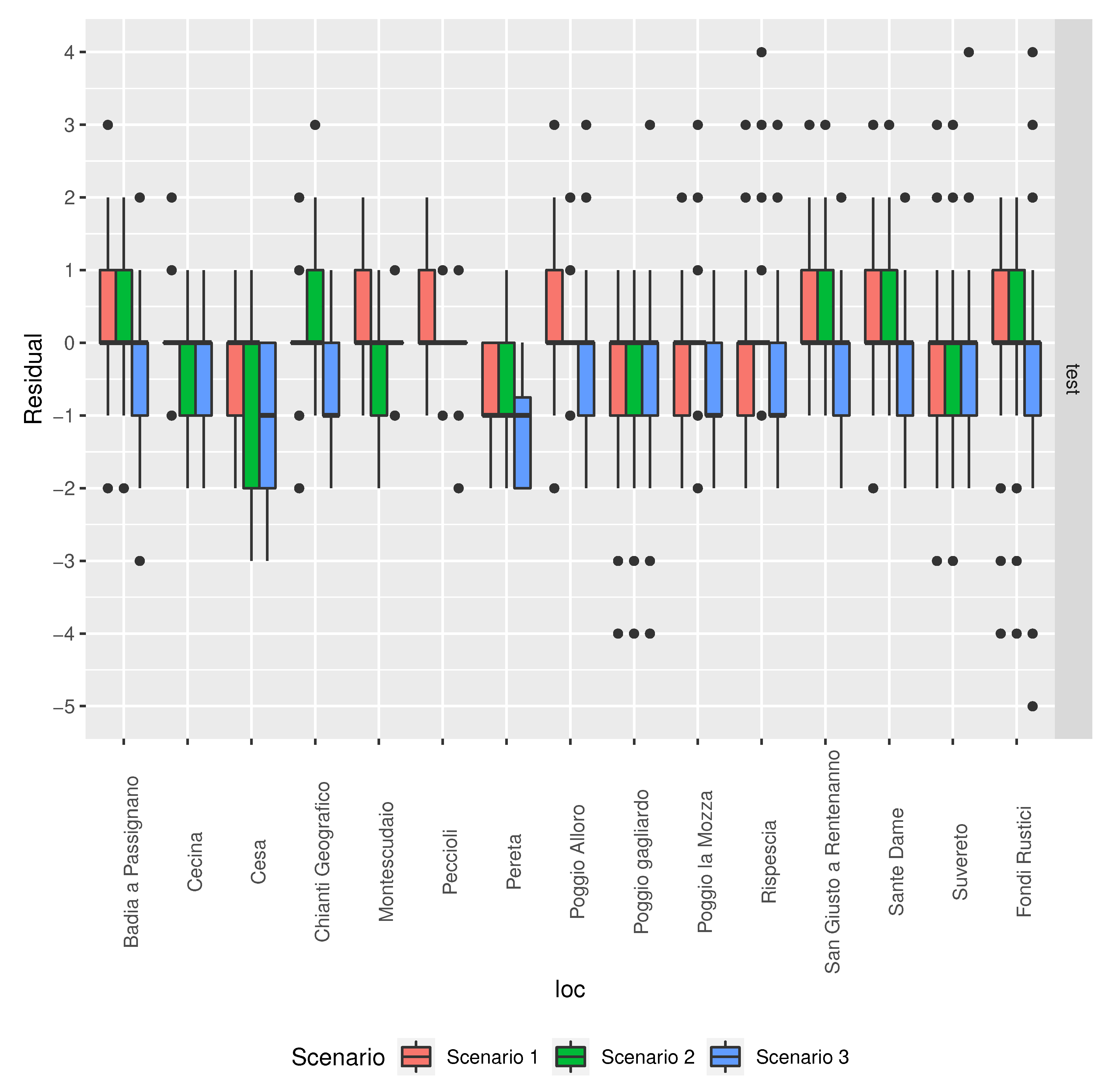
3.1. Weather Station and Era5 Data Comparison
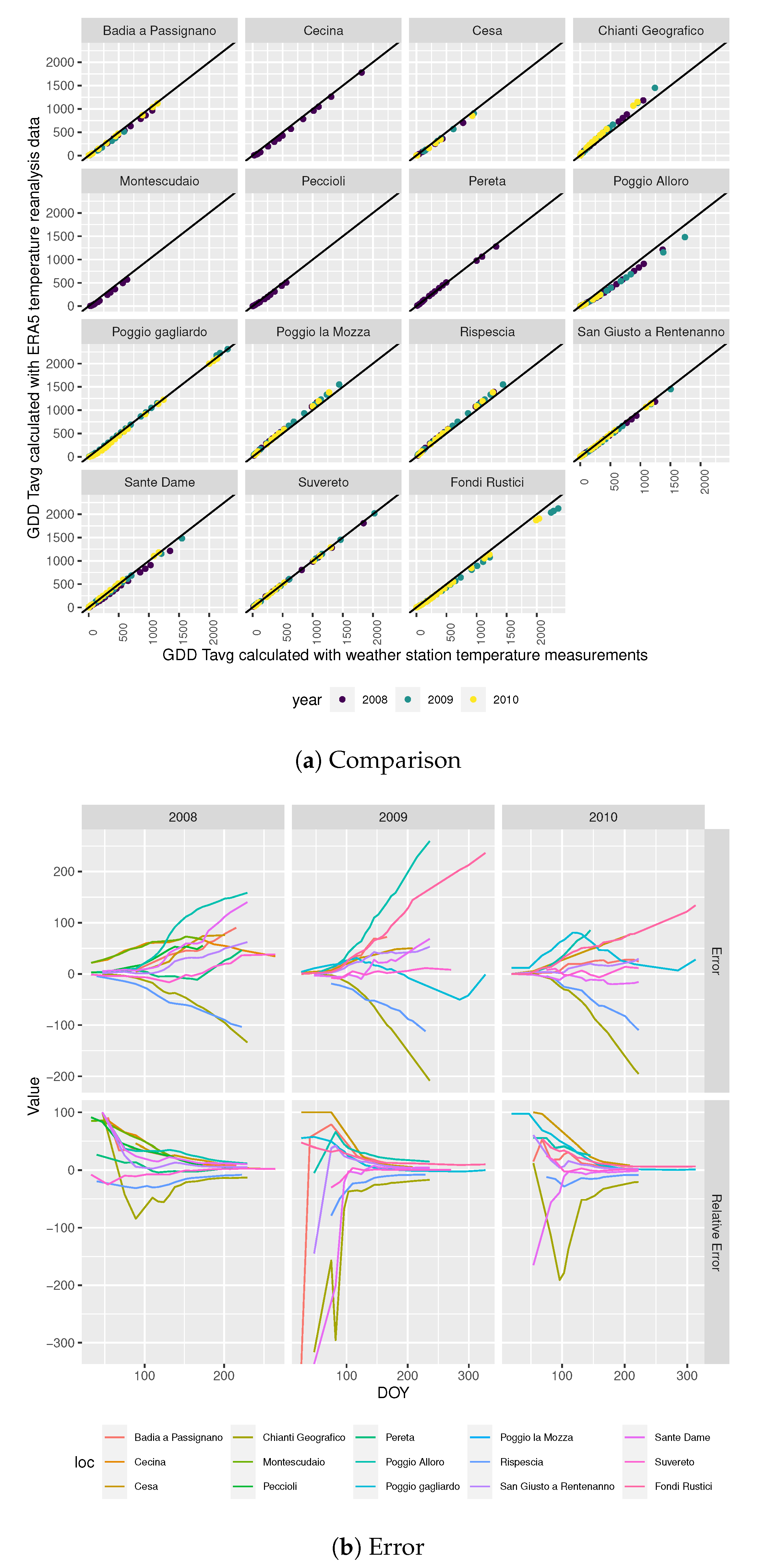
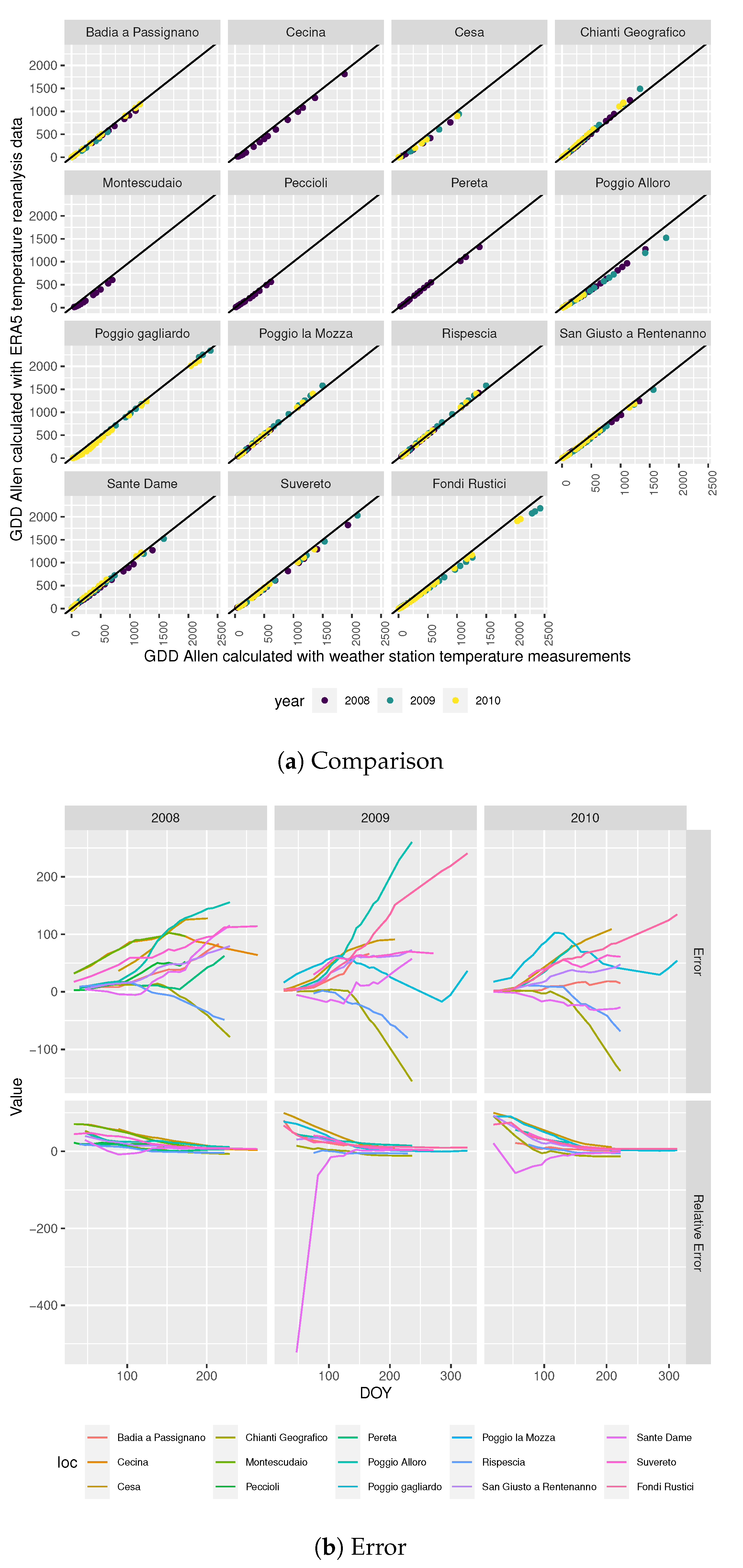
3.1.1. Gdd Calculation Comparison
GDD Tavg
GDD Allen
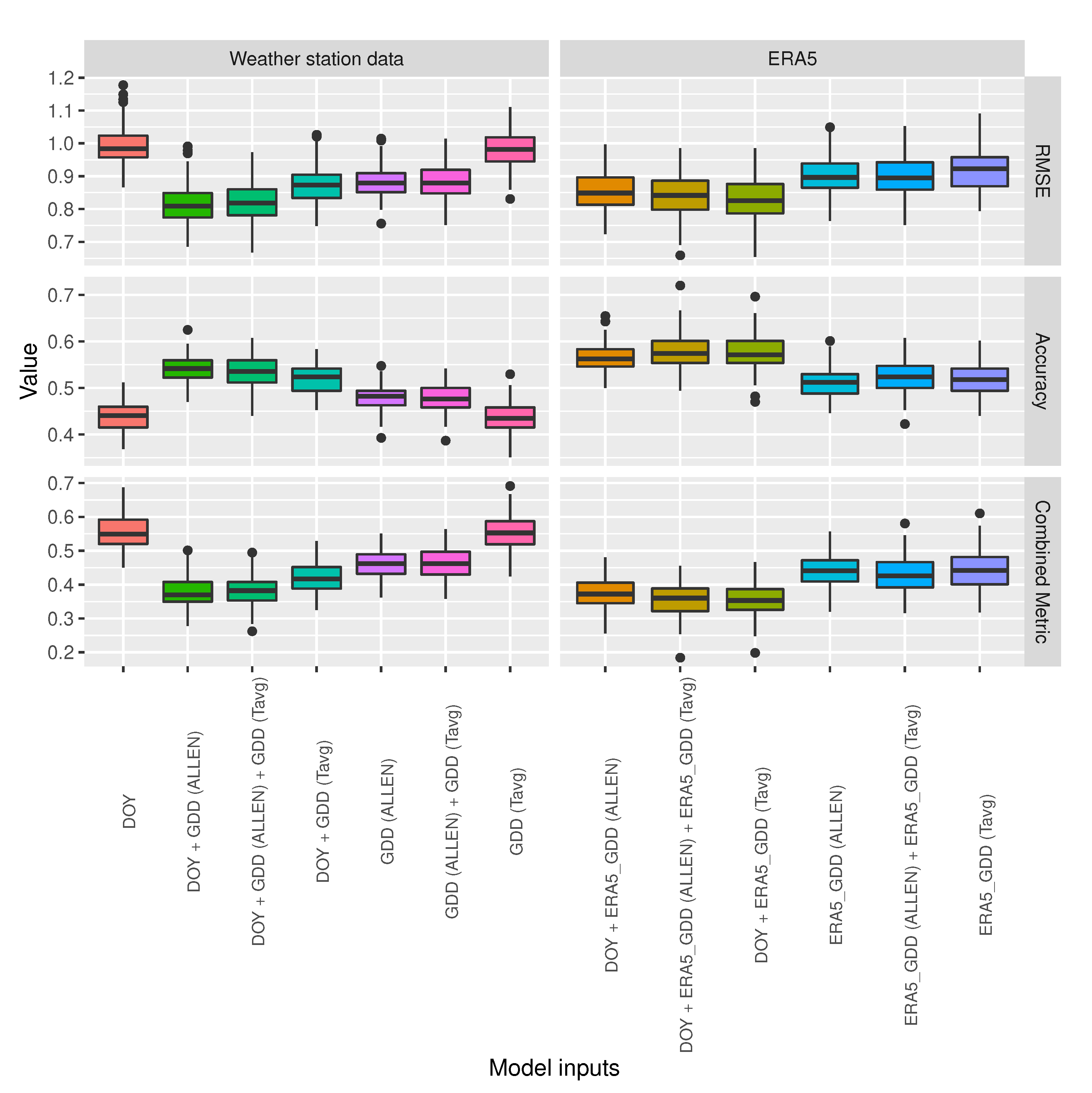
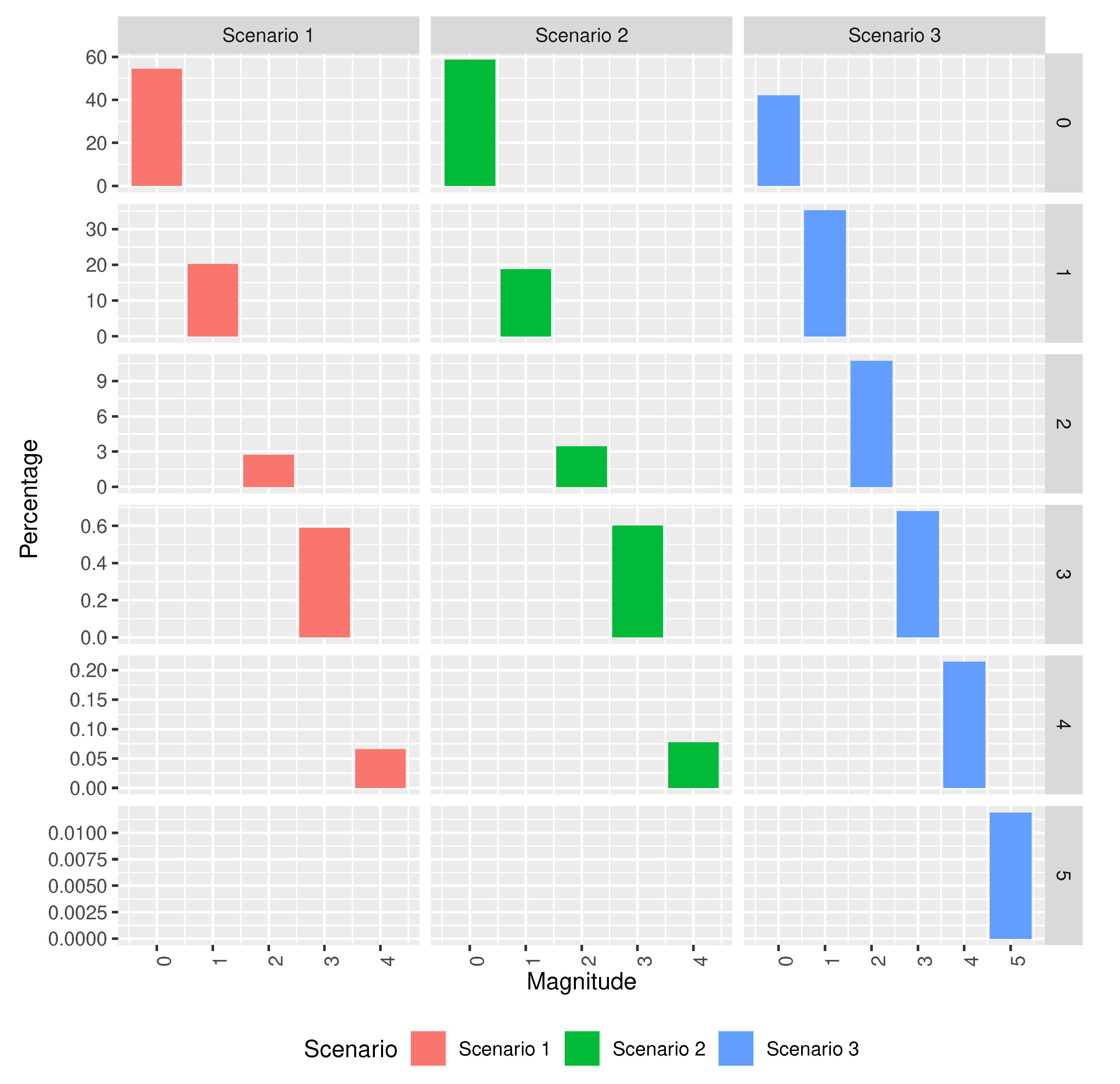
3.1.2. Predictor Performance Comparison
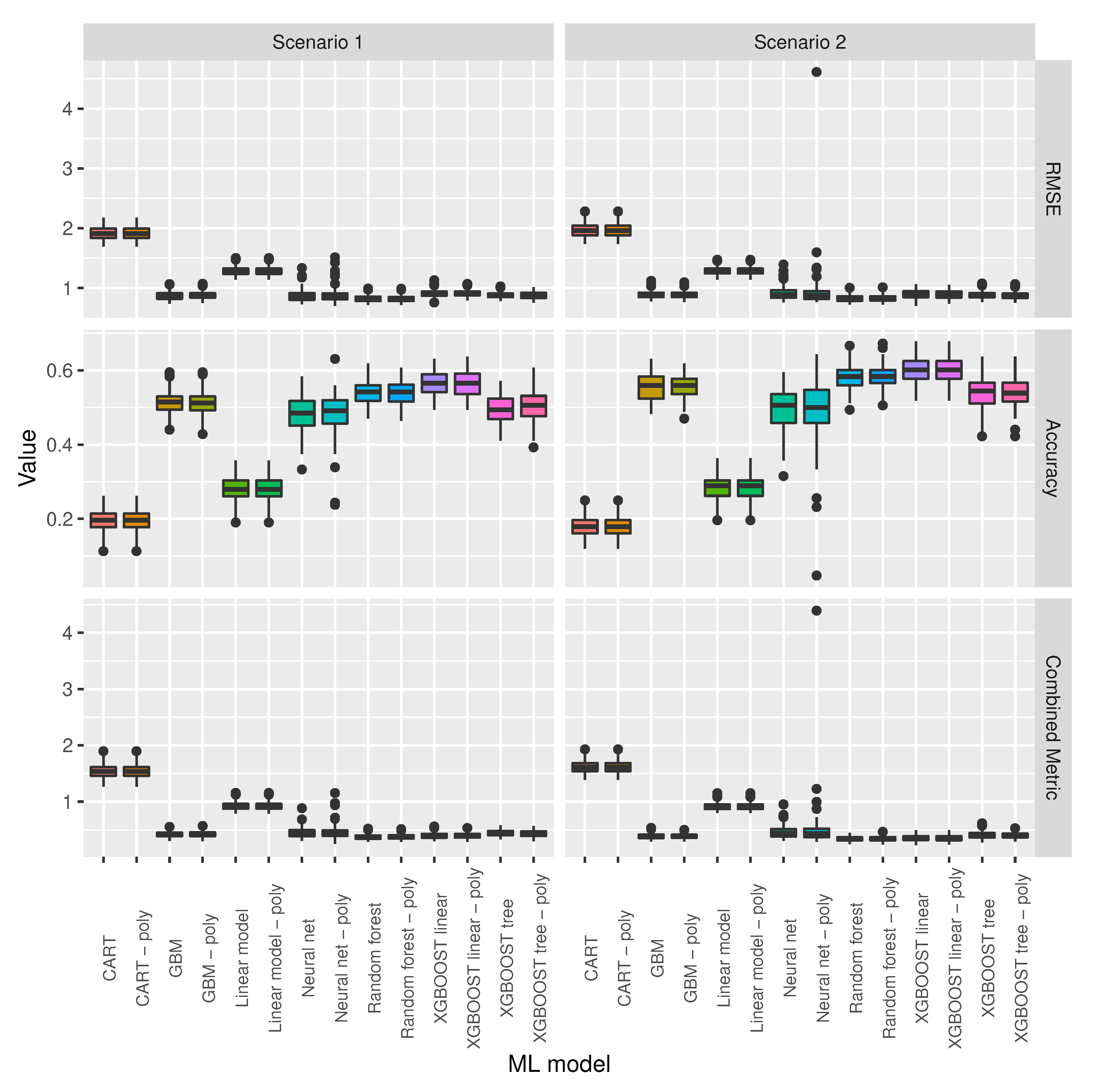
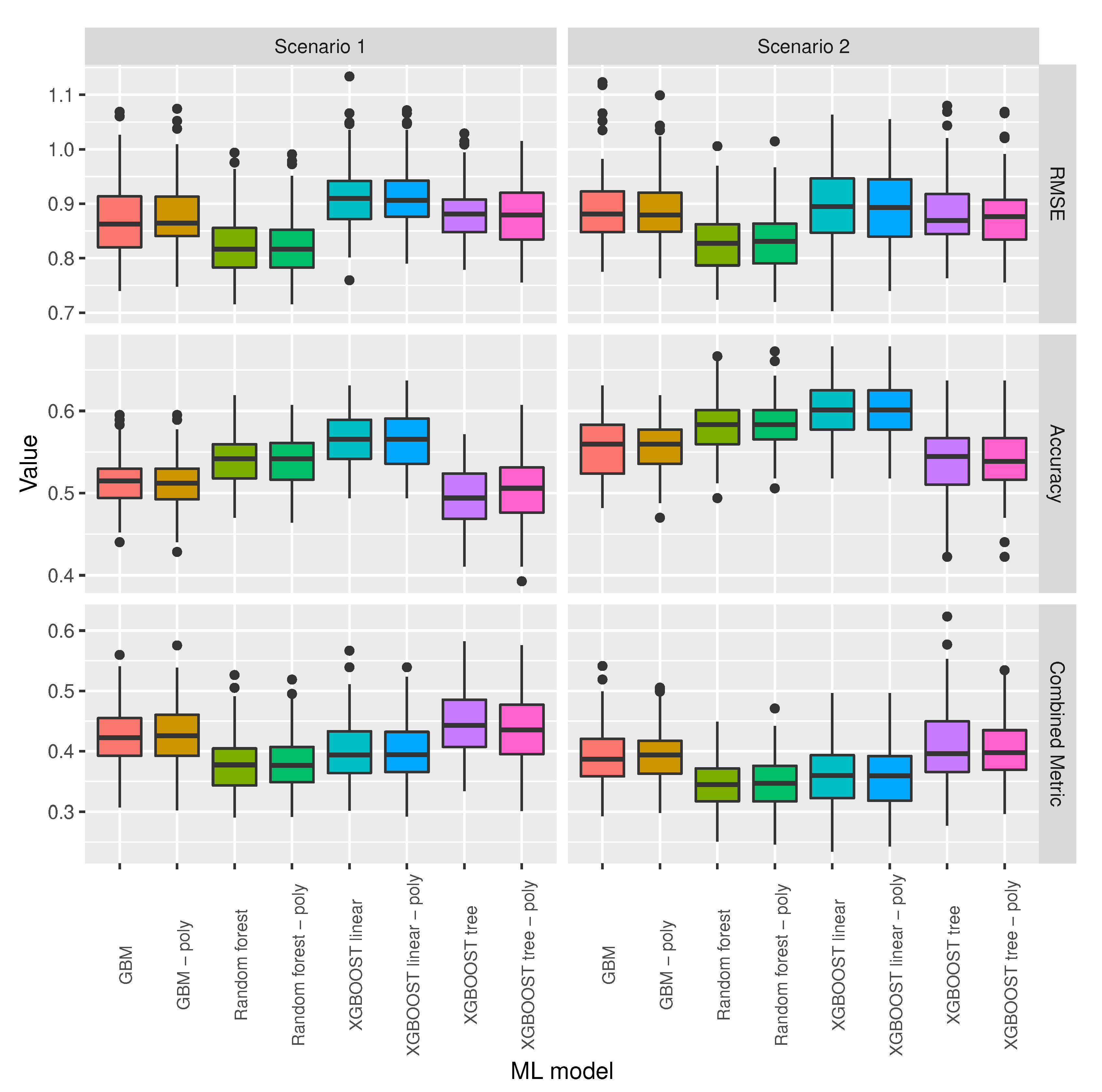
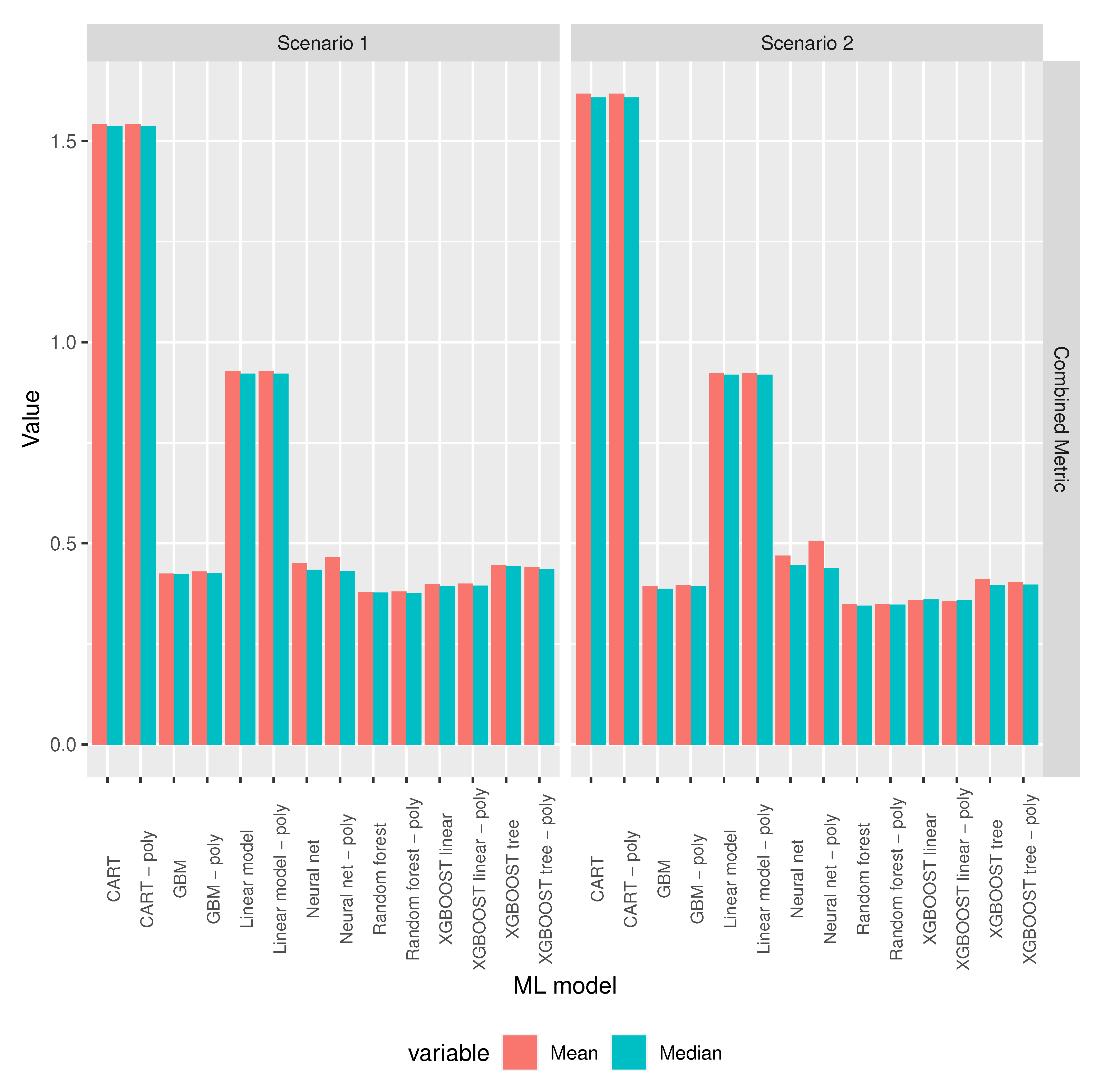
3.2. ML Model Selection
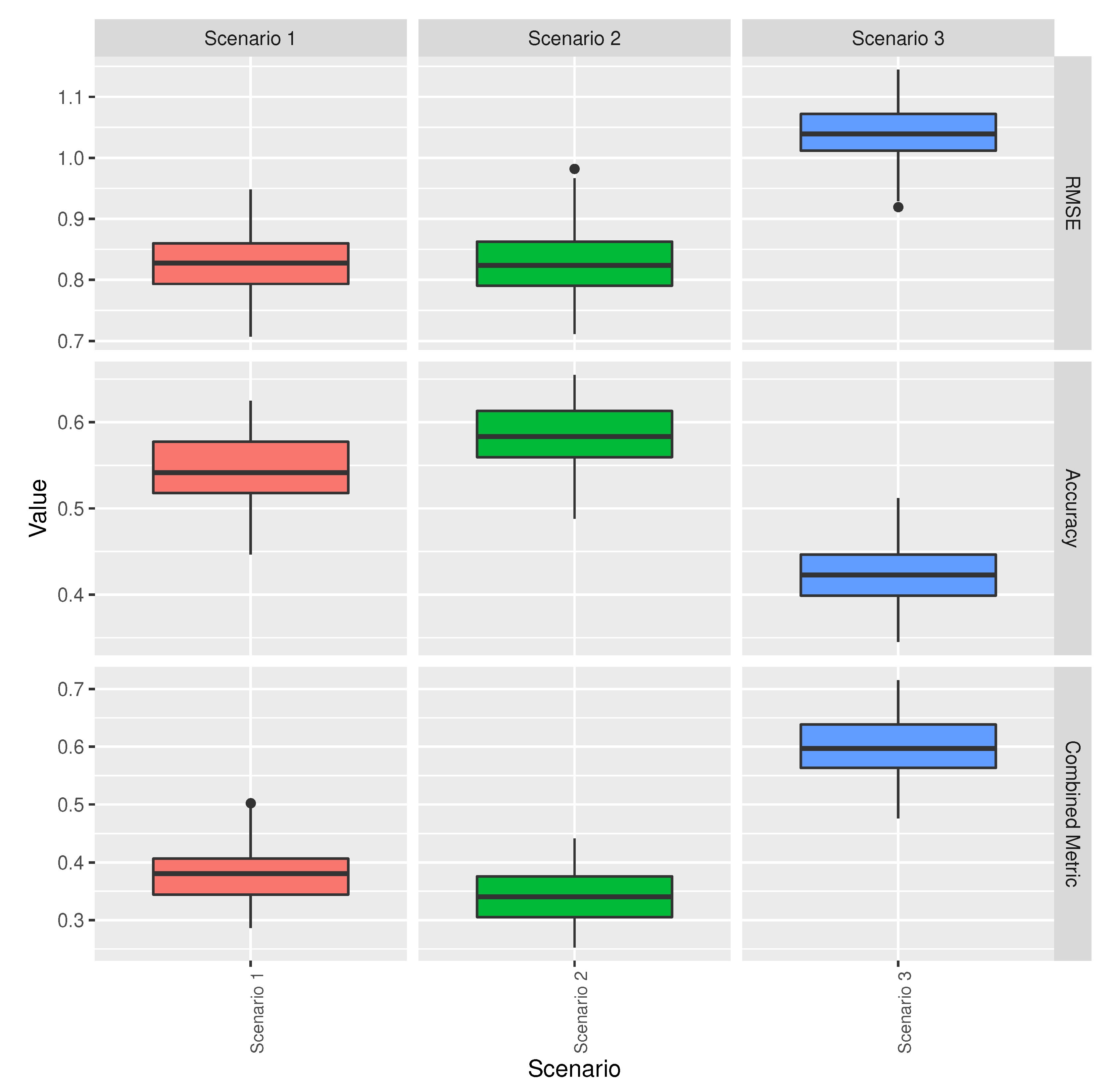
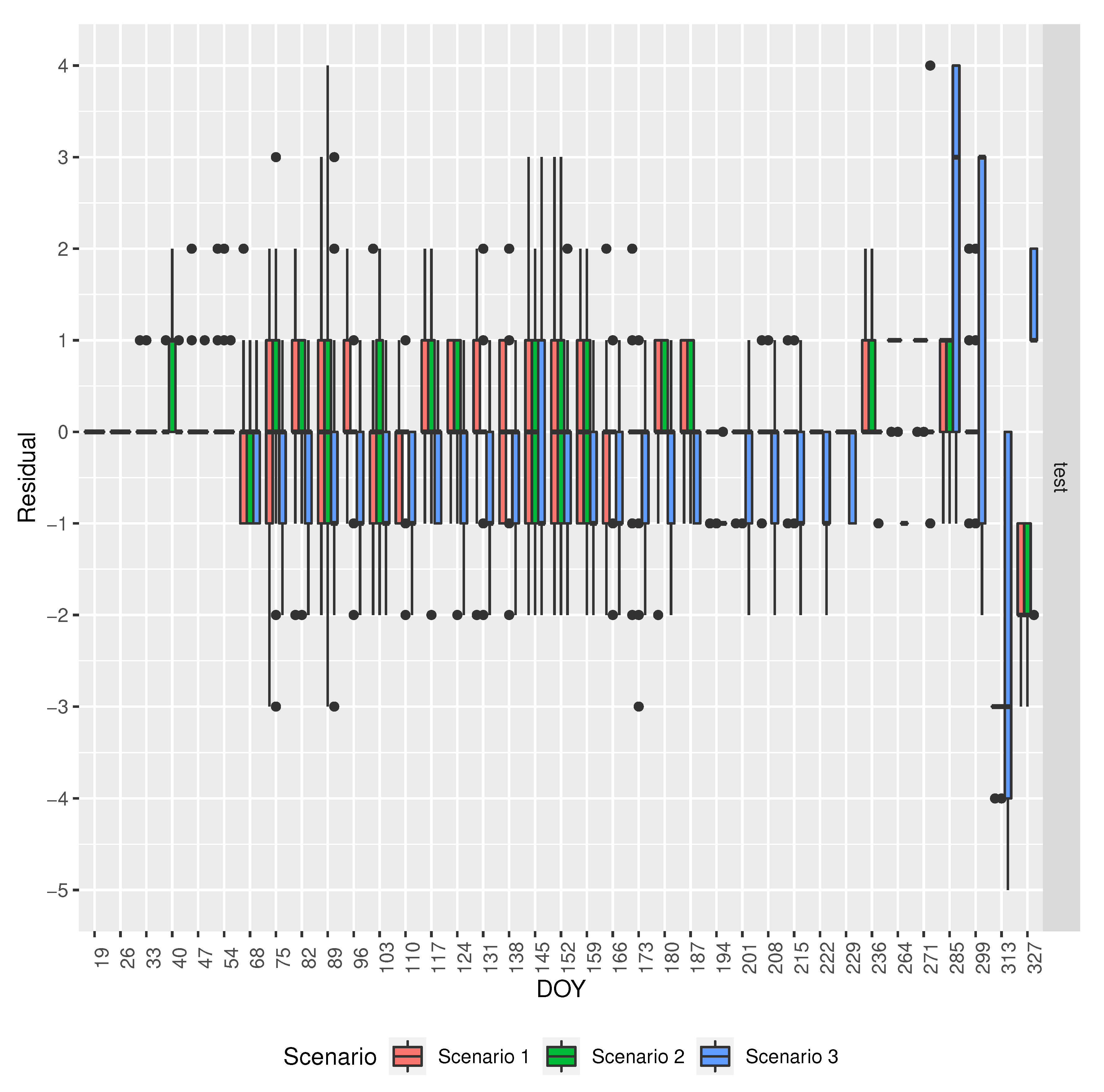
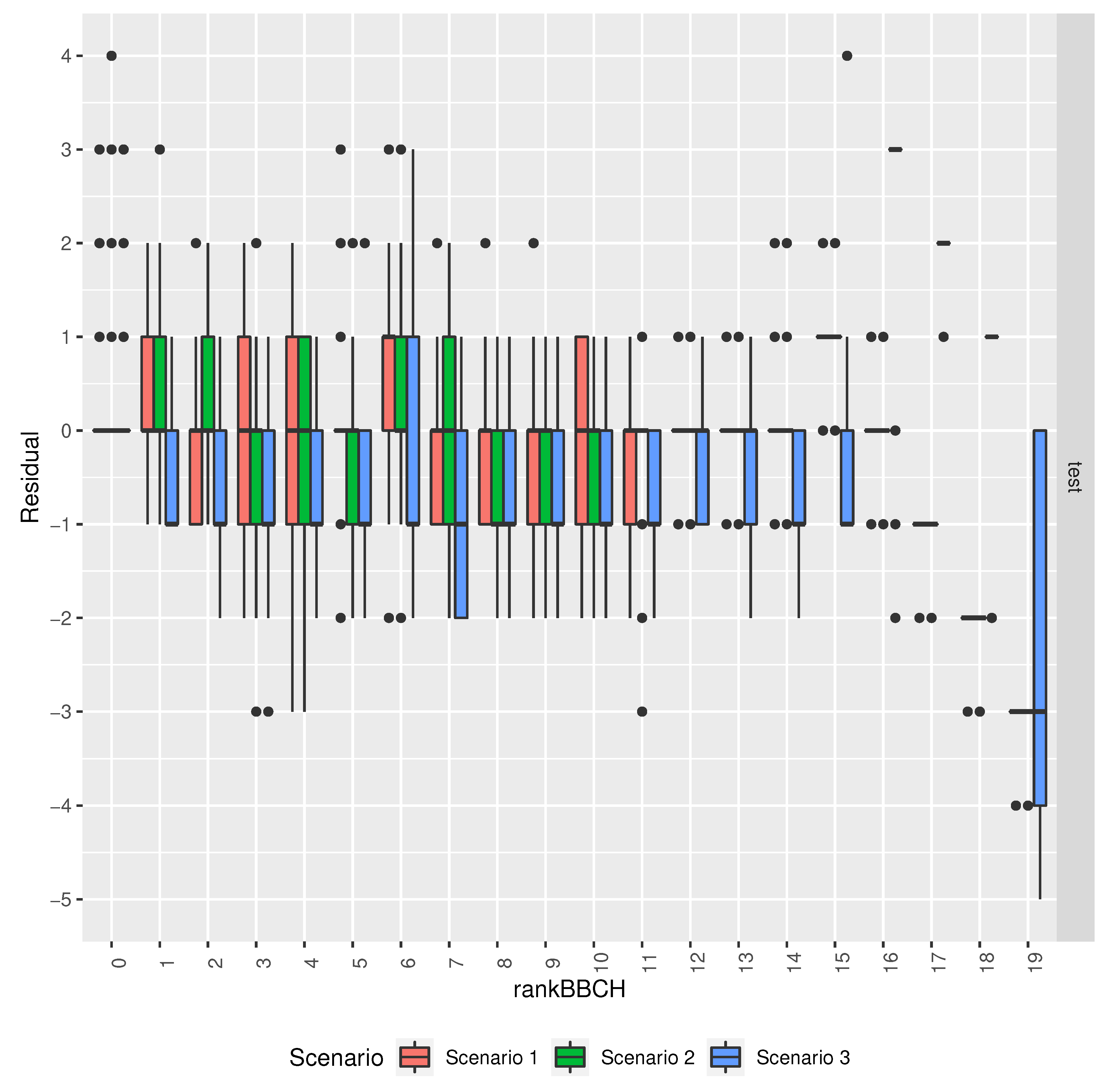
3.3. Baseline and Selected ML Models’ Comparison
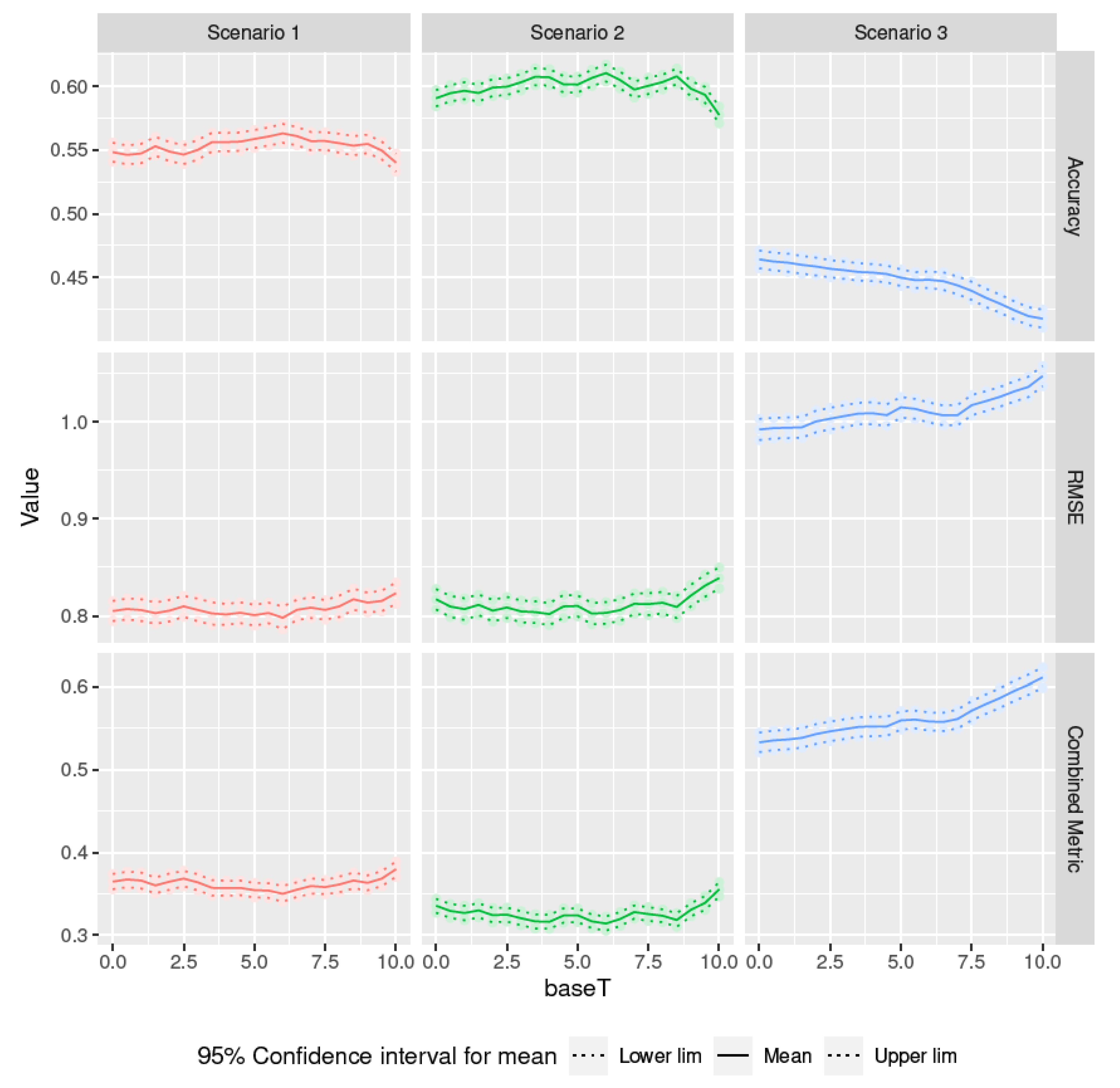
3.4. Optimisation of the Base Temperature
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ECMWF | European Centre for Medium-Range Weather Forecasts |
| ERA5 | ECMWF Reanalysis 5th Generation |
| BBCH | Biologische Bundesanstalt, Bundessortenamt und Chemische Industrie |
| GDD | Growing degree day |
| DOY | Day of year |
| DSS | Decision Support System |
| CART | Classification and regression trees |
| ANN | Artificial neural networks |
| GBM | Stochastic gradient boosting |
| XGBoost | Extreme gradient boosting |
| RF | Random forest |
| RMSE | Root mean square error |
| GDD Tavg | GDD calculated following the average temperature method using weather station data |
| ERA5 GDD Tavg | GDD calculated following the average temperature method using ERA5 data |
| GDD Allen | GDD calculated following the Allen method using weather station data |
| ERA5 GDD Allen | GDD calculated following the Allen method using ERA5 data |
References
- Vitasse, Y.; Francois, C.; Delpierre, N.; Dufrêne, E.; Kremer, A.; Chuine, I.; Delzon, S. Assessing the effects of climate change on the phenology of European temperate trees. Agric. For. Meteorol. 2011, 151, 969–980. [Google Scholar] [CrossRef]
- Lee, M.A.; Monteiro, A.; Barclay, A.; Marcar, J.; Miteva-Neagu, M.; Parker, J. A framework for predicting soft-fruit yields and phenology using embedded, networked microsensors, coupled weather models and machine-learning techniques. Comput. Electron. Agric. 2020, 168, 105103. [Google Scholar] [CrossRef]
- Aguilera, F.; Ruiz-Valenzuela, L. A new aerobiological indicator to optimize the prediction of the olive crop yield in intensive farming areas of southern Spain. Agric. For. Meteorol. 2019, 271, 207–213. [Google Scholar] [CrossRef]
- Loumou, A.; Giourga, C. Olive groves: “The life and identity of the Mediterranean”. Agric. Hum. Values 2003, 20, 87–95. [Google Scholar] [CrossRef]
- Marra, F.P.; Macaluso, L.; Marino, G.; Caruso, T. Predicting olive flowering phenology with phenoclimatic models. Acta Hortic. Int. Soc. Hortic. Sci. 2018, 1229, 189–194. [Google Scholar] [CrossRef]
- Alcala, A.; Barranco, D. Prediction of Flowering Time in Olive for the Cordoba Olive Collection. HortScience 1992, 27, 1205–1207. [Google Scholar] [CrossRef]
- Mancuso, S.; Pasquali, G.; Fiorino, P. Phenology modelling and forecasting in olive (Olea europaea L.) using artificial neural networks. Adv. Hortic. Sci. 2002, 2002, 155–164. [Google Scholar]
- Garcia-Mozo, H.; Orlandi, F.; Galan, C.; Fornaciari, M.; Romano, B.; Ruiz, L.; de la Guardia, C.D.; Trigo, M.; Chuine, I. Olive flowering phenology variation between different cultivars in Spain and Italy: Modeling analysis. Theor. Appl. Climatol. 2009, 95, 385. [Google Scholar] [CrossRef]
- Bacelar, E.A.; Moutinho-Pereira, J.M.; Gonçalves, B.C.; Lopes, J.I.; Correia, C.M. Physiological responses of different olive genotypes to drought conditions. Acta Physiol. Plant. 2009, 31, 611–621. [Google Scholar] [CrossRef]
- Dias, A.B.; Peça, J.; Pinheiro, A. Long-term evaluation of the influence of mechanical pruning on olive growing. Agron. J. 2012, 104, 22–25. [Google Scholar] [CrossRef]
- Avolio, E.; Pasqualoni, L.; Federico, S.; Fornaciari, M.; Bonofiglio, T.; Orlandi, F.; Bellecci, C.; Romano, B. Correlation between large-scale atmospheric fields and the olive pollen season in Central Italy. Int. J. Biometeorol. 2008, 52, 787. [Google Scholar] [CrossRef]
- Bonofiglio, T.; Orlandi, F.; Sgromo, C.; Romano, B.; Fornaciari, M. Influence of temperature and rainfall on timing of olive (Olea europaea) flowering in southern Italy. N. Z. J. Crop. Hortic. Sci. 2008, 36, 59–69. [Google Scholar] [CrossRef]
- García-Mozo, H.; Galán, C.; Vázquez, L. The reliability of geostatistic interpolation in olive field floral phenology. Aerobiologia 2006, 22, 95. [Google Scholar] [CrossRef]
- Aguilera, F.; Valenzuela, L.R. Study of the floral phenology of Olea europaea L. in Jaen province (SE Spain) and its relation with pollen emission. Aerobiologia 2009, 25, 217. [Google Scholar] [CrossRef]
- Moriondo, M.; Ferrise, R.; Trombi, G.; Brilli, L.; Dibari, C.; Bindi, M. Modelling olive trees and grapevines in a changing climate. Environ. Model. Softw. 2015, 72, 387–401. [Google Scholar] [CrossRef]
- Ruml, M.; Vuković, A.; Milatović, D. Evaluation of different methods for determining growing degree-day thresholds in apricot cultivars. Int. J. Biometeorol. 2010, 54, 411–422. [Google Scholar] [CrossRef]
- Galán, C.; Carinanos, P.; Garcia-Mozo, H.; Alcázar, P.; Dominguez-Vilches, E. Model for forecasting Olea europaea L. airborne pollen in South-West Andalusia, Spain. Int. J. Biometeorol. 2001, 45, 59–63. [Google Scholar] [CrossRef]
- Orlandi, F.; Garcia-Mozo, H.; Ezquerra, L.; Romano, B.; Dominguez-Vilches, E.; Galán, C.; Fornaciari, M. Phenological olive chilling requirements in Umbria (Italy) and Andalusia (Spain). Plant Biosyst. 2004, 138, 111–116. [Google Scholar] [CrossRef]
- Orlandi, F.; Bonofiglio, T.; Romano, B.; Fornaciari, M. Qualitative and quantitative aspects of olive production in relation to climate in southern Italy. Sci. Hortic. 2012, 138, 151–158. [Google Scholar] [CrossRef]
- Marchi, S.; Guidotti, D.; Ricciolini, M.; Sebastiani, L. Un esempio di supporto on line alle decisioni per gli olivicoltori | Archivio della ricerca della Scuola Superiore Sant’Anna. L’Informatore Agrario 2012, 4, 60–63. [Google Scholar]
- Moriondo, M.; Orlandini, S.; Nuntiis, P.D.; Mandrioli, P. Effect of agrometeorological parameters on the phenology of pollen emission and production of olive trees (Olea europea L.). Aerobiologia 2001, 17, 225–232. [Google Scholar] [CrossRef]
- Crimmins, M.A.; Crimmins, T.M. Does an Early Spring Indicate an Early Summer? Relationships Between Intraseasonal Growing Degree Day Thresholds. J. Geophys. Res. Biogeosci. 2019, 124, 2628–2641. [Google Scholar] [CrossRef]
- Allen, J.C. A modified sine wave method for calculating degree days. Environ. Entomol. 1976, 5, 388–396. [Google Scholar] [CrossRef]
- Niccolai, M.; Marchi, S. Il clima della Toscana. In RaFT 2005: Rapporto Sullo Stato Delle Foreste in Toscana; Sherwood: London, UK, 2005; pp. 16–21. [Google Scholar]
- Adua, M. Continua a crescere la filiera degli oli dop e igp. L’Informatore Agrario 2010, 12, 26–31. [Google Scholar]
- Copernicus Climate Change Service (C3S). C3S ERA5-Land Reanalysis. 2019. Available online: https://cds.climate.copernicus.eu/cdsapp#!/dataset/10.24381/cds.e2161bac (accessed on 15 September 2020).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote. Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Copernicus Climate Change Service (C3S). ERA5: Fifth Generation of ECMWF Atmospheric Reanalyses of the Global Climate. Copernicus Climate Change Service Climate Data Store (CDS). 2017. Available online: https://cds.climate.copernicus.eu/cdsapp (accessed on 5 October 2020).
- Galton, F. Regression Towards Mediocrity in Hereditary Stature. J. Anthropol. Inst. 1886, 15, 246–263. [Google Scholar] [CrossRef]
- Wu, X.; Kumar, V.; Quinlan, R.; Ghosh, J.; Yang, Q.; Motoda, H.; Mclachlan, G.; Ng, S.K.A.; Liu, B.; Yu, P.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2007, 14. [Google Scholar] [CrossRef]
- Ho, T.K. Random Decision Forests. In Proceedings of the Third International Conference on Document Analysis and Recognition, ICDAR ’95, Montreal, QC, Canada, 14–16 August 1995; IEEE Computer Society: Washington, DC, USA, 1995; Volume 1, p. 278. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Oses, N.; Azpiroz, I.; Quartulli, M.; Olaizola, I.; Marchi, S.; Guidotti, D. Machine Learning for olive phenology prediction and base temperature optimisation. In Proceedings of the 2020 Global Internet of Things Summit (GIoTS), Dublin, Ireland, 3–5 June 2020; pp. 1–6. [Google Scholar]
- Oteros, J.; García-Mozo, H.; Vázquez, L.; Mestre, A.; Domínguez-Vilches, E.; Galán, C. Modelling olive phenological response to weather and topography. Agric. Ecosyst. Environ. 2013, 179, 62–68. [Google Scholar] [CrossRef]
- Holloway, P.; Kudenko, D.; Bell, J.R. Dynamic selection of environmental variables to improve the prediction of aphid phenology: A machine learning approach. Ecol. Indic. 2018, 88, 512–521. [Google Scholar] [CrossRef]
- Czernecki, B.; Nowosad, J.; Jabłońska, K. Machine learning modeling of plant phenology based on coupling satellite and gridded meteorological dataset. Int. J. Biometeorol. 2018, 62, 1297–1309. [Google Scholar] [CrossRef] [PubMed]
- Moriondo, M.; Trombi, G.; Ferrise, R.; Brandani, G.; Dibari, C.; Ammann, C.M.; Lippi, M.M.; Bindi, M. Olive trees as bio-indicators of climate evolution in the Mediterranean Basin. Glob. Ecol. Biogeogr. 2013, 22, 818–833. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Data Group | Features |
|---|---|---|
| Scenario 1 | Weather station data | DOY, GDD (ALLEN) |
| Scenario 2 | ERA5 | DOY, ERA5_GDD (Tavg) |
| Scenario | Data Group | Feature Set | Selected Model | Mean |
|---|---|---|---|---|
| Scenario 1 | Weather station data | DOY, GDD (ALLEN) | Random forest | 0.38 |
| Scenario 2 | ERA5 | DOY, ERA5_GDD (Tavg) | Random forest | 0.35 |
| Scenario | Data Group | Feature Set | Selected Model |
|---|---|---|---|
| Scenario 1 | Weather station data | DOY, GDD (ALLEN) | Random forest |
| Scenario 2 | ERA5 | DOY, ERA5_GDD (Tavg) | Random forest |
| Scenario 3 | Weather station data | GDD (Allen) | Agricolus baseline |
| Scenario | Metric | Optimal Base Temperature |
|---|---|---|
| Scenario 1 | Accuracy | 6.00 |
| Scenario 1 | RMSE | 6.00 |
| Scenario 1 | Combined Metric | 6.00 |
| Scenario 2 | Accuracy | 6.00 |
| Scenario 2 | RMSE | 4.00 |
| Scenario 2 | Combined Metric | 6.00 |
| Scenario 3 | Accuracy | 0.00 |
| Scenario 3 | RMSE | 0.00 |
| Scenario 3 | Combined Metric | 0.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oses, N.; Azpiroz, I.; Marchi, S.; Guidotti, D.; Quartulli, M.; G. Olaizola, I. Analysis of Copernicus’ ERA5 Climate Reanalysis Data as a Replacement for Weather Station Temperature Measurements in Machine Learning Models for Olive Phenology Phase Prediction. Sensors 2020, 20, 6381. https://doi.org/10.3390/s20216381
Oses N, Azpiroz I, Marchi S, Guidotti D, Quartulli M, G. Olaizola I. Analysis of Copernicus’ ERA5 Climate Reanalysis Data as a Replacement for Weather Station Temperature Measurements in Machine Learning Models for Olive Phenology Phase Prediction. Sensors. 2020; 20(21):6381. https://doi.org/10.3390/s20216381
Chicago/Turabian StyleOses, Noelia, Izar Azpiroz, Susanna Marchi, Diego Guidotti, Marco Quartulli, and Igor G. Olaizola. 2020. "Analysis of Copernicus’ ERA5 Climate Reanalysis Data as a Replacement for Weather Station Temperature Measurements in Machine Learning Models for Olive Phenology Phase Prediction" Sensors 20, no. 21: 6381. https://doi.org/10.3390/s20216381
APA StyleOses, N., Azpiroz, I., Marchi, S., Guidotti, D., Quartulli, M., & G. Olaizola, I. (2020). Analysis of Copernicus’ ERA5 Climate Reanalysis Data as a Replacement for Weather Station Temperature Measurements in Machine Learning Models for Olive Phenology Phase Prediction. Sensors, 20(21), 6381. https://doi.org/10.3390/s20216381