Toward Mass Video Data Analysis: Interactive and Immersive 4D Scene Reconstruction

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
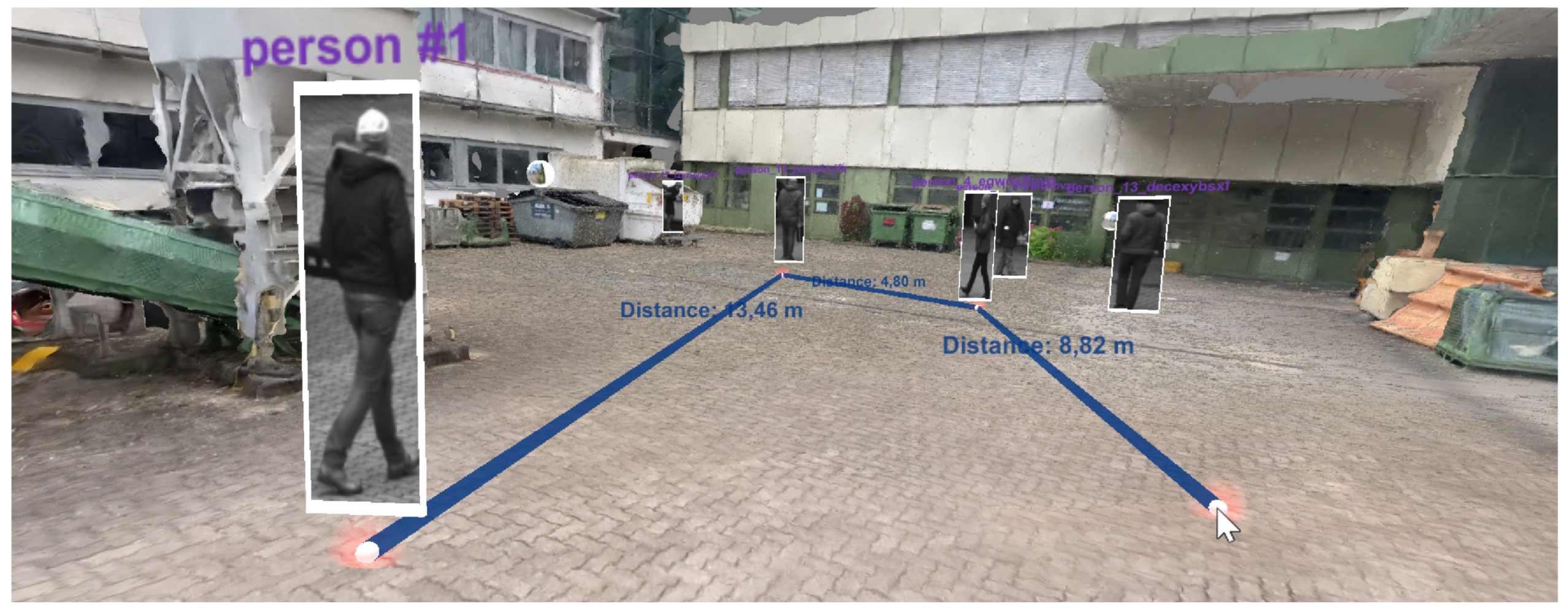{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. 3D Scene Reconstruction
2.2. Video Content Synthesis: Object Detection and Re-Identification
2.3. Multi-Video Surveillance Systems
2.4. Visual and Immersive Analytics
3. Crime Scene Analysis Framework: Processing Pipeline
3.1. Input Data
3.2. Reconstruction of the Static Scene
3.3. Reconstruction of the Dynamic Scene
3.3.1. Classical Stereo Depth Estimation
3.3.2. Neural Network-Based Monocular Depth Estimation
3.3.3. Object Detector-Based Dynamic Object Placement
3.3.4. Orthogonal Depth Estimation Approach
3.3.5. Neural Network-Based Full Body Reconstruction
3.4. High-Level Scene Analysis
3.4.1. Object Processing in Camera Space
3.4.2. Position Mapping to World Space
3.5. Temporal Footage Synchronization
3.6. Preprocessing Run Times
4. Visual Exploration of 4D Reconstruction
4.1. GUI
4.1.1. Menu Bar
4.1.2. Minimap
4.1.3. Bottom Panel
4.2. Reconstruction (3D) & Spatial Navigation
4.2.1. Photospheres and Time-Independent Materials
4.2.2. Annotations
4.3. Dynamic Content
4.3.1. Temporal Navigation & Timeline
4.3.2. Camera Positions
4.3.3. Detections
4.3.4. Dynamic Point Clouds
4.3.5. Animated Annotations
4.4. Visual Analysis
4.5. VR Exploration
5. Use Cases
5.1. Mass Data Analysis & Preparation of Evidence
5.2. Crime Scene Investigation
5.3. Real-Time Surveillance Scenario
5.4. Mission Planning and Training
6. Discussion
6.1. Limitations
6.2. Ethical Considerations and Legal Aspects
6.3. Future Work
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Qu, C.; Metzler, J.; Monari, E. ivisX: An Integrated Video Investigation Suite for Forensic Applications. In Proceedings of the 2018 IEEE Winter Applications of Computer Vision Workshops (WACVW), Lake Tahoe, NV, USA, 15 March 2018; pp. 9–17. [Google Scholar]
- Noack, R. Leaked document says 2000 men allegedly assaulted 1200 German women on New Year’s Eve. The Washington Post. Available online: https://www.washingtonpost.com/news/worldviews/wp/2016/07/10/leaked-document-says-2000-men-allegedly-assaulted-1200-german-women-on-new-years-eve/ (accessed on 21 September 2020).
- Pollok, T.; Kraus, M.; Qu, C.; Miller, M.; Moritz, T.; Kilian, T.; Keim, D.; Jentner, W. Computer vision meets visual analytics: Enabling 4D crime scene investigation from image and video data. In Proceedings of the 9th International Conference on Imaging for Crime Detection and Prevention (ICDP-2019), London, UK, 16–18 December 2019; pp. 44–49. [Google Scholar]
- Lemaire, T.; Berger, C.; Jung, I.; Lacroix, S. Vision-Based SLAM: Stereo and Monocular Approaches. Int. J. Comput. Vis. 2007, 74, 343–364. [Google Scholar] [CrossRef]
- Schönberger, J.L.; Frahm, J. Structure-from-Motion Revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Zhong, F.; Wang, S.; Zhang, Z.; Chen, C.; Wang, Y. Detect-SLAM: Making Object Detection and SLAM Mutually Beneficial. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Bullinger, S.; Bodensteiner, C.; Arens, M. 3D Object Trajectory Reconstruction using Stereo Matching and Instance Flow based Multiple Object Tracking. In Proceedings of the International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 27–31 May 2019. [Google Scholar]
- Mustafa, A.; Kim, H.; Guillemaut, J.; Hilton, A. General Dynamic Scene Reconstruction from Multiple View Video. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 900–908. [Google Scholar]
- Ji, D.; Dunn, E.; Frahm, J.M. Spatio-Temporally Consistent Correspondence for Dense Dynamic Scene Modeling. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 3–18. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Zhou, D.; Frémont, V.; Quost, B.; Dai, Y.; Li, H. Moving object detection and segmentation in urban environments from a moving platform. Image Vis. Comput. 2017, 68, 76–87. [Google Scholar] [CrossRef]
- Huang, Q.; Mo, W.; Pei, L.; Zeng, L. 3D Coordinate Calculation and Pose Estimation of Power Meter based on Binocular Stereo Vision. In Proceedings of the 8th International Conference on Software and Computer Applications (ICSCA’19), Penang, Malaysia, 19–21 February 2019; pp. 282–285. [Google Scholar]
- Li, X.; Loy, C.C. Video Object Segmentation with Joint Re-identification and Attention-Aware Mask Propagation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Lecture Notes in Computer Science. Volume 11207, pp. 93–110. [Google Scholar]
- Bialkowski, A.; Denman, S.; Sridharan, S.; Fookes, C.; Lucey, P. A database for person re-identification in multi-camera surveillance networks. In Proceedings of the 2012 International Conference on Digital Image Computing Techniques and Applications (DICTA), Fremantle, Australia, 3–5 December 2012; pp. 1–8. [Google Scholar]
- Pham, T.T.T.; Le, T.L.; Vu, H.; Dao, T.K. Fully-automated person re-identification in multi-camera surveillance system with a robust kernel descriptor and effective shadow removal method. Image Vis. Comput. 2017, 59, 44–62. [Google Scholar] [CrossRef]
- Yang, T.; Chen, F.; Kimber, D.; Vaughan, J. Robust people detection and tracking in a multi-camera indoor visual surveillance system. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 675–678. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-d human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2014, 45, 1340–1352. [Google Scholar] [CrossRef]
- Goffredo, M.; Bouchrika, I.; Carter, J.N.; Nixon, M.S. Performance analysis for automated gait extraction and recognition in multi-camera surveillance. Multimed. Tools Appl. 2010, 50, 75–94. [Google Scholar] [CrossRef]
- Collins, R.T.; Lipton, A.J.; Fujiyoshi, H.; Kanade, T. Algorithms for cooperative multisensor surveillance. Proc. IEEE 2001, 89, 1456–1477. [Google Scholar] [CrossRef]
- Javed, O.; Rasheed, Z.; Alatas, O.; Shah, M. KNIGHTM: A real time surveillance system for multiple and non-overlapping cameras. In Proceedings of the 2003 International Conference on Multimedia and Expo (ICME’03), (Cat. No. 03TH8698), Baltimore, MD, USA, 6–9 July 2003; Volume 1, p. I-649. [Google Scholar]
- Lee, L.; Romano, R.; Stein, G. Monitoring activities from multiple video streams: Establishing a common coordinate frame. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 758–767. [Google Scholar] [CrossRef]
- Kettnaker, V.; Zabih, R. Bayesian multi-camera surveillance. In Proceedings of the 1999 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, (Cat. No PR00149), Fort Collins, CO, USA, 23–25 June 1999; Volume 2, pp. 253–259. [Google Scholar]
- Zhao, J.; Sen-ching, S.C. Multi-camera surveillance with visual tagging and generic camera placement. In Proceedings of the 2007 First ACM/IEEE International Conference on Distributed Smart Cameras, Vienna, Austria, 25–28 September 2007; pp. 259–266. [Google Scholar]
- Lim, S.N.; Elgammal, A.; Davis, L.S. Image-based pan-tilt camera control in a multi-camera surveillance environment. In Proceedings of the 2003 International Conference on Multimedia and Expo (ICME’03), (Cat. No. 03TH8698), Baltimore, MD, USA, 6–9 July 2003; Volume 1, p. I-645. [Google Scholar]
- Shen, C.; Zhang, C.; Fels, S. A multi-camera surveillance system that estimates quality-of-view measurement. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 3, p. III-193. [Google Scholar]
- Keim, D.; Andrienko, G.; Fekete, J.D.; Görg, C.; Kohlhammer, J.; Melançon, G. Visual analytics: Definition, process, and challenges. In Information Visualization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 154–175. [Google Scholar]
- Wong, P.C.; Thomas, J. Visual analytics. IEEE Comput. Graph. Appl. 2004, 5, 20–21. [Google Scholar] [CrossRef]
- Keim, D.A.; Mansmann, F.; Schneidewind, J.; Thomas, J.; Ziegler, H. Visual analytics: Scope and challenges. In Visual Data Mining; Springer: Berlin/Heidelberg, Germany, 2008; pp. 76–90. [Google Scholar]
- Sacha, D.; Stoffel, A.; Stoffel, F.; Kwon, B.C.; Ellis, G.; Keim, D.A. Knowledge generation model for visual analytics. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1604–1613. [Google Scholar] [CrossRef] [PubMed]
- Malik, A.; Maciejewski, R.; Towers, S.; McCullough, S.; Ebert, D.S. Proactive spatiotemporal resource allocation and predictive visual analytics for community policing and law enforcement. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1863–1872. [Google Scholar] [CrossRef] [PubMed]
- Braga, A.A.; Papachristos, A.V.; Hureau, D.M. The effects of hot spots policing on crime: An updated systematic review and meta-analysis. Justice Q. 2014, 31, 633–663. [Google Scholar] [CrossRef]
- Sathiyanarayanan, M.; Junejo, A.K.; Fadahunsi, O. Visual Analysis of Predictive Policing to Improve Crime Investigation. In Proceedings of the 2019 International Conference on contemporary Computing and Informatics (IC3I), Singapore, 12–14 December 2019; pp. 197–203. [Google Scholar]
- Sacha, D.; Jentner, W.; Zhang, L.; Stoffel, F.; Ellis, G.; Keim, D. Applying Visual Interactive Dimensionality Reduction to Criminal Intelligence Analysis. In VALCRI White Paper Series; VALCRI: London, UK, 2017; pp. 1–11. [Google Scholar]
- Jentner, W.; Sacha, D.; Stoffel, F.; Ellis, G.; Zhang, L.; Keim, D.A. Making machine intelligence less scary for criminal analysts: Reflections on designing a visual comparative case analysis tool. Vis. Comput. 2018, 34, 1225–1241. [Google Scholar] [CrossRef]
- Pausch, R.; Crea, T.; Conway, M. A literature survey for virtual environments: Military flight simulator visual systems and simulator sickness. Presence Teleoperators Virtual Environ. 1992, 1, 344–363. [Google Scholar] [CrossRef]
- Merchant, Z.; Goetz, E.T.; Cifuentes, L.; Keeney-Kennicutt, W.; Davis, T.J. Effectiveness of virtual reality-based instruction on students’ learning outcomes in K-12 and higher education: A meta-analysis. Comput. Educ. 2014, 70, 29–40. [Google Scholar] [CrossRef]
- Gutiérrez, F.; Pierce, J.; Vergara, V.; Coulter, R.; Saland, L.; Caudell, T.; Goldsmith, T.; Alverson, D. The Impact of the Degree of Immersion Upon Learning Performance in Virtual Reality Simulations for Medical Education. J. Investig. Med. 2007, 55, S91. [Google Scholar] [CrossRef]
- Marriott, K.; Schreiber, F.; Dwyer, T.; Klein, K.; Riche, N.H.; Itoh, T.; Stuerzlinger, W.; Thomas, B.H. Immersive Analytics; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11190. [Google Scholar]
- Probst, D.; Reymond, J.L. Exploring drugbank in virtual reality chemical space. J. Chem. Inf. Model. 2018, 58, 1731–1735. [Google Scholar] [CrossRef]
- Zhang, S.; Demiralp, C.; Keefe, D.F.; DaSilva, M.; Laidlaw, D.H.; Greenberg, B.D.; Basser, P.J.; Pierpaoli, C.; Chiocca, E.A.; Deisboeck, T.S. An immersive virtual environment for DT-MRI volume visualization applications: A case study. In Proceedings of the Visualization (VIS’01), San Diego, CA, USA, 21–26 October 2001; pp. 437–584. [Google Scholar]
- Donalek, C.; Djorgovski, S.G.; Cioc, A.; Wang, A.; Zhang, J.; Lawler, E.; Yeh, S.; Mahabal, A.; Graham, M.; Drake, A. Immersive and collaborative data visualization using virtual reality platforms. In Proceedings of the 2014 IEEE International Conference on Big Data (BigData), Washington DC, USA, 27–30 October 2014; pp. 609–614. [Google Scholar]
- Kraus, M.; Weiler, N.; Breitkreutz, T.; Keim, D.A.; Stein, M. Breaking the curse of visual data exploration: Improving analyses by building bridges between data world and real world. In Proceedings of the 10th International Conference on Information Visualization Theory and Applications (IVAPP), Prague, Czech Republic, 25–27 February 2019; pp. 19–27. [Google Scholar]
- Kraus, M.; Weiler, N.; Oelke, D.; Kehrer, J.; Keim, D.A.; Fuchs, J. The impact of immersion on cluster identification tasks. IEEE Trans. Vis. Comput. Graph. 2019, 26, 525–535. [Google Scholar] [CrossRef]
- Kraus, M.; Angerbauer, K.; Buchmüller, J.; Schweitzer, D.; Keim, D.A.; Sedlmair, M.; Fuchs, J. Assessing 2D and 3D Heatmaps for Comparative Analysis: An Empirical Study. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Merino, L.; Fuchs, J.; Blumenschein, M.; Anslow, C.; Ghafari, M.; Nierstrasz, O.; Behrisch, M.; Keim, D.A. On the Impact of the Medium in the Effectiveness of 3D Software Visualizations. In Proceedings of the 2017 IEEE Working Conference on Software Visualization (VISSOFT), Shangahi, China, 18–19 September 2017; pp. 11–21. [Google Scholar]
- Etemadpour, R.; Monson, E.; Linsen, L. The effect of stereoscopic immersive environments on projection-based multi-dimensional data visualization. In Proceedings of the 2013 17th International Conference on Information Visualisation, London, UK, 16–18 July 2013; pp. 389–397. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Triggs, B.; McLauchlan, P.; Hartley, R.; Fitzgibbon, A. Bundle Adjustment—A Modern Synthesis. In International Workshop on Vision Algorithms; Springer: Berlin/Heidelberg, Germany, 2000; pp. 298–375. [Google Scholar]
- Cernea, D. OpenMVS: Multi-View Stereo Reconstruction Library. Available online: https://cdcseacave.github.io/openMVS (accessed on 19 September 2020).
- Konolige, K. Small vision system: Hardware and implementation. In Robotics Research; Springer: London, UK, 1997; pp. 111–116. [Google Scholar]
- Hirschmuller, H. Accurate and efficient stereo processing by semi-global matching and mutual information. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 July 2005; Volume 2, pp. 807–814. [Google Scholar]
- Godard, C.; Aodha, O.M.; Brostow, G.J. Digging Into Self-Supervised Monocular Depth Estimation. arXiv 2018, arXiv:1806.01260. [Google Scholar]
- Tosi, F.; Aleotti, F.; Poggi, M.; Mattoccia, S. Learning monocular depth estimation infusing traditional stereo knowledge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Hermann, M.; Ruf, B.; Weinmann, M.; Hinz, S. Self-Supervised Learning for Monocular Depth Estimation from Aerial Imagery. arXiv 2020, arXiv:2008.07246. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Li, Z.; Dekel, T.; Cole, F.; Tucker, R.; Snavely, N.; Liu, C.; Freeman, W.T. Learning the Depths of Moving People by Watching Frozen People. arXiv 2019, arXiv:1904.11111. [Google Scholar]
- Guizilini, V.; Ambrus, R.; Pillai, S.; Gaidon, A. PackNet-SfM: 3D Packing for Self-Supervised Monocular Depth Estimation. arXiv 2019, arXiv:1905.02693. [Google Scholar]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2018, arXiv:1812.08008. [Google Scholar] [CrossRef]
- Saito, S.; Simon, T.; Saragih, J.; Joo, H. PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Online, 14–19 June 2020. [Google Scholar]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization. arXiv 2019, arXiv:1905.05172. [Google Scholar]
- Wang, T.; Hu, X.; Wang, Q.; Heng, P.A.; Fu, C.W. Instance Shadow Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 14–19 June 2020. [Google Scholar]
- Sarafianos, N.; Boteanu, B.; Ionescu, B.; Kakadiaris, I.A. 3D Human pose estimation: A review of the literature and analysis of covariates. Comput. Vis. Image Underst. 2016, 152, 1–20. [Google Scholar] [CrossRef]
- Pollok, T. A New Multi-Camera Dataset with Surveillance, Mobile and Stereo Cameras for Tracking, Situation Analysis and Crime Scene Investigation Applications. In Proceedings of the 2018 the 2nd International Conference on Video and Image Processing (ICVIP 2018), Hong Kong, China, 29–31 December 2018; pp. 171–175. [Google Scholar]
- Valve Index Developer Website. 2020. Available online: https://store.steampowered.com/valveindex/ (accessed on 30 July 2020).
- Ruddle, R.A.; Payne, S.J.; Jones, D.M. Navigating large-scale virtual environments: What differences occur between helmet-mounted and desk-top displays? Presence Teleoperators Virtual Environ. 1999, 8, 157–168. [Google Scholar] [CrossRef]
- Riecke, B.E.; Schulte-Pelkum, J. Perceptual and cognitive factors for self-motion simulation in virtual environments: How can self-motion illusions (“vection”) be utilized? In Human Walking in Virtual Environments; Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–54. [Google Scholar]
- Naudts, L.; Vogiatzoglou, P. The VICTORIA Ethical and Legal Management Toolkit: Practice and Theory for Video Surveillance. 2019. Available online: https://lirias.kuleuven.be/2954812?limo=0 (accessed on 19 August 2020).
- Oneto, L.; Chiappa, S. Fairness in Machine Learning. In Recent Trends in Learning From Data; Springer: Berlin/Heidelberg, Germany, 2020; pp. 155–196. [Google Scholar]
- Rademacher, T. Artificial intelligence and law enforcement. In Regulating Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 225–254. [Google Scholar]
- Naudts, L. Criminal Profiling and Non-Discrimination: On Firm Grounds for the Digital Era? In Security and Law. Legal and Ethical Aspects of Public Security, Cyber Security and Critical Infrastructure Security; Intersentia: Cambridge, UK; Antwerp, Belgium; Chicago, IL, USA, 2019; pp. 63–96. [Google Scholar]
- Kindt, E.J. Having yes, using no? About the new legal regime for biometric data. Comput. Law Secur. Rev. 2018, 34, 523–538. [Google Scholar] [CrossRef]
- Clark, H.H.; Brennan, S.E. Grounding in communication. In Perspectives on Socially Shared Cognition; American Psychological Association: Washington DC, USA, 1991; pp. 127–149. [Google Scholar]
- Müller, J.; Butscher, S.; Feyer, S.P.; Reiterer, H. Studying collaborative object positioning in distributed augmented realities. In Proceedings of the 16th International Conference on Mobile and Ubiquitous Multimedia, Stuttgart, Germany, 26–29 November 2017; pp. 123–132. [Google Scholar]
































© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kraus, M.; Pollok, T.; Miller, M.; Kilian, T.; Moritz, T.; Schweitzer, D.; Beyerer, J.; Keim, D.; Qu, C.; Jentner, W. Toward Mass Video Data Analysis: Interactive and Immersive 4D Scene Reconstruction. Sensors 2020, 20, 5426. https://doi.org/10.3390/s20185426
Kraus M, Pollok T, Miller M, Kilian T, Moritz T, Schweitzer D, Beyerer J, Keim D, Qu C, Jentner W. Toward Mass Video Data Analysis: Interactive and Immersive 4D Scene Reconstruction. Sensors. 2020; 20(18):5426. https://doi.org/10.3390/s20185426
Chicago/Turabian StyleKraus, Matthias, Thomas Pollok, Matthias Miller, Timon Kilian, Tobias Moritz, Daniel Schweitzer, Jürgen Beyerer, Daniel Keim, Chengchao Qu, and Wolfgang Jentner. 2020. "Toward Mass Video Data Analysis: Interactive and Immersive 4D Scene Reconstruction" Sensors 20, no. 18: 5426. https://doi.org/10.3390/s20185426
APA StyleKraus, M., Pollok, T., Miller, M., Kilian, T., Moritz, T., Schweitzer, D., Beyerer, J., Keim, D., Qu, C., & Jentner, W. (2020). Toward Mass Video Data Analysis: Interactive and Immersive 4D Scene Reconstruction. Sensors, 20(18), 5426. https://doi.org/10.3390/s20185426