Crowd of Oz: A Crowd-Powered Social Robotics System for Stress Management

 ,
,  , and
, and
Abstract
1. Introduction
- present CoZ, a system designed to crowdsource the teleoperation of a social robot for conversational tasks. CoZ does that by: (a) live streaming the robot’s AV feed to workers, thereby enhancing their contextual and social awareness, (b) managing workers’ asynchronous arrival and departure during the conversational task, (c) supporting workers’ task performance through its UI. Our entire code base is open source and is available on Github (https://github.com/tahir80/Crowd_of_Oz).
- evaluate the trade-off between response latency and dialogue quality by systematically varying the number of workers. We release our data set (https://doi.org/10.6084/m9.figshare.9878438.v1) containing all dialogues between CoZ and the actress to promote further research.
- provide RTC-specific guidelines for social robots operating in complex life-coaching tasks.
2. Related Work
2.1. Remote Teleoperation
⋯ the process through which a human directs remote sensors and manipulators using a communication channel subject to latency and bandwidth limitations in such a way that robot behaviors are physically, emotionally, socially, and task appropriate.
2.2. Crowdsourcing
2.3. Real-Time Crowd-Powered Systems
2.4. Crowd or Web Robotics
2.5. Social Robotics and Stress
2.6. Latency in Crowdsourced Tasks
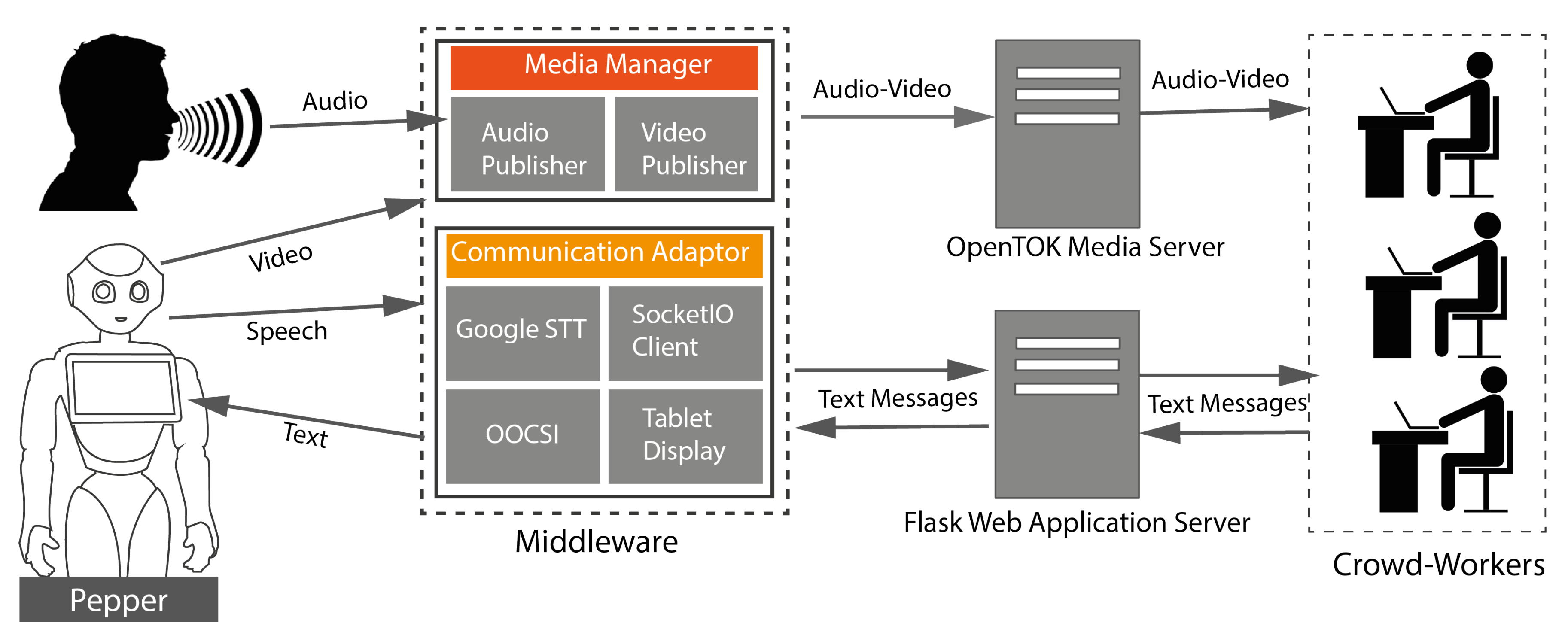
3. Crowd of Oz System
3.1. Pepper Robot
3.2. Middleware
3.2.1. Media Manager
3.2.2. Communication Adaptor
3.3. Flask Web App
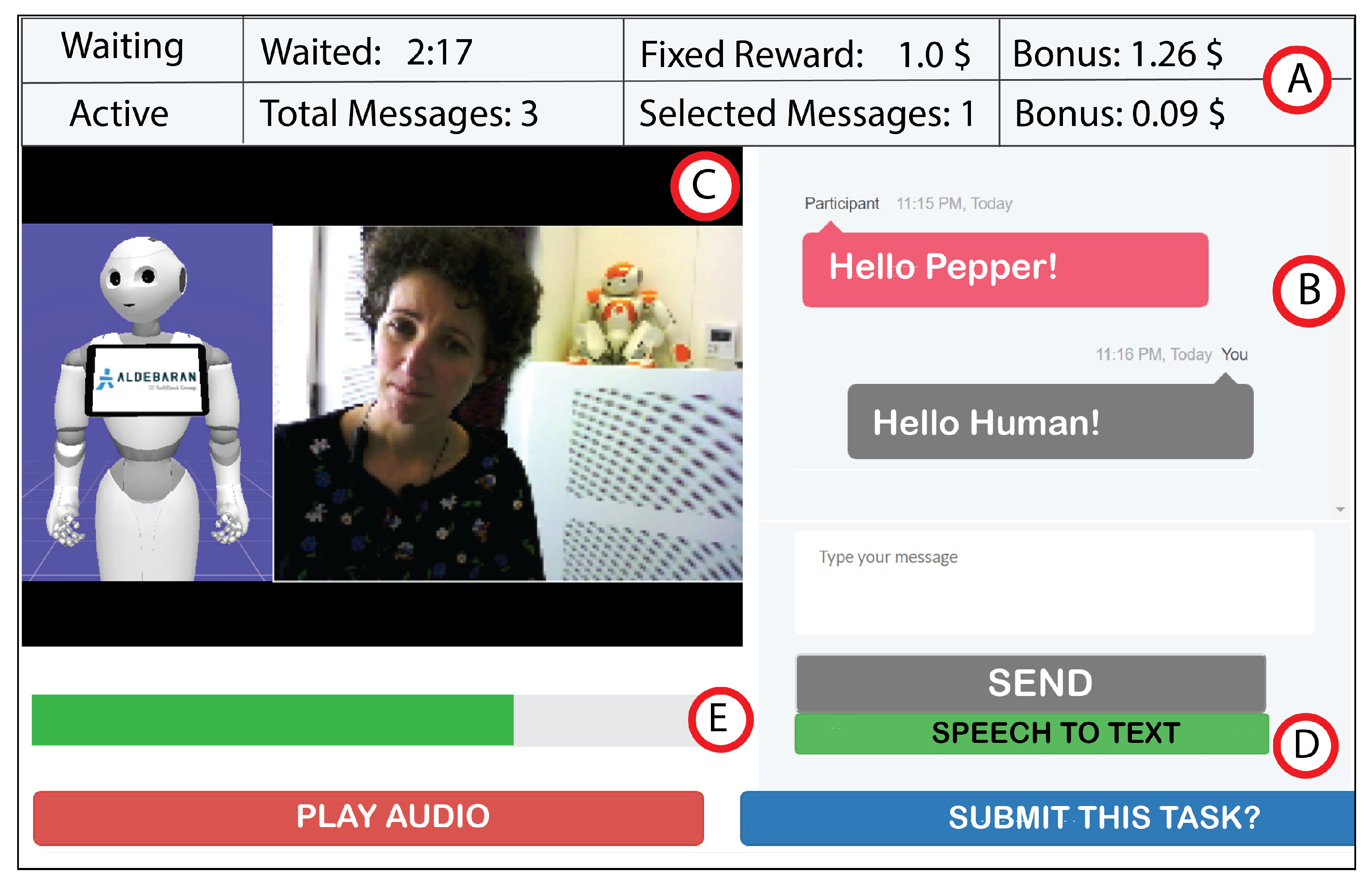
3.4. Crowd Interfaces
4. Pavilion Algorithm
4.1. How It Works
- Initially, Pavilion keeps adding workers in the waiting queue until the current count of waiting workers becomes equal to . At that point, when a new worker joins the session, all previous workers who were waiting are transferred to the active queue to initiate the conversation (except the one who has most recently joined the session who stays in the waiting queue). For the task to start we expect at least one worker to be in the waiting queue .
- On the background, Pavilion continues adding workers in the waiting queue during the execution of the task until the maximum condition for the waiting queue is reached: .
- When a worker leaves the active queue (from the actual conversation task) either by submitting the task or returning it. (There is a difference between submitting and returning a HIT. In submitting, a worker leaves the task by actually submitting the HIT to MTurk for reviewing and rewarding. While in returning, a worker leaves the task but is not interested in the monetary reward and the returned HIT is available for other workers on MTurk.), Pavilion immediately pushes one worker from the waiting queue to the active queue to keep the target number of workers fixed. If the task is actually submitted by the worker, then Pavilion also posts one extra HIT (with one assignment) to fulfil the deficiency in the waiting queue.
- When a worker leaves the waiting queue by submitting the task, Pavilion hires a new worker. Nevertheless, when a worker leaves the waiting queue by returning the HIT, Pavilion does nothing because the returned HIT is immediately available to new workers on MTurk.
- In the worst case, when the waiting queue only contains one worker or none and a worker leaves from the active queue, then Pavilion waits until another worker(s) joins the session and then it moves a worker(s) from the waiting to the active queue until the following condition is false:where and represents the current number of waiting and active workers respectively.
4.2. Differences between Pavilion and Ignition
5. Materials and Methods
5.1. Task for Crowd Workers
You are asked to act as a teleoperator of a robot and chat with a university master student who is experiencing stress due to study burden and not being able to keep work-life balance. Your task is to empathize with the student through conversing and try to find out why the student is stressed by asking open questions. Only after having a good understanding of the context and only when you have asked several open questions think about politely suggesting solutions to student to get out of this stressful situation.
5.2. Participants
5.3. Procedure
5.4. Measures
6. Results
6.1. Summary of Crowd Responses
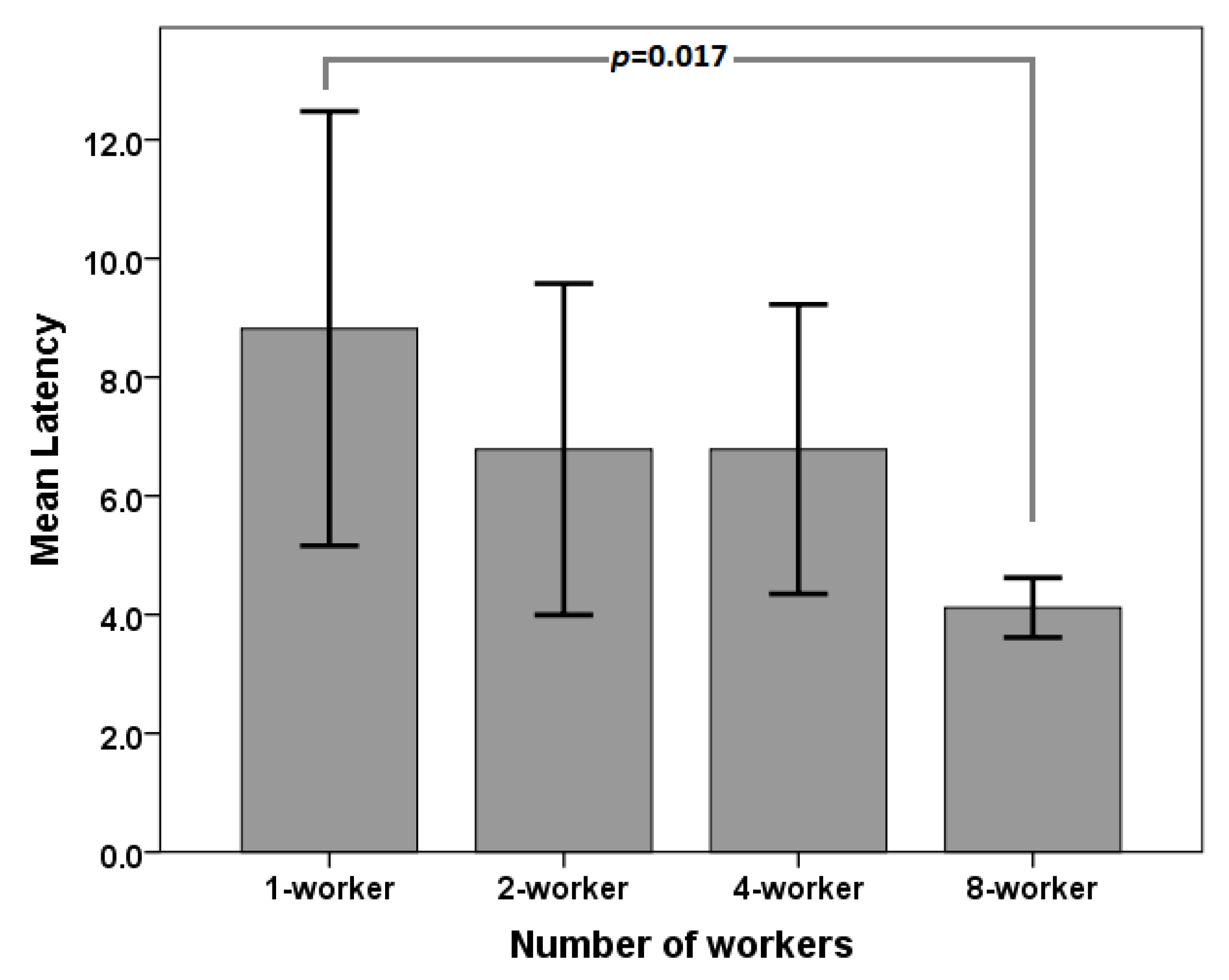
6.2. Response Latency
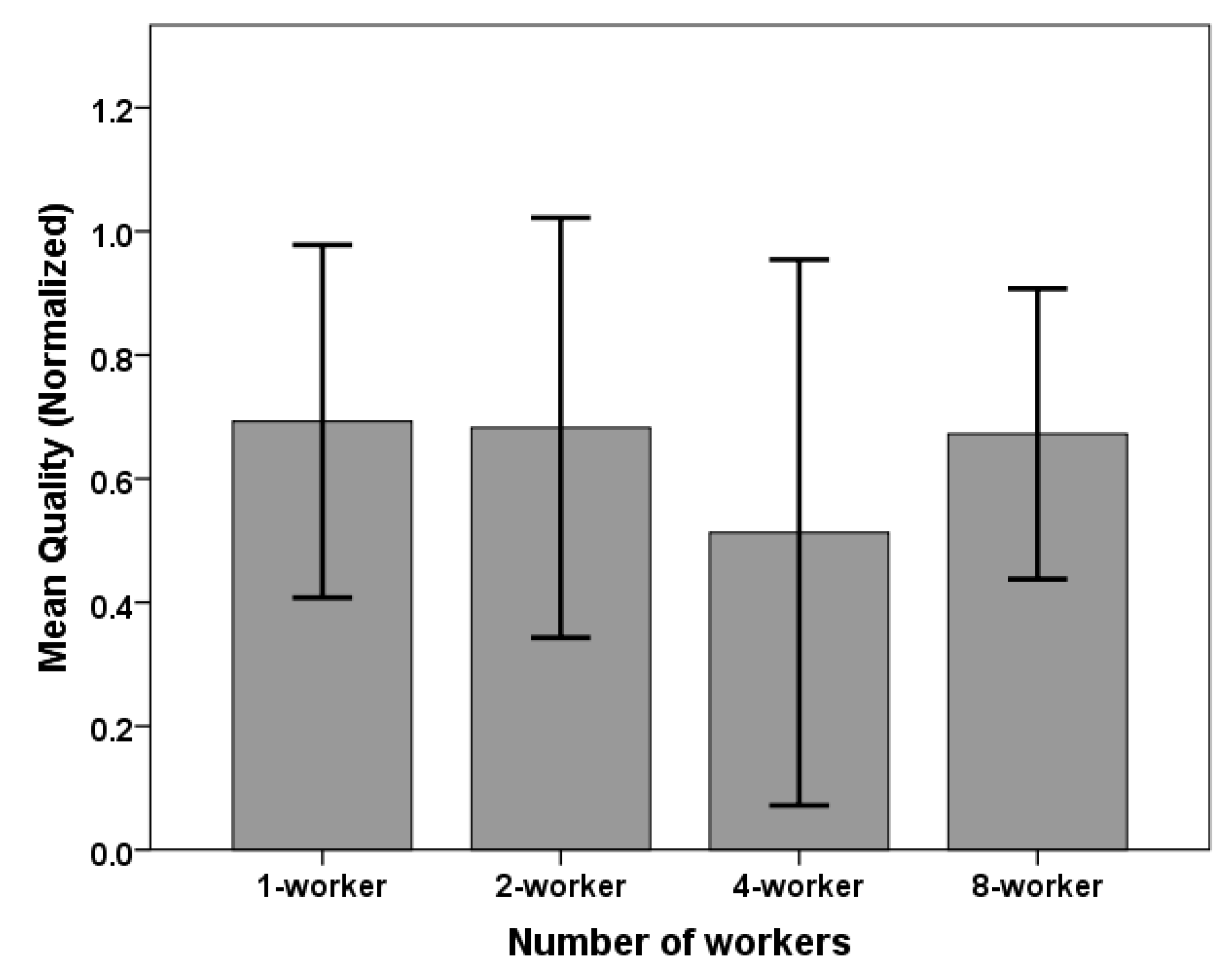
6.3. Dialogue Quality
6.4. Cost
6.5. Assessing the Quality of Robot Utterances Through Liwc
6.6. Average Waiting Time for Eliciting Multiple Responses
6.7. Effect of Progress Bar and STT on Response Latency
6.8. Experts’ Evaluation and Detailed Feedback
6.9. Qualitative Feedback from Psychologists
6.9.1. Building upon User Strengths
6.9.2. Assessing Coping Skills
6.9.3. Let the User Express Herself
6.9.4. Recalling Positive Things about Life
6.10. Suggestions for Improvements
6.10.1. Coz Should Introduce Itself as a Coach
6.10.2. Reflect Back and Validate
6.10.3. Avoid Unnecessary Small Talk
6.11. Discontinuities/Non-Cohesiveness in the Crowd Generated Conversations
6.11.1. Switching Topics Prematurely
Robot: Doing short activities to get your mind off of your studies might help, and then you can come back with a clearer mind.
User: yeah, I can see how that’s work. What do you think of when you say short activities like what maybe?
Robot: Perhaps trying some herbal remedies
6.11.2. Newly Joined Workers
6.11.3. Small Talk
6.11.4. Side Chatter
Robot: Do you allow repeats? I feel like we didn’t finish our conversation properly.
Robot: where are the instructions?
6.11.5. Technical Problems
Robot: I have not heard voice if I can hear I will help to you.
Robot: video is OK but not have a sound
6.11.6. Spam Worker
Robot: who cares about your studies?
Robot: You’re having trouble studying, but you can’t stop using your phone? I understand.
User: well I should have started with saying that I did get rid of my phone.
6.12. Performance of Pavilion
7. Discussion
7.1. Guidelines for Enabling Social Robotics to Handle Stress Management via RTC
7.1.1. Handling Quality
- Allow the user to express his/her stressors/concerns without interruption (at least initially without interrupting or changing the topic).
- Avoid simplistic answers/solutions that are also too general or not realistically applicable for the user (e.g., “just try to think positive” or “maybe you can just move to another apartment”).
- Use empathy, understanding, and reflection to let the user know the robot is listening and cares about the users concerns.
- Respond on topic and in line with the users expressed concerns/stressors.
- Avoid jumping from topic to topic rather than maintaining an organization and structure to the session
- Assess the coping skills that the user is currently employing/applying to try to manage stressors. This avoids giving advice about coping skills that the user may have already attempted.
7.1.2. Handling Latency:
7.1.3. Handling Privacy
7.2. Potential for Re-Purposing
8. Future Work
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CoZ | Crowd of Oz |
| MTurk | Amazon Mechanical Turk |
| HIT | Human intelligence task |
| AI | Artificial intelligence |
| RTC | Real time crowdsourcing |
| AV | Audio–video |
| STT | Speech to text |
| MI | Motivational interviewing |
| LIWC | Linguistic inquiry and word count |
| WC | Word count |
| WPS | Words per sentences |
| Sixltr | Six letter |
| posemo | Positive emotion |
| negemo | Negative emotion |
| coproc | Cognitive process |
| percept | Perceptual |
References
- Taelman, J.; Vandeput, S.; Spaepen, A.; Van Huffel, S. Influence of mental stress on heart rate and heart rate variability. In Proceedings of the 4th European Conference of the International Federation for Medical and Biological Engineering, Antwerp, Belgium, 23–27 November 2008; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1366–1369. [Google Scholar]
- Joëls, M.; Pu, Z.; Wiegert, O.; Oitzl, M.S.; Krugers, H.J. Learning under stress: How does it work? Trends Cogn. Sci. 2006, 10, 152–158. [Google Scholar] [CrossRef]
- Eskin, M.; Sun, J.M.; Abuidhail, J.; Yoshimasu, K.; Kujan, O.; Janghorbani, M.; Flood, C.; Carta, M.G.; Tran, U.S.; Mechri, A.; et al. Suicidal behavior and psychological distress in university students: A 12-nation study. Arch. Suicide Res. 2016, 20, 369–388. [Google Scholar] [CrossRef] [PubMed]
- Nam, B.; Hilimire, M.R.; Jahn, D.; Lehmann, M.; DeVylder, J.E. Predictors of suicidal ideation among college students: A prospective cohort study. Soc. Work. Ment. Health 2018, 16, 223–237. [Google Scholar] [CrossRef]
- Denovan, A.; Macaskill, A. Stress and subjective well-being among first year UK undergraduate students. J. Happiness Stud. 2017, 18, 505–525. [Google Scholar] [CrossRef]
- Elias, H.; Ping, W.S.; Abdullah, M.C. Stress and academic achievement among undergraduate students in Universiti Putra Malaysia. Procedia-Soc. Behav. Sci. 2011, 29, 646–655. [Google Scholar] [CrossRef]
- Chowdhury, R.; Mukherjee, A.; Mitra, K.; Naskar, S.; Karmakar, P.R.; Lahiri, S.K. Perceived psychological stress among undergraduate medical students: Role of academic factors. Indian J. Public Health 2017, 61, 55–57. [Google Scholar] [CrossRef] [PubMed]
- Shah, M.; Hasan, S.; Malik, S.; Sreeramareddy, C.T. Perceived stress, sources and severity of stress among medical undergraduates in a Pakistani medical school. BMC Med. Educ. 2010, 10, 2. [Google Scholar] [CrossRef]
- Ward-Griffin, E.; Klaiber, P.; Collins, H.K.; Owens, R.L.; Coren, S.; Chen, F.S. Petting away pre-exam stress: The effect of therapy dog sessions on student well-being. Stress Health 2018, 34, 468–473. [Google Scholar] [CrossRef]
- Crossman, M.K.; Kazdin, A.E.; Kitt, E.R. The influence of a socially assistive robot on mood, anxiety, and arousal in children. Prof. Psychol. Res. Pract. 2018, 49, 48–56. [Google Scholar] [CrossRef]
- Pu, L.; Moyle, W.; Jones, C.; Todorovic, M. The Effectiveness of Social Robots for Older Adults: A Systematic Review and Meta-Analysis of Randomized Controlled Studies. Gerontologist 2018. [Google Scholar] [CrossRef]
- Rose, E.J. Designing for engagement: Using participatory design to develop a social robot to measure teen stress. In Proceedings of the 35th ACM International Conference on the Design of Communication, Halifax, NS, Canada, 11–13 August 2017; pp. 1–10. [Google Scholar] [CrossRef]
- Kim, J.; Kim, Y.; Kim, B.; Yun, S.; Kim, M.; Lee, J. Can a Machine Tend to Teenagers’ Emotional Needs? In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems-CHI ’18, Montreal, QC, Canada, 21–26 April 2018; ACM Press: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Kang, H.; Hebert, M.; Kanade, T. Discovering object instances from scenes of Daily Living. In Proceedings of the 2011 IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 762–769. [Google Scholar] [CrossRef]
- Morris, R.R.; Picard, R. Crowd-powered positive psychological interventions. J. Posit. Psychol. 2014, 9, 509–516. [Google Scholar] [CrossRef]
- Morris, R. Crowdsourcing workshop: The emergence of affective crowdsourcing. In Proceedings of the 2011 Annual Conference Extended Abstracts on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; ACM: New York, NY, USA, 2011. [Google Scholar]
- Emotional Baggage Check. Available online: https://emotionalbaggagecheck.com/ (accessed on 19 January 2020).
- Bernstein, M.S.; Brandt, J.; Miller, R.C.; Karger, D.R. Crowds in two seconds. In Proceedings of the 24th annual ACM Symposium on User Interface Software and Technology, Proc. UIST’11, Santa Barbara, CA, USA, 16–19 October 2011; p. 33. [Google Scholar] [CrossRef]
- Gadiraju, U.; Möller, S.; Nöllenburg, M.; Saupe, D.; Egger-Lampl, S.; Archambault, D.; Fisher, B. Crowdsourcing versus the laboratory: Towards human-centered experiments using the crowd. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2017; Volume 10264 LNCS, pp. 6–26. [Google Scholar]
- Lasecki, W.S.; Murray, K.I.; White, S.; Miller, R.C.; Bigham, J.P. Real-time crowd control of existing interfaces. In Proceedings of the 24th annual ACM Symposium on User Interface Software and Technology, Santa Barbara, CA, USA, 16–19 October 2011; ACM Press: New York, NY, USA, 2011; p. 23. [Google Scholar] [CrossRef]
- Gouravajhala, S.R.; Yim, J.; Desingh, K.; Huang, Y.; Jenkins, O.C.; Lasecki, W.S. EURECA: Enhanced Understanding of Real Environments via Crowd Assistance. In Proceedings of the Sixth AAAI Conference on Human Computation and Crowdsourcing, Zürich, Switzerland, 5–8 July 2018. [Google Scholar]
- Berry, D.C.; Butler, L.T.; De Rosis, F. Evaluating a realistic agent in an advice-giving task. Int. J. -Hum.-Comput. Stud. 2005, 63, 304–327. [Google Scholar] [CrossRef]
- Powers, A.; Kiesler, S.; Fussell, S.; Fussell, S.; Torrey, C. Comparing a computer agent with a humanoid robot. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Arlington, VA, USA, 10–12 March 2007; ACM: New York, NY, USA, 2007; pp. 145–152. [Google Scholar]
- Pepper | Softbank. Available online: https://www.softbankrobotics.com/emea/en/pepper (accessed on 19 January 2020).
- Chen, J.Y.; Haas, E.C.; Barnes, M.J. Human performance issues and user interface design for teleoperated robots. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 1231–1245. [Google Scholar] [CrossRef]
- Butler, D.J.; Huang, J.; Roesner, F.; Cakmak, M. The Privacy-Utility Tradeoff for Remotely Teleoperated Robots. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction, Portland, OR, USA, 2–5 March 2015; pp. 27–34. [Google Scholar] [CrossRef]
- Goodrich, M.A.; Crandall, J.W.; Barakova, E. Teleoperation and Beyond for Assistive Humanoid Robots. Rev. Hum. Factors Ergon. 2013, 9, 175–226. [Google Scholar] [CrossRef]
- Van den Berghe, R.; Verhagen, J.; Oudgenoeg-Paz, O.; van der Ven, S.; Leseman, P. Social Robots for Language Learning: A Review. Rev. Educ. Res. 2019, 89, 259–295. [Google Scholar] [CrossRef]
- Torta, E.; Oberzaucher, J.; Werner, F.; Cuijpers, R.H.; Juola, J.F. Attitudes towards Socially Assistive Robots in Intelligent Homes: Results From Laboratory Studies and Field Trials. J. -Hum.-Robot. Interact. 2013, 1. [Google Scholar] [CrossRef]
- Glas, D.F.; Kanda, T.; Ishiguro, H.; Hagita, N. Teleoperation of multiple social robots. IEEE Trans. Syst. Man Cybern. Part A Syst. Humans 2012, 42, 530–544. [Google Scholar] [CrossRef]
- Huskens, B.; Verschuur, R.; Gillesen, J.; Didden, R.; Barakova, E. Promoting question-asking in school-aged children with autism spectrum disorders: Effectiveness of a robot intervention compared to a human-trainer intervention. Dev. Neurorehabilit. 2013, 16, 345–356. [Google Scholar] [CrossRef]
- Van Straten, C.L.; Smeekens, I.; Barakova, E.; Glennon, J.; Buitelaar, J.; Chen, A. Effects of robots’ intonation and bodily appearance on robot-mediated communicative treatment outcomes for children with autism spectrum disorder. Pers. Ubiquitous Comput. 2018, 22, 379–390. [Google Scholar] [CrossRef]
- Sono, T.; Satake, S.; Kanda, T.; Imai, M. Walking partner robot chatting about scenery. Adv. Robot. 2019. [Google Scholar] [CrossRef]
- Mao, K.; Capra, L.; Harman, M.; Jia, Y. A Survey of the Use of Crowdsourcing in Software Engineering. J. Syst. Softw. 2017, 126, 57–84. [Google Scholar] [CrossRef]
- Von Ahn, L.; Dabbish, L. Labeling images with a computer game. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vienna, Austria, 24–29 April 2004; pp. 319–326. [Google Scholar]
- Bernstein, M.S.; Little, G.; Miller, R.C.; Hartmann, B.; Ackerman, M.S.; Karger, D.R.; Crowell, D.; Panovich, K. Soylent: A Word Processor with a Crowd Inside. In Proceedings of the ACM Symposium on User Interface Software and Technology-UIST’10, New York, NY, USA, 3–6 October 2010; pp. 313–322. [Google Scholar] [CrossRef]
- Cooper, S.; Khatib, F.; Treuille, A.; Barbero, J.; Lee, J.; Beenen, M.; Leaver-Fay, A.; Baker, D.; Popović, Z.; Players, F. Predicting protein structures with a multiplayer online game. Nature 2010, 466, 756–760. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Nickerson, J.V. Cooks or cobblers? In Proceedings of the 2011 Annual Conference on Human Factors In Computing Systems-CHI ’11, Vancouver, BC, Canada, 7–12 May 2011; ACM Press: New York, NY, USA, 2011; p. 1393. [Google Scholar] [CrossRef]
- Lasecki, W.S.; Homan, C.; Bigham, J.P. Architecting Real-Time Crowd-Powered Systems. Hum. Comput. 2014, 1, 67–93. [Google Scholar] [CrossRef][Green Version]
- Bigham, J.P.; Jayant, C.; Ji, H.; Little, G.; Miller, A.; Miller, R.C.; Miller, R.; Tatarowicz, A.; White, B.; White, S.; et al. VizWiz: Nearly Real-Time Answers to Visual Questions. In Proceedings of the 23nd Annual ACM Symposium on User Interface Software and Technology, New York, NY, USA, 3–6 October 2010; pp. 333–342. [Google Scholar] [CrossRef]
- Lasecki, W.S.; Wesley, R.; Nichols, J.; Kulkarni, A.; Allen, J.F.; Bigham, J. Chorus: A Crowd-powered Conversational Assistant. In Proceedings of the 26th Annual ACM Symposium on User Interface Software and Technology, St. Andrews Scotland, UK, 8–11 October 2013; pp. 151–162. [Google Scholar] [CrossRef]
- Huang, T.H.K.; Chang, J.C.; Bigham, J.P. Evorus: A Crowd-powered Conversational Assistant Built to Automate Itself over Time. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Lasecki, W.S.; Thiha, P.; Zhong, Y.; Brady, E.; Bigham, J.P. Answering visual questions with conversational crowd assistants. In Proceedings of the 15th International ACM SIGACCESS Conference on Computers and Accessibility, Bellevue, WA, USA, 21–23 October 2013; ACM: New York, NY, USA, 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, T.H.; Azaria, A.; Romero, O.J.; Bigham, J.P. InstructableCrowd: Creating IF-THEN Rules for Smartphones via Conversations with the Crowd. arXiv 2019, arXiv:1909.05725. [Google Scholar] [CrossRef]
- Andolina, S.; Schneider, H.; Chan, J.; Klouche, K.; Jacucci, G.; Dow, S. Crowdboard: Augmenting in-person idea generation with real-time crowds. In Proceedings of the 2017 ACM SIGCHI Conference on Creativity and Cognition, Singapore, 27–30 June 2017; pp. 106–118. [Google Scholar] [CrossRef]
- Salisbury, E.; Stein, S.; Ramchurn, S.D. Real-time opinion aggregation methods for crowd robotics. In Proceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, Istanbul, Turkey, 4–8 May 2015; Volume 2, pp. 841–849. [Google Scholar]
- Toris, R.; Kent, D.; Chernova, S. The Robot Management System: A Framework for Conducting Human-Robot Interaction Studies Through Crowdsourcing. J. Hum. Robot. Interact. 2014, 3, 25. [Google Scholar] [CrossRef][Green Version]
- Crick, C.; Osentoski, S.; Jenkins, O.C.; Jay, G. Human and robot perception in large-scale learning from demonstration. In Proceedings of the HRI 2011, 6th ACM/IEEE International Conference on Human-Robot Interaction, Lausanne, Switzerland, 8–11 March 2011; pp. 339–346. [Google Scholar] [CrossRef]
- Björling, E.A.; Rose, E.; Ren, R. Teen-Robot Interaction: A Pilot Study of Engagement with a Low-fidelity Prototype. In Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction, Chicago, IL, USA, 5–8 March 2018; Volume Part F1351, pp. 69–70. [Google Scholar] [CrossRef]
- Huang, T.H.K.; Bigham, J.P. A 10-Month-Long Deployment Study of On-Demand Recruiting for Low-Latency Crowdsourcing. In Proceedings of the Fifth AAAI Conference on Human Computation and Crowdsourcing, Québec City, QC, Canada, 23–26 October 2017. [Google Scholar] [CrossRef]
- Webb, N.; Benyon, D.; Hansen, P.; Mival, O. Evaluating Human-Machine Interaction for Appropriateness. LREC Conf. Proc. 2010, 2, 84–92. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Miller, W.R.; Rollnick, S. Motivational Interviewing: Helping People Change; Guilford Press: New York, NY, USA, 2013; p. 482. [Google Scholar]
- Shiwa, T.; Kanda, T.; Imai, M.; Ishiguro, H.; Hagita, N. How quickly should communication robots respond? In Proceedings of the Third International Conference on Human Robot Interaction-HRI ’08, Amsterdam, The Netherlands, 12–15 March 2008; ACM Press: New York, NY, USA, 2008; p. 153. [Google Scholar] [CrossRef]
- Zimmerman, D.H. Acknowledgment Tokens and Speakership Incipiency Revisited. Res. Lang. Soc. Interact. 1993, 26, 179–194. [Google Scholar] [CrossRef]
- Srinivasan, V.; Takayama, L. Help Me Please. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 4945–4955. [Google Scholar] [CrossRef]
- Caine, K.; Sabanovic, S.; Carter, M. The effect of monitoring by cameras and robots on the privacy enhancing behaviors of older adults. In Proceedings of the Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction, Boston, MA, USA, 5 March 2012; p. 343. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Use Case | Input | Output | Device |
|---|---|---|---|---|
| Chorus [41] | Information retrieval | User queries in natural language | Text message | Mobile phones or PC |
| Evorus [42] | Information retrieval | User queries in natural language | Text message | Mobile phones or PC |
| VizWiz [40] | Assisting blind users to interact with devices | Video stream and recorded audio question + text | Audio through voice-over screen reader | Mobile phones |
| Chorus:view [43] | Assisting blind users to interact with devices | Video stream and recorded audio question + text | Audio through voice-over screen reader | Mobile phones |
| CrowdBoard [45] | Creativity | Write ideas on sticky notes | Textual ideas from crowd workers | Digital whiteboard |
| InstructableCrowd [44] | Programming | User’s problem in natural language | IF-THEN rules | Mobile phones |
| CoZ | Live conversational task for stress management | Real time audio and video feed + transcribed text messages | Animated Speech by Pepper robot and text message displayed on the Pepper robot’s Tablet | Pepper or NAO robot |
| Reference | Use Case | Input | Output | Robot |
|---|---|---|---|---|
| Legion [20] | Robot navigation | Video stream of rovio robot + arrow key presses | Robot movement | Rovio robot |
| CrowdDrone [46] | Drone navigation | Simulated or real imagery from drone’s camera + arrow key presses | Robot movement | Drone robot |
| EURECA [21] | Scene manipulation | Natural language query + scene manipulation (zoom, pan, orbit) + selection tools | Segmented and labelled objects | Fetch robot |
| Robot Management System (RMS) [47] | Robot navigation + manipulation | Arrow keys for changing direction + camera feeds + 2D map + slider control to alter speed + arm controls | Robot movement and object retrieval | PR2 robot |
| Learning from demonstration [48] | Robot learning | Web interface for controlling a robot | Robot movement | iRobot |
| CoZ | Live conversational task for stress management | Real time audio and video feed + transcribed text messages | Animated speech by Pepper robot and text message displayed on the Pepper robot’s Tablet | Pepper or NAO robot |
| Problem/Topic | Indicative Excerpt |
|---|---|
| Opening a discussion | User: I have been stressed for the past few weeks really and it’s very difficult to focus on my studies and it would be nice just to talk about that. Robot: What is stressing you about your studies? |
| Moving to a new city | User: I moved from Belgium to the Netherlands 3 months ago to do this minor so its new city and new house I am living in. Robot: Are there any language barriers you have to deal with? User: Not really because in Belgium we speak Flounderish and in Holland, they speak Dutch and it’s the same language. Robot: So, the differences between your studies and studying life are feeling overwhelming? |
| Difficulty in study | User: So, I’m doing a minor here in Eindhoven and it’s new subjects and it’s so different working than before…I am anxious about it⋯ it’s a new style of working…new content, so I do not know how to deal with that. Robot: Why did you chose this subject? User: I thought it was interesting… it is more focused on user experience. Robot: But learning it is not giving you happiness? User: I think it will give me… we disagree maybe because I think my study gives me fulfillment. Robot: How come fulfilment and stress at same time? |
| Difficulty in finding people for an interview | User: I need to find people to interview and I don’t know so many people. So, I have tried putting an Ad up, but it didn’t work. It mixes up with all my planning. Robot: Try social media for getting connections. User: so, what would you put up on social media who would like to go out for a coffee with me then. Robot: Yes, they have groups for locals on places like Meetups. |
| Noisy roommates | User: I was hoping I would get some sleep, but I have 5 extremely noisy roommates. Robot: Can you try playing low volume rain sounds or something to drown them out? User: What is white noise? Robot: A background sound that’s relaxing to listen to that will drown out the loud sounds that your roommates make. |
| Showing empathy | User: I am saying that I am very stressed and that I like to speak about that, and I can’t focus on my studies Robot: Oh, that’s terrible what can I do to help? |
| Solutions | Indicative Excerpt |
|---|---|
| Mindfulness | Robot: I just do mindfulness, where I’m no judgmentally aware of my thoughts and feelings |
| Prayers | Robot: Do prayer Robot: God is always with u |
| Exercise | Robot: Walking is good to clear your mind. |
| Having a dog | Robot: maybe get a dog Robot: Do you like dogs? |
| Socializing | Robot: Sometimes talking to your family helps too. They can give you advice and love Robot: Maybe you could do some volunteer work in the area to try to meet some new people |
| Playing sports | Robot: you can try playing sports as well |
| Sleeping aid | Robot: I’d definitely say sleep will help you a lot. You’ll be able to focus a lot more. Maybe try taking a nap during the day if you can find a time when your roommates are gone. |
| Taking a break from work | Robot: Perhaps clearing some free time in your schedule to relax while going through this transition would help. |
| Voicing one’s thoughts aloud | Robot: voice your thoughts out loud. |
| Focusing on one thing | Robot: It sounds like you need to break down your bigger problems into smaller parts to begin with. |
| Using calming teas | Robot: I drink hot tea and think about my past. Robot: take some calming teas. |
| Using ear plug or white noise machine | Robot: Have you tried ear plugs or a white noise machine? |
| Watching something interesting | Robot: watch something that you find funny or interesting Robot: watch YouTube |
| Listen to music | Robot: Another thing you could do is try and listen to music when stressed it is a great way to relax. |
| Yoga | Robot: Have you tried exercise or yoga? |
| Miscellaneous | Robot: Short walks or exercise, writing, meditation, watching a TV show, or talking to a friend. |
| Condition | Latency | Quality | ||
|---|---|---|---|---|
| Mean | SD | Mean | Mean | |
| 1-worker | 8.82 | 2.95 | 0.69 | 0.23 |
| 2-worker | 6.79 | 2.25 | 0.68 | 0.27 |
| 4-worker | 6.79 | 1.96 | 0.51 | 0.35 |
| 8-worker | 4.12 | 0.40 | 0.67 | 0.19 |
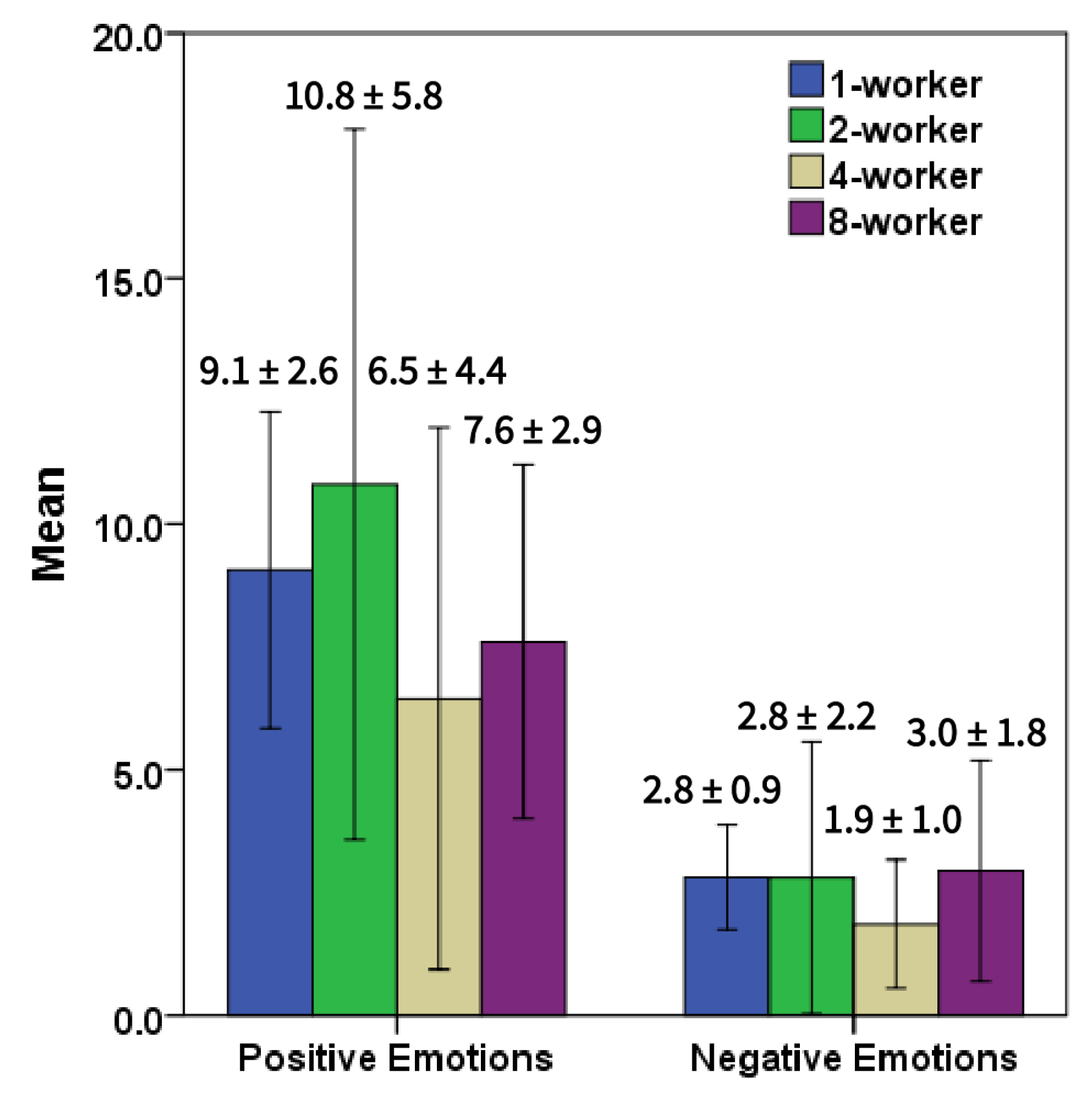
| Condition | WC | WPS | Sixltr | Posemo | Negemo |
|---|---|---|---|---|---|
| 1-worker | |||||
| 2-worker | |||||
| 4-worker | |||||
| 8-worker |
| Condition | Avg. Waiting Time | Avg. Responses/User Query | Max. |
|---|---|---|---|
| 2-worker | 6.88 ± 2.81 | 1.25 ± 0.17 | 4 |
| 4-worker | 6.60 ± 1.29 | 1.40 ± 0.23 | 6 |
| 8-worker | 5.56 ± 0.71 | 1.53 ± 0.20 | 5 |
| Condition | Number of Workers | |||
|---|---|---|---|---|
| 1 | 2 | 4 | 8 | |
| <9 s | 65 | 88 | 79 | 130 |
| >9 s | 38 | 31 | 30 | 14 |
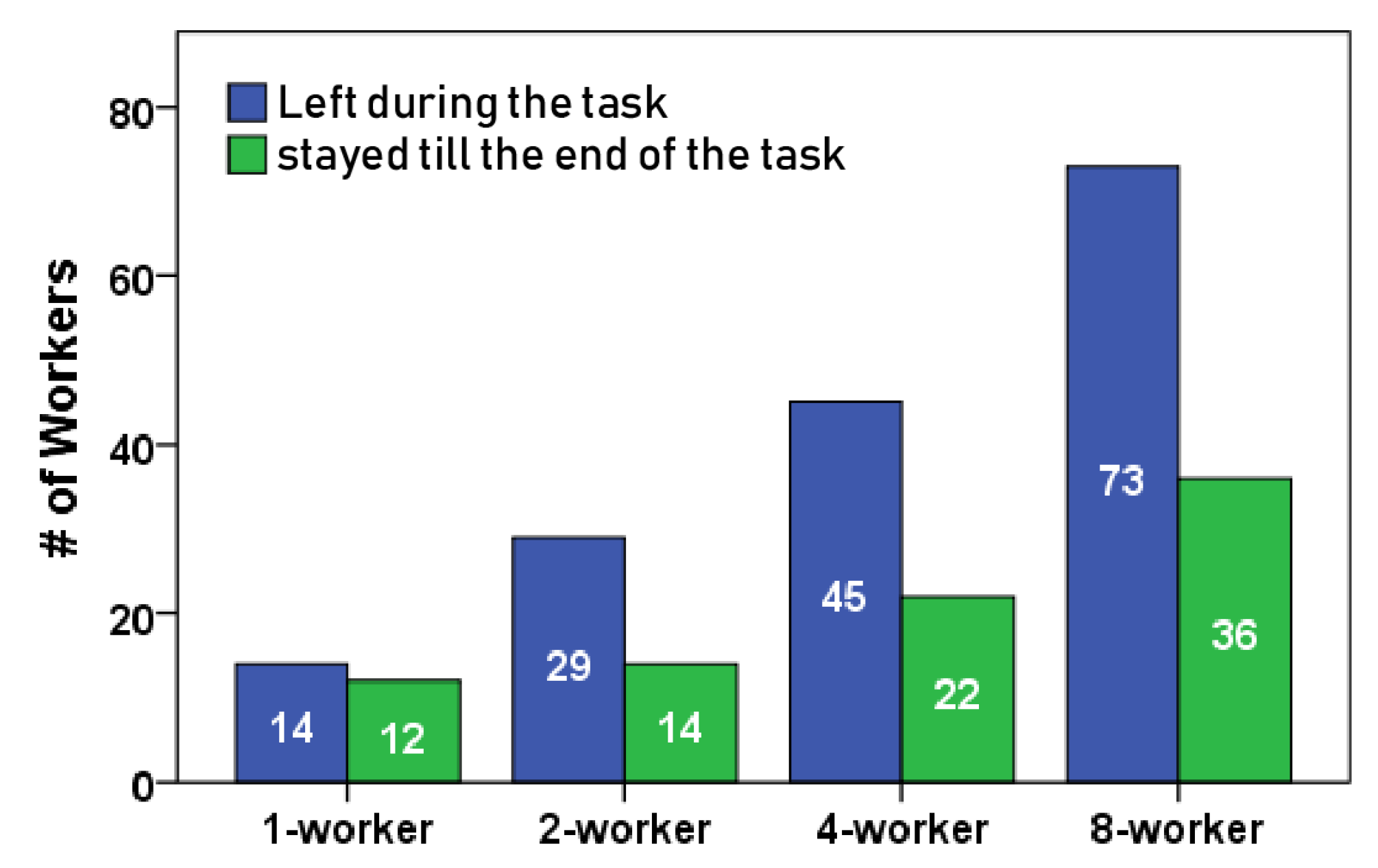
| Condition | Total | Mean (SD) |
|---|---|---|
| 1-worker | 11 | 2.2 (2.9) |
| 2-worker | 15 | 3.0 (2.9) |
| 4-worker | 28 | 5.6 (4.3) |
| 8-worker | 36 | 7.2 (4.8) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, T.; Khan, V.-J.; Gadiraju, U.; Barakova, E.; Markopoulos, P. Crowd of Oz: A Crowd-Powered Social Robotics System for Stress Management. Sensors 2020, 20, 569. https://doi.org/10.3390/s20020569
Abbas T, Khan V-J, Gadiraju U, Barakova E, Markopoulos P. Crowd of Oz: A Crowd-Powered Social Robotics System for Stress Management. Sensors. 2020; 20(2):569. https://doi.org/10.3390/s20020569
Chicago/Turabian StyleAbbas, Tahir, Vassilis-Javed Khan, Ujwal Gadiraju, Emilia Barakova, and Panos Markopoulos. 2020. "Crowd of Oz: A Crowd-Powered Social Robotics System for Stress Management" Sensors 20, no. 2: 569. https://doi.org/10.3390/s20020569
APA StyleAbbas, T., Khan, V.-J., Gadiraju, U., Barakova, E., & Markopoulos, P. (2020). Crowd of Oz: A Crowd-Powered Social Robotics System for Stress Management. Sensors, 20(2), 569. https://doi.org/10.3390/s20020569