Fusion of Multiple Lidars and Inertial Sensors for the Real-Time Pose Tracking of Human Motion

 , , , ,
, , , ,  and
and
Abstract
1. Introduction
2. Related Work
3. Method Overview
3.1. Initial Data and Pose Extraction
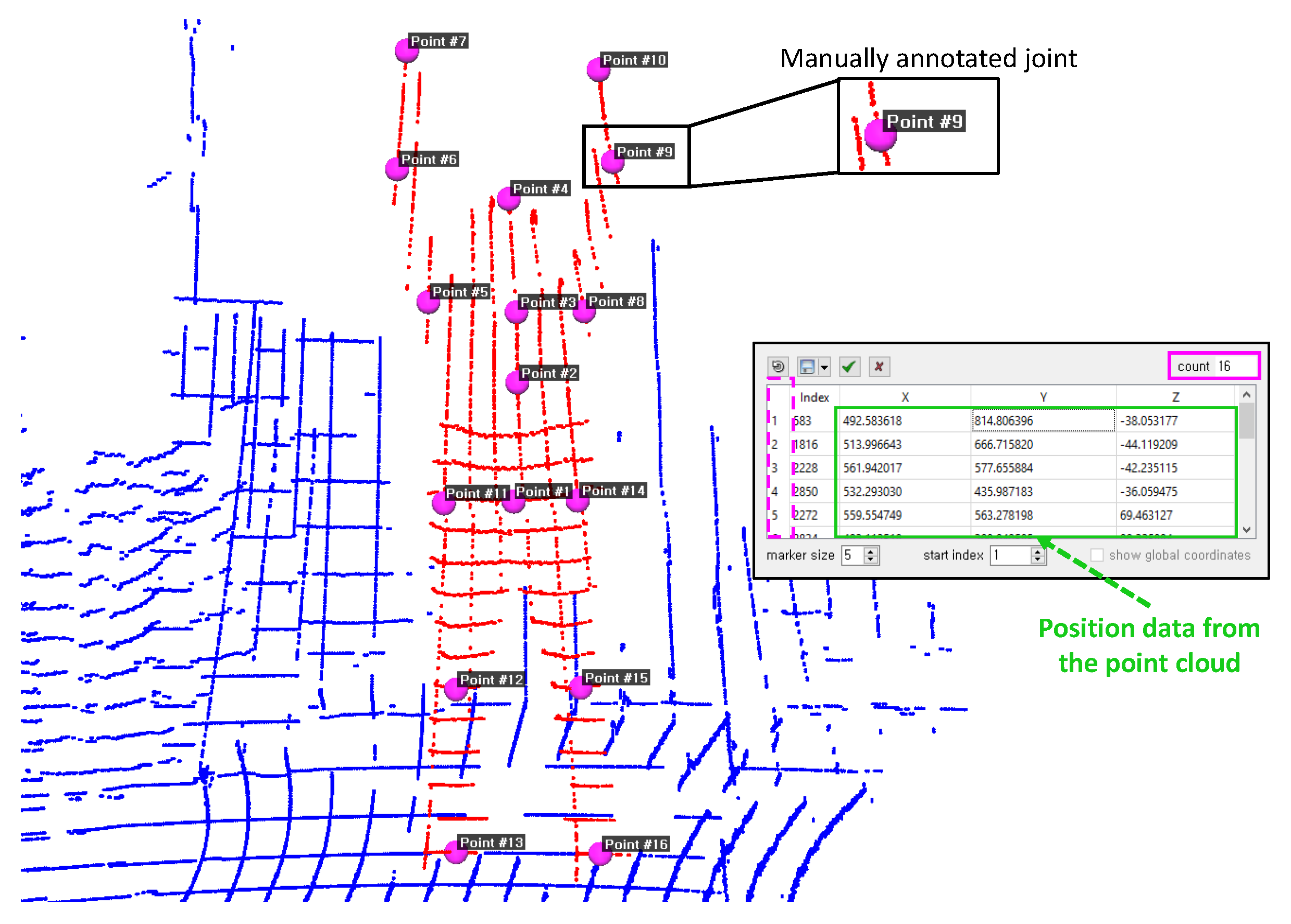
3.2. Identifying the Human Skeletal Structure
3.3. Real-Time Pose Tracking
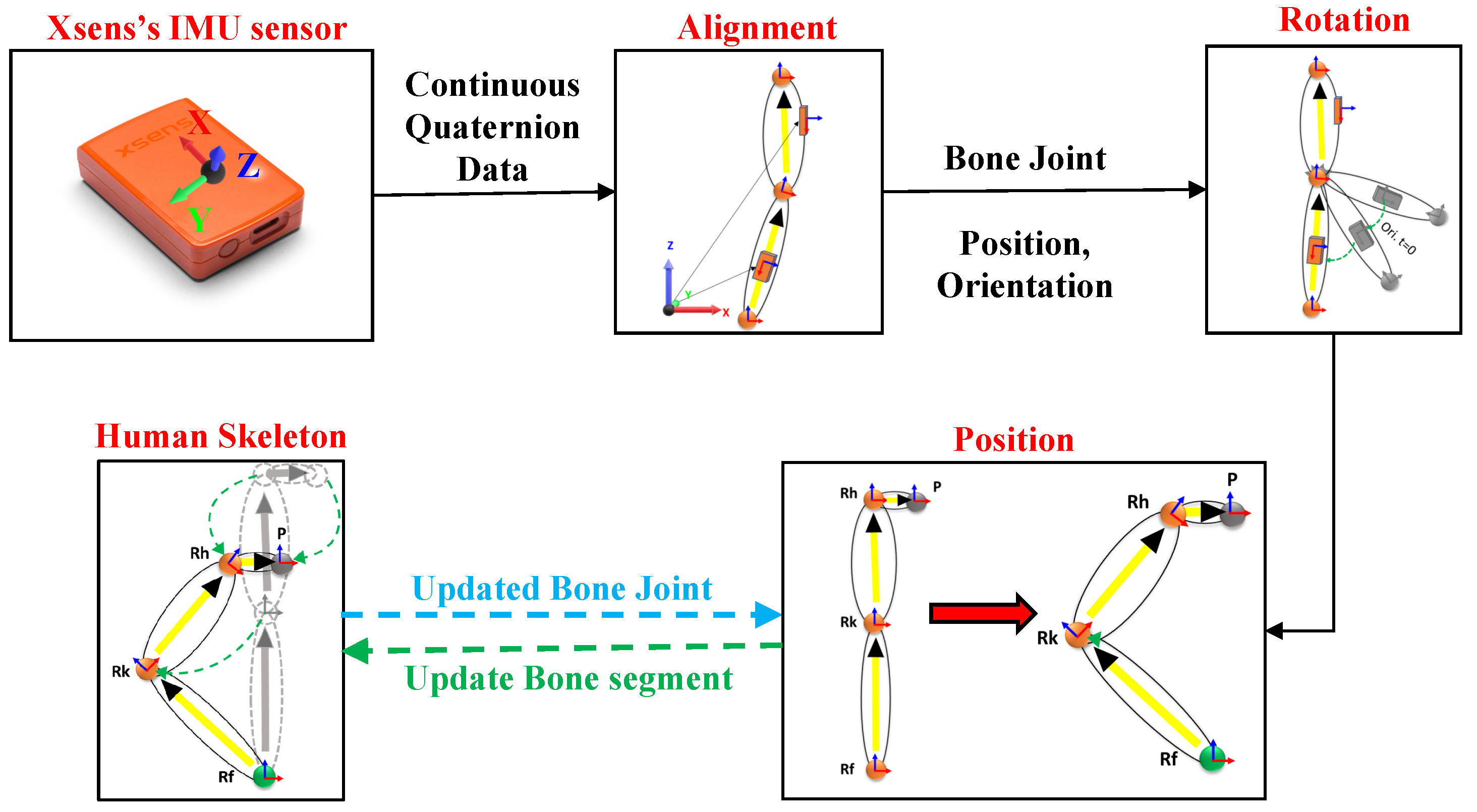
3.3.1. Position and Orientation from Inertial Sensors
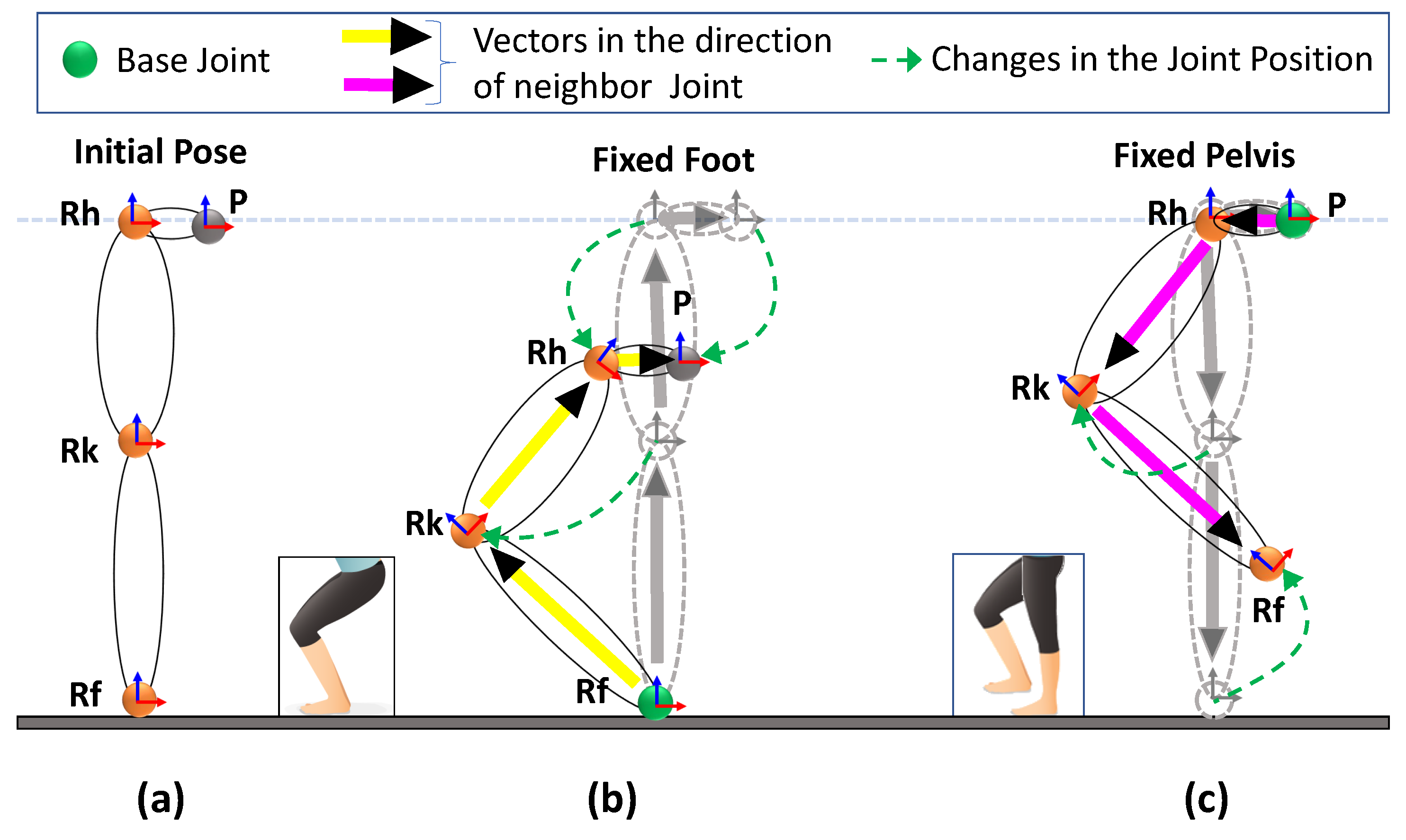
3.3.2. Position Tracking from Lidars
4. Implementation Details
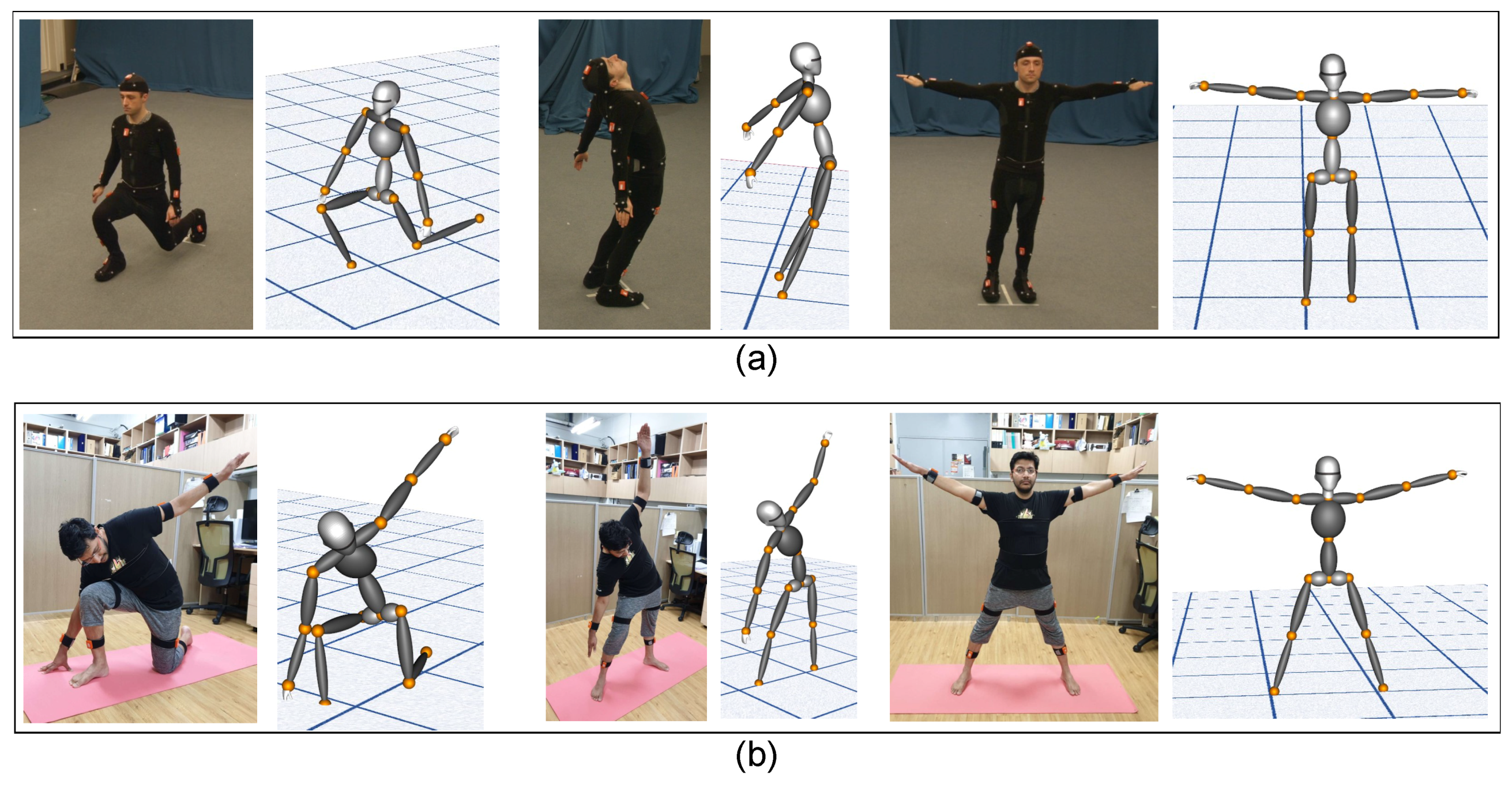
5. Experiments
5.1. Height Accuracy
5.2. Orientation Accuracy
5.3. Full-Body Position Accuracy
5.4. Position Estimation Using the Total Capture Dataset
5.5. Accuracy of Reconstruction on the Avatar
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| lidar | Light Detection and Ranging |
| IMU | Inertial Measurement Unit |
| FoV | Field of View |
| MMS | Marker-less Motion Capture System |
| ROM | Range of Motion |
References
- Menache, A. Understanding Motion Capture for Computer Animation and Video Games; Morgan Kaufmann: San Francisco, CA, USA, 2000. [Google Scholar]
- Jobanputra, C.; Bavishi, J.; Doshi, N. Human activity recognition: A survey. Procedia Comput. Sci. 2019, 155, 698–703. [Google Scholar] [CrossRef]
- Prilutsky, B.I.; Zatsiorsky, V.M. Optimization-based models of muscle coordination. Exerc. Sport Sci. Rev. 2002, 30, 32. [Google Scholar] [CrossRef] [PubMed]
- Cappozzo, A.; Catani, F.; Della Croce, U.; Leardini, A. Position and orientation in space of bones during movement: Anatomical frame definition and determination. Clin. Biomech. 1995, 10, 171–178. [Google Scholar] [CrossRef]
- Leardini, A.; Chiari, L.; Della Croce, U.; Cappozzo, A. Human movement analysis using stereophotogrammetry: Part 3. Soft tissue artifact assessment and compensation. Gait Posture 2005, 21, 212–225. [Google Scholar] [CrossRef] [PubMed]
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Wang, Q.; Kurillo, G.; Ofli, F.; Bajcsy, R. Evaluation of pose tracking accuracy in the first and second generations of Microsoft Kinect. In Proceedings of the 2015 International Conference on Healthcare Informatics, Dallas, TX, USA, 21–23 October 2015; pp. 380–389. [Google Scholar]
- Omelina, L.; Jansen, B.; Bonnechere, B.; Oravec, M.; Jarmila, P.; Jan, S.V.S. Interaction detection with depth sensing and body tracking cameras in physical rehabilitation. Methods Inf. Med. 2016, 55, 70–78. [Google Scholar] [PubMed]
- Kawai, A.; Taniguchi, S.; Li, H.L.; Izumi, S. A physical strength measurement and analysis system for elderly people using motion sensors. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; p. 755. [Google Scholar]
- de Freitas, P.V.A.; Mendes, P.R.C.; Busson, A.J.G.; Guedes, Á.L.V.; da Giovanni Lucca, S.F.; de Paiva, A.C.; Colcher, S. An ergonomic evaluation method using a mobile depth sensor and pose estimation. In Proceedings of the 25th Brazilian Symposium on Multimedia and the Web, Rio de Janeiro, Brazil, 29 October–1 November 2019; pp. 445–452. [Google Scholar]
- Yan, S.; Wirta, J.; Kämäräinen, J. Anthropometric clothing measurements from 3D body scans. Mach. Vis. Appl. 2020, 31, 7. [Google Scholar] [CrossRef]
- Geerse, D.J.; Coolen, B.H.; Roerdink, M. Kinematic validation of a multi-Kinect v2 instrumented 10-meter walkway for quantitative gait assessments. PLoS ONE 2015, 10, e0139913. [Google Scholar] [CrossRef] [PubMed]
- Lim, D.; Kim, C.; Jung, H.; Jung, D.; Chun, K.J. Use of the Microsoft Kinect system to characterize balance ability during balance training. Clin. Interv. Aging 2015, 10, 1077. [Google Scholar] [PubMed]
- Staranowicz, A.N.; Ray, C.; Mariottini, G. Easy-to-use, general, and accurate multi-Kinect calibration and its application to gait monitoring for fall prediction. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 4994–4998. [Google Scholar]
- Stone, E.E.; Skubic, M. Passive in-home measurement of stride-to-stride gait variability comparing vision and Kinect sensing. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 6491–6494. [Google Scholar]
- Müller, B.; Ilg, W.; Giese, M.A.; Ludolph, N. Validation of enhanced Kinect sensor based motion capturing for gait assessment. PLoS ONE 2017, 12, e0175813. [Google Scholar] [CrossRef] [PubMed]
- Shingade, A.; Ghotkar, A. Animation of 3D human model using markerless motion capture applied to sports. arXiv 2014, arXiv:1402.2363. [Google Scholar] [CrossRef]
- Bian, Z.; Hou, J.; Chau, L.; Magnenat-Thalmann, N. Fall detection based on body part tracking using a depth camera. IEEE J. Biomed. Health Inform. 2014, 19, 430–439. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Shotton, J.; Kohli, P.; Criminisi, A.; Fitzgibbon, A. Efficient regression of general-activity human poses from depth images. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 415–422. [Google Scholar]
- Martin, C.C.; Burkert, D.C.; Choi, K.R.; Wieczorek, N.B.; McGregor, P.M.; Herrmann, R.A.; Beling, P.A. A real-time ergonomic monitoring system using the Microsoft Kinect. In Proceedings of the 2012 IEEE Systems and Information Engineering Design Symposium, Charlottesville, VA, USA, 27 April 2012; pp. 50–55. [Google Scholar]
- Jebeli, M.; Bilesan, A.; Arshi, A. A study on validating KinectV2 in comparison of Vicon system as a motion capture system for using in health engineering in industry. Nonlinear Eng. 2017, 6, 95–99. [Google Scholar] [CrossRef]
- Jamali, Z.; Behzadipour, S. Quantitative evaluation of parameters affecting the accuracy of Microsoft Kinect in gait analysis. In Proceedings of the 2016 23rd Iranian Conference on Biomedical Engineering and 2016 1st International Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 24–25 November 2016; pp. 306–311. [Google Scholar]
- Kharazi, M.R.; Memari, A.H.; Shahrokhi, A.; Nabavi, H.; Khorami, S.; Rasooli, A.H.; Barnamei, H.R.; Jamshidian, A.R.; Mirbagheri, M.M. Validity of Microsoft Kinect tm for measuring gait parameters. In Proceedings of the 2015 22nd Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 25–27 November 2015; pp. 375–379. [Google Scholar]
- Iskakov, K.; Burkov, E.; Lempitsky, V.; Malkov, Y. Learnable triangulation of human pose. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7718–7727. [Google Scholar]
- Cheng, Y.; Yang, B.; Wang, B.; Tan, R.T. 3D Human Pose Estimation using Spatio-Temporal Networks with Explicit Occlusion Training. arXiv 2020, arXiv:2004.11822. [Google Scholar] [CrossRef]
- He, Y.; Yan, R.; Fragkiadaki, K.; Yu, S. Epipolar Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7779–7788. [Google Scholar]
- Brezov, D.S.; Mladenova, C.D.; Mladenov, I.M. New perspective on the gimbal lock problem. In Proceedings of the AIP Conference Proceedings, Sozopol, Bulgaria, 8–13 June 2013; pp. 367–374. [Google Scholar]
- Meredith, M.; Maddock, S. Motion Capture File Formats Explained; Department of Computer Science, University of Sheffield: Sheffield, UK, 2001; Volume 211, pp. 241–244. [Google Scholar]
- Yuan, Q.; Chen, I. Localization and velocity tracking of human via 3 IMU sensors. Sens. Actuators Phys. 2014, 212, 25–33. [Google Scholar] [CrossRef]
- Glowinski, S.; Łosiński, K.; Kowiański, P.; Waśkow, M.; Bryndal, A.; Grochulska, A. Inertial Sensors as a Tool for Diagnosing Discopathy Lumbosacral Pathologic Gait: A Preliminary Research. Diagnostics 2020, 10, 342. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Park, G.; Lee, S.; Nam, Y. Analysis of Machine Learning-Based Assessment for Elbow Spasticity Using Inertial Sensors. Sensors 2020, 20, 1622. [Google Scholar] [CrossRef] [PubMed]
- Helten, T.; Muller, M.; Seidel, H.; Theobalt, C. Real-time body tracking with one depth camera and inertial sensors. In Proceedings of the IEEE International Conference on Computer Vision, Darling Harbour, Sydney, 1–8 December 2013; pp. 1105–1112. [Google Scholar]
- Islam, S.; Ionescu, B.; Gadea, C.; Ionescu, D. Full-body tracking using a sensor array system and laser-based sweeps. In Proceedings of the 2016 IEEE Symposium on 3D User Interfaces (3DUI), Greenville, SC, USA, 19–20 March 2016; pp. 71–80. [Google Scholar]
- Ziegler, J.; Kretzschmar, H.; Stachniss, C.; Grisetti, G.; Burgard, W. Accurate human motion capture in large areas by combining IMU-and laser-based people tracking. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, Francisco, CA, USA, 25–30 September 2011; pp. 86–91. [Google Scholar]
- Yan, Z.; Duckett, T.; Bellotto, N. Online learning for human classification in 3D lidar-based tracking. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 864–871. [Google Scholar]
- Kammerl, J.; Blodow, N.; Rusu, R.B.; Gedikli, S.; Beetz, M.; Steinbach, E. Real-time compression of point cloud streams. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MI, USA, 14–18 May 2012; pp. 778–785. [Google Scholar]
- Larson, D. Standard Proportions of the Human Body. Available online: https://www.makingcomics.com/2014/01/19/standard-proportions-human-body/ (accessed on 15 September 2020).
- Li, M.; Yang, T.; Xi, R.; Lin, Z. Silhouette-based 2D human pose estimation. In Proceedings of the 2009 Fifth International Conference on Image and Graphics, Xi’an, China, 20–23 September 2009; pp. 143–148. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point cloud library (PCL). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Rao, R. Setting Up and Calibrating Multiple LiDAR Sensors. Available online: https://wowelec.wordpress.com/2019/06/18/setting-up-and-calibrating-multiple-lidar-sensors/ (accessed on 20 August 2020).
- Xsens MTw Awinda. Available online: https://www.xsens.com/products/mtw-awinda (accessed on 20 August 2020).
- Trumble, M.; Gilbert, A.; Malleson, C.; Hilton, A.; Collomosse, J.P. Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017; pp. 1–13. [Google Scholar]
- Using Inertial Measurement Units to Calculate Knee Flexion Angle. Available online: https://simtk-confluence.stanford.edu/pages/viewpage.action?pageId=21006384 (accessed on 15 September 2020).
- Daniel, G.-M. CloudCompare. Available online: http://www.cloudcompare.org/ (accessed on 20 August 2020).
- Schroeder, W.J.; Avila, L.S.; Hoffman, W. Visualizing with VTK: A tutorial. IEEE Comput. Graph. Appl. 2000, 20, 20–27. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Person | Ground Truth Height | Lidars Calculated Height | Change in Height | Error |
|---|---|---|---|---|
| 1 | 180 | 178 | −2 | |
| 2 | 168 | 165 | −3 | |
| 3 | 171 | 172 | 1 | |
| 4 | 155 | 158 | 3 | SD = 0.44, |
| 5 | 175 | 178 | 3 | Mean = 2.7 |
| 6 | 164 | 162 | −2 | |
| 7 | 161 | 164 | 3 |
| Sl. No. | Motion Type | Frame No. | Observed Joints | Standard Deviation | Mean Difference |
|---|---|---|---|---|---|
| 1 | Upper Arm Swing | 292–351 | Rs, Re, Rw, Ls, Le, Lw | 0.02 | 0.45 |
| 2 | Upper Arm Rotation | 745–818 | Rs, Re, Rw, Ls, Le, Lw | 0.08 | 0.36 |
| 3 | Lower Arm Swing | 1235–1300 | Re, Rw, Le, Lw | 0.02 | 0.33 |
| 4 | Pelvis Bending | 2475–2389 | P, S, T, H | 0.21 | 0.73 |
| 5 | Right Upper Leg Swing | 3200–3250 | Rh, Rk, Ra | 0.40 | 0.98 |
| 6 | Squat | 4703–4836 | Full Body | 0.68 | 2.35 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patil, A.K.; Balasubramanyam, A.; Ryu, J.Y.; B N, P.K.; Chakravarthi, B.; Chai, Y.H. Fusion of Multiple Lidars and Inertial Sensors for the Real-Time Pose Tracking of Human Motion. Sensors 2020, 20, 5342. https://doi.org/10.3390/s20185342
Patil AK, Balasubramanyam A, Ryu JY, B N PK, Chakravarthi B, Chai YH. Fusion of Multiple Lidars and Inertial Sensors for the Real-Time Pose Tracking of Human Motion. Sensors. 2020; 20(18):5342. https://doi.org/10.3390/s20185342
Chicago/Turabian StylePatil, Ashok Kumar, Adithya Balasubramanyam, Jae Yeong Ryu, Pavan Kumar B N, Bharatesh Chakravarthi, and Young Ho Chai. 2020. "Fusion of Multiple Lidars and Inertial Sensors for the Real-Time Pose Tracking of Human Motion" Sensors 20, no. 18: 5342. https://doi.org/10.3390/s20185342
APA StylePatil, A. K., Balasubramanyam, A., Ryu, J. Y., B N, P. K., Chakravarthi, B., & Chai, Y. H. (2020). Fusion of Multiple Lidars and Inertial Sensors for the Real-Time Pose Tracking of Human Motion. Sensors, 20(18), 5342. https://doi.org/10.3390/s20185342