Surface Reconstruction Assessment in Photogrammetric Applications



Abstract
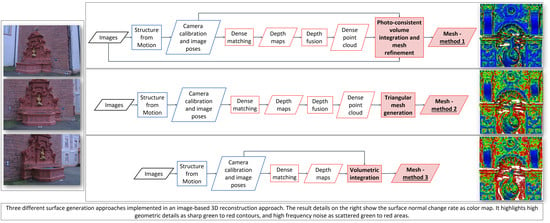
1. Introduction
Paper’s Motivation and Aim
- In a traditional photogrammetric pipeline, the meshing step interpolates a surface over the input 3D points. This is usually disjointed from the 3D point cloud generation DIM but can potentially leverage and take advantage of additional information from the previous steps of the workflow, i.e., visibility constraints and photo-consistency measures which are generally not considered in popular meshing algorithms as Poisson [14].
- Dense point clouds can be heavily affected by poor image quality or textureless areas, resulting in high frequency noise, holes and uneven point density. These issues can be propagated during the mesh generation process.
- Volumetric approaches for surface reconstruction based on depth maps are well-established, time-efficient methods for depth sensors, also known as RGB-D [15], and might be a valid approach also for pure image-based approaches.
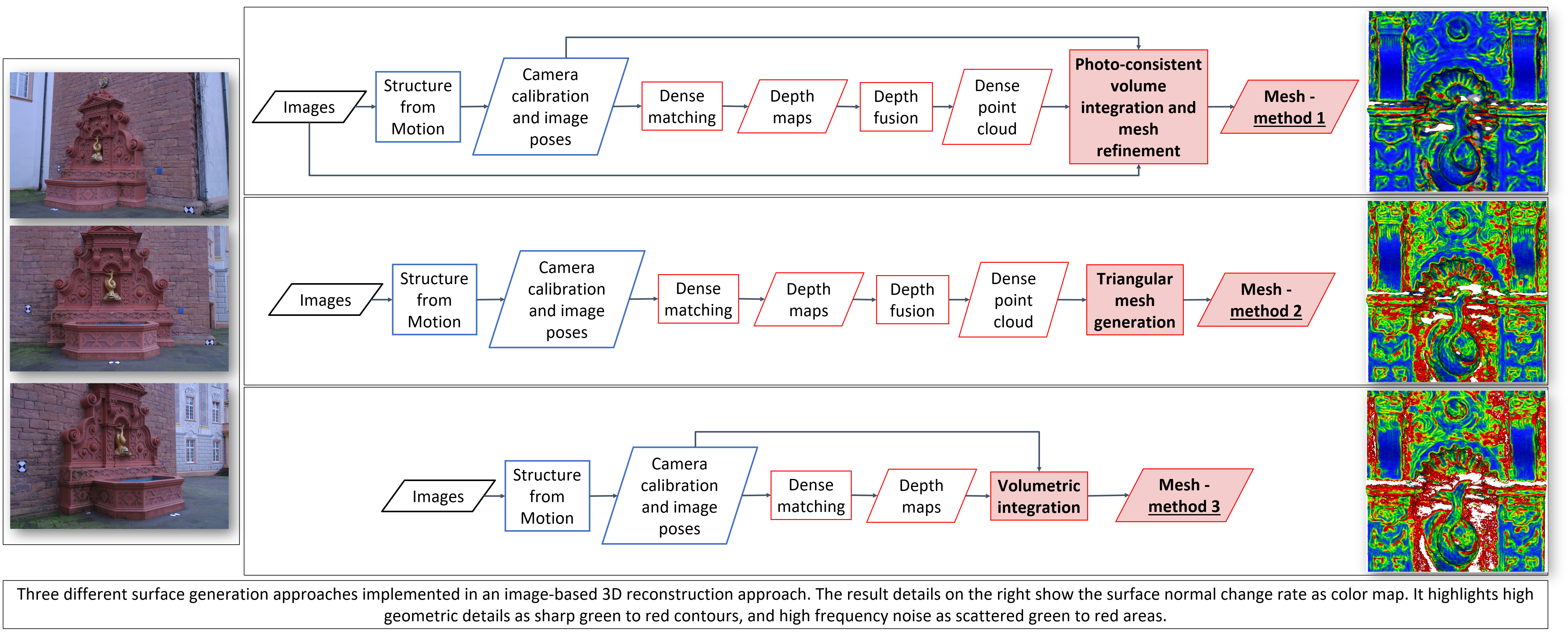
- Method 1: Surface generation and refinement are incorporated in the 3D reconstruction pipeline. The mesh is generated after depth maps and dense point clouds are estimated and is subsequently refined considering visibility information (i.e., image orientation) to optimize a photo-consistency score over the reconstructed surface [13,16].
2. On DIM and MVS
3. Benchmarks and Assessment of Surface Reconstruction Approaches
3.1. DIM/MVS Benchmarks
3.2. Surface Reconstruction and Assessment Criteria
4. Investigated Surface Generation Methods
4.1. Photo-Consistent Volume Integration and Mesh Refinement (Method 1, M1)
4.2. Surface Generation from Point Cloud (Method 2, M2)
4.3. TSDF Volume Integration (Method 3, M3)
5. Datasets and Evaluation Metrics
5.1. Datasets
5.2. Evaluation Approach and Criteria
- Accuracy was evaluated as the signed Euclidean distance between the vertices of the (photogrammetric) data mesh and the (scanner) reference mesh. The signed Euclidean distance was chosen instead of the Hausdorff distance to highlight any possible systematic error. For this, both CloudCompare and Meshlab [85] implementations were tested, providing equivalent results. The following values were computed: mean, standard deviation (STDV), median and normalized maximum absolute deviation from the median (NMAD = 1.4826 × MAD), root mean square (RMS) and outliers percentage.
- Completeness was defined as the signed Euclidean distance between the (scanner) reference mesh and the (photogrammetric) data mesh. The percentage of vertices of photogrammetric data mesh falling within the defined threshold (in%) was adopted as a measure for completeness.
- Local roughness was computed as the absolute distance between the mesh vertex and the best fitting plane estimated on its nearest neighbors within a defined kernel size. The method implemented in CloudCompare was adopted. Adapting the standard parameters generally used to quantify the roughness [86], mean and RMS roughness values are reported to describe the local behavior of the vertices in their local region (i.e., within the selected kernel). The kernel size was carefully selected according to surface resolution.
- Local noise was assessed on selected planar regions where the plane fitting RMS was computed.
- Sections were extracted from the meshes and the mean and RMS signed distance values from data to reference are reported.
- Local curvature variation, expressed as normal change rate, was computed over a kernel size, i.e., the radius defining the neighbor vertices around each point where the curvature was estimated. As for the roughness metric, the kernel size was decided according to the surface resolution and size of the geometric elements (3D edges). The normal change rate is shown as a color map to highlight high geometric details (e.g., 3D edges), which appear as sharp green to red contours, and high frequency noise, shown as scattered green to red areas. The method implemented in CloudCompare was here adopted.
- The topology of each generated surface is evaluated in terms of the percentage of self-intersecting triangles over the total number of faces.
6. Results and Discussion
6.1. Evaluation without a Reference Mesh: The Aerial Case Study
6.2. Evaluation with a Reference Mesh
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yogeswaran, A.; Payeur, P. 3D Surface Analysis for Automated Detection of Deformations on Automotive Body Panels; New Advances in Vehicular Technology and Automotive Engineering: Ijeka, Croatia, 2012. [Google Scholar]
- Nicolae, C.; Nocerino, E.; Menna, F.; Remondino, F. Photogrammetry applied to problematic artefacts. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2014, 40, 451. [Google Scholar] [CrossRef]
- Scopigno, R.; Cignoni, P.; Pietroni, N.; Callieri, M.; Dellepiane, M. Digital fabrication techniques for cultural heritage: A survey. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2017; pp. 6–21. [Google Scholar]
- Starek, M.J.; Mitasova, H.; Hardin, E.; Weaver, K.; Overton, M.; Harmon, R.S. Modeling and analysis of landscape evolution using airborne, terrestrial, and laboratory laser scanning. Geosphere 2011, 7, 1340–1356. [Google Scholar] [CrossRef]
- Barbarella, M.; Fiani, M.; Lugli, A. Landslide monitoring using multitemporal terrestrial laser scanning for ground displacement analysis. Geomat. Nat. Hazards Risk 2015, 6, 398–418. [Google Scholar] [CrossRef]
- Haala, N.; Rothermel, M. Image-Based 3D Data Capture in Urban Scenarios. In Proceedings of the Photogrammetric Week 2015, Stuttgart, Germany, 7–11 September 2015; pp. 119–130. [Google Scholar]
- Toschi, I.; Ramos, M.M.; Nocerino, E.; Menna, F.; Remondino, F.; Moe, K.; Poli, D.; Legat, K.; Fassi, F. Oblique photogrammetry supporting 3D urban reconstruction of complex scenarios. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2017, 42, 519–526. [Google Scholar] [CrossRef]
- Krombach, N.; Droeschel, D.; Houben, S.; Behnke, S. Feature-based visual odometry prior for real-time semi-dense stereo SLAM. Robot. Auton. Syst. 2018, 109, 38–58. [Google Scholar] [CrossRef]
- Remondino, F.; Spera, M.G.; Nocerino, E.; Menna, F.; Nex, F. State of the art in high density image matching. Photogram. Rec. 2014, 29, 144–166. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin, Germany, 2010. [Google Scholar]
- Ressl, C. Assessing the Accuracy of Dense Image Matching (or Benchmarking DIM). Keynote Presentation. In Proceedings of the ISPRS Technical Commission II Symposium, Riva del Garda, Italy, 2018; Available online: https://www.isprs.org/tc2-symposium2018/images/ISPRS-Keynote_Ressl.pdf (accessed on 15 October 2020).
- Furukawa, Y.; Hernández, C. Multi-view stereo: A tutorial. Found. Trends Comput. Graph. Vis. 2015, 9, 1–48. [Google Scholar] [CrossRef]
- Jancosek, M.; Pajdla, T. Exploiting visibility information in surface reconstruction to preserve weakly supported surfaces. Int. Sch. Res. Not. 2014. [Google Scholar] [CrossRef]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Cagliari, Sardinia, 26–28 June 2006; Volume 7. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Vu, H.H.; Labatut, P.; Pons, J.P.; Keriven, R. High accuracy and visibility-consistent dense multiview stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 889–901. [Google Scholar] [CrossRef]
- Jamin, C.; Alliez, P.; Yvinec, M.; Boissonnat, J.D. CGALmesh: A generic framework for Delaunay mesh generation. ACM Trans. Math. Softw. TOMS 2015, 41, 1–24. [Google Scholar] [CrossRef]
- Curless, B.; Levoy, M. A Volumetric Method for Building Complex Models from Range Images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques August 1996, New Orleans, LA, USA, 4–9 August 1996. [Google Scholar]
- Zhou, Q.Y.; Park, J.; Koltun, V. Open3D: A modern library for 3D data processing. arXiv 2018, arXiv:1801.09847. Available online: https://arxiv.org/abs/1801.09847 (accessed on 14 October 2020).
- Fisher, R.B.; Breckon, T.P.; Dawson-Howe, K.; Fitzgibbon, A.; Robertson, C.; Trucco, E.; Williams, C.K. Dictionary of Computer Vision and Image Processing; HOVA MART LLC: Bayonne, NJ, USA, 2013. [Google Scholar]
- Granshaw, S.I. Photogrammetric terminology. Photogrammet. Rec. 2016, 31, 210–252. [Google Scholar] [CrossRef]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 807–814. [Google Scholar]
- Furukawa, Y.; Ponce, J. Accurate, dense, and robust multiview stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1362–1376. [Google Scholar] [CrossRef]
- Shen, S. Accurate multiple view 3D reconstruction using patch-based stereo for large-scale scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef] [PubMed]
- Remondino, F.; Zhang, L. Surface reconstruction algorithms for detailed close-range object modeling. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2006, 36, 117–123. [Google Scholar]
- Remondino, F.; El-Hakim, S.; Gruen, A.; Zhang, L. Development and performance analysis of image matching for detailed surface reconstruction of heritage objects. IEEE Signal. Process. Mag. 2008, 25, 55–65. [Google Scholar] [CrossRef]
- Seitz, S.M.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A comparison and evaluation of multi-view stereo reconstruction algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-scale data for multiple-view stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef]
- Campbell, N.D.; Vogiatzis, G.; Hernández, C.; Cipolla, R. Using multiple hypotheses to improve depth-maps for multi-view stereo. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 766–779. [Google Scholar]
- Goesele, M.; Curless, B.; Seitz, S.M. Multi-view stereo revisited. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2402–2409. [Google Scholar]
- Hiep, V.H.; Keriven, R.; Labatut, P.; Pons, J.P. Towards high-resolution large-scale multi-view stereo. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1430–1437. [Google Scholar]
- Tola, E.; Strecha, C.; Fua, P. Efficient large-scale multi-view stereo for ultra high-resolution image sets. Mach. Vis. Appl. 2012, 23, 903–920. [Google Scholar] [CrossRef]
- Hernández, C.; Vogiatzis, G.; Cipolla, R. Probabilistic visibility for multi-view stereo. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Kolev, K.; Brox, T.; Cremers, D. Fast joint estimation of silhouettes and dense 3D geometry from multiple images. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 493–505. [Google Scholar] [CrossRef]
- Liu, S.; Cooper, D.B. A complete statistical inverse ray tracing approach to multi-view stereo. In Proceedings of the IEEE CVPR 2011, Providence, RI, USA, 20–25 June 2011; pp. 913–920. [Google Scholar]
- Zach, C.; Pock, T.; Bischof, H. A globally optimal algorithm for robust tv-l 1 range image integration. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Kuhn, A.; Mayer, H.; Hirschmüller, H.; Scharstein, D. A TV prior for high-quality local multi-view stereo reconstruction. In Proceedings of the IEEE 2014 2nd International Conference on 3D Vision, Tokyo, Japan, 8–11 December 2014; Volume 1, pp. 65–72. [Google Scholar]
- Werner, D.; Al-Hamadi, A.; Werner, P. Truncated signed distance function: Experiments on voxel size. In International Conference Image Analysis and Recognition; Springer: Cham, Switzerland, 2014; pp. 357–364. [Google Scholar]
- Proença, P.F.; Gao, Y. Probabilistic RGB-D odometry based on points, lines and planes under depth uncertainty. Robot. Auton. Syst. 2018, 104, 25–39. [Google Scholar] [CrossRef]
- Bakuła, K.; Mills, J.P.; Remondino, F. A Review of Benchmarking in Photogrammetry and Remote Sensing. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing & Spatial Information Sciences, Warsav, Poland, 16–17 September 2019. [Google Scholar]
- Özdemir, E.; Toschi, I.; Remondino, F. A multi-purpose benchmark for photogrammetric urban 3D reconstruction in a controlled environment. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4212, 53–60. [Google Scholar] [CrossRef]
- Knapitsch, A.; Park, J.; Zhou, Q.Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. ToG. 2017, 36, 1–3. [Google Scholar] [CrossRef]
- Schops, T.; Schonberger, J.L.; Galliani, S.; Sattler, T.; Schindler, K.; Pollefeys, M.; Geiger, A. A multi-view stereo benchmark with high-resolution images and multi-camera videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Middlebury, M.V.S. Available online: https://vision.middlebury.edu/mview/ (accessed on 2 September 2020).
- DTU Robot Image Data Sets. Available online: http://roboimagedata.compute.dtu.dk/ (accessed on 2 September 2020).
- 3DOMcity Benchmark. Available online: https://3dom.fbk.eu/3domcity-benchmark. (accessed on 2 September 2020).
- Strecha, C.; Von Hansen, W.; Van Gool, L.; Fua, P.; Thoennessen, U. On benchmarking camera calibration and multi-view stereo for high resolution imagery. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- ETH3D. Available online: https://www.eth3d.net/ (accessed on 2 September 2020).
- Tanks and Temples. Available online: https://www.tanksandtemples.org/ (accessed on 2 September 2020).
- Cavegn, S.; Haala, N.; Nebiker, S.; Rothermel, M.; Tutzauer, P. Benchmarking high density image matching for oblique airborne imagery. In Proceedings of the 2014 ISPRS Technical Commission III Symposium, Zurich, Switzerland, 5–7 September 2014; pp. 45–52. [Google Scholar]
- ISPRS-EuroSDR. Benchmark on High Density Aerial Image Matching. Available online: https://ifpwww.ifp.uni-stuttgart.de/ISPRS-EuroSDR/ImageMatching/default.aspx (accessed on 2 September 2020).
- Berger, M.; Tagliasacchi, A.; Seversky, L.M.; Alliez, P.; Guennebaud, G.; Levine, J.A.; Sharf, A.; Silva, C.T. A survey of surface reconstruction from point clouds. Comput. Graph. Forum 2017, 36, 301–329. [Google Scholar] [CrossRef]
- Guthe, M.; Borodin, P.; Klein, R. Fast and Accurate Hausdorff Distance Calculation between Meshes. In Proceedings of the Conference Proceedings WSCG’2005, Plzen, Czech Republic, 31 January–4 February 2005; ISBN 80-903100-7-9. [Google Scholar]
- Aspert, N.; Santa-Cruz, D.; Ebrahimi, T. Mesh: Measuring errors between surfaces using the hausdorff distance. In Proceedings of the IEEE International Conference on Multimedia and Expo, Lausanne, Switzerland, 26–29 August 2002; Volume 1, pp. 705–708. [Google Scholar]
- Cignoni, P.; Rocchini, C.; Scopigno, R. Metro: Measuring error on simplified surfaces. In Computer Graphics Forum; Blackwell Publishers: Oxford, UK; Boston, MA, USA, 1998; Volume 17, pp. 167–174. [Google Scholar]
- O’Gwynn, B.D. A Topological Approach to Shape Analysis and Alignment. Ph.D. Dissertation, The University of Alabama at Birmingham, Birmingham, AL, USA, 2011. [Google Scholar]
- Berger, M.; Levine, J.A.; Nonato, L.G.; Taubin, G.; Silva, C.T. A benchmark for surface reconstruction. ACM Trans. Graph. 2013, 32, 1–7. [Google Scholar] [CrossRef]
- Opalach, A.; Maddock, S.C. An Overview of Implicit Surfaces. Available online: https://www.researchgate.net/publication/2615486_An_Overview_of_Implicit_Surfaces (accessed on 15 October 2020).
- Dong, L.; Fang, Y.; Lin, W.; Seah, H.S. Perceptual quality assessment for 3D triangle mesh based on curvature. IEEE Trans. Multimed. 2015, 17, 2174–2184. [Google Scholar] [CrossRef]
- Lavoué, G.; Mantiuk, R. Quality assessment in computer graphics. In Visual Signal Quality Assessment; Springer: Cham, Switzerland, 2015; pp. 243–286. [Google Scholar]
- Corsini, M.; Larabi, M.C.; Lavoué, G.; Petřík, O.; Váša, L.; Wang, K. Perceptual metrics for static and dynamic triangle meshes. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2013; Volume 32, pp. 101–125. [Google Scholar]
- Abouelaziz, I.; Chetouani, A.; El Hassouni, M.; Cherifi, H. Mesh visual quality assessment Metrics: A Comparison Study. In Proceedings of the IEEE 2017 13th International Conference on Signal.-Image Technology & Internet-Based Systems (SITIS), Jaipur, India, 4–7 December 2017; pp. 283–288. [Google Scholar]
- Moreau, N.; Roudet, C.; Gentil, C. Study and Comparison of Surface Roughness Measurements. In Proceedings of the Journées du Groupe de Travail en Modélisation Géométrique, Lyon, France, 27 March 2014. [Google Scholar]
- Kushunapally, R.; Razdan, A.; Bridges, N. Roughness as a shape measure. Comput. Aided Des. Appl. 2007, 4, 295–310. [Google Scholar] [CrossRef]
- Yildiz, Z.C.; Capin, T. A perceptual quality metric for dynamic triangle meshes. EURASIP J. Image Video Process. 2017, 2017, 12. [Google Scholar] [CrossRef][Green Version]
- Subjective Quality Assessment of 3D Models. Available online: https://perso.liris.cnrs.fr/guillaume.lavoue/data/datasets.html (accessed on 2 September 2020).
- Abouelaziz, I.; Chetouani, A.; El Hassouni, M.; Latecki, L.J.; Cherifi, H. No-reference mesh visual quality assessment via ensemble of convolutional neural networks and compact multi-linear pooling. Pattern Recognit. 2020, 100, 107174. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant key points. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Cheng, J.; Leng, C.; Wu, J.; Cui, H.; Lu, H. Fast and Accurate Image Matching with Cascade Hashing for 3d Reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1–8. [Google Scholar]
- Moulon, P.; Monasse, P.; Perrot, R.; Marlet, R. Openmvg: Open multiple view geometry. In International Workshop on Reproducible Research in Pattern Recognition; Lecture Notes in Computer Science; Springer: Berlin, Germany, 2016. [Google Scholar]
- Barnes, C.; Shechtman, E.; Finkelstein, A.; Goldman, D.B. PatchMatch: A randomized correspondence algorithm for structural image editing. ACM Trans. Graph. 2009, 28. [Google Scholar] [CrossRef]
- Bleyer, M.; Rhemann, C.; Rother, C. PatchMatch Stereo-Stereo Matching with Slanted Support Windows. InBmvc 2011, 11, 1–11. [Google Scholar]
- Stathopoulou, E.K.; Welponer, M.; Remondino, F. Open-Source Image-Based 3d Reconstruction Pipelines: Review, Comparison and Evaluation. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2019, 42, 331–338. [Google Scholar] [CrossRef]
- Stathopoulou, E.K.; Remondino, F. Multi-view stereo with semantic priors. Int. Arch. Photogram. Remote Sens. Spat. Inf. Sci. 2019, 4215, 1157–1162. [Google Scholar] [CrossRef]
- Zaharescu, A.; Boyer, E.; Horaud, R. Transformesh: A topology-adaptive mesh-based approach to surface evolution. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2007; pp. 166–175. [Google Scholar]
- Waechter, M.; Moehrle, N.; Goesele, M. Let there be color! Large-Scale Texturing of 3D Reconstructions. Available online: https://www.gcc.tu-darmstadt.de/media/gcc/papers/Waechter-2014-LTB.pdf (accessed on 14 October 2020).
- Kazhdan, M.; Hoppe, H. Screened Poisson surface reconstruction. ACM Trans. Graph. ToG. 2013, 32, 1–3. [Google Scholar] [CrossRef]
- CloudCompare. Available online: https://www.danielgm.net/cc/ (accessed on 2 September 2020).
- Bondarev, E.; Heredia, F.; Favier, R.; Ma, L.; de With, P.H. On photo-realistic 3D reconstruction of large-scale and arbitrary-shaped environments. In Proceedings of the 2013 IEEE 10th Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2013; pp. 621–624. [Google Scholar]
- Li, F.; Du, Y.; Liu, R. Truncated signed distance function volume integration based on voxel-level optimization for 3D reconstruction. Electron. Imaging. 2016, 21, 1–6. [Google Scholar] [CrossRef]
- Whelan, T.; Johannsson, H.; Kaess, M.; Leonard, J.J.; McDonald, J. Robust real-time visual odometry for dense RGB-D mapping. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 5724–5731. [Google Scholar]
- Splietker, M.; Behnke, S. Directional TSDF: Modeling Surface Orientation for Coherent Meshes. arXiv 2019, arXiv:1908.05146. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. ACM Siggraph Comput. Graph. 1987, 21, 163–169. [Google Scholar] [CrossRef]
- Dong, W.; Shi, J.; Tang, W.; Wang, X.; Zha, H. An efficient volumetric mesh representation for real-time scene reconstruction using spatial hashing. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 6323–6330. [Google Scholar]
- Meshlab. Available online: https://www.meshlab.net/ (accessed on 2 September 2020).
- Santos, P.M.; Júlio, E.N. A state-of-the-art review on roughness quantification methods for concrete surfaces. Construct. Build. Mater. 2013, 38, 912–923. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type of Scene | Type of Acquisition | Num of Images/Total Mpx | Scene Size/Mean Image GSD | Ground Truth | Evaluation Criteria |
|---|---|---|---|---|---|---|
 |  | |||||
| FBK/AVT | Urban | Aerial nadir—single shots | 4/120 | (1 × 1 × 0.1) km3/10 cm | - | Profiles, plane fitting, topology correctness |
 |  | |||||
| Strecha Fountain | Building facade | Terrestrial—single shots | 11/66 | (5 × 4 × 5) m3/30 mm | Mesh from laser scanner | Accuracy, completeness, roughness, profiles, topology correctness |
 |  | |||||
| FBK/3DOModena | Building facade | Terrestrial—single shots | 14/320 | (11 × 3 × 9) m3/20 mm | Mesh from laser scanner | Accuracy, completeness, roughness, profiles, topology correctness |
 |  | |||||
| Tanks and Temples—Ignatius | Statue | Terrestrial—video | 263/535 | (2 × 2 × 3) m3/30 mm | Mesh from laser scanner | Accuracy, completeness, roughness, profiles, topology correctness |
 |  | |||||
| FBK/3DOM wooden ornament | Asset | Terrestrial—single shots | 32/740 | (305 × 95 × 25) mm3/0.6 mm | Mesh from structured light scanner | Accuracy, completeness, roughness, profiles, topology correctness |
| FBK/AVT | Strecha Fountain | Tanks and Temples—Ignatius | FBK/3DOM Modena | FBK/3DOM Wooden Ornament | ||
|---|---|---|---|---|---|---|
| Image Resolution for Depth Maps and Dense Point Cloud Generation | ¼ | Full | Full | ¼ | Full | |
| M1 | Regularity weight | 0.4 | 0.4 | 0.4 | 0.4 | 0.4 |
| Resolution (mm) | 80.0 | 1.3 | 1.2 | 3.0 | 0.04 | |
| M2 | Voxel grid size (mm) | 160.0 | 0.7 | 0.3 | 1.5 | 0.02 |
| Samples per node | 20 | 1.5 | 20 | 1.5 | 20 | |
| Resolution (mm) | 160.0 | 0.3 | 0.2 | 0.7 | 0.01 | |
| M3 | Voxel grid size (mm) | 500.0 | 3.8 | 15 | 6.2 | 1.4 |
| Resolution (mm) | 160.0 | 2.7 | 5.0 | 3.0 | 0.07 | |
| Method | Plane Fitting RMS (m) | Percent of Self-Intersecting Faces | |
|---|---|---|---|
| P1 | P2 | ||
| M1 | 0.352 | 0.602 | - |
| M2 | 0.391 | 0.606 | 0.01% |
| M3 | 0.385 | 0.547 | 0.5% |
| Method | Accuracy | Completeness | F-Score | Roughness | Sections | % of Self-Intersecting Faces | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MEAN | STDV | RMS | MEDIAN | NMAD | OUT% | IN% | MEAN | RMS | MEAN | RMS | |||
| M1 | 3.3 | 11.0 | 11.5 | 1.7 | 6.8 | 3.7 | 73.4 | 0.886 | 1.0 | 1.3 | 6.5 | 14.9 | - |
| 0.4 | 15.9 | ||||||||||||
| M2 | 2.1 | 12.6 | 12.7 | 0.4 | 6.7 | 4.1 | 73.6 | 0.898 | 1.7 | 2.2 | 6.9 | 16.2 | 0.03% |
| 0.1 | 15.0 | ||||||||||||
| M3 | 3.6 | 27.9 | 28.1 | 2.1 | 8.6 | 7.8 | 71.1 | 0.827 | 1.8 | 2.3 | 8.7 | 18.3 | 0.07% |
| −0.2 | 27.7 | ||||||||||||
| Method | Accuracy | Completeness | F-Score | Roughness | Sections | % of Self-Intersecting Faces | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MEAN | STDV | RMS | MEDIAN | NMAD | OUT% | IN% | MEAN | RMS | MEAN | RMS | |||
| M1 | 5.4 | 21.2 | 21.9 | −0.1 | 5.6 | 9.8 | 54.3 | 0.779 | 1.0 | 1.4 | −0.1 | 6.0 | - |
| 1.3 | 8.4 | ||||||||||||
| M2 | 5.0 | 17.5 | 18.2 | 0.8 | 6.4 | 7.5 | 52.7 | 0.758 | 1.5 | 2.0 | 1.0 | 8.0 | - |
| 2.0 | 9.0 | ||||||||||||
| M3 | 7.1 | 20.9 | 22.1 | 1.3 | 7.1 | 9.1 | 52.7 | 0.736 | 2.1 | 2.8 | 0.9 | 7.2 | - |
| 1.7 | 9.0 | ||||||||||||
| Method | Accuracy | Completeness | F-Score | Roughness | Sections | % of Self-Intersecting Faces | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MEAN | STDV | RMS | MEDIAN | NMAD | OUT% | IN% | MEAN | RMS | MEAN | RMS | |||
| M1 | 1.6 | 3.2 | 3.6 | 1.4 | 2.7 | 1.5 | 65.3 | 0.820 | 0.4 | 0.5 | 3.4 | 7.3 | - |
| 0.5 | 2.7 | ||||||||||||
| M2 | 1.7 | 7.4 | 7.6 | 1.0 | 3.0 | 2.7 | 85.7 | 0.798 | 1.2 | 1.5 | 2.5 | 7.8 | 0.02% |
| −0.2 | 3.1 | ||||||||||||
| M3 | 4.9 | 11.4 | 12.4 | 3.0 | 3.0 | 9.2 | 58.8 | 0.643 | 3.6 * | 3.3 * | 5.4 | 9.7 | - |
| 2.4 | 4.3 | ||||||||||||
| Method | Accuracy | Completeness | F-Score | Roughness | Sections | % of Self-Intersecting Faces | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MEAN | STDV | RMS | MEDIAN | NMAD | OUT% | IN% | MEAN | RMS | MEAN | RMS | |||
| M1 | 0.06 | 0.23 | 0.24 | 0.03 | 0.11 | 5.5 | 99.9 | 0.80 | 0.02 | 0.03 | 0.05 | 0.12 | - |
| 0.05 | 0.14 | ||||||||||||
| M2 | 0.05 | 0.13 | 0.14 | 0.04 | 0.11 | 1.9 | 90.8 | 0.93 | 0.06 | 0.07 | 0.04 | 0.14 | 0.002% |
| 0.07 | 0.10 | ||||||||||||
| M3 | 0.36 | 1.34 | 1.4 | 0.03 | 0.14 | 10.1 | 77.9 | 0.86 | 0.04 | 0.05 | 0.09 | 0.17 | 0.06% |
| 0.61 | 0.13 | ||||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nocerino, E.; Stathopoulou, E.K.; Rigon, S.; Remondino, F. Surface Reconstruction Assessment in Photogrammetric Applications. Sensors 2020, 20, 5863. https://doi.org/10.3390/s20205863
Nocerino E, Stathopoulou EK, Rigon S, Remondino F. Surface Reconstruction Assessment in Photogrammetric Applications. Sensors. 2020; 20(20):5863. https://doi.org/10.3390/s20205863
Chicago/Turabian StyleNocerino, Erica, Elisavet Konstantina Stathopoulou, Simone Rigon, and Fabio Remondino. 2020. "Surface Reconstruction Assessment in Photogrammetric Applications" Sensors 20, no. 20: 5863. https://doi.org/10.3390/s20205863
APA StyleNocerino, E., Stathopoulou, E. K., Rigon, S., & Remondino, F. (2020). Surface Reconstruction Assessment in Photogrammetric Applications. Sensors, 20(20), 5863. https://doi.org/10.3390/s20205863