Transform-Based Multiresolution Decomposition for Degradation Detection in Cellular Networks





Abstract
1. Introduction
2. Related Work
3. Methods
3.1. Wavelet Analysis
3.2. Proposed Framework
- A quantifiable degradation score indicating the level of the abnormality of the samples for each of the scales considered.
- The classification of the metric samples as degraded or not degraded and the scale where the degradation has been detected.
3.2.1. Inputs
- The set of pseudoperiods of the metric, , which includes different values of periodicity , where it is expected that the values of follow approximately the values of . The variable depends on the nature of the monitored cellular network. For instance, the hourly metric typically follows a daily pattern that generally repeats each day. Additionally, the same dates in different weeks share common trends, associated with the varying distribution of workers’ activity through the week (e.g., Sundays have reduced activity). For the hourly metric, . For the set of pseudoperiods, the minor one would be identified as , e.g., for the hourly metric. The value can be derived from either the metric metadata or the automatic analysis of the metric (e.g., calculating the FFT of the available metric samples and obtaining the frequency component with higher energy).
- A reference sequence of R samples will be used as an indication of the normal behavior of the network or as a typical degradation pattern. For the best performance, . Ideally, R must be equal to or larger than any of the W periodicities. Hereafter, it is assumed that the signal consists of the initial R samples of . That is, if the first gathered samples of the metric are normal, the reference consists of those first R samples. If the first samples do not present a normal behavior, a set of R samples representing the normal state will be placed at the beginning of .The definition of the reference sequence is not trivial, as it is difficult to establish a complete set of what can be considered normal behavior, and this normality will typically change in time and for different cells due to differences in network use, long-term variations, etc.Because of this, classical approaches typically imply additional inputs (e.g., expert knowledge) to define it. Conversely, the proposed system uses the complete input sequence as the reference; thus, , . In this case, the system would be able to identify outliers at different scales. Outliers refer to those values that are outside of the usual range of the metric. These could not easily be identified from the original metric with classical techniques due to its periodic variabilities and trend behavior. However, the proposed system decomposition allows isolating each temporal trend, making it possible to identify the outliers at different scales.
3.2.2. Metric Characterization
3.2.3. Multiresolution Decomposition
- Transform type: By default, the discrete wavelet transform with db7 filters is chosen, being the one considered the most suitable for the analysis of cellular metrics (as described in Section 3.1). However, other discrete transforms (e.g., STFT) and kernel functions could be straightforwardly applied.
- Maximum level for detection (): This refers to the maximum level of the components (provided by the decomposition) that will be considered for the detection subsystem.For the particular case of DWT, given the relation between the coefficient levels and the possible period of the component (see Equation (6)), the maximum level of the decomposition is estimated as:which is the minimum between two limits rounded down to the nearest integer ( function). The limit represents the maximum level of downsampling steps that can be applied to so that the output sequence has at least the same number of samples as the filter impulse response, denoted as F (where is the order of the filter). For example, for “db7”.The limit indicates the maximum decomposition level where the reference sequence would contain at least times the number of samples of its temporal period (see Equation (3)). This guarantees the statistical significance for the estimation of normal values during the detection phase (as at least periods of the higher-level component would be considered).
- Decomposition level (L): This is the highest level of the generated components for a discrete decomposition. It must be satisfied that . The decomposition L can be superior to for visualization reasons to provide further information of the metric behavior to a possible human operator or other systems. Furthermore, the components of levels higher than can be required for inter-component compensations, as is detailed in Section 3.2.4.
3.2.4. Multiresolution Degradation Detection
4. Evaluation
- Metric Statistical Threshold (MST): The level of anomaly of each sample metric is directly measured by how far it is from its mean values, also considering a tolerance associated with its standard deviation (three times) [40]. The calculation of the degradation score is here equal to the one defined in Equation (13), but calculated directly from the metric instead of the components.where and the statistics are calculated for the complete input metric .
- Forward Linear Predictor (FLP): Following a similar scheme to the one in [24], a method based on the forward linear predictor of the 10th order is implemented, representing the predictor-based approaches discussed in Section 2. The prediction absolute error for each sample is the value used in this type of approach to detect anomalies. The original work [24] established some formulation in order to distinguish between metrics where the sign of the degradation is relevant, as well as assuming a zero mean for the error. However, a degradation score as the one for MST is in terms of the normalized error, this being fully consistent with the original approach:where again, , consistent with the values in [24], and the error is calculated for the complete input metric (no reference period).
- Degraded Patterns’ Correlation (DPC): The approach in [22], referenced in Section 2, works by establishing a certain pseudoperiod or set of pseudoperiods of as reference, e.g., a period of 24 h. Degraded patterns are then generated by adding a negative or positive synthetic pattern (e.g., a positive-sign impulse or negative-sign impulse) to the reference sequence. This is done for all possible shifts of the synthetic pattern inside the reference sequence (e.g., the reference with a positive-sign impulse at n = 0, 1, 2, …24). The Pearson coefficient is calculated for all these possible degraded patterns and each pseudoperiod of the remaining of under analysis. High values of this correlation might indicate an anomaly of , whereas the level of correlation between the original reference set (without added patterns) and the pseudoperiod under analysis is also taken into account for the detection decision. Hence, fully complying with the original definitions in [22], the associated degradation score (with values outside to be considered degraded) is defined as:with . For this technique, the score will be calculated for both a positive impulse degradation pattern (labeled as DPC+) and a negative one (DPC−) [22]. This mechanism requires a reference sequence, which is one of its main shortcomings in respect to our proposed method.
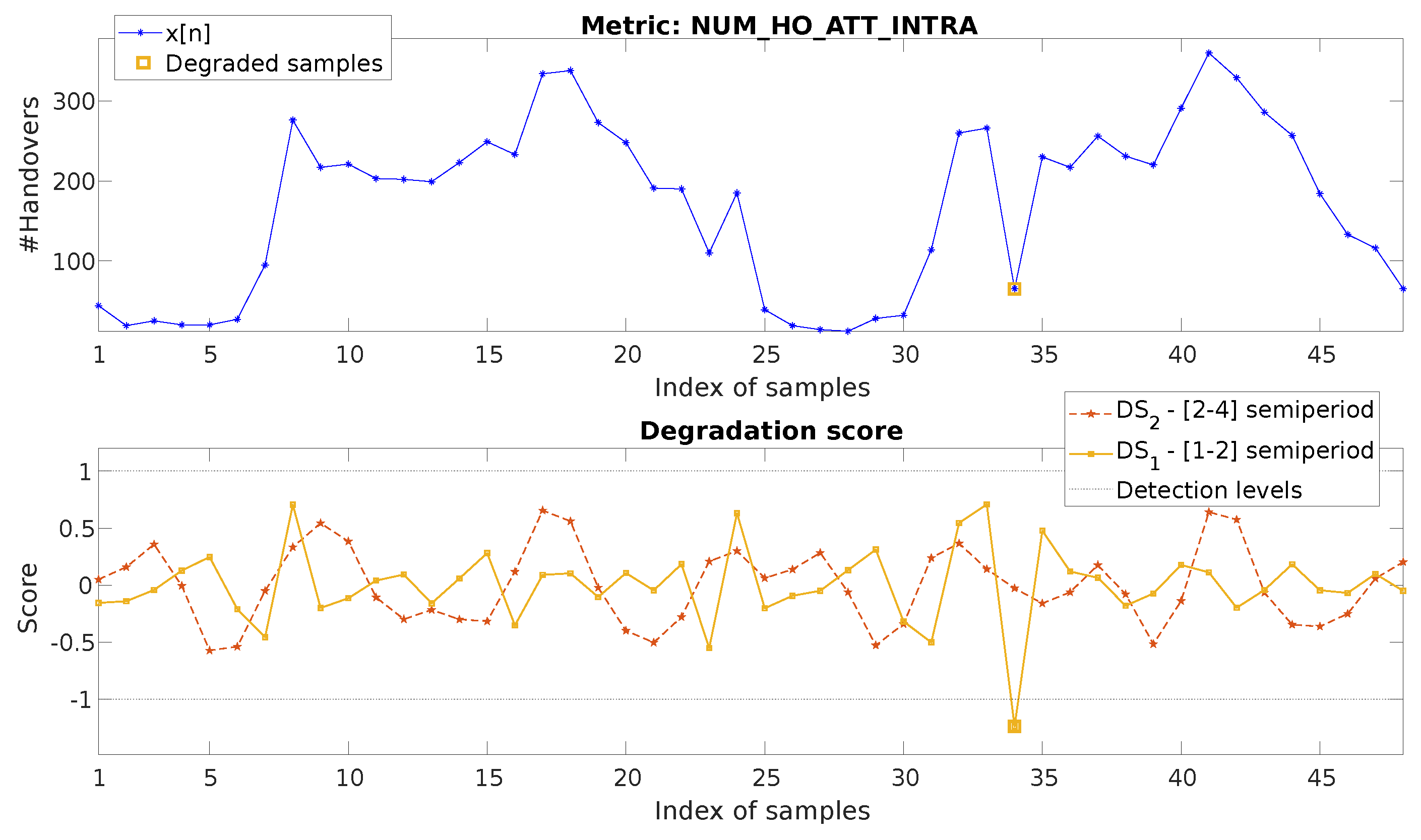
4.1. Hourly Metric, Down-Degradation
4.2. Hourly Metric, Up-Degradation
4.3. Weekly Metric, Multiple-Degradations
- Degradation 1: shows a typical one-week pattern, but of a duration of six samples, instead of seven.
- Degradation 2: There are anomalous low metric values in and (part of the week pattern of ).
- Degradation 3: A sequence of more than one week has an overall out-of-trend reduction of the metric values. Furthermore, and show values breaking the normal weekly pattern.
- Degradation 4: and n=160 present degraded values.
5. Conclusions and Outlook
6. Patents
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jorguseski, L.; Pais, A.; Gunnarsson, F.; Centonza, A.; Willcock, C. Self-organizing networks in 3GPP: Standardization and future trends. IEEE Commun. Mag. 2014, 52, 28–34. [Google Scholar] [CrossRef]
- NGNM. Recommendation on SON and O&M Requirements. Whitepaper 1.23, Next Generation Mobile Networks Alliance. 2008. Available online: https://www.ngmn.org/publications/ngmn-recommendation-on-son-and-om-requirements.html (accessed on 1 September 2020).
- Szilagyi, P.; Novaczki, S. An Automatic Detection and Diagnosis Framework for Mobile Communication Systems. IEEE Trans. Netw. Serv. Manag. 2012, 9, 184–197. [Google Scholar] [CrossRef]
- Fortes, S.; Barco, R.; Aguilar-Garcia, A. Location-based distributed sleeping cell detection and root cause analysis for 5G ultra-dense networks. EURASIP J. Wirel. Commun. Netw. 2016, 2016, 1–18. [Google Scholar] [CrossRef]
- Chernov, S.; Cochez, M.; Ristaniemi, T. Anomaly Detection Algorithms for the Sleeping Cell Detection in LTE Networks. In Proceedings of the 2015 IEEE 81st Vehicular Technology Conference (VTC Spring), Glasgow, UK, 11–14 May 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Khatib, E.J.; Barco, R.; Serrano, I.; Noz, P.M. LTE performance data reduction for knowledge acquisition. In Proceedings of the 2014 IEEE Globecom Workshops (GC Wkshps), Austin, TX, USA, 8–12 December 2014; pp. 270–274. [Google Scholar] [CrossRef]
- Mulvey, D.; Foh, C.H.; Imran, M.A.; Tafazolli, R. Cell Fault Management Using Machine Learning Techniques. IEEE Access 2019, 7, 124514–124539. [Google Scholar] [CrossRef]
- Welch, P. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Rioul, O.; Vetterli, M. Wavelets and signal processing. IEEE Signal Process. Mag. 1991, 8, 14–38. [Google Scholar] [CrossRef]
- Vikhe, P.S.; Nehe, N.S.; Thool, V.R. Heart Sound Abnormality Detection Using Short Time Fourier Transform and Continuous Wavelet Transform. In Proceedings of the 2009 Second International Conference on Emerging Trends in Engineering Technology, Nagpur, India, 16–18 December 2009; pp. 50–54. [Google Scholar] [CrossRef]
- Mdini, M. Anomaly Detection and Root Cause Diagnosis in Cellular Networks. Ph.D. Thesis, Ecole Nationale Sup’erieure Mines-T’el’ecom Atlantique, Brest, France, 2019. [Google Scholar]
- Fortes, S.; Barco, R.; Muñoz Luengo, P.; Serrano, I. Method and Network Node for Detecting Degradation of Metric of Telecommunications Network. International Patent PCT/EP2016/064144, 20 June 2016. [Google Scholar]
- Khatib, E.J.; Barco, R.; Serrano, I. Degradation Detection Algorithm for LTE Root Cause Analysis. Wirel. Pers. Commun. 2017, 97, 4563–4572. [Google Scholar] [CrossRef]
- Khatib, E.J.; Barco, R.; Muñoz, P.; Serrano, I. Knowledge acquisition for fault management in LTE networks. Wirel. Pers. Commun. 2017, 95, 2895–2914. [Google Scholar] [CrossRef]
- Novaczki, S. An improved anomaly detection and diagnosis framework for mobile network operators. In Proceedings of the 2013 9th International Conference on the Design of Reliable Communication Networks (DRCN), Budapest, Hungary, 4–7 March 2013; pp. 234–241. [Google Scholar]
- Fortes, S.; Garcia, A.A.; Fernandez-Luque, J.A.; Garrido, A.; Barco, R. Context-Aware Self-Healing: User Equipment as the Main Source of Information for Small-Cell Indoor Networks. IEEE Veh. Technol. Mag. 2016, 11, 76–85. [Google Scholar] [CrossRef]
- Muñoz, P.; Barco, R.; Cruz, E.; Gómez-Andrades, A.; Khatib, E.J.; Faour, N. A method for identifying faulty cells using a classification tree-based UE diagnosis in LTE. EURASIP J. Wirel. Commun. Netw. 2017, 2017, 130. [Google Scholar] [CrossRef]
- Ciocarlie, G.F.; Lindqvist, U.; Novaczki, S.; Sanneck, H. Detecting anomalies in cellular networks using an ensemble method. In Proceedings of the 9th International Conference on Network and Service Management (CNSM 2013), Zurich, Switzerland, 14–18 October 2013; pp. 171–174. [Google Scholar]
- Cheung, B.; Kumar, G.; Rao, S.A. Statistical algorithms in fault detection and prediction: Toward a healthier network. Bell Labs Tech. J. 2005, 9, 171–185. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Fehlmann, R.; Ristaniemi, T. Correlation-Based Cell Degradation Detection for Operational Fault Detection in Cellular Wireless Base-Stations. In Mobile Networks and Management: 5th International Conference, MONAMI 2013, Cork, Ireland, 23–25 September 2013, Revised Selected Papers; Springer International Publishing: Cham, Switzerland, 2013; pp. 83–93. [Google Scholar] [CrossRef]
- Guerzoni, R. Identifying Fault Category Patterns in a Communication Network. WO Patent App. PCT/EP2012/068,092, 20 March 2014. [Google Scholar]
- Noz, P.M.; Barco, R.; Serrano, I.; Gomez-Andrades, A. Correlation-Based Time-Series Analysis for Cell Degradation Detection in SON. IEEE Commun. Lett. 2016, 20, 396–399. [Google Scholar] [CrossRef]
- Fortes, S.; Palacios, D.; Serrano, I.; Barco, R. Applying Social Event Data for the Management of Cellular Networks. IEEE Commun. Mag. 2018, 56, 36–43. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, N.; Pan, Z.; Deng, T.; You, X. A fault detection model for mobile communication systems based on linear prediction. In Proceedings of the 2014 IEEE/CIC International Conference on Communications in China (ICCC), Shanghai, China, 13–15 October 2014; pp. 703–708. [Google Scholar]
- Al Mamun, S.M.A.; Beyaz, M. LSTM Recurrent Neural Network (RNN) for Anomaly Detection in Cellular Mobile Networks. In Machine Learning for Networking; Renault, É., Mühlethaler, P., Boumerdassi, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 222–237. [Google Scholar]
- Barford, P.; Kline, J.; Plonka, D.; Ron, A. A Signal Analysis of Network Traffic Anomalies. In Proceedings of the 2nd ACM Sigcomm Workshop on Internet Measurment (IMW ’02), Marseille, France, 6–8 November 2002; ACM: New York, NY, USA, 2002; pp. 71–82. [Google Scholar] [CrossRef]
- Du, Z.; Ma, L.; Li, H.; Li, Q.; Sun, G.; Liu, Z. Network Traffic Anomaly Detection Based on Wavelet Analysis. In Proceedings of the 2018 IEEE 16th International Conference on Software Engineering Research, Management and Applications (SERA), Kunming, China, 12–15 June 2018; pp. 94–101. [Google Scholar]
- Lu, W.; Ghorbani, A.A. Network Anomaly Detection Based on Wavelet Analysis. EURASIP J. Adv. Signal Process. 2008, 2009, 837601. [Google Scholar] [CrossRef]
- Mdini, M.; Blanc, A.; Simon, G.; Barotin, J.; Lecoeuvre, J. Monitoring the network monitoring system: Anomaly Detection using pattern recognition. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 983–986. [Google Scholar] [CrossRef]
- Slimen, Y.B.; Allio, S.; Jacques, J. Anomaly Prevision in Radio Access Networks Using Functional Data Analysis. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Onireti, O.; Zoha, A.; Moysen, J.; Imran, A.; Giupponi, L.; Imran, M.A.; Abu-Dayya, A. A Cell Outage Management Framework for Dense Heterogeneous Networks. IEEE Trans. Veh. Technol. 2016, 65, 2097–2113. [Google Scholar] [CrossRef]
- Sahinoglu, Z.; Tekinay, S. Multiresolution decomposition and burstiness analysis of traffic traces. In Proceedings of the 1999 IEEE Wireless Communications and Networking Conference (Cat. No.99TH8466) (WCNC), New Orleans, LA, USA, 21–24 September 1999; Volume 2, pp. 560–563. [Google Scholar] [CrossRef]
- Samiee, K.; Kov’acs, P.; Gabbouj, M. Epileptic Seizure Classification of EEG Time-Series Using Rational Discrete Short-Time Fourier Transform. IEEE Trans. Biomed. Eng. 2015, 62, 541–552. [Google Scholar] [CrossRef] [PubMed]
- Akansu, A.N.; Haddad, R.A. (Eds.) Series in Telecommunications, 2nd ed.; Academic Press: San Diego, CA, USA, 2001; p. ii. [Google Scholar] [CrossRef]
- Rioul, O.; Duhamel, P. Fast algorithms for discrete and continuous wavelet transforms. IEEE Trans. Inf. Theory 1992, 38, 569–586. [Google Scholar] [CrossRef]
- Agrawal, S.K.; Sahu, O.P. Two-Channel Quadrature Mirror Filter Bank: An Overview. ISRN Signal Process. 2013, 2013, 10. [Google Scholar] [CrossRef]
- Stolojescu, C.; Railean, I.; Moga, S.; Isar, A. Comparison of wavelet families with application to WiMAX traffic forecasting. In Proceedings of the 2010 12th International Conference on Optimization of Electrical and Electronic Equipment, Brasov, Romania, 20–22 May 2010; pp. 932–937. [Google Scholar] [CrossRef]
- Shiralashetti, S.C. An application of the Daubechies Orthogonal Wavelets in Power system Engineering. Int. J. Comput. Appl. 2014, 975, 8878. [Google Scholar]
- Wai Keng, N.; Salman Leong, M.; Meng Hee, L.; Abdelrhman, A. Wavelet Analysis: Mother Wavelet Selection Methods. Appl. Mech. Mater. 2013, 393, 953–958. [Google Scholar] [CrossRef]
- Grubbs, F.E. Procedures for Detecting Outlying Observations in Samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anomaly Detection and Thresholding in Cellular Networks | |||
|---|---|---|---|
| Category | Techniques | Summary | Ref. |
| Human thresholding | State machine | Degradation interval identification based on the crossing of manually defined thresholds. | [13] |
| Entropy minimizationDiscretization | Calculation of numerical thresholds from labeled metric samples. | [14] | |
| Statistical thresholding | Deviation from average, probability distributioncomparison, discretization | Thresholds based on statistics coming from normal samples or the average of the observed samples. | [3,15,16,17] |
| ML classifiers | Naive Bayes classifier, kNN, SVM, etc. | Automatic training based on labeled data (normal and degraded). Often, classification is based on the metric values without considering the time variable. | [16,18] |
| Patterns’ comparison | Correlation, clustering | Comparison of the observed time-series with normal/healthy patterns from the past or neighbor cells, synthetic degraded patterns, or contextual sources. | [19,20,21,22,23] |
| Predictor-based | ARIMA, forward linearpredictors, LSTM, etc. | The error between the predicted metric and the observed one is used as a degradation score. | [18,24,25] |
| Transform-Based Applications | ||
|---|---|---|
| Field of Application | Transform | Ref. |
| Phonocardiogram signals | STFT, CWT | [10] |
| Network traffic anomaly detection | DWT | [26] |
| Packet length anomaly detection (network layer traces) | DWT | [27] |
| Network intrusion detection | DWT | [28] |
| Cellular metric smoothing | DoM | [29] |
| Cellular metric smoothing | Wavelet | [30] |
| Degradation periodicity identification | FFT | [6] |
| UE-level measurement prediction | Fourier series | [31] |
| Traffic burstiness identification | Wavelet | [32] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fortes, S.; Muñoz, P.; Serrano, I.; Barco, R. Transform-Based Multiresolution Decomposition for Degradation Detection in Cellular Networks. Sensors 2020, 20, 5645. https://doi.org/10.3390/s20195645
Fortes S, Muñoz P, Serrano I, Barco R. Transform-Based Multiresolution Decomposition for Degradation Detection in Cellular Networks. Sensors. 2020; 20(19):5645. https://doi.org/10.3390/s20195645
Chicago/Turabian StyleFortes, Sergio, Pablo Muñoz, Inmaculada Serrano, and Raquel Barco. 2020. "Transform-Based Multiresolution Decomposition for Degradation Detection in Cellular Networks" Sensors 20, no. 19: 5645. https://doi.org/10.3390/s20195645
APA StyleFortes, S., Muñoz, P., Serrano, I., & Barco, R. (2020). Transform-Based Multiresolution Decomposition for Degradation Detection in Cellular Networks. Sensors, 20(19), 5645. https://doi.org/10.3390/s20195645