An Effective Dense Co-Attention Networks for Visual Question Answering


Abstract
1. Introduction
- An improved multimodal co-attention model is proposed by stacking the self-attention unit and the guided-attention unit. It can not only describe the interactions between multimodalities in a more effective way but also take account of the dense self-attention in each modality. Compared with the existing scheme MCAN, DCAN achieves higher precision.
- Ablation studies on VQA-v2 are conducted to explain the effectiveness of DCAN. The qualitative evaluation results demonstrate how it generates reasonable attention to questions and images.
2. Related Work
2.1. Attention-Based Vqa Model
2.2. Multimodal Feature Fusion
3. Co-Attention Layer
3.1. Scaled Dot-Product Attention
3.2. Multi-Head Attention
3.3. Pointwise Feed Forward Layer
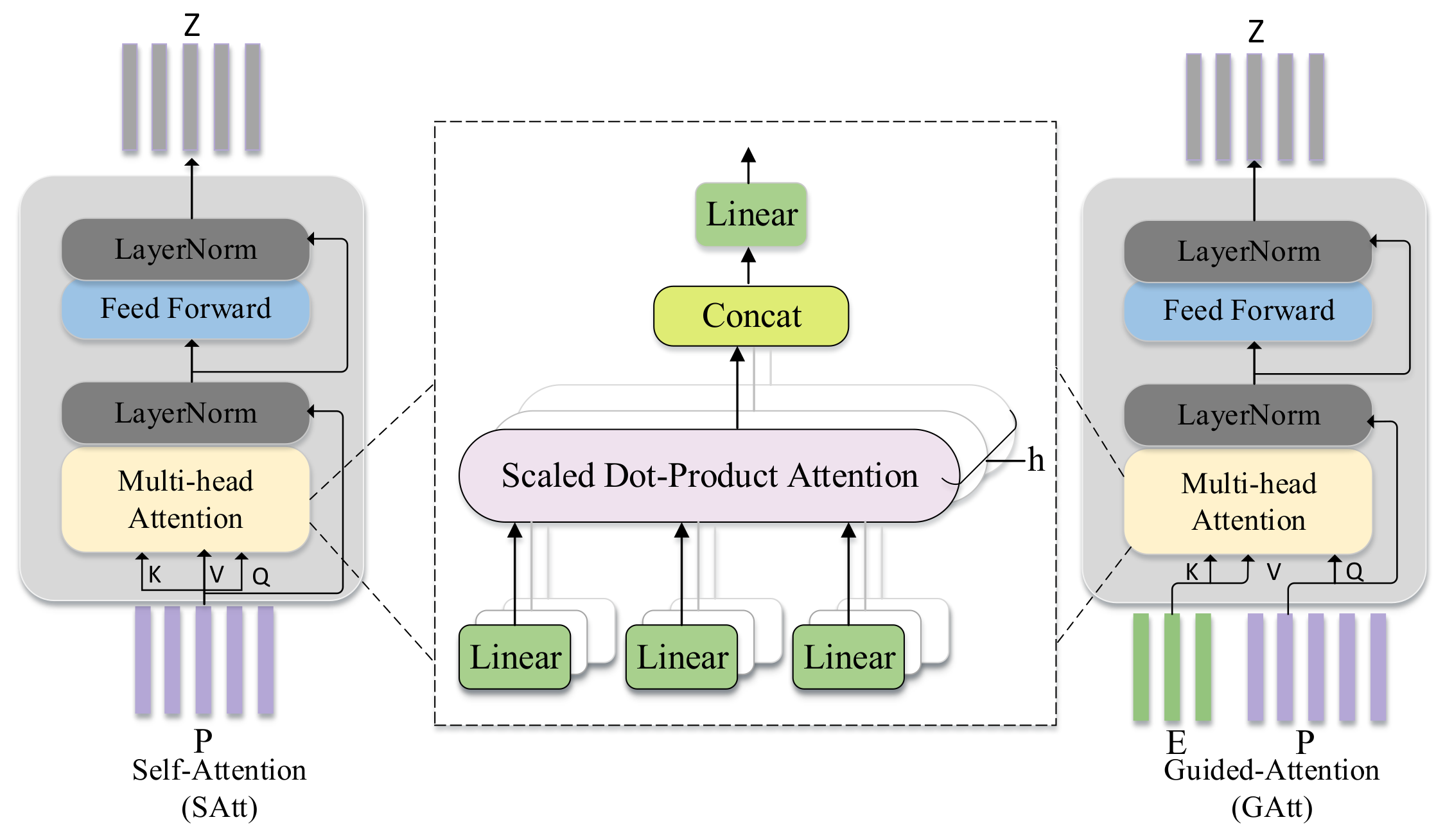
3.4. Self-Attention and Guided-Attention
3.4.1. Self-Attention Unit
3.4.2. Guided-Attention Unit
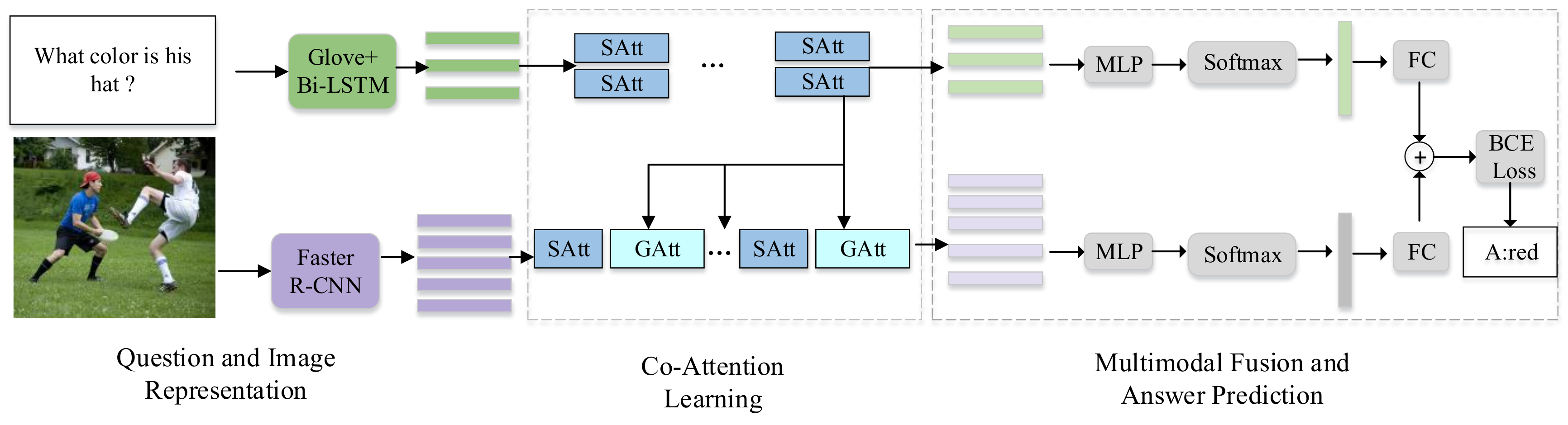
4. Network Architecture for Vqa
4.1. Feature Extraction
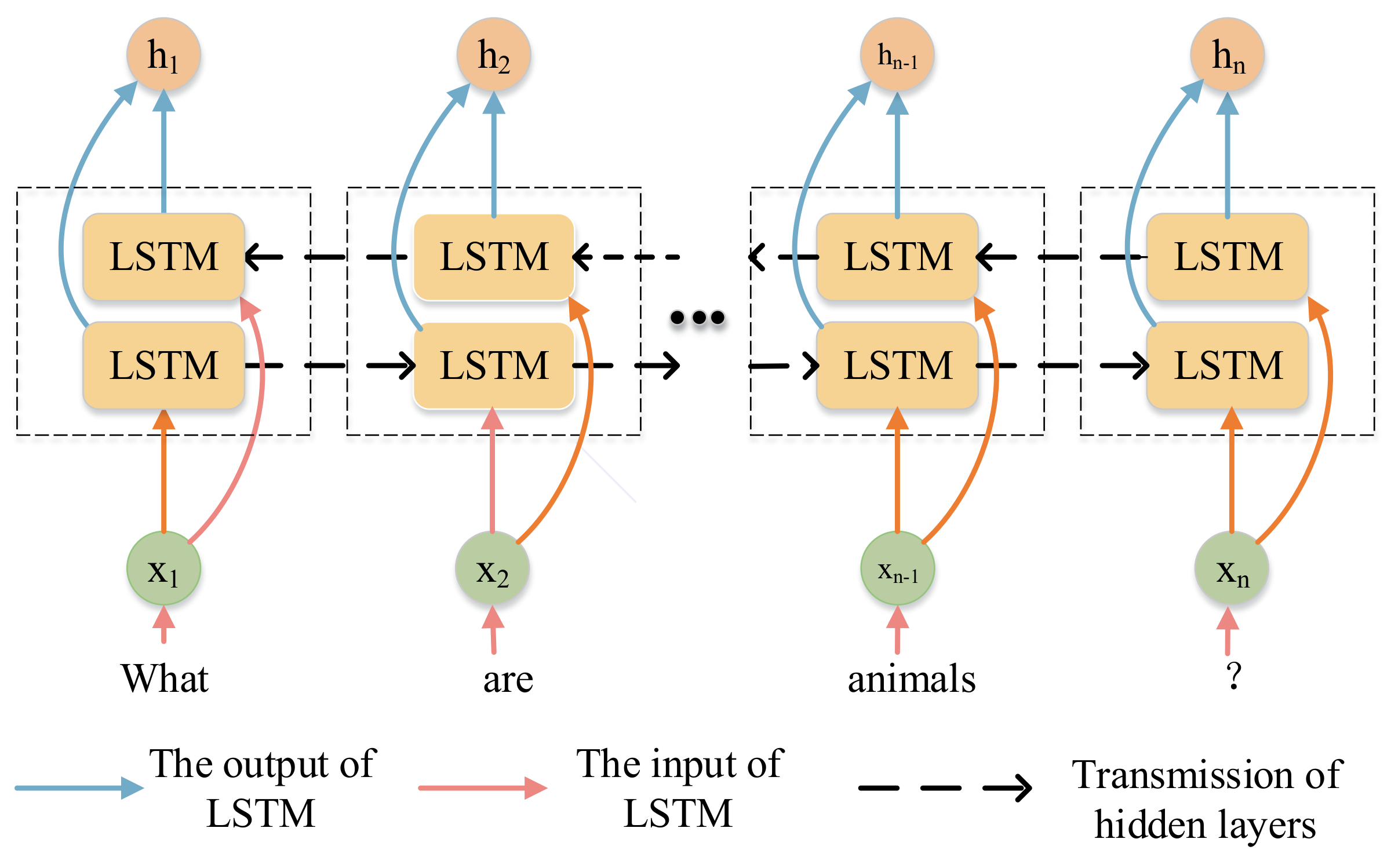
4.1.1. Question and Answer Representation
4.1.2. Image Representation
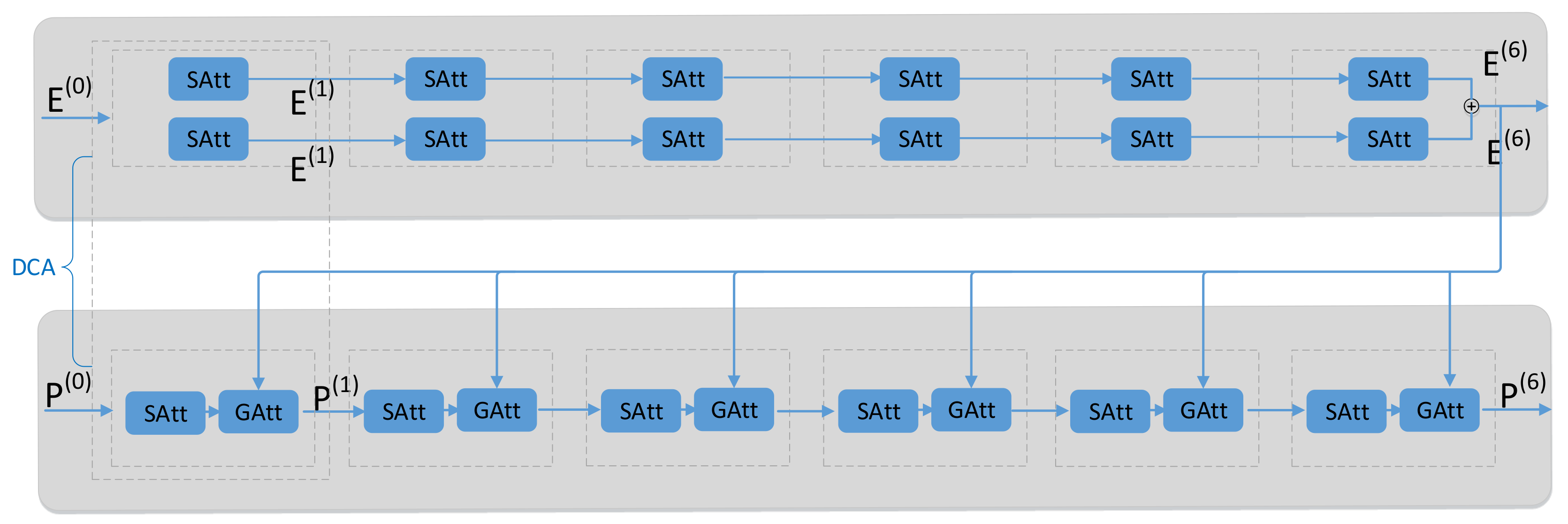
4.2. Dense Co-Attention Model
4.3. Multimodal Fusion and Answer Prediction
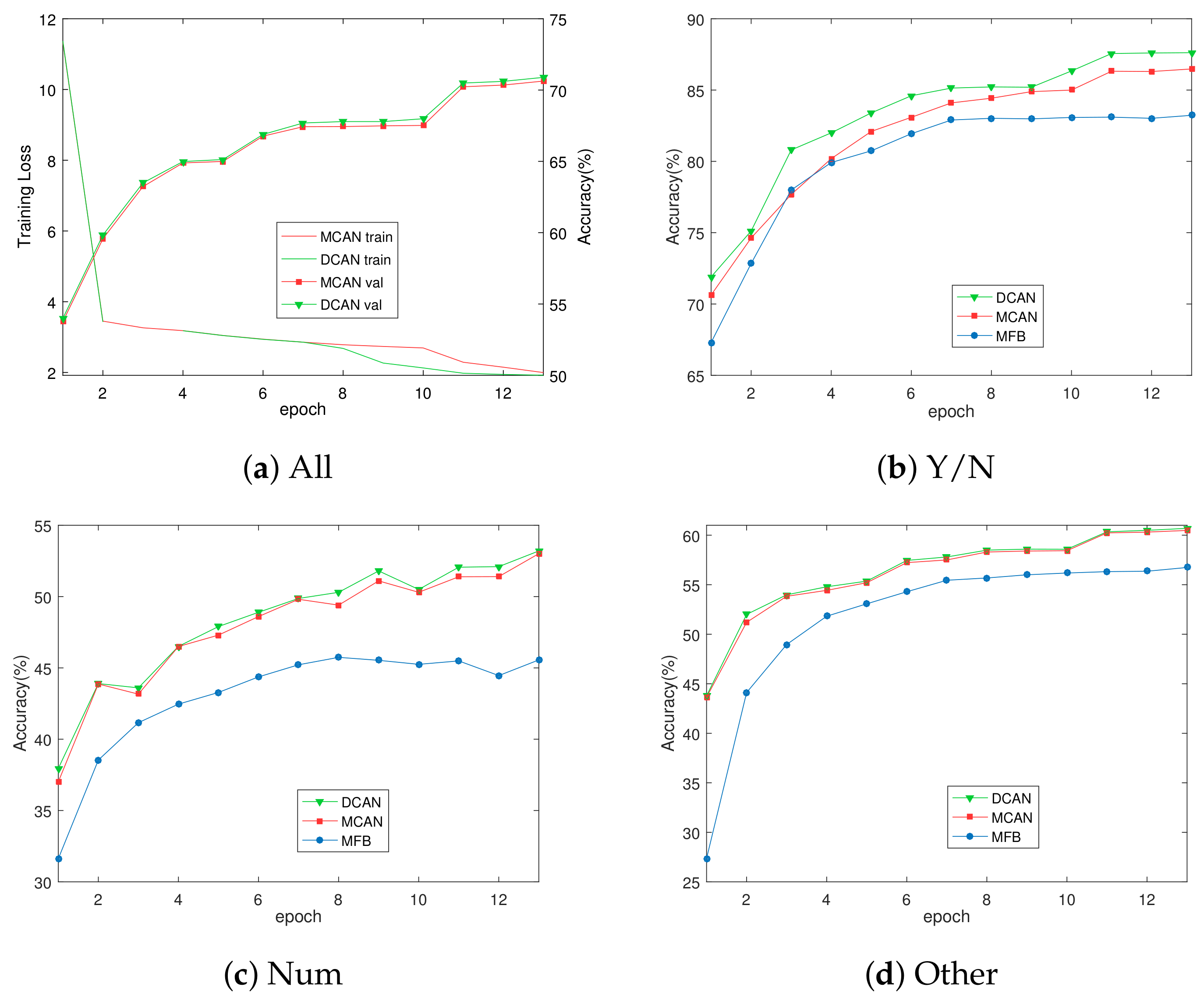
5. Experiments and Results
5.1. Dataset
5.2. Experimental Setup
5.3. Ablation Analysis
5.3.1. Effectiveness of Dca
5.3.2. Number of Heads
5.3.3. Question Representation
5.3.4. Depth of DCA
5.4. Comparisons with Existing Methods
5.5. Qualitative Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| VQA | Visual Question Answering |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional neural network |
| RPN | Region Proposal Network |
| ROI | Region of Interest |
| MFB | Multimodal Factorized Bilinear |
| MFH | Multimodal Factorized High-order |
| BAN | Bilinear Attention Networks |
| AI | Artificial Intelligence |
References
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Rohrbach, A.; Rohrbach, M.; Hu, R.; Darrell, T.; Schiele, B. Grounding of Textual Phrases in Images by Reconstruction. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 817–834. [Google Scholar]
- Chen, C.; Han, D.; Wang, J. Multimodal Encoder-Decoder Attention Networks for Visual Question Answering. IEEE Access 2020, 8, 35662–35671. [Google Scholar] [CrossRef]
- Liang, W.; Long, J.; Li, C.; Xu, J.; Ma, N.; Lei, X. A Fast Defogging Image Recognition Algorithm based on Bilateral Hybrid Filtering. ACM Trans. Multimed. Comput. Commun. Appl. 2020. [Google Scholar] [CrossRef]
- Zheng, C.; Pan, L.; Wu, P. Multimodal Deep Network Embedding with Integrated Structure and Attribute Information. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1437–1449. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Qiu, L.; Sangaiah, A.K.; Liu, A.; Bhuiyan, M.Z.A.; Ma, Y. Edge-Computing-based Trustworthy Data Collection Model in the Internet of Things. IEEE Internet Things J. 2020, 7, 4218–4227. [Google Scholar] [CrossRef]
- Wang, T.; Cao, Z.; Wang, S.; Wang, J.; Qi, L.; Liu, A.; Xie, M.; Li, X. Privacy-Enhanced Data Collection Based on Deep Learning for Internet of Vehicles. IEEE Trans Ind. Inform. 2020, 16, 6663–6672. [Google Scholar] [CrossRef]
- Cui, M.; Han, D.; Wang, J. An Efficient and Safe Road Condition Monitoring Authentication Scheme Based on Fog Computing. IEEE Internet Things J. 2019, 6, 9076–9084. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Lee, S.; Moura, J.M.F.; Parikh, D.; Batra, D. Visual Dialog. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1242–1256. [Google Scholar] [CrossRef]
- Bigham, J.P.; Jayant, C.; Ji, H.; Little, G.; Miller, A.; Miller, R.; Tatarowicz, A.; White, B.; White, S.; Yeh, T. VizWiz: Nearly Real-time Answers to Visual Questions. User Interface Softw. Technol. 2010, 333–342. [Google Scholar] [CrossRef]
- Wang, T.; Luo, H.; Zeng, X.; Yu, Z.; Liu, A.; Sangaiah, A.K. Mobility Based Trust Evaluation for Heterogeneous Electric Vehicles Network in Smart Cities. IEEE Trans. Intell. Transp. 2020. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.M.O.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Dozat, T.; Manning, C.D. Deep Biaffine Attention for Neural Dependency Parsing. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Han, D.; Pan, N.; Li, K.-C. A Traceable and Revocable Ciphertext-policy Attribute-based Encryption Scheme Based on Privacy Protection. IEEE Trans. Dependable Secur. Comput. 2020. [Google Scholar] [CrossRef]
- Liang, W.; Zhang, D.; Lei, X.; Tang, M.; Zomaya, Y. Circuit Copyright Blockchain: Blockchain-based Homomorphic Encryption for IP Circuit Protection. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical Question-Image Co-Attention for Visual Question Answering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 289–297. [Google Scholar]
- Yu, Z.; Yu, J.; Fan, J.; Tao, D. Multi-modal Factorized Bilinear Pooling with Co-attention Learning for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1839–1848. [Google Scholar]
- Kim, J.-H.; Jun, J.; Zhang, B.-T. Bilinear Attention Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1571–1581. [Google Scholar]
- Nguyen, D.-K.; Okatani, T. Improved Fusion of Visual and Language Representations by Dense Symmetric Co-attention for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6087–6096. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, H.; Han, D.; Li, D. Fabric-iot: A Blockchain-Based Access Control System in IoT. IEEE Access 2020, 8, 18207–18218. [Google Scholar] [CrossRef]
- Gao, P.; You, H.; Zhang, Z.; Wang, X.; Li, H. Multi-modality latent interaction network for visual question answering. In Proceedings of the IEEE International Conference on Computer Vision, Thessaloniki, Greece, 23–25 September 2019; pp. 5824–5834. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep Modular Co-Attention Networks for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6281–6290. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. Int. J. Comput. Vis. 2019, 398–414. [Google Scholar] [CrossRef]
- Hu, H.; Chao, W.-L.; Sha, F. Learning Answer Embeddings for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5428–5436. [Google Scholar]
- Shih, K.J.; Singh, S.; Hoiem, D. Where to Look: Focus Regions for Visual Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4613–4621. [Google Scholar]
- Fukui, A.; Park, D.H.; Yang, D.; Rohrbach, A.; Darrell, T.; Rohrbach, M. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 457–468. [Google Scholar]
- Li, R.; Jia, J. Visual Question Answering with Question Representation Update (QRU). In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4655–4663. [Google Scholar]
- Teney, D.; Anderson, P.; He, X.; Van Den Hengel, A. Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4223–4232. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.M.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Ben-younes, H.; Cadène, R.; Cord, M.; Thome, N. MUTAN: Multimodal Tucker Fusion for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2631–2639. [Google Scholar]
- Wu, C.; Liu, J.; Wang, X.; Li, R. Differential Networks for Visual Question Answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8997–9004. [Google Scholar]
- Kim, J.-H.; On, K.-W.; Lim, W.; Kim, J.; Ha, J.-W.; Zhang, B.-T. Hadamard product for low-rank bilinear pooling. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Yu, Z.; Yu, J.; Xiang, C.; Fan, J.; Tao, D. Beyond Bilinear: Generalized Multimodal Factorized High-Order Pooling for Visual Question Answering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5947–5959. [Google Scholar] [CrossRef]
- Yu, Z.; Cui, Y.; Yu, J.; Tao, D.; Tian, Q. Multimodal Unified Attention Networks for Vision-and-Language Interactions. arXiv 2019, arXiv:1908.04107. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition Supplementary Materials. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.H.; Wang, X.; Li, H. Dynamic fusion with intra- and inter-modality attention flow for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6639–6648. [Google Scholar]
- Wu, Y.; Huang, H.; Wu, Q.; Liu, A.; Wang, T. A Risk Defense Method Based on Microscopic State Prediction with Partial Information Observations in Social Networks. J. Parallel Distrib. Comput. 2019, 131, 189–199. [Google Scholar] [CrossRef]
- Chen, P.; Han, D.; Tan, F.; Wang, J. Reinforcement-Based Robust Variable Pitch Control of Wind Turbines. IEEE Access 2020, 8, 20493–20502. [Google Scholar] [CrossRef]
- Liang, W.; Huang, W.; Long, J.; Zhang, K.; Li, K.; Zhang, D. Deep Reinforcement Learning for Resource Protection and Real-Time Detection in IoT Environment. IEEE Internet Things J. 2020, 7, 6392–6401. [Google Scholar] [CrossRef]
- Tian, Q.; Han, D.; Li, K.-C.; Liu, X.; Duan, L.; Castiglione, A. An intrusion detection approach based on improved deep belief network. Appl. Intell. 2020. [Google Scholar] [CrossRef]
- Li, H.; Han, D. EduRSS: A Blockchain-Based Educational Records Secure Storage and Sharing Scheme. IEEE Access 2019, 7, 179273–179289. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Setting | Accuracy |
|---|---|---|
| Question encoding | Bi-LSTM | 65.71 |
| LSTM | 65.6 | |
| Number of heads | h = 2 | 65.38 |
| h = 4 | 65.51 | |
| h = 8 | 65.67 | |
| h = 16 | 65.67 | |
| Attention model | ID(E)-GAtt(P, E) | 64.8 |
| SAtt(E)-GAtt (P, E) | 65.2 | |
| SAtt(E)-SGAtt (P, E) | 65.4 | |
| SAtt(E)-SGAtt (P, E+E) | 65.6 |
| L | Y/N | Number | Other | All |
|---|---|---|---|---|
| 2 | 84.36 | 47.98 | 57.92 | 66.55 |
| 4 | 84.74 | 49.01 | 58.37 | 67.05 |
| 6 | 84.96 | 49.20 | 58.30 | 67.13 |
| 8 | 84.93 | 49.45 | 58.28 | 67.14 |
| Model | Test-Dev | Test-Std | |||
|---|---|---|---|---|---|
| All | Y/N | Num | Other | All | |
| Bottom-up [31] | 65.32 | 81.82 | 44.21 | 56.05 | 65.67 |
| MFH [36] | 68.76 | 84.27 | 49.56 | 59.89 | - |
| BAN [19] | 69.52 | 85.31 | 50.93 | 60.26 | - |
| BAN+counter [19] | 70.04 | 85.42 | 54.04 | 60.52 | 70.35 |
| DCN [20] | 66.87 | 83.51 | 46.61 | 57.26 | - |
| DFAF [41] | 70.22 | 86.09 | 53.32 | 60.49 | 70.34 |
| MCAN [25] | 70.63 | 86.82 | 53.26 | 60.72 | 70.9 |
| DCAN (ours) | 70.89 | 88.02 | 53.40 | 60.88 | 71.21 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, S.; Han, D. An Effective Dense Co-Attention Networks for Visual Question Answering. Sensors 2020, 20, 4897. https://doi.org/10.3390/s20174897
He S, Han D. An Effective Dense Co-Attention Networks for Visual Question Answering. Sensors. 2020; 20(17):4897. https://doi.org/10.3390/s20174897
Chicago/Turabian StyleHe, Shirong, and Dezhi Han. 2020. "An Effective Dense Co-Attention Networks for Visual Question Answering" Sensors 20, no. 17: 4897. https://doi.org/10.3390/s20174897
APA StyleHe, S., & Han, D. (2020). An Effective Dense Co-Attention Networks for Visual Question Answering. Sensors, 20(17), 4897. https://doi.org/10.3390/s20174897