1. Introduction
Point cloud data of buildings can be used for making 3D models for civil engineering applications [
1]. These applications include urban mapping [
2], building maintenance [
3], energy analysis [
4], and historic building preservation [
5]. The building geometry represented in the point cloud format is a list of points in 3D space containing attributes such as 3D coordinates and RGB color. Point cloud data can easily be collected using terrestrial laser scanners (TLS), cameras, or Red-Green-Blue-Depth (RGBD) sensors. However, using the point cloud data is still problematic because of numerous sources of defects such as noise, occlusions, and moving objects [
6]. The main source of these defects in both indoor and outdoor environments is occlusion. In indoor environments, occlusions are usually caused by furniture. Whereas in outdoor environments, scans of building facades are often occluded by trees and lamp posts. One way to fix the problem of having missing data is to capture scans from multiple locations and combine the scans together. However, this process is labor-intensive, time-consuming, and still may not fully collect the required data due to difficulty of access for data collection. Even with advanced scanning methods such as robotic scanning, the problem of occlusions and missing data remains a significant challenge.
Having an automatic point cloud scene completion method has several benefits, including improving data quality and reducing manual labor for data acquisition. Furthermore, point cloud completion has many application scenarios including reducing errors in registration [
7], improving accuracy in object recognition [
8], and improving quality for 3D modeling [
9]. Several automated methods [
8,
10,
11,
12] exist in the literature but have their own limitations in terms of applicability to large, complex scenes and requirements for the input data. Many methods only work on point cloud data of small objects or data with only small, local-scale defects [
10,
11]. Other methods like ScanComplete [
8] and SSCNet [
12] predict the 3D geometry only and do not complete the color information. There exists a strong research need to explore methods that can reconstruct a complete 3D scene in terms of both geometry and color for large outdoor scenes such as building facades.
This research proposes a point cloud scene completion method for building facades using orthographic projection and generative adversarial inpainting methods. Since a scan of a building facade lies on a mostly two-dimensional surface, it is beneficial to convert the 3D unstructured data into a 2D structured representation that can encode neighborhood information. Thus, the raw 3D point cloud is first converted into a depth image and a color image using an orthographic projection. Next, a 2D inpainting method is applied to predict the location and color information of missing pixels in the converted image. The inpainting method consists of a deep neural network that is trained on a database with pairs of incomplete and complete images. Finally, the inpainted 2D image is converted back into a 3D point cloud by remapping the previously stored depth information. The output point cloud is evaluated by comparing it to the ground truth point cloud in a dataset of laser scans of building facades. The rest of the paper is organized in the following order: literature review, methodology, results, discussion, and conclusion.
5. Discussions
This discussion section was aimed at qualitatively comparing the performance of different types of scene completion methods and analyzing the effect of different hyperparameters used in this study. The strengths, weaknesses, and limitations of each method was first discussed in the following subsections:
Poisson reconstruction: the advantage of using Poisson reconstruction is that it smoothly reconstructs the surface of the buildings even in the presence of noise, and it usually completely fills in smaller occlusions. A limitation of Poisson reconstruction is that it may not preserve original geometric information in the scene. As seen in
Figure 15, when Poisson reconstruction was applied (left), the openings between each floor level (red circle) became smaller, even though they should not change size as they were not caused by occlusions but rather were part of the building. Additionally, a common challenge in surface reconstruction is the recovery of sharp features, and Poisson reconstruction tends to incorrectly smoothen the sharp edges of the buildings.
Hole filling: this method works well for simple walls with a few larger occluded regions but does not perform well in the environments with more complex geometries with irregular-sized openings. The method relies on a size threshold parameter to differentiate between openings caused by occlusions and openings that are naturally present in the scene. Thus, when it comes to smaller holes, the hole filling algorithm may not correctly detect them as valid openings to be filled. As seen in
Figure 16, when the hole filling algorithm was applied (middle), mostly the larger occlusions were filled, whereas the smaller ones were ignored.
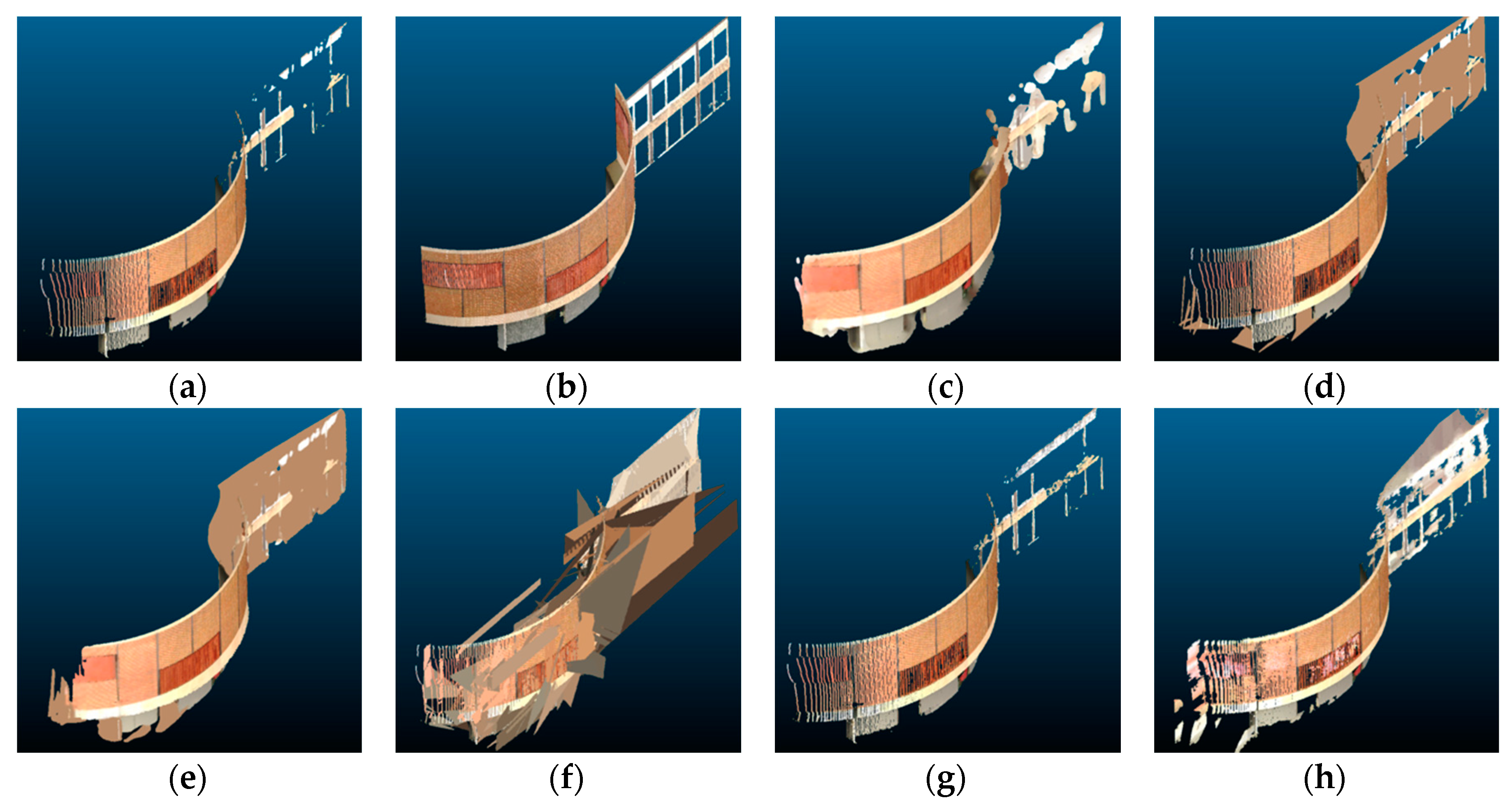
Hybrid: this method combines the previous two algorithms by applying the hole-filling procedure and then applying Poisson reconstruction. The intuition is that the hole-filling step could fill in larger holes in the scene, whereas Poisson reconstruction could fill in smaller holes in the scene. However, the downside of this approach is that the combined process is too aggressive in filling in holes in the scene. As a result, even natural openings and empty spaces that are originally present in the scene are covered up in the output point cloud. This can be observed in
Figure 10 and
Figure 12, where the scene completion results for the hybrid method had many false positive points in regions that were supposed to be empty space in the ground truth point cloud.
Plane fitting: this method has the advantage that it relies on a simple geometric model and can be quickly implemented and computed. However, this leads to the limitation that it relies on the closeness of fit and generally sacrifices object details for the speed of reconstruction [
66]. As can be observed in the result figures in the previous section, building facades were usually not completely flat but could have different widths at each floor as well as multiple protruding sections.
Figure 12 shows a clear example where the plane fitting method did not work, which was a building with a curved wall.
Partial convolutions: in contrast with the previous methods that are more geometry-based, this inpainting method performs scene completion by learning a mapping from incomplete inputs to complete outputs in a data-driven manner. The strength of data-driven methods is that they are more robust to variations of the input data and rely less on preset threshold parameters but can be trained to adapt to different types of data defects. Results in
Table 2 show that this method with partial convolutions worked well overall. The advantage of using this method with partial convolutions is that the convolution operation is conditioned only on valid pixels, so it performs better for irregular holes. However, the limitation of this method is that it is only semiautomated since it requires manually specifying an input mask over the incomplete regions.
Proposed method with generative adversarial inpainting: one advantage of using Pix2Pix as the base network for 2D inpainting is that it uses a U-Net architecture instead of an encoder–decoder architecture. This allows for lower-level information to propagate to higher layers of the network, ultimately improving the visual cohesiveness of the results. However, the quality of the output for sparse inputs is still problematic in certain regions. This is because the generator does not enforce global consistency, and therefore may not produce output images with consistent color, pattern, and texture. As seen in
Figure 17, after applying Pix2Pix (b) on a sparse input, the resulting image had uneven quality, texture, and color when compared to the target ground truth (c).
To partially address this limitation, this study made several modifications in our implementation compared to the original Pix2Pix network to improve its performance on the scene completion task. First, the original incomplete image was very sparse due to large regions with missing information. To overcome this, feature augmentation was applied to append three augmented feature channels to the input image in addition to the original RGB color channels. The augmented feature channels were obtained by taking the RGB color from the nearest neighbor pixel that had a non-null value. Next, the output pixels were generated as independent predictions from the Pix2Pix network even though there should be local correlations between neighboring pixels to generate a smooth image. To address this, a color smoothing operation was applied to the output image by updating the RGB color of filled-in pixels with an average of 10 nearest neighbor pixels from the input image. The improvement in the scene completion performance metrics after implementing each modification is summarized in
Table 2.
For future work using generative adversarial networks for inpainting, further steps can be taken to improve the scene completion results. The major component to be improved is the quantity and quality of the training data. This research uses ten building scenes to train the network and one scene to test. Adding more building scenes in the training data will improve the network’s ability to generalize and fill in differently shaped defects in the building facades. Improving the quality of our ground truth data will also help train the Pix2Pix network better since some of the current ground truth point clouds still contain occluded regions. This can be resolved by using a more cutting-edge 3D scanner, collecting more scans to eliminate holes, or synthetically filling in the missing regions.
Aspect ratio ablation study: in resizing the images to fit the input size of the inpainting methods discussed in
Section 3.2.2, this study resized the images without preserving the aspect ratio of the original image. This caused the resized input images to appear horizontally compressed, especially for rectangular building facades with long widths.
Figure 11 shows some examples of compressed images due to the altered aspect ratio. Due to the concerns that ignoring the aspect ratio will result in lost features when performing inpainting and appear blurry when resized back to the original image dimensions, we analyzed the difference in performance when preserving the aspect ratio compared to when ignoring the aspect ratio.
Table 3 demonstrates the results of an accuracy comparison on part of the test dataset. Four buildings that have rectangular facades were chosen for this analysis. The averaged F1-score was slightly better when having the aspect ratio preserved, whereas the color RMSE was better when ignoring the aspect ratio. However, these changes were too marginal to affect the overall performance. Thus, in the final evaluation, the authors used the variant that ignored the aspect ratio due to the simpler implementation.
Depth remapping ablation study: in the depth remapping step, depth values were assigned to newly filled points. This research used nearest neighbors to assign the depth of the closest neighboring point.
Table 4 below shows the accuracy results of filled point clouds when more than one nearest neighbor was used for depth assignment. In the case below, one, two, or ten nearest neighbors were chosen and the average of their depth values was assigned to the new point. The results demonstrated that the 1-Nearest Neighbor setting had the best performance overall in terms of the voxel precision, voxel recall, and color RMSE.
Voxel size ablation study: when computing the accuracy metrics such as voxel precision and voxel recall, an important parameter that is involved is the voxel size. Results in
Table 5 show that changes in voxel size changed the absolute value of each performance measurement, but the relative order of rankings of the methods remained mostly the same. With a lower voxel size, the accuracy metrics generally decreased, while with a higher voxel size, the accuracy metrics generally increased. For each voxel size, the proposed method still achieved the highest F1-score.
In general, a smaller voxel size allows the accuracy metrics to capture whether the scene completion methods are able to reconstruct fine-level detail in the point clouds. A smaller voxel size imposes a stricter criterion for matching the predicted point cloud to the ground truth point cloud when computing the voxel prediction and recall. For example, a voxel size of 0.01 m means that a predicted point has to be within 0.01 m of a ground truth point in order to be considered a true positive whereas a voxel size of 0.2 m means that a predicted point can be within 0.2 m of a ground truth point and still be considered a true positive. In addition, using small voxel sizes also cause the metrics to be more sensitive to noise in the input data that is caused by the sensing device and not due to errors in the scene completion algorithm.
Natural ground truth vs. manual ground truth: this study mainly used the technique of combining multiple scans to generate a “natural” ground truth for scene completion. However, this form of ground truth data still contains missing data due to limitations in scanning hardware and scanning time. To investigate how much this will bias the comparison results of point cloud completion, we made several samples of “manual” ground truth data by shifting and merging points from the existing ground truth point cloud to create a more complete point cloud. These manually modified point clouds thus consist of a combination of real and synthetic data. The point cloud completion results were then re-evaluated with the manual ground truth and compared to the natural ground truth data for the Pettit building scene (
Figure 18). Results in
Table 6 show that the evaluated metrics show generally worse results when using the “manual” ground truth since it could account for many points that were not included in the “natural” ground truth. However, the relative performance between different scene completions was still maintained.
Computation time analysis:
Table 7 shows the computation time required for each method to perform scene completion. The computation time was recorded for each of the 11 scenes in the test data and averaged over all scenes. Results show that the proposed method had a somewhat longer computation time than some of the baseline methods, but it was still reasonable. The results also show that the method using partial convolutions took an especially long time since it required the manual step of creating image masks.
Comparison with point-based neural networks: this section provides a performance comparison with several end-to-end methods for point cloud completion that use point-based neural networks such as PCN [
7], TopNet [
54], and FoldingNet [
55]. These methods have different architectures but are based on the same principle of directly predicting an output point cloud from an input point cloud using a neural network. In this study, PCN, TopNet, and FoldingNet were implemented using a forked repository from the original Completion3D benchmark [
67]. For a fair comparison, each network was retrained with our building facade dataset using the same cross-validation scheme as described in
Section 3.2.2. Similar to the proposed method, each network was trained with 467 point clouds and tested with 11 point clouds. The point clouds were also preprocessed using the same normalization procedure, which is to center at the origin and to rescale to unit length. Note that these methods did not directly predict the color information; thus, we used a nearest neighbor search to assign the color channels for the output point cloud.
Figure 19b shows the output point cloud predicted by PCN given the input point cloud in
Figure 19a. In the original implementation of PCN [
7], the output point cloud was limited to 16,384 points and the point cloud was clearly much sparser compared to the input point cloud. This study used a mesh-based upsampling technique to increase the number of points to 1,000,000. However, results in
Figure 19c show that the result still lacked the ability to represent detailed geometry due to the sparsity of the original prediction.
Table 8 shows a quantitative comparison of the scene completion performance metrics for PCN, TopNet, and FoldingNet, averaged across the test set of 11 building facades. The results show that the upsampled version had a higher recall rate across all three networks. However, there was still a significant gap between the performance of these point-based neural networks compared to the proposed method when applied to the building facade dataset. The main problem of these methods is that they only predict a constant number of output points, which could work well with point clouds of simple CAD models but not with large and complex building facades. Another problem is that these methods do not preserve the scale and offset information in the original point cloud and instead rely on an encoder–decoder structure to translate the input point cloud into an output point cloud.
Qualitative evaluation:
Table 9 summarizes the qualitative improvement over other methods in the literature that were not directly evaluated. Compared to most existing methods in the literature, the proposed method is advantageous because it works directly with point cloud data, is able to reconstruct color information, and works for curved surfaces.
Limitations: there are several remaining limitations that need to be taken into account when using the proposed orthographic projection and generative adversarial inpainting method for point cloud scene completion. First, this study was mainly targeted towards scene completion of building facades to take advantage of the structure and symmetry in the scene. To apply this method for more general 3D scenes, a different set of training data needs to be used. Another limitation is the requirement to separately use orthographic projection to convert the 3D point cloud into a 2D image followed by depth remapping to convert the inpainted 2D image back into the 3D point cloud. To make the process more streamlined, the network architecture can be modified so that it is trainable end-to-end.
The targeted scenario for the application of the proposed scene completion method was mainly for the case of point cloud data collection with terrestrial laser scanning (TLS), which usually has the critical issue of occlusions and missing data. There are other alternatives to address the problem of occlusions such as using advanced laser scanners with multistation measurements, increasing the number of scan locations, or using advanced scan planning and optimization techniques. These scanning methods could still have missing data when taking multiple scans due to inaccessibility or occlusions that are too close to or in close contact with the target object (e.g., trees and shrubs). The main advantage of applying an automated scene completion algorithm is the ability to save manual labor and manual operation in laser scanning at the cost of having some uncertainty in the reconstructed point cloud. In any case, the authors expect that the idea of automated scene completion is still applicable to fix imperfections in the acquired data.
In this study, the point cloud preprocessing steps such as registration, segmentation, filtering, and extraction of individual facades from the original scene were carried out manually for simplicity and convenience. In an actual application, these steps can potentially be automated using established point cloud processing algorithms. For example, the point cloud scans can be automatically registered by feature point matching [
68]. In addition, individual facades can be extracted using learning-based segmentation or recognition algorithms [
69].

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}