FusionSense: Emotion Classification Using Feature Fusion of Multimodal Data and Deep Learning in a Brain-Inspired Spiking Neural Network



Abstract
1. Introduction
2. Signals for Affect Detection
2.1. Facial Expression
2.2. Speech
2.3. Posture and Body Movements
2.4. Physiological Signals
3. Multimodal Affect Recognition
3.1. Feature-Level Fusion
3.2. Decision-Level Fusion
4. Spiking Neural Networks
4.1. NeuCube
- 1.
- 2.
- A three-dimensional SNN reservoir (3D-SNNr), which takes the spike trains as input. The 3D-SNNr contains neurons that have pre-defined spatial co-ordinates and are modelled as leaky integrate and fire neurons. The initial structural connections between the neurons can be established in several ways, including small-world organization [104] or based on the DTI data. Several studies utilizing EEG, fMRI, and MEG have demonstrated the presence of small-world connectivity in the brain [105,106] and, thus, this is the preferred initial setup for the spatial structure of 3D-SNNr. Based on the temporal association between the input spikes, connections between the neurons is modified while using the spike timing dependent plasticity (STDP) rule. This is a deep unsupervised learning, as deep connectionist structures of many neurons are created as a results of the learning in space and time [96].
- 3.
- A classification module, which takes the spiking patterns from 3D-SNNr as its input to perform classification.
- 4.
- An optional, Gene Regulatory Network (GRN) for controlling the learning parameter and optimization of 3D-SNNr, exploiting the fact that spiking activity is influenced by the gene and protein dynamics.
5. Methods
5.1. Mahnob Database
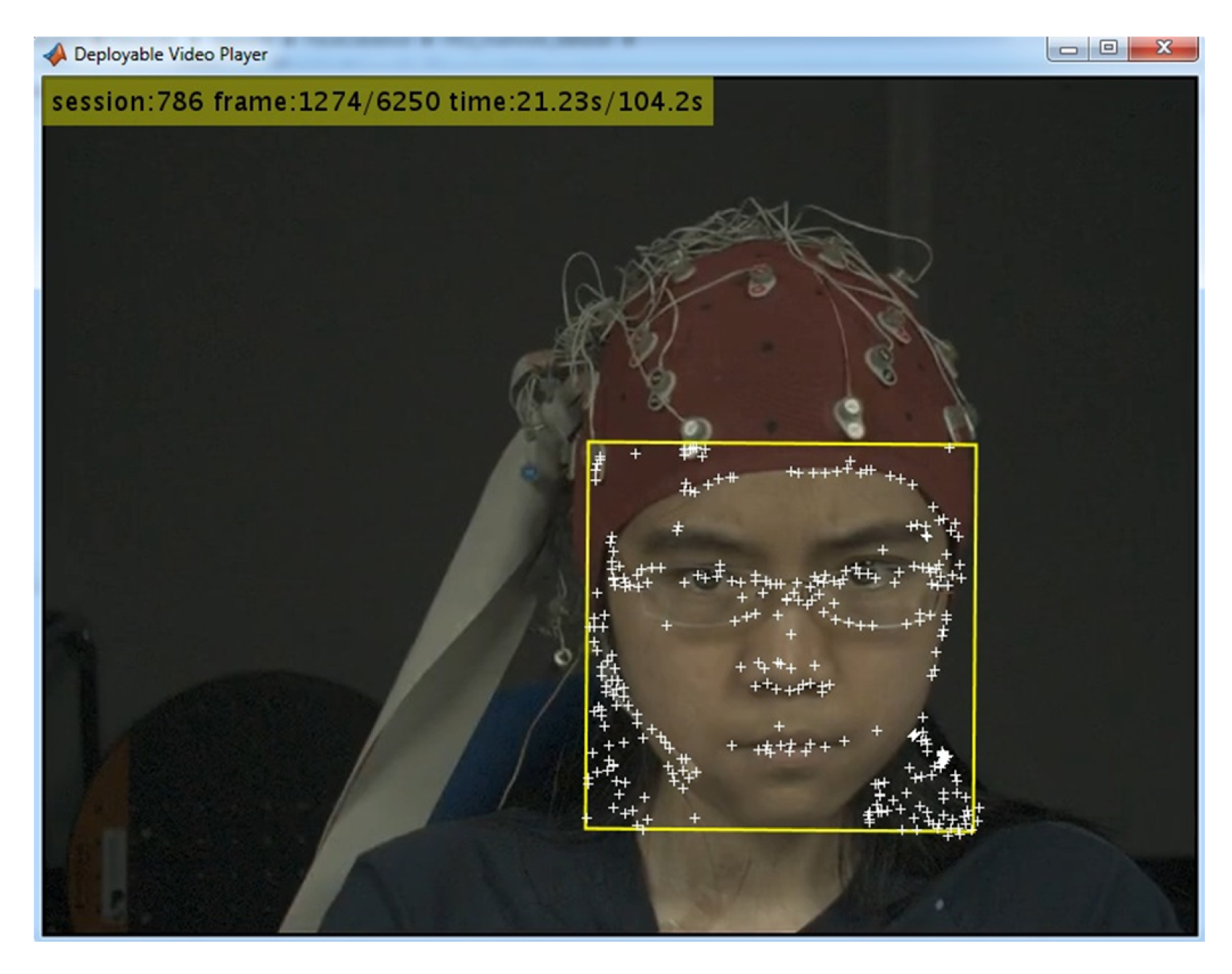
5.2. Face Detection and Tracking
- 1.
- The face in the first frame was detected using the vision.CascadeObjectDetector object in the CV toolbox. This function uses the Viola-Jones algorithm [108] to detect people’s faces, noses, eyes, mouth, or upper body. It outputs the region of interest (ROI) for the face as a polygon, enclosing the face. Specifically, the algorithm uses the histogram-of-oriented gradients (HOG), Local Binary Patterns (LBP), Haar-like features, and a cascade of classifiers trained using boosting.
- 2.
- The corner features in the first frame ROI were detected using the detectMinEigenFeatures function in CV toolbox, which uses the minimum eigenvalue algorithm [109].
- 3.
- 4.
- Finally, in order to estimate the motion of the face, we used estimateGeometricTransform function in the CV toolbox to apply the same transformation to the ROI that was detected in the previous frame to obtain the ROI in the next frame.
5.3. Face Landmarks Detection
5.4. Face Features Extraction
- 1.
- Vertical distance between the horizontal line connecting the inner corners of the eyes and outer eyebrow (f1, f2).
- 2.
- Vertical distances between the upper eyelids and the lower eyelids (f3, f4).
- 3.
- Distances between the upper lip and mouth corners (f5, f6).
- 4.
- Distances between the lower lip and mouth corners (f7, f8).
- 5.
- Vertical distance between the upper and the lower lip (f9) and distance between the mouth corners (f10)
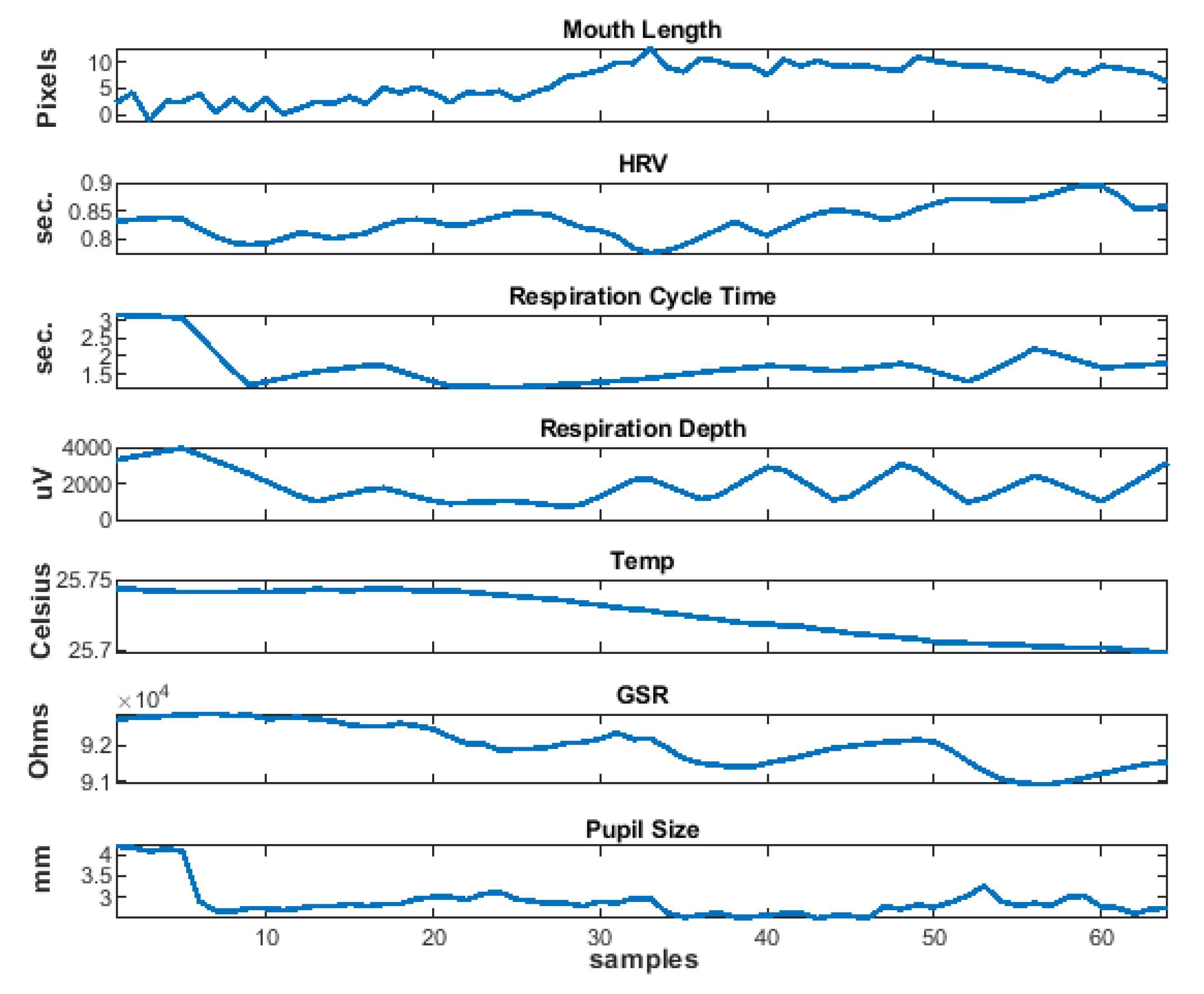
5.5. Physiological Features
5.6. NeuCube SNN for Facial Emotion Recognition
- Encoding: encode the spatio-temporal data (features) into trains of spikes.
- SNNr: construct a recurrent 3D SNNr and initialize the connection weights among neurons.
- Input neurons location: locate the input neurons in the SNNr keeping related inputs near in space.
- Unsupervised learning: feed the SNNr with training data to learn in an unsupervised mode the spatio-temporal patterns in the data.
- Supervised learning: construct an eSNN classifier to learn to classify different dynamic pattern in SNNr activities.
- Classification: feed the SNNr with testing data for classification purposes.
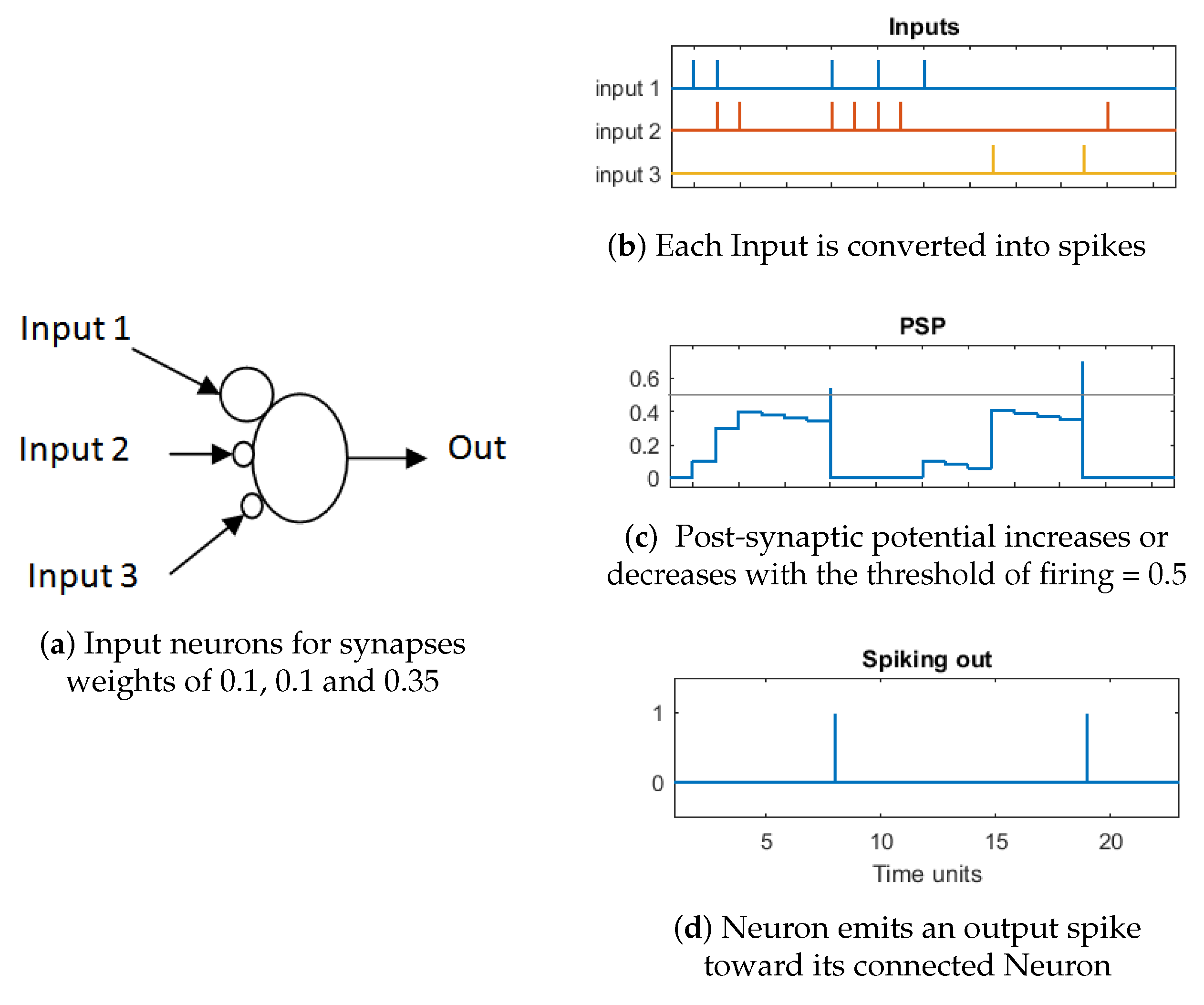
5.6.1. Encoding
5.6.2. Construction of SNNr
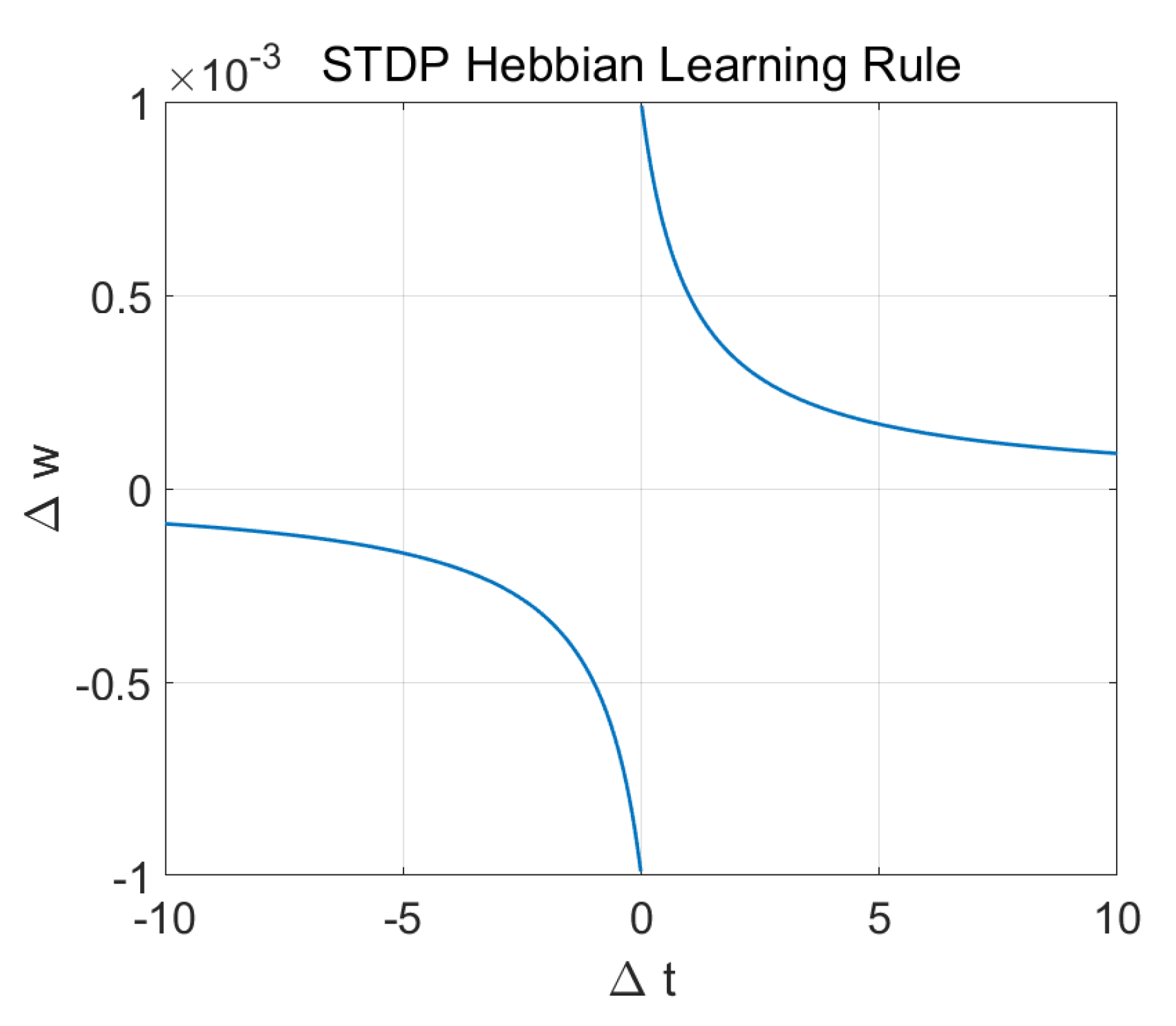
5.6.3. Deep, Unsupervised SNN Training
5.6.4. Supervised Output Neurons Training
5.6.5. Classification
5.6.6. Fusion of Multimodal Signals
5.6.7. NeuCube Parameters
6. Results
Clustering Spike Communication
7. Discussion
7.1. Related Work
7.2. Limitations
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Calvo, R.A.; D’Mello, S. Affect detection: An interdisciplinary review of models, methods, and their applications. IEEE Trans. Affect. Comput. 2010, 1, 18–37. [Google Scholar] [CrossRef]
- Edwards, J.; Jackson, H.J.; Pattison, P.E. Emotion recognition via facial expression and affective prosody in schizophrenia: A methodological review. Clin. Psychol. Rev. 2002, 22, 789–832. [Google Scholar] [CrossRef]
- Fong, T.; Nourbakhsh, I.; Dautenhahn, K. A survey of socially interactive robots. Robot. Auton. Syst. 2003, 42, 143–166. [Google Scholar] [CrossRef]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Gunes, H.; Schuller, B.; Pantic, M.; Cowie, R. Emotion representation, analysis and synthesis in continuous space: A survey. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011; pp. 827–834. [Google Scholar]
- Plutchik, R. The nature of emotions: Human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. Am. Sci. 2001, 89, 344–350. [Google Scholar] [CrossRef]
- Danelakis, A.; Theoharis, T.; Pratikakis, I. A survey on facial expression recognition in 3D video sequences. Multimed. Tools Appl. 2015, 74, 5577–5615. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hussain, A.; Huang, G.B. Towards an intelligent framework for multimodal affective data analysis. Neural Netw. 2015, 63, 104–116. [Google Scholar] [CrossRef]
- Yeasin, M.; Bullot, B.; Sharma, R. Recognition of facial expressions and measurement of levels of interest from video. IEEE Trans. Multimed. 2006, 8, 500–508. [Google Scholar] [CrossRef]
- Tang, Y. Deep learning using linear support vector machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]
- Gudi, A.; Tasli, H.E.; Den Uyl, T.M.; Maroulis, A. Deep learning based facs action unit occurrence and intensity estimation. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 6, pp. 1–5. [Google Scholar]
- Ionescu, R.T.; Popescu, M.; Grozea, C. Local learning to improve bag of visual words model for facial expression recognition. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Kahou, S.E.; Pal, C.; Bouthillier, X.; Froumenty, P.; Gülçehre, Ç.; Memisevic, R.; Vincent, P.; Courville, A.; Bengio, Y.; Ferrari, R.C.; et al. Combining modality specific deep neural networks for emotion recognition in video. In Proceedings of the 15th ACM on International conference on multimodal interaction, Sydney, Australia, 9–13 December 2013; pp. 543–550. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. arXiv 2018, arXiv:1804.08348. [Google Scholar] [CrossRef]
- Schwenker, F.; Boeck, R.; Schels, M.; Meudt, S.; Siegert, I.; Glodek, M.; Kaechele, M.; Schmidt-Wack, M.; Thiam, P.; Wendemuth, A.; et al. Multimodal Affect Recognition in the Context of Human-Computer Interaction for Companion-Systems. In Companion Technology: A Paradigm Shift in Human-Technology Interaction; Springer: Berlin, Germany, 2017; pp. 387–408. [Google Scholar]
- Dhoble, K.; Nuntalid, N.; Indiveri, G.; Kasabov, N. Online spatio-temporal pattern recognition with evolving spiking neural networks utilising address event representation, rank order, and temporal spike learning. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–7. [Google Scholar]
- Kasabov, N.K. NeuCube: A spiking neural network architecture for mapping, learning and understanding of spatio-temporal brain data. Neural Netw. 2014, 52, 62–76. [Google Scholar] [CrossRef] [PubMed]
- Mehrabian, A. Nonverbal Communication; Transaction Publishers: Piscataway, NJ, USA, 2007. [Google Scholar]
- Ekman, P. An argument for basic emotions. Cognit. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Ekman, P. Are there basic emotions? Psychol. Rev. 1992, 99, 550–553. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W.V. Measuring facial movement. Environ. Psychol. Nonverbal Behav. 1976, 1, 56–75. [Google Scholar] [CrossRef]
- El Kaliouby, R.; Robinson, P. Real-time inference of complex mental states from facial expressions and head gestures. In Real-Time Vision for Human-Computer Interaction; Springer: Berlin, Germany, 2005; pp. 181–200. [Google Scholar]
- Liu, P.; Han, S.; Meng, Z.; Tong, Y. Facial expression recognition via a boosted deep belief network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1805–1812. [Google Scholar]
- Uddin, M.Z.; Hassan, M.M.; Almogren, A.; Alamri, A.; Alrubaian, M.; Fortino, G. Facial expression recognition utilizing local direction-based robust features and deep belief network. IEEE Access 2017, 5, 4525–4536. [Google Scholar] [CrossRef]
- Breuer, R.; Kimmel, R. A deep learning perspective on the origin of facial expressions. arXiv 2017, arXiv:1705.01842. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint fine-tuning in deep neural networks for facial expression recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2983–2991. [Google Scholar]
- Zhao, K.; Chu, W.S.; Zhang, H. Deep region and multi-label learning for facial action unit detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3391–3399. [Google Scholar]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Rifai, S.; Bengio, Y.; Courville, A.; Vincent, P.; Mirza, M. Disentangling factors of variation for facial expression recognition. In European Conference on Computer Vision; Springer: Berlin, Germany, 2012; pp. 808–822. [Google Scholar]
- Zeng, N.; Zhang, H.; Song, B.; Liu, W.; Li, Y.; Dobaie, A.M. Facial expression recognition via learning deep sparse autoencoders. Neurocomputing 2018, 273, 643–649. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, H.; Jin, Z. An efficient unconstrained facial expression recognition algorithm based on Stack Binarized Auto-encoders and Binarized Neural Networks. Neurocomputing 2017, 267, 385–395. [Google Scholar] [CrossRef]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Picard, R.W.; Vyzas, E.; Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1175–1191. [Google Scholar] [CrossRef]
- Shami, M.T.; Kamel, M.S. Segment-based approach to the recognition of emotions in speech. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005. [Google Scholar]
- Ververidis, D.; Kotropoulos, C. Emotional speech classification using Gaussian mixture models and the sequential floating forward selection algorithm. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; pp. 1500–1503. [Google Scholar]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Lee, C.M.; Yildirim, S.; Bulut, M.; Kazemzadeh, A.; Busso, C.; Deng, Z.; Lee, S.; Narayanan, S. Emotion recognition based on phoneme classes. In Proceedings of the Eighth International Conference on Spoken Language Processing, Jeju Island, Korea, 4–8 October 2004. [Google Scholar]
- Albornoz, E.M.; Milone, D.H.; Rufiner, H.L. Spoken emotion recognition using hierarchical classifiers. Comput. Speech Lang. 2011, 25, 556–570. [Google Scholar] [CrossRef]
- Huang, Z.W.; Xue, W.T.; Mao, Q.R. Speech emotion recognition with unsupervised feature learning. Front. Inf. Technol. Electr. Eng. 2015, 16, 358–366. [Google Scholar] [CrossRef]
- Cibau, N.E.; Albornoz, E.M.; Rufiner, H.L. Speech emotion recognition using a deep autoencoder. Anales de la XV Reunion de Procesamiento de la Informacion y Control 2013, 16, 934–939. [Google Scholar]
- Deng, J.; Zhang, Z.; Marchi, E.; Schuller, B. Sparse autoencoder-based feature transfer learning for speech emotion recognition. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 511–516. [Google Scholar]
- Huang, C.; Gong, W.; Fu, W.; Feng, D. A research of speech emotion recognition based on deep belief network and SVM. Math. Prob. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Wen, G.; Li, H.; Huang, J.; Li, D.; Xun, E. Random deep belief networks for recognizing emotions from speech signals. Comput. Intell. Neurosci. 2017, 2017. [Google Scholar] [CrossRef] [PubMed]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Huang, Z.; Dong, M.; Mao, Q.; Zhan, Y. Speech emotion recognition using CNN. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 801–804. [Google Scholar]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Korea, 13–15 October 2017; pp. 1–5. [Google Scholar]
- Walk, R.D.; Homan, C.P. Emotion and dance in dynamic light displays. Bull. Psychon. Soc. 1984, 22, 437–440. [Google Scholar] [CrossRef]
- De Meijer, M. The contribution of general features of body movement to the attribution of emotions. J. Nonverbal Behav. 1989, 13, 247–268. [Google Scholar] [CrossRef]
- Darwin, C.; Prodger, P. The Expression of the Emotions in Man and Animals; Oxford University Press: Oxford, MI, USA, 1998. [Google Scholar]
- Coulson, M. Attributing emotion to static body postures: Recognition accuracy, confusions, and viewpoint dependence. J. Nonverbal Behav. 2004, 28, 117–139. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Nonverbal leakage and clues to deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef]
- Saha, S.; Datta, S.; Konar, A.; Janarthanan, R. A study on emotion recognition from body gestures using Kinect sensor. In Proceedings of the 2014 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2014; pp. 56–60. [Google Scholar]
- Kosti, R.; Alvarez, J.M.; Recasens, A.; Lapedriza, A. Emotion recognition in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1667–1675. [Google Scholar]
- Barnea, O.; Shusterman, V. Analysis of skin-temperature variability compared to variability of blood pressure and heart rate. In Proceedings of the 17th International Conference of the Engineering in Medicine and Biology Society, Montreal, QC, Canada, 20–23 September 1995; Volume 2, pp. 1027–1028. [Google Scholar]
- Nakasone, A.; Prendinger, H.; Ishizuka, M. Emotion recognition from electromyography and skin conductance. In Proceedings of the 5th International Workshop on Biosignal Interpretation, Tokyo, Japan, 6–8 September 2005; pp. 219–222. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Hjortskov, N.; Rissén, D.; Blangsted, A.K.; Fallentin, N.; Lundberg, U.; Søgaard, K. The effect of mental stress on heart rate variability and blood pressure during computer work. Eur. J. Appl. Physiol. 2004, 92, 84–89. [Google Scholar] [CrossRef] [PubMed]
- Scheirer, J.; Fernandez, R.; Picard, R.W. Expression glasses: A wearable device for facial expression recognition. In Proceedings of the CHI’99 Extended Abstracts on Human Factors in Computing Systems, Pittsburgh, PA, USA, 15–20 May 1999; pp. 262–263. [Google Scholar]
- Ekman, P.; Friesen, W.V.; Ellsworth, P. Emotion in the Human Face: Guidelines for Research and an Integration of Findings; Elsevier: Amsterdam, The Netherlands, 2013; Volume 11. [Google Scholar]
- Healey, J.A. Affect detection in the real world: Recording and processing physiological signals. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; pp. 1–6. [Google Scholar]
- Homma, I.; Masaoka, Y. Breathing rhythms and emotions. Exp. Physiol. 2008, 93, 1011–1021. [Google Scholar] [CrossRef] [PubMed]
- Nykliček, I.; Thayer, J.F.; Van Doornen, L.J. Cardiorespiratory differentiation of musically-induced emotions. J. Psychophysiol. 1997, 11, 304–321. [Google Scholar]
- Grossman, P.; Wientjes, C.J. How breathing adjusts to mental and physical demands. In Respiration and Emotion; Springer: Berlin, Germany, 2001; pp. 43–54. [Google Scholar]
- Zheng, W.L.; Zhu, J.Y.; Peng, Y.; Lu, B.L. EEG-based emotion classification using deep belief networks. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Chanel, G.; Kronegg, J.; Grandjean, D.; Pun, T. Emotion assessment: Arousal evaluation using EEG’s and peripheral physiological signals. In International Workshop on Multimedia Content Representation, Classification and Security; Springer: Berlin, Germany, 2006; pp. 530–537. [Google Scholar]
- Horlings, R.; Datcu, D.; Rothkrantz, L.J. Emotion recognition using brain activity. In Proceedings of the 9th International Conference on Computer Systems and Technologies and Workshop for PhD Students in computing, Phagwara, India, 19–20 April 2008. [Google Scholar]
- Granholm, E.E.; Steinhauer, S.R. Pupillometric measures of cognitive and emotional processes. Int. J. Psychophysiol. 2004, 52, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Partala, T.; Jokiniemi, M.; Surakka, V. Pupillary responses to emotionally provocative stimuli. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Palm Beach Gardens, FL, USA, 6–8 November 2000; pp. 123–129. [Google Scholar]
- Jia, X.; Li, K.; Li, X.; Zhang, A. A novel semi-supervised deep learning framework for affective state recognition on eeg signals. In Proceedings of the 2014 IEEE International Conference on Bioinformatics and Bioengineering, Boca Raton, FL, USA, 10–12 November 2014; pp. 30–37. [Google Scholar]
- Jung, T.P.; Sejnowski, T.J.; Siddharth, S. Multi-modal Approach for Affective Computing. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 291–294. [Google Scholar]
- Cho, Y.; Bianchi-Berthouze, N.; Julier, S.J. DeepBreath: Deep learning of breathing patterns for automatic stress recognition using low-cost thermal imaging in unconstrained settings. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 456–463. [Google Scholar]
- Zhang, Q.; Chen, X.; Zhan, Q.; Yang, T.; Xia, S. Respiration-based emotion recognition with deep learning. Comput. Ind. 2017, 92, 84–90. [Google Scholar] [CrossRef]
- D’mello, S.K.; Kory, J. A review and meta-analysis of multimodal affect detection systems. ACM Comput. Surv. CSUR 2015, 47, 1–36. [Google Scholar] [CrossRef]
- Pantic, M.; Rothkrantz, L.J. Toward an affect-sensitive multimodal human-computer interaction. Proc. IEEE 2003, 91, 1370–1390. [Google Scholar] [CrossRef]
- Sarkar, C.; Bhatia, S.; Agarwal, A.; Li, J. Feature analysis for computational personality recognition using youtube personality data set. In Proceedings of the 2014 ACM Multi Media on Workshop on Computational Personality Recognition, Orlando, FL, USA, 7 November 2014; pp. 11–14. [Google Scholar]
- Wang, S.; Zhu, Y.; Wu, G.; Ji, Q. Hybrid video emotional tagging using users’ EEG and video content. Multimed. Tools Appl. 2014, 72, 1257–1283. [Google Scholar] [CrossRef]
- Atrey, P.K.; Hossain, M.A.; El Saddik, A.; Kankanhalli, M.S. Multimodal fusion for multimedia analysis: A survey. Multimed. Syst. 2010, 16, 345–379. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Alam, F.; Riccardi, G. Predicting personality traits using multimodal information. In Proceedings of the 2014 ACM Multi media on Workshop on Computational Personality Recognition, Orlando, FL, USA, 7 November 2014; pp. 15–18. [Google Scholar]
- Cai, G.; Xia, B. Convolutional neural networks for multimedia sentiment analysis. In Natural Language Processing and Chinese Computing; Springer: Berlin, Germany, 2015; pp. 159–167. [Google Scholar]
- Yamasaki, T.; Fukushima, Y.; Furuta, R.; Sun, L.; Aizawa, K.; Bollegala, D. Prediction of user ratings of oral presentations using label relations. In Proceedings of the 1st International Workshop on Affect & Sentiment in Multimedia, Brisbane, Australia, 30 October 2015; pp. 33–38. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Wang, W.; Pedretti, G.; Milo, V.; Carboni, R.; Calderoni, A.; Ramaswamy, N.; Spinelli, A.S.; Ielmini, D. Learning of spatiotemporal patterns in a spiking neural network with resistive switching synapses. Sci. Adv. 2018, 4, eaat4752. [Google Scholar] [CrossRef]
- Taherkhani, A.; Belatreche, A.; Li, Y.; Cosma, G.; Maguire, L.P.; McGinnity, T. A review of learning in biologically plausible spiking neural networks. Neural Netw. 2019, 122, 253–272. [Google Scholar] [CrossRef] [PubMed]
- Tan, C.; Šarlija, M.; Kasabov, N. Spiking Neural Networks: Background, Recent Development and the NeuCube Architecture. Neural Process. Lett. 2020, 1–27. [Google Scholar] [CrossRef]
- Maass, W.; Markram, H. On the computational power of circuits of spiking neurons. J. Comput. Syst. Sci. 2004, 69, 593–616. [Google Scholar] [CrossRef]
- Maass, W. Fast sigmoidal networks via spiking neurons. Neural Comput. 1997, 9, 279–304. [Google Scholar] [CrossRef]
- Bohte, S.M.; Kok, J.N.; La Poutre, H. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 2002, 48, 17–37. [Google Scholar] [CrossRef]
- Bohte, S.M.; La Poutré, H.; Kok, J.N. Unsupervised clustering with spiking neurons by sparse temporal coding and multilayer RBF networks. IEEE Trans. Neural Netw. 2002, 13, 426–435. [Google Scholar] [CrossRef]
- Meftah, B.; Lezoray, O.; Benyettou, A. Segmentation and edge detection based on spiking neural network model. Neural Process. Lett. 2010, 32, 131–146. [Google Scholar] [CrossRef]
- Ghosh-Dastidar, S.; Adeli, H. Improved spiking neural networks for EEG classification and epilepsy and seizure detection. Integr. Comput.-Aided Eng. 2007, 14, 187–212. [Google Scholar] [CrossRef]
- Thorpe, S.; Gautrais, J. Rank order coding. In Computational Neuroscience; Springer: Berlin, Germany, 1998; pp. 113–118. [Google Scholar]
- Kasabov, N.K. Evolving Connectionist Systems: The Knowledge Engineering Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Wysoski, S.G.; Benuskova, L.; Kasabov, N. Evolving spiking neural networks for audiovisual information processing. Neural Netw. 2010, 23, 819–835. [Google Scholar] [CrossRef] [PubMed]
- Kasabov, N.K. Time-Space, Spiking Neural Networks and Brain-Inspired Artificial Intelligence; Springer: Berlin, Germany, 2018; Volume 7. [Google Scholar]
- Kasabov, N.; Dhoble, K.; Nuntalid, N.; Indiveri, G. Dynamic evolving spiking neural networks for on-line spatio-and spectro-temporal pattern recognition. Neural Netw. 2013, 41, 188–201. [Google Scholar] [CrossRef]
- Kasabov, N. Neucube evospike architecture for spatio-temporal modelling and pattern recognition of brain signals. In Iapr Workshop on Artificial Neural Networks in Pattern Recognition; Springer: Berlin, Germany, 2012; pp. 225–243. [Google Scholar]
- Kasabov, N.; Hu, J.; Chen, Y.; Scott, N.; Turkova, Y. Spatio-temporal EEG data classification in the NeuCube 3D SNN environment: Methodology and examples. In International Conference on Neural Information Processing; Springer: Berlin, Germany, 2013; pp. 63–69. [Google Scholar]
- Kasabov, N.; Capecci, E. Spiking neural network methodology for modelling, classification and understanding of EEG spatio-temporal data measuring cognitive processes. Inf. Sci. 2015, 294, 565–575. [Google Scholar] [CrossRef]
- Kasabov, N.; Scott, N.M.; Tu, E.; Marks, S.; Sengupta, N.; Capecci, E.; Othman, M.; Doborjeh, M.G.; Murli, N.; Hartono, R.; et al. Evolving spatio-temporal data machines based on the NeuCube neuromorphic framework: Design methodology and selected applications. Neural Netw. 2016, 78, 1–14. [Google Scholar] [CrossRef]
- Mastebroek, H.A.; Vos, J.E.; Vos, J. Plausible Neural Networks for Biological Modelling; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2001; Volume 13. [Google Scholar]
- Liu, S.C.; Delbruck, T. Neuromorphic sensory systems. Curr. Opin. Neurobiol. 2010, 20, 288–295. [Google Scholar] [CrossRef]
- Bullmore, E.; Sporns, O. Complex brain networks: Graph theoretical analysis of structural and functional systems. Nat. Rev. Neurosci. 2009, 10, 186. [Google Scholar] [CrossRef]
- Stam, C.J. Functional connectivity patterns of human magnetoencephalographic recordings: A ‘small-world’network? Neurosci. Lett. 2004, 355, 25–28. [Google Scholar] [CrossRef]
- Chen, Z.J.; He, Y.; Rosa-Neto, P.; Germann, J.; Evans, A.C. Revealing modular architecture of human brain structural networks by using cortical thickness from MRI. Cerebral Cortex 2008, 18, 2374–2381. [Google Scholar] [CrossRef]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2011, 3, 42–55. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Shi, J. Good features to track. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 24–28 August 1981. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar]
- Pan, J.; Tompkins, W.J. A real-time QRS detection algorithm. IEEE Trans. Biomed. Eng. 1985, BME-32, 230–236. [Google Scholar] [CrossRef] [PubMed]
- Braitenberg, V.; Schüz, A. Cortex: Statistics and Geometry of Neuronal Connectivity; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Simard, D.; Nadeau, L.; Kröger, H. Fastest learning in small-world neural networks. Phys. Lett. A 2005, 336, 8–15. [Google Scholar] [CrossRef]
- Song, S.; Miller, K.D.; Abbott, L.F. Competitive Hebbian learning through spike-timing-dependent synaptic plasticity. Nat. Neurosci. 2000, 3, 919. [Google Scholar] [CrossRef]
- Koelstra, S.; Patras, I. Fusion of facial expressions and EEG for implicit affective tagging. Image Vis. Comput. 2013, 31, 164–174. [Google Scholar] [CrossRef]
- Koelstra, S.; Pantic, M.; Patras, I. A dynamic texture-based approach to recognition of facial actions and their temporal models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1940–1954. [Google Scholar] [CrossRef]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Workshop on EMOTION (satellite of LREC): Corpora for Research on Emotion and Affect, Paris, France, 23 May 2010; p. 65. [Google Scholar]
- Zhong, B.; Qin, Z.; Yang, S.; Chen, J.; Mudrick, N.; Taub, M.; Azevedo, R.; Lobaton, E. Emotion recognition with facial expressions and physiological signals. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- McDuff, D.; Mahmoud, A.; Mavadati, M.; Amr, M.; Turcot, J.; Kaliouby, R.E. AFFDEX SDK: A cross-platform real-time multi-face expression recognition toolkit. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, ACM, San Jose, CA, USA, 7–12 May 2016; pp. 3723–3726. [Google Scholar]
- Huang, Y.; Yang, J.; Liu, S.; Pan, J. Combining Facial Expressions and Electroencephalography to Enhance Emotion Recognition. Future Internet 2019, 11, 105. [Google Scholar] [CrossRef]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal emotion recognition using deep learning architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Torres-Valencia, C.; Álvarez-López, M.; Orozco-Gutiérrez, Á. SVM-based feature selection methods for emotion recognition from multimodal data. J. Multimodal User Interfaces 2017, 11, 9–23. [Google Scholar] [CrossRef]
- Liu, J.; Su, Y.; Liu, Y. Multi-modal emotion recognition with temporal-band attention based on LSTM-RNN. In Pacific Rim Conference on Multimedia; Springer: Berlin, Germany, 2017; pp. 194–204. [Google Scholar]
- Huang, X.; Kortelainen, J.; Zhao, G.; Li, X.; Moilanen, A.; Seppänen, T.; Pietikäinen, M. Multi-modal emotion analysis from facial expressions and electroencephalogram. Comput. Vision Image Underst. 2016, 147, 114–124. [Google Scholar] [CrossRef]
- Hu, X.; Chen, J.; Wang, F.; Zhang, D. Ten challenges for EEG-based affective computing. Brain Sci. Adv. 2019, 5, 1–20. [Google Scholar] [CrossRef]
- Wang, Y.; See, J.; Phan, R.C.W.; Oh, Y.H. Efficient spatio-temporal local binary patterns for spontaneous facial micro-expression recognition. PLoS ONE 2015, 10, e0124674. [Google Scholar] [CrossRef]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Wu, Q.; Shen, X.; Fu, X. The machine knows what you are hiding: An automatic micro-expression recognition system. In International Conference on Affective Computing and intelligent Interaction; Springer: Berlin, Germany, 2011; pp. 152–162. [Google Scholar]
- Guo, Y.; Tian, Y.; Gao, X.; Zhang, X. Micro-expression recognition based on local binary patterns from three orthogonal planes and nearest neighbor method. In Proceedings of the 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 3473–3479. [Google Scholar]
- Murphy-Chutorian, E.; Trivedi, M.M. Head pose estimation in computer vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 607–626. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Lei, Z.; Liu, X.; Shi, H.; Li, S.Z. Face alignment across large poses: A 3d solution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 146–155. [Google Scholar]
- Jourabloo, A.; Liu, X. Pose-invariant 3D face alignment. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3694–3702. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Small world radius (r) | 25 |
| STDP learning rate () | 0.001 |
| Threshold of firing | 0.5 |
| Potential leak rate | 0.002 |
| Refractory time | 1 s |
| mod | 0.84 |
| drift | 0.005 |
| K | 3 |
| Subject ID | Facial Features Accuracy (%) | Physiological Features Accuracy (%) | Fusion Detection Accuracy (%) | Fusion Features (%) |
|---|---|---|---|---|
| 1 | 73.33 | 66.67 | 66.67 | 73.33 |
| 2 | 62.5 | 50 | 62.5 | 56.25 |
| 3 | 75 | 72.73 | 75 | 81.82 |
| 4 | 78.57 | 66.67 | 66.67 | 83.33 |
| 5 | 75 | 50 | 75 | 68.75 |
| 6 | 58.82 | 70.59 | 58.82 | 70.59 |
| 7 | 75 | 60 | 75 | 93.33 |
| 8 | 64.29 | 50 | 64.29 | 64.29 |
| 9 | 60 | 100 | 60 | 90 |
| 10 | 61.54 | 69.23 | 61.54 | 69.23 |
| 11 | 78.57 | 61.54 | 61.54 | 76.92 |
| 13 | 64.29 | 71.43 | 64.29 | 85.71 |
| 14 | 50 | 57.14 | 50 | 71.43 |
| 16 | 72.73 | 63.64 | 63.64 | 63.64 |
| 17 | 62.5 | 80 | 62.5 | 40 |
| 18 | 41.67 | 50 | 41.67 | 62.5 |
| 19 | 61.54 | 75 | 61.54 | 58.33 |
| 20 | 53.33 | 73.33 | 53.33 | 80 |
| 21 | 66.67 | 71.43 | 66.67 | 71.43 |
| 22 | 66.67 | 66.67 | 66.67 | 80 |
| 23 | 75 | 50 | 75 | 75 |
| 24 | 69.23 | 53.85 | 69.23 | 76.92 |
| 25 | 66.67 | 77.78 | 66.67 | 55.56 |
| 27 | 68.75 | 60 | 68.75 | 80 |
| 28 | 66.67 | 66.67 | 66.67 | 86.67 |
| 29 | 68.75 | 50 | 68.75 | 64.29 |
| 30 | 78.57 | 57.14 | 78.57 | 78.57 |
| Total | 66.67 | 63.84 | 65.11 | 73.15 |
| Works | Features | Method | Classes | Cross-Validation | Accuracy % |
|---|---|---|---|---|---|
| [116] Koelstra | Facial + EEG | Free-form Deformation and Motion History Images | Binary valence | Trained with MMI dataset, and data from the same subject | 74 |
| [119] Zhong | Facial + Physiological | Temporal Information Preserving Framework, SVM | Valence (3 classes) | LOSO | 69 |
| [121] Huang | Facial + EEG | LBP-TOP, Transfer learning CNN, SVM | 9 emotion categories | LOSO | 62.28 |
| [122] Ranga- nathan | Facial + Body + Physiologic | Convolutional deep belief network (CDBN) and SVM | Not mentioned | LOSO | 58.5 |
| [123] Torres- Valencia | EEG + Peripheral | Discriminant-based algorithm, SVM | Binary valence | 80% train data-20% test data | 66.09 |
| [124] Liu | Facial + EEG | LSTM-RNN | Valence, 9 classes | 24 subject training and 3 for testing | 74.5 |
| [125] Huang | Facial + EEG | Pretrained CNN | Binary valence | LOSO | 75.21 |
| ours | Facial + Peripheral | SNN, feature-level fusion | Binary valence | LOSO | 73.15 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, C.; Ceballos, G.; Kasabov, N.; Puthanmadam Subramaniyam, N. FusionSense: Emotion Classification Using Feature Fusion of Multimodal Data and Deep Learning in a Brain-Inspired Spiking Neural Network. Sensors 2020, 20, 5328. https://doi.org/10.3390/s20185328
Tan C, Ceballos G, Kasabov N, Puthanmadam Subramaniyam N. FusionSense: Emotion Classification Using Feature Fusion of Multimodal Data and Deep Learning in a Brain-Inspired Spiking Neural Network. Sensors. 2020; 20(18):5328. https://doi.org/10.3390/s20185328
Chicago/Turabian StyleTan, Clarence, Gerardo Ceballos, Nikola Kasabov, and Narayan Puthanmadam Subramaniyam. 2020. "FusionSense: Emotion Classification Using Feature Fusion of Multimodal Data and Deep Learning in a Brain-Inspired Spiking Neural Network" Sensors 20, no. 18: 5328. https://doi.org/10.3390/s20185328
APA StyleTan, C., Ceballos, G., Kasabov, N., & Puthanmadam Subramaniyam, N. (2020). FusionSense: Emotion Classification Using Feature Fusion of Multimodal Data and Deep Learning in a Brain-Inspired Spiking Neural Network. Sensors, 20(18), 5328. https://doi.org/10.3390/s20185328