1. Introduction
The multi-robot system has been proven to have better stability, stronger robustness, and lower redundancy than the single-robot system. Consequently, it has been widely applied in large-scale searches, post-disaster searches, and alert patrols, where all robots are expected to be fully aware of their locations in order to efficiently perform cooperative tasks. In this context, precise localization is critical and requires comprehensive investigation.
There are generally three steps in the traditional autonomous localization methods when it comes to sensor information processing. The first step is to collect the information obtained by both internal and external sensors [
1,
2]; the second step is to process the collected information and ensure that it conforms to the filtering algorithm’s format; the last step is to calculate the localization result based on the information processed by the filtering algorithm [
3]. In the case of a multi-robot system, the localization methods are usually extended from those designed for the single-robot system. For example, Roumeliotis et al. [
4] distributed the interaction term to the relevant robots in the extended Kalman filtering (EKF) algorithm for multi-robot co-localization. Zhang et al. [
5] proposed a cooperative localization approach with communication delays, using the EKF technique based on state estimation, and they suggested reducing the state estimation error of delay filtering based on the error compensation. Wang et al. [
6] implemented the co-localization for wireless sensor networks (WSNs) by using a hard decision-based method with outlier constraints in the cooperative localization phase, which helped successfully solve the issue of range-free estimation and effectively avoided large errors in node localization. In order to provide positioning services in larger area, P.N. Pathirana et al. [
7] adopted the method of multiple robots touring around the WSNs and used the robust EKF to eliminate measurement noise. However, this method has a large delay and poor performance in real-time. A. Baggio et al. [
8] improved the Monte Carlo localization algorithm in WSNs. They optimized the performance of unknow nodes calling position information. H. Chen et al. [
9] studied the localization issues in WSNs with physical obstacles. They adopted the convex optimization method to reduce the moving distance of mobile elements in the networks, which extended the life of the mobile elements, while ensuring high-precision localization. Guo et al. [
10] suggested supporting the co-localization of unmanned aerial vehicles (UAVs) in a non-GPS environment by adopting an Ultra-Wide Band (UWB)-based EKF localization algorithm. Pirník et al. [
11] investigated the performances of inertial devices in controlling wheeled mobile platforms and developed an algorithm to integrate inertial sensor-recorded data into the system control. In this context, they experimentally proved the necessity of the inertial devices to interact with other absolute sensors. Liu et al. [
12] combined particle filtering (PF) with the particle swarm optimization algorithm to deal with the co-localization of heterogeneous robot systems.
However, all the dynamic models in the abovementioned studies are of simple trajectories of motion, which means that they are difficult to apply in actual situations. Accordingly, efforts have been made to fill the gap by some European scholars [
13]. For instance, Božek et al. [
14] used the Newton–Euler method to formulate a dynamic model of a six-axis hexacopter equipped with a robotic arm, and a dynamic model for controlling a four-wheeled highly-dynamic robot was proposed by Kilin et al. [
15]. In addition, C. Yu et al. did some studies on identification of state-space in the case of unknown dynamic model [
16,
17] or unknown input [
18]. These studies made great contributions to filtering for complex dynamic models.
Although the above-mentioned methods manage to effectively solve the co-localization problem of the multi-robot system, they are frequently vulnerable to conflicting relative observation information that would lead to divergence in the Kalman filtering (KF) and increase the computational burden. When extending the localization algorithms from single-robot systems to multi-robot counterparts, it is of critical importance to fuse the relative observation information between multiple robots. Otherwise, the possibly present conflicts among different robots in terms of the relative observation information could lead to inconsistent co-localization and even filter divergence. Taking this into consideration, Hua et al. [
19] integrated the complete information static game theory into the EKF algorithm for both one-way and two-way observations in the multi-robot systems, which suppressed the observation conflicts significantly.
However, the EKF algorithm adopted by Hua et al. [
19] is of low precision, and its improvement is the main focus of this study. Meanwhile, efforts are made to not incur other side effects (e.g., computational burden and instability). In this respect, the work of this study is summarized as follows:
Finally, a high-precision co-localization algorithm is obtained, which is more effective than the original algorithm in eliminating information conflicts caused by multiple sensors, with similar stability and computational burden. This is the major contribution of this article.
The rest of the paper is organized as follows. In
Section 2, a game theory-based algorithm is introduced for co-localization, accompanied by the analysis of its filtering component. Moreover, attention is paid to investigating the KF series algorithms and the UKF-based derivative method as well as comparing UKF with EKF. In
Section 3, the dynamic model of the system is established, and an estimation fusion algorithm is proposed based on the derivative UKF in the game theory-based co-localization algorithm framework. Specifically, KF is used to simplify the calculation of the measurement update without reducing the estimation precision. In addition, SVD is applied to the derivative UKF (DUKF) algorithm to improve the stability of the algorithm and to avoid ill-posed problems during Cholesky decomposition. The game theory-based co-localization algorithm is optimized with the proposed filter algorithm and provides the specific steps of the optimized algorithm in
Section 4. In
Section 5, the optimized algorithm is verified by numerical simulations of the motion system. Eventually, conclusions are drawn in
Section 6.
The relationship between these filtering algorithms is shown in
Figure 1.
3. Improvement for the UKF
3.1. Relevant Work on the Kalman Filtering
The KF series algorithms have attracted extensive attention from the engineering community since they were adopted by NASA to solve the navigation problem in the Apollo moon-landing program. However, the traditional KF algorithm is exclusively suitable for linear systems; consequently, it fails to solve problems in nonlinear systems that are ubiquitous in reality (e.g., state estimation and system identification). In this context, nonlinear filtering algorithms are urgently needed.
Recently, a large number of nonlinear filtering algorithms have been proposed, such as the Extended Kalman Filtering (EKF), the Gaussian Sum Filtering, the Gauss–Hermite Filtering, the Particle Filtering (PF), and the Unscented Kalman Filtering (UKF). Among them, EKF is the most commonly used in research on localization and navigation. Its main idea is to first approximately linearize the nonlinear functions and then apply the traditional KF algorithm to filter the linearized system. Although the EKF algorithm is very mature and widely used, it eliminates high-order terms when linearizing a system by the Taylor expansion, thereby leading to truncation errors and ultimately affecting the filtering precision. Moreover, the complexity in calculating the associated Jacobian matrix hinders the wide application of the EKF algorithm in engineering practice [
20].
In order to avoid the problem of insufficient accuracy caused by the process of linear approximation, Julier and Uhlmann [
22] proposed the UKF algorithm to approximate the posterior probability density function of the nonlinear system based on a set of sigma points by the unscented transformation (UT).
The UKF outperforms the EKF in the following aspects:
Based on the above advantages, we believe that the accuracy of localization will be improved by using the UKF algorithm for filtering, which can also reduce information conflicts among multiple robots during the process of co-localization. The flow and step of the game theory-based UKF co-localization algorithm has been given in our previous work [
23], so they are not repeated here.
3.2. Improvement of the Computational Burden Based on the Derivative Method
Compared with EKF, the high precision of UKF is unfortunately accompanied by a significantly increased computational burden. As a countermeasure, UKF is properly modified in this study by introducing the derivative method.
In the original algorithm, Hua et al. [
19] adopted
to describe the state of the system. Instead of this,
is used for such a description in this study. In this way, the time update can be achieved by the classical KF. Nonlinear filtering is adopted for the observation update based on UT.
The derivative UKF (DUKF) algorithm has the same form as the classical KF algorithm in terms of the time update. This allows DUKF to avoid UT of the time update, which is required in the traditional UKF. As a consequence, the state estimation and its covariance can be calculated concisely, thus reducing the computational burden efficiently. In the observation update phase, the DUKF algorithm relies on the traditional UKF to update the predicted observations, thereby inheriting the excellent performance of the traditional UKF algorithm for nonlinear systems.
3.3. System Model Establishment
The considered nonlinear discrete-time system is represented by
where
and
denote the state and measurement vectors at the time
k, respectively,
is the state prediction matrix,
t is the sampling time,
is the nonlinear measurement function, and
is the distance between the
i-th UWB sensor and the robot at time
k. To increase the real-time performance of the system, we adopt the distance
r instead of the coordinates
x and
y as the observation value in the measurement vector [
24].
is defined as
The
and
are the uncorrelated zero-mean Gaussian white noise processes, with covariances as
It can be seen from the system model that the system has a linear time update matrix and a nonlinear measurement function. Therefore, it meets the conditions required for the application of the DUKF algorithm.
To transplant the algorithm to the physical platform in the future, the values of error variance and system state are determined according to the robot and sensors we purchased. Specifications of simulated sensors and mobile robots are shown in
Figure 3. Each base station is equipped with one UWB sensor to measure the distance, and each robot is equipped with three UWB sensors that form an antenna array to obtain the azimuth information during the relative observation.
3.4. Comparison between UKF and DUKF in Terms of Computational Complexity
To evaluate the computational burden of the identification algorithm, we count the number of multiplication and addition operations of the algorithm. Each multiplication or addition operation is called a flop, and the total number of flops represents the computational burden.
For the considered system, the computational burden of DUKF is significantly lower than that of UKF. Specifically, it is necessary for UKF to select the sigma point set to derive the nonlinear system during the time update and measurement update. Consequently, UKF brings about a large but unnecessary computational burden because the time prediction equation of the considered system is linear. In contrast, DUKF uses KF in the linear part of the system, avoiding redundant calculations for measurement updates.
Table 1 comprehensively compares UKF and DUKF in terms of the computational costs, especially for the time update part since they share the same measurement updates. It is deduced, through the analysis of the computational cost, that UKF requires a total of
flops more than DUKF in each cycle, and they present comparative precision.
As shown in
Figure 4, the calculation time of DUKF is in general concentrated below that of UKF.
Table 2 shows that the variance of DUKF is 24.1% higher than that of UKF.
The 18% longer calculation time of DUKF than EKF is compensated by the much higher precision, and therefore we believe that the lengthened calculation time is worthwhile.
3.5. Improvement of the Stability of the DUKF
Compared with the traditional UKF algorithm, the DUKF algorithm adopted in this study is sensitive to the error of the initial system state estimation. Specifically, when the estimated initial system state is much different from the real counterpart, the DUKF algorithm is prone to divergence.
Due to the randomness of the covariance matrix, ill-posed problems are often encountered during the decomposition process, affecting the filtering performance and even causing divergence [
25,
26]. Countermeasures have been proposed in the study by Hu [
20], who comprehensively analyzed the error characteristics and discussed the stability of the DUKF algorithm. According to his research, the observation covariance
is required to be a positive definite matrix to bound the estimation error of the DUKF algorithm. In this context, the noise variance
needs to be a positive definite matrix as a precondition. However,
may be a positive semi-definite matrix, which causes
to be a positive semi-definite matrix as well. To stabilize the algorithm, Hu added a small positive definite matrix
to
:
However, the introduction of
subjects the algorithm to reduced filtering precision. In the study by Geng et al. [
27], the SVD is introduced into the UKF algorithm to deliver a more complex iteration of the covariance matrix, which results in higher stability. Similarly, the SVD is introduced into the derived CKF algorithm to improve the stability in our previous research [
28], which achieved good performance. In this study, the SVD is integrated with the previously introduced DUKF to form an SVD-DUKF method, followed by a simple proof and numerical experiments that verify its effectiveness.
Different from the Cholesky decomposition, the SVD can decompose positive semi-definite matrices. Therefore, is not needed anymore in the SVD-DUKF method. In other words, the stability of the algorithm can be guaranteed without increasing the measurement errors. This method not only optimizes the iterative process and reduces the amount of calculation, but also ensures the stability of the algorithm iteration, contributing to greatly improved system convergence.
3.6. The Method of the SVD-DUKF
Matrix
A, assumed to be an
order matrix, can be decomposed into orthogonal matrices
U and
V according to the singular value decomposition theory:
where
is the singular value of
A, and the values are changed in a descending order.
When matrix
A is a positive definite matrix, Formula (7) can be rewritten as
In Formula (8), all of the are greater than zero.
The error covariance matrix in the DUKF algorithm is subjected to the singular value decomposition, and the decomposition matrix is iterated by the properties of the matrix, which contributes to the improved SVD-DUKF algorithm.
Specific steps of the SVD-DUKF algorithm are detailed in Algorithm 1.
| Algorithm 1. The flow of the derivative SVD-DUKF algorithm. |
| Input: |
|
Output: |
| 1. Time update to the system based on the classical Kalman filter: |
|
|
| 2. SVD of state covariance matrix can be obtained: |
|
| 3. Select a set of SIGMA points as follows: |
|
| 4. Update the observations based on the set of sigma points as follows: |
|
|
| 5. Calculate the covariance of the observation: |
|
| 6. Calculate the cross-covariance variance of observation and state: |
|
| where . |
| 7. Obtain the Kalman gain: |
|
| 8. Update the system status and covariance of the system: |
|
| 9. end. |
To demonstrate the performance of the SVD-DUKF algorithm, a simulation is implemented in a simple model, which demonstrates that the number of convergence of the SVD-DUKF algorithm is 56.7% higher than that of the DUKF algorithm (
Table 3).
4. The Method of the Static Game Theory-Based SVD-DUKF Algorithm for Co-Localization
If we set robot i to be the observer and robot j to be observed in our one-way observation model, then robot i will provide the observation information, while robot j will select the strategy of localization, which depends on the information provided by robot i.
The observation information obtained by robot
i concerning the location of robot
j can be expressed as follows:
where the superscript
means that the information is provided by robot
i. Other parameters are listed in
Figure 1. The SVD of the state covariance matrix
can be obtained:
Based on the result of the SVD and the previous independent localization, the sigma point set can be obtained:
After that, the sigma point set is transformed based on the measurement equation:
The predicted measurement and its covariance are then calculated:
Subsequently, the cross-covariance between the state and the measurement can be calculated:
where
a is an adjustment parameters.
The gain matrix
K can be determined by the covariance matrix
and the cross covariance matrix
:
Finally, based on the gain matrix
and the state covariance matrix
, the covariance matrix
of co-localization by robot
i to robot
j can be obtained:
The difference between
and
is taken as the judging criteria. The eigenvalues of
, namely
and
, are the semi-major and semi-short axes of the pose uncertainty ellipse, respectively. Similarly, by calculating the eigenvalues of
, namely
and
, we have
Based on Formula (20), the following benefit function is obtained:
The game benefits of
i and
j are shown in
Table 4. Moreover, in the case of the one-way observation, robot i performs autonomous localization and the benefit of the game is 1. If
,
, the game can reach the unique Nash equilibrium (independent localization; co-localization). If
,
, the game can reach the unique Nash equilibrium (independent localization; independent localization). If
, the benefit function of the game is always equal to 1. Co-localization tends to increase the computational burden, and independent localization is thus generally selected by the robots.
After identifying the selection strategy of the game with two robots in the case of one-way relative observation, the proposed SVD-DUKF algorithm is adopted to obtain the location information of each robot. Specific steps of the SVD-DUKF algorithm are shown in Algorithm 1.
Finally, the calculation results are assigned to the corresponding robots participating in the co-localization. Specific steps of the game theory-based SVD-DUKF co-localization algorithm (with localization of robot
j as an example) are shown in Algorithm 2. The flow chart of the algorithm is shown in
Figure 5.
| Algorithm 2. The flow of the game theory-based SVD-DUKF algorithm. |
| Input: , , , |
| Output: , , , |
| 1. Calculate the , , , by Algorithm 1. |
| 2. Calculate the , , , by the SVD. |
| 3. Substitute the above results into the benefit function (Formula (21)). |
| 4. Based on the result of Formula (21), choose the game strategy. |
| 5. Based on the strategy, return the , , , . |
| 6. end. |
5. Simulations
In order to demonstrate the performance of the proposed algorithm, a MATLAB simulation is implemented based on the open-source program that is provided by OpenSLAM [
29].
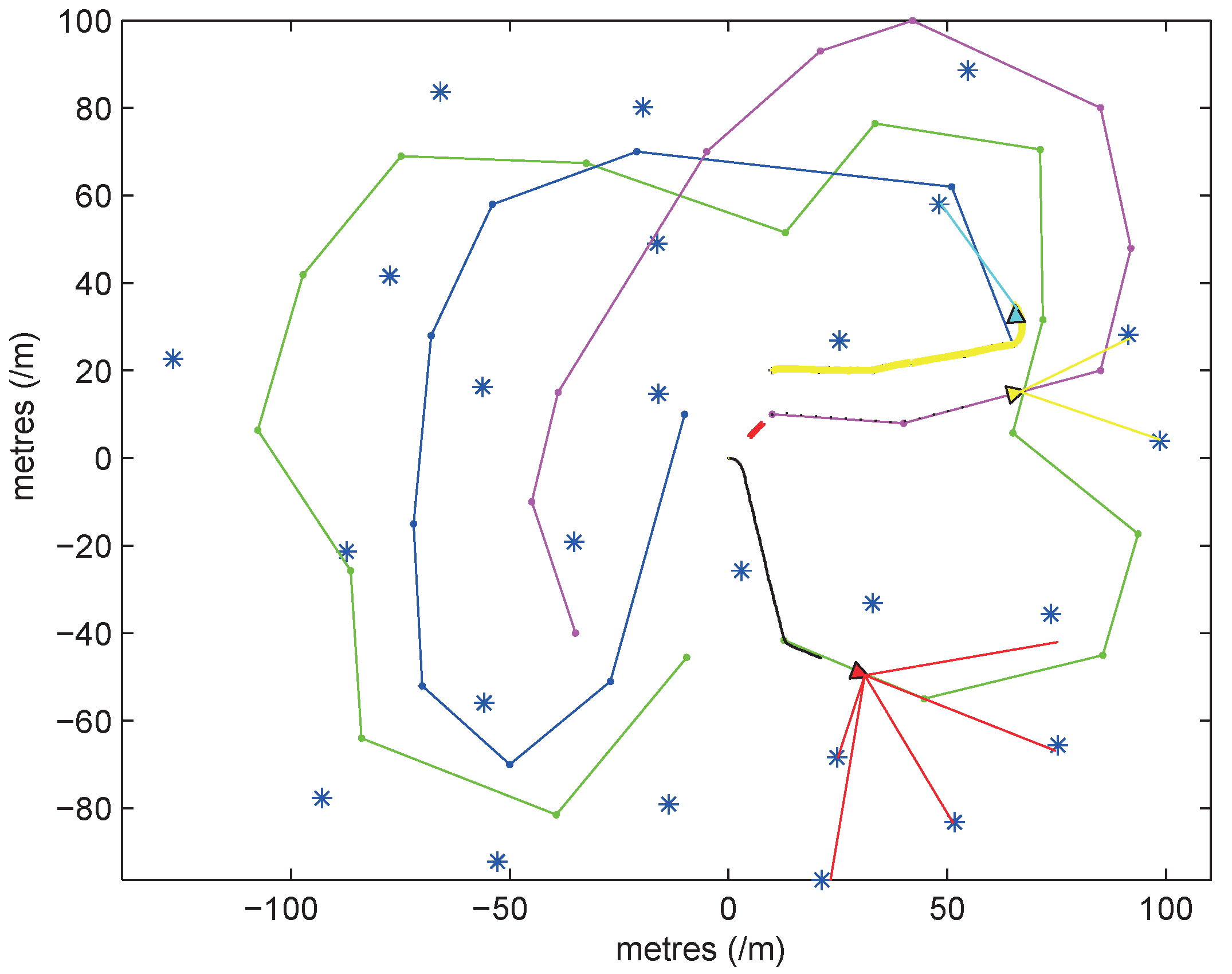
As shown in
Figure 6, the connection between the asterisk and the triangle indicates that the UWB sensor (asterisk) is measuring the distance of the robot (triangle). All robots can observe the relative angle and distance of the objects in a range of 180 degrees in front of them, with a maximum observation range of 15 m, and the paths they move are represented by green, purple, and blue lines. The simulation space is a 200 m × 200 m square. The dynamic model of the robot and the error variance of the sensor are determined by the system model proposed in
Section 3.3.
The SVD-DUKF algorithm is adopted when each robot is localized individually, and the optimized game theory-based algorithm is used when a relative observation occurs.
To demonstrate the performance of the proposed algorithm, five algorithms are evaluated by the simulations, including the original EKF, the static game theory-based EKF, the static game theory-based UKF, and the static game theory-based SVD-DUKF. Moreover, another nonlinear filtering algorithm (square root cubature Kalman filter, SR-CKF) proposed by Liu et al. [
30], which is also of higher precision and convergence, is assessed as the control group. The simulation results are shown in
Figure 7,
Figure 8,
Figure 9 and
Figure 10.
Localization errors of the other four algorithms are all less than that of the original EKF (
Figure 7). Moreover, the game theory-based UKF has fewer localization errors than the original EKF and the game theory-based EKF (
Figure 8). In addition, the SVD-DUKF algorithm further reduces the localization error (
Figure 9). As shown in
Figure 10, the SR-CKF as a control group also presents higher performance than the game theory-based EKF, and it performs similarly well with the algorithm proposed in this research.
However, due to the introduction of the derivative method, the game theory-based SVD-DUKF proposed in this paper is subjected to a smaller computational burden than SR-CKF, which is proven in the average calculation time of 50 times of simulations (
Table 5).
Figure 11 and
Figure 12 show the average localization errors and variances of all the five algorithms. Consistent with the previous analyses, the game theory-based SVD-DUKF presents better performance than other original algorithms and UKF series algorithms. Its average error is almost the same as that of SR-CKF, but its variance is much smaller than that of SR-CKF. Therefore, it is safe to conclude that the algorithm proposed in this study has the best performance among the five algorithms.
It is confirmed by the simulation results that SR-CKF and SVD-DUKF have better performances than the others. Moreover, as has been stated in
Section 2, UKF has higher precision than the game theory-based EKF, which explains the poor performance of EKF in the simulation. Different from the original UKF, SVD-DUKF adopts the linear update in the time update, thus removing the linearization error. Therefore, SVD-DUKF has higher precision than the original UKF in the simulations. Although SR-CKF also presents very high precision in the simulation, it needs to calculate the volume point set during the time update phase, thereby resulting in a much heavier calculation burden than SVD-DUKF. Consequently, SVD-DUKF is believed to outperform SR-CKF, although they have almost the same precision and variance.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}